THE AWS CERTIFIED CLOUD PRACTITIONER EXAM OBJECTIVES COVERED IN THIS CHAPTER MAY INCLUDE, BUT ARE NOT LIMITED TO, THE FOLLOWING:
Domain 2: Security
2.1 Define the AWS Shared Responsibility model
Domain 3: Technology
3.2 Define the AWS global infrastructure
Introduction
The way you’ll use AWS services for your cloud workloads will be largely defined by the way AWS itself organizes its hardware, networking, and security infrastructure. So, the best way to learn how to configure things as efficiently and effectively as possible is to understand exactly how AWS infrastructure works.
This chapter will help you map out the “lay of the AWS land” in your mind. You’ll learn about how—and why—Amazon’s hundreds of globally distributed data centers are divided into regions that, in turn, are further divided into Availability Zones. You’ll explore how you can design your own applications to take the best advantage of those divisions.
You’ll also learn about how AWS can extend the network reach of your applications through its globally distributed edge locations that make up the front end of CloudFront, Amazon’s content delivery network (CDN). Finally, you’ll learn how the ways you use and rely on Amazon’s resources are governed by the terms of both the AWS Shared Responsibility Model and the AWS Acceptable Use Policy. Failing to properly understand those two frameworks will, at best, lead you to make expensive mistakes and, at worst, lead to disaster.
AWS Global Infrastructure: AWS Regions
AWS performs its cloud magic using hundreds of thousands of servers maintained within physical data centers located in a widely distributed set of geographic regions. As Amazon’s global footprint grows, the number of regions grows with it. You’ll soon see why having as wide a choice of regions as possible is a valuable feature of cloud computing.
As of the time of this writing, Table 4.1 represents the full list of available regions. But by the time you read this, there will probably be more. The documentation page at https://aws.amazon.com/about-aws/global-infrastructure should always contain the latest information available.
TABLE 4.1 The Current List of AWS Regions and Their Designations
Region
Designation
US West (Oregon) Region
us-west-2
US West (N. California) Region
us-west-1
US East (Ohio) Region
us-east-2
US East (N. Virginia) Region
us-east-1
Asia Pacific (Mumbai) Region
ap-south-1
Asia Pacific (Osaka-Local)
ap-northeast-3
Asia Pacific (Seoul) Region
ap-northeast-2
Asia Pacific (Singapore) Region
ap-southeast-1
Asia Pacific (Sydney) Region
ap-southeast-2
Asia Pacific (Tokyo) Region
ap-northeast-1
Canada (Central) Region
ca-central-1
China (Beijing) Region
cn-north-1
EU (Frankfurt) Region
eu-central-1
EU (Ireland) Region
eu-west-1
EU (London) Region
eu-west-2
EU (Paris) Region
eu-west-3
South America (São Paulo) Region
sa-east-1
AWS GovCloud (US)
us-gov-west-1
Not all of those regions are accessible from regular AWS accounts. Deploying resources into the U.S. government GovCloud region (or the AWS secret region designed for the U.S. intelligence community), for instance, requires special permission.
Regionally Based Services
When you request an instance of an AWS service, the underlying hardware of that instance will be carved out of a server running in one—and only one—AWS Region. This is true whether you’re talking about an Elastic Compute Cloud (EC2) virtual machine instance, its Elastic Block Store (EBS) storage volume, a bucket within Simple Storage Service (S3), or a new Lambda “serverless” function. In all those cases, although that anyone anywhere in the world can be given access to your resources, their underlying physical host can exist in no more than one region.
Of course, that’s not to say you can’t choose to run parallel resources in multiple regions—or that there aren’t sometimes edge-case scenarios where it makes sense to do so. But you must always be aware of the region that’s active for any resource launch you’re planning.
We should emphasize that point since it’s something that can, if forgotten, cause you grief. Through no fault of the AWS designers, it’s surprisingly easy to accidentally launch a new resource into the wrong region. Doing this can make it impossible for mutually dependent application components to find each other and, as a result, can cause your application to fail. Such accidental launches can also make it hard to keep track of your running resources, leading to the avoidable expense caused by unused and unnecessary instances not being shut down. Of course, as you saw in Chapter 2, “Understanding Your AWS Account,” the Billing & Cost Management Dashboard can provide helpful insights into all this.
Checking your current region should become a second-nature reflex—much like the quick mirror checks (we hope) you regularly perform while you’re driving a car. Figure 4.1 shows how your region status is displayed in the top right of the AWS Management Console page and how it can easily be changed from the drop-down menu.
FIGURE 4.1 The AWS Management Console feature indicating the region that’s currently active and permitting you to switch to a different available region
What’s in all this for you? Dividing resources among regions lets you do the following:
Locate your infrastructure geographically closer to your users to allow access with the lowest possible latency
Locate your infrastructure within national borders to meet regulatory compliance with legal and banking rules
Isolate groups of resources from each other and from larger networks to allow the greatest possible security
Globally Based Services
Remember that absolute, immutable, and fundamental law we mentioned a bit earlier about all AWS resources existing in one and only one region? Well, rest assured, dear friend, that it is indeed absolutely, immutably, and fundamentally true.
Except where it isn’t.
You see, some AWS resources are not visibly tied to any one region. Even if those resources are, technically, running on hardware that must exist within a single region, AWS presents them as global. As a rule, their global status will generally make sense from a structural perspective. Here are some examples of global services:
AWS Identity and Access Management (IAM) is the service for managing the way access to your account resources is achieved by way of users and groups, roles, and policies. You’ll learn much more about IAM in Chapter 5, “Securing Your AWS Resources.”
Amazon CloudFront is the content delivery network you can use to lower access latency for your application users by storing cached versions of frequently requested data at AWS edge locations.
While Amazon S3 buckets must, as we mentioned earlier, exist within a single region, S3 is nevertheless considered a global service (open the S3 Console page and look at the region indicator).
The region indicated on the AWS Management Console pages for each of those services will be Global.
Service Endpoints
To work with or access the resources you’re running within AWS Regions, you’ll have to know how they’re identified. Your developers or administrators will, for instance, want to connect with resources through their application code or shell scripts. For such access, they’ll often authenticate into your account and list and administrate resources and objects by referring to the endpoint that’s specific to a particular region and service.
For example, the correct endpoint for an EC2 instance in the us-east-1 (Northern Virginia) region would be
ec2.us-east-1.amazonaws.com
The endpoint for the Amazon Relational Database Service (RDS) in the eu-west-3 (Paris) region is
rds.eu-west-3.amazonaws.com
For a long, up-to-date, and complete list of endpoints for all AWS services, see this page:
An AWS Region (with the current exception of the Osaka-Local region) encompasses at least two distinct Availability Zones connected to each other with low-latency network links. Although, for security reasons, Amazon zealously guards the street addresses of its data centers, we do know that a single AZ is made up of at least one fully independent data center that’s built on hardware and power resources used by no other AZ.
As shown in Figure 4.2, AWS resources based in a single region can be requested and run within any AZ in the region.
FIGURE 4.2 A representation of AWS infrastructure divided among multiple regions and Availability Zones
The advantage of this level of separation is that if one AZ loses power or suffers some kind of catastrophic outage, the chances of it spreading to a second AZ in the region are minimal. You can assume that no two AZs will ever share resources from a single physical data center.
Availability Zone Designations
Understanding how Availability Zones work has immediate and practical importance. Before launching an EC2 instance, for example, you’ll need to specify a network subnet associated with an AZ. It’s the subnet/AZ combination that will be your instance’s host environment. Unsure about that subnet business? You’ll learn more in just a few moments.
For now, though, you should be aware of how AZs are identified within the AWS resource configuration process. Recall from earlier in this chapter that the Northern Virginia region is described as us-east-1. With that in mind, us-east-1a would be the first AZ within the us-east-1 region, and us-east-1d would be the fourth. Working through Exercise 4.1 will help you picture all this in action.
You may have noticed that the AZs weren’t listed in order in the subnet drop-down menu. For example, us-east-1a was probably not first and, equally probably, it wasn’t immediately followed by us-east-1b. The reason for this strange setup reflects Amazon’s familiarity with human nature: faced with two, three, or six choices that all appear equal, which one do you suppose most people will select? Did you vote for “whichever one appears first on the list”? Good call.
The problem with consistently listing the AZs in order is that the vast majority of users would always go for us-east-1a. But launching so many resources in just that first AZ would place unmanageable stress on the resources in poor old us-east-1a and leave all the others underutilized. So, Amazon solves the problem by displaying the AZs out of order.
Availability Zone Networking
You’ll only get the full value out of the resources you run within an AWS Region by properly organizing them into network segments (or subnets). You might, for instance, want to isolate your production servers from your development and staging servers to ensure that there’s no leakage between them. This can free your developers to confidently experiment with configuration profiles without having to worry about accidentally bringing down your public-facing application. Distributing production workloads among multiple subnets can also make your applications more highly available and fault tolerant. We’ll talk more about that in the next section.
A subnet is really nothing more than a single block of Internet Protocol (IP) addresses. Any compute device that requires network connectivity must be identified by an IP address that’s unique to the network. The servers or other networked devices that are assigned an IP address within one subnet are generally able to communicate with each other by default but might have traffic coming into and/or out of the subnet restricted by firewall rules.
Private networks—including AWS subnets—using the IPv4 protocol are allowed to use all the addresses within the three address ranges shown in Table 4.2.
There’s nothing preventing a private network manager from subdividing those addresses into hundreds of smaller subnets. The default subnets provided by AWS as part of its Availability Zones are, in fact, just such subdivided networks. AWS, as a matter of fact, permits up to 200 subnets per AZ.
Calculating netmasks for those ranges to properly understand their Classless Inter-Domain Routing (CIDR) notation goes way beyond the scope of this chapter—and of the AWS Cloud Practitioner exam objectives. But it can’t hurt to consider that AWS might describe the address range available to a particular subnet as something like 172.31.16.0/20 or 172.31.48.0/20. Whenever you see such a notation in an AWS configuration dialog, you’ll now know that you’re looking at the IP address range for a subnet.
Availability Zones and High Availability
One of the key principles underlying the entire business of server administration is that all hardware (and most software) will eventually fail. It may be an important router today or a storage volume tomorrow, but nothing can last forever. And when something does break, it usually takes your application down with it. A resource running without backup is known as a single point of failure.
The only effective protection against failure is redundancy, which involves provisioning two or more instances of whatever your workload requires rather than just one. That way, if one suddenly drops off the grid, a backup is there to immediately take over. But it’s not enough to run parallel resources if they’re going to be sitting right next to each other in the same data center. That wouldn’t do you a lot of good in the event of a building-wide blackout or a malicious attack, leaving your backup just as dead as the instance it was supposed to replace. So, you’ll also need to distribute your resources across remote locations.
In this context, it really makes no difference whether your workload is running in your on-premises data center or in the Amazon cloud. In either case, you’ll need resource redundancy that’s also geographically parallel. What is different is how much easier—and sometimes cheaper—it can be to build resilience into your cloud infrastructure.
Since the AWS cloud is already available within dozens and dozens of Availability Zones spread across all continents (besides, for now at least, Antarctica), deploying or, at least, preparing quick-launch templates for remote backup instances is easy. And since AWS workloads can be requested and launched on-demand, the job of efficiently provisioning parallel resources is built into the platform’s very DNA.
The configuration and automation stage can be a bit tricky, but that’s for your developers and administrators to figure out, isn’t it? They’re the ones who took and passed the AWS Solutions Architect Associate (or Professional) certification, right?
You should at least be aware that AWS slays the application failure dragon using autoscaling and load balancing:
Autoscaling can be configured to replace or replicate a resource to ensure that a predefined service level is maintained regardless of changes in user demand or the availability of existing resources.
Load balancing orchestrates the use of multiple parallel resources to direct user requests to the server resource that’s best able to provide a successful experience. A common use case for load balancing is to coordinate the use of primary and (remote) backup resources to cover for a failure.
AWS Global Infrastructure: Edge Locations
The final major piece of the AWS infrastructure puzzle is its network of edge locations. An edge location is a site where AWS deploys physical server infrastructure to provide low-latency user access to Amazon-based data.
That definition is correct, but it does sound suspiciously like the way you’d define any other AWS data center, doesn’t it? The important difference is that your garden-variety data centers are designed to offer the full range of AWS services, including the complete set of EC2 instance types and the networking infrastructure customers would need to shape their compute environments. Edge locations, on the other hand, are much more focused on a smaller set of roles and will therefore stock a much narrower set of hardware.
So, what actually happens at those edge locations? You can think of them as a front-line resource for directing the kind of network traffic that can most benefit from speed.
Edge Locations and CloudFront
Perhaps the best-known tenant of edge locations is CloudFront, Amazon’s CDN service. How does that work? Let’s say you’re hosting large media files in S3 buckets. If users would have to retrieve their files directly from the bucket each time they were requested, delivery—especially to end users living continents away from the bucket location—would be relatively slow. But if you could store cached copies of the most popular files on servers located geographically close to your users, then they wouldn’t have to wait for the original file to be retrieved but could be enjoying the cached copy in a fraction of the time.
Not all content types are good candidates for CloudFront caching. Files that are frequently updated or that are accessed by end users only once in a while would probably not justify the expense of saving to cache.
In addition to CloudFront, there are other AWS services that make use of edge locations. Here are few examples:
Amazon Route 53 Amazon’s Domain Name System (DNS) administration tool for managing domain name registration and traffic routing
AWS Shield A managed service for countering the threat of distributed denial-of-service (DDoS) attacks against your AWS-based infrastructure
AWS Web Application Firewall (WAF) A managed service for protecting web applications from web-based threats
Lambda@Edge A tool designed to use the serverless power of Lambda to customize CloudFront behavior
So all this talk will make more sense, we suggest you explore the configuration process for a CloudFront distribution by following Exercise 4.2.
Regional Edge Cache Locations
In addition to the fleet of regular edge locations, Amazon has further enhanced CloudFront functionality by adding what it calls a regional edge cache. The idea is that CloudFront-served objects are maintained in edge location caches only as long as there’s a steady flow of requests. Once the rate of new requests drops off, an object will be deleted from the cache, and future requests will need to travel all the way back to the origin server (like an S3 bucket).
Regional edge cache locations—of which there are currently nine worldwide—can offer a compromise solution. Objects rejected by edge locations can be moved to the regional edge caches. There aren’t as many such locations worldwide, so the response times for many user requests won’t be as fast, but that’ll still probably be better than having to go all the way back to the origin. By design, regional edge cache locations are more capable of handling less-popular content.
The AWS Shared Responsibility Model
The AWS cloud—like any large and complex environment—is built on top of a stack of rules and assumptions. The success of your AWS projects will largely depend on how well you understand those rules and assumptions and on how fully you adopt the practices that they represent. The AWS Shared Responsibility Model is a helpful articulation of those rules and assumptions, and it’s worth spending some time thinking about it.
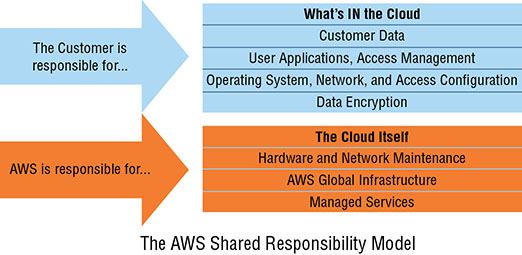
Amazon distinguishes between the security and reliability of the cloud, which is its responsibility, and the security and reliability of what’s in the cloud, which is up to you, the customer.
The cloud itself consists of the physical buildings, servers, and networking hardware used by AWS data centers. AWS is responsible for making sure that its locations are secure, reliably powered, and properly maintained. AWS is also on the hook for patching, encrypting (where relevant), and maintaining the operating systems and virtualization software running its physical servers and for the software running its managed services.
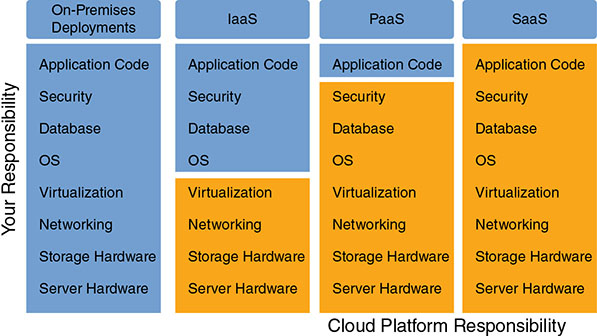
But that’s where things can get a bit complicated. What exactly is “managed” and what’s “unmanaged”? Figure 4.3 (which you saw previously in Chapter 1, “The Cloud”) compares the “of the cloud/in the cloud” mix as it applies across the three key cloud models: Infrastructure as a Service, Platform as a Service, and Software as a Service.
FIGURE 4.3 A general comparison between local and managed deployments
Figure 4.4 illustrates the way responsibility for the integrity and security of AWS infrastructure is divided between Amazon and its customers.
FIGURE 4.4 A representation of the AWS Shared Responsibility Model
Managed Resources
A managed cloud service will “hide” all or some of the underlying configuration and administration work needed to keep things running, leaving you free to focus on the “business” end of your project. For example, an application running on an EC2 instance might need a database in the backend. You could install and configure a MySQL database engine on the instance itself, but you’d be responsible for patches, updates, and all the regular care and feeding (not to mention letting it out for its morning walks).
Alternatively, you could point your application to a stand-alone database you launch on Amazon’s Relational Database Service (RDS). AWS is responsible for patching an RDS database and ensuring its data is secure and reliable. You only need to worry about populating the database and connecting it to your application.
RDS, therefore, is a good example of a partially managed service. How would the next level of managed service work? Look no further than Elastic Beanstalk, which hides just about all the complexity of its runtime environment, leaving nothing for you to do beyond uploading your application code. Beanstalk handles the instances, storage, databases, and networking headaches—including ongoing patches and administration—invisibly.
Unmanaged Resources
The most obvious example of an unmanaged AWS service is EC2. When you launch an EC2 instance, you’re expected to care for the operating system and everything that’s running on it exactly the way you would for a physical server in your on-premises data center. Still, even EC2 can’t be said to be entirely unmanaged since the integrity of the physical server that hosts it is, of course, the responsibility of AWS.
Think of it as a sliding scale rather than a simple on-off switch. Some cloud operations will demand greater involvement from you and your administration team, and some will demand less. Use this simple rule of thumb: if you can edit it, you own it. The key—especially during a project’s planning stages—is to be aware of your responsibilities and to always make security a critical priority.
Service Health Status
As part of its end of the bargain, AWS makes regularly updated, region-by-region reports on the status of its services publicly available. Any service outages that could affect the performance of anyone’s workload will appear on Amazon’s Service Health Dashboard (https://status.aws.amazon.com)—often within a minute or two of the outage hitting.
While configuration errors are always a possible cause of a failure in your infrastructure, you should always make the Service Health Dashboard one of your first stops whenever you dive into a troubleshooting session.
AWS Acceptable Use Policy
Because they’re so easy to scale up, cloud computing services are powerful tools for accomplishing things no one had even dreamed of just a decade ago. But for that same reason, they’re also potential weapons that can be used to commit devastating crimes.
The AWS Acceptable Use Policy (https://aws.amazon.com/aup) makes it abundantly clear that it does not permit the use of its infrastructure in any illegal, harmful, or offensive way. Amazon reserves the right to suspend or even terminate your use of its services should you engage in illegal, insecure, or abusive activities (including the sending of spam and related mass mailings). Even running penetration testing operations against your own AWS infrastructure can cause you trouble if you don’t get explicit permission from Amazon in advance.
You should take the time to read the document and keep its terms in mind as you deploy on AWS.
Summary
An AWS Region connects at least two Availability Zones located within a single geographic area into a low-latency network. Because of the default isolation of their underlying hardware, building secure, access-controlled regional environments is eminently possible.
An Availability Zone is a group of one or more independent (and fault-protected) data centers located within a single geographic region.
It’s important to be aware of the region that’s currently selected by your interface (either the AWS Management Console or a command-line terminal), as any operations you execute will launch specifically within the context of that region.
The design structure of Amazon’s global system of regions allows you to build your infrastructure in ways that provide the best possible user experience while meeting your security and regulatory needs.
AWS offers some global resources whose use isn’t restricted to any one region. Those include IAM, CloudFront, and S3.
You can connect to AWS service instances using their endpoint addresses, which will (generally) incorporate the host region’s designation.
EC2 virtual machine instances are launched with an IP address issued from a network subnet that’s associated with a single Availability Zone.
The principle of high availability can be used to make your infrastructure more resilient and reliable by launching parallel redundant instances in multiple Availability Zones.
AWS edge locations are globally distributed data servers that can store cached copies of AWS-based data from which—on behalf of the CloudFront service—they can be efficiently served to end users.
The elements of the AWS platform that you’re expected to secure and maintain and those whose administration is managed by Amazon are defined by the AWS Shared Responsibility Model.
Exam Essentials
Understand the importance of resource isolation for cloud deployments. Properly placing your cloud resources within the right region and Availability Zone—along with carefully setting appropriate access controls—can improve both application security and performance.
Understand the role of autoscaling in a highly available deployment. The scalability of AWS resources means you can automate the process of increasing or decreasing the scale of a deployment based on need. This can automate application recovery after a crash.
Understand the role of load balancing in a highly available deployment. The ability to automatically redirect incoming requests away from a nonfunctioning instance and to a backup replacement is managed by a load balancer.
Understand the principles of the AWS Shared Responsibility Model. AWS handles security and administration for its underlying physical infrastructure and for the full stack of all its managed services, while customers are responsible for everything else.
Understand the principles of the AWS Acceptable Use Policy. Using AWS resources to commit crimes or launch attacks against any individual or organization will result in account suspension or termination.
Review Questions
Which of the following designations would refer to the AWS US West (Oregon) region?
us-east-1
us-west-2
us-west-2a
us-west-2b
Which of the following is an AWS Region for which customer access is restricted?
AWS Admin
US-DOD
Asia Pacific (Tokyo)
AWS GovCloud
When you request a new virtual machine instance in EC2, your instance will automatically launch into the currently selected value of which of the following?
Service
Subnet
Availability Zone
Region
Which of the following are not globally based AWS services? (Select TWO.)
RDS
Route 53
EC2
CloudFront
Which of the following would be a valid endpoint your developers could use to access a particular Relational Database Service instance you’re running in the Northern Virginia region?
us-east-1.amazonaws.com.rds
ecs.eu-west-3.amazonaws.com
rds.us-east-1.amazonaws.com
rds.amazonaws.com.us-east-1
What are the most significant architectural benefits of the way AWS designed its regions? (Select TWO.)
It can make infrastructure more fault tolerant.
It can make applications available to end users with lower latency.
It can make applications more compliant with local regulations.
It can bring down the price of running.
Why is it that most AWS resources are tied to a single region?
Because those resources are run on a physical device, and that device must live somewhere
Because security considerations are best served by restricting access to a single physical location
Because access to any one digital resource must always occur through a single physical gateway
Because spreading them too far afield would introduce latency issues
You want to improve the resilience of your EC2 web server. Which of the following is the most effective and efficient approach?
Launch parallel, load-balanced instances in multiple AWS Regions.
Launch parallel, load-balanced instances in multiple Availability Zones within a single AWS Region.
Launch parallel, autoscaled instances in multiple AWS Regions.
Launch parallel, autoscaled instances in multiple Availability Zones within a single AWS Region.
Which of the following is the most accurate description of an AWS Availability Zone?
One or more independently powered data centers running a wide range of hardware host types
One or more independently powered data centers running a uniform hardware host type
All the data centers located within a broad geographic area
The infrastructure running within a single physical data center
Which of the following most accurately describes a subnet within the AWS ecosystem?
The virtual limits imposed on the network access permitted to a resource instance
The block of IP addresses assigned for use within a single region
The block of IP addresses assigned for use within a single Availability Zone
The networking hardware used within a single Availability Zone
What determines the order by which subnets/AZ options are displayed in EC2 configuration dialogs?
Alphabetical order
They (appear) to be displayed in random order.
Numerical order
By order of capacity, with largest capacity first
What is the primary goal of autoscaling?
To ensure the long-term reliability of a particular physical resource
To ensure the long-term reliability of a particular virtual resource
To orchestrate the use of multiple parallel resources to direct incoming user requests
To ensure that a predefined service level is maintained regardless of external demand or instance failures
Which of the following design strategies is most effective for maintaining the reliability of a cloud application?
Resource isolation
Resource automation
Resource redundancy
Resource geolocation
Which of the following AWS services are not likely to benefit from Amazon edge locations? (Select TWO.)
RDS
EC2 load balancers
Elastic Block Store (EBS)
CloudFront
Which of the following is the primary benefit of using CloudFront distributions?
Automated protection from mass email campaigns
Greater availability through redundancy
Greater security through data encryption
Reduced latency access to your content no matter where your end users live
What is the main purpose of Amazon Route 53?
Countering the threat of distributed denial-of-service (DDoS) attacks
Managing domain name registration and traffic routing
Protecting web applications from web-based threats
Using the serverless power of Lambda to customize CloudFront behavior
According to the AWS Shared Responsibility Model, which of the following are responsibilities of AWS? (Select TWO.)
The security of the cloud
Patching underlying virtualization software running in AWS data centers
Security of what’s in the cloud
Patching OSs running on EC2 instances
According to the AWS Shared Responsibility Model, what’s the best way to define the status of the software driving an AWS managed service?
Everything associated with an AWS managed service is the responsibility of AWS.
Whatever is added by the customer (like application code) is the customer’s responsibility.
Whatever the customer can control (application code and/or configuration settings) is the customer’s responsibility.
Everything associated with an AWS managed service is the responsibility of the customer.
Which of the following is one of the first places you should look when troubleshooting a failing application?
AWS Acceptable Use Monitor
Service Status Dashboard
AWS Billing Dashboard
Service Health Dashboard
Where will you find information on the limits AWS imposes on the ways you can use your account resources?