
Understanding the XQuery Data Model and type system is central to understanding all the rest of the XQuery language. The XQuery Data Model consists not only of the XML data over which a query operates, but also any other values that the query can produce (as either intermediate values or the final query result). The XQuery type system associates static types with every expression at compile time, and also dynamic types with every value in the data model. The data model and type system both involve a lot of details, but these details are fairly straightforward.
Almost every XML standard has introduced a data model slightly different from those of its predecessors, and XQuery is no different in this respect. This chapter first explores some previous data models and the reasons XQuery differs from them, and then focuses on the details of the XQuery Data Model itself.
The type system pervades all aspects of the XQuery Data Model and language. For better or worse, this type system is based on XML Schema 1.0, with some minor modifications (mostly to accommodate untyped XML data, unnamed nodes, and cardinalities). In this chapter I focus only on the parts of the XQuery type system that you need to know to effectively use XQuery.
Appendix A provides a reference for every type (even the ones you'll rarely need) and every aspect of the Data Model. Additional references on XML Schema 1.0 can be found in the “Further Reading” section at the end of this chapter.
What is XML? Is it an ordered sequence of characters or other lexical tokens? Is it a tree of nodes labeled with information? Is it a graph? Is it typed, and if so, what is its type system? Must the data model faithfully preserve all the lexical information present in the original XML document—including entity references, CDATA sections, and all space characters (even spaces between attributes), or can it treat some of this information as insignificant? And what exactly constitutes a “node,” anyway?
An XML data model must answer these questions and many more; however, many of the possible answers conflict with one another. Effectively, each data model defines what information in an XML document “really matters” and what information is considered irrelevant for its purposes.
Over time, popular opinion as to what information is important and what can be ignored has shifted, reflecting a more general trend to view XML as data and not merely document markup. To better understand why there are so many XML data models, let's consider two simple examples.
Consider a block of text containing an entity or CDATA section in the middle of it, as shown in Listing 2.1. If the data model must preserve the entity or CDATA section with full fidelity, then the data model must maintain separate “nodes” or structures for each piece of information. In this example, one text node for the character sequence Punctuation like (including the trailing space), one entity node for the entity &, another text node for the characters and , (including the boundary space characters) a CDATA node for <![CDATA[<]]>, and finally a text node for the remaining characters can be tricky in XML. (including the leading space).
Example 2.1. CDATA sections and entity references in the middle of text
<x>Punctuation like & and <![CDATA[<]]> can be tricky in XML.</x>
However, you might instead prefer to work with this text directly as a single node containing the string value Punctuation like & and < can be tricky in XML. This approach resolves all entities and CDATA sections first, and then merges the result into a single text value.
The first approach loses no information, but requires a parser to perform more work—creating five nodes where one might suffice—and requires applications to handle text values that have been divided into separate chunks. The second approach is more efficiently represented and easier for most applications to consume, but loses some information about the original XML representation, whether characters were entitized, wrapped in CDATA blocks, or just appeared normally.
As a second example, suppose we are working with typed XML. The XML characters will be mapped to some other value space, like integers, so that we can work with them efficiently. This process drops leading zeros on numeric values, so it is certainly lossy. However, this approach is even lossier than we might first appreciate, as Listing 2.2 illustrates.
Example 2.2. Comments and processing instructions may appear in a typed value
<x xsi:type="xs:integer"> 04<!-- comments are annoying -->2 </x>
XML allows comments and processing instructions to appear anywhere, even in the middle of a text value. In this example, preserving the comment would result in a sequence of three nodes: a text node with the value 04, a comment node, and another text node with the value 2. However, treating the XML as a typed value, as XML Schema does, would ignore the comment node and instead result in a single, typed value— the integer 42—losing the leading zero, whitespace characters, and the XML comment node.
Generally speaking, conflicts like these are what differentiate the different XML data models in use today. One data model chooses one solution, and another data model chooses a different (possibly incompatible) solution. In some cases, a data model may attempt to preserve both sets of information simultaneously, trading memory consumption for flexibility.
Initially, most people viewed XML in the light of HTML, and believed the two should share a common API. This belief led to the creation of the Document Object Model (DOM) Levels 1 and 2. (Level 3 is under development at the time of this writing.) The DOM is especially popular as the component model in Web browsers. Although the DOM focuses on an API for working with XML data, this API implies an underlying data model.
In the DOM Data Model, all lexical information is preserved—entities and CDATA sections, for example, are kept as individual nodes in the DOM. It is tempting to think that the DOM is not typed, but actually the DOM does process the limited type information available in DTDs and applies some of this type information to its data model (for example, attributes may be ID-typed, which then confers special meaning to their parent elements).
For text processing, or manually navigating what is essentially an XML parse tree, the DOM is very useful. For query processing, the two most obvious drawbacks to the DOM are that it consumes a large amount of memory relative to the original text and that simple string comparisons must take into account the possibility of separate text nodes. Also, the DOM representation focuses more on the original lexical shape of the data than the underlying values it contains (storing, for example, the characters 042 instead of the integer 42). For these reasons and others, XML query languages have pretty much abandoned the DOM as an unworkable data model for XML query processing.
The XPath 1.0 Data Model picks up where the Document Object Model leaves off. The XPath Data Model is formally defined only for the XML data over which it operates; oddly, it doesn't consider the types of intermediate query expressions as part of its data model.
XPath has effectively five data types: boolean, double (called number), string, sequence of nodes (called node-sets), and external objects of unknown type. Host languages wrapped around XPath often add additional types, for example, XSLT has result tree fragments. Node-sets are always sorted in document order.
The XPath Data Model differs from the DOM in several respects. Character entities and CDATA sections are always expanded and merged with adjacent text nodes. XPath cannot determine whether text nodes contained entities or CDATA sections. Some DTD information (notably ID types using the id() function) can be queried and therefore must be processed and preserved, but other DTD information is also lost.
For query processing, the XPath 1.0 Data Model is not bad. Its main flaws are the omission of many other useful data types (such as integer or date), its inability to construct sequences of values, its inability to construct sequences of nodes sorted in arbitrary order, and its lack of support for XML Schema (which appeared later). The XPath Data Model is also specified too informally, something that the next data model discussed, the XML Infoset, addressed.
Around this time, the XML community realized that the informal treatment given to XML data models by previous standards efforts was insufficient. A more rigorous definition was required, one that could become the basis for future XML standards. This effort led to the creation of the XML Information Set, aka the Infoset.
The Infoset treats XML as a collection of information items. An Infoset always contains at least one information item—for the document node. Like the XPath data model, the Infoset is lossy with respect to the original XML syntax (if there was one; the Infoset is an abstraction that could be applied to other data sources, such as databases).
The Infoset doesn't preserve many kinds of syntactic information, including general parsed entities, CDATA sections, the difference between various end-of-line sequences, the difference between self-closed (<x/>) and empty (<x></x>) elements, the order in which attributes appear, and so on. It's clear that these decisions reflected the shift in thinking about what information was important and what wasn't.
From the point of view of XML query processing, the Infoset has one major characteristic, namely that it heralds the beginning of virtual XML, data that is viewed as though it were XML, without necessarily being XML.
The importance of this step is best explained by analogy. There was a time when mathematics concerned itself only with concepts having some physical meaning. Concepts like imaginary numbers and powers greater than three dimensions were initially resisted as too abstract, too disconnected from the real world. Similarly, before the Infoset, XML data models focused on the “physical” XML serialization format. The Infoset represents a major shift in thinking; for the first time, the XML data model is viewed as an abstraction that might be created from some entirely different data format.
The Infoset is still fundamentally untyped; it doesn't even require XML to be valid according to a DTD or schema. The XML Schema specification introduces validation information about an XML document, such as types, default values, whether content may be empty or not, relationships to other types, and so on. The Post-Schema-Validation Infoset (PSVI) is an Infoset that has been validated and augmented with additional information by the validation process.
The PSVI is almost ideal for XML query processing. It is abstract, relatively lightweight, and strongly-typed. However, it still suffers from a few drawbacks, probably the worst of which is that it represents only nodes and values inside of nodes—the data model always contains one node, which precludes possibilities like a “list of integers.”
Ideally, XQuery would use one of the existing data models verbatim, such as the PSVI, without additions or caveats. Unfortunately, even the PSVI introduces a few difficulties for query languages, and these difficulties compelled XQuery to define its own data model that is almost, but not quite, the PSVI.
The greatest difficulty is that XQuery, like XPath, has intermediate expressions whose values are not XML and have no obvious XML analogue. For example, an XQuery expression can result in a list of integers and attributes, or a list of documents, neither of which is directly supported in the PSVI. Also, two of the requirements for XQuery are that it must be able to handle XML fragments (which are not directly supported by the Infoset either), and that it must support both typed and untyped XML data. Consequently, the XQuery Data Model covers more possibilities than either the Infoset or PSVI alone.
Finally, XQuery encountered difficulties when working with certain XML Schema types. For example, the duration types of XML Schema are not well suited to addition, comparisons, and other query operations. To compensate for these issues, XQuery has added a few types to the existing XML Schema type system.
Now that we've explored some of the XML data models that have been employed over the past years, let's focus on the details of the XQuery Data Model and type system. The justifications for all the previous data models should shed some light on the technical descriptions that follow. The XQuery Data Model is detailed but straightforward, given its design choices.
Note that the XQuery Data Model places no limitations on the number of nodes or the sizes of strings and names. However, some implementations may impose practical limits on the maximum size of a data model.
As mentioned in Chapter 1, every XQuery data model is an ordered sequence of zero or more items.
Items are always singletons. An item is equivalent to a sequence of length one containing that item, so, for example, (0) is equivalent to just 0. A sequence may be empty, but cannot contain other sequences (nested sequences are always flattened), so, for example, the sequence (0, (), (1, 2)) is the same as (0, 1, 2).
XQuery uses a sequence type expression to describe types. Except for the special sequence type empty() (which is the type of the empty sequence), sequence type consists of two parts: a type name and an optional occurrence indicator.
The type name can be any qualified name or one of several built-in type names, all of which are written like functions. The meaning of the type name is explained throughout the rest of this chapter. The occurrence indicator, if used, can be a plus sign (+), asterisk (*), or question mark (?), with the same meanings as in regular expressions: + denotes one or more (not empty), * means zero or more (any number), and ? means zero or one (not more). When the occurrence indicator is omitted, the sequence must contain exactly one item with the named type.
For example, item()* is the type of a sequence containing any number of items, while item() is the type of a sequence containing exactly one item. Several different types may be used to describe a particular value; for example, a sequence of integers (xs:integer*) is also a sequence of items (item()*). The type rules are fairly complex, so I'll wait until Section 2.6 to explain them.
Items are further classified into atomic values and nodes. Because the two item kinds are so different from one another, let's cover each one separately, starting with atomic values.
Atomic values are so named to emphasize the fact that they are singletons with essentially no structure. XQuery defines 50 built-in atomic types, although as mentioned in Chapter 1, you really only need to know 14 of them. These types are described in Section 2.4, and all 50 are covered in Appendix A.
Every atomic value has an atomic type that derives from the special XQuery type xdt:anyAtomicType. As its name suggests, this type is used to represent any atomic type.
Nodes are structures with many properties including kind, name, and type. There are seven node kinds in XQuery, the same as in XML. The node() type matches all node kinds, just like xdt:anyAtomicType matches any atomic value.
Unlike atomic values, each node has a unique identity that distinguishes it from every other node. Also, all nodes have an inherent ordering to them, known as document order, which actually applies even to nodes from different documents. These and other node properties are discussed in Section 2.5.
Every built-in atomic type name belongs to one of two namespaces: the XML Schema namespace http://www.w3.org/2001/XMLSchema, which is bound to the prefix xs, or the XQuery type namespace http://www.w3.org/2003/11/xpath-datatypes, which is bound to the prefix xdt.
Atomic values can be obtained in several different ways. As shown in Chapter 1, some types can be constructed using literals, and almost all atomic types can be constructed using the type constructor syntax. Atomic values can also be extracted from typed XML data using the data() function (see Section 2.6.1). Type conversion operators such as cast as (see Chapter 9) can convert values of one atomic type to a different type. And finally, many other XQuery functions and operators result in atomic values. Of these, all but the last category can also result in a user-defined type (derived from one of the built-in types).
XQuery uses a special type, xdt:untypedAtomic, for values from untyped XML data. This type derives from xdt:anyAtomicType and it behaves like a kind of weakly-typed string. In most cases it behaves exactly like xs:string, but some XQuery operators treat it differently in implicit type conversions. For example, xs:string("1") + 1 is an error because the string and integer types are incompatible for addition, but xdt:untypedAtomic("1") + 1 results in the double value 2E0—first the untyped value is promoted to double, then the integer is also promoted to double, and then the two are added together.
In this way, the “untyped” type allows users to work with untyped data without needing to add lots of explicit casts to the query. In fact, for the most part untyped data causes expressions to have the same meaning they did in XPath 1.0 (in which strings were converted to xs:double by most expressions).
Boolean values have the type xs:boolean, which derives from xdt:anyAtomicType. In XQuery, the two boolean constants true and false are written using the true() and false() functions, respectively. There are several other ways to create boolean values. One is to use the xs:boolean() type constructor, as mentioned in Chapter 1. Like all type constructors, this takes a single string argument and parses it into a boolean value. If the argument is “true” or “1,” then it results in true; if it is “false” or “0,” then it results in false, and anything else causes an error.
Another way is to use the fn:boolean() function, which takes any item sequence as its argument, and returns its Effective Boolean Value, as explained in Section 2.6.2. Many operators, such as and and or, convert their arguments to boolean using Effective Boolean Value.
Listing 2.3 illustrates these three ways to create boolean constants.
XQuery defines many numeric types, but you'll most frequently use the four types xs:float, xs:double, xs:integer, and xs:decimal, explained next.
Numeric types in all languages have two main aspects: how they handle the decimal point (integral, fixed, or floating) and how they handle precision (limited, arbitrary).
Integral numbers have no decimal point. They represent only integer numbers within some range.
Fixed-point numbers have a fixed number of digits after the decimal point. When this number is zero, they are equivalent to integers, but when it is positive, they can represent fractional amounts. (Some implementations also allow this number to be negative, in which case the number is integral and that many digits in front of the decimal point are all zero.) Fixed-point numbers are commonly used in financial and scientific applications when greater control over rounding is required, or when fractional numbers need to be compared exactly.
Floating-point numbers may have a variable number of digits after the decimal point. Most numeric operations on them suffer from some amount of round-off error, but can be implemented more efficiently and in less space (trading accuracy for efficiency).
Limited-precision numbers can represent only a finite number of digits (the precision). For non-integer numbers, the number of digits after the decimal point is the scale. Limited-precision numbers occupy a fixed amount of space, and are commonly implemented in hardware. Limited-precision numbers are similar to fixed-width string buffers.
As the name suggests, arbitrary-precision numbers can represent any number of digits. Arbitrary-precision numbers are similar to resizable string arrays. They can grow as necessary to represent more digits. They are much more accurate than limited-precision numbers, but are rarely implemented in hardware. Consequently, they are often several hundred or thousand times slower than limited-precision numbers.
XQuery defines sixteen numeric types, but you really need only four of them: xs:integer, xs:decimal, xs:float, and xs:double. These types correspond to integer, fixed-point, and single- and double-precision floating-point numbers, respectively. Most XQuery arithmetic expressions and functions promote their operands and arguments to one of these types (see Section 2.6.5).
The other 12 types all derive from xs:integer and represent special cases like xs:unsignedByte and xs:positiveInteger. Although a few implementations may optimize these types specially, they are available in XQuery primarily because they are part of XML Schema 1.0. XQuery has no complex number type.
In XQuery and XML Schema 1.0, the xs:integer and xs:decimal types are technically arbitrary-precision, but implementations are allowed to use limited-precision instead, so that arithmetic operations can be as efficient as possible. Because arbitrary-precision arithmetic is so much slower than limited-precision arithmetic commonly supported in hardware, most implementations do make this choice.
This implementation-defined behavior makes it impossible to port your XQuery applications from one implementation to another unless they make the same choice. Using limited precision to represent xs:integer or xs:decimal can also cause some confusion with derived types (like xs:unsignedLong, which occupies the range 0 to 264-1) that may require more bits than the implementation used for the base type xs:integer. For this reason, I recommend avoiding the types derived from xs:integer unless your XQuery implementation uses arbitrary-precision arithmetic.
All numeric types support the type constructor syntax. If the string does not parse according to the rules for that type, or maps to a value out of range, then an error is raised. For example, xs:integer("010") results in the integer 10, but xs:positiveInteger("-2") is an error.

The xs:integer, xs:decimal, and xs:double types can be constructed more simply using literal constants: Any sequence of digits without a decimal point is an integer literal. With a decimal point, the number is a decimal literal unless the number is followed by an exponent using scientific E-notation, in which case the number is a double literal. This means that in XQuery, xs:decimal is the default type for numbers containing decimal points (unlike other languages, in which float or double is the default). Listing 2.4 illustrates the difference.
Example 2.4. Numeric literals
12345 (: xs:integer("12345") :)
12.345 (: xs:decimal("12.345") :)
12.345E0 (: xs:double("12.345") :)
You should exercise some care when converting numeric types to and from string or other types, because the supported formats for numbers may not be what you expect (see Appendix A for exact definitions). In particular, XQuery uses a different conversion process from the one used by the printf() function in C.
Technically, the xs:double, xs:float and xs:decimal types are all unrelated to one another (xs:integer derives from xs:decimal). However, many XQuery operations do convert across these types. The general rule is that xs:decimal may be converted to xs:float or xs:double, and xs:float may be promoted to xs:double. See Section 2.6.5 for more information.
As with the numeric types, XQuery defines a large number of string types (13 in all—see Figure 2.2). However, you really only need the xs:string type, which represents any string value. String values can be constructed by single- or double-quoted strings and are also returned by most XQuery string functions. The xs:string type is used to represent a (possibly empty) sequence of Unicode code points (see Chapter 8).
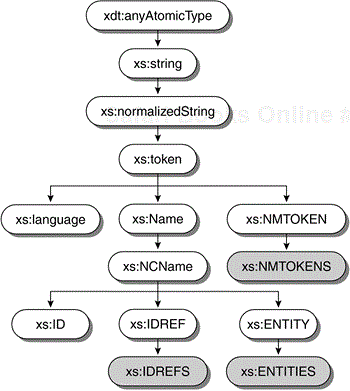
The other string types all derive from xs:string. All of these types can be constructed using the type constructor syntax, such as xs:ID("x") or xs:language("en-us"), except for the three special types xs:NMTOKENS, xs:IDREFS, and xs:ENTITIES (greyed out in Figure 2.2). These three types are odd because in XML Schema they derive by list from xs:string, but XQuery already has types for lists of values. Consequently, XQuery uses the sequence type xs:NMTOKEN* instead of the schema type xs:NMTOKENS. However, these three types are still “built-in” to XQuery, for example, for use with validate. See Chapter 9 and Appendix A for more details.
XQuery places no limit on the maximum length of a string; however, most implementations impose practical limits of anywhere between 216 bytes (64KB) and 232 bytes (1GB). Note that implementations usually store strings internally in the UTF-16 encoding, so most characters occupy two bytes in memory and some require up to four. So-called surrogate pairs (two special characters in a row, used to represent code points that don't fit in two bytes) are treated as a single character by most string functions (e.g., string-length), so you won't ever notice the underlying implementation.
XQuery defines five calendar types of interest: xs:date, xs:time, xs:dateTime, xdt:dayTimeDuration, xdt:yearMonthDuration. XQuery also defines another type, xs:duration, and five Gregorian calendar types (with names like xs:gDay) that you are unlikely to use. For details on the xs:duration and Gregorian types, see Appendix A.
The xs:date, xs:time, and xs:dateTime types represent a single point in time. The xdt:dayTimeDuration and xdt:yearMonthDuration represent time spans. All of these types are constructed using the type constructor syntax and a string representation of the value.
Programming with calendar types is notoriously difficult for a variety of reasons. The types are complex and they must satisfy somewhat arbitrary conditions. Some applications must also account for irregularities in the value space, such as leap years to historical changes, and in some cases legislated requirements.
The XQuery syntax for dates and times is derived from the ISO 8601 standard. XQuery accepts values of the form ...YYYY-MM-DDThh:mm:ss.sssssss...Z where the letters Y, M, D, h, m, and s are replaced by digits for years, months, days, hours, minutes, and seconds, respectively. Hyphens are used to separate the date parts (years, months, days), colons are used to separate the time parts (hours, minutes, seconds), and the letter T stands between the two. The seconds part can be fractional. The letter Z stands for an optional time zone designator. We explain each part next.

Also, XQuery defines functions for accessing each of these components, with names like get-hours-from-dateTime() and get-year-from-date(). See Appendix C for examples. These accessors may be simplified before XQuery is finalized.
Values of type xs:date have only the part before the T; xs:time values have only the part after the T; xs:dateTime values have both parts, including the T (see Listing 2.5).
Example 2.5. Date and time values
xs:date("2004-02-08") (: February 8, 2004 :)
xs:time("12:00:00") (: noon :)
xs:time("00:00:00") (: midnight :)
xs:datetime("2004-02-08T00:00:00") (: midnight Feb 8, 2004 :)
The year must always contain at least four digits (which is also the maximum number of digits that implementations are required to support) and may be preceded by an optional + or - sign (+ is the default). Leading zeros must be used if the year would have fewer than four digits; otherwise, leading zeros are not allowed. The year 0000 is also not allowed, but otherwise every year between -9999 and 9999 inclusive is supported, and some implementations may support years beyond this range.
The month must be a value between 01 and 12 inclusive. The day must be a value between 01 and 31 inclusive, and must be valid for the given month. For example, 28 is the maximum day value allowed for month 2 (February) in non-leap years. Both day and month must have exactly two digits.
The hour must be a value between 00 and 23 inclusive; the minutes must be a value between 00 and 59 inclusive; and the seconds must be a value between 00 and 60 inclusive. All three parts must have exactly two digits, using leading zeros if necessary. The fractional seconds part is optional. Implementations are required to support a minimum of up to at least seven digits after the decimal point (100 nanosecond resolution), although this requirement may be relaxed to only six digits (to match ANSI/SQL). Seconds with values greater than 60 but less than 61 are allowed, but only for leap-seconds.
For types that have a time component—xs:time and xs:dateTime—the time zone component may be empty or may have a value in hours and minutes. When parsing string values, the time zone designator can be omitted or can be the character Z; in both cases, it signifies Coordinated Universal Time (UTC). It can also specify a time offset in the form +hh:mm or -hh:mm, where the hours and minutes must both be two-digit numbers satisfying the same constraints as before. Listing 2.6 shows values with and without time zones.
Example 2.6. Time zones may be used with types that have a time component
(: February 8, 2004, 3:41 pm, Pacific Standard Time :)
xs:dateTime("2004-02-08T15:41:00-08:00")
(: the same time in UTC :)
xs:dateTime("2004-02-08T23:41:00")
Note that this definition differs slightly from that of XML Schema 1.0: When no time zone is specified, the XQuery constructors normalize the values to the time zone Z and have an empty sequence time zone part.
Durations define time and/or date spans. They are designed to be added to existing date/time values to produce new date/time values. For example, today plus a one-day duration is tomorrow.
The xs:duration type is part of the XML Schema 1.0 standard. The other two duration types were added by XQuery to make up for a deficiency in the xs:duration type, namely that it is not totally ordered for use in comparisons. Just as xs:date and xs:time can be viewed as subsets of xs:dateTime, so xs:yearMonthDuration and xs:dayTimeDuration can be viewed as subsets of xs:duration, containing only the year/month or only the day/time parts of the duration, respectively.
The format for a duration is PnYnMnDTnHnMnS. Every duration begins with the letter P (for “period” of time). The remaining parts are optional, although at least one part must be present. Each part consists of an arbitrary non-negative number (n) followed by a capital letter designating which part it represents: year, month, day, hour, minute, or second, respectively. The entire duration may be negated by using a leading minus sign (leading plus is not allowed).
As before, the T separates the date and time parts of the duration. For durations, T is also used to disambiguate the M used for months from the M used for minutes. P1M designates one month, while PT1M designates one minute (and P1MT1M means one month and one minute). The T must be omitted in xdt:yearMonthDuration values, and also in xdt:dayTimeDuration values when there is no time component.
Unlike the numbers used in date/time values, the numbers in durations are not constrained to fit within any given range, and leading zeros are allowed. For all parts other than seconds, the number must be an integer; the seconds value can be any non-negative decimal number. Consequently, there are many different ways to represent the same duration, (e.g., P1Y is the same as P12M). Listing 2.7 shows two different durations.
XQuery has one type for qualified names: xs:QName. This type is used to represent an XML name. Recall that XML names consist of two significant parts, the local name and namespace name. In some respects, xs:QName behaves like a structure containing this pair of values, and in other respects it behaves like an ordinary atomic value.
The xs:QName type is special in that it cannot be constructed using the type constructor syntax, but instead has its own special constructor function, expanded-QName(). This function takes two arguments, the namespace name and the local name, and constructs the corresponding xs:QName value. For example, expanded-QName("http://www.awprofessional.com/", "hello") constructs a QName with namespace part equal to http://www.awprofessional.com/ and local part equal to hello.
QName values can also be constructed using a prefix and local part by looking up the namespace in scope for that prefix. The function resolve-QName() takes a qualified name string (with prefix) and an element to provide namespace scope, parses the string, looks up the namespace corresponding to that prefix, and returns the corresponding QName. If there isn't a prefix, then the default namespace is used. If there isn't a namespace in scope for a prefix, then an error is raised. For example, resolve-QName("hello", <x xmlns = "http://www.awprofesional.com/" />) produces the same QName value as the previous example.
As with the calendar types, XQuery provides functions for accessing the individual parts of an xs:QName value: get-local-name-from-QName() and get-namespace-from-QName(). Each of these takes a QName value and returns an xs:string with the corresponding part of the QName value. These accessors are demonstrated in Listing 2.8.
XQuery defines four other types not already mentioned in this chapter: xs:anyURI, xs:NOTATION, and the binary types xs:base64Binary and xs:hexBinary, all of which are from XML Schema 1.0. It is unlikely you will ever use these types, but if you do, see Appendix A for information.
XQuery also supports user-defined types (see Chapter 9). Any user-defined type can be named in an XQuery—for example, for use with the validate operator—but only types that derive by restriction can be constructed as values. Types that derive by union or derive by list such as xs:IDREFS, xs:ENTITIES, and xs:NMTOKENS cannot be constructed as values in a query.
XQuery, like XPath, has seven node kinds. These have the type names attribute(), comment(), document-node(), element(), namespace(), processing-instruction(), and text().
Like atomic values, nodes can be obtained in a couple of different ways: by selecting them from existing XML documents (typed or untyped), or by using XQuery construction expressions (see Chapter 7) to create them in the query.
Nodes have several properties observable either directly or indirectly (see Table 2.1). Some properties apply only to certain kinds of nodes; in such cases, the value for other node kinds is the empty sequence. These properties are described in the following sections.
Table 2.1. Node properties
Property | Type | XQuery Accessor |
|---|---|---|
attributes |
|
|
base-uri |
|
|
children |
|
|
identity | n/a | n/a |
namespaces |
|
|
nilled |
| n/a |
node-kind |
|
|
node-name |
|
|
order | n/a | n/a |
parent |
|
|
string-value |
|
|
type |
| n/a |
typed-value |
|
|
unique-id |
|
|
Nodes in the XQuery Data Model have three fundamental properties: node kind, node identity, and order. Every node has these properties.
The node kind of a node is its XML node kind (such as “element” or “comment”). XQuery has navigation operators that can select nodes by node kind (see Chapter 3) and type expressions such as typeswitch that can be used with them to compute the node kind as a string value (see Chapter 9).
Each node has a unique node identity. This identity is not a value, although XQuery provides comparison operators to determine whether two nodes have the same identity or not (see Chapter 5). Node identity should not be confused with similarly named but completely unrelated concepts such as the xs:ID type and the unique-id node property.
All nodes, even those from different documents, are ordered relative to each other. Like node identity, this ordering isn't directly observable as a value, although XQuery provides several operators that can be used to determine whether one node is ordered before or after another (again, see Chapter 5). This is an absolute ordering that doesn't depend on the current expression, and it shouldn't be confused with the relative position of a node in a sequence.
The node ordering is often called document order, because it corresponds to the order of appearance of these nodes in the XML serialization of a document—that is, a pre-order, left depth-first traversal of the tree. However, this nomenclature is misleading because even nodes from different documents are ordered relative to one another; in this case, the ordering can vary from one execution of a query to the next, although it is required to be stable during the execution of a single query.
When we think of nodes, probably the first aspect that comes to mind is their hierarchical nature. In the XQuery Data Model, every node belongs to exactly one tree, and every tree has exactly one root node (trees are never empty). When the root node kind is document, the tree is called a document; otherwise, it is called a fragment. Some node properties relate to the structure of this tree; other properties (such as unique-id) may be scoped to a tree.
Navigation through this hierarchy is supported through a variety of operators (see Chapter 3), but in the XQuery Data Model it is quite simple: Every node has four properties related to hierarchy—parent, children, attributes, and namespaces.
The parent of a node is either the unique document or element node that contains it, or else the empty sequence (for the root node, which has no parent). The children of a node are the nodes it contains, and are always text, processing-instruction, comment, or element node kinds. The attributes and namespaces of a node are its sequences of attribute and namespace nodes, respectively, and may be empty. A node is the parent of its children, attributes, and namespaces.
Only the element and document node kinds may have children, and only the element node kind may have attributes and namespaces; for all other node kinds, these properties are always empty. The document node always has at least one child. The element node may have any number of children (including none), and also any number of attributes and any number of namespaces.
Element and attribute nodes have a node name property that is the qualified name of the node; for all other node kinds this property is the empty sequence. The name property is accessible in an XQuery using the node-name() function, which takes a single node argument and returns the xs:QName value that is its name (or else the empty sequence, for node kinds that have no name). Remember that qualified names consist of the namespace and local parts only; the prefix matters only in the serialization format and isn't part of the data model.
For backwards compatibility with XPath 1.0, XQuery also supports three other functions for retrieving the name, or parts of the name, of a node: name(), local-name(), and namespace-uri(). All three functions take an optional node argument and return a string value. If no node is specified, then the current context item (see Chapter 3) is used as the argument.
The local-name() and namespace-uri() functions return the local and namespace parts of the node name, respectively. If the name doesn't have one of those parts, or if the node has no name, then the empty string is returned.
The name() function is somewhat unusual. It returns the unparsed name string, consisting of the prefix, if any, and the local part of the name. Implementations are allowed to preserve the original prefix used, or use any prefix in scope that is bound to the namespace of the node, or else generate a new prefix distinct from all prefixes in scope. If the node has no name, then name() returns the empty string.
Listing 2.9 shows the effect of these functions on an element node.
Element and attribute nodes also have a type (for all other node kinds, the type property returns the empty sequence). Even if the XML data is untyped, the XQuery Data Model assigns a special type, xdt:untypedAtomic, to the node. Otherwise, the type of the node is its XML Schema type.
The XQuery Data Model treats each node type as a qualified name (xs:QName). Although this type name isn't directly accessible in an XML query, many operators, such as typeswitch, can use the type name of a node (see Chapter 9).
The typed-value and string-value of a node are used by many XQuery expressions, and consequently have functions dedicated to them: fn:data() and fn:string(), respectively. Both of these functions can be applied to a node, in which case they return its typed value or string value accordingly.
Actually, fn:data() takes any sequence of items and returns a sequence of atomic values. Items that are already atomic values are returned unchanged; items that are nodes are replaced by their typed values. For example, an element typed as xs:integer with the content 42 has as its typed-value the integer 42 (see Listing 2.10). Only simple-typed elements and attributes can have a typed value; for all other node kinds, and for complex-typed elements, the typed value is empty.
The string-value of a node is always a single string, which is the string representation of the node. This string may differ from the original representation of the node. For example, the string-value of a node with complex content is the concatenation of the string values of all its descendants (see Listing 2.11).
Additionally, the XQuery Data Model keeps track of whether an element is nilled. Nillable elements are typed elements that allow their content to be empty. For example, an integer normally must contain some digits; a nillable integer allows no digits to occur (in which case the typed value is the empty sequence). The nilled property is true for an element node if it is nillable and its typed-value is empty; otherwise, nilled is false. This property is not directly accessible in an XQuery, although there are several expressions that can indirectly test whether an element is nil, such as the path self::*[@xsi:nil="true"] or the type test instance of element(*, * nilled). See Chapter 9 for additional information about nil elements.
Document, element, and processing-instruction nodes also have a base-uri property, which can be accessed using the base-uri() function. This function takes a single node argument and returns an xs:anyURI value or the empty sequence. For other node kinds, base-uri() returns the base-uri of the parent node, or the empty sequence if there is none.
Some elements may have an attribute that is typed as xs:ID (using a schema or DTD). There can be only one such attribute on an element. Every ID within a tree must be unique, and satisfy the lexical constraints of the xs:ID type (see Appendix A). The unique ID of an element can be retrieved using the unique-id() function.
Now that you understand the core features of the XQuery Data Model and type system, you're ready to learn about three related operations that are applied by many XQuery expressions: atomization, Effective Boolean Value, and sequence type matching.
Atomization is the process of turning a sequence of items into a sequence of atomic values. Atomization is applied by many expressions that work only on atomic values (for example, arithmetic operators).
Atomization takes a sequence of items and returns atomic values in it unchanged, but replaces nodes by their typed values. The typed value of a single node can itself be a sequence of atomic values; for example, a node typed as xs:IDREFS by an XML Schema atomizes to a sequence of xs:IDREF values.
An expression can be atomized explicitly by applying the data() function as shown in Listing 2.12; however, many operators also atomize their operands implicitly (see Chapter 5).
The Effective Boolean Value (EBV) is the process of converting a sequence of items into a logical value (true or false). The EBV can be computed explicitly by applying the boolean() function, and many operators, such as and and or, apply EBV implicitly to their operands (see Chapter 5).
The EBV of a sequence is false if the sequence is empty, true if the sequence contains more than one item, and otherwise depends on the single item. The EBV of a singleton boolean value is that value unchanged. The EBV of a string is false if the string is empty, and true otherwise. The EBV of a number is false if the number is zero or NaN, and true otherwise. For all other types (including nodes), the EBV is true. In other words, EBV essentially tests for existence, non-zero and non-NaN numbers, and non-empty strings.
Don't confuse EBV with a cast to xs:boolean type, which follows a different set of rules (see Chapter 9).
Section 2.3.1 introduced the sequence type syntax, which can be used to express the type of an expression. For example, xs:integer* means a sequence of zero or more integers, and (element() | document-node())? means zero or one document or element nodes.
Because XQuery is strongly-typed, meaning that every expression has a type and that types of values used together must be “compatible”— an integer cannot be added to a string, for example. As mentioned in Chapter 1, some implementations perform type checking statically, while others perform only dynamic type checking. Also, many XQuery operators (see Chapter 9) perform various kinds of type checking. The process of determining whether one type matches another is called sequence type matching.
Sequence type matching is a complex process, but central to the design of the XQuery language. Although this is explained completely here, you can safely skim the explanation below for now and return to it as necessary.
If two sequence types are exactly equal, then of course they match. More commonly you find yourself wondering, for example, whether an xs:integer expression can be used in place of an xs:decimal one (or vice versa), or whether a sequence of elements can be used for a sequence of nodes (or vice versa).
The only expression that matches the empty() type is the empty sequence. Otherwise, the expression must match both the occurrence indicator and item type parts of the sequence type.
If there isn't an occurrence indicator, then the expression matches only if it is a singleton. If the occurrence indicator is +, then the expression matches only if it is non-empty. If the occurrence indicator is ?, then the expression matches only if it is empty or a singleton. Every expression matches the * occurrence indicator.
Independently, each item in a non-empty sequence must match the item type. The item type item() matches any item. An atomic type name matches that type and any type derived (by restriction) from that type. For example, the xs:decimal type matches an expression with type xs:integer (because xs:integer derives from xs:decimal); however, the xs:integer type does not match an expression with type xs:decimal.
The node() item type matches any node. The other node kind item types, such as comment() or text(), match only those node kinds. The element(), document-node(), processing-instruction(), and attribute() item kinds may take an optional argument. Without an argument, these match any node of that kind.
When the processing-instruction() type is used with an optional string argument, it matches only processing-instruction nodes whose name (aka PITarget) is that value. For example, processing-instruction("X") matches <?X?> but not <?Y?>, while processing-instruction() matches both.
When the document-node() type is used with an optional element test argument, it matches document nodes containing a single element matching that element test. For example, document-node(element(X)) matches any document node containing a single element named X, while document-node() matches any document node at all.
Element and attribute sequence types are much more complicated. When used without arguments, or when used with wildcard arguments, they match any element or attribute at all. For example, element(), element(*), and element(*,*) match all elements. Otherwise, these tests can specify a name and or a type, in which case they match only nodes with that name or type (or derived from that type by restriction). For example, attribute(@foo) matches attributes named foo, while attribute(@foo, xs:integer) matches any attribute named foo whose type is xs:integer (or a type derived from xs:integer). See Appendix A for additional examples.
Most XQuery expressions, especially those that work with numbers, allow subtype substitution. Subtype substitution takes place whenever an expression requires some type T but will accept a value whose type is a subtype of T. For example, a function declared as taking an argument of type xs:decimal will accept a value of type xs:integer passed to it, because xs:integer is a subtype of xs:decimal. Subtype substitution does not change the value.
Subtype substitution is similar to subclassing in object-oriented languages. In such languages, a variable of type T may be assigned to an object that is a subclass of T. The type of the variable is still T, even though the type of its value is a subclass of T.
Many XQuery numeric expressions, especially arithmetic operators and function invocations, apply numeric type promotion. Type promotion is a common feature of most languages, although in XQuery it behaves a little differently than usual.
The type xs:float can be promoted to xs:double. This type promotion may cause loss of precision but doesn't otherwise change the value.
The type xs:decimal can be promoted to both of the types xs:float and xs:double. The result is the floating-point value of that type that is closest to the original decimal value. This promotion can cause loss of precision and may alter the value significantly when the decimal value is much larger than the largest possible, or smaller than the smallest, floating-point value of that type.
The second of these allows xs:integer—and other subtypes of xs:decimal—to be promoted to xs:float or xs:double, first by performing subtype substitution treating the xs:integer (or other subtype) as an xs:decimal value, and then applying the type promotion rule for xs:decimal.
In this chapter, we explored the XQuery Data Mode and type system. Every XQuery Data Model consists of a sequence of items. Items are nodes or atomic values.
There are seven kinds of nodes. Every node belongs to exactly one tree; every tree is a document or fragment (depending on whether the root node is a document node or not). Nodes have various properties, some of which are directly obtainable in a query, such as name and kind, and others that cannot be retrieved as values but do affect many query operations, such as identity and document order.
Atomic values are instances of atomic types (built-in or user-defined). They can be created within a query itself, or retrieved from typed XML nodes. Early XML query languages such as XSLT had too few types, a problem XQuery deftly avoids with its 50 atomic types. Of these, you'll certainly use at least eight: xs:boolean, xs:string, xs:integer, xs:decimal, xs:double, xdt:anyAtomicType, xdt:untypedAtomic and xs:QName and possibly another six: xs:float, xs:date, xs:time, xs:dateTime, xdt:yearMonthDuration, and xdt:dayTimeDuration. If you ever need any of the rest, Appendix A awaits you.
XQuery provides a convenient atomic value constructor syntax, typename ("value"), that can be used to construct any atomic type, even user-defined ones, except for those types, like xs:IDREFS, that are derived by list or union. XQuery also provides a convenient node constructor syntax, already mentioned in Chapter 1 and described in greater detail in Chapter 7.
Many XQuery operations implicitly promote or convert their arguments. Two common cases are atomization and Effective Boolean Value, which result in a sequence of atomic values or a boolean value, respectively.
And finally, XQuery uses a sequence type syntax to describe types of expressions. A process known as sequence type matching is applied to determine when an expression with one type may be used in a context expecting a different type.
An understanding of XML Schema is not necessary to use XQuery, but will certainly be helpful in understanding some of the deeper complexities of the XQuery type system. The book Definitive XML Schema by Priscilla Walmsley is a great practical introduction to XML Schema.
W3C references for the many other data models briefly mentioned in this chapter can be found in the Bibliography. A deep look at the design influences and rationale of XQuery and its data model and type system can be found in Chapter 1 of the book XQuery from the Experts: A Guide to the W3C XML Query Language by Howard Katz. The book Data on the Web: From Relations to Semistructured Data and XML by Serge Abiteboul, Dan Suciu, and Peter Buneman explores some of the connections between the document and database models, from a more academic perspective.