
Frameworks, in plural form? Yes, we have more than one in OFM, as we already mentioned. From the components' inheritance, we have similar features that are based on:
We are not going to spend a lot of time discussing standard OFM EH mechanisms; they have been around since 10g, and since 2008, they have been presented in many books and Oracle ACEs' blogs in great detail (here again, we can refer to Lucas Jellema's handbook). Another, and probably the main reason to make it short, is because of rule 6: Standard OFM EH mechanisms are excellent for services with strictly predefined service roles, preferably, static. In our case (the CTU example), when complex compositions are handled by an agnostic composition controller dynamically, standard tools must become part of a more complex Error Management solution, as we will see further. Now, we will quickly touch upon some of the most common realizations, and if you are familiar with the basics, please proceed to the complex Exception Handler.
This classic example involves a Mediator (but it can be BPEL or the whole of SCA), as presented in the following figure. We will use the Oracle illustration to clarify the concept, and we are quite sure that you will find many other examples if you are not already familiar with mediator policies.
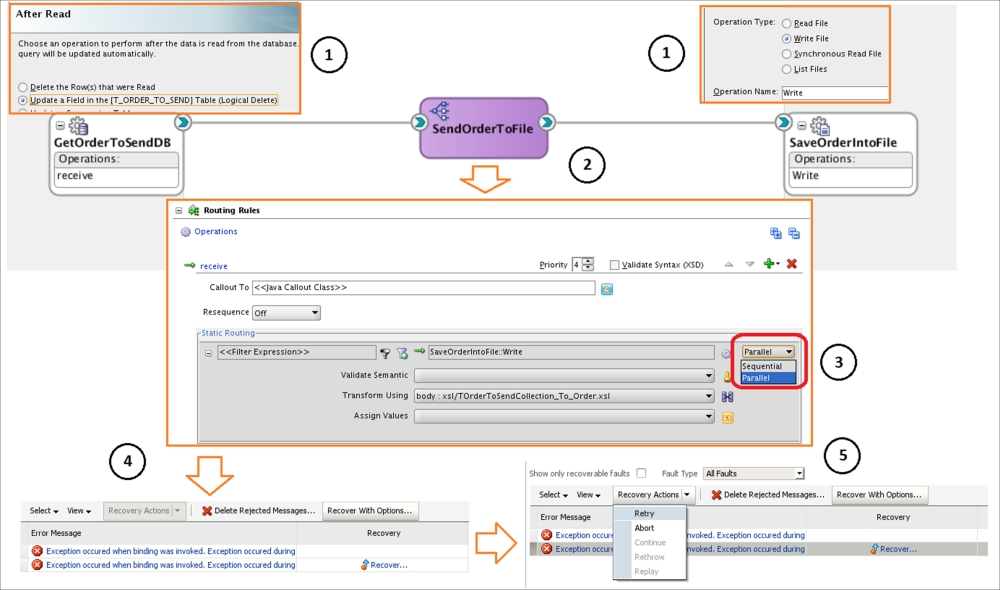
SCA policy-based fault handling
Following are the implementation steps that explain the approach taken in the preceding figure:
- Create the SCA project used to transfer orders from OrderDB to any file location. You will need two PartnerLinks (adapters): one for reading DB, extracting the Order data, and updating the status field (Logical Delete) and another for FileWriter as presented in the preceding figure. Feel free to implement your own XSDs (for database and file-based orders) and a simple table structure; just a couple of fields will suffice. Set the polling frequency to 10 seconds or any other duration of your choice. Set the statuses for (N)ew, (P)olling and (R)ead Orders accordingly; you will need them for the select criteria.
- Add a mediator initially with sequential operations and one transformation, for instance, changing the order ID. Use the current
dateTime()for timestamp elements. Deploy and test the application. Everything should be fine, calm, and simple. - Let's emulate the error while operations are sequential (3). Any method will do if you are running it on Unix chmod 444 on the destination file folder; simply assign the OrderID initially defined as
xs:integerin the message XSD, any string value in DB, and so on. Redeploy and test the application. You will see the dull and simple red-marked statusFailedon the SOA Dashboard for Recent Instances. Recent Faults and Rejected Messages will inform you thatException occurred when.... Go to the Flow Trace and check what the reason was, which you already know. The main point here is that we can't do much about it; we cannot even Retry or perform any other action, and Recovery actions are unavailable. - Copy the following two files to the
projectfolder (or any other location, including MDS, but then change the references forfault-bindings.xmlandfault-policies.xmlincomposite.xmlas explained earlier).The following is the first file that contains the Fault Policy XML definition:
<?xml version="1.0" encoding="UTF-8" ?> <faultPolicies xmlns="http://schemas.oracle.com/bpel/faultpolicy"> <faultPolicy version="2.0.1" id="SendOrderFaults" xmlns:env="http://schemas.xmlsoap.org/soap/envelope/" xmlns:xs="http://www.w3.org/2001/XMLSchema" xmlns="http://schemas.oracle.com/bpel/faultpolicy" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"> <Conditions> <faultName> <condition> <action ref="ora-human-intervention"/> </condition> </faultName> </Conditions> <Actions> <Action id="ora-human-intervention"> <humanIntervention/> </Action> </Actions> </faultPolicy> </faultPolicies>In the second file, we performed the binding for the policy ID
SendOrderFaults:<faultPolicyBindings version="2.0.1" xmlns="http://schemas.oracle.com/bpel/faultpolicy" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"> <component faultPolicy="SendOrderFaults"> <name>SendOrderToFile</name> </component> </faultPolicyBindings> - Go to the Mediator and change routing to Parallel. Now we have to redeploy and test the application again.
- Fix the error's cause (chmod 777 or modify message element in Trace Flow). Go to Enterprise Manager and Fault and Rejected Messages and see that the Recovery Actions options are available now. Select Retry for the process with the Recovery Needed status and confirm your choice. Open the Trace Flow after its completion and see that the problem is as good as gone.
Well, we did a Retry operation manually; so much for automation you say! This is because for this action, we selected ora-human-intervention. Guess what ora-retry would do? You will have plenty of additional parameters to set: Retry count, Retry interval, and what would be the next action if a Retry fails/succeeds (action chaining)?
The ora-terminate option is similar to human intervention; it's a simple realization, and no parameters are really needed. We can also rethrow the fault or replay the scope. No doubt, the most powerful option is ora-java, which allows you to execute any Java class defined in the related element as shown in the following code:
javaAction className="somepackage.someClass"
Generally, all that you should do is describe an error's condition and declare the action (reference to action) for this condition. The condition will be tested against the fault code, part of fault message/payload, and so on. See the following examples:
$fault/*:reason/text();$fault/ctx:errorCode/text();ora:getFaultAsString();$fault.payload$fault.code
The list is not complete; you have great freedom when it comes to selecting error sources in addition to the standard $fault. Conditions/faults can be (and actually shall be) grouped into Business, Technical, and so on, with the desired level of details. For instance, refer to the following bullet list:
- The
$fault.code="WSDLReadingError"error is purely a technical error, but it is in fact related to the remote API availability, that is, the error is related to service edges on North/South. When$fault.code="3220", it indicates the standard ORA-03220 code, which is a problem related to the data quality (we gotNULLinstead of something meaningful). Necessary automated actions can be clearly defined for these situations. - A fault (raised by your application) that is displayed with
$fault.payload="Client with bad credit history"is a business fault (not really a fault, but the condition is still critical). Although the temptation to put this kind of fault on theora-human-interventionresolution is high, it is better if you devise an automated solution; it's not that hard.
The last step is to associate all policies with the SOA composite application or individual component (BPEL or Mediator as in the Policy-based handling section) using fault binding. It would be either <composite faultPolicy=…> or <component faultPolicy=…>, where you list all your individual policies, associated with the component/composite name.
In addition to this, you have great flexibility for declaring <Properties> in the property set within your policies in order to support your complex actions; please see the syntax in the Oracle documentation.
Oh! the possibilities. They are truly boundless. Honestly, the OFM policy-based Exception Handling Framework is the second best thing in OFM after BPEL; this mechanism is extremely powerful. You can employ any category of Faults (embedded, default, or declared), assess (test) faults as you want, group them under any types (technical or functional), create new or employ existing actions for resolutions, chain actions within any fault, associate the actions returnValue parameter with any other following action (another form of action chaining), declare property sets for your actions (highly useful for Java Actions, but for others as well), and finally, centralize your policies using bindings. Applied to Mediator as in the earlier example, which generally acts as a mini-ESB within SCA; you will have an excellent realization of Policy Centralization. What else can you wish for?
Please look closely at rules 6, 9, and especially 5 when it comes to Metadata Centralization. Before building complex policies for agnostic controllers, you must be 110 percent sure that all possible scenarios are accounted for, all composition members and their roles are identified, and all appropriate resolutions are detected:
- Even in static composition controllers, due to BPEL's easy-to-implement ways of services' invocation, you could have long chaining of synchronous and asynchronous task-orchestrated services. Some of them can have parallel flows, spawning subsequent parallel flows; some sync BPELs can call async BPELs comprising JMS adapters with triggered dehydrations causing callbacks in separate threads so that you lose your request-response correlations; third-party components can propagate faults incorrectly; and so on and so forth. In dynamic composition controllers, without understanding the initial situation, your analysis will be even worse. So, quite soon all your Policy Centralization will be centralized around a single
ora-human-intervention, as it is the only option to keep control. - The simplicity of default fault actions can be deceptive. Regarding the preceding point, we could have different use cases for seemingly identical
throw-versus-replyandreply-with-fault. Please see the Oracle documentation for more details. - The endless policy-based exception handling possibilities multiplied on endless Java capabilities of the
ora-javaaction can lead to disaster if applied uncontrollably. A Java guru can decide to put all the handling scenarios into Java action. Quite soon, business logic will silently sneak into this handler as well, and why not? It's fast, simple, and understandable for all Java coders. Do we need to explain where the catch is? (Refer back to Chapter 1, SOA Ecosystem – Interconnected Principles, Patterns, and Frameworks; check all the principles and the initial CTU's SOA status.) - The policies are preloaded on startup for best performance. That's surely a decent thing to do. Therefore, we have two concerns here: naturally, your policy size matters (and not always positively), and secondly, you have to restart/redeploy your application every time you update your policies. This is another reason to perform the service-error mapping exercise we started with results presented in an Excel spreadsheet.
Yet again, OFM fault policies are brilliant and the concerns expressed in the preceding points should not prevent you from using them for static compositions. Just follow the proposed rules and generic SOA principles/patterns.
The compensative transaction feature is proprietary for long running transactions, and thus, it's incorporated into BPEL. Like with most Oracle BPEL features, it is presented graphically; thanks to this, it's quite well known and widely used. Probably, we should not waste your time here by explaining the obvious, but as long as the Compensative Transaction SOA pattern is involved, a brief walkthrough should be in order.
The classic example (and you can find plenty of them) is based on SCA's booking application: while planning your vacation, you consequently book a hotel, a flight, and a car. If a car is not an option, you still have no reason to cancel your vacation, flight, and hotel reservation (the error resolution action would be Continue). Now, if there are no rooms available (you should start earlier this year) and living in a tent hardly makes your spouse happy, you definitely have to cancel your flight and consider another destination (we hope that you can).
So what do we know? Refer to the following bullet points:
- We are aware of the blue double-arrow icon (like the one on your remote control) on the left-hand side of the BPEL scope. It is second from the bottom, named Add Compensation Handler.
- We know that we are not in the same atomic transaction: ACID rollback is not possible.
- As rollback is not possible, physical delete (as opposite to insert, the so-called business rollback) will be implemented, probably as a separate BPEL scope or additional process call: invoke the "ClearBooking". Thus, some more effort is required from us. Our Entity services must have the full set of basic operations:
add<..>,get<..>,delete<..>.
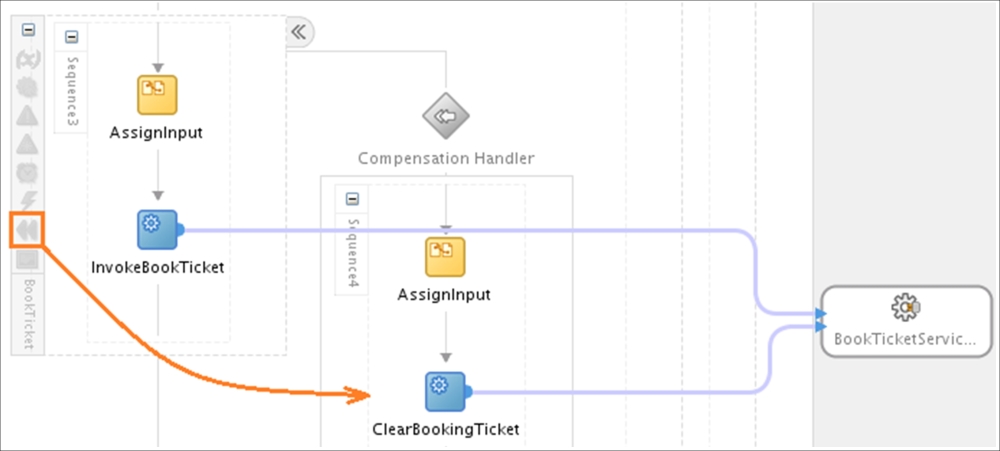
In the preceding figure, we performed compensation to scope the BookTicket element, that is, <compensate scope=" BookTicket"/>, in the booking task service. This service is a static composition controller with three scopes dedicated to three different bookings explained in the previous points. As you understand, to the modularity, every type of booking is a separate service (could be BPEL). You can keep insert and delete operations for every booking type in one service or present them as different BPEL processes if you want to maintain them in a single SCA. In this case, you can connect them to the master controller using Mediators (HotelReservation, BookTicket, and CarRent) and apply (optional) Policies to Mediators as well, as in the previous example. Thus, in the preceding figure, we connected to the BookTicketService mediator, WSDL, for reservation and cancellation (from the compensation sequence). Do not forget to extend your master controller with the Catch(All) exception handler for technical errors provided by composition members, and we are done.
The realization of the Compensative Transaction SOA pattern by the Ora BPEL compensation handlers is elegant and intuitive, and you can always rely on the business rollback feature in your static composition controllers.
Now, we have to look at the standard handlers available on service edges, usually maintained on OSB as Business/Proxy services. The fault handler is one of the three pillars (together with request and response) on which OSB stands. For handling any abnormal situation, you have the same activities as you have in happy flows (refer to the following figure). Thus, everything we said about the mapping exercise during the error analysis phase is true here as well.
After catching the error, you can analyze the content of the fault message (the same $fault/ctx:errorCode or any other part of it) and act accordingly; route to the predefined destination, update the message content (for instance, Message Tracking Data), and perform the service callout to EJB or another service.

As we are discussing the cooperation of service edges (the composition member's endpoints) and composition controller, we do not have much freedom here at OSB, especially at the South end (see the figure from the Maintaining Exception Discoverability section again). We should be very careful with individual handlers, as they can be quite off from the entire composition logic; technically, we should be concerned about three main things:
- Log the caught error (the first step in the preceding figure) properly.
- Update the message tracking information in the XML container to help the service broker with error resolution. We can even perform the conversion of the error code if necessary, but this will usually require SR lookup.
- Depending on the service location and use case, we can try basic recovery operations such as Retry (see the following figure) on Business Service, which is under the Transport tab. Despite its simplicity, the Retry operation must be applied with extra care, after the analysis of fault types. For instance, we can double the transaction if the service in not idempotent and our timeout interval is not adjusted according to the processing time.

Maintaining service policies on OSB
As the name service edge denotes, here we have to apply a lot of message handling and security policies as well. Not all of them are directly EH-related, but all of them contribute to the composition's resiliency. Another thing that is apparent from the preceding figure is that they are different policies from what we discussed while explaining SCA EH. Well, complete Policy Centralization is not really achievable in OFM, and we have already mentioned that; however, we are quite capable to maintain the desired level of centralization per SOA framework. At least two policy types are essential for the OSB implementation: WSM and standard (almost) WS-Policies. You can see a list of the available default policy resources in the preceding screenshot; they are applicable for Business and Proxy services (see the Policy tab).
Two WS-Policies are contributing a lot to EH in general: WS-Addressing and WS-ReliableMessaging. Despite all the differences with SCA's fault-handling policies, the mechanism of binding them to the WSDL has a lot of similarities. A discussion on practical WS-Policy implementation is a bit out of the scope of this chapter, but you could find good explanations in Web Service Contract Design and Versioning for SOA, Thomas Erl, Prentice Hall (Chapters 16 and 17) in addition to the Oracle OSB documentation.