
Chapter 6
Code Quality
Most technical interviewers have a view on what is important in software development. They universally agree that code quality is vitally important, but the exact definition of quality is a bit less clear. Some put code clarity ahead of efficiency, and some put efficiency first. Others say that correctness is paramount, with clarity and efficiency vying for second place, and some interviewers say none of those things matter if the customer is unhappy.
At another level you will find some interviewers concerned with the layout and consistency of code. Choosing good names for variables and classes is a common concern, and many put their trust in the SOLID principles (if you've not heard of SOLID it is explained later in this chapter).
In this chapter you will find questions covering all these angles. These are the questions that technical interviewers use to assess your understanding of what code quality means. It's an opportunity to demonstrate some important things, specifically that you:
- Can read and comprehend someone else's code
- Can spot potentially bad code
- Have a view on what constitutes good code
- Can articulate reasons why code is good or bad
Programmers with any experience will recognize the importance of the first point—reading and comprehending code written by someone else. As a programmer, relatively rarely are you asked to write a lot of code from scratch. Far more commonly, you're asked to maintain or add features to an existing code base. Reading and understanding code, therefore, is a vital skill that every programmer must acquire.
As an interviewer, and as a programmer with strongly held views about code quality, it always surprises and disappoints me when a programmer cannot find fault with code that is clearly substandard. Many interviewers will routinely produce sample code at the interview and ask, “What's wrong with this?” The questions and answers provided in this chapter will ensure you are prepared for this style of questioning.
A natural follow-up to the question, “What's wrong with this code?” is “What could you do to improve it?” In some ways this question is as important as spotting bad code in the first place. After all, the interviewer will reason that, if you, the interviewee, can't improve bad code then you're not going to be much help when you do find it. This is not a new idea.
“It is easier to criticize than to correct our past errors.”
—Titus Livius, written sometime between 27 and 25 BC
Finally, after you have identified poor code and formulated ideas about how you might improve it, you need to communicate those ideas. In the same way that identifying poor code but not being able to improve it is of little value, being unable to articulate your opinions is equally unhelpful. Your thoughts might be golden, but they are worthless at the interview unless you can communicate them clearly to the interviewer.
Writing Clear Code
The cost of unclear code is enormous. It costs the programmer at every step—from the initial struggle to make the unclear code compile and work correctly, to the needless complications it causes when testing and debugging, to the abject misery it causes throughout the long years of product maintenance. If you think I'm exaggerating, talk to any experienced maintenance programmer. All this extra effort and stress translates to extra cost for the product owner or the business that relies on or sells that product. The end user of such a product suffers from bugs and quirks caused by the unclear code. Unclear code adds a real and quantifiable cost that is ignored at peril.
If you accept—and I believe you should—that writing code is a special form of communication, where ideas and algorithms are communicated from a programmer to a machine and—in some ways more importantly—to other programmers, then understanding how unclear code comes into existence is easy. It's a basic human failing. If you replace the word code with communication (as in unclear communication) then all the reasons you can think of that contribute to poor communication, such as laziness, misapprehension, and a poor grasp of the language—all these apply equally well to unclear code.
Your job during the interview is to demonstrate that you can recognize unclear code and that you can write clear code. It's all about good communication.
“As simple as possible but not simpler”
—attributed to Albert Einstein
The idea of being as simple as possible but not simpler applies perfectly here; you want the code to be correct and useful, and ideally you want it to be extensible and flexible, but not at the expense of clarity. You should write the minimum code that is necessary to satisfy all the requirements and still be easy to understand. You must avoid sacrificing simplicity for the sake of some hypothetical future requirement.
Of course, if the requirement is more than hypothetical, if you can realistically anticipate a future requirement that forces a complication upon the immediate solution, and you can justify it to yourself (and to whomever reviews your code), then go for it. Don't be too disappointed, however, when the requirement never eventuates and the code remains forever more difficult to maintain than it really ought to have been.
Of course, it is important when designing a system to create abstractions of the problem space, and to generalize the solution so that it can apply to more than just the immediate problem. The danger lies in going too far and (to pick just one unfortunate outcome), ending up with many layers of abstraction that serve no immediate purpose, existing only to satisfy some theoretical future requirement or constraint that might never eventuate. The Extreme Programming movement dismisses this kind of needless embellishment with the acronym YAGNI, “You ain't gonna need it.”
Sometimes after a long struggle to get an algorithm working correctly, it might seem appropriate that the resulting code should reflect the effort that went into it. Or, to put it in the words of an anonymous cynic:
“If it was hard to write it should be hard to read.”
—Anonymous
That idea is wrong. The next programmer will not thank you. It is much better, and frankly it is good coding manners to spend a little more time making the intent as obvious as possible.
Writing Expressive Code
Expressiveness in code is the quality of being able to convey a lot of information (or intention) in a small amount of code. Expressive code is often succinct—a quality that can help readability in some cases and hurt it in others. One way to think about expressiveness in code is to compare it to your English vocabulary. As your vocabulary grows, you become aware of words that are packed with more meaning. Instead of speaking in long rambling sentences, you can now speak more efficiently, saying more with less. The drawback is that sometimes when you use these words, other people won't understand them. From your point of view, you're communicating more effectively, but from their point of view you're using needlessly complicated words.
Your programming vocabulary is exactly the same. As your proficiency grows, you will tend to take advantage of advanced language or framework features. These advanced features will seem needlessly complicated to the less experienced programmer.
So what is the answer: Should you write code in baby-talk, or should you write code in such a concentrated form that only experts will understand it?
The answer is to write for your audience. A programmer's audience consists of the maintenance programmers who will follow. If you don't know who that might be, then write with some restraint. Think of your own learning experience and show the programmers that follow you some consideration; they may not be as expert as you are. Add code comments where helpful, avoid the tersest expressions, and instead favor simple, clear constructs.
Measuring Efficiency and Performance
Efficiency can be measured in a number of ways. When programmers talk about the efficiency of a function they may be thinking of one or more things, including:
- Speed of function execution; that is, time complexity
- Working-space requirements
- Avoiding needless steps in an algorithm
- The effort required to develop and support the function
- All of the above
As a well-rounded programmer, you should be aware of the different ways that efficiency can be measured. At a standard programming interview you will rarely be quizzed on how much developing a bit of code might cost (in money terms), but you will often be assessed on your ability to assess and compare the efficiency of two alternative functions in terms of time and space complexity. This is particularly true in companies that develop leading-edge software, where performance might be the key to the next generation of solutions in a given domain.
Big-O notation
If you have been formally educated in computer science then the concepts of time-complexity, space-complexity, and big-O notation won't be new to you. But if, like many practicing programmers, you've learned your skills on the job then this book might be the first time you've ever heard of these ideas. Don't be put off by the necessary mathematical references; you don't need an advanced degree to grasp the concepts.
In big-O notation the O stands for order, and n denotes the size of input given to a function. Big-O is shorthand for describing the performance classification of a function in terms of the number of steps it can be expected to take relative to the size of its input. You might, for example, say function A is O(n²); it takes on the order of n² steps to execute.
Slightly more formally, big-O notation characterizes functions according to the asymptotic upper bound of their performance growth rate. Functions that always perform a fixed number of steps (regardless of how long they actually take) are said to perform in constant time or O(1) time. Functions that perform a number of steps in direct proportion to the size of their input are said to take linear time or O(n) time.
Note that inputs in this context are not necessarily supplied to a function as arguments; they may be read from a database or some other resource pool.
The following are some of the most common classifications, shown in order from best (usually fastest) to worst (usually slowest). Note that the scale of each diagram is far less important than the rate of growth shown.
Constant, O(1)
If a function always performs in the same amount of time, regardless of input, it runs in O(1) time, as shown in Figure 6.1. This is not to say that a function that takes constant time will always take the same amount of time, but that the number of steps it performs (and hence the time it takes) will never grow beyond a constant maximum.
Here is an example:
int constantTime(int j, int k) {
if ((j+k) % 2 == 0)
return 0;
int m = j * k;
int n = m - 42;
return Math.Max(n,0);
}
Figure 6.1 Constant time

Logarithmic, O(log n)
Functions that take logarithmic time are usually not much slower than those that take constant time, as illustrated in Figure 6.2. A binary search takes time O(log n), as do most functions that eliminate half of the input at each stage of processing.
Figure 6.2 Logarithmic time

Linear, O(n)
If a function will always take time in direct proportion to the size of its input then it is said to take time O(n), as shown in Figure 6.3. Here is an example:
int linearTime(int j, int k) {
if ((j+k) % 2 == 0)
return 0;
int m = j * k;
int n = m - 42;
for (int index = 0; index < (m + n); index++)
if (index % 1337 == 0)
return index;
return Math.Max(n,0);
}
Figure 6.3 Linear time
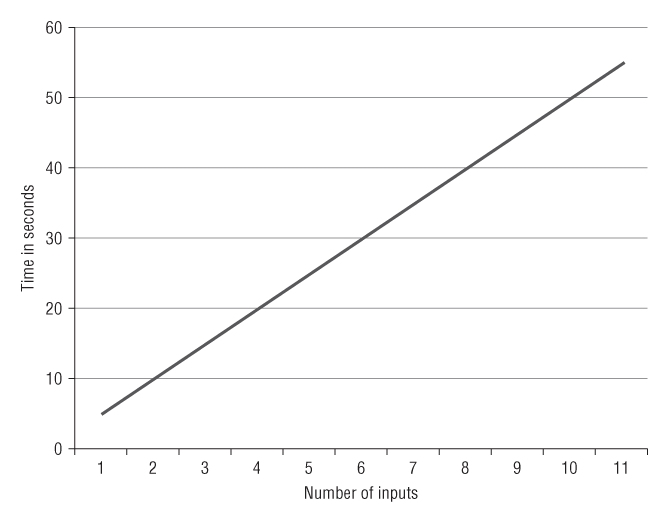
Quadratic, O(n²)
Functions that take quadratic time generally contain two nested loops over the input, as shown in Figure 6.4 and in the following code example:
int quadraticTime(int[] n) {
int result = 0;
for (int i = 0; i < n.Length; i++)
for (int j = 0; j < n.Length; j++)
result += n[i] + n[j];
return result;
}
Figure 6.4 Quadratic time

Using big-O
Big-O notation is useful when comparing the theoretical performance of alternative functions. It abstracts away the practical difficulties of comparing performance and it intentionally ignores the fixed overhead of a function. For example, it ignores the time a function might require to initialize a hash table prior to processing its input. Big-O focuses squarely on the most significant factor that will affect the performance of a function and effectively ignores the rest.
When considering the practical implications of time complexity, you must be familiar with the range of inputs a function will called upon to process. Sometimes the case, usually when inputs are small, is that the big-O classification of two functions suggests relative performance that is contrary to the actual, measured performance. This is counterintuitive and might seem wrong, but consider the performance of two functions, as shown in Figure 6.5.
Figure 6.5 Function performance

Function A takes time O(n3), which is theoretically slower than function B, which takes time O(n²). As you can see, for small values of n, function A is faster, the opposite of what their big-O classifications would suggest.
Measure performance
The most common reason for measuring the performance of a function or procedure is so it can be optimized. If you don't have a measurement, then you won't know (except perhaps theoretically) whether your “improvement” is an optimization or a pessimization.
Wherever possible, you should use CPU time and measures of I/O rather than elapsed (wall-clock) time. CPU time is the time spent by the processor in serving your code, and excludes time spent waiting for I/O operations and other delays caused by the operating system as it multitasks. Measuring a function by timing it with a watch on your wrist is the least sophisticated and most error-prone way of timing a function, and should be done only as a last resort.
Consider context
When considering the real-world performance of a function, context is everything. Will your function be called exactly once per day, or millions of times per hour? What are the typical scenarios that will lead to your function's being called? Will users be waiting for it to finish, or will it be a background process with no dependencies? You want to avoid the embarrassment of benchmarking a function on your machine, declaring it fit for purpose, and then releasing it, only to find everything grinds to a halt and your users have formed an angry mob.
Have a goal
The optimization of a function must be done with a goal in mind. Before you begin measuring and tweaking a function, you must determine exactly what will constitute acceptable performance. Optimization can be fun in a nerdy kind of way, but you won't want to be doing it forever. You need to know the point at which you have finished. If you don't know how to determine performance targets then you should involve your users. Ask them how quickly they expect operations to run, what benchmarks they have (such as other, comparable systems they've used), and so on.
Measure more than once, take an average
When measuring, you should run a function many times and derive an average run time. If you run a function and measure its performance just once then you have only a tiny glimpse of how the function might perform. More often than not you will find that measurements vary, sometimes markedly, depending on what else is running on the machine at the time. By taking many measurements and calculating an average you reduce the significance of these variations.
Divide and conquer
When users report a performance problem, it is usually not obvious where the bottleneck lies. They might complain about the time it takes to produce a monthly report, but you won't know from that complaint whether the performance problem lies in the report itself, or the back-end database, the network, and so on. The problem might be a combination of all these layers.
As a rule, you should first partition the problem and measure each of these partitions in isolation. Sometimes this involves writing a test harness to break the interdependence of components and run each part in isolation.
After you see where the majority of time is being spent, you can progressively drill down until you have something concrete that you can improve.
Try the easy things first
Quite often, performance problems are due to something obvious being missed. Does the table have appropriate indexes? Does an unnecessary dependency exist that can be eliminated? Is the server simply overloaded?
Before getting down to any detailed analysis, consider the obvious potential problems. You can resolve many apparently difficult problems by fixing the environment (the server, database, and so on) rather than the code.
Use a profiler
Developers today are fortunate to have many excellent tools available for profiling an application to home-in on performance bottlenecks. It was once the case that the best a developer could do was to introduce logging code and then somehow analyze the log for clues.
Today, a good profiler will let the developer evaluate the performance profile of an application without introducing any logging code. A profiler can show the programmer details of how memory is allocated in an application, and how much time is spent in the parts of the application. It can show object creation and (hopefully) object destruction (if not, you could have a memory leak).
Understanding What “Modular” Means
I recall the first time I was asked to review some code written by another programmer. The most serious problem I noticed was that the programmer had written one enormous subroutine—it must have been many hundreds of lines. At the time I was relatively inexperienced, but I knew this practice wasn't good. I suggested to the programmer that he (it was a he) should break the long subroutine into smaller, more modular subroutines. I assumed he knew what I was talking about.
He didn't.
He had broken the large subroutine into smaller subroutines, but he did it like this:
public void mysubroutine() {
// about 40 lines of code...
mysubroutine1();
}
public void mysubroutine1() {
// 40 more lines of code...
mysubroutine2();
}
public void mysubroutine2() {
// 40 more lines of code...
mysubroutine3();
}
public void mysubroutine3() {
// 40 more lines of code...
}
I remember asking why he had broken the subroutines into chunks of about 40 lines each. He said that was the most he could see on his screen at one time. To my shame, I gave up at that point.
Although this story was, I hope, a rare and unusual take on what “modular” means, it does illustrate the point that programmers don't necessarily understand what modular means.
Here are some characteristics of a modular design:
- Functions and subroutines are small rather than big.
- Each function has a single, specific purpose.
- Functions can be reused in a number of ways.
- Functions are well-named so that the purpose of each one is obvious.
- Functions have little or no side-effects outside the function.
- Functions make little or no assumptions about the state of a system in which they are run.
Note that I've used the word function to describe these attributes, but they apply equally to methods, classes, and code libraries.
Understanding the SOLID principles
SOLID is an acronym that stands for five widely accepted principles of object-oriented programming and design. These principles are:
- Single Responsibility Principle
- Open/Closed Principle
- Liskov Substitution Principle
- Interface Segregation Principle
- Dependency Inversion Principle
A recurring theme throughout the SOLID principles is the avoidance of dependencies. It makes intuitive, practical, and theoretical sense to minimize class dependencies: the more things you depend on, the greater the chance something will go wrong.
Single Responsibility Principle
The Single Responsibility Principle (SRP) states that a class should have exactly one responsibility. It should have exactly one reason (or one class of reasons) that cause it to be changed. If you have ever tried to modify a tangled mass of code in which tangential concerns have been mixed up together, where a seemingly innocuous change has unexpected and disastrous consequences, then you might have been a victim of code that ignores this principle.
To illustrate the point, a violation of this principle might look like this:
var myReport = new CashflowReport();
formatReportHeader(myReport);
printReport(myReport);
void formatReportHeader(Report report) {
report.Header.Bold = true;
if (report is CashflowReport && report.Content.Profit < 10000) {
SendAlertToCEO(“Profit warning!”);
}
}
All well and good—until the CEO asks for the report header to be reset to the default format, without any bold bits. The maintenance programmer (maintenance programmers are usually harassed and short of time) looks at the first few lines of code, and because it appears to be well-structured she innocently deletes the line that calls formatReportHeader. The code now looks like this:
var myReport = new CashflowReport();
printReport(myReport);
void formatReportHeader(Report report) {
report.Header.Bold = true;
if (report is CashflowReport && report.Content.BankBalance < 1000) {
SendAlertToCEO(“Profit warning!”);
}
}
Testing confirms that the report header is no longer emboldened, so the modified system is released to the customer. In this disastrous scenario, warnings about a low bank balance are no longer sent to the CEO and the business quickly becomes insolvent.
I've provided an over-simplified and artificial example that illustrates the point. In real projects it won't be anywhere near as obvious that a small change in one area of the system might affect an unrelated but critical feature in an unrelated part of the system. It isn't hard to see why some programmers develop superstitions about the systems they maintain. Don't touch the Frobbit module. The last programmer who changed it was blamed for the extinction of pink-frilled lizards.
Another difficulty many programmers have with following the SRP lies in deciding what single responsibility means. This definition can be hard to pin down. You can take a broad view that a single responsibility refers to a group of related business processes (such as invoicing, for example) or you can take a stricter view that invoicing is far too broad and should be broken down in its constituent parts, with each part designated as a responsibility. How far you go depends on your stamina and tolerance. Cross-cutting concerns also muddy the water: Is it consistent with SRP to call logging routines from an invoicing class? (No it isn't, but everyone does it.)
Like many principles, the theory is easier to grasp than the practice. In practice, you must rely on experience and common sense. You really shouldn't remove all your logging from a class, that would be counterproductive, but you really do want to avoid mixing up code for formatting a report with code for enforcing business logic.
Open/Closed Principle
The Open/Closed Principle (OCP) states that a class (or function) should be open for extension but closed for modification. This principle attempts to counter the tendency for object-oriented code to become fragile or easily broken, when base classes are modified in ways that break the behavior of inheriting (child) classes.
It hasn't escaped my attention that one of the key benefits touted for object-oriented programming is the ease with which you can change an entire inheritance chain through modification of the base class. If all your animals (textbook examples of inheritance for some reason seem to favor animals) are to be endowed with a new “panic” behavior, for instance, then you simply add a panic method to the base Animal class. All animals can now panic, even the ones that carry towels and that should therefore be immune to this kind of emotional distress.
In a nutshell, adhering to the OCP means that when adding new behavior you should leave base classes alone and instead create new, inheriting classes, adding behavior to these instead of the base class, and thereby avoiding the problem of unintended consequences for classes that inherit from the same base class.
Liskov Substitution Principle
One of the nice things about inheriting from a class is that you can pass this new class to an existing function that has been written to work with the base class, and that function will perform its work just as if you had passed an instance of the base class.
The Liskov Substitution Principle (LSP) is intended to keep that happy working relationship between classes and functions alive and well.
The LSP is similar to the Open/Closed Principle. Both the OCP and the LCP imply that you should avoid modifying the behavior of a base class, but the LSP forbids modification of that behavior through the mechanism of inheritance. LSP states that if type S inherits from type T then both T and S should be interchangeable in functions that expect T.
In other words, if you follow the LSP, you should be free to substitute a child class in a function that expects to deal with the base class. If you can't, you're looking at a violation of the LSP.
But wait! Doesn't this principle undermine one of the key benefits of object-oriented programming? Isn't it a feature of object-oriented programming that you can modify the behavior of a class through inheritance?
Indeed it is. However, experience tells us that changing the behavior of a class in many cases leads to problems elsewhere in a code base. It is another example of how you should strive to minimize dependencies of all kinds in the interest of writing robust and maintainable software.
In many cases, instead of inheritance, programmers should create classes that are composed of base classes. In other words, if the programmer wants to use the methods or properties of a class, she can create an instance of that class rather than inheriting from it. By avoiding inheritance, the programmer also avoids violation of the LSP. Functions that expect to deal with a certain base class are guaranteed to remain unaffected by the new class, and the code base of an application is therefore more robust and less likely to break.
In C#, you can prevent the inheritance of a class by using the sealed keyword. In Java, you can use the final keyword.
Interface Segregation Principle
The Interface Segregation Principle (ISP) is very simple. It says to avoid writing monstrous interfaces that burden classes with responsibilities they don't need or want. You should instead create a collection of smaller, discrete interfaces, partitioning interface members according to what they concern. Classes can then pick and choose what they implement rather than having to swallow all or nothing.
Here is one of these monstrous interfaces:
public interface IOneInterfaceToRuleThemAll {
void DoThis();
void DoThat();
void GoHere();
void GoThere();
bool MyFavoriteTogglyThing {get; set;}
string FirstName {get; set;}
string LastName {get; set;}
}
Here is a nicer alternative; a collection of interfaces that segregate different areas of concern:
public interface IActionable {
void DoThis();
void DoThat();
}
public interface IMovable {
void GoHere();
void GoThere();
}
public interface IToggly {
bool MyFavoriteTogglyThing {get; set;}
}
public interface INamed {
string FirstName {get; set;};
string LastName {get; set;}
}
Nothing prevents the programmer from creating a class that implements all of these interfaces, but with smaller interfaces the programmer is free to implement just those parts she needs, ignoring the irrelevant parts. The programmer can now create one class that moves and toggles, and another class that performs actions and has a name.
Dependency Inversion Principle
The Dependency Inversion Principle (DIP) says to “depend upon abstractions, not upon concretions.” Somewhat surprisingly it turns out that “concretions” is in fact a real word (I checked). What this principle means is that instead of writing code that refers to actual classes, you should instead write code that refers to interfaces or perhaps abstract classes.
This is consistent with writing code that has minimal dependencies. If class A instantiates concrete class B, then these two classes are now bound together. If instead of a concrete class you rely on an interface IB, then the concrete class that implements IB can (in theory) be switched out for a different class through dependency injection.
In the following code, class A has a dependency on class B:
class B
{
// ...
}
class A
{
public void DoSomething()
{
B b = new B(); // A now depends on B
}
}
Here is the same code, rewritten to depend on an interface IB rather than the concrete class B:
interface IB
{
// ...
}
class B : IB
{
// ...
}
class AlternativeB : IB
{
// ...
}
class A
{
public void DoSomething(IB b)
{
// b can be either B or AlternativeB
}
}
Incidentally, but very conveniently, now that you are free to substitute any class you choose, it becomes trivial to substitute fake or mock classes when writing unit tests, avoiding the overhead of classes that aren't needed for the sake of the test.
A whole class of tools exists for introducing dependency injection to legacy code. If programmers writing this legacy code had created dependencies on interfaces rather than on concrete classes, we wouldn't need these tools.
Avoiding Code Duplication
A respected software architect of my acquaintance once told me—I'm sure it was tongue in cheek—that a valid form of code reuse is to copy and paste code throughout a code project. I probably gave him the reaction he was expecting; I'm easily excited on this topic.
Code reuse, for the record, is achieved through writing code that is modular and suitably generic. It is not achieved through copy and paste. Copy and paste means code duplication, one of the nastier problems you can face as a programmer.
Why is it so awful? It's awful because it injects latent problems into your code project. You won't find them at compile time, and you won't find them through initial testing. The code will work at first, but now you have a bear-trap, set with jaws agape, waiting for the maintenance programmer.
Have you ever fixed a bug in an application only to find that the exact same bug exists in many places other than the one you fixed? That's code duplication in action. To the user it makes you appear careless or dim-witted.
Here's an example related to the adjustment of meeting times:
if (start.Hour == 8)
PostponeOneHour (start);
if (start.Hour == 6)
PostponeFiveHours (start);
void PostponeOneHour (DateTime start) {
var time = new TimeSpan(1,0,0);
start.Add(time);
// Further delay meetings that start before ten-past
if (start.Minute <= 10) {
time = new TimeSpan(0,5,0);
start.Add(time);
}
}
void PostponeFiveHours (DateTime start) {
var time = new TimeSpan(5,0,0);
start.Add(time);
// Further delay meetings that start before ten-past
if (start.Minute <= 10) {
time = new TimeSpan(0,5,0);
start.Add(time);
}
}
In this example I've invented some dubious business rules for when meetings should start; meetings scheduled for 8 a.m. should be delayed at least one hour, and meetings scheduled for 6 a.m. should be delayed at least five hours (the delay for early birds is suitably punitive). Meetings should be further delayed by some minutes if they start in the first 10 minutes past the hour.
Code duplication is rife in this example, but the most glaring duplication is of the two nearly identical methods: one that adds five hours and another that adds one hour. These two methods could easily be combined into one:
void Postpone (DateTime start, int delayHours) {
var time = new TimeSpan(delayHours,0,0);
start.Add(time);
// Further delay meetings that start before ten-past
if (start.Minute <= 10) {
time = new TimeSpan(0,5,0);
start.Add(time);
}
}
If you permit duplication like this you commit yourself (and all future maintenance programmers) to duplicating their efforts. Instead of fixing a bug or adding a feature in one method, now everyone must fix that bug or add that feature in two methods. Not only have you made yourself more work, you now have twice the opportunity to make a mistake.
Suppose you decided that the rule about not starting before ten-past should be removed. You delete the relevant lines of code from the PostponeOneHour method, and also from the PostponeFiveHours method—if you remember it exists! If you don't remember, you've just sprung the trap.
Imagine these methods are contained within a much larger code base than shown in this example, and you glimpse the potential scale of the problem. In a large code base it is just a matter of time before a maintenance programmer forgets or doesn't realize that this logic has been implemented in two places. Inevitably you will have inconsistency, and you will have users who think their programmers are lazy or feeble-minded.
QUESTIONS
Code quality is one of the more difficult things to detect with automated code review tools. You can find some things, sure, but the best code-review tool I know of is the gaze of a skilled programmer.
Cast your gaze over the sample code in these questions, and see what you think could be improved:
enum Bool
{
True,
False,
FileNotFound
};
public class Person : PersonCollection
{
// [Class definition removed…]
}
if (new[] { height, width }.Any(c => c != 0))
{
// Do something with the non-zero value(s) ...
}
for ( int i=0 ; i < MyControl.TabPages.Count ; i++ )
{
MyControl.TabPages.Remove (MyControl.TabPages[i] );
i--;
}
if (conditionExists()) {
doSomething();
myTimer.Interval = 86400000;
} else {
myTimer.Interval = 21600000;
}
myTimer.Start();
bool getAnswerLength(int questionId) {
return ( (string[]) answers[questionId]).Length;
}
bool stringArraysAreEqual(string[] a, string[] b) {
if (a.Length != b.Length) return false;
for (int i = 0; i < a.Length; i++)
if (!a[i].Equals(b[i])) return false;
return true;
}
bool function ReticulateSplines(List<Splines> splines) {
foreach (var spline in splines) {
var length = EvaluateLength(spline.Length);
if (length > 42) {
var page = RetrievePageFromPublicInternet(spline.WebPage);
if (page.RetrievedOk)
Reticulate(spline, page);
}
Reticulate(spline)
}
return false;
}
if (
long.TryParse(ds.Tables[0].Rows[0][0].ToString(), out committeId)
)
{
committeId = long.Parse(ds.Tables[0].Rows[0][0].ToString());
}
if (this.Month == 12)
{
return true;
}
else
{
return false;
}
IF P_TYPE IS NOT NULL THEN
SELECT MEM.BODY_ID AS BODYID,
MEM.BODY_NAME AS BODYNAME,
AD.ONE_LINE_ADDRESS AS ONELINEADDRESS,
AD.TELEPHONE AS TELEPHONE,
MEM.ACTIVE AS ACTIVE
FROM
MEM_BODY MEM, BODY_ADDRESS_DETAIL AD
WHERE MEM.BODY_ID = AD.BODY_ID(+)
AND
MEM.BODY_TYPE LIKE UPPER(P_TYPE) || ‘%')
ORDER BY BODYNAME;
ELSE
SELECT MEM.BODY_ID AS BODYID,
MEM.BODY_NAME AS BODYNAME,
AD.ONE_LINE_ADDRESS AS ONELINEADDRESS,
AD.TELEPHONE AS TELEPHONE,
MEM.ACTIVE AS ACTIVE
FROM
MEM_BODY MEM, BODY_ADDRESS_DETAIL AD
WHERE MEM.BODY_ID = AD.BODY_ID(+)
ORDER BY BODYNAME;
END IF;
if (length == 1)
{
return 455;
}
else if (depth == 2)
{
return 177;
}
else if (depth == 3)
{
return 957;
}
else if (depth == 4)
{
return 626;
}
else if (depth == 5)
{
return 595;
} else if (depth == 6)
{
return 728;
}
public enum SwissArmyEnum
{
Create,
Read,
Update,
Delete,
Firstname,
Lastname,
Dateofbirth,
Statusok,
Statuserror,
Statusfilenotfound,
Small,
Medium,
Large
}
public bool StrangeFunction(int n)
{
for (int i = 0; i <= 13; i++)
{
if ((i == 1) || (i == 3) || (i == 5)
|| (i == 5) || (i == 7) || (i == 9)
|| (i == 11))
{
return true;
}
}
return false;
}
public interface IDateRange
{
DateTime? Start { get; set; }
DateTime? End { get; set; }
}
ANSWERS
enum Bool
{
True,
False,
FileNotFound
};
public class Person : PersonCollection
{
// [Class definition removed…]
}
if (new[] { height, width }.Any(c => c != 0))
{
// Do something with the non-zero value(s) ...
}
if (new[] { height, width }.Any(c => c != 0))
if (new[] { height, width }.Any(c => c != 0))
if (new[] { height, width }.Any(c => c != 0))
{
// Do something with the non-zero value(s) ...
}
if (height != 0 || width != 0)
{
// Do something with the non-zero value(s) ...
}
for ( int i=0 ; i < MyControl.TabPages.Count ; i++ )
{
MyControl.TabPages.Remove (MyControl.TabPages[i] );
i--;
}
“Don't monkey with the loop index”
—Steve McConnell, Code Complete 2
foreach (var t in MyControl.TabPages)
{
// ...
}
while(MyControl.TabPages.Count > 0)
{
MyControl.TabPages.Remove(MyControl.TabPages[0]);
}
while(MyControl.TabPages.Count > 0)
{
MyControl.TabPages.RemoveAt(0);
}
MyControl.TabPages.Clear();
if (conditionExists()) {
doSomething();
myTimer.Interval = 86400000;
} else {
myTimer.Interval = 21600000;
}
myTimer.Start();
myTimer.Interval = 86400000; // 24 hours, in milliseconds
myTimer.Interval = 21600000; // 6 hours, in milliseconds
myTimer.Interval = 14400000; // 6 hours, in milliseconds
const int FOUR_HOURS_IN_MS = 14400000;
const int SIX_HOURS_IN_MS = 21600000;
const int TWENTYFOUR_HOURS_IN_MS = 86400000;
if (conditionExists()) {
doSomething();
myTimer.Interval = TWENTYFOUR_HOURS_IN_MS;
} else {
myTimer.Interval = FOUR_HOURS_IN_MS;
}
const int FOUR_HOURS_IN_MS = 4 * 60 * 60 * 1000; const int SIX_HOURS_IN_MS = 6 * 60 * 60 * 1000; const int TWENTYFOUR_HOURS_IN_MS = 24 * 60 * 60 * 1000;
const int ONE_HOUR_IN_MS = 60 * 60 * 1000;
const int FOUR_HOURS_IN_MS = 4 * ONE_HOUR_IN_MS; const int SIX_HOURS_IN_MS = 6 * ONE_HOUR_IN_MS; const int TWENTYFOUR_HOURS_IN_MS = 24 * ONE_HOUR_IN_MS;
const int ONE_HOUR_IN_MS = 60 * 60 * 1000; // 60 min * 60 sec
if (conditionExists()) {
doSomething();
myTimer.Interval = 24 * ONE_HOUR_IN_MS;
} else {
myTimer.Interval = 4 * ONE_HOUR_IN_MS;
}
myTimer.Start();
bool getAnswerLength(int questionId) {
return ( (string[]) answers[questionId]).Length;
}
bool stringArraysAreEqual(string[] a, string[] b) {
if (a.Length != b.Length) return false;
for (int i = 0; i < a.Length; i++)
if (!a[i].Equals(b[i])) return false;
return true;
}
bool function ReticulateSplines(List<Splines> splines) {
foreach (var spline in splines) {
var length = EvaluateLength(spline.Length);
if (length > 42) {
var page = RetrievePageFromPublicInternet(spline.WebPage);
if (page.RetrievedOk)
Reticulate(spline, page);
}
Reticulate(spline)
}
return false;
}
if (
long.TryParse(ds.Tables[0].Rows[0][0].ToString(), out committeId)
)
{
committeId = long.Parse(ds.Tables[0].Rows[0][0].ToString());
}
ds.Tables[INVOICE_TABLE].Rows[0][COMMITTE_ID]
if (this.Month == 12)
{
return true;
}
else
{
return false;
}
if (this.Month == 12)
if (this.Month == DECEMBER)
if (this.Month == 12)
{
return true;
}
else
{
return false;
}
return (this.Month == 12);
IF P_TYPE IS NOT NULL THEN
SELECT MEM.BODY_ID AS BODYID,
MEM.BODY_NAME AS BODYNAME,
AD.ONE_LINE_ADDRESS AS ONELINEADDRESS,
AD.TELEPHONE AS TELEPHONE,
MEM.ACTIVE AS ACTIVE
FROM
MEM_BODY MEM, BODY_ADDRESS_DETAIL AD
WHERE MEM.BODY_ID = AD.BODY_ID(+)
AND
MEM.BODY_TYPE LIKE UPPER(P_TYPE) || ‘%')
ORDER BY BODYNAME;
ELSE
SELECT MEM.BODY_ID AS BODYID,
MEM.BODY_NAME AS BODYNAME,
AD.ONE_LINE_ADDRESS AS ONELINEADDRESS,
AD.TELEPHONE AS TELEPHONE,
MEM.ACTIVE AS ACTIVE
FROM
MEM_BODY MEM, BODY_ADDRESS_DETAIL AD
WHERE MEM.BODY_ID = AD.BODY_ID(+)
ORDER BY BODYNAME;
END IF;
IF P_TYPE IS NOT NULL THEN
SELECT MEM.BODY_ID AS BODYID,
MEM.BODY_NAME AS BODYNAME,
AD.ONE_LINE_ADDRESS AS ONELINEADDRESS,
AD.TELEPHONE AS TELEPHONE,
MEM.ACTIVE AS ACTIVE
FROM
MEM_BODY MEM, BODY_ADDRESS_DETAIL AD
WHERE MEM.BODY_ID = AD.BODY_ID(+)
AND
MEM.BODY_TYPE LIKE UPPER(P_TYPE) || ‘%')
ORDER BY BODYNAME;
ELSE
SELECT MEM.BODY_ID AS BODYID,
MEM.BODY_NAME AS BODYNAME,
AD.ONE_LINE_ADDRESS AS ONELINEADDRESS,
AD.TELEPHONE AS TELEPHONE,
MEM.ACTIVE AS ACTIVE
FROM
MEM_BODY MEM, BODY_ADDRESS_DETAIL AD
WHERE MEM.BODY_ID = AD.BODY_ID(+)
ORDER BY BODYNAME;
END IF;
SELECT MEM.BODY_ID AS BODYID, MEM.BODY_NAME AS BODYNAME, AD.ONE_LINE_ADDRESS AS ONELINEADDRESS, AD.TELEPHONE AS TELEPHONE, MEM.ACTIVE AS ACTIVE FROM MEM_BODY MEM, BODY_ADDRESS_DETAIL AD WHERE MEM.BODY_ID = AD.BODY_ID(+) AND (P_TYPE IS NULL OR MEM.BODY_TYPE LIKE UPPER(P_TYPE) || ‘%')) ORDER BY BODYNAME;
if (length == 1)
{
return 455;
}
else if (depth == 2)
{
return 177;
}
else if (depth == 3)
{
return 957;
}
else if (depth == 4)
{
return 626;
}
else if (depth == 5)
{
return 595;
} else if (depth == 6)
{
return 728;
}
var lookupTable = new Dictionary<int,int>(); lookupTable.Add(1, 455); lookupTable.Add(2, 177); lookupTable.Add(3, 957); lookupTable.Add(4, 626); lookupTable.Add(5, 595); lookupTable.Add(6, 595);
if (length == 1)
{
return 455;
}
else if (depth == 2)
{
return 177;
}
else if (depth == 3)
{
return 957;
}
else if (depth == 4)
{
return 626;
}
else if (depth == 5)
{
return 595;
} else if (depth == 6)
{
return 728;
}
return lookupTable[length];
public int countDistinctChars(string input)
{
// *This is not the ideal solution*
// Obtain the number of unique characters
// in a string by looping over the input,
// looking at each character in turn.
// If we have seen it before then ignore it,
// otherwise add it to our derived string
//
// Once we have finished, the length of the
// derived string equals the number of unique
// characters in the input string.
string distinctChars = string.Empty;
for (int i = 0; i <= input.Length; i++)
if (distinctChars.IndexOf(input[i]) < 0)
distinctChars += input[i];
// The number of characters in our derived string equals
// the number of unique characters in the input string
return distinctChars.Length;
}
static int countDistinctChars2(string input)
{
List<char> distinctChars = new List<char>();
foreach (char c in input)
if (!distinctChars.Contains(c))
distinctChars.Add(c);
return distinctChars.Count();
}
public enum SwissArmyEnum
{
Create,
Read,
Update,
Delete,
Firstname,
Lastname,
Dateofbirth,
Statusok,
Statuserror,
Statusfilenotfound,
Small,
Medium,
Large
}
public enum CRUD
{
Create,
Read,
Update,
Delete
}
public enum PersonAttributes
{
Firstname,
Lastname,
Dateofbirth,
}
public enum Status
{
Ok,
Error,
Filenotfound
}
public enum Sizes
{
Small,
Medium,
Large
}
public bool StrangeFunction(int n)
{
for (int i = 0; i <= 13; i++)
{
if ((i == 1) || (i == 3) || (i == 5)
|| (i == 5) || (i == 7) || (i == 9)
|| (i == 11))
{
return true;
}
}
return false;
}
bool isOdd = (n % 2 != 0);
bool IsOddAndLessThan13(int n)
{
return (n < 13 && n % 2 != 0);
}
bool IsOdd(int n)
{
return (n % 2 != 0);
}
public interface IDateRange
{
DateTime? Start { get; set; }
DateTime? End { get; set; }
}
Figure 6.6 Date range comparison scenarios
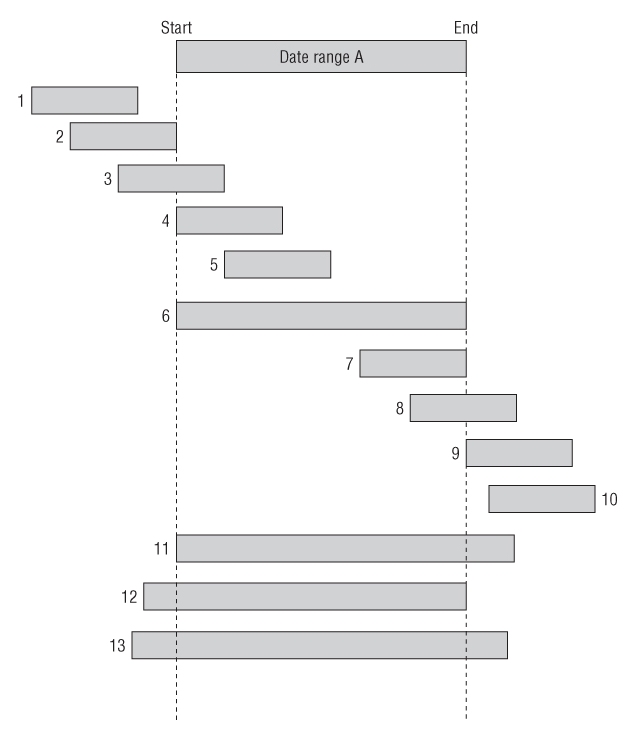
if (B.Start < A.Start && B.End < A.Start) {
return false; // Case 1, no overlap
}
if (B.Start < A.Start && B.End == A.Start) {
return true; // Case 2, overlap
}
if (B.Start < A.Start && B.End > A.Start && B.End < A.End) {
return true; // Case 3, overlap
}
if (B.Start == A.Start && B.End > A.Start && B.End < A.End) {
return true; // Case 4, no overlap
}
// and so on, etc...
(B.End <= A.Start)
(B.Start >= A.End)
if (B.End <= A.Start || B.Start >= A.End) {
return false; // dates do not overlap
} else {
return true; // dates overlap
}
return !(B.End <= A.Start || B.Start >= A.End);
DateTime? AStart = A.Start ?? DateTime.MinDate; DateTime? AEnd = A.End ?? DateTime.MaxDate; DateTime? BStart = B.Start ?? DateTime.MinDate; DateTime? BEnd = B.End ?? DateTime.MaxDate; return !(BEnd <= AStart || BStart >= AEnd);