

CHAPTER 9
Privacy Preserving in Data Mining
Privacy preserving in data mining is an important issue because there is an
increasing requirement to store personal data for users. The issue has been
thoroughly studied in several areas such as the database community, the
cryptography community, and the statistical disclosure control community.
In this chapter, we present the basic concepts and main strategies for the
privacy-preserving data mining.
The k-anonymity approach will be presented in Section 9.1. The
l-diversity strategy will be introduced in Section 9.2. The t-Closeness
method will be presented in Section 9.3. Discussion on privacy preserving
data mining will be presented in Section 11.4. Chapter summary will be
presented in Section 11.5.
9.1 The K-Anonymity Method
Due to the importance of privacy preserving in various applications,
especially for protecting personal information, Samarati [21] fi rst introduced
the issue and proposed several effi cient strategies to address it. Samarati
observed that although the data records in many applications are made
public by removing some key identifi ers such as the name and social-
security numbers, it is not diffi cult to identify the records with the help of
taking into account some other public data. This happens especially more
commonly in the medical and fi nancial fi eld where microdata that are
increasingly being published for circulation or research, can lead to abuse,
compromising personal privacy.
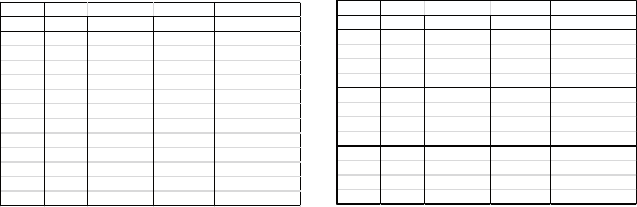
Figure 9.1.1 shows a concrete example to explain the personal
information leaking issue. The published data in Fig. 9.1.1 (a) has been
de-identifi ed by removing the users’ names and Social Security Numbers
(SSNs). It is thus thought to be safe enough. Nevertheless, some attributes
of the public data, such as ZIP, DateOfBirth, Race, and Sex can also exist
in other public datasets and therefore, this information can be jointly used

to identify the concrete person. As shown in Fig. 9.1.1 (a), the attributes of
ZIP, DateOfBirth, and Sex in the Medical dataset can be linked to that of
the Voter List (Fig. 9.1.1 (b)) to discover the corresponding persons’ Name,
Party, and so forth. Given the concrete example, we can observe that there
is one female in the Medical dataset who was born on 09/15/61 and lives in
the 94142 area. This information can uniquely recognize the corresponding
record in the Voter list, that the person’s name is Sue J. Carlson and her
address is 900 Market Street, SF. Through this example, we can see that there
exists personal information leak by jointly considering the public data.
㪪㪪㪥 㪥㪸㫄㪼 㪩㪸㪺㪼 㪛㪸㫋㪼㪦㪽㪙㫀㫉㫋㪿 㪪㪼㫏 㪱㫀㫇 㪤㪸㫉㫋㫀㪸㫃㩷㪪㫋㪸㫋㫌㫊 㪟㪼㪸㫃㫋㪿㪧㫉㫆㪹㫃㪼㫄
㪸㫊㫀㪸㫅 㪇㪋㪆㪈㪏㪆㪍㪋 㫄㪸㫃㪼 㪐㪋㪈㪊㪐 㫄㪸㫉㫉㫀㪼㪻 㪺㪿㪼㫊㫋㩷㫇㪸㫀㫅
㪸㫊㫀㪸㫅 㪇㪐㪆㪊㪇㪆㪍㪋 㪽㪼㫄㪸㫃㪼 㪐㪋㪈㪊㪐 㪻㫀㫍㫆㫉㪺㪼㪻 㫆㪹㪼㫊㫀㫋㫐
㪹㫃㪸㪺㫂 㪇㪊㪆㪈㪏㪆㪍㪊 㫄㪸㫃㪼 㪐㪋㪈㪊㪏 㫄㪸㫉㫉㫀㪼㪻 㫊㪿㫆㫉㫋㫅㪼㫊㫊㩷㫆㪽㩷㪹㫉㪼㪸㫋㪿
㪹㫃㪸㪺㫂 㪇㪐㪆㪇㪎㪆㪍㪋 㪽㪼㫄㪸㫃㪼 㪐㪋㪈㪋㪈 㫄㪸㫉㫉㫀㪼㪻 㫆㪹㪼㫊㫀㫋㫐
㫎㪿㫀㫋㪼 㪇㪌㪆㪈㪋㪆㪍㪈 㫄㪸㫃㪼 㪐㪋㪈㪊㪏 㫊㫀㫅㪾㫃㪼 㪺㪿㪼㫊㫋㩷㫇㪸㫀㫅
㫎㪿㫀㫋㪼 㪇㪐㪆㪈㪌㪆㪍㪈 㪽㪼㫄㪸㫃㪼 㪐㪋㪈㪋㪉 㫎㫀㪻㫆㫎 㫊㪿㫆㫉㫋㫅㪼㫊㫊㩷㫆㪽㩷㪹㫉㪼㪸㫋㪿
㵺㵺㵺㵺 㵺㵺㵺㵺 㵺㵺㵺㵺 㵺㵺㵺㵺 㵺㵺㵺㵺 㵺㵺㵺㵺
㪥㪸㫄㪼 㪘㪻㪻㫉㪼㫊㫊 㪚㫀㫋㫐 㪱㪠㪧 㪛㪦㪙 㪪㪼㫏 㪧㪸㫉㫋㫐 㵺㵺㵺㵺㪅
㵺㵺㵺㵺 㵺㵺㵺㵺 㵺㵺㵺㵺 㵺㵺㵺㵺 㵺㵺㵺㵺 㵺㵺㵺㵺 㵺㵺㵺㵺 㵺㵺㵺㵺
㵺㵺㵺㵺 㵺㵺㵺㵺 㵺㵺㵺㵺 㵺㵺㵺㵺 㵺㵺㵺㵺 㵺㵺㵺㵺 㵺㵺㵺㵺 㵺㵺㵺㵺
㪪㫌㪼㩷㪡㪅㩷㪚㪸㫉㫃㫊㫆㫅 㪐㪇㪇㩷㪤㪸㫉㫂㪼㫋㩷㪪㫋㪅 㪪㪸㫅㩷㪝㫉㪸㫅㪺㫀㫊㪺㫆 㪐㪋㪈㪋㪉 㪇㪐㪆㪈㪌㪆㪍㪈 㪽㪼㫄㪸㫃㪼 㪻㪼㫄㫆㪺㫉㪸㫋 㵺㵺㵺㵺
㵺㵺㵺㵺 㵺㵺㵺㵺 㵺㵺㵺㵺 㵺㵺㵺㵺 㵺㵺㵺㵺 㵺㵺㵺㵺 㵺㵺㵺㵺 㵺㵺㵺㵺
(a) Medical dataset
(b) Voter list
Figure 9.1.1: Re-identifying anonymous data by linking to external data [21]
To address the problem mentioned above, Samarati [21] introduced an
effective concept, i.e., k-anonymity, defi ned as follows:
Defi nition 1 (k-anonymity) Each release of the data must be such that every
combination of values of quasi-identifi ers can be indistinguishably matched to at
least k respondents.
The key idea is that, to reduce the risk of record identifi cation, it requires
that each record in the public table should be not distinct and no fewer than
k records can be returned according to any query.
To fulfi ll the purpose of k-anonymity, the author in [21] introduced two
main strategies, i.e., generalization and suppression. For the generalization
approach, it generalizes the attribute values of records to a larger range so
that the granularity of the representation is reduced. For the above example,
it could generalize the date of birth to the year of birth and therefore, make
those records indistinct. The idea of the suppression strategy is to remove
those sensitive attributes’ value or hide them. As we can see, the privacy
obtained from these strategies is at the price of losing some information
of the original data. Therefore, there is always a trade-off between privacy
preserving and the accuracy of the transformed data. To take a good balance
between privacy and accuracy, the author in [21] introduced the concept of
Privacy Preserving in Data Mining 205
206 Applied Data Mining
k-minimal generalization to limit the level of generalization while keeping
as much data information as possible with regard to some determined
anonymity.
Although the work in [21] has tackled the privacy preserving issue
for some extent, the problem itself is very diffi cult to solve optimally. It is
well known that the problem of optimal k-anonymization is NP-hard, as
demonstrated in [20]. As a result, most existing studies aim to introduce
effective and effi cient heuristic strategies to address it, such as [21, 5, 13].
More detail survey about the issue can be found in [6].
Bayardo et al. [5] introduced an order-based strategy to improve
the effi ciency of tackling the issue. It takes the attributes of records into
two groups, i.e., quantitative attribute and categorical attribute. For the
quantitative attributes, the values of them are discretized into intervals. For
the categorical attributes, the values are clustered into different classes. The
authors deal with each group as an item that could be ordered. Similar to
traditional database techniques, the authors [5] introduced an effective index
to facilitate the traversing process on a set enumeration tree. This tree is in
a similar sense of that applied in the frequent pattern mining literature (See
Chapter 6), which is used to enumerate all the candidate generalizations
based on the items. The construction of the tree is as follows: (1) fi rst set
the root of the tree, which is a null node; and (2) each successive level of
the tree is built by adding one item which is larger than all the items in
the previous tree. The order is based on the lexicographical order. We can
see that it could be possible the tree grows too large and thus, could be
impractical to deal with. To address this issue, the authors [5] proposed
several effective strategies to prune the candidate generalizations as early as
possible. However, all of these techniques are heuristic and the complexity
of the tree building (and item generalization) is not optimal. The proposed
strategy in [5] follows a branch and bound manner, that it could terminate
the item generalization process earlier. As demonstrated in the paper [5],
the introduced algorithm shows a good performance compared with the
state-of-the-art ones.
To further improve the effi ciency, in a later paper [13], LeFevre et
al. proposed the Incognito algorithm. The basic idea of Incognito is that it
utilizes bottom-up breadth fi rst search strategy to traverse all the candidate
generalizations. Specifi cally, it generates all minimal k-anonymous tables
through the following steps: (1) for each attribute, it removes those
generalizations which could not satisfy the k-anonymity; (2) it joins two
(k)-dimensional generalizations to obtain the (k+1)-dimensional candidate
generalization and then evaluate the candidate. If it cannot pass the
k-anonymity test, the candidate will be pruned. This step is in a similar sense
of that introduced for frequent pattern mining (i.e., candidate-generate-
and -test in Chapter 6). All the candidate generalizations can be traversed
without duplication and loss. There is a distinct for [14, 13] that the authors
deal with the data as a graph instead of a tree, which was assumed in the
previous work [21].
There are some other works applying the generalization and suppression
strategies to tackle the privacy preserving issue [23, 10]. The basic idea of
[10] is that it applies a top down approach to traverse all the candidate
generalization. Because of the special property of the process, which is to
reverse the bottom up process, it will decrease the privacy and increase
the accuracy of the data while traversing the candidates. As stated in the
paper [10], the method can control the process so as to obey the k-anonymity
rule. In a later paper [23], the authors introduced several complementary
strategies, e.g., bottom-up generalization, to further improve the whole
performance.
The essential step to generate the candidate generalization is to
traverse all the subspaces of multi-dimensions. As a result, it could use
genetic algorithm or simulated annealing to tackle the issue. Iyengar [11]
introduced the genetic algorithm based strategy to transform the original
into k-anonymity model. In another work [24], the authors proposed a
simulated annealing algorithm to address the problem.
In addition to the commonly used strategies, i.e., generalization and
regression, there is some other techniques proposed, such as the cluster
based approach [8, 2, 3]. The basic idea for these works is that the records
are fi rst clustered and each cluster is represented by some representative
value (e.g., average value). With the help of these pseudo data, privacy can
be effectively preserved while the aggregation characteristics of the original
data is well reserved. However, how to measure the trade-off between the
privacy and the reserved data information seems to be an issue.
1RQ6HQVLWLYH 6HQVLWLYH
=LS&RGH $JH 1DWLRQDOLW &RQGLWLRQ
5XVVLDQ +HDUW'LVHDVH
$PHULFDQ +HDUW'LVHDVH
-DSDQHVH 9LUDO,QIHFWLRQ
$PHULFDQ 9LUDO,QIHFWLRQ
,QGLDQ &DQFHU
5XVVLDQ +HDUW'LVHDVH
$PHULFDQ 9LUDO,QIHFWLRQ
$PHULFDQ 9LUDO,QIHFWLRQ
$PHULFDQ &DQFHU
,QGLDQ &DQFHU
-DSDQHVH &DQFHU
$PHULFDQ &DQFHU
1RQ6HQVLWLYH 6HQVLWLYH
=LS&RGH $JH 1DWLRQDOLW &RQGLWLRQ
+HDUW'LVHDVH
+HDUW'LVHDVH
9LUDO,QIHFWLRQ
9LUDO,QIHFWLRQ
ı &DQFHU
ı +HDUW'LVHDVH
ı 9LUDO,QIHFWLRQ
ı 9LUDO,QIHFWLRQ
&DQFHU
&DQFHU
&DQFHU
&DQFHU
D,QSDWLHQW0LFURGDWD
EDQRQPRXV,QSDWLHQW0LFURGDWD
Figure 9.2.1: Example for l-diversity [17]
Using views appropriately is another technique to protect privacy. The
basic idea is that we can just show a small part of the views (that sensitive
attributes can be controlled) to the public. However, this approach may fail if
we unintentionally publish some important part of the views, which lead to
Privacy Preserving in Data Mining 207
208 Applied Data Mining
the violation of k-anonymity. [26] studied the issue of using multiple views
and clarifi ed that the problem is NP-hard. Moreover, the authors introduced
a polynomial time approach if the assumption of existing dependencies
between views holds.
The complexity of tackling the k-anonymity issue is diffi cult to measure.
The existing works limit the analysis on the approximation algorithms
[4, 3, 20]. These methods guaranteed the solution complexity to be within a
certain extent. In [20], the authors introduced an approximate method that
at O(k · logk) cost, while in [4, 3], the authors proposed some algorithms
that guaranteed O(k) computation cost.
9.2 The l-Diversity Method
Although the k-anonymity is simple and effective to tackle the issue of
privacy preserving to some extent, it is susceptible to many vicious attacks,
such as homogeneity attack and background knowledge attack [17, 18],
defi ned as follows.
• Homogeneity Attack: For this case, there are k tuples that have the
same value of a sensitive attribute. From the previous viewpoint, it
follows the privacy preserving of the k-anonymity. However, these k
tuples as a group can be identifi ed uniquely.
• Background Knowledge Attack: For this case, it is possible that the
sensitive and some quasi-identifi er attributes can be combined together
to infer certain values of some sensitive attributes.
The concrete examples which describe the attacks are illustrated in
Fig. 9.2.1. It shows the patient information from a New York hospital (Fig.
9.2.1 (a)). There are no critical attributes such as name, SSN, and so forth.
The attributes are classifi ed into two categories, i.e., the sensitive and non-
sensitive attributes. The values of the sensitive attributes are preferred by
adversaries. Figure 9.2.1 (b) presents the 4-anonymity transformed data,
i.e., the mark
*
indicates a suppression value between 0 and 9 for Zip code
and Age. The examples for the attacks which cannot be prevented by the
k-anonymity are shown as follows:
• Example of Homogeneity Attack [17]: Alice and Bob are neighbors
who know each other very well. Alice fi nds the 4-anonymous table,
i.e., Fig. 9.2.1 (b), which is published by the hospital and she knows
that Bob’s information exists in it. Moreover, Alice knows that Bob is
an American whose age is 31 and lives in the 13053 area. As a result,
it is easy to infer that Bob’s number is between 9 and 12. From the
table, Alice can make a conclusion that Bob has cancer because any
person whose number in the range (i.e., [9,12]) has the same health
problem.
..................Content has been hidden....................
You can't read the all page of ebook, please click here login for view all page.