
Chapter 11. Mutation
Clojure’s main tenet isn’t the facilitation of concurrency. Instead, Clojure at its core is concerned with the sane management of state, and facilitating concurrent programming naturally falls out of that. The JVM operates on a shared-state concurrency model built around juggling fine-grained locks that protect access to shared data. Even if you can keep all of your locks in order, rarely does such a strategy scale well, and even less frequently does it foster reusability. But Clojure’s state management is simpler to reason about and promotes reusability.
Clojure Aphorism
A tangled web of mutation means that any change to your code potentially occurs in the large.
In this chapter, we’ll take the grand tour of the mutation primitives and see how Clojure makes concurrent programming not only possible, but fun. Our journey will take us through Clojure’s four major mutable references: Refs, Agents, Atoms, and Vars. When possible and appropriate, we’ll also point out the Java facilities for concurrent programming (including locking) and provide information on the trade-offs involved in choosing them. We’ll also explore parallelism support in Clojure using futures, promises, and a trio of functions pmap, pvalues, and pcalls.
Before we dive into the details of Clojure’s reference types, let’s start with a high-level overview of Clojure’s software transactional memory (STM).
Concurrency refers to the execution of disparate tasks at roughly the same time, each sharing a common resource. The results of concurrent tasks often affect the behavior of other concurrent tasks, and therefore contain an element of nondeterminism. Parallelism refers to partitioning a task into multiple parts, each run at the same time. Typically, parallel tasks work toward an aggregate goal and the result of one doesn’t affect the behavior of any other parallel task, thus maintaining determinacy.
11.1. Software transactional memory with multiversion concurrency contr- rol and snapshot isolation
A faster program that doesn’t work right is useless.
Simon Peyton-Jones in “Beautiful Concurrency”
In chapter 1, we defined three important terms:
- Time—The relative moments when events occur
- State—A snapshot of an entity’s properties at a moment in time
- Identity—The logical entity identified by a common stream of states occurring over time
These terms form the foundation for Clojure’s model of state management and mutation. In Clojure’s model, a program must accommodate the fact that when dealing with identities, it’s receiving a snapshot of its properties at a moment in time, not necessarily the most recent. Therefore, all decisions must be made in a continuum. This model is a natural one, as humans and animals alike make all decisions based on their current knowledge of an ever-shifting world. Clojure provides the tools for dealing with identity semantics via its Ref reference type, the change semantics of which are governed by Clojure’s software transactional memory; this ensures state consistency throughout the application timeline, delineated by a transaction.
11.1.1. Transactions
Within the first few moments of using Clojure’s STM, you’ll notice something different than you may be accustomed to: no locks. Consequently, because there’s no need for ad-hoc locking schemes when using STM, there’s no chance of deadlock. Likewise, Clojure’s STM doesn’t require the use of monitors and as a result is free from lost wakeup conditions. Behind the scenes, Clojure’s STM uses multiversion concurrency control (MVCC) to ensure snapshot isolation. In simpler terms, snapshot isolation means that each transaction gets its own view of the data that it’s interested in. This snapshot is made up of in-transaction reference values, forming the foundation of MVCC (Ullman 1988). As illustrated in figure 11.1, each transaction merrily chugs along making changes to in-transaction values only, oblivious to and ambivalent about other transactions. At the conclusion of the transaction, the local values are examined against the modification target for conflicts. An example of a simple possible conflict is if another transaction B committed a change to a target reference during the time that transaction A was working, thus causing A to retry. If no conflicts are found, then the in-trans-action values are committed and the target references are modified with their updated values. Another advantage that STM provides is that in the case of an exception during a transaction, its in-transaction values are thrown away and the exception propagated outward. In the case of lock-based schemes, exceptions can complicate matters ever more, because in most cases locks need to be released (and in some cases, in the correct order) before an exception can be safely propagated up the call stack.
Figure 11.1. Illustrating an STM retry: Clojure’s STM works much like a database.

Because each transaction has its own isolated snapshot, there’s no danger in retrying—the data is never modified until a successful commit occurs. STM transactions can easily nest without taking additional measures to facilitate composition. In languages providing explicit locking for concurrency, matters of composability are often difficult, if not impossible. The reasons for this are far-reaching and the mitigating forces (Goetz 2006) complex, but the primary reasons tend to be that lock-based concurrency schemes often hinge on a secret incantation not explicitly understandable through the source itself: for example, the order in which to take and release a set of locks.
11.1.2. Embedded transactions
In systems providing embedded transactions, it’s often common for transactions to be nested, thus limiting the scope of restarts (Gray 1992). Embedding transactions within Clojure operates differently, as summarized in figure 11.2.
Figure 11.2. Clojure’s embedded transactions: a restart in any of Clojure’s embedded transactions A, B, b, and C causes a restart in the whole subsuming transaction. This is unlike a fully embedded transaction system where the subtransactions can be used to restrain the scope of restarts.
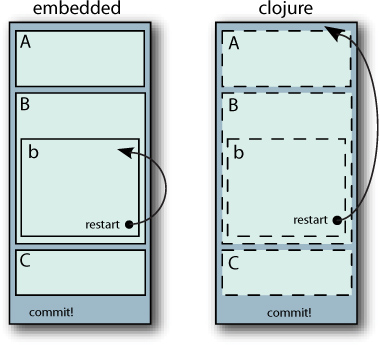
In some database systems, transactions can be used to limit the scope of a restart as shown when transaction embedded.b restarts only as far back as its own scope. Clojure has but one transaction per thread, thus causing all subtransactions to be subsumed into the larger transaction. Therefore, when a restart occurs in the (conceptual) subtransaction clojure.b, it causes a restart of the larger transaction. Though not shown, some transaction systems provide committal in each subtransaction; in Clojure, commit only occurs at the outermost larger transaction.
11.1.3. The things that STM makes easy
The phrase TANSTAAFL, meaning “There ain’t no such thing as a free lunch,” was popularized in the excellent sci-fi novel The Moon Is a Harsh Mistress (Heinlein 1966) and is an apt response to the view that STM is a panacea for concurrency complexities.
As you proceed through this chapter, we urge you to keep this in the back of your mind, because it’s important to realize that though Clojure facilitates concurrent programming, it doesn’t solve it for you. But there are a few things that Clojure’s STM implementation simplifies in solving difficult concurrent problems.
Consistent Information
The STM allows you to perform arbitrary sets of read/write operations on arbitrary sets of data in a consistent (Papadimitriou 1986) way. By providing these assurances, the STM allows your programs to make decisions given overlapping subsets of information. Likewise, Clojure’s STM helps to solve the reporting problem—the problem of getting a consistent view of the world in the face of massive concurrent modification and reading, without stopping (locking).
No Need for Locks
In any sized application, the inclusion of locks for managing concurrent access to shared data adds complexity. There are many factors adding to this complexity, but chief among them are the following:
- You can’t use locks without supplying extensive error handling. This is critical in avoiding orphaned locks (locks held by a thread that has died).
- Every application requires that you reinvent a whole new locking scheme.
- Locking schemes often require that you impose a total ordering that’s difficult to enforce in client code, frequently leading to a priority inversion scenario.
Locking schemes are difficult to design correctly and become increasingly so as the number of locks grows. Clojure’s STM eliminates the need for locking and as a result eliminates dreaded deadlock scenarios. Clojure’s STM provides a story for managing state consistently. Adhering to this story will go a long way toward helping you solve software problems effectively. This is true even when concurrent programming isn’t a factor in your design.
Aci
In the verbiage of database transactions is a well-known acronym ACID, which refers to the properties ensuring transactional reliability. Clojure’s STM provides the first three properties: atomicity, consistency, and isolation. The other, durability, is missing due to the fact that Clojure’s STM resides in-memory and is therefore subject to data loss in the face of catastrophic system failure. Clojure relegates the problem of maintaining durability to the application developer instead of supplying common strategies by default: database persistence, external application logs, serialization, and so on.
11.1.4. Potential downsides
There are two potential problems inherent in STMs in general, which we’ll only touch on briefly here.
Write Skew
For the most part, you can write correct programs simply by putting all access and changes to references in appropriately scoped transactions. The one exception to this is write skew, which occurs in MVCC systems such as Clojure’s. Write skew can occur when one transaction uses the value of a reference to regulate its behavior but doesn’t write to that reference. At the same time, another transaction updates the value for that same reference. One way to avoid this would be to do a “dummy write” in the first transaction, but Clojure provides a less costly solution: the ensure function. This scenario is rare in Clojure applications, but possible.
Live-Lock
Live-lock refers to a set of transaction(s) that repeatedly restart one another. Clojure combats live-lock in a couple of ways. First, there are transaction restart limits that will raise an error when breached. Generally this occurs when the units of work within some number of transactions is too large. The second way that Clojure combats live-lock is called barging. Barging refers to some careful logic in the STM implementation allowing an older transaction to continue running while younger transactions retry.
11.1.5. The things that make STM unhappy
Certain things can rarely (if ever) be safely performed within a transaction, and in this section we’ll talk briefly about each.
I/O
Any I/O operation in the body of a transaction is highly discouraged. Due to restarts, the embedded I/O could at best be rendered useless, and cause great harm at worst. It’s advised that you employ the io! macro whenever performing I/O operations:
(io! (.println System/out "Haikeeba!")) ; Haikeeba!
When this same statement is used in a transaction, an exception is thrown:
(dosync (io! (.println System/out "Haikeeba!"))) ; java.lang.IllegalStateException: I/O in transaction
Though it may not be feasible to use io! in every circumstance, it’s a good idea to do so whenever possible.
Class Instance Mutation
Unrestrained instance mutation is often not idempotent, meaning that running a set of mutating operations multiple times often displays different results.
Large Transactions
Though the size of transactions is highly subjective, the general rule of thumb when partitioning units of work should always be get in and get out as quickly as possible.
Though it’s important to understand that transactions will help to simplify the management of state, you should strive to minimize their footprint in your code. The use of I/O and instance mutation is often an essential part of many applications; it’s important to work to separate your programs into logical partitions, keeping I/O and its ilk on one side, and transaction processing and mutation on the other. Fortunately for us, Clojure provides a powerful toolset for making the management of mutability sane, but none of the tools provide a shortcut to thinking. Multithreaded programming is a difficult problem, independent of specifics, and Clojure’s state-management tools won’t solve this problem magically. We’ll help to guide you through the proper use of these tools starting with Clojure’s Ref type.
11.2. When to use Refs
Clojure currently provides four different reference types to aide in concurrent programming: Refs, Agents, Atoms, and Vars. All but Vars are considered shared references and allow for changes to be seen across threads of execution. The most important point to remember about choosing between reference types is that although their features sometimes overlap, each has an ideal use. All the reference types and their primary characteristics are shown in figure 11.3.
Figure 11.3. Clojure’s four reference types are listed across the top, with their features listed down the left. Atoms are for lone synchronous objects. Agents are for asynchronous actions. Vars are for thread-local storage. Refs are for synchronously coordinating multiple objects.

The unique feature of Refs is that they’re coordinated. This means that reads and writes to multiple refs can be made in a way that guarantees no race conditions. Asynchronous means that the request to update is queued to happen in another thread some time later, while the thread that made the request continues immediately. Retriable indicates that the work done to update a reference’s value is speculative and may have to be repeated. Finally, thread-local means that thread safety is achieved by isolating changes to state to a single thread.
To illustrate some major points, we’ll use a function dothreads! that launches a given number of threads each running a function a number of times:
(import '(java.util.concurrent Executors))
(def *pool* (Executors/newFixedThreadPool
(+ 2 (.availableProcessors (Runtime/getRuntime)))))
(defn dothreads! [f & {thread-count :threads
exec-count :times
:or {thread-count 1 exec-count 1}}]
(dotimes [t thread-count]
(.submit *pool* #(dotimes [_ exec-count] (f)))))
The dothreads! function is of limited utility—throwing a bunch of threads at a function to see if it breaks.
Value access via the @ reader feature or the deref function provide a uniform client interface, regardless of the reference type used. On the other hand, the write mechanism associated with each reference type is unique by name and specific behavior, but similar in structure. Each referenced value is changed through the application[1] of a pure function. The result of this function will become the new referenced value. Finally, all reference types allow the association of a validator function via setvalidator that will be used as the final gatekeeper on any value change.
1 Except for ref-set on Refs, reset! on Atoms, and set! on Vars.
11.2.1. Coordinated, synchronous change using alter
A Ref is a reference type allowing synchronous, coordinated change to its contained value. What does this mean? By enforcing that any change to a Ref’s value occurs in a transaction, Clojure can guarantee that change happens in a way that maintains a consistent view of the referenced value in all threads. But there’s a question as to what constitutes coordination. We’ll construct a simple vector of Refs to represent a 3 x 3 chess board:
(def initial-board
[[:- :k :-]
[:- :- :-]
[:- :K :-]])
(defn board-map [f bd]
(vec (map #(vec (for [s %] (f s))) bd)))
Just as in section 2.4, the lowercase keyword represents a dark king piece and the uppercase a light king piece. We’ve chosen to represent the board as a 2D vector of Refs (which are created by the board-map function). There are other ways to represent our board, but we’ve chosen this because it’s nicely illustrative—the act of moving a piece would require a coordinated change in two reference squares, or else a change to one square in one thread could lead to another thread observing that square as occupied. Likewise, this problem requires synchronous change, because it would be no good for pieces of the same color to move consecutively. Refs are the only game in town to ensure that the necessary coordinated change occurs synchronously. Before you see Refs in action, we need to define auxiliary functions:
(defn reset!
"Resets the board state. Generally these types of functions are a
bad idea, but matters of page count force our hand."
[]
(def board (board-map ref initial-board))
(def to-move (ref [[:K [2 1]] [:k [0 1]]]))
(def num-moves (ref 0)))
(def king-moves (partial neighbors
[[-1 -1] [-1 0] [-1 1] [0 -1] [0 1] [1 -1] [1 0] [1 1]] 3))
(defn good-move? [to enemy-sq]
(when (not= to enemy-sq) to))
(defn choose-move [[[mover mpos][_ enemy-pos]]]
[mover (some #(good-move? % enemy-pos)
(shuffle (king-moves mpos)))])
The to-move structure describes the order of moves, so in the base case, it states that the light king :K at y=2,x=1 moves before the dark king :k at y=0,x=1. We reuse the neighbors function from section 7.4 to build a legal-move generator for chess king pieces. We do this by using partial supplied with the kingly position deltas and the board size. The good-move? function states that a move to a square is legal only if the enemy isn’t already located there. The function choose-move destructures the to-move vector and chooses a good move from a shuffled sequence of legal moves. The choose-move function can be tested in isolation:
(reset!) (take 5 (repeatedly #(choose-move @to-move))) ;=> ([:K [1 0]] [:K [1 1]] [:K [1 1]] [:K [1 0]] [:K [2 0]])
And now we’ll create a function to make a random move for the piece at the front of to-move, shown next.
Listing 11.1. Using alter to update a Ref

The alter function appears four times within the dosync, so that the from and to positions, as well as the to-move Refs, are updated in a coordinated fashion. We’re using the place function as the alter function, which states “given a to piece and a from piece, always return the to piece.” Observe what occurs when make-move is run once:
(make-move) ;=> [[:k [0 1]] [:K [2 0]]] (board-map deref board) ;=> [[:- :k :-] [:- :- :-] [:K :- :-]] @num-moves ;=> 1
We’ve successfully made a change to two board squares, the to-move structure, and num-moves using the uniform state change model. By itself, this model of state change is compelling. The semantics are simple to understand: give a reference a function that determines how the value changes. This is the model of sane state change that Clojure preaches. But we can now throw a bunch of threads at this solution and still maintain consistency:
(defn go [move-fn threads times] (dothreads! move-fn :threads threads :times times)) (go make-move 100 100) (board-map #(dosync (deref %)) board) ;=> [[:k :- :-] [:- :- :-] [:K :- :-]] @to-move ;=> [[:k [0 0]] [:K [2 0]]] @num-moves ;=> 10001
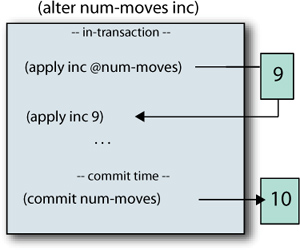
Figure 11.4 shows that at the time of the transaction, the in-transaction value of the to square is set to (apply place @SQUARE-REF PIECE). At the end of the transaction, the STM uses this in-transaction value as the commit value. If any other transaction had updated any other coordinated Ref before commit time, then the whole transaction would be retried.
Figure 11.4. Alter path: the in-transaction value 9 for the Ref num-moves is retrieved in the body of the transaction and manipulated with the alter function inc. This resulting value 10 is eventually used for the commit-time value, unless a retry is required.
Clojure’s retry mechanism guarantees that the Refs in a transaction are always coordinated upon commit because all other transactions line up waiting their turn to commit their coordinated values. Look at what happens should the Ref updates happen in separate transactions:
(defn bad-make-move []
(let [move (choose-move @to-move)]
(dosync (move-piece move @to-move))
(dosync (update-to-move move))))
(go bad-make-move 100 100)
(board-map #(dosync (deref %)) board)
;=> [[:- :K :-] [:- :- :-] [:- :K :-]]
Clearly something has gone awry, and as we mentioned, the reason lies in splitting the updates of the to and from Refs into different transactions. Being separated into two transactions means that they’re (potentially) running on different timelines. Because board and to-move are dependent, their states must be coordinated, but we’ve broken that necessity with bad-make-move. Therefore, somewhere along the line board was updated from two subsequent timelines where it was :K’s turn to move!
As shown in figure 11.5, either transaction can commit or be restarted; but because the two Refs are no longer in the same transaction, the occurrences of these conditions become staggered over time, leading to inconsistent values.
Figure 11.5. Splitting coordinated Refs: if Refs A and B should be coordinated, then splitting their updates across different transactions is dangerous. Value a? is eventually committed to A, but the update for B never commits due to retry and coordination is lost. Another error occurs if B’s change depends on A’s value and A and B are split across transactions. There are no guarantees that the dependent values refer to the same timeline.

11.2.2. Commutative change with commute
Figure 11.4 showed that using alter can cause a transaction to retry if a Ref it depends on is modified and committed while it’s running. But there may be circumstances where the value of a Ref within a given transaction isn’t important to its completion semantics. For example, the num-moves Ref is a simple counter, and surely its value at any given time is irrelevant for determining how it should be incremented. To handle these loose dependency circumstances, Clojure offers an operation named commute. What if we were to change the make-move function to use the commute function instead of alter?
(defn move-piece [[piece dest] [[_ src] _]] (commute (get-in board dest) place piece) (commute (get-in board src ) place :-) (commute num-moves inc)) (reset!) (go make-move 100 100) (board-map deref board) ;=> [[:K :- :-] [:- :- :-] [:- :- :k]] @to-move ;=> [[:K [0 0]] [:k [2 2]]]
Everything looks great! But you can’t assume that the same will work for update-to-move:
(defn update-to-move [move] (commute to-move #(vector (second %) move))) (go make-move 100 100) (board-map #(dosync (deref %)) board) ;=> [[:- :- :-] [:- :K :-] [:- :- :K]] @to-move [[:K [2 2]] [:K [1 1]]]
Thanks to our rash decision, we’ve once again introduced inconsistency into the system. But why? The reason lies in the fact that the new update-to-move isn’t amenable to the semantics of the commute function. commute allows for more concurrency in the STM by devaluing in-transaction value disparity resulting from another transaction’s commit. In other words, figure 11.6 shows that the in-transaction value of a Ref is initially set as when using alter, but the commit time value is reset just before commute commits.
Figure 11.6. Commute path: the in-transaction value 9 in the num-moves Ref is retrieved in the body of the transaction and manipulated with the commute function. But the commute function inc is again run at commit time with the current value 13 contained in the Ref. The result of this action serves as the committed value 14.

By retrieving the most current value for a Ref at the time of commit, the values committed might not be those corresponding to the in-transaction state. This leads to a condition of update reordering that your application must accommodate. Of course, this new function isn’t commutative because vector doesn’t give the same answer if its argument order is switched.
Using commute is useful as long as the following conditions aren’t problematic:
- The value you see in-transaction may not be the value that gets committed at commit time.
- The function you give to commute will be run at least twice—once to compute the in-transaction value, and again to compute the commit value. It might be run any number of times.
11.2.3. Vulgar change with ref-set
The function ref-set is different from alter and commute in that instead of changing a Ref based on a function of its value, it does so given a raw value:
(dosync (ref-set to-move '[[:K [2 1]] [:k [0 1]]])) ;=> [[:K [2 1]] [:k [0 1]]]
In general, this sort of vulgar change should be avoided. But because the Refs have become out of sync, perhaps you could be forgiven in using ref-set to fix it—just this once.
11.2.4. Fixing write-skew with ensure
Snapshot isolation means that within a transaction, all enclosed Ref states represent the same moment in time. Any Ref value that you see inside a transaction will never change unless you change it within that transaction. Your algorithms should be devised so that all you care about is that the values of the references haven’t changed before commit (unless your change function is commutative, as mentioned previously). If those values have changed, then the transaction retries, and you try again. Earlier, we talked about write skew, a condition occurring when you make decisions based on the intransaction value of a Ref that’s never written to, which is also changed at the same time. Avoiding write skew is accomplished using Clojure’s ensure function, which guarantees a read-only Ref isn’t modified by another thread. The make-move function isn’t subject to write skew because it has no invariants on read data and in fact never reads a Ref that it doesn’t eventually write. This design is ideal because it allows other threads to calculate moves without having to stop them, while any given transaction does the same. But in your own applications, you may be confronted with a true read invariant scenario, and it’s in such a scenario that ensure will help.
11.2.5. Refs under stress
After you’ve created your Refs and written your transactions, and simple isolated tests are passing, you may yet run into difficulties in larger integration tests because of how Refs behave under stress from multiple transactions. As a rule of thumb, it’s best to avoid having both short- and long-running transactions interacting with the same Ref. Clojure’s STM implementation will usually compensate eventually regardless, but you’ll soon see some less-than-ideal consequences of ignoring this rule.
To demonstrate this problem, listing 11.2 shows a function designed specifically to over-stress a Ref. It does this by starting a long-running or slow transaction in another thread, where work is simulated by a 200ms sleep, but all it’s really doing is reading the Ref in a transaction. This requires the STM to know of a stable value for the Ref for the full 200ms. Meanwhile, the main thread runs quick transactions 500 times in a row, each one incrementing the value in the Ref and thereby frustrating the slow transaction’s attempts to see a stable value. The STM works to overcome this frustration by growing the history of values kept for the Ref. But by default this history is limited to 10 entries, and our perverse function can easily saturate that:
(stress-ref (ref 0)) ;=> :done ; r is: 500, history: 10, after: 26 tries
You may see a slightly different number of tries, but the important detail is that the slow transaction is unable to successfully commit and print the value of r until the main thread has finished its frantic looping and returned :done. The Ref’s history started at a default of 0 and grew to 10, but this was still insufficient.
Listing 11.2. How to make a Ref squirm

Remember that our real problem here is mixing short- and long-running transactions on the same Ref. But if this is truly unavoidable, Clojure allows us to create a Ref with a more generous cap on the history size:
(stress-ref (ref 0 :max-history 30)) ; r is: 410, history: 20, after: 21 tries ;=> :done
Again, your numbers may be different, but this time the Ref’s history grew sufficiently (reaching 20 in this run) to allow the slow transaction to finish first and report about r before all 500 quick transactions completed. In this run, only 410 had finished when the slow transaction committed.
But the slow transaction still had to be retried 20 times, with the history growing one step large each time, before it was able to complete. If our slow transaction were doing real work instead of just sleeping, this could represent a lot of wasted computing effort. If your tests or production environment reveal this type of situation and the underlying transaction size difference can’t be resolved, one final Ref option can help. Because you can see that the history will likely need to be 20 anyway, you may as well start it off closer to its goal:
(stress-ref (ref 0 :min-history 15 :max-history 30)) ; r is: 97, history: 19, after: 5 tries ;=> :done
This time the slow transaction finished before even 100 of the quick transactions had finished; and even though the history grew to roughly the same size, starting it off at 15 meant the slow transaction only retried 4 times before succeeding.
The use of Refs to guarantee coordinated change is generally simple for managing state in a synchronous fashion, and tuning with :min-history and :max-history is rarely required. But not all changes in your applications will require coordination, nor will they need to be synchronous. For these circumstances, Clojure also provides another reference type, the Agent, that provides independent asynchronous changes, which we’ll discuss next.
11.3. When to use Agents
Like all Clojure reference types, an Agent represents an identity, a specific thing whose value can change over time. Each Agent has a queue to hold actions that need to be performed on its value, and each action will produce a new value for the Agent to hold and pass to the subsequent action. Thus the state of the Agent advances through time, action after action, and by their nature only one action at a time can be operating on a given Agent. Of course, other actions can be operating on other Agents at the same time, each in its own thread.
You can queue an action on any Agent by using send or send-off, the minor difference between which we’ll discuss later. Agents are integrated with STM transactions, and within a transaction any actions sent are held until the transaction commits or are thrown away if the transaction retries. Thus send and send-off are not considered side-effects in the context of a dosync, because they handle retries correctly and gracefully.
11.3.1. In-process versus distributed concurrency models
Both Clojure and Erlang are designed (Armstrong 2007) specifically with concurrent programming in mind, and Erlang’s process[2] model is similar in some ways to Clojure Agents, so it’s fair to briefly compare how they each approach the problem.
2 It’s interesting that popular opinion has tagged Erlang processes with the “actor” tag although the language implementers rarely, if ever, use that term. Therefore, because the Erlang elite choose not to use that term, we’ll avoid doing so also... almost.
Erlang takes a distributed, share-nothing (Armstrong 2007b) approach; Clojure instead promotes shared, immutable data. The key to Clojure’s success is the fact that its composite data structures are immutable, because immutable structures can be freely shared among disparate threads. Erlang’s composite data structures are also immutable, but because the communication model is distributed, the underlying theme is always one of dislocation. The implications of this are that all knowledge of the world under consideration is provided via messages. But with Clojure’s in-process model, data structures are always accessible directly, as illustrated in figure 11.7, whereas Erlang makes copies of the data sent back and forth between processes. This works well for Erlang and allows it to provide its fault recovery guarantees, but many application domains can benefit from the shared-memory model provided by Clojure.
Figure 11.7. Clojure agents versus Erlang processes: each Agent and process starts with the value 1. Both receive an inc request simultaneously but can only process one at a time, so more are queued. Requests to the process are queued until a response can be delivered, whereas any number of simultaneous derefs can be done on an Agent. Despite what this illustration may suggest, an Agent is not just an actor with a hat on.

The second difference is that Erlang messages block on reception, opening up the possibility for deadlock. On the other hand, when interacting with Clojure Agents, both sends and derefs proceed immediately and never block or wait on the Agent. Clojure does have an await function that can be used to block a thread until a particular Agent has processed a message, but this function is specifically disallowed in Agent threads (and also STM transactions) in order to prevent accidentally creating this sort of deadlock.
The final difference lies in the fact that Agents allow for arbitrary update functions whereas Erlang processes are bound to static pattern-matched message handling routines. In other words, pattern matching couples the data and update logic, whereas the former decouples them. Erlang is an excellent language for solving the extremely difficult problem of distributed computation, but Clojure’s concurrency mechanisms service the in-process programming model more flexibly than Erlang allows (Clementson 2008).
11.3.2. Controlling I/O with an Agent
One handy use for Agents is to serialize access to a resource, such as an file or other I/O stream. For example, imagine we want to provide a way for multiple threads to report their progress on various tasks, giving each report a unique incrementing number.
Because the state we want to hold is known, we can go ahead and create the Agent:
(def log-agent (agent 0))
Now we’ll supply an action function to send to log-agent. All action functions take as their first argument the current state of the Agent and can take any number of other arguments that are sent:
(defn do-log [msg-id message] (println msg-id ":" message) (inc msg-id))
Here msg-id is the state—the first time do-log is sent to the Agent, msg-id will be 0. The return value of the action function will be the new Agent state, incrementing it to 1 after that first action.
Now we need to do some work worth logging about, but for this example we’ll just pretend:
(defn do-step [channel message] (Thread/sleep 1) (send-off log-agent do-log (str channel message))) (defn three-step [channel] (do-step channel " ready to begin (step 0)") (do-step channel " warming up (step 1)") (do-step channel " really getting going now (step 2)") (do-step channel " done! (step 3)"))
To see how log-agent will correctly queue and serialize the messages, we need to start a few threads, each yammering away at the Agent, shown next:
(defn all-together-now [] (dothreads! #(three-step "alpha")) (dothreads! #(three-step "beta")) (dothreads! #(three-step "omega"))) (all-together-now) ; 0 : alpha ready to being (step 0) ; 1 : omega ready to being (step 0) ; 2 : beta ready to being (step 0) ; 3 : alpha warming up (step 1) ; 4 : alpha really getting going now (step 2) ; 5 : omega warming up (step 1) ; 6 : alpha done! (step 3) ; 7 : omega really getting going now (step 2) ; 8 : omega done! (step 3) ; 9 : beta warming up (step 1) ; 10 : beta really getting going now (step 2) ; 11 : beta done! (step 3)
Your output is likely to look different, but one thing that should be exactly the same is the stable, incrementing IDs assigned by the Agent, even while the alpha, beta, and omega threads fight for control.
There are several other possible approaches to solving this problem, and it can be constructive to contrast them. The simplest alternative would be to hold a lock while printing and incrementing. Besides the general risk of deadlocks when a complex program has multiple locks, there are some specific drawbacks even if this would be the only lock in play. For one, each client thread would block anytime there was contention for the lock, and unless some fairness mechanism were used, there’d be at least a slight possibility of one or more threads being “starved” and never having an opportunity to print or proceed with their work. Because Agent actions are queued and don’t block waiting for their action to be processed, neither of these is a concern.
Another option would be to use a blocking queue to hold pending log messages. Client threads would be able to add messages to the queue without blocking and with adequate fairness. But you’d generally need to dedicate a thread to popping messages from the queue and printing them, or write code to handle starting and stopping the printing thread as needed. Why write such code when Agents do this for you already? When no actions are queued, the Agent in our example has no thread assigned to it.[3]
3 Using Agents for logging might not be appropriate in all cases. For example, in probing scenarios, the number of log events could be extremely high. Coupling this volume with serialization could make the Agent unable to catch its ever-growing queue.
Agents have other features that may or may not be useful in any given situation. One is that the current state of an Agent can be observed cheaply. In the previous example, this would allow us to discover the ID of the next message to be written out, as follows:
@log-agent ;=> 11
Here the Agent is idle—no actions are queued or running, but the same expression would work equally well if the Agent were running.
Other features include the await and await-for functions, which allow a sending thread to block until all the actions it’s sent to a given set of Agents have completed. This could be useful in this logging example if we wanted to be sure a particular message had been written out before proceeding:
(do-step "important: " "this must go out") (await log-agent)
The await-for function is similar but allows you to specify a number of milliseconds after which to time out, even if the queued actions still haven’t completed.
A final feature Agents provide is that the set of actions you can send to an Agent is open. You can tell an Agent to do something that wasn’t even conceived of at the time the Agent was designed. For example, we could tell the Agent to skip ahead several IDs, and this action would be queued up along with all the log-message actions and executed by the Agent when its turn came:
(send log-agent (fn [_] 1000)) (do-step "epsilon " "near miss") ; 1000 : epsilon near miss
This is another area in which Clojure allows you to extend your design on the fly instead of requiring recompiling or even restarting your app. If you’re paying attention, you might wonder why we used send in that last example rather than send-off.
11.3.3. The difference between send and send-off
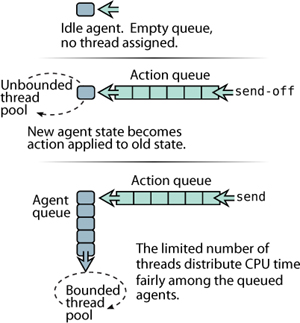
You can use either send or send-off with any Agent. When you use send-off as we did in most of the examples so far, only a single action queue is involved: the one managed by the individual Agent. Anytime the Agent has a send-off action queued, it has a thread assigned to it, working through the queue. With send, there’s a second queue—actions still go into the Agent’s queue, but then the Agent itself queues up waiting for a thread from a fixed-sized pool of threads. The size of this fixed pool is based on the number of processors the JVM is running on, so it’s a bad idea to use send with any actions that might block, tying up one of these limited number of threads. These differences are illustrated in figure 11.8.
Figure 11.8. Agents using send versus send-off. When an Agent is idle, no CPU resources are being consumed. Each action is sent to an Agent using either send or send-off, which determines which thread pool will be used to dequeue and apply the action. Because actions queued with send are applied by a limited thread pool, the Agents queue up for access to these threads, a constraint that doesn’t apply to actions queued with send-off.
We can make this scenario play out if we make a gaggle of Agents and send them actions that sleep for a moment. Here’s a little function that does this, using whichever send function we specify, and then waits for all the actions to complete:
(defn exercise-agents [send-fn]
(let [agents (map #(agent %) (range 10))]
(doseq [a agents]
(send-fn a (fn [_] (Thread/sleep 1000))))
(doseq [a agents]
(await a))))
If we use send-off, all the agents will begin their one-second wait more or less simultaneously, each in its own thread. So the entire sequence of them will complete in slightly over one second:
(time (exercise-agents send-off)) ; "Elapsed time: 1008.771296 msecs"
Now we can demonstrate why it’s a bad idea to mix send with actions that block:
(time (exercise-agents send)) ; "Elapsed time: 3001.555086 msecs"
The exact elapsed time you’ll see will depend on the number of processors you have, but if you have fewer than eight you’ll see this example takes at least two seconds to complete. The threads in the fixed-size pool are all clogged up waiting for sleep to finish, so the other Agents queue up waiting for a free thread. Because clearly the computer could complete all 10 actions in about one second using send-off, using send is a bad idea.
So that’s it: send is for actions that stay busy using the processor and not blocking on I/O or other threads, whereas send-off is for actions that might block, sleep, or otherwise tie up the thread. This is why we used send-off for the threads that printed log lines and send for the one that did no I/O at all.
11.3.4. Error handling
We’ve been fortunate so far—none of these Agent actions have thrown an exception. But real life is rarely so kind. Most of the other reference types are synchronous and so exceptions thrown while updating their state bubble up the call stack in a normal way, to be caught with a regular try/catch in your application (or not). Because Agent actions run in other threads after the sending thread has moved on, we need a different mechanism for handling exceptions that are thrown by Agent actions. As of Clojure 1.2, you can choose between two different error-handling modes for each Agent: :continue and :fail.
:Fail
By default, new Agents start out using the :fail mode, where an exception thrown by an Agent’s action will be captured by the Agent and held so that you can see it later. Meanwhile, the Agent will be considered failed or stopped and will stop processing its action queue—all the queued actions will have to wait patiently until someone clears up the Agent’s error.
One common mistake when dealing with Agents is to forget that your action function must take at least one argument for the Agent’s current state. For example, we might try to reset the log-agent’s current message ID like this:
(send log-agent (fn [] 2000)) ; incorrect @log-agent ;=> 1001
At first glance it looks like the action we sent had no effect, or perhaps hasn’t been applied yet. But we’d wait in vain for that Agent to do anything ever again without intervention, because it’s stopped. One way to determine this is with the agent-error function:
(agent-error log-agent) ;=> #<IllegalArgumentException java.lang.IllegalArgumentException: ; Wrong number of args passed to: user$eval--509$fn>
This returns the error of a stopped Agent, or nil if it’s still running fine. Another way to see whether an Agent is stopped is to try to send another action to it:
(send log-agent (fn [_] 3000)) ; java.lang.RuntimeException: Agent is failed, needs restart
Even though this action would’ve worked fine, the Agent has failed and so no further sends are allowed. The state of log-agent remains unchanged:
@log-agent ;=> 1001
In order to get the Agent back into working order, we need to restart it:
(restart-agent log-agent 2500 :clear-actions true) ;=> 2500
This resets the value of log-agent to 2500 and deletes all those actions patiently waiting in their queue. If we hadn’t included the :clear-actionstrue option, those actions would’ve survived and the Agent would continue processing them. Either way, the Agent is now in good working order again, and so we can again send and send-off to it:
(send-off log-agent do-log "The agent, it lives!") ; 2500 : The agent, it lives! ;=> #<Agent@72898540: 2500>
Note that restart-agent only makes sense and thus is only allowed when the Agent has failed. If it hasn’t failed, any attempt to restart it throws an exception in the thread making the attempt, and the Agent is left undisturbed:
(restart-agent log-agent 2500 :clear-actions true) ;=> java.lang.RuntimeException: Agent does not need a restart
This mode is perhaps most appropriate for manual intervention. Agents that normally don’t have errors but in a running system end up failing can use the :fail mode to keep from doing anything too bad until a human can take things in hand, check to see what happened, choose an appropriate new state for the Agent, and restart it just as we did here.
:Continue
The other error mode that Agents currently support is :continue, where any action that throws an exception is skipped and the Agent proceeds to the next queued action if any. This is most useful when combined with an error handler—if you specify an :error-handler when you create an Agent, that Agent’s error mode defaults to :continue. The Agent calls the error handler when an action throws an exception and doesn’t proceed to the next action until the handler returns. This gives the handler a chance to report the error in some appropriate way. For example, we could have log-agent handle faulty actions by logging the attempt:
(defn handle-log-error [the-agent the-err] (println "An action sent to the log-agent threw " the-err)) (set-error-handler! log-agent handle-log-error) (set-error-mode! log-agent :continue)
With the error mode and handler set up, sending faulty actions does cause reports to be printed as we wanted:
(send log-agent (fn [x] (/ x 0))) ; incorrect
; An action sent to the log-
agent threw java.lang.ArithmeticException: Divide by zero
;=> #<Agent@66200db9: 2501>
(send log-agent (fn [] 0)) ; also incorrect
; An action sent to the log-agent threw java.lang.IllegalArgumentException:
; Wrong number of args passed to: user$eval--820$fn
;=> #<Agent@66200db9: 2501>
And the Agent stays in good shape, always ready for new actions to be sent:
(send-off log-agent do-log "Stayin' alive, stayin' alive...") ; 2501 : Stayin' alive, stayin' alive...
Note that error handlers can’t change the state of the Agent (ours keeps its current message id of 2501 throughout the preceding tests). Error handlers are also supported in the :fail error mode, but handlers can’t call restart-agent so they’re less often useful for :fail than they are for the :continue error mode.
11.3.5. When not to use Agents
It can be tempting to repurpose Agents for any situation requiring the spawning of new threads. Their succinct syntax and “Clojurey” feel often make this temptation strong. But though Agents perform beautifully when each one is representing a real identity in your application, they start to show weaknesses when used a sort of “green thread” abstraction. In cases where you just need a bunch of worker threads banging away on some work, or you have a specific long-running thread polling or blocking on events, or any other kind of situation where it doesn’t seem useful that the Agent maintain a value, you’ll usually be able to find a better mechanism than Agents. In these cases, there’s every reason to consider using a Java Thread directly, or a Java executor (as we did with dothreads!) to manage a pool of threads, or in some cases perhaps a Clojure future.
Another common temptation is to use Agents when you need state held but you don’t actually want the sending thread to proceed until the Agent action you sent is complete. This can be done by using await, but it’s another form of abuse that should be avoided. For one, because you’re not allowed to use await in an Agent’s action, as you try to use this technique in more and more contexts you’re likely to run into a situation where it won’t work. But in general, there’s probably a reference type that will do a better job of behaving the way you want. Because this is essentially an attempt to use Agents as if they were synchronous, you may have more success with one of the other shared synchronous types. In particular, Atoms are shared and uncoordinated just like Agents, but they’re synchronous and so may fit better.
11.4. When to use Atoms
Atoms are like Refs in that they’re synchronous but are like Agents in that they’re independent (uncoordinated). An Atom may seem at first glance similar to a variable, but as we proceed you’ll see that any similarities are at best superficial. The use cases for Atoms are similar to those of compare-and-swap (CAS) spinning operations. Anywhere you might want to atomically compute a value given an existing value and swap in the new value, an Atom will suffice. Atom updates occur locally to the calling thread, and execution continues after the Atom value has been changed. If another thread B changes the value in an Atom before thread A is successful, then A retries. But these retries are spin-loop and don’t occur within the STM, and thus Atom changes can’t be coordinated with changes to other reference types. You should take care when embedding changes to Atoms within Clojure’s transactions because as you know, transactions can potentially be retried numerous times. Once an Atom’s value is set, it’s set, and it doesn’t roll back when a transaction is retried, so in effect this should be viewed as a side effect. Therefore, use Atoms in transactions only when you’re certain that an attempt to update its value, performed numerous times, is idempotent.
Aside from the normal use of @ and deref to query an Atom’s value, you can also use the mutating functions swap!, compare-and-set!, and reset!.
11.4.1. Sharing across threads
As we mentioned, Atoms are thread safe and can be used when you require a lightweight mutable reference to be shared across threads. A simple case is one of a globally accessible incrementing timer created using the atom function:
(def *time* (atom 0)) (defn tick [] (swap! *time* inc)) (dothreads! tick :threads 1000 :times 100) @*time* ;=> 100000
Though this will work, Java already provides a concurrent class for just such a purpose, java.util.concurrent.atomic.AtomicInteger, which can be used similarly:
(def *time* (java.util.concurrent.atomic.AtomicInteger. 0)) (defn tick [] (.getAndIncrement *time*)) (dothreads! tick :threads 1000 :times 100) *time* ;=> 100000
Though the use of AtomicInteger is more appropriate in this case, the use of an Atom works to show that it’s safe to use across threads.
11.4.2. Using Atoms in transactions
Just because we said that Atoms should be used carefully within transactions, that’s not to say that they can never be used in that way. In fact, the use of an Atom as the reference holding a function’s memoization cache is idempotent on update.
Memoization
Memoization is a way for a function to store calculated values in a cache so that multiple calls to the function can retrieve previously calculated results from the cache, instead of performing potentially expensive calculations every time. Clojure provides a core function memoize that can be used on any referentially transparent function.
Individual requirements from memoization are highly personal, and a generic approach isn’t always the appropriate solution for every problem. We’ll discuss personalized memoization strategies in section 12.4, but for now we’ll use an illustrative example appropriate for Atom usage.
Atomic Memoization
The core memoize function is great for creating simple function caches, but it has some limitations. First, it doesn’t allow for custom caching and expiration strategies. Additionally, memoize doesn’t allow you to manipulate the cache for the purposes of clearing it in part or wholesale. Therefore, we’ll create a function manipulable-memoize that allows us to get at the cache and perform operations on it directly. Throughout the book, we’ve mentioned Clojure’s metadata facility, and for this example it will come in handy. We can take in the function to be memoized and attach some metadata[4] with an Atom containing the cache itself for later manipulation.
4 The ability to attach metadata to functions is a recent addition to Clojure version 1.2.
Listing 11.3. A resettable memoize function

As shown in listing 11.3, we’ve slightly modified the core memoize function to attach the Atom to the function being memoized. You can now observe manipulable-memoize in action:
(def slowly (fn [x] (Thread/sleep 3000) x)) (time [(slowly 9) (slowly 9)]) ; "Elapsed time: 6000.63 msecs" ;=> [9 9] (def sometimes-slowly (manipulable-memoize slowly)) (time [(sometimes-slowly 108) (sometimes-slowly 108)]) ; "Elapsed time: 3000.409 msecs" ;=> [108 108]
The call to slowly is always... well... slow, as you’d expect. But the call to sometimes-slowly is only slow on the first call given a certain argument. This too is just as you’d expect. Now we can inspect sometimes-slowly’s cache and perform some operations on it:
(meta sometimes-slowly)
;=> {:cache #<Atom@e4245: {(108) 108}>}
(let [cache (:cache (meta sometimes-slowly))]
(swap! cache dissoc '(108)))
;=> {}
You may wonder why we used swap! to dissoc the cached argument 108 instead of using (reset! cache {}). There are certainly valid use cases for the wholesale reset of an Atom’s value, and this case is arguably one. But it’s good practice to set your reference values via the application of a function rather than the in-place value setting. In this way, you can be more selective about the value manipulations being performed. Having said that, here are the consequences our actions had:
(meta sometimes-slowly)
;=> {:cache #<Atom@e4245: {}>}
(time (sometimes-slowly 108))
; "Elapsed time: 3000.3 msecs"
;=> 108
And yes, you can see that we were able to remove the cached argument value 108 using the metadata map attached to the function sometimes-slowly. There are better ways to allow for pointed cache removal than this, but for now you can take heart in that using an Atom, we’ve allowed for the local mutation of a reference in a thread-safe way. Additionally, because of the nature of memoization, you can use these memoized functions in a transaction without ill effect. Bear in mind that if you do use this in a transaction, then any attempt to remove values from the cache may not be met with the results expected. Depending on the interleaving of your removal and any restarts, the value(s) you remove might be reinserted on the next time through the restart. But even this condition is agreeable if your only concern is reducing total cache size.
11.5. When to use locks
Clojure’s reference types and parallel primitives cover a vast array of use cases. Additionally, Java’s rich set of concurrency classes found in the java.util.concurrent package are readily available. But even with this arsenal of tools at your disposal, there still may be circumstances where explicit locking is the only option available, the common case being the modification of arrays concurrently. We’ll start with a simple protocol to describe a concurrent, mutable, safe array that holds an internal array instance, allowing you to access it or mutate it safely. A naive implementation can be seen in the following listing.
Listing 11.4. A simple SafeArray protocol

If you’ll notice, we used the :refer-clojure namespace directive to :exclude the array and sequence functions that the SafeArray protocol overrides. We did this not only because it’s important to know how to use :refer-clojure, but also because we’re changing the semantics of aset to take a mutating function as its last argument instead of a raw value. We then used the :require directive to alias the Clojure namespace as clj, thus avoiding the need to use the fully qualified function names a la clojure.core/aget.
The dumb array created by make-dumb-array is stored in a closure created by reify, and unguarded access is provided without concern for concurrent matters. Using this implementation across threads is disastrous, as shown:
(defn pummel [a] (dothreads! #(dotimes [i (count a)] (aset a i inc)) :threads 100)) (def D (make-dumb-array Integer/TYPE 8)) (pummel D) ;; wait for pummel to terminate (seq D) ;=> (82 84 65 63 83 65 83 87)
This is very wrong—100 threads incrementing concurrently should result in 100 for each array slot. To add insult to injury, Clojure didn’t throw a Concurrent-ModificationException as you might’ve expected, but instead just silently went along doing very bad things. Next, we’ll talk a little about locking and provide an alternate implementation for SafeArray using locking primitives.
11.5.1. Safe mutation through locking
Currently, the only[5] way to safely modify and see consistent values for a mutable object across threads in Clojure is through locking.
5 Although a potential future addition to Clojure named pods may provide another.
References Around Evil Mutable Things
Wrapping a mutable object in a Clojure reference type provides absolutely no guarantees for safe concurrent modification. Doing this will at best explode immediately or, worse, provide inaccurate results.
If at all possible, locking should be avoided; but for those times when it’s unavoidable, the locking macro will help. The locking macro takes a single parameter acting as the locking monitor and a body that executes in the monitor context. Any writes and reads to the monitor object are thread safe, and as a bonus the monitor is always released at the end of the block. One of the major complexities in concurrent programming using locks is that all errors must be handled fully and appropriately; otherwise you risk orphaned locks, and they spell deadlock. But the locking macro will always release the lock, even in the face of exceptions.
Listing 11.5. An implementation of the SafeArray protocol using the locking macro

We used the locking macro on both the aget and aset functions so that they can both maintain consistency concurrently. Because aset calls aget, the locking macro is called twice. This isn’t a problem because locking is reentrant, or able to be called multiple times in the same thread. Typically, you’d have to manage the releasing of reentrant locking mechanism to match the number of times called, but fortunately locking manages that for us.
The locking macro is the simplest way to perform primitive locking in Clojure. But the implementation of make-safe-array is coarse in that the locks used are guarding the entire array. Any readers or writers wishing to access or update any slot in the array must wait their turn, a bottleneck known as contention. If you need finer-grained locking, the locking facilities provided by Java will help to gain more control, a topic we cover next.
11.5.2. Using Java’s explicit locks
Java provides a set of explicit locks in the java.util.concurrent.locks package that can also be used as shown in the following listing. One such lock is provided by the java.util.concurrent.locks.ReentrantLock class.
Listing 11.6. An implementation of the SafeArray protocol using ReentrantLock

The first point of note is that we use a technique (simplified for clarity) called lock striping (Herlihy 2008) to reduce the contention of guarding the array as a whole using locking. The target array a’s slots are guarded by half the number of locks, each chosen using the simple formula (mod target-index num-locks). This scheme allows readers and writers to (potentially) act independently when accessing different array slots. It’s crucial that we closed over the lock instance array L because for explicit locks to work, each access must lock and unlock the same instance. Additionally, we’re calling the .unlock method in the body of a finally expression, because failing to do so is a recipe for disaster. Unlike the locking macro, the ReentrantLock class doesn’t manage lock release automatically. Finally, you can also use the ReentrantLock in a way equivalent to using the locking macro, but using ReentrantLock gives you the choice of using proxy to provide more complex semantics than locking can provide.
One flaw of the make-smart-array function is that it uses the same locks for readers and writers. But you can allow for more concurrency if you enable some number of readers to access array slots without blocking at all by using the java.util.concurrent.locks.ReentrantReadWriteLock class. The ReentrantReadWriteLock class holds two lock instances, one for reads and one for writes, and by adding another lock array you can take advantage of this fact. We won’t get into that exercise here, but if you choose to do so then you can use the implementation of make-smart-array as a guide.
Using the various locking mechanisms, you can guarantee consistency across threads for mutable objects. But as we showed with explicit locks, there’s an expected incantation to unlocking that must be strictly observed. Though not necessarily complex in the SafeArray implementations, the conceptual baggage incurred in the semantics of explicit locking scheme doesn’t scale well. The java.util.concurrent package contains a cacophony of concurrency primitives above and beyond simple locks, but it’s not our goal to provide a comprehensive survey herein.
Now that we’ve covered the matter of guaranteeing coordinated state across disparate threads, we turn our attention to a different topic: parallelization.
11.6. When to use futures
Clojure includes two reference types supporting parallelism: futures and promises. Futures, the subject of this section, are simple yet elegant constructs useful for partitioning a typically sequential operation into discrete parts. These parts can then be asynchronously processed across numerous threads that will block if the enclosed expression hasn’t finished. All subsequent dereferencing will return the calculated value. The simplest example of the use of a future is as shown:
(time (let [x (future (do (Thread/sleep 5000) (+ 41 1)))] [@x @x])) ; "Elapsed time: 5001.682 msecs" ;=> [42 42]
The processing time of the do block is only paid for on the first dereference of the future x. Futures represent expressions that have yet to be computed.
11.6.1. Futures as callbacks
One nice use case for futures is in the context of a callback mechanism. Normally you might call out to a remote-procedure call (RPC), wait for it to complete, and then proceed with some task depending on the return value. But what happens if you need to make multiple RPC calls? Should you be forced to wait for them all serially? Thanks to futures, the answer is no. In this section, we’ll use futures to create an aggregate task that finds the total number of occurrences of a string within a given set of Twitter[6] feeds. This aggregate task will be split into numerous parallel subtasks via futures.
6 Twitter is online at http://twitter.com.
Counting Word Occurrences in a Set of Twitter Feeds
Upon going to a personal Twitter page such as http://twitter.com/fogus, you can find a link to the RSS 2.0 feed for that user. We’ll use this feed as the input to our functions. An RSS 2.0 feed is an XML document used to represent a piece of data that’s constantly changing. The layout of a Twitter RSS entry is straightforward:
<rss version="2.0">
<channel>
<title>Twitter / fogus</title>
<link>http://twitter.com/fogus</link>
<item>
<title>fogus: Thinking about #Clojure futures.</title>
<link>http://twitter.com/fogus/statuses/12180102647/</link>
</item>
</channel>
</rss>
There’s more to the content of a typical RSS feed, but for our purposes we wish to only retrieve the title element of the item elements (there can be more than one). To do this, we need to first parse the XML and put it into a convenient format. If you recall from section 8.4, we created a domain DSL to create a tree built on a simple node structure of tables with the keys :tag, :attrs, and :content. As mentioned, that structure is leveraged in many Clojure libraries, and we’ll take advantage of this fact. Clojure provides some core functions in the clojure.xml and clojure.zip namespaces to help make sense of the feed:
(require '(clojure [xml :as xml]))
(require '(clojure [zip :as zip]))
(defmulti rss-children class)
(defmethod rss-children String [uri-str]
(-> (xml/parse uri-str)
zip/xml-zip
zip/down
zip/children))
Using the function clojure.xml/parse, we can retrieve the XML for a Twitter RSS feed and convert it into the familiar tree format. That tree is then passed into a function clojure.zip/xml-zip that converts that structure into another data structure called a zipper. The form and semantics of the zipper are beyond the scope of this book (Huet 1997), but using it in this case allows us to easily navigate down from the root rss XML node to the channel node, where we then retrieve its children. The child nodes returned from rss-children contain other items besides item nodes (title, link, and so forth) that need to be filtered out. Once we have those item nodes, we then want to retrieve the title text and count the number of occurrences of the target text (case-insensitive). We perform all of these tasks using the function count-tweet-text-task, defined in the following listing.
Listing 11.7. Creating a future task to count word occurrences in a tweet

We’ll now try to count some text in a Twitter feed to see what happens:
(count-tweet-text-task "#clojure" "http://twitter.com/statuses/user_timeline/46130870.rss") ;=> 7
The result you see is highly dependent on when you run this function, because the RSS feeds are ever-changing. But using the count-tweet-text-task function, we can build a sequence of tasks to be performed over some number of Twitter feeds. Before we do that, we’ll create a convenience macro as-futures to take said sequence and dispatch the enclosed actions across some futures.
Listing 11.8. A macro to dispatch a sequence of futures
(defmacro as-futures [[a args] & body]
(let [parts (partition-by #{'=>} body)
[acts _ [res]] (partition-by #{:as} (first parts))
[_ _ task] parts]
`(let [~res (for [~a ~args] (future ~@acts))]
~@task)))
The as-futures macro implemented in listing 11.8 names a binding corresponding to the arguments for a given action, which is then dispatched across a number of futures, after which a task is run against the futures sequence. The body of as-futures is segmented so that we can clearly specify the needed parts—the action arguments, the action to be performed for each argument, and the tasks to be run against the resulting sequence of futures:
(as-futures [<arg-name> <all-args>] <actions-using-args> :as <results-name> => <actions-using-results>)
To simplify the macro implementation, we use the :as keyword and => symbol to clearly delineate its segments. The as-futures body only exits after the task body finishes—as determined by the execution of the futures. We can use as-futures to perform the original task with a new function tweet-occurrences, implemented in the following listing.
Listing 11.9. Counting string occurrences in Twitter feeds fetched in parallel
(defn tweet-occurrences [tag & feeds]
(as-futures [feed feeds]
(count-tweet-text-task tag feed)
:as results
=>
(reduce (fn [total res] (+ total @res))
0
results)))
The as-futures macro builds a sequence of futures named results, enclosing the call to count-tweet-text-task across the unique set of Twitter feeds provided. We then sum the counts returned from the dereferencing of the individual futures, as shown:
(tweet-occurrences "#Clojure" "http://twitter.com/statuses/user_timeline/46130870.rss" "http://twitter.com/statuses/user_timeline/14375110.rss" "http://twitter.com/statuses/user_timeline/5156041.rss" "http://twitter.com/statuses/user_timeline/21439272.rss") ;=> 22
And that’s that. Using only a handful of functions and macros, plus using the built-in core facilities for XML parsing and navigation, we’ve created a simple Twitter occurrences counter. Our implementation has some trade-offs made in the name of page count. First, we blindly dereference the future in tweet-occurrences when calculating the sum. If the future’s computation freezes, then the dereference would likewise freeze. Using some combination of future-done?, future-cancel, and future-cancelled? in your own programs, you can skip, retry, or eliminate ornery feeds from the calculation. Futures are only one way to perform parallel computation in Clojure, and in the next section we’ll talk about another—promises.
11.7. When to use promises
Another tool that Clojure provides for parallel computation is the promise and deliver mechanisms. Promises are similar to futures, in that they represent a unit of computation to be performed on a separate thread. Likewise, the blocking semantics when dereferencing an unfinished promise are also the same. Whereas futures encapsulate an arbitrary expression that caches its value in the future upon completion, promises are placeholders for values whose construction is fulfilled by another thread via the deliver function. A simple example is as follows:
(def x (promise)) (def y (promise)) (def z (promise)) (dothreads! #(deliver z (+ @x @y))) (dothreads! #(do (Thread/sleep 2000) (deliver x 52))) (dothreads! #(do (Thread/sleep 4000) (deliver y 86))) (time @z) ; "Elapsed time: 3995.414 msecs" ;=> 138
Promises are write-once; any further attempt to deliver will throw an exception.
11.7.1. Parallel tasks with promises
We can create a macro similar to as-futures for handling promises, but because of the more advanced value semantics, the implementation is thus more complicated. We again wish to provide a named set of tasks, but we’d additionally like to name the corresponding promises so that we can then execute over the eventual results, which we do next.
Listing 11.10. A macro to dispatch a sequence of promises across a number of threads
(defmacro with-promises [[n tasks _ as] & body]
(when as
`(let [tasks# ~tasks
n# (count tasks#)
promises# (take n# (repeatedly promise))]
(dotimes [i# n#]
(dothreads!
(fn []
(deliver (nth promises# i#)
((nth tasks# i#))))))
(let [~n tasks#
~as promises#]
~@body))))
We could then build a rudimentary parallel testing facility, dispatching tests across disparate threads and summing the results when all of the tests are done:
(defrecord TestRun [run passed failed])
(defn pass [] true)
(defn fail [] false)
(defn run-tests [& all-tests]
(with-promises
[tests all-tests :as results]
(into (TestRun. 0 0 0)
(reduce #(merge-with + %1 %2) {}
(for [r results]
(if @r
{:run 1 :passed 1}
{:run 1 :failed 1}))))))
(run-tests pass fail fail fail pass)
;=> #:user.TestRun{:run 5, :passed 2, :failed 3}
This unit-testing model is simplistic by design in order to illustrate parallelization using promises and not to provide a comprehensive testing framework.
11.7.2. Callback API to blocking API
Promises, much like futures, are useful for executing RPC on separate threads. This can be useful if you need to parallelize a group of calls to an RPC service, but there’s a converse use case also. Often, RPC APIs take arguments to the service calls and also a callback function to be executed when the call completes. Using the rss-children function from the previous section, we can construct an archetypal RPC function:
(defn tweet-items [k feed]
(k
(for [item (filter (comp #{:item} :tag) (rss-children feed))]
(-> item :content first :content))))
The tweet-items function is a distillation of the count-tweet-text-task function from the previous chapter, as shown:
(tweet-items count "http://twitter.com/statuses/user_timeline/46130870.rss") ;=> 16
The argument k to tweet-items is the callback, or continuation, that’s called with the filtered RPC results. This API is fine, but there are times when a blocking call is more appropriate than callback based call. We can use a promise to achieve this blocking behavior with the following:
(let [p (promise)]
(tweet-items #(deliver p (count %))
"http://twitter.com/statuses/user_timeline/46130870.rss")
@p)
;=> 16
And as you see, the call blocks until the deliver occurs. This is a fine way to transform the callback into a blocking call, but we’d like a way to do this generically. Fortunately, most well-written RPC APIs follow the same form for their callback functions/methods, so we can create a macro to wrap this up nicely in the following listing.
Listing 11.11. A macro for transforming a callback-based function to a blocking call
(defmacro cps->fn [f k]
`(fn [& args#]
(let [p# (promise)]
(apply ~f (fn [x#] (deliver p# (~k x#))) args#)
@p#)))
(def count-items (cps->fn tweet-items count))
(count-items "http://twitter.com/statuses/user_timeline/46130870.rss")
;=> 16
This is a simple solution to a common problem that you may have already encountered in your own applications.
11.7.3. Deterministic deadlocks
You can cause a deadlock in your applications by never delivering to a promise. One possibly surprising advantage of using promises is that if a promise can deadlock, it’ll deadlock deterministically. Because only a single thread can ever deliver on a promise, only that thread will ever cause a deadlock. We can create a cycle in the dependencies between two promises to observe a deadlock using the following code:
(def kant (promise)) (def hume (promise)) (dothreads! #(do (println "Kant has" @kant) (deliver hume :thinking))) (dothreads! #(do (println "Hume is" @hume) (deliver kant :fork)))
The Kant thread is waiting for the delivery of the value for kant from the Hume thread, which in turn is waiting for the value for hume from the Kant thread. Attempting either @kant or @hume in the REPL will cause an immediate deadlock. Furthermore, this deadlock will happen every time; it’s deterministic rather than dependent on odd thread timings or the like. Deadlocks are never nice, but deterministic deadlocks are better than nondeterministic.[7]
7 There are experts in concurrent programming who will say that naïve locking schemes are also deterministic. Our simple example is illustrative, but alas it isn’t representative of a scheme that you may devise for your own code. In complex designs where promises are created in one place and delivered in a remote locale, determining deadlock will naturally be more complex. Therefore, we’d like to use this space to coin a new phrase: “determinism is relative.”
We’ve only touched the surface for the potential that promises represent. In fact, the pieces that we’ve assembled in this section represent some of the basic building blocks of dataflow (Van Roy 2004) concurrency. But any attempt to serve justice to dataflow concurrency in a single section would be a futile effort. At its essence, dataflow deals with the process of dynamic changes in values causing dynamic changes in dependent “formulas.” This type of processing finds a nice analogy in the way that spreadsheet cells operate, some representing values and others dependent formulas that change as the former also change.
Continuing our survey of Clojure’s parallelization primitives, we’ll next discuss some of the functions provided in the core library.
11.8. Parallelism
In the previous two sections we built two useful macros as-futures and with-promises, allowing you to parallelize a set of operations across numerous threads. But Clojure has functions in its core library providing similar functionality named pmap, pvalues, and pcalls, which we’ll cover briefly in this section.
11.8.1. pvalues
The pvalues macro is analogous to the as-futures macro, in that it executes an arbitrary number of expressions in parallel. Where it differs is that it returns a lazy sequence of the results of all the enclosed expressions, as shown:
(pvalues 1 2 (+ 1 2)) ;=> (1 2 3)
The important point to remember when using pvalues is that the return type is a lazy sequence, meaning that your access costs might not always present themselves as expected:
(defn sleeper [s thing] (Thread/sleep (* 1000 s)) thing)
(defn pvs [] (pvalues
(sleeper 2 :1st)
(sleeper 3 :2nd)
(keyword "3rd")))
(-> (pvs) first time)
; "Elapsed time: 2000.309 msecs"
;=> :1st
The total time cost of accessing the first value in the result of pvs is only the cost of its own calculation. But accessing any subsequent element costs as much as the most expensive element before it, which you can verify by accessing the last element:
(-> (pvs) last time) ; "Elapsed time: 4001.435 msecs" ;=> :3rd
This may prove a disadvantage if you want to access the result of a relatively cheap expression that happens to be placed after a more costly expression. More accurately, all seq values within a sliding window[8] are forced, so processing time is limited by the most costly element therein.
8 Currently, the window size is N+2, where N is the number of CPU cores. But this is an implementation detail, so it’s enough to know only that the sliding window exists.
11.8.2. pmap
The pmap function is the parallel version of the core map function. Given a function and a set of sequences, the application of the function to each matching element happens in parallel:
(->> [1 2 3]
(pmap (comp inc (partial sleeper 2)))
doall
time)
; "Elapsed time: 2000.811 msecs"
;=> (2 3 4)
The total cost of realizing the result of mapping a costly increment function is again limited by the most costly execution time within the aforementioned sliding window. Clearly, in this contrived case, using pmap provides a benefit, so why not just replace every call to map in your programs with a call to pmap? Surely this would lead to faster execution times if the map functions were all applied in parallel, no? The answer is a resounding: it depends. A definite cost is associated with keeping the resulting sequence result coordinated, and to indiscriminately use pmap might actually incur that cost unnecessarily, leading to a performance penalty. But if you’re certain that the cost of the function application outweighs the cost of the coordination, then pmap might help to realize performance gains. Only through experimentation will you be able to determine whether pmap is the right choice.
11.8.3. pcalls
Finally, Clojure provides a pcalls function that takes an arbitrary number of functions taking no arguments and calls them in parallel, returning a lazy sequence of the results. The use shouldn’t be a surprise by now:
(-> (pcalls
#(sleeper 2 :1st)
#(sleeper 3 :2nd)
#(keyword "3rd"))
doall
time)
; "Elapsed time: 3001.039 msecs"
;=> (:1st :2nd :3rd)
The same benefits and trade-offs associated with pvalues and pmap also apply to pcalls and should be considered before use.
Executing costly operations in parallel can be a great boon when used properly, but should by no means be considered a magic potion guaranteeing speed gains. There’s currently no magical formula for determining which parts of an application can be parallelized—the onus is on you to determine your application’s parallel potential. What Clojure provides is a set of primitives, including futures, promises, pmap, pvalues, and pcalls as the building blocks for your own personalized parallelization needs.
In the next section, we’ll cover the ubiquitous Var, but from a different perspective than we have thus far.
11.9. Vars and dynamic binding
The last reference type we’ll explore is perhaps the most commonly used—the Var. Vars are most often used because of two main features:
- Vars can be named and interned in a namespace.
- Vars can provide thread-local state.
It’s through the second feature that Vars contribute most usefully to the reference type landscape. The thread-local value of a Var by definition can only be read from or written to a single thread, and thus provides the thread-safe semantics you’ve come to expect from a Clojure reference type.
But before you can start experimenting with Vars at the REPL, we to need address some consequences of the first feature. The other reference objects you’ve looked at aren’t themselves named and so are generally stored in something with a name. This means that when the name is evaluated, you get the reference object, not the value. To get the object’s value, you have to use deref. Named Vars flip this around—evaluating their name gives the value, so if you want the Var object, you need to pass the name to the special operator var.
With this knowledge in hand, you can experiment with an existing Var. Clojure provides a Var named *read-eval*,[9] so you can get its current value by evaluating its name:
9*read-eval* happens to be a Var that has a default configuration useful for this discussion about Vars—its actual purpose is unimportant here.
*read-eval* ;=> true
No deref needed, because *read-eval* is a named Var. Now for the Var object itself:
(var *read-eval*) ;=> #'clojure.core/*read-eval*
That’s interesting—when a named Var object is printed, it starts with #' and is then followed by the fully qualified name of the Var. The #' reader feature expands to the Var operator—it means the same thing:
#'*read-eval* ;=> #'clojure.core/*read-eval*
Now that you’ve seen how to refer to Var objects, you can look at how they behave. The Var *read-eval* is one of those provided by Clojure that’s specifically meant to be given thread-local bindings but by default has only a root binding. You should’ve seen its root binding when you evaluated it earlier—by default, *read-eval* is bound to true.
11.9.1. The binding macro
The root binding of a Var can act as the base of a stack, with each thread’s local bindings pushing onto that stack and popping off of it as requested. The most common mechanism for pushing and popping thread-local bindings is the macro binding. It takes one or more Var names and a value for each that will initialize the new binding when it’s pushed. These bindings remain in effect until control passes out of the binding macro, at which point they’re popped off the stack.
Here’s a simple example of a function that prints the current value of the Var *read-eval*, either the root or thread-local value, whichever is currently in effect:
(defn print-read-eval [] (println "*read-eval* is currently" *read-eval*))
This function calls print-read-eval three times, the first and last of which will print the root binding. The middle time, binding is in effect:
(defn binding-play []
(print-read-eval)
(binding [*read-eval* false]
(print-read-eval))
(print-read-eval))
This results in the Var temporarily having a thread-local value of false:
(binding-play) ; *read-eval* is currently true ; *read-eval* is currently false ; *read-eval* is currently true
This is a like thread B in figure 11.9, which also shows a simpler scenario than thread A and a more complex one than thread C.
Figure 11.9. Thread-local Var bindings. This illustration depicts a single Var being used from three different threads. Each rounded box is a Var binding, either thread-local or root. Each star is the Var being deref’ed, with the solid arrow pointing to the binding used. The dotted lines point from a thread-local binding to the next binding on the stack.
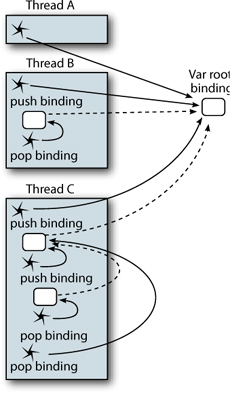
11.9.2. Creating a named Var
Vars are most commonly created with the special operator def or one of the many macros that expands to a form that has a def inside:
- defn—For putting a function in a Var
- defmacro—For putting a macro in a Var
- defonce—For setting the value of an unbound Var
- defmulti—For putting a multimethod in a Var
There are a few others in clojure.core[10] and many more in contrib. What they have in common is that each of these will intern a Var in the current namespace. Clojure will search for the named Var in the current namespace. If one is found, it’s used; otherwise, a new Var is created and added to the namespace, and that one is used.[11] The Var (specifically the root binding of the Var) is bound to whatever value, function, or macro (and so on) was given. The Var itself is returned:
10 It’s likely that starting with Clojure 1.3 Vars will only have the ability to take on thread-local values when defined using defdynamic or marked with metadata like ^{:dynamic true}. Throughout this book, we will take the latter approach with high confidence that it will just work in 1.3.
11 Not all macros starting with def necessarily create or intern Vars. Some that don’t: defmethod, defrecord, and deftype.
(def favorite-color :green) #'user/favorite-color
When a Var is printed, its fully qualified name is given, along with the namespace where the Var is interned (user) and the Var’s name itself (favorite-color). These are preceded by #' because unlike the other reference types, a named Var is automatically dereferenced when its name is evaluated—no explicit @ or call to deref is required:
favorite-color ;=> :green
So in order to refer to a Var instead of the value it’s bound to, you need to use #' or the special form var, which are equivalent:
(var favorite-color) ;=> #'user/favorite-color
A Var can exist (or not exist) in any of four states. The precise state a Var is in can be determined using the functions resolve, bound?, and thread-bound? as shown in Table 11.1.
Table 11.1. Var states
|
Initialization mechanism |
(resolve ’x) |
(bound? #’x) |
(thread-bound? #’x) |
|---|---|---|---|
| (def x) | #'user/x | false | false |
| (def x 5) | #'user/x | true | false |
| (binding [x 7] ...) | #'user/x | true | true |
| (with-local-vars [x 9] ...) | nil | true (bound? x) | true (thread-bound? x) |
The first row of the table shows the results of resolve, bound?, and thread-bound? when a var x is unbound. The remaining rows show how to change x to cause those functions to return the values shown.
11.9.3. Creating anonymous Vars
Vars don’t always have names, nor do they need to be interned in a namespace. The with-local-vars macro creates Vars and gives them thread-local bindings all at once, but it won’t intern them. Instead, they’re bound to locals, which means that the associated Var isn’t implicitly looked up by symbolic name. You need to use deref or var-get to get the current value of the Var. Here’s an example of a Var x created and interned with def, and then a local x that shadows it and is bound to a new var via with-local-vars:
(def x 42)
{:outer-var-value x
:with-locals (with-local-vars [x 9]
{:local-var x
:local-var-value (var-get x)})}
;=> {:outer-var-value 42,
:with-locals {:local-var #<Var: --unnamed-->,
:local-var-value 9}}
Within the body of the with-local-vars macro, the bound value can bet set using (var-set <var> <value>), which will of course only affect the thread-local value. It’s almost stunning how rarely with-local-vars is useful.
11.9.4. Dynamic scope
Vars have dynamic scope, which contrasts with the lexical scope of let locals. The most obvious difference is that with a lexical local, you can easily see where it was initialized by looking at the nested structure of the code. A Var, on the other hand, may have been initialized by a binding anywhere earlier in the call stack, not necessarily nearby in the code at all. This difference can create unexpectedly complex interactions and is one of the few areas where Clojure does little to help you address such complexity.
An example of this complexity is shown by using the binding macro or any macro built on top of it, such as with-precision and with-out-str. For example, we can use the with-precision macro to conveniently set up the *math-context* Var:
(with-precision 4 (/ 1M 3)) ;=> 0.3333M
We need to use with-precision here because if we don’t tell BigDecimal we’re okay with it rounding off the result, it’ll refuse to return anything in this case:
(/ 1M 3) ; java.lang.ArithmeticException: Non-terminating decimal expansion; ; no exact representable decimal result.
With that in mind, can you see why with-precision isn’t doing its job in the next snippet? The only thing that makes it different from the example that worked earlier is we’re using map to produce a sequence of three numbers instead of just one:
(with-precision 4 (map (fn [x] (/ x 3)) (range 1M 4M))) ; java.lang.ArithmeticException: Non-terminating decimal expansion; ; no exact representable decimal result.
The problem is that map is lazy and therefore doesn’t call the function given to it immediately. Instead, it waits until the REPL tries to print it, and then does the division. Although the map and the function it calls are within the lexical scope of with-binding, and with-binding itself uses a thread-local binding internally, it doesn’t care about lexical scope. When the division operation is performed, we’ve already left the dynamic scope of the with-precision, and it no longer has any effect. The BigDecimal behavior drops back to its default, and it throws an exception.
One way to solve this is to make sure that all the division is done before leaving the dynamic scope. Clojure’s doall function is perfect for this:
(with-precision 4 (doall (map (fn [x] (/ x 3)) (range 1M 4M)))) ;=> (0.3333M 0.6667M 1M)
One drawback is that it completely defeats map’s laziness. An alternate solution is to have the function provided to map re-create, when it’s run, the dynamic scope in which the function was created. Clojure provides a handy macro bound-fn to do exactly that:
(with-precision 4 (map (bound-fn [x] (/ x 3)) (range 1M 4M))) ;=> (0.3333M 0.6667M 1M)
Now the sequence being returned is still lazy, but before each item is computed, the dynamic scope of *math-context* is re-created and the exception is avoided.
This kind of mismatch between a function definition that appears lexically inside a form like with-precision or binding and yet has a different dynamic scope when called doesn’t cause problems with lazy sequences alone. You may also see problems with functions sent to Agents as actions or with the body of a future, because these are executed in other threads outside the dynamic scope where they’re set up.
Problems related to dynamic scope aren’t even exclusive to Vars. The scope of a try/catch is also dynamic and can have similarly unexpected behavior. For example, with-open uses try/finally to close a file automatically when execution leaves its dynamic scope. Failing to account for this can lead to an error when trying to write to a closed file, because the dynamic scope of with-open has been left. Though bound-fn can help make the dynamic scope of a Var borrow from its lexical scope, the only way to deal with try/catch is to make sure everything is executed before leaving its dynamic scope.
11.10. Summary
This has been the most complex chapter of the book. State management is a complicated process that can quickly lose all semblance of sanity in the face of concurrent modifications. Clojure’s main tenet is not to foster concurrency, but instead to provide the tools for the sane management of state. As a result of this focus, sane concurrency follows. Clojure also provides the building blocks for you to parallelize computations across disparate threads of execution. From the expression-centric future, to the function-centric set-once “variable” promise, to the core functions pcalls, pvalues, and pmap, Clojure gives you the raw materials for your specialized needs. Finally, we talked in depth about Clojure’s Var, dynamic binding, and the mechanics of thread-locals.
The next chapter deals with performance considerations and how to make your Clojure programs much faster.