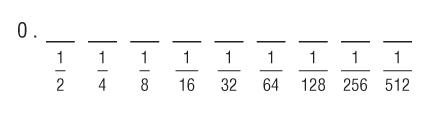Chapter 8
Quirks and Idioms
Just like languages spoken around the world, every programming language has its own idioms and quirks. These quirks make a language interesting and are powerfully expressive, just as much as they might infuriate the language student. A clever trick such as the Schwartzian Transform might seem unmaintainable madness to the uninitiated, but knowledge of the Schwartzian Transform is one of the hallmarks of fluency in Perl. A programmer fluent with .NET will generally prefer LINQ over looping constructs. A fluent C programmer will not overheat at the semantic implications of a pointer-to-a-pointer-to-a-pointer. The list goes on.
An interviewer who tests you on the quirks of a language will generally not be testing your ability to remember programming language trivia. The interviewer will be testing your familiarity and fluency with a language or a framework. The assumption is that if you are proficient with a language, then you will know most of its idioms and many of its quirks.
In this chapter I barely scratch the surface of the many, many quirks and idioms you will find in the wild as a practicing programmer. If, after attempting these questions, you find that you aren't as familiar with a language as you would like, the best way to improve is to study the code of others and focus on anything that isn't obvious. You won't improve your knowledge by sticking to what you already know.
I have divided this chapter into sections based on language so that you can jump to what interests you. Floating point numbers are in a section of their own because they can affect every programmer no matter which language is used.
Perhaps the world's most common coding question is, “Write code that reverses a string.” As a tribute to this popular question, I have included a variation of it in each language section, including the section on T-SQL.
Binary Fractions and Floating Point Numbers
You might remember from school that some fractions can't be accurately represented by a decimal number. The fraction 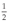 is exactly 0.5 in decimal, but the fraction
is exactly 0.5 in decimal, but the fraction 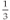 is not exactly 0.3, nor is it exactly 0.33 or 0.333 or 0.3333333333. No matter how many 3s you use, you can't represent
is not exactly 0.3, nor is it exactly 0.33 or 0.333 or 0.3333333333. No matter how many 3s you use, you can't represent 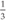 as an exact decimal number without resorting to special notation. Irrational numbers like π cannot be exactly represented in any number system. The best you can do is an approximation of π (even if that approximation is trillions of digits long). The inability to represent some numbers exactly is not a significant problem in practice because, for all practical (and most theoretical) purposes, you never need a degree of accuracy more than around 20 decimal places. Even the infinitesimally small unit of Planck Time can be written using around 50 decimal places. For all practical purposes, a super-high degree of accuracy is simply not that important.
as an exact decimal number without resorting to special notation. Irrational numbers like π cannot be exactly represented in any number system. The best you can do is an approximation of π (even if that approximation is trillions of digits long). The inability to represent some numbers exactly is not a significant problem in practice because, for all practical (and most theoretical) purposes, you never need a degree of accuracy more than around 20 decimal places. Even the infinitesimally small unit of Planck Time can be written using around 50 decimal places. For all practical purposes, a super-high degree of accuracy is simply not that important.
It is the exact same thing with computers and binary numbers. Some fractions can be represented accurately in binary and other fractions cannot. The degree of accuracy you need depends entirely on your application.
A quick word on terminology: You will be familiar with the decimal point when discussing decimal fractions. When discussing binary fractions, the correct terminology is binary point, or more generally radix point.
The term floating point refers to how the position of the radix point varies depending on the scale of the number. Large numbers will have more digits to the left of the radix point, and small numbers have more to the right. This allows a computer to use a fixed-width data type (like an int) to store both very large and very small numbers.
In addition to the flexibility of floating point numbers, programming frameworks often provide extensions to overcome hardware limitations; Java has java.math.BigInteger, Perl has bigint, and C# has System.Numerics.BigInteger. These extensions allow numbers to exceed the usual limitation of ±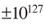 in exchange for reduced performance in some operations.
in exchange for reduced performance in some operations.
Quite often, the simplest and most effective way to avoid inaccuracies caused by floating point calculations is to use an alternative data type such as decimal. Most (if not all) built-in decimal data types will use a floating point representation internally, but they provide the programmer with a predictable façade of accuracy, making it more suitable for storing (for instance) currency values where accuracy (or at least predictable inaccuracy) is desirable. If your framework has a currency data type, then that will be the best data type for storing currency values. You can also sometimes skirt around the issue by using integer data types to perform arithmetic and then inserting your decimal point for display after the arithmetic is done.
QUESTIONS
1. Write 0.1 as a binary fraction
The decimal fraction
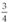
(0.75) can be written as a binary number 0.11. Convert the decimal fraction

to a binary number by hand on paper or on a whiteboard.
2. Simple addition, surprising results
Why does the following JavaScript give the unexpected result of 0.30000000000000004?
var n = 0.1;
n += 0.2;
document.writeln('0.1 + 0.2 = ' + n); // 0.30000000000000004
JavaScript
Love it or hate it, JavaScript is here to stay. The last decade has seen JavaScript rise from a language that was often confused for “Java” to the number one language of client-side web developers around the world. I know many programmers who love JavaScript, many programmers who hate it, and a few who both love it and hate it.
If you write code for the World Wide Web, then sooner or later you will find yourself confronted with what looks like strange behaviour in JavaScript. Take a look at the second question in this section (the one about expressions that evaluate to true or false) to see a good example of “strange” behaviour that a lot of JavaScript programmers take for granted.
QUESTIONS
3. Reverse the words in a string
Write a short program in JavaScript to reverse the order of words in the following string:
var dwarves = “bashful doc dopey grumpy happy sleepy sneezy”;
Your output should look like this:
sneezy sleepy happy grumpy dopey doc bashful
4. Some expressions are more equal than others
To what does each of the following JavaScript expressions evaluate?
" == '0'
" == 0
false == 'false'
false == 0
false == '0'
null == undefined
'
' == 0
undefined == undefined
NaN == NaN
1 == true
1 === true
5. Block scope
What is the output of the following JavaScript code?
x();
function x() {
var x = 1;
document.writeln("1: " + x);
{
var x = 4;
}
document.writeln("2: " + x);
var f = function ()
{
document.writeln("3: " + x);
var x = 3;
};
f();
document.writeln("4: " + x);
}
6. Let me help you with that…
What is the value returned from this function?
function returnTrue()
{
return
{
result: true;
};
}
7. NaN
What is wrong with this test for
NaN?
if (dubiousNumber === NaN)
{
// ...
}
8. What is the meaning of this!
To what does
this refer in each occurrence of
document.writeln()?
document.writeln("A: " + this);
var o = {
f: function() {
return this;
}
};
document.writeln("B: " + o.f());
var f = o.f;
document.writeln("C: " + f());
var obj = {};
document.writeln("D: " + f.call(obj));
var o = {
f: function() {
var ff = function() {
return this;
};
return ff();
},
g: {
h: function() {
return this;
}
}
};
document.writeln("E: " + o.f());
document.writeln("F: " + o.g.h());
C#
The popularity of C# is not really surprising. The C# language combines some of the best features from Java and C, but without the pain associated with pointer manipulation. C# has a gentle learning curve and recent releases have added some very cool features to the language such as lambda expressions and built-in support for asynchronous and concurrent programming constructs.
Trivia: If it were not for potential trademark concerns, the language we know as C# might have been released to the world with the name “Cool,” which stood for “C-like Object Oriented Language.” This was its internal code-name while it was in development at Microsoft. I will leave it up to you to decide if that name would have made any difference to the popularity the language presently enjoys.
QUESTIONS
9. Reverse the words in a string
Write a short program in C# to reverse the order of words in the following string:
string dwarves = "bashful doc dopey grumpy happy sleepy sneezy";
Your output should look like this:
sneezy sleepy happy grumpy dopey doc bashful
10. Avoid Magic Numbers
The following method was written to calculate the difference between two years. If it receives a “year of birth” that is greater than the supplied “current year” then it returns 999 to signify an invalid year of birth. Suggest three alternative ways this method could be improved so that it doesn't involve the “magic number,” 999.
Hint: Consider how you might indicate failure without returning a specific integer.
static int CalculateAge(int yearOfBirth, int currentYear)
{
if (yearOfBirth > currentYear)
return 999; // invalid year of birth
return currentYear - yearOfBirth;
}
11. A path on any platform
The following code does not work properly when run on Linux (compiled with Mono!) Suggest a way to improve this snippet so that it will produce a path that is compatible on other platforms while still retaining compatibility with Windows.
string path = folder + "\" + file;
12. Debugging helper
What is the effect of applying the
DebuggerDisplay attribute as per the following code?
[DebuggerDisplay("X = {X}, Y = {Y}")]
public class LittleHelp
{
private int x;
public int X { get { return x; } set { x = value; Y = -value; } }
public int Y { get; set; }
}
13. The “as” keyword
What does the as keyword do, and how is it helpful?
14. Verbatim String Literals
What is a verbatim string literal and how is it helpful?
15. Immutable Strings
If strings are immutable, meaning that strings cannot be altered, what happens to
myString when you append to it as in the following code?
string myString = "prince";
myString += "ss"; // How can I do this if strings are immutable?
Java
Java is one of the most popular languages in the world. It has evolved more slowly than languages like C# but it still dominates in the corporate world, and it is particularly dominant in server-side development.
Java is notorious for its verbosity, although this is perhaps more the fault of Java libraries and frameworks rather than the language itself. Java assumes very little and provides nearly no syntactic shortcuts. This can be annoying for programmers familiar with less formal languages (like Perl), but on the positive side it encourages a consistent and uniform style of programming that greatly assists the maintenance programmer.
QUESTIONS
16. Reverse the words in a string
Write a short program in Java to reverse the order of words in the following string:
String dwarves = "bashful doc dopey grumpy happy sleepy sneezy";
Your output should look like this:
sneezy sleepy happy grumpy dopey doc bashful
17. Double brace initialization
The following code declares, creates, and initializes an instance of List<String> using what is often called double brace initialization.
Explain how double brace initialization works and rewrite this code to initialize the instance without using double brace initialization.
List<String> list = new ArrayList<String>() {{
add("Lister");
add("Rimmer");
add("Kryten");
}};
18. Labelled blocks
Although Java does not have a goto statement it does have a similar construct that uses labeled blocks in combination with break and continue statements.
Explain what happens when the
break statement is executed in the following code excerpt:
int i;
int j = 0;
boolean found = false;
int[][] arr = {
{ 4, 8, 15, 16, 23, 42 },
{ 11, 23, 29, 41, 43, 47 },
{ 757, 787, 797, 919, 929, 10301 }
};
int find = 41;
iterate:
for (i = 0; i < arr.length; i++) {
for (j = 0; j < arr[i].length; j++)
{
if (arr[i][j] == find) {
found = true;
break iterate;
}
}
}
if (found) {
System.out.println("Found");
} else {
System.out.println("Not found");
}
19. There can be only one
Describe the
design pattern that is being implemented in the following code:
public enum Highlander {
INSTANCE;
public void execute () {
//... perform operation here ...
}
}
Perl
Perl was created in 1987, which makes it the oldest language covered in this chapter. It is widely regarded as a flexible and powerful language although these qualities have earned it the dubious nickname of “the Swiss army chainsaw of scripting languages.” Some programmers go so far as to refer to Perl as a “write-only” language, unkindly implying that Perl code is uniformly difficult to read. These unkind programmers point to Perl's numerous special variables and shortcuts, and, in particular, to the way that Perl is not only forgiving of ambiguous code but also tries to guess what the programmer intended. Many of these criticisms are also the reasons why some programmers fall in love with Perl. Here's an example of Perl trying very hard to do what the programmer probably intends, even when most other languages would throw an exception and refuse to run at all:
C:code>perl -d -e 1
Loading DB routines from perl5db.pl version 1.37
Editor support available.
Enter h or 'h h' for help, or 'perldoc perldebug' for more help.
main::(-e:1): 1
DB<1> $i=1; print ++$i; # Normal increment
2
DB<2> $i='A'; print ++$i; # Alpha increment
B
DB<3> $i='AA'; print ++$i; # Alpha sequence increment
AB
DB<4> $i='A1'; print ++$i; # Alpha numeric sequence increment
A2
DB<5> $i='ZZ'; print ++$i; # Alpha sequence increment with rollover
AAA
DB<6> $i='Z9'; print ++$i; # Alpha num sequence increment
# with rollover
AA0
DB<7>
Depending on your programming experiences to date, you might find this “do what I mean” behavior to be somewhat liberating or somewhat scary.
QUESTIONS
20. Reverse the words in a string
Write a short program in Perl to reverse the order of words in the following string:
my $dwarves = "bashful doc dopey grumpy happy sleepy sneezy";
Your output should look like this:
sneezy sleepy happy grumpy dopey doc bashful
21. Sorting 101
The following Perl code is an attempt to sort a list of numbers into numerical order, but it does not work correctly. Explain what might be wrong and suggest an improvement that will properly sort these numbers into ascending numerical order.
my @list = ( 1, 4, 1, 5, 9, 2, 6, 5, 3, 5, 10, 20, 30, 40 );
print join ",", sort @list;
22. Sorting 201
Suppose you have a list of characters as follows. Write code to produce two lists: the first sorted by race, the second sorted by age then race.
my @list = (
[qw(Pippin Hobbit 29)],
[qw(Merry Hobbit 37)],
[qw(Frodo Hobbit 51)],
[qw(Legolas Elf 650)],
[qw(Gimli Dwarf 140)],
[qw(Gandalf Maiar 2021)],
[qw(Aragorn Man 88)],
[qw(Sam Hobbit 36)],
[qw(Boromir Man 41)],
);
23. Sorting 301: The Schwartzian Transform
The
Schwartzian Transform is a particularly idiomatic (you could say
Perlish) way of sorting a list. It is an excellent illustration of how Perl operators can be combined to perform complex transformations with just a small amount of code. Here is a transform that sorts a list of integers by the number of characters in each integer:
my @list = (111111111,22222222,3333333,444444,55555,6666,777,88,9);
my @sorted =
map { $_->[1] }
sort { $a->[0] <=> $b->[0] }
map { [length $_, $_] } @list;
print join ',', @sorted
When run, this program prints:
9,88,777,6666,55555,444444,3333333,22222222,111111111
Here is another list, this time with numbers represented by English words:
my @list = qw/three two one six five four nine eight seven/;
Write a Schwartzian Transform that will sort this list into numeric order, from “one” to “nine.”
24. It depends…
Built-in functions such as sort are sensitive to the context in which they are called. If you call sort in a list context you will get back a list. If you call sort in a scalar context you will get back undefined.
Write a sensitiveSort subroutine that sorts @_ and returns a string if called in scalar context. In other words, wrap the built-in sort routine so that sort no longer returns undefined in scalar context.
25. The branch you're standing on
The following code is intended to loop over an array of numbers and print the square of each number and the total of all squares. This code works but it has unintended consequences. What are these unintended consequences and how can they be avoided?
use strict; use warnings;
my @array = (1 .. 9);
my $sum = 0;
foreach my $num (@array) {
print "$num^2=";
$num = $num * $num;
print "$num
";
$sum += $num;
}
print "Sum of squares is $sum
";
The output is:
1^2=1
2^2=4
3^2=9
4^2=16
5^2=25
6^2=36
7^2=49
8^2=64
9^2=81
Sum of squares is 285
26. Perl isn't Java
This Perl code does not behave as the programmer intended. What is wrong with it? Rewrite it so that it will behave as the programmer probably intended.
my $dwarves = "bashful doc dopey grumpy happy sleepy sneezy";
print &ReverseWords($dwarves);
sub ReverseWords {
my $arg = shift;
if ($arg != null) {
return join ' ', reverse split ' ', $dwarves;
}
}
Ruby
Ruby is considered by some programmers to be just like Perl, only with better support for object-oriented programming and with fewer idiosyncrasies.
QUESTIONS
27. Reverse the words in a string
Write a short program in Ruby to reverse the order of words in the following string:
dwarves = "bashful doc dopey grumpy happy sleepy sneezy";
Your output should look like this:
sneezy sleepy happy grumpy dopey doc bashful
28. Swap variable values without a temp variable
Write code to swap the values of two variables without using a temporary variable.
In other words, start with
x == 1
y == 2
and write code to obtain
x == 2
y == 1
29. &&= operator
What does the following code do, and how is it potentially helpful?
myString &&= myString + suffix
Transact-SQL
Transact-SQL (T-SQL, Microsoft's version of SQL) is unlike any other language covered in this chapter. It is primarily a language for querying and processing data in a relational database (specifically SQL Server) and it builds on the standard SQL language. SQL is sometimes described as a declarative language, meaning that the programmer will write code that describes what results to obtain rather than writing code that describes how to obtain those results. Despite being called a declarative language, SQL (and especially T-SQL) does contain procedural elements such as looping constructs, IF statements, and text-manipulation functions. These constructs can be very convenient, but they can also mislead the inexperienced SQL programmer into thinking that SQL is just like any other language, only uglier.
Programmers who learn other languages before learning SQL often find themselves struggling to reproduce the idioms of those other languages in SQL. These programmers are almost without exception disappointed and frustrated. You can write procedural SQL code just as you can bang in a nail with a screwdriver. With effort and creativity you can do just about anything in T-SQL that you can do in other languages, but that does not mean that you should. Writing code to reverse the order of words in a string using T-SQL (see the first question in this section) is most certainly possible, but I would prefer to use almost any other language for this kind of purpose.
The power of SQL lies in its ability to query and filter large amounts of data with relatively few lines of code. Just as Perl and JavaScript enable the programmer to do a lot with very little code, SQL enables the programmer to perform complex operations on sets of data with very little code. If you think SQL is verbose, try writing the equivalent code without a database engine.
Writing SQL code that iterates over rows in a table instead of performing a set-based operation is a common newbie mistake. Quite often the SQL novice will write many hundreds of lines of complicated and bug-ridden code without realizing that they can obtain better (meaning faster, more efficient, and easier to debug) results with far fewer lines of set-based SQL.
Just because an interviewer might encourage you to stretch the limits of SQL in an interview question does not mean that this should be standard practice. Use SQL for what it was intended and leave these shenanigans to eccentric interviewers and oddball websites.
QUESTIONS
30. Reverse the words in a string
Write a short T-SQL script to reverse the order of words in the following string:
DECLARE @dwarves VARCHAR(MAX)
SET @dwarves = 'bashful doc dopey grumpy happy sleepy sneezy'
Your output should look like this:
sneezy sleepy happy grumpy dopey doc bashful
31. Correlated subquery
Consider the following table, which contains a list of users, each with a reputation and a location:
CREATE TABLE [dbo].[Users](
[Id] [int] NOT NULL,
[Reputation] [int] NULL,
[DisplayName] [nchar](40) NULL,
[Location] [nchar](100) NULL,
[JoinDate] [smalldatetime] NULL
)
Write a SELECT statement that uses a correlated subquery to obtain a list of users with a higher-than-average reputation within that user's location.
32. Which date is that?
The following two lines of SQL are supposed to insert a new row into the Users table. Assuming that this SQL worked correctly at least once (when the developer wrote and tested it) what could potentially go wrong it, and how could you rewrite it to avoid this problem?
INSERT INTO Users (Id, DisplayName, JoinDate)
VALUES (1, 'Ted', CONVERT(smalldatetime,'12/01/2015'))
33. Collation order
Consider a scenario where your SQL Server database is deployed to a customer site and to an existing SQL Server instance alongside other databases that you don't control or know anything about. In that circumstance, what is potentially wrong (or perhaps missing) in this
CREATE TABLE statement, and how should you rewrite it to avoid this potential problem?
CREATE TABLE #temp
(
[Id] int identity(1,1) NOT NULL,
[Name] nvarchar(100) NULL,
[DateJoined] smalldatetime NULL
)
34. Selecting a random row from a table
Write a SELECT statement that will select a single row at random from the Users table. Assume the table has between 10 and 10,000 rows.
ANSWERS
This section contains answers to questions asked previously in this chapter.
1. Write 0.1 as a binary fraction
The decimal fraction (0.75) can be written as a binary number 0.11. Convert the decimal fraction to a binary number by hand (on paper or on a whiteboard).
An interviewer might ask a question like this to test your understanding of how decimal fractions numbers are stored in binary. This particular question is a bit of a trick because it is impossible to convert the decimal fraction
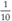
to an exact binary equivalent. It is possible to store a number that is very close to
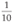
and that is what a computer does. It stores an approximation and leaves it up to programming frameworks to “pretend” (or not, in many cases) that they are storing an exact number.
Just knowing that it is impossible to represent 0.1 exactly in binary might not be enough for some interviewers. You might be pressed to “show your work.” Here is an example of how you would try to convert 0.1 to binary by hand:
First, write a 0 followed by the binary point, followed by nine or ten place holders as shown in
Figure 8.1.
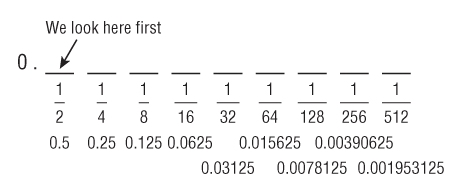
Next, draw in the value of each place as shown in
Figure 8.2. If you weren't already aware, notice how the value of each place after the binary point is a progression of the sequence 2
-1, 2
-2, 2
-3, and so on.
You might not be able to remember values beyond
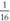
, in which case you could ask your interviewers whether they remember, or borrow a calculator just for working out
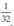
and so on as decimal numbers. It is unlikely you will be penalized for this; not many people walk around with these decimal numbers in their head, I certainly don't. By this point your interviewer will see you are heading in the right direction.
Now you are ready to start the conversion of 0.1 to a binary fraction. The process is quite mechanical:
1. Start at the binary point.
2. Move (that is, look at) one place to the right.
3. If the current place value is greater than your decimal fraction, then write a “0” in that place and repeat from step 2.
4. If the current place value is less than or equal to your decimal fraction then write a “1” in that place and subtract the place value from your decimal fraction.
5. If the subtraction in step 4 gives 0 then you are finished.
6. Otherwise, repeat from step 2.
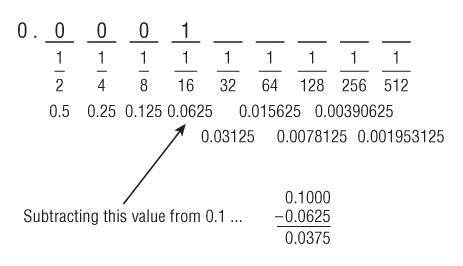
Following this process for 0.1, start at the binary point and move one place to the right. You should be looking at the value of this place, which is 0.5, as shown in
Figure 8.3.
Step 3 indicates that you write a “0” in this place.
Figure 8.4 shows the work so far.
Now repeat steps 2 and 3, writing “0” in each place until you come to the fourth place, which has a value of 0.0625, as shown in
Figure 8.5.
Following the instruction at step 4, write a “1” in the fourth place, and subtract the value of this place from your value.
Figure 8.6 shows the progress so far and the subtraction performed.
Having performed the subtraction you are left with a value of 0.0375. Steps 5 and 6 say to repeat the process from step 2. Continue with the next binary place, writing a “1” because the value of 0.0375 is greater than the place value of 0.03125.
By this point your interviewer should have interrupted to either stop you (because you clearly know what you are doing) or to ask (perhaps sarcastically) how many places you intend to calculate. If the interviewer doesn't stop you I recommend stopping yourself after the first few digits to explain that the sequence doesn't end at nine binary places but continues indefinitely like this:
0.00011001100110011001100110011001100110011…
Trying to derive an exact representation in this fashion would require an infinite sequence of digits, which makes representing the decimal value exactly as a binary fraction impossible.
By the way, I hope you never need to do this kind of conversion by hand outside of an interview.
2. Simple Addition, Surprising Results
Why does the following JavaScript give the unexpected result of 0.
30000000000000004?
var n = 0.1;
n += 0.2;
document.writeln('0.1 + 0.2 = ' + n); // 0.30000000000000004
Results like this are less surprising when you appreciate the inherent limitations of representing floating point numbers in binary. Recall that 0.1 is stored internally as an approximation rather than an exact number. The surprising result is a consequence of performing addition with an approximate number.
Also recall that although many fractions cannot be represented exactly, many others can. If you aren't aware of this limitation then you might incorrectly conclude that JavaScript (or another language) is returning inconsistent results.
This same question could have been phrased as:
What is the result of the following JavaScript expression, true or false?
(0.1 + 0.2) === 0.3
This isn't quite as obvious as the answer to the previous question. The answer here is “false,” and again, the key is to appreciate the inexact binary representation of decimal fractions.
3. Reverse the words in a string
Write a short program to reverse the order of words in the following string.
var dwarves = "bashful doc dopey grumpy happy sleepy sneezy";
Your output should look like this:
sneezy sleepy happy grumpy dopey doc bashful
For brevity, JavaScript is sometimes on a par with Perl. Just like Perl, JavaScript has a
join function, a
split function, and a
reverse function that works on arrays.
var sevrawd = dwarves.split(' ').reverse().join(' '),
document.writeln(sevrawd);
4. Some expressions are more equal than others
To what does each of the following JavaScript expressions evaluate?
" == '0'
" == 0
false == 'false'
false == 0
false == '0'
null == undefined
'
' == 0
undefined == undefined
NaN == NaN
1 == true
1 === true
The result of some of these comparisons might surprise you. You should appreciate that the equals operator
== will generally attempt to coerce each value to have the same type before it does the comparison. Sometimes this does what you might expect, and sometimes it doesn't. The strict-equals operator
=== returns
false if the values do not have the same type and is therefore more predictable in most cases. One notable exception to the usual rules is that
NaN === NaN will always return
false.
" == '0' // false
" == 0 // true
false == 'false' // false
false == 0 // true
false == '0' // true
null == undefined // true
'
' == 0 // true
undefined == undefined // true
NaN === NaN // false
1 == true // true
1 === true // false
5. Block scope
What is the output of the following JavaScript code?
x();
function x() {
var x = 1;
document.writeln("1: " + x);
{
var x = 4;
}
document.writeln("2: " + x);
var f = function ()
{
document.writeln("3: " + x);
var x = 3;
};
f();
document.writeln("4: " + x);
}
The output of this code is:
1: 1
2: 4
3: undefined
4: 4
The first step in understanding the answer to this question is to appreciate that JavaScript does not have block scope like other languages. In most other languages this block…
{
var x = 4;
}
…would declare a new variable confined to the scope of the block (or else it would generate a compiler error). In JavaScript this variable replaces the original, changing the value of x.
So why doesn't the second “block” change the value of x?
Even though JavaScript doesn't have block scope it does have what is known as function scope. Function scope is a bit one sided; it means that a function inherits the scope in which it is declared (which in this case is the scope of the function x) but it cannot change any of these variables. Functions also have their own “private” (or “inner”) scope that overrides the inherited scope within the function block. If a variable name conflicts then the innermost scope wins.
But if the function inherits the scope of its context, why does x show as undefined when calling f()?
Variable declarations are always
hoisted to the top of the declaring block regardless of where the
var declaration appears inside the block. The following function
function () {
document.writeln(x);
var x = 1;
}
is interpreted as
function () {
var x = undefined;
document.writeln(x);
x=1;
}
Notice that while variable declarations are hoisted, variable assignments are not.
Returning to the original question this means that the function expression
var f = function ()
{
document.writeln("3: " + x);
var x = 3;
};
is interpreted as
var f = function ()
{
var x = undefined;
document.writeln("3: " + x);
x = 3;
};
Variables declared and assigned within the scope of this inner (anonymous) function do not affect variables in the scope of the outer function, so the assignment x = 3 does not change x as shown in the final line of output.
As you can see, JavaScript is fertile ground for the creative interviewer.
6. Let me help you with that…
What is the value returned from this function?
function returnTrue()
{
return
{
result: true;
};
}
Somewhat surprisingly (or perhaps somewhat predictably given the nature of this chapter) the return value is not what it might seem. At first glance this function appears to return an object with a result property set to true. Actually, this function returns
undefined. Here's a hint: The function works as expected if you rewrite at as follows:
function returnTrue()
{
return {
result: true;
};
}
The difference is in the line containing the
return statement. JavaScript expects return values to be on (or to start on) the same line as the
return statement; otherwise, JavaScript assumes you missed a semicolon and adds one for you. In other words, a line like this…
return
5;
…is interpreted as
return;
5;
The automatic insertion of semicolons in certain statements is not a bug in JavaScript; it is according to the EMCAScript Language Specification (ECMA-262 section 7.9), which says (emphasis added):
Certain ECMAScript statements (empty statement, variable statement, expression statement, do-while statement, continue statement, break statement, return statement, and throw statement) must be terminated with semicolons. Such semicolons may always appear explicitly in the source text. For convenience, however, such semicolons may be omitted from the source text in certain situations.
7. NaN
What is wrong with this test for NaN?
if (dubiousNumber === NaN)
{
// ...
}
NaN is the only value in JavaScript that always returns false when compared to itself. This means the preceding test will always evaluate to false, even if dubiousNumber is NaN.
Fortunately, JavaScript provides a built-in function to test for
NaN.
isNaN(NaN) === true
8. What is the meaning of this!
To what does this refer in each occurrence of document.writeln()?
document.writeln("A: " + this);
var o = {
f: function() {
return this;
}
};
document.writeln("B: " + o.f());
var f = o.f;
document.writeln("C: " + f());
var obj = {};
document.writeln("D: " + f.call(obj));
var o = {
f: function() {
var ff = function() {
return this;
};
return ff();
},
g: {
h: function() {
return this;
}
}
};
document.writeln("E: " + o.f());
document.writeln("F: " + o.g.h());
When run, this JavaScript produces the following output:
A: [object Window]
By default,
this refers to the global object (
window).
B: [object Object]
The function
f() is a property of object
o. When a function is called via an object as in
o.f(),
this refers to the parent object
o.
C: [object Window]
When the function
f is called directly (without referencing an object)
this refers to the global object (
window).
D: [object Object]
When a function is called via
call(), the value of
this refers to the first argument supplied. If the first argument is not an object, or if it is
null then
this refers to the global object (
window). Here I supplied object
obj so
this is an object:
E: [object Window]
The function
ff() is not a property of object
o, so
this refers to the global object (
window).
F: [object Object]
The function h() is a function of nested object g, so this refers to the parent object g.
9. Reverse the words in a string
Write a short program in C# to reverse the order of words in the following string:
string dwarves = "bashful doc dopey grumpy happy sleepy sneezy";
Your output should look like this:
sneezy sleepy happy grumpy dopey doc bashful
This C# program splits the sentence with
String.Split(). It then uses
Enumerable.Reverse() to reverse and
String.Join() to reconstruct the list of words
using System;
using System.Linq; // For the Reverse() method
namespace Ace
{
public class ReverseWords
{
public static void Main(string[] args)
{
string dwarves =
"bashful doc dopey grumpy happy sleepy sneezy";
string sevrawd = String.Join(" ",
dwarves.Split(' ').Reverse() );
Console.WriteLine(sevrawd);
}
}
}
10. Magic numbers, avoiding
The following method was written to calculate the difference between two years. If it receives a “year of birth” that is greater than the supplied “current year” then it returns 999 to signify an invalid year of birth. Suggest three alternative ways this method could be improved so that it doesn't rely on a magic number 999.
Hint: Consider how you might indicate failure without returning a specific integer.
static int CalculateAge(int yearOfBirth, int currentYear)
{
if (yearOfBirth > currentYear)
return 999; // invalid year of birth
return currentYear - yearOfBirth;
}
Magic numbers are generally best avoided. In the example shown, the number 999 is used as an indicator that the calculation failed. This is a magic number, and it puts the onus on the maintenance programmer to be aware of this number forever after. Also, if the number 999 should one day become a valid age (it is conceivable!) then this code would stop working.
One way of avoiding the problem would be to have the method return a nullable integer instead of an integer, so that if the calculation failed then the function could simply return
null instead of an integer. This way there can be no confusion about the return value—you get an
int if it works and a
null if it fails, and because
null is not even a valid integer it can never be confused for a valid age.
static int? CalculateAge(int yearOfBirth, int currentYear)
{
if (yearOfBirth > currentYear)
return null; // invalid year of birth
return currentYear - yearOfBirth;
}
Another possibility would be to use an
out parameter to return the calculated age, and change the method type to
bool so that if the calculation fails the method will return
false. The caller would need to check the return value before using the calculated age.
static bool CalculateAge(
int yearOfBirth,
int currentYear,
out int Age)
{
Age = currentYear - yearOfBirth;
return Age >= 0;
}
One more possibility would be to throw an exception if the calculation fails, perhaps an
ArgumentOutOfRangeException. The caller would need to catch and handle this exception, but there is no chance of an invalid date leaking out of this function. The invalid result is unambiguous.
static int CalculateAge(int yearOfBirth, int currentYear)
{
if (yearOfBirth > currentYear)
throw new ArgumentOutOfRangeException();
return currentYear - yearOfBirth;
}
11. A path on any platform
The following code does not work properly when run on Linux (compiled with Mono!) Suggest a way that this snippet could be improved so that it will produce a path that is compatible on other platforms while still retaining compatibility with Windows.
string path = folder + "\" + file;
After you've discovered
Path.Combine() you will never combine parts of a path with string concatenation ever again. (Will you promise?)
string path = Path.Combine(folder, file);
12. Debugging helper
What is the effect of applying the DebuggerDisplay attribute as per the following code?
[DebuggerDisplay("X = {X}, Y = {Y}")]
public class LittleHelp
{
private int x;
public int X { get { return x; } set { x = value; Y = -value; } }
public int Y { get; set; }
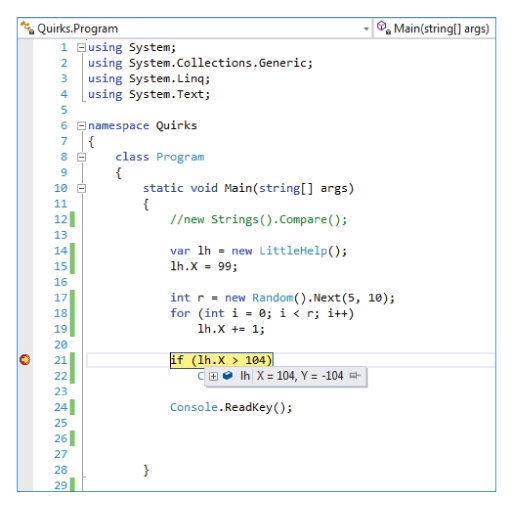
}
This is an extremely useful attribute during development and debugging with Visual Studio. When you've interrupted an executing program (Debug Break All) you can then simply hover over the object instance and get a nicely formatted display of whatever you have put into the
DebuggerDisplay attribute, as illustrated in
Figure 8.7.
Figure 8.8 shows what you get by default, without using
DebuggerDisplay attribute.
13. The “as” keyword
What does the as keyword do, and how is it helpful?
The
as keyword is like a cast operation, it attempts to convert a variable to a specified type. Unlike cast however, if the conversion is not possible it will return null instead of throwing an exception. This is useful when the cast might fail because it avoids the need to catch and handle an
Exception. It is equivalent to the following expression:
expression is type ? (type)expression : (type)null
The following code illustrates the difference:
public class Foo
{
}
public class Bar : Foo
{
}
public class TestFooBar
{
public void test()
{
Foo foo = new Foo();
Bar bar = new Bar();
Object list = new List<string>();
var test = bar as Foo; // OK, casts bar as Foo
var test1 = list as Foo; // OK, but test1 is null
var test2 = (Foo)list; // Throws an exception
}
}
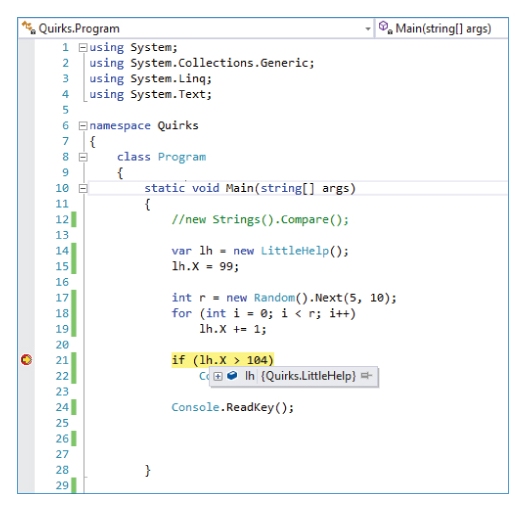
14. Verbatim string literals
What is a verbatim string literal and how is it helpful?
String literals in C# can contain escape sequences like
(tab) and
(newline) and
u00BB (Unicode symbol
»).
string s = "My string
contains u00BB symbols";
When output to the console, this string is shown as in
Figure 8.9.
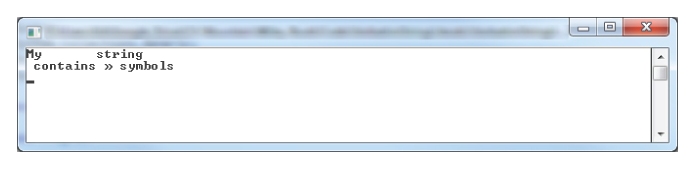
If you want to avoid this interpretation of escape sequences, you can use a verbatim string literal by prefixing the string with an
@ symbol, as follows:
string s = @"My string
contains u00BB symbols";
When output to the console this string is shown as in
Figure 8.10.
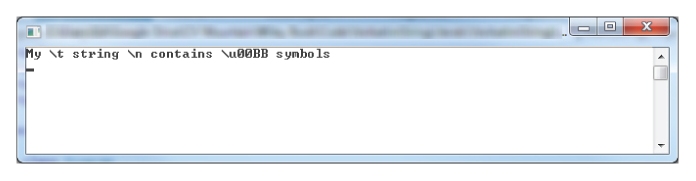
If you want to include a quote character inside a verbatim string literal you need to escape it by using two consecutive quotes.
string s = @"My string
""contains"" u00BB symbols";
When output to the console, this string is shown as in
Figure 8.11.
15. Immutable strings
If strings are immutable, meaning that strings cannot be altered, what happens to myString when you append to it as in the following code?
string myString = "prince";
myString += "ss"; // How can I do this if strings are immutable?
Strings in .NET (and Java) are truly immutable. After they come into existence they can't be changed without resorting to unsafe code. Examples like the one in this question appear to contradict this fact, but looks are deceptive.
The syntax used to manipulate strings gives the appearance of modification but under the hood the object that
myString references is actually being replaced with a new
string object. This can be confirmed easily using the
Object.ReferenceEquals() method, which returns
true if two object instances are the same instance.
public void Compare()
{
string a = "prince";
string b = a;
Console.WriteLine(string.Format("a == '{0}', b=='{1}'", a, b));
Console.WriteLine(string.Format("(a == b) == {0}", (a == b)));
Console.WriteLine("Object.ReferenceEquals(a,b) == " +
Object.ReferenceEquals(a, b));
// Now "modify" a, the reference changes!
a += "ss";
Console.WriteLine(string.Format("a == '{0}', b=='{1}'", a, b));
Console.WriteLine(string.Format("(a == b) == {0}", (a == b)));
Console.WriteLine("Object.ReferenceEquals(a,b) == " +
Object.ReferenceEquals(a, b));
// Restore the original value, the original reference returns!
a = "prince";
Console.WriteLine(string.Format("a == '{0}', b=='{1}'", a, b));
Console.WriteLine(string.Format("(a == b) == {0}", (a == b)));
Console.WriteLine("Object.ReferenceEquals(a,b) == " +
Object.ReferenceEquals(a, b));
}
16. Reverse the words in a string
Write a short program to reverse the order of words in the following string:
String dwarves = "bashful doc dopey grumpy happy sleepy sneezy";
Your output should look like this:
sneezy sleepy happy grumpy dopey doc bashful
This answer splits the string on whitespace and then uses a LIFO (last in, first out) stack to reverse the list:
import java.util.*;
import java.lang.*;
public class Main
{
public static void main (String[] args)
throws java.lang.Exception
{
String dwarves =
"bashful doc dopey grumpy happy sleepy sneezy";
List<String> list = Arrays.asList(dwarves.split(" "));
Stack<String> s = new Stack<String>();
s.addAll(list);
String sevrawd = "";
while (!s.empty()) {
sevrawd += s.pop() + " ";
}
System.out.println(sevrawd);
}
}
17. Double brace initialization
The following code declares, creates, and initializes an instance of List<String> using what is often called double brace initialization.
Explain how double brace initialization works and rewrite this code to initialize the instance without using double brace initialization.
List<String> list = new ArrayList<String>() {{
add("Lister");
add("Rimmer");
add("Kryten");
}};
Quite a lot is going on within these two braces. The first brace creates a new anonymous inner class. The second brace declares an instance initializer block. This initializer block is run when the anonymous inner class is instantiated, adding three strings to the new list. This style of initialization does not work for final classes because it relies on the creation of an anonymous subclass.
The code shown in the question could have been written as:
List<String> list = new ArrayList<String>();
list.add("Lister");
list.add("Rimmer");
list.add("Kryten");
18. Labelled blocks
Explain what happens when the break statement is executed in the following code excerpt:
int i;
int j = 0;
boolean found = false;
int[][] arr = {
{ 4, 8, 15, 16, 23, 42 },
{ 11, 23, 29, 41, 43, 47 },
{ 757, 787, 797, 919, 929, 10301 }
};
int find = 41;
iterate:
for (i = 0; i < arr.length; i++) {
for (j = 0; j < arr[i].length; j++)
{
if (arr[i][j] == find) {
found = true;
break iterate;
}
}
}
if (found) {
System.out.println("Found");
} else {
System.out.println("Not found");
}
This excerpt searches a two-dimensional array of integers for the integer 41. It does this by iterating over each dimension and comparing each element to the value of find. When it finds a match it sets found to true and then executes a break statement. The break statement terminates the loop that is labelled iterate. Execution continues at the if (found) statement.
19. There can be only one
Describe the design pattern that is being implemented in the following code:
public enum Highlander {
INSTANCE;
public void execute () {
//... perform operation here ...
}
}
The singleton pattern is a design pattern that is intended to limit the number of instances of a class to exactly one. This can useful when an object is responsible for coordinating access to a unique resource such as a system queue or an item of hardware. There are a number of different ways of implementing this pattern but this implementation using enum is said to be the best (by Joshua Bloch in Effective Java, Second Edition).
20. Reverse the words in a string
Write a short program to reverse the order of words in the following string:
my $dwarves = "bashful doc dopey grumpy happy sleepy sneezy";
Your output should look like this:
sneezy sleepy happy grumpy dopey doc bashful
A simple algorithm that works well with Perl is
1. Split the string into words.
2. Reverse the list of words obtained in step 1.
3. Join the words obtained in step 2 using a single space between them.
You accomplish step 1 with the
split operator.
my @words = split ' ', $dwarves;
When a single space is used as the separator character, split looks for any contiguous whitespace (not just a single space). The split operator discards leading spaces, trailing spaces, and extra spaces between words, so it works well regardless of spacing in the string.
Step 2 is to reverse the list of words.
my @reverse = reverse @words;
Step 3 is to put the reversed words back together, joining them with a single space.
my $sevrawd = join ' ', @reverse;
Mission accomplished in three lines. It could be done in one:
my $sevrawd = join ' ', reverse split ' ', $dwarves;
21. Sorting 101
The following Perl code is an attempt to sort a list of numbers into numerical order, but it does not work correctly. Explain what might be wrong and suggest an improvement that will properly sort these numbers into ascending numerical order.
my @list = ( 1, 4, 1, 5, 9, 2, 6, 5, 3, 5, 10, 20, 30, 40 );
print join ",", sort @list;
By default, the
sort operator sorts values alphabetically using the
cmp operator. The
sort in this question is equivalent to
sort { $a cmp $b } @list;
This results in an alphabetically sorted list of numbers:
1,1,10,2,20,3,30,4,40,5,5,5,6,9
To sort values numerically you must use the numeric comparison operator as follows:
sort { $a <=> $b } @list;
This returns a numerically sorted list:
1,1,2,3,4,5,5,5,6,9,10,20,30,40
To sort the list in descending numeric order you simply reverse the arguments in the
sort block.
sort { $b <=> $a } @list;
This returns a numerically descending sorted list:
40,30,20,10,9,6,5,5,5,4,3,2,1,1
22. Sorting 201
Suppose you have a list of characters as follows. Write code to produce two lists; the first sorted by race, the second sorted by age then race.
my @list = (
[qw(Pippin Hobbit 29)],
[qw(Merry Hobbit 37)],
[qw(Frodo Hobbit 51)],
[qw(Legolas Elf 650)],
[qw(Gimli Dwarf 140)],
[qw(Gandalf Maiar 2021)],
[qw(Aragorn Man 88)],
[qw(Sam Hobbit 36)],
[qw(Boromir Man 41)],
);
Sorting by race is relatively simple; you just need to refer to the race column in each list item as follows:
my @race = sort { $a->[1] cmp $b->[1] } @list;
Sorting by age and then by race requires a bit more logic. Because Perl comparison operators return 0 when two items are equal you can use the logical-or operator
|| to introduce a “tie break” comparison, as follows:
my @race = sort { $a->[2] <=> $b->[2]
|| $a->[1] cmp $b->[1] } @list;
Putting this together, here is a complete Perl program to produce the two lists as required by the question:
use strict; use warnings;
my @list = (
[qw(Pippin Hobbit 29)],
[qw(Merry Hobbit 37)],
[qw(Frodo Hobbit 51)],
[qw(Legolas Elf 650)],
[qw(Gimli Dwarf 140)],
[qw(Gandalf Maiar 2021)],
[qw(Aragorn Man 88)],
[qw(Sam Hobbit 36)],
[qw(Boromir Man 41)],
);
my @race = sort { $a->[1] cmp $b->[1] } @list;
print "Sorted by race:
";
&printCompany(@race);
print "Sorted by age then race:
";
@race = sort { $a->[2] <=> $b->[2]
|| $a->[1] cmp $b->[1] } @list;
&printCompany(@race);
sub printCompany() {
foreach my $i (@_) {
print "$i->[0] $i->[1] $i->[2]
";
}
print "---
";
}
This program produces the following output:
Sorted by race:
Gimli Dwarf 140
Legolas Elf 650
Pippin Hobbit 29
Merry Hobbit 37
Frodo Hobbit 51
Sam Hobbit 36
Gandalf Maiar 2021
Aragorn Man 88
Boromir Man 41
---
Sorted by age then race:
Pippin Hobbit 29
Sam Hobbit 36
Merry Hobbit 37
Boromir Man 41
Frodo Hobbit 51
Aragorn Man 88
Gimli Dwarf 140
Legolas Elf 650
Gandalf Maiar 2021
---
23. Sorting 301: The Schwartzian Transform
Write a Schwartzian Transform that will sort the following list into numeric order, from “one” to “nine.
”
my @list = qw/three two one six five four nine eight seven/;
This problem becomes much easier if you introduce a hash to map the English words to their integer equivalents. Then, you can simply sort on the integer value of each word using the hash to look up values for each word.
my @numbers = qw/three two one six five four nine eight seven/;
my %values = (
'one' => 1,
'two' => 2,
'three' => 3,
'four' => 4,
'five' => 5,
'six' => 6,
'seven' => 7,
'eight' => 8,
'nine' => 9
);
# Here is the ST, taking advantage of the %values hash
my @sorted =
map { $_->[1] }
sort { $a->[0] <=> $b->[0] }
map { [$values{$_}, $_] } @numbers;
print join ',', @sorted;
24. Context matters
Built-in functions such as sort are sensitive to the context in which they are called. If you call sort in a list context you will get back a list. If you call sort in a scalar context you will get back undefined.
Write a sensitiveSort subroutine that sorts @_ and returns a string if called in scalar context. In other words, wrap the built-in sort routine so that sort no longer returns undefined in scalar context.
The key to this answer is being aware of the
wantarray operator. This is the only reliable way to determine whether a subroutine (or
eval block) has been called in list or scalar (or void) context. Here is one possible solution that uses
wantarray:
use strict; use warnings;
sub sensitiveSort {
return wantarray ? sort @_ : join ',', sort @_;
}
my @list = ( 1, 4, 1, 5, 9, 2, 6, 5, 3, 5, 10, 20, 30, 40);
# list context
print "The first element is: " . (sensitiveSort (@list))[0];
# scalar context
print "
The sorted list: " . sensitiveSort(@list);
25. The branch you're standing on
The following code is intended to loop over an array of numbers and print the square of each number and the total of all squares. This code works but it has unintended consequences. What are these unintended consequences and how can they be avoided?
use strict; use warnings;
my @array = (1 .. 9);
my $sum = 0;
foreach my $num (@array) {
print "$num^2=";
$num = $num * $num;
print "$num
";
$sum += $num;
}
print "Sum of squares is $sum
";
The output is:
1^2=1
2^2=4
3^2=9
4^2=16
5^2=25
6^2=36
7^2=49
8^2=64
9^2=81
Sum of squares is 285
In this question you have a loop that iterates over an array, using the variable
$num as the iterator variable. You modify this iterator variable to obtain the square of each number. The mistake is that by modifying this variable, you are also modifying each element of the original array. This is almost certainly an unintended consequence. You can see the modified array by printing it after your loop.
print join "
", @array;
You can see that the array now contains squares instead of the original values 1 to 9.
1
4
9
16
25
36
49
64
81
Making this mistake without realizing that the original data is being changed is easy. The best way to avoid this unintended consequence is to avoid modifying an iterator variable within a loop, as shown next.
use strict; use warnings;
my @array = (1 .. 9);
my $sum = 0;
foreach my $num (@array) {
my $square = $num * $num;
print "$num^2=" . $square . "
";
$sum += $square;
}
print "Sum of squares is $sum
";
print join "
", @array;
Now, when you run this improved program you get the same result, but this time you avoid modification of the original array.
1^2=1
2^2=4
3^2=9
4^2=16
5^2=25
6^2=36
7^2=49
8^2=64
9^2=81
Sum of squares is 285
The original array remains as first initialised:
1
2
3
4
5
6
7
8
9
26. Perl isn't Java
This Perl code does not behave as the programmer intended. What is wrong with it? Rewrite it so that it will behave as the programmer probably intended.
my $dwarves = "bashful doc dopey grumpy happy sleepy sneezy";
print &ReverseWords($dwarves);
sub ReverseWords {
my $arg = shift;
if ($arg != null) {
return join ' ', reverse split ' ', $dwarves;
}
}
If you spend much time programming in languages such as Java and C#, then you might develop a habit of checking that arguments are not null before performing operations on them. This is generally a good habit to have.
If you haven't already realized, the code in this question fails because Perl does not have a built-in value of
null. The closest equivalent is
undef. Perl interprets the
null (without any quotes) as a
bareword (a string) meaning that this line
if ($arg != null) {
is interpreted as if it had been written as
if ($arg != 'null') { # Bareword interpreted as string
But that is not all. Another problem is that the numeric comparison operator
!= has been used instead of the string comparison operator
cmp. This leads Perl further astray, as if this line had been written as
if ($arg != 0) { # Numeric interpretation of the string 'null'
Now when the seven dwarves are passed as an argument, Perl will also interpret that dwarfish string as a number; that is, 0, meaning that you end up with an expression that will never evaluate to
true.
if (0 != 0) { # Will never be true
Seasoned Perl programmers will have noticed that this code is missing two useful pragma directives:
use warnings;
use strict;
When these are added Perl complains loudly about the mistaken code.
C:code>PerlIsNotJava.pl
Bareword "null" not allowed while "strict subs" in use
at C:codePerlIsNotJava.pl line 11.
Execution of C:codePerlIsNotJava.pl aborted due to
compilation errors.
The programmer who wrote this probably intended simply to check that an argument is supplied before attempting to operate on it. The following code works correctly:
use warnings;
use strict;
my $dwarves = "bashful doc dopey grumpy happy sleepy sneezy";
print &ReverseWords($dwarves);
sub ReverseWords {
my $arg = shift;
if ($arg) {
return join ' ', reverse split ' ', $dwarves;
}
}
27. Reverse the words in a string
Write a short program to reverse the order of words in the following string:
dwarves = "bashful doc dopey grumpy happy sleepy sneezy";
Your output should look like this:
sneezy sleepy happy grumpy dopey doc bashful
print dwarves.split.reverse.join(' ')
28. Swap variable values without a temp variable
Write code to swap the values of two variables without using a temporary variable.
In other words, start with
x == 1
y == 2
and write code to obtain
x == 2
y == 1
Swapping the values of two variables was one of the first programming techniques I was ever taught. The pattern I was shown was to use a temporary variable to hold one of the values while you replace that variable.
initialize two variables...
x = 1
y = 2
now swap them...
temp = x
x = y
y = temp
Ruby (and Perl) removes the need for a temporary variable by supporting a language feature called
parallel assignment:
x = 1
y = 2
x,y = y,x # Parallel assignment, swapping values
You should also be aware of the technique known as the
XOR swap. This is a “clever” bit of code that I would never recommend for real production code simply because understanding it is hard unless you happen know the trick.
# initialize two variables
x = 1
y = 2
# now swap them with xor
x = x ^ y
y = x ^ y
x = x ^ y
To understand this magical swap it helps to remember how the bitwise XOR operator works. The rule for XOR is “one or the other, but not both.” Here is the XOR truth table:
0 xor 0 = 0
0 xor 1 = 1
1 xor 0 = 1
1 xor 1 = 0
If you step through the XOR swap with binary numbers (in place of decimal) then seeing how it works is a bit easier.
# Binary numbers
x = 01 # = decimal 1
y = 10 # = decimal 2
# swap them
x = x ^ y # 01 ^ 10 = 11 = decimal 3 (x accumulates the value of y)
y = x ^ y # 11 ^ 10 = 01 = decimal 1 (swapped!)
x = x ^ y # 11 ^ 01 = 10 = decimal 2 (swapped!)
29. &&= operator
What does the following code do, and how is it potentially helpful?
myString &&= myString + suffix
You are probably familiar with the
|| and
&& operators, the Boolean OR and Boolean AND operators. You might also be aware of the Boolean OR EQUALS operator
||= , which assigns a value to variable if it doesn't already have one. It is handy when you want to assign a default value.
a ||= 1 # If a has no value, give it a value of 1
The AND EQUALS operator works similarly, but it will assign a value only if the variable already has one. It is handy when you want to append a string (like a suffix, for example), but only if the variable already has a value.
30. Reverse the words in a string
Write a short program to reverse the order of words in the following string:
DECLARE @dwarves VARCHAR(MAX)
SET @dwarves = 'bashful doc dopey grumpy happy sleepy sneezy'
Your output should look like this:
sneezy sleepy happy grumpy dopey doc bashful
If you contrast the code for this answer with the equivalent code in other languages (most of which are one-liners) you will, I hope, come to the conclusion that T-SQL is not the best language for this kind of operation.
DECLARE @dwarves VARCHAR(MAX)
SET @dwarves = 'bashful doc dopey grumpy happy sleepy sneezy'
DECLARE @sevrawd VARCHAR(MAX)
SET @sevrawd = ''
WHILE LEN(@dwarves) > 0
BEGIN
IF CHARINDEX(' ', @dwarves) > 0
BEGIN
SET @sevrawd =
SUBSTRING(@dwarves,0,CHARINDEX(' ', @dwarves))
+ ' ' + @sevrawd
SET @dwarves =
LTRIM(RTRIM(SUBSTRING(@dwarves,CHARINDEX(' ',
@dwarves)+1,LEN(@dwarves))))
END
ELSE
BEGIN
SET @sevrawd = @dwarves + ' ' + @sevrawd
SET @dwarves = ''
END
END
SELECT @sevrawd
31. Correlated subquery
Consider the following table. This table contains a list of users, each with a reputation and a location.
CREATE TABLE [dbo].[Users](
[Id] [int] NOT NULL,
[Reputation] [int] NULL,
[DisplayName] [nchar](40) NULL,
[Location] [nchar](100) NULL,
[JoinDate] [smalldatetime] NULL
)
Write a select statement that uses a correlated subquery to obtain a list of users with a higher-than-average reputation within that user's location.
A
correlated subquery is a nested (or inner) query that references one or more values in the parent (or outer) query. In the following answer, the inner query references the location of the user from the parent query. Notice that table aliases are used to uniquely identify each table.
SELECT DisplayName, Reputation, Location
FROM Users u
WHERE Reputation >
(SELECT AVG(Reputation)
FROM Users u1
WHERE u1.Location = u.Location)
Now that you know what a correlated subquery actually is, you can write the SQL and you can casually mention its fancy name. The bonus points are all yours.
It is also worth being aware (and mentioning at the interview) that most correlated subqueries can be written using joins. For instance, you could have written the answer to this question as follows:
SELECT u.DisplayName, u.Reputation, u.Location
FROM Users u
INNER JOIN
(SELECT Location, AVG(Reputation) as AvgRep
FROM Users
GROUP BY Location) as u1
ON u.Location = u1.Location
AND u.Reputation > AvgRep
The query optimizer (most RDBMSs have one) will usually work out an optimal execution plan regardless of the presence or absence of a correlated subquery. If performance is important (it isn't always the most important thing) then you would benchmark and compare alternative queries to determine the most efficient. Very few hard-and-fast rules exist about the efficiency of correlated subqueries versus joins.
32. Which date is that?
The following two lines of SQL are supposed to insert a new row into the Users table. Assuming that this SQL worked correctly at least once (when the developer wrote and tested it) what could potentially go wrong with it, and how could you rewrite it to avoid this problem?
INSERT INTO Users (Id, DisplayName, JoinDate)
VALUES (1, 'Ted', CONVERT(smalldatetime,'12/01/2015'))
The potential problem with this SQL is that the date literal might be interpreted incorrectly. The date ‘12/01/2015’ is ambiguous because it could mean the first day of December or the twelfth day of January, depending on the active date format.
If you think that the date format on server or in a database will never change, you join a very large group of programmers to whom the inevitable is yet to happen. If it doesn't happen on the server-side, it will happen on the client-side, in a third-party component, or in some data provided by a customer. Sooner or later it will happen.
The correct handling of dates is not difficult, provided you follow a few simple rules. Foremost of these rules is that whenever you write a date literal you should use an unambiguous date format.
You can easily see the impact of different language settings in T-SQL by converting a string containing a date to a
smalldatetime as demonstrated in the following lines of SQL:
set language us_english
select CONVERT(smalldatetime,'12/01/2015') as [Date]
Output:
Changed language setting to us_english.
Date
-----------------------
2015-12-01 00:00:00
When the language is set to
british, SQL Server interprets this as a completely different date.
set language british
select CONVERT(smalldatetime,'12/01/2015') as [Date]
Output:
Changed language setting to British.
Date
-----------------------
2015-01-12 00:00:00
A date that is misinterpreted this way can be disastrous; for example it could be the expiry date of an immigration visa, or of a life insurance policy. To avoid ambiguity in date literals you should always use one of the following two formats:
// Format 1
YYYYMMDD // For a date-only (no time), notice no hyphens!
20121210 // 10th of December, 2012
19011111 // 11th of November, 1901
// Format 2
YYYY-MM-DDTHH:MM:SS // For specifying a time + date, notice the 'T'
1920-08-18T00:00:00 // 18th of August, 1920
2012-01-10T01:02:03 // 10th of Jan, 2012, at 3 seconds past 1:02am
These two formats are from the ISO 8601 standard for calendar dates, and SQL Server will always interpret these dates in a predictable way regardless of language or date-format settings. Note that you should avoid a few “close but not quite” date formats because they are also ambiguous.
YYYY-MM-DD // Ambiguous!
YYYY-MM-DD HH:MM:SS // Ambiguous! (Missing the 'T')
33. Collation order
Consider a scenario where your SQL Server database is deployed to a customer site and to an existing SQL Server instance alongside other databases that you don't control or know anything about. In that circumstance, what is potentially wrong (or perhaps missing) in thisCREATE TABLE statement, and how should you rewrite it to avoid this potential problem?
CREATE TABLE #temp
(
[Id] int identity(1,1) NOT NULL,
[Name] nvarchar(100) NULL,
[DateJoined] smalldatetime NULL
)
When a table is created, all the text columns in that table (for example,
varchar,
nvarchar, and so on) will, by default assume the same
collation as the database in which the table is created. However, the same is not true of temporary tables (indicated by the
#) which, by default, take on the collation of the
tempdb database (this is the database in which temporary tables are created by SQL Server). The collation of the tempdb database can be different to the collation of your database and this can lead to runtime errors such as “cannot resolve the collation conflict.” Depending on the nature of the problem, one solution is to add
COLLATE DATABASE_DEFAULT to all text columns when creating a temporary table.
CREATE TABLE #temp
(
[Id] int identity(1,1) NOT NULL,
[Name] nvarchar(100) COLLATE DATABASE_DEFAULT NULL,
[DateJoined] smalldatetime NULL
)
Another possible solution is to add the same collation modifier to the join clause.
SELECT * from #temp
INNER JOIN Users ON
[name]=[DisplayName] COLLATE DATABASE_DEFAULT
34. Selecting a random row from a table
Write a SELECT statement that will select a single row at random from the Users table. Assume the table has between 10 and 10,000 rows.
At least two solutions exist to this problem. The first takes advantage of the
TABLESAMPLE clause, introduced with SQL Server 2005.
SELECT TOP 1 *
FROM Users
TABLESAMPLE (1 ROWS)
This solution is not ideal for several reasons. First, the TABLESAMPLE clause works on a page level, not a row level. It will pick a random page from the table and return all rows in that page. If you want just one row (or n rows), you need to add the TOP 1 (or TOP n) clause to your select statement. Unfortunately, if you restrict the number of rows this way, then some rows might never be selected. For example, if a page contains 10 rows and you constrain your query to return just the TOP 5 rows, the last 5 rows on this page will never be selected. This is a trade-off when using the TABLESAMPLE clause.
Another problem with TABLESAMPLE is that if you have a table with just one page then TABLESAMPLE will return either all rows or no rows at all. That probably isn't what you want!
TABLESAMPLE is good for obtaining an approximate number of rows from a large table, but poor at obtaining a single row at random from smaller tables.
The limitations of TABLESAMPLE are by design, and are well-described in the official documentation on MSDN. The documentation includes an alternative (as follows) for when you “really want a random sample of individual rows.”
Here is the documented suggestion for obtaining a 1 percent sample of random rows from a table called
SalesOrderDetail:
SELECT * FROM Sales.SalesOrderDetail
WHERE 0.01 >= CAST(CHECKSUM(NEWID(), SalesOrderID)
& 0x7fffffff AS float)
/ CAST (0x7fffffff AS int)
This query is worth a closer look because it contains a few useful techniques. First, notice that the CHECKSUM function takes two arguments: the built-in function NEWID() and the value of SalesOrderID for each row. Basing a checksum on these values ensures that a unique checksum value will be generated for each row in the table.
The second thing to notice is how this query converts this unique value to a number between 0 and 1. The CHECKSUM function returns an INT in the range -231 to 231. This INT is converted to a positive number by discarding the sign-bit (bitwise AND with 0x7fffffff) and then casting as a float. The final step of dividing by 0x7fffffff results in a number between 0 and 1. If this number is less than or equal to 0.01 (1%), then the row is included in the selected results. This query relies on a uniform distribution of random numbers.
If a single row (or a fixed number of rows) is required then this query can be greatly simplified as follows:
SELECT TOP 1 * FROM Users
ORDER BY NEWID()
This is the simplest method to select one row at random and it is the answer most interviewers will be looking for.