
If you have been in the business of software development for a while, or probably even by virtue of your having selected this short cut to read, you have come to recognize change as the principal concern in software development.[1] This view is correct: Change-readiness is—and should be—the primary driver in our design decisions. Reacting to change is, after all, the problem that most Agile practices solve.
This short cut is intended for Agile software developers who have enjoyed success with the majority of these practices, but who have found databases, and data in general, to be a source of difficulty. One of my friends referred to databases as a sort of “Wild West”: untamed, uncontrolled, and lacking the kind of rigor you find in Agile software development. This description is, unfortunately, quite accurate in many cases. Where it is not, we find the other extreme: rigid Waterfall processes impeding Agile application development by failing to respond to change in a timely manner.
Traditional Agile practices—especially those that enable changes to design, such as refactoring—do not work on their own in the database world. Several notable reasons explain this phenomenon, but the root cause of this failure is that they are all based on the principles of evolution, and they don’t just co-opt the word “evolution”; they rely on the actual concept. The source of trouble seems to be the mechanism that makes evolution work: the replacement of old generations with newer ones. Virtually every Agile process for developing code in small increments I’ve seen or heard of has this notion at its core. Put simply, in Agile programming, the old version of a program is supplanted by the new one.
That strategy simply won’t work in most data environments. In most cases, the knowledge contained within a database must survive any changes to that database. Trying to take practices based on the principles of evolution and apply them, unaltered, to a new domain in which evolution is not a suitable driver for change is, in essence, like trying to walk around on Mars in your street clothes: The environment is almost similar enough to allow such a stroll (when compared to, say, the environment of Mercury), but not quite—we need something more.
In actuality, databases can be built incrementally, with their designs emerging over time as they should. The best part is that you don’t need to abandon any of your tried-and-true Agile software development practices; you just need to add a few new ones. In other words, all we need to walk around on Mars is a spacesuit; we don’t need to figure out the rules of some magical realm where one plus one equals three.
That is what this short cut is about: employing new practices to support Agility in the as-yet-untamed domain of Agile database development. This short cut does not have enough space to extensively cover the theory. Instead, I ask you to trust that I do have a theory even though I’m only showing you some problems, solutions, and just enough of the underlying concepts to provide any required context.
Throughout the course of this short cut, you will see how a real database used in production is born, grows, and is transformed to adapt to new requirements. Along the way, enough context is provided that you should be able to connect this process with the theory underlying the examples.
Let’s spend a few minutes setting the stage. I decided, in the course of writing this short cut, to make some headway on one of my (far too many) side projects.
I am also a fiction writer, or at least I wish I was. ![]() As a would-be author of a novel, I participate in writing critique groups. The standard operating procedure for these groups is for members to make their writing available in soft-copy form on the Internet to other members of the group with essentially no security and no audit trail. You then trust the members of this group—for whom there are virtually no entry criteria—not to steal your work.
As a would-be author of a novel, I participate in writing critique groups. The standard operating procedure for these groups is for members to make their writing available in soft-copy form on the Internet to other members of the group with essentially no security and no audit trail. You then trust the members of this group—for whom there are virtually no entry criteria—not to steal your work.
Did I mention that I am extremely paranoid? That factor probably is relevant here, although the word “paranoid” does not really apply, because I don’t think there are conspirators specifically targeting me. Let’s just say I am “untrusting of strangers.”
So how does someone who is not particularly trusting participate in these groups? I decided that the way to do so was to create a Web site that gives the author of a work control over, and an audit trail of, who accesses his or her intellectual property (http://www.authoreyes.net).
That will be the context in which the events chronicled in this short cut took place: the development of AuthorEyes.net. I will cover the tests and code that directly relate to the development of that Web site’s database.
The short cut includes only artifacts that directly relate to the database, however. No acceptance tests are provided here because they are out of scope. Also, only a few of the database unit tests will be given in the short: Once you’ve seen one, you’ve kind of seen them all.
My goal is that you get a feel for the practices I’ve developed as you watch the database behind AuthorEyes.net change over time.
A number of stories will be completed in the process of developing this Web site. This short cut is not intended to serve as a course on Agile analysis, though, so we don’t need to know all of that information. Instead of discussing every story I’ve done, we’ll cover only iteration goals.
There are three iterations within the scope of this short cut:
Allowing a user to create an account, log in, and stay logged in
Allowing a user to upload, list, and download his or her works
Allowing a user to control who can see works the user has uploaded
In a full-scale book, I could make sure that you were at least familiar with all of the basic concepts involved. Real estate is more limited in this short cut, however; it’s kind of a “get to the point” format. As a consequence, I have to make certain assumptions about you, the reader:
You are familiar with test-driven development and unit testing.
You are familiar with modern programming languages such as C# (if you know Java instead, don’t worry—you’ll understand this short cut).
You are familiar with and value the concept of incrementally improving design as necessity dictates.
You are involved in the development of a database and understand the basic mechanics, such as how to use SQL.
If you do not meet these criteria, that’s okay. It won’t be too hard to get there. At the risk of sounding like a broken record, you can find everything except for the database skills in Emergent Design (Bain). If you are not familiar with basic SQL syntax, then download a free database engine such as MySQL or SQL Express and play with it for a few hours.
The assertion that it will be easy for you to get up to speed, of course, assumes that you intended to buy this short cut and not something completely unrelated, like Change, Databases, and Other Myths by Watt R. Fall.
Throughout this short cut, I will build the underlying conceptual framework little by little. Given the size constraints on this document, however, I don’t have room for a complete discussion. The section you are reading right now is intended to make sure that you have a basic understanding of the reasoning behind the techniques proposed here.
In a nutshell, the theory is this: We need to stop worrying about what a database is until we have some kind of control over how a database is made. This idea stems from the unreliability of the processes through which databases are made these days. These processes tend to boil down to manually invoking scripts and manually verifying that those scripts did what they were supposed to do.
It’s not a huge logical leap to think that we should automate and verify the process of making a database. Other Agile processes hinge on precise knowledge of the intended behavior of the thing we are developing. Part of this knowledge is usually that our product will be built by a highly reliable compiler.
Think about this: How much confidence would your tests give you if your compiler was not guaranteed to convert the same input to the same output every time? That’s the situation we’ve been in for decades when dealing with databases.
If you cannot count on the reliability of your database build process, then how can you know whether your test database is an effective stand-in for your production database? You can’t. Without the ability to know that your test database is truly representative of your production database, do your tests really validate anything about the database that will actually service your customer’s needs? No.
Without repeatability, there is no autonomation.[2] Over the years, many have tried to solve the problem of how databases are built. In the same way that we keep beating our heads against the ORM[3] wall, we continue to try “new” ways of building databases the same old way.
Following are a few examples of these methodological anti-patterns.
You can use a graphical user interface (GUI) designer and then trust it to build the database for you. That step will usually get you about as far as version 1. This solution seems to be more focused on what the database should be, and less on how it is made, than almost any other approach.
First, you manually tweak some representation of what you want until you think you have a pretty good shot at having correctly described the new database. Then you tell the tool to “make it so.” Maybe it works; maybe it doesn’t. The greater the complexity of the change, the lower the chance that the tool will be able to apply it correctly.
Almost certainly, at some point you will introduce a change that this tool simply cannot digest.
You can use a prototype database for development that you modify by hand and a differentiation tool that attempts to reverse-engineer what you’ve done. This approach will carry you a little further: At least it recognizes that how a database is made is part of that database’s character. Unfortunately, this technique has the same Achilles heel as use of a design tool. Put simply, it works until you make a change that the differentiation tool isn’t smart enough to understand. Then, if you’re lucky, the tool will tell you it doesn’t know how to apply your changes. Any “if” that precedes “you’re lucky” is too big an “if” for me.
You can make the database an end unto itself. All you need to apply this approach is a bunch of smart people with beards and a management structure that understands how valuable its data actually is. Eventually, the true nature of the relationship between an application and the databases it uses will be inverted: Instead of use dictating design, the database will tell its clients how they will use it.
The good news is that this technique actually does a good job of preventing data loss as a result of change. Unfortunately, this effect is made possible, largely, because change itself is impeded. All this anti-pattern really does is trade the risk of losing data for the risk of losing a feature.
Many people have a strong inclination to simply ignore an impediment. It seems to be human nature to silently convert “don’t know how” to “cannot.” Aside from its impact on databases, I find this to be one of the most insidious traits in the human character. We are forever wasting energy building and reinforcing prisons we have created for our own minds.
In the past and, to a lesser extent, in the present, people have used similar reasoning as an argument against test-driven development (TDD): “Figuring out TDD is hard,” becomes “TDD is hard,” which eventually turns into “TDD costs more than it is worth.” This reasoning is not true with TDD and it is not true for principled database development and design.
In Emergent Design, Scott Bain has an interesting anecdote about whitewater rafting:
Once upon a time, I was a Boy Scout. My troop was planning a white-water rafting trip down the Colorado River in the eastern part of California, just above the Imperial Dam. We were given safety training before the trip began, and one thing they emphasized was what to do if we fell out of the raft, which was a distinct possibility in some of the rougher sections.
They said: if you become separated from the raft:
Keep your life vest on, and
Do not fight the current.
Keeping your life vest on means you will be less dense than the water (which is why you float), and letting the current take you means you will not run into the rocks. The current, after all, goes around the rocks, not through them, and as you will be less dense than the water, it will be able to take you around them too.
This can be uncomfortable. The water can go through narrow defiles that are not fun for a person to go through, but it will not slam you into a boulder that can injure you or kill you. So, don’t fight it. Let the nature of the river take you.
(Bain, p.29.)
Scott’s focus is the profession of software development as a whole, but in this passage he alludes to the fact that there might be a life lesson in it. In my opinion, the moral of the story is that life is generally better if you work with the forces involved rather than against them.
Don’t fight the current of a river—the current goes around the rocks instead of through them. Don’t fight the grain of the wood—the wood wants to be cut a certain way. Don’t try to force a design when one can emerge at least as easily, and don’t try to make a software system do something it doesn’t want to do.
We need to stop looking for a “magic bullet” solution. You know the one—that perfect thing that enables us to define and build our databases with neither effort nor error. Instead, we need to look to data structures and ask what they want in a deployment solution: “How would you like to change, data structures?”
This approach achieves two goals:
It allows us to start working with our data in a much safer, cleaner, and easier way immediately.
It will give the Perfect Solution an opportunity to emerge over time.
So how do we work with data until the Perfect Solution makes itself known? I suggest that, as an interim solution, we define databases as a series of deltas in structure and behavior. That’s how a database is built in a production environment anyway, so why not start out by defining it in those terms?
If you do this—if you accept that the way we define a database should be a series of changes rather than a description of momentary characteristics—then you will find that a whole world of opportunity for change opens itself up to you.
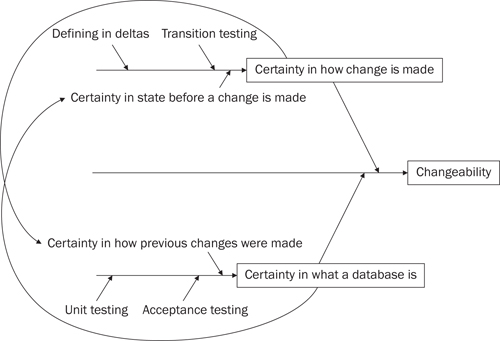
As this short cut unfolds, you will see that a feedback loop develops between certainty in how a database is made and in what it is. Each change after the first depends on the structures and behavior created by its predecessor, at least to some extent. The more certain you are of how your database is made, the more confident you can be in what it is. The more confidence you have in what your database is, the more certainty you can have in how you will transition to the next version of your database. Rinse. Repeat.
You’ve probably already noticed that the notion of defining your database in terms of a sequence of deltas pairs nicely with the idea of iterative software development. This is no coincidence. The ease with which new software could replace the old hid from us the iterative nature of software development for a long time.[4] Databases rose out of the cosmic soup of software development so we just copied the destructive memes to which we had been subjected and continued the “plan–do–review” way of working.
Because new databases cannot replace old ones nearly so easily as programs do, embracing change means we have to rethink how we introduce change in conjunction with databases. In fact, the principles and practices delineated in this short cut could apply to all data structures: file systems, registry structures, configuration files, documents your application saves, and so on.
We could seize this moment as an opportunity to rethink how we do a lot of things in an iterative environment. This document, however, is a short cut written by an Agile pundit—and an important part of Agility is not biting off more than you can chew. So I’ll stick with databases here.
I wouldn’t say that in order to achieve Agility we need to make this change. The fact is that we need to start expressing databases in terms that will reflect how they are actually built and maintained. We’ve always needed to do this, but Waterfall development and other defect-masking techniques have allowed us to stick our heads in the sand for years. Rather than create the need, the struggle to achieve database Agility merely uncovered the fact that we need an accurate, precise database build methodology.
That leaves us with a new question: How do we gain confidence in how our database is made? Defining databases by the way they will be built in real life is a step in that direction, in the same way that compilers made the production of programs from source more reliable. As with compilers, however, it’s not really enough. The answer to the question “How do we gain confidence in how our database is made?” is “The same way we gain confidence everywhere else in our profession: through automated testing.”
In addition to the fact that the description of your database actually reflects what will happen in real life, you gain the ability to drive your changes from tests through this development approach. I call tests that validate the database build scripts “transition tests” because they validate the database’s transition from one state to another. In actuality, they are probably just unit tests for your database build tool, but they are different enough in purpose from regular unit tests that a new name seems appropriate.
The same kind of testing you would already do to a software system should be done to a database. What does that mean?
Databases should be fully covered by automated unit tests that have few or no dependencies.
Databases should be fully covered by automated acceptance tests that validate the product of which they are a part as a whole.
The thesis of this short cut is that there is no changeability without certainty and that, in addition to adopting traditional Agile techniques such as automated unit and acceptance testing, Agile database developers must take into account how databases are built. Certainty in how a database is built helps you achieve certainty in what a database is. Certainty in what a database is provides a stable platform for gaining an understanding of subsequent changes.
The relationships between these factors are depicted in the cause-and-effect diagram shown in Figure 1 on page 16.
So, without further ado, let’s get started.
[1] If not, I highly recommend that you read the book Emergent Design by Scott L. Bain. Not only is Scott a good friend, but he is also a good author who makes an excellent case for software development as a profession with maintainability in response to change as the central concerns.
[2] For all intents and purposes, autonomation means “to render autonomic.” It’s possibly not technically a word yet, but it is a well-known and well-understood concept in the Lean community. More information can be found at http://en.wikipedia.org/wiki/Autonomation.
[3] Object-relational mapping.
[4] Or perhaps it allowed us to hide from the iterative nature of software development. I guess it all depends on how you look at it.