
Aggregation of related messages is a frequent use case in integration. It is also one of the more complicated cases to write by hand, since it involves state, which can be lost if you are not careful, as well as considerations like timing. Camel's implementation of the Aggregator EIP abstracts away the complexity of this task, leaving you to define the following:
- How two exchanges ought to be aggregated into one. This is done by providing an implementation of an
AggregationStrategy, which is an interface used to merge multiple exchanges together. - Which exchanges are to be aggregated with each other. This is defined by an expression that determines the grouping value from the exchange.
- When an aggregation is considered complete. For this, we use one of a number of completion conditions defined through the DSL that allow us to make this decision by: an aggregated exchange count; a predicate against the aggregated, or incoming, exchange; interval since last message; or a timeout.
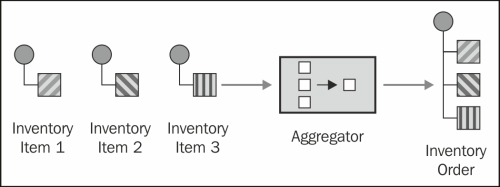
This recipe will show you how to use the Aggregator pattern to merge related exchanges into one using an aggregated exchange count, or completion size.
The Java code for this recipe is located in the org.camelcookbook.splitjoin.aggregate package. The Spring XML files are located under src/main/resources/META-INF/spring and prefixed with aggregate.
To aggregate related exchanges use the aggregate DSL statement with an associated AggregationStrategy implementation. The EIP implementation will use this class to do the actual combining of the exchanges:
- Implement an
AggregationStrategy. The following strategy aggregatesStringmessages into aSet:public class SetAggregationStrategy implements AggregationStrategy{ @Override public Exchange aggregate(Exchange oldExchange, Exchange newExchange) { String body = newExchange.getIn().getBody(String.class); if (oldExchange == null) { Set<String> set = new HashSet<String>(); set.add(body); newExchange.getIn().setBody(set); return newExchange; } else { Set<String> set = oldExchange.getIn().getBody(Set.class); set.add(body); return oldExchange; } } }The
AggregationStrategyinterface defines a single method:Exchange aggregate(Exchange oldExchange, Exchange newExchange);
It receives two Exchange objects as parameters, and returns a single Exchange object that represents the merged result.
When it is called for the first time, the
AggregationStrategywill receive anullfor theoldExchangeparameter, and, as such, needs to be able to deal with this condition. On subsequent invocations, theoldExchangeparameter will contain the previously aggregated exchange.If using the XML DSL, you will also need to instantiate your aggregation strategy implementation inside your Spring configuration:
<bean id="setAggregationStrategy" class="org.camelcookbook,splitjoin.aggregate.SetAggregationStrategy"/> - In your route, define an
aggregatestatement with a reference to the aggregation strategy bean you created in thestrategyRefattribute. You will then need to set some other options on theaggregatestatement to refine its behavior.The
completionSizeattribute is used to define the number of messages that will be aggregated before the resulting message is processed through the remainder of theaggregateblock.Within the block, the
correlationExpressionelement is used to define the value that will be used to aggregate messages. Exchanges that evaluate to the same expression result will be aggregated. The correlation expression appears as a nested element within theaggregateblock.In the XML DSL, this is written as:
<route> <from uri="direct:in"/> <aggregate strategyRef="setAggregationStrategy" completionSize="5"> <correlationExpression> <simple>${headers.group}</simple> </correlationExpression> <to uri="mock:out"/> </aggregate> </route>In the Java DSL, the
aggregateblock looks quite different. Here the correlation expression, which is always required, is passed directly in to theaggregate()statement. ThecompletionSizeoption (which is one of two possible completion options—the other option beingcompletionTimeout) follows on using the DSL's builder pattern:from("direct:in") .aggregate(header("group"), new SetAggregationStrategy()) .completionSize(5) .to("mock:out") .end();The
end()method designates the end of theaggregate()block.
When a message is processed through the route, and reaches the aggregate block, the Aggregator's correlation expression is evaluated against that message. The resulting value is used to identify the group of related (correlated) messages that the current message belongs to.
The associated AggregationStrategy is invoked with the current Exchange instance in the newExchange argument.
If this message is the first message in that group, no oldExchange value is provided—a null value is passed in instead. In this case, the strategy will set the body of newExchange to an initial aggregated state. In the preceding example, this is a Set with a single value—the original body of the message. The newExchange value is then returned as the aggregated exchange.
Subsequent invocations of the strategy for this group will receive this aggregated Exchange instance as the oldExchange argument. It will then be augmented with the incoming message body before being returned.
Once a message has been aggregated, the completion condition is evaluated. If the condition is satisfied, the aggregated message is processed through the steps defined in the aggregate block.
If the completion condition is not satisfied, the aggregated exchange is saved away in an Aggregation Repository—the default behavior uses an in-memory implementation. The thread then finishes processing the exchange through that route.
Aggregations can be completed based on the number of messages aggregated according to completionSize, or by a completion predicate using any of Camel's Expression Languages. The predicate is evaluated against the aggregated message.
The following example shows the use of a completion predicate that examines the aggregated Set from our example above to determine whether or not to complete the aggregation.
In the XML DSL, this is written as:
<aggregate strategyRef="setAggregationRepository">
<correlationExpression>
<simple>${headers.group}</simple>
</correlationExpression>
<completionPredicate>
<simple>${body.size} == 5</simple>
</completionPredicate>
<!-- ... -->
</aggregate>In the Java DSL, the same thing is expressed as:
.aggregate(header("group"), new SetAggregationStrategy())
.completionPredicate(simple("${body.size} == 5"))
The completionSize option can also be dynamically set using an expression. Unlike the completionPredicate statement, however, it is checked against the incoming exchange versus the the aggregated exchange.
In the XML DSL, this is written as:
<aggregate strategyRef="setAggregationRepository">
<correlationExpression>
<simple>${headers.group}</simple>
</correlationExpression>
<completionSize>
<simple>${header[batchSize]}</simple>
</completionSize>
<!-- ... -->
</aggregate>In the Java DSL, the same thing is expressed as:
.aggregate(header("group"), new SetAggregationStrategy())
.completionSize(header("batchSize"))
Any aggregated state needs to be stored externally to the application if it is to survive the application shutting down. This is especially important if you are consuming high-value messages that cannot be replayed. Alternative AggregationRepository implementations that persist this state can be plugged into the aggregator through the use of the aggregationRepository attribute.
For example, the JdbcAggregationRepository, provided within the Camel SQL Component, is an excellent candidate for external storage of aggregated messages. Each time an aggregated state is saved, it is serialized through standard Java serialization, and stored inside a table as a BLOB associated with the aggregation's correlation expression. When a new message arrives to be aggregated, the stored state is read from the database, deserialized back into an exchange, and passed into the AggregationStrategy.
The processing of the aggregated message is fully transactional.
Tip
Since the serialized exchanges are constantly being written into, and read from the database, you need to keep in mind that the total aggregated message size is growing linearly. There comes a point when the cost of this I/O activity impacts the performance of the aggregation, especially when dealing with large message bodies. After all, a disk can only spin so fast. It is therefore worth doing some performance testing to ensure that the throughput meets your requirements. See the Validating route behavior under heavy load recipe in Chapter 9, Testing, for further details on how to do this.
You may also like to consider alternative AggregationRepository implementations, such as that provided by Camel HawtDB and Camel LevelDB Components, which allow you to trade off performance against reliability through background disk syncs.
- Aggregator: http://camel.apache.org/aggregator2.html
- Camel SQL: http://camel.apache.org/sql-component.html
- Camel HawtDB: http://camel.apache.org/hawtdb.html
- Camel LevelDB: http://camel.apache.org/leveldb.html