
CHAPTER 4
Data Curation and Governance
When building an intelligent system, there are two main components. The first is the collection of algorithms that build the machine learning models underlying the technology. The second is the data that is fed into these algorithms. The data, in this case, is what provides the specific intelligence for the system.
Historically, the field of machine learning has focused its research on improving the algorithms to produce increasingly better models over time. Recently, however, the algorithms have improved to a point where they are no longer the bottleneck in the race for improved AI technology. These algorithms are now capable of consuming vast amounts of data and storing that intelligence in complex internal structures. Today, the race for improved AI systems has turned its focus to improvements in data, both in quality and volume.
Due to this shift in focus, when building your own AI system, you must first identify data sources and gather all the data necessary to build the system. Data that is used to build AI systems is typically referred to as ground truth—that is, the truth that underpins the knowledge in an AI system. Good ground truth typically comes from or is produced by organizational systems already in use. For instance, if a system is trying to predict what genre of music a user might like at a particular time of day, that system's ground truth can be pulled from the history of what users have selected to play throughout the day in the past. This ground truth is genuine and representative of real users. If no existing data is available, subject matter experts (SMEs) can manually create this ground truth, though it would not necessarily be as accurate.
After it is selected, the ground truth is then used for training your AI system. Additionally, it is a best practice for a percentage of the ground truth to be reserved for validation so that the AI system's accuracy can be empirically validated. Now that you understand the importance of data to your machine learning system, let's discuss how to find and curate the data you will be using to fulfill your use cases.
Before continuing with our ground truth discussion, let's investigate a particular type of machine model called a classifier. A classifier groups an input into one of two or more possible output classes. A simple classifier might distinguish between pictures of chocolate or fruity candies. This classifier has two possible output classes: (a) chocolate candies and (b) fruity candies. A classifier like this could be further developed or extended to recognize pictures of specific types of candies such as (a) M&Ms, (b) Reeses, (c) Snickers, (4) Skittles, (5) Starbursts, and (6) Gummy Bears. Now that we have covered the concept of classifiers, we'll continue with ground truth.
There are typically two key methods to build the distribution of your ground truth when building an AI model. The first is to have a balanced number of examples for each class you want to recognize. In the classic example of recognizing pictures of handwritten characters (also known as the EMNIST1 dataset), having an equal number of training examples for lowercase letters would mean having approximately 1,000 examples of each letter, for a total of 26,000 training data samples. This would be considered a balanced ground truth.
Alternatively, instead of a balanced ground truth, your training data could be proportionately representative of how your system will be used. Using the same lowercase letters example, a proportional ground truth would mean there would be more s training data samples than there would be q training samples because s is a more commonly used letter than q in the English language. However, if the AI system was to be used for a different language, such as Spanish, the proportion of training samples for each letter would have to change to ensure that the ground truth continued to be representative of the users' inputs.
Typically, both balanced and proportional ground truths are valid approaches, but there is one scenario where balanced can be advantageous: in the case of outlier detection, where outliers are so uncommon they make up less than 3 percent of the total, real-world distribution. Looking at an example of image analysis for skin cancer detection, it is likely that most submitted images will not denote a form of skin cancer but that a few will. In this case, a proportional approach will likely not have enough training samples to intelligently recognize the outlier. Instead, including additional training samples of the small class (images representing skin cancer) will be important. Because the underrepresented class is an outlier, you might have a hard time getting an equal number of training examples, but including more samples will improve your AI system's overall accuracy.
Data Collection
Before you can start to curate the data for your machine learning system, you must first identify and acquire it. Data can not only come from your own organization, but it can also be licensed from a third-party data collection agency or consumer service, or created from scratch (see Figure 4.1). In fact, it is not uncommon for an AI system to depend on data from all of these sources. For a better look, let's examine each of these approaches in greater detail.
FIGURE 4.1 Data Available for Training AI Models
Internal Data Collection: Digital
With technology touching every part of our personal lives, it makes sense that it is also ubiquitous within our organizations. Technology helps make us more efficient and simplifies some of the mundane processes that keep our organizations moving. This is some of the same value you are planning to harness by reading this book and adopting AI systems.
Fortuitously, there is an amazing side effect to having all these technological systems in your organization. They typically generate a significant amount of valuable data. Sales, manufacturing, employee, and many other systems all generate data. It is kept in many forms, from structured databases to unstructured log files. In this era of big data, the value of data is known, and therefore most organizations default to saving all their data for future use, regardless of having any immediate use for it. It is impossible to go back in time and save discarded data once you have found a use for it.
Some organizations choose to take a more active role in data generation. They seek to equip themselves with valuable data to improve the efficacy of business decisions they make. One of the primary growth areas for this has been with the Internet of Things (IoT) and networked devices. Companies who distribute their products, whether they be hardware or software, are able to collect enormous amounts of usage data—everything from the time of day a person uses the product to the specific functions being performed and in what order and, sometimes, even geospatial data as well.
What happens, however, if you want to build an AI system but have not started to make data collection a priority? Even in this scenario you may already have more data than you think. In this scenario it makes sense to do an internal data exploration and come up with a data collection strategy for your organization. The two parts of this data exploration will be digital systems and manual systems.
The first part of data exploration consists of identifying and listing all existing digital systems used in your organization. With this list in hand, inquire as to what data is being stored internally by this system. Again, this can be data explicitly being stored by the system (e.g., customer records) or just system usage data that is being saved in log files. Ask if this data is easily accessed or exported so that it can be used within other systems (e.g., the AI system you are building). Some possible access methods include the following:
Application Programming Interface (API)
The best-case scenario for data integration is that the existing system provides a well-documented API to access the data. APIs are preferable since they are secure, are easily and pragmatically accessed, and provide real-time access to data. Additionally, APIs can provide convenient capabilities on top of the raw data being stored, such as roll-up statistics or other derived data. Since APIs (especially those based in HTTP) are one of the newer methods of exposing data, legacy systems will likely not have this capability.
File Export
If a system does not have a convenient API for exporting data, it might have a file export capability. This capability is likely in the system's user interface and allows an end user to export data in a standardized format such as a comma-separated value (CSV) file. While this method is officially supported, only certain data may be able to be exported, instead of all possible internal data. For instance, highly structured data with a lot of internal structure may be harder to export in a single file. The other downside of this method is that it will probably not be easy to access programmatically, and therefore will have to be manually exported periodically. This might not be a problem if you are looking for monthly reports, but the reports will never be current in the way that a real-time dashboard is.
Direct Database Connection
If the system does not provide any supported data exporting capabilities and it is infeasible or monetarily ineffective to add one, you could instead connect directly to the system's internal database if one exists. This involves setting up a secure connection to the database that the system uses in order to directly access database tables. While this data is structured, and therefore easier to work with, you will likely have to reverse-engineer the internal table schemas to see what data is available. Before reverse-engineering the database's structure, however, speak with the system's vendor to see if they have any documentation they can share or an SME. An important point to keep in mind is that you should access this data in a read-only fashion so you don't inadvertently affect the application. Additionally, you must be aware that the system might programmatically transform the internal data before it is displayed to the end user. For instance, if there is a field in the database called
<code>circle_size</code>, it is ambiguous whether this is the radius or the diameter of the circle. Furthermore, the units of the circle are unknown. Is the value in the database in inches, centimeters, or what? Without documentation like source code from the vendor, your only option is to map that value into the UI of the system and reverse-engineer the mapping.
With the digital systems' data accounted for, it is time to start looking at what nondigital data is available.
Internal Data Collection: Physical
The next step in data exploration is to identify potentially existing manual processes used within your organization. For example, doctors' offices often collect insurance information each year from their patients using a physical form. This process generates a large amount of data, which, if not digitized after using manual data entry, is locked away in its physical form. You may find that a number of the systems in your organization have physical components as well. Perhaps your employees' timecards or inspection report forms coming from those in the field are physical. This data is just waiting to be included in an analytical system.
This data is valuable, but a decision must be made to determine how valuable it is. Data in its physical form must be digitized before it can be used to create an AI system. However, digitization is not a trivial task for a large organization, or for smaller ones that have been around a while (e.g., doctors' offices). Therefore, the decision needs to be weighed against the amount of time (and cost) required to digitize the data. Is this historical data relevant? Is it sufficient to just start collecting data in a digital format going forward?
If you do decide the physical data is valuable, then it makes sense to start using a digital system that can automatically record the data, thus removing the manual data entry piece. For instance, employees in the field might start using tablets with a mobile application to track their hours and inspections. In this way, not only is the data saved in a historical record, but it is also immediately available for dashboards and other systems to consume. Implementing these new systems will not happen overnight, but the earlier you can invest in such systems the more value from data and increased efficiency you will realize.
Data Collection via Licensing
If you have not been collecting data, or you require data that you are unable to collect internally, one possible option is data licensing. Many companies are built with the business model of selling data to support their operations. For instance, the company OneSignal2 provides easy-to-use mobile push notification capabilities to developers for free. This is because OneSignal makes their money by selling aggregated data such as generalized phone numbers and usage times. Other free consumer services, such as Facebook, monetize by building highly detailed profiles for their users and allow advertisers to use that data for extremely effective marketing (a method that has come under scrutiny in recent times). In the age where consumers have come to expect free services, this is an implicit assumption outlined in privacy policies. There is a common saying in Silicon Valley:
This personal information (albeit typically anonymized) can also be made available to be directly licensed to others, including your organization.
To determine if data licensing is feasible for you, you can first see whether any sites or companies have a freely available dataset that fits your purposes. You might be surprised how many datasets are free on the web today. Typically, free datasets are published by public institutions, within academia, or by data enthusiasts. Here are some good places to start:
- data.gov3: Over 200,000+ public datasets
- Kaggle4: A data science competition website that makes competition data available
- Awesome Public Datasets5: An index to a number of accessible datasets
Although these datasets might be incomplete or consist of older data, they can be a good starting point to vet potential ideas.
If you are lucky and the data license is agreeable, your licensed data search could already be over. However, if you are not so lucky to find a free dataset that works for you, then it is time to look at data licensing companies. There are a number of them, ranging from small, focused dataset companies such as YCharts,6 which compiles company data for sale as CSV files to large media organizations such as Thomson Reuters, which owns a vast library of content. Thinking outside the box, approaching tech companies in the particular area you are focusing on could also be relevant. For instance, if you need transportation data, licensing data from one of the ride-sharing services might be an option. If you need geospatial images, a number of satellite companies provide imaging at various resolutions. Assuming you are not building a product that directly competes with them, it is likely they will be amenable to you using their data.
If you can find a company that likely has the data you require but is not openly advertising licensing opportunities, it is worth starting a dialogue with them. Perhaps they are bound by current privacy policies, or perhaps they just have not thought of that monetization strategy. If they do not know the demand exists, they might have just written off the idea prematurely. Regardless, starting a partnership dialogue is a good first step.
One of the main disadvantages of licensing non-free data is that data can be costly. The big data and AI movements have made data's value more apparent than ever. That said, data licensing pricing, especially in larger deals, can be negotiated based on how you are planning to use the data. For instance, using data to build a machine learning model instead of directly displaying the data to your end users might be cheaper. Using any derivative or aggregate data from that dataset might be more affordable. Additionally, your use case might play into their pricing. Using data to feed a system that is used by a small team of 10 internal employees might be cheaper than, say, if that same data is being displayed to 1 million end users. Scale-based pricing might be advantageous to you and also allow the licensing company greater upside based on your success. Lastly, data recency can affect price. Licensing static data from last year will likely be cheaper than receiving a real-time data stream. Again, all of this depends on your use case, but data licensing companies want to set prices that establish a long-lasting economic benefit for both parties.
Another potential disadvantage of licensing data is that you are somewhat beholden to the licensing company for their data. Unless a perpetual license is established with defined payment terms, renegotiation will occur at some point. If, for whatever reason, a new agreement cannot be reached, the system you built using this data may all of a sudden become useless. Although this is an unlikely scenario, it is important to keep in mind that this is a risk with licensing data. One way to hedge against this risk, if your use case allows, is to just use the licensed data to bootstrap your system. That is, use the licensed data to build the initial system, but also collect usage data from your AI system that can be used later instead. That approach will enable you to use the data you own and choose whether you want to renew your data license.
If you do not have the data you require, whether you have not been collecting it or it is impossible to collect, data licensing can be very effective.
Data Collection via Crowdsourcing
We have covered obtaining data from within your organization and data licensing, but what happens when you do not have the data you need and cannot license it due to unavailability, poor quality, or cost issues? In this case, crowdsourcing technologies might be applicable.
Crowdsourcing platforms consist of two different types of users. The first are users who have questions that need to be answered. For instance, if I am trying to build an image classifier to categorize an image as daytime or nighttime, I need to make a labeled training set consisting of daytime images and nighttime images. All I need to make use of a crowdsourcing platform are my unlabeled daytime and nighttime images. I can then create a job in the crowdsourcing platform specifying the question “Is this a daytime or a nighttime image?” The crowdsourcing platform then notifies their users that an image classification job is available.
The crowdsourcing platform's other class of users are the humans who will be answering these questions. In this way, they are imbuing your AI system with their intelligence. These users are monetarily incentivized to answer questions quickly and with high accuracy. Typically, the same question is asked to multiple people for consistency. If there are discrepancies for a single question, perhaps the image is ambiguous. If one particular user has many discrepancies, this might mean the user is answering randomly and should be removed from the job or that the user did not understand the prompt. Crowdsourcing platforms use the power of large numbers to ensure accurate responses to the questions being asked.
After a sufficient number of users have answered the question for each data point in your dataset, you then receive a job summary. This summary includes the individual responses as well as a summarized view of the judgments for each data point. This data can be used to train your AI system.
There are a number of crowdsourcing platforms to choose from. They range across a spectrum of “cheap with low-quality answers” to “expensive with high data quality.” A few you might want to look into are Figure Eight,7 Mechanical Turk,8 and Microworkers.9
Although crowdsourcing can be a great way to label datasets so that they can be used as training data for machine learning systems, it does have some other limitations. For instance, it is hard to use a crowdsourcing platform if you have zero data to start with. That is, crowdsourcing jobs tend to take the form of a survey where you have users either give some judgment, based on data, or complete some menial lookup task and provide you with the result, based on data. If you truly have no data, you can take a look at existing intelligent systems to seed your crowdsourcing job.
Leveraging the Power of Existing Systems
Related to the idea of free datasets, there are already a number of intelligent systems available that can be used to generate a dataset. For instance, Google search results can give you a dataset of pages related to a particular keyword. A starter dataset of images can be created similarly from an image site such as Google Images or Flickr. Just make sure you select the appropriate license filter depending on your use case (e.g., labeled for reuse).
Let's continue our previous example of building a daytime/nighttime image classifier. If we need a set of labeled daytime and nighttime images for training, we could mobilize users on a crowdsourcing platform to label images for us, or we could use the power of an existing system. We could use Google Images with a search of “daytime pictures” and then use a browser extension to download all the images on that page. With all the daytime images downloaded, a human can easily glance through them and throw out any images that are not “daytime.” This process can be repeated with a search of “nighttime pictures” to get a collection of nighttime images. In the span of 30 minutes, it is easy to build your collection of 600 images (300 of each type) to build a daytime/nighttime image classifier.
Although this approach can be a great way to obtain labeled training data quickly, you may choose to ultimately license a dataset that is already labeled and ready for training. Even if that is the case, using intelligent systems to generate a quick dataset can help you test an idea without a large upfront investment. In this way, many competing ideas can be heuristically whittled down to those that are most promising.
The Role of a Data Scientist
With all these data curation and transformation tasks, it is important that you have someone skilled to complete these tasks. Data scientists are pioneers that work with business leaders to solve problems by understanding, preparing, and analyzing data to predict emerging trends. They are able to take raw data and turn it into actionable business insights or predictive models, which can be used throughout the organization. An example data scientist's flow is shown in Figure 4.2.
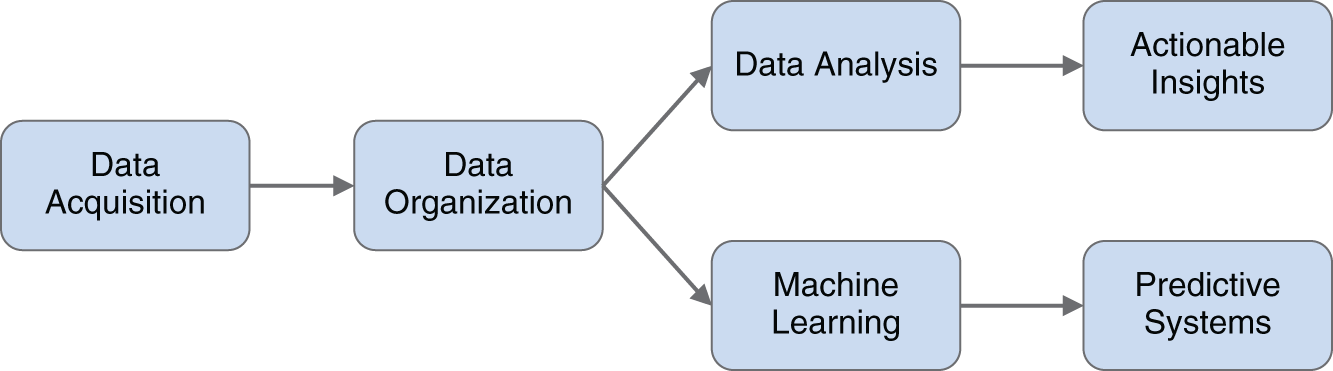
FIGURE 4.2 The Typical Data Science Flow
Data scientists also apply AI technology to supplement human intelligence for more informed worker decisions. Data scientists typically have a background in the following:
- Data storage technology
- Machine learning/deep learning
- Natural language processing
- Numerical analysis and analytics software
Data science has a place in every modern organization, and if your organization does not already have one, it makes sense to start looking. Familiarity with your existing data systems is a plus, but most experienced data scientists will be able to get going quickly with new data environments. Analysis languages tend to have similar capabilities, and libraries primarily differ only in syntax.
Just remember that as your data volume grows, the more data scientists you will need.
Feedback Loops
As with software development processes, feedback loops are very important while developing an AI system. The quality of the output generated by an AI system is based on the dataset used to train it. A bad training dataset will lead to all kinds of disasters.
One goal of a data scientist is to shepherd this process and ensure that data quality and integrity is maintained with each feedback loop. Each loop is a sprint toward the stated objectives, and at the end of each sprint, feedback should be given by either end users or SMEs to ensure maximum benefit from the adoption of Agile loops. The feedback thus generated should be constructive, focusing not only on “what went wrong” but rather on “how to improve the next iteration.”
Feedback loops will aid the organization in creating a faster usable program. The loop will ensure that errors are caught early through regular reviews of functionality. This helps reduce cost escalations due to errors in the project. Error costs occur when development time needs to be spent to correct past mistakes. Via feedback, the project managers will have information that will allow them to course-correct sooner. As feedback is given at the end of every sprint (typically once every two weeks), this ensures that engineering time is not being spent on unproductive or “rarely used” features.
SMEs are central to this process. They will help the engineers find gaps and inaccurate predictions by the AI. The feedback given by a SME should hold the most weight, and future development sprints should be done after taking this feedback into consideration.
Abraham Wald was a statistical expert who worked on wartime problems during World War II. American bombers were being evaluated for structural reinforcement. The initial plan was to reinforce the areas of the planes that were hit with bullets. Wald came to the conclusion that only the planes that survived were available for analysis and those that were shot down completely were not. Hence, it would not be prudent to limit reinforcing the areas with holes, as the planes had clearly survived despite them. Wald, an SME, helped save costs and put into place a better scheme for reinforcement around the engines since those were more likely the planes that did not return from the battle. Feedback given by SMEs should not be ignored.
Feedback should be constructive and not merely criticize the existing program. The outlook should be on the future, but care should be taken not to fall into the sunk cost fallacy. Sunk costs are costs that have already been incurred in the past and cannot be recovered. Since such costs cannot be recouped, future decisions should not necessarily be based on them. To illustrate, say a support department decides to develop a chatbot. After two months of development, the project manager should not be afraid to abandon the entire project if met with an impassible problem or when potential gains will likely be outweighed by the costs of completion. Past costs that have already been incurred cannot decide the future viability of a project.
A feedback loop can help prevent the butterfly effect from ruining the project. The nature of AI code dictates that a small error at the start of a project, like choosing the wrong dataset, can expand the errors in the latter stages of the project. Errors are cheaper to fix at the beginning of a project. Therefore, a feedback loop will help to detect and correct errors at the earliest stage possible.
When an AI program is in the learning, or “training,” stage, it can become overfitted. Overfitting is the technical term for an AI that has developed models that work only with the training and validation datasets. In such a case, feedback about increasing the variability of the dataset or changing the model parameters should be given.
Feedback should be given as soon as testing begins. Feedback must be forward-looking, clear, concise, and direct. It should focus on the output of the AI and whether the development is in line with the objectives designated at the start of the project. At the end of every sprint, the system should be tested thoroughly and suitable course-corrections should be made.
Making Data Accessible
After the data is collected, it is typically stored in an organization's data warehouse, which is a system that colocates data in a central location to be conveniently accessed for analysis and training. Regardless of how the data is stored, the important point here is that the organization now has all the data it needs in a central, accessible format. Keeping necessary data accessible is critical when building AI systems.
Having data and being able to use it to train an AI system are two different things. Data in an organization can sometimes be siloed, meaning that each department maintains their own data. For instance, sales and customer data might be stored in a customer relationship management (CRM) system such as Salesforce, whereas the operations data is stored separately in a shop floor database. This division makes it hard to have a holistic view of all the data within an organization.
For an example of the limitations of siloing data, imagine trying to link from a customer's record to that customer's manufacturing yields. This would be nearly impossible in a silo-structured system. If this were the goal, the organization would need to build a data platform that collected and compiled all siloed data into a central location. Platforms such as Apache Hadoop10 provide a method to create an integrated schema and synchronize data. Setting up this data and unlocking its value is a task well suited to the newly established role of the data scientist.
Data Governance
Data being the cornerstone of artificial intelligence, it is important to understand the ethical and legal ramifications of obtaining and using any data. Governance is a term that has been applied to a number of areas of technologies. Governance is about ensuring that processes follow the highest standards of ethics while following legal provisions in spirit, as well as to the letter of the law. We have the ability to capture large amounts of data today. Most of this data comes from customers' devices and equipment, and the vast majority of internal data is also usually customer data. The bigger problem that comes with storing vast amounts of data, from whatever the source, is ensuring its security. As the holder of data, an organization is responsible for not disclosing any user's data to third parties without the user's consent. For good theft-prevention and regulatory practices, data privacy cannot merely be an afterthought after the information has been stolen. Data storage systems, if designed with security in mind, can go a large way in thwarting attempted hackers.
Data governance involves ensuring that the data is being used to further the goals of the organization while remaining compliant with local laws and ethical requirements. On the ethical side, data should not be obtained without the consent of the individuals featured in it. Additionally, the individuals featured, as well as the proprietors of said data, should all be aware what the data will be used for. Data that is collected without the express consent of the user should not be used and should not have been collected in the first place. “Do Not Track” requests by browsers of the users should also be honored. Most modern browsers allow this option to be set, but the implementation is left up to the integrity of individual websites.
Complete data governance should be the goal, but it will likely take some time for the organization's thinking to mature, so the initial focus should be on improving processes and avoiding repeat mistakes. A proactive approach is always better in data management, since abuse of data could have potentially huge impacts. Companies have gone bankrupt in the wake of critical data breaches.
Listed next are some data policy measures that can act as a good starting point:
Data Collection Policies
Users should be made aware of what data is being collected and for how long it will be stored. Dark design patterns that imply consent rather than ask the user explicitly should not be implemented. Data collection should be “opt-in” rather than “opt-out,” or in other words, data collection should not be turned on by default and no data should be collected without specific user approval. If data will be sent to third parties for processing/storage, the user should also be informed of this upfront. A smart data collection policy goes a long way in establishing goodwill and customer satisfaction.
Encryption
Encrypting sensitive information such as credit card information has become a standard industry practice, although user data remains unprotected. The impact of a data breach can be lessened if the data is encrypted. Encryption alone could be the sole factor between a bankrupting event and simply a public relations issue. It is obviously necessary to protect the keys and the passwords used to encrypt the data as well. If the keys are exposed, they should be revoked and passwords should be changed for good measure.
User Password Hashing
In some areas such as user passwords, a technique called hashing can be applied instead of encryption. Hashing is a process that takes a user's password and turns it into a unique text string, which can be generated only from the original password. This process works in only one direction, meaning that there is no way to retrieve the original password from the password hash. For example, the password password123 (which is a terrible password) could be converted using a hash function into the string
a8b3423a93e0d248c849d. This hashed password is then stored in the database instead of the real password. The next time a user wants to log into the system, the provided password is hashed and then checked to see if it matches the stored hashed password. In this way, hackers would be able to steal only password hashes that are worthless and not the original passwords. This extra layer of protection especially aids users who use the same password for multiple sites (also not a recommended practice), since once a hacker has a password, they can attempt to use that same email and password combination on other popular Internet sites, hoping to get lucky.Access Control Systems
All data should be classified based on an assessment of factors such as its importance to the user and the company and whether it contains personal data of users or company secrets. For example, the data could be classified as “public,” “internal,” “restricted,” or “top secret.” Based on the classification assigned to the data, appropriate security measures should be established and followed. Access to data must be controlled, and only approved users should be granted access.
Anonymizing the Data
If the data needs to be sent to a third parties or even other less secure internal groups, all potentially identifying information, such as names, addresses, telephone numbers, and IP addresses, should be scrubbed from the data. If a unique number is allotted to an individual, it should be randomized and reset as well. No data should be shared with third parties without sufficient consent being obtained from the users who are featured in the data being shared.
Creating a Data Governance Board
As you have seen, data governance is a critical part of any organization's data strategy. In order to develop the initial data governance policies, a data governance board can be constituted. The board will develop the organization's data governance policies by looking at best practices across the globe like General Data Protection Regulation (GDPR), Health Insurance Portability and Accountability Act (HIPAA) provisions (more on these in a moment), and so forth. The board should be formed with people who can drive these big decisions. The necessity may arise for the board to push through difficult decisions that are at odds with the aims of the organization in order to protect the rights of the people whose data is at risk.
Initiating Data Governance
In most cases, it is easier to start with an existing set of data governance rules and then adapt the rules to fit your organization. Your data governance board will aid in making key decisions for which policies may not yet have been established, setting precedents, and then instating newer policies as the organization evolves and grows to handle more data. Such a process will help to ensure that the costs of governing the data do not exceed the benefits derived from it.
HIPAA
The Health Insurance Portability and Accountability Act (HIPAA) dictates the procedures to be followed and the safeguards to be adopted regarding medical data. If you are dealing with medical data, it is critical to be compliant with these laws and regulations from the get-go.
In 2013, the Health Information Technology for Economic and Clinical Health Act (HITECH Act) was also implemented. The HITECH Act makes it mandatory to report breaches that affect 500 or more people to the U.S. Department of Health and Human Services, the media, and the persons affected. Only authorized entities are allowed to access patients' medical data.
With this in mind, an organization should be careful that the data being sourced is not violating any provisions of HIPAA or HITECH and that it is ethically and legally sourced.
GDPR
In 2018, the European Union introduced a new set of privacy policies called the General Data Privacy Regulation (GDPR). These privacy policies put the user as the data owner, irrespective of whether data is stored. Under GDPR, data collection must be explicit, and any implicit consent—such as “fine print” stating that signing up for an account implies that your data can automatically be collected—is in contravention of GDPR. GDPR also mandates that requests for deletion of user data should be as simple as the form for consent. GDPR mandates that users be made aware of their rights under the policy, as well as how their data is processed, what data is being collected, and how long will it be retained, among other things. GDPR is a step in the right direction for user privacy, aimed to protect the users from data harvesters and unethical data collection.
The responsibility and accountability have been put squarely on the shoulders of the data collectors under GDPR. The data controller is responsible for the nondisclosure of data to unauthorized third parties. The data controller is required to report any breaches of privacy to the supervisory authority; however, notifying users is not a mandatory requirement if the data was disclosed in an encrypted format.
Although these regulations are only legally applicable to users in the European Union, adopting GDPR policies for users across the globe will put your organization at the forefront for compliance and data governance practices.
Are You Being Data Responsible?
Securing your data should be considered a critical mission rather than an afterthought. For an AI-oriented organization, data is the cornerstone of all research activities. Good data will lead to better decisions, and the age-old cliché about computers, “garbage in, garbage out,” still holds true today. Ethically sourced data will add goodwill and keep your organization on the right side of the law. Data governance might seem like a daunting task, but with the help of a solid plan, it can be managed just like everything else.
Are You Data Ready?
Data is critical to any organization, but it is essential when building an AI system. It is important to take stock of all your digital and manual systems to see what data is being generated. Is this data sufficient for your system's needs? Do you need to start looking at data licensing or starting your own crowdsourcing jobs? Do you have the necessary talent (such as data scientists) to make this happen? Have you established your data governance model? Once you have answered these questions, you are prepared to move to the next step: prototyping.
Pitfalls
Here are some pitfalls you may encounter during data curation and governance.
Pitfall 1: Insufficient Data Licensing
When it comes to data, having sufficient licensing is critical. Using unlicensed data for your use case is the quickest way to derail a system just as it is about to launch. Sometimes, developers will take liberties with data in the name of exploration, stating “I am just seeing if this approach will even work first.” As time goes on, the solution is built using this “temporary” data while the sales and marketing teams run with it, without knowing that the underlying data licensing has not been resolved. At this point, hopefully, the data licensing problem surfaces before users are onboarded to the system. In the worst case, you find the issue when the data owners bring legal action against your organization. To prevent this, it is imperative to have a final audit (or even better, periodic audits) to review all the data being used to build the system. This audit should also include validation of third-party code packages, because this is another area where licensing tends to be ignored for the sake of exploration.
Pitfall 2: Not Having Representative Ground Truth
This pitfall relates primarily to the role data plays in training a machine learning system. Specifically selected data will serve as the system's ground truth, which means the knowledge it will use to provide its answers. It is important that your ground truth contains the necessary knowledge to answer these questions. For instance, if you are building the aforementioned daytime and nighttime classifier but your ground truth does not include any nighttime images, it will be impossible for your model to know what a nighttime image is. In this case, the ground truth is not representative given the target use case, and it should have included training data for every class you wished to identify.
Pitfall 3: Insufficient Data Security
For information to be useful, it has to satisfy three major conditions: confidentiality, integrity, and accessibility. In practice, however, accessibility and integrity overpower confidentiality. In order to ensure legal, ethical, and cost-effective compliance, security should not be an afterthought, especially for your data storage systems. Data stores should be carefully designed from the start of the project. Data leakage can lead to major trust issues among your customers and can prove to be very costly. Companies have gone bankrupt over inefficient security. Customer data should be stored only in an encrypted format. This will ensure that even if the entire database is leaked, the data will be meaningless to the hackers. It should be confirmed that the encryption method that is selected has sufficient key strength and is used as an industry standard, like RSA (Rivest–Shamir–Adleman) or Advanced Encryption Standard (AES). The key size should be sufficiently long to avoid brute-force attempts; as of this writing, anything above 2,048 bits should be sufficient. The keys should not be stored in the same location as the data store. Otherwise, you could have the most advanced encryption in the world and it would still be useless.
Employees also need to be trained in security best practices. Humans are almost always the weakest link in the chain. Spear phishing is the technique of using targeted phishing scams on key persons in the organization. Such techniques can be thwarted only through adequate training of personnel. It is important to include not only employees but also any contract resources that you are using to ensure that they are trained in the best security practices. Training and hardening your organization's managers, engineers, and other resources, just like your software, is the best way to avoid security compromises.
Computer security is a race between hackers and security researchers. In such a scenario, one other critical component to winning is to patch everything as soon as possible. Auditing your infrastructure and servers by professional penetration testers will go a long way in achieving your organization's security goals. These specialists think like hackers and use the same tools that are used by hackers to try to break into your system and give you precise recommendations to improve your security. Although getting security right on the first attempt might not be possible, it is nonetheless necessary to take the first steps and consider security from the beginning of the design phase.
Pitfall 4: Ignoring User Privacy
Dark designs are design choices that trick the user into giving away their privacy. These designs work in such a way that a user might have given consent for their data to be analyzed/stored without the user understanding what they have consented to. Dark design should be avoided on an ethical and, depending on your jurisdiction, legal basis. As the world progresses into an AI era, more data than ever is being collected and stored, and it is in the interest of everyone involved that the users understand the purposes for which their consent is being recorded. A quick way to judge whether your design choices are ethical is to check whether answering “no” to data collection and analysis imposes a penalty on the user beyond the results of analysis.
If third-party vendors are used for data analysis, it becomes imperative to ensure that anonymization of the data has taken place. This is to lessen the likelihood that the third party will misuse the data. With third-party vendors, it becomes necessary to take further measures like row-level security, tokenization, and similar strategies. Conducting software checks to ensure that the terms of a contract are upheld is very important if third parties are going to be allowed to collect data on your behalf. Cambridge Analytica abused its terms of service as Facebook merely relied on the good nature and assumed integrity of Cambridge Analytica's practices. Having software checks that ensured third parties could access data only as defined in their contracts would have shortened Cambridge Analytica's reach by a huge amount, as it would not have been able to then collect data on the friends of people taking their quizzes.
Respecting users' rights and privacy in spirit is a process. Although it might be costly, it is necessary given the amount of data that is now possible to collect and analyze. When fed into automated decision-making AIs, these large amounts of data have the potential to cause indefinite and undue misery. It is in this interest that it becomes necessary to implement policies that make the user aware of how their data is being collected, how it will be analyzed, and most importantly, with whom it will be shared.
Pitfall 5: Backups
Although most people today understand the importance of backups, what they often fail to do is implement correct backup procedures. At a minimum, a good backup plan should involve the following steps: backing up the data (raw data, analyzed data, etc.), storing the backup safely, and routinely testing backup restorations. This last step is frequently missed and leads to problems when the system actually breaks. Untested backups fail to recover lost data or produce errors and require a lot of time to restore, thus costing the organization time and money to fix the problems. To resolve this, you should routinely restore full backups and ensure that everything still works while operating on the backup systems. A full data-restore operation should be undertaken on preselected days of every year, and all live systems should be loaded with data from the backups. Such a mock drill will identify potential engineering issues and help locate other problems as well, enabling you to develop a coherent and reliable restoration plan should the actual need for one ever arise.
With cloud storage becoming so commonplace, it is essential to remember that the cloud is “just another person's computer” and it can go down, too. Although cloud solutions are typically more stable than a homegrown solution because they are able to rely on the economies of scale and the intelligence of industry experts, they can still have issues. Relying only on cloud backups may make your life easier in the short term, but it is a bad long-term strategy. Cloud providers could turn off their systems. They could have downtime when you need to do that critical data recovery procedure. It is therefore necessary to implement off-site and on-site physical storage media backups. These physical backups should also be regularly tested and the hardware regularly upgraded to ensure that everything will work smoothly in the case of a disaster.
All data backups should be encrypted as well. This is especially important to prevent a rogue employee from directly copying the physical media or grabbing it to take home. With encrypted backups, you will have peace of mind and your customers will sleep soundly, knowing their data is safe.
Action Checklist
- ___ Determine the possible internal and external datasets available to train your system.
- ___ Have a data scientist perform a data consolidation exercise if data is not currently easily accessed.
- ___ Understand the data protection laws applicable to your organization and implement them.
- ___ Appoint a data governance board to oversee activities relating to data governance in order to ensure your organization stays on the right track.
- ___ Put together a data governance plan for your organization's data activities.
- ___ Create and then release a data privacy policy for how your organization uses the data it accesses.
- ___ Establish some data security protections such as using data encryption, providing employee security training, and building relationships with white-hat security firms.