
After completing this chapter, you will be able to
Understand how the term relevancy applies to search engines.
Understand the terminology used to describe search architecture.
Understand search engine features such as linguistic handling and query syntax.
The field of search consists of several key concepts. People who work with Microsoft FAST Search Server 2010 for SharePoint (FS4SP) or any other search engine should know the complete data flow: from retrieving content, enriching and organizing it into searchable pieces, to displaying it for end users using either manual or automated queries. Understanding how content is collected can help you debug problems with search quality and determine the applicability and value of adding content to the corpus.
You should also understand how the quality of search can be improved by processing unstructured text, enriching that text, and by associating it with metadata. Knowing these processes and concepts can help you to implement and optimize a search solution with FS4SP more effectively.
This chapter outlines the basic concepts of Enterprise Search engines and introduces the key concepts for understanding how a search engine works. It also investigates the concepts that are unique to FAST and how they have been merged with Microsoft SharePoint to create FS4SP.
The goal of any search engine is simple: For any given query, the search engine should list the result(s) that the user is looking for at the top of the result list. Unfortunately, accomplishing that goal is much more difficult than it seems. As a result, search engines rely on a number of complex processes and features to achieve the best result for any query. Understanding relevancy—how items are considered relevant and eventually ranked in a result set—will help you determine how to tune FS4SP to achieve the goal of placing the best results at the top of the result list.
All search engines have two main operations: content processing and query processing. Content processing includes content collection, content enrichment, and indexing. Query processing includes receiving queries from the users, enriching the queries with additional query parameters or logical delineation, matching result items in the search index, and returning the result set to the end user. To achieve the goal of relevant results, both query processing and content processing enrich the content, the queries, and the process of matching the queries in the index. To understand how these work together, let’s first look at relevancy.
Relevancy is a measure of precision in a search engine and refers to how accurately the returned results match the user’s query and intent. Users who search for a given term expect to see the item they are looking for or an item containing the information they are looking for at the top of the result list. They consider useful matches as relevant. Relevancy tuning techniques can improve precision by ranking the matches in the result set in a manner that more accurately matches the user’s intent. Relevancy is calculated using a number of factors and is determined by the item’s rank in the result set.
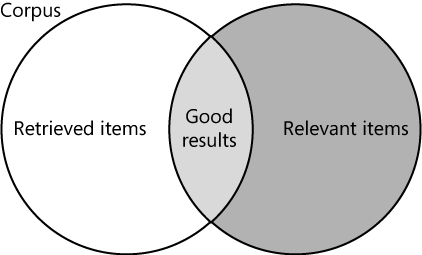
Recall and precision are two factors that determine the quality and effectiveness of a search engine. Recall refers to the number of results a search engine returns for a specific query, and precision refers to how precisely the results match the search user’s intent. You must make a compromise between recall and precision. If recall is too large, you essentially flood the result set with noise, and precision suffers. On the other hand, when recall is too small, you run the risk of missing useful results, so the item(s) the user is looking for may not appear in the result set; again, precision suffers. The goal of any search engine is to get adequate recall while giving high precision so that, for any given query, the correct result is at the top of the search results.
You can see the tradeoff between recall and precision in Figure 2-1, where the corpus is represented as the total body of all items and the result set is the set of retrieved items. The items returned in the result set consist of a set of matches to the specific query. The search engine relies on the query to return items that match the user’s intentions. Items that are relevant may not match the given query, and irrelevant items may match that query. Increasing the number of items in the retrieved result set improves recall but can hamper precision; adding more items and increasing the size of the result set effectively reduces the overlap of relevant items and retrieved items. For example, if a user searches for the term job, a search engine will usually return all items where the term job appears. However, relevant items may exist that use the terms jobs, occupation, or career instead. Likewise, the term job may appear in items that do not match the user’s goal of finding employment. Recall can be improved by including terms that are considered synonyms (career, occupation) or by expanding the query with other methods, such as stemming (jobs). But this may also introduce results that the search user never intended to be included, and may thus reduce precision.
You can choose from several methods to improve recall and precision in the search index. You can also add features that users can use to expand queries or filter result sets, enabling the users to adjust recall and precision themselves. This chapter explains these features and discusses, where possible, how these features and methods improve either recall or precision or affect the balance of the two.
Improving the quality of the content to be searched can help the search engine improve both recall and precision. The old computer adage of “Garbage In, Garbage Out” also applies to a search engine, which relies on indexed content to return an appropriate result set. Item processing is the process of enriching the crawled content before it is indexed. Several different operations are applied during item processing in FS4SP, some of which are optional. These stages detect language, separate text streams into words, extract metadata, and expand terms, among other tasks.
Processing the content before indexing takes place can add important information to the items in the index. This improves recall and supports more precise matches in the result set, for example, expanding a product number to the full product name.
Query expansion techniques improve recall by expanding the search term or terms based on specific rules to find more possible matches in the corpus and return them in the result set. Some standard techniques are as follows:
Lemmatization. This is a method by which terms are expanded based on their lemma (the canonical form of the term). By finding the lemma, the search engine can associate all inflections of the term and add those to the index. In this way, for example, the term fishy can be morphed into the lemma fish, enabling the search to match fishing, fishes, fished, and so on. This expands the result set to include items containing any of the associated terms. Lemmatization can expand queries beyond the literal values of the text because it can identify lemmas that don’t actually appear in the given search term. For example, the lemma for the term better is good. Contrast this with stemming, which merely substitutes endings on an identified term root (such as run, runs, running—but not ran).
Note
Because of a common API with SharePoint search, FS4SP lemmatization is referred to as stemming in TechNet documentation. FS4SP always performs lemmatization during configuration, even though it uses the term stemming.
Synonyms. These are an effective way to expand queries by associating known terms that are the same or similar to those in the query. This kind of expansion can be used to associate true synonyms or to correct spelling mistakes or simple misunderstandings about the content. Jargon can often be replaced with accepted terms and common language usage, and organizational terminology can be aligned.
Best bets. These are promoted results on the SharePoint Search result page. Best bets are usually a link to the content that the site collection administrator thinks is best for the particular search term. The link and a description are placed at the top of the result page for a given query.
FS4SP takes this concept a step forward by allowing the site collection administrator to use a visual best bet—that is, a link and description with an image or some other HTML content (see Figure 2-2). This type of result is much more eye-catching for end users, and can help a great deal to lead them to the promoted content.

Corpus is the Latin term for body. In search engine terminology, it refers to all items to be indexed. Items may be documents such as Microsoft Word or Microsoft PowerPoint, Adobe PDF documents, webpages, text files, rich text format files, or any number of other file formats. They may also be records from tables in a database or other content captured through Business Connectivity Services (BCS) in SharePoint. Each one of these unique files or pages and all of its associated metadata and security information is considered to be an item in the corpus.
Ranking is the method by which a value is applied to a given item to place it in a position of relevance in the result set. The ranking value is applied with a mathematical algorithm against the content of the item and its associated metadata. In FS4SP, several methods can be used for modifying the ranking values of items in a result set. Two of these methods are static rank tuning and dynamic rank tuning, discussed in the following sections.
Static rank is the rank value applied to items in the index independent of the specific query. This is also known as quality rank. Four factors are taken into consideration, by default, to determine this rank:
URL depth rank
Doc rank
Site rank
Hardwired boost (HW boost)
URL depth rank gives a higher ranking value to more shallow items—that is, items that have a shorter URL with few slashes (/). The number of slashes roughly indicates how many clicks a user had to make from the entry point of the site to get to the content. How close an item is to the top of the site may be a good indication of value because users typically organize important content near the entry level of the page and store less important content in deeper libraries and folders. Doc rank is a Google PageRank–like evaluation that gives higher value to items that have a larger number of links pointing to it. Similarly, site rank gives additional weighting based on the number of links pointing to items on a site. Finally, HW boost is a default item property for adding quality rank. Rank values can be tuned for static rank by using Windows PowerShell to add or remove static rank values.
More Info
See Chapter 6, for an example of modifying the static rank of the rank profile. For more information about static rank tuning, go to http://technet.microsoft.com/en-us/library/ff453906.aspx.
The dynamic ranking value is calculated based on the query terms and their relation to the items in the result set. The factors taken into consideration are managed property context, proximity weight, managed property field boost, anchor text weight, click-through weight, and stop-word thresholds.
More Info
For more information about dynamic rank tuning, go to http://technet.microsoft.com/en-us/library/ff453912.aspx.
To make sense of languages, search engines perform a number of language-specific tasks on the data as it is being indexed. FS4SP has several features that break text streams into language-specific words; recognize those languages; expand them with lemmatization; and apply anti-phrasing, spell-checking, and synonyms.
FS4SP can automatically recognize 80 different languages in all common document encodings. The detected language is then used to further process the text and apply language-specific rules to it, such as property extraction and offensive language filtering.
More Info
For more information about linguistic features, go to http://technet.microsoft.com/en-us/library/ff793354.aspx.
Tokenization is an important element for identifying terms in a search engine. The crawler delivers a stream of information to the indexing pipeline. The job of the indexing pipeline is to make sense of that information and make it storable to in the search engine. Tokenization is the process of breaking apart the stream of text received from the document converters and identifying individual terms. Depending on the language detected, the stream of text picked up by the crawler may be tokenized (broken into unique words) in a different manner.
Keyword rank boosts the value of specific documents when a certain keyword is searched for. This can be done by specifying keywords and assigning document and site promotions to the keyword.
Document promotion is a useful and effective method of forcing ranking on specific items for specific keywords. Alternatively, best bets can be used to place a specific hit or information above the result list.
More Info
See more information about best bets in the Query Expansion section earlier in this chapter. For an example of document promotions, see the section Keyword, Synonym, and Best Bet Management in Chapter 6. For information about keyword rank tuning, go to http://technet.microsoft.com/en-us/library/ff453900.aspx.
Rank profiles are a part of the FS4SP index schema that provides a mechanism for defining how ranking values for each item in the result set is determined. FS4SP has a default Rank Profile with settings that may be adjusted by using Windows PowerShell (see Figure 2-3). New Rank Profiles may be created with Windows PowerShell and custom weights applied to a number of components, including freshness, proximity, authority, query authority, context, and managed properties. A number of rank profiles may be created and exposed for the end user to choose from depending on their search intent.

An FS4SP installation, naturally, relies on and requires SharePoint. Most readers already know and understand most of the core concepts of SharePoint before looking into FS4SP. However, knowing SharePoint or how to take advantage of its other capabilities is not a requirement to use FS4SP as an Enterprise Search solution. Therefore, the topics in this section define some of the core concepts of SharePoint that FS4SP relies on.
A web front end (WFE) is a SharePoint term used to describe a server with a web application role. For the most part, WFEs are web servers that handle user requests and deliver web content for the GUI, in addition to delivering other requests to the appropriate service applications in SharePoint. However, a WFE server can host other server roles if necessary. A WFE can also be set as a dedicated server for handling requests from the crawler. In such a case, the WFE should be excluded from the Network Load Balancer, and the crawl server should be set to crawl only the WFE. In large deployments, a dedicated set of WFE servers can be used for crawling.
More Info
The term web front end is not an official Microsoft term and is no longer used in Microsoft documentation since Microsoft Office SharePoint Server 2007 (MOSS). However, the term is still widely used in the SharePoint community and is an accepted term to refer to servers with the web application role. For more information about servers with the web application role, go to http://technet.microsoft.com/en-us/library/cc261752.aspx.
Central Administration is the administrative interface of SharePoint. It is the central location for modifying and monitoring most operations of the SharePoint farm. For FS4SP, Central Administration displays the FAST Query Search Service Application (SSA) and FAST Content SSA. Central Administration is a SharePoint Site Collection itself with preconfigured menus for settings pages. Figure 2-4 shows the SharePoint Central Administration site.
In SharePoint, service applications control much of the service-based functionality in a SharePoint farm. In SharePoint Search, the Search Service Application handles crawling, indexing, and querying of its own search index. In FS4SP, because we are connecting to an external search farm and because the People Search capability is still handled by a SharePoint index, two Search Service Applications need to be provisioned to make search work. See Chapter 4, for more details about the following two SSAs:
FAST Query Search Service Application (FAST Query SSA). The FAST Query Search Service Application hosts the query processing part of FS4SP search in addition to a separate index for People Search. Depending on whether search is being submitted from the People Search scope or from another scope, the FAST Query SSA directs the query to the appropriate index. If the search is directed to FS4SP, the QR Proxy takes the query and handles it on the FS4SP farm, passing it to the QR Server after resolving security claims.
FAST Content Service Application (FAST Content SSA). The FAST Content Service Application handles the crawling of content sources via the built-in connectors. The content crawled by the FAST Content SSA is passed to the content distributor on the FS4SP farm for processing and indexing.
The Federated Search Object Model is an application programming interface designed to query and return results from multiple search engines. Search Centers in SharePoint use this query API when executing search queries. Federated Search Object Model usage is explained in Chapter 8.
To support remote access by client applications, SharePoint—and therefore, FS4SP—also supports SOAP Web Service access to the Query Object Model via the Query Web Service. When SharePoint is installed, the Query Web Service can be found at http://server/[sitecollection/]_vti_bin/search.asmx.
The Query Web Service can allow external applications to pass a standard XML-based query to the Query Object Model and receive results. This is especially powerful for integrating legacy applications and external systems with FS4SP.
More Info
For more information about using the Query Web Service, see Chapter 8 and go to http://msdn.microsoft.com/en-us/library/ee872313.aspx.
An RSS feed is provided for very simple queries to the Query Object Model. The RSS feed takes a simple search query and returns a result set by using the RSS standard. This standard may also be called to apply a simple federated search from one farm to another.
The Query Object Model is the core object model that passes the query on to the SSA. The keywords and any attributes needed to satisfy the search are executed using the KeywordQuery class. Figure 2-5 shows a diagram of the path the query takes to the Query Object Model and beyond.
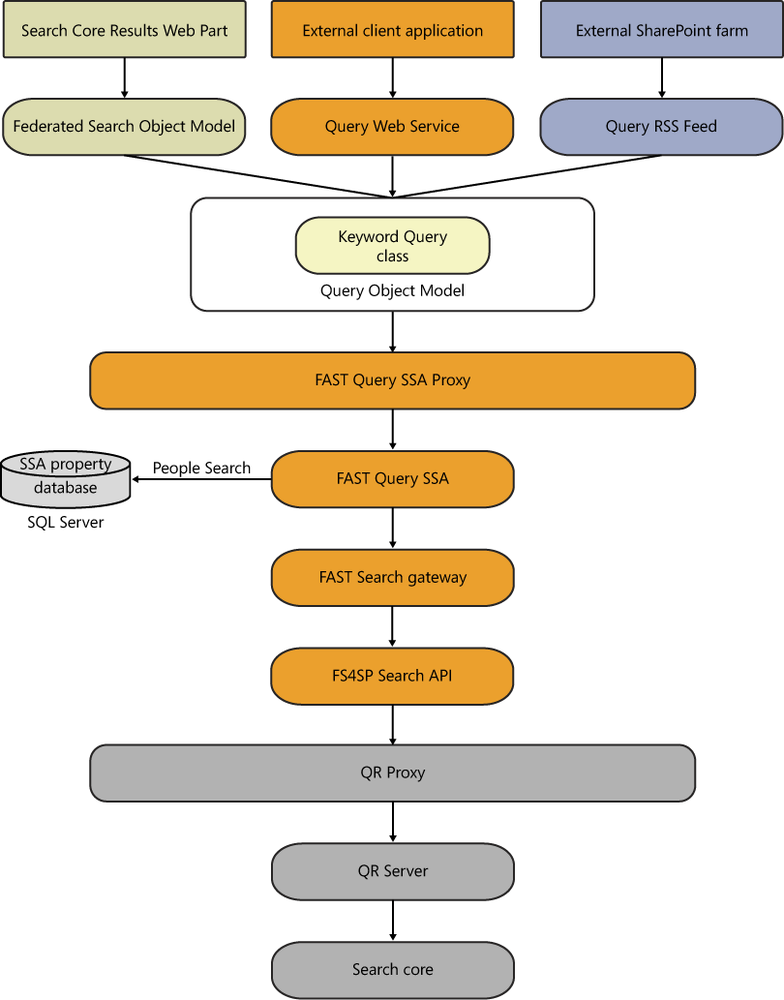
SharePoint uses Web Parts in its webpages to display content, retrieve information from users, and allow for interaction with the various functions of the platform. Web Parts are essentially web-based applications that are ASP.NET server controls embedded into Web Part zones in SharePoint. The Search Centers (both FS4SP and standard search) in SharePoint use a number of Web Parts that interact with the FAST Query SSA to query the index and display results, refiners, sorting mechanisms, and a variety of other search features.
The most important Web Part in an FS4SP Search Center is the Search Core Results Web Part, which handles both sending queries to the query mechanisms and displaying the results returned to the Search Center. The Search Core Results Web Part sends the user’s query via the Federated Search Object Model, which in turn sends it to the Query Object Model, which passes it to the FAST Query SSA, which then sends it on to FS4SP. A detailed diagram showing the path of the query is shown in Figure 2-6.

SharePoint has a feature-rich, built-in expertise and People Search functionality. This functionality is built not only on imported users from a directory service but also from enriched user information from SharePoint MySites. Therefore, SharePoint People Search is used in FS4SP; a separate people index that uses FS4SP is not available.
It is the utilization of the SharePoint People Search capability that requires two separate Search Service Applications in an FS4SP deployment. The FAST Content SSA is used for crawling content sent to the FS4SP farm; the FAST Query SSA crawls people content by using the SharePoint index and directs queries appropriately (either to the FS4SP farm or to the SharePoint index for People Search queries).
Content processing includes all the parts of the search engine that perform the collection, enrichment, and indexing of the items in the corpus.
Content sources are crawler definitions that specify the type of content to be crawled and where crawling should begin. A single content source may have a number of start addresses but only one kind of content is defined. That is, if you choose a SharePoint content source, only SharePoint sites can be crawled by adding start addresses to them; if you choose a file share content source, only addresses of file shares are crawled. This is because the content sources define which code is used to request the content from that source. Content sources are sometimes referred to as connectors, but connectors are actually the binaries that are executed when accessing the source systems defined in the content sources. FS4SP has built-in connectors that are set in the content source when it is created. After creating a content source in the FAST Content SSA in SharePoint, you can add or remove start addresses but you may not change the connector type.
Note
Content sources should not be confused with Content Collections. Content Collections are logical separations of content in the index where the content is tagged as belonging to a specific collection. Read more about content sources in Chapter 5.
Although often used interchangeably, crawling and indexing are two separate stages for a search engine. Crawling is the process in which requests are made to content sources and the received content is collected and passed on for further processing. For example, in the case of a web crawler, a request is sent asking a web server for the webpage, the same way a browser would request the page. The retrieved data consists of all the information the web server returns, including the HTML content and HTTP headers from the web server. For other content sources, such as databases or a document management system, a query is made to the content source and whatever is returned by the source system is passed on by the crawler for processing and indexing. Depending on the logic of the connector to the content source, the crawled item can include metadata.
Indexing is the process of organizing the extracted terms from the content and storing them in a searchable index with references to the source documents or pages. FS4SP has an intermediary stage called Item Processing, which implements a number of stages known as the indexing pipeline. This pipeline is where the documents are converted, broken into individual terms, recognized for language, enriched with metadata, and associated with properties, among several other stages.
The type of content indexed depends on what content sources can be effectively crawled and if the content received from those content sources can be converted into storable data. All collected content is effectively normalized into plain text terms, properties, and document references, which are then stored in the index. So, to be able to index content, the content must first be collected by a content source connector or protocol handler and then processed in the indexing pipeline.
Federated Search is the method by which results from another, external search engine are displayed on the result page together with the result set of a search engine. In many cases, it would be ideal for the federated results to be combined with the existing result set and normalized for ranking. But this would require a benchmark value for both indexes, so usually federated results are displayed side by side with the core results.
Federated search in FS4SP supports the OpenSearch 1.1 standard. This standard defines an XML format by which search results should be delivered and is supported by most global search engines and popular websites with search capabilities, for example, Bing. A noteworthy exception is Google, which does not expose an OpenSearch interface as of this writing. A Federated Search using Bing as the source is shown in Figure 2-7.
More Info
For more information about OpenSearch, go to http://www.opensearch.org.

The document processor takes the content that the crawler has collected and sent via the content distributor and organizes it into searchable text by sending the content through the indexing pipeline. As such, the document processor is the mechanism that pushes items through the pipeline in which different processors perform different, specific tasks on the content. Document processors can perform many tasks, such as extracting text from files, breaking the text into words, identifying languages, and extracting entities. By the end of the indexing pipeline, several unique processors are passed and the text is in a format that can be stored in the index and made searchable.
Documents can be converted using IFilters or some other document conversion filter. The IFilter interface is a mechanism for handling document conversion filters that are built into Windows operating systems. IFilters themselves are either added with a search engine like those installed by the Microsoft Office Filter Pack or added individually from third-party vendors. They can be called to convert a variety of document types. FS4SP comes with additional document conversion filters in the Advanced Filter Pack, which can be enabled via Windows PowerShell.
More Info
For more information about the IFilter interface, go to http://msdn.microsoft.com/en-us/library/ms691105.
After the crawled items run through the document processors in the indexing pipeline, intermediate XML files with a data structure containing items prepared for indexing are created. The XML file is in an internal format called FIXML, which is described in detail at http://msdn.microsoft.com/en-us/library/ee628758(office.12).aspx. All data and metadata about the items are present in the files.
The FIXML files are stored below <FASTSearchFolder>datadata_fixml and the files are processed by the indexing component in FS4SP.
Metadata is data about data, that is, information that describes another piece of information. Generally, metadata appears as properties or meta tags that describe an item. A simple example is a keywords meta tag on a webpage. The keywords are placed in the meta tag in the HTML of the page to let search engines understand, in a few words, what the webpage is about.
Metadata can come from several different sources. Physical metadata is data about the item that accompanies the item and is often reported by the source system. This can be file type, file size, mime type, or date. Defined metadata can come from within the document or in files or properties associated with the item in the source system. For example, SharePoint has columns associated with every document in a document library. Custom columns can also be added to extend associated properties. FS4SP indexes this metadata in addition to any metadata found on the document.
Another type of potential metadata is extracted properties (also known as entities). These are properties that are extracted from the body of the document or item. Properties such as person names or place names are common extracted properties.
Any metadata that is picked up by the crawler is stored as crawled properties. This does not make the metadata automatically searchable. In order for metadata to be searchable, either it must be mapped from a crawled property to a managed property, or the crawled property has to be marked as searchable by itself. This is done in the FAST Query SSA in SharePoint Central Administration or with Windows PowerShell. For more information about mapping properties, see Chapter 6.
An index schema is a model of how the index is created and what elements are part of that model. FS4SP has four basic parts to the index schema. These are crawled properties, managed properties, full-text indexes, and rank profiles. The diagram shown in Figure 2-8 illustrates the hierarchy of these parts in the index schema.
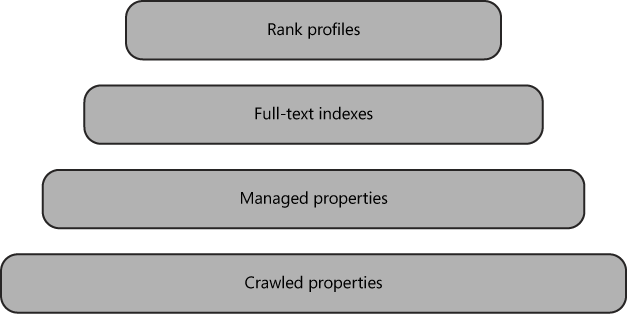
A crawled property is any document property that FS4SP knows about. It might be a column from a database, the last modified date of a Microsoft Excel spreadsheet, or a title from a crawled blog post—in short, any document metadata that has entered FS4SP during content crawling or that has been extracted in the indexing pipeline. As such, these crawled properties are not yet available in the index and are not searchable. They are simply what they are called: crawled. However, you can set a flag on the crawled property to make it searchable from the full-text index. This is default behavior for all SharePoint columns.
Managed properties, on the other hand, are available in the index and are searchable. These properties are chosen from the set of crawled properties and are made members of the index. After mapping managed properties from crawled properties, you can use managed properties to construct targeted queries, use them for sorting, or use them as refiners.
A full-text index is actually a property containing many managed properties. Indeed, in previous FAST technology, it was referred to as a composite field. A full-text index is what FS4SP uses behind the scenes when you run an untargeted query. Just like you can map crawled properties into managed properties, you define a full-text index by mapping managed properties into it. You also set different levels of importance on each managed property that you map into a full-text index. These levels are used when FS4SP is calculating a given item’s relevance against a certain search query.
The last key concept of the index schema is the rank profile. A rank profile is referenced by a full-text index and defines more specifically how the different managed properties in the full-text index should contribute to rank calculations.
Query processing is the stage of the search where the query is received from (for example, the Search Center) and is processed to apply certain rules or expansion before being matched to the content of the index. Query processing in FS4SP is a set of components (QR Proxy, QR Server, and Topfdispatch) that receive the query from the FAST Query SSA, process it, and pass it onto the Query Matching component. The query dispatching part (Topfdispatch) passes the query to the index columns and eventually to any index partitions.
The Query & Results Server (QR Server) is the component on the search server that is responsible for executing searches in FS4SP. The QR Server also provides its own web-based interface that is mainly intended for testing FAST Query Language (FQL) expressions and debugging any potential issues with FS4SP. Read more about FQL in the Query Language section later in this chapter.
Refiners are clickable terms on the search result page that allow users to narrow a search based on common properties in a result set. This method of displaying the most prevalent common properties from metadata on items has also been known as faceted search, which refers to the similar “faces,” or properties, of the items in the result set. Faceted search is a poor linguistic association, and the new Microsoft terminology of refiners is a better description of what is actually happening: The result set is getting refined to a purer set of results by focusing in on items with desirable properties.
FS4SP is capable of providing both shallow and deep refiners. Deep refiners are refiners that are listed based on the entire result set. Shallow refiners include only a limited number of results. Sometimes that result set can be very large and the number of common properties also very large. FS4SP has the ability to analyze the entire result set (regardless of size), display the refiners, and report the exact number of matching items for each. In contrast, standard SharePoint search can analyze only a very shallow set of results (up to 500).
FS4SP supports a robust search syntax. Users can add query syntax to the search query, or that syntax can be added programmatically. The query language can be used to fetch a custom and specific result set. The query language is required to make sense of the keywords that users search for, in addition to any refinement the users may apply. Predefined queries using complex query language may also be desirable for building custom search experiences or search-based applications.
SharePoint has its own query language, the Keyword Query Syntax. This is also known as KQL (Keyword Query Language), where K stands for keyword and is the parameter used for passing keyword queries to SharePoint. FS4SP also has its own query language, which is known as FQL or FAST Query Language. However, users of SharePoint will not see FQL because KQL works on both SharePoint search and FS4SP. The QR Server does the job of translating KQL into the appropriate platform-specific query languages and receiving the correct results. However, in some cases, a developer may want to use the added functionality of FQL to pass more complicated queries and retrieve specialized result sets. Some examples may be when adjusting ranking order or custom sorting is desirable. See Chapter 8 for a detailed explanation of the query languages in FS4SP.
More Info
For more information about query languages in SharePoint and FS4SP, go to http://msdn.microsoft.com/en-us/library/hh144966.aspx.
Token expressions are the simplest queries of words, phrases, numbers, or identification values that may be expected to return a specific item in the index. Token expressions can be a single word, multiple words, or a phrase. They can also be numbers or letter-number combinations that represent a title or document ID.
Properties or metadata are often more useful to search for than free text in the body of a document. Properties are often applied to describe a document and fill in information missing from the body of the document. In FS4SP, properties can also be searched for independently of token expressions. Specifying a property and its value can return all documents with the matching property and property value, regardless of text within the item.
George Boole was an English mathematician who invented Boolean logic, which has conjunction, disjunction, and negation operators. For search engines, these operators are applied as Boolean AND, OR, and NOT operators. A Boolean AND operator, which is the default operator for most search engines, provides a result set with only items that match all of the terms searched. For example, if a search user enters the query Swedish meatballs, only items with both the term Swedish and the term meatballs are returned. Alternatively, an OR operator returns all items with either Swedish or meatballs in them.
The NOT operator returns only items that do not contain the term immediately following the NOT operator. For example, if the search user searches for Swedish meatballs NOT Chefs, the search engine should return items that contain both Swedish and meatballs (not necessarily together) and do not contain the term Chefs.
The default operator when querying against FS4SP from the Search Center or via the API is the AND operator. This means that when two or more terms are searched for, only items with all of the terms are returned. This allows for refinement of the search results by adding terms to the search query. This is what most users expect from a search engine. If a user wants to get all documents with any of the terms, that user is required to manually enter the OR operator in the search query field. An example of an AND search with a NOT operator can be seen in Figure 2-9.

More Info
For more information about using operators in keyword queries, go to http://msdn.microsoft.com/en-us/library/ee872310.aspx. A complete reference can be found at http://msdn.microsoft.com/en-us/library/ff394462.aspx. Using Keyword Query Syntax and FAST Query Language is discussed in more detail in Chapter 8.
Search scopes are a SharePoint concept of delimiting search result sets prior to query. Essentially, a search scope is a logical separation of the search index based on a property query. The property query is added to the search terms at query time and the entire search is submitted to the index, retrieving only results that match the terms searched for and all rules in the scope.
Scopes help users search in a subset of the index and can be set on specific search pages or search-based applications to limit the scope of the search regardless of the query syntax. Scopes can also be made available through drop-down menus next to the search box, allowing users to select the section of the site or search index they want to query. This is very useful for building search interfaces that query only a specific site or level of a site in a portal. Users may not even know that the index contains information from other sites because they receive only results within that specific site. Scopes can also be used in certain circumstances to filter the result set in order to remove noise or improve ranking by forcing the inclusion or exclusion of content to queries.
Note
Scopes are appended to search queries as a logical AND operation, which means the matching result set applies your query in addition to any rules set in the scope and returns only those results that match all the criteria. Several scopes can even be applied to a single search result Web Part by using an AND operator to separate them. However, the scopes setting only supports AND settings, not OR or AND NOT operators.
Those familiar with SharePoint search know that scopes can be set in the SSA or in Site Collection Administration on the Site Settings of the Site Collection, and then applied to the Search Centers. Scopes in SharePoint allow for rules by address (folder, host name, or domain), by property queries, or by content source. In FS4SP, these scopes are limited to address (folder, host name, or domain) and property queries; however, because the scope rules are property filters that are defined in FQL, the query can be set to virtually any available property as long as that property is mapped as a managed property in the Metadata Property mappings in the FAST Query SSA or with Windows PowerShell. If the Scopes user interface in SharePoint is used, the FQL statements are autogenerated by SharePoint. If Windows PowerShell is used, the administrator can define his or her own FQL. This makes scope usage in FS4SP very powerful.
More Info
For information about using Windows PowerShell to define an FQL, go to http://technet.microsoft.com/en-us/library/ff453895.aspx#BKMK_ReviewSearchScopesIncludingFQL.
A typical use of scopes in FS4SP is to create separate search tabs in the search UI and set a specific scope for each tab. This gives the users a different search page for each type of search or section of the site. This is seen in the Search Center with All Sites and People Search tabs (see Figure 2-9). These submit different scopes and, as described previously, the People Search scope is captured and passed to a different index. Additionally, it is not too difficult to create an image tab, a site tab, or tabs for different departments or document types. Analyzing business needs and user behavior before creating different search tabs that submit to different scopes can be helpful in determining which scopes to define.
As shown in Figure 2-10, the SharePoint interface has two scope rule types:
Web Address. Any URL that can be set. The path and all subdirectories are automatically included in the rule.
Property Query. A property query defined with allowable syntax in a property query field.
The default rules have three basic behaviors:
Include. Include all the content that matches the path or property rule specified in the rule definition. A good example is when you are building a sub site–specific search and including only items from the path and subdirectories of a specific site. For a property, you may want to include all the items that match a specific property (for example, approved items).
Require. This rule is similar to the inclusion rule but is stricter insofar as all items must match any rule defined with this behavior. This rule behavior is usually used for properties that must match all items.
Exclusion. Anything matching a rule with this behavior is excluded from the scope.
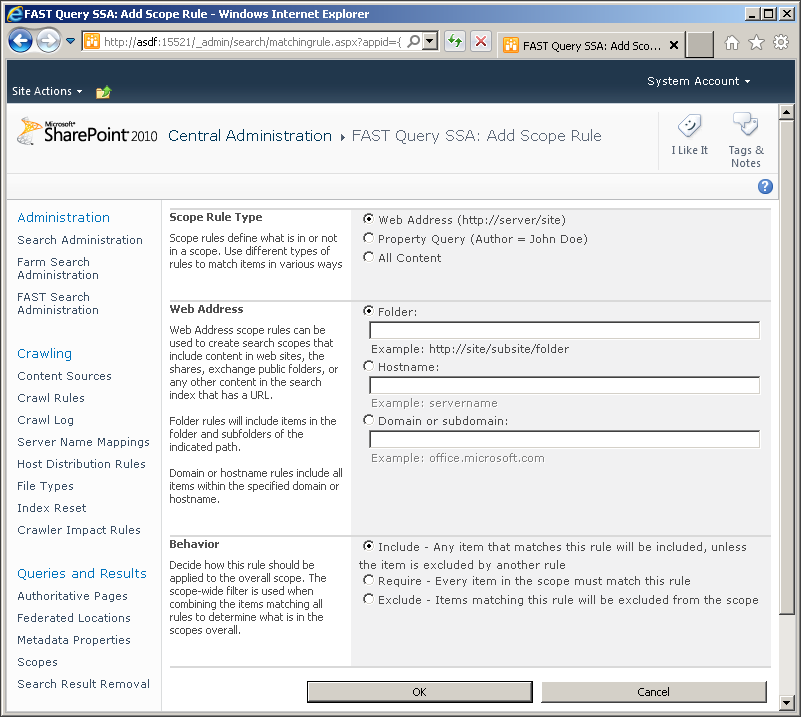
After a scope is set up and defined, it can be set on the Search Result Web Part or used in a search box. To delimit a search result page with a scope, you should edit the result page and then edit the Search Core Results Web Part. Scopes can be defined in the Location Properties section, shown in Figure 2-11.
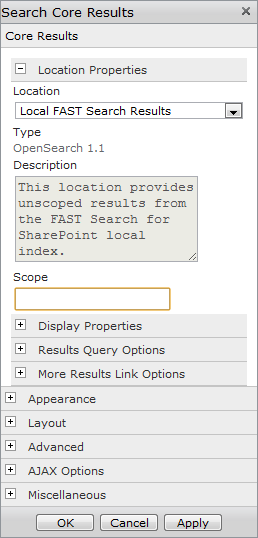
To add a Scopes drop-down list to the search query box so that users can select a predefined scope, edit the page that has the search box on it and then edit the Search Box Web Part. The top section allows for a number of scope drop-down settings, as shown in Figure 2-12.
Scopes are a useful and user-friendly feature of SharePoint and FS4SP. Consideration must be given as to how to appropriately implement them on a site, but they can quickly and easily add value for the search user by helping them delimit search results without additional query terms or property filters.
Security trimming is an important part of an Enterprise Search Solution. The result set given to any specific user should contain only results that user has rights to view.
When content is indexed, a property that is picked up and added to each item in the index is its authorization token. This is usually in the form of an Access Control List (ACL) that is returned with the item by the source system to the user defined to crawl (Content Access Account). Having this information stored in the index with the content is essential to being able to match the search user’s own logged information with that stored ACL.
More Info
For more information about security tokens, go to http://msdn.microsoft.com/en-us/library/aa379570(VS.85).aspx and http://msdn.microsoft.com/en-us/library/aa374872(VS.85).aspx.
When a search is performed, the Security Identifier (SID) of the user performing the search is passed with the query to the search engine. The SID is then matched with the authorization properties of the items in the index, usually with the aid of a directory system like Active Directory or a Lightweight Directory Access Protocol (LDAP) server. All items that do not have a matching authorization property—and therefore should not be viewable by the user—are filtered out.
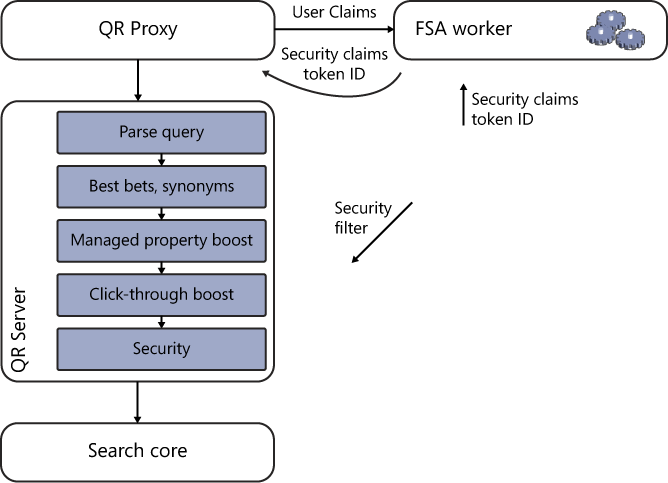
FS4SP trims the result set by interacting with the FAST Search Authorization (FSA) component. The FSA component in turn communicates with the Claims Services, Active Directory Services, or another LDAP service to identify the user doing the searching and compare that user’s SID to those associated with the items in the result set. The main task of the QR Proxy, which passes the queries forward to the QR Server from the FS4SP Search API, is to capture the User Claims that it receives with the query and pass them to the FSA Worker process. The FSA Worker process returns the SID to the QR Proxy, which passes the entire query forward to the QR Server for processing.
Within the QR Server is a Security stage that again communicates with the FSA worker after a set of query enrichment stages to match that SID with the user’s associated access rights. This includes all groups or associated privileges that the user may have on specific content. This entire query, including these access rights, is then submitted to the search core; items that satisfy all the parameters, including security access, are then returned.
Note
A requirement for FS4SP to filter result sets based on security is the availability of authenticated user tokens. FS4SP does not itself authenticate users. This task is performed by SharePoint, and the user’s claims information is passed to FS4SP. If authentication is not performed, if the user is not logged in (for example, anonymous access is enabled), or if the security filter of the QR Server is disabled, security trimming may not perform as expected.
Support for claims-based authentication is available in SharePoint 2010. Claims-based authentication is an alternative authentication model whereby users are not directly authenticated by Active Directory but a claim is made to some other system that is trusted to authenticate that user. This can be useful when the directory service or user permissions of a particular system are not supported by SharePoint directly. FS4SP is specifically powerful because it can support these claims and authenticate against external systems. Figure 2-13 shows the interactions with which security information is added to the query in FS4SP.
The terms used in search terminology are new to many people. This chapter serves as an introduction to give you a better understanding of what constitutes a search engine—in particular, FS4SP.
In this chapter, you looked at how search engines return results and how the concepts of recall and precision are balanced to deliver good search results to end users. You explored content processing and query processing and the concepts within each of these areas in an FS4SP deployment. The chapter also explained key terminology related to search engines, such as linguistics, refiners, and metadata. Finally, you looked at the index schema in FS4SP and the relationship of its elements.