
Chapter 6
Mobile Web 2.0, Apps, and Owners
6.1 Overview
In addition to telephony services and mobile devices discussed in the previous chapters, Internet applications are another important driver for the evolution of wireless communication. After all, it is the use of applications and their demand for connectivity and bandwidth that drives network operators to roll out more capable fixed and wireless IP-based networks. This chapter looks at the application domain from a number of different angles.
In the first part of this chapter the evolution of the Web is discussed, to show the changes that the shift from “few-to-many communication” to “many-to-many” brought about for the user. This shift is often described as the transition from Web 1.0 to Web 2.0. However, as will be shown, Web 2.0 is much more than just many-to-many Web-based communication.
As this book is about wireless networks, this chapter then shows how the thoughts behind Web 2.0 apply to the mobile domain, that is, to mobile Web 2.0. Mobility and small-form factors can be as much an opportunity as a restriction. Therefore, the questions of how Web 2.0 has to be adapted for mobile devices and how Web 2.0 can benefit from mobility are addressed. During these considerations it is also important to keep an eye on how the constantly evolving Web 2.0 and mobile Web 2.0 impacts networks and mobile devices.
Native applications on mobile devices have also undergone a tremendous evolution in recent years and have become at least as important as web-based services for improving the way we communicate and gather information. Differences and commonalities to web-based applications are described and an introduction to programing in the Android environment is given.
In a world where users are no longer only consumers of information but also creators, privacy becomes a topic that requires special attention. It is important for users to realize what impact giving up private information has in the short and long term. Some Web 2.0 applications implicitly gather data about the actions of their users. How this can lead to privacy issues and how users can act to prevent this will also be discussed.
In practice, there are many different motivations for developing applications. Students, for example, create new applications because they have ideas they want to realize and can experiment without financial pressure or the need for a business model. Such an environment is quite different from the development environment in companies where deadlines, business models, and backwards compatibility rule during the development process. With this in mind this chapter will also discuss how the different environments shape the development of Web 2.0 vs the development of mobile Web 2.0 and examine the impact.
6.2 (Mobile) Web 1.0—How Everything Started
For most users the Internet age started with two applications: e-mail and the Web. While the first form of e-mail dates back to the beginnings of the Internet in the 1960s and 1970s, the World Wide Web, or Web for short, is much younger. The first Web server and browser date back to the early 1990s. Becoming widespread in the research community by the mid 1990s, it took until the end of the decade before the Web became popular with the general public. Popularity increased once computers became powerful enough and affordable for the mass market. Content proliferated and became more relevant to everyday life, as shops started to offer their products online, banks opened their virtual portals on the Web, companies started to inform people about their products and news started being distributed on the Web much faster than via newspapers and magazines. Furthermore, the availability of affordable broadband Internet connections via DSL (Digital Subscriber Line) and TV cable since the early 2000s helped to accelerate the trend. While the Web was initially intended for sharing information between researchers, it got a different spin once it left the university campus. For the general public, the Internet was at first a top-down information distribution system. Most people connected to the Internet purely used the Web to obtain information. Some people also refer to this as the “read-only” Web, as users only consumed information and provided little or no content for others. Thus, from a distribution point of view, the Internet was very similar to the “offline” world where media companies broadcast their information to a large consumer audience via newspapers, magazines, television, movies, and so on. Non-media companies also started to use the Web to either advertise their services or sell them online. Amazon is a good example of a company that quickly started using the Web not only to broadcast information but also as a sales platform. However, what Amazon, and other online stores, had in common with media companies was that they were the suppliers of information or goods and the user was merely the consumer. Note that this has now changed, to some degree, as will be discussed in the next section.
In the mobile world, the Web had a much more difficult start. First attempts by mobile phone manufacturers to mobilize the Web were a big disappointment. In the fixed line world the Internet had an incubation time of at least a decade to grow, to be refined and fostered by researchers and students at universities before being used by the public, who already had sufficiently capable notebooks, PCs, and a reasonably priced connection to the Internet. In the mobile world, things were distinctly different when the first Web browsers appeared on mobile phones around 2001:
- Mobile Internet access was targeted at the general public instead of first attracting researchers and students to develop, use, and refine the services.
- Unlike at universities, where the Web was free for users, companies wanted to charge for the mobile service from day 1.
- It was believed that the Web could be extended into the mobile domain solely by adapting successful services to the limitations of mobile devices, rather than looking at the benefits of mobility. That is like taking a radio play, assembling the actors and their microphones in front of a camera, and broadcasting them reading the radio play on TV [1].
- Little, if any, appealing content for the target audience was available in an adapted version for mobile phones.
- Mobile access to the Internet was very expensive so only a few were willing to use it.
- Circuit-switched bearers were used at the beginning, which were slow and not suitable for packet-switched traffic.
- The mobile phone hardware was not yet powerful enough for credible mobile Web browsers. Display sizes were small, screen resolutions not suited for graphics, there was no color, not enough processing power and not enough memory for rendering pages.
- The use of a dedicated protocol stack (the Wireless Application Protocol, (WAP)) instead of HyperText Markup Language (HTML) required special tools for Web page creation and at the same time limited the possibilities to design mobile and user-friendly Web pages.
Any of the points mentioned above could have been enough to stop the mobile Web in its tracks. Consequently, there was a lot to overcome before the Internet on mobile devices started to gain the interest of a wider audience. This coincided with the emergence of the Web 2.0 and its evolution into the mobile domain, as described in the next section.
6.3 Web 2.0—Empowering the User
While the Web 1.0 was basically a read-only Web, with content being pushed to consumers, advances in technology, thinking, and market readjustment (with the bursting of the dot com bubble at the beginning of the century) have returned the Internet to its original idea: exchange of information between people. The ideas that have brought about this seismic shift from a read-only Web to a read/write Web are often combined into the term Web 2.0. Web 2.0, however, is not a technology that can be accurately defined; it is a collection of different ideas. With these ideas also being applicable to the experience of the Web, and the Internet in general, on mobile devices, it makes sense to first discuss Web 2.0 before looking at its implications for mobile devices and networks. The following sections look at Web 2.0 from a number of different angles: from the user's point of view, from a principal point of view and from a technical point of view.
6.4 Web 2.0 from the User's Point of View
For the user, the Web today offers many possibilities for creating as well as consuming information, be it text-based or in the form of pictures, videos, audio files, and so on. The following section describes some of the applications that have been brought about by Web 2.0 for this purpose.
6.4.1 Blogs
A key phenomenon that has risen with Web 2.0 is blogging. A Blog is a private Web page with the following properties:
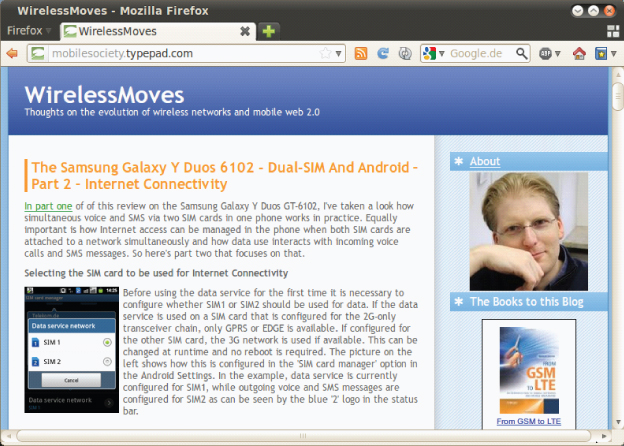
- Dynamic information—Blogs are not used for displaying static information but are continuously updated by their owners with new information in the form of articles, also referred to as Blog entries. Thus, many people compare Blogs with online diaries. In practice, however, most Blogs are not personal diaries accessible to the public, but platforms on which people share their knowledge or passions with other people. Companies have also discovered Blogs as a means of telling their story to a wider audience in a semi-personal fashion. Blogs can also be valuable additions to books, giving the author the possibility to interact with his readers, go into details of specific topics, and to share his thoughts. Figure 6.1, for example, shows the Blog that complements this book.
- Ease of use—Blogs are created, maintained, and updated via a Web-based interface. No Web programing skills are required. Thus, Blogs can be created and used by everyone, not only technically skilled people.
- Blogs order content in a chronological fashion with the latest information usually presented at the top of the main page.
- Readers of a Blog can leave comments, which encourages discussion and interaction.
- Other people can subscribe to an automated news feed of a Blog. This way they can easily find the Blog again (bookmarking functionality) and be automatically informed when the author of the Blog publishes a new entry. This is referred to as aggregation and is discussed in more detail in Section 6.6.3.
- A Blog is often the central element for the online activities of a user. It may be used to link to other online activities, for example, links to accounts at picture sharing sites, the user's pages in social networks and so on. Readers of the Blog can thus easily discover additional information from or about the owner of the Blog.
Figure 6.1 The author's blog.
6.4.2 Media Sharing
Blogs can also be used to share nontextual content such as pictures and videos. In many cases, however, it is preferable to share such content via dedicated sharing sites such as Flickr [2] for pictures, YouTube [3] for videos, and so on. This has the advantage that users looking for a video or picture about a specific subject can go to such a sharing site and obtain a relevant list of videos that other people have made available to share. In private Blogs, links can then be used to point Blog readers to the content. It is also possible to embed pictures and videos from sharing platforms directly in Blog entries. Thus, no redirection is required for Blog readers, while people who are unaware of the Blog can still find the content.
6.4.3 Podcasting
Podcasting is another important form of media sharing. The word itself is a combination of the words iPod and broadcasting. Podcasting combines audio recording and making the recording available on Blogs, Web pages, and via automated feeds. Automated feeds allow interested users to be informed about a new podcast in a feed and connected MP3 players can automatically download new podcasts from feeds selected by the user. Thus, distributing audio content is no longer an exclusive domain of radio stations. Radio stations, however, have also discovered the value of podcasting and today many stations offer their content as podcasts after the initial traditional broadcast. The advantage for listeners is that radio shows can now be downloaded and consumed at any time and any place.
While Web sites exist that offer podcast directories and podcast archives, many podcasters host the audio files themselves and only use podcast directories to make others aware of their podcasts.
6.4.4 Advanced Search
Being a publisher of information is only useful when a potential audience can find the content (Blog entries, pictures, videos, etc.). This is made possible by advanced search engines such as Google, Bing, Yahoo, Technorati, and others, who are constantly updating their databases. The ranking of the search results is based on a combination of different parameters such as the number of other sites linking to a page and their own popularity, when the page was last updated and algorithms which are the well guarded secrets of search companies. While search engines can analyze text-based information, automated analysis of images and videos is still difficult. To help search engines find such nontextual information, users often add text-based tags to their multimedia content. Tags are also useful to group pieces of information together. It is thus possible to quickly find additional information on a specific topic on the same Blog or sharing site.
6.4.5 User Recommendation
In addition to ensuring a certain quality in reporting news, traditional media, such as newspapers and magazines, select the content they want to publish. Their selection is based on their understanding of user preferences and their own views. Consequently, a few people select the content that is then distributed to a large audience. Furthermore, mass media tailors content only for a mass audience and are thus not able to service niche markets. The Web 2.0 has opened the door for democratizing the selection process. User recommendation sites, such as Digg [4], let users recommend electronic articles. If enough people recommend an article it is automatically shown on the front page of Digg or in a section dedicated to a specific subject. This way the selection is not based on the preferences of a few but based on the recommendation of many.
6.4.6 Wikis—Collective Writing
Wikis are the opposite of Blogs. While a Blog is a Web site where a single user can publish their information and express their views, Wikis let many users contribute toward a common goal by making it easy to work on the same content in a Web-based environment. The most popular Wiki is undoubtedly the Wikipedia project. Within a short time the amount of articles and popularity has far surpassed other online and offline lexica of traditional media companies. Today, Wikipedia has hundreds of thousands of users helping to write and maintain the online encyclopedia. Participating is simple, since no account is needed to change or extend existing articles. The quality of individual articles is usually very good since people interested in a certain topic often ensure that the related articles on Wikipedia are accurate. As anyone can change any article on Wikipedia, entries on controversial topics sometimes go from one extreme to the other. In such cases, articles can be put under change control or set to immutable by users with administrator privileges. This shows that, in general, the intelligence and knowledge of the crowd is superior to the intelligence and knowledge of the few, but that the concept has its limits as well.
It is also possible to subscribe to Wiki Web pages in a similar fashion as subscribing to Blogs and podcasts. Thus, changes are immediately reported to interested people.
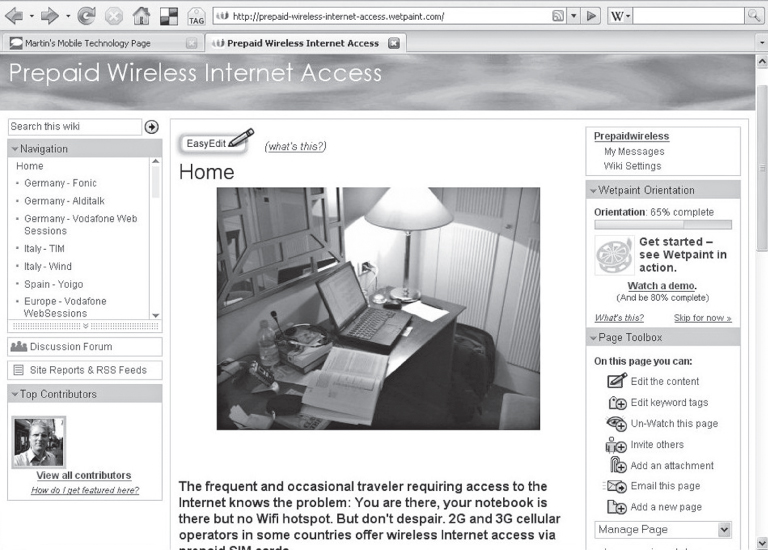
Apart from Wikipedia, a wide range of other Wikis exist on the Web today that are dedicated to specific topics. Starting a Wiki is just as easy as starting a Blog, since there are many Wiki hosting services on the net where new Wikis can be created by anyone with a few minutes to spare. Figure 6.2 shows a Wiki dedicated to the topic of how to access the Internet with prepaid Subscriber Identity Module (SIM) cards of 2G and 3G network operators. Started by the author of this book, many people have since contributed and added information about prepaid SIM cards and Internet access in their countries. As is the nature of a Wiki, articles are frequently updated when people notice that network operators have changed their offers.
Figure 6.2 A small Wiki running on a server of a Wiki hosting service.
(Reproduced by permission of Wetpaint.com, Inc., 307 third Avenue S., Suite 300, Seattle, WA 98104, USA. Photograph reproduced from Martin Sauter.)
Wikis are also finding their way into the corporate world, where they are used for collaboration, sharing of information or to help project teams to work together on a set of documents.
6.4.7 Social Networking Sites
While Blogs, Wikis, and sharing sites make it easy to publish, share, and discover any type of content, social networking sites are dedicated to connecting people and making it easy to find other people with similar interests. Famous social network sites are Facebook [5] in the private domain and LinkedIn [6] for business contacts. It is interesting to note that the popularity of early social networking sites such as Myspace [7] has as quickly diminished as it rose initially. This shows how dynamic this area of technology continues to be. Being a member of a social networking site means sharing and exchanging private information with others. Many different types of social networks exist. Some focus on fostering professional contacts and offer few additional functionalities, while others focus on direct communication between people, for example, by offering blogging functionality and automatically distributing new entries to all people who the user has declared as friends on the site. The Blogging behavior on social networking sites is usually different to dedicated Blogs, since entries are shorter, usually more personal and dedicated to the people in the friends list rather than a wider audience. Many social networking platforms also allow users to create personalized Web pages on which they present themselves to others.
6.4.8 Web Applications
In the days of Web 1.0 most programs had to be installed on a device and the Web was mostly used to retrieve information. Advanced browser capabilities, however, have brought about a wide range of Web applications which do not have to be installed locally. Instead, Web applications are loaded from a Web server as part of a Web page. They are then either exclusively executed locally or are split into a client and server part, with the server part running on a server in the Internet. Google has many Web applications, a very popular one being Google maps. While the maps application itself is executed in the browser, as a JavaScript application, the “maps and search” databases are in the network. When users search for a specific location, or for hotels, restaurants, and so on at a location, the application connects to Google's search database, retrieves answers, and displays the results on a map that is also loaded from the network server. The user can then perform various actions on the map, like zooming and scrolling. These actions are performed locally in the browser until further mapping data is required. At this point the map's application running on the Web browser asynchronously requests the required data. During all these steps the initial Web page on which the map's application is executed is never left. The application processes all input information itself, updates the Web page and communicates with the backend server.
Today, even sophisticated programs such as spreadsheets and word processors are available as Web applications. Documents are usually not stored locally, but on a server in the network. This has the advantage that several people at different locations can work on a document simultaneously. Also, a user can work on documents via any device connected to the Web, without taking the document with him. Another benefit of Web applications is that they do not have to be deployed and installed on a device. This makes deployment very simple and changes to the software can be done seamlessly, when the application is sent to the Web browser as part of the Web page. The downside of Web applications and Web storage is that the user becomes dependent on a functioning network connection and relies on the service provider to keep their documents safe and private.
6.4.9 Mashups
Mashups are a special form of Web application. Instead of a single entity providing both the application and the database, mashups retrieve data from several databases in the network via an open Application programing Interface (API) and combine the sources in a new way. An example of a mashup is a Web application that uses cartographic data from the Google maps database to display the locations of the members of a user's social network, where data about the members is retrieved from the social networking site of the user. This is something neither Google maps nor the social networking site can do on their own. The crucial point for mashups is that other Web services allow their data to be used without their own Web front end. This is the case for many Web services today, with Google maps just being a prominent example. Also important for mashups is that the interface provided by a Web application does not change, otherwise the mashup stops working. Mashups also depend on the availability of their data sources. As soon as one of the data sources is not available the mashup stops working as well.
6.4.10 Virtual Worlds
Another way how the Internet connects people is the concept of virtual worlds. The most prominent virtual world is Second Life by Linden Labs [8] even though their popularity has diminished somewhat in recent years. Virtual worlds create a world in which real people are represented by their avatars. Avatars can look like the real person owning them or, more commonly, how that person would like to look. Avatars can then walk through the virtual world, meet other avatars and communicate with them. Avatars can also own land, buy objects, and create new objects themselves. While virtual worlds might have initially been conceived as pure games, companies have experimented with the concept and have opened virtual store fronts. Avatars of employees work as shop assistants and interact with customers. Also, some universities have experimented with virtual worlds for online learning by holding classes in the virtual world, which are attended by real-life students, who visit the classroom with their avatars. Communication is possible via instant messaging but also via an audio channel. It should be noted at this point that most virtual worlds require a client application on the user's device. Therefore, they are not strictly a part of the Web 2.0, as they are not running in a Web browser. Nevertheless, in everyday life most people count virtual worlds as part of the Web 2.0.
6.4.11 Long-Tail Economics
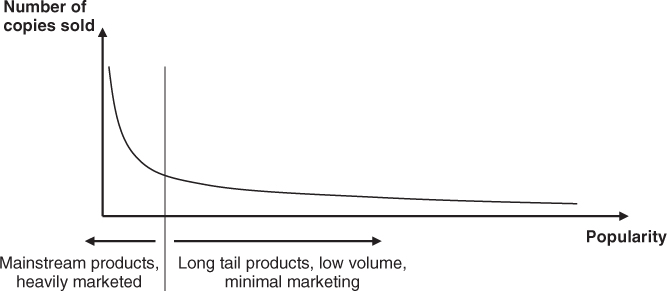
Web 2.0 services enable users to move on from purely being consumers to also become creators of content, which in turn considerably increases the variety of information, viewpoints, and goods available via the Web. By using search engines or services such as eBay, Amazon, iTunes, and so on, this information, or these goods, can also be found and consumed by others without having to be promoted by media companies and advertisements. The ability to find things “off the beaten path” also facilitates the production and sale of goods for which, traditionally, there has been no market, because people were not aware of them. Chris Anderson has described this phenomenon as long-tail economics in [9]. The term long-tail is explained in Figure 6.3. The vertical axis represents the number of copies sold of a product, for example, a book, and the horizontal axis shows its popularity. Very popular items start out on the left of the graph, with the long tail beginning when it is economically no longer feasible to keep the items in stock, that is, when only limited space and local customers are available.
Figure 6.3 The long tail.
While still making a fair percentage of their revenue with mainstream products, companies like Amazon today are successful because they can offer goods which only sell in quantities too small to be profitable when they have to be physically distributed and stored in many places. This in turn again increases the popularity of the site since goods are available which cannot be bought at a local store where floor space is limited and interest in stocking products which sell in small quantities is not high. As there are many more products sold in small quantities compared with the few products sold in very large quantities, a substantial amount of revenue can be generated for the company running the portal. eBay is another good example of long-tail economics. While not stocking any goods itself, eBay generates its revenue from auctions of goods from the long tail and not from those sold at every street corner. Whether it is possible to be profitable by producing goods or content on the long tail, however, is another matter [10]. For many, however, generating revenue is not the goal of providing content on the long tail, as their main driver is to express their views and give something back for the information, produced by others, that they have consumed for free.
6.5 The Ideas behind Web 2.0
Most of the Web 2.0 applications discussed in the previous section have a number of basic ideas behind them. Tim O'Reilly, who originally coined the term Web 2.0, has written an extensive essay [11] about the ideas behind Web 2.0. Basically, he sees seven principles that make up Web 2.0 and points out that, for applications to be classified as belonging to Web 2.0, they should fulfill as many of the criteria as possible. This section gives a brief overview of these principles as they form the basis for the subsequent analysis, that is how these principles are enhanced or limited by mobile Internet access and if the mobile Web 2.0 is just an extension of Web 2.0 or requires its own definition.
6.5.1 The Web as a Platform
A central element of Web 2.0 is the fact that applications are no longer installed locally but downloaded as part of a Web page before being executed locally. Also, the data used by these applications is no longer present on the local device but is stored on a server in the network. Thus, both the application and the data are in the network. This means that software and data can change and evolve independently and the classic software release cycle which consists of regularly upgrading locally installed software is no longer necessary. As software and data change, Web 2.0 applications are not packaged software but rather a service.
6.5.2 Harnessing Collective Intelligence
User participation on Web 2.0 services is the next important element. Services that only exist because of user participation are, for example, Wikipedia, Flickr, and Facebook. While the organizations behind these services work on the software itself, the data (Wiki entries, pictures, personal entries, etc.) is entirely supplied by the users. Users submit their information for free, working toward the greater goal of creating a database that everybody benefits from. While in the traditional top-down knowledge distribution model, the classification of information (taxonomy) was done by a few experts, having a countless number of people working on a common database and classifying information is often referred to as folksonomy. Classifying information is often done by tagging, that is by adding text-based information (catch words) to anything from articles to pictures and videos. This way it is possible to find nontextual information about a certain topic and quickly correlate information from different sources.
Collective intelligence also means that software should be published as open source and distributed freely so everybody can build on the work of others. This idea is similar to contributing information to a database (e.g., Wikipedia) that can then be used by others.
Blogs are also a central element of the Web 2.0 idea, as they allow everyone with a computer connected to the Internet to easily share their views in articles, also referred to as Blog entries. Blog entries are usually sorted by date so visitors to a Blog will always see the latest entries first. In contrast to the above services, however, Blogs are not collecting information from several users but are a platform for individuals to express themselves. Therefore, powerful search algorithms are required to open up this “wisdom,” created by the crowds, to a larger audience as users first of all need to discover a Blog before they can benefit from the information. Some Blogs have become very successful because users have found the information so interesting that they have linked to the source from their own Blogs. When this is repeated by others a snowball effect occurs. As one input parameter for modern search algorithms is the relevance of a page based on the number of links pointing to it, this snowball effect gives such Web pages a high rating with search engines and thus moves them higher in the search result lists. This in turn again increases their popularity and creates more incoming links.
Less frequented Blogs, however, are just as important to Web 2.0 as the few famous ones. Many topics, such as mobile network technology, for example, are only of interest to a few people. Before Blogs became popular, little to no information could be found about these topics on the Web, since large media companies focus on content that is of interest to large audiences and not niche ones. With the rise of Web 2.0, however, it has become much simpler to find people discussing such topics on the net. Blogrolls, which are placed on Blogs and contain links to Blogs discussing similar topics, help newcomers to quickly find other resources.
As many Blogs are updated infrequently and thus interesting information is spread over many different sources, a method is required to automatically notify users when a Blog is updated. This is necessary since it is not practical to visit all previously found interesting Blogs every day to see if they have been updated. Automatic notification is done with feeds, to which a user can subscribe to with a feed reader. A feed reader combines all feeds and shows the user which Blogs have updated information. The Blog entries are then either read directly in the feed reader or the feed reader offers a link to the Blog.
6.5.3 Data is the next Intel Inside
While users buy standalone applications like, for example, word processors because of their functionality, Web 2.0 services are above all successful because of their database in the background. If services offer both information and the possibility for users to enhance the database or be the actual creator of most of the information the service is likely to become even more popular, due to the rising amount of useful information that even the most powerful company could not put together. An example of this is a database of restaurants, hotels, theaters, and so on. Directories assembled by companies will never be as complete or accurate as directories maintained by the users themselves. Control over such user-maintained databases is an important criterion for them to become successful, as the more information is in the database the harder it gets for similar services to compete. To stimulate users to add content it is also important to make the database accessible beyond the actual service, via an open interface. This allows mashups to combine the information of different databases and offer new services based on the result. This can in turn help to promote the original service. An example is Google maps. It allows other applications to request maps via an open interface. When mashups use maps for displaying location information (e.g., about houses for sale, hotels, etc.), the design of the map and the copyright notice always point back to Google.
6.5.4 End of the Software Release Cycle
As software is no longer locally installed, there are no longer different versions of the software that have to be maintained so users no longer need to upgrade applications. Errors can thus be corrected very quickly and it enables services to evolve gradually instead of in distinctive steps over a longer period of time. This concept is also known as an application being in perpetual beta state. This term, however, is a bit misleading as beta often suggests that an application is not yet ready for general use.
Running applications in a Web browser and having the database and possibly some processing logic in the network also allows the provider of the service to monitor which features are used and which are not. New features can thus be tested to see if they are acceptable or useful to a wider audience. If not, they can be removed again quickly, which prevents rising entropy that makes the program difficult to use over time.
Web 2.0 services often regard their users as co-developers, as their opinions of what works and what does not can quickly be put into the software. Also, new ideas coming from users of a service can be implemented quickly if there is demand and deployed much faster than in a traditional development model, in which software has to be distributed and local installations have to be upgraded. This shortens the software development cycle and helps services to evolve more quickly.
6.5.5 Lightweight Programing Models
Some Web 2.0 services retrieve information from several databases in the network and thus combine the information of several information silos. Information is usually accessed either via Real Simple Syndication (RSS) feeds or a simple interface based on Hypertext Transport Protocol (HTTP) and Extensible Markup Language (XML). Both methods allow loose coupling between the service and the database in the network. Loose coupling means that the interface has no complex protocol stack for information exchange, no service description and no security requirements to protect the exchange of data. This enables developers to quickly realize ideas, but of course also limits what kind of data can be exchanged over such a connection.
6.5.6 Software above the Level of a Single Device
While in a traditional model, software is deployed, installed, and executed on a single device, Web 2.0 applications and services are typically distributed. Software is downloaded from the network each time the user visits the service's Web page. Some services make extensive use of software in the backend and only have the presentation layer implemented in the software downloaded to the Web browser. Other Web 2.0 software runs mostly in the browser on the local machine and only queries a database in the network.
Some services are especially useful because they are device-independent and can be used everywhere with any device that can run a Web browser. Web-based bookmark services, for example, allow users to get to their bookmarks from any computer, as both the service and the bookmarks are Web-based.
Yet another angle to look at software above the level of a single device is that some services become especially useful because they can be used from different kinds of devices and not only computers. Instant messaging and social networks, for example, can be enhanced when the user does not only have access to the service and data when at home or at the office, but also when he roams outside and only has a small mobile device with him. As both the service and the data reside in the network and are used with a browser, no software needs to be installed and use of the service on both stationary and mobile devices is easy. This topic will be elaborated in more detail in the next section on mobile Web 2.0.
Some companies have also combined Web 2.0 services, traditional installable software and mobile devices to offer a compelling overall service to users. Apple, for example, offers iTunes, which is a traditional program that has to be installed. The media database it uses, however, is not only created by Apple and media companies but also includes a podcast catalog entirely managed by users. To make the service useful, a mobile device is sold as part of the package, to which content can be downloaded directly over the network or via the software installed on the computer.
6.5.7 Rich User Experience
Web 2.0 services usually offer a simple but rich user experience. This requires methods beyond static Web pages and links. Modern browsers support JavaScript to create interactive Web pages in addition to XHTML and CSS for describing Web page content. The XML is used to encapsulate information for the transfer between the service and the database in the network. This way, standard XML libraries can be used to encapsulate and retrieve information from a data stream without the programers having to reinvent data encapsulation formats for every new service. All methods together are sometimes referred to as Asynchronous JavaScript and XML (AJAX). Asynchronous in this context means that the JavaScript code embedded in a page can retrieve information from a database in the network and show the result on the Web page, without requiring a full page reload. This way it is possible for services running in a browser to behave in a similar way to locally installed applications and not like a Web page in the traditional sense.
6.6 Discovering the Fabrics of Web 2.0
The previous sections have taken a look at Web 2.0 from the user's perspective and which basic ideas are shared by Web 2.0 services. This section now introduces the technical concepts of the most important Web 2.0 methods and processes.
6.6.1 HTML
A central idea of the World Wide Web is that web pages are not sent from a Web server to a Web browser as they are presented on the screen. Instead, a description of a web page is downloaded in a language referred to as HyperText Markup Language and then rendered into the web page presented to the user.
Markups are instructions in the HTML document that tell the Web browser how to present (render) different parts of a web page. A typical example are markup instructions that tell the Web browser that a certain part of the text is to be shown in bold, while another part is to be shown to the user in a certain color or different size from the rest of the text. Other elements of the page such as text input boxes or buttons are also described as a markup and not downloaded as an image from the Web server. One of the most important markup instructions is doubtlessly the “referrer” with which links to other web pages can be included in a web page.
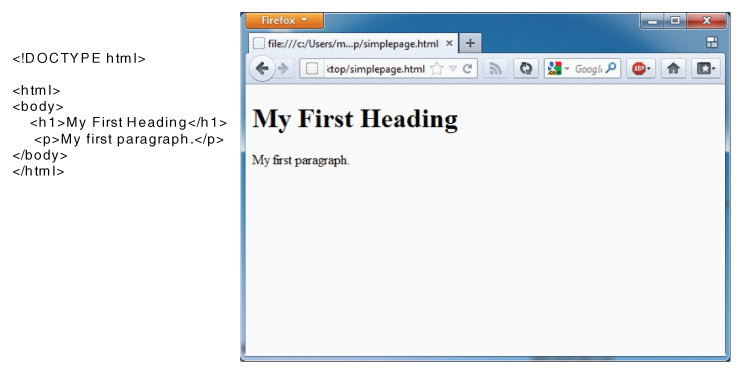
Figure 6.4 shows how the HTML markups and text look like for a very basic web page. In practice, most web pages are obviously far more complex and contain many more markup commands. To visualize the HTML code of a page, Web browsers usually have an option to show the “source code” of the page. Firefox, for example, shows the HTML code when the mouse pointer is placed over a web page after pressing the right mouse button and selecting “View Page Source” in the context menu.
Figure 6.4 HTML code and the corresponding Web page in a Web browser.
The address of a web page that usually leads to a HTML document usually only contains the skeleton of a web page and just references many other objects to be included on the page such as pictures and embedded objects such as videos. These have then to be requested separately from the same or a different Web server and are included in the overall web page.
A web page (the document) usually consists of many parts (objects) that are either part of the HTML description or loaded separately such as text, pictures, input boxes, buttons, and so on, which are all described in HTML. The Web browser parses the HTML description of the page and assembles what is referred to as the document object model (DOM) tree to render the page object by object. The DOM tree is then also used to enable the Javascript code embedded in the web page to modify objects on the page. This can be used, for example, to validate input text from the user and return feedback whether the input is correct or not before the information is returned to the web server for processing. Further details on Javascript are discussed in the following.
Over the years, HTML was significantly extended and the latest version, HTML5, is an industry-wide harmonization approach to ensure interoperability between different browsers. In addition to describing how web pages look like, HTML5 is now also capable to describe how to include the following functionalities in a web page:
- Video and audio content which has previously been done by including the proprietary Adobe Flash player in a web page.
- A local access API for Javascript. This way, scripts that are part of a web page can access local resources such as storage, location information, a built-in web cam, and so on.
- Drag and drop support.
- 2D and 3D graphics.
Many functionalities of HTML5 have been designed specifically with Web browsers on mobile devices in mind. Details on the different HTML5 elements and support in mobile Web browsers can be found in [12].
6.6.2 AJAX
In Web 2.0 the Web browser is the user interface for services. The more capabilities Web browsers have, the better the user experience. In Web 1.0 most Web pages were static. Whenever the user, for example, put text into an input field or set a radio button and pressed the “ok” or “continue” button, the information was sent to a Web server for processing and a new Web page with the result was returned. The user experience of such an approach is relatively poor compared with local applications where the reaction to user input is displayed on the same screen without the typical reload effect of one Web page being replaced by another.
The solution to this problem comes in three parts. The first part is the support of JavaScript code on Web pages by the Web browser. The JavaScript code can interact with the user via the Web page by reading user input such as text input or when the user clicks on buttons on the Web page and so on. Unlike in the previous approach, where such actions resulted in immediate communication with the Web server in the network and the transmission of a new Web page as a result of the action, the JavaScript code can process the input locally and change the appearance of the Web page without the page reload effect.
The second part is allowing a JavaScript application on a Web page to send data to a Web server and receive a response without impacting what is shown on the Web page. The JavaScript can thus take the user input and send it to the Web server in the background. The Web server then sends a response and the JavaScript application embedded in the Web page will alter the appearance of the page without the need for loading a new Web page. Since this exchange of data is done in the background, it is also referred to as being asynchronous, since the exchange does not prevent the user interacting with the Web page (scrolling, pressing a button, etc.) while the JavaScript application is waiting for a response. The JavaScript application embedded in a Web page can modify the page in a similar way as a program running locally is able to modify the content of its window. Thus, for the user the behavior is similar to that of a local program.
The third part is a standardized way of exchanging information between the JavaScript application running in the Web browser and the program running on a Web server on the web. A format often used for this exchange is XML, which is also used as a descriptive language for Atom and RSS feeds, as shown in Figure 6.5. XML is a tag-based language that encapsulates information between tags in a structured way. The class used in JavaScript to exchange information with the backend includes sophisticated functions for extracting information from an XML formatted stream. This makes manipulation of the received data very simple for a JavaScript application embedded in a Web page. All three parts taken together are commonly referred to as Asynchronous JavaScript and XML for short.
Figure 6.5 An atom feed of a blog.

An example of a very simple JavaScript application embedded in a Web page communicating asynchronously with an application hosted on the Web server is shown in Figure 6.6. The actual content of the Web page is very small and is contained in lines 25–27 between the <body> tags. The JavaScript code itself is embedded in the Web page before the visible content from line 0 to 23. On line 5 the JavaScript code instantiates an object from class XMLHttpRequest. This class has all the required functions to send data back to the Web server from which the Web page was loaded via the HTTP, asynchronously receive an answer and extract information from an XML formatted data stream. The XMLHTTP object is first used in line 18 where it is given the URL to be sent to the Web server. In this example, the JavaScript application sends the URL of a Blog feed. The application on the Web server then interprets the information and returns a result, for example, it retrieves the Blog's feed and returns what it has received back to the JavaScript application running in the Web browser. This is done asynchronously as the send function on line 20 does not block until it receives an answer. Instead a pointer to a function is given to the XMLHTTP object, which is called when the Web server returns the requested information. In the example, this is done in line 19 and the function which is called when the Web server returns data is defined starting from line 7.
Figure 6.6 A Web page with a simplified embedded JavaScript Application.

The JavaScript application therefore does not block and is able to react to other user input while waiting for the server response. Functions handling user input, however, are not part of the example in order to keep it short.
When the Web server returns the requested information, in the example the XML-encoded feed of a Blog, the “OutputContent” function in line 7 is called. In line 12 the text from line 26 of the Web page is imported into a variable of the JavaScript application. In line 13, the “getAttribute” function of the XMLHTTP object is used to retrieve the text between the first <title> tags of the feed. This text is then appended to the text already present in line 26 and put on the Web page without requiring a reload.
While the JavaScript application shown in Figure 6.6 is not really useful, due to its limited functionality, it nevertheless shows how AJAX can be used in practice. More sophisticated JavaScript applications can make use of the asynchronous communication to download much more useful information and draw graphics and other style elements on the Web page based on the data received.
6.6.3 Aggregation
The glue that holds Web 2.0 together is aggregation, or the ability to automatically retrieve information from many sources for presentation in a common place or for further processing. Blog or feed-reading programs, for example, are based on aggregation. The idea of Blog or feed readers is to be a central place from which a user can check if new articles have been published on Blogs or Web pages supporting aggregation. For the user, using a feed reader saves time that has otherwise to be spent on visiting each Blog in a Web browser to check for news. Figure 6.7 shows Mozilla Thunderbird, an e-mail and feed reader program. On the left side, the program shows all subscribed feeds and marks those in bold which have new articles. On the upper right, the latest feed entries of the selected Blog are shown. New entries are marked in bold so they can be found easily. On the lower right, the selected Blog entry is then shown. The link to the article on the Blog is also shown, as it is sometimes preferable to read the article on the Blog itself rather than in the feed reader, as sometimes no pictures or only scaled down versions are embedded in the feed.
Figure 6.7 Mozilla Thunderbird used as a feed reader.
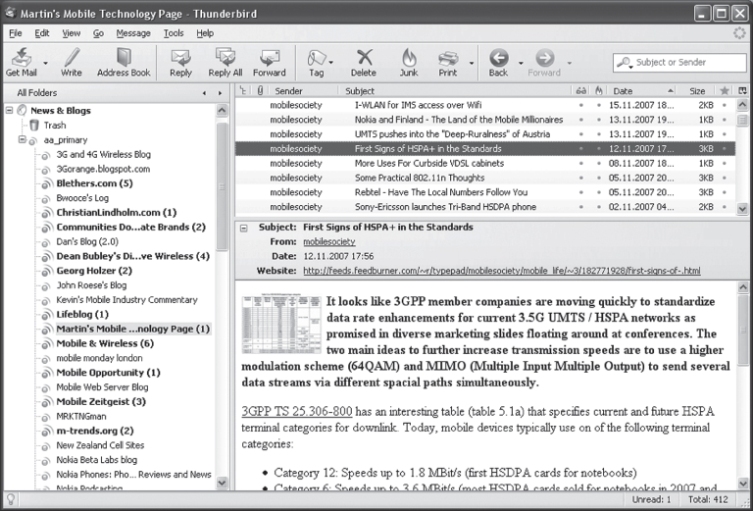
From a technical point of view, feed readers make use of Blog feeds, which contain the articles of the Blog in a standardized and machine readable form. When a user publishes a new article on a Blog, the feed is automatically updated as well. Each time a user starts a feed reader, the feeds of all sources, the user is interested in are automatically retrieved with a HTTP request, just like a normal Web page, and analyzed for new content, which is then presented in the feed reader. In practice, there are two different feed formats, and feed readers usually support both:
- RSS, specified in [13], and
- ATOM syndication format, specified in [14].
Both feed formats are based on XML, which is a descriptive language and a generalization of the HTML, used for describing Web pages.
Figure 6.5 shows an extract of an Atom Blog feed. Information is put between standardized tags (e.g., <title> and </title>); so feed readers or other programs can search XML feeds for specific information. Besides the text of Blog entries, a lot of additional information is contained in feeds, such as the date an entry was created, information about the Blog itself, name of the author, and so on. The text of the Blog entries can be formatted as HTML text and can thus also contain references to pictures embedded in the article or links to external pages. The feed reader can then request the pictures from the Blog for presentation in the Blog entry and open a Web browser if the user wants to follow a link in the article to another Web page.
In practice, users do not have to deal with the XML description delivered by an XML feed directly. The usual method to import a feed is by clicking on the feed icon that is shown next to the URL of the Web page, as shown in Figure 6.8. The Web browser then shows the URL of the feed which the user can then copy and paste into the feed reader.
Figure 6.8 Feed icon of a Blog on the right of the URL of the Web page.

Feeds are not only used for aggregating Blog feeds in a Blog reader. Today, other types of Web pages also offer RSS or Atom feeds; so content from those pages can also be viewed in a feed reader program. Picture-sharing sites such as Flickr, for example, offer feeds for individual users or tags. Each time the feed reader requests updated information from a Flickr feed, Flickr includes the latest pictures of a user in the feed or the pictures for the specified tags.
Feeds are also used by applications to automatically aggregate a user's information from different places. An example is social networking sites. Pictures from picture sharing sites or new Blog entries are thus automatically imported into the user's page on a social networking platform.
Feeds are also used in combination with podcasts. Apple's iTunes is a good example, which among other functionalities also works as a podcast directory. A podcast directory is in essence a list of podcast feeds. The feeds themselves contain a description of the podcasts available from a source, information about the audio file (e.g., size) and a link from which the podcast can be retrieved. It is also possible to use a podcast feed in a feed reader program, which will then present the textual information for the podcast and present a link from which the audio file can be retrieved. Most people, however, prefer programs like iTunes for podcast feeds.
6.6.4 Tagging and Folksonomy
While analyzing textual information on Blog entries and Web pages is a relatively easy task for search engines, classifying other available media such as pictures, videos, and audio files (e.g., podcasts) is still not possible without additional information supplied by the person making the content available. A lot of research is ongoing to automatically analyze the content of nontextual sources on the Web and a result of this is, for example, the face recognition feature on pictures uploaded to Facebook [15]. However, for the time being, search engines and other mechanisms linking content still rely on additional textual information. The most common way of adding additional information is by adding tags, that is, search words. As this form of classification is done by the users and not by a central instance, it is sometimes also referred to as folksonomy, that is, taxonomy of the masses.
Flickr, an image hosting and sharing Web service, is a good example of a service that uses tagging and folksonomy. Tags can be added to pictures by the creator, describing the content and location as shown in Figure 6.9. Tags can also contain other information like, for example, emotion, event information, and so on. Tags can also contain geographical location tags (latitude and longitude), which were generated automatically by the mobile device with which the picture was taken because it was able to retrieve the GPS position from a GPS device (internal or external) at the time the picture was taken. The tags are then used by the image-sharing service and other services for various purposes. The picture sharing service itself converts the tags into user clickable links. When the user clicks on a tag the service searches for other pictures with the same tag and presents the search result to the user. Thus, it is easy to find pictures taken by other users at the same location or about the same topic.
Figure 6.9 Tags alongside a picture on Flickr, an image-sharing service.
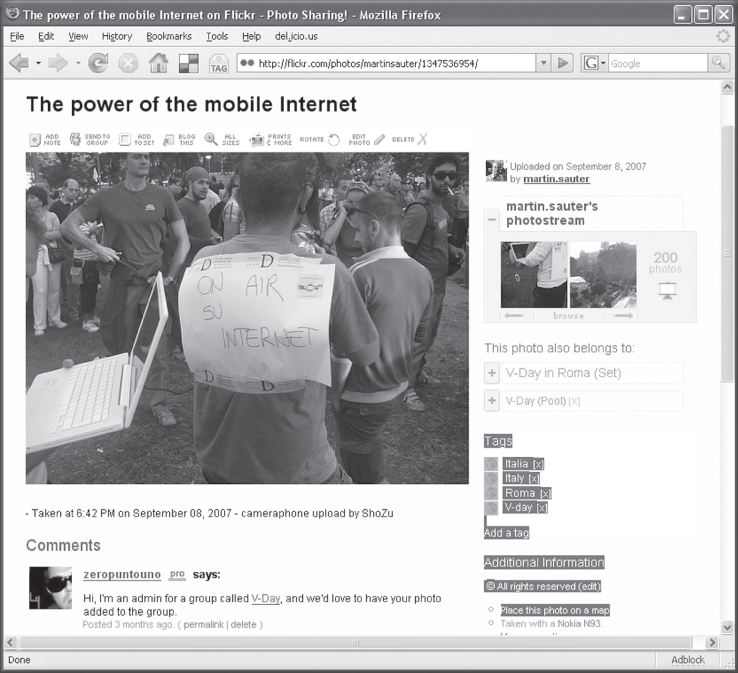
The picture sharing service treats the geographic location tags in a special way. Instead of showing the GPS coordinates, which would not be very informative for the user, it creates a special “map” link. When the user clicks on the “map” link a window opens up in which a map of the location is shown. The user can then zoom in and out and move the map in any direction to find out more about the location where the picture was taken. The picture sharing site also inserts the location of other pictures the user has taken in the area which is currently shown and on request presents pictures other users have taken in this area, which are also stored together with geographical location tags. This functionality is a typical combination of the use of tags to find and correlate information, of AJAX for creating an interactive and user-friendly Web page and of open interfaces which allow information stored in different databases to be combined (pictures and text in the image database and the maps in a map database on the network).
The tags and geographical location information alongside images are also used by other services. Search engines such as Yahoo or Google periodically scan Web pages created by Flickr from its image/tag/user database. It is then possible to find pictures not only directly in Flickr but also via a standard Internet search. This is important since Flickr is not the only picture-sharing service on the net and searching for pictures with a general Web search service results in a wider choice, as the search includes the pictures of many sharing sites. It is important to note at this point that without tags the value of putting a picture online for sharing with others is very limited, since it cannot be found and correlated with other pictures.
6.6.5 Open Application Programing Interfaces
Many services are popular today because they offer an open API, which allows third party applications to access the functionality of the service and the database behind it. Atom and RSS feeds are one form of open API to retrieve information from Blogs or Web pages. Requesting the feed is simple, as it only requires knowledge of the URL (Universal Resource Locator, for example, http://mobilesociety.typepad.com/feed). Analyzing a feed is also possible since the feed is returned as an Atom or RSS formatted XML stream. How the XML file can be analyzed is part of the open RSS and Atom specifications. In Figure 6.7, Thunderbird, a locally installed feed reader was shown. There are also Web 2.0 feed readers which run as JavaScript applications in Web pages and which get feed updates and store information in a database in the network (e.g., which feeds the user has subscribed to, which Blog entries have already been read, etc.).
While feeds only deliver information and leave the processing to the Web service running on a user's computer, remote services can also share a library of functions with a JavaScript application running in the local Web browser. Examples of this approach are the APIs of Yahoo [16], Google maps [17] and OpenStreetMap [18]. These APIs allow other Web 2.0 services to show location data on a map generated by these services. A practical example is a Web statistics service that logs the IP addresses from which a Web site was visited. When the owner later on calls the statistics Web page, the service in the background queries an Internet database for the part of the world in which the IP addresses are registered. This information is then combined with that of the mapping service and a map with markers at the locations where the IP addresses are registered is shown on the Web page. As the map is loaded directly from the server of the mapping service it is interactive and the user can zoom and scroll in the same way as if he had visited the map service directly via the mapping portal.
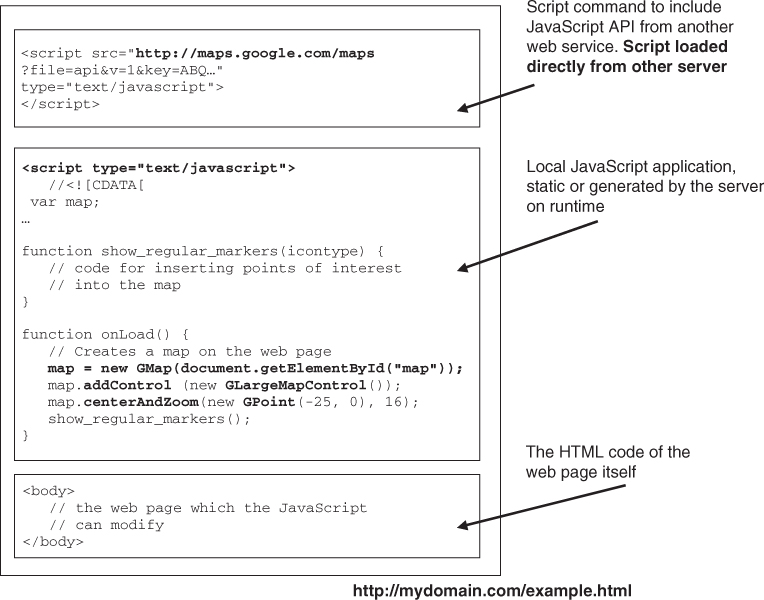
Figure 6.10 shows how this is done in principle. The statistics service comprises both a server component and a front-end component, that is a program or script running on the Web server and a JavaScript application executed in a Web page. The backend component on the Web server is called when people visit a Web site which contains an image that has to be loaded from the statistics server. Requesting the image then invokes a counting procedure. It is also possible to trigger an HTTP request to the statistics server for counting purposes with a tiny JavaScript application that is embedded in the Web page. The counting service on the statistics Web server processes the incoming request to retrieve the origin of the request and stores it in its database. When the owner of the Web site later on visits the statistics service Web page, the following actions are performed:
- After the user has identified himself to the service running on the Web server, the IP addresses from which the user's Web site was visited in the past are retrieved from the statistics database. The service running on the Web server then queries an external database to get the locations at which those IP addresses are registered.
- Once the locations are known the statistics service generates a Web page. At the beginning of the Web page, a reference to Goggle's mapping API is included. It is important to note that this is just a reference to where the Web browser can retrieve the API, that is, the Web browser loads the API directly from Google's server and not from the Web statistics server.
- Next, the JavaScript code of the statistics service is put into the Web page by the server application. As the source code is assembled at run time, it can contain the information about where to put the location markers on the map either in variables or as parameters of function calls. In the “onLoad” function shown in Figure 6.10, the JavaScript application embedded in the page then calls the JavaScript API functions of the mapping service that have been loaded by the script command above.
- As the API functions were loaded from the mapping service Web server, they have permission to establish a network connection back to the map server. They can thus retrieve all information required for the map.
- The map API functions also have permissions to access the local Web page. Thus, they can then draw the map at the desired place and react to input from the user to zoom and move the map.
- In the example above the local “show_regular_markers” function is called afterwards to draw the markers on to the map with further calls to API functions. Note that the implementation of the function is not shown to keep the example short.
Figure 6.10 Remote JavaScript code embedded in a Web page.
6.6.6 Open Source
In his Web 2.0 essay [11], Tim O'Reily also mentions that a good Web 2.0 practice is to make software available as open source. This way the Web community has access to the source code and is allowed to use it free of charge for their own projects. There are many popular open source license schemes and this section takes a closer look at three of the most important ones.
6.6.6.1 GNU Public License (GPL)
Software distributed under the GNU Public License (GPL) [19], originally conceived by Richard Stallman, must be distributed together with the source code. The company distributing the software can do this for free or request a fee for the distribution. The GPL allows anyone to use the source code free of charge. The condition imposed by the GPL is that in case the resulting software is redistributed this also has to be done under the GPL license. This ensures that software based on freely received open source software must also remain open source.
The GPL open source principle—to make the source code of derivate work available—only applies when the derivate work is also distributed. If open source software is used as the basis for a service offered to others, the GPL does not require the derivate source code to be distributed. The following example puts this into perspective: a company uses open source database software licensed under the GPL (e.g., a database system) and modifies and integrates it into a new Web-based e-mail service to store e-mails of users. The Web-based e-mail service is then made available to the general public via the company's Web server. Users are charged a monthly fee for access to the system. As it is the service and not the software that is made available to users (the software remains solely on the company's server), the modified code does not have to be published. If, however, the company sells or gives away the software for free to other companies, so they can set up their own Web-based e-mail systems, the distributed software falls under the terms of the GPL. This means that the source code has to be open and given away free of charge. Other companies are free to change the software and to sell or distribute it for free again. The idea of the GPL is that freely available source code makes it easy for anybody to build upon existing software of others, thus accelerating innovation and new developments. The most successful project under the GPL license is the Linux operating system. The business model of companies using GPL software to develop and distribute their own software is not usually based on the sale of the software itself. This is why all Linux distributions are free. Instead, such companies are typically selling support services around the product such as technical support or maintenance.
Many electronic devices such as set-top boxes, Wi-Fi access points and printers with built-in embedded computers are based on the Linux operating system. Thus, the software of such systems is governed by the GPL and the source code has to be made available to the public. This has inspired projects such as OpenWrt [20], which is an alternative operating system for Wi-Fi routers based on a certain chipset. The alternative operating system, developed by the Web community, has more features than the original software and can be extended by anyone.
6.6.6.2 The BSD and Apache License Agreements
Software distributed under the Berkeley Software Distribution (BSD) license agreement [21] is also provided as source code and the license gives permission to modify and extend the source code for derivate work. The big difference to source code distributed under the GPL license is that the derivate work does not have to be redistributed under the same licensing conditions. This means that a company is free to use the software developed by a third party under the BSD license within its own software and is allowed to sell the software and keep the copyright, that is to restrict others from redistributing the software. Also, it is not required to release the source code.
A license agreement similar to BSD is the Apache license [22], which got its name from the very popular Apache Web server—the first product to be released under this license. In addition to the BSD license, the Apache license requires software developers to include a notice when distributing the product that the product includes Apache licensed code.
Google's Android operating system, discussed in the previous chapter, makes use of the Apache license for applications created in the user space and the GPL license for the Linux kernel [23]. This means that companies adopting the Android OS for their own developments do not need to publish the code for the software running on the application layer of Android if they do not wish to do so. It is likely that this decision was made in order to attract more terminal manufacturers to Android than would be the case if the whole system was put under the GPL, which would force companies to release their source code.
6.7 Mobile Web 2.0—Evolution and Revolution of Web 2.0
The previous sections have focused on the evolution of the Web as it happens today on PCs and notebooks. With the rising capabilities of mobile devices, as discussed in Chapter 5, the Web also extends more and more into the mobile world. The following sections now discuss how Web 2.0 services can find their way to mobile devices and also how mobility and other properties of mobile devices can revolutionize the community-based services aspects of Web 2.0 and the possibilities for self expression.
As the extension of Web 2.0 into the mobile domain is both an evolution and revolution, many people use the terms Mobile Web 2.0 or Mobile 2.0 when discussing topics around the Internet and Web-based services on mobile devices.
6.7.1 The Seven Principles of Web 2.0 in the Mobile World
In Section 6.5 the seven principles of Web 2.0 as seen by Tim O'Reily [11] were discussed. Most of these principles also apply for Web 2.0 on mobile devices:
6.7.1.1 The Web as a Platform
As on PCs and notebooks, services or applications can be used on mobile devices either via the built-in (mobile) Web browser or via local applications. Local applications can run entirely locally and store their data on the device. In this case they are “non-connected” applications and do not come into the Web 2.0 category. If local applications communicate with services or databases in the network and in addition incorporate several of the other principles, they can be counted as Web 2.0 applications.
A few years ago, Java and a standardized mobile device API was the most popular way to program local applications as programs could be run on different mobile operating systems. The disadvantage was, however, that those programs could not use device-specific features or adapt to the “look and feel” of the user interface of a particular device or operating system. With the rise of iOS and Android, most applications today are thus developed in the programing language and the API of a particular operating system.
As in the Web 2.0 world, many mobile Web 2.0 services use the Web browser as their execution and user interaction environment. While in the past, there were a wide range of different browsers in the mobile space with significantly different capabilities and feature implementations, this has improved over time. Today, the Google and Apple mobile Web browsers are used in the majority of mobile devices and both strive for interoperable support of HTML 5 and JavaScript. Their capabilities have significantly advanced compared to browsers available when the first edition of this book was published in 2008 and it can be observed that web pages are now designed with large buttons and Java Script code for use on the desktop, on tablet devices, and also on smartphones.
When considering the Web as a platform for a service it has to be kept in mind that mobile devices are not always connected to the network when the user wants to use a service. When possible and desirable from a user's point of view, a service should have an online component but also be usable when no network is available. A distributed calendar application is a good example of a service that requires an online and an offline component. It is desirable to integrate a calendar application with a central database on a Web server so people can share a common calendar—even for a single user a distributed calendar with a central database in the network is interesting as many users today use several devices—but the calendar must also be usable on a device even when no network is available. In the future, there will certainly be fewer places where no network is available and therefore, an offline component will become dispensable for some applications, while for others, such as calendars, it will remain an important aspect due to the required instant availability of the information, at any time and in any place. A number of different approaches are currently under development to make Web applications available in offline mode. This topic is discussed further in Section 6.7.3.
Another scenario which has to be kept in mind when developing Web-based mobile services is that a network might be available but cannot be used for a certain service due to the limited bandwidth (e.g., General Packet Radio Service (GPRS) only) or high costs for data transfers. While checking the weather forecast is likely to cause only minimal cost no matter what kind of connection is used, streaming a video from YouTube should be avoided without a flat rate cellular data subscription if outside the coverage area of a home or office Wi-Fi network.
Services could in theory be aware of the connections they can use and which they cannot in terms of available bandwidth and cost and adapt their behavior accordingly. This is referred to as “bearer awareness”. This term is somewhat inaccurate however, as it is not only the bearer technology (UMTS, LTE, etc.) that sets the limits but rather the cost for the use of the bearer set by the network operator. Therefore, the neutral term “connection” is used in this chapter instead of “bearer.”
It should be noted at this point however, that today, most mobile applications are unaware of the type of network connectivity available and its cost. At the time of publication, there are no large-scale efforts underway to focus on this; so it is likely that bearer awareness will remain an academic concept for the foreseeable future. It is thus left to the user to control the data usage of applications himself, for example, by only using a video streaming application such as a mobile Youtube viewer at home over Wi-Fi if his cellular data subscription only includes a small monthly data volume.
6.7.1.2 Harnessing Collective Intelligence
Many Web 2.0 applications and services enable users to share information with each other and break up the traditional model of top-down content and information distribution. This applies for mobile devices as well and is moreover significantly enhanced since mobile devices offer access to information in far more situations than desktop computers or notebooks, which rely on Wi-Fi networks and sufficient physical space around the user. Furthermore, users carry their mobile devices with them almost everywhere and access to information is therefore not limited to times when a notebook is available. Thus, it is possible to use the Internet in a context-sensitive way, for example, to search for an address or to get background information about a topic in almost any situation.
Mobility also simplifies the sharing of content, as mobile devices are used to capture images, videos, and other multimedia content. Downloading content from a mobile device to the desktop computer or notebook before publishing is complicated and content is not shared at the time of inspiration. Connected mobile devices simplify this process as no intermediate step via a computer is necessary. Furthermore, users can share their content and thoughts at the point of inspiration, that is, right when the picture or the video was made or when a thought occurred. This will be discussed in more detail in the following sections.
On the software side, harnessing collective intelligence describes using open source software and making new developments available as open source again for others to base their own ideas on. While at the publication of the first edition of this book, only few manufacturers were using open source software, this has changed significantly in the meantime because of Google's Android operating system. The operating system kernel is based on Linux and the GPL open source license and the application environment is distributed under the Apache open source license. In the same way as on the desktop, developers can now modify all layers of the software stack of mobile devices and are no longer confined to the API of an operating system.
6.7.1.3 Data is the next Intel Inside
Another attribute of Web 2.0 is a network-based database. The database becomes more valuable as more people use it and contribute information. In the mobile world, network databases are even more important since local storage capacity is limited. Furthermore, databases supplying location-dependent information (e.g., restaurant information or local events) and up-to-date information from other people are very valuable in the mobile space as mobile search is often related to the user's location.
6.7.1.4 End of the Software Release Cycle
The idea behind the end of the software release cycle is that applications are executed in the Web browser and have a Web-server-based backend and database. This way, software modifications can be made very quickly and new versions of an application are automatically distributed to a device when it loads the Web page of the service. This applies to mobile devices as well but, as discussed above for “the Web as a platform” principle, many mobile applications have to include local extensions as network access might not always be available.
6.7.1.5 Lightweight Programing Models
Easy to use APIs are very important to foster quick development of applications using the services (APIs) of other Web-based services. As in the desktop world, Javascript applications running in mobile Web browsers and XML-based communication with network databases and services provide a standardized way across the many different devices of different manufactures to create new services. Whenever confidential user data is transmitted over the network, a secure connection (e.g., secure HTTP, HTTPS (Hypertext Transport Protocol Secure)) should be used to protect the transmission. This is especially important when Wi-Fi hotspots are used, as data is transferred unencrypted over the air which makes it easy for attackers to intercept the communication of other hotspot users. While security awareness is a growing trend, there were still instances of popular services in 2012 that did not use adequate security measures to protect the exchange of data. Details can be found in [24].
6.7.1.6 Software above the Level of a Single Device
Most services are not exclusively used on a mobile device but always involve other devices as well. A good example is a Web-based Blog reader application such as Google Reader [25], which can be used both on the desktop and also via a Web browser of a mobile device. Such Web 2.0-based applications have a huge advantage over software that is installed on a device and keep information in a local database, as the same data is automatically synchronized over all devices. An example, while at home a user might read their Blog feeds with a Web-based feed reader and mark Blog entries as being read or mark them for later on. When out of the home, the user can use a version of the application adapted to mobile devices and continue from the point where he stopped reading on the desktop. Articles already read on the desktop will also appear as read on the mobile device since both Web-based front ends query the same database on the Web server. All actions performed on the mobile device are also stored in the network so the process also works vice versa.
Another example of software (and data) above the level of a single device is a music library and applications which enable the use of the music library via the network from many devices. If the music library is stored on a mobile device which allows other devices to access the library, the music files can be streamed to other devices over the network. This could be done over Bluetooth, for example, and a mobile device could output the music stream via a Bluetooth connection to a Bluetooth enabled hi-fi sound system. Music can also be streamed over the local Wi-Fi network to a network enabled hi-fi sound system which is either Universal Plug and Play (UPnP) capable or can access the music library of a mobile device via a network share.
Yet another example is streaming audio and video media files via the network to a mobile device. The Slingbox [26] is such a device and adapts TV channels and recorded video files to the display resolution of mobile devices and sends the media stream over the network to the player software on a mobile device. Such services also have to take the underlying network into account and have to adapt the stream to the available network speed.
6.7.1.7 Rich User Experience
Early Web-capable mobile phones suffered from relatively low processing power and screen resolutions which made it difficult to develop an appealing user front end. Since then, however, display sizes and screen resolutions have significantly improved and enough processing power is available to run sophisticated operating systems and appealing graphical user interfaces. The user interface of Apple's iPhone is a good example of a mobile device with a rich user experience and fast reaction to user input. At the same time, the device is small enough to be carried around almost anywhere and battery capacity is sufficient for at least a full day of use.
6.7.2 Advantages of Connected Mobile Devices
The Internet cannot and should not be replicated piece by piece from the desktop onto mobile devices. This is partly because of the limitations of small devices, such as the need to scroll to see more than a few lines of text, a small keypad, or virtual keypad, which makes it difficult to input text, no mouse for easy navigation, and a smaller screen size then on the desktop. However, it is also because mobile devices are game changing, that is they are much more then just the “small” Internet. Tomi Ahonen sees the Internet on mobile devices as the seventh mass media and explains in an essay that instead of looking at the disadvantages one should rather explore the unique elements of connected mobile devices and how they can be used to create new kinds of applications [1].
The current mass media channels are:
- print media (e.g.. books, newspapers, magazines);
- various forms of discs or tapes (recording and music industry);
- movies and documentaries for entertainment;
- radio broadcasting;
- television broadcasting; and
- personal computers and the Internet.
Each channel has unique elements, with the Internet being a bit of an exception since it universally embraces all other mass media types and adds interactivity and search.
New forms of mass media have been able to establish themselves alongside already existing media because they offered something the previous channels did not have. One of the advantages of radio broadcasting over print media is, for example, that news can be spread much faster than would ever be possible with newspapers.
The emergence of a new mass media usually does not lead to a complete demise of previous types of mass media, as some of their properties are not shared by the new media. Instead, it can be observed that media types usually adapt to the arrival of new media. In the case of the print media, newspapers adapted to the fact that they were no longer the source of breaking news once radio and television broadcasting became popular. They have still retained a roll in the media landscape, however, due to their ability to cover news in much more depth and because they are much more suitable for delivering background information. Even with the emergence of the Internet, the print media is still alive and well, as in some circumstances it is still more convenient to read an article in the newspaper than on a computer screen.
Ahonen describes the following advantages of connected mobile devices over previous mass media channels.
6.7.2.1 Mobile is Personal
Previous mass media channels were not personal. A single copy of a newspaper, a book, a movie, a CD, or a television set is potentially used by more than one person. Therefore it is difficult to establish a direct relationship with a customer through a single copy or a single device. Even connected desktop PCs or notebooks at home are often not personal, as the device is usually used by several family members. The connected mobile device on the other hand is highly personal, as it is not shared with friends or even family members. For content creators one device therefore equals one user, which is ideal for assembling statistics about the use of a service, for marketing purposes, and also as a sales channel. As the number of personal devices per user increases, the downside is that the marketer can no longer assume that one device represents one person.
6.7.2.2 Always On
Connected mobile devices are the first type of mass media that is always online. Thus, users can be informed or alerted about events even more quickly than via radio or television—which users do not watch or listen to all of the time. Mobile devices are rarely switched off. A service that has capitalized on this is mobile e-mail, for example, which can be delivered instantly to mobile devices. RIM was probably the first company to fulfill this need with its Blackberry mobile e-mail devices.
6.7.2.3 Always Carried
Always on is so valuable because users tend to carry their mobile devices with them most of the time. Users can be informed instantly about breaking news and they can get access to information at any time. Studies show that many people even keep their phones switched on at night and have them on their bedside table, mostly to serve as alarm clocks. Equally, users have the ability to get or search for information at any time and at any place. As a consequence, search engines are now taking into account that searching for information on a topic while on the move with a mobile device is usually different than searching for information via a desktop or notebook.
The idle screen or the screen saver of connected mobile devices is also an ideal place to display content. Opera's mobile widgets were one of the first programs to explore this area by displaying content retrieved from the Web, sending updates to users in real time from their favorite news feeds [27]. Others have followed in the meantime and popular information to be displayed on the idle screen ranges from weather forecasts to Facebook status updates.
6.7.2.4 Built-In Payment Channel
Most of the traditional mass media channels use advertisements as a source of revenue. Companies advertise via mass media channels in the hope that people like a product and will buy it later on. The issue for advertisers is that there is a gap between users reacting to the advertisement and the opportunity to actually buy the product. This gap has been shortened considerably by advertising on the Internet but users usually still have to type in credit card details before the product is sold. As connected mobile devices are personal and as connecting to a cellular network requires identification and authentication, even this final step of typing in credit card details can be removed. The process from advertising something and giving the user the possibility to buy the product thus becomes a single click, or “single click to buy.” This approach is used on Web portals and online stores of network operators and third-party companies such as those of Google, Apple, Microsoft, Nokia, and others to sell games, music, ebooks, magazines, and so on. The user can browse a catalog and when deciding on a game, for example, can pay instantly by clicking on a purchase button. No identification is necessary as the mobile is personal and the transaction is performed in the background and either deducted immediately from the user's prepaid account, via his telephone bill, via credit card information stored in the shop's database, and so on.
6.7.2.5 At the Point of the Creative Impulse
As connected mobile devices are personal and continuously carried, they are a unique tool to capture thoughts and impressions at the point of inspiration. An advantage of this is the capture of pictures and videos that would otherwise never have been recorded, as other nonconnected and single-purpose devices such as digital photo cameras are not always at hand. In addition, by being connected, mobile devices enable users to instantly send that picture, video, or thought to a picture or video-sharing platform, to a social network, to an instant messaging service, to a microblogging service like Twitter, or to a personal Blog. This helps to inform others of big and small events as they break. Thoughts are also quickly recorded for personal use as, unlike PCs, mobile devices do not need a minute to boot before an application is available for note taking. Also, connected mobile devices simplify the sharing process as it is no longer necessary to first transfer pictures and videos from a digital camera to a PC and then upload the files to Web-based services. By simplifying this process it is much more likely that people will be willing to share content, as it can be made available with much less effort.
6.7.2.6 Summary
When looking at the unique properties of connected mobile devices, it becomes clear that their importance as a new mass media channel will continue to grow and that other channels will have to adapt, as print media had to, following the emergence of radio broadcasting at the beginning of the last century.
6.7.3 Access to Local Resources for Web Apps
On the desktop, many Web-browser-based JavaScript applications exist today with well-designed user interfaces and connectivity to services and databases on the Web. Web-based applications such as Gmail (e-mail reader), Google Reader (Blog reader), Google Docs (text processor, spreadsheet), and so on are now even taking over some of the functionality of locally installed programs. On mobile devices, this trend is growing but not as widespread yet mainly because of two reasons:
- Applications need to be available even without network coverage. This is crucial for applications such as calendars, address books, and so on, which have to be accessible at any time and any place.
- Many applications require access to the file system, the camera, and other services of the device. This is important for applications that upload information, such as pictures, to the Web or for applications that use the device's built-in GPS unit, in order to include information relevant to the user's current location with uploaded content.
To address these shortcomings, a number of different initiatives have developed solutions for these shortcomings. By 2012, many results had been incorporated in the HTML5 standard and mobile browser support was rising. A good overview is given in [12] and the following paragraphs describe some of the key HTML 5 functionalities now available in mobile browsers.
To address the requirement that a web application must remain usable even when a device is currently not connected to a network, HTML5 describes mechanisms to store web pages and data on the device. This is done by declaring in the main Web page of the Web app which resources are to be stored in a locally. Later on if the user invokes the Web app and no network connectivity is available, the browser recognizes that the Web app and its data are available locally and loads it from local storage.
To store data locally a JavaScript application get access to local Web storage [28] and a local SQL database [29] unless the user takes steps to prevent this for privacy reasons. A calendar application, for example, could store and modify a copy of the user's calendar entries that are usually held in a web-based database locally and synchronize the modified data with the web-based database once connectivity is restored.
As synchronizing the local and the remote data depository after going online could take considerable time, it is important that such activities do not block the execution of the JavaScript application on the Web page. Thus, HTML5 has defined the “web workers” API that can be used by a JavaScript application embedded in a web page to spawn background threads to perform actions that are not directly related to interacting with the user [30].
HTML5 also enables access to local resources and information such as:
- GPS and network location information,
- motion sensors such as accelerometers, gyroscopes, and magnetometers built into every smartphone today,
- network connection type info (Wi-Fi, cellular), and
- access to the audio, image, and video capture capabilities of the mobile device.
If and how access to these resources are granted depends on the implementation of the Web browser. Security- and privacy-aware browsers therefore actively request the user's consent before access to such resources is granted to Web apps.
It should be noted at this point that not all functionalities listed in this section are necessarily supported in all mobile browsers. Consequently, developers are either restricted to a subset to be cross-platform compatible or have to focus on specific browsers or operating systems. Owing to the broad acceptance of HTML5 as a common standard, however, most functionalities described above are already implemented by mainstream mobile Web browsers and future enhancements are likely to further improve cross-platform compatibility.
6.7.4 2D Barcodes and Near Field Communication (NFC)
In the desktop world, URLs of new Web pages found in print magazines, books, and so on can usually be quickly entered into the Web browser via the keyboard. In the mobile world, however, this is much more difficult as there is usually just a numeric keypad available. The use of T9 (text on nine keys), a predictive text input technology to speed up the writing process of text on numeric keypads, is difficult to use with URLs as names of Web sites are often composed of words that do not exist in the local language. Even if short Web site names are chosen, entering the Web site name into a mobile Web browser is still time-consuming. This tends to keep users from viewing new Web pages on their mobile device unless there is a very strong motivation to do so.
Most mobile phones, however, are equipped with a camera which can be used to simplify the process. In the future, mobile phones may become powerful enough to include text recognition algorithms which are able to extract URLs from a picture the user has taken from an advertisement or a Web site URL in a print magazine. The extracted URL can then be forwarded automatically to the mobile Web browser and the page opened without any further interaction with the user.
A current alternative is two-dimensional (2D) barcodes. 2D barcodes are similar to standard one-dimensional Universal Product Code (UPC) barcodes which have been in use for a long time on everyday products. These are used in combination with cash registers in supermarkets, for example, to speed up the checkout process. Two-dimensional barcodes have an advantage over one-dimensional UPC barcodes in that much more information can be encoded in them. Figure 6.11 shows a 2D barcode that can typically be found today on advertisements, in magazines, and shop windows. Instead of typing a URL into a mobile web browser, barcode reader apps can now be downloaded to smartphones and used to scan a 2D barcode and to automatically decode the content as shown on the right in Figure 6.11. After decoding, the barcode application forwards the URL to the mobile browser, where it is opened automatically.
Figure 6.11 A two-dimensional barcode.

Another emerging technology to bridge the gap between an advertisement in the physical world and an online Web presence is Near Field Communications (NFCs) as described in the previous chapter. If posters and advertisements contain an Radio Frequency ID (RFID) tag in addition to a 2D barcode and the mobile device is NFC capable, a URL or other information can be obtained by simply holding a device close to the poster or advertisement. This is simpler and faster than starting a 2D bar code scanning application as the process of detecting the RFID tag is fully automatic. This is because in the default configuration an NFC-capable device is scanning for RFID tags continuously while the screen is not locked.
Another advantage of 2D barcodes in magazines, on posters, on advertisements, and so on is the strong message to the user that the Web site behind the barcode can be viewed with a mobile device and that no PC or notebook is required.
6.7.5 Web Page Adaptation for Mobile Devices
Today, the majority of Web pages are still designed for desktop-based screen resolutions and often it is also assumed that the user is connected via a broadband connection, that is, that pictures and other content can be downloaded almost instantly. This is an issue for mobile Web browsing since the screen is usually much smaller. Advanced Web browsers on mobile devices are “full screen” Web browsers as they can render the page exactly as intended for the desktop and only show part of the Web page on the screen. The part that is shown on the screen is either a particular area of the Web page or the text from a particular area, reformatted to fit into the mobile device's display.
While this works quite well, there are a number of disadvantages to the approach depending on the situation. The first disadvantage is the processing power required to render a standard Web page. Long pages with a lot of content take some time to be rendered and require the user to wait for some time. Fortunately, because of increasing processing power available on mobile devices, this disadvantage is about to disappear more and more. A second disadvantage is the time required to download all parts of a page if only a slow connection to the network is available.
In practice, a number of different solutions exist to compensate for these shortcomings, which are discussed in the sections as follows.
6.7.5.1 Mobile-Friendly Pages
Some Web sites and Blogs are available in a full desktop browser format and also with a mobile layout. The mobile friendly layout usually does not use JavaScript and Flash, the page is formatted differently and advertisements are either missing or inserted in a different way, that is, not on a side bar since the screen of a mobile device is too small for Web pages to have sidebars. Mobile-friendly Web pages can be requested from the Web server in a number of different ways. One approach is to have different URLs for the desktop Web site and the corresponding mobile Web site. How this is done is not standardized. Google, for example, offers a mobile-friendly search engine page via http://google.com/m. Others put the indication that a Web site contains mobile content at the beginning of the URL such as http://mobile.domain.org or http://m.domain.org.
Since these methods are not standardized, the mobile industry created a new top-level domain, “.mobi.” URLs like http://martin.mobi indicate that the Web pages on this Web site are specifically tailored for mobile devices. The creation of the mobi domain was quite controversial at the time as the top-level domain now indicates the type of device for which it is intended. No other top-level domain has done this before and many had been against such a solution as they were in favor of the “one Web” (for all devices) approach to prevent the World Wide Web from splitting into a desktop and a mobile sphere. One of the advocates of the “one Web” movement was Sir Tim Berners Lee, inventor of the world wide Web. In the article “New Top Level Domains.mobi and .xxx Considered Harmful” [31] he gives some details of why he fears that a mobile-specific top-level domain might have a detrimental effect on the Web. In the end he did not prevail and the .mobi domain was created.
6.7.5.2 Web Servers with Content Adaptation
An approach to web page adaptation that has become quite popular in recent years is that Web sites themselves analyze the browser identification string in an HTTP request message and deliver a standard Web page for desktop browsers and an adapted version for mobile devices. From a theoretical point of view, this approach is superior as:
- The Web is not fractured and the “one Web” paradigm is fulfilled.
- No external content adaptation services are needed and pages get rendered according to the capabilities of the requesting device.
Unfortunately the disadvantage of this approach in practice is that users have no way of determining from the URL that the content will be delivered in a mobile-friendly format and thus might not consider visiting the Web site from their mobile phone if they are not informed by other means like, for example, a “mobile-friendly” logo on the Web site itself.
In addition, this approach does not take the type of network connection and the associated costs into account. A mobile Web browser might be capable of rendering sophisticated Web pages and thus the Web server can send the standard desktop page, but the user might prefer a scaled down version due to the high transmission costs.
6.7.5.3 Web Browser Content Adaptation Proxies
Yet another way to adapt Web pages for mobile devices is to combine a light-weight mobile Web browser with a content adaptation proxy in the network. Opera very successfully uses this strategy with its Opera Mini web browser, a Java, and native application on iOS, Android, and Symbian available for most mobile phones and other mobile devices [32]. The Opera Mini Web browser on the mobile phone only communicates with the Web proxy, which requests the page on the user's behalf, modifies the page, and leaves it to Opera Mini to display it. Since the proxy and the Web browser work together, the resulting adaptation is usually excellent. This way it is also possible for the browser to show an overview of the full page without having to load the full content of the page. Figure 6.12 shows how this content adaptation approach looks in practice on an entry-level Android device.
Figure 6.12 Opera Mini with network-based proxy and light-weight browser. (The screen-shot of OperaMini and the Opera logo is reproduced with kind permission from: Opera Software ASA, Norway.)

6.7.5.4 Web-Based Transparent Proxies
Many network operators today use transparent proxies to reduce the amount of data transferred for a Web page and decrease the page loading times. This is done, for example, by compressing images and removing unnecessary HTML code from Web pages. As the proxy is transparent, the Web browser and Web server do not need to be modified. While the approach has some advantages, the downside is that the quality of the images embedded in a Web page is significantly reduced. As current 3G networks and future B3G networks are fast enough to serve full Web pages, most operators allow the user to deactivate this kind of content adaptation. Deactivation is done either via a Web page, or via proprietary software which was shipped together with the wireless network card or by sending a modified HTTP header [33].
6.7.5.5 Conclusion
In practice, a number of factors determine how the user can or prefers to surf the Web with their mobile device:
- the capabilities of the device itself (processing power, screen resolution, etc.),
- the mobile Web browser delivered with the device,
- the speed of the network connection, and
- the cost of a particular network connection.
In theory, the “one Web” approach is a good idea, but it does not work well in some usage scenarios since not all Web sites supply their Web pages in formats adapted to specific types of devices and wireless networks. Thus, users that only have access to slow networks, for example, during their commute, in remote areas, or in developing markets have to be aware of which sites support optimization techniques and which do not and consequently less ideal approaches than “one Web” are sometimes still preferable in practice. Fortunately, devices have become more powerful in recent years, costs for using cellular networks have decreased significantly, and network coverage of high-speed wireless broadband networks has increased; so content adaptation is required in fewer and fewer usage scenarios. These trends are likely to continue further. In developed markets, server side content adaptation and wireless broadband network coverage will at some point be widespread enough; so users will no longer require Web browser content adaptation proxies or other means of adapting to slow networks and low-end mobile devices with limited browsing capabilities.
6.8 (Mobile) Web 2.0 and Privacy and Security Considerations
The inherent goal of many (mobile) Web 2.0 social networking applications is to let users share private information with the rest of the world or with a group of other people. Privacy on this level can be controlled by the user, that is, by consciously deciding what kind of information they want to share with others. When making a decision of what to share and what not to share, one should not only think about the immediate implications of sharing private thoughts, ideas, and so on, but also about what happens to this information over time. Everything that is shared publicly will remain on the Internet for an indefinite time and can be found via search engines by anyone and not only by those for whom the information might have initially been intended. Everything shared with a group of users is also shared with the company running the social networking site and so this information can be used for various things such as directed advertising or later on sold to other companies. Where the boundary lies between what to share and what to keep private is an individual decision and can be controlled at the time the information is shared.
There are, however, many mechanisms at work behind the scenes which track user behavior and collect sensitive private information without the direct consent of users at the time this information is gathered and stored. Thus, users cannot make individual and conscious decisions about such processes. Instead, users are required to know about these mechanisms and to actively take countermeasures in case they do not agree to this kind of private data collection and analysis. The following examples show some of the Web techniques used by companies to collect information about user behavior and what users can do protect their privacy if they not agree with these methods. Unfortunately, these countermeasures require a fair amount of technical knowledge which the majority of Internet users do not have.
6.8.1 On-Page Cookies
The oldest form of tracking users is a mechanism known as “HTTP cookies.” When requesting a Web page, a Web server can, in addition to the requested Web page, return a cookie (a text string) to the Web browser. The Web browser stores the cookie in an internal database and returns it in future requests to the same Web server. This is one of the most popular mechanisms used today by Web sites to track a user through their Web pages. It is a useful tool during an order process, for example, which requires the user to go through several pages. Without cookies or similar technologies, the Web server could not correlate the information the user has supplied in the different pages. Cookies are also useful for online services such as Web-based e-mail, blogging tools, or social networking sites. Here, a Web-based environment is used which is spread over many different Web pages and it would not be practical to require the user to identify himself on each new page.
Cookies are also used by many companies to correlate user actions during site visits in order to specifically alter the content of a page based on previous behavior. Amazon is a good example. When browsing through the Amazon store the system tracks which items have been looked at and presents previous items as part of the new page. The system also tracks which articles the user has viewed during a session. Based on this knowledge, other users will later on get suggestions like “other users who have viewed this item have also viewed the following item …” There are a number of privacy concerns with such behavior. First, the shop owner stores and uses information not only about which items a user has bought in the past, but also which items she has only looked at. Over time the shop owner can thus collect a huge amount of information about customers which can then be used to deduce preferences and to place specifically targeted ads on a Web page. Also, if this private information is sold to a third company or stolen, private data is revealed without the knowledge or consent of the user.
Second, cookies are stored in the Web browser's database for an indefinite amount of time by default and are stored even when the browser is closed. This is shown in Figure 6.13 for a cookie that has set its expiry time to the year 2035. By default, cookies are still present in a Web browser's database and are resent to the Web server when the user revisits the Web site at some later date. The advantage for the user is that he does not need to log in again as they are immediately recognized. This is useful in some instances, for example, for frequently used services such as Web-based e-mail or blogging, as the user does not have to identify himself again. A potential downside side, however, is that user behavior can be tracked without a gap. Again, Amazon is a good example of a company that tracks user behavior across sessions. As soon as a user revisits the Amazon store, the user's browsing record is retrieved from a database and information and ads are presented based on the items the user has bought and viewed during their previous visits. The shop or service software logic in the background then also tracks the user's current visit and stores their browsing record for future analysis.
Figure 6.13 Cookie information stored in the browser.

6.8.1.1 How can Cookie Use be Controlled?
By default, Web browsers today accept cookies from all Web sites and keep them as long as requested by the Web servers. It is possible, however, to manually ban cookies from certain Web sites and to configure the browser to delete all cookies at the end of the session from the remaining sites. This ensures that long-term behavior tracking by Web sites is not possible unless the user identifies himself by logging in. For selected Web sites, where the user sees a benefit in remaining identifiable over a restart of the browser, the cookie can be exempted from deletion when the browser is closed. The author, for example, only allows about a dozen Web services to permanently store their cookie while the rest get deleted. To ensure that shopping Web sites do not use the information they have gathered about a user while browsing the shop, the user should manually delete the cookie before logging in or restart the browser before logging in to buy an item.
6.8.1.2 Applicability to the Mobile Web
Cookies are also used to preserve a session state for Web services adapted to mobile use. Unlike desktop Web browsers, however, mobile Web browsers do not yet give users the ability to define which cookies are acceptable, which are not, which should be deleted when the browser is closed and which are allowed to be stored between sessions. It remains to be seen when the configuration options of mobile browsers will be extended to allow this.
6.8.2 Inter-Site Cookies
Cookies can also be used to track a user over several Web sites. All that is required for this is that Web sites include a picture or other element from the same third-party Web server. When this picture or page element is retrieved from the third-party server the cookie previously stored when visiting another site will be sent alongside the request. This can be used for marketing purposes, for example, to track how the user navigates through the Web. A precondition is, of course, that the Web sites the user visits use the same external marketing partner. As there are only a few large online marketing companies, inter-site user tracking and use of the gathered data for targeted marketing and other purposes is easily achieved.
Inter-site cookies can be controlled in the same way as described above for single-site cookies that are only used on one Web site, since from the Web browser point of view there is no difference. Some browsers also offer an option to disable third-party cookies. In addition, Web browser plug-ins such as Adblock Plus reduce the amount of advertising shown on Web pages loaded from third-party servers and their corresponding cookies.
In general, third-party cookies are also applicable for mobile Web browsing where privacy issues today are greater than for standard Web browsing, as most mobile Web browsers do not allow the user to view and manage cookie information properly.
6.8.3 Flash Shared Objects
Interactive Web page content and animations based on Adobe's Flash environment [34] are found on many Web pages for various purposes today. These range from social Web site flash plug-ins to advertisement banners. The Flash environment allows applications to store information on the local hard drive. Information is not removed when a Web page is left or when the browser session ends. In effect, Flash animations/applications have a cookie-like mechanism which cannot be controlled via the browser. The same advantages and disadvantages discussed for HTTP cookies thus also apply for Web page Flash applications.
6.8.3.1 How to Control Shared Objects
Depending on the kind of Flash player installation, the environment can be configured to deny applications the right to store local information. Another possibility to prevent Flash applications from tracking user behavior is to use freely available Web browser plug-ins such as Adblock [35]. With such plug-ins the user can control which Flash applications and other page elements are loaded and executed.
6.8.3.2 Applicability to Mobile Web Surfing
While Apple has banned the use of Flash on web pages on its smartphones and tablets, it is supported on many other mobile operating systems and mobile web browsers, most notably Android. Leakage of private information via Flash local storage is thus also a concern on mobile devices.
6.8.4 Session Tracking
One of the big benefits of Blogs is that readers can discuss articles with the author and other readers by leaving a comment on the Web page. In the past, some companies have extended this principle to allow background discussions on any Web page. This worked by installing a browser plug-in so that for every Web page the user visits, an indication is provided of whether other people have left a comment for this page. While this functionality is quite interesting, the issue with this approach is that the plug-in queries a database in the background for every Web page the user visits, to find out if other people have left a “virtual” comment. In effect the database in the network can thus record every step made by all users who have installed the plug-in. From a privacy point of view this is problematic as it potentially allows an external service to track a user's every move on the Web.
6.8.4.1 Countermeasures
The only effective countermeasure is not installing Web browser plug-ins which contain such a functionality, even if it is only a part of their overall functionality. Also users should be careful when installing plug-ins from an unknown author as in recent history, such functionality was attempted to be included in browser plug-ins such as, for example, ShowIP [36]. This was quickly discovered by users however and pointed out on the download page of the plugin-in on the Mozilla web site.
6.8.4.2 Applicability to Mobile Web Surfing
Most mobile Web browsers do not yet support plug-ins and thus the threat is small to mobile Web surfing today.
6.8.5 HTML5 Security and Privacy Considerations
As discussed in Section 6.7, HTML5 allows a Web application to store data locally or to even access local information beyond the browser cache. This has a number of security and privacy implications, which should be considered from a development and from a user point of view. The main issue with having a local application and data cache in the Web browser is that JavaScript applications could use the local cache for user tracking. Advertisement services could use the local interface to write a JavaScript program that is included in all Web pages of their advertising partners, which records the pages from which it has been invoked in the local cache. Each time the same JavaScript application is executed from a different page, it reports the last page back to the advertisement server, which can then generate a user profile. As most users are unlikely to agree with such methods, the user should be informed that an application wants to store information locally and what kind of privacy issues this could bring with it. The user should then have the choice to allow or deny the use of local storage. If allowed, then this should be either temporarily or, where the JavaScript application is trusted, more permanently.
Access to local device information outside the browser cache is even more sensitive, as malicious JavaScript applications could read the user's private data and send it to a server in the network. Therefore, the user has to be informed if a JavaScript application tries to access local data and give the user the opportunity to allow or deny the request. The user then has to decide whether he trusts the application and thus allows access to local resources. Again, the user should have the choice to allow access temporarily or permanently as trusted applications should be able to access local data without further queries to the user once consent has been given. Otherwise, usability of the application would suffer.
At the time of writing, many PC and mobile Web browsers do not yet offer fine grained control of web storage settings. One exception is Firefox which explicitly asks the user for permission if a Web app wants to store data. Also, users can later on verify which Web apps use local storage and can revoke storage rights for individual web apps as shown in Figure 6.14.
Figure 6.14 Control of local storage for Web apps in Firefox.
6.8.5.1 Countermeasures
Depending on the Web browser, local storage can be disabled globally or by rejecting individual requests.
6.8.5.2 Applicability to Mobile Web Surfing
As this functionality was specifically designed for mobile devices, the feature is available in most mobile browsers today. Most of them, however, do not offer fine grained control beyond the possibility to occasionally delete local storage data of all web apps.
6.8.6 Private Information and Personal Data in the Cloud
The purpose of many Web services is to offer social services to connect people with each other. This usually requires that personal information is stored on a server in the network (“the cloud”), which is then combined with data of other users. The risk of this is that once personal data leaves the personal devices of a user, control is lost over the data. Privacy declarations of cloud-based services describe for what purposes the user's data can be used by the service and many cloud-based service providers such as Google and Facebook grant themselves far reaching rights concerning monetization. Furthermore, cloud-based services are usually required by law of their country of origin to provide detailed information about usage of the service and data stored about a user to law enforcement agencies ranging from the police to homeland security. This extends far beyond personal information and also includes, for example, any kind of files a user has uploaded to a cloud-based services such as, for example, a remote backup server. If data is stored unencrypted or in an encrypted format with the encryption key also being stored by the service provider puts users at risk that their data might fall into the hands of hackers, which can then be used for all kinds of purposes. Examples are stolen credit card records and social security numbers that can be used for performing illegal actions such as unauthorized monetary transactions and identity theft for other purposes. For companies, storing confidential information on external servers opens the door for industrial espionage unless the company takes care that all data is encrypted before it is sent to the remote storage server.
6.8.6.1 Countermeasures
Protection of data sent to social network services such as Facebook is not possible as the purpose of such services is to share information. Users should be aware that they are not actually the customer of social network services as it is usually not them who pay for the service. In reality, companies paying for the presentation of advertisement are the customers of social networking services. Users should be aware that they loose control over what their data will be used for by the service today and in the future and should thus be cautious on what kind of information is released into the public domain. Also, users should be aware that many social services collect information about the location via their IP address, Wi-FI SSID (Service Set ID), GPS, and other means. This has to be kept in mind when interacting with such services and only data should be shared that the user would be willing to share with the public.
For cloud-based data storage, users should ensure that their service of choice offers true pre-Internet encryption (PIE) [37], that is, the data is encrypted on the device of the user with their personal encryption key that is not stored on the cloud-based server. Even if the data stored on the cloud server is later stolen, the attacker will have gained nothing as the key is not part of the compromised data.
6.8.6.2 Applicability to Mobile Web Surfing
The privacy considerations just described for cloud-based social networks and cloud-based storage are also applicable for services used on mobile devices as both types of services are now typically available on mobile devices as well. In many cases, services are offering a Web site for small screens and desktop-based browsers.
6.9 Mobile Apps
The advantages of connected mobile devices compared to desktop-based devices such as always on, always carried, a built-in payment channel, and so on, as described in Section 6.7.2, are not only realized with services running in a Web browser but also with native applications. While lacking some Web 2.0 characteristics such as the end of the release cycle and not running in the Web browser, they share many others such as harnessing the collective intelligence, data as the next Intel inside, and the rich user experience paradigm as described in Section 6.7.1. Furthermore, many apps in use today extensively use databases in the network (“the cloud”) and are updated and enhanced on a regular basis with semi- or fully automatic procedures.
Some Web 2.0 services such as Facebook, for example, have expanded into the mobile domain and are now widely used on mobile devices. Like on the PC, Facebook is available as a Web-browser-based application. As mobile Web browsers still have some limitations compared to their desktop counterparts and over native applications in terms of speed and access to local resources, Facebook decided to also implement native applications on several mobile platforms. These behave in a similar way as the Web application but in addition they have access to local information such as the address book and location information via GPS, network cell-id's, and by identifying nearby Wi-Fi networks. It will be interesting to see if Facebook will over time make use of increasing browser capabilities and HTML5 extensions for local access or if the current trend of providing local application that is superior to their Web app counterparts continues.
The following sections now take a look at a number of aspects of local applications beginning from describing the different local ecosystem approaches, security and privacy implications, an introduction to programing mobile applications for the Android operating system, and how applications should behave to optimize power consumption and interaction with the network.
6.9.1 App Stores and Ecosystem Approaches
Third-party applications on mobile devices have been available for many years and many mobile operating systems offered the possibility to install programs downloaded directly from the Internet or via a PC. The lack of Internet access on mobile devices, small screens, and limited user interfaces, however, kept the popularity and use of such applications rather low. This changed with the emergence of the iPhone and Android-based devices that brought the following changes to the mobile ecosystem:
- Large displays,
- An easy to use touch-based graphical user interface,
- A central market place from which mobile applications could be downloaded,
- Easy access for developers to these markets, also referred to as app stores,
- Many free of charge apps either written by enthusiasts or monetized through advertisement banners.
While there is a central app store for each mobile operating system, their philosophies and terms of use for application developers and users are very different. On the one hand, there are app stores that enforce a walled garden ecosystem. The Apple iPhone environment is a typical example of this category as users can only install third-party applications via Apple's app store. Application developers can thus only distribute their applications under Apple's control and by adhering to Apple's developer guidelines. These guidelines significantly restrict the developer's freedom and monetization capabilities outside Apple's control. Also, developers do not have access to the source code of the operating system and no API exists to modify the system's behavior. As a consequence, developers cannot innovate outside the narrow confines of the API and users are limited to applications that comply with Apple's moral and monetary view.
On the other hand, there are mobile application stores and environments that are completely opposite from the walled garden approach described above. Google's Android is an example of such an open garden approach in which the user is free to download applications not only from the central application store but from any source they like. Also, the operating system is open, the source code is available, and many API functions are available to change the behavior of the operating system. This is as far reaching as allowing developers to replace the complete user interface look and feel [38].
Applications wishing to access local and private information such as calendar and address book entries, location information, network access, and so on have to request proper permissions at installation time. This allows the users to detect when applications would like to access information they have no need for and helps to stop potential privacy breaches and loss of personal information. An alarm clock application, for example, does not require access to location information and the network. If still requested, it is likely that the application is either not well programed or wants to access this information to send it to the network, for example, for selecting advertisements relevant to the user's location as a form of monetization. The user can then decide if he is willing to give up his privacy in exchange for a free application or not. It should be noted that many users may not review the permissions requested by an application during the installation process, which is somewhat a security issue in itself. However, this approach has worked for many decades in the personal computer world, where users are free to install any kind of software from any source desired. From the author's point of view, having a choice and the freedom to make an informed decision is preferable to a walled garden environment.
6.10 Android App Programing Introduction
After a general introduction to mobile applications and central market places in the previous section, the following section gives the reader a high-level introduction on how software is written for mobile devices in practice and how the API provided by a mobile platform is used. Google's Android is taken as an example because all tools are freely available and excellent documentation is available online. Also, no application certification or complex mobile device setup is required to test the program during the development process.
6.10.1 The Eclipse Programing Environment
Most Android apps run in a virtual machine referred to as “Dalvik” and are programed in Java. The main benefit of using a virtual machine is that it makes applications independent from the CPU architecture. To interact with the user, the device hardware, and the network, the Android API is used. The API and the virtual machine have been developed by Google; so Dalvik programs will work on devices of all manufacturers using Android as the operating system for their devices. This is a significant difference to the previous Java approach that became very fragmented over time and developers often having to write different versions of their application for phones with different Java API implementations.
Applications for mobile devices are usually programed on a desktop or notebook computer. There are different development environments that can be used. Google recommends the use of the open-source Eclipse development environment together with the Android Software Development Kit (SDK) and describes how it can be installed in [39]. Eclipse can either be installed directly in Windows, Mac OS, or a Linux distribution. While a high screen resolution and a fast processor increase the efficiency during the development and debugging process, it is also possible to use Eclipse on netbooks with a small screen and low processing power as shown in Figure 6.15. The major drawbacks are that less information and fewer windows of the development environment can be seen on the screen and that it is better to use a real mobile device for testing and debugging the application as the Android device simulator requires significant resources to run sufficiently fast.
Figure 6.15 The Eclipse programing environment running on a netbook.

6.10.2 Android and Object Oriented Programing
In essence, an Android application is based on two major concepts. The understanding of these is the basis for the subsequent discussion of a simple application. The first concept of every Android App is that it is programed in Java, which is an object-oriented language. The core of object orientation can be described in two parts:
First, object orientation means that every line of code of an app is part of a class. On the highest level of abstraction, every app has at least one class and one method in the class that contains the code. This method is called when the app is started by the user. That method then creates what the user sees, that is, it arranges text, buttons, and other things on the screen. As an app usually performs more than just a startup procedure, additional methods are defined which are then called when necessary.
The question that arises at this point is how Android knows which method to call when the App is launched. This can be answered by looking at the second idea of object orientation. Classes are a kind of blueprint and to make them come alive, they have to be instantiated. This can be thought of in terms of real objects. The abstract term “car” is a good example. The “car” class contains the basic description of what all cars have in common such as a steering wheel, doors, and so on. A particular car is then instantiation of the abstract term car. There can be several instances of a car, like, for example, John's car and Debby's car. In object orientation, an instance is called an object. In other words, an object is an instance of a class. What Android does with object orientation is describing the basic principles of how an app is supposed to work and defines the names and parameters of the methods that are called by the OS when specific events occur.
When the app is started, a specific method of an object is called. To make this approach useful, the app only uses the method definition, that is, how the method looks to the outside but defines what is inside the method itself. This is called “overriding.” So if there are two apps running, they both have the same method that is called by the OS when the app is launched. The content of that method, however, is defined by the programer of each app.
The method that is called when the app is started is only one of many that are already contained in the basic app class and the application programer is free to either use methods and variables as they are defined or override them and perform their own actions with it. What remains the same in all apps are the method names and the parameters the method exchanges with the external word. Thus, there is a uniform way for the OS to interact with an app as will be further discussed below.
Object orientation is a means to an end. How the app interacts with the world is a different matter. For that purpose, the OS needs to provide an API. Apple's iOS also offers an object-oriented interface to programing but the API is quite different to that of Android. To display an “OK” button on the screen, for example, an object of the type “button” is instantiated from the button class. The text displayed on the button and many other things are then defined by the app by calling methods of that object that then do their job inside the class to bring the button to live.
The second major concept of Android app programing is call back methods. Whenever an event occurs that the app should become aware of, such as, for example, the user clicking on a button on the screen, the user pressing a hardware button, the app being sent to the background because the user starts another app, data arriving from the network for the app, and so on, a callback method is called by the OS. But how can the OS know which method of the app to call? If the callback method is part of the general app class described above, then there is nothing special to do because the callback methods are predefined and the programer can simply override the existing methods for the different events. Most elements a user interacts with such as buttons, for example, are not part of the general Android app class. As described above, the user instantiates a button object from the button class and then the app object contains a button object. To be informed about the user clicking on the button, the programer needs to define a method in the app class to receive the event. A reference to that method is then given to the button object. When the user then clicks on the button, the button object calls the given method.
Most apps that interact with the user are fully callback controlled. When the app starts, everything is put on the screen and callback methods are put in place. Then, while the user is not interacting with the app, no further processing power is needed for the app and no code is executed. Only once the user interacts with the app by, for example, clicking on a button, a callback method is called. The callback method can then perform an action when the button is clicked, for example, a calculation is made and an output is made to the screen, and then go back to sleep until a new event arrives.
And finally, in addition to callback methods, an app can also spawn background threads for actions that are continuously performed without user interaction or for actions that take a long time to complete. A separate execution thread has to be used for this; so the main thread with the callback methods can be called by the OS at any time the user interacts with the app.
6.10.3 A Basic Android Program
After the general introduction to the Eclipse programing environment and the basic concepts of object orientation and how it is used, this section now takes a look at how Android programs are implemented in practice. For this purpose, some parts of an application are shown that retrieves information about the network information such as cell-ids, signal strength, and other data that Android provides to apps via its API. The full source code and the packaged app can be found in the Android store or at the web site to this book [40].
As described in the previous post, Android apps use an event-driven execution approach. When the app is started by the user, Android loads the app into memory and then jumps to the “onCreate” method. The following code excerpt shows the beginning of the onCreate method of the app:
/* Called when the activity is first created. */
@Override
public void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.main);
/* If saved variable exist from last run still exist, recover them */
if (savedInstanceState != null) {
[…]
}
As the app has a number of specific actions to perform, the onCreate method is “overridden.” This means that while the original input and output parameters of the method are used in the app to allow Android to call the method in a defined way, the code in the method itself is unique for this application. In some cases, it makes sense to not only have individual functionality in overridden methods but to also execute the code of the original method. This is done in the first line of the method by calling “super.onCreate.”
The onCreate method receives a parameter that references data that the app has saved while it was last executed. This way, the app can populate all necessary variables at startup; so it can continue from its previous state. This is quite helpful as Android closes an app automatically for various reasons such as, for example, when the system runs out of memory. An app is also closed and then automatically reopened when the user rotates the device and the screen orientation changes, something that happens quite frequently. As a consequence, the app uses this reference to populate a number of variables, such as the number of cell and location area changes that have occurred before (not shown in the code excerpt above).
Once the variables are initialized, the onCreate method performs a number of preparations to get access to the network information. The app is mainly interested in the cell-id, the location area code, the signal strength, and when one of these parameters change. On a machine that only runs a single program, a loop could be used to periodically check if these parameters have changed and then display them on the screen. In practice, however, this would not work as Android is a multitasking operating system; so a single program must not lock-up the device by running in a loop. Therefore, apps are event driven, that is, a handler method is called when something happens. The app then performs an action such as updating the display and then goes back to sleep until another event happens and the handler is called again. So the way to get to the network status information and to be informed about changes is to create a listener class with listener methods that Android calls when certain cellular network events such as signal strength changes occur. This is done with the following code:
/* Get a handle to the telephony manager service and install a
listener */
MyListener = new MyPhoneStateListener();
Tel = (TelephonyManager)
getSystemService(Context.TELEPHONY_SERVICE);
Tel.listen(MyListener, PhoneStateListener.LISTEN_SIGNAL_STRENGTHS);
In the first line, an object is instantiated from a class that that has been defined further below in the source code, the “MyPhoneStateListener” class. In the second line, a reference is retrieved to the service object that manages the cellular network connectivity. In Android, this object is called the “Telephony_Service,” which is a bit misleading. In the third line of the code, the listener object is then installed as a listener of the telephony system service. This way, whenever the signal strength or other properties of the cellular network connectivity changes, the app is automatically notified and can then perform appropriate actions such as displaying the updated signal strength, cell-id, and other information on the screen.
The code for the listener object is part of the app and is a private class that is only visible to the app but not to the outside world. The following code excerpt shows how it looks like:
private class MyPhoneStateListener extends PhoneStateListener {
/* Get the Signal strength from the provider,
each time there is an update */
@Override
public void onSignalStrengthsChanged(SignalStrength signalStrength) {
[…]
try {
/* output signal strength value directly on canvas of
the main activity */
outputText = "v7, number of updates: " +
String.valueOf(NumberOfSignalStrengthUpdates);
NumberOfSignalStrengthUpdates += 1;
outputText += "
Network Operator: " +
Tel.getNetworkOperator() +
" "+ Tel.getNetworkOperatorName() + "
";
outputText += "Network Type: " +
String.valueOf(Tel.getNetworkType()) +
"
";
[…]
To keep things simple, the app only uses one listener method in the listener object, “onSignalStrengthsChanged.” As the name implies, this method is called whenever the signal strength of the current cell changes. It is “overridden” as the Android default actions should not be executed. Instead the method should only perform the actions in this instance of the class. When this method is called, it also retrieves other network status information and compares it to previously received values. If, for example, the cell-id has changed, it increases a corresponding counter variable accordingly.
Reading network status information only works while the mobile device receives a network. If network coverage is lost and the method is invoked, status query methods return an error, known as an “exception” in Java. If the exception is not handled, the application will be terminated with an error message presented to the user. To prevent this from happening, all network status queries are performed in a “try-catch” construct. If an exception occurs in the “try” part of the code, execution continues in the “catch” part where the exception can be handled. In the case of this app, the code for the “catch” part is rather short as it does not do anything with the exception and the method just exits gracefully without the app terminated by the operating system.
The following methods provided by the Android API are used by the demo app:
TelephonyManager.getNetworkOperator() TelephonyManager.getNetworkOperatorName() TelephonyManager.getNetworkOperatorType() SignalStrength.getGsmSignalStrength() --> works for UMTS as well… GsmCellLocation.getCid() GsmLellLocation.getLac()
There are also objects and methods in the API to get information about neighboring cells. Unfortunately, this functionality is not implemented consistently across different devices and network technologies. Only one out of several device models tested would return correct neighboring cell information and then only for GSM but not for UMTS. Here is the code for it:
/* Neighbor Cell Stuff */
List<NeighboringCellInfo> nbcell = Tel.getNeighboringCellInfo ();
outputText += "Number of Neighbors: " +
String.valueOf(nbcell.size()) + "
";
Iterator<NeighboringCellInfo> it = nbcell.iterator();
while (it.hasNext()) {
outputText += String.valueOf((it.next()getCid())) + "
";
}
And finally, the output text that has been generated needs to be presented on the screen. There are several ways to do this and the app uses the most straightforward approach:
/* And finally, output the generated string with all the info retrieved */ TextView tv = new TextView(getApplicationContext()); tv.setText(outputText); setContentView(tv);
Seeing the current location area code and cell-id on the screen is a first step, but having a record of cell and signal strength changes would be even better for further analysis later on. In other words, the data needs to be written to a file that can then be retrieved and further processed on the PC. The best place to store the file is on the flash disk, which can then be either accessed via a USB cable or by removing it and connecting it via an adapter to a PC. Here is to code for this operation:
try {
File root = Environment.getExternalStorageDirectory();
if (root.canWrite()){
File logfile = new File(root, filename);
FileWriter logwriter = new
FileWriter(logfile, true); /* true=append */
BufferedWriter out = new BufferedWriter(logwriter);
/* now save the data buffer into the file */
out.write(LocalFileWriteBufferStr);
out.close();
}
}
catch (IOException e) {
/* don't do anything for the moment */
}
Writing a file could fail, in which case Java would throw an exception and terminate the program if unhandled. Hence the need for the “try” construct that has already been introduced. In the first line of the code excerpt given above, the directory name of the flash disk is retrieved with the “getExternalStorageDirectory()” method, which is part of the Android API. If the disk is present and writable, a file is opened in append mode, that is, if it already exists, all new data is appended. Then, the standard Java “out.write()” and “out.close()” methods are used to write the data to the file and then to close it again.
To ensure that no data is lost when the flash card is suddenly removed while the file is open, data is written and then the file is closed again immediately. This has been done as it is entirely possible that the flash disk is removed while the app is running, either physically or when a USB cable is connected to the PC. To reduce the wear on the flash memory because of frequent file operations, the app uses a cache string in memory and only writes to the file after several kilobytes of data have accumulated. The downside of this is that the app has to be aware when it is closed and restarted, for example, when the user turns the device and the screen is switched from portrait to landscape mode or when the app is sent to the background.
And finally, the app includes a menu; so it can show an “About” text to reset counters and toggle the debug mode. This is done in Android as follows:
@Override
public boolean onCreateOptionsMenu(Menu menu) {
menu.add(0, RESET_COUNTER, 0, "Rest Counters");
menu.add(0, ABOUT, 0, "About");
menu.add(0, TOGGLE_DEBUG, 0, "Toggle Debug Mode");
return true;
}
@Override
public boolean onOptionsItemSelected (MenuItem item) {
switch (item.getItemId()) {
case RESET_COUNTER:
NumberOfCellChanges = 0;
[…]
return true;
case ABOUT:
AlertDialog.Builder builder = new
AlertDialog.Builder(this);
[…]
AlertDialog alert = builder.create();
alert.show();
return true;
case TOGGLE_DEBUG:
/* Toggle the debug behavior of the program
when the user selects this menu item */
if (outputDebugInfo == false) {
outputDebugInfo = true;
}
else {
outputDebugInfo = false;
}
default:
return super.onOptionsItemSelected(item);
}
}
As mentioned before, the code excerpts shown in this section are not the full program and the reader is invited to go the web site of this book at www.wirelessmoves.com to download the full source code and the executable program that can be installed and run directly from the Web page on Android-based devices.
6.11 Impact of Mobile Apps on Networks and Power Consumption
When GSM networks were first launched in the early 1990s, voice and Short Message Service (SMS) messaging were the main services. The network and mobile devices were designed to be as power and resource efficient as possible. Standby time of devices reached several weeks and talk (usage) times of 5 h and more became possible. This has changed significantly with smartphones, and more importantly with the arrival of Internet connectivity on these devices. It is not now uncommon for smartphone users to recharge their device once a day when used for more than just voice calls and text messaging. A number of factors contribute to this trend and are described in the following paragraphs.
A major contributing factor are the larger, brighter, and higher resolution displays that draw significantly more power than the small screens with low resolutions used in mobile devices only a few years earlier. In combination with the power required for maintaining an active communication link to the network during activities that exchange data over the network such as Web surfing, device batteries tend to only have enough capacity to support such activities for 2 or 3 h at most. Advances in battery technology are slow and overall capacity has only slowly risen over time, while power consumption in mobile devices because of the ever increasing number of usage scenarios has increased significantly.
One countermeasure taken by mobile devices and networks in recent years is to optimize the network state switching during an active communication session to:
- reduce power consumption,
- minimize the number of simultaneous users per cell in a fully active state, and
- reduce the amount of signaling traffic required to maintain connections.
As described in Chapter 2, the radio link between a subscriber and the base station can be in a number of different states. In UMTS, for example, data can be sent and received instantaneously and at a very high speed in the fully active state, referred to as Cell-DCH (Cell Dedicated Channel), at the expense of high power consumption. When no data has been transferred for some time, usually between 15 and 20 s, the connection to a device is usually put to the Idle state. Very little power is required in this state as the mobile device only occasionally monitors the network; so it can change between cells when the user is moving and receive incoming communication requests on the paging channel. The disadvantage of the idle state is that when renewed communication takes place, for example, when the user has clicked on a link on a Web page, it takes between 2.5 and 3 s before the link is reestablished. This is clearly noticeable to the user. This is why many network operators do not send the mobile device into the Idle state anymore but a state referred to as Cell-PCH or URA-PCH (UTRAN Registration Area—Physical Channel). These states are similar to the Idle state but the mobile keeps its radio identity and ciphering parameters. Reestablishing the communication link is thus accomplished in around 700 ms, which significantly improves the response time to user input. In most networks, mobile devices are not transferred from the fully active state to the almost fully dormant state immediately. Instead, a state in the middle referred to as Cell-FACH (Forward Access Channel) offers a compromise between power consumption, response time, and data transfer speeds.
Programers wishing to optimize the power consumption of their mobile applications should be aware of these state transitions and use network connectivity accordingly if possible. Many applications, for example, are advertisement banner supported and reload banners on a frequent basis, such as, for example, once or twice a minute. This does not only incur a significant amount of signaling between the mobile device and the network to transition between the different status of the radio link but also increases power consumption as the radio link is almost never in a dormant state. Power and network-optimized advertisement supported applications; therefore load several advertisements at once and cache them locally instead of loading each advertisement banner individually at the time it is needed. A more detailed discussion of this and how this can be implemented on different mobile operating systems can be found in [41].
Another contributing factor to higher power consumption are data transfers taking place in the background even when the user is currently not interacting with the device. Most email applications, for example, are continuously keeping a connection to the server in the network; so incoming messages can be pushed to the device immediately. This requires keep-alive messages being sent to the server in the network, usually in the order between 15 and 20 min, that is, three to four times an hour. Also, instant messaging clients rely on a continuous connection to the server in the network and thus have a similar behavior in addition to the messages that are received in the background. This background behavior has a significant impact to the mobile device's standby time as the device establishes a connection to the network several times an hour. In essence, there are two measures to decrease power consumption. How often a keep alive message is required to keep the connection to the server in the network in place depends on the Transmission Control Protocol (TCP) connection timeout at the gateway between the mobile network and the Internet and the server in the network. A power-efficient connection implementation should adapt the keep-alive interval to the maximum time experienced in a particular network. A second method to significantly reduce power consumption for sporadic background traffic is for the device's radio protocol stack to implement a feature referred to as “fast dormancy.” Instead of waiting for the network to change the radio connection through the different states as described above, the device can signal to the network that no further data is expected to be sent and that the connection can therefore be set to an energy-efficient state right way. How the device determines that no further data is to be sent is implementation specific. Often, devices invoke the fast dormancy mechanism when the display is not active and no data has been received for a few seconds. Further details of this mechanism from a network point of view are described in Chapter 2. From the mobile device's point of view, the mechanisms and how they can be used in a mobile application are also described in [41].
Another shortcoming from an efficiency point of view often observed in mobile applications is that content is only adapted for the mobile device after it has been received. In some cases as described in [42], it has been observed that applications download images in their full resolution, which requires downloading several megabytes of data only to scale them to a fraction of their size to display them. Such behavior not only increases the users waiting time until content is presented but also leads to a significant amount of unnecessary data traffic that the user has to pay for. It is much better, therefore, to download content that is already adapted for mobile viewing on smaller screens.
6.12 Mobile Apps Security and Privacy Considerations
Today, mobile devices have reached a level of complexity, flexibility, and connectivity that equals that of desktop devices. As in the PC world, only a few operating systems make up the majority of connected devices, which is likely to lead over time to similar malware and virus issues as can be found on desktop systems today.
Outside attacks on mobile devices are especially worrying because of the increasing amount of private data stored on mobile devices such as contacts, email addresses, calendar entries, private images, credit card information, and so on that could be stolen. If attackers manage to make hidden phone calls or send SMS messages to premium numbers, they can incur significant financial loss that can often only be detected when the next phone bill is delivered to the customer.
The following sections give examples of how Internet connectivity and access to personal data and payment information on mobile devices have already been exploited and how users can protect themselves from similar attacks in the future.
6.12.1 Wi-Fi Eavesdropping
One of the most straightforward security and privacy attacks that can be easily implemented even by people with little technical knowledge is Wi-Fi eavesdropping in public Wi-Fi hotspots. Data packets in Wi-Fi hotspots are usually not encrypted to enable users to easily join the network. Proper authentication and encryption is thus left to individual applications. Even in 2012, however, many popular applications on notebooks and mobile devices were still sending their data without any encryption. Facebook and Whatsapp [43] were two examples of apps that used nonsecure communication, and a number of programs had appeared on the market to eavesdrop on the communication of other users in Wi-Fi networks. Two examples are Firesheep, a plugin for the Firefox desktop Web browser [44] and Droidsheep, a standalone application for Android devices [24]. These programs set the network card into a special mode that forward all packets it receives to the IP protocol stack of the device independent on whether those packets are destined for the device or not. Firesheep and Droidsheep then read these data packets and in case Facebook content is found, they display the content to the user in a way that a single click suffices to take over the connection and impersonate another user that is in the same Wi-Fi hotspot. Such eavesdropping could easily be prevented if the service used secure http (https) instead of http for communication and it is likely that over time, services will adopt this measure as their use on mobile devices becomes even more popular. As it cannot be seen from the outside whether an application transmits data in encrypted form, users should be very careful when using public Wi-Fi hotspots. Web apps and local apps should only be used if it has been ascertained that proper encryption is used.
6.12.2 Access to Private Data by Apps
While on notebooks and other desktop-based devices, private data such as contacts, calendar information, email, and so on is administered by different programs and a variety of programs exist for each purpose. On mobile devices, however, this kind of data is usually administered by applications that are delivered as part of the operating system and offer a standardized API for other applications to access the information. On the one hand, this offers the tremendous advantage that third-party programs such as, for example, an alternative mobile email program such as K9 mail [45] can access contact information from the device's phonebook application to retrieve email addresses. On the other hand, such standardized APIs also open the door for third-party applications to access the local database and export private information over the network to their remote central database. While popular social networking apps offer the possibility to deactivate this feature, this is not straightforward to perform for the average user. Malicious programs that perform such actions without asking for the user's permission before retrieving and uploading private information have also been observed in practice.
On the Android mobile platform, applications have to ask for the user's consent before they can use functions to access private data or resources ranging from contact information, getting access to the Internet to the retrieval of location information. This is done once at installation time and the user can either grant all permissions requested or reject the installation of the app entirely. On other mobile platforms, no such measures are used and the user has to trust the app store screening policy to check applications for malicious or privacy breaching actions before listing them. Central app stores on the other hand make it easier to counter malware threats as once detected, malicious apps can be removed quickly. Already installed apps can even be deleted from mobile devices by the app store owner and this has been done in the past [46]. While there is certainly a good side to this, it should also be noted that an external party has significant control over mobile devices, which is perhaps not in everyone's interest.
6.12.3 User Tracking by Apps and the Operating System
Many people are not aware that once they have entered their a username and password into an mobile device to benefit from synchronization and other network-based services offered by the device or operating system manufacturer, private information is collected in the background across different programs and combined centrally in a single account. The following list gives some examples:
- Web searches in the Web browser are recorded in the network,
- A background task records and forwards GPS location information,
- Wi-Fi and cell-ids are observed and combined with GPS location information while the user is moving,
- The use of online mapping and navigation applications leaves traces of locations the user was searching for or has visited,
- The app market stores information about which apps have been installed,
- Calendar and address book information is uploaded to centralized servers, and
- Instant messaging clients send information to centralized servers on when the user has locked and unlocked his phone to show other contacts that the user might not be reachable.
Further details can be found in [47]. All of these separate pieces of information are combined and stored under a single account, often in addition to the traces left by online activities of the user on his desktop devices. This gives the company collecting the information incredibly detailed information about their users, their preferences, whereabouts, and activities. This information is not even anonymized as many users also give their full name, address, phone number, and credit card information for online purchases to at least one of the services all administered under the same user account.
Mitigating this loss of privacy is difficult as per default this information is sent once the username and password are known to the device unless the user explicitly disables this functionality in each application separately. Also, loss of privacy can be reduced using alternative programs such as a different Web browser or an offline navigation application from an independent company.
6.12.4 Third-Party Information Leakage
While users still have some means to control information leakage on their own devices, no control can be gained of one self's private information released by other people. As many apps on mobile devices scan and export the data contained in the contact list to the centralized server, social networking services usually also have information on members not giving personal details to the service and also nonmembers who have never interacted with the service such as name, address, phone number, and their relationship with other people. In addition, features such as automatic face recognition allow social network services to identify persons once one has been identified by someone else on a picture. Some social networks offer the possibility for a user to restrict such information to be given out to others but it is likely that the internal database is still aware of which pictures a person is on and may make use of it for various purposes.
6.13 Summary
Despite the security and privacy considerations mentioned above, sophisticated mobile devices have been adopted by the masses and have doubtlessly enriched the way we interact and communicate with each other. For privacy and security conscious users, remedies and alternatives are available and this is likely to be the case in the future as well as long as open-source-based mobile devices exist on the market that can be adapted by the community.
Over the years, there have been many debates about the advantages and disadvantages of Web-based vs. native applications and which approach will eventually dominate the mobile space. Until now, native apps are used for more purposes than Web apps, but both types of apps have found their place in the current mobile ecosystem, while each side is trying to increase its usability to extend into the domain of the other and into uncharted territory altogether.
On the Web app side, the most advanced approach is Google's Chromebook [48], which aims at giving users a fully Web-based environment on a desktop device. All applications are downloaded from a Web server and are executed in the Web browser. Also, all data is stored in the network instead of being saved locally, which makes the device only useful while network coverage is available. This is a major weakness of the approach, which will however decrease over time because of coverage extensions of mobile broadband networks and software enhancements that enable local caching of Web apps and data while no network is available.
On the native mobile application side, a trend is visible toward the use of tablets, which have taken over tasks for which many people would have previously used a desktop PC or notebook. Using a tablet with dedicated apps for Youtube video streaming, Web browsing, writing emails, and viewing documents is often more convenient on a tablet than on desktop-based devices and it is going to be interesting to observe how the gap between desktop-based devices and tablets will shrink over time as tablets overcome their shortcomings such as limited multitasking support, no physical keyboard and operating systems being not as flexible, and versatile as those on desktop devices today.
References
1. Ahonen, T. (2007) Mobile: The 7th Mass Media is to Internet Like TV is to Radio, Communities, Dominate Brands Blog, February 2007, http://communities-dominate.blogs.com/brands/2007/02/mobile_the_7th_.html (accessed 2012).
2. Flickr (2008) www.flickr.com (accessed 2012).
3. YouTube (2008) www.youtube.com (accessed 2012).
4. Digg (2008) Digg/all News, Videos & Images, http://www.digg.com (accessed 2012).
5. Facebook (2008) http://www.facebook.com/ (accessed 2012).
6. LinkedIn (2008) Relationships Matter, http://www.linkedin.com/ (accessed 2012).
7. Myspace (2008) http://www.myspace.com/ (accessed 2012).
8. Linden Lab (2008) Makers of Second Life & Virtual World Platform Second Life Grid, http://lindenlab. com/ (accessed 2012).
9. Anderson, C. (2004) The Long Tail. Wired Magazine (Oct. 2004), http://www.wired.com/wired/archive/12.10/tail.html (accessed 2012).
10. Iskold, A. (2007) There's No Money in the Long Tail of the Blogosphere, ReadWriteWeb, http://www.readwriteweb.com/archives/blogosphere_long_tail.php (accessed 2012).
11. O'Reily, T. (2005) What is Web 2.0–Design Patterns and Business Models for the Next Generation of Software, September 2005, http://www.oreillynet.com/pub/a/oreilly/tim/news/2005/09/30/what-is-web-20.html?page=1 (accessed 2012).
12. Firtman, M. (2012) Mobile HTML5 Compatability Overview, http://mobilehtml5.org/.
13. The RSS Advisory Board (2007) RSS 2.0 Specification, October 2007, http://www.rssboard.org/rss-specification (accessed 2012).
14. Nottingham, M. and Sayre, R. (2005) RFC 4287. The Atom Syndication Format, The Internet Society, http://tools.ietf.org/html/rfc4287 (accessed 2012).
15. Mitchel, J. (2011) Making Photo Tagging Easier, June 30, 2011, http://blog.facebook.com/blog.php?post=467145887130 (accessed 2012).
16. Yahoo (2008) Yahoo! Maps Web Service–AJAX API Getting Started Guide, http://developer.yahoo.com/maps/ajax/index.html (accessed 2012).
17. Google (2012) Google Maps API Reference, https://developers.google.com/maps/documentation/javascript/ (accessed 2012).
18. OpenStreetMap (2012) http://www.openstreetmap.org/ (accessed 2012).
19. The Free Software Foundation (2007) GNU General Public License, Version 3, http://www.gnu.org/licenses/gpl-3.0.html (accessed 2012).
20. OpenWrt (2012) http://www.openwrt.org/ (accessed 2012).
21. The Open Source Initiative (OSI) (2006) The BSD License, October 31, 2006, http://www.opensource.org/licenses/bsd-license.php (accessed 2012).
22. The Apache Software Foundation (2004) Apache License, Version 2, January 2004, http://www.apache.org/licenses/LICENSE-2.0.txt (accessed 2012).
23. Google (2012) Licenses, http://source.android.com/source/licenses.html (accessed 2012).
24. Sauter, M. (2012) Droidsheep : Firesheep Moves to Android, January 2012, http://mobilesociety.typepad.com/mobile_life/2012/01/firesheep-moves-to-android.html (accessed 2012).
25. Google (2012) Google Reader, http://reader.google.com (accessed 2012).
26. Slingbox (2012) http://www.slingmedia.com/ (accessed 2012).
27. Belic Dusan (2007) Opera Widgets on New 3G Phones from KDDI, October 2007, http://www.intomobile.com/2007/10/25/opera-widgets-on-new-3g-phones-from-kddi/ (accessed 2012).
28. W3C (2012) Web Storage, April 2012, http://dev.w3.org/html5/webstorage/ (accessed 2012).
29. W3C (2010) Web SQL Database, November 2010, http://www.w3.org/TR/webdatabase/ (accessed 2012).
30. W3C (2012) Web Workers, April 2012, http://dev.w3.org/html5/workers/ (accessed 2012).
31. Sir Berners-Lee, T. (April 2004) New Top Level Domains .mobi and .xxx Considered Harmful. http://www.w3.org/DesignIssues/TLD (accessed 2012).
32. Opera (2008) Opera Mini–Free Mobile Web Browser for Your Phone, http://www.operamini.com/. (accessed 2012).
33. Sauter, M. (2007) Deactivating the Vodafone Websession Compression Proxy, July 2007, http://mobilesociety.typepad.com/mobile_life/2007/07/deactivating-th.html (accessed 2012).
34. Adobe Flash Player (2008) http://www.adobe.com/products/flashplayer (accessed 2012).
35. Adblock (2008) https://addons.mozilla.org/en-US/firefox/addon/adblock-plus/?src=search#id=1865 (accessed 2012).
36. Sauter, M (2012) Privacy Breached and Adware With an Update, May 2012, http://mobilesociety.typepad.com/mobile_life/2012/05/privacy-breached-and-adware-with-an-update.html (accessed 2012).
37. Gibson, S. and Laporte, L. (2011) Security Now! #307, June 2011, http://www.grc.com/sn/sn-307.txt (accessed 2012).
38. Bogawat, A. (2011) Customize Every Aspect of Your Android Experience, April 2011, http://android.appstorm.net/roundups/customize-every-aspect-of-your-android-experience/ (accessed 2012).
39. Google Android Developer Guide, http://developer.android.com/guide/developing/index.html (accessed 30 April 2012).
40. Sauter, M. (2011) Cell-Logger Source, http://www.wirelessmoves.com (accessed 30 April 2012).
41. The GSM Association (2012) Smarter Apps for Smarter Phones, April 2012, http://www.gsma.com/technicalprojects/smarter-apps-for-smarter-phones/ (accessed 2012).
42. Hunt, T. (2011) Secret iOS Business; What you Don't Know about Your Apps, October 2011, http://www.troyhunt.com/2011/10/secret-ios-business-what-you-dont-know.html (accessed 2012).
43. Tyson, M. (2012) WhatsApp Chat Spying? There's an App for that! May 2012, http://hexus.net/mobile/news/general/38813-whatsapp-chat-spying-theres-app-that/ (accessed 2012).
44. Sauter, M. (2010) Firesheep and Hotspot Hacking, November 2010, http://mobilesociety.typepad.com/mobile_life/2010/11/firesheep-and-hotspot-hacking.html (accessed 2012).
45. The K9 Project k9mail for Android, http://code.google.com/p/k9mail/ (accessed 28 May 2012).
46. Wallen, J. (2011) Google Deletes Malware-Infected Android Apps from users' Phones, March 2011, http://www.techrepublic.com/blog/smartphones/google-deletes-malware-infected-android-apps-from-users-phones/2375.
47. Sauter, M. (2011) Android Calling Home–Part 2, May 2011, http://mobilesociety.typepad.com/mobile_life/2011/05/android-calling-home-part-2.html.
48. Google Introducing Chromebooks, http://www.google.com/intl/en/chrome/devices/ (accessed May 2012).