
Chapter 7. Aggregates and Consistency Boundaries
In this chapter we’d like to revisit our domain model to talk about invariants and constraints, and see how our our domain objects can maintain their own internal consistency, both conceptually and in persistent storage. We’ll discuss the concept of a consistency boundary, and show how making it explicit can help us to build high-performance software without compromising maintainability.
Figure 7-1 shows a preview of where we’re headed: we’ll introduce
a new model object called Product to wrap multiple batches, and make
the old allocate() domain service available as a method on Product instead.
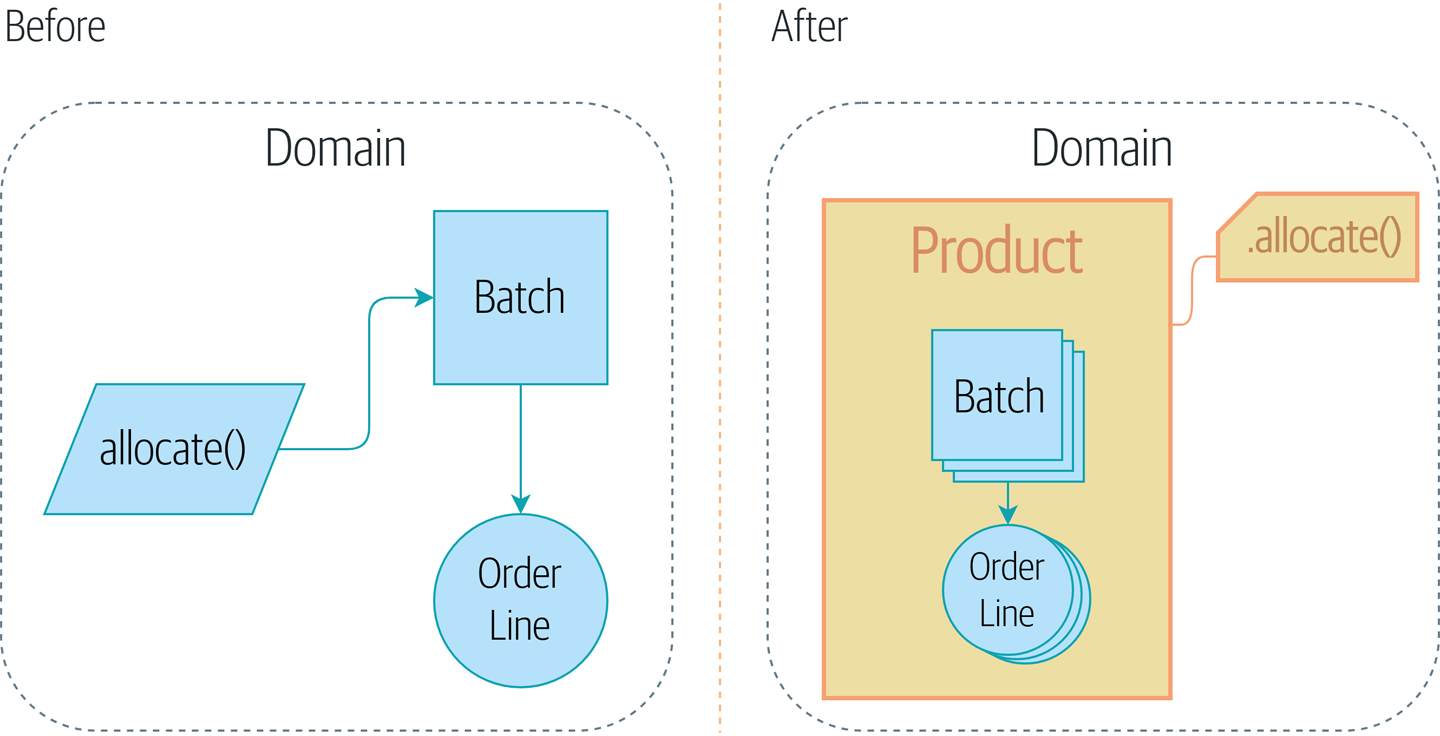
Figure 7-1. Adding the Product Aggregate
Why? Let’s find out.
Tip
You can find our code for this chapter at github.com/cosmicpython/code/tree/appendix_csvs.
git clone https://github.com/cosmicpython/code.git && cd code git checkout appendix_csvs # or, if you want to code along, checkout the previous chapter: git checkout chapter_06_uow
Why Not Just Run Everything in a Spreadsheet?
What’s the point of a domain model anyway? What’s the fundamental problem we’re trying to addresss?
Couldn’t we just run everything in a spreadsheet? Many of our users would be delighted by that. Business users like spreadsheets because they’re simple, familiar, and yet enormously powerful.
In fact, an enormous number of business processes do operate by manually sending spreadsheets back and forward over e-mail. This “csv over smtp” architecture has low initial complexity but tends not to scale very well because it’s difficult to apply logic and maintain consistency.
Who is allowed to view this particular field? Who’s allowed to update it? What happens when we try to order -350 chairs, or 10,000,000 tables? Can an employee have a negative salary?
These are the constraints of a system. Much of the domain logic we write exists to enforce these constraints in order to maintain the invariants of the system. The invariants are the things that have to be true whenever we finish an operation.
Invariants, Constraints and Consistency
The two words are somewhat interchangeable, but a constraint is some kind of rule that restricts the possible states our model can get into. An invariant is defined a little more precisely, as a condition that is always true.
If we were writing a hotel booking system, we might have the constraint that double bookings are not allowed. This supports the invariant that a room cannot have more than one booking for the same night.
Of course, sometimes we might need to temporarily bend the rules. Perhaps we need to shuffle the rooms around due to a VIP booking. While we’re moving bookings around in memory we might be double booked, but our domain model should ensure that, when we’re finished, we end up in a final consistent state, where the invariants are met. If we can’t find a way to fit all our guests in we should raise an error and refuse to complete the operation.
Let’s look at a couple of concrete examples from our business requirements
An order line can only be allocated to one batch at a time.
the business
This is a business rule that imposes an invariant. The invariant is that an
order line is allocated to either zero or one batch, but never more than one.
We need to make sure that our code never accidentally calls Batch.allocate()
on two different batches for the same line, and currently, there’s nothing
there to explicitly stop us doing that.
Invariants, Concurrency and Locks
Let’s look at another one of our business rules:
I can’t allocate to a batch if the available quantity is less than the quantity of the order line.
the business
Here the constraint is that we can’t allocate more stock than is available to a batch, so we never oversell stock by allocating two customers to the same physical cushion. Every time we update the state of the system, our code needs to ensure that we don’t break the invariant, which is that the available quantity must be greater than or equal to zero.
In a single threaded single user application it’s relatively easy for us to maintain this invariant. We can just allocate stock one line at a time, and raise an error if there’s no stock available.
This gets much harder when we introduce the idea of concurrency. Suddenly we might be allocating stock for multiple order lines simultaneously. We might even be allocating order lines at the same time as processing changes to the batches themselves.
We usually solve this problem by applying locks to our database tables. This prevents two operations happening simultaneously on the same row or same table.
As we start to think about scaling up our app, we realize that our model
of allocating lines against all available batches may not scale. If we’ve
got tens of thousands of orders per hour, and hundreds of thousands of
order lines, we can’t hold a lock over the whole batches table for
every single one—we’ll get deadlocks or performance problems at the very least.
What is an Aggregate?
Okay, so if we can’t lock the whole database every time we want to allocate an order line, what should we do instead? We want to protect the invariants of our system but allow for the greatest degree of concurrency. Maintaining our invariants inevitably means preventing concurrent writes - if multiple users can allocate DEADLY-SPOON at the same time, we run the risk of over-allocating.
On the other hand, there’s no reason why we can’t allocate DEADLY-SPOON at the same time as FLIMSY-DESK. It’s safe to allocate two different products at the same time because there’s no invariant that covers them both. We don’t need them to be consistent with each other.
The aggregate pattern is a design pattern from the DDD community that helps us to resolve this tension. An aggregate is just a domain object that contains other domain objects and lets us treat the whole collection as a single unit.
The only way to modify the objects inside the aggregate is to load the whole thing, and to call methods on the aggregate itself.
As a model gets more complex and grows more Entity and Value Objects, referencing each other in a tangled graph, it can be hard to keep track of who can modify what. Especially when we have collections in the model like we do (our batches are a collection), it’s a good idea to nominate some entities to be the single entrypoint for modifying their related objects. It makes the system conceptually simpler and easy to reason about if you nominate some objects to be in charge of consistency for the others.
For example, if we’re building a shopping site, the “Cart” might make a good aggregate: it’s a collection of items that I can treat as a single unit. Importantly, I want to load the entire basket as a single blob from my data store. I don’t want two requests to modify my basket at the same time, or I run the risk of weird concurrency errors. Instead, I want each change to my basket to run in a single database transaction.
We don’t want to modify multiple baskets in a transaction, because there’s no use-case for changing the baskets of several customers at the same time. Each basket is a single consistency boundary responsible for maintaining its own invariants.
An AGGREGATE is a cluster of associated objects that we treat as a unit for the purpose of data changes.
Eric Evans, DDD blue book
Per Evans, our aggregate has a root entity (the cart) which encapsulates access to items. Each item has its own identity, but other parts of the system will only ever refer to the cart as an indivisible whole.
Tip
Just like we sometimes use _leading_underscores to mark methods or functions
as “private”, you can think of aggregates as being the “public” classes of our
model, and the rest of the Entities and Value Objects are “private”.
Choosing an Aggregate
What aggregate should we use for our system? The choice is somewhat arbitrary, but it’s important. The aggregate will be the boundary where we make sure every operation ends in a consistent state. This helps us to reason about our software and prevent weird race issues. We want to draw a boundary around a small number of objects - the smaller the better for performance - that have to be consistent with one another, and we need to give it a good name.
The object we’re manipulating under the covers is the Batch. What do we call a collection of batches? How should we divide all the batches in the system into discreet islands of consistency?
We could use the Shipment as our boundary. Each shipment contains several batches, and they all travel to our warehouse at the same time. Or perhaps we could use the Warehouse as our boundary: each warehouse contains many batches and it could make sense to count all the stock at the same time.
Neither of these concepts really satisfies us, though. We should be able to allocate DEADLY-SPOONs and FLIMSY-DESKs at the same time, even if they’re in the same warehouse, or the same shipment. These concepts have the wrong granularity.
When we allocate an order line, we’re actually only interested in batches
that have the same SKU as the order line. Some sort of concept like
GlobalSkuStock could work: a collection of all the batches for a given SKU.
It’s an unwieldy name though, so after some bikeshedding via SkuStock, Stock,
ProductStock, and so on, we decided to simply call it Product — after all, that was the first concept we came across in our exploration of the
domain language back in Chapter 1.
So the plan is: when we want to allocate an order line, instead of
Figure 7-2, where we looking up all the Batch objects in
the world and passing them to the allocate() domain service…

Figure 7-2. Before: allocate against all batches using domain service
[plantuml, before_aggregates_diagram, config=plantuml.cfg]
@startuml
hide empty members
package "Service Layer" as services {
class "allocate()" as allocate {
}
hide allocate circle
hide allocate members
}
package "Domain Model" as domain_model {
class Batch {
}
class "allocate()" as allocate_domain_service {
}
hide allocate_domain_service circle
hide allocate_domain_service members
}
package repositories {
class BatchRepository {
list()
}
}
allocate -> BatchRepository: list all batches
allocate --> allocate_domain_service: allocate(orderline, batches)
@enduml
…we’ll move to the world of Figure 7-3, in which there is a new
the Product object for the particular SKU of our order line, and it will be in charge
of all the batches for that sku, and we can call a .allocate() method on that
instead.
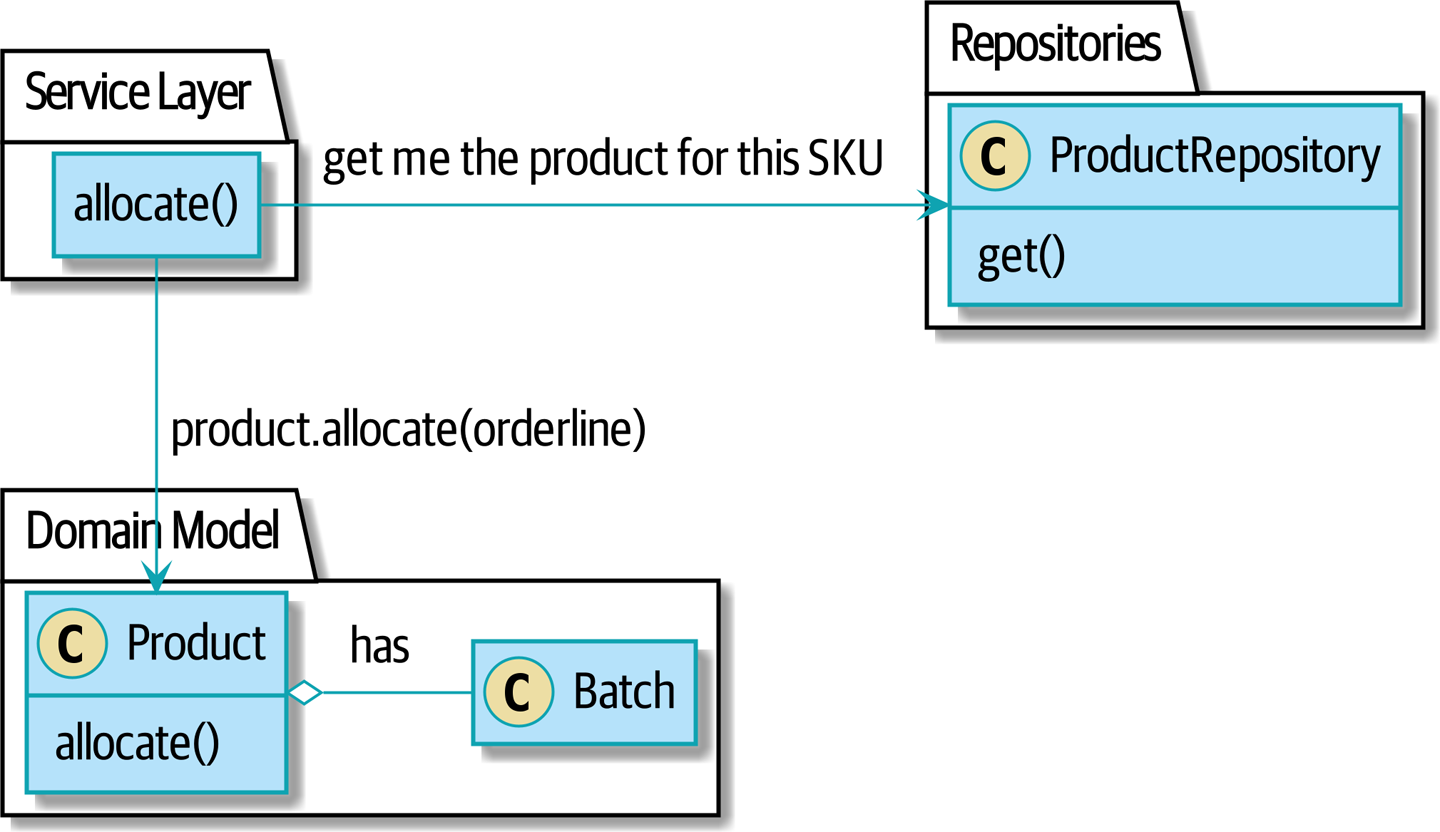
Figure 7-3. After: ask Product to allocate against its batches
[plantuml, after_aggregates_diagram, config=plantuml.cfg]
@startuml
hide empty members
package "Service Layer" as services {
class "allocate()" as allocate {
}
}
hide allocate circle
hide allocate members
package "Domain Model" as domain_model {
class Product {
allocate()
}
class Batch {
}
}
package repositories {
class ProductRepository {
get()
}
}
allocate -> ProductRepository: get me the product for this sku
allocate --> Product: product.allocate(orderline)
Product o- Batch: has
@enduml
Let’s see how that looks in code form:
Our chosen Aggregate, Product (src/allocation/domain/model.py)
classProduct:def__init__(self,sku:str,batches:List[Batch]):self.sku=skuself.batches=batchesdefallocate(self,line:OrderLine)->str:try:batch=next(bforbinsorted(self.batches)ifb.can_allocate(line))batch.allocate(line)returnbatch.referenceexceptStopIteration:raiseOutOfStock(f'Out of stock for sku {line.sku}')

Product’s main identifier is thesku
It holds a reference to a collection of
batchesfor that sku
And finally, we can move the
allocate()Domain Service to being a method on theProductaggregate.
Note
This Product might not look like what you’d expect a Product
model to look like. No price, no description, no dimensions…
Our allocation service doesn’t care about any of those things.
This is the power of bounded contexts, the concept
of Product in one app can be very different from another.
See the sidebar on bounded contexts for more
discussion.
1 Aggregate = 1 Repository
Once you define certain entities to be aggregates, we need to apply the rule that they are the only entities that are publicly accessible to the outside world. In other words, the only repositories we are allowed should be repositories that return aggregates.
In our case, we’ll switch from BatchRepository to ProductRepository:
Our new UoW and Repository (unit_of_work.py and repository.py)
classAbstractUnitOfWork(abc.ABC):products:repository.AbstractProductRepository...classAbstractProductRepository(abc.ABC):@abc.abstractmethoddefadd(self,product):...@abc.abstractmethoddefget(self,sku)->model.Product:...
The ORM layer will need some tweaks so that the right batches automatically get
loaded and associated with Product objects. The nice thing is, Repository
pattern means we don’t actually have to worry about that yet, we can just use
our FakeRepository and then feed through the new model into our service
layer, to see how it looks with Product as its main entrypoint:
Service layer (src/allocation/service_layer/services.py)
defadd_batch(ref:str,sku:str,qty:int,eta:Optional[date],uow:unit_of_work.AbstractUnitOfWork):withuow:product=uow.products.get(sku=sku)ifproductisNone:product=model.Product(sku,batches=[])uow.products.add(product)product.batches.append(model.Batch(ref,sku,qty,eta))uow.commit()defallocate(orderid:str,sku:str,qty:int,uow:unit_of_work.AbstractUnitOfWork)->str:line=OrderLine(orderid,sku,qty)withuow:product=uow.products.get(sku=line.sku)ifproductisNone:raiseInvalidSku(f'Invalid sku {line.sku}')batchref=product.allocate(line)uow.commit()returnbatchref
Optimistic Concurrency With Version Numbers
We’ve got our new aggregate so we’ve solved the conceptual problem of choosing an object to be in charge of consistency boundaries. Let’s now spend a little time talking about how to enforce data integrity at the database level.
We don’t want to hold a lock over the entire batches table, but how will we
implement holding a lock over just the rows for a particular sku? The answer
is to have a single attribute on the Product model which acts as a marker for
the whole state change being complete, and we use it as the single resource
that concurrent workers can fight over: if two transactions both read the
state of the world for batches at the same time, and they both want to update
the allocations tables, we force both of them to also try and update the
version_number in the products table, in such a way that only one of them
can win and the world stays consistent.
Figure 7-4 shows an illustration: two concurrent
transactions do their read operations at the same time, so they see
a Product with (eg) version=3. They both call Product.allocate()
in order to modify some state. But we set up our database integrity
rules such that only one of them is allowed to commit the new Product
with version=4, and the other update will be rejected.
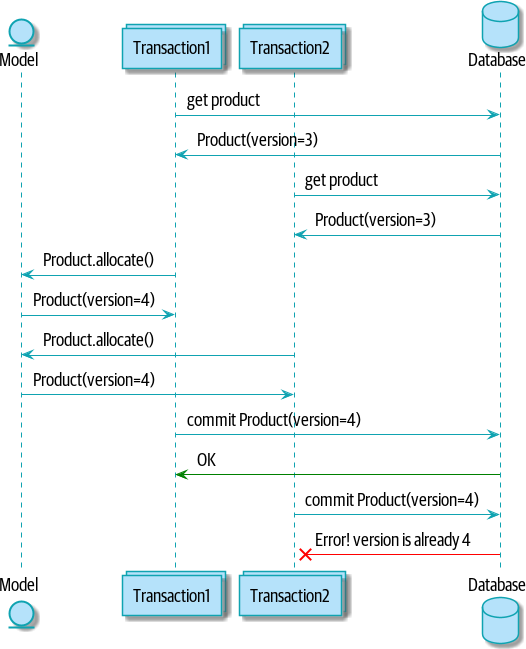
Figure 7-4. Sequence Diagram: Two Transactions Attempt a Concurrent Update on Product
[plantuml, version_numbers_sequence_diagram, config=plantuml.cfg] @startuml entity Model collections Transaction1 collections Transaction2 database Database Transaction1 -> Database: get product Database -> Transaction1: Product(version=3) Transaction2 -> Database: get product Database -> Transaction2: Product(version=3) Transaction1 -> Model: Product.allocate() Model -> Transaction1: Product(version=4) Transaction2 -> Model: Product.allocate() Model -> Transaction2: Product(version=4) Transaction1 -> Database: commit Product(version=4) Database -[#green]> Transaction1: OK Transaction2 -> Database: commit Product(version=4) Database -[#red]>x Transaction2: Error! version is already 4 @enduml
Tip
When two operations conflict in this way we usually retry the failed
operation from the beginning. Imagine we have two customers, Harry and Bob,
and both submit orders for SHINY-TABLE. Both threads load the product at
version 1 and allocate stock. The database prevents the concurrent update,
and Bob’s order fails with an error. When we retry the operation, Bob’s
order loads the product at version 2, and tries to allocate again. If there
is enough stock left all is well, otherwise he’ll receive OutOfStock. Most
operations can be retried this way in the case of a concurrency problem.
More on this in “Recovering From Errors Synchronously” and “Footguns”.
Implementation Options for Version Numbers
There are essentially 3 options for implementing version numbers:
-
version_numberlives in domain, we add it to theProductconstructor, andProduct.allocate()is responsible for incrementing it. -
The services layer could do it! The version number isn’t strictly a domain concern, so instead our service layer could assume that the current version number is attached to
Productby the repository, and the service layer will increment it before it does thecommit() -
Or, since it’s arguably an infrastructure concern, the UoW and repository could do it by magic. The repository has access to version numbers for any products it retrieves, and when the UoW does a commit, it can increment the version number for any products it knows about, assuming them to have changed.
Option 3 isn’t ideal, because there’s no real way of doing it without having to assume that all products have changed, so we’ll be incrementing version numbers when we don’t have to1.
Option 2 involves mixing the responsibility for mutating state between the service layer and the domain layer, so it’s a little messy as well.
So in the end, even though version numbers don’t have to be a domain concern, you might decide the cleanest tradeoff is to put them in the domain.
Our chosen Aggregate, Product (src/allocation/domain/model.py)
classProduct:def__init__(self,sku:str,batches:List[Batch],version_number:int=0):self.sku=skuself.batches=batchesself.version_number=version_numberdefallocate(self,line:OrderLine)->str:try:batch=next(bforbinsorted(self.batches)ifb.can_allocate(line))batch.allocate(line)self.version_number+=1returnbatch.referenceexceptStopIteration:raiseOutOfStock(f'Out of stock for sku {line.sku}')
There it is!
Note
If you’re scratching your head at this version number business, it might help to remember that the number isn’t important. What’s important is that the Product database row is modified whenever we make a change to the Product aggregate. The version number is a simple human-comprehensible way to model a thing that changes on every write, but it could equally be a random UUID every time.
Testing for Our Data Integrity Rules
Now to actually make sure we can get the behavior we want: if we have two
concurrent attempts to do allocation against the same Product, one of them
should fail, because they can’t both update the version number.
First let’s simulate a “slow” transaction using a function that does allocation, and then does an explicit sleep:
time.sleep can reliably produce concurrency behavior (tests/integration/test_uow.py)
deftry_to_allocate(orderid,sku,exceptions):line=model.OrderLine(orderid,sku,10)try:withunit_of_work.SqlAlchemyUnitOfWork()asuow:product=uow.products.get(sku=sku)product.allocate(line)time.sleep(0.2)uow.commit()exceptExceptionase:(traceback.format_exc())exceptions.append(e)
Then we have our test invoke this slow allocation twice, concurrently, using threads:
An integration test for concurrency behavior (tests/integration/test_uow.py)
deftest_concurrent_updates_to_version_are_not_allowed(postgres_session_factory):sku,batch=random_sku(),random_batchref()session=postgres_session_factory()insert_batch(session,batch,sku,100,eta=None,product_version=1)session.commit()order1,order2=random_orderid(1),random_orderid(2)exceptions=[]# type: List[Exception]try_to_allocate_order1=lambda:try_to_allocate(order1,sku,exceptions)try_to_allocate_order2=lambda:try_to_allocate(order2,sku,exceptions)thread1=threading.Thread(target=try_to_allocate_order1)thread2=threading.Thread(target=try_to_allocate_order2)thread1.start()thread2.start()thread1.join()thread2.join()[[version]]=session.execute("SELECT version_number FROM products WHERE sku=:sku",dict(sku=sku),)assertversion==2[exception]=exceptionsassert'could not serialize access due to concurrent update'instr(exception)orders=list(session.execute("SELECT orderid FROM allocations""JOIN batches ON allocations.batch_id = batches.id""JOIN order_lines ON allocations.orderline_id = order_lines.id""WHERE order_lines.sku=:sku",dict(sku=sku),))assertlen(orders)==1withunit_of_work.SqlAlchemyUnitOfWork()asuow:uow.session.execute('select 1')
We start two threads that will reliably produce the concurrency behavior we want:
read1, read2, write1, write2.We assert that the version number has only been incremented once.
We can also check on the specific exception if we like

And we double-check that only one allocation has gotten through.
Enforcing Concurrency Rules by Using Database Transaction Isolation Levels
To get the test to pass as it is, we can set the transaction isolation level on our session:
Set isolation level for session (src/allocation/service_layer/unit_of_work.py)
DEFAULT_SESSION_FACTORY=sessionmaker(bind=create_engine(config.get_postgres_uri(),isolation_level="SERIALIZABLE",))
Transaction isolation levels are tricky stuff, it’s worth spending time understanding the documentation.
SELECT FOR UPDATE Can Also Help
An alternative to using the SERIALIZABLE isolation level is to use
SELECT FOR UPDATE,
which will produce different behavior: two concurrent transactions will not
be allowed to do a read on the same rows at the same time.
SQLAlchemy with_for_update (src/allocation/adapters/repository.py)
defget(self,sku):returnself.session.query(model.Product).filter_by(sku=sku).with_for_update().first()
This will have the effect of changing the concurrency pattern from
read1, read2, write1, write2(fail)
to
read1, write1, read2, write2(succeed)
In our simple case, it’s not obvious which to prefer. In a more complex
scenario, SELECT FOR UPDATE might lead to more deadlocks, while SERIALIZABLE
having more of an “optimistic locking” approach and might lead to more failures,
but the failures might be more recoverable. So, as usual, the right solution
will depend on circumstances.
Note
Some people refer to this as the “read-modify-write” failure mode. This page has a good overview.
| Pros | Cons |
|---|---|
|
|
1 Perhaps we could get some ORM/SQLAlchemy magic to tell us when an object is dirty, but how would that work in the generic case, eg for a CsvRepository?