
Chapter 2. Repository Pattern
It’s time to make good on our promise to use the dependency inversion principle as a way of decoupling our core logic from infrastructural concerns.
We’ll introduce the Repository, a simplifying abstraction over data storage, allowing us to decouple our model layer from the data layer. We’ll see a concrete example of how this simplifying abstraction makes our system more testable by hiding the complexities of the database.
Figure 2-1 shows a little preview of what we’re going to build:
a Repository object that sits between our Domain Model and the database.
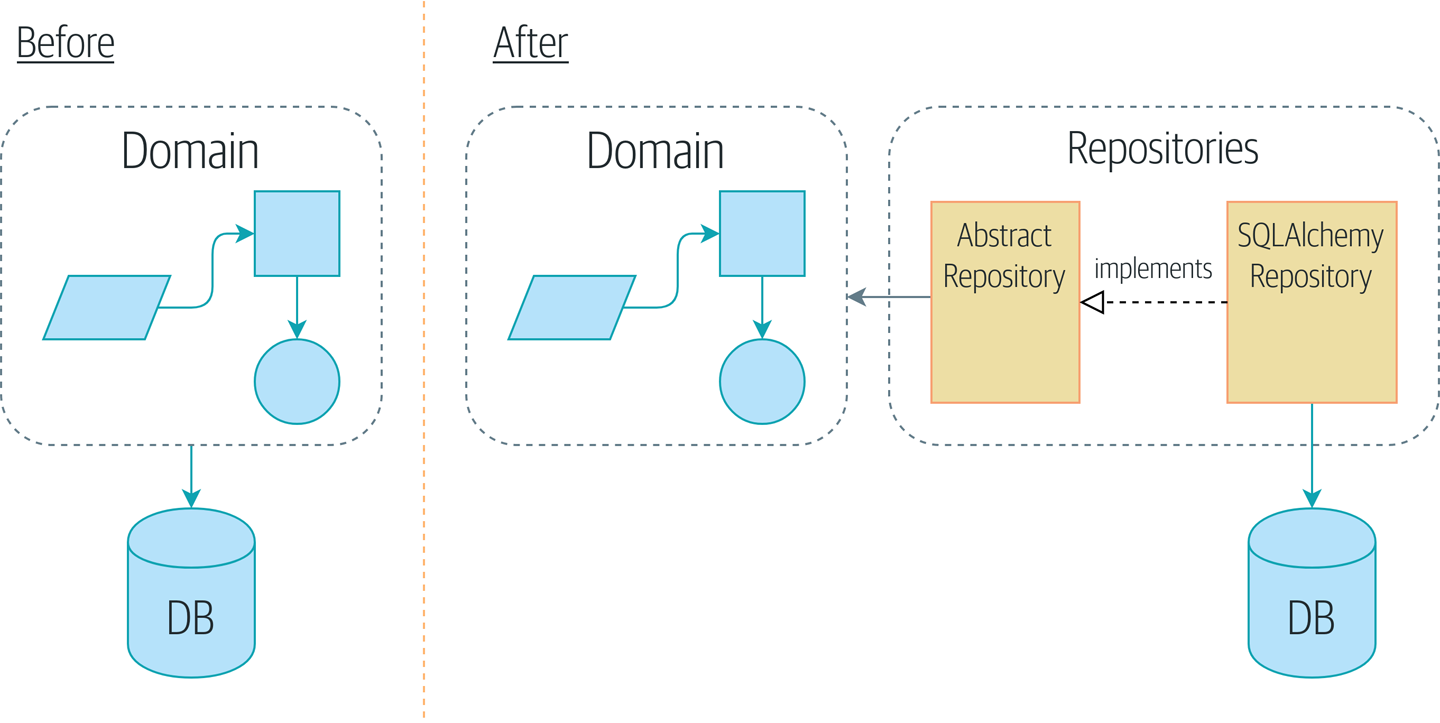
Figure 2-1. Before and after Repository Pattern
Tip
You can find our code for this chapter at github.com/cosmicpython/code/tree/chapter_02_repository.
git clone https://github.com/cosmicpython/code.git && cd code git checkout chapter_02_repository # or, if you want to code along, checkout the previous chapter: git checkout chapter_01_domain_model
Persisting Our Domain Model
In the previous chapter we built a simple domain model that can allocate orders to batches of stock. It’s easy for us to write tests against this code because there aren’t any dependencies or infrastructure to set up. If we needed to run a database or an API and create test data, our tests would be harder to write and maintain.
Sadly, at some point we’ll need to put our perfect little model in the hands of users and we’ll need to contend with the real world of spreadsheets and web browsers and race conditions. For the next few chapters we’re going to look at how we can connect our idealized domain model to external state.
We expect to be working in an agile manner, so our priority is to get to a minimum viable product as quickly as possible. In our case, that’s going to be a web API. In a real project, you might dive straight in with some end-to-end tests and start plugging in a web framework, test-driving things outside-in.
But we know that, no matter what, we’re going to need some form of persistent storage, and this is a textbook, so we can allow ourselves a tiny bit more bottom-up development, and start to think about storage and databases.
Some Pseudocode: What Are We Going to Need?
When we build our first API endpoint, we know we’re going to have some code that looks more or less like Example 2-1. (We’ve used Flask because it’s lightweight, but you don’t need to understand Flask to understand this book. One of the main points we’re trying to make is that your choice of web framework should be a minor implementation detail).
What our first API endpoint will look like
@flask.route.gubbinsdefallocate_endpoint():# extract order line from requestline=OrderLine(request.params,...)# load all batches from the DBbatches=...# call our domain serviceallocate(line,batches)# then save the allocation back to the database somehowreturn201
We’ll need a way to retrieve batch info from the DB and instantiate our domain model objects from it, and we’ll also need a way of saving them back to the database.
(What? Oh, “gubbins” is a British word for “stuff”. You can just ignore that. It’s pseudocode, OK?)
Applying the Dependency Inversion Principle to the Database
As mentioned in Introduction: Why Do Our Designs Go Wrong?, the “layered architecture” is a common approach to structuring a system that has a UI, some logic, and a database (see Figure 2-2).

Figure 2-2. Layered Architecture
Django’s Model-View-Template structure is closely related, as is Model-View-Controller (MVC). In any case, the aim is to keep the layers separate (which is a good thing), and to have each layer depend only on the one below…
But we want our domain model to have no dependencies whatsoever1. We don’t want infrastructure concerns bleeding over into our domain model and slowing down our unit tests or our ability to make changes.
Instead, as discussed in the introduction, we’ll think of our model as being on the “inside,” and dependencies flowing inwards to it; what people sometimes call “onion architecture” (see Figure 2-3.)

Figure 2-3. Onion architecture
[ditaa, onion_architecture]
+------------------------+
| Presentation Layer |
+------------------------+
|
V
+--------------------------------------------------+
| Domain Model |
+--------------------------------------------------+
^
|
+---------------------+
| Database Layer |
+---------------------+
Reminder: Our Model
Let’s remind ourselves of our domain model (see Figure 2-4):
An allocation is the concept of linking an OrderLine to a Batch. We’re
storing the allocations as a collection on our Batch object.

Figure 2-4. Our Model
Let’s see how we might translate this to a relational database.
The “Normal” ORM Way: Model Depends on ORM
These days it’s unlikely that your team members are hand-rolling their own SQL queries. Instead, you’re almost certainly using some kind of framework to generate SQL for you based on your model objects.
These frameworks are called object-relational mappers (ORMs) because they exist to bridge the conceptual gap between the world of objects and domain modeling, and the world of databases and relational algebra.
The most important thing an ORM gives us is persistence ignorance: the idea that our fancy domain model doesn’t need to know anything about how data are loaded or persisted. This helps to keep our domain clean of direct dependencies on particular databases technologies.3
But if you follow the typical SQLAlchemy tutorial, you’ll end up with something like this:
SQLAlchemy “declarative” syntax, model depends on ORM (orm.py)
fromsqlalchemyimportColumn,ForeignKey,Integer,Stringfromsqlalchemy.ext.declarativeimportdeclarative_basefromsqlalchemy.ormimportrelationshipBase=declarative_base()classOrder(Base):id=Column(Integer,primary_key=True)classOrderLine(Base):id=Column(Integer,primary_key=True)sku=Column(String(250))qty=Integer(String(250))order_id=Column(Integer,ForeignKey('order.id'))order=relationship(Order)classAllocation(Base):...
You don’t need to understand SQLAlchemy to see that our pristine model is now full of dependencies on the ORM, and is starting to look ugly as hell besides. Can we really say this model is ignorant of the database? How can it be separate from storage concerns when our model properties are directly coupled to database columns?
Inverting the Dependency: ORM Depends on Model
Well, thankfully, that’s not the only way to use SQLAlchemy. The alternative is to define your schema separately, and an explicit mapper for how to convert between the schema and our domain model, what SQLAlchemy calls a classical mapping.
Explicit ORM Mapping with SQLAlchemy Table objects (orm.py)
fromsqlalchemy.ormimportmapper,relationshipimportmodelmetadata=MetaData()order_lines=Table('order_lines',metadata,Column('id',Integer,primary_key=True,autoincrement=True),Column('sku',String(255)),Column('qty',Integer,nullable=False),Column('orderid',String(255)),)...defstart_mappers():lines_mapper=mapper(model.OrderLine,order_lines)

The ORM imports (or “depends on” or “knows about”) the domain model, and not the other way around.
We define our database tables and columns using SQLAlchemy’s abstractions.4

And when we call the
mapperfunction, SQLAlchemy does its magic to bind our domain model classes to the various tables we’ve defined.
The end result will be that, if we call start_mappers(), we will be able to
easily load and save domain model instances from and to the database. But if
we never call that function, then our domain model classes stay blissfully
unaware of the database.
This gives us all the benefits of SQLAlchemy, including the ability to use
alembic for migrations, and the ability to transparently query using our
domain classes, as we’ll see.
When you’re first trying to build your ORM config, it can be useful to write some tests for it, as in Example 2-5:
Testing the ORM directly (throwaway tests) (test_orm.py)
deftest_orderline_mapper_can_load_lines(session):session.execute('INSERT INTO order_lines (orderid, sku, qty) VALUES''("order1","RED-CHAIR", 12),''("order1","RED-TABLE", 13),''("order2","BLUE-LIPSTICK", 14)')expected=[model.OrderLine("order1","RED-CHAIR",12),model.OrderLine("order1","RED-TABLE",13),model.OrderLine("order2","BLUE-LIPSTICK",14),]assertsession.query(model.OrderLine).all()==expecteddeftest_orderline_mapper_can_save_lines(session):new_line=model.OrderLine("order1","DECORATIVE-WIDGET",12)session.add(new_line)session.commit()rows=list(session.execute('SELECT orderid, sku, qty FROM"order_lines"'))assertrows==[("order1","DECORATIVE-WIDGET",12)]
If you’ve not used pytest, the
sessionargument to this test needs explaining. You don’t need to worry about the details of pytest or its fixtures for the purposes of this book, but the short explanation is that you can define common dependencies for your tests as “fixtures,” and pytest will inject them to the tests that need them by looking at their function arguments. In this case, it’s a SQLAlchemy database session.
You probably wouldn’t keep these tests around—as we’ll see shortly, once you’ve taken the step of inverting the dependency of ORM and Domain Model, it’s only a small additional step to implement an additional abstraction called the repository pattern, which will be easier to write tests against, and will provide a simple, common interface for faking out later in tests.
But we’ve already achieved our objective of inverting the traditional dependency: the domain model stays “pure” and free from infrastructure concerns. We could throw away SQLAlchemy and use a different ORM, or a totally different persistence system, and the domain model doesn’t need to change at all.
Depending on what you’re doing in your domain model, and especially if you stray far from the OO paradigm, you may find it increasingly hard to get the ORM to produce the exact behavior you need, and you may need to modify your domain model5. As so often with architectural decisions, there is a trade-off you’ll need to consider. As the Zen of Python says, “Practicality beats purity!”
At this point though, our API endpoint might look something like Example 2-6, and we could get it to work just fine.
Using SQLAlchemy directly in our API endpoint
@flask.route.gubbinsdefallocate_endpoint():session=start_session()# extract order line from requestline=OrderLine(request.json['orderid'],request.json['sku'],request.json['qty'],)# load all batches from the DBbatches=session.query(Batch).all()# call our domain serviceallocate(line,batches)# save the allocation back to the databasesession.commit()return201
Introducing Repository Pattern
The Repository pattern is an abstraction over persistent storage. It hides the boring details of data access by pretending that all of our data is in memory.
If we had infinite memory in our laptops, we’d have no need for clumsy databases. Instead, we could just use our objects whenever we liked. What would that look like?
You’ve got to get your data from somewhere
importall_my_datadefcreate_a_batch():batch=Batch(...)all_my_data.batches.add(batch)defmodify_a_batch(batch_id,new_quantity):batch=all_my_data.batches.get(batch_id)batch.change_initial_quantity(new_quantity)
Even though our objects are in memory, we need to put them somewhere so we can
find them again. Our in-memory data would let us add new objects, just like a
list or a set, and since the objects are in memory we never need to call a
.save() method, we just fetch the object we care about, and modify it in memory.
The Repository in the Abstract
The simplest repository has just two methods: add to put a new item in the
repository, and get to return a previously added item.6
We stick rigidly to using these methods for data access in our domain and our
service layer. This self-imposed simplicity stops us from coupling our domain
model to the database.
Here’s what an abstract base class (ABC) for our repository would look like:
The simplest possible repository (repository.py)
classAbstractRepository(abc.ABC):@abc.abstractmethoddefadd(self,batch:model.Batch):raiseNotImplementedError@abc.abstractmethoddefget(self,reference)->model.Batch:raiseNotImplementedError
Warning
We’re using abstract base classes in this book for didactic reasons:
we hope they help explain what the interface of the repository abstraction
is. In real life, we’ve sometimes found ourselves deleting ABCs from our
production code, because Python makes it too easy to ignore them, and
they end up unmaintained and, at worst, misleading.
In practice we often just rely on Python’s duck-typing to enable abstractions.
To a Pythonista, a repository is any object that has add(thing) and
get(id) methods.
Python tip:
@abc.abstractmethodis one of the only things that makes ABCs actually “work” in Python. Python will refuse to let you instantiate a class that does not implement all theabstractmethodsdefined in its parent classraise NotImplementedErroris nice but neither necessary nor sufficient. In fact, your abstract methods can have real behavior which subclasses can call out to, if you want.
Note
To really reap the benefits of ABCs (such as they may be) you’ll want to
be running some helpers like pylint and mypy.
What Is the Trade-Off?
You know they say economists know the price of everything and the value of nothing? Well, programmers know the benefits of everything and the tradeoffs of nothing.
Rich Hickey
Whenever we introduce an architectural pattern in this book, we’ll always be trying to ask: “What do we get for this? And what does it cost us?.”
Usually at the very least we’ll be introducing an extra layer of abstraction, and although we may hope it will be reducing complexity overall, it does add complexity locally, and it has a cost in terms raw numbers of moving parts and ongoing maintenance.
Repository pattern is probably one of the easiest choices in the book though,
if you’ve already heading down the DDD and dependency inversion route. As far
as our code is concerned, we’re really just swapping the SQLAlchemy abstraction
(session.query(Batch)) for a different one (batches_repo.get) which we
designed.
We will have to write a few lines of code in our repository class each time we add a new domain object that we want to retrieve, but in return we get a very simple abstraction over our storage layer, which we control. It would make it very easy to make fundamental changes to the way we store things (see Appendix C), and as we’ll see, it is very easy to fake out for unit tests.
In addition, Repository Pattern is so common in the DDD world that, if you do collaborate with programmers that have come to Python from the Java and C# worlds, they’re likely to recognize it. Figure 2-5 shows an illustration.

Figure 2-5. Repository pattern
[ditaa, repository_pattern_diagram]
+-----------------------------+
| Application Layer |
+-----------------------------+
|^
|| /------------------
||----------| Domain Model |
|| | objects |
|| ------------------/
V|
+------------------------------+
| Repository |
+------------------------------+
|
V
+------------------------------+
| Database Layer |
+------------------------------+
As always, we start with a test. This would probably be classified as an integration test, since we’re checking that our code (the repository) is correctly integrated with the database; hence, the tests tend to mix raw SQL with calls and assertions on our own code.
Tip
Unlike the ORM tests from earlier, these tests are good candidates for staying part of your codebase longer term, particularly if any parts of your domain model mean the object-relational map is nontrivial.
Repository test for saving an object (test_repository.py)
deftest_repository_can_save_a_batch(session):batch=model.Batch("batch1","RUSTY-SOAPDISH",100,eta=None)repo=repository.SqlAlchemyRepository(session)repo.add(batch)session.commit()rows=list(session.execute('SELECT reference, sku, _purchased_quantity, eta FROM"batches"'))assertrows==[("batch1","RUSTY-SOAPDISH",100,None)]
repo.add()is the method under test hereWe keep the
.commit()outside of the repository, and make it the responsibility of the caller. There are pros and cons for this, some of our reasons will become clearer when we get to Chapter 6.And we use the raw SQL to verify that the right data has been saved.
The next test involves retrieving batches and allocations so it’s more complex:
Repository test for retrieving a complex object (test_repository.py)
definsert_order_line(session):session.execute('INSERT INTO order_lines (orderid, sku, qty)''VALUES ("order1","GENERIC-SOFA", 12)')[[orderline_id]]=session.execute('SELECT id FROM order_lines WHERE orderid=:orderid AND sku=:sku',dict(orderid="order1",sku="GENERIC-SOFA"))returnorderline_iddefinsert_batch(session,batch_id):...deftest_repository_can_retrieve_a_batch_with_allocations(session):orderline_id=insert_order_line(session)batch1_id=insert_batch(session,"batch1")insert_batch(session,"batch2")insert_allocation(session,orderline_id,batch1_id)repo=repository.SqlAlchemyRepository(session)retrieved=repo.get("batch1")expected=model.Batch("batch1","GENERIC-SOFA",100,eta=None)assertretrieved==expected# Batch.__eq__ only compares referenceassertretrieved.sku==expected.skuassertretrieved._purchased_quantity==expected._purchased_quantityassertretrieved._allocations=={model.OrderLine("order1","GENERIC-SOFA",12),}
This tests the read side, so the raw SQL is preparing data to be read by the
repo.get()We’ll spare you the details of
insert_batchandinsert_allocation, the point is to create a couple of different batches, and for the batch we’re interested in to have one existing order line allocated to it.And that’s what we verify here. The first
assert ==checks that the types match, and that the reference is the same (because, if you remember,Batchis an Entity, and we have a customeqfor it).
So we also explicitly check on its major attributes, including
._allocations, which is a Python set ofOrderLineValue Objects.
Whether or not you painstakingly write tests for every model is a judgement
call. Once you have one class tested for create/modify/save, you might be
happy to go on and do the others with a minimal roundtrip test, or even nothing
at all, if they all follow a similar pattern. In our case, the ORM config
that sets up the ._allocations set is a little complex, so it merited a
specific test.
You end up with something like Example 2-11:
A typical repository (repository.py)
classSqlAlchemyRepository(AbstractRepository):def__init__(self,session):self.session=sessiondefadd(self,batch):self.session.add(batch)defget(self,reference):returnself.session.query(model.Batch).filter_by(reference=reference).one()deflist(self):returnself.session.query(model.Batch).all()
And now our flask endpoint might look something like Example 2-12:
Using our repository directly in our API endpoint
@flask.route.gubbinsdefallocate_endpoint():batches=SqlAlchemyRepository.list()lines=[OrderLine(l['orderid'],l['sku'],l['qty'])forlinrequest.params...]allocate(lines,batches)session.commit()return201
Building a Fake Repository for Tests Is Now Trivial!
Here’s one of the biggest benefits of Repository Pattern.
A simple fake repository using a set (repository.py)
classFakeRepository(AbstractRepository):def__init__(self,batches):self._batches=set(batches)defadd(self,batch):self._batches.add(batch)defget(self,reference):returnnext(bforbinself._batchesifb.reference==reference)deflist(self):returnlist(self._batches)
Because it’s a simple wrapper around a set, all the methods are one-liners.
Using a fake repo in tests is really easy, and we have a simple abstraction that’s easy to use and reason about:
Example usage of fake repository (test_api.py)
fake_repo=FakeRepository([batch1,batch2,batch3])
You’ll see this fake in action in the next chapter.
Tip
Building fakes for your abstractions is an excellent way to get design feedback: if it’s hard to fake, then the abstraction is probably too complicated.
What is a Port and What is an Adapter, in Python?
We don’t want to dwell on the terminology too much here because the main thing we want to think about is dependency inversion, and the specifics of the technique you use don’t matter too much. And we’re also aware that different people use slightly different definitions.
“Ports and Adapters” came out of the OO world, and the definition we hold onto is that the Port is the interface between our application and whatever it is we wish to abstract away, and the Adapter is the implementation behind that interface or abstraction.
Now Python doesn’t have interfaces per se, so that means that although it’s usually easy to say what’s an adapter, defining the port can be harder. If you’re using an abstract base class, then that’s the port. If not, the port is just the duck type that your adapters conform to, and that your core application expects — the function and method names in use, and their argument names and types.
Concretely, in this chapter, AbstractRepository is the port, and
SqlAlchemyRepository and FakeRepository are the adapters.
Wrap-Up
Bearing the Rich Hickey quote in mind, in each chapter we’re going to try and summarize the costs and benefits of each architectural pattern we introduce. We want to be very clear that we’re not saying every single application needs to be built this way; only sometimes does the complexity of the app and domain make it worth investing the time and effort in adding these extra layers of indirection. With that in mind, Table 2-1 shows some of the pros and cons of Repository Pattern and our persistence ignorant model.
| Pros | Cons |
|---|---|
|
|
Figure 2-6 shows the basic thesis: yes, for simple cases, a decoupled domain model is harder work than a simple ORM / ActiveRecord pattern. But the more complex the domain, the more an investment in freeing yourself from infrastructure concerns will pay off, in terms of the ease of making changes:7
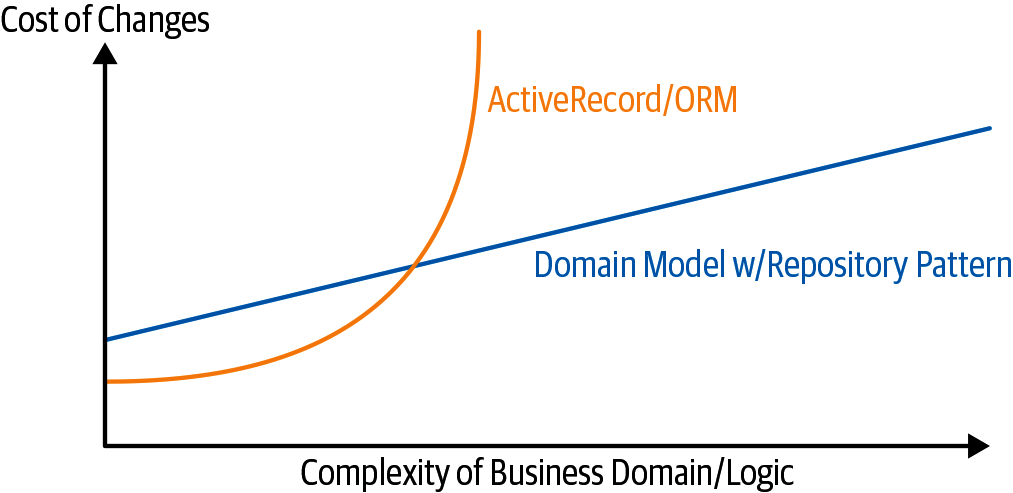
Figure 2-6. Domain Model tradeoffs as a diagram
[ditaa, domain_model_tradeoffs_diagram]
Cost of changes
^ /
| ActiveRecord / ORM |
| | ----/
| / ----/
| | ----/
| / ----/
| | ----/ Domain Model w/ Repository Pattern
| / ----/
| | ----/
| ----/
| ----/ /
| ----/ /
| ----/ -/
|----/ --/
| ---/
| ----/
|------/
|
+--------------------------------------------------------------->
Complexity of Business Domain/Logic
Our example code isn’t really complex enough to give more than a hint of what
the right-hand side of the graph looks like, but the hints are there.
Imagine, for example, if we decide one day that we want to change allocations
to live on the OrderLine instead of on the Batch object: if we were using
Django, say, we’d have to define and think through the database migration
before we could run any tests. As it is, because our model is just plain
old Python objects, we can change a set() to being a new attribute, without
needing to think about the database until later.
You’ll be wondering, how do we actually instantiate these repositories, fake or real? What will our Flask app actually look like? We’ll find out in the next exciting installment, the Service Layer pattern.
But first, a brief digression.
1 I suppose we mean, “no stateful dependencies.” Depending on a helper library is fine, depending on an ORM or a web framework is not
2 Mark Seeman has an excellent blog post on the topic.
3 In this sense, using an ORM is already an example of the DIP. Instead of depending on hardcoded SQL, we depend on an abstraction, the ORM. But that’s not enough for us, not in this book!
4 Even in projects where we don’t use an ORM, we would often use SQLAlchemy alongside Alembic to declaratively create schemas in Python and manage migrations; also to manage database connections and sessions.
5 Shout out to the amazingly helpful SQLAlchemy maintainers, and Mike Bayer in particular
6 You may be thinking, what about list or delete or update, but in the ideal world, we only modify our model objects one at a time, and delete is usually handled as a soft-delete, ie batch.cancel(). Finally, update is taken care of by the Unit of Work, as we’ll see in Chapter 6.
7 Diagram inspired by a post called Global complexity, local simplicity, by Rob Vens)