
Chapter 3. Implementing SRE
When it comes time to implement a new SRE team, the main factor that contributes to the plan is whether you are starting “fresh”—a “greenfield” project—or taking a “brownfield” approach and migrating an existing team. In either scenario, the amount of cultural change needed can be daunting.
Even before a team is formed, one must prioritize the work to be done. A guide for figuring out where to start is the Hierarchy of Reliability. Since this hierarchy is going to guide the future changes, let’s start by explaining what it is.
Hierarchy of Reliability
In late 2013, an SRE from Google, Mikey Dickerson, was asked to help the struggling HealthCare.gov. (To demonstrate the previous terms, he stepped into a situation that had a number of pieces in place, but the site as a whole was not functioning as desired. This is a great example of a “brownfield” scenario.) There was some intense time pressure to get things working quickly. He needed a way to explain “reliability” in a simple and straightforward way, so he borrowed from a theory in psychology, Maslow’s Hierarchy of Needs. The Hierarchy of Reliability that Dickerson used to help HealthCare.gov is shown in Figure 3-1.
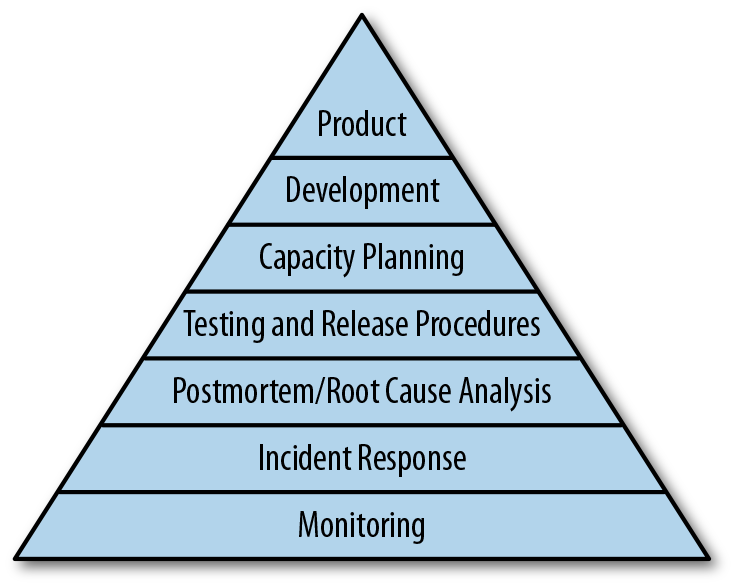
Figure 3-1. Hierarchy of Reliability
The idea is that topics at the bottom are more “basic,” and they gradually get more advanced as you progress up the pyramid. But each topic (or “level,” as we will refer to them) is not exclusively dependent on the levels below it. Rather, they build on one another. When each level is done well, then the other levels naturally benefit.1
As an extreme example, let’s look at the very bottom (“monitoring”) and the very top (“product”). Obviously, your company could have a product without monitoring. But nobody would know if, say, half of your customers only saw error pages, or if they saw the product (site) that you had designed.
While the levels used in Figure 3-1 are a proven set that a team can use to prioritize work, there are two things that we want to add.
In Chapter 1, we mentioned how being “data-informed” was critical to having valuable feedback loops. One of the key ways to gather data is through the various metrics that your software produces. While it is implied that (good) metrics are necessary for monitoring, we do want to call this out explicitly to enforce its importance.
Figure 3-2 adds that “metrics” level.

Figure 3-2. Hierarchy of Reliability with metrics
The other level to add has to do with the people that make up the team. Being on call can be very stressful. Even if there are no issues or outages, the people on call have to be available, which can impact the quality time they spend with their families and friends. And when an outage occurs, there is often immense pressure to get things working as quickly as possible. This can lead to long hours that drift into the early morning. Be aware of the impact this has on the people that work in the team. We add that “softer” level of “life” (food, sleep, family, etc.) in Figure 3-3.
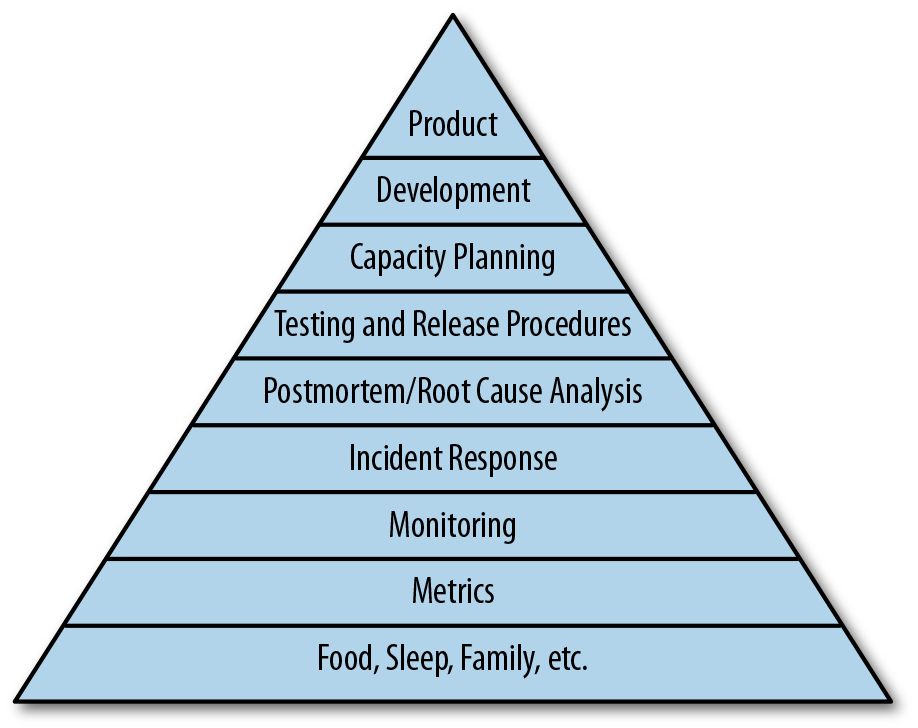
Figure 3-3. Hierarchy of Reliability with metrics and life
The resulting pyramid presents a solid guide for the work that needs to get done to make a site (or system) reliable.
Starting a New Organization with SRE
We have already mentioned how critical it is to get buy-in from management. How far up the management chain one needs to go really depends on the size of the organization and the potential impact of the new team. As an example, if the team is going be driving a project that is critical to the long-term prospects of the entire company and the progress of that project (and, thus, the team) is discussed company-wide, then it becomes important to have the most senior portions of management sold on the concept of SRE. However, if the new project is implementing a small feature, then you may only need to convince the immediate manager to use the SRE model.
Before we continue, it is important to note that the hierarchy shown in Figure 3-3 presents a sorted list of tasks that need to be managed well in order to have a reliable site. If you are solid in every level, then one could say that you have implemented the SRE model. You don’t have to hire people that specifically have the title “SRE” if the team is properly covering all of these bases. However, it is far too often the case that the engineers that are focused on feature development either have less interest or less knowledge when it comes to the details of the SRE role. Management needs to determine if they can deliver a reliable product with existing staff or need to hire specialists. In either case, the goal is to make sure the hierarchy is as solid as possible at every level.
In Chapter 2, we mentioned how “success begets success.” Once you have demonstrated the value of the SRE model, either with existing staff or new hires, it becomes much easier to add SREs as the team grows. This success will be a result of building up those solid layers.
It’s highly likely that at some point you will want to hire specialists (i.e., SREs). But hiring is always difficult. Arguably, this is even more true for SREs. A good SRE has the skills you would find in someone filling a “classic ops” position as well as the solid programming skills you would find in a software engineer from a product-focused team. Finding a good technical fit is only part of the challenge, though. A good cultural fit is just as important. This is especially true in a small, growing team because a single hire can have a drastic impact—good or bad—on everyone else. However, in a larger company, the existing team members are likely to have established a culture that anyone new can fall into. The impact of every hire is just as important when one is trying to build a new team.
Once you’ve hired an SRE, it is important to enable that individual (and the entire team) to be successful. Make sure everyone understands the role of the SRE. The SRE is not the “ops person” for the team. It is easy for everyone to just hand off deployments, configuration management, etc. to this one individual. But if that happens you have implemented “classic ops,” just at a smaller scale. The SRE is there to enable and empower every other engineer on the team. Each engineer is responsible for deploying their own code and managing their own configurations. The same goes for metrics, monitoring, etc. The SRE is the expert in these various aspects of delivering high-quality software. They are there to help other engineers with the details, but not to implement everything for them. Also, since the SRE is an engineer in their own right, they will be writing code to make these various processes simpler.
It is important to be aware of the type of work that the SREs on the team do. They are there to make the jobs of every other engineer easier and faster, but they are not just another software developer working on features. They need to remain focused on the overall reliability of the site. To assist in this, some companies use a “double reporting model.” Essentially, the SRE works (and sits) with the development team, but they report to a different organization whose mandate is not product features. That other organization may or may not report to the same VP. Regardless of what common senior management exists between the development organization and the SRE one, it is important that SREs continue to focus on reliability and leave the product features up to other teams.
Case Study: SRE at Slack
Slack did not start, out of the gate, with an SRE model, but it has built one in the throes of hypergrowth in order to scale with the demand for its services.
According to Holly Allen, Slack had grown from just 100 AWS instances at the time of its initial public unveiling in 2014 to over 15,000 instances by late 2018 (just over four years later). In the same period, the company itself grew from less than 50 people to over 1,600.
As the company started specialization, its first phase was to have a centralized ops team that focused on provisioning cloud instances and building the Chef and Terraform tooling for automation. This team also served as first-tier response for all alerts and incidents. As Slack expanded, the ops/infrastructure team focused on infrastructure-related breakages and had to route any app-level incidents to the appropriate product teams.
The next phase of evolution was a reorganization of ops to “service engineering,” with the inclusion of the internal developer tools team. The new combined team focused on figuring out how to push operational ownership of services back onto the dev teams so that the teams that could make the real code fixes received the incident alerts. Some feature teams had the skills to handle the on-call demands, but other teams needed training and hands-on help on how to handle the operational load. Slack created an SRE team to uplevel the operational capabilities of the dev groups.
Allen’s talk illustrates one of the problems with excessive toil—in this case driven largely by low-quality, noisy alerting. SRE teams were so consumed by interrupt-driven toil from the noisy alerts that they were barely able to make any significant progress on improving the working conditions.
In September 2018, Slack explicitly committed to the importance of reliability over feature velocity and implemented a cathartic purge of all the historical, host-based alerting that was causing such a problem. Since then the SRE teams have been able to focus on making “tomorrow better than today” across the teams in which they are embedded.
Introducing SRE into an Existing Organization
Introducing any kind of cultural change into an existing organization is always difficult. As we mentioned earlier, existing teams often have a culture all their own. Altering that culture can take a lot of work. Regardless of the day-to-day challenges the team faces and how much desire there may be for something new, there is always comfort in “the devil you know.” As a result, the people leading the change have to demonstrate that the place they are trying to get to is significantly better than where they are.
In a large organization with many teams, one way to accomplish this is to find a development team that is motivated to change and implement a small SRE team (or individual) there. Over time, you can use that success as a positive example to other teams. The idea is to focus all of your energy into that one product team that is leading the cultural change, and make sure it’s successful with its transition. The members of that product team can then be advocates to their peers on other teams. Those advocates can explain what pains they went through and how much better things are with SREs.
This grassroots approach can be very powerful, as other engineering teams may be more pessimistic about an edict coming from upper management. Then those engineers can communicate their desire to try the new model with their managers. Hopefully, this will start a snowball of change throughout the organization.
However, it is rarely that simple. Even in the best of cases, there are likely to be some teams that simply do not want to change. At this point, management will need to step in, but they can still use the successful SRE implementations as the rationale behind any coming changes.
In the worst of cases, all progress is halted early on. At this point, it is up to senior management to move things forward.
Overlap Between Greenfield and Brownfield
The previous sections outlined some approaches for implementing SRE in both “greenfield” and “brownfield” situations. But it is rare that teams or organizations are that clear-cut. In fact, you can probably see some overlap in the previous discussion. The hope is that you can take inspiration from this discussion and come up with a strategy that works for your unique situation.
Case Study: LinkedIn
The SRE team at LinkedIn was created around 2010, when the company was about seven years old and staggering under an unsupportable weight of brittle, barely maintainable systems. Interestingly, the group of people who became the SRE team was about the same size as Google’s initial formation team. As the number of users began to grow significantly, the site was experiencing daily outages during the morning usage peaks. New versions of the site required grueling merge gauntlets and inevitably broke when deployed into production. The “site ops” team of about 10 people was unable to keep up.
The SRE team was created and organized around three cardinal principles:
-
Site up and secure is the prime directive.
-
Everyone in the engineering organization should be able to safely deploy code.
-
Operations is an engineering problem.
At around the same time, another team (now known as the foundation team) was chartered to develop consistent tooling and processes for the engineering org to use as they developed the site’s codebase. The foundation team focuses on engineering productivity, building and supporting the development environment tooling from base libraries, IDEs, and version control through the CI/CD pipelines into production.
As the engineering organization has grown, the SRE and foundation teams have also grown, with each now accounting for about 10% of the total engineering headcount. As the scale of the problems increased, so have the services and systems that are developed and maintained by the SRE organization in order to keep up with the demands of the site.
1 For a more complete discussion of the pyramid, see Part 3 of the book Site Reliability Engineering.