
Before we discuss the essential steps in exception handling in an agnostic composition controller implemented in the CTU SOA farm, we will mention the importance of clear and consistent identification of all fault messages related to certain process instances. You could use a standard Ora ECID for this purpose in addition to the initial Java-based labeling process instance at the beginning of every BPEL:
- Go to the Receive activity tab at the top and select Edit after a right-click.
- In the Properties tab, click on the green cross and select tracking.ecid from the drop-down list. Assign it to the variable of your choice. Use it within your Message Tracking Records Object.
We will start with recalling the structure of the composition controller (async Service Broker). Basically, it has two parts (if we omit the standard initialization): acquiring the execution plan and looping through EPs elements. Thus, we should have three exception scopes: sequentially, one for master loop and one for the EP endpoint, and one generic outer handler for the entire process. (In your version, you can implement additional handlers for every new scope.) For all cases, you can declare a generic SBFault and use it with fault variables based on the Message Tracking Record type (see the declaration in the following figure).
When the entire process fails, we can employ standard catches: one for SBFault and the master, CatchAll; however, in any of these handling sequences, we cannot really fix the problem. All that we have to do is identify at what nested level the error occurred (master or subcontroller; this should be visible in message tracing records) and assign status code in the Message Header and MTR objects. After this, we perform the Audit (depending on the Audit level of the current invocation) and return to the composition initiator (client, using Invoke).
When the extraction of the execution plan fails, we should invoke ErrorManager for the first time; see the following figure:
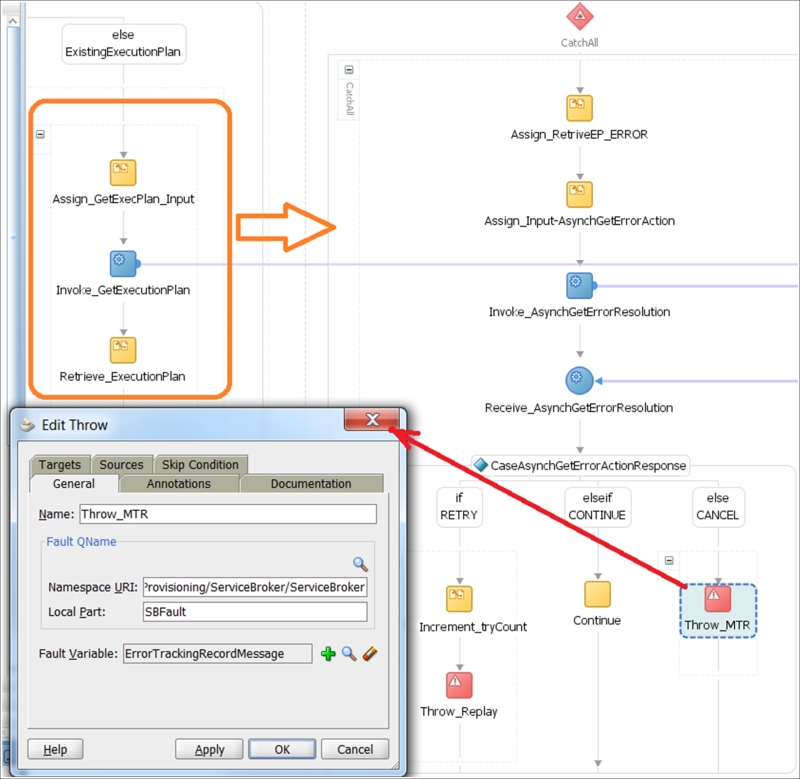
The number of actions required is still limited as we are not in EP's traversing mode yet. If SB is acting as a master composition controller, actions such as Retry and Cancel (after several retries) would be appropriate. If we are in a subcontroller, then the Continue resolution is quite acceptable, depending on the business logic.
Prevention measures are more important here than just getting the possible resolutions; we should have redundant EP storage implementation as we mentioned it in the rules: DB- and File-based. ExecutionLookupService should encapsulate these two approaches.
Finally, the EP execution could fail because of error(s) occurred during the execution in the main tasks loop. This is the place where the first table in the chapter will be exceedingly handy. Most importantly, not only primitive suggestions will be returned, but also the entire Message payload after the error-compensation process, instantiated by ErM. Thus, for keeping SB truly generic, two main blocks must be implemented for the main loop scope:
- The invocation of ErM with the entire payload and descriptive
SBFaultfrom the Catch handler (see the next figure, part 1) - Updating the MTR object and processing flags in the message header after receiving the response and updating the payload (see the next figure, part 2)
Providing a list of possible combinations in the second part can be extremely long, as you can see from the following figure; therefore, please consider only some of the logical outcomes:
- When the
RETRYresolution is returned, we should:- Increment the loop counter
- Check the new payload received from EH and update the current task's payload accordingly
- When
CONTINUEis suggested, we should check the following:- Are we continuing with
ROLLBACK(this is an agnostic composition controller used everywhere) or a regular task? - Is it the last task in a loop, and do we have to summarize all executions (such as calculate orders and grand totals)?
- Are we continuing with
- When
CANCELis received:- Stop execution
Certainly, we should have other resolution options such has ROLLBACK, ROLLBACK_FAILED, and ROLLBACK_DONE. If we are in the first task in the loop, then we probably do not need to perform any rollback. One really important thing to understand here is that we cannot put any error-specific execution logic into our agnostic composition controller; it will just break the whole idea. This big case logic in the second part of the following figure is only setting the flags and MTR/MH assignments.
Only the invocation of services with standard contracts through the Adapter Factory is allowed here. Resolution and execution logic is completely abstracted and centralized in Enterprise Repository and provided in the form of XML execution plans by the Service Inventory Endpoint. It is implemented as a database with a friendly interface that will allow you to apply new execution policies without SCA redeployment. Proper testing and other governance procedures will be applied later.

Fault handling logic in Agnostic Composition Controller
If SB fault-catch scenarios are clear, we can now look into the internal Error Manager architecture, presented as SCA (refer to the next figure). We have five main blocks completely aligned with our generic requirements that are expressed in the first paragraph of this chapter:
- We employ Oracle's Composite Sensors to monitor ErM's incoming and outgoing messages. This information will be available for search and analysis of the Instances page of the SB SOA composition application in the Oracle Enterprise Manager Fusion Middleware Control Console. From the following figure, you can see what elements we decide to concatenate in the Sensor's expression. Bear in mind that all these elements must be parts of the payload. Thus, as mentioned earlier, ECID could actually be part of the
ProcessNameelement. Assigning a Sensor for an outgoing message is much simpler: it's an ErM Response. Here, we are not using Mediator as the central component of the handler; all inbound messages are going to the BPEL process, which will help us with dispatching faults to other components, thereby fulfilling generic requirements. - For error code conversions, a resolution action's lookup, and the extraction of compensation workflows, we have to call ServiceInventoryEndpoint. If the first task is optional, as it can be handled by Domain Value Maps (DVM) in SCA Mediators, the second and third are the core of Error Manager.
- It would be prudent to notify Ops or other involved parties as part of the resolution action. This part is implemented as NotificationService, employing the whole bunch of Oracle communication adapters.
- When the resolution action is identified, it will be passed back to the caller. If the resolution is complex and requires a new instance of Service Broker (as a compensative EP), then we assign the extracted EP to the new Process Header's container and invoke an async SB.
- Our last resort is the manual resolution that is used when automation is not possible, number of retries has exceeded, or we get a critical error during rollback.

Complete Error Manager SCA for Agnostic Composition Controller
Sensors are another nice feature in OFM SCAs, and we encourage you to use them actively, although with some limitations applied (such as the payload as the only source); please see the Oracle documentation. Thus, we can go directly to the main feature here: ServiceInventoryEndpoint (see the next figure).
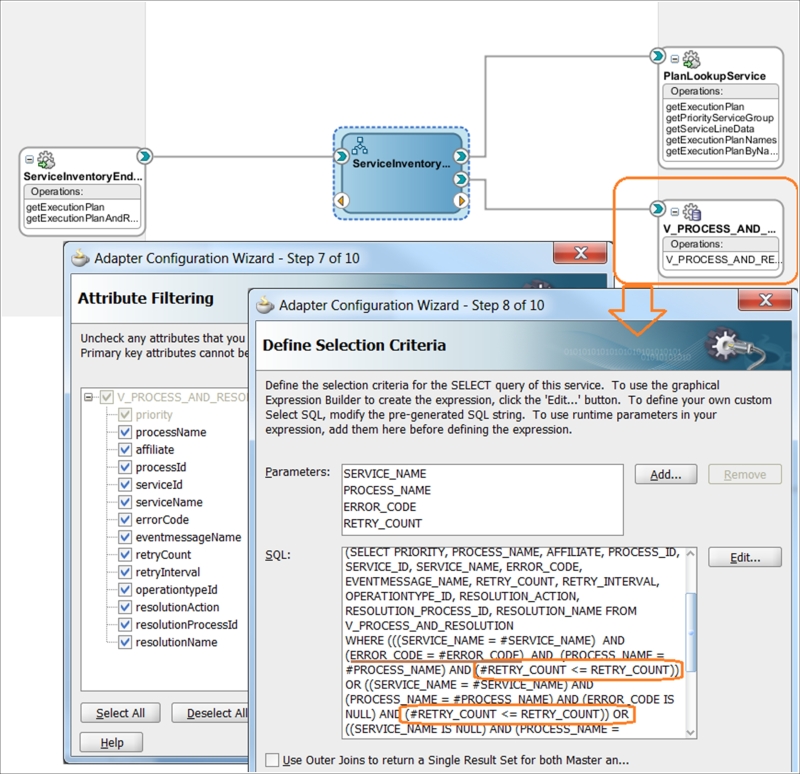
In the following figure, you can see the developer's version of this service, presenting a typical versioning strategy around Oracle SCAs. We do this on purpose, as you may remember. Initially, when we started with the Service Broker implementation (Chapter 3, Building the Core – Enterprise Business Flows and Chapter 4, From Traditional Integration to Composition – Enterprise Business Services) and relied only on standard Oracle fault handlers, we implemented ExecutionPlanLookupService for happy paths only. Now we have to consolidate the Service Repository DB (from Chapter 5, Maintaining the Core – the Service Repository) under a unified endpoint for consolidated EP and the extraction of resolution actions'. Ideally, this should be that one entity service with all the required operations (Java is a good choice for this type, and if functional decomposition is required, we will apply it later); for now, we can implement the BPEL process with an additional DB adapter, wrapping ExecutionPlanLookupService.
For this DB adapter, the set of parameters provided by EH and MTR is employed in the simple SELECT, as presented in the next figure. Needless to say, ESR DB records are completely based on the first table in this chapter.
For better resiliency, we should add another adapter for files to extract execution plans and resolution actions stored in XML FSO. With the RAC DB and NAS-based FSO in a clustered environment, this type of realization will be truly bulletproof.
We leave it to you to count how many SOA patterns we covered in the preceding paragraph. Surely, the presented implementation is not really suitable for production, and we offered it only for demonstrating the capabilities of Oracle SCA.
Now, we should look inside the main ErM dispatcher, the BPEL process that will handle different recovery scenarios (see the next screenshot). From the error handling perspective, it can also be divided into three main areas where the faults will be accounted for: request parameter initialization, a call to Audit service, and the ServiceInventoryEndpoint invocation (see the next figure, part 2). This entire process will also be covered; all that we can do here is perform proper logging. The whole design will be kept as simple as possible for better resiliency, and we must assume that any disaster happened during compensative actions can be fixed either manually or by ART, which is implemented externally (rule 15, Proactive Automated Error Management).
Manual Recovery (see the next figure, part 3) is a typical SCA Human Task Service component with standard outcomes. All configuration parameters around it are pretty basic, and we will not focus on it here. Again, in the Oracle documentation, it is explained very clearly.

Fault handling scenarios in Error Manager
The last two scopes of this BPEL dispatcher within ErM that we should mention here are as follows:
- The first is the ServiceInventoryEndpoint invocation scope (see the next figure). This is where we actually invoke the service explained in the previous figure.

- With a positive outcome from the previous step, we invoke Service Broker to execute compensative transactions. (See the next figure.)
The compensation outcome (or resolution action if the case is simple) with modified payload is returned to the master controller. In some complex cases, we can put a lot into compensation EP(s) in order to return to a consistent state, and all that the master controller needs to do is finalize its activities, that is, exit gracefully. Adapter poller will start with another complex composition in time, based on the new (or as good as new) data's state.

This is it! We have shortly demonstrated how Oracle's standard fault-handling tools can be employed for fixing errors in a static composition (and not only policy-based framework is really powerful for all cases) and how we can reuse an agnostic composition controller to handle errors in dynamic compositions.
Finally, we have to look at how we can use external solutions for proactive monitoring and automated recovery.