
7
XML and Java
7.1 BASICS OF PARSING
7.1.1 What is Parsing?
The term parsing should not be new to the students and practitioners of information technology.
We know that there are compilers of programming languages, which translate one programming language into an executable language (or something similar). For example, a C compiler translates a C program (called object program) into an executable language version (called object program). These compilers use the concept of parsing quite heavily. For example, we say that such compilers parse an expression when they convert a mathematical expression such as a = b + c, from C language to the corresponding executable code. So, what do we exactly mean? We mean that a compiler reads, interprets, and translates C into another language. More importantly, it knows how to do this job of translation, based on certain rules. For example, with reference to our earlier expression, the compiler knows that it must have exactly one variable before the = sign, and an expression after it, etc. Thus, the rules are set, and the compiler is programmed to verify and interpret those rules. We cannot write the same expression in C as b + c = a, because the compiler is not programmed to handle this. Thus, we can define parsing in the context of compilation process as follows.
Parsing is the process of reading and validating a program written in one format and converting it into the desired format.
Of course, this is a limited definition of parsing, when applied to compilers. Now, let us extend this concept to the XML. We know that an XML document is organised as a hierarchical structure, similar to a tree. Furthermore, we know that we can have well-formed and valid XML documents. Thus, if we have something equivalent to a compiler for XML that can read, validate, and optionally convert XML, we have a parser for XML. Thus, we can define the concept of a parser for XML now.
Parsing of XML is the process of reading and validating an XML document and converting it into the desired format. The program that does this job is called a parser.
This concept is shown in Figure 7.1.
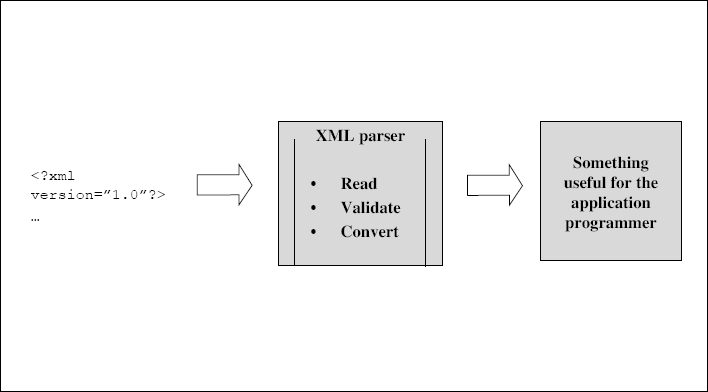
Figure 7.1 Concept of XML parsing
Let us now understand what a parser would need to do to make something useful for the application programmer. Clearly, an XML file is something that exists on the disk. So, the parser has to first of all bring it from the disk into the main memory. More importantly, the parser has to make this in-memory representation of an XML file available to the programmer in a form that the programmer is comfortable with.
Today's programming world is full of classes and objects. Today's popular programming languages such as Java, C++, and C# are object-oriented in nature. Naturally, the programmer would love to see an XML file in memory also as an object. This is exactly what a parser does. A parser reads a file from the disk, converts it into an in-memory object and hands it over to the programmer. The programmer's responsibility is then to take this object and manipulate it the way she wants. For example, the programmer may want to display the values of certain elements, add some attributes, count the total number of elements, and so on. This concept is shown in Figure 7.2.

Figure 7.2 The parsing process
This should clarify the role of a parser. Often, application programmers are confused in terms of where the parser starts and where it ends. We need to remember that the parser simply assists us in reading an XML file as an object.
Now an obvious question is, why do we need such a parser? Why can we ourselves not do the job of a parser? For example, if we disregard XML for a minute and think about an ordinary situation where we need to read say an employee file from the disk and produce a report out of it, do we use a parser? Of course, we do not. We simply instruct our application program to read the contents of a file. But wait a minute. How do we instruct our program to do so? We know how the file is structured and rely on the programming environment to provide us the contents of the file. For example, in C# or Java, we can instruct our application program to read the next n bytes from the disk, which we can treat as a record (or the fields of a record). In a more programmer-friendly language such as COBOL, we need not even worry about asking the application program to read a certain number of bytes from the disk, etc. We can simply ask it to read the next record, and the program knows what we mean.
Let us come back to XML. Which of the approaches should we use now? Should we ask our application program to read the next n bytes every time, or say something like, read the next element? If we go via the n bytes approach, we need to know how many bytes to read every time. Also, remember that apart from reading the next n bytes, we also need to know where an element begins, where it ends, whether all its attributes are declared properly, whether the corresponding end element tag for this element is properly defined, whether all the sub-elements (if any) are correctly defined, and so on! Moreover, we also need to validate these next n bytes against an appropriate section of a DTD or schema file, if one is defined. Clearly, we are getting into the job of writing something like a compiler ourselves! How nice it would be, instead, if we can just say in the COBOL style of programming, read the next record. Now, we need not handle it, whether that means reading the next 10 bytes or 10,000 bytes, or ensuring well-formedness and validity, etc. Remember that we need to deal with hundreds of XML files. In each of our application programs, we do not want to write our own logic of doing all these things ourselves. It would leave us with a humungous amount of work even before we can convert an XML file into an object. Not only that, it would be quite cumbersome and error-prone.
Therefore, we rely on an XML parser to take care of these things on our behalf, and give us an XML file as an object; provided all the validations are also successful.
If we do not have XML parsers, we would need logic to read, validate, and transform every XML file ourselves, which is a difficult task.
7.1.2 Parsing Approaches
Suppose that someone younger in your family has returned from playing a cricket match. He is excited about it, and wants to describe what happened in the match. He can describe it in two ways, as shown in Figure 7.3.

Figure 7.3 Two ways of describing the events of a cricket match
Now we will leave this example for a minute and come back to it after establishing its relevance to the current discussion.
There is tremendous confusion about the various ways in which XML documents can be processed inside a Java program. The problem is that several technologies have emerged, and there has been insufficient clarity in terms of which technology is useful for what purposes. Several terms have been in use for many years, most prominently SAX, DOM, JAXP, JDOM, Xerces, dom4j, and StAX. Let us first try to make sense of them before we actually embark on the study of working with XML inside Java programs.
We have noted earlier that the job of an XML parser is to read an XML document from the disk, and present it to a Java program in the form of an object. With this central theme in mind, we need to know that, over several years, many ways were developed to achieve this objective. That is what has caused the confusion, as mentioned earlier. Let us demystify this now.
When an XML document is to be presented to a Java program as an object, there are two main possibilities:
- Present the document in bits and pieces, as and when we encounter certain sections or portions of the document.
- Present the entire document tree at one go. This means that the Java program has to then think of this document tree as one object, and manipulate it the way it wants.
We have discussed this concept in the context of the description of a cricket match earlier. We can either describe the match as it happened, event-by-event; or first describe the overall highlights and then get into specific details. For example, consider an XML document as shown in Figure 7.4.
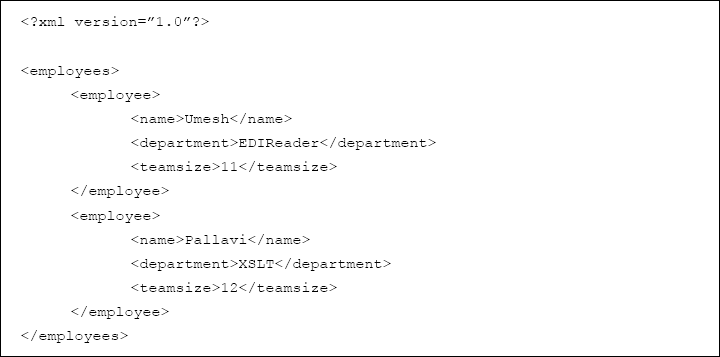
Figure 7.4 Sample XML document
Now, we can look at this XML structure in two ways:
- Go through the XML structure, item-by-item (for example, to start with, the line <?xml version="1.0"?>, followed by the element <employees>, and so on).
- Read the entire XML document in the memory as an object, and parse its contents as per the needs.
Technically, the first approach is called the Simple API for XML (SAX), whereas the latter is known as the Document Object Model (DOM).
We now take a look at the two approaches diagrammatically. More specifically, they tell us how the same XML document is processed differently by these two different approaches. Refer to Figure 7.5.

Figure 7.5 SAX approach for our XML example
It is also important to know the sequence of elements as seen by the XSLT. If we have an XML document visualised as a tree-like structure as shown in Figure 7.6, then the sequence of elements considered for parsing by the XSLT would be as shown in Figure 7.7.

Figure 7.6 An XML document depicted as a tree-like structure

Figure 7.7 SAX view of looking at a tree-like structure
In general, we can equate the SAX approach to our example of the step-by-step description of a cricket match. The SAX approach works on an event model. This works as follows.
- The SAX parser keeps track of various events, and when an event is detected, it informs our Java program.
- Our Java program needs to then take appropriate action, based on the requirements of handling that event. For example, there could be an event Start element as shown in the diagram.
- Our Java program needs to constantly monitor such events, and take appropriate action.
- Control comes back to SAX parser, and steps (i) and (ii) repeat.
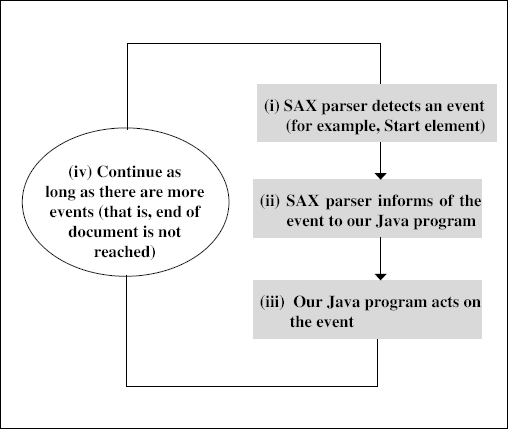
Figure 7.8 SAX approach explained further
In general, we can equate the DOM approach to our example of the overall description of a cricket match. This works as follows:
- The DOM approach parses through the whole XML document at one go. It creates an in-memory tree-like structure of our XML document, the way it is depicted in Figure 7.9.
- This tree-like structure is handed over to our Java program at one go, once it is ready. No events get fired unlike what happens in SAX.
- The Java program then takes charge and deals with the tree the way it wants, without actively interfacing with the parser on an event-by-event basis. Thus, there is no concept of something such as Start element, Characters, End element, etc. This is shown in Figure 7.10.
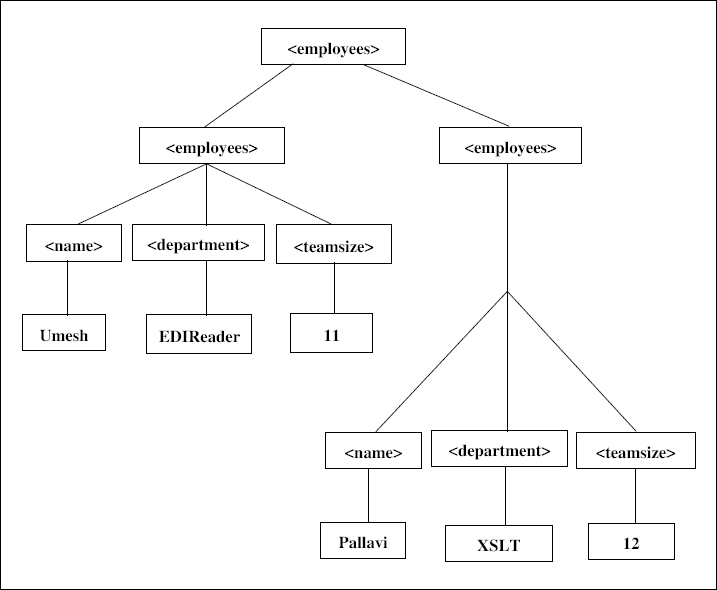
Figure 7.9 DOM approach for our XML example
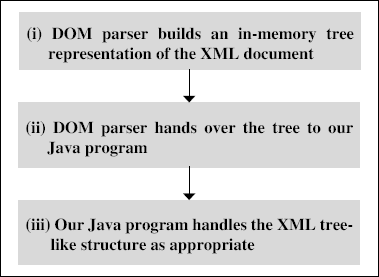
Figure 7.10 DOM approach explained further
7.1.3 The StAX API
Sometime back, work started to happen in the area of an API that could inherit the best features of the SAX and the DOM. The SAX is an event-driven API, which means that it indicates to the program where the document starts and ends, where an element or its contents start and end, what are the attribute names and pairs, and so on. On the other hand, the DOM builds the XML document as an in-memory tree before the program can process it. SAX is fast and memory-efficient – however, it pushes XML data to the program, whether or not it is ready to receive it. Hence, it can be a bit of nuisance at times.
Considering these limitations of the SAX and the DOM, a new API called Streaming API for XML (StAX) was developed as a part of the Java Community Process (JCP). StAX is a pull API. In other words, it does not push XML data at the program – instead, the program decides when to pull it. Also, unlike DOM, it does not need to load and hold the entire XML document as a tree in the memory. Instead, it processes the XML document in small chunks, bringing in the data of interest as and when needed (hence the term streaming). Here, the program processing an XML document decides when to retrieve the next element, unlike what happens in the case of SAX. Hence, the whole programming approach of StAX is different from that of SAX. In the case of StAX, we do not need to capture events such as the starting of a document, the starting of an element, and so on. Instead, the program is written in a style that is quite conventional in nature. For example, it is similar to how a C program reads the file and processes it as per its requirements, rather than the file contents being pushed at it.
The differences between StAX and the other two APIs are illustrated in Table 7.1.

Figure 7.1 SAX, DOM, and StAX
The visual difference between the three APIs is shown in Figure 7.11.
We will talk more about StAX subsequently.
7.2 JAXP
The Java API for XML Processing (JAXP) is a Sun standard API that allows us to validate, parse, and transform XML with the help of several other APIs. It is important to clarify that JAXP itself is not a parser API. Instead, we should consider JAXP as an abstraction layer over the actual parser APIs. That is, JAXP is not a replacement for SAX, DOM or StAX. Instead, it is a layer above them. This concept is shown in Figure 7.12.
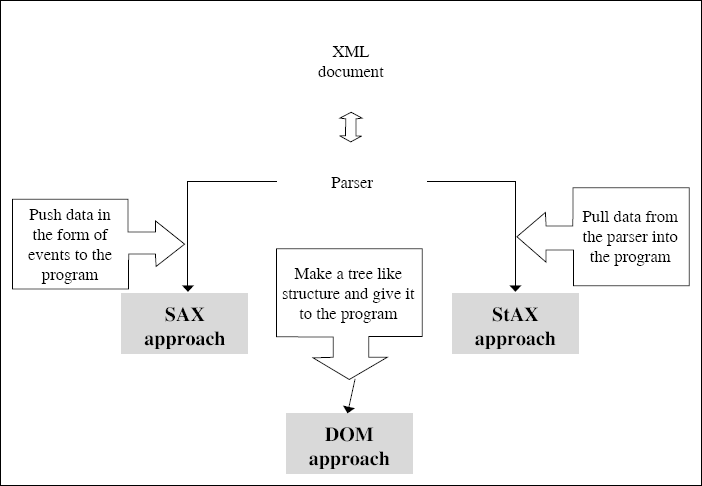
Figure 7.11 SAX, DOM and StAX differences

Figure 7.12 Where JAXP fits
As we can see, our application program would need to interface with JAXP. JAXP, in turn, would interface with SAX or DOM, as appropriate.
JAXP is not a new means for parsing XML. It does not also add to SAX or DOM. Instead, JAXP allows us to work with SAX and DOM more easily and consistently. We must remember that we cannot parse an XML document without SAX, DOM, or another parser API (such as JDOM or dom4j). We need to remember this:
SAX, DOM, JDOM and dom4j parse XML. JAXP provides a way to invoke and use such a parser, but does not parse an XML document itself.
At this juncture, we need to clarify that even JDOM and dom4j sit on top of other parser APIs. Although both APIs provide us a different approach for parsing XML as compared to SAX and DOM, they use SAX internally. In any case, JDOM and dom4j are not popular as standards, and hence we will not discuss them. Instead, we will concentrate on JAXP, which is a standard.
7.2.1 Sun's JAXP
A lot of confusion about JAXP arises because of the way Sun's version of it has been interpreted. When the idea of JAXP was born, the concept was clear. JAXP was going to be an abstraction layer API that would interface with an actual parser API, as illustrated earlier. However, this was not going to be sufficient for developers, since they needed an actual parser API as well, to try out and work with JAXP. Otherwise, they would only have the abstract API of JAXP, which would not do parsing itself. How would a developer then try it out?
To deal with this issue, when Sun released JAXP initially, it included the JAXP API (that is, the abstract layer) and a parser API (called Crimson) as well. Now, JAXP comes with the Apache Xerces parser, instead. Thus, the actual JAXP implementation in real life slightly modified our earlier diagram, as shown in Figure 7.13.

Figure 7.13 Understanding where JAXP fits – Modified
Let us now understand how this works at the coding level.
When we write an application program to deal with XML documents, we need to work with JAXP. It should be clear by now. How should our application program work with JAXP?
- Looking at the modified diagram, our application program would interface with the abstraction layer of JAXP API.
- This abstraction layer of the JAXP API, in turn, interfaces with the actual implementation of JAXP (such as Apache Xerces). This allows our application program to be independent of the JAXP implementation. Tomorrow, if we replace the JAXP implementation with another parser, our application program would remain unchanged.
- The JAXP implementation (for example, Apache Xerces) would then perform parsing of the XML document by using SAX, DOM, or StAX, as appropriate to our given situation. Of course, whether to use SAX, DOM, or StAX must be decided and declared in our application program.
To facilitate this, Sun's JAXP API first expects us to declare:
- Which parser implementation we want to use (for example, Apache Xerces), and
- Whether we want to use SAX, DOM, or StAX as the parsing approach
We have discussed that the aim is to keep our application program independent of the actual parser implementation, for instance. In other words, we should be expected to code our application program in exactly the same manner, regardless of which parser implementation is used. Conceptually, talking to the abstraction layer of the JAXP API facilitates this. This is achieved by using the design pattern of abstract factory. The subject of design patterns is separate, and is not in the scope of the current discussion. Design patterns allow us to simplify our application design by conforming to certain norms. There are many design patterns, of which one is abstract factory. However, we can illustrate conceptually how the abstract factory works, as shown in Figure 7.14, in the context of JAXP.
Let us understand this in more detail.
import javax.xml.parsers.SAXParserFactory;
This import statement makes the SAX parser factory package, defined in JAXP, available to our application program. As we had mentioned earlier, an abstract factory design pattern allows us to create an instance of a class without worrying about the implementation details. In other words, we do not know at this stage whether we want to eventually create an instance of the Apache Xerces parser, or another parser. This hiding of unwanted details from our code, so that it will work with any parser implementation, is what abstract factory gives us.
This line tells us that we want to create an instance of the SAX parser factory, and assign it to an object named spf. This statement tells JAXP that we are interested in using SAX later in the program. But, at this stage, we simply want to create an instance of a SAX parser. But then, which SAX parser? Is it the Apache Xerces version of SAX, or something else? This is hidden from the application programmer in a beautiful manner. Whether to use Apache Xerces or another implementation of the parser is defined in various ways, but away from the code (to make it implementation-independent). For example, this property can be defined in a Java system property named javax.xml.parsers.SAXParserFactory, etc. There, we can set the value of this property to Apache Xerces, or the parser name that we are using. This is how the abstract layer of the JAXP API knows which implementation of JAXP should be used.

Figure 7.14 How to work with JAXP at the code level – Basic concepts
Now that we have specified that we want to use a certain implementation of SAX as outlined above, we want to create an instance of that implementation. This instance can be used to work with the XML document we want to parse, as we shall study later. Think about this instance as similar to how a file pointer or file handle works with a file, or how a record set works with a relational database table.
Of course, this example showed the basic concepts of starting to work with SAX in JAXP. These remain more or less the same for DOM, as we shall study later. What will change is the package names, class names, etc. Regardless of that, we can summarise the conceptual approach of working with JAXP, as shown in Figure 7.15.

Figure 7.15 Initial steps in using JAXP
Now it should be clear how JAXP makes our application program independent of the parser implementation. In other words, our application program talks to the abstraction layer of JAXP, and in our properties file we specify which JAXP implementation this abstract layer should be linked with.
7.2.2 JAXP and SAX
We will now take a detailed look at the JAXP programming concepts with reference to the SAX approach.
As we know, the SAX approach works on the basis of event handling. It captures events such as the start of an XML document, start of an element, end of an element, start of text, end of text, and so on. Therefore, when it comes to programming for SAX, the approach is fairly simple. We need to watch out for all these events, and write a code to handle them. In other words, we need to specify what we would like to do on the occurrence of a certain event. This is quite similar to how we handle events in Windows programming (Microsoft) or in Swing (Java).
We can conceptually depict this process as shown in Figure 7.16.
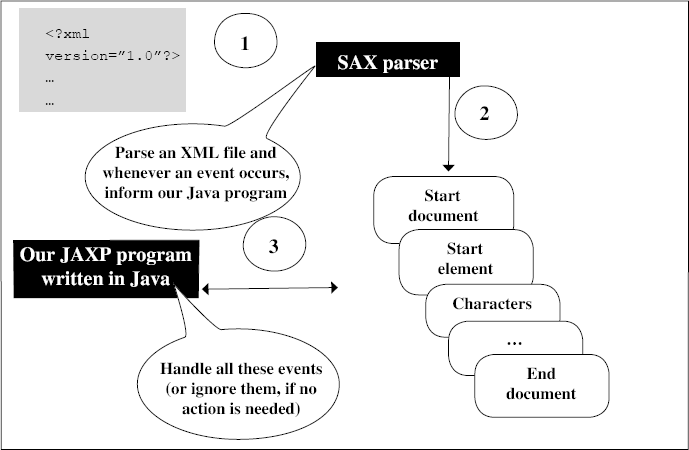
Figure 7.16 How a Java program uses JAXP to work with SAX
As described in the diagram, the process works as follows.
- The SAX parser reads the input XML file, and parses it.
- As the SAX parser parses the file, it keeps taking note of various events, such as start document, start element, characters, …, and end document.
- On the occurrence of every such event, the SAX parser informs our JAXP program written in Java. Our program can choose to handle these events or ignore them. This can be done for all events, or on a selective basis. For example, we can decide that we want to deal with the start element event, but ignore all the other events. Or we can say that we want to handle all events, or at the other extreme, ignore all the events. Thus, our Java program is actually an event handler, which keeps a watch on the events generated (or fired) by the SAX parser, and handles them. For this purpose, we need to write the event handlers in our code, which are methods that deal with the various events. The event handlers are also known by another name, titled callback methods or simply callbacks. This name is given because the SAX parser calls our event handler methods, which run in the background, waiting to be called when the relevant event occurs.
Based on these concepts, let us take a look at a Java program that uses JAXte the following XML document titled book.xml. Write a JAXP program, using S Po work with an XML file using the SAX approach.
Before that, a few things are required to set up JAXP on Windows.
- Download the JAXP software from Sun's site. Alternatively, download the Java Web Services Developers Pack (JWSDP) Version 2.0 from Sun's site. Install it. It contains various folders, one of which is JAXP.
- Download the Apache Xerces parser from www.apache.com and add the relevant JAR file names to your CLASSPATH.
Exercise 1: Consider that we have the following XML document titled book.xml. Write a JAXP program, using SAX to display all the element names, as they are found in the XML document.
XML document (book.xml)
<?xml version=»1.0»?>
<books>
<book category=»reference»>
<author>Nigel Rees</author>
<title>Sayings of the Century</title>
<price>8.95</price>
</book>
<book category=»fiction»>
<author>Evelyn Waugh</author>
<title>Sword of Honour</title>
<price>12.99</price>
</book>
<book category=»fiction»>
<author>Herman Melville</author>
<title>Moby Dick</title>
<price>8.99</price>
</book>
</books>
Solution 1: We need to simply display the element titles, as and when a new element is found. We will directly write the code here. Explanation follows.
import java.io.IOException;
import java.lang.*;
import javax.xml.parsers.SAXParser;
import javax.xml.parsers.SAXParserFactory;
import org.xml.sax.Attributes;
import org.xml.sax.Locator;
import org.xml.sax.SAXException;
import org.xml.sax.SAXNotRecognizedException;
import org.xml.sax.SAXNotSupportedException;
import org.xml.sax.SAXParseException;
import org.xml.sax.XMLReader;
import org.xml.sax.ext.LexicalHandler;
import org.xml.sax.helpers.DefaultHandler;
import org.xml.sax.helpers.ParserAdapter;
import org.xml.sax.helpers.XMLReaderFactory;
public class BookElements extends DefaultHandler{
public void startDocument() throws SAXException {
System.out.println(«Start document …»);
}
public void startElement(String uri, String local, String raw,
Attributes attrs) throws SAXException {
System.out.println («Current element = « + raw);
}
public static void main (String[] args) throws Exception {
BookElements handler = new BookElements ();
try {
SAXParserFactory spf = SAXParserFactory.newInstance ();
SAXParser parser = spf.newSAXParser ();
parser.parse (“book.xml”, handler);
}
catch (SAXException e) {
System.err.println(e.getMessage());
}
}
}
Let us now understand the code.
import java.io.IOException;
import java.lang.*;
import javax.xml.parsers.SAXParser;
import javax.xml.parsers.SAXParserFactory;
import org.xml.sax.Attributes;
import org.xml.sax.Locator;
import org.xml.sax.SAXException;
import org.xml.sax.SAXNotRecognizedException;
import org.xml.sax.SAXNotSupportedException;
import org.xml.sax.SAXParseException;
import org.xml.sax.XMLReader;
import org.xml.sax.ext.LexicalHandler;
import org.xml.sax.helpers.DefaultHandler;
import org.xml.sax.helpers.ParserAdapter;
import org.xml.sax.helpers.XMLReaderFactory;
The code begins with a series of import statements. We need not discuss all of them, except the ones relevant to JAXP and SAX. In general, we can conclude the following:
- The packages beginning with javax.xml.parsers are related to the JAXP portion of the code. More specifically, in this case, we are interested in the SAX parser factory (abstract) and the actual SAX parser (implementation). Hence, we have included two packages, namely javax.xml.parsers.SAXParserFactory and javax.xml.parsers.SAXParser. As we shall see later, just as there are two classes for SAX (abstract in the form of factory and actual implementation), this package defines two similar classes for DOM, namely javax.xml.parsers.DocumentBuilderFactory and javax.xml.parsers.DocumentBuilder. We have discussed SAXParserFactory and SAXParser earlier, and will skip that discussion here.
- The other important sets of packages begin with the name org.xml.sax. The package org.xml.sax contains the core SAX APIs. Following are the important aspects of this package with reference to the current example:
- org.xml.sax.XMLReader is an interface that can be used to read an XML document using callbacks. This interface allows an application to set and query features and properties in the parser, to register event handlers for document processing, and to initiate a document parse. It contains an important method named parse, which initiates the parsing of the XML document. We shall discuss this shortly.
- org.xml.sax.helpers.DefaultHandler is a class, which takes care of the various events, such as start document, start element, and so on. That is, this class has various methods to handle each of these events.
The basic concept is illustrated in Figure 7.17.
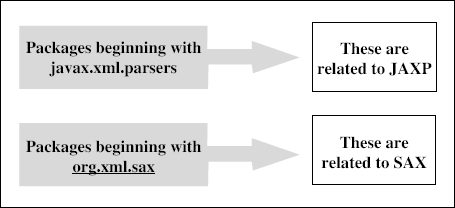
Figure 7.17 Packages in JAXP and SAX
Next, take look at our class declaration:
public class BookElements extends DefaultHandler{
Our class extends the DefaultHandler class of the org.xml.sax.helpers package. As mentioned earlier, the DefaultHandler class defines all the various event handler or callback methods that we want to call. For example, this class defines the following methods (only a few ones are listed):
- startDocument ( ) – Indicates the start of an XML document.
- startElement ( ) – Indicates the start of a new element inside the XML document.
- characters ( ) – Indicates the start of the contents inside an element.
- endElement ( ) – Indicates the end of an element.
- endDocument ( ) – Indicates the end of an XML document.
Next, our class now defines the startDocument ( ) method:
public void startDocument() throws SAXException {
System.out.println(“Start document …”);
}
This declaration overrides the startDocument ( ) method of the DefaultHandler class. When the SAX parser starts reading the XML document and realises that it has been able to start reading it, it fires an event called start document. It then looks for a method by the name startDocument ( ) in our Java class. If it is defined, the SAX parser calls this method. If it is not defined in our Java class, the SAX parser simply ignores the start document event.
In our example, we have overridden the basic startDocument ( ) method of the DefaultHandler. Therefore, when the SAX parser opens in the XML document, it will pass control to this method. Here, we simply display an information message that the start document event has happened, for our debugging purposes. In real life applications, we can perform all the initialisations that we need, inside this method. For example, we can open database connections, declare common variables, open files, etc.
Also note that the method throws a SAXException if it notices a problem. This is needed in SAX.
After this, our class now overrides the startElement ( ) method:
public void startElement(String uri, String local, String raw,
Attributes attrs) throws SAXException {
System.out.println (“Current element = “ + raw);
}
It should now be obvious that this method gets called on the start of a new element. Clearly, while the start document event occurs only once in an XML document, the start element event will occur for as many elements as we have in an XML document. Mind you, this will happen for elements at all the levels, not just at the root level or at the next level.
Thus, if we want to perform actions based on the occurrence or finding of something in an element, we need to override this method and code the appropriate logic therein. In this particular case, we are simply displaying the name of the element by referring to the third parameter received by this method, which we have named as raw. Let us understand what these four parameters are, that this method receives from the SAX parser:
- uri - The Namespace URI, or the empty string if the element has no Namespace URI or if Namespace processing is not being performed.
- local - The local name (without prefix), or the empty string if Namespace processing is not being performed.
- raw - The raw or qualified name (with prefix), or the empty string if qualified names are not available.
- attrs - The attributes of this element. If there are no attributes, it shall be an empty Attributes object.
Figure 7.18 shows a sample interpretation of this method call.
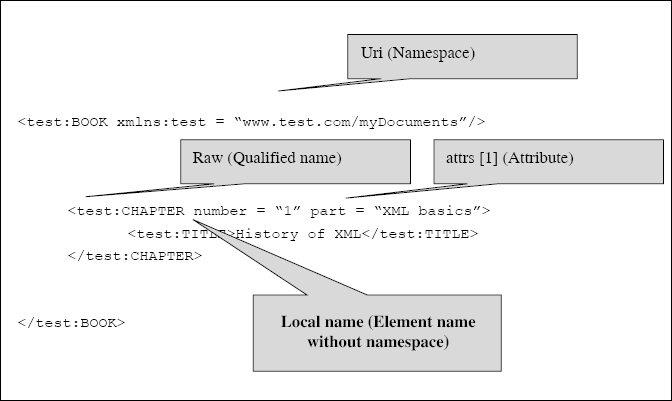
Figure 7.18 Sample interpretation of a startElement ( ) method call
As we can see, our current XML element is this:
<test:BOOK xmlns:test = “www.test.com/myDocuments”/>
<test:CHAPTER number = “1” part = “XML basics”>
<test:TITLE>History of XML</test:TITLE>
</test:CHAPTER>
</test:BOOK>
If the startElement ( ) method in our program has encountered the start of this element in the execution currently (that is, the BOOK element), it processes this and the remaining elements one by one. As SAX moves from one element to the next, the following interpretations are used:
- uri – www.test.com/myDocuments
- local – BOOK followed by CHAPTER followed by TITLE
- raw – test:BOOK followed by test:CHAPTER followed by test:TITLE
- attrs – Only for the element CHAPTER, we will have attrs [0] = 1 and attrs [1] = XML basics
In our code, we are displaying the value of raw. This means we want to display the element names, along with their namespaces, if any.
This leaves us with our main ( ) method:
public static void main (String[] args) throws Exception {
BookElements handler = new BookElements ();
try {
SAXParserFactory spf = SAXParserFactory.newInstance ();
SAXParser parser = spf.newSAXParser ();
parser.parse (“book.xml”, handler);
}
catch (SAXException e) {
System.err.println(e.getMessage());
}
}
}
We first create an instance of our class (BookElements).
We then try to instantiate the SAX parser factory. From there, we try to obtain an instance of the appropriate SAX parser. We then call the parse method of the SAX parser instance, passing it two parameters:
- The name of the XML document that we want to parse, and
- The instance of the SAX parser handler that is going to handle this XML document
This is where the main ( ) method ends.
Now, the XML document is already open and the SAX parser knows that it has to inform about the various events that happen in that XML document to a handler object of the class BookElements, that is, actually to this current class. Therefore, the SAX parser starts parsing the XML document and immediately notices an event by the name start document. Therefore, it searches the BookElements class to see if we have defined a method to handle this event, that is, a method titled startDocument ( ). Since we have defined this method, control is passed to our startDocument ( ) method. In a similar manner, control will keep coming to our startElement ( ) method for every start of an element. Other events would trigger no method calls, since we have chosen to ignore them, that is, we have not defined call back methods for those events.
The output of this program is shown in Figure 7.19.

Figure 7.19 Output of the program – 1
As we can see, the program initially captures the start document event. It then captures all the start element events one by one (for example, books, book, author, … ). When all the elements are exhausted, the program just stops.
Exercise 2: For the same XML document as earlier, count the number of books.
Solution 2:
import java.io.IOException;
import java.lang.*;
import javax.xml.parsers.SAXParser;
import javax.xml.parsers.SAXParserFactory;
import org.xml.sax.Attributes;
import org.xml.sax.Locator;
import org.xml.sax.SAXException;
import org.xml.sax.SAXNotRecognizedException;
import org.xml.sax.SAXNotSupportedException;
import org.xml.sax.SAXParseException;
import org.xml.sax.XMLReader;
import org.xml.sax.ext.LexicalHandler;
import org.xml.sax.helpers.DefaultHandler;
import org.xml.sax.helpers.ParserAdapter;
import org.xml.sax.helpers.XMLReaderFactory;
public class BookCount extends DefaultHandler{
private int count = 0;
public void startDocument() throws SAXException {
System.out.println (“Start document …”);
}
public void startElement(String uri, String local, String raw, Attributes attrs) throws SAXException {
System.out.println (“Current element = “ + raw);
if (raw.equals (“book”))
count++;
}
public void endDocument() throws SAXException {
System.out.println(“The total number of books = “ + count);
}
public static void main (String[] args) throws Exception {
BookCount handler = new BookCount ();
try {
SAXParserFactory spf = SAXParserFactory.newInstance ();
SAXParser parser = spf.newSAXParser ();
parser.parse (“book.xml”, handler);
}
catch (SAXException e) {
System.err.println(e.getMessage());
}
}
}
Let us now study what changes we have done.
We have added a variable named count, initialised to 0 at the beginning of the class definition. Then, in our startElement ( ) method, we display the current element name, as earlier. Additionally, we also check if the current element is book. If it is, we increment count by 1. We have also added an endDocument ( ) method now. This method would get invoked only once, when the SAX parser has parsed all the elements in the XML document, and has encountered the end of the document. At this stage, we simply display the final value of count.
The output now looks as shown in Figure 7.20.

Figure 7.20 Output of the program – 2
By now, we should have the confidence of working with elements. We now know how to capture the basic SAX events, and then how to link them up with our objectives of processing elements the way we want.
Let us now do something more interesting. Suppose that we have a catalogue of Compact Disks (CDs) stored inside an XML document. We have captured the information about the CDs in the form of the title, artist, etc., including the price of the CD. We now want to calculate the total price of all the CDs in the catalogue.
We discuss this example now.
Exercise 3: For the following XML document, compute the total price of all the CDs.
<?xml version="1.0"?>
<catalog>
<cd>
<title>Raga Todi</title>
<artist>Kishori Amonkar</artist>
<country>India</country>
<company>HMV</company>
<price>250</price>
<year>2001</year>
</cd>
<cd>
<title>Be <artist>Bhimsen Joshi</artist>
<country>India</country>
<company>Times Music</company>
<price>300</price>
<year>1999</year>
</cd>
</catalog>
Solution 3:
import java.io.IOException;
import java.lang.*;
import javax.xml.parsers.SAXParser;
import javax.xml.parsers.SAXParserFactory;
import org.xml.sax.Attributes;
import org.xml.sax.Locator;
import org.xml.sax.SAXException;
import org.xml.sax.SAXNotRecognizedException;
import org.xml.sax.SAXNotSupportedException;
import org.xml.sax.SAXParseException;
import org.xml.sax.XMLReader;
import org.xml.sax.ext.LexicalHandler;
import org.xml.sax.helpers.DefaultHandler;
import org.xml.sax.helpers.ParserAdapter;
import org.xml.sax.helpers.XMLReaderFactory;
public class CDPrice extends DefaultHandler{
private int total = 0;
private boolean flagIsCurrentElementPrice = false;
public void startDocument() throws SAXException {
System.out.println(“Start document …”);
}
}
public void startElement(String uri, String local, String raw,
Attributes attrs) throws SAXException {
System.out.println (“Current element = “ + raw);
if (raw.equals (“price”)) {
flagIsCurrentElementPrice = true;
System.out.println (“INSIDE if of startElement ===”);
}
}
public void characters (char [] ch, int start, int len) throws SAXException {
if (flagIsCurrentElementPrice) {
System.out.println (“ch = “ + ch);
System.out.println (“start = “ + start);
System.out.println (“len = “ + len);
StringBuffer buffer = new StringBuffer ();
for (int i=0; i<len; i++)
buffer.append (ch[start+i]);
System.out.println (“*** buffer = “ + buffer + “ ***”);
String str = buffer.substring (0);
int uprice = Integer.parseInt(str);
total += uprice;
flagIsCurrentElementPrice = false;
System.out.println (“Current total = “ + total);
}
}
public void endDocument() throws SAXException {
System.out.println(“The total price of available CDs = “ + total);
}
public static void main (String[] args) throws Exception {
CDPrice handler = new CDPrice();
try {
SAXParserFactory spf = SAXParserFactory.newInstance ();
SAXParser parser = spf.newSAXParser ();
parser.parse (“cdcatalog.xml”, handler);
}
catch (SAXException e) {
System.err.println(e.getMessage());
}
}
}
Let us understand what we are doing in this example.
There is a change in the startElement ( ) method now. We check to see if the name of the current element is price. If it is the case, we want to find out the value of this element. However, the startElement ( ) method does not give us the value of an element. It just gives us the name of the element. Therefore, we cannot obtain the values of the various price elements inside the startElement ( ) method and have them added together. Instead, we have to use a novel technique, as follows:
- We know that the SAX parser calls the startElement ( ) method when it encounters the start of an element in our XML document. In this particular case, we are interested in trying to find a match on the price element. Therefore, we need to write an extra code inside the startElement ( ) method to check if we can find a match on the price element. When the current element is found to be price, we set a flag to true.
- Once the call to the startElement ( ) method is over, the SAX parser encounters the value of the price element. To handle this, the SAX parser calls the next callback method, which is characters ( ). This callback method gets called when the SAX parser encounters the start of the value of an element (as opposed to its name). Now, inside this method, we can check for which element this method is getting called. For example, the characters ( ) method can get called on encountering the values for the title element, the artist element, and so on. However, our interest is only in the value of the price element currently. Therefore, we would now check if this is the value of the price element. But how?
Remember that before coming to the characters ( ) callback method, the SAX parser had taken us to the startElement ( ) method, and there we had checked for the name of the current element. If it was price, we had set a flag to true. We will now use this flag. If this flag is true, it means that the startElement ( ) method had set the flag to true if the name of the current element is price. Therefore, we can now use the value returned by the SAX parser as the value of the current price element for our computations.
Here, we need to use Java-specific features such as string buffers, sub-string operations, and converting strings to text, etc. This will give us the value of the current price element in numeric format. We can then add it to the current running sub total of prices, and reset the flag value to false, so that for the next characters ( ) callback, the code will not attempt to add its value to the current running sub-total of prices.
This concept is shown in Figure 7.21.
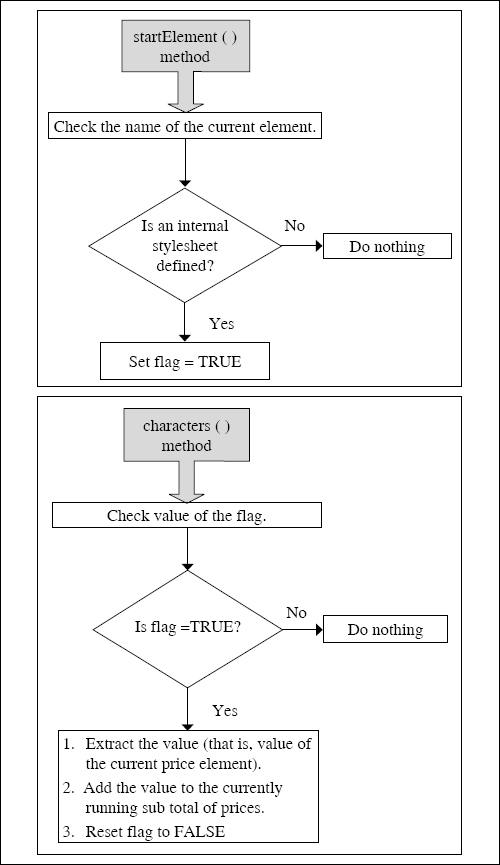
Figure 7.21 Logic for extracting the value of the price element
Finally, at the end of the document, when the endDocument ( ) callback method gets called, we display the final total of the prices of all the books.
The output is shown in Figure 7.22.
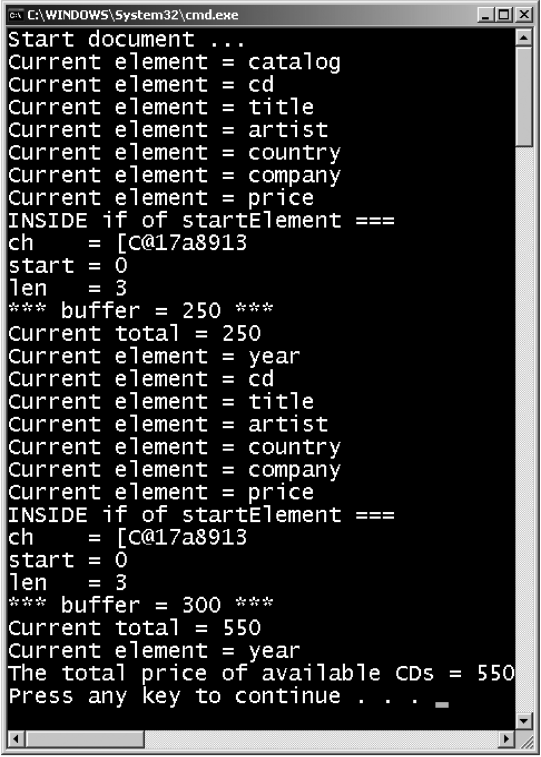
Figure 7.22 Output of the program – 3
Having looked at the key features of SAX while dealing with elements, let us now shift our attention to attributes. We have so far ignored them.
We would have noticed that the third parameter to the startElement ( ) method is Attributes attrs. In JAXP, Attributes is defined as an interface. It allows access to a list of attributes of an element by using the attribute name or index. For this purpose, we need to use the getValue ( ) method of the Attributes interface. For example, consider the following element:
<PERSON age = “30” title = “Mr”> Prashant </PERSON>
As we can see, the PERSON element has two attributes, namely age and title. When the startElement ( ) method reaches this element, we can call the getValue ( ) method on the attrs object of the Attributes interface to get the value of the age attribute:
int age = 0;
String attrValue;
attrValue = attrs.getValue (0);
age = Integer.parseInt (attrValue);
We can, of course, pass the name of the attribute (age), instead of the index (0). Thus, we can modify the above getValue ( ) method call as follows:
attrValue = attrs.getValue (age);
With these basic concepts in mind, let us proceed.
Exercise 4: For the following XML document, find out the books that were published in the 1970s.
<BOOKS>
<BOOK pubyear="1929">
<BOOK_TITLE>Look Homeward, Angel</BOOK_TITLE>
<AUTHOR>Wolfe, Thomas</AUTHOR>
</BOOK>
<BOOK pubyear="1973">
<BOOK_TITLE>Gravity's Rainbow</BOOK_TITLE>
<AUTHOR>Pynchon, Thomas</AUTHOR>
</BOOK>
<BOOK pubyear="1977">
<BOOK_TITLE>Cards as Weapons</BOOK_TITLE>
<AUTHOR>Jay, Ricky</AUTHOR>
</BOOK>
<BOOK pubyear="2001">
<BOOK_TITLE>Computer Networks</BOOK_TITLE>
<AUTHOR>Tanenbaum, Andrew</AUTHOR>
</BOOK>
</BOOKS>
Solution 4
import java.io.IOException;
import java.lang.*;
import javax.xml.parsers.SAXParser;
import javax.xml.parsers.SAXParserFactory;
import org.xml.sax.Attributes;
import org.xml.sax.Locator;
import org.xml.sax.SAXException;
import org.xml.sax.SAXNotRecognizedException;
import org.xml.sax.SAXNotSupportedException;
import org.xml.sax.SAXParseException;
import org.xml.sax.XMLReader;
import org.xml.sax.ext.LexicalHandler;
import org.xml.sax.helpers.DefaultHandler;
import org.xml.sax.helpers.ParserAdapter;
import org.xml.sax.helpers.XMLReaderFactory;
public class SeventiesBooks extends DefaultHandler {
private int count = 0;
public void startDocument() throws SAXException {
System.out.println (“Start document …”);
}
public void startElement (String uri, String local,
String raw, Attributes attrs) throws SAXException {
int year = 0;
String attrValue;
System.out.println (“Current element = “ + raw);
if (attrs.getLength () > 0) {
attrValue = attrs.getValue (0);
year = Integer.parseInt (attrValue);
if (year >= 1970 && year <= 1979) {
count++;
}
}
}
public void endDocument() throws SAXException {
System.out.println (“The total number of
matching elements = “ + count);
}
public static void main (String[] args) throws Exception {
SeventiesBooks handler = new SeventiesBooks ();
try {
SAXParserFactory spf = SAXParserFactory.newInstance ();
SAXParser parser = spf.newSAXParser ();
parser.parse (“countAttr.xml”, handler);
}
catch (SAXException e) {
System.err.println (e.getMessage());
} }
}
Let us now understand what we are doing here.
In our startElement ( ) method, we check for the attribute of interest as follows:
if (attrs.getLength () > 0) {
attrValue = attrs.getValue (0);
year = Integer.parseInt (attrValue);
if (year >= 1970 && year <= 1979) {
count++;
}
}
The Attributes interface provides a useful method called getLength ( ). This method returns the number of attributes present in the current element. For example, for the following element as the current element, this method would return 3, since there are three attributes:
<STUDENT code = “100” group = “Science”
class = “first”>Bhushan Mahajan
</STUDENT>
In our example, we have the following element of interest:
<BOOK pubyear="…">
Therefore, the getLength ( ) method would return 1 here.
We check if there is at least one attribute, and then we check whether its value falls in the range of 1970 and 1979. If it does, we increment a counter variable that we had initially set to 0.
In our XML document, there are two elements that have the year attribute with a value in the 1970s (that is, between 1970 and 1979, both inclusive). Therefore, the program would display 2 when all the elements are exhausted and control moves to the endDocument ( ) method. The output is shown in Figure 7.23.

Figure 7.23 Output of the program – 4
Keep in mind that many of these tasks can be accomplished by using XSLT, instead of JAXP. In a number of cases, XSLT can turn out to be faster to work with and easier to develop.
However, we have attempted to present different ways of achieving the same thing.
7.2.3 JAXP and DOM
As we know, DOM creates an in-memory tree-like structure for processing XML documents. This tree is loaded and kept in the main memory until the program execution is completed.
Let us first understand the important classes in the DOM implementation of JAXP.
Just as we have a parser factory and a parser implementation class for SAX, as discussed earlier, we have similar concepts for DOM, as well. Here, we have a class named DocumentBuilderFactory. This factory is responsible for producing an implementation class for DOM, depending on which parser is being used. It works exactly like the SAXParserFactory class, and hence, we would not describe it. Once this factory provides an instance of the DOM parser to be used (which is in the form of a DocumetBuilder class), we can make use of the DocumentBuilder class to call the parse ( ) method. This is again similar to our SAX implementation of the code. This call returns us an instance of the Document interface, which is the in-memory tree-like structure of the XML document. We can then call various methods of this interface to parse the XML document, translated into an in-memory tree-like structure. We also have interfaces such as Element inside the Document interface, which return us the root element inside the XML document, and so on.
Figure 7.24 shows the concept
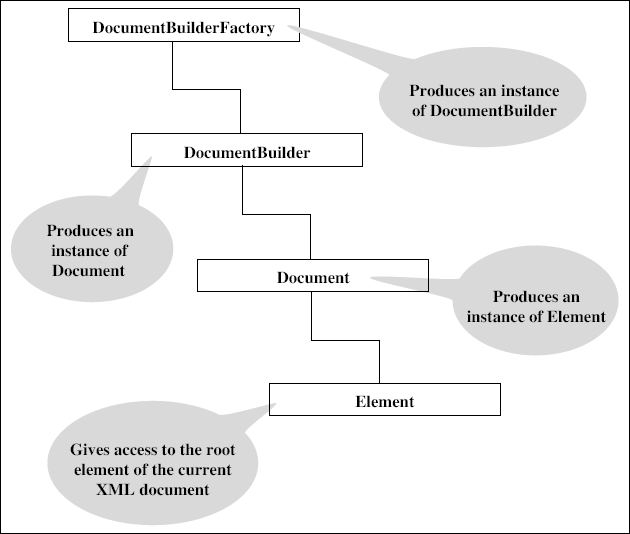
Figure 7.24 DOMprocessing in JAXP – Initial steps
Figure 7.25 shows the corresponding code steps.

Figure 7.25 DOM coding in JAXP – Initial steps
Let us now discuss a few examples, based on these concepts.
Exercise 1: Using the DOM approach, simply attempt to open an XML document without processing.
Solution 1:
import org.w3c.dom.*;
import javax.xml.parsers.*;
import org.xml.sax.*;
public class DOMExample1 {
public static void main (String[] args) {
try {
DocumentBuilderFactory factory =
DocumentBuilderFactory.newInstance ();
DocumentBuilder builder = factory.
newDocumentBuilder ();
Document document = builder.parse (“cdcatalog.
xml”);
Element root = document.getDocumentElement ();
System.out.println (“In main … XML file openend successfully …”);
}
catch (ParserConfigurationException e1) {
System.out.println (“Exception: “ + e1);
}
catch (SAXException e2) {
System.out.println (“Exception: “ + e2);
}
catch (java.io.IOException e3) {
Let us understand the code.
First, take a look at the import statements:
import org.w3c.dom.*;
import javax.xml.parsers.*;
import org.xml.sax.*;
The package org.w3c.dom is the main DOM package, which contains the key DOM classes and interfaces. Most notable of them are:
- Document – As explained earlier, this interface represents the entire XML document.
- Element – As explained earlier, this interface represents an element in the XML document, starting with the root element.
- Attr – This interface represents an attribute in an Element object.
We have already discussed the package javax.xml.parsers, which is the common JAXP package for SAX and DOM at the highest level.
The third package org.xml.sax seems to be out of place. Here, we are dealing with DOM, and are using a SAX package! This is a bit strange, but that is the way JAXP works. This package is needed to deal with exceptions, since even in the case of DOM parsing using JAXP, SAXException gets thrown in, in the case of an error. This exception is defined in this package.
DocumentBuilderFactory factory = DocumentBuilderFactory.
newInstance ();
DocumentBuilder builder = factory.newDocumentBuilder ();
Document document = builder.parse (“cdcatalog.xml”);
Element root = document.getDocumentElement ();
We have discussed this code block earlier. It attempts to instantiate a DOM builder factory, and uses it to instantiate a DOM builder class. It then uses the DOM builder class to create an instance of the Document interface. Finally, the Document interface provides us an inroad into the Element interface. From here, we can start accessing the various elements, beginning with the root.
The output is shown in Figure 7.26.

Figure 7.26 Output of the program – 5
Exercise 2: Consider the following XML document.
<?xml version="1.0"?>
<catalogue>
<cd available = “Yes”>
<title>Empire Burlesque</title>
<artist>Bob Dylan</artist>
<country>USA</country>
<company>Columbia</company>
<price>10</price>
<year>1985</year>
</cd>
<cd available = “No”>
<title>Candle in the wind</title>
<artist>Elton John</artist>
<country>UK</country>
<company>HMV</company>
<price>8</price>
<year>1998</year>
</cd>
</catalogue>
List all the occurrences of the element cd.
Solution 2:
import org.w3c.dom.*;
import javax.xml.parsers.*;
import org.xml.sax.*;
public class DOMExample2 {
public static void main (String[] args) {
NodeList elements;
String elementName = “cd”;
try {
DocumentBuilderFactory factory = DocumentBuilderFactory.
newInstance ();
DocumentBuilder builder = factory.newDocumentBuilder ();
Document document = builder.parse (“cdcatalog.xml”);
Element root = document.getDocumentElement ();
System.out.println (“In main … XML file openend
successfully …”);
elements = document.getElementsByTagName(elementName);
// is there anything to do?
if (elements == null) {
return;
}
// print all elements
int elementCount = elements.getLength();
System.out.println (“Count = “ + elementCount);
for (int i = 0; i < elementCount; i++) {
Element element = (Element) elements.item(i);
System.out.println (“Element Name = “ + element.
getNodeName());
System.out.println (“Element Type = “ +
element.getNodeType());
System.out.println (“Element Value = “ + element.
getNodeValue());
System.out.println (“Has attributes = “ + element.
hasAttributes());
}
}
catch (ParserConfigurationException e1) {
System.out.println (“Exception: “ + e1);
}
catch (SAXException e2) {
System.out.println (“Exception: “ + e2);
}
catch (DOMException e2) {
System.out.println (“Exception: “ + e2);
}
catch (java.io.IOException e3) {
System.out.println (“Exception: “ + e3);
}
}
}
The part of opening the XML document is the same as it was in the earlier example. Therefore, we will not spend time in discussing it. Instead, we would concentrate on the part where we use DOM to parse an XML document.
We can see that even inside the main ( ) method, we have declared two variables:
NodeList elements;
String elementName = “cd”;
The second declaration is straightforward, which is simply a Java String.
NodeList is an interface in DOM. It provides an abstraction of an ordered collection of nodes. The actual implementation of the collection is not defined, and is left to the actual implementation. Let us understand this point.
When DOM parsing happens, the whole XML document is read in memory in the form of a tree-like structure. This tree-like structure, when flattened, has many elements, attributes, etc., depending on the contents of the XML document. This is made available to a Java program in the form of various nodes. The collection of all these nodes (that is, the tree-like structure in memory) is called a node list. To be able to deal with these nodes of a node list, we need Java data structures so that we can run through these nodes. The idea is illustrated in Figure 7.27.

Figure 7.27 Creation of a node list consisting of nodes
Therefore, the NodeList interface defines two methods:
- getLength: This method returns the number of items (that is, nodes) in the node list.
- item: This method takes an index (starting with 0) into the collection as a parameter and returns the item found at that index of type Node. Node is another interface, which represents a single node in the DOM tree. For example, if the parser is currently on an element, the Node is an element, if the parser is on an attribute, the Node is an attribute, and so on.
Let us now take a look at the next code block:
elements = document.getElementsByTagName(elementName);
// is there anything to do?
if (elements == null) {
return;
}
Now, we call a method named getElementsByTagName of the Document object. We pass the name of the element on which we want to search (in this case, cd). Thus, all the cd nodes would be searched, and made available to us in the form of a NodeList titled elements. We then check if there are elements returned by this method. If no, we simply return.
// print all elements
int elementCount = elements.getLength();
System.out.println (“Count = “ + elementCount);
for (int i = 0; i < elementCount; i++) {
Element element = (Element) elements.item(i);
System.out.println (“Element Name = “ + element.
getNodeName());
System.out.println (“Element Type = “ + element.
getNodeType());
System.out.println (“Element Value = “ + element.
getNodeValue());
System.out.println (“Has attributes = “ + element.
hasAttributes());
}
At this stage, we call the getLength ( ) method on the elements node list to find out how many instances of the cd element were found, and we print this.
We then run a loop over the elements of this node list, each time extracting the current node as an element, and then printing its name, type, contents, and whether it has attributes. For this, several methods of the Element interface are used.
The output of this program is shown in Figure 7.28

Figure 7.28 Output of the program – 6
Now let us take these concepts further.
Exercise 3: For the same XML document, apart from element details, also display attribute details.
Solution 3:
import org.w3c.dom.*;
import javax.xml.parsers.*;
import org.xml.sax.*;
public class DOMExample3 {
public static void main (String[] args) {
NodeList elements;
String elementName = “cd”;
try {
DocumentBuilderFactory factory = DocumentBuilderFactory.
newInstance ();
DocumentBuilder builder = factory.newDocumentBuilder ();
Document document = builder.parse (“cdcatalog.xml”);
Element root = document.getDocumentElement ();
System.out.println (“In main … XML file openend successfully …”);
elements = document.getElementsByTagName(elementName);
// is there anything to do?
if (elements == null) {
return;
}
// print all elements
int elementCount = elements.getLength();
System.out.println (“Count = “ + elementCount);
for (int i = 0; i < elementCount; i++) {
Element element = (Element) elements.item(i);
System.out.println (“Element Name = “ + element.
getNodeName());
System.out.println (“Element Type = “ + element.
getNodeType());
System.out.println (“Element Value = “ + element.
getNodeValue());
System.out.println (“Has attributes = “ + element.
hasAttributes());
// If attributes exist, print them
if(element.hasAttributes())
{
// if it does, store it in a NamedNodeMap object
NamedNodeMap AttributesList = element.
getAttributes();
// iterate through the NamedNodeMap and get the
attribute names and values
for(int j = 0; j < AttributesList.getLength();
j++) {
System.out.println(“Attribute: “ +
AttributesList.item(j).getNodeName() +
“ = “ +
AttributesList.item(j).getNodeValue());
}
}
}
}
catch (ParserConfigurationException e1) {
System.out.println (“Exception: “ + e1);
}
catch (SAXException e2) {
System.out.println (“Exception: “ + e2);
}
catch (DOMException e2) {
System.out.println (“Exception: “ + e2);
}
catch (java.io.IOException e3) {
System.out.println (“Exception: “ + e3);
}
}
}
Let us take a look at this.
if(element.hasAttributes())
{
// if it does, store it in a NamedNodeMap object
NamedNodeMap AttributesList = element.getAttributes();
…
Now, apart from checking whether our cd element has attributes, we also display the attribute names and their values. In this particular example, there is only one attribute associated with the cd element, hence we would get only that attribute currently. The list of attributes is made available in a data structure named NamedNodeMap.
To access the individual attribute names and their values, we do the following:
AttributesList.item(j).getNodeName() + “ = “ +
AttributesList.item(j).getNodeValue());
Now we shift our attention back from attributes to elements, and see how to access the sub-elements (that is, children) of an element. See Figure 7.29.
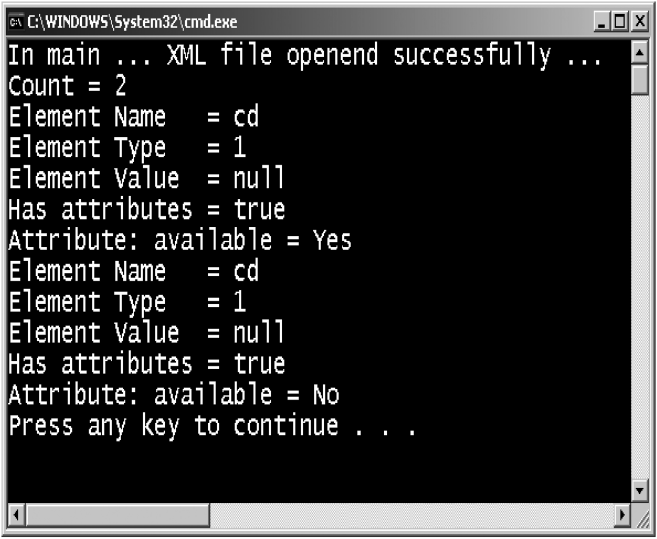
Figure 7.29 Output of the program – 7
Exercise 4: For the same XML document, display all the sub-element details in addition to that of the cd element.
Solution 4:
import org.w3c.dom.*;
import javax.xml.parsers.*;
import org.xml.sax.*;
public class DOMExample4 {
public static void main (String[] args) {
NodeList elements, Children;
String elementName = “cd”;
String local = "";
Element element = null;
try {
DocumentBuilderFactory factory = DocumentBuilderFactory.
newInstance ();
DocumentBuilder builder = factory.newDocumentBuilder ();
Document document = builder.parse (“cdcatalog.xml”);
Element root = document.getDocumentElement ();
System.out.println (“In main … XML file openend successfully
…”);
elements = document.getElementsByTagName(elementName);
// is there anything to do?
if (elements == null) {
return;
}
// print all elements
int elementCount = elements.getLength();
System.out.println (“Count = “ + elementCount);
for (int i = 0; i < elementCount; i++) {
element = (Element) elements.item(i);
System.out.println (“Element Name = “ + element. getNodeName());
System.out.println (“Element Type = “ + element. getNodeType());
System.out.println (“Element Value = “ + element. getNodeValue());
System.out.println (“Has attributes = “ + element. hasAttributes());
// Find out if child nodes exist for this element
Children = element.getChildNodes();
if (Children != null) {
for (int j=0; j< Children.getLength(); j++) {
local = Children.item(j).getNodeName();
System.out.println (“Child element name = “ + local);
}
}
}
}
catch (ParserConfigurationException e1) {
System.out.println (“Exception: “ + e1);
}
catch (SAXException e2) {
System.out.println (“Exception: “ + e2);
}
catch (DOMException e2) {
System.out.println (“Exception: “ + e2);
}
catch (java.io.IOException e3) {
System.out.println (“Exception: “ + e3);
}
}
}
Let us look at the logically relevant code, grouped together below.
NodeList elements, Children;
String elementName = “cd”;
String local = "";
Element element = null;
elements = document.getElementsByTagName(elementName);
int elementCount = elements.getLength();
for (int i = 0; i < elementCount; i++) {
element = (Element) elements.item(i);
// Find out if child nodes exist for this element
Children = element.getChildNodes();
if (Children != null) {
for (int j=0; j< Children.getLength(); j++) {
local = Children.item(j).getNodeName();
System.out.println (“Child element name = “ + local);
}
}
}
}
As we can see, first we retrieve all the elements whose name is cd, as before. We then count how many instances of these cd elements were found. Then we run for loop over these instances. In each case, call a method titled getChildNodes ( ). This gives us a list of all the sub-elements (that is, children) of the cd element. We then run a second for loop over these children. In each case, we display the name of the sub-element.
The output of this program is shown in Figure 7.30.
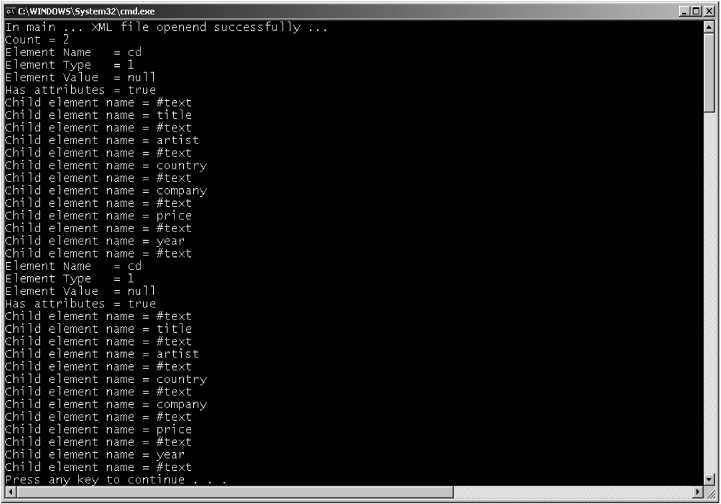
Figure 7.30 Output of the program – 8
7.2.4 JAXP and StAX
The StAX API is straightforward to use. We shall classify the usage of the API based on two requirements: (a) creating an XML document and writing to it, and (b) reading it.
Creating an XML document
There are three important classes that we need to import at the beginning of the program:
import javax.xml.stream.XMLOutputFactory;
import javax.xml.stream.XMLStreamWriter;
import javax.xml.stream.XMLStreamException;
We then need to create an instance of the XMLOutputFactory class by using the standard factory technique:
XMLOutputFactory outputFactory = XMLOutputFactory.newInstance();
Once we have obtained an instance of the XMLOutputFactory class, we need to call the createXMLStreamWriter method on this instance, passing a FileWriter object (which holds the name of the XML document where we want to store our content). This returns to us an instance of the XMLStreamWriter class:
FileWriter fileWriter = new FileWriter(“d:\FT.xml”);
XMLStreamWriter writer = outputFactory.createXMLStreamWriter(fileWriter);
Once we have an instance of the XMLStreamWriter class as shown above, we can call the various write methods on this instance, such as writeStartDocument (), writeComment (), writeStartElement (), and so on. Finally, we need to flush and close the XMLStreamWriter instance:
writer.writeStartDocument(“1.0”);
writer.writeComment(“Funds Transfer Data”);
writer.writeStartElement(“FundsTransfer”);
…
…
writer.flush();
writer.close();
The complete code is shown in Figure 7.31.

Figure 7.31 StAX example to create an XML document from scratch
7.3 XML AND JAVA – A CASE STUDY
As we can see, the hierarchy of classes in the case of StAX can be depicted as shown in Figure 7.32.

Figure 7.32 Flow of StAX write program
The program to read the contents of an XML document using StAX is similar. Here, we have the XMLInputFactory, giving an instance of XMLStreamReader. Note that this is remarkably similar to the write operation. At this stage, we can run a loop over this XMLStreamReader object using the hasNext () method. This starts at the root element and takes us till the end of the XML document. At each stage, we can use methods such as getLocalName (), getElementText (), etc. To move to the next content of the XML document, we need to call a method next () on the same XMLStreamReader object.
Figure 7.33 shows the code for reading the contents of the same XML document and returning them back to the calling program. The assumption is that the calling program passes the name of the element to search to the parseXML method of our XML reading program. Our program returns the contents of the first matching instance of that element to the caller.

Figure 7.33 Flow of StAX read program – 1

Figure 7.33 Flow of StAX read program – 2
7.4 CASE STUDY
We now present a case study that discusses how XML can be used in real life Web applications, based on Java. To keep things simple, we consider just a couple of screens, and investigate how we can write the logic for working with them in an efficient manner, so as to extend the basic concepts to the various situations that arise in a Web application.
Requirement
We assume that the end user of the application has logged on to our banking application, and wants to perform an action of transferring Rs.10,000 from her account to her friend's account. The user's account number is 12345 and the friend's account is 56789. Therefore, the screen shown in Figure 7.34 is presented to the user.
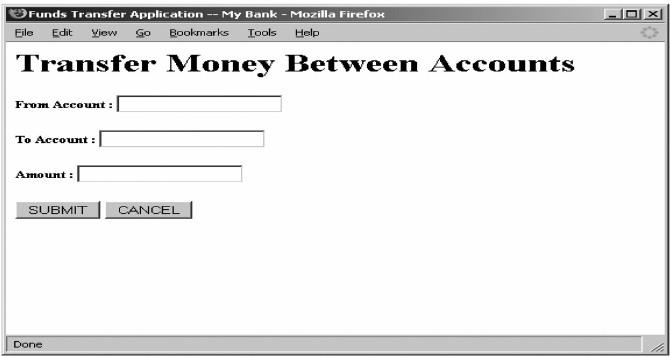
Figure 7.34 Sample screen to be shown to the user
The user can type the account numbers (from and to) for effecting the movement of money, and can also enter the amount. The user can then choose to go ahead or cancel this process.
Architecture
There are several ways in which we can architect and design this application. One of the best ways in which it can be done is considered to be the Model-View-Controller (MVC) architecture. Although the subject of MVC is not what we are discussing here, we shall provide a quick overview to facilitate ease of understanding. The recommendation of the MVC architectural approach is that we consider our Web applications as composed of three layers:
- Model: This is the actual application logic, or data from the database, or any other interfacing system, etc. For instance, in our example, the jobs of verifying the from and to accounts, performing account balance checks, and actually accomplishing the funds transfer are all responsibilities of the model.
- View: The view is the portion of the application that makes the view, or presentation of data ready for the end user. For example, after the funds transfer process is successful (or has failed), the user would have to be shown an appropriate result, possibly with an option to do something else within the application. This is the responsibility of the view.
- Controller: This is the aspect of the application, which is responsible for the overall co-ordination. For instance, it is the controller, which accepts the funds transfer request from the user, uses the model to process it, and prepares the view to be sent back to the user.
These concepts are further illustrated in Figure 7.35.

Figure 7.35 MVC architecture in a nutshell
Now, if we create a conceptual flow of our application based on these principles, we can depict the overall idea as shown in Figure 7.36.
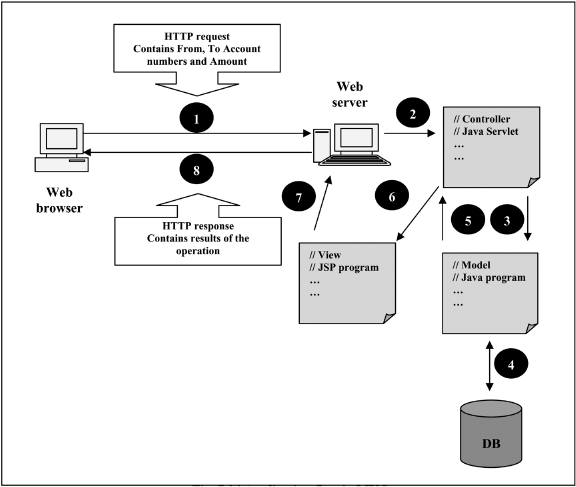
Figure 7.36 Application flow in MVC
This is described below.
- The user is shown a screen where the user enters the from and to account numbers and the amount to be transferred between them. Once this information is entered, some basic validations would be performed (for example, to ensure that the account numbers and amount entered are numeric) by client-side JavaScript and then an HTTP request would be sent to the Web server.
- The Web server invokes a controller program (usually a Java servlet), which receives this HTTP request, and decides what to do next. In this case, the servlet named FTServlet.java realises that it needs to pass the control to a model Java program (FundsTransfer.java), which would perform the job of the funds transfer. The servlet sends the from and to account numbers and the amount to the Java class in the form of an XML message.
- When the control is passed to the model Java program (FundsTransfer.java), it parses the XML message and performs the funds transfer by moving money between the two accounts.
- For the purpose of the funds transfer, the model Java program updates the database with the values post-funds transfer.
- If the funds transfer is successful, the model Java program transfers control back to the controller servlet.
- The controller servlet realises that the funds transfer was successful, and hence, it now passes control to the view (FTResult.jsp), which would send an updated status to the user in the form of a success HTML page.
- The view JSP prepares the view (that is, the success HTML page) and the Web server realises it.
- The Web server sends this view back to the user, and the user sees a message similar to the one shown in Figure 7.37.

Figure 7.37 Result of funds transfer
Let us now take a look at the code, as shown in Figure 7.38.

Figure 7.38 FTForm.html (HTML form)
As we can see, FTForm.html accepts the from and to account numbers and the amount to be transferred. It then calls the servlet named FTServlet on the server side. We have deliberately avoided any client-side validations in user inputs to keep things simple. In real life, those need to be added.
Let us now see how the FTServlet (the controller) looks like, as shown in Figure 7.39.

Figure 7.39 FTServlet (Controller)
The controller servlet reads the form values into three local variables and converts them into integers (as by default, they are received as strings). It then instantiates the model class, FundsTransfer. Before calling it, it calls the createXML () method of the CreateFTXML class to transform the user input into an XML document. Once it is ready, it passes control to the model class FundsTransfer.
Figure 7.40 shows how the CreateFTXML class transforms the input received as three integers into an XML document.

Figure 7.40 CreateFTXML class
As we can see, the createXML () method of our CreateFTXML class receives three integers, and creates an XML document using these three integers. It uses the StAX approach.
Figure 7.41 shows the code for the FundsTransfer model class.

Figure 7.41 FundsTransfer model class
We should note that the model class makes use of the Derby database that is shipped with the Java Development Kit as a default now. The reader is requested to consult appropriate documentation to understand how to create an accounts table in Derby, containing only two columns, namely the account_number and the balance.
The model class firstly makes use of the ReadFTXML class to read the XML document and parse it back into the three integers that the user had entered on the screen. It then runs the JDBC code to update the funds transfer in the database. It finally commits, if the update process is successful.
Figure 7.42 illustrates the ReadFTXML class.

Figure 7.42 ReadFTXML class
This class also uses the StAX approach for reading the XML document and parsing it back into the three integers. We have discussed this earlier.
If everything is all right so far, the controller servlet now sets a status variable to the value returned by the model class (true if successful, false in the case of a failure) and transfers control to the view JSP, named FTResult.jsp. The JSP page looks at the status, and displays a success or failure message back to the user, as shown in Figure 7.43.

Figure 7.43 FTResult.jsp (View)
One question that we may have is, why does the controller create an XML document and pass it to the model? Why does it not directly pass the parameters in the basic integer form? The answer to that question is that in this simplistic case, it may work fine. However, in real life situations, the front-end application that accepts values from the user in the HTML form may be different from the one that actually does the funds transfer at the back end. In some cases, this may even be developed by different companies altogether! In such cases, it is far more effective for the sending application to send data in the XML format, and also for the receiving application to receive it in the XML format. This neutrality is one of the beauties of XML!
KEY TERMS AND CONCEPTS
- Abstract factory
- Callback methods
- Design pattern
- Document Object Model (DOM)
- Event handler
- Java API for XML Processing (JAXP)
- Model-View-Controller (MVC)
- Parser
- Simple API for XML (SAX)
- Streaming API for XML (StAX)
CHAPTER SUMMARY
- Parsing is the process of reading and validating a program written in one format and converting it into the desired format.
- Parsing of XML is the process of reading and validating an XML document and converting it into the desired format. The program that does this job is called a parser.
- If we do not have XML parsers, we would need logic to read, validate, and transform every XML file ourselves, which is a difficult task.
- If we go through the XML structure, item-by-item (for example, to start with, the line <?xml version="1.0"?>, followed by the element <employees>, and so on), it is the Simple API for XML (SAX) approach.
- If we read the entire XML document in the memory as an object, and parse its contents as per the needs, it is the Document Object Model (DOM) approach.
- The SAX parser keeps track of various events, and when an event is detected, it informs our Java program.
- Our Java program needs to constantly monitor SAX events, and take appropriate action.
- The DOM approach parses through the whole XML document at one go. It creates an in-memory tree-like structure of our XML document.
- In DOM, the tree-like structure is handed over to our Java program at one go, once it is ready. No events get fired unlike what happens in SAX.
- Streaming API for XML (StAX) is a pull API. In other words, it does not push XML data at the program – instead, the program decides when to pull it. Also, unlike DOM, it does not need to load and hold the entire XML document as a tree in the memory.
- The Java API for XML Processing (JAXP) is a Sun standard API that allows us to validate, parse, and transform XML with the help of several other APIs.
- JAXP itself is not a parser API. Instead, we should consider JAXP as an abstraction layer over the actual parser APIs.
- JAXP is not a replacement for SAX, DOM, or StAX.
PRACTICE SET
True or False Questions
- SAX is a sequential approach.
- DOM is an event-based API.
- DOM creates a tree-like in-memory structure.
- DOM is slower than SAX.
- SAX is useful in all situations, unlike DOM.
- The factory pattern is used in JAXP.
- JAXP can replace either SAX or DOM.
- JAXP is not Java-specific.
- StAX is a pull API.
- StAX loads the entire document in memory.
Multiple Choice Questions
- The ________ approach of parsing is event-based.
- SAX
- DOM
- StAX
- JAXP
- The ________ approach of parsing is based on loading the entire XML document in memory.
- SAX
- DOM
- StAX
- JAXP
- The ________ approach of parsing is pull-oriented.
- SAX
- DOM
- StAX
- JAXP
- The ________ API is a part of the Java specifications for working with XML.
- SAX
- DOM
- StAX
- JAXP
- The ________ is the first callback event that gets fired in the SAX approach.
- startDocument
- startElement
- characters
- endElement
- The ________ event is fired in the SAX approach when the contents of an element are encountered.
- startDocument
- startElement
- characters
- endElement
- The ________ class is at the highest level of the DOM programming approach.
- DocumentBuilderFactory
- DocumentBuilder
- Document
- Element
- The ________ method needs to be called in order for the DOM processing to start.
- begin
- start
- init
- parse
- The first call to the getDocumentElement () method in DOM would return the ________ element(s).
- xml
- root
- all
- last
- The ________ class is used in StAX for reading the contents of an XML document.
- XMLReader
- Reader
- XMLStreamReader
- XmlReader
Detailed Questions
- Discuss the concept of parsing.
- Explain how SAX works.
- How is DOM different from SAX?
- Why is DOM slower?
- In which situations would SAX be better than DOM?
- When would you prefer DOM to SAX?
- Explain the concept of JAXP.
- Discuss the overall flow of a SAX or DOM-based program.
- Explain how JAXP works.
- Discuss the StAX approach.
Exercises
- Consider an XML document that stores the following information about inventory of items: item code, item name, quantity available, unit price, discount percentage, and reorder level. Write the StAX code to create five items in this XML document.
- Use the above XML document and display all the items in the inventory on the screen, using SAX.
- Use the above XML document and display all the items in the inventory on the screen, using DOM.
- Use the above XML document and display all the items in the inventory on the screen, using StAX.
- Display only the price elements from the XML document.
- Display all the elements in the descending order of price.
- Compute the total value of the inventory by using the formula of Total of all (prices multiplied by the respective unit prices).
- Display the names of all the items whose reorder level is < 5.
- Investigate alternatives to JAXP.
- How can we process XML documents via JavaScript? Investigate.
ANSWERS TO EXERCISES
True or False Questions
| 1. True | 2. False | 3. True | 4. True |
| 5. False | 6. True | 7. False | 8. False |
| 9. True | 10. False |
Multiple Choice Questions
| 1. a | 2. b | 3. c | 4. d |
| 5. a | 6. c | 7. a | 8. d |
| 9. b | 10. c |