
CHAPTER 6
Production
Now that the prototype is complete and validated, it is time to start building the rest of your AI system. The prototype tackled a few top-priority user stories, but building the production system will be about completing the rest of the user stories you identified during the “Defining the Project” step.
Before your development team starts building the rest of the user stories, however, it is prudent to go through the existing user stories list to ensure that they are all still valid. Over time, your priorities might have shifted or you might have learned more from building the prototype. For instance, perhaps another team already implemented one of the AI models that your system was going to need to use in their system. Instead of implementing the same AI model, you can save development and debugging time by using theirs. Further methods for increasing AI model reuse will be discussed in the next chapter. In this way, user stories may need to be updated or dropped to ensure that users will still receive value for each production user story.
Reusing the Prototype vs. Starting from a Clean Slate
There are differing viewpoints on leveraging prototype code when building a full production system. Some are of the mindset that you should throw away the prototype code completely and start from scratch, taking only what you have learned. This way, you are not bringing over suboptimal code and initial bad practices. Others say to start with the same code base and continue building—why repeat what you have already done? Both sides have their merits, so we believe the best approach tends to be a hybrid of the two.
The hybrid approach initially looks like starting from scratch. Start with a new design using what you have learned. Perhaps you have discovered there is a more efficient architecture with only a few key changes to make. After the design is in place, create a new code repository for the production code, and then start implementing. This is where the hybridization comes in. Instead of writing all the code from scratch, copy chunks of code from the existing prototype. A lot of code will be directly reusable. The process of copying allows the developers to evaluate the code and look for improvements. For instance, code that connects to APIs and services will typically not need to be changed much, if at all, since documentation usually prescribes this code. This way, you can keep your code organized in the new layout without having to start from square one. After all, this production system will be around for years and good code organization will set the precedent for keeping code orderly and easy to maintain.
For the AI pieces of the project, this process is very similar. The data used in the prototype will almost always be the same data used in the production build. If anything, additional data will be included to improve the representational quality of the ground truth. In some circumstances, the requirements of the model will have changed and constructing a new dataset will be required based on the results of the prototype. If needed, the change should be embraced and resolved at this point so as not to propagate this issue into the production system. If ignored, it will only cause a larger headache with your AI models further in the project, likely close to the time you would like to launch.
Code used to build the AI models will probably not change much between the prototype or production unless the topology of the deep learning technology needs to be modified. What you will likely change in the production phase (and as the project continues) is the hyper-parameters of your model. For instance, tweaking the learning rate during your model's training could improve its overall production accuracy as other components of your data or model change.
Continuous Integration
Once the solution is deployed and users start to depend on its availability, it is important to set up a rigorous process for updating the production instance. This update process should also include automated tests to validate every code change. This is necessary, since a seemingly innocuous change can have detrimental effects, breaking the solution for some users. For instance, imagine a scenario where two developers are calculating the diameter of a circle using its radius. It is possible for one developer to put the line
diameter = 2 * radius in a function called
getCircleSize() while another developer concurrently adds the same line of code in a different code location, further up the call chain. Since the code was changed in different files, there is no code conflict between the developers, and the source control (e.g., git) will not complain about any issues. However, the result is a circle size value that is twice as large as it should be. If this code had automated tests written for it, the error would be caught immediately.
The Continuous Integration Pipeline
Another great practice for maintaining stability is to promote code through a series of quality assurance environments. Together, these environments make a continuous integration pipeline. A pipeline can consist of any number of environments, but most include the following three:
- The development environment, which enables internal developers and product managers to access the latest version of the code
- The stage environment, also sometimes called the test environment, which is configured similarly to the production environment and runs new code and models that will eventually become production if they pass all quality assurance checks
- The production environment, which is the live environment that end users are actively using
The first environment in this continuous integration pipeline is the development environment. It serves as the latest and greatest version of the system. The development environment can be redeployed after every successful code/model integration, or once a day (typically in the evening). In the latter case, the development environment is said be to running the nightly build. Developers and product managers use the development environment to check that closed tickets have been implemented correctly and, separately, that no feature misunderstandings have occurred. This distinction is so important in software engineering that there are defined terms for each. Verification is defined as ensuring that the code performs a function without causing errors, and validation is defined as ensuring that each function is useful and correctly fulfills the software's intended requirements. Although automated tests can perform verification, it is rare that they are also set up to perform validation since the same developer typically writes the tests for their code. In most cases, other developers and product managers perform validation manually.
Since the development environment is primarily used to ensure feature correctness, it tends to be a smaller version of the fully deployed production environment. This enables the development environment to be updated and redeployed more quickly, but it also means that representative performance tests and other scalability tests cannot be performed until the next stage of the pipeline.
When a sufficient number of features and bug fixes have been pushed to development, it is time to promote the development environment to the stage environment (see Figure 6.1). Promoting code to the next level of the pipeline involves deploying the same version of code and models as in the previous environment. Since the stage environment is the same size as the full production environment, it is a good place to test performance and scalability. New code additions, especially if they are the first implementation of a feature, may be fine when run in isolation but cause issues when run hundreds of times concurrently. For instance, new code might call an external system that is not set up to handle scale itself. In this case, reducing calls to the external system by caching results may be necessary to ensure that your users do not experience performance issues from excess load.

FIGURE 6.1 Promoting Application Code from Stage to Production
Because the stage environment is always the last stage in the continuous integration pipeline before production, quality assurance becomes critical. The stage environment is the last line of defense before bugs are introduced to the production environment, which will affect real users. The stage environment's acceptance process should include both code and models.
Once the stage environment has been thoroughly tested, it is time to promote its code and models to production. In this way, features that were implemented and originally deployed into the development environment have now made their way to providing value to real users. The improved models that are now deployed will provide more accurate results or have increased capabilities. For instance, an object detection model may have been improved through this process to recognize some new objects that have been frequently requested by its users.
For machine learning models in particular, this continuous integration pipeline can promote new models without their even requiring additional programming (see Figure 6.2). Simply including additional data can be sufficient for a model to be retrained and enhanced. This additional data can come from an external source or, more interestingly, from the production users of the system. In the latter case, this feedback loop is perpetually self-improving, an incredibly powerful concept.
True Continuous Integration
Up until now, we have primarily discussed feedback loops in the context of Agile and as a way to ensure that the system is meeting stakeholder requirements. Now, we see that feedback loops can also be applicable, and very useful, in building self-improving machine learning systems. This simple yet revolutionary concept of using the results from a previous activity to partially determine the next activity is a fundamental principle that drives most human learning and behavior. Once you are aware of it, you will start to see this pattern in most intelligent processes. Even a human adjusting how hard to press on a car's accelerator while looking at the speedometer comes from a type of feedback loop, with the desired speed being the goal. We will dive deeper into this concept in the next chapter.
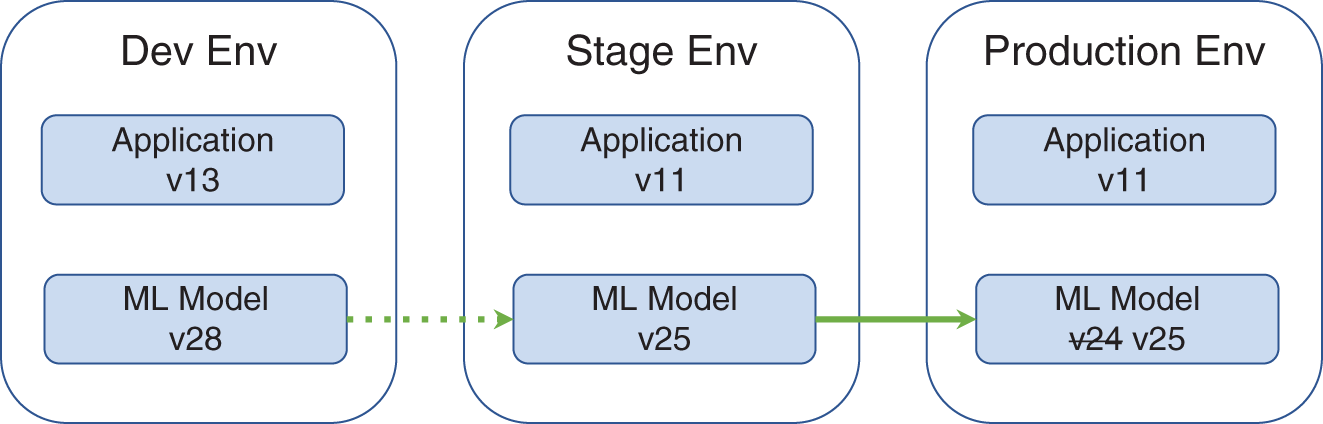
FIGURE 6.2 Promoting a Model from Stage to Production
In a world where organizations are global, systems have to stay live 24 hours a day. Any downtime can hurt users' immediate productivity and start to erode their trust in the brand. Therefore, upgrades to production must forgo incurring any downtime whenever possible. In large systems, multiple instances of code may be deployed for intentional redundancy. It is common to replace each redundant instance with the new deployment, one at a time, upon updating. Similarly, models might be deployed multiple times to handle scalability, and they too can be replaced one at a time to ensure that there is no modal downtime.
An alternative upgrade option involves swapping the stage environment completely with the current product environment with a simple networking change. In this scenario, you would have two production environments; call them A and B. Let's say users are currently using production environment A. You would then use production environment B as a staging environment. Once environment B has passed quality assurance, the network is changed so that my-system.my-company.com points to environment B instead of environment A. There is some complexity with this approach (e.g., handling currently-in-flight transactions), but this process will ensure that the system experiences no downtime.
The benefit of continuous integration is that code pushes are immediately tested and validated so that stage could, if stakeholders trust the process enough, be promoted to production as soon as all the tests are complete. Gone are the days where bug fixes have to wait weeks for the next update to be released. This approach works well for a centralized AI system such as one implemented using a software as a service (SaaS)-like architecture. If your system is physically deployed in different locations, this aspect of continuous integration is less practical. There are a number of continuous integration tools, such as Travis CI and Jenkins, that provide detailed usage instructions on their websites.
Continuous integration principles are applicable not only to software, but also to any machine learning models that are being built. For instance, updating an object detection model to recognize one additional object may break its ability to identify a previously recognized object. For scenarios such as this, it is important to have a test suite of images to which precision and recall metrics (discussed in more detail in the next chapter) can be calculated for each object type each time the model is updated or re-created. This way, problems with new models can be identified before they make it through the pipeline and are integrated with the production system.
Ideally, this continuous integration system would have been established during the prototype phase to ensure quality, but as is typical with most prototypes, testing functionality is not the priority. The logic behind this is that if the prototype does not pay off, no further investment has been made in building test frameworks or other supporting infrastructure. Alternatively, if the prototype is successful and quality assurance was postponed until after the prototype was successful, it can be a large undertaking to set up the infrastructure at this point. Unit tests and other automated testing would need to be created for the existing code. Additionally, any incurred technical debt (coding shortcuts, which can also introduce bugs into the system) will need to be resolved at this point in time. If you decide to start your production code from a clean slate or use the aforementioned hybrid approach, most of these issues can be mitigated while either writing fresh code or reviewing it as you copy over pieces of the prototype.
Automated Testing
As mentioned earlier, code must be validated each time it is pushed in order for us to have trust in our continuous integration. This means running a test suite each and every time to ensure code that could negatively affect the end users is never pushed through to production. Ideally, every line of code would be tested in some capacity. For example, the following code has two branching paths:
if amount> 100:// branch Aelse:// branch B
In this sample code, a good test suite would contain tests that validate both branch A and branch B. This means having tests with the value of
amount being greater than 100 and also less than or equal to 100. Only in this way can this code be considered to have 100 percent test coverage.
Test Types
Automated tests are typically broken into three types:
- Unit tests, which validate self-contained pieces of code.
- Integration tests, which validate code that controls the interactions between systems—for instance, code that talks to a database or a third-party API.
- Acceptance tests, which validate the system as a whole, testing functionality in ways that an end user would use the system. These can be direct methods like user interface inputs or programmatic API calls if your solution is an API.
Each of these test types helps validate the code base at different levels and are ordered by increasing scope. Ideally, most bugs will be caught with targeted unit tests where bugs are fairly easy to isolate. As scope increases and multiple systems become involved, problems become more complex and harder to identify. Integration tests are responsible for all bugs that make it past unit testing and will catch them if an API you are using had an interface change (e.g., renamed a parameter). Acceptance tests then become your last line of defense against remaining bugs as they peruse and test large swaths of user features. A good sample acceptance test might be logging in as a user and updating your account information. These sets of tests flow together as depicted in Figure 6.3.
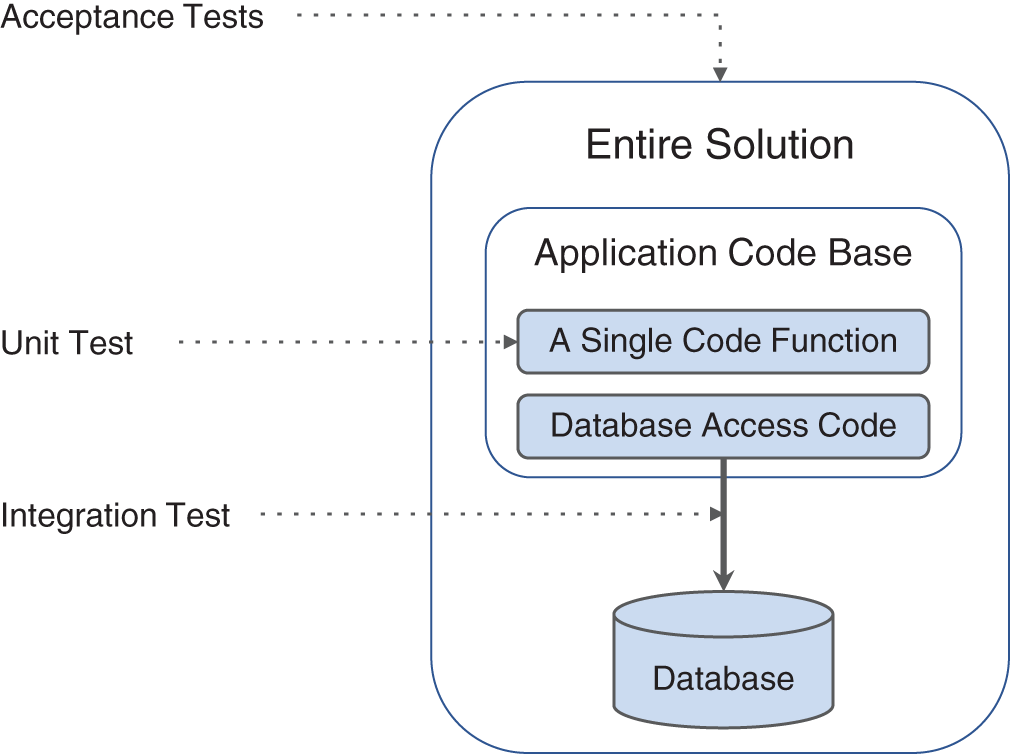
FIGURE 6.3 Acceptance, Integration, and Unit Testing
AI Model Testing Example
Given that your AI system will contain AI models that you train, it is important that these models are tested as well. With appropriate tests, you can be certain that new models are as good, if not better, before they replace an older one in production. Let's dive into an example of creating unit tests that evaluate our AI model's ability to determine the correct user intent for a particular user input. Let's use a chatbot in the banking domain for this example. Assume our chatbot contains an AI model that is able to recognize and handle the following three user intents and a “catch-all” intent for if the user's input does not match an intent with enough confidence:
-
HOURS_OPEN: Provide the user with the hours that the bank is open. -
OPEN_BANK_ACCOUNT: Provide the user with instructions for opening a bank account. -
CLOSE_BANK_ACCOUNT: Provide the user with instructions for closing a bank account. -
CATCH_ALL: A generic response pointing the user to the existing FAQs webpage or that provides the ability to fall back to a human operator.
Since we want to ensure that our system correctly classifies inputs into these intents, we should have unit tests for the AI model that prove it is correctly classifying intents. The tests could be as simple as the following code:
# Test HOURS_OPENassert classifyUserIntent("What time do you open?") ==HOURS_OPENassert classifyUserIntent("Are you open tomorrow at 9am?") ==HOURS_OPEN# Test OPEN_BANK_ACCOUNTassert classifyUserIntent("I want to open a newaccount with you guys?") == OPEN_BANK_ACCOUNTassert classifyUserIntent("I am interested in achecking account?") == OPEN_BANK_ACCOUNT# Test CLOSE_BANK_ACCOUNTassert classifyUserIntent("I want to close myaccount?") == CLOSE_BANK_ACCOUNTassert classifyUserIntent("I am moving to a new bank,how do I do that?") == CLOSE_BANK_ACCOUNT# Test CATCH_ALLassert classifyUserIntent("How do I add my spouse tomy account?") == CATCH_ALLassert classifyUserIntent("Does your bank provide IRAaccounts?") == CATCH_ALL
In this example there are only two unit tests per intent, which may not seem like enough but they will provide a sanity check that your system is still generally working as expected. Remember that these unit tests will be run after any model is created and before a new model is promoted into production. This should increase the confidence that problems will not sneak into production and negatively affect real users.
When working with AI models specifically, there are methods of splitting your model's ground truth into a training set (data used to create the model) and a test set (data used to evaluate the accuracy of the model). This process should be used to generate and select a model, which will then be further checked by the unit tests as defined earlier.
As you increase the number of recognized intents and therefore your chatbot's capabilities, you will also want to make sure that you add their respective unit tests. Classifiers that have to distinguish between a large number of classes (e.g., intents) have to learn more nuanced complexity, causing the overall model to suffer. This shows just how important tests are to feeling confident that your system has not regressed in any way.
What if You Find a Bug?
What happens, however, when a defect is found in the production code? Well, this means that there was no appropriate test case to catch the bug. Therefore, the first step is to write a new test that catches this issue. In doing so, other bugs in the code might also become apparent, and tests for those defects should be written as well. With the test written, we need to validate that the test does indeed catch the offending issue(s). Once we are sure it does, we can then fix the code and validate that the issue is resolved by running the new test cases again. Not only has this particular issue been fixed, but if that same error is ever reintroduced into the code (e.g., code rollbacks), the new test coverage will immediately identify the issue and bring it to your attention before it is rolled out to production with real end users.
Infrastructure Testing
The automated tests we have been discussing are important for ensuring code and model quality. However, a system is only as stable as its deployment configuration and the hardware it is deployed on. If you deploy your solution on a single server and that server goes down, your users will be affected. If you deploy your solution on three servers in a redundant fashion and one server goes down, your users might not even notice a difference. Therefore, it is important to ensure a robust, multiserver deployment.
But how do you know that your deployment is robust enough to handle issues and recover gracefully? This is the problem Netflix faced in 2011. The solution they came up with is the result of some out-of-the-box thinking. They decided to intentionally cause random errors in their deployment and ensure that users were not affected. Since they were causing the errors, they could immediately stop the issue if the error impacted users. Using this technique, they could identify errors in the deployment configuration, which could then be updated to fill any gaps. That way, the next time any of the errors occurred for real-world reasons, their deployment would stay resilient. Netflix named their successful project Chaos Monkey, after an imagined monkey running around their data center causing havoc. Netflix has since open-sourced the Chaos Monkey code and made it available on GitHub.1
Because the Chaos Monkey approach operates at the deployment level, there is no need to build a separate Chaos Monkey for your machine learning models. Since the models will be deployed on infrastructure for execution, Chaos Monkeys can easily be pointed to test that part of your deployment as well. In this way, code and models alike will be tested for robustness via the Chaos Monkey approach.
Ensuring a Robust AI System
When you're building a completely autonomous AI system, there will always be times when the system will simply not know how to handle the user's request—whether that's because the user asked their question in an unexpected way or because the user asked an inappropriate question you have no intention of supporting. In these scenarios, the AI system must be able to handle the user's request gracefully.
To demonstrate, let's continue our example of an automated chat support system for a bank. The bank's original design defines a system that can handle any organization-appropriate inquiry with an accurate response. This would include queries such as checking an available balance, making a deposit, and searching for nearby locations—actions associated with customer banking activities. However, a question such as purchasing movie tickets would be out of left field for the chatbot. Indeed, unless that bank is running a special promotion for movie tickets, an off-topic activity like this is probably not something the developers accounted for when designing their chatbot. One of the best practices that came out of the early efforts in this field is to ensure that chatbots have a mechanism to gracefully handle off-topic requests. It is important to have “guide rails” and instructive responses detailing what a user can achieve with your chatbot and letting them know when they have strayed from the purview of your chatbot's function. One way you might arrive at this goal is by designing your chatbot to respond to any off-topic queries with a response along the lines of
Conversely, still using our example, when a user is attempting to perform a legitimate activity, such as checking a bank balance, they should never see a message stating that they have gone off topic. Such a message would cause warranted frustration and immediately erode confidence in the system. Your chatbot serves as your organization's representative, so any lack of performance will directly reflect on the reputation of your organization. With this understanding in mind, we must also recognize that any given project will always have a finite amount of time and budget before the developers must release the first version of their chat support system. The important point is that the system should continue to be improved over time as additional users start to use the system.
Human Intervention in AI Systems
In reality, no matter how robust the chat automation system is designed to be, there will always be issues and failure points. To prepare for these contingencies, your system should be scoped with a “failover” protocol in mind. This can mean using the best practices of guide rails as we just discussed or, alternatively, a hybrid approach leveraging humans for the cases where the chatbot falls short. The inclusion of humans into our system gives new meaning to acronym of “AI”: augmented intelligence.
However, deciding when to employ a human is not always a simple if-this, then-that type of decision; indeed, the decision tree process is an art unto itself. A simple method of deciding might involve monitoring for users who repeatedly receive your default “I am sorry” response. At this point, the chat system could allow a chat specialist to seamlessly take control of the chat and deliver their own responses. This fallback capability will cover the variety of unforeseen edge cases that are important to users.
Another method to determine when a human should be brought into the chat could leverage a different AI capability: tone analysis. Tone analysis technology analyzes not what the user is saying, but rather how the user is saying it. For instance, there is a difference between
and
The first and second example both convey the same message but their tone and delivery are drastically different. The second example's use of hyperbole and vivid language (sometime even explicit language) can be strong indicators that a human's touch is warranted at this point. Even if the chatbot is able to fulfill the user's first need by providing an answer to their question, the chatbot might not fulfill the user's second need, which is recognizing how the user feels about this issue and validating their frustration.
In scenarios such as these, it can be helpful to adopt a hybrid approach of using a chatbot to handle 80 percent of user questions while filling its gaps with a real human. A human resource can be the difference between the failure of a fully automated system versus the success of a human augmented system (see Figure 6.4 for a sample hybrid architecture). Additionally, as time progresses, the chatbot can be improved by looking at the user questions that required human involvement. As the common gaps are filled, the chatbot will begin to rely less and less on human augmentation.
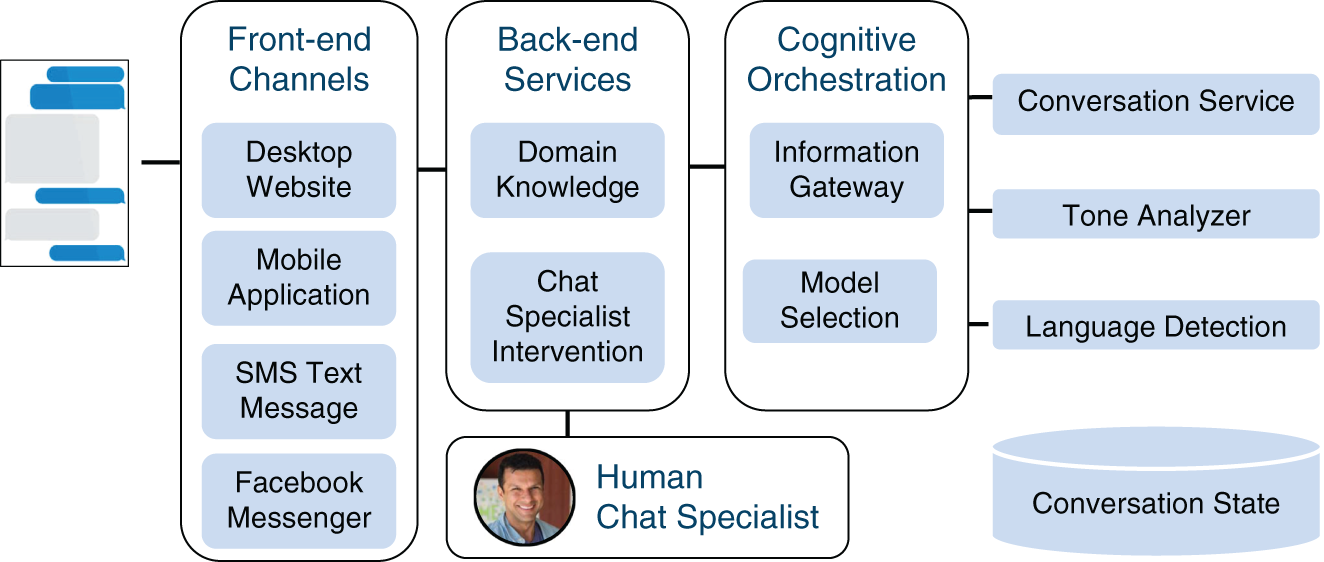
FIGURE 6.4 Sample Chatbot Architecture that Includes a Human in the Loop
Ensure Prototype Technology Scales
After you start to build the rest of your system, it is important to start as early as possible determining whether the technologies are working—not as much in regard to the functionality they provide, since that is likely not to be any different than what you encountered during the prototype phase, but rather if the technology is scaling suitably. With a small number of users or transactions, this is probably going to be a trivial verification. However, as your number of users or transactions per second grows, technology that has poor scalability becomes a deal-breaker.
Load and performance tests are the primary way of testing whether a system is scalable. A load test, at its core, works by simulating a substantial number of virtual users (for this example, let's say 1,000) using the system concurrently. There is no definitive guide as to how many virtual users to include in a load test, but conservatively testing with 20 percent more users than you expect is a good guideline. That means if you expect 1,000 users to be using your system at any given time, you should be testing with 1,200 users in your load test.
Many open source and proprietary tools are available to perform load testing. Some of the open source options are Apache JMeter and The Grinder. On the proprietary side, you will find offerings such as WebLOAD and LoadRunner. Although some of these load testing frameworks have more features than others, all will be able to simulate concurrent users accessing your system.
While accessing the site, specific load testing for each of your AI models is very important. Even though training a model is an order of magnitude more computationally intense than performing a single evaluation of that finished model, allowing thousands of concurrent model evaluations can bog down any unprepared AI system. With this in mind, you should test the production deployments for each of the AI models you have created. This either means writing a custom load testing driver that calls the model or standing up a thin API that simply passes data to a model for evaluation. In this way, your evaluation can ensure your model's scalability, which is potentially the key value of your entire AI system.
Scalability and the Cloud
Some might argue that modern cloud platforms make load testing irrelevant. They assume that the cloud can automatically scale to any load, as needed. Unfortunately, this is not always the case. At the very least, you will need to perform load tests to validate that the cloud scales as expected. You might also find that the cloud scaling is not instantaneous and there is up to three minutes of inaccessibility as it scales to the correct capacity. This happens especially often with workloads that spike or that have a sudden increase and decrease in usage (see Figure 6.5).
The next validation point is to ensure that your system is implemented in such a way that it takes advantage of the cloud scalability. It may be true that the cloud is scalable, but if user information is stuck in a single database instance, then a scaled application layer, though no longer a bottleneck, will still provide slow responses. In this case, the addition of database mirrors or a server-side cache to maintain session data is required. This is also something that may not become apparent until a load test is performed.
Even for machine learning models, there are dedicated clouds that can spawn multiple model instances, as needed, to limit latency. These clouds are relatively new, such as Google's Cloud Machine Learning Engine. For scalability, it is important to determine which parts of your system will likely be a bottleneck using load testing and ensure that those components are designed and deployed accordingly. We will discuss cloud deployments further in the next section.
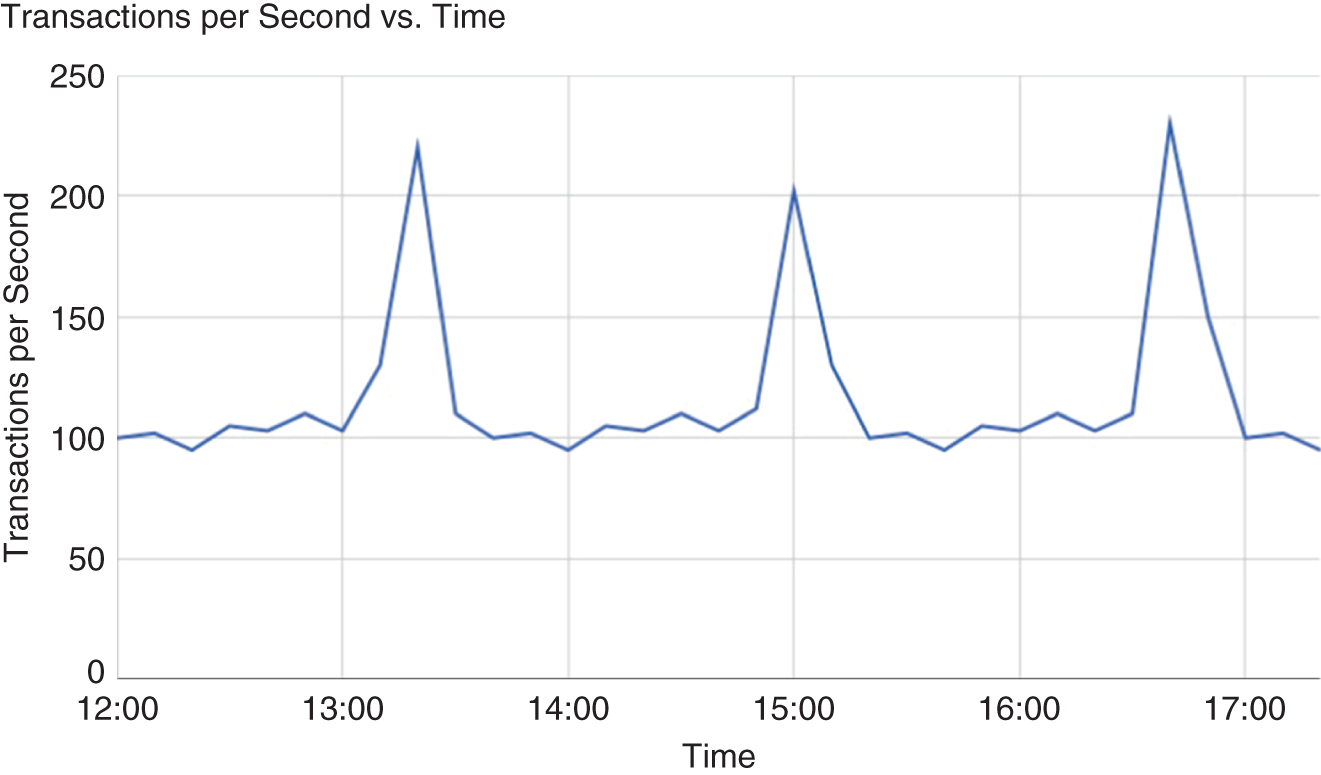
FIGURE 6.5 Example of a Workload that Exhibits Spikes
Cloud Deployment Paradigms
The cloud has morphed over the years, offering a number of deployment patterns. Originally, data centers offered “bare metal,” physical machines that were wholly dedicated to a single user. With the popularization of visualization during the dot-com boom, physical machines were being dynamically carved into smaller, isolated virtual machines (VMs) as requested by cloud customers. This started the design paradigm of only paying for what you used or “pay as you go.” Customers were now able to request the specific amount of storage, RAM, and disk resources they needed, without needing to buy any of the traditional underlying hardware. They could even turn off their virtual machines and incur costs only for the direct storage of their data. This opened the door to drastically reducing hosted computing costs, and this type of on-demand VM deployment gave rise to what is called infrastructure-as-a-service (IaaS).
As time progressed, cloud providers started to innovate further. Since each virtual machine contains an entire copy of an operating system (OS), such as Windows or Linux, a chunk of the VM resources were being consumed just to run the OS. The smaller the VM, the larger the percentage being used for the OS. This was a problem given the increasing trend toward small, dedicated microservices. Instead of using traditional virtualization technology, cloud providers started to turn to another technology called “containers.” Containers are advantageous because they do not have their own OS, but they still have isolated computing resources, which provides security from other containers running on the same computer. Avoiding multiple copies of an OS running on a server may not sound like a huge savings win, but being able to apply the savings across all machines in a data center makes the whole operation more affordable.
One of the more popular container technologies is Docker. It is open source, which has made Docker accessible and somewhat of a de facto standard in the container space. An associated technology named Kubernetes enables the deployment of multiple interconnected containers that can be managed as a single unit. This is powerful because you do not need to manually set up every component in your application. Instead you simply define a pod file which specifies all of the individual containers and their parameters. Then whenever you want to deploy this group of resources you simply provide the pod file to Kubernetes. Pod files can be stored in a version control system and managed similar to code. This is an example of the “infrastructure as code” paradigm where you define your deployment in text files and leverage a framework, such as Kubernetes, to set up the actual computing components. This leads to repeatable infrastructure deployments and the ability to migrate among cloud providers easily if need be.
With all of this great cloud technology, it was only a matter of time before special-purpose AI clouds became available. Traditionally, machine learning models had to be deployed by creating a virtual machine and then installing the model libraries, such as TensorFlow. The situation improved when data centers started providing machines with graphical processing units (GPUs), which greatly improve AI model performance. Today, engineers can simply upload their machine learning model to AI clouds and pay only for the time their model is executing. Google provides such a service, but it's only one of many. This AI deployment paradigm is powerful because it reduces the knowledge required to host AI models. Instead of worrying about model deployment best practices, engineers can focus their time on building the best possible models.
Cloud API's SLA
Assuming your solution will be deployed on the cloud, you will want to understand the available service level agreements (SLAs). An SLA is an agreement between you and the cloud provider for the quality of service you can expect. They will typically specify metrics such as availability, which is how many minutes per month your system can be down. It is important to note that this is not the average expected downtime per month, but rather the worse-case scenario a cloud provider is promising.
Better SLAs will be more expensive, so you will need to determine how much unavailability your application can tolerate. If a cloud provider does not abide by the SLA, consumers typically receive some compensation, such as service credits that can be used for future service. Large outages are uncommon for most modern cloud providers, typically making news since they affect many popular consumer websites.2
Continuing the Feedback Loop
As we discussed in the previous chapter, starting a feedback loop is critical to ensuring that issues are caught early and do not propagate, causing larger issues later. This continues to be true as you build your production system. Regular meetings with stakeholders and end users will continue to be one of the best feedback-generating methods at your disposal. Again, these can be done through the Agile mechanism of sprint reviews.
Pitfalls
Here are some pitfalls you may encounter during production.
Pitfall 1: End Users Resist Adopting the Technology
This pitfall is common with all new technology but especially with AI solutions. Automation technology can be unsettling for end users, since it replaces some of the work they are used to doing themselves. Opinions range from “This technology will just be a hindrance to how I work,” to “It's only a matter of time until my skills are obsolete, the robots take over, and I'm out of a job.” Change is hard, no matter what form it takes.
Another issue with AI solutions in particular is that most AI systems require input from a subject matter expert (SME) to create the ground truth used to train the underlying machine learning models. These SMEs are also typically the ones directly affected by the integration of a new AI solution. For many reasons, it is important that the AI solution be an augment to the SMEs' knowledge and capabilities, instead of a direct replacement of their role. Remember that a machine learning model is only as good as the ground truth used to train it.
To avoid this pitfall, early end user engagement is critical. End users need to be part of the planning process to ensure that they fully understand the solution and feel they have contributed to the end product. This might even mean inviting a few influential end users during the Ideation/Use Case phases to build excitement and a voice for your user base. While early input is in no way a guarantee (end users might think they want one thing at first, only to realize they need something else once they start using the solution), it will help mitigate the fear associated with adopting new technology.
Pitfall 2: Micromanaging the Development Team
Under Agile, the development team is given full responsibility for the successful technical implementation of the project. The team works on the combined values of transparency and mutual trust. In such an environment, it would not be prudent to control every aspect of the development team. Nor would it be a good practice to set the targets for each sprint for the developers. This will lead to a lack of motivation, weakening Agile. The development team should be able to focus on the project by themselves with minimal intervention from the product owner. Some teams pick the Scrum manager from among the dev team as well. This is to ensure that the benefits of Agile are preserved.
Pitfall 3: Not Having the Correct Skills Available
Since building a machine learning system requires a number of specialized skills, it is critical to have these skills available and ready to go before your project starts. Whether this means hiring full-time employees or establishing relationships with contracting firms, it is worth the up-front effort to avoid delays. Skills we have mentioned thus far that will be required include AI, data science, software engineering, and DevOps. The hiring issue is twofold in that you must find the individuals with the proper skillsets for your project and, of course, have the appropriate budget in place to fund them. With these items addressed, there should not be any skill roadblocks in the way of getting your system deployed.
Action Checklist
- ___ Reevaluate user stories to ensure that they are still relevant.
- ___ Establish a continuous integration pipeline with automated tests to ensure system quality.
- ___ Allow the system to involve human intervention as necessary.
- ___ Perform load testing on your system to ensure that it and its components are scalable.
- ___ If your system is deployed in the cloud, review the SLAs and make sure they are sufficient for your user stories.
- ___ Release the live production system to users and begin the feedback lifecycle process.
Notes
- 1
https://github.com/Netflix/chaosmonkey - 2 For an example of an SLA, see the Amazon EC2 SLA at
https://aws.amazon.com/compute/sla/.