
Chapter 3. Challenges with Data Platform Infrastructure
The Trouble with Building Up a Data Platform
Across all industries, growth in data generation is exploding inexorably, gaining in size, extent, and speed like an avalanche in motion. With the shift from 4G to 5G networks, telecommunications companies have opened the door to gigabit (>1 GBps) bandwidth speeds. Considering that 4G LTE bandwidth tops out at up to 300 MBps, the increase in data volume and speeds alone will enable mobile connected services to produce and consume entire orders of magnitude more data globally.
This includes Internet of Things (IoT) sensor data, higher-resolution real-time event streams, and usage statistics from mobile applications, as well as native 4k video streams. With the new capability, we can expect more devices to be connected as well.
Scalability across all components within the data platform is of vital importance to enable the elastic growth necessary to handle the processing requirements for all that lies on the road ahead. Realizing and harnessing the value of the data produced across the business will drive more autonomous decision making as well as providing a necessary, unbiased “voice” when making critical business decisions. Lastly, as companies are trending toward a “store everything” attitude with respect to their data, architects must always be focused on providing key infrastructure to help reduce friction and enable holistic solutions to be used across the company.
Selecting the correct initial platform capabilities and deliverables provides a stable base upon which many more core foundational platform components can be built. Like a foundation, keystone, or cornerstone, these building blocks will be used to support future additions and enhancements within the platform. A transparent strategic vision and clear blueprint of the road ahead can help guide the team around the quick-win style shortcuts that inevitably lead to critical design flaws in the fundamental architecture of the data platform.
In the next section, we take a look at the key common components of the modern data platform and understand why they must exist in order to support near-real-time operational analytics systems.
Database Types
Databases are core containers that hold and store a company’s most valuable assets. The data that your business generates comes in many shapes and sizes, and the way in which that data is queried should be considered when deciding what capabilities are necessary for a given database technology.
Given the general proliferation of databases over the years, it’s useful to look at the main categories of databases in order to understand what capabilities define a given database technology and to understand what challenges might need to be addressed.
OLTP Databases
The online transaction processing (OLTP) database has been around for a while and is probably the best known and understood, conceptually, in the industry. The makers of these databases pride themselves on their reliability and accuracy when it comes to transactions, or sequential mutations—updates—to data stored within them.
These databases adhere strictly to what is known as ACID compliance. ACID is an acronym that stands for Atomic, Consistent, Isolated, and Durable.
Within the OLTP database there are tables comprised of many rows of structured data, as depicted in Figure 3-1. Each row of data can be further broken down into one or more columns (or fields), which can be thought of as pointers to atomic data of a specific type.
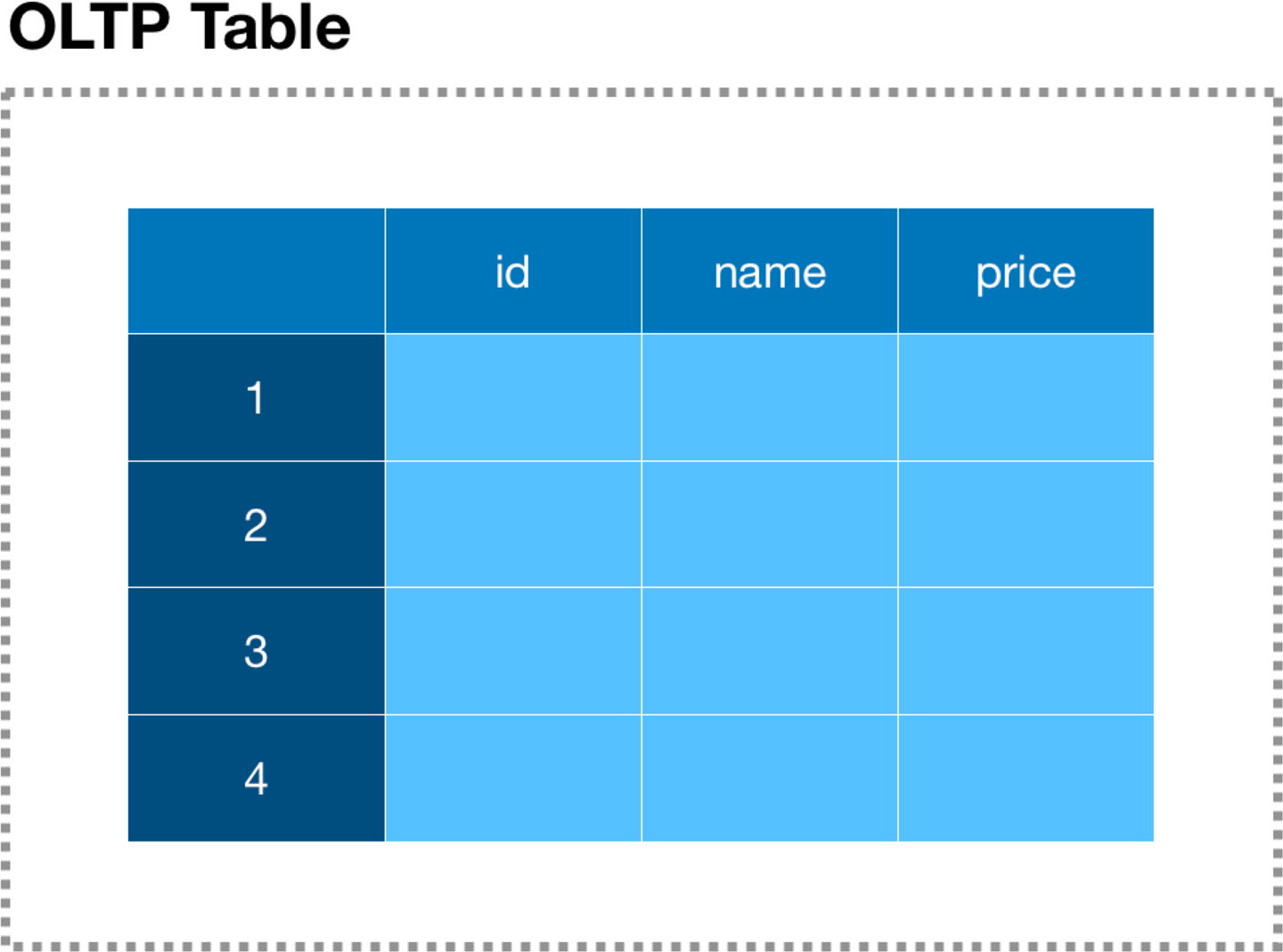
Figure 3-1. Database rows and columns
Given that these systems support multiple connected user sessions, accuracy and consistency of the underlying data contained within these databases is critical. This capability is made possible by the transactional architecture within the database engine. If one user is to manipulate the value of a field within a row of data—for example, in the case of an ATM withdrawal from a shared bank account—a subsequent withdrawal from a different location, by a different user from the same account, should reflect the prior withdrawal as well as the current withdrawal, regardless of the current state of the data currently cached or available at that location.
These transactions are isolated events that will only succeed after the transaction has been completed and the underlying value recorded. This consistency through sequential, isolated events maintains a durable record, or one that exists even if the database suddenly goes offline, or experiences connectivity hiccups.
These databases are traditionally relational in nature, and exist under the umbrella term relational database management systems (RDBMS). This includes popular RDBMS flavors such as MySQL and PostgreSQL. An RDBMS allows data from one or more tables to be joined to generate new views of data, while also adhering to strict user access and permission policies known as grants.
These capabilities make OLTP the first choice for most organizations as a general-purpose platform for accessing data, given all that is provided out of the box. The core language used to query these systems is structured query language (SQL), which is supported by most OLTP and also most online analytical processing (OLAP) systems (see the upcoming discussion). SQL is the most common language used to interact with most databases.
Even though there are many upsides to traditional OLTP databases, the downside is that scalability comes at a much higher cost, given that the architectures of these systems maintain ACID compliance at the cost of not being able to scale out across industry-standard, low-cost machines. Their architecture is referred to as a scale-up or shared-everything architecture because to scale beyond the system’s current memory and available disk size, larger hardware must be provisioned. Scaling out—horizontal scalability—is not supported.
OLAP Databases
The OLAP database is optimized to provide fast responses to both single-dimensional analytical queries, such as queries within a specific data table, and multidimensional analytical queries, which require data to be combined across multiple tables. These queries analyze data across a search space from many different vantage points, referred to as dimensions, and provide analytical query support, which can be categorized under the umbrella of rollup, drill-down, and slice-and-dice aggregation.
These capabilities provide a means for an analyst to efficiently explore the data, in aggregate, across the subset of a bounded search space within what are called cubes or hypercubes. For example, the approach to typical data mining takes a top-down approach starting with a rollup, which is a high-level aggregate view of all data within a search space. To uncover interesting patterns and enable further analysis of the data, the next step is to drill down into subsets within the dimensional space.
This is achieved in an opposite approach as the rollup, in that data is aggregated across subsets of specific dimensionality, as in the example of drilling into performance characteristics from a regional level, down to the state level and finally across a city, or subdivision level like area code or zip code. As a means to investigate more finely, an analyst will slice and dice across any level, from the initial rollup to some level of drill-down, to look at how patterns emerge across multiple dimensional filters.
An example of this would be an analyst producing a business impact report based on the results of a specific targeted marketing campaign, to understand the impact across critical markets when compared to normal nontargeted areas. In a now infamous story of transaction analysis for items purchased together, a retailer found that there was a high correlation between late-night purchases of diapers and beer. This data was used to put beer closer to the diaper aisle, and sales of both beer and diapers continued to skyrocket.
OLAP engines, and newer search engines, can provide critically necessary analytics support via traditional Business Intelligence (BI) systems. OLAP engines enable complex queries to be executed for purposes such as data mining, trend analysis, forecasting, cohort analysis, and many more. Enabling faster analytics and report generation can also help boost revenue across the company by enabling sales and marketing organizations to move quicker and follow more intelligently selected leads and other data-driven opportunities.
Although there are many upsides to OLAP, this style of query provides scaling challenges in different ways than OLTP. Instead of supporting narrow and isolated transactions, OLAP queries operate widely across multiple fact tables to support on-the-fly aggregations to answer focused analytical queries.
These queries can become performance bottlenecks, especially when run on top of existing OLTP databases, due to the nature of what is required to support transactions (ACID) within a shared-everything architecture with a single active node. To address the scalability concerns that arise when running queries on top of OLTP systems, companies transition OLAP processing onto read-only databases. Removing the write/transaction capabilities allows the database to utilize RAM (memory) and CPU more efficiently because the concerns of maintaining atomic mutable state go away. In other words, transactions can then run on one dedicated system, and queries on another, speeding up both. As use cases continue to grow in size and complexity, they eventually run separate hardware and software stacks in order to support continued scalability.
NoSQL Databases
The portrait of the modern data platform wouldn’t be complete without mention of NoSQL. NoSQL databases became popular in the 2000s as a means to tackle the lack of horizontal scalability within the available RDBMS systems of that era. NoSQL databases provide key/value, document, as well as graph-style data stores, among other types, across distributed keyspaces. These keys act as pointers to memory or disk space allocated to store arbitrary blobs of data within the data nodes of the system.
Although these data stores can grow horizontally and maintain high availability, this comes at a cost to consistency and, more generally, a lack of schema—more or less rigid structures for arranging data. Values associated with a given key can contain any kind of value. As a result, companies had to either enact strict internal policies as to what can go in a key (or other) field, or deal with additional schema inference when analytics are run against the data. Ensuring that data could be extracted in a predefined format was a complication to these schema-less data stores.
Cassandra, Redis, and MongoDB are some of the more well-known NoSQL databases that emerged during the NoSQL movement that are still popular and being maintained today. Each of these databases constructed a query paradigm that feels SQL-like, while not adhering strictly to the specifications for ANSI SQL.
Cassandra has CQL, which uses keyspace indexes and table definitions to add search capabilities to the underlying key/value store. Redis created RedisSearch to provide secondary index capabilities and full-text search to the data stored within its in-memory data structure store. Lastly, MongoDB offers a map-reduce style search approach over its document store and have defined their own SQL-like nomenclature, which is different enough that they provide a conceptual mapping from SQL to MongoDB parlance to assist people new to their database offering.
NoSQL stores can provide high availability and horizontal scalability over lower-cost hardware, as well as distributed fault-tolerance, at the cost of consistency. They can, however, provide a very good solution to fetching append-only or write-once data that can be used to record a great deal of data quickly and efficiently while shifting much of the burden of making the data useful to the querying process.
Besides the three types of general-purpose databases described here—OLTP, OLAP, and NoSQL—there is a fourth type, NewSQL, which we describe in Chapter 4. We then compare all four types of databases to each other in Chapter 5.
Special-Purpose Data Stores
The aforementioned major database types can each be used for a wide variety of purposes, and they have given rise to variants as well. Here you’ll find the major categories of database-like systems powered by the database types above.
Data Warehouses
The data warehouse was envisioned as a means to help mitigate the myriad challenges that arise from querying data across many disparate sources of siloed data, produced across the company by many different teams, and to provide unified data to power BI environments for the purpose of making informed business decisions from a “single source of truth” data store.
The challenges of working with data tend to cluster more generally around naming and context, data formats (DateTime versus Date versus Long), inconsistent temporal information (UTC versus PST or system.time), missing values and nullability, data lineage, and general data availability. To address the challenges of standardization, the data warehouse emerged to become the final resting place for clean and normalized source-of-truth, business-centric data.
To get data into the data warehouse, data from one or more sources is extracted, transformed, and loaded into the data warehouse through an externally scheduled or on-demand batch job, which is known as an extract, transform, and load (ETL) job. The data imported to the data warehouse is historic in nature, due to the time it takes to batch input data, run transactions, and run the ETL process. Data in a data warehouse can be made more up-to-date with the use of data lineage rules and strict data SLAs.
Data Lakes
The data lake is a general purpose, highly scalable, low-cost storage tier for raw data. If the data warehouse is a source of purposeful structured data that has been preprocessed and loaded to answer specific business-centric questions, the data lake is the staging area for data that might have importance in the future.
Given that businesses are moving to a “store everything” mentality across most of the data they produce, it is essential to have a storage tier that can scale to meet the storage needs of tomorrow while also providing benefits today.
The challenges of storing raw data, however, can manifest when the time comes to make use of and provide purpose to these deep pools of raw potential. The challenge is that over the months and years that data is sitting and waiting, changes to the data being produced and a lack of records as to what exactly was being recorded at various points can make older data unusable. This can dramatically increase the lead time to make use of the data or cause years of data to be thrown away due to corruption of data over time.
So even though the data lake is conceptually a storage area for raw, underpurposed data, there is still a need to provide a moderate level of effort in order to ensure that data corruption doesn’t occur along the way, and that the business can make practical use of the data when the time comes to put it into action.
Distributed File Systems
To provide a horizontally scalable file system that can accommodate the needs of the data warehouse or the data lake, technologies like Apache Hadoop have been utilized, due to the overall performance that comes from an atomic, highly available, rack-aware, fault-tolerant distributed filesystem. Hadoop handles massive data growth through a scale-out architecture that can utilize commodity hardware or specialized hardware, hard-disk drives (HDDs) or solid-state drives (SSDs). The underlying distributed filesystem that ships with Hadoop is called HDFS, which stands for the Hadoop Distributed File System. HDFS can scale out to handle billions of files across a multipetabyte distributed filesystem.
Managing data has its ups and downs, and with large volumes of data, it can be difficult to scale without dedicated teams of administrators who are focused on the health and well-being of these distributed data stores. So, to handle the growing pains of scaling almost infinitely, cloud vendors like Amazon Web Services (AWS), Microsoft Azure, and Google Cloud Platform (GCP) all have provided an offering that “acts like” HDFS and promises a 99.9x% uptime guarantee.
Although there are definitely many upsides to farming out these services, the downside can actually be hidden. In the case of Amazon Simple Storage Service (Amazon S3), the filesystem is eventually consistent. This comes at a performance cost when compared to native HDFS, which can do atomic writes, especially when you consider the role these file systems play within your data platform.
Data Pipelines
Lastly, we arrive at the data pipeline. The data pipeline can be used to connect the different types of just-described databases and data stores to each other, or to connect any of them to ingest sources, such as sensors or data entry systems.
This component is strategically essential to connecting all of the various components within the data platform. You can think of these pipelines in the same way as the assembly line is to car manufacturing.
In the beginning, they start out with some raw material, like event or sensor data, generated from within one of many services running within a company’s product offerings. This data is then ingested through a service gateway or API that act as a means of initially validating, authenticating, and eventually enqueuing data into one or many ingress (entry) points within the larger data pipeline network.
Once the data has entered the pipeline, it is free to then move through a predefined series of steps which typically include sanitizing or cleaning, normalizing or fitting to a schema, and, potentially, joining with other data sources. At one or many egress (exit) points, this data can be used to satisfy the data needs of another downstream system. This process of specific transformations is referred to as data lineage, and these multiphasic processing steps are enabled through the use of the data pipeline, but are not actors within a physical data pipeline.
This can come across as a confusing concept, but the data pipeline is a name given to the actual processing of data, in a controlled and repeatable way, whereas the sources of data can reside across any data store within the data platform.
Recently there has been a move toward streaming data pipelines that can be tapped into at specific predefined junction points, enabling new data processing capabilities that more effectively reuse their upstream transformations. One of the key technologies that has led to the proliferation of streaming data pipelines is Apache Kafka.
Kafka allows data processing pipelines to be constructed by connecting applications through a series of event-specific topics, which are associated with a specific type of structured or semi-structured data (such as JSON, Avro, or Protocol Buffers) that encapsulates a specific event or message type.
Consider the assembly line. Raw materials and components arrive at one or more ingress points. Each station works on one specific job, and at the egress point, a car pops out. In the event streams use case, each station along the proverbial assembly line represents an application, one which consumes data from a specific data topic, processes the stream of event data, and feeds the results along to the next application via another topic.
This pattern scales out to generate exponentially expanding data networks, enabling organizations of all sizes to operate in more agile ways by connecting various data-processing applications to these streaming data networks. For example, this enables new paths to fill the data lake as well as more optimized ETL flows, which can develop from batch to streaming through the use of available streaming data. These streams ultimately enable lower end-to-end latency, which in turn yields faster ingest times to the data warehouse and connected operational analytics systems.
Spark and the Shift from Batch to Streaming
One of the many projects that helped to lead the transformation to faster and smarter decision making is Apache Spark, created by Matei Zaharia in 2009 and donated to the Apache Foundation in 2013. Spark started out as a batch-processing framework that could run alongside, or on top of, the Hadoop ecosystem.
The focus of the project was to easily distribute MapReduce-style distributed compute jobs across horizontally scaling infrastructure, in a resilient way, that was at the same time highly available and fault tolerant. This new approach to distribution of work was made possible by generating transformative lineage-aware datasets that are called Resilient Distributed Data (RDD). The use of RDD and the Spark compute framework led to speed and performance gains across the platform that reach the level of orders of magnitude, when compared to similar workloads run in a standard MapReduce framework such as Hadoop.
Today, Spark is one of the most popular big data frameworks of all time and has added support to handle streaming data, machine learning at scale, as well as a unified API for graph search. Spark is now considered part of the standard toolkit for machine learning and AI projects.
Kafka Takes Streaming Further
Around the same time that Spark was gaining popularity, LinkedIn was making huge strides in the distributed producer/consumer (pub/sub) space with a project called Kafka, officially open-sourced through the Apache Foundation in 2011.
Kafka can be utilized as a data platform Swiss Army knife. This one platform can solve dozens of complex data engineering problems, but is best known as a general stream-processing platform for event data. Apache Kafka has taken the ideas implemented in Spark and generalized them in such a way that, today, Kafka and Spark are often used together.
At its core, Apache Kafka simplifies how data is written to a streaming resource, through what is known as a Kafka topic. Topics are the top-level resource. You can think of them as scalable collections of specific time-series events.
Topics can be configured to have one or more partitions of data that achieve high availability through the notion of replicas. These replicas are then strategically stored across a cluster of machines to allow for a “zero point of failure” architecture.
Data that resides on servers, called brokers in Kafka, can be written to by producers who write data into a given topic, and read out by consumers of the topic, as demonstrated in Figure 3-2. Scaling out a topic is as simple as adding more partitions, which can increase both read and write throughput as brokers suffer from less contention in reading and writing to their associated topics.
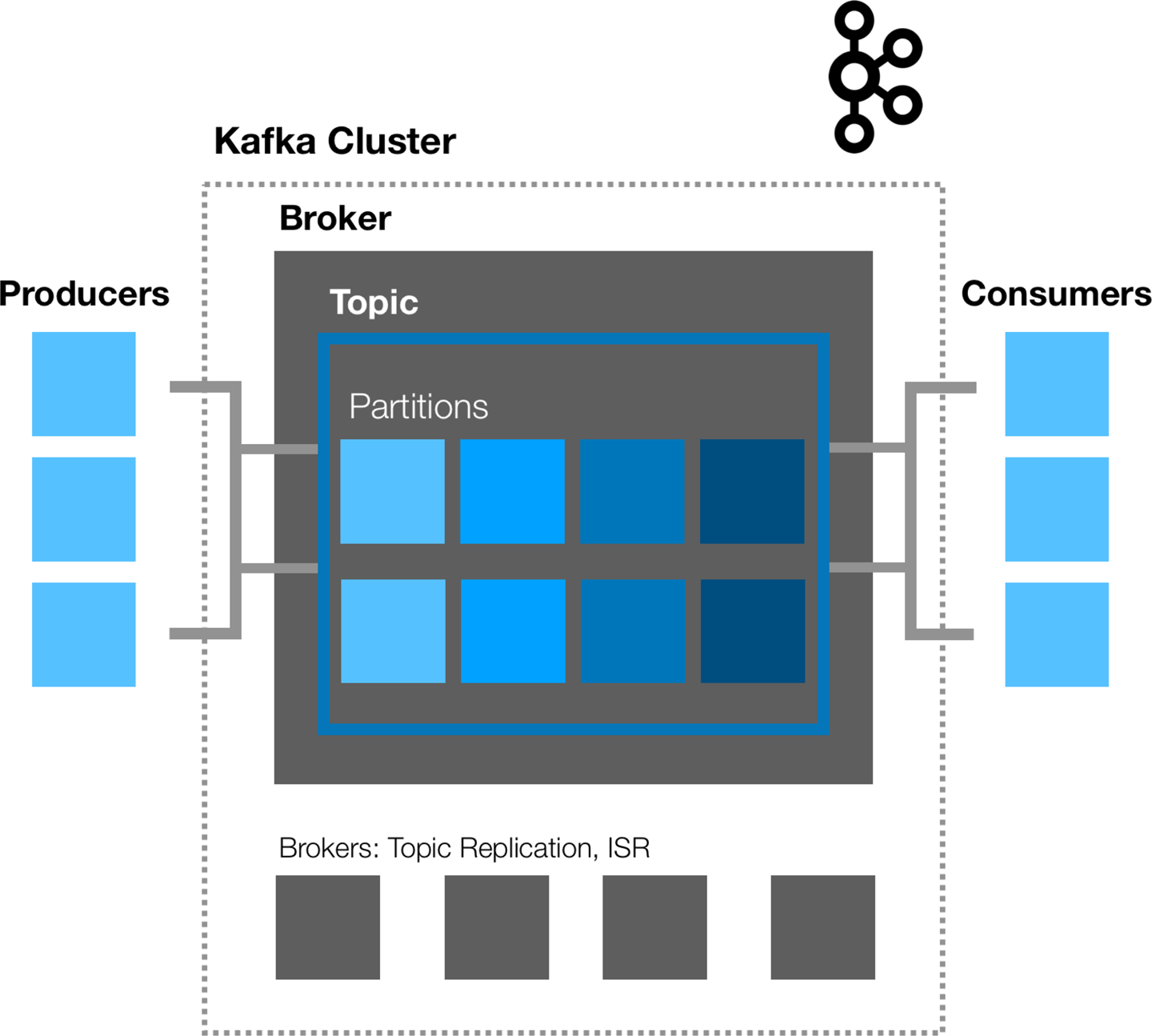
Figure 3-2. Kafka architecture with an example of a Producer and Consumer model
Kafka usage across the data industry has grown immensely for many reasons. For example, it is the perfect solution for time-series data, given that insertion into a topic partition will maintain explicit synchronous order in a first-in, first-out (FIFO) paradigm. This is critically important for maintaining a clear and accurate stream of events to the downstream consumer of a specific topic. Kafka can be used to broadcast data as it becomes available, without causing site-wide reliability issues.
As is often the case with innovation, initial ideas are made better through collaboration and widespread accessibility. Apache Spark and Kafka, both open source projects, benefited from widespread participation across the tech community. These tools have helped to provide the building blocks for continuous-streaming systems. They serve as a solid foundation for further progress and innovation. In the next chapter we look at how these concepts helped ready the path for operational analytics.
Achieving Near-Real-Time Capabilities for Data Transfer
Achieving near-real-time capabilities requires a different approach to the use of the different database types, data stores, and data transfer capabilities described earlier. In an operationally oriented system, a Kafka data pipeline brings data from transaction systems to an operational database. Analytics run against the operational database. It might even be possible to integrate transactions into the operational data store, greatly speeding and simplifying data flows. Noncritical data can be stored in a data lake and used for record keeping, data science experimentation, and other, less-critical purposes.
Companies are spending billions of dollars annually moving data around their systems, and as SpiceWorks pointed out in its 2020 state of IT report, “89% of companies are going to maintain or increase their IT budget,” with “56% of larger-sized companies (5,000 employees or more) seeing their budgets increasing.”
These increases are targeted toward replacing older IT systems, investing in new initiatives, handling new regulations like the European Union’s General Data Protection Regulation (GDPR) and other compliance certifications, and growing teams in key IT sectors. These budgets are also used to purchase SaaS solutions to pave the way into new, emerging markets, without the long lead times traditionally associated with building up new infrastructure in house.
Depending on the size and capabilities of the data platform, teams can easily take three to five years to build out all the requisite components, build trust through uptime and stability, and provide the self-service capabilities that help to simplify access and adoption of these critical data platform components. Appropriate selection of self-service SaaS solutions can help the company focus the budget on more critical projects.
A simpler, speedier approach to data processing and data transfer can ultimately save money and make it easier to integrate externally provided solutions, such as SaaS solutions and public cloud platforms, with a company’s in-house software and systems.