
Chapter 10. Chatbots
In this chapter we will explore one of the fastest-growing language-aware applications: conversational agents. From Slackbot to Alexa to BMW’s Dragon Drive, conversational agents are quickly becoming an indispensable part of our everyday experiences, integrated into an ever broader range of contexts. They enhance our lives with extended memory (e.g., looking stuff up on the internet), increased computation (e.g., making conversions or navigating our commute), and more fluid communication and control (e.g., sending messages, managing smart homes).
The primary novelty of such agents is not the information or assistance they provide (as that has been available in web and mobile applications using point-and-click interfaces for a long time); rather, it is their interface that makes them so compelling. Natural language interactions provide a low-friction, low-barrier, and highly intuitive method of accessing computational resources. Because of this, chatbots represent an important step forward in user experience, such as inlining commands naturally with text-based applications thereby minimizing poorly designed menu-based interfaces. Importantly, they also allow new human–computer interactions in new computational contexts, such as in devices not well suited to a screen like in-car navigation.
So why is this rise happening now, given the long history of conversational agents in reality (with early models like Eliza and PARRY) and in fiction (“Computer” from Star Trek or “Hal” from 2001: A Space Odyssey)? Partly it’s because the “killer app” for such interfaces requires ubiquitous computing enabled by today’s Internet of Things. More importantly, it’s because modern conversational agents are empowered by user data, which enriches their context, and in turn, their value to us. Mobile devices leverage GPS data to know where we are and propose localized recommendations; gaming consoles adapt play experiences based on the number of people they can see and hear. To do this effectively, such applications must not only process natural language, they must also maintain state, remembering information provided by the user and situational context.
In this chapter we propose a conversational framework for building chatbots, the purpose of which is to manage state and use that state to produce meaningful conversations within a specific context. We will demonstrate this framework by constructing a kitchen helper bot that can greet new users, perform measurement conversions, and recommend good recipes. Through the lens of this prototype, we’ll sketch out three features—a rule-based system that uses regular expressions to match utterances; a question-and-answer system that uses pretrained syntax parsers to filter incoming questions and determine what answers are needed; and finally, a recommendation system that uses unsupervised learning to determine relevant suggestions.
Fundamentals of Conversation
In the 1940s, Claude Shannon and Warren Weaver, pioneers of information theory and machine translation, developed a model of communication so influential it is still used to understand conversation today.1 In their model, communication comes down to a series of encodings and transformations, as messages pass through channels with varying levels of noise and entropy, from initial source to destination.
Modern notions of conversation, as shown in Figure 10-1, extend the Shannon–Weaver model, where two (or more) parties take turns responding to each other’s messages. Conversations take place over time and are generally bounded by a fixed length. During a conversation, a participant can either be listening or speaking. Effective conversation requires at any given time a single speaker communicating and other participants listening. Finally, the time-ordered record of the conversation must be consistent such that each statement makes sense given the previous statement in the conversation.
To you, our human reader, this description of a conversation probably seems obvious and natural, but it has important computational implications (consider how garbled and confusing a conversation would be if any of the requirements were not satisfied). One simple way to satisfy conversational requirements is to have each participant in the conversation switch between speaking and listening by taking turns. In each turn, the initiative is granted to the speaker who gets to decide where the conversation goes next based on what was last said. Turn taking and the back-and-forth transfer of initiative keeps the conversation going until one or more of the participants decides to end it. The resulting conversation meets all the requirements described here and is consistent.
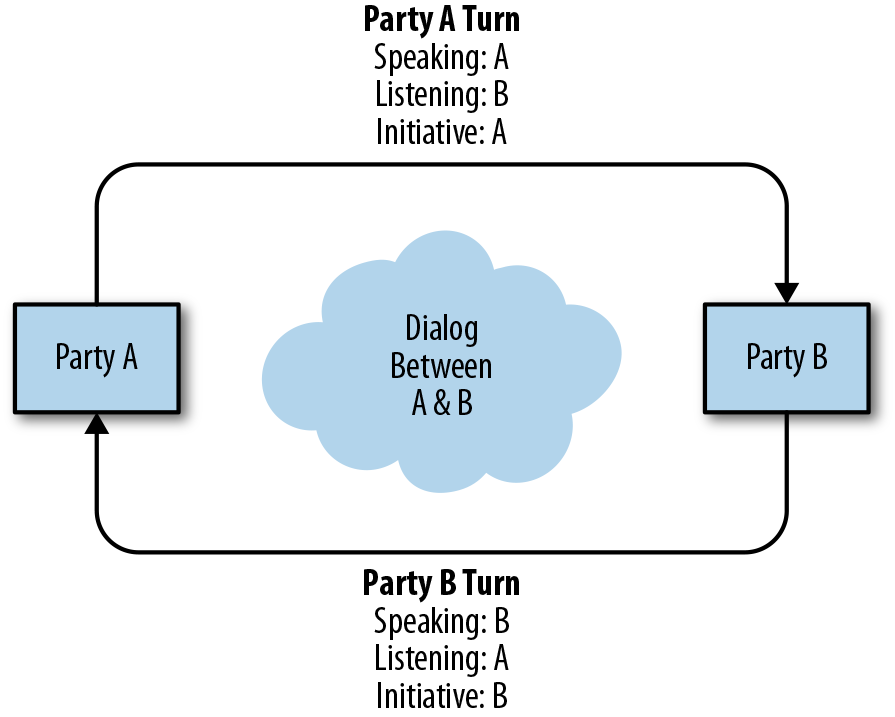
Figure 10-1. Structure of a conversation
A chatbot is a program that participates in turn-taking conversations and whose aim is to interpret input text or speech and to output appropriate, useful responses. Unlike the humans with whom they interact, chatbots must rely on heuristics and machine learning techniques to achieve these results. For this reason, they require a computational means of grappling with the ambiguity of language and situational context in order to effectively parse incoming language and produce the most appropriate reply.
A chatbot’s architecture, shown in Figure 10-2, is comprised of two primary components. The first component is a user-facing interface that handles the mechanics of receiving user input (e.g., microphones for speech transcription or a web API for an app) and delivering interpretable output (speakers for speech generation or a mobile frontend). This outer component wraps the second component, an internal dialog system that interprets text input, maintains an internal state, and produces responses.
The outer user interface component obviously can vary widely depending on the use and requirements of the application. In this chapter we will focus on the internal dialog component and show how it can be easily generalized to any application and composed of multiple subdialogs. To that end we will first create an abstract base class that formally defines the fundamental behavior or interface of the dialog. We will then explore three implementations of this base class for state management, questions and answers, and recommendations and show how they can be composed as a single conversational agent.

Figure 10-2. Architecture of a chatbot
Dialog: A Brief Exchange
To create a generalizable and composable conversational system, we must first define the smallest unit of work during an interaction between chatbot and user. From the architecture described in the last section, we know that the smallest unit of work must accept natural language text as input and produce natural language text as output. In a conversation many types of parses and responses are required, so we will think of a conversation agent as composed of many internal dialogs that each handle their own area of responsibility.
To ensure dialogs work together in concert, we must describe a single interface that defines how dialogs operate. In Python no formal interface type exists, but we can use an abstract base class via the abc standard library module to list the methods and signatures expected of all subclasses (if a subclass does not implement the abstract methods, an exception is raised). In this way we can ensure that all subclasses of our Dialog interface behave in an expected way.
Generally, Dialog is responsible for listening to utterances, parsing the text, interpreting the parse, updating its internal state, and then formulating a response on demand. Because we assume that the system will sometimes misinterpret incoming text, Dialog objects must also return a relevance score alongside the response to quantify how successfully the initial utterance has been interpreted. To create our interface, we’ll break this behavior into several methods that will be specifically defined in our subclasses. However, we’ll first start by describing a nonabstract method, listen, the primary entry point for a Dialog object that implements the general dialog behavior using (soon-to-be-implemented) abstract methods:
importabcclassDialog(abc.ABC):"""A dialog listens for utterances, parses and interprets them, then updatesits internal state. It can then formulate a response on demand."""deflisten(self,text,response=True,**kwargs):"""A text utterance is passed in and parsed. It is then passed to theinterpret method to determine how to respond. If a response isrequested, the respond method is used to generate a text responsebased on the most recent input and the current Dialog state."""# Parse the inputsents=self.parse(text)# Interpret the inputsents,confidence,kwargs=self.interpret(sents,**kwargs)# Determine the responseifresponse:reply=self.respond(sents,confidence,**kwargs)else:reply=None# Return initiativereturnreply,confidence
The listen method contains a global implementation, which unifies our (soon-to-be-defined) abstract functionality. The listen signature accepts text as a string, as well as a response boolean that indicates if initiative has passed to the Dialog and a response is required (if False, the Dialog simply listens and updates its internal state). Finally, listen also takes arbitrary keyword arguments (kwargs) that may contain other contextual information such as the user, session id, or transcription score.
The output of this method is a response if required (None if not) as well as a confidence score, a floating-point value between 0.0 and 1.0. Since we may not always be able to successfully parse and interpret incoming text, or formulate an appropriate response, this metric expresses a Dialog object’s confidence in its interpretation, where 1.0 is extremely confident in the response and 0 is completely confused. Confidence can be computed or updated at any point during the Dialog.listen execution, which we have defined by three abstract steps: parse, interpret, and respond, though generally speaking confidence is produced during the interpret phase:
@abc.abstractmethoddefparse(self,text):"""Every dialog may need its own parsing strategy, some dialogs may needdependency vs. constituency parses, others may simply require regularexpressions or chunkers."""return[]
The parse method allows Dialog subclasses to implement their own mechanism for handling raw strings of data. For instance, some Dialog subclasses may require dependency or constituency parsing while others may simply require regular expressions or chunkers. The abstract method defines the parse signature: a subclass should implement parse to expect a string as input and return a list of data structures specific to the needs of the particular Dialog behavior. Ideally, in a real-world implementation, we’d also include optimizations to ensure that computationally expensive parsing only happens once so that we don’t unnecessarily duplicate the work:
@abc.abstractmethoddefinterpret(self,sents,**kwargs):"""Interprets the utterance passed in as a list of parsed sentences,updates the internal state of the dialog, computes a confidence of theinterpretation. May also return arguments specific to the responsemechanism."""returnsents,0.0,kwargs
The interpret method is responsible for interpreting an incoming list of parsed sentences, updating the internal state of the Dialog, and computing a confidence level for the interpretation. This method will return interpreted parsed sentences that have been filtered based on whether they require a response, as well as a confidence score between 0 and 1. Later in this chapter, we’ll explore a few options for calculating confidence. The interpret method can also accept arbitrary keyword arguments and return updated keyword arguments to influence the behavior of respond:
@abc.abstractmethoddefrespond(self,sents,confidence,**kwargs):"""Creates a response given the input utterances and the current state ofthe dialog, along with any arguments passed in from the listen or theinterpret methods."""returnNone
Finally, the respond method accepts interpreted sentences, a confidence score, and arbitrary keyword arguments in order to produce a text-based response based on the current state of the Dialog. The confidence is passed to respond to influence the outcome; for example, if the confidence is 0.0 the method might return None or return a request for clarification. If the confidence is not strong the response might include suggested or approximate language rather than a firm answer for stronger confidences.
By subclassing the Dialog abstract base class, we now have a framework that enables the maintenance of conversational state in short interactions with the user. The Dialog object will serve as the basic building block for the rest of the conversational components we will implement throughout the rest of the chapter.
Maintaining a Conversation
A Dialog defines how we handle simple, brief exchanges and is an important building block for conversational agents. But how do we maintain state during a longer interaction, where the initiative may be passed back and forth between user and system multiple times and require many different types of responses?
The answer is a Conversation, a specialized dialog that contains multiple internal dialogs. For a chatbot, an instance of a Conversation is essentially the wrapped internal dialog component described by our architecture. A Conversation contains one or more distinct Dialog subclasses, each of which implements a separate internal state and handles different types of interpretations and responses. When the Conversation listens, it directs the input to its internal dialogs, then returns the response with the highest confidence.
In this section, we’ll implement a SimpleConversation class that inherits the behavior of our Dialog class. The main role of the SimpleConversation class is to maintain state across a sequence of dialogs, which we’ll store as an internal class attribute. Our class will also inherit from collections.abc.Sequence from the standard library, which will enable SimpleConversation to behave like a list of indexed dialogs (with the abstract method __getitem__) and retrieve the number of dialogs in the collection (with __len__):
fromcollections.abcimportSequenceclassSimpleConversation(Dialog,Sequence):"""This is the most simple version of a conversation."""def__init__(self,dialogs):self._dialogs=dialogsdef__getitem__(self,idx):returnself._dialogs[idx]def__len__(self):returnlen(self._dialogs)
On Conversation.listen, we will go ahead and pass the incoming text to each of the internal Dialog.listen methods, which will in turn call the internal Dialog object’s parse, interpret, and respond methods. The result is a list of (responses, confidence) tuples, and the SimpleConversation will simply return the response with the highest confidence by using the itemgetter operator to retrieve the max by the second element of the tuple. Slightly more complex conversations might include rules for tie breaking if two internal dialogs return the same confidence, but the optimal Conversation composition is one in which ties are rare:
fromoperatorimportitemgetter...deflisten(self,text,response=True,**kwargs):"""Simply return the best confidence response"""responses=[dialog.listen(text,response,**kwargs)fordialoginself._dialogs]# Responses is a list of (response, confidence) pairsreturnmax(responses,key=itemgetter(1))
Because a SimpleConversation is a Dialog, it must implement parse, interpret, and respond. Here, we implement each of those so that they call the corresponding internal method and return the results. We also add a confidence score, which allows us to compose a conversation according to our confidence that the input has been interpreted correctly:
...defparse(self,text):"""Returns parses for all internal dialogs for debugging"""return[dialog.parse(text)fordialoginself._dialogs]definterpret(self,sents,**kwargs):"""Returns interpretations for all internal dialogs for debugging"""return[dialog.interpret(sents,**kwargs)fordialoginself._dialogs]defrespond(self,sents,confidence,**kwargs):"""Returns responses for all internal dialogs for debugging"""return[dialog.respond(sents,confidence,**kwargs)fordialoginself._dialogs]
The Dialog framework is intended to be modular, so that multiple dialog components can be used simultaneously (as in our SimpleConversation class) or used in a standalone fashion. Our implementation treats dialogs as wholly independent, but there are many other models such as:
- Parallel/async conversations
-
The first response with a positive confidence wins.
- Policy-driven conversations
-
Dialogs are marked as “open” and “closed.”
- Dynamic conversations
-
Dialogs can be dynamically added and removed.
- Tree structured conversations
-
Dialogs have parents and children.
In the next section, we will see how we can use the Dialog class with some simple heuristics to build a dialog system that manages interactions with users.
Rules for Polite Conversation
In 1950, renowned computer scientist and mathematician Alan Turing first proposed what would later be known as the Turing test2—a machine’s ability to fool a human into believing he or she was conversing with another person. The Turing test inspired a number of rule-based dialog systems over the next several decades, many of which not only passed the test, but became the first generation of conversation agents, and which continue to inform chatbot construction to this day.
Built by Joseph Weizenbaum in 1966 at MIT, ELIZA is perhaps the most well-known example. The ELIZA program used logic to match keyword- and phrase-patterns from human input and provide preprogrammed responses to move the conversation forward. PARRY, built by Kenneth Colby several years later at Stanford, responded using a combination of pattern matching and a mental model. This mental model made PARRY grow increasingly agitated and erratic to simulate a patient with paranoid schizophrenia, and successfully fooled doctors into believing they were speaking with a real patient.
In this section, we will implement a rules-based greeting feature inspired by these early models, which uses regular expressions to match utterances. Our version will maintain state primarily to acknowledge participants entering and leaving the dialog, and respond to them with appropriate salutations and questions. This implementation of a Dialog is meant to highlight the importance of keeping track of the state of a conversation over time as well as to show the effectiveness of regular expression–based chatbots. We will conclude the session by showing how a test framework can be used to exercise a Dialog component in a variety of ways, making it more robust to the variety of user input.
Greetings and Salutations
The Greeting dialog implements our conversational framework by extending the Dialog base class. It is responsible for keeping track of participants entering and exiting a conversation as well as providing the appropriate greeting and salutation when participants enter and exit. It does this by maintaining a participants state, a mapping of currently active users and their names.
At the heart of the Greeting dialog is a dictionary, PATTERNS, stored as a class variable. This dictionary maps the kind of interactions (described by key) to a regular expression that defines the expected input for that interaction. In particular, our simple Greeting dialog is prepared for greetings, introductions, goodbyes, and roll calls. Later, we’ll use these regular expressions in the parse method of the dialog:
classGreeting(Dialog):"""Keeps track of the participants entering or leaving the conversation andresponds with appropriate salutations. This is an example of a rules basedsystem that keeps track of state and uses regular expressions and logic tohandle the dialog."""PATTERNS={'greeting':r'hello|hi|hey|good morning|good evening','introduction':r'my name is ([a-z-s]+)','goodbye':r'goodbye|bye|ttyl','rollcall':r'roll call|who's here?',}def__init__(self,participants=None):# Participants is a map of user name to real nameself.participants={}ifparticipantsisnotNone:forparticipantinparticipants:self.participants[participant]=None# Compile regular expressionsself._patterns={key:re.compile(pattern,re.I)forkey,patterninself.PATTERNS.items()}
To initialize a Greeting we can instantiate it with or without a prior list of participants. We can think of the internal state of the dictionary as tracking a username with a real name, which we will see updated later with the introduction interpretation. To ensure fast and efficient parsing of text, we conclude initialization by compiling our regular expressions into an internal instance dictionary. Regular expression compilation in Python returns a regular expression object, saving a step when the same regular expression is used repeatedly as it will be in this dialog.
Note
This is a fairly minimalist implementation of the Greeting class, which could be extended in many ways with rules to support other speech and text patterns, as well as different languages.
Next, we will implement a parse method, whose purpose is to compare the incoming user-provided text to each of the compiled regular expressions to determine if it matches the known patterns for a greeting, introduction, goodbye, or attendance check:
defparse(self,text):"""Applies all regular expressions to the text to find matches."""matches={}forkey,patterninself._patterns.items():match=pattern.match(text)ifmatchisnotNone:matches[key]=matchreturnmatches
If a match is found, parse returns it. This result can then be used as input for the Greeting-specific interpret method, which takes in parsed matches and determines what kind of action is called for (if any). If interpret receives input that matched none of the patterns, it immediately returns with a 0.0 confidence score. If any of the text was matched, interpret simply returns a 1.0 confidence score because there is no fuzziness to regular expression matching.
The interpret method is responsible for updating the internal state of the Greeting dialog. For example, if the input matched an introductory exchange (e.g., if the user typed “my name is something”), interpret will extract the name, add any new user to self.participants, and add the (new or existing) user’s real name to the value corresponding to that key in the dictionary. If a greeting was detected, interpret will check to see if the user is known in self.participants, and if not, will add a keyword argument to the final return result flagging that an introduction should be requested in the respond method. Otherwise, if a goodbye was matched, it removes the user (if known) from the self.participants dictionary and from the keyword arguments:
definterpret(self,sents,**kwargs):"""Takes in parsed matches and determines if the message is an enter,exit, or name change."""# Can't do anything with no matchesiflen(sents)==0:returnsents,0.0,kwargs# Get username from the participantsuser=kwargs.get('user',None)# Determine if an introduction has been madeif'introduction'insents:# Get the name from the utterancename=sents['introduction'].groups()[0]user=userorname.lower()# Determine if name has changedifusernotinself.participantsorself.participants[user]!=name:kwargs['name_changed']=True# Update the participantsself.participants[user]=namekwargs['user']=user# Determine if a greeting has been madeif'greeting'insents:# If we don't have a name for the userifnotself.participants.get(user,None):kwargs['request_introduction']=True# Determine if goodbye has been madeif'goodbye'insentsanduserisnotNone:# Remove participantself.participants.pop(user)kwargs.pop('user',None)# If we've seen anything we're looking for, we're pretty confidentreturnsents,1.0,kwargs
Finally, our respond method will dictate if and how our chatbot should respond to the user. If the confidence is 0.0, no response is provided. If the user sent a greeting or introduction, respond will either return a request for the new user’s name or a greeting to the existing user. In the case of a goodbye, respond will return a generic farewell. If a user has asked about who else is in the chat, respond will get a list of the participants and return either all the names (if there are other participants), or just the user’s name (if she/he is in there alone). If there are no users currently recorded in self.participants, the chatbot will respond expectantly:
defrespond(self,sents,confidence,**kwargs):"""Gives a greeting or a goodbye depending on what's appropriate."""ifconfidence==0:returnNonename=self.participants.get(kwargs.get('user',None),None)name_changed=kwargs.get('name_changed',False)request_introduction=kwargs.get('request_introduction',False)if'greeting'insentsor'introduction'insents:ifrequest_introduction:return"Hello, what is your name?"else:return"Hello, {}!".format(name)if'goodbye'insents:return"Talk to you later!"if'rollcall'insents:people=list(self.participants.values())iflen(people)>1:roster=", ".join(people[:-1])roster+=" and {}.".format(people[-1])return"Currently in the conversation are "+rostereliflen(people)==1:return"It's just you and me right now, {}.".format(name)else:return"So lonely in here by myself ... wait who is that?"raiseException("expected response to be returned, but could not find rule")
Note that in both the interpret and respond methods, we simply have branching logic that handles each type of matched input. As this class gets larger, it is helpful to break down these methods into smaller chunks such as interpret_goodbye and respond_goodbye to encapsulate the logic and prevent bugs. We can experiment with the Greeting class a bit using different inputs here:
if__name__=='__main__':dialog=Greeting()# `listen` returns (response, confidence) tuples; just print the response(dialog.listen("Hello!",user="jakevp321")[0])(dialog.listen("my name is Jake",user="jakevp321")[0])(dialog.listen("Roll call!",user="jakevp321")[0])(dialog.listen("Have to go, goodbye!",user="jakevp321")[0])
Here are the results:
Hello, what is your name? Hello, Jake! It's just you and me right now, Jake.
However, it’s important to note that our rule-based system is pretty rigid and breaks down quickly. For instance, let’s see what happens if we leave off the user keyword argument in one of our calls to the Greeting.listen method:
if__name__=='__main__':dialog=Greeting()(dialog.listen("hey",user="jillmonger")[0])(dialog.listen("my name is Jill.",user="jillmonger")[0])(dialog.listen("who's here?")[0])
In this case, the chatbot recognizes Jill’s salutation, requests an introduction, and greets the new participant. However, in the third call to listen, the chatbot doesn’t have the user keyword argument and so fails to appropriately address her in the roll call response:
Hello, what is your name? Hello, Jill! It's just you and me right now, None.
Indeed, rules-based systems do tend to break down easily. Test-driven development, which we’ll explore in the next section, can help us to anticipate and pre-empt the kinds of problems that may occur in practice with users.
Handling Miscommunication
Rigorous testing is a useful way to handle possible miscommunications and other kinds of parsing and response errors. In this section, we’ll use the PyTest library to test the limits of our Greeting class, experiment with edge cases, and see where things start to break down.
To fully implement our chatbot, we would begin with a set of tests for our Dialog base class. Below we show the general framework we would use for the TestBaseClasses class, testing, for instance, classes that subclass the Dialog successfully inherit the listen method.
Our first test, test_dialog_abc, uses the pytest.mark.parametrize decorator, which allows us to send many different examples into the test with little effort:
importpytestclassTestBaseClasses(object):"""Tests for the Dialog class"""@pytest.mark.parametrize("text",["Gobbledeguk","Gibberish","Wingdings"])deftest_dialog_abc(self,text):"""Test the Dialog ABC and the listen method"""classSampleDialog(Dialog):defparse(self,text):return[]definterpret(self,sents):returnsents,0.0,{}defrespond(self,sents,confidence):returnNonesample=SampleDialog()reply,confidence=sample.listen(text)assertconfidence==0.0assertreplyisNone
Next, we can implement some tests for our Greeting class. The first of these, test_greeting_intro, uses the parametrize decorator to test many different combinations of input strings and usernames to see if the class successfully returns a 1 for the interpretation confidence, that respond generates a response, and that the chatbot asks for the user’s name:
classTestGreetingDialog(object):"""Test expected input and responses for the Greeting dialog"""@pytest.mark.parametrize("text",["Hello!","hello",'hey','hi'])@pytest.mark.parametrize("user",[None,"jay"],ids=["w/ user","w/o user"])deftest_greeting_intro(self,user,text):"""Test that an initial greeting requests an introduction"""g=Greeting()reply,confidence=g.listen(text,user=user)assertconfidence==1.0assertreplyisnotNoneassertreply=="Hello, what is your name?"
If any of these tests fail, it will serve as a signal that we should refactor our Greeting class so that it anticipates a broader range of possible inputs.
We should also create a test_initial_intro class that tests what happens when an introduction happens before a greeting. In this case, since we already know that this functionality is error-prone, we use the pytest.mark.xfail decorator to validate the cases that we expect are likely to fail; this will help us to remember the edge cases we want to address in future revisions:
...@pytest.mark.xfail(reason="a case that must be handled")@pytest.mark.parametrize("text",["My name is Jake","Hello, I'm Jake."])@pytest.mark.parametrize("user",[None,"jkm"],ids=["w/ user","w/o user"])deftest_initial_intro(self,user,text):"""Test an initial introduction without greeting"""g=Greeting()reply,confidence=g.listen(text,user=user)assertconfidence==1.0assertreplyisnotNoneassertreply=="Hello, Jake!"ifuserisNone:user='jake'assertusering.participantsassertg.participants[user]=='Jake'
Rules-based systems continue to be a very effective technique for keeping track of state within a dialog, particularly when augmented with robust edge-case exploration and test-driven development. The simple combination of regular expressions and logic to handle the exchanges (like ELIZA and PARRY, and our Greeting class) can be surprisingly effective. However, modern conversational agents rarely rely solely on heuristics. In the next part of the chapter, as we begin integrating linguistic features, we’ll start to see why.
Entertaining Questions
One of the most common uses of chatbots is to quickly and easily answer fact-based questions such as “How long is the Nile river?” There exists a variety of fact and knowledge bases on the web such as DBPedia, Yago2, and Google Knowledge Graph; it is also very common for microknowledge bases such as FAQs to exist for specific applications. These tools provide an answer; the challenge is converting a natural language question into a database query. While statistical matching of questions to their answers is one simple mechanism for this, more robust approaches use both statistical and semantic information; for example, using a frame-based approach to create templates that can be derived into SPARQL queries or using classification techniques to identify the type of answer required (e.g., a location, an amount, etc.).
In a general chat system, however, there exists a preliminary problem—to detect when we’ve been asked a question, and to determine what type of question it is. An excellent first step is to consider what questions look like; we might easily employ a regular expression to look for sentences that begin with a “wh”-question (“Who,” “What,” “Where,” “Why,” “When,” “How”) and end in a question mark.
However, this approach is likely to lead to false positives, such as ignoring questions that start with non-“wh”-words (e.g., “Can you cook?”, “Is there garlic?”) or statements that “wrap” questions (e.g., “You’re joining us?”). This approach may also generate false negatives, mistakenly promoting nonquestions that start with “wh”-words (e.g., “When in Rome…”) or rhetorical questions that do not require a response (e.g., “Do you even lift?”).
Though questions are often posed in irregular and unexpected ways, some patterns do exist. Sentences encode deep structures and relationships that go far beyond simple windowing and matching. To detect these patterns, we will need to perform some type of syntactic parsing—in other words, a mechanism that exploits context-free grammars to systematically assign syntactic structure to incoming text.
In “Extracting Keyphrases” we saw that NLTK has a number of grammar-based parsers, but all require us to provide a grammar to specify the rules for building up parts-of-speech into phrases or chunks, which will unnecessarily limit our chatbot’s flexibility. In the following sections we will instead explore pretrained dependency parsing and constituency parsing as more flexible alternatives.
Dependency Parsing
Dependency parsers are a lightweight mechanism to extract the syntactic structure of a sentence by linking phrases together with specific relationships. They do so by first identifying the head word of a phrase, then establishing links between the words that modify the head. The result is an overlapping structure of arcs that identify meaningful substructures of the sentence.
Consider the sentence “How many teaspoons are in a tablespoon?”. In Figure 10-3, we see a dependency parse as visualized using SpaCy’s DisplaCy module (available as of v2.0). This parse aims to tell us how the words in the sentence interact and modify each other. For instance, we can clearly see that the root of this phrase is the head verb (VERB) “are,” which joins an adverbial phrase (ADV,ADJ,NOUN) “How many teaspoons” to a propositional phrase (ADP,DET,NOUN) “in a tablespoon” through the subject dependency of the head noun “teaspoons” and the prepositional dependency “in” (ADP is a cover term for prepositions).

Figure 10-3. SpaCy dependency tree
Note
Whereas NLTK uses the Penn Treebank tagset, which we first saw in “Part-of-Speech Tagging”, SpaCy’s convention is to use the Universal part-of-speech tags (e.g., “ADJ” for adjectives, “ADV” for adverbs, “PROPN” for proper nouns, “PRON” for pronouns, etc.). The Universal PoS tags are written by linguists (not programmers, like the Penn Treebank tags), which means they are generally richer, though they don’t allow for things like using tag.startswith("N") to identify nouns.
To recreate the parse shown in Figure 10-3, we first load SpaCy’s prebuilt English language parsing model. We then write a function, plot_displacy_tree, that parses incoming sentences using the prebuilt model and plots the resulting dependency parse using the displacy.serve method. If executed within a Jupyter notebook, the plot will render in the notebook; if run on the command line, the plot can be viewed in the browser at http://localhost:5000/:
importspacyfromspacyimportdisplacy# Required first: python -m spacy download enspacy_nlp=spacy.load("en")defplot_displacy_tree(sent):doc=spacy_nlp(sent)displacy.serve(doc,style='dep')
Dependency parsers are extremely popular for producing fast and correct grammatical analyses and when combined with part-of-speech tagging, perform much of the work required for phrase-level analysis. The relationships between words produced by dependency parsers may also be of interest to syntactic analysis. However, dependency parsing does not offer as rich and deep a view of the structure of sentences, and as such, may not always be sufficient or optimal. In our chatbot, we’ll demonstrate how to leverage a more comprehensive tree representation, the constituency parse.
Constituency Parsing
Constituency parsing is a form of syntactic parsing whose goal is to break down a sentence into nested phrase structures similar to those we diagrammed when we were in grade school. The output is a tree structure that captures complex interrelationships between subphrases. Constituency parsers provide an opportunity to apply tree-traversal algorithms that easily enable computation on text, but because language is ambiguous, there is usually more than one way to construct a tree for a sentence.
We can parse our example question, “How many teaspoons in a tablespoon?”, shown as a tree in Figure 10-4. Here we can see a much more complex structure of subphrases and more direct, unlabeled relationships between nodes in the tree.
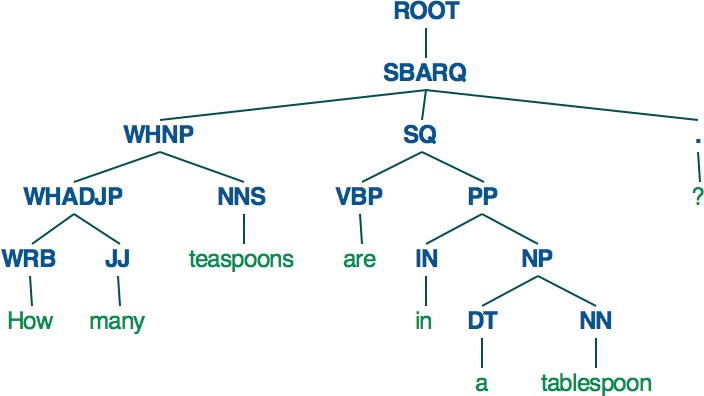
Figure 10-4. Stanford CoreNLP constituency tree
Constituency parse trees are comprised of terminal leaf nodes, the part-of-speech tag, and the word itself. The nonterminal nodes represent phrases that join the part-of-speech tags into related groupings. In this question, the root phrase is an SBARQ, a clause identified as a direct question because it is introduced by a “wh”-word. This clause is composed of a WHNP (a noun phrase with a “wh”-word) and an SQ, the main clause of the SBARQ, which itself is a verb phrase. As you can see, a lot of detail exists in this parse that gives a lot of clues about how to treat this question in its syntactic parts!
For questions and answers, the WRB, WP, and WDT tags identify words that are of interest to our particular context, and may signal a measurement-conversion question; WRB is a “wh”-adverb (e.g., a “wh”- word used as a verbal modifier, as in “When are you leaving?”); WP is a “wh”-pronoun (as in “Who won the bet?”); and WDT is a “wh”-determiner (as in “Which Springfield?”).
The Stanford CoreNLP package is a comprehensive suite of natural language processing tools written in Java. It includes methods for part-of-speech tagging, syntactic parsing, named entity recognition, sentiment analysis, and more.
In a recent update to the library, NLTK made available a new module nltk.parse.stanford that enables us to use the Stanford parsers from inside NLTK (assuming you have set up the requisite .jars and PATH configuration) as follows:
fromnltk.parse.stanfordimportStanfordParserstanford_parser=StanfordParser(model_path="edu/stanford/nlp/models/lexparser/englishPCFG.ser.gz")defprint_stanford_tree(sent):"""Use Stanford pretrained model to extract dependency treefor use by other methodsReturns a list of trees"""parse=stanford_parser.raw_parse(sent)returnlist(parse)
We can plot the Stanford constituency tree using nltk.tree to generate the tree shown in Figure 10-4, which allows us to visually inspect the structure of the question:
defplot_stanford_tree(sent):"""Visually inspect the Stanford dependency tree as an image"""parse=stanford_parser.raw_parse(sent)tree=list(parse)tree[0].draw()
As you visually explore syntax parses produced by StanfordNLP you’ll notice that structures get much more complex with longer parses. Constituency parses provide a lot of information, which may simply end up being noise in some text-based applications. Both constituency and dependency parsing suffer from structural ambiguity, meaning that these parses may also produce some probability of a correct parse that can be used when computing confidence. However, the level of detail a syntax provides makes it an excellent candidate for easily identifying questions and applying frames to extract queryable information, as we’ll see in the next section.
Question Detection
The pretrained models in SpaCy and CoreNLP give us a powerful way to automatically parse and annotate input sentences. We can then use the annotations to traverse the parsed sentences and look for part-of-speech tags that correspond to questions.
First, we will inspect the tag assigned to the top-level node of the ROOT (the zeroth item of the parse tree, which contains all its branches). Next, we want to inspect the tags assigned to the branch and leaf nodes, which we can do using the tree.pos method from nltk.tree.Tree module:
tree=print_stanford_tree("How many teaspoons are in a tablespoon?")root=tree[0]# The root is the first item in the parsed sents tree(root)(root.pos())
Once parsed, we can next explore how different questions manifest using the Penn Treebank tags, which we first encountered in “Part-of-Speech Tagging”. In our example, we can see from the root that our input is an SBARQ (a direct question introduced by a “wh”-word), which in this case is a WRB (a “wh”-adverb). The sentence begins with a WHNP (a “wh”-noun phrase) that contains a WHADJP (a “wh”-adjective phrase):
(ROOT
(SBARQ
(WHNP (WHADJP (WRB How) (JJ many)) (NNS teaspoons))
(SQ (VBP are) (PP (IN in) (NP (DT a) (NN tablespoon))))
(. ?)))
[('How', 'WRB'), ('many', 'JJ'), ('teaspoons', 'NNS'), ('are', 'VBP'),
('in', 'IN'), ('a', 'DT'), ('tablespoon', 'NN'), ('?', '.')]
The major advantage of using a technique like this for question detection is the flexibility. For instance, if we change our question to “Sorry to trouble you, but how many teaspoons are in a tablespoon?”, the output is different, but the WHADJP and WRB question markers are still there:
(ROOT
(FRAG
(FRAG
(ADJP (JJ Sorry))
(S (VP (TO to) (VP (VB trouble) (NP (PRP you))))))
(, ,)
(CC but)
(SBAR
(WHADJP (WRB how) (JJ many))
(S
(NP (NNS teaspoons))
(VP (VBP are) (PP (IN in) (NP (DT a) (NN tablespoon))))))
(. ?)))
[('Sorry', 'JJ'), ('to', 'TO'), ('trouble', 'VB'), ('you', 'PRP'), (',', ','),
('but', 'CC'), ('how', 'WRB'), ('many', 'JJ'), ('teaspoons', 'NNS'),
('are', 'VBP'), ('in', 'IN'), ('a', 'DT'), ('tablespoon', 'NN'), ('?', '.')]
Table 10-1 lists some of the tags we have found most useful in question detection; a complete list can be found in Bies et al.’s “Bracketing Guidelines for Treebank II Style.”3
| Tag | Meaning | Example |
|---|---|---|
SBARQ |
Direct question introduced by a wh-word or a wh-phrase |
“How hot is the oven?” |
SBAR |
Clause introduced by subordinating conjunction (e.g., indirect question) |
“If you’re in town, try the beignets.” |
SINV |
Inverted declarative sentence |
“Rarely have I eaten better.” |
SQ |
Inverted yes/no question or main clause of a wh-question |
“Is the gumbo spicy?” |
S |
Simple declarative clause |
“I like jalapenos.” |
WHADJP |
Wh-adjective phrases |
The “How hot” in “How hot is the oven?” |
WHADVP |
Wh-adverb phrase |
The “Where do” in “Where do you keep the chicory?” |
WHNP |
Wh-noun phrase |
The “Which bakery” in “Which bakery is best?” |
WHPP |
Wh-prepositional phrase |
The “on which” in “The roux, on which this recipe depends, should not be skipped.” |
WRB |
Wh-adverb |
The “How” in “How hot is the oven?” |
WDT |
Wh-determiner |
The “What” in “What temperature is it?” |
WP$ |
Possessive wh-pronoun |
The “Whose” in “Whose bowl is this?” |
WP |
Wh-pronoun |
The “Who” in “Who’s hungry?” |
In the next section, we will see how to use these tags to detect questions most relevant to our kitchen helper bot.
From Tablespoons to Grams
The next feature we will add to our chatbot is a question-and-answer system that leverages the pretrained parsers we explored in the previous section to provide convenient kitchen measurement conversions. Consider that in everyday conversation, people frequently phrase questions about measurements as “How” questions—for example “How many teaspoons are in a tablespoon?” or “How many cups make a liter?” For our question-type identification task, we will aim to be able to interpret questions that take the form “How many X are in a Y?”
We begin by defining a class Converter, which inherits the behavior of our Dialog class. We expect to initialize a Converter with a knowledge base of measurement conversions, here a simple JSON file stored in CONVERSION_PATH and containing all of the conversions between units of measure. On initialization, these conversions are loaded using json.load. We also initialize a parser (here we use CoreNLP), as well as a stemmer from NLTK and an inflect.engine from the inflect library, which will enable us to handle pluralization in the parse and respond methods, respectively. Our parse method will use the raw_parse method from CoreNLP to generate constituency parses as demonstrated in the previous section:
importosimportjsonimportinflectfromnltk.stem.snowballimportSnowballStemmerfromnltk.parse.stanfordimportStanfordParserclassConverter(Dialog):"""Answers questions about converting units"""def__init__(self,conversion_path=CONVERSION_PATH):withopen(conversion_path,'r')asf:self.metrics=json.load(f)self.inflect=inflect.engine()self.stemmer=SnowballStemmer('english')self.parser=StanfordParser(model_path=STANFORD_PATH)defparse(self,text):parse=self.parser.raw_parse(text)returnlist(parse)
Next, in interpret, we initialize a list to collect the measures we want to convert from and to, an initial confidence score of 0, and a dictionary to collect the results of our interpretation. We retrieve the root of the parsed sentence tree and use the nltk.tree.Tree.pos method to scan through the part-of-speech tags for ones that match the adverbial phrase question pattern (WRB). If we find any, we increment our confidence score, and begin to traverse the tree using an nltk.util.breadth_first search with a maximum depth of 8 (to limit recursion). For any subtrees that match the syntactic patterns in which “how many”-type questions typically arise, we identify and store any singular or plural nouns that represent the source and target measures. If we identify any numbers within the question phrase subtree, we store that in our results dictionary as the quantity for the target measure.
For demonstration purposes, we’ll use a naive but straightforward mechanism for computing confidence here; more nuanced methods are possible and may be advisable, given your particular context. If we are successful at identifying both a source and target measure, we increment our confidence again and add these to our results dictionary. If either measure is also in our knowledge base (aka JSON lookup), we increase the confidence accordingly. Finally, we return a (results, confidence, kwargs) tuple, which the respond method will use to determine whether and how to respond to the user:
fromnltk.treeimportTreefromnltk.utilimportbreadth_first...definterpret(self,sents,**kwargs):measures=[]confidence=0results=dict()# The root is the first item in the parsed sents treeroot=sents[0]# Make sure there are wh-adverb phrasesif"WRB"in[tagforword,taginroot.pos()]:# If so, increment confidence & traverse parse treeconfidence+=.2# Set the maxdepth to limit recursionforclauseinbreadth_first(root,maxdepth=8):#find the simple declarative clauses (+S+)ifisinstance(clause,Tree):ifclause.label()in["S","SQ","WHNP"]:fortoken,taginclause.pos():# Store nouns as target measuresiftagin["NN","NNS"]:measures.append(token)# Store numbers as target quantitieseliftagin["CD"]:results["quantity"]=token# Handle duplication for very nested treesmeasures=list(set([self.stemmer.stem(mnt)formntinmeasures]))# If both source and destination measures are provided...iflen(measures)==2:confidence+=.4results["src"]=measures[0]results["dst"]=measures[1]# Check to see if they correspond to our lookup tableifresults["src"]inself.metrics.keys():confidence+=.2ifresults["dst"]inself.metrics[results["src"]]):confidence+=.2returnresults,confidence,kwargs
However, before we can implement our respond method, we need a few helper utilities. The first is convert, which converts from the units of the source measurement to those of the target measurement. The convert method takes as input string representations of the source units (src), the target units (dst), and a quantity of the source unit, which may be either a float or an int. The function returns a tuple with the (converted, source, target) units:
defconvert(self,src,dst,quantity=1.0):"""Converts from the source unit to the dest unit for the given quantityof the source unit."""# Stem source and dest to remove pluralizationsrc,dst=tuple(map(self.stemmer.stem,(src,dst)))# Check that we can convertifdstnotinself.metrics:raiseKeyError("cannot convert to '{}' units".format(src))ifsrcnotinself.metrics[dst]:raiseKeyError("cannot convert from {} to '{}'".format(src,dst))returnself.metrics[dst][src]*float(quantity),src,dst
We will also add round, pluralize, and numericalize methods, which leverage utilities from the humanize library to transform numbers to more natural human-readable form:
importhumanize...defround(self,num):num=round(float(num),4)ifnum.is_integer():returnint(num)returnnumdefpluralize(self,noun,num):returnself.inflect.plural_noun(noun,num)defnumericalize(self,amt):ifamt>100.0andamt<1e6:returnhumanize.intcomma(int(amt))ifamt>=1e6:returnhumanize.intword(int(amt))elifisinstance(amt,int)oramt.is_integer():returnhumanize.apnumber(int(amt))else:returnhumanize.fractional(amt)
Finally, in the respond method, we check to see if our confidence in our interpretation is sufficiently high, and if so, we use convert to perform the actual measurement conversions, and then round, pluralize, and numericalize to ensure the final response is easy for the user to read:
defrespond(self,sents,confidence,**kwargs):"""Response makes use of the humanize and inflect libraries to producemuch more human understandable results."""ifconfidence<.5:return"I'm sorry, I don't know that one."try:quantity=sents.get('quantity',1)amount,source,target=self.convert(**sents)# Perform numeric roundingamount=self.round(amount)quantity=self.round(quantity)# Pluralizesource=self.pluralize(source,quantity)target=self.pluralize(target,amount)verb=self.inflect.plural_verb("is",amount)# Numericalizequantity=self.numericalize(quantity)amount=self.numericalize(amount)return"There {} {} {} in {} {}.".format(verb,amount,target,quantity,source)exceptKeyErrorase:return"I'm sorry I {}".format(str(e))
Now we can experiment with using the listen method on a few possible input questions to see how well our Converter class is able to handle different combinations and quantities of source and target units:
if__name__=="__main__":dialog=Converter()(dialog.listen("How many cups are in a gallon?"))(dialog.listen("How many gallons are in 2 cups?"))(dialog.listen("How many tablespoons are in a cup?"))(dialog.listen("How many tablespoons are in 10 cups?"))(dialog.listen("How many tablespoons are in a teaspoon?"))
The resulting output, which is in the form of (reply, confidence) tuples, shows that Converter is able to successfully produce conversions with consistently high confidence:
('There are 16 cups in one gallon.', 1.0)
('There are 32 cups in two gallons.', 1.0)
('There are 16 tablespoons in one cup.', 1.0)
('There are 160 tablespoons in 10 cups.', 1.0)
('There are 1/3 tablespoons in one teaspoon.', 1.0)
Learning to Help
While providing dynamic measurement conversions is certainly convenient, we’d like to incorporate something a bit more unique—a recipe recommender. In this section, we walk through a pipeline that will leverage a recipe corpus to perform text normalization, vectorization, and dimensionality reduction, and finally use a nearest-neighbor algorithm to provide recipe recommendations, as shown in Figure 10-5. In this case the state maintained by our Dialog variant will be an active learning model, capable of providing recommendations and incorporating user feedback to improve over time.
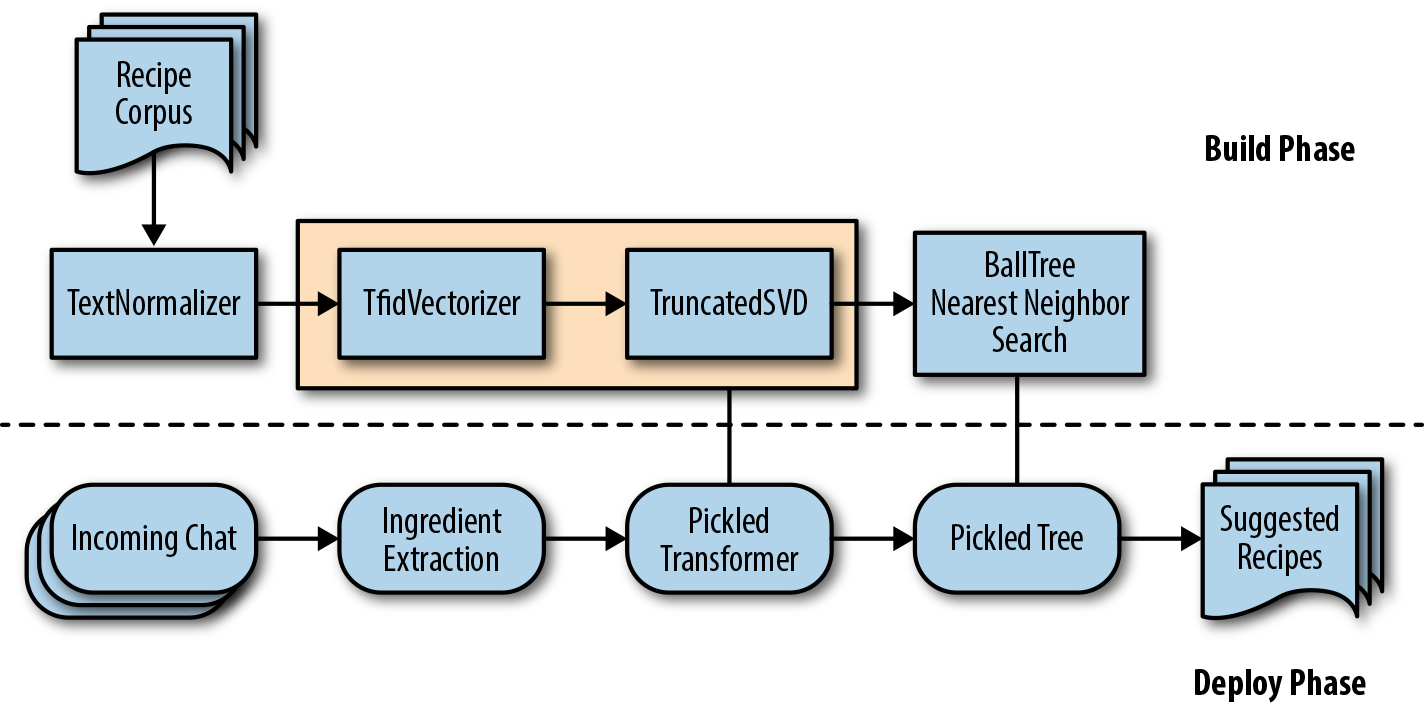
Figure 10-5. Recipe recommender schema
Being Neighborly
The main drawback of the nearest-neighbor algorithm is the complexity of search as dimensionality increases; to find the k nearest neighbors for any given vectorized document d, we have to compute the distances from d to every other document in the corpus. Since our example corpus contains roughly 60,000 documents, this means we’ll need to do 60,000 distance computations, with an operation for each dimension in our document vector. Assuming a 100,000-dimensional space, which is not unusual for text, that means 6 billion operations per recipe search!
That means we’ll need to find some ways to speed up our search so our chatbot can provide recommendations quickly. First, we should perform dimensionality reduction. We are already doing some dimensionality reduction, since the TextNormalizer we used in Chapters 4 and 5 performs some lemmatization and other “light touch” cleaning that effectively reduces the dimensions of our data. We could further reduce the dimensionality by using the n-gram FreqDist class from Chapter 7 as a transformer to select only the tokens that constitute 10%–50% of the distribution.
Alternatively, we can pair our TfidfVectorizer with Scikit-Learn’s TruncatedSVD, which will compress the dimensions of our vectors into fewer components (the rule of thumb for text documents is to set n_components to at least 200). Keep in mind that TruncatedSVD does not center the data before computing the Singular Value Decompositions, which may result in somewhat erratic results, depending on the distribution of the data.
We can also leverage a less computationally expensive alternative to traditional unsupervised nearest-neighbor search, such as ball tree, K-D trees, and local sensitivity hashing. A K-D tree (sklearn.neighbors.KDTree) is an approximation of nearest neighbor, which only computes the distances from our instance d to a subset of the full dataset. However, K-D does not perform particularly well on sparse, high-dimensional data because it uses the values of random features to partition the data (recall that with a given vectorized document, most values will be zero). Local sensitivity hashing is more performant on high-dimensional data, though the current Scikit-Learn implementation, sklearn.neighbors.NearestNeighbors, has been found to be inefficient and is scheduled for deprecation.
Note
Of course, there are also approximate nearest-neighbor implementations in other libraries, such as Annoy (a C++ library with Python bindings), which is currently used by Spotify to generate dynamic song recommendations.
For our chatbot, we will use a ball tree algorithm. Like K-D trees, the ball tree algorithm partitions data points so that the nearest-neighbor search can be performed on a subset of the points (in this case, nested hyperspheres). As the dimensionality of a nearest-neighbor search space increases, ball trees have been shown to perform fairly well.4 Conveniently, the Scikit-Learn implementation, sklearn.neighbors.BallTree, exposes a range of different distance metrics that can be used and compared for performance optimization.
Finally, we can accelerate our recipe recommendation search by serializing both our trained transformer (so that we can perform the same transformations on incoming text from users), and our tree, so that our chatbot can perform queries without having to rebuild the tree for every search.
First, we’ll create a BallTreeRecommender class, which is initialized with a k for the desired number of recommendations (which will default to 3), paths to a pickled fitted transformer svd.pkl, and fitted ball tree tree.pkl. If the model has already been fit, these paths will exist, and the load method will load them from disk for use. Otherwise, they will be fitted and saved using Scikit-Learn’s joblib serializer in our fit_transform method:
importpicklefromsklearn.externalsimportjoblibfromsklearn.pipelineimportPipelinefromsklearn.neighborsimportBallTreefromsklearn.decompositionimportTruncatedSVDfromsklearn.feature_extraction.textimportTfidfVectorizerclassBallTreeRecommender(BaseEstimator,TransformerMixin):"""Given input terms, provide k recipe recommendations"""def__init__(self,k=3,**kwargs):self.k=kself.trans_path="svd.pkl"self.tree_path="tree.pkl"self.transformer=Falseself.tree=Noneself.load()defload(self):"""Load a pickled transformer and tree from disk,if they exist."""ifos.path.exists(self.trans_path):self.transformer=joblib.load(open(self.trans_path,'rb'))self.tree=joblib.load(open(self.tree_path,'rb'))else:self.transformer=Falseself.tree=Nonedefsave(self):"""It takes a long time to fit, so just do it once!"""joblib.dump(self.transformer,open(self.trans_path,'wb'))joblib.dump(self.tree,open(self.tree_path,'wb'))deffit_transform(self,documents):ifself.transformer==False:self.transformer=Pipeline([('norm',TextNormalizer(minimum=50,maximum=200)),('transform',Pipeline([('tfidf',TfidfVectorizer()),('svd',TruncatedSVD(n_components=200))]))])self.lexicon=self.transformer.fit_transform(documents)self.tree=BallTree(self.lexicon)self.save()
Once a sklearn.neighbors.BallTree model has been fitted, we can use the tree.query method to return the distances and indices for the k closest documents. For our BallTreeRecommender class, we will add a wrapper query method that uses the fitted transformer to vectorize and transform incoming text and return only the indices for the closest recipes:
defquery(self,terms):"""Given input list of ingredient terms, return k closest matching recipes."""vect_doc=self.transformer.named_steps['transform'].fit_transform(terms)dists,inds=self.tree.query(vect_doc,k=self.k)returninds[0]
Offering Recommendations
Assuming that we have fit our BallTreeRecommender on our pickled recipe corpus and saved the model artifacts, we can now implement the recipe recommendations in the context of our Dialog abstract base class.
Our new class RecipeRecommender is instantiated with a pickled corpus reader and an estimator that implements a query method, like our BallTreeRecommender. We use the corpus.titles() method referenced in “A Domain-Specific Corpus”, which will allow us to reference the stored recipes using the blog post titles as their names. If the recommender isn’t already fitted, the __init__ method will ensure that it is fit and transformed:
classRecipeRecommender(Dialog):"""Recipe recommender dialog"""def__init__(self,recipes,recommender=BallTreeRecommender(k=3)):self.recipes=list(corpus.titles())self.recommender=recommender# Fit the recommender model with the corpusself.recommender.fit_transform(list(corpus.docs()))
Next, the parse method splits the input text string into a list and performs part-of-speech tagging:
defparse(self,text):"""Extract ingredients from the text"""returnpos_tag(wordpunct_tokenize(text))
Our interpret method takes in the parsed text and determines whether it is a list of ingredients. If so, it transforms the utterance into a collection of nouns and then assigns a confidence score according to the percent of the input text that is nouns. Again, we are using a naive method for computing confidence here, primarily for its straightforwardness. In practice, it would be valuable to validate confidence scoring mechanisms; for instance, by having reviewers evaluate performance on an annotated test set to confirm that lower confidence scores correspond to lower quality responses:
definterpret(self,sents,**kwargs):# If feedback detected, update the modelif'feedback'inkwargs:self.recommender.update(kwargs['feedback'])n_nouns=sum(1forpos,taginsentsifpos.startswith("N"))confidence=n_nouns/len(sents)terms=[tagforpos,taginsentsifpos.startswith("N")]returnterms,confidence,kwargs
Finally, the respond method takes in the list of nouns extracted from the interpret method as well as the confidence. If interpret has successfully extracted a sufficient number of nouns from the input, the confidence will be high enough to generate recommendations. We will retrieve these recommendations by calling the internal recommender.query method with the extracted nouns:
defrespond(self,terms,confidence,**kwargs):"""Returns a recommendation if the confidence is > 0.15 otherwise None."""ifconfidence<0.15:returnNoneoutput=["Here are some recipes related to {}".format(", ".join(terms))]output+=["- {}".format(self.recipes[idx])foridxinself.recommender.query(terms)]return"".join(output)
Now we can test out our new RecipeRecommender:
if__name__=='__main__':corpus=HTMLPickledCorpusReader('../food_corpus_proc')recommender=RecipeRecommender(corpus)question="What can I make with brie, tomatoes, capers, and pancetta?"(recommender.listen(question))
And here are the results:
('Here are some recipes related to brie, tomatoes, capers, pancetta
- My Trip to Jamaica - Cookies and Cups
- Turkey Bolognese | Well Plated by Erin
- Cranberry Brie Bites', 0.2857142857142857)
As discussed in Chapter 1, machine learning models benefit from feedback, which can be used to more effectively produce results. In the context of a kitchen chatbot producing recipe recommendations, we have the perfect opportunity to create the possibility for natural language feedback. Consider implicit feedback: we know the user is interested if they respond “OK, show me the Cranberry Brie Bites recipe” and we can use this information to rank cheesy deliciousness higher in our recommendation results by modifying a new vector component specifically related to the user’s preference.
Alternatively, we could initiate the conversation with the user and explicitly ask them what they thought about the recipe! Chatbots are an opportunity to get increasingly detailed user feedback that simply doesn’t exist in current clickstream-based feedback mechanisms.
Conclusion
With flexible language models trained on domain-specific corpora, coupled with effective task-oriented frames, chatbots increasingly allow people to find information and receive answers not only faster than via other means, but also more intuitively. As natural language understanding and generation improve, chatting with a bot may eventually become a better experience than chatting with a human!
In this chapter we presented a framework for conversational agents centered around the abstract Dialog object. Dialog objects listen for human input, parse and interpret the input, updating an internal state, then respond if required based on the updated state. A Conversation is a collection of dialogs that allow us to create chatbots in a composable fashion, each dialog having their own responsibility for interpreting particular input. We presented a simple conversation that passes all input to all internal dialogs then responds with the interpretation with the highest confidence.
The Dialog framework allows us to easily create conversational components and add them to applications, extending them without much effort and decoupling them for easy testing. Although we couldn’t get to it in this chapter, we have examples of how to implement conversations inside of a command-line chat application or a Flask-based web application in our GitHub repository for the book: https://github.com/foxbook/atap/.
Our kitchen helper is now capable of parsing incoming text, detecting some different types of questions, and providing measurement conversions or recipe recommendations, depending on the user’s query. For next steps, we might extend our chatbot’s ability to be conversational by training an n-gram language model as discussed in Chapter 7 or a connectionist model, which we’ll investigate in Chapter 12 on a conversational food corpus. In the next chapter we will explore scaling techniques that enable us to build more performant language-aware data products, and see how they can be applied to accelerate the text analytics workflow from corpus ingestion and preprocessing to transformation and modeling.
1 Claude Shannon, A Mathematical Theory of Communication, (1948) http://bit.ly/2JJnVjd
2 Alan Turing, Computing Machinery and Intelligence, (1950) http://bit.ly/2GLop6D
3 Ann Bies, Mark Ferguson, Karen Katz, and Robert MacIntyre, Bracketing Guidelines for Treebank II Style: Penn Treebank Project, (1995) http://bit.ly/2GQKZLm
4 Ting Liu, Andrew W. Moore, and Alexander Gray, New Algorithms for Efficient High-Dimensional Nonparametric Classification, (2006) http://bit.ly/2GQL0io