

This chapter includes the following topics:
Accelerators are generally able to provide optimization at two distinct layers. The first layer of optimization is application-agnostic, otherwise referred to as WAN optimization, which consists of transport protocol optimization and compression (discussed in Chapter 6, “Overcoming Transport and Link Capacity Limitations”). WAN optimization is primarily employed to overcome conditions caused by or otherwise encountered in the WAN, including latency, bandwidth constraints, and packet loss, as well as conditions caused by lower-performing implementations of transport protocols on end nodes.
The second layer of optimization is functionality that interacts with or otherwise improves behavior of the application layer itself, also known as application acceleration. Most accelerators provide a combination of WAN optimization and application acceleration, as well as content distribution, as described in Chapter 5, “Content Delivery Networks,” which can also be considered a form of application acceleration. Application acceleration capabilities interact within the context of specific applications and application protocols to improve performance for users accessing applications and content over a WAN, including protocol-specific behaviors such as pipelined or multiplexed transactions.
Application acceleration (application-specific) and WAN optimization (application-agnostic) are two separate layers of optimization that commonly coexist on the same accelerator device and leverage one another. When combined, application acceleration and WAN optimization can overcome a host of challenges that plague application performance in WAN environments.
Simply put, accelerators make the WAN a place that is conducive to application performance and make application protocols perform better over networks. This chapter examines how accelerators make application protocols perform better over networks by examining optimization techniques that minimize the impact of bandwidth and latency, including reactive and proactive acceleration techniques including caching, read-ahead optimization and pre-fetching, write-behind optimization, video stream splitting, message prediction, pipelining, and multiplexing. The optimizations discussed in this chapter, as well as the Content Delivery Network (CDN) capabilities discussed in Chapter 5, serve as a foundation for application-specific acceleration. These techniques combine with the WAN optimization principles found in Chapter 6 to form the foundation of accelerator solutions, which help ensure networks provide the performance levels necessary to enable high-performance access to centralized applications, data, and content in a global infrastructure environment.
Application-specific acceleration refers to mechanisms employed at the application layer within an accelerator to mitigate application latency, improve data transfer times, and provide disconnected service in the event of network disruption. The level of application-specific acceleration applied to a specific application is directly dependent on the application and protocols themselves and what can be done within the confines of correctness, coherency, and data integrity.
Some application protocols are robust and complicated, requiring a large degree of message exchange, or chatter, between nodes. Such protocols might be feature rich and robust but yield poor performance over the WAN when not using some form of acceleration. In many cases, applications that depend on these protocols dictate that you deploy infrastructure to support those applications in remote office locations to provide adequate levels of performance. Deploying infrastructure in such a distributed manner can overcome performance limitations of applications that rely on protocols that do not perform well over the WAN but also leads to dramatically higher capital costs and IT management expenditure.
Application acceleration can be categorized into two primary types: reactive acceleration and proactive acceleration. Reactive acceleration refers to the behavior employed by an accelerator device when a specific type of stimulus is seen. These are behaviors and functions that are implemented upon encountering a specific request from a given user. Proactive acceleration, on the other hand, refers to the behavior employed by an accelerator device based on administrator configuration. With proactive acceleration, accelerators may be preconfigured with instructions on how to handle specific data types, specific messages or requests, or specific protocols, and on which sets of data to proactively distribute throughout the fabric of accelerators. Both of these approaches work cohesively and in conjunction with WAN optimization to ensure significant performance improvements for users accessing files, content, and applications over a WAN.
Caching is a method commonly used in computer and networking systems to help compensate for I/O requests that are performance bound to the slowest device in the processing path. Caching refers to the introduction of an intermediary buffer between two devices within a processing path, where the intermediary buffer can retain a copy of data found in the slower device, albeit at a much smaller capacity.
For instance, caching is employed between the CPU of a personal computer or server and the main memory, which acts as primary storage. Although we commonly consider main memory to be high performance, main memory is dramatically slower than the CPU itself, as well as the CPU registers. By introducing a cache between the CPU and main memory, content fetched from memory can be stored authoritatively in the cache and retrieved from there by the CPU (as opposed to paying the performance penalty of fetching the data directly from memory), because the cache has performance characteristics that are more similar to those of the CPU registers as compared to the system’s main memory. This helps to dramatically improve performance of applications running on a PC or server. Similarly, caches are commonly used in other areas of a system, including the disk subsystem, which provides far greater levels of throughput and better response times as compared to continually fetching data from the mechanical disk drives.
Similar to how caching is deployed within a PC or a server, application-specific caching can be deployed as a function within an accelerator in the network to allow that accelerator to maintain local copies of previously requested objects (reactive) or objects that have been distributed to the accelerator by way of administrative configuration (proactive). This minimizes the number of requests for objects and corresponding objects that require transmission over the low-speed network. Along with providing performance improvements, application-specific caching also helps to offload other accelerators in the network path to the origin server and provides a significant amount of workload reduction on the origin server itself, as it no longer has to serve redundant copies of data. This section examines caching in detail along with how content is managed and object validity is preserved.
The process of caching objects accessed by a target protocol, or employing other optimizations (discussed later in the chapter in sections such as “Read-Ahead” and others), is considered an application-specific process. For application-specific acceleration that includes caching, protocols such as HTTP, HTTPS, and Common Internet File System (CIFS), or even streaming media protocols such as Real-Time Streaming Protocol (RTSP), become the cache’s primary processing objective. An application-specific cache stores not only the intercepted objects, but also any related metadata and directory information associated with the location of the object. By maintaining a repository of previously accessed objects and the associated metadata, the accelerator is in a position to determine not only the validity of cached objects, but also the safety in employing optimizations against object requests or other operations.
An application-specific cache within an accelerator offers more than just copies of cached objects that traverse its network interfaces. First, the process of caching a specific piece of content during the initial request places the content in the accelerator memory and disk. Second, the content must be stored in a location that is quickly accessible in the event that a subsequent request is received by the accelerator. Lastly, in the event of a request for content that exists on the accelerator, the accelerator must be able to validate the freshness of the given object prior to serving the object to the requesting user, while also ensuring that application semantics such as authentication and authorization are preserved. This is done to ensure that data is not served to a user when the data has been changed or the user is not allowed to access it. Each of these steps allows an application-specific cache to interoperate with the requesting user, origin server, and application in the interest of accelerating object requests over the target protocol.
Application-specific caches are useful to any requesting user whose request traverses a target protocol. The accelerator’s ability to intercept the protocol messages exchanged between a requesting user and the origin server is inspected and compared against requests that may have traversed the accelerator previously. Once validated, each reactively stored object is served over the LAN and is delivered in a more efficient manner than if it were served by an origin server located across the WAN, thereby mitigating the performance penalty of the WAN for the majority of the transaction. Although the requesting user might not know that his request was intercepted and processed by an accelerator, his object request has been satisfied faster than a remote origin server could respond and transferred more quickly than the WAN could possibly handle. The ability to speak the application protocol allows application and network administrators to implement application-specific caching with little to no changes on the origin server or client.
The four entities that benefit the most from an application cache are the user, the WAN, intermediary accelerators, and the origin server itself. The user experiences a noticeable improvement in performance when requesting objects that are accelerated by an accelerator, because the majority of the workload is done locally on the LAN at near-LAN speeds as opposed to the WAN. With application-specific caching, less data needs to traverse the WAN. This directly translates into bandwidth savings on the WAN and also minimizes the amount of traffic that must be handled by any intermediary accelerators that are deployed in the network between the accelerator closest to the user and the origin server. Similarly, the origin server will likely see a substantial decrease in the number of requests and amount of application I/O it must service, thereby allowing increased levels of scalability with existing origin server infrastructure. In this way, accelerators that provide application acceleration and object caching as a component of a performance-enhancing solution not only improve user performance, but also offload the network and the origin server dramatically while maintaining content freshness, validity, and correctness.
An accelerator that provides application-specific caching validates content items stored on its disks at the time it receives a request that matches the properties of an item that is stored in the cache. Cached content validation prevents stale content from being served to any requesting user and ensures compatibility with existing security semantics and correctness from an application protocol perspective. Content validation is a function that is required of an accelerator that performs application-specific caching, and the next paragraph demonstrates why it is required.
To demonstrate the impact of serving stale content to a requesting user, consider the business impact of an out-of-date payroll spreadsheet being served to an accountant who is requesting the spreadsheet from the payroll server. The spreadsheet, which is hosted on the origin server, might be several minutes or hours newer than what the accountant has obtained if an application cache does not check the spreadsheet’s freshness. Any last-minute changes that do not exist in the outdated spreadsheet might cause an employee to receive an incorrect paycheck. As another example of the importance of cache validation, suppose that an employee of the corporation checks his online banking statement via a web browser. Unknowingly, the employee might be served a cached record of a banking statement that belongs to another employee of the corporation. Or, the information that was just served from the application cache might have been cached the previous day, leading the employee to believe that an account has more or less in it than what is actually there.
Each application dictates how an accelerator that is providing application-specific caching should validate content items that have been cached, to maintain coherency and correctness. Each validation method involves protocol interaction between the client and the origin server, which the accelerator is able to intercept and leverage for the purposes of validating cached objects based on stored metadata and origin server responses. Accelerators that perform application-specific caching must adhere strictly to protocol and application semantics and must use existing protocol and application messages as a means of validating the freshness of cached objects. Although the behavior of an accelerator that has an application-specific cache might be different on a protocol-by-protocol or application-by-application basis (each has its own requirements and methods of validation), the conceptual process of cached object validation remains the same. Every request intercepted by the accelerator with the application-specific cache will be parsed and associated with any matching local cached content. The content that already resides on the application-specific cache’s disks is then compared to the content that is provided as part of the response by the origin server.
Each method of object validation within an accelerator with an application-specific cache must have the ability to natively communicate with the origin server as needed and exchange information specific to the application and the content item that requires validation. For protocols such as HTTP and HTTPS, a generic web application cache inspects the origin server’s response to a client’s proxied request, comparing the text within the header to the header information recorded from the previous request that placed the content into the cache’s storage. For CIFS file server traffic, which has no inherent freshness metrics built into the protocol, each object accessed must first be checked against the origin server to examine whether or not the object has changed based on time stamps, size, or other version-control mechanisms.
The two levels of freshness check implemented for requests follow:
Strict content coherency: The object must be validated directly against the origin server by the accelerator.
Nonstrict content coherency: The object can be validated based on responses sent to the user by the origin server.
The CIFS protocol, for instance, dictates the use of a strict coherency check because it does not natively include information within message exchanges that defines the coherency of the content being accessed. Furthermore, with CIFS, users from potentially many locations have the ability to apply read and write functions to the content stored on the origin server. With CIFS, it must be assumed that the object could possibly have been edited since the previous access. CIFS also provides metrics for collaboration and multiuser access, which means that an accelerator with CIFS caching and acceleration capabilities must be able to accommodate such scenarios. Given the possibility of multiuser access scenarios, the accelerator must be prepared to dynamically adjust the level of caching and optimization applied to object interaction based on what can be done safely and without violation of the correctness requirements of the protocol. The accelerator must also take ownership of content validation and leverage this information as part of its adaptive optimization model.
Protocols such as HTTP and HTTPS commonly employ nonstrict coherency and cache validation because information about content validity is commonly carried in protocol messages that are exchanged between clients and servers. HTTP and HTTPS are commonly used in a unidirectional request and response form, meaning that the content that is served is generally not edited at the edge of the network, with the exception commonly being collaborative workspaces and web-enabled document management applications. Protocols such as HTTP and HTTPS can rely, and commonly have relied, on tags contained within messages exchanged between nodes to determine the freshness of content stored in the application-specific cache.
Some accelerator protocol caching functions can be configured to completely bypass the function of cache freshness validation, but this type of configuration exposes the client to the risk of accessing stale content from the application-specific cache. This kind of configuration is common with HTTP and the Internet, where bandwidth savings are more important than freshness. If an administrator applies freshness validation bypass settings to a caching device, the administrator must have detailed information specific to the application and its content provided to clients.
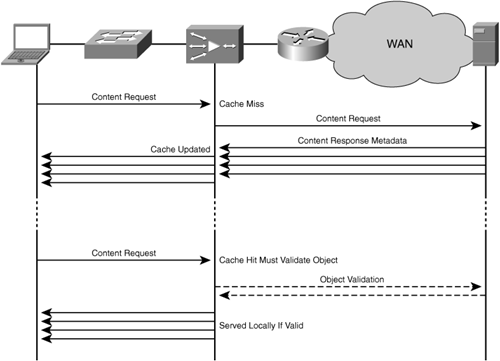
Figure 4-1 illustrates nonstrict coherency where an accelerator employing application-specific caching is able to examine client and server message exchanges to understand content validation periods. This figure shows an example of a cache hit (top portion of the example) and a cache miss (bottom portion of the example). Any data exchanged between the user and the origin server that traverses the accelerator is a candidate for optimization through compression, flow optimizations, and other WAN optimization capabilities.
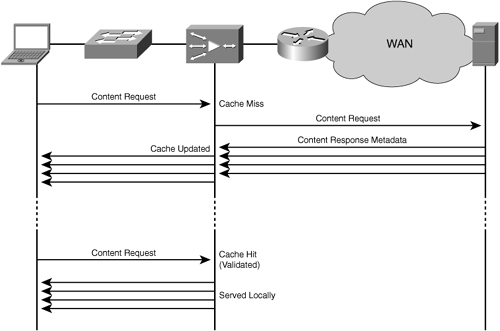
Figure 4-2 illustrates the strict coherency model, where an accelerator employing application-specific caching is not able to examine client and server message exchanges to understand content validation periods. For these applications and protocols, the accelerator must validate the content against the origin server using other means such as time stamps or other version-control methods. This figure shows an example of a cache miss (top portion of the example) and a cache hit (bottom portion of the example). Any data exchanged between the user and the origin server that traverses the accelerator is a candidate for optimization through compression, flow optimizations, and other WAN optimization capabilities.
The next sections will examine caching and optimization in more detail relative to CIFS, HTTP, HTTPS, and SSL/TLS.
File-related content that traverses a WAN link over CIFS can range from just a few bytes to several gigabytes in size. CIFS, which is most commonly used between Microsoft Windows–based clients and servers, provides a protocol for accessing named pipes, network resources, and file shares. Given that CIFS works to make portions of a local file system accessible via a network, file system semantics must be supported over the network between client and server. As such, the CIFS protocol is rather robust, providing over 100 different types of messages that can be exchanged, spread over ten or more different dialects (protocol versions).
An accelerator that provides CIFS acceleration and caching for CIFS must be aware of how clients and servers negotiate the dialect to be used and how to handle the different types of messages that are exchanged between client and server. Some messages can be safely suppressed or otherwise handled locally by the accelerator, without compromise to data integrity or coherency. Other messages are so critical to data integrity and coherency that they must be handled in a synchronous fashion by the origin server, and the accelerator must be prepared to accelerate delivery of such messages to the server. Because CIFS is not dictated by published protocol standards, an accelerator must also be prepared to handle messages that are structured in a way that it does not understand and gracefully pass them through to ensure support for vendor-specific implementations that deviate from others.
When an accelerator with CIFS caching and acceleration capabilities resides in the path of the client to server session, several WAN traffic reduction benefits and performance improvements will be realized, including these:
The number of messages exchanged between the client and server will be greatly reduced, because the accelerator can safely minimize the amount of chatter that must be exchanged over the WAN. This helps to improve response time to the client, minimize the amount of work that must be performed by the origin server, and negate the penalty of WAN latency on user performance.
The file on the server that is accessed by the client can be captured and cached by the application-specific cache if it is safe to do so. This allows the accelerator to mitigate the need to transfer files across the WAN that have been previously accessed, assuming that the user is authenticated and authorized and the object in cache is successfully validated against the origin server.
The most important aspect of a cache is its ability to store entire objects or portions of objects that are usable at an application layer. This stored copy becomes the primary source of benefit when implementing an application-specific cache; the content does not need to be served by the origin server a second time if validation and freshness requirements are met, which also translates to a reduction of the number of bytes that must be served over the potentially low-bandwidth and high-latency WAN. The realized benefits of an application-specific cache increase with each additional request received for a piece of content that already resides within the cache and can be validated as coherent when compared to the copy on the origin server. The benefits of the cache’s ability to re-serve any given piece of cached content can be tracked linearly, based on the number of requests that are processed and serviced following the initial caching of content.
In addition to the reduction in the number of requests that must traverse the WAN, the CIFS messaging overhead is also significantly reduced by the application-specific cache and protocol optimization. Some messages might not be required to traverse the WAN for a client to successfully acquire a given piece of content or search a directory, while others require message exchanges with the origin server. For instance, an accelerator may have performed a read-ahead function (as discussed in the “Read-Ahead” section later in this chapter) and temporarily stored the results of the read-ahead data for use by a user. A request for this data may be satisfied locally, thereby removing the need to send the user’s read request to the origin server.
Many accelerators that optimize CIFS also prefetch large amounts of information about the directory structure and stage this data at the edge of the network. If a user browses a directory structure, the directory traversal data may be served out of the accelerator if it is considered valid. Most accelerators that optimize directory traversal use a very short window of validation on directory traversal data (for example, 30 seconds) to allow directory updates to be received by the user in a timely fashion.
It is those messages that do not need to communicate with the origin server that the application-specific cache will interpret and terminate or otherwise respond to locally at the accelerator. Messages that are critical to data integrity, security, or state, however, must traverse the WAN to ensure compliance with CIFS object freshness and protocol semantics. Such messages include those that provide protocol negotiation, user authentication, user authorization, file locking, file open requests, and write operations. These messages can, however, be optimized through WAN optimization techniques that operate in an application-agnostic manner, including compression, flow optimization, and loss mitigation.
CIFS natively creates a tremendous amount of overhead traffic in native client to server exchanges. In many instances, a seemingly simple operation such as a file open of a 1-MB document might require that over 500 messages be exchanged between the client and the server. In a WAN environment, the maximum throughput that can be achieved is directly impacted by the amount of total network latency and is easily calculated as the number of messages multiplied by the latency per operation.
For instance, in a 100-ms roundtrip WAN, 500 messages being exchanged can lead to upwards of 100 seconds of latency to open a simple document. With CIFS acceleration and CIFS caching, clients benefit from the elimination or reduction of certain types of overhead traffic and potentially the elimination of the redundant transfer of requested files. Reducing the amount of latency experienced by the client during client to server exchanges will improve the overall perceived performance of a given application, file transfer, or other operation. Coupling the accelerator’s capabilities to accelerate the protocol (mitigate latency and minimize bandwidth consumption) with WAN optimization capabilities (discussed in Chapter 6), accelerators can help to improve performance over the WAN to the degree that remote office file servers can be consolidated into a centralized data enter.
Many accelerators rely on a built-in CIFS capability called the opportunistic lock, which is a message sent from the server that can effectively relay the state of a file in question to an end user. The original intent of the opportunistic lock was to enable the client to, when determined safe to do so by the server, leverage optimizations built into the CIFS redirector on the client. These optimizations include client-side read-ahead, write-behind, and other types of operations including local open and lock handling. All of these not only help to improve the client experience, but also minimize the workload on the origin server. In a way, this same information about state is leveraged by accelerators to determine how “safe” it is to apply a specific optimization or set of optimizations to a file that has been requested, and file caching is one of those optimizations. In essence, most accelerators maintain CIFS protocol semantics and apply only a level of optimization that is safe based on what the origin server says the state of the file is and, furthermore, based on what the origin server allows a client to do on his own. In this way, the accelerator is able to employ additional optimizations that work in concert with the capabilities that the server permits the client to utilize.
Opportunistic locks and standard locks are also used to inform any clients requesting a file that the requested file is already in use by another client. The level of access in multiuser, concurrent access, collaborative types of scenarios is largely dependent upon another security mechanism called a share mode, which determines whether or not multiple users have privileges to read, write, delete, or otherwise manipulate a file while someone else is accessing that same file. From the perspective of an accelerator, these state relay messages (authentication, authorization, locking, and others) must not be handled locally and must be passed to the origin server synchronously. This is to ensure full compliance with protocol correctness, content freshness, and security. For instance, if a user accesses a file on a CIFS file server, whether accelerators are optimizing the session or not, and another user is already accessing that same file, the server must notify the requesting user that the file is unavailable for read-write access, as shown in Figure 4-3. Some applications permit multiuser concurrent access scenarios and might permit users to have read privileges to certain areas of the object and read-write privileges to other areas that are not in use.
There are three types of opportunistic locks in the latest CIFS dialect:
Batch: A batch opportunistic lock involves a client accessing a file on a CIFS file server with complete and unrestricted access. When a batch opportunistic lock is provided to the client, the client is allowed to make any changes to the content that his privileges allow, including local open, close, read, and write operations. The batch opportunistic lock is considered the least restrictive opportunistic lock a client can be provided, as it provides the client with the most freedom to perform operations locally.
Exclusive: An exclusive opportunistic lock, as with a batch opportunistic lock, informs the client that he is the only one to have a given piece of content open. Like the batch opportunistic lock, many operations, including open, close, read, and others, can be performed against the local client cache. The primary difference between exclusive and batch is that with an exclusive opportunistic lock, the server must be updated synchronously with any changes made to the state of the file (contents of the file or attributes of the file).
Level II: The Level II opportunistic lock informs the requesting client that there are other users who already have access to the file, but none has changed the contents or state of the object. In this case, the client may perform local read operations against the file and its attributes from the local client cache, but any other requests must be sent to the server synchronously. The level II opportunistic lock is considered the most restrictive opportunistic lock but still provides the client with the ability to perform many of the operations locally, thereby providing better performance than a standard lock, which requires all messages to propagate synchronously to the server.
An application-specific cache for CIFS within an accelerator will commonly intercept requests over the standard TCP ports used by CIFS—TCP/139 and TCP/445 and many can be configured to accelerate CIFS on non-standard ports if necessary, which is not common. The main purpose of a CIFS application-specific cache is to minimize bandwidth consumption and improve response times for requested content or file transfers. The larger the objects stored in the application-specific cache, the faster the response times will be to any clients who request previously cached content, as compared to accessing the same object over the native WAN. Accelerator-based CIFS caching is useful in environments where file server consolidation is desired, especially environments where large files are present, because the performance provided by the accelerator is similar to that provided by a local file server. Accelerators with CIFS caching and acceleration are equally useful in environments where large objects are being used.
System administrators often use CIFS to distribute large objects across the network. Some of the more common applications that leverage large content objects include computer-aided design/computer-aided manufacturing (CAD/CAM) applications. The objects that these applications create might be as small as a few hundred kilobytes to as large as several hundred megabytes or gigabytes. Applications that focus on graphics and imaging involve a significant amount of detail and, thus, the objects in use consume a tremendous amount of storage capacity. With increased image resolution requirements, the amount of disk usage consumed increases as well. Medical applications that involve imaging consume large amounts of disk storage depending on the type of imaging being done. Enterprise network administrators also commonly leverage CIFS to distribute software updates, operating system patches, or entire operating system images. It is common for these applications to rely upon CIFS drive mappings to a central server in the data center (or a local software distribution server that can then be consolidated once accelerators are deployed).
Each of these large distribution jobs tax the WAN for each request. Regardless of the file’s purpose, an application-specific cache stores the object when safe to do so and can potentially serve it locally, thereby mitigating unnecessary transfer. For environments that require interactive read-write operations against large files, such as CAD/CAM applications, software development applications, and others, CIFS acceleration and caching can leverage the accelerator’s WAN optimization components (discussed in Chapter 6) along side object caching to further improve performance of both read and write operations over the WAN.
For CIFS, the accelerator intercepts and examines each message that is transferred between the client and server. The accelerator determines where the client and server are in their message exchange and what function is being performed, which enables the accelerator to make intelligent decisions on how to process and optimize the conversation. While observing the traffic between hosts, the accelerator can safely eliminate some messages after determining that they are not required by the origin server.
Beyond the messaging resides the requested file itself, which is evaluated within a process different from the CIFS messaging. Each file that traverses the accelerator may or may not be stored on the accelerator’s local disks depending on the level of optimization that the accelerator can safely apply. For content that is stored on the accelerator’s disks, the content might be whole content objects or portions of a given piece of content. A whole content object does not need to be received at the accelerator for the accelerator to successfully cache or serve the portions of traffic that traverse it. If a request arrives at the accelerator, the application-specific cache will deterministically serve the content that is stored on its disks to the client when safe to do so and fetch any missing portions of the partially cached object from the origin server. The application-specific cache will proactively read ahead of the client’s request to fetch the content missing from the partial cache. Overall, this dual method of content fetch and serve will improve the performance to the user and dynamically populate the remaining portions of the partially cached file’s missing data.
An application-specific cache might cache only portions of a given file based on the needs of the requesting application; a partially cached file does not demonstrate a faulty application-specific cache. Figure 4-4 illustrates a partially cached object being served from the accelerator’s cache, while the accelerator is acquiring any missing segments of the content from the origin server.
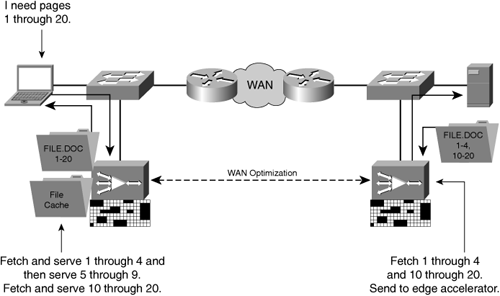
Caching and read-ahead functionality combine to provide a dramatic performance improvement when accessing objects over the WAN. For content requests that can be served locally, the accelerator can respond to data requests when doing so is safe. For content requests that cannot be satisfied by the accelerator, the accelerator can choose to apply additional optimizations such as read-ahead, discussed later in the chapter, to proactively fetch a larger degree of an object, which helps to satisfy future requests for portions of the object locally.
When CIFS requests arrive at the accelerator, cached content is not served to the requesting client until the accelerator has performed validation and it has been deemed safe to do so. The validation process is dependent on a number of factors, including the state of the opportunistic lock supplied to the client and verification with the origin server that the object has not changed. The process of determining the file’s coherency is automated and subject to the origin server’s proper delivery of state and response to inquiries from the accelerator. In any scenario, the origin server will always own the state of the data, thereby ensuring that in hybrid accelerated and nonaccelerated environments where users access from remote locations with accelerators and locations without accelerators, the security, safety, and freshness characteristics are identical with or without the presence of an accelerator that is optimizing or caching CIFS data.
As noted earlier, when an application-specific cache receives a request for content that already partially exists within the cache’s storage, the accelerator may generate additional read requests on behalf of the client to acquire the remaining portions of the partially cached file. The application-specific cache will recognize the pattern created by a client requesting a series of small content reads for a larger content item. Once this pattern has been observed, the application-specific cache will initiate read-ahead requests for the remainder of the content item prior to the actual client’s request for the remaining data. Several applications exhibit the trait of smaller data reads, ultimately building to request an entire file. When operating in this default mode, the application-specific cache transitions from content request cache misses to content request cache hits proactively. To the requesting client, the overall throughput of the WAN appears dramatically faster in the presence of accelerators. With the read-ahead requests having been pipelined between the accelerator and server, latency is significantly reduced.
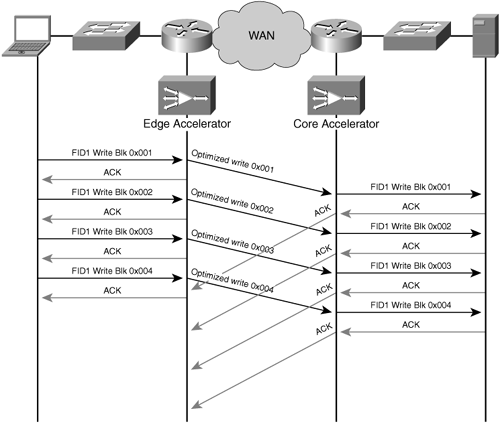
Optimizations gained by the accelerator are not limited just to the process of caching or read-ahead. Accelerators commonly also provide pipelining for user write requests when safe to do so, which is discussed later in this chapter. Prior to an application-specific cache’s implementation, the origin server would receive write requests directly from the client. When the write requests are intercepted by an application-specific cache, these writes are batched by the application accelerator when applicable, allowing for the writes to be pipelined and streamlined over the WAN. In many cases, write requests are also filtered against the known contents of the cached object to ensure that unnecessary write operations need not traverse the WAN.
When writes are made to the origin server directly by the client, each write requires the origin server to provide acknowledgment to the client for each operation. When writes are sent to a server with accelerators in the network, the accelerator can make a determination, based on safety, on whether or not optimization can be applied that would allow the accelerator to generate acknowledgments on behalf of the server. These acknowledgements allow the accelerator to temporarily buffer data while managing the process of transferring the writes on behalf of the user to the origin server in a more write-optimized fashion. Figure 4-5 illustrates the process of automated write responses from the accelerator to the server.
Many accelerators employ acceleration capabilities for file access protocols other than CIFS, such as the Network File System (NFS) for UNIX environments. The concepts of file protocol acceleration are largely similar to the concepts of acceleration that can be provided to other file access protocols and other application protocols in general. The primary differences among them are the structuring of the messages and the way state is maintained. CIFS, for instance, is an extremely stateful protocol, whereas NFS is stateless and requires that all operations be idempotent. Regardless of the file system protocol in use, an accelerator that performs acceleration and object caching must be employed in a way that preserves data integrity and coherency.
The HTTP application-specific cache functions of an accelerator allow for reactive caching of objects that are requested through on-demand HTTP content requests. To appropriately intercept HTTP traffic via traditional caching, the accelerator must have the ability to natively speak the HTTP protocol. Although HTTP and the secured HTTPS share the same foundational transfer methods, HTTPS is treated differently by accelerators. Session encryption is the primary difference between the protocols, and some accelerators can become a man-in-the-middle through a process of decryption, optimization, and re-encryption. Any responses served locally are re-encrypted, and any requests that must be sent upstream are re-encrypted to maintain security semantics.
An HTTP cache can transparently or explicitly intercept HTTP requests from devices such as personal computers or even personal digital assistants. An HTTP request consists of a connection commonly established over TCP port 80. From a client to a given origin server, the majority of enterprise web traffic uses port 80 and is commonly classified as intranet traffic. If the origin server resides on the public Internet, this traffic is considered Internet traffic. HTTP requests are not limited to TCP port 80 but have been observed on TCP ports 8000, 8001, 8080, 3128, and many other ports. Each one of these ports and any other custom port number can be intercepted by the HTTP application-specific cache based on predefined port number understanding or administrator configuration.
Depending on the version of HTTP supported between the client and origin web server, requests might be sequential, as with HTTP version 1.0 traffic. HTTP 1.0 also requires that a new TCP connection be established between the client and server for each object that is being requested. HTTP 1.1 addresses these limitations by providing support for multiple concurrent connections to be established between the client and the server, thereby minimizing the amount of time that is spent establishing TCP connections. Request pipelining is also supported with HTTP 1.1, although it might not be implemented in some specific web-server or application-server instances. HTTP 1.0 sequential requests require a response for each request, prior to the next request being issued by the client to the web server after establishing a new TCP connection. HTTP 1.0 requests are very inefficient, due to the start and stop nature of the protocol and the start and stop use of TCP as a transport protocol. When combined with a WAN that has a significantly high latency, HTTP 1.0 becomes extremely inefficient to the requesting client and can present a severe performance bottleneck.
Traditional application-specific caches rely on HTTP headers or relative time values to determine the freshness validity of a given piece of content. When a client initiates a request for content from an origin server, through an accelerator with HTTP caching and protocol acceleration, the accelerator first checks the object cache to see if the content already resides within storage. If the content does not exist in storage, the accelerator forwards the request upstream toward the origin server to fetch the content and update the local object cache. When the origin server responds to the request, a copy of the content is served to the user while simultaneously updating the local object cache with the object itself. At this point, the object may be a candidate for use upon receipt of a subsequent request.
If the content already resides in the application-specific cache, the accelerator initiates an HTTP If-Modified-Since (IMS) request to the origin server, checking the date, time, and entity tag, or “ETag,” properties of the content on the origin server within the response header. If the date, time, or ETag properties have changed at the origin server, the server provides the updated content to the accelerator. To prevent the serving of stale content from the accelerator’s cache, newer content will always be acquired, stored, and served to the requesting client. Example 4-1 illustrates the common structure of an HTTP response header that the accelerator will inspect to determine object validity.
When an HTTP application-specific cache is combined with compression and other optimization techniques such as read-ahead, the overall traffic that traverses the WAN between a core accelerator and edge accelerator is significantly minimized. Although many web servers today apply gzip or DEFLATE compression to served objects, a cache still bases its decisions on the header properties provided by the web server. Many times, the objects served by the web server contain data patterns that the accelerator can leverage through data suppression algorithms, as discussed in Chapter 6. An object served from a web server might contain patterns that the core and edge accelerators have already recorded, eliminating the traffic patterns found within the response to the client’s HTTP GET. When combined, HTTP caching, read-ahead, transport optimization, compression, and data suppression provide a vast improvement to the requesting user’s web experience.
Although similar to HTTP, HTTPS adds security through encryption to the transfer of content between a client and web server. Unless the accelerator is able to actively participate in the session with the use of a valid key and certificate, the accelerator can provide only WAN optimization components. Both in-session (man-in-the-middle) and out-of-session (TCP flow optimization only) optimization services provide performance improvements to the end user. To provide a greater degree of optimization for HTTPS traffic, accelerators that are participating in the optimization of such flows must either be preloaded with the keys necessary to decrypt encrypted flows or be able to participate in the secure session establishment as a man-in-the-middle using single-sided key distribution and session keys (as opposed to private keys).
To establish a successful HTTPS session between a client and server, the two hosts must establish a secure session based on a successful exchange of certificates and keys. If the negotiation process of the certificate and key cannot be established, the attempt to establish an HTTPS session fails. With a failed HTTPS session, content is not transferred between the origin server and requesting client, and the client must reattempt the certificate and key negotiation or seek an alternative method of access to the origin server.
For accelerators to actively participate in and optimize an HTTPS session, the accelerators in the network path between the client and the server must have access to the proper certificates and keys needed by the origin server. HTTPS certificates and keys must be administratively applied to the accelerators prior to the first secure session traversing the accelerator.
Alternatively, accelerators may employ techniques that allow for single-sided distribution of keys to the data center accelerators and leverage the session establishment and session keys to participate in the encryption and decryption of traffic. In this way, the data center accelerator must become an SSL proxy on behalf of the origin server and may also use its own encryption between the user and itself, as opposed to using the server’s encryption. This type of deployment, which minimizes the distribution of keys outside of the data center, may also create complications in environments with client keys.
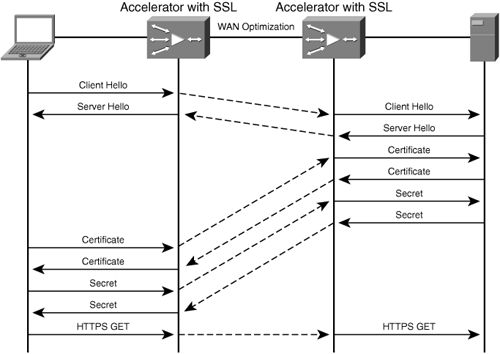
Once keys have been distributed to an accelerator, the accelerator can then safely inject itself into the message exchange through the process of decryption and re-encryption. When an accelerator is actively a part of the HTTPS session and receives HTTPS traffic, the secure traffic is first decrypted. After the traffic is decrypted, the accelerator has visibility to the clear-text data being exchanged between the user and the server. With clear-text data visibility, the accelerator can then parse the data for any cacheable content or requests that can be optimized and employ any optimizations that are safe to employ for that particular request.
For content requests that cannot be satisfied locally, the request and any optimized requests are passed through WAN optimization components such as compression and data suppression (discussed in Chapter 6) and then encrypted and sent upstream toward the origin server through the optimized transport. For content requests that can be satisfied locally, the accelerator can fetch the requested object from the local object cache and apply the encryption necessary to serve the object to the user. Other forms of optimization, such as read-ahead and pre-fetching, are employed in a similar fashion. Figure 4-6 illustrates the data flow of an accelerator that is an active participant in an HTTPS session between a client and server.
The next section takes a more in-depth look at SSL and Transport Layer Security (TLS) and how accelerators that provide optimization for encrypted traffic interact with these security layers.
Secure Sockets Layer (SSL) is a cryptographic protocol. This protocol provides session-layer encryption for users and servers to ensure that exchange of application traffic over the network is done in an encrypted manner. For HTTP, SSL provides secured browsing access to targeted hosts that have been configured to support the SSL protocol at the application server. Although SSL can be used for a plethora of application protocols, HTTPS is the most common implementation of SSL and thus is the focus of this section. Not all web servers support SSL, nor do all web servers have SSL enabled, but SSL is becoming progressively more popular given customer security requirements and demands from regulatory bodies. SSL sessions create added requirements and workload on the server and client to properly encrypt and decrypt data, which impacts components such as the CPU and memory subsystems. In many cases, SSL can have an impact on performance given how compute intensive it can be, unless SSL processing is offloaded to a secondary processor, which may be installed as a PCI or PCI/X card within a workstation or server.
SSL has progressed to version 3.0, which offers encrypted authentication and communication between the client and server. When an accelerator is introduced in the path of an SSL session, the client establishes a session with and through the accelerator, which in turn provides the predefined credentials to the origin server.
For an accelerator to actively participate in an HTTPS session between a client and server, a hardware decoder card may be used to offload SSL processing to hardware, thereby nearly eliminating the performance bottleneck that is created by managing SSL in software on the CPU. Such hardware acceleration cards for SSL are intended to reside in an open PCI slot within an accelerator. Although external dedicated HTTPS decryption devices exist today, it is rare to find a dedicated SSL decryption device installed in a remote network location. Many can be found in the data center, however, and are typically deployed in existing server load balancing (SLB) devices.
When implemented in an accelerator, the SSL acceleration card handles the decryption and re-encryption of the session with the requesting client and the origin server. Without such a card present, these functions must be handled by the accelerator CPU and software. The accelerator itself is still responsible for establishing the session setup, key exchanges, and any negotiations required during the establishment of the SSL session. The use of an active SSL card in an accelerator does not completely eliminate the need for added resources at the accelerator but does greatly reduce the processing requirements that consume resources at the accelerator device while optimizing an SSL session.
Transport Layer Security (TLS) version 1.1 is the successor to SSL version 3.0. The primary differences between the two involve recent RSA enhancements to TLS 1.1 that did not exist in SSL 3.0. TLS 1.1 supports RSA, DSA, RC2, triple DES, AES MD2, MD4, MD5, and SHA algorithms. Depending on which is negotiated at the time a session is being established, a TLS 1.1 session might become an SSL 3.0 session. If HTTPS interception and SSL acceleration are enabled on an accelerator, and the required key and certificate have not been provided to the accelerator or are otherwise unavailable, the request transparently passes through the application-specific acceleration capabilities of the accelerator yet may still leverage the benefits provided by the WAN optimization capabilities between accelerator appliances to improve the performance of the connection.
Streaming media has become one of the most popular methods of corporate communication. Streaming media brings the presenter to his audience, taking the messaging contained within the streaming media to a more personal level with the viewer. The following four major contributors are foundational to the success of streaming media:
Microsoft Corp., with its Windows Media Server and client-based Windows Media Player
RealNetworks, Inc., with its Helix Server and client-based RealPlayer
Apple, Inc., with its Darwin Stream Server and client-based QuickTime Player
Adobe Systems, Inc., with its Flash Media Server and client-based Flash Player
Each of these streaming media vendors requires two common components: a server that provides content over the vendor’s native transport protocol and a dedicated media player or browser plug-in installed on the client’s computer to effectively decode and play back the media. From an application perspective, streaming media has taken a corporation’s ability to communicate to a new level, bringing executive management to the employee.
The protocols used by each of the major streaming media vendors may be based on a protocol as basic as HTTP or may progress into other protocols, such as the Real Time Streaming Protocol (RTSP). To become an active participant in the streaming media event, an accelerator must have the ability to properly match an RTSP-based request to the proper instance of the streaming media server or proxy. Although HTTP sessions are a progressive download or unmanaged flow of content to participating clients, RTSP requires intelligent decision awareness at the streaming media–specific cache or server.
As discussed in greater detail in Chapter 5, there are two methods of delivering streaming media to the requesting client: video on demand and live streaming. Video on demand involves serving streaming media to a client reactively. The client’s request is served by the delivery of content at either the beginning of the media or at a specified offset contained within the client’s request to the accelerator. Access to content served as video on demand involves the client accessing a given predefined URL that points to a video file on a server. The target of this predefined URL may reside at an origin server or an accelerator.
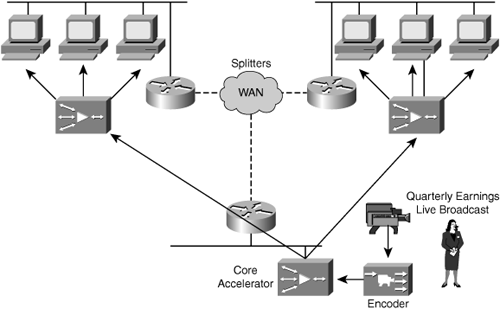
Live streaming media is used within an enterprise network less frequently than video on demand is. Live streaming media involves much more planning and schedule synchronization. For an accelerator to participate within the flow of a live streaming media event, the accelerator commonly becomes the live stream’s splitting point at the data center and edge of the network. The stream splitting process allows for the accelerator to acquire a single live feed from the media’s server source and provide that single stream to multiple participating clients behind the accelerator. This method of splitting streams allows an accelerator to serve a large number of streams without requiring multiple copies of the same stream to traverse the WAN. A streaming-focused application-specific cache will not obtain a copy of the live event as it traverses the accelerator but merely facilitates the ability to distribute a single feed to multiple users simultaneously. Figure 4-7 shows how a small number of streams from an origin server can be used to serve live content to a large number of users.
When an accelerator that supports optimizations for RealNetworks, Windows Media, and QuickTime receives the initial RTSP request for content, it looks for the client’s media player to be identified within the first eight transactions of the request. Once the accelerator has identified the client’s media player, it routes the request to the proper streaming engine within the accelerator. For requests that require the accelerator to communicate across the WAN, the accelerator applies WAN optimization components such as transport protocol optimization to the TCP-based stream as it traverses the WAN. To the client of the live stream, the optimizations might not be as apparent as they are to the network administrator.
Video-on-demand content that has been prepositioned to the accelerator over protocols such as HTTP or CIFS, also leverages WAN optimization components while traversing the WAN. Although video content by nature is already compressed, repeated data patterns can be safely eliminated through data suppression when traversing the WAN, as discussed in Chapter 6.
Just as with other media accessed via the WAN, video-on-demand content is subject to the same risks of stale status and latent freshness. If the video-on-demand content is accessed over CIFS or HTTP, then the accelerator confirms that the content to be served is the absolute latest version available from the origin server. If the content is to be accessed over a native protocol such as RTSP, then the application accelerator first validates the freshness factor of the content with the origin server prior to its delivery to the requesting client.
For live streaming events, the concerns of content freshness do not apply; the live streaming event is delivered to participating clients at the exact time the content is being broadcast throughout the network. The accelerator may simply serve as a platform for optimized delivery through multicast or stream splitting to minimize bandwidth consumption on the WAN for a large number of remote viewers.
Three of the most commonly used web-based applications found within the enterprise today include Oracle Corporation’s Oracle and Siebel database, as well as SAP AG of Germany’s SAP. Each of these applications has the following traits:
The ability to allow client access to an application via a web browser as an alternative to or in conjunction with the deployment of a legacy desktop application that is preinstalled or installed on-the-fly
A common authenticated HTTP access model, with the option to transition to HTTPS for added security
The use of Java applets to generate the application within the client’s web browser
Potentially long wait times required of the user accessing the application, because large Java applets may be used and must be transferred from the database server to the client’s web browser over the WAN
Web-based applications can be addressed by accelerators via two different models. The first involves the application-specific caching described earlier. Accelerators that perform application-specific caching of the protocols used by applications are able to keep a cached copy of objects, such as Java applets, that have been previously transferred. This allows the accelerator to minimize the redundant transfer of objects across the network. The second approach involves the use of the WAN optimization components provided by accelerators, which include transport protocol optimization (overcome packet loss, latency, and throughput), compression, and data suppression. This section illustrates both models, showing the benefits that each approach provides to these sample business-critical applications. Chapter 6 provides a more in-depth examination of the WAN optimization components in a more application-agnostic manner.
Oracle, Siebel, and SAP support the use of HTTP to provide simplified distributed access throughout a corporate network. The HTTP requests that are served by the database server to the requesting client carry several cache-friendly objects. Depending on how the database server is configured, the primary Java applet delivered to the client will be a JAR file, specifically the Jinitiator for Oracle clients. Siebel delivers Java applets and graphics objects while SAP uses JS, GIF, and CSS objects. Depending on the application and origin server configuration, objects served to the client may or may not be identified as cacheable content to a traditional HTTP cache.
When using HTTP acceleration and caching in an accelerator, three simple steps help identify how cacheable the application is:
Enable the accelerator to intercept the client’s requests made to the database server. This might involve special configuration changes on the accelerator, allowing the interception and application acceleration of traffic on nonstandard ports such as 8802. Many accelerators will automatically recognize ports that are commonly used by application vendors.
Enable transaction logging on the accelerator. Transaction logs easily identify which types of content are already cacheable and which types are not.
Gain access to a packet-capture or protocol analyzer application such as Ethereal or Wireshark, to inspect the HTTP responses of the object headers that traverse the network between the database server and client.
Once you have configured the accelerator with HTTP acceleration, including caching to intercept the client’s database traffic, check the accelerator’s statistics for any initial cache savings and compression savings. There is a possibility that no additional configuration changes will be needed on the accelerator, providing the simplest of implementations. Although unlikely, you might find that the server has no privacy or cache header parameters defined to prevent the HTTP cache within the accelerator from storing current requests and serving future requests.
When you are inspecting the transaction logs assembled by the accelerator, the client generating the test traffic must request the same database applets at least twice. If the user has requested a given object only once, there is no way to validate whether the cache was able to serve the object that might have been cached. Transaction logs help to quickly identify the filename and URL associated with the request as well as how the accelerator processed the requested content during the second request. Any transaction log entries that state that the second request was a MISS require additional network trace–based investigation by the administrator.
Many of the objects served by the dynamically generated pages are sourced from static, common URLs within the database server. For accelerators that implement standards-compliant forward caching for HTTP, such changes should be made at the server or data center load balancer, where applicable, to improve cacheability. If these changes are not made, other components such as data suppression (discussed in Chapter 6) will still provide potentially tremendous levels of optimization and bandwidth savings.
Some HTTP accelerators support the ability to override the unique headers defined by the server, including an Oracle database server. This type of configuration change is not generally recommended unless the person performing the configuration is intimately familiar with the application content and freshness requirements. In some instances, the Ethernet trace utility will identify which header variables have been set by the Oracle database server.
Knowing which headers prevent object caching aids the administrator in tuning the accelerator. When properly configured, an accelerator with HTTP acceleration capabilities can reduce database object traffic by as much as 90 percent or more and reduce response times by as much as 80 percent or more. A 90 percent reduction in bandwidth utilization and an 80 percent reduction in response time help to provide faster application access for employees, while reducing bandwidth consumption and overall server workload.
Some database applications serve their objects to clients who present a valid cookie during the transaction process. This cookie provides session information to the database server, which commonly includes information specific to the requesting client, or state of the overall business transaction that the client is attempting to perform. Cookies are based on previous transactions that have taken place with the database server. The actual cookie issued by the database server commonly has an associated expiration timer, preventing a session from being accessed at a later date. Although the use of cookies interferes with the actual caching process, cookies and intelligent web caching can be configured to work together properly. Cookies are unique to a specific user’s session with the application and are easily identified within the header of a server’s response to a client’s GET request. By default, any content that has an assigned cookie is not reactively cached in preparation of future requesting clients.
If cookies have been defined by the database application server, or the database application, many accelerators with HTTP acceleration capabilities support configurability of a function that ignores the cookie variables defined within the header and forces the act of caching upon any cookie-related responses. Cookie bypassing does not break the cookies required by the database server to track client application status or database administrator monitoring abilities. Any bypassed cookie variables are transparently passed between the database application server and requesting client, with no disruption to the performance of the application.
Another trait infrequently found within browser-based database transactions is the use of byte range requests, sometimes known as range requests. Support for byte range requests is not a common requirement of most Internet web servers but has become a requirement of many database application servers. A byte range request made by a client to an application server is a request for a specific range of bytes within a larger object. To an intelligent accelerator, the entire object may never be provided to the clients that reside behind the intelligent cache, prohibiting the cache from storing the database server’s response. To address this unique situation, the intelligent accelerator HTTP cache supports the ability to cache the byte range responses provided by the database server. Once the range has been stored by the cache, it becomes immediately available to future requesting clients.
Range requests and session cookies are not taken into consideration by an application-specific cache. The requests presented to the application server include any session cookies needed for a successful transaction with the database server. Range requests also traverse the application-specific cache, allowing for proper application functionality. It is not until the response from the database application itself is provided to the core accelerator that the responses are inspected for any previously known packet structures. The core accelerator provides any known signatures to the branch accelerator, while preserving any session information required by the database application.
When users attempt to access a database server that challenges them for valid credentials, one of two authentication methods may be applied:
Database server hosted
User domain based
One method involves the use of the passwords held within the database server. This method challenges the client during its initial HTTP session between the client and database server. This process places a dependency on the database server administrator to properly manage any credentials associated with access to the database application, as well as how the application interacts with any requesting clients. In-database authentication involves challenges over HTTP or HTTPS between the client and database server. If authentication is handled centrally, based on external authentication hosts, then the database application operates independently of any operating system–based authentication. Using external hosts, the operating system of the database server initiates a challenge to the requesting client prior to allowing access to the database application that resides on the server.
Regardless of the authentication method, the intelligent web cache supports the ability to cache authenticated content that has been provided by the database server. By default, client requests for authenticated content require the client to first provide valid credentials to the server’s challenge. Once the client has provided valid credentials, the content is delivered to the client. The intelligent web cache will acknowledge that the content had required valid credentials at the time the object was stored in its cache, establishing that any future requests for the cached object will also require the authentication process to be completed successfully.
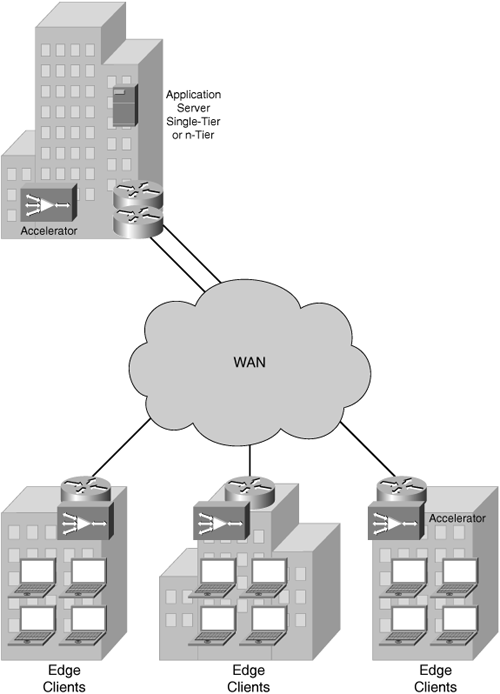
Figure 4-8 illustrates the traditional intelligent web-caching capabilities of accelerators with the database server in a central data center and requesting clients at remote branch locations.
Much of the object-based data served by a database application is sourced from static locations. These objects do not change. They are the Java applets required by the client to execute the application within the client’s browser. These reoccurring object requests make an application-specific cache perform very well. Once the core accelerator has observed and identified an object served by the application server, the packets representing the database server’s response become a signature or signatures. The dynamic content served by the database server is often a significantly smaller amount of data when compared to the Java-based applets required by the client’s browser. Performance observed by the requesting client may be as high as ten times quicker than a nonaccelerated connection that would traverse the WAN.
Accelerators with application-specific caching allow the authentication sessions to pass through the accelerator transparently. The accelerator does not participate in the authentication process, nor does it need to be aware of the actual session established between the client and server when the challenge is issued by the database server over HTTP. During the authentication process, the client and database server communicate with each other, qualifying the client’s credentials. These credentials, as well as any server responses, are not stored by the accelerator. The accelerator will store only the content or any metadata related to the server’s response.
Figure 4-9 illustrates a traditional database application with core and edge accelerators providing application-specific caching.
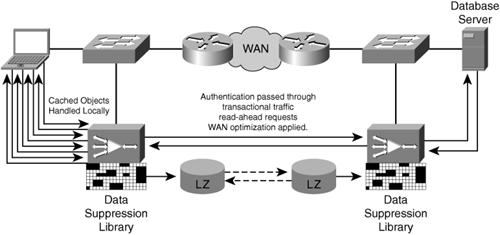
Optimizing enterprise applications with accelerators is done through a hierarchy of components, including application caching, protocol acceleration, and WAN optimization components. When combined, these functions provide bandwidth savings (object caching, data suppression, and compression), latency mitigation (object caching, acceleration), and throughput improvements.
Many applications use a series of read requests to fetch objects or data from a server. In low-bandwidth, high-latency WAN environments, each transaction incurs the latency penalty of the WAN and is subject to performance limitations introduced by the WAN. Application-specific caching is a means by which objects are stored locally on an accelerator during the first client request to ensure that objects do not need to traverse the network redundantly. Although application-specific caching provides a significant performance improvement for the second requestor of an object, it does little to improve performance for the first requestor and very little for the second user if the first requestor requested only part of an object.
Application-specific read-ahead is a technique that can be employed within an accelerator that is or is not performing caching for a specific application or protocol. Read-ahead examines incoming application or protocol read requests and augments the requests to either fetch a larger amount of data on behalf of the user or instantiate a larger number of read requests on behalf of the user. In essence, read-ahead tries to retrieve more data than the user is requesting. As the accelerator fetches a larger amount of data, thereby populating the compression history as well as the object cache, subsequent read operations that are made for data that has been read ahead by the accelerator can be serviced locally. In this way, read-ahead prevents the “back and forth” syndrome of read requests that occur between clients and servers.
When an application-specific cache has only part of an object stored in cache, or when an accelerator employs protocol acceleration that does not involve caching, there is a chance that a future request might seek an area of an object that has been used previously but was never requested. In environments where caching is present, the accelerator’s application-specific cache begins serving the existing cached data to the client or his application while simultaneously requesting the remainder of the object from the origin server. In environments with accelerators where caching is not employed, the accelerator can still perform read-ahead optimization against the object and temporarily buffer the response from the origin server in an attempt to use the read-ahead data to satisfy a future client request. In such cases, the data is maintained only for a very short period of time and not persistently. An application-specific cache monitors for sequential read requests against a given object and then proactively reads ahead for the remainder of the content (or a larger sequential portion of the object) from the origin server if the client’s read patterns persist. Read-ahead caching provides an intelligent method of demand-based content prepositioning onto the accelerator without additional configuration changes by the administrator.
The most efficient model of read-ahead application-specific caching involves two devices: a branch accelerator, which services the client’s requests locally, and a core accelerator, which serves both as an aggregation point for several branch accelerators and a termination point for WAN optimization capabilities such as data suppression and transport optimization.
When requests are made for regions of an object that cannot be satisfied locally (cached object, or where read-ahead is a safe optimization to apply), the edge or core accelerator may initiate a read request on behalf of the user. These read requests, when issued by the accelerator, are used as a means of prefetching additional data on behalf of the user such that if the user submits a request for that data, it can be served by the accelerator.
Accelerators can commonly parse human-readable container pages, such as the index file used with HTML, to identify objects that a page viewer might request and to prefetch the objects before the user requests them. In the case of prefetching an object, a user might request a range of bytes from within an object, and the accelerator might submit a larger number of requests against the object on behalf of the user, as is common when accessing a file using the CIFS protocol through an accelerator system. Figure 4-10 shows an example of accelerator read-ahead when employed for segments within an object being accessed by CIFS.
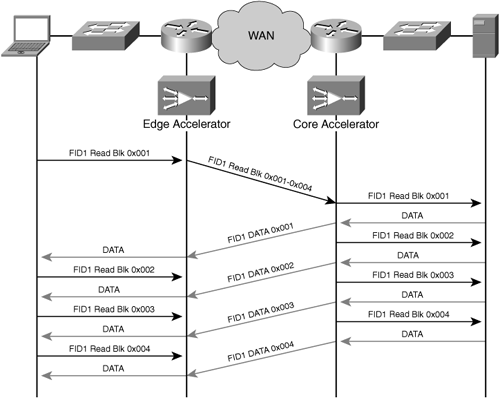
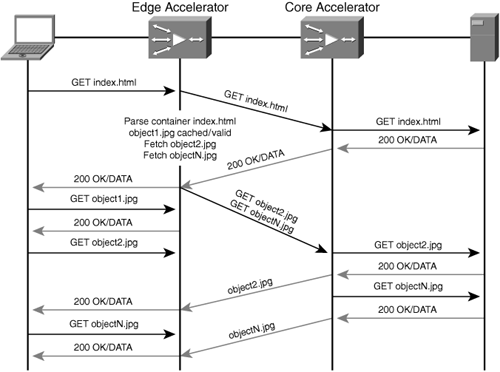
Figure 4-11 shows a similar example where the edge accelerator parses HTML container pages to issue read-ahead requests in a prefetch fashion. This type of read-ahead, based on container page parsing, can be implemented on either the core accelerator (as shown in Figure 4-11) or on the edge accelerator.
When read-ahead acceleration is actively processing client requests, the accelerators provide added intelligence to proactively fetch content and improve the application’s performance. When monitoring the accelerator’s performance, statistics such as request hits increase and request misses decrease. As the requesting client’s application initiates gradual requests for a larger object, the WAN optimization components of the accelerator will likely begin to recognize the request and response data patterns and initiate requests on behalf of the client’s application. As the data suppression compression library increases in capacity, the amount of actual compressed data that must traverse the WAN between the core and edge accelerators decreases.
Applications that rely on protocols that are sensitive to latency perform significantly better when leveraging read-ahead technology. When non-accelerated requests traverse the WAN, each individual request made by the requesting client or his application is subject to any roundtrip latency imposed by the protocol or network. Each one of the roundtrip requests adds to the overall response time of the given application. Many times, the latency issues can be safely mitigated at the edge through local protocol handling or through the accelerator’s ability to serve requested content locally. Any content requests that cannot be served locally by the accelerator will prefetch via the edge accelerator’s read-ahead functionality, reducing future latency in advance of the application’s actual request for the data. This also, again, serves the purpose of populating the data suppression library on the accelerators, which will help improve performance as the library grows.
Many applications exist today that exhibit the trend of requesting smaller blocks of data from larger files. It is these specific applications that benefit the most from the read-ahead technologies that an accelerator offers for specific protocols.
Alternative methods to read-ahead caching involve prepositioning the target content. When content is prepositioned, the content distribution process benefits from the use of WAN optimization techniques provided by the accelerators, including compression and data suppression. Prepositioning of content eliminates the need for read-ahead acceleration, due to the intentional predistribution of target content to the edge accelerator object cache, which can also populate the data suppression library. Prepositioning should be considered for large batches of content that the administrator knows must reside at targeted edge accelerators, such as software distribution images or other large objects that are accessed in a collaborative fashion, such as CAD/CAM objects or software development files. Content request read-ahead caching will still continue to function, in conjunction with prepositioning, providing an optimal scenario for known and unknown content requests to an edge-serving accelerator. Content request read-ahead is particularly helpful in environments where the object being used has changed since the last preposition.
The process of observing a client’s messaging patterns and developing statistics on his application’s habits becomes the foundation for an accelerator’s ability to perform message prediction. With message prediction, the accelerator can begin to learn the patterns of interactive client object access and begin to predict which operations might occur shortly after a certain operation is seen. Once predicted, the accelerator may initiate a series of requests on behalf of the client based on previously exhibited behavior and probability.
Figure 4-12 shows an example of a probability table built by an accelerator based on previously seen operations. The accelerator can then use this table to proactively calculate what operations are most likely to occur in sequence. The accelerator can then use this information to proactively submit requests on behalf of the user in an effort to minimize the latency penalty caused by each of the operations should they need to be performed individually and in sequence over the WAN.
Message prediction tracks the message history of clients whose requests traverse a given edge accelerator and analyzes the recorded patterns for trends and probability. For an accelerator that employs message prediction, this process is performed automatically and on a per-application or per-protocol basis with no administrative intervention.
There are two primary benefits gained from message prediction:
The accelerator begins to initiate client commands on behalf of the client, potentially beyond simple read-ahead, based on the probability learned from previous client interaction. Alternatively, this behavior may be programmatic and implemented in protocol acceleration functions within the accelerator.
The accelerator begins to make intelligent predictions based on previous history and operations performed by the client’s application, now making requests on behalf of the client’s applications in predictable patterns. The response from these operations can be safely buffered at the edge device and used should the client actually make the request that was predicted by the accelerator.
The message prediction function of an accelerator initiates client application commands prior to the actual request by the client’s application. The accelerator makes decisions based on an observed history of the client’s request patterns, basing its decisions on previously exhibited behavior. The requests initiated by the accelerator, in advance of the client’s request, might replace chatty CIFS communications between the client and origin server.
Another application for message prediction involves recognizing patterns in MAPI communications and improving the performance of the sessions between a client’s mail reader and mail server. Message prediction can be applied in a generic manner but is commonly implemented as a programmatic function within accelerators today in a very protocol-specific and case-specific capacity.
Messages that are requested by the accelerator itself, on behalf of the requesting client, are staged at the client’s accelerator. The response is stored temporarily, allowing the accelerator to safely respond to the user on behalf of the origin server should the predicted message actually be initiated by the client. Message prediction proactively initiates requests, which facilitates reduced latency for future client requests.
When an application uses only a single connection between the client and the server, requests are commonly serialized over this connection, which can lead to an excessive amount of latency. This can easily translate into performance challenges for the user who is using this application. Many accelerators implement two features to overcome latency, called pipelining and multiplexing.
Pipelining refers to the process of sending multiple requests within a single TCP session, where a TCP socket remains open and multiple requests traverse the same common socket. With pipelining, multiple requests traverse the same connection in serial but can be sent without requiring that the previous request be satisfied. In this way, the performance exposure to roundtrip latency is greatly reduced. In some cases, requests can even be optimized beyond pipelining by batching multiple requests into a single round trip. Figure 4-13 illustrates a pipelined server response to a client request for three content objects.
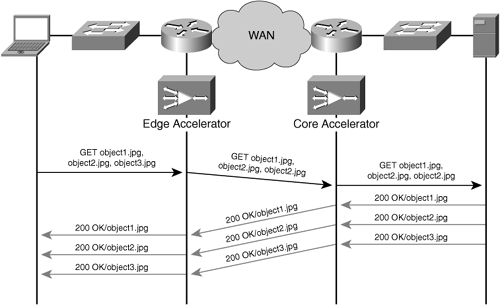
For some networks, a single pipelined session may not fully consume a WAN link, because other constraints exist such as the maximum window size and packet loss. Chapter 6 discusses these topics in detail. In such cases, multiple connections can be opened between the client and server (or between accelerators). This function is called multiplexing.
Multiplexing is commonly implemented in one of two ways. The most common, which is a client and server implementation, uses multiple connections and spreads requests across each of the connections. The other form of multiplexing, which is more commonly implemented in accelerators, uses packet distribution across multiple concurrent connections rather than request-based distribution across multiple concurrent connections. Multiplexing is an application-specific means of overcoming the performance limitations of the WAN and can be used in conjunction with the WAN optimization techniques described in Chapter 6.
Figure 4-14 illustrates multiplexed sessions between a core and edge accelerator, which are traversing a 45-Mbps WAN link.
When pipelining and multiplexing functions interoperate, the amount of data that is passed between devices is in a better position to leverage the full capacity of the WAN. As shown in Figure 4-14, both devices shared the same 45-Mbps WAN link. When the single pipelined session was traversing the WAN link, the fastest throughput the single TCP session could sustain was just over 6.5 Mbps. It was not until introducing multiplexing to the same network environment that the throughput increased to a full 45 Mbps of throughput from seven pipelined TCP sessions. The actual throughput observed by clients placing requests to their local accelerator will far exceed the actual WAN capacity limit until TCP stabilizes. All TCP requests received by any application-specific adapters on the accelerator will provide compression and other optimization to any qualifying traffic that is sent upstream over the WAN.
An accelerator that provides application-specific object caching, application protocol acceleration, and WAN optimization can provide a dramatic improvement in the performance of that application. Many accelerators provide acceleration components for the most commonly used applications, including Internet/intranet, file server access, streaming media, e-mail, and more. Application-specific acceleration and caching components are not necessarily focused on a given software product or application, but rather on the actual protocol that the application’s sessions ride upon. When an accelerator has the ability to inspect and understand the actual application messages being exchanged, it has a strong posture to be able to apply application-specific acceleration to minimize the number of messages traversing an already latent WAN and save precious WAN bandwidth by mitigating the need to redundantly transfer previously requested objects. Application-specific acceleration and caching also provide significant performance improvement for the end user. These techniques are complemented by WAN optimization capabilities provided by the accelerator system, which are discussed in Chapter 6.