
Now it's time to put your new skills into practice, start coding, and shape up your AI skills! You've learned all about Thompson Sampling, and now it's time to implement this AI model to solve a real-world problem, maximizing the sales of an e-commerce business.
In this practical exercise, you'll really take action and build the AI yourself to solve the problem. It's really important that you stay active in this chapter, because this is where you will have the chance to learn by doing, which is the most effective way to learn something; practice truly makes perfect. In other words, I want you to be the hero of this AI adventure. You, and not me. Ready?
Problem to solve
Imagine an e-commerce business that has millions of customers. These customers are people buying products on the website from time to time, getting those products delivered to their homes. The business is doing well, but the board of executives has decided to follow an action plan to maximize revenue.
This plan consists of offering the customers the option to subscribe to a premium plan, which will give them benefits like reduced prices, special deals, and so on. This premium plan is offered at a yearly price of $200, and the goal of this e-commerce business is, of course, to get the maximum number of customers to subscribe to this premium plan. Let's do some quick math to give us some motivation for building an AI to maximize the revenue of this business.
Let's say that this e-commerce business has 100 million customers. Now consider two strategies to convert the customers to the premium plan: a bad one, with a conversion rate of 1%, and a good one, with a conversion rate of 11%. If the business deploys the bad strategy, in one year it will make a total of: 100,000,000 × 0.01 × 200 = $200,000,000 in extra revenue from the premium plan subscriptions.
On the other hand, if the business deploys the good strategy, in one year it will make a total of: 100,000,000 × 0.11 × 200 = $2,200,000,000 in extra revenue from the premium plan subscriptions. By figuring out the best strategy to deploy, the business maximizes its revenue by making 2 billion extra dollars.
In this Utopian example, we only had two strategies, and besides, we knew their conversion rates. In our case study, we will be facing nine different strategies. Our AI will have no idea of which is the best one, and absolutely no prior information on any of their conversion rates.
We will, however, make the assumption that each of these nine strategies does have a fixed conversion rate. These strategies were carefully and smartly elaborated by the marketing team, and each of them has the same goal: convert the maximum number of clients to the premium plan. However, these nine strategies are all different. They have different forms, different packages, different ads, and different special deals to convince and persuade the clients to subscribe to the premium plan. Of course, the marketing team has no idea of which of these nine strategies will turn out to be the best one. Let's sum up the differences in features of these nine strategies:

Figure 1: The nine strategies – Which one sells best?
The marketing team wants to figure out which strategy has the highest conversion rate as soon as possible, and by spending the minimum amount. They know that finding and deploying the best strategy can significantly increase the business's revenue. The marketing experts have also chosen not to send an email directly to their 100 million customers, because that would be costly and would risk spamming too many customers. Instead, they will subtly look for that best strategy through online learning. What is online learning? It consists of deploying a different strategy each time a customer browses the e-commerce website.
As the customer navigates the website, they will suddenly get a pop-up ad, suggesting to them that they subscribe to the premium plan. For each customer browsing the website, only one of the nine strategies will be displayed. Then the user will choose, or not, to take action and subscribe to the premium plan. If the customer subscribes, the strategy is a success; otherwise, it is a failure. The more customers we do this with, the more feedback we collect, and the better idea we get of what the best strategy is.
But of course, we will not figure this out manually, visually, or with some simple math. Instead we want to implement the smartest algorithm that will figure out what the best strategy is in the shortest time. That's for the same two reasons: firstly, because deploying each strategy has a cost (for example, coming from the pop-up ad); and secondly, because the company wants to annoy the fewest customers with their ad.
Building the environment inside a simulation
This section is quite special, because there's something crucial to understand which is not obvious at first sight. The reason for this warning is my experience in teaching this subject; many of my students had issues understanding why we have to do a simulation here, for this whole problem.
It was the same for me when I started! If you already understand why we have to make a simulation, that's great—it means you already have online learning under your skin. If not, follow me here and let me explain carefully.
To understand, let's start by explaining what would happen in real life: you would simply display the "call to action" pop-up ad of one of the nine strategies to customers who are navigating the website, and you'd do this one customer at a time. You'd have to do it one customer at a time, customer after customer, because for each customer you need to collect their response: whether or not the customer subscribes to the premium plan. If the customer does, the reward is 1. If not, the reward is 0. It would go like this:
Round 1: We display Ad 1 of Strategy 1 to a customer, Customer 1, and we check to see if the customer chooses to subscribe. If yes, we get a 1 reward, if no, we get a 0 reward. After collecting our reward, we move on to the next customer (next round).
Round 2: We display Ad 2 of Strategy 2 to a new customer, Customer 2, and we check to see if the customer chooses to subscribe. If yes, we get a 1 reward, if no, we get a 0 reward. After collecting our reward, we move on to the next customer (next round).
…
Round 9: We display Ad 9 of Strategy 9 to a new customer, Customer 9, and we check to see if the customer chooses to subscribe. If yes, we get a 1 reward, if no, we get a 0 reward. After collecting our reward, we move on to the next customer (next round).
Round 10: We finally start activating Thompson Sampling! We use the Thompson Sampling AI to tell us which ad has the strongest magic touch to convert the maximum customers to subscribe to the premium plan. We want that extra revenue! The AI (powered by Thompson Sampling) selects one of the 9 ads to display to a new customer, Customer 10, and then checks to see if the customer chooses to subscribe. If yes, we get a 1 reward, if no, we get a 0 reward. After collecting our reward, we move on to the next customer (next round).
Round 11: The AI (powered by Thompson Sampling) selects one of the 9 ads to display to a new customer, say Customer 11, and then checks to see if the customer chooses to subscribe. If yes, we get a 1 reward, if no, we get a 0 reward. After collecting our reward, we move on to the next customer (next round).
OK, I'll stop! You get the idea. That continues on and on for hundreds of rounds, or at least until the AI has found the best ad—the one with the highest conversion rate.
This is what would happen in real life. We don't need anything else at each round; if you look at the Thompson Sampling algorithm, at each round it only needs the number of times each ad has received a 1 reward in the previous rounds, and the number of times each ad has received a 0 reward in the previous rounds. In conclusion, and this is a very important conclusion: Thompson Sampling absolutely does not need to know the conversion rates of the ads in order to figure out the best ad.
However, in order to simulate this application, we will need to attribute a conversion rate to each of these ads. That's for the simple reason that if we don't do this, we will never be able to verify that Thompson Sampling indeed found the best ad. This is just to check that the AI works!
What we will do is attribute a different conversion rate to each of the nine strategies. The purpose of this simulation will only be to check that the AI manages to catch the best ad, with the highest conversion rate. Let me rephrase this as two essential points:
- Thompson Sampling at no time needs to know the conversion rates in order to figure out the highest one.
- The only reason we know the conversion rates in advance is because we are doing a simulation, just to check that Thompson Sampling actually manages to figure out the ad that has the highest conversion rate.
Now we've got that covered, let's finally set these conversion rates. We will assume the nine strategies have the following conversion rates:

Figure 2: Conversion rates of the 9 strategies
Now, we behind the scenes know in advance which strategy has the highest conversion rate: Strategy number 7. However, Thompson Sampling doesn't know it. If you pay attention, you can see the fact that at no time does Thompson Sampling use the conversion rates when running its algorithm over the rounds. It only knows the number of successes (subscriptions) and failures (no subscriptions) that have been accumulated over the previous rounds. You can see that most clearly in the code.
Lastly, please make sure to keep in mind that in a real-life situation we would have no idea of what these conversion rates might be. We only know them here for simulation purposes, so that we can check in the end that our AI has managed to figure out the best strategy—which in our simulation here is Strategy 7.
The next question is: how exactly are we going to run that simulation?
Running the simulation
First, let's recap the different components of the environment (state, action, and reward):
- The state is simply a specific customer onto whom we deploy a strategy and show them the ad of that strategy.
- The action is the strategy selected to be deployed on the customer.
- The reward is 1 if the customer subscribes to the premium plan, and 0 otherwise.
Then, let's say that this e-commerce business wants to run the experiment of figuring out the best strategy on 10,000 customers. Why the choice of 10,000? Because statistically, this is a large enough sample size to represent the whole base of customers. So, how are we going to simulate the response of 10,000 customers, based on the conversion rates of the ads established before? We don't have a choice other than to take a spreadsheet like Excel, or Google Sheets, and simulate how the 10,000 customers would respond to each of the 9 ads. Here's how we are going to do this; it's a pretty nice trick.
We are going to create a matrix of 10,000 rows and 9 columns. Each row will correspond to a specific customer, and each column will correspond to a specific strategy. To be clear, let's say that:
Row 1 corresponds to Customer 1.
Row 2 corresponds to Customer 2.
…
Row 10000 corresponds to Customer 10000.
Column 1 corresponds to Strategy 1.
Column 2 corresponds to Strategy 2.
…
Column 9 corresponds to Strategy 9.
In the cells of this matrix, we'll place a reward of 1 or 0 depending on whether each of these 10,000 customers would respond positively (subscription) or negatively (no subscription) to each of the 9 strategies. Here's where the "pretty nice trick" comes into play. In order to simulate the response of these 10,000 customers to the 9 ads while considering the conversion rates of these ads, here is what we do:
For each customer (row) and for each strategy (column), we draw a random number between 0 and 1. If this random number is lower than the conversion rate of the strategy, the reward is 1. If this random number is higher than the conversion rate of the strategy, the reward is 0. Why does that work? Because by doing so, we will always have a p% chance of getting a 1, where p is the conversion rate of the strategy deployed to that customer.
For example, let's take Strategy 4, which has a conversion rate of 0.16. For each of the customers, we draw a random number between 0 and 1. That random number has a 16% chance of being between 0 and 0.16, and a (100 – 16) = 84% chance of being between 0.16 and 1. Therefore, since we get a 1 when our random number is between 0 and 0.16, and we get a 0 when our random number is between 0.16 and 1, then that means we have a 16% chance of getting a 1, and an 84% chance of getting a zero.
That simulates exactly the fact that when Strategy 4 is deployed on a customer, that same customer will have a 16% chance of subscribing to the premium plan; that exactly corresponds to getting a 1 reward.
I hope you like the trick. It's pretty classic, but it's used very often in AI; it's important for you to know about it. We apply that trick to each of the 10,000 x 9 pairs of (customer, strategy) and we get the following matrix (this image only shows the first 10 rows):

Figure 3: Simulated matrix of rewards
Let's go through the three first rows in detail:
- The first customer (row of index 0) would not subscribe to the premium plan after being approached by any strategy.
- The second customer (row of index 1) would subscribe to the premium plan after being approached by Strategy 5 or Strategy 7 only.
- The third customer (row of index 2) would not subscribe to the premium plan after being approached by any strategy.
We can already see in this preview that our little trick works; the ads with the lowest conversion rates (Strategies 1, 6, and 9) have only 0 rewards for the 11 first customers, while the ads with the highest conversion rates (Strategies 4 and 7) have some 1 rewards already. Note that the indexes here in this Python table start at 0; it's always like that in Python, and unfortunately there is nothing we can do about it. Don't worry, though, you'll get used to it!
If you're a code lover, the code that generated this simulation is presented a little further along in the chapter.
Our next step is to take a step back and recap.
Recap
We're ready to simulate the actions of Thompson Sampling on 10,000 customers successively being approached by one of the 9 strategies, thanks to the preceding matrix, which will exactly simulate the decision of the customer to subscribe or not to the premium plan.
If the cell corresponding to a specific customer and a specific selected strategy has a 1, that simulates a conversion by the customer to the premium plan. If the cell has a 0, that simulates a rejection. Thompson Sampling will collect the feedback of whether or not each of these customers subscribes to the premium plan, one customer after the other. Then, thanks to its powerful algorithm, it will quickly figure out the strategy with the highest conversion rate.
That strategy is the best one to be deployed on millions of customers, maximizing the company's income from this new revenue stream.
AI solution and intuition refresher
Before you enjoy seeing your AI in action, let's refresh our memories and adapt the whole Thompson Sampling AI model to this new problem.
By the way, if you don't like this e-commerce business application, feel totally free to imagine yourself back into the casino, surrounded by nine slot machines having the same conversion rates as the ones given to our strategies. It's exactly the same scenario; the 9 strategies could very well be nine slot machines giving with the same conversion rates either a 1 reward (making you money) or a 0 reward (taking your money). Your goal would be to figure out as quickly as possible which slot machine has the highest chance of giving you the jackpot! It's up to you. Feel free to either go for Vegas or the AI Street, but as far as this chapter is concerned, I'll stick with our e-commerce business.
For starters, let's remind ourselves that each time we show an ad to a new customer, that's considered a new round, n, and we select one of our 9 strategies to attempt a conversion (subscription to the premium plan). The goal is to figure out the best strategy (associated with the ad with the highest conversion rate) in the lowest number of rounds. Here's how Thompson Sampling does that:
AI solution
For each round n over 10,000 rounds, repeat the following three steps:
Step 1: For each strategy i, take a random draw from the following distribution:

where:
 is the number of times the strategy i has received a 1 reward up to round n.
is the number of times the strategy i has received a 1 reward up to round n. is the number of times the strategy i has received a 0 reward up to round n.
is the number of times the strategy i has received a 0 reward up to round n.
Step 2: Select the strategy ![]() that has the highest
that has the highest ![]() :
:

Step 3: Update  and
and  according to the following conditions:
according to the following conditions:
- If the strategy selected
 received a 1 reward:
received a 1 reward:

- If the strategy selected
 received a 0 reward:
received a 0 reward:

Now we've seen the mathematical steps, let's remind ourselves of the intuition behind them.
Intuition
Each strategy has its own Beta distribution. Over the rounds, the Beta distribution of the strategy with the highest conversion rate will progressively be shifted to the right, and the Beta distributions of the strategies with lower conversion rates will be progressively shifted to the left (Steps 1 and 3). Therefore, in Step 2, the strategy with the highest conversion rate will be selected more and more often. Here is a graph displaying three Beta distributions of three strategies to help you visualize this:

Figure 4: Three Beta distributions
You've taken a step back and you've had a refresher; I think you're ready for the implementation! In the next section, you'll put all that theory into practice—in other words, into code.
Implementation
You'll develop the code as you work along this chapter, but keep in mind that I've provided the whole implementation of Thompson Sampling for this application; you have it available on the GitHub page (https://github.com/PacktPublishing/AI-Crash-Course) of this book. If you want to try and run the code, you can do it on Colaboratory, Spyder in Anaconda, or simply your favorite IDE.
Thompson Sampling vs. Random Selection
While implementing Thompson Sampling, you'll also implement the Random Selection algorithm, which will simply select a random strategy at each round. This will be your benchmark to evaluate the performance of your Thompson Sampling model. Of course, Thompson Sampling and the Random Selection algorithm will be competing on the same simulation, that is, on the same environment matrix.
Performance measure
In the end, after the whole simulation is done, you can assess the performance of Thompson Sampling by computing the relative return, defined by the following formula:

You'll also have the chance to plot the histogram of selected ads, just to check that the strategy with the highest conversion rate (Strategy 7) was the one selected the most.
Let's start coding
First, import the three following required libraries:
numpy, which you will use to build the environment matrix.matplotlib.pyplot, which you will use to plot the histogram.random, which you will use to generate the random numbers needed for the simulation.
Here is the extracted code from GitHub:
# AI for Sales & Advertizing - Sell like the Wolf of AI Street
# Importing the libraries
import numpy as np
import matplotlib.pyplot as plt
import random
Then set the parameters for the number of customers and strategies:
N= 10,000 customers.d= 9 strategies.
Code:
# Setting the parameters
N = 10000
d = 9
Then, create the simulation by building the
environment matrix of 10,000 rows corresponding to the customers and 9
columns corresponding to the strategies. At each round, and for each
strategy, you draw a random number between 0 and 1. If this random
number is lower than the conversion rate of the strategy, the reward
will be 1. Otherwise, it will be 0. The environment matrix is named X in the code.
Code:
# Building the environment inside a simulation
conversion_rates = [0.05,0.13,0.09,0.16,0.11,0.04,0.20,0.08,0.01]
X = np.array(np.zeros([N,d]))
for i in range(N):
for j in range(d):
if np.random.rand() <= conversion_rates[j]:
X[i,j] = 1
Now that the environment is ready, you can start implementing the AI. To do so, the first step is to introduce and initialize the variables you will need for the implementation:
strategies_selected_rs: A list that will contain the strategies selected over the rounds by the Random Selection algorithm. Initialize it as an empty list.strategies_selected_ts: A list that will contain the strategies selected over the rounds by the Thompson Sampling AI model. Initialize it as an empty list.total_rewards_rs: The total reward accumulated over the rounds by the Random Selection algorithm. Initialize it as 0.total_rewards_ts: The total reward accumulated over the rounds by the Thompson Sampling AI model. Initialize it as 0.number_of_rewards_1: A list of 9 elements which will contain for each strategy the number of times it received a 1 reward. Initialize it as a list of 9 zeros.number_of_rewards_0: A list of 9 elements which will contain for each strategy the number of times it received a 0 reward. Initialize it as a list of 9 zeros.
Code:
# Implementing Random Selection and Thompson Sampling
strategies_selected_rs = []
strategies_selected_ts = []
total_reward_rs = 0
total_reward_ts = 0
numbers_of_rewards_1 = [0] * d
numbers_of_rewards_0 = [0] * d
Then you need to begin the for
loop that will iterate the 10,000 rows (that is, the customers) of this
environment matrix. At each round you'll get two separate selections of
the deployed strategy; one from the Random Selection algorithm, and one from Thompson Sampling.
Let's start with the Random Selection algorithm, which simply selects a random strategy in each round.
Code:
for n in range(0, N):
# Random Selection
strategy_rs = random.randrange(d)
strategies_selected_rs.append(strategy_rs)
reward_rs = X[n, strategy_rs]
total_reward_rs = total_reward_rs + reward_rs
Next, you need to implement Thompson Sampling following exactly Steps 1, 2, and 3 provided previously. I recommend looking at these steps again before coding the next part, and try to code by yourself before seeing my solution. That's the best way you can progress; practice makes perfect. You have all the elements required to code this; you even have similar code in Chapter 5, Your First AI Model – Beware the Bandits!. Good luck! Here is the solution.
You should implement Thompson Sampling step by step, starting with the first step. Let's remind ourselves of it:
Step 1: For each strategy i, take a random draw from the following distribution:

where:
 is the number of times the strategy i has received a 1 reward up to round n
is the number of times the strategy i has received a 1 reward up to round n is the number of times the strategy i has received a 0 reward up to round n
is the number of times the strategy i has received a 0 reward up to round n
Let's see how Step 1 is implemented.
Code a second for loop that iterates the 9 strategies, because you have to take a random draw from the Beta distribution of each of the 9 strategies.
The random draws from the Beta distributions are generated by the betavariate() function taken from the random library, which you imported at the beginning.
Code:
# Thompson Sampling
strategy_ts = 0
max_random = 0
for i in range(0, d):
random_beta = random.betavariate(numbers_of_rewards_1[i] + 1, numbers_of_rewards_0[i] + 1)
Now implement Step 2, that is:
Step 2: Select the strategy  that has the highest
that has the highest ![]() :
:

To implement Step 2, you stay in the second for loop which iterates the 9 strategies, and use a simple trick with an if condition that will figure out the highest ![]() .
.
The trick is the following: while iterating the strategies, if you find a random draw (random_beta) that is higher than the maximum of the random draws obtained so far (max_random), then that maximum becomes equal to that higher random draw.
Code:
# Thompson Sampling
strategy_ts = 0
max_random = 0
for i in range(0, d):
random_beta = random.betavariate(numbers_of_rewards_1[i] + 1, numbers_of_rewards_0[i] + 1)
if random_beta > max_random:
max_random = random_beta
strategy_ts = i
reward_ts = X[n, strategy_ts]
And finally, let's implement Step 3, the easiest one:
Step 3: Update 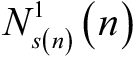 and
and  according to the following conditions:
according to the following conditions:
- If the strategy selected
 received a 1 reward:
received a 1 reward:

- If the strategy selected
 received a 0 reward:
received a 0 reward:

Implement that simply with the exact same two if conditions, translated into code.
Code:
# Thompson Sampling
strategy_ts = 0
max_random = 0
for i in range(0, d):
random_beta = random.betavariate(numbers_of_rewards_1[i] + 1, numbers_of_rewards_0[i] + 1)
if random_beta > max_random:
max_random = random_beta
strategy_ts = i
reward_ts = X[n, strategy_ts]
if reward_ts == 1:
numbers_of_rewards_1[strategy_ts] = numbers_of_rewards_1[strategy_ts] + 1
else:
numbers_of_rewards_0[strategy_ts] = numbers_of_rewards_0[strategy_ts] + 1
Next, don't forget to add the strategy selected in Step 2 to our list of strategies (strategies_selected_ts), and also to compute the total reward accumulated over the rounds by Thompson Sampling (total_reward_ts).
Code:
# Thompson Sampling
strategy_ts = 0
max_random = 0
for i in range(0, d):
random_beta = random.betavariate(numbers_of_rewards_1[i] + 1, numbers_of_rewards_0[i] + 1)
if random_beta > max_random:
max_random = random_beta
strategy_ts = i
reward_ts = X[n, strategy_ts]
if reward_ts == 1:
numbers_of_rewards_1[strategy_ts] = numbers_of_rewards_1[strategy_ts] + 1
else:
numbers_of_rewards_0[strategy_ts] = numbers_of_rewards_0[strategy_ts] + 1
strategies_selected_ts.append(strategy_ts)
total_reward_ts = total_reward_ts + reward_ts
Then compute the final score, which is the relative return of Thompson Sampling with respect to our benchmark, which is Random Selection:
Code:
# Computing the Relative Return
relative_return = (total_reward_ts - total_reward_rs) / total_reward_rs * 100
print("Relative Return: {:.0f} %".format(relative_return))
The final result
By executing this code, I obtained a final relative return of 91%. In other words, Thompson Sampling almost doubled the performance of my Random Selection benchmark. Not too bad!
Finally, plot a histogram of the selected strategies to check that Strategy 7 (at index 6) was the one most selected, since it is the one with the highest conversion rate. To do this, use the hist() function from the matplotlib library.
Code:
# Plotting the Histogram of Selections
plt.hist(strategies_selected_ts)
plt.title('Histogram of Selections')
plt.xlabel('Strategy')
plt.ylabel('Number of times the strategy was selected')
plt.show()
This is the most exciting time—the code is complete (congrats by the way), and you can enjoy the results. Having the final relative return is nice, but finishing with a clean visualization plot is even better. And that's what you get by executing the final code:

Figure 5: Histogram of Selections
You can see that the strategy at index 6, Strategy 7, was by far selected the most. Thompson Sampling was quickly able to identify it as the best strategy. In fact, if you re-run the same code but with only 1,000 customers, you'll see that Thompson Sampling is still able to identify Strategy 7 as the best one.
Thompson Sampling did an amazing job for this e-commerce business. Not only was it able to identify the best strategy in a small number of rounds—that means fewer customers, which saves on advertising and operating costs—but also it was able to clearly figure out the strategy with the highest conversion rate.
If this e-commerce business has, for example, 50 million customers, and if the premium plan has a price of $200 per year, then deploying this best strategy with a conversion rate of 20 % would lead to generate an extra revenue of 50,000,000 × 0.2 × $200 = $2 billion!
In other words, Thompson Sampling clearly and quickly smashed the sales and advertising for this e-commerce business, so much so that we really can call it the wolf of AI Street.
Now, take a break, you deserve it. Get refreshed, and as soon as you are recharged and all set for a new AI adventure, I'll be here ready as well to start the next chapter. See you back soon!
Summary
In this first practical tutorial, you implemented Thompson Sampling to solve the multi-armed bandit problem as applied to an advertising campaign. Thompson Sampling was able to find the best business strategy quickly, something which Random Selection was unable to do. In total you generated 91% of relative return, which, after making some assumptions, would generate an extra 2 billion dollars in revenue. You did that in just one file in less than 60 lines of code. Quite astounding, right?