
The whole point with “everything is a file” is … the fact that you can use common tools to operate on different things.
—Linus Torvalds in an email
What Is a File?
Directories
Shell scripts
Running terminal emulators
LibreOffice documents
Serial ports
Kernel data structures
Kernel tuning parameters
Hard drives - /dev/sda
/dev/null
Partitions - /dev/sda1
Logical Volumes (LVM) - /dev/mapper/volume1-tmp
Printers
Sockets
To Unix and Linux, they are all files and that is one of the most amazing concepts in the history of computing. It makes possible some very simple yet powerful methods for performing many administrative tasks that might otherwise be extremely difficult or impossible.
Linux handles almost everything as a file. This has some interesting and amazing implications. This concept makes it possible to copy an entire hard drive, boot record included, because the entire hard drive is a file, just as are the individual partitions.
“Everything is a file” is possible because all devices are implemented by Linux as these things called device files. Device files are not device drivers; rather they are gateways to devices that are exposed to the user.
Device Files
Device files are technically known as device special files.1 Device files are employed to provide the operating system and, even more importantly in an open operating system, the users, an interface to the devices that they represent. All Linux device files are located in the /dev directory, which is an integral part of the root (/) filesystem because they must be available to the operating system during early stages of the boot process – before other filesystems are mounted.
Device File Creation
The udev daemon is designed to simplify the chaos that has overtaken the /dev directory with huge numbers of mostly unneeded devices. Understanding how udev works is key to dealing with devices, especially hotplug devices and how they can be managed.
The /dev/directory has always been the location for the device files in all Unix and Linux operating systems. In the past, device files were created at the time the operating system was created. This meant that all possible devices that might ever be used on a system needed to be created in advance. In fact, tens of thousands of device files needed to be created to handle all of the possibilities. It became very difficult to determine which device file actually related to a specific physical device, or if one was missing.
udev Simplification
udev is designed to simplify this problem by creating entries in /dev only for those devices that actually currently exist at boot time or which have a high probability of actually existing on the host. This significantly reduces the total number of device files required.
In addition, udev assigns names to devices when they are plugged into the system, such as USB storage and printers, and other non-USB types of devices as well. In fact, udev treats all devices as plug and play, or plug’n’pray as some like to say, even at boot time. This makes dealing with devices consistent at all times, whether at boot time or when they are hot-plugged later.
Let’s use an experiment to see how this works.
Experiment 5-1
Perform this experiment as root.
Plug in the USB thumb drive you prepared earlier. If you are using a VM you may also have to make the device available to the VM.
Enter these commands.
Look at the date and time on the USB device, which in my host is /dev/sdb and /dev/sdb1, respectively. The creation date and time of the device files for the USB drive and partitions on that drive should be just at the time the device was inserted into the USB port, and different from the timestamp on the other devices that would have been created at boot time. The specific results you see will be different from mine.
It is not necessary for us as SysAdmins to do anything else for the device files to be created. The Linux kernel takes care of everything. It is only possible to mount the partition in order to access its contents after the device file /dev/sdb1 has been created.
Greg Kroah-Hartman , one of the creators of udev, has written a paper2 that provides some insight into the details of udev and how it is supposed to work. Note that udev has matured since the article was written and some things have changed, such as the udev rule locations and structure. Regardless, this paper provides some deep and important insight into udev and current device naming strategies.
Naming Rules
In modern versions of Fedora and CentOS , udev stores its default naming rules in files in the /usr/lib/udev/rules.d directory, and its local rules and configuration files in the /etc/udev/rules.d directory. Each file contains a set of rules for a specific device type. CentOS 6 and earlier stored the global rules in /lib/udev/rules.d/. The location of the udev rules files may be different on your distribution.
In earlier versions of udev, there were many local rulesets created, including a set for network interface card (NIC) naming. As each NIC was discovered by the kernel and renamed by udev for the very first time, a rule was added to the ruleset for the network device type. This was initially done to ensure consistency before names had changed from “ethX” to more consistent ones.
Rule Change Blues
One of the main consequences of using udev for persistent plug’n’play naming is that it makes things much easier for the average nontechnical user. This is a good thing in the long run; however there have been migration problems and many SysAdmins were – and still are – not happy with these changes.
The rules changed over time, and there were at least three significantly different naming conventions for network interfaces cards. That naming disparity caused a great deal of confusion and many configuration files and scripts had to be rewritten multiple times during the period of these changes.
For example, the name of a NIC that was originally eth0 would have changed from that to em1 or p1p2, and finally to eno1. I wrote an article3 on my technical web site that goes into some detail about these naming schemes and the reasons behind them.
Now that udev has multiple consistent default rules for determining device names, especially for NICs, storing the specific rules for each device in local configuration files is no longer required to maintain that consistency.
Device Data Flow
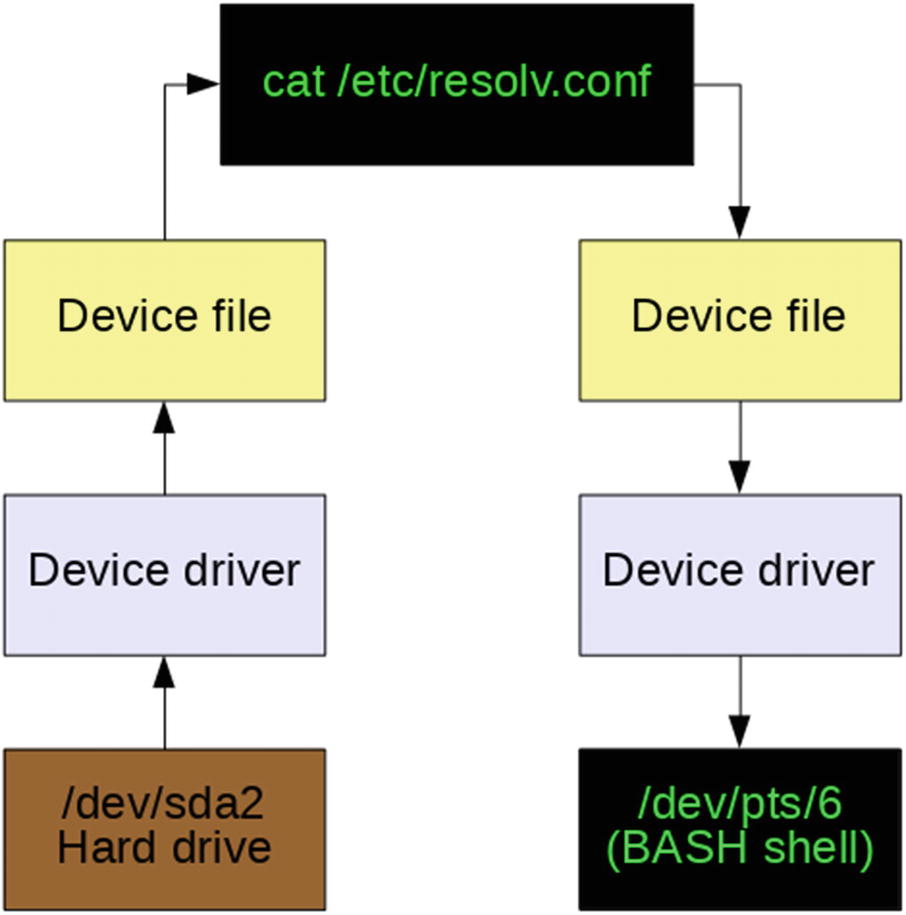
Simplified data flow with device special files
Of course the output of the cat command could have been redirected to a file in the following manner, cat /etc /resolv.conf > /etc/resolv.bak in order to create a backup of the file. In that case the data flow on the left side of Figure 5-1 would remain the same while the data flow on the right would be through the /dev/sda2 device file, the hard drive device driver, and then back onto the hard drive in the /etc directory as the new file, resolv.bak.
These device special files make it very easy to use Standard Streams (STDIO) and redirection to access any and every device on a Linux or Unix computer. They provide a consistent and easy to access interface to every device. Simply directing a data stream to a device file sends the data to that device.
One of the most important things to remember about these device special files is that they are not device drivers. They are most accurately described as portals or gateways to the device drivers. Data is passed from an application or the operating system to the device file, which then passes it to the device driver, which then sends it to the physical device.
By using these device files that are separate from the device drivers, it is possible for users and programs to have a consistent interface to every device on the host computer. This is how common tools can be used to operate on different things as Linus says.
The device drivers are still responsible for dealing with the unique requirements of each physical device. That is, however, outside the scope of this book.
Device File Classification
Device files can be classified in at least two ways. The first and most commonly used classification is that of the type of data stream commonly associated with the device. For example, tty and serial devices are considered to be character based because the data stream is transferred and handled one character or byte at a time. Block type devices such as hard drives transfer data in blocks, typically a multiple of 256 bytes.
Let’s take a look at the /dev/directory and some of the devices in it.
Experiment 5-2
This experiment should be performed as the user student.
Open a terminal session and display a long listing of the /dev/directory.
The results from this command are too long to show here in full, but you will see a list of device files with their file permissions and their major and minor identification numbers.
The voluminous output of the ls -l command is piped through the less transformer utility to allow you to page through the results; use the Page Up, Page Down, and up and down arrow keys to move around. Type q to quit and get out of the less display.
The pruned listing of device files shown in experiment 5-1 are just a few of the ones in the /dev/directory on my Fedora workstation. They represent disk and tty type devices among many others. Notice the leftmost character of each line in the output. The ones that have a “b” are block type devices and the ones that begin with “c” are character devices.
The more detailed and explicit way to identify device files is by using the device major and minor numbers. The disk devices have a major number of 8 that designates them as SCSI block devices. Note that all PATA and SATA hard drives have been managed by the SCSI subsystem because the old ATA subsystem was many years ago deemed as not maintainable due to the poor quality of its code. As a result, hard drives that would previously been designated as “hd[a-z]” are now referred to as “sd[a-z]”.
You can probably infer the pattern of disk drive minor numbers in the small sample shown above. Minor numbers 0, 16, 32, and so on up through 240 are the whole disk numbers. So major/minor 8/16 represents the whole disk /dev/sdb and 8/17 is the device file for the first partition, /dev/sdb1. Numbers 8/34 would be /dev/sdc2.
The tty device files in the list above are numbered a bit more simply from tty0 through tty63. I find the number of tty devices a little incongruous because the whole point of the new udev system is to create device files for only those devices that actually exist; I am not sure why it is being done this way. However you can also see from the listing in Figure 5-2 that all of these device files were created at the 07:06 on November 7, which was when the host was booted. The device files on your host should also have a timestamp that is the same as the last boot time.
The Linux Allocated Devices4 file at Kernel.org is the official registry of device types and major and minor number allocations. It can help you understand the major/ minor numbers for all currently defined devices.
Fun with Device Files
Let’s take a few minutes now and have some fun with some of these device files. We will perform a couple of fun experiments that illustrate the power and flexibility of the Linux device files.
Most Linux distributions have multiple virtual consoles, 1 through 7, that can be used to log in to a local console session with a shell interface. These can be accessed using the key combinations Ctrl-Alt-F1 for console 1, Ctrl-Alt-F2 for console 2, and so on.
Experiment 5-3
In this experiment we will show that simple commands can be used to send data between devices, in this case, different console and terminal devices. Perform this experiment as the student user.
Press Ctrl-Alt-F2 to switch to console 2. On some distributions, the login information includes the tty (Teletype) device associated with this console, but many do not. It should be tty2 because you are in console 2. You might need to use a different key combination if you are using a local instance of a VM.
Log in to console 2 as student. Then use the who am i command—yes, just like that, with spaces—to determine which tty device is connected to this console.
This command also shows the date and time that the user on the console logged in.
Before we proceed any further with this experiment, let’s look at a listing of the tty2 and tty3 devices in /dev. We do that by using a set [23] so that only those two devices are listed.
There are a large number of tty devices defined at boot time, but we do not care about most of them for this experiment, just the tty2 and tty3 devices. As device files, there is nothing special about them, they are simply character type devices; note the “c” in the first column of the results. We will use these two TTY devices for this experiment. The tty2 device is attached to virtual console 2 and the tty3 device is attached to virtual console 3.
Press Ctrl-Alt-F3 to switch to console 3 and log in again as the student user. Use the who am i command again to verify that you really are on console 3 and then enter the echo command.
Press Ctrl-Alt-F2 to return to console 2. The string "Hello world" (without quotes) should displayed on console 2.
This experiment can also be performed with terminal emulators on the GUI desktop. Terminal sessions on the desktop use pseudo terminal devices in the /dev tree, such as /dev/pts/1, where pts stands for “pseudo terminal session.”
Open at least two terminal sessions on the GUI desktop using Konsole , Tilix , Xterm or your other favorite graphical terminal emulator. You may open several if you wish. Determine which pseudo-terminal device files they are connected to with the who am i command and then choose one pair of terminal emulators to work with for this experiment. Use one to send a message to the another with the echo command.
On my test host, I sent the text “Hello world” from /dev/pts/9 to /dev/pts/4. Your terminal devices will be different from the ones I have used on my test VM. Be sure to use the correct devices for your environment for this experiment.
Another interesting experiment is to print a file directly to the printer using the cat command.
Experiment 5-4
This experiment should be performed as the student user.
You may need to determine which device is your printer. If your printer is a USB printer, which almost all are these days, look in the /dev/usb directory for lp0, which is usually the default printer. You may find other printer device files in that directory as well.
I used LibreOffice Writer to create a short document that I then exported as a PDF file, test.pdf. Any Linux word processor will do so long as it can export to the PDF format.
We will assume that your printer device is /dev/usb/lp0, and that your printer can print PDF files directly, as most can. Be sure to use a PDF file and change the name test.pdf in the command to the name of your own file.
This command should print the PDF file test.pdf on your printer.
The /dev directory contains some very interesting device files that are portals to hardware that one does not normally think of as a device like a hard drive or display. For one example, system memory – RAM – is not something that is normally considered as a “device,” yet /dev/mem is the device special file through which direct access to memory can be achieved.
Experiment 5-5
This experiment must be run as the root user. Because you are only reading the contents of memory, this experiment poses little danger.
Note Some testers have reported that this experiment does not work for them. I have not found any problems on several physical and virtual hosts. Just be aware that this experiment may produce a permissions error instead of the desired output.
If a root terminal session is not already available, open a terminal emulator session and log in as root. The next command will dump the first 200K of RAM to STDOUT.
It may not look like that much and what you do see will be unintelligible. To make it a bit more intelligible – to at least display the data in a decent format that might be interpreted by an expert – pipe the output of the previous command through the od utility.
Root has more access to read memory than a non-root user, but most memory is protected from being written by any user, including root.
The dd command provides significantly more control than simply using the cat command to dump all of memory, which I have also tried. The dd command provides the ability to specify how much data is read from /dev/mem and would also allow me to specify the point at which to start reading data from memory. Although some memory was read using the cat command, the kernel eventually responded with the error in Figure 5-2.
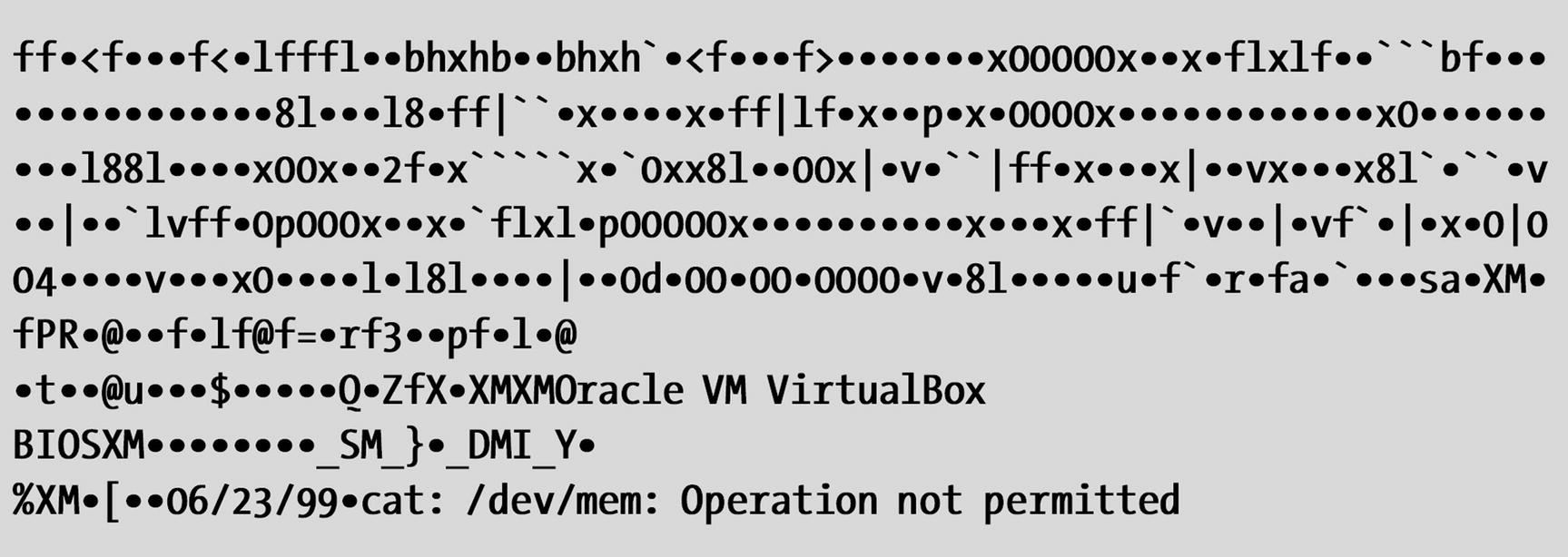
The error on the last line was displayed when the cat command attempted to dump protected memory to STDOUT
These memory errors mean that the kernel is doing its job by protecting memory that belongs to other processes, which is exactly how it should work. So, although you can use /dev/mem to display data stored in RAM memory, access to most memory space is protected and will result in errors. Only that virtual memory that is assigned by the kernel memory manager to the bash shell running the dd command should be accessible without causing an error. Sorry, but you cannot snoop in memory that does not belong to you unless you find a vulnerability to exploit.
Many types of malware depend upon privilege escalation to allow them to read the contents of memory that they would not normally be able to access. This allows the malware to find and steal personal data such as account numbers, user ID, and stored passwords. Fortunately Linux protects against memory access by non-root users. It also protects against privilege escalation.
But even Linux security is not perfect. It is important to install security patches to protect against vulnerabilities that allow privilege escalation. You should also be aware of human factors such as the tendency people have to write down their passwords, but that is all another book.5
You can now see that memory is also considered to be a file and can be treated as such using the memory device file.
Randomness, Zero, and More
There are some other very interesting device files in /dev. The device special files null, zero, random, and urandom are not associated with any physical devices. These device files provide sources of zeros, nulls, and random numbers.
The null device /dev/null can be used as a target for the redirection of output from shell commands or programs so that they are not displayed on the terminal.
Experiment 5-6
I frequently use /dev/null in my bash scripts to prevent users from being presented with output that might be confusing to them. Enter the command below to redirect the output to the null device. Nothing will be displayed on the terminal. The data is just dumped into the big bit bucket in the sky.
Look at /dev/null as a source for “null” characters.
There is really no visible output from the /dev/null because the null device simply returns an end of file (EOF) character. Note that the byte count is zero. The null device is much more useful as a place to redirect unwanted output so that it is removed from the data stream.
The /dev/random and /dev/urandom devices are both useful as data stream sources. As their names imply, they both produce random output – not just numbers but any and all byte combinations. The /dev/urandom device produces deterministic6 random output and is very fast.
Experiment 5-7
Use this command to view typical output from /dev/urandom. You can use Ctrl-c to break out.
I have shown only a part of the data stream from the command but it should give you a sense for what you should see on your system.
You could also pipe the output of experiment 5-6 through the od command to make it a little more human readable just for this experiment. That makes little sense for most real-world applications because it is, after all, random data.
The man page for od shows that it can be used to obtain data directly from a file as well as specify the amount of data to be read.
Experiment 5-8
In this case I have used -N 128 to limit the output to 128 Bytes.
The dd command could also be used to specify a limit to the amount of data taken from the [u]random devices but it cannot directly format the data.
The /dev/random device file produces non-deterministic7 random output but it produces output more slowly. This output is not determined by an algorithm that is dependent only upon the previous number that was generated, but it is generated in response to keystrokes and mouse movements. This method makes it far more difficult to duplicate a specific series of random numbers. Use the cat command to view some of the output from the /dev/random device file. Try moving the mouse to see how it affects the output.
The random data generated from /dev/random and /dev/urandom, regardless of how it is read from those devices, is usually redirected to a file on some storage media or to STDIN of another program. Random data seldom needs to be viewed by the SysAdmin, developer, or the end user. But it does make a good demonstration for this experiment.
As its name implies, the /dev/zero device file produces an unending string of zeroes as output. Note that these are Octal zeroes and not the ASCII character zero (0).
Experiment 5-9
Use the dd command to view some output from the /dev/zero device file. Note that the byte count for this command is non-zero.
Back Up the Master Boot Record
Consider, for example, the simple task of making a backup of the Master Boot Record (MBR) of a hard drive. I have had, on occasion, needed to restore or re-create my MBR, particularly the partition table. Re-creating it from scratch is very difficult. Restoring it from a saved file is easy. So let’s back up the boot record of the hard drive.
Note that all of the experiments in this section must be performed as root.
Experiment 5-10
We are going to create a backup of your master boot recod (MBR), but we will not attempt to restore it.
The dd command must be run as root because for security reasons non-root users do not have access to the hard drive device files in the /dev directory. The bs value is not what you might think; it stands for Block Size. Count is the number of blocks to read from the source file.
This command creates a file, myMBR.bak in the /tmp directory. The file is 512 bytes in size and contains the contents of the MBR including the bootstrap code and partition table.
Now look at the contents of the file you just created.
Because there is no end-of-line character at the end of the boot sector, the command prompt is on the same line as the end of the boot record.
If the MBR were damaged, it would be necessary to boot to a rescue disk and use the command in Code Sample 5-1 that would perform the reverse operation of the one above. Notice that it is not necessary to specify the block size and block count as in the first command because the dd command will simply copy the backup file to the first sector of the hard drive and stop when it reaches the end of the source file.
Code Sample 5-1
The following code would restore the backup master boot record to the first sector on the hard drive.
Do not run this code because it may damage your system if entered improperly.
So now that you have performed a backup of the boot record of your hard drive and verified the contents of that backup, let’s move to a safer environment to destroy the boot record and then restore it.
Experiment 5-11
This is a rather long experiment and it must be performed as root. You are going to make a backup of the MBR for the USB device, damage the MBR on the device, try to read the device, and then restore the MBR. Do not mount the USB drive.
Ensure that the USB drive is inserted in your computer and verify the device file name. In my case it is still /dev/sdb.
First we look at the partition table with fdisk to provide a basis for later comparison, and then we back up the MBR of the USB device and verify the content of the backup file. As in previous similar experiments, the warning messages are part of the content of the MBR.
So now comes the fun part in which we overwrite the MBR of the USB device with one 512 Byte block of random data, then view the new content of the MBR to verify the change. Notice that the warning messages are no longer there because they have been overwritten.
Let’s try a couple more things to test out this state of affairs before we move on to restoring this MBR First we use fdisk to verify that the USB drive no longer has a partition table, which means that the MBR has been overwritten.
An attempt to mount the original partition will fail. The error message indicates that the special device does not exist. This shows that most of the special device files are created and removed as necessary, on demand.
It is time to restore the boot record you backed up earlier. Because you used the dd command to carefully overwrite with random data only the MBR that contains the partition table for the drive, all of the other data remains intact. Restoring the MBR will make it available again. Restore the MBR, view the MBR on the device, then mount the partition and list the contents.
Wow – how cool is that! This series of experiments is designed to illustrate that you can use the fact that all devices can be treated like files and therefore use some very common but powerful CLI tools in some very interesting ways.
It is not necessary to specify the amount of data to be copied with the sb= and count= parameters because the dd command only copies the amount of data available, in this case a single 512 Byte sector.
Unmount the USB device because we are finished with it for now.
Implications of Everything Is a File
Clone hard drives.
Back up partitions.
Back up the master boot record (MBR).
Install ISO images onto USB thumb drives.
Communicate with users on other terminals.
Print files to a printer.
Change the contents of certain files in the /proc pseudo filesystem to modify configuration parameters of the running kernel.
Overwrite files, partitions, or entire hard drives with random data or zeros.
Redirect unwanted output from commands to a null device where it disappears forever.
etc., etc., etc.
There are so many possibilities here that any list can really only scratch the surface. I am sure that you have – or will – figure out many ways to use this tenet of the Philosophy far more creatively than I have discussed here.
Summary
It is all part of the filesystem. Everything on a Linux computer is accessible as a file in the filesystem space. The whole point of this is to be able to use common tools to operate on different things – common tools such as the standard GNU/Linux utilities and commands that work on files will also work on devices – because, in Linux, they are files.