
Introduction
- Purpose of this Book
.NET is an amazing system for building software. It allows us to build functional, connected apps in a fraction of the time it would have taken us a decade ago. So much of it just works, and that is a great thing. It offers applications memory and type safety, a robust framework library, services like automatic memory management, and so much more.
Programs written with .NET are called managed applications because they depend on a runtime and framework that manages many of their vital tasks and ensures a basic safe operating environment. Unlike unmanaged, or native, software written directly to the operating system’s APIs, managed applications do not have free reign of their process.
This layer of management between your program and the computer’s processor can be a source of anxiety for developers who assume that it must add some significant overhead. This book will set you at ease, demonstrate that the overhead is worth it, and that the supposed performance degradation is almost always exaggerated. Often, the performance problems developers blame on .NET are actually due to poor coding patterns and a lack of knowledge of how to optimize their programs on this framework. Skills gained from years of optimizing software written in C++, Java, or VB may not always apply to managed code, and some advice is actually detrimental. Sometimes the rapid development nature of .NET can encourage people to build bloated, slow, poorly optimized code faster than ever before. Certainly, there are other reasons why code can be of poor quality: lack of skill generally, time pressure, poor design, lack of developer resources, laziness, and so on. This book will explicitly remove lack of knowledge about the framework as an excuse and attempt to deal with some of the others as well. With the principles explained in this book, you will learn how to build lean, fast, efficient applications that avoid these missteps. In all types of code, in all platforms, the same thing is true: if you want performant code, you have to work for it.
This is not a language reference or tutorial. It is not even a detailed discussion of the CLR. For those topics, there are other resources (see Appendix C—Bibliography for a list of useful books, blogs, and people to pay attention to). To get the most out of this book you should already have in-depth experience with .NET.
There are many code samples, especially of underlying implementation details in IL or assembly code. I caution you not to gloss over these sections. You should try to replicate my results as you work through this book so that you understand exactly what is going on.
This book will teach you how to get maximum performance out of managed code, while sacrificing none or as little of the benefits of .NET as possible. You will learn good coding techniques, specific things to avoid, and perhaps most importantly, how to use freely available tools to easily measure your performance. This book will teach you those things with minimum fluff. This book is what you need to know, relevant and concise, with no padding of the content. Most chapters begin with general knowledge and background, followed by specific tips, and finally ending with a section on step-by-step measurement and debugging for many different scenarios.
Along the way you will deep-dive into specific portions of .NET, particularly the underlying Common Language Runtime (CLR) and how it manages your memory, generates your code, handles concurrency, and more. You will see how .NET’s architecture both constrains and enables your software, and how your programming choices can drastically affect the overall performance of your application. As a bonus, I will share relevant anecdotes from the last six years of building very large, complex, high-performance .NET systems at Microsoft. You will likely notice that my bias throughout this book is for server applications, but nearly everything discussed in this book is applicable to desktop and mobile applications as well. Where appropriate, I will share advice for those specific platforms.
You will gain a sufficient understanding of .NET and the principles of well-performing code so that when you run into circumstances not specifically covered in this book, you can apply your newfound knowledge and solve unanticipated problems.
Programming under .NET is not a completely different experience from all the programming you have ever done. You will still need your knowledge of algorithms and most standard programing constructs are pretty much the same, but we are talking about performance optimizations, and if you are coming from an unmanaged programming mindset, there are very different things you need to observe. You may not have to call delete explicitly any more (hurray!), but if you want to get the absolute best performance, you better believe you need to understand how the garbage collector is going to affect your application.
If high availability is your goal, then you are going to need to be concerned about JIT compilation to some degree. Do you have an extensive type system? Interface dispatch might be a concern. What about the APIs in the .NET Framework Class Library itself? Can any of those negatively influence performance? Are some thread synchronization mechanisms better than others?
Beyond pure coding, I will discuss techniques and processes to measure your performance over time and build a culture of performance in yourself and in your team. Good performance is not something you do once and then move on. It needs constant nourishment and care so that it does not degrade over time. Investing in a good performance infrastructure will pay massive dividends over time, allowing you to automate most of the grunt work in maintaining good performance.
The bottom line is that the amount of performance optimization you get out of your application is directly proportional to the amount of understanding you have not only of your own code, but also your understanding of the framework, the operating system, and the hardware you run on. This is true of any platform you build upon.
All of the code samples in this book are in C#, the underlying IL, or occasionally x86 assembly code, but all of the principles here apply to any .NET language. Throughout this book, I assume that you are using .NET 4 or higher. If this is not the case, strongly consider moving to the latest version so that you can take advantage of the latest technologies, features, bug fixes, and performance improvements.
I do not talk about specific sub-frameworks of .NET, such as WPF, WCF, ASP.NET, Windows Forms, MVC, ADO.NET, or countless others. While each of those frameworks has its own issues and performance techniques, this book is about the fundamental knowledge and techniques that you must master to develop code under all scenarios in .NET. Once you acquire these fundamentals, you can apply this knowledge to every project you work on, adding domain-specific knowledge as you gain experience.
- Why Should You Choose Managed Code?
There are many reasons to choose managed code over unmanaged code:
- Safety—The compiler and runtime can enforce type safety (objects can only be used as what they really are), boundary checking, numeric overflow detection, security guarantees, and more. There is no more heap corruption from access violations or invalid pointers.
- Automatic memory management—No more delete or reference counting.
- Higher level of abstraction—Higher productivity with fewer bugs.
- Advanced language features—Delegates, anonymous methods, and dynamic typing.
- Huge existing code base—Framework Class Library, Entity Framework, Windows Communication Framework, Windows Presentation Foundation, Task Parallel Library, and so much more.
- Easier extensibility—With reflection capabilities, it is much easier to dynamically consume late-bound modules, such as in an extension architecture.
- Phenomenal debugging—Exceptions have a lot of information associated with them. All objects have metadata associated with them to allow thorough heap and stack analysis in a debugger, often without the need for PDBs (symbol files).
All of this is to say that you can write more code quickly, with fewer bugs. You can diagnose what bugs you do have far more easily. With all of these benefits, managed code should be your default pick.
.NET also encourages use of a standard framework. In the native world, it is very easy to have fragmented development environments with multiple frameworks in use (STL, Boost, or COM, for example) or multiple flavors of smart pointers. In .NET, many of the reasons for having such varied frameworks disappear.
While the ultimate promise of true “write once, run everywhere” code is likely always a pipe dream, it is becoming more of a reality. .NET now supports Portable Class Libraries, which allow you to target platforms such as Windows, Windows Phone, and Windows Store with a single class library. For more information about cross-platform development, see http://www.writinghighperf.net/go/1/. With each release of .NET, the various platforms share more of the same set of APIs.
Given the enormous benefits of managed code, if native code is an option for your project, consider it to have the burden of proof. Will you actually get the performance improvement you think you will? Is the generated code really the limiting factor? Can you write a quick prototype and prove it? Can you do without all of the features of .NET? In a complex native application, you may find yourself implementing some of these features yourself. You do not want to be in awkward position of duplicating someone else’s work.
One reason for considering native code over managed code is access to the full processor instruction set, particularly for advanced data processing applications using SIMD instructions. However, this is changing. See Chapter 3 for a discussion of the abilities of future versions of the JIT compiler.
Another reason is a large existing native code base. In this case, you can consider the interface between new code and the old. If you can easily manage it with a clear API, consider making all new code managed with a simple interop layer between it and the native code. You can then transition the native code to managed code over time.
- Is Managed Code Slower Than Native Code?
There are many unfortunate stereotypes in this world. One of them, sadly, is that managed code cannot be fast. This is not true.
What is closer to the truth is that the .NET platform makes it very easy to write slow code if you are sloppy and uncritical.
When you build your C#, VB.NET, or other managed language code, the compiler translates the high-level language to Intermediate Language (IL) and metadata about your types. When you run the code, it is just-in-time compiled (“JITted”). That is, the first time a method is executed, the CLR will invoke the compiler on your IL to convert it to assembly code (e.g., x86, x64, ARM). Most code optimization happens at this stage. There is a definite performance hit on this first run, but after that you will always get the compiled version. As we will see later, there are ways around this first-time hit when it is necessary.
The steady-state performance of your managed application is thus determined by two factors:
- The quality of the JIT compiler
- The amount of overhead from .NET services
The quality of generated code is generally very good, with a few exceptions, and it is getting better all the time, especially quite recently.
The cost of the services .NET provides is not free, but it is also lower than you may expect. You do not have to reduce this cost to zero (which is impossible); just reduce it to a low enough threshold that other factors in your application’s performance profile are more significant.
In fact, there are some cases where you may see a significant benefit from managed code:
- Memory allocations–There is no contention for memory allocations on the heap, unlike in native applications. Some of the saved time is transferred to garbage collection, but even this can be mostly erased depending on how you configure your application. See Chapter 2 for a thorough discussion of garbage collection behavior and configuration.
- Fragmentation–Memory fragmentation that steadily gets worse over time is a common problem in large, long-running native applications. This is less of an issue in .NET applications because garbage collection will compact the heap.
- JITted code–Because code is JITted as it is executed, its location in memory can be more optimal than that of native code. Related code will often be collocated and more likely to fit in a single memory page. This leads to fewer page faults.
The answer to the question “Is managed code slower than native code?” is an emphatic “No” in most cases. Of course, there are bound to be some areas where managed code just cannot overcome some of the safety constraints under which it operates. They are far fewer than you imagine and most applications will not benefit significantly. In most cases, the difference in performance is exaggerated. See Chapter 3 (JIT Compilation) for a discussion of these areas.
It is much more common to run across code, managed or native, that is in reality just poorly written code; e.g., it does not manage its memory well, it uses bad patterns, it defies CPU caching strategies or is otherwise unsuitable for good performance.
- Am I Giving Up Control?
One common objection to using managed code is that it can feel like you are giving up too much control over how your program executes. This is a particular fear over garbage collection, which occurs at what feels like random and inconvenient times. For all practical purposes, however, this is not actually true. Garbage collection is deterministic, and you can significantly affect how often it runs by controlling your memory allocation patterns, object scope, and GC configuration settings. What you control is different from native code, but the ability is certainly there.
- Work With the CLR, Not Against It
People new to managed code often view things like the garbage collector or the JIT compiler as something they have to “deal with” or “tolerate” or “work around.” This is the wrong way to look at it. Getting great performance out of any system requires dedicated performance work, regardless of the specific frameworks you use. For this and other reasons, do not make the mistake of viewing the GC and JIT as “problems” that you have to fight.
As you come to appreciate how the CLR works to manage your program’s execution, you will realize that you can make many performance improvements just by choosing to work with the CLR rather than against it. All frameworks have expectations about how they are used and .NET is no exception. Unfortunately, many of these assumptions are implicit and the API does not, nor cannot, prohibit you from making bad choices.
I dedicate a large portion of this book to explaining how the CLR works so that your own choices may more finely mesh with what it expects. This is especially true of garbage collection, for example, which has very clearly delineated guidelines for optimal performance. Choosing to ignore these guidelines is a recipe for disaster. You are far more likely to achieve success by optimizing for the framework rather than trying to force it to conform to your own notions, or worse, throwing it out altogether.
Some of the advantages of the CLR can be a double-edged sword in some sense. The ease of profiling, the extensive documentation, the rich metadata, and the ETW event instrumentation allow you to find the source of problems quickly, but this visibility also makes it easier to place blame. A native program might have all sorts of similar or worse problems with heap allocations or inefficient use of threads, but since it is not as easy to see that data, the native platform will escape blame. In both the managed and native cases, often the program itself is at fault and needs to be fixed to work better with the underlying platform. Do not mistake easy visibility of the problems for a suggestion that the entire platform is the problem.
All of this is not to say that the CLR is never the problem, but the default choice should always be the application, never the framework, operating system, or hardware.
- Layers of Optimization
Performance optimization can mean many things, depending on which part of the software you are talking about. In the context of .NET applications, think of performance in four layers:
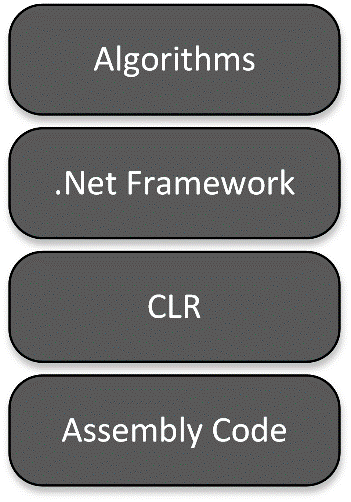
Figure 0-1. Layers of abstraction—and performance priority.
At the top, you have your own software, the algorithms you are using to process data. This is where all performance optimization starts because it has the greatest potential impact to overall performance. Changing your own code causes all the layers below it to change drastically, so make sure you have that right first. Only then should you move down the layers. This rule of thumb is related to a similar rule with debugging: An experienced programmer will always assume their own code is buggy rather than blaming the compiler, platform, operating system, or hardware. That definitely applies to performance optimization as well.
Below your own code is the .NET Framework—the set of classes provided by Microsoft or 3rd parties that provide standard functionality for things like strings, collections, parallelism, or even full-blown sub-frameworks like Windows Communication Framework, Windows Presentation Foundation, and more. You cannot avoid using at least some portion of the framework, but most individual parts are optional. The vast majority of the framework is implemented using managed code exactly like your own application’s code (you can even read the framework code online at http://www.writinghighperf.net/go/2 or from within Visual Studio).
Below the Framework classes lies the true workhorse of .NET, the Common Language Runtime (CLR). This is a combination of managed and unmanaged components that provide services like garbage collection, type loading, JITting, and all the other myriad implementation details of .NET.
Below that is where the code hits the metal, so to speak. Once the CLR has JITted the code, you are actually running processor assembly code. If you break into a managed process with a native debugger, you will find assembly code executing. That is all managed code is—regular machine assembly instructions executing in the context of a particularly robust framework.
To reiterate, when doing performance design or investigation, you should always start at the top layer and move down. Make sure your program’s structure and algorithms make sense before digging into the details of the underlying code. Macro-optimizations are almost always more beneficial than micro-optimizations.
This book is primarily concerned with those middle layers: the .NET Framework and the CLR. These consist of the “glue” that hold your program together and are often the most invisible to programmers. However, many of the tools we discuss are applicable to all layers. At the end of the book I will briefly touch on some practical and procedural things you can do to encourage performance at all layers of the system.
Note that, while all the information in this book is publically available, it does discuss some aspects of the internal details of the CLR’s implementation. These are all subject to change.
- Sample Source Code
This book makes frequent references to some sample projects. These are all quite small, encapsulated projects meant to demonstrate a particular principle. As simple examples, they will not adequately represent the scope or scale of performance issues you will discover in your own investigations. Consider them a starting point of techniques or investigation skills, rather than as serious examples of representative code.
You can download all of the sample code from the book’s web site at http://www.writinghighperf.net. They were developed in Visual Studio Ultimate 2012, but should open and build with minimal fuss in other versions as well.
- Why Gears?
Finally, I would like to say a brief note about the cover. The image of gears has been in my mind since well before I decided to write this book. I often think of effective performance in terms of clockwork, rather than pure speed, though that is an important aspect too. You must not only write your program to do its own job efficiently, but it has to mesh well with .NET, its own internal parts, the operating system, and the hardware. Often, the right approach is just to make sure your application is not doing anything that interferes with the gear works of the whole system, but encourages it to keep running smoothly, with minimal interruptions. This is clearly the case with things like garbage collection and asynchronous thread patterns, but this metaphor also extends to things like JIT, logging, and much more.
As you read this book, keep this metaphor in mind to guide your understanding of the various topics.