
Chapter 8
Data Considerations in the Cloud
If we have data, let’s look at the data. If we have opinions, let’s go with mine.
—Jim Barksdale, former CEO of Netscape
When it comes to cloud computing decision making, nothing influences those decisions more than data requirements. Architects and product managers should have a firm understanding of the requirements for all information that flows in and out of the system. This chapter analyzes the many characteristics of data and how those characteristics influence design decisions.
Data Characteristics
There are many characteristics of data that should be taken into consideration when building cloud services. Here is a short list of categories:
- Physical characteristics
- Performance requirements
- Volatility
- Volume
- Regulatory requirements
- Transaction boundaries
- Retention period
All of the data requirements listed here factor into the decision of how to store the underlying data. There are two key decisions to make that we will discuss toward the end of the chapter:
In the following sections we will discuss design considerations for each data characteristic.
Physical Characteristics
When analyzing physical characteristics, many data points need to be collected. The location of the data is an important piece of information. Does the data already exist or is this a new data set? If it already exists, does the data need to be moved to the cloud or will the data be created in the cloud? If the data has to be transported to the cloud, how big is it? If we are talking about a huge amount of data (terabytes), this presents a challenge. Some cloud vendors offer the capability to ship large amounts of data to them so they can manually load the data on the customer’s behalf, but if the data is highly sensitive, do we really want a truckload of sensitive data going off-site? If the data is new, more than likely all of the data can be created in the cloud (public or private) and the ugly step of transferring huge amounts of data for an initial load is not needed. The location of the data also is relevant when analyzing legal responsibilities. Different countries have different laws about data entering and leaving the country’s borders.
Who owns the data? Does the company building the software own it, is the data coming from a third party, or does the customer of the system own the data? Can the data be shared with other companies? If so, do certain attributes need to be masked to hide it from other parties? Ownership of data is an important characteristic and the answer to the ownership question should be written in the contracts between the service providers and their customers. For a company building Software as a Service (SaaS), Platform as a Service (PaaS), or Infrastructure as a Service (IaaS) solutions, answers to data ownership and sharing could drive design decisions on whether separate databases and even separate database servers are required per client in order to meet certain demands around privacy, security, and service level agreements (SLAs).
Performance Requirements
Performance falls into three categories: real time, near real time, and delayed time. Real-time performance is usually defined as subsecond response time. Websites typically strive for half-second response time or less. Near real time usually refers to within a second or two. Sometimes near real time means “perceived real time.” Perceived real time means the performance is near real time but to the end user it appears to be real time. For example, with point-of-sale (POS) technology, the perceived time for cashing out a customer at the cash register is the time it takes to spit out the receipt after all the items are scanned and the discounts are processed. Often, tasks are performed during the entire shopping experience that may take one second or more, but these tasks are finished by checkout. Even though some tasks take longer than the real-time standard of half a second, the tasks visible to the consumer (generating the receipt) occur in real time, hence the term perceived real time. Delayed time can range from a few seconds to batch time frames of daily, weekly, monthly, and so on.
The response time categories drive major design decisions. The faster the response time required, the more likely the architects will need to leverage memory over disk. Common design patterns for high-volume fast-performing data sets are:
- Use a caching layer.
- Reduce the size of data sets (store hash values or binary representations of attributes).
- Separate databases into read-only and write-only nodes.
- Shard data into customer-, time-, or domain-specific shards.
- Archive aging data to reduce table sizes.
- Denormalize data sets.
There are many other methods. Understanding performance requirements is key in driving these types of design decisions.
Volatility
Volatility refers to the frequency in which the data changes. Data sets are either static or dynamic. Static data sets are usually event-driven data that occur in chronological order. Examples are web logs, transactions, and collection data. Common types of information in web logs are page views, referring traffic, search terms, user IP addresses, and the like. Common transactions are bank debits and credits, point-of-sale purchases, stock trading, and so forth. Examples of collection data are readings from manufacturing machines, environmental readings like weather, and human genome data. Static data sets like these are write-once, read-many type data sets because they occur in a point of time but are analyzed over and over to detect patterns and observe behaviors. These data sets often are stored over long periods of time and consume terabytes of data. Large, static data sets of this nature often require nonstandard database practices to maximize performance. Common practices for mining these types of data sets are to denormalize the data, leverage star or snowflake schemas, leverage NoSQL databases, and, more recently, apply big data technologies.
Dynamic data requires entirely different designs. If data is changing frequently, a normalized relational database management system (RDMS) is the most common solution. Relational databases are great for processing ACID (atomicity, consistency, isolation, durability) transactions to ensure the reliability of the data. Normalized relational databases protect the integrity of the data by ensuring that duplicate data and orphan records do not exist.
Another important characteristic of volatility is the frequency of the data. One million rows of data a month is a much easier problem to design for than one million rows a minute. The speed at which data flows (add, change, delete) is a huge factor in the overall architecture of the data layer within the cloud. Understanding the different disk storage systems within the cloud is critical. For example, on Amazon Web Services (AWS), S3 is a highly reliable disk storage system, but it is not the highest performing. EBS volumes are local disk systems that lack the reliability and redundancy of S3 but perform faster. It is key to know the data requirements so that the best disk storage system is selected to solve specific problems.
Volume
Volume refers to the amount of data that a system must maintain and process. There are many advantages of using relational databases, but when data volumes hit a certain size, relational databases can become too slow and too expensive to maintain. Architects must also determine how much data is relevant enough to be maintained online and available for access and how much data should be archived or stored on slower and less expensive disks. Volume also impacts the design of a backup strategy. Backing up databases and file systems is a critical component of business continuity and disaster recovery, and it must be compliant with regulations such as SSAE16 and others. Backups tend to consume large amounts of CPU cycles and could impact the overall system performance without a sound design. Full backups are often performed daily while incremental backups are performed multiple times throughout the day. One common strategy is to perform backups on a slave database so that the application performance is not impacted.
Regulatory Requirements
Regulation plays a major role in design decisions pertaining to data. Almost any company delivering cloud services in a B2B model can expect customers to demand certifications in various regulations such as SAS 70, SSAE 16, ISO 27001, HIPAA, PCI, and others. Data that is classified as PII (personally identifiable information) must be encrypted in flight and at rest, which creates performance overhead, especially if those fields have high volatility and volumes. PII data is a big contributor for companies choosing to leverage private and hybrid clouds. Many companies refuse to put sensitive and private data in a public, multitenant environment. Understanding regulatory constraints and risks can drive deployment model decisions.
Transaction Boundaries
Transaction boundaries can be thought of as a unit of work. In e-commerce, shoppers interact with data on a web form and make various changes to the data as they think through their shopping event. When they place an order, all of the decisions they have made are either committed or rejected based on whether they have a valid credit card and available balance or if the items are still in stock. A good example of a transaction boundary is the following process flow common to travel sites like Expedia.com.
A consumer from Chicago is looking to take a family vacation to Disney World in Orlando, Florida. She logs onto Expedia.com and proceeds to book a flight, a hotel, and a rental car. Behind the scenes, Expedia is calling application programming interfaces (APIs) to three different companies, like US Airways for the airfare, Marriott for the hotel, and Hertz for the rental car. As the consumer is guided through the process flow of selecting an airline, a hotel, and a car, the data is uncommitted until the consumer confirms the purchase. Once the consumer confirms the itinerary, Expedia calls the three different vendors’ APIs with a request to book the reservation. If any one of the three calls fails, Expedia needs to ask the consumer if she still wants to proceed with the other two. Even though the initial call to US Airways may have been valid, the entire transaction boundary is not yet complete, and, therefore, the flight should not yet be booked. Committing each part of the transaction independently could create real data quality and customer satisfaction issues if any of the parts of the transaction are purchased while other parts fail. The consumer may not want the trip if any one of the three parts of the trip can’t be booked.
Understanding transaction boundaries is critical for determining which data points need to store state and which don’t. Remember that RESTful (Representational State Transfer) services are stateless by design, so the architect needs to determine the best way to maintain state for this multipart transaction, which might require caching, writing to a queue, writing to a temp table or disk, or some other method. The frequency in which a multipart transaction like the Expedia example occurs and the volume of these transactions also come into play. If this use case is expected to occur often, then writing the data to tables or disk will likely create performance bottlenecks, and caching the data in memory might be a better solution.
Retention Period
Retention period refers to how long data must be kept. For example, financial data is usually required to be stored for seven years for auditing purposes. This does not mean that seven years must be available online; it simply means the data should not be destroyed until it is older than seven years. For example, online banking usually provides six months’ to a year’s worth of bank statements online. Users need to submit requests for any statements older than a year. These requests are handled in batch and sometimes come with a processing fee, because the bank has to retrieve the data from off-line storage.
Understanding retention periods is a deciding factor in selecting the proper storage solutions. Data that needs to be maintained but does not have to be available online in real time or near real time can be stored on very cheap off-line disk and/or tape solutions. Often this archived data is kept off-site at a disaster recovery site. Data that needs to be retrieved instantly needs to be stored on a fast-performing disk that is redundant and can recover quickly from failures.
Multitenant or Single Tenant
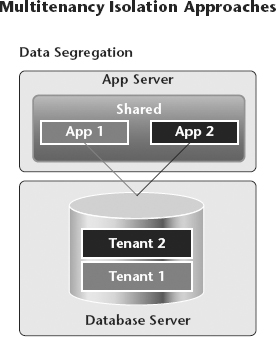
The tenancy of a system should be determined by the data characteristics just described. When referring to the data layer of an architecture, multitenancy means that multiple organizations or customers (tenants) share a group of servers. Most definitions would say a single server, but it typically requires multiple servers (i.e., master–slave) to support a tenant. Single tenant means that only one tenant is supported per each group of servers. Figures 8.1 and 8.2 show three multitenancy design strategies that each solve a unique set of requirements.
Figure 8.1 Total Isolation and Data Isolation

Figure 8.2 Data Segregation
In Figure 8.1, the image on the left is the “total isolation” strategy, which is an example of single tenant. In this example, both the database layer and the application layer have dedicated resources for each tenant.
| Advantages | Disadvantages |
| Provides independence | Most expensive |
| Privacy | Minimal reuse |
| Highest scalability | Highest complexity |
By isolating tenants to their own servers, each tenant has a high degree of independence, meaning that if there is an application or database bottleneck in any of the servers, it has limited or no impact on the other tenants. Because no other tenant has access to these servers, there is a higher degree of privacy. Also, systems with dedicated servers for each tenant scale better because of the increase in compute power. However, these advantages come with costs. Single tenant is the most expensive strategy. Each tenant bears an independent cost to the overall system. The ability to reuse existing infrastructure is limited, which creates complexities for managing infrastructure due to the increasing number of servers. The applications must also be infrastructure aware and know how to point to the correct infrastructure.
The image on the right in Figure 8.1 is the “data isolation” strategy. In this model, the application takes a multitenant approach to the application layer by sharing application servers, web servers, and so on. The database layer is single tenant, making this a hybrid approach between multitenancy and single tenant. In this model, we still get the advantages of independence and privacy while reducing some of the cost and complexities. Figure 8.2 shows a true multitenancy model.
The “data segregation” strategy separates the tenants into different database schemas, but they do share the same servers. In this model, all layers are shared for all tenants.
| Advantages | Disadvantages |
| Most cost effective | Lack of independence |
| Least complex | Lowest performance |
| Highest reuse | Lowest scalability |
This model is the most cost effective due to the large amount of reuse. It is also the least complex because it requires many fewer servers. The challenge is that a performance issue with one tenant can create issues for other tenants. Also, fewer servers means less performance and less scalability. In fact, as tenants are added to the system, the system becomes more vulnerable to failure.
When would we use these strategies? The total isolation approach is commonly used when a tenant has enormous amounts of traffic. In this case it makes sense to dedicate servers to this tenant so it can maximize scaling while not causing disruptions to other clients. The data isolation strategy is often used to protect the privacy of each tenant’s data and also to allow tenants to scale independently. The data isolation strategy is often used when the amount of traffic is not overwhelming, yet there still is a need to store a tenant’s data in its own schema for privacy reasons.
One company I worked for had many retail clients. Some clients had hundreds and even thousands of stores with several millions shoppers, while other retailers may have had a dozen or fewer stores with shopper counts under a million. The really big retailers were very strict about security and privacy while the smaller chains were not as strict. As a young start-up, we had to balance our costs with our contractual agreements with the retailers. We implemented a hybrid solution. We had one extremely large client that had several thousand stores. We decided to implement a total isolation strategy for this client because of its potential to drive enormous amounts of traffic and because of the importance of delivering to a customer of that size. For all of the smaller retailers that had very average traffic, we used the data segregation model to keep our costs to a minimum. For all other customers that were large to average size in terms of both stores and traffic, we used the data isolation method. Each tenant had its own independent database servers but a shared web and application layer.
Every business is different. It is important to understand what the different tenancy options are. Based on the business requirements, choose the right strategy or combination of strategies to support the needs around independence, security, privacy, scalability, complexity, and costs.
Choosing Data Store Types
Another important design decision to make is what type of data store to use. Many IT shops are very familiar with relational databases and immediately default to solving every data problem with a relational database. You can build a house with a hammer, but if a nail gun is available, you should probably use it.
Relational databases are great for online transaction processing (OLTP) activities because they guarantee that transactions are processed successfully in order for the data to get stored in the database. In addition, relational databases have superior security features and a powerful querying engine. Over the last several years, NoSQL databases have soared in popularity mainly due to two reasons: the increasing amount of data being stored and access to elastic cloud computing resources. Disk solutions have become much cheaper and faster, which has led to companies storing more data than ever before. It is not uncommon for a company to have petabytes of data in this day and age. Normally, large amounts of data like this are used to perform analytics, data mining, pattern recognition, machine learning, and other tasks. Companies can leverage the cloud to provision many servers to distribute workloads across many nodes to speed up the analysis and then deprovision all of the servers when the analysis is finished.
When data gets this big, relational databases just cannot perform fast enough. Relational databases were built to force referential integrity. To accomplish this, a lot of overhead is built into the database engine to ensure that transactions complete and are committed before data is stored into the tables. Relational databases also require indexes to assist in retrieval of records. Once record counts get big enough, the indexes become counterproductive and database performance becomes unacceptable.
NoSQL databases were built to solve these problems. There are four types of NoSQL databases.
Key-Value Store
Key-value store databases leverage a hash table where a unique key with a pointer points to a particular item of the data. This is the simplest of the four NoSQL database types. It is fast and highly scalable and useful for processing massive amounts of writes like tweets. It is also good for reading large, static, structured data like historical orders, events, and transactions. Its disadvantage is that it has no schema, making it a bad choice for handling complex data and relationships. Examples of key-value store databases are Redis, Voldemort (used by LinkedIn), and Amazon’s DynamoDB.
Column Store
Column store databases were created to store and process large amounts of data distributed over many machines. The hash key points to multiple columns that are organized in column families. The power of this database is that columns can be added on the fly and do not have to exist in every row. The advantage of column store databases is that they are incredibly fast and scalable and easy to alter on the fly. It is a great database to use when integrating data feeds from different sources with different structures. It is not good for interconnected data sources. Examples of column store databases are Hadoop and Cassandra.
Document Store
Document store databases are used for storing unstructured data stored within documents. Data is often encapsulated with XML, JSON, PDF, Word, Excel, and other common document types. Most logging solutions use a document store to combine log files from many different sources, such as database logs, web server logs, applications server logs, application logs, and so on. These databases are great at scaling large amounts of data made up of different formats but struggle with interconnected data. Examples of document store databases are CouchDB and MongoDB.
Graph Database
Graph databases are used for storing and managing interconnected relationships. These databases are often used to show visual representations of relationships, especially in the area of social media analysis. These databases are great at graphing, but not efficient for much else as the entire relationship tree must be traversed in order to produce results. Examples of graph databases are Neo4j and InfoGrid.
Other Storage Options
We discussed SQL and NoSQL options, but there are also good reasons to store data as files, as well. For example, large files such as photos, videos, and MP3s can be several megabytes or bigger. Web applications that try to store and retrieve these large fields from databases will struggle to create a fast-performing user experience. A better strategy is to leverage a content delivery network (CDN). A CDN is a network of distributed computers located in multiple data centers across the Internet that provides high availability and high performance. CDNs are the tool of choice for streaming media and other bandwidth-intensive data.
- Online transaction processing (OLTP) data
- Transactional data
- Logging data
- Rich media content
- Financial data
- OLTP data. Relational database
- Transaction. NoSQL, column store
- Logging. Document store
- Rich media. Files, leverage CDN
- Financial data. Relational database
Summary
There are many characteristics of data, and understanding the characteristics and the requirements for each characteristic is crucial for selecting the correct cloud service model, cloud deployment model, database design(s), and data storage systems. Nobody would ever attempt to build a house without first understanding the requirements of the house and analyzing the floor plan, yet some companies rush to start building software before completely understanding their data requirements. Whether an architect is building a new system or migrating an existing one, the architect would be wise to spend time with the product team to evaluate each of the data characteristics described in this chapter. Without a complete understanding of each data characteristic, it will be extremely difficult to build a system optimized to meet the needs of the business.
Reference
Valentine, D. (2013, February 28). “Rules of Engagement: NoSQL Column Data Stores.” Retrieved from http://www.ingenioussql.com/2013/02/28/rules-of-engagement-nosql-column-data-stores/.