
4. Async Tasks and Loaders
Try to understand what the author wished to do, and do not blame him for not achieving what he did not attempt.
John Updike, Picked-Up Pieces
The AsyncTask is the first Android concurrency tool to which most developers are introduced when learning the platform. It is a clever and powerful tool for certain kinds of jobs. Unfortunately, developers who have not yet discovered any other tools frequently apply it in situations for which it is completely inappropriate. Community knowledge of best practices for using AsyncTasks—and even some prejudice against using it at all—become more firmly established and more broadly distributed than they were even five years ago. Still, including the word “thread” in a question posted to the StackOverflow Android group will almost certainly cause at least one response that describes a solution involving an AsyncTask—whether it is appropriate or not.
Async Task Architecture
Conceptually, an AsyncTask is pretty simple. It is just a way to execute a segment of code on another thread. Consider Listing 4.1.
// Things that happen before the db query...
Cursor c = getContentResolver().query(
DataProvider.URI,
REQ_COLS,
COL_LAST_NAME + "=?",
new String[] { userName },
COL_LAST_NAME + " ASC" );
// Things that happen after the db query...
The code, though perhaps a little ugly, is completely correct and already does exactly what it should. The only problem is that because the database query might easily take many milliseconds, it should not be executed on the main thread. The necessary change appears so minor and so unrelated to the job of getting data from the database that it seems as though it should be possible to accomplish it with an equally minor change in the code. It would be wonderful if, in some idealized computer language, it were possible to write something like the code shown in Listing 4.2.
Listing 4.2 Idealistic Backgrounding
// Things that happen before the db query...
Cursor c;
inBackground {
c = getContentResolver().query(
DataProvider.URI,
REQ_COLS,
COL_LAST_NAME + "=?",
new String[] { userName },
COL_LAST_NAME + " ASC");
}
// Things that happen after the db query...
Sadly, there is no inBackground keyword in Java.
The idea though, is not at all unreasonable. Some languages (Swift and Scala, to name two) support constructs that look a lot like this. In those languages, the block of code following inBackground is wrapped in a language construct called a closure.
Java 8 supports closures with its new lambda expression syntax. As of the, currently un-named, Android N, Android’s Java will support them too. Suppose that Listing 4.2 were code that could be compiled by some future Android compiler. Can closures actually solve the problem? Are they sufficient?
In languages that support closures, inBackground need not be a keyword. Instead, it could be a call to a method that takes a single argument—a closure—and executes that closure on a different thread. Listing 4.2 might be rewritten as shown in Listing 4.3.
Listing 4.3 Passing a Closure to a Function
// Things that happen before the db query...
inBackground(
closure (localUserName = userName) {
getContentResolver().query(
DataProvider.URI,
REQ_COLS,
COL_LAST_NAME + "=?",
new String[] { localUserName },
COL_LAST_NAME + " ASC" );
});
// State of the query is undefined, here...
Clearly, this is still not Java. The argument to the inBackground method is, roughly, a reference to a block of code, not the result of executing it. In the listing, this is represented by the invented keyword closure.
The inBackground method runs the closure on another thread. In particular, one can imagine that it uses exactly the safe publication pattern described in Chapter 3, “The Android Application Model.” It would push the closure onto a queue from which it would be retrieved for execution by a background thread.
There are, however, several loose ends. There are restrictions on the code inside the closure (the enclosed code) that are necessary to make it behave exactly as the corresponding code did in Listing 4.1.
First (at least in this imaginary language), the code inside the closure cannot use the keywords return, break, or continue. Inside the closure those keywords have a very different meaning than they do outside it. If Listing 4.1 contained a return statement, for instance, executing it would return control to the caller. If that same return statement were wrapped in a closure and executed on a background thread it almost certainly could not do the same thing.
Another restriction is that if the code in the closure throws an exception, that exception will not abruptly terminate the code that calls the inBackground method. Just as in the case of the return statement, if the postulated inBackground method runs the closure on a different thread, the exception will unwind the background thread stack, not that of the calling thread.
A more onerous restriction is that any preconditions like variables and so on that are used in the enclosed code must have their values available from within the closure. If the closure is to behave, when executed at a completely different time and in a completely different environment, as it would have had it been executed in place, all the variables used within it must have the values they would have had when the closure was created.
Assuming normal Java naming conventions, the only symbol in the enclosed code that does not represent a constant is userName. Listing 4.3 postulates using the invented closure keyword to assign its value to a new local constant, localUserName. Obviously, things would be wildly more complex if the enclosed code referred to lots of variables, assigned any of them, or worse yet, depended on side effects in the surrounding code.
Anyone who has done any significant amount of Java development will realize that it is possible to do something similar in Java, using an anonymous class. The example from Listing 4.3 might be rewritten in compilable Java, as shown in Listing 4.4.
// Things that happen before the query...
final String localUserName = userName;
inBackground(
new Runnable () {
@Override public void run() {
getContentResolver().query(
DataProvider.URI,
REQ_COLS,
COL_LAST_NAME + "=?",
new String[]{localUserName},
COL_LAST_NAME + " ASC");
} });
// State of the query is undefined, here...
Since its creation, Java has always been able to emulate closure-like behavior. It is just that its expression is verbose and, as this example demonstrates, fairly restrictive.
The restrictions are beginning to mount up, too. This attempt at expressing in code something that is so easy to say: “just run this fragment on a different thread,” turns out to be fairly difficult. Closures, even in their historical implementation as anonymous classes are, without doubt, useful tools. It is already clear, though, that they will not support the ideal of a simple construct that executes arbitrary code, unmodified, on another thread.
There is one more issue. While left for last, it is the most obvious and troublesome. Somehow, the post-conditions—the changes in state resulting from the execution of the enclosed code—must be returned to the caller. In the example, the cursor, c, must be available to the code that follows the call to inBackground.
The whole point of this exercise has been to get a segment of code executed asynchronously. The most obvious direct consequence is that the enclosed code will no longer be executed strictly before the first line of code after the closure block. Suddenly the code that used to happen after the query and thus after the cursor had been obtained no longer does so.
The AsyncTask provides a solution to this problem.
The fact that Java 8 closures have been introduced into Android Java in the version called “N”, at the time of this writing, does not affect this discussion at all. Whether represented as anonymous classes, or implemented with the new invokedynamic instruction closures are, for all of the reasons cited here, insufficient, alone, for moving a block of code to another thread.
Async Task Basics
At its heart, an AsyncTask is just an extension of the scheme from the previous section, warts and all. Inspired by Java’s SwingWorker, it has the same goal as the previous examples—moving a segment of code to a background thread—and all the same constraints. Its sole purpose is to run a code segment on a background thread. Ideally the code segment would just be cut from its current location, pasted into the task, and the cut code replaced by a call that executes the task.
Architecturally, the AsyncTask class is the realization of a classic design pattern, the type-safe template. Its definition has one abstract method, the template method doInBackground. As is typical with the template pattern, the AsyncTask class is abstract, and the only way to use it is to create a subclass. To execute code on a background thread, create a subclass of AsyncTask and paste the code into the implementation of the doInBackground method in the subclass.
Code encapsulated in an AsyncTask is executed in the steps illustrated in Figure 4.1:
1. Create a new instance of the task. A task instance can be used only once. An attempt to run it a second time will cause it to throw an IllegalStateException.
2. Call the new instance’s execute method, passing parameters.
3. The task’s onPreExecute method is invoked on the caller’s thread. If there is setup common to all executions of the task, that setup belongs in the subclass’s implementation of onPreExecute.
4. The task’s doInBackground method is scheduled on an executor. The arguments passed to the task’s execute method (in step #1) are published into the executor thread and become the parameters to doInBackground.
5. The doInBackground method executes and completes. During its execution, a call to the task’s cancel method will mark the task as cancelled. Only a flag, cancellation does not necessarily interrupt the task or cause to terminate immediately. An exception, thrown in the doInBackground method will, however, terminate the entire task abruptly. None of the subsequent steps are executed.
6. One of the two completion methods is scheduled on the main thread. If the task’s cancel method was called at any time before the task resumes on the main thread, its onCancel method is called, with the return value from doInBackground. If cancel was not called, onPostExecute is called with the return value instead.
7. The task is now complete and should be released so that it can be garbage collected.

As the preceding exercise illustrated, the code to be executed on the background thread must have its environment passed to it and must be able to return the results of its computations. The AsyncTask class makes this explicit by using the parameters and return value of the doInBackground method. It uses Java generics to make these values type-safe.
Listing 4.5 shows the code from Listing 4.1 implemented as an AsyncTask.
Listing 4.5 A Simple Async Task
private class GetNamesTask extends AsyncTask<String, Void, Cursor> {
@Override protected Cursor doInBackground(String... userName) {
return getContentResolver().query(
DataProvider.URI,
REQ_COLS,
COL_LAST_NAME + "=?",
new String[] { userName[0] },
COL_LAST_NAME + " ASC");
}
@Override
public onPostExecute(Cursor cursor) {
onCursorReceived(cursor);
}
}
The first generic parameter to the abstract AsyncTask class (String in Listing 4.5) is the type of the parameters to execute and also to doInBackground. This is the environment passed into the enclosed code.
Note
The AsyncTask execute method uses Java varargs. It accepts multiple arguments and passes them, eventually, to doInBackground as an array. The first argument to execute, for example, is param[0] in doInBackground, the second is param[1], and so on.
For example, a subclass of AsyncTask defined like this:
class SomeTask extends AsyncTask<Uri, Void, Void>
might be called like this:
new SomeTask.execute(
Uri.parse("content://sample.com/table1")
Uri.parse("content://sample.com/table2"));
In which case, within the doInBackground method, declared as:
public void doInBackground(Uri... uris)
uris[0] is the uri content://sample.com/table1, and uris[1] is the uri content://sample.com/table2.
The only constraint is that all the arguments must be of the parameter type or one of its subtypes. Attempting to call the execute method, like this, for instance:
new SomeTask.execute(
"content://sample.com/table1"
Uri.parse("content://sample.com/table2"));
... with one String and one Uri, would cause a compiler error.
Listing 4.5 also demonstrates the AsyncTask solution to the problem of delivering the results of the background computation back to the calling code. The return from the call to doInBackground is delivered to another method, onPostExecute. onPostExecute runs on the main thread and is guaranteed to execute only after doInBackground completes. At last, there is a place to put code that can be executed, only after the background code has run. The third generic argument (Cursor in Listing 4.5) is the type of the value returned by doInBackground and therefore, the type of the parameter to onPostExecute.
Note
The second generic parameter to AsyncTask controls the type of the parameters to a progress-reporting feature implemented by the two methods publishProgress (called on the worker thread, by implementation code, from within doInBackground) and onProgressUpdate (called back on the main thread, in response).
This mechanism is nifty, but does not materially affect the behavior of the AsyncTask and thus is not discussed here. It is described in the documentation at http://developer.android.com/reference/android/os/AsyncTask.html.
Listing 4.6 Executing an AsyncTask
// Things that happen before the db query...
new GetNamesTask().execute(userName);
// ...
}
void onCursorReceived(Cursor cursor) {
// Things that happen after the db query...
}
The code that originally followed the database query in program order is now in a new method that is called from the task. Previously, program order guaranteed that this code was executed after the query. Now the AsyncTask contract guarantees it.
AsyncTask Execution
The precise implementation of AsyncTask has changed over time. Reviewing the actual code, though, both present and historical, reveals facts that are at odds with the official documentation.
The documentation claims that the AsyncTask mechanism was single-threaded, until API level 4, Donut. It seems entirely plausible that in very old versions of Android, AsyncTask (like its close relative, AsyncQueryHandler), ran on a single background thread. As early as API level 3, Cupcake, however, they were executed as they are now, on a Java thread-pool executor, the THREAD_POOL_EXECUTOR. Until fairly recently, regardless of the device, this executor used between 1 and 10 threads.
This strategy changed significantly in 2011, near the release of API Level 11, Honeycomb. Instead of submitting tasks directly to the executor, where they might be executed out of order, a new implementation of AsyncTask introduced a new executor, the SERIAL_EXECUTOR. This new executor is simply the old executor with a queue in front of it. Tasks submitted to the SERIAL_EXECUTOR for execution are pushed onto the queue, where they wait until previously submitted tasks have completed execution. When a task’s turn arrives, it is executed on an executor that is, essentially, identical to that used in Cupcake. Because of the queue, though, tasks are executed in submission order and each runs to completion before the next begins.
Without a doubt, this change was made, as the Android documentation says, “... to avoid common application errors caused by parallel execution” (http://developer.android.com/reference/android/os/AsyncTask.html). One can imagine a developer tearing his hair out over a seldom-occurring crash caused by an attempt to store something in a database that did not yet exist, or write to a file that was not yet open. That is now less likely to happen.
On the other hand, AsyncTasks are no longer executed concurrently! There is, however, a way to return to parallel execution. At the same time that normal AsyncTask execution was serialized, the framework introduced a new method, executeOnExecutor. The new method’s first argument is the executor to which the AsyncTask is to be submitted. Because the bare thread-pool executor THREAD_POOL_EXECUTOR is a public constant in the AsyncTask class, developers who are certain that they want parallel execution can bypass the queue by calling:
task.executeOnExecutor(AsyncTask.THREAD_POOL_EXECUTOR,...)
Note that with this method, it is also possible to enqueue AsyncTasks onto application-specific executors. For example, developers who find the serial execution model of the default AsyncTask appealing but who have to accommodate the occasional long-running background task that blocks the timely execution of all other tasks, might consider creating a third executor, the LARGE_TASK_EXECUTOR, strictly for the parallel execution of slower tasks. This kind of architecture—creating a tiered priority scheme for different types of tasks—can be quite effective.
The fact that the tasks are now run in order does not imply that they are all run on a single thread! This is the second deviation from the official documentation. It is absolutely possible that the executor uses only a single thread for all tasks. As mentioned earlier, versions of Android prior to API Level 19 initialized the AsyncTask executor thread pool with a single thread. If, either by chance or because of the queue, only one task at a time is ever presented to the executor, it might never grow its pool beyond that single thread. In that case, the single thread would run all the tasks.
In 2013, though, for API Level 19, KitKat, the core size of the thread pool was changed to be the number of CPUs plus one. The maximum size of the pool was changed to be twice the number of CPUs, plus one. The executor’s thread pool, since then, is likely to have at least two threads and can have more.
This is significant because it means that doInBackground methods of AsyncTasks cannot safely communicate without synchronization. Listing 4.7 would be correct if there were a guarantee that all doInBackground methods ran on the same thread. Because there is no such guarantee, the code is not correct.
Listing 4.7 Incorrect Cross-Task Communication
static boolean mFlag;
private class IncorrectTask extends AsyncTask<Void, Void, Void> {
@Override protected Void doInBackground(Void... empty) {
if (!mFlag) { // !!! Incorrect
mFlag = true;
// ...
}
// ...
return null;
}
}
AsyncTask Completion
The AsyncTask framework does not support exceptions thrown from within the doInBackground method. If the code in doInBackground terminates abruptly, the entire task lifecycle is also terminated abruptly, and neither onPostExecute, nor onCancelled is called. This is almost certainly a program error. The doInBackground method should always exit normally.
When doInBackground finishes, the AsyncTask framework completes the task lifecycle by scheduling the execution of exactly one of the two methods, onCancelled or onPostExecute, back on the main thread. Normally, it is the latter method, onPostExecute, that is called. If, however, the task’s cancel method is called between the time the task is started (with the call to its execute method) and the time the framework decides which of the two completion methods to call, the onCancelled method is called instead.
Note that the AsyncTask contract does not promise that the completion methods onPostExecute or onCancelled will be run on the thread from which the execute method was called. It promises only that that method will be run on the main thread. If execute is called from some other thread—for instance, in the doInBackground method of some other AsyncTask—onPreExecute will be called on the same thread as that on which execute was invoked. The onPostExecute method, however, will run on the main thread. The normal assumption that onPreExecute and onPostExecute are run on the same thread is not valid in this case and all rules about concurrent access to mutable state apply.
A call to a task’s onCancelled method is not evidence that the doInBackground method observed a call to the cancel method. There are several ways that onCancelled might be called even after doInBackground completes normally. The simplest of these is that the call to cancel occurs between the completion of doInBackground and the time that the completion method is scheduled, back on the main thread.
Another possibility, though, occurs because the cancel method is extremely polite. The default implementation does very little to force the doInBackground method to abort. It simply sets a flag that says the task has been cancelled and, if the boolean argument to cancel was set true, uses Java’s thread interruption mechanism to request that the thread running the task stop doing so. It is up to the implementation of doInBackground to notice this request and to act on it.
If the task is waiting for the completion of a blocking operation, when cancel is called with its argument set true, the thread will be interrupted and the operation aborted. Most I/O operations and all the low-level thread-blocking operations terminate abruptly with an exception when interrupted. I/O operations throw an InterruptedIOException, and thread-blocking operations throw an InterruptedException. In either case, a correctly written doInBackground method must catch the exception and return some partial value or failure flag. Of course, a task that enables itself to be interrupted with cancel(true) must also gracefully handle thread interrupts even when they happen elsewhere, when the code is not blocked.
If, on the other hand, the computation in doInBackground is CPU bound—perhaps translating a bitmap or computing the value of π to a million digits—it must periodically check to see whether it has been interrupted. This check is accomplished with a call to the AsyncTask method isCancelled.
Don’t swallow interrupts!
Interrupting a thread sets a flag in the Thread object. The Thread.interrupted method returns the value of that flag and clears it! Most of the blocking operations that terminate abruptly in response to interruption also clear the flag before they throw. The Thread.currentThread().isInterrupted method is the only way of discovering the interrupted state without changing it.
When designing interruptible tasks, the state of the interrupt flag is a part of the API. If callers need to be aware of an interruption, be sure to reset the flag, using the Thread.currentThread().interrupt method, after using Thread.interrupted to test its state, or catching an interruption exception.
Making the doInBackground method cancellable can be a significant challenge and might require adaptations in architecture far from the task itself. Consider Listing 4.8, a task that is very similar to those in the previous examples.
Listing 4.8 Incorrect Cross-Task Communication
private class DbInsert extends AsyncTask<ContentValues, Void, Integer> {
@Override protected Void doInBackground(ContentValues... values) {
return Integer.valueOf(
getContentResolver().bulkInsert(DataProvider.URI, values))
}
}
Instead of a query, this task is doing a potentially large insert. It is entirely possible that it will take several seconds to complete. Sadly, SQLite operations are not interruptible. Most of the implementation of SQLite is portable C code. It pays no attention at all to Java’s thread interruption flag.
Is it even possible, then, to make this task cancellable? Under some circumstances, it is possible. Making the task cancellable in this case, for instance, might be accomplished with changes to the architecture of the provider. The example is instructive.
Remember that the call to ContentResolver.bulkInsert is proxied to whichever content provider has authority for the URL: DataProvider.URI. The call to ContentResolver.bulkInsert is handled by that provider’s bulkInsert method. If the AsyncTask in Listing 4.8 is to be interruptible, it is that method that must support interruption. Listing 4.9 demonstrates this.
Listing 4.9 Interruptable Bulk Insert
@Override
public int bulkInsert(Uri uri, ContentValues[] rows) {
SQLiteDatabase db = getDb();
db.beginTransaction();
try {
int inserted = 0;
for (int len = rows.length; inserted < len; inserted++) {
db.insert(Db.TABLE, null, rows[inserted]);
if (Thread.interrupted()) { break; } // not recommended :-(
}
db.setTransactionSuccessful();
}
finally { db.endTransaction(); }
return inserted;
}
This kind of trick is fragile and definitely not recommended. It works, for instance, only if the bulkInsert method runs on the same background thread as the doInBackground method. If, as is sometimes the case, the content provider is running in a separate process, it will not observe or honor the interruption. A much better solution would have DbInsert chunk the records into multiple, separate insert calls to the provider, and to check the isCancelled method between those calls.
Making an AsyncTask cancellable can depend on making the best of code over which the designer of the task itself has no control.
Using AsyncTasks
Armed with an understanding of the implementation of the AsyncTask, let’s turn to exploring how to use them effectively in applications. Such a simple tool! What could possibly go wrong?
AsyncTask: Considered Dangerous
Sadly, there are just so many things that can go wrong. Errors with AsyncTasks fall into two categories: concurrency errors and lifecycle errors.
Getting It Wrong: Concurrency
Concurrency errors are simple violations of Java concurrency rules. Listing 4.10 is an example.
Listing 4.10 AsyncTask with a Concurrency Error
@Override
public void onClick(View v) {
new AsyncTask<Void, Void, Void>() {
@Override
protected Void doInBackground(Void... args) {
String msg = textView.getText(); // !!!
textView.setText(""); // !!!
network.post(msg);
return null;
}
}.execute();
}
The whole point of the doInBackground method is that it runs on a different thread! The observant reader will notice that the call to textView.getText is an unsynchronized reference to an object visible to another thread (in this case a View object owned by the main thread). This code is incorrect.
Fortunately, this code will fail in a very obvious way at runtime. Many of the methods in the Android view framework verify that they are called from the main thread and fail if they are not. The call to setText in this AsyncTask will generate a ViewRootImpl$CalledFromWrongThreadException. Note, though, that the call to getText is equally incorrect but does not generate an exception.
Static analysis tools, discussed in Chapter 8, “Concurrency Tools,” might be able to identify issues like this, before runtime. Among such tools, recent versions of Android Studio support the new Android annotations @UiThread, @MainThread, @WorkerThread and @BinderThread. These annotations, applied to methods, help static analysis tools report incorrect code.
Listing 4.10 demonstrates the concurrency issues that can arise from references to in-scope variables from within the doInBackground method. Listing 4.11 shows a related problem.
Listing 4.11 Another AsyncTask with a Concurrency Error
@Override
public void onClick(View v) {
new AsyncTask<TextView, Void, Void>() {
@Override
protected Void doInBackground(TextView... args) {
TextView view = args[0]
String msg = view.getText(); // !!!
view.setText(""); // !!!
network.post(msg);
return null;
}
}.execute(textView);
}
Passing the mutable value into doInBackground as a parameter does not help! In fact, it just makes the problem a little more difficult to spot. The local variable view, the method parameter args[0] and the class member textView all refer to exactly the same object. Because those references are visible from multiple threads, the code is incorrect.
Listing 4.11 will fail, dramatically, at runtime, exactly as did the code in Listing 4.10. Listing 4.12 illustrates the same problem yet one more time, but in a way that will fail in a much less predictable manner.
Listing 4.12 Yet Another AsyncTask with a Concurrency Error
@Override
public void updateHandler(List<String> strings) {
new AsyncTask<List<String>, Void, Void>() {
@Override
protected Void doInBackground(List<String>... args) {
List<String> s = args[0]
for (int i = 0, n = s.size(), i < n; i++) {
network.post(s.get(i));
}
return null;
}
}.execute(strings);
}
The problem here is that once again the code is leaking references to a mutable object into the worker thread. The parameter to updateHandler, strings, is aliased, inside doInBackground as args[0] and s. Because strings is a reference to a mutable data structure passed to updateHandler as a parameter, it is impossible to know how many other references are being used, elsewhere in the program.
Note
Collections.unmodifilable is not a solution.
Wrapping a mutable object in an immutable view does not solve the problem. The Java Collections Library method Collections.unmodifiableList, for example, simply creates an unmodifiable view of the list. Unless all references to a list are wrapped, with the unmodifiable wrapper, the thread on which the doInBackground method runs still holds a reference to an object that can be modified from another thread.
The only way to make this code correct is, as Listing 4.13 demonstrates, to make local copies of all mutable data structures. In this case, that simply means copying the list. If the elements of the list were mutable, they would have to be copied, too.
Listing 4.13 A Less-Broken AsyncTask
@Override
public void updateHandler(List<String> strings) {
new AsyncTask<List<String>, Void, Void>() {
@Override
@WorkerThread
protected Void doInBackground(List<String>... args) {
List<String> s = args[0];
for (int i = 0, n = s.size(), i < n; i++) {
network.post(s.get(i));
}
return null;
}
}.execute(new ArrayList(strings));
}
To summarize, the problem is that Java’s block structure and threading structure don’t always play nicely together. Things that happen automatically are sometimes very dangerous. Just getting concurrency right in an AsyncTask requires attention to detail.
... And concurrency is not the end of it.
Getting It Wrong: Lifecycles
Among the most common errors in using AsyncTasks are those that relate to Android component lifecycles. Listings 4.14 and 4.15 are perfect examples of this kind of error. Both are trying to post data to the network in response to user input. Consider, for a moment, how this code might fail.
Suppose a user installs the app containing this code on his phone and, just by chance, invokes that AsyncTask just as the subway train he is riding goes underground and loses connectivity. Without connectivity, the post request will, eventually, time out.
A reasonable choice of timeout interval might be something like 60 seconds. Although many mobile applications choose much smaller numbers (10 to 15 seconds) for actions for which a user must wait, 30 to 90 seconds might make sense for a task performed asynchronously.
When a connection times out, it is typically retried, perhaps with some kind of back-off algorithm. The post method in Listing 4.12 might, for instance, retry after 30 seconds, 90 seconds and, finally at 180 seconds. The task is working away for a full 3 minutes after the user took the action that started it.
Recall Figure 3.4 from Chapter 3. It showed the lifecycle of an activity and how it related to the user’s perception of the application’s lifecycle. Figure 4.2 shows that same lifecycle but adds an AsyncTask, spawned by the activity.

The Android framework controls the lifecycle of the Activity. There are many reasons—screen rotation is the most often cited—that the framework might decide to discard one instance of an Activity, and replace it with another instance at a later time.
The lifecycle of the AsyncTask, however, is not managed at all. Figure 4.2 illustrated the example under consideration, in which the task is around for several minutes after the Activity that spawned it is gone. Clouds are beginning to gather.
To understand exactly why this is a problem, consider first a slight refactoring of the example code. In Listing 4.14, the task is promoted to the named inner class PostTask, instead of the anonymous class used previously. In particular, note that in its constructor, PostTask takes a Context as an argument and retains a reference to it in the networking object that it creates. The Context passed into PostTask is the current Activity.
Figure 4.3 illustrates the resulting problem.
Listing 4.14 AsyncTask with a Lifecycle Error
private static class PostTask extends AsyncTask<String, Void, Void>() {
private final Network network;
public PostTask(Context ctxt) { this.network = new Network(ctxt); }
@Override
protected Void doInBackground(String... args) {
network.post(args[0]);
return null;
}
}
// ...
public void onClick(View v) {
view.setText("");
new PostTask(this).execute(textView.getText().toString);
}

Because the task holds a reference to the Activity, the Activity cannot be garbage collected, even after the Android framework has created its replacement. As shown in Figure 4.3, the AsyncTask hangs around for several minutes. During those several minutes, the redundant Activity, a very large object, and most of the objects to which it refers—perhaps an entire redundant view hierarchy—are stuck in memory.
Notice that all implementations of AsyncTasks as non-static inner classes—and this includes all anonymous classes—have this problem! In Java, any non-static class B defined within another class A holds a reference to the instance of A that created it. The two classes B1 and B2, for instance, in Listing 4.15, have nearly identical implementations.
Listing 4.15 Inner Class Implementation
class A {
private class B1 { }
private static class B2 {
private A parent;
public B2(A parent) { this.parent = parent }
}
}
Every anonymous subclass of AsyncTask holds the Activity that created it in memory until the task completes.
There is another reason that the zombie Activity is a problem: The task might actually try to use the reference that it is holding. On noticing that an the AsyncTask.onPostExecute method is run on the main thread, a developer can be forgiven for thinking she’s found a perfect way to notify the user of a task’s completion. She simply stores a reference to a notification view in the task, and updates it in onPostExecute.
Figure 4.3 illustrates why this doesn’t work. At the very best, the onPostExecute method updates a zombie view that is no longer attached to the screen. At worst, because the Activity has been run through the end of its lifecycle and its onDestroy method called, it is in an inconsistent state and throws an exception, crashing the application.
Weak references are often suggested as a solution to this problem. Experienced Java developers will recall that the Java runtime regards an object as garbage when there are no strong references to it. Nearly all references in Java are strong: objects are never garbage as long as there are variables that point to them.
A WeakReference is a special Java object. It contains a reference to a single other Java object. One might think of it as a list that can have only one thing in it. It is special because the object to which it refers can be garbage collected. If all the remaining references to an object are weak references, the object is garbage collected and all the weak reference are set to null.
If an AsyncTask holds only weak references to its Activity, then it is impossible for it to create a zombie. When all framework references—hard references—to the Activity are gone, it will be garbage collected. At some later time, when the AsyncTask attempts to refer to the Activity, it simply checks, finds that the reference to it is null, and takes appropriate action. This certainly seems like a silver bullet. It is not and there are three reasons why.
Note
AsyncTasks are almost never the right choice for network operations.
This might seem like a strong statement. There are many applications in the App Store, some perhaps with 4- and 5-star ratings, that have networking architectures that depend on AsyncTasks.
... And the Leaning Tower of Pisa is still upright, mostly. Choosing a better architecture for network operations will mean less erratic behavior and will give you more time to focus on delighting your users.
The most obvious reason is that the task might need to take action and might be unable to do so. In the previous sample scenario, three minutes after the user believes she has posted something to the network, the post fails. If the AsyncTask cannot report the failure, the application is breaking promises. The user’s post was not sent, and there is no longer any reliable way of informing her that it failed.
The second reason is the cost. Consider an AsyncTask that does something fairly complex: perhaps making calls to two or more REST services and computing some kind of aggregation of the data it receives. Now consider what happens if this task loses its Activity early in its lifecycle. It proceeds to make each expensive network transfer and then heats up the CPU calculating the aggregate and, finally throws the result away. The data transfer can cost the user real money. The calculation certainly costs real battery life. When the work is done, however, there is no place to put the result, so it is just discarded. What a waste!
The final reason that using weak references to embed AsyncTasks in Activities is bad design is that it is, well, bad design. The entire concern about zombie activities is not really a problem to be solved, but rather an artifact of a bad architecture. Long running asynchronous tasks do not belong in Activities at all. Activities are meant to be short-lived objects. Chapter 3 compared them to servlets. No one would put business logic into a servlet. Chapter 3 also noted that a process that contains only Activities that are not visible is eligible for process reaping. An AsyncTask running in an application that contains only an invisible Activity can be killed, mid-process, with no warning and no chance to report failure.
Android applications, like their three-tier web-service counterparts, should put substantial asynchronous work into a more appropriate component. In Android, that component is usually a Service. Services are the subject of Chapter 6, “Services, Processes, and IPC.”
Getting It Right
At this point the reader can be forgiven for thinking that AsyncTasks are an abomination that should never be used at all. This reactionary opinion is not unheard of within the Android developer community. Discussions among Android developers with an app or two under their belts often include a tacit, unspecific assumption that AsyncTasks are something that the cat dragged in.
As is so often the case in software development, it is the specific details that make the difference. AsyncTasks are not a panacea. Neither, however, are they useless. Understanding them, when they are useful and when they are not, will be very helpful in assessing the next new hotness when it arrives.
AsyncTasks have their place. Here are a couple of recipes for building ones that are resilient and useful.
Autonomous Tasks
To qualify as autonomous, an AsyncTask must have only side effects: it must not try to resynchonize and return information—even status—to the caller. It should also be relatively short-running—no more than a few seconds.
Such a task can be very useful for accomplishing something that is either very likely to succeed or that can be tested and retried if it fails. Creating and initializing a file, for instance, is appropriate work for this kind of task. If the application needs the file and it does not exist, it starts a task to create it. At some future time, when it discovers again that it needs the file, the file is probably there. If not, it just starts another task.
Cancellable Tasks
A cancellable task is one that actually responds to the cancel method by ceasing processing. Such a task terminates its doInBackground method as quickly as possible, and exits, upon receiving cancellation notification. When the executor releases it and it finishes its lifecycle, it is garbage collected and cannot cause the retention of objects to which it holds references.
Of course, a cancellable task needs to be cancelled! When an Activity starts a cancellable AsyncTask, it must remember it and then cancel it, typically in response to onPause or onStop events.
Loaders and Cursor Loaders
The CursorLoader is a nearly ideal example of an appropriate use of an AsyncTask. Its base class, Loader, is an abstraction of asynchronous data loading. The subclass AsyncTaskLoader is an implementation of the abstraction as an AsyncTask. CursorLoader, a subclass of AsyncTaskLoader is perhaps the best answer to the problem that begins this chapter: asynchronously loading a cursor full of data from a database.
Mark Murphy, author of “The Busy Coder’s Guide to Android Development” (2009) once called Loaders “a failed abstraction.” This is an accurate assessment. Loaders just haven’t caught on as the generic solution for loading data into a view. Although not successful as a generalized abstraction, the specific derived class CursorLoader is a solid and popular tool.
The goal when using a CursorLoader is to get the data from the database. The solution at first seems like the long way around the barn. It is a three-step process that seems to start off in the wrong direction entirely:
1. Ask the loader manager to create a loader.
2. Give the loader manager a loader when it asks for it.
3. Accept the cursor returned by the loader when it is delivered.
Consider an application that will display the results of a database query in a list view. The skeleton Activity might look something like Listing 4.16.
Listing 4.16 Skeleton Cursor List Activity
public class LoaderActivity extends ListActivity {
// ...
@Override
protected void onCreate(Bundle state) {
super.onCreate(state);
SimpleCursorAdapter adapter = new SimpleCursorAdapter(
this,
R.layout.list_row,
null,
FROM,
TO,
0);
setListAdapter(adapter);
}
// ...
}
The third argument to the SimpleCursorAdapter constructor is the cursor whose contents are to be displayed in the list view. In Listing 4.16, there is as yet no cursor to display, so the actual parameter is null. The point of the rest of this chapter is to replace that value with the cursor full of data, acquired asynchronously from a database.
The first step as just described is to ask the LoaderManager to start a loader. That takes two lines of code, as shown in Listing 4.17.
Listing 4.17 Initializing the Loader
public class LoaderActivity extends ListActivity {
private static final int DATA_LOADER = -8954;
// ...
@Override
protected void onCreate(Bundle state) {
super.onCreate(state);
SimpleCursorAdapter adapter = new SimpleCursorAdapter(
this,
R.layout.list_row,
null,
FROM,
TO,
0);
setListAdapter(adapter);
Bundle args = getIntent().getExtras();
getLoaderManager().initLoader(DATA_LOADER, args, this);
}
// ...
}
The first argument to the call to initLoader is the name of the loader to be initialized. It is an integer: any integer unique across the application will do.
Recall that the onCreate method for this Activity will be called many times, sometimes more than once in a second. Creating a new loader instance each time onCreate is called would be wasteful. Instead, when initLoader is called it checks to see if a loader with the given name already exists. Only if none exists does it initialize and start a new one.
The second argument is the parameters passed to loader creation. They will reappear in a moment.
The third argument to initLoader is the callback handler. In a fractal-like repetition of the way that the Android framework calls an Activity with lifecycle events, the LoaderManager will call the callback handler with events representing the lifecycle of the Loader.
Expressing interactions between a process and an asynchronous collaborator as a stream of events is a pattern that will become an important architectural tool throughout the rest of this book. In this case, there are three events: onCreateLoader, onLoadFinished, and onLoaderReset.
To receive these events, the callback handler must implement the interface LoaderManager.LoaderCallbacks<T> (which declares those three methods), where T is the type of the object the loader will return. In this case, that object will be a Cursor. Listing 4.18 illustrates extending the LoaderActivity to accept loader lifecycle events.
Listing 4.18 Accepting Loader Events
public class LoaderActivity
extends ListActivity
implements LoaderManager.LoaderCallbacks<Cursor>
{
private static final int DATA_LOADER = -8954;
@Override
public Loader<Cursor> onCreateLoader(int id, Bundle args) { }
@Override
public void onLoadFinished(Loader<Cursor> l, Cursor c) { }
@Override
public void onLoaderReset(Loader<Cursor> c) { }
@Override
protected void onCreate(Bundle state) {
super.onCreate(state);
SimpleCursorAdapter adapter = new SimpleCursorAdapter(
this,
R.layout.list_row,
null,
FROM,
TO,
0);
setListAdapter(adapter);
Bundle args = getIntent().getExtras();
getLoaderManager().initLoader(DATA_LOADER, args, this);
}
// ...
}
At some point after the call to initLoader, the LoaderManager will call the callback handler—in this case, the Activity—to request a Loader. This is the first of the three lifecycle events. Because the goal here is to load a cursor, this Activity will supply a CursorLoader, as shown in Listing 4.19.
Listing 4.19 Creating a Cursor Loader
public class LoaderActivity
extends ListActivity
implements LoaderManager.LoaderCallbacks<Cursor>
{
private static final int DATA_LOADER = -8954;
@Override
public Loader<Cursor> onCreateLoader(int id, Bundle args) {
return new CursorLoader(
this,
DataProvider.URI,
new String[] {
DataProvider.Columns.ID,
DataProvider.Columns.FNAME,
DataProvider.Columns.LNAME},
DataProvider.Columns.LNAME + "=?",
new String[] { args.getString(DataProvider.Columns.LNAME) },
DataProvider.Columns.LNAME + " DESC");
}
@Override
public void onLoadFinished(Loader<Cursor> l, Cursor c) { }
@Override
public void onLoaderReset(Loader<Cursor> c) { }
@Override
protected void onCreate(Bundle state) {
super.onCreate(state);
SimpleCursorAdapter adapter = new SimpleCursorAdapter(
this,
R.layout.list_row,
null,
FROM,
TO,
0);
setListAdapter(adapter);
Bundle args = getIntent().getExtras();
getLoaderManager().initLoader(DATA_LOADER, args, this);
}
// ...
}
There are two things to notice in the new code. The first is that the bundle that was passed into the LoaderManager at initialization as the second argument, appears here as the parameter args. The code uses a value in that bundle as the argument to the query WHERE clause.
More important, though, is that the constructor parameters to the CursorLoader are almost identical to the parameters to a database query statement: URI, projection, restriction, restriction args, and ordering. The returned instance of the CursorLoader contains a complete, encapsulated representation of the query to be run.
Once the loader manager has the Loader, it runs it asynchronously. As mentioned earlier, CursorLoader inherits from AsyncTaskLoader, which uses a new instance of an AsyncTask to run the query embodied in the loader in the background. Figure 4.4 illustrates the entire lifecycle.

The Activity initialized the loader. The call returns immediately. At some later point, the loader manager calls back to the Activity to obtain a Loader. The Loader creates a new instance of a subclass of AsyncTask and runs it, passing the query parameters.
Running on a background thread, the AsyncTask queries the database and eventually obtains a cursor full of data. In its onPostExecute method, it calls back to a completion method in the Loader, which in turn calls back to the Activity’s onLoadFinished method, to deliver the cursor. This is the second loader lifecycle event.
Listing 4.20 shows the completely implemented activity.
Listing 4.20 Complete Cursor Loader
public class LoaderActivity
extends ListActivity
implements LoaderManager.LoaderCallbacks<Cursor>
{
private static final int DATA_LOADER = -8954;
@Override
public Loader<Cursor> onCreateLoader(int id, Bundle args) {
return new CursorLoader(
this,
DataProvider.URI,
new String[] {
DataProvider.Columns.ID,
DataProvider.Columns.FNAME,
DataProvider.Columns.LNAME},
DataProvider.Columns.LNAME + "=?",
new String[] { args.getString(DataProvider.Columns.LNAME) },
DataProvider.Columns.LNAME + " DESC");
}
@Override
public void onLoadFinished(Loader<Cursor> l, Cursor c) {
((SimpleCursorAdapter) getListAdapter()).swapCursor(c);
}
@Override
public void onLoaderReset(Loader<Cursor> c) {
((SimpleCursorAdapter) getListAdapter()).swapCursor(null);
}
@Override
protected void onCreate(Bundle state) {
super.onCreate(state);
SimpleCursorAdapter adapter = new SimpleCursorAdapter(
this,
R.layout.list_row,
null,
FROM,
TO,
0);
setListAdapter(adapter);
Bundle args = getIntent().getExtras();
getLoaderManager().initLoader(DATA_LOADER, args, this);
}
// ...
}
Upon receiving the cursor from the Loader, the onLoadFinished method simply swaps the new cursor into the adapter created earlier in onCreate. Suddenly the contents of the cursor appear in the list view.
There is one more thing to notice. The loader does conform to one of the two AsyncTask patterns previously described. It is cancellable.
Although it is not obvious from the code, the LoaderManager observes lifecycle events for the Activity to which a Loader is attached. When it determines that the related Activity is being destroyed and that no other instance of the same Activity will immediately replace it (that is, when this is not just a screen rotation or similar event), it properly cancels the Loader.
As noted earlier, it might not be possible to cancel a query in mid-process. The CursorLoader comes as close as possible. It attempts to cancel the query, and discards the result as quickly as possible should the cancel fail.
It also calls the registered callback handler to notify it that the Loader has been cancelled. This is the third loader lifecycle event, and it is handled by the code in Listing 4.20 by replacing the cursor in the view adapter with null.
The loader demonstrates smart use of an AsyncTask in several ways:
![]() The details of the task are well hidden from the client. Although getting to this point was a bit complicated, in the end the code looks very much like our original ideal. There is an object that embodies the query and a method call when the query completes. The mechanism by which the query is run in the background is nearly invisible.
The details of the task are well hidden from the client. Although getting to this point was a bit complicated, in the end the code looks very much like our original ideal. There is an object that embodies the query and a method call when the query completes. The mechanism by which the query is run in the background is nearly invisible.
![]() The task is, as much as possible, cancellable. When the requested cursor is no longer useful, it is discarded as quickly as possible. It does not pin memory or busy the CPU for data that it already knows it does not need.
The task is, as much as possible, cancellable. When the requested cursor is no longer useful, it is discarded as quickly as possible. It does not pin memory or busy the CPU for data that it already knows it does not need.
![]() The LoaderManager makes smart use of the lifecycle of an AsyncTask. If the loader for a particular dataset might be useful to some future Activity, the manager can let it run to completion, even though the Activity that requested the data is long gone. Instead, the manager delivers the loaded data to a new instance of the Activity when it becomes available.
The LoaderManager makes smart use of the lifecycle of an AsyncTask. If the loader for a particular dataset might be useful to some future Activity, the manager can let it run to completion, even though the Activity that requested the data is long gone. Instead, the manager delivers the loaded data to a new instance of the Activity when it becomes available.
AsyncTasks: What Went Wrong
It is easy to understand how developers end up using AsyncTasks incorrectly. When an aspiring Java developer creates her first Java application in an IDE, she probably sees skeleton code provided by the IDE, that looks something like Listing 4.21.
Listing 4.21 A Skeleton Java Application
public class AwesomeNewApp {
public static void main(String... args) {
// ...
}
}
If this same programmer decides to take up Android development, the exact same IDE will generate code like that in Listing 4.22 for her first attempt at an Android app.
Listing 4.22 A Skeleton Android Application
public class AwesomeNewApp extends Activity {
protected void onCreate(Bundle state) {
// ...
}
}
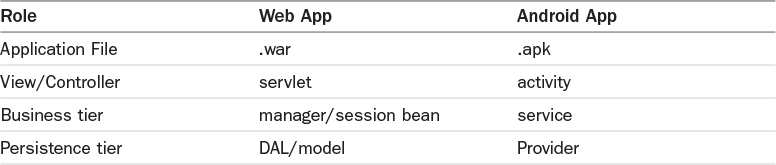
“Ah ha!” she says, and in her mind forms the model shown in Table 4.1.

Building on this model, the developer crams more and more functionality into an Activity. Of course, an experienced developer will factor some behavior into new packages and classes, to keep things modular. Nonetheless, a beginning Android programmer is likely to build an application in which one or more Activites are the center of the design.
To build great Android applications, it helps a lot to understand that they are, as pointed out in Chapter 3, web applications. A developer with Table 4.2 in mind will build programs that are more stable, behave more consistently, and are more delightful.
In this more accurate model, AsyncTasks make sense: They are a way to get small, slow tasks out of the way, so that the UI can be responsive and blindingly fast.
Updating the model, synchronizing with remote data, and business computations belong elsewhere. They belong in Services, described in Chapter 6, “Processes and Bound Services.”
Summary
This chapter has been a deep dive into the architecture of the AsyncTask. AsyncTask is a modest tool for moving the execution of small bits of code off the main thread and onto a worker thread. The exploration revealed the following points:
![]() AsyncTasks are type-safe templates and must be subclassed to be used. To execute a task, one creates a new instance of the subclass and calls its
AsyncTasks are type-safe templates and must be subclassed to be used. To execute a task, one creates a new instance of the subclass and calls its execute method. An instance can be executed only once.
![]() The template method of an AsyncTask,
The template method of an AsyncTask, doInBackground is run on an Executor’s worker thread. The default Executor, the SERIAL_EXECUTOR, executes tasks one at a time in order, but not necessarily on a single thread. It is possible to use other Executors.
![]() It is not possible to execute code on a background thread simply by wrapping it in an AsyncTask. Because code moved into an AsyncTask is executed on another thread, many normal Java keywords—
It is not possible to execute code on a background thread simply by wrapping it in an AsyncTask. Because code moved into an AsyncTask is executed on another thread, many normal Java keywords—break, continue, throw, and return—have an entirely different meaning from what they had in their original position. More important, though, the basic block structure of the Java language practically guarantees that such tasks will contain concurrency errors.
![]() AsyncTasks have lifecycles that are quite different from those of the Android components with which they interact. The incongruence of the two kinds of lifecycle can lead to memory leaks and application failure.
AsyncTasks have lifecycles that are quite different from those of the Android components with which they interact. The incongruence of the two kinds of lifecycle can lead to memory leaks and application failure.
![]() AsyncTasks can be quite effective for the purposes for which they were originally conceived: small autonomous or cancellable tasks. Android Loaders,
AsyncTasks can be quite effective for the purposes for which they were originally conceived: small autonomous or cancellable tasks. Android Loaders, CursorLoaders in particular, are examples of the effective use of AsyncTasks.
AsyncTasks have been put to many uses for which they were never intended and for which they are frequently inappropriate. Most of the time this misuse stems from a misunderstanding of Android’s architecture on the part of the developer. Understanding Android applications as Web-apps makes it obvious that AsyncTasks make sense for small, local tasks, but not for heavy lifting.