
Deep learning has provided great accuracy in the field of computer vision, particularly for object detection. In the past, segmenting images was done by partitioning images into grab cuts, superpixels, and graph cuts. The main problem with the traditional process was that the algorithm was unable to recognize parts of the images.
On the other hand, semantic segmentation algorithms aim to divide the image into relevant categories. They associate every pixel in an input image with a class label: person, tree, street, road, car, bus, and so on. Semantic segmentation algorithms are dynamic and have many use cases, including self-driving cars (SDCs).
In this chapter, you will learn how to perform semantic segmentation using OpenCV, deep learning, and the ENet architecture. As you read this chapter, you will learn how to apply semantic segmentation to images and videos using OpenCV.
In this chapter, we will cover the following topics:
- Semantic segmentation in images
- Semantic segmentation in videos
Let's get started!
Semantic segmentation in images
In this section, we are going to implement one project on semantic segmentation using a popular network called ENet.
Efficient Neural Network (ENet) is one of the more popular networks out there due to its ability to perform real-time, pixel-wise semantic segmentation. ENet is up to 18x faster, requires 75x fewer FLOPs, and has 79x fewer parameters than other networks. This means ENet provides better accuracy than the existing models, such as U-Net and SegNet. ENet networks are typically tested on CamVid, CityScapes, and SUN datasets. The model's size is 3.2 MB.
The model we are using has been trained on 20 classes:
- Road
- Sidewalk
- Building
- Wall
- Fence
- Pole
- TrafficLight
- TrafficSign
- Vegetation
- Terrain
- Sky
- Person
- Rider
- Car
- Truck
- Bus
- Train
- Motorcycle
- Bicycle
- Unlabeled
We will start with the semantic segmentation project:
- First, we will import the necessary packages and libraries, such as numpy, openCV, and argparse:
import argparse import cv2
import numpy as np
import imutils
import time
- Next, we will read the sample input image, resize the image, and construct a blob from the sample image:
start = time.time()
SET_WIDTH = int(600)
normalize_image = 1 / 255.0
resize_image_shape = (1024, 512)
sample_img = cv2.imread('./images/example_02.jpg')
sample_img = imutils.resize(sample_img, width=SET_WIDTH)
blob_img = cv2.dnn.blobFromImage(sample_img, normalize_image, resize_image_shape, 0,swapRB=True, crop=False)
- Then, we will load our serialized ENET model from disk:
print("[INFO] loading model...")
cv_enet_model = cv2.dnn.readNet('./enet-cityscapes/enet-model.net')
- Now, we'll perform a forward pass using the segmentation model:
cv_enet_model.setInput(blob_img)
cv_enet_model_output = cv_enet_model.forward()
- Then, we'll load the class name labels:
label_values = open('./enet-cityscapes/enet-classes.txt').read().strip().split("
")
- In the following code, we're inferring the shape of the total number of classes, along with the spatial dimensions of the mask image:
IMG_OUTPUT_SHAPE_START =1
IMG_OUTPUT_SHAPE_END =4
(classes_num, h, w) = cv_enet_model_output.shape[IMG_OUTPUT_SHAPE_START:IMG_OUTPUT_SHAPE_END]
The output class ID map will be  in size. Therefore, we take argmax to find the class label with the highest probability for each and every (x, y) coordinate:
in size. Therefore, we take argmax to find the class label with the highest probability for each and every (x, y) coordinate:
class_map = np.argmax(cv_enet_model_output[0], axis=0)
- If we have a colors file, we can load it from disk; otherwise, we need to randomly generate RGB colors for each class. A list of colors is initialized to represent each class:
if os.path.isfile('./enet-cityscapes/enet-colors.txt'):
CV_ENET_SHAPE_IMG_COLORS = open('./enet-cityscapes/enet-colors.txt').read().strip().split("
")
CV_ENET_SHAPE_IMG_COLORS = [np.array(c.split(",")).astype("int") for c in CV_ENET_SHAPE_IMG_COLORS]
CV_ENET_SHAPE_IMG_COLORS = np.array(CV_ENET_SHAPE_IMG_COLORS, dtype="uint8")
else:
np.random.seed(42)
CV_ENET_SHAPE_IMG_COLORS = np.random.randint(0, 255, size=(len(label_values) - 1, 3),
dtype="uint8")
CV_ENET_SHAPE_IMG_COLORS = np.vstack([[0, 0, 0], CV_ENET_SHAPE_IMG_COLORS]).astype("uint8")
- Now, we will map each class ID with the given class ID:
mask_class_map = CV_ENET_SHAPE_IMG_COLORS[class_map]
- We will resize the mask and class map in such a way that its dimensions match the original size of the input image:
mask_class_map = cv2.resize(mask_class_map, (sample_img.shape[1], sample_img.shape[0]),
interpolation=cv2.INTER_NEAREST)
class_map = cv2.resize(class_map, (sample_img.shape[1], sample_img.shape[0]),
interpolation=cv2.INTER_NEAREST)
- We will get a weighted combination of the input image and the mask to form a visualized output. Here, mask to image means filtering the image. The sum of weight in the convolution mask affects the overall intensity of the resulting image. The convolution mask can have weight sum of 1 or 0. In our case it is the sum of 0.4 and 0.6 that is, 1. Pixels with negative values may be generated using masks with negative weights:
cv_enet_model_output = ((0.4 * sample_img) + (0.6 * mask_class_map)).astype("uint8")
- Then, we initialize the legend's visualization:
my_legend = np.zeros(((len(label_values) * 25) + 25, 300, 3), dtype="uint8")
- It will loop over the class names and colors, thereby drawing the class name and color on the legend:
for (i, (class_name, img_color)) in enumerate(zip(label_values, CV_ENET_SHAPE_IMG_COLORS)):
# draw the class name + color on the legend
color_info = [int(color) for color in img_color]
cv2.putText(my_legend, class_name, (5, (i * 25) + 17),
cv2.FONT_HERSHEY_SIMPLEX, 0.5, (0, 0, 255), 2)
cv2.rectangle(my_legend, (100, (i * 25)), (300, (i * 25) + 25),
tuple(color_info), -1)
- Now, we can show the input and output images:
cv2.imshow("My_Legend", my_legend)
cv2.imshow("Img_Input", sample_img)
cv2.imshow("CV_Model_Output", cv_enet_model_output)
cv2.waitKey(0)
end = time.time()
- After that, we can show the amount of time the inference took:
print("[INFO] inference took {:.4f} seconds".format(end - start))
The legend for the semantic segmentation process can be seen in the following screenshot:

The input image for the model is as follows:

Let's take a look at the output image:

In the preceding image, we can observe the segmentation. We can see that a person is segmented in blue, a car is segmented in red, the sidewalks are segmented in pink, and that the buildings are segmented in gray. You can play with the implementation by applying it to images containing objects.
In the next section, we will develop a software pipeline for semantic segmentation for videos.
Semantic segmentation in videos
In this section, we are going to write a software pipeline using the OpenCV and ENet models to perform semantic segmentation on videos. Let's get started:
- Import the necessary packages, such as numpy, imutils, and openCV:
import os
import time
import cv2
import imutils
import numpy as np
DEFAULT_FRAME = 1
WIDTH = 600
- Then, load the class label names:
class_labels = open('./enet-cityscapes/enet-classes.txt').read().strip().split("
")
- We can load the files from disk if we are supplied with the color file; otherwise, we will need to create the RGB colors for each class:
if os.path.isfile('./enet-cityscapes/enet-colors.txt'):
CV_ENET_SHAPE_IMG_COLORS = open('./enet-cityscapes/enet-colors.txt').read().strip().split("
")
CV_ENET_SHAPE_IMG_COLORS = [np.array(c.split(",")).astype("int") for c in CV_ENET_SHAPE_IMG_COLORS]
CV_ENET_SHAPE_IMG_COLORS = np.array(CV_ENET_SHAPE_IMG_COLORS, dtype="uint8")
else:
np.random.seed(42)
CV_ENET_SHAPE_IMG_COLORS = np.random.randint(0, 255, size=(len(class_labels) - 1, 3),
dtype="uint8")
CV_ENET_SHAPE_IMG_COLORS = np.vstack([[0, 0, 0], CV_ENET_SHAPE_IMG_COLORS]).astype("uint8")
- Now, load the model:
print("[INFO] loading model...")
cv_enet_model = cv2.dnn.readNet('./enet-cityscapes/enet-model.net')
- Let's initialize the video stream so that we can output the video file:
sample_video = cv2.VideoCapture('./videos/toronto.mp4')
sample_video_writer = None
- Now, we need to try and determine the total number of frames the video file contains:
try:
prop = cv2.cv.CV_CAP_PROP_FRAME_COUNT if imutils.is_cv2()
else cv2.CAP_PROP_FRAME_COUNT
total_time = int(sample_video.get(prop))
print("[INFO] {} total_time video_frames in video".format(total_time))
- Now, we will write except if any errors occurred when determining the video frames:
except:
print("[INFO] could not determine # of video_frames in video")
total_time = -1
- In the following code block, we loop over the frames from the video file stream and then read the next frame from the file. If a frame isn't grabbed, then this means we have reached the end of the stream:
while True:
(grabbed, frame) = sample_video.read()
if not grabbed:
break
- In the following code, we are constructing a blob from the video frame and performing a forward pass using the segmentation model:
normalize_image = 1 / 255.0
resize_image_shape = (1024, 512)
video_frame = imutils.resize(video_frame, width=SET_WIDTH)
blob_img = cv2.dnn.blobFromImage(video_frame, normalize_image, resize_image_shape, 0,
swapRB=True, crop=False)
cv_enet_model.setInput(blob_img)
start = time.time()
cv_enet_model_output = cv_enet_model.forward()
end = time.time()
- Now, we can infer all the classes, along with the spatial dimensions of the mask image, through the output array shape:
(classes_num, h, w) = cv_enet_model_output.shape[1:4]
Here, the output class' ID map is num_classes (height (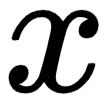 ) and width (
) and width ( )) in size. We are going to take argmax to find the most likely class label for each and every coordinate
)) in size. We are going to take argmax to find the most likely class label for each and every coordinate  in the image:
in the image:
class_map = np.argmax(enet_output[0], axis=0)
- After getting the class's ID map, we can map each of the class IDs to their corresponding color codes:
mask_class_map = CV_ENET_SHAPE_IMG_COLORS[class_map]
- Now, we will resize the mask in such a way that its dimensions should match the original size of its input frame:
mask_class_map = cv2.resize(mask_class_map, (video_frame.shape[1], video_frame.shape[0]),
interpolation=cv2.INTER_NEAREST)
- We are going to perform a weighted combination of the input frame and the mask to form an output visualization:
cv_enet_model_output = ((0.3 * video_frame) + (0.7 * mask_class_map)).astype("uint8")
- Now, we are going to check whether the video writer is None. If the writer is None, we have to initialize the video writer:
if sample_video_writer is None:
fourcc_obj = cv2.VideoWriter_fourcc(*"MJPG")
sample_video_writer = cv2.VideoWriter('./output/output_toronoto.avi', fourcc_obj, 30,
(cv_enet_model_output.shape[1], cv_enet_model_output.shape[0]), True)
if total_time > 0:
execution_time = (end - start)
print("[INFO] single video_frame took {:.4f} seconds".format(execution_time))
print("[INFO] estimated total_time time: {:.4f}".format(
execution_time * total_time))
- The following code helps us write the output frame to disk:
sample_video_writer.write(cv_enet_model_output)
- The following code will help us verify whether we should display the output frame to our screen:
if DEFAULT_FRAME > 0:
cv2.imshow("Video Frame", cv_enet_model_output)
if cv2.waitKey(0) & 0xFF == ord('q'):
break
- Release the file pointers and check the output video:
print("[INFO] cleaning up...")
sample_video_writer.release()
sample_video.release()
The following image shows the output of the video:

Here, we can see that the performance of the ENet architecture is good. You can also test the model with different videos and images. As we can see, it is able to segment the video and images with good accuracy. Using this architecture with autonomous cars will help them identify objects in real time.
Summary
In this chapter, we learned how to apply semantic segmentation using OpenCV, deep learning, and the ENet architecture. We used the pretrained ENet model on the Cityscapes dataset and performed semantic segmentation for both images and video streams. There were 20 classes in the context of SDCs and road scene segmentation, including vehicles, pedestrians, and buildings. We implemented and performed semantic segmentation on an image and a video. We saw that the performance of ENet is good for both videos and images. This will be one of the great contributions to making SDCs a reality as it helps them detect different types of objects in real time and ensures the car knows exactly where to drive.
In the next chapter, we are going to implement an interesting project called behavioral cloning. In this project, we are going to apply all the computer vision and deep learning knowledge we have gained from the previous chapters.