
Chapter 3. Context Aware Agents
Imagine you’re in a security-conscious organization. Each employee is given a highly credentialed laptop to do their work. With today’s work and personal life blending together, some also want to view their email and calendar on their phone. In this hypothetical organization, the security team applies fine-grained policy decisions based on which device the user is using to access a particular resource.
For example, perhaps it is permissible to commit code from the employee’s company issued laptop, but doing so from their phone would be quite a strange thing. Since source code access from a mobile device is decidedly riskier than from an enrolled laptop, the organization blocks such access. That said, an employee accessing corporate email from a personal device may be permitted. As you will learn throughout this chapter, context is critical when making decisions in a zero-trust environment.
The story described here is a fairly typical application of zero trust, in that multiple factors of authentication and authorization take place, concerning both the user and the device. In this example, however, it is clear that one factor has influenced the other—a user which might “normally” have source code access won’t enjoy such access from their mobile device. Additionally, this organization does not want authenticated users to commit code from just any trusted device—they expect users to use their organization’s device.
This marriage of user and device is a new concept that zero trust introduces, which we are calling an agent. In a zero trust network, it is insufficient to treat the user and device separately, because policy often needs to consider the two together to accurately enforce desired behavior. By defining an agent formally in the system, we are able to capture this relationship and use it to drive policy decisions.
This chapter will define what an agent is and how it is used. In doing that, we will discuss the types of data that are included in an agent, some of which is potentially sensitive. Given the nature of that data, we will discuss when and how an agent should be exposed to data plane systems. An agent, being a new concept, could benefit from standardization. We will explore the benefits of standardizing this agent.
What Is an Agent?
An agent is a combination of data known about the actors in a request. This typically consists of a user (also known as the subject), a device (an asset used by the subject to make the request), and an application (Web App, Mobile App, API endpoint etc.). Traditionally, these entities have been authorized separately, but zero trust networks recognize that policy is best captured as a combination of all participants in a request. By authorizing the entire context of a request, the impact of credential theft is greatly mitigated.
It’s best to think of an agent as an ephemeral entity that is formed on demand to evaluate a policy. The data that is used to form an agent—user or device information— will typically be stored in persistent storage and queried to form an agent.
When this data is queried, the union of the data at that point in time is what we call an agent. The benefit of this approach is that any changes to the data used to form an agent will change the agent itself. For example, if a user’s role changes, the agent used to evaluate policy for that user will also change. If a device is unenrolled from the system, any agents associated with that device will no longer be valid.
What is a subject?
The term “user” is commonly used to refer to user identity, but it is important to understand that the term “subject” is also used, particularly by standard bodies such as National Institute of Standards and Technology (NIST) and others, to define both human and non-human users (like headless or machine identities). This distinction will be emphasized further in subsequent chapters when we examine users in Chapter 6 and devices in Chapter 5. When we talk about the user in the rest of this chapter, we mean both user and machine identities.
Agent Volatility
Some fields in the agent are made available specifically to mitigate against active attacks, and are therefore expected to change rapidly relative to the infrequent changes that IT organizations normally expect. Trust scores are an example of this type of dynamic data. Trust score systems can evaluate each request in the network, using that activity feed to update the trust scores of users, applications, and devices. Therefore, in order for a trust score to mitigate a novel attack, it needs to be updated as close to real time as possible. Chapter 4 goes into greater detail about trust scores.
In addition to rapidly changing data, agents will frequently have sparse data. A device undergoing bootstrapping is an example scenario where the agent will have less data when compared to a mature device. During the bootstrapping process, little is known about the device, yet it must still interact with corporate infrastructure to perform tasks like device enrollment and software installation. In this case, the bootstrapping device is not yet assigned to a user and can run into problems if policy expects an assigned user to be present in the agent. This scenario should be expected and reflected in the authorization policy.
Sparse data isn’t just found in bootstrapping scenarios. Autonomous systems in a zero trust network will frequently have sparse data when compared to human-operated systems. These systems, for example, will likely not authenticate the user account the application runs under, relying instead on the security of the configuration management system that created that user.
What’s in an Agent?
The granularity of data contained within an agent can vary based on needs and maturity. It can be as high level as a user’s name or a device’s manufacturer, or as low level as serial numbers and place of residence or issue. It should be noted that the more detailed data is more likely to have data cleanliness issues, which must be dealt with.
Agent Data Fields
The type of data stored in an agent can greatly vary in both presence and granularity. Here are some examples of data that one might find in an agent:
-
Agent trust score
-
User trust score
-
User role or entitlements
-
User groups
-
User location
-
User authentication method (MFA, Password, etc.)
-
Device trust score
-
Device manufacturer
-
Host operating system manufacturer and version
-
Hardware Security Module (HSM) manufacturer and version
-
Trusted Platform Module (TPM) manufacturer and version
-
Current device location
-
IP address
Another point of consideration is if the data contained in the agent is trusted or not. For instance, device data populated during the procurement process is more trusted than device data which is reported back from an agent running on it. This difference in trust arises from difficulties in ensuring the accuracy and integrity of the reported information in the event that the device is compromised.
How Is an Agent Used?
When making an authorization decision in a zero trust network, it is the agent that is in fact authorized. While it is tempting to authorize the device and user separately, this approach is not recommended. Since the agent is the entity which is authorized, it is also the thing against which policy is written.
As noted in the previous section, the agent carries many pieces of information. So while more “traditional” authorization information like IP address can still be used, leveraging the agent also unlocks the use of “nontraditional” authorization information like device type or city of residence. As such, zero trust network policy is written against the agent as a whole, as opposed to crafting disjoint user and device policy. Using an agent to drive authorization policy encourages authors to consider the totality of the communication context. The marriage of user and device is very important in zero trust authorization decisions, and co-locating the data in an agent makes it difficult to ignore one or the other. As with other portions of the zero trust architecture, lowering barrier to entry is key, and co-locating the data to make device/user comparisons easier is no different.
Data co-location
When user and device data are combined or co-located in a request forming an agent requesting access to a resource, the overall context becomes much clearer.
Consider the following scenario: Adam requests access to a high business impact quarterly sales report via his iPhone running iOS operating system, which he uses as part of Bring Your Own Device (BYOD). If his iPhone does not have any mobile device management solution installed on it that can perform policy enforcement, his request may be denied because the device used is not considered trustworthy. The combination of user and device attributes is critical here; otherwise, Adam has access to the report as a user.
An agent, being the primary actor in the network, plays an additional role in the calculation of trust scores. The trust engine can use recorded actions, in addition to data contained within the agent itself, to score agents for their trustworthiness. This trust score will then be exposed as an additional attribute on the agent against which most policy should be defined. We’ll talk more about how the trust score is calculated in the next chapter.
Agents are Not for Authentication
It is important to understand the difference between authentication and authorization in the context of an agent. Agents serve solely as authorization components and do not play any part in authentication. In fact, authentication is a precursor to agent formation and is generally performed separately for user and device. For example, devices could be authenticated with X.509 certificates, while users might be authenticated through a traditional multifactor approach.
Following successful authentication, the canonical identifiers for users and devices can be used to form an agent and its details. A device-specific certificate might be used as the canonical identifier for the device and therefore be used to populate information like device type or device owner. Similarly, a username might serve as the lookup key to populate user information like their role in the company.
Typically authentication is session oriented, but in the case of authorization, it is best to be request oriented. As a result, caching the outcome of an authentication request is permissible, but caching an agent or the result of an authorization request is ill advised. This is because details in the agent, which are used to make authorization decisions, can change rapidly based on a number of factors, and it is desirable to make authorization decisions using the latest data. This is in contrast to authentication materials, which change much less often and don’t directly affect authorization itself.
Finally, the act of generating an agent should be as lightweight as possible. If agent generation is expensive, it will discourage frequent authorization requests due to performance reasons. We will talk more about how performance affects authorization in the next chapter.
Revoke Authorization First, Credentials Second
Successful authentication is the act of proving one’s identity to a remote system. That verified identity is then used to determine if the user actually has rights to access the resource in question (the authorization). In the event that access must be revoked, updating authorization is more effective than changing authentication credentials. This is doubly so when considering that authentication results are typically cached and assigned to session identifier. The act of validating an authenticated session is really an authorization decision.
How to Expose an Agent?
The data contained in an agent is potentially sensitive. Personally identifiable user information (e.g., name, address, phone number) will usually be present on the agent to facilitate detailed authorization decisions. This data should be treated with care to protect the privacy of users.
The sensitive nature of the data extends beyond users, however. Device details can also be sensitive data when it falls into the hands of a determined attacker. An attacker with detailed knowledge of a user’s device could use that data to craft a targeted remote attack, or even learn a pattern of that user’s physical location to steal the device.
To adequately secure the sensitive agent details, the entirety of the agent lifecycle should be contained to trusted control plane systems, which themselves are heavily secured. These systems should be logically and physically separated from the data plane systems, have clear boundaries, and change infrequently.
Most policy decisions will be made in the control plane systems, since the agent data is needed to make those decisions. However, it will often be the case that the authorization engine in the control plane is not in the best position to enforce application-centric policy, despite its ability to enforce authorization on a request-by-request basis. This is especially so in user-facing systems. As a result, some agent details will need to be exposed to data plane systems.
Let’s look at an example. An administrative application stores details on all the customers of a particular company. This system exposes that data to employees based on their role within the company. A search feature allows employees to search within the subset of data that they are allowed to access. The application needs to implement this logic, and it needs access to the role of the user in order to do so.
In order to allow applications to implement their own fine-grained authorization logic, agent details can be exposed to applications via a trusted communication channel. This could be as simple as injecting headers into network requests that flow through a reverse proxy. The proxy, being a zero trust control plane system, can view the agent to enforce its own authorization decisions and expose a subset of the data to the downstream application for further authorization.
Exposing agent details to the downstream application can also be useful to enable compatibility with pre-existing applications that have a rich authorization system. This compatibility goal highlights that agent details should be exposed to the application in a format that is preferred by the application. For third-party applications, the format of the agent data will vary. For first-party applications, a common structure for the agent data will ease management of the system.
Rigidity and Fluidity, at the Same Time
Knowing the format of an agent, and where to find particular pieces of data within it, is very important when considering how and by what it will be consumed. The “coordinates” of certain pieces of data must be fixed and well known in order to ensure consistency across control plane systems. A good analogy here is the schema of a relational database, which applications accessing the data must have knowledge of in order to extract the right pieces of information.
This data compatibility is extremely important when it comes to implementing and maintaining zero trust control plane systems. Zero trust networks, particularly more mature ones, are likely to construct an agent from multiple systems and data sources. Without a schema of sorts, not only will it be difficult to surface the data in a consistent manner, but it will also contribute negatively to the amount of effort required to introduce new control plane systems or agent data, something which is considered critical for a maturing zero trust network.
One thing to keep in mind, however, is that agent data is likely to be fairly sparse, thanks to the practically unavoidable data cleanliness issues encountered in source systems like device inventories. The result is a “best-effort” agent, where many fields may be unpopulated for one reason or another. Rather than seeking data cleanliness (a problem that only gets harder with scale), it is best to accept reality and craft policy that understands that not all data may be present. So while one may still require a particular piece of data to be present in the agent, it is a useful thought exercise to consider alternative pieces of data in its absence.
Standardization Desirable
One might wonder how it would be possible to standardize a data format that is so seemingly inextricably tied to the organization consuming it. After all, an agent is likely to contain information types that relate to business logic or other proprietary/local information. Is standardization even feasible in such a case?
Luckily, there are already some standards out there defining data formats that behave in such a way. One of the best examples is the Simple Network Management Protocol (SNMP), and its associated management information base (MIB).
SNMP is a protocol frequently used for network device management, allowing devices to expose data to operators and management systems in a standard yet flexible way. The MIB component describes the format of the data itself, which is a collection of OIDs, or object identifiers. Each OID describes (and is reserved for) a particular piece of data and is registered with ISO, a global standardization body. This lends itself well to widely accepted “coordinates” for certain pieces of data. Let’s look at an example, shown in Figure 3-1, of a simplified set of nodes in an OID tree.
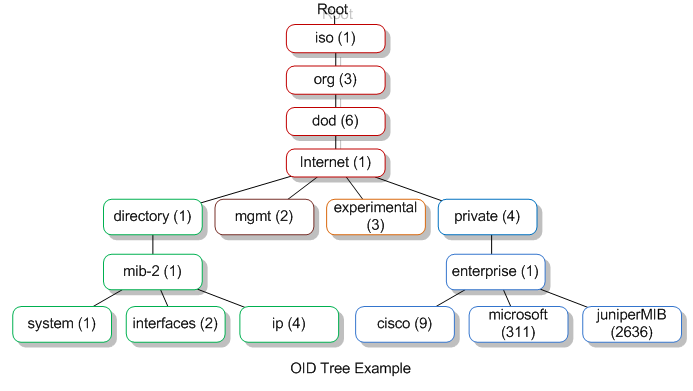
Figure 3-1. A simplified diagram showing the organization of nodes in an object identifier (OID) tree
In this example, the “ip” node and associated data would be addressed as 1.3.6.1.1.1.4. A MIB arranges and gives color to a set of OIDs. For example, a Cisco MIB might provide definitions for all OIDs under the 1.3.6.1.4.1.9 portion of the tree, including human-readable descriptions.
Of course, this registered list can be extended, and oftentimes chunks of OID space are carved out for organizations or manufacturers. In this way, an OID can be compared to an IP address, where an IP address globally identifies a computer system and an OID globally identifies a piece of data.
Unfortunately, there is no good OID equivalent of private IP address space, which would be useful for ad hoc or site-specific data. The best available compromise is to register (http://pen.iana.org/pen/PenApplication.page) for a Private Enterprise Number with IANA, which will give you a dedicated OID prefix for private use. Luckily, such registration is free and with few questions asked. There have been some efforts to create a private range similar to that found in IP. However, such efforts have been unsuccessful. Despite the lack of a truly free/private OID space for experimental or internal use, SNMP remains a useful analogy to make when considering the standardization of an agent. It describes the format and packaging of a set of data—data that is easily found and identified using their unique OIDs—and how that data can be transmitted and understood from one system to another.
In the Meantime?
While there have been several developments in zero trust networks in recent years, and standard bodies such as National Institute of Standards and Technology (NIST) and others have issued architecture guidance, agent standardization remains primarily an implementation task. In the meantime, agents take the form of least resistance, given the needs of the implementor. Whether it be a JSON blob, signed and encrypted JSON Web Token (JWT), Protocol Buffers,FlatBuffers, or a any other custom binary format, it is recommended to ensure that the data contained within it be flexible and easily extensible. Loose typing or no typing should be preferred over strong typing, as the latter will make introducing new data and systems more difficult. Pluggable design patterns may help in moving to a standardized agent in the future. However, this is far from required, and should not be pursued if they impede the adoption of agent authorization in your network.
The following is an illustration of a possible JSON that carries an agent information.
{
"iss": "Wayne Corporation ",
"iat": 1676938201,
"exp": 1708474201,
"aud": "APP01091",
"sub": "[email protected]",
"given_name": "Bob",
"email": "[email protected]",
"assigned_roles": [
"Manager",
"Project Administrator"
],
"device_id": "D98VCVQ3JMBH",
"device_patched": "yes",
"device_os_version": "13.2 (22D49)",
"device_os_type": "MacOS",
"user_id": "UID1233",
"user_location": "Dallas,TX",
"user_ip_address": "1.2.3.4",
"user_auth_method": "X.509",
"trust_score": "7"
}Once signed and encoded, the JSON from above yields a JWT token that looks like the one below. Any common JWT decoder will work to decode it. For instance, by pasting the encoded token into website like https://jwt.io , you can decode its content online. Note that you can also encrypt the token, though the example omits this step for clarity.
eyJ0eXAiOiJKV1QiLCJhbGciOiJIUzI1NiJ9.eyJpc3MiOiJXYXluZSBDb3Jwb3JhdGlvbiAiLCJpYXQiOjE2NzY5MzgyMDEsImV4cCI6MTcwODQ3NDIwMSwiYXVkIjoiQVBQMDEwOTEiLCJzdWIiOiJib2JAd2F5bmVjb3JwLmNvbSIsImdpdmVuX25hbWUiOiJCb2IiLCJlbWFpbCI6ImJvYkB3YXluZWNvcnAuY29tIiwicm9sZSI6WyJNYW5hZ2VyIiwiUHJvamVjdCBBZG1pbmlzdHJhdG9yIl0sImRldmljZV9pZCI6IkQ5OFZDVlEzSk1CSCIsImRldmljZV9wYXRjaGVkIjoieWVzIiwiZGV2aWNlX29zX3ZlcnNpb24iOiIxMy4yICgyMkQ0OSkiLCJkZXZpY2Vfb3NfdHlwZSI6Ik1hY09TIiwidXNlcl9pZCI6IlVJRDEyMzMiLCJ1c2VyX2xvY2F0aW9uIjoiRGFsbGFzLFRYIiwidXNlcl9pcF9hZGRyZXNzIjoiMS4yLjMuNCIsInVzZXJfYXV0aF9tZXRob2QiOiJYLjUwOSIsInRydXN0X3Njb3JlIjoiNyJ9.eSE9Onzyb3s_WGGi5kE2eaH5h8KVCSlOcCoNeWMWwOE
Sharing Agent Data Fields Using JWT
JSON Web Token (JWT), as defined by RFC 7519, is a compact way for two parties to exchange claims. JWTs are encoded as JSON objects that can carry the data fields needed to represent an agent. Additionally, you can also digitally sign and encrypt the JWT token when sharing information about an agent to ensure high integrity and confidentiality.
Protocol buffers, as shown below, are another popular cross-platform mechanism for serializing structural data that can be used to represent agent information. Look at the protocol buffers message definition of an agent below stored in the “agent.proto” file. The protocol buffers message definition needs to be stored with .proto file extension.
syntax = "proto3";
package waynecorp.agent;
import "google/protobuf/timestamp.proto";
message Agent {
string device_id=1;
bool device_patched=2;
string device_os_version=3;
string device_os_type=4;
string user_id=5;
string given_name = 6;
string email=7;
string user_location=8;
string user_ip_address=9;
string user_auth_method=10;
int32 trust_score=11;
string iss=12;
string aud=13;
google.protobuf.Timestamp iat=14;
google.protobuf.Timestamp exp=15;
repeated Role assigned_roles=16;
message Role{
string role_name=1;
}
}After the message definition is created, the required code artifacts are created using the targeted platform of choice, in this case Python (but all major platforms are supported). For example, the following command generates the code artifacts required to both persist data (serialization) and read/prase data (deserialization) for the agent defined above.
protoc -I=. --python_out=. ./agent.proto
The command above generates the “agent pb2.py” Python file, which you can use to create an agent object, and use methods to persist it to the file, and read it back as shown in the sample code below. For more information about the methods please review the the Python reference for protocol buffers.
import agent_pb2 as agent_v1
agent = agent_v1.Agent()
# Not all fields are set for brevity
agent.iss = "Wayne Corporation"
agent.aud="APP01091"
agent.user_id="UID1233"
# Seralize the agent as string
agent_obj = agent.SerializeToString()
print(agent_obj)
# Write the agent back to disk.
with open("agent.bin","wb") as f:
f.write(agent.SerializeToString())
# Read the agent back from disk
with open("agent.bin", "rb") as f:
agent_from_file = agent_v1.Agent()
agent_from_file.ParseFromString(f.read()) Sharing Agent Data Fields Using JWT
JSON Web Token (JWT), as defined by RFC 7519, is a compact way for two parties to exchange claims. JWTs are encoded as JSON objects that can carry the data fields needed to represent an agent. Additionally, you can also digitally sign and encrypt the JWT token when sharing information about an agent to ensure high integrity and confidentiality.
Summary
This chapter introduced the concept of an agent, a new entity in a zero trust network against which authorization decisions are made. Adding this concept is critical to realizing the benefits of a zero trust network.
We explored what goes into creating an agent. Agents contain rapidly changing data and frequently have data that is unavailable or inconsistent. Accepting that reality is important for success when introducing the agent concept.
Agents are used purely for making authorization decisions. Authentication is a separate concern, and the current authentication status is reflected in the properties of an agent. Control plane systems use the agent to authorize requests. These systems are the primary enforcers of authorization in a zero trust network, but sometimes they must expose agent details to applications that are better positioned to implement fine-grained authorization decisions. We explored how to expose this data to applications while maintaining privacy.
While standard bodies such as NIST have recently developed guidance around zero trust, the administration side of it is still very new, and as a result, no proven standard for agents exists. Defining a standard would allow for better reuse and interoperability of zero trust systems, aiding the adoption of this technology. We discussed a possible approach for standardizing the definition of an agent.
The next chapter will focus on the systems that are responsible for authorizing all requests in a zero trust network.