
Attentional Mechanisms in Computer Vision
2.1 INTRODUCTION
Biological vision is foveated, highly goal oriented and task dependent. This observation, which is rather clear if we trace the behavior of practically every vertebrate, is now being taken seriously into consideration by the computer vision community. This is evident from recent work on active vision systems and heads (Clark and Ferrier, 1988; Brunnstrome et al., 1992; Crowley, 1991; Rimey and Brown, 1992) and general active vision concepts and algorithms (Aloimonos et al., 1987; Bajcsy, 1988; Aboot and Ahuja, 1988; Ballard, 1990; Culhane and Tsotsos, 1992). One of the fundamental features of active vision is the use of space-variant vision and sensors (Yeshurun and Schwartz, 1989; Tistarelli and Sandini, 1990; Rojer and Schwartz, 1990), that allows, in the case of the log-polar representation, data reduction as well as a certain degree of size and rotation invariance.
The use of such sensors require efficient mechanisms for gaze control, that are, in turn, directed by attentional algorithms. Using psychophysical terms, these algorithms are either overt, analysing in detail the central foveated area, or covert, analysing various regions within the field of view that are not necessarily in the central foveated area.
Like many other issues in computational vision, the attention problem seems to be trapped in the typical top-down bottom-up cycle, as well as in the global-local cycle: global processes are necessarily based on local features and processes, whose crucial parameters, in turn, depend on global estimates. This is the case for recognition tasks, where, for example, thresholds and size tuning of local feature detectors are optimally determined by the model of the object the system expects. In curve and edge detection, local discontinuities are classified as signals or as noise according to global matching based on these very local estimates (Zucker et al., 1989).
Similarly, attention is undoubtedly a concurrent top-down and bottom-up process: computational resources are assigned to regions of interest. But detection of regions of interest is both context dependent (top down), since the system is task oriented, and context free (bottom up), since one of the most important aspects of such a system is detection of unexpected signals. Thus, attention must be based on highly coupled low-level and high-level processes. While we do not offer a solution to this fundamental problem, we describe in this review a number of methodologies that begin this cycle with a low-level attentional mechanism.
Visual processes, in general, and attentional mechanisms, in particular, seem effortless for humans. This introspection, however, is misleading. Psychophysical experiments show that infants (age 1−2 months) tend to fixate around an arbitrary single distinctive feature of the stimulus, like the corner of a triangle (Haith et al., 1977; Salapatek and Kessen, 1973). Moreover, when presented with line drawings, children up to age 3−4 spend most of their time dwelling only on the internal details of a figure, and in general, children make more eye movements and are less likely than adults to look directly at a matching target in their first eye movements (Cohen, 1981). In comparison, adults display a strong tendency to look directly at forms that are informative, unusual, or of particular functional value (Antes, 1974; Loftus and Mackworth, 1978). Thus, it seems that gaze control in adults is indeed task and context dependent, but it is probably based on natal (hardwired) low-level local and context-free attentional mechanisms. At first, only the low-level context-free mechanisms are available. Gradually, as more information regarding the environment is being learned, higher-level processes take their place.
Active vision definitely needs high-level context-dependent attentional algorithms, but these should be adaptive trainable algorithms based on acquired knowledge, that use lower-level context-free attentional modules. Considering the fact that this research area is rather new, robust and efficient low-level attentional algorithms are the basic building blocks for machine visual attention.
2.2 MECHANISMS OF FOVEATION
Foveation in active vision is primarily motivated by biological systems, and thus, it is most natural to imitate the biological vision systems. The diversity of these systems is enormous (Vallerga, 1994), and in fact, every existing implementation of acquisition device has its biological counterpart.
The main approaches that are being used in computer vision for implementing foveation (in the sense of non-uniform resolution across the visual field) are the following:
• A single camera mounted on a moving device. The camera acquires a non-uniformly scanned image that is typically a log-polar one (Rojer and Schwartz, 1990; Biancardi et al., 1993; Yamamoto et al., 1995).
• Two monocular cameras configuration, consisting of a narrow-field-of-view high-resolution one, and a wide-field-of-view low-resolution one. In this configuration, the large field of view is used to received general information on the environment, and the narrow field of view is directed at regions of interest (Dickmanns and Graefe, 1988).
• Omni-directional lens with electronic foveation. In this configuration, a very large field of view is acquired using a fish-eye lens, and the image is projected on a regular CCD device. Once a region of interest is defined, however, the defined region could be sampled in high resolution by electronically correcting the image (Zimmermann and Kuban, 1992).
2.3 ATTENTIONAL MECHANISMS IN COMPUTER VISION
Attention in computer vision systems could be either overt, guiding the gaze, or covert, selecting a ROI within the captured image. In both cases, algorithms that analyse the image and select a region in it should be developed.
The first step in practically every artificial vision system consists of some form of edge detection. This step, which follows in general the early stages of biological systems, leads to the simplest mechanism for selecting ROI – looking for areas with large amount of edges. An early attentional operator based on grey-level variance (Moravec, 1977) is still being widely used in many systems. This operator is closely related to edge-based algorithms, since edges correspond to the variance in grey level. Other researchers suggested to measure busyness – the smoothed absolute value of the Laplacian of the data (Peleg et al., 1987), rapid changes in the grey levels (Sorek and Zeevi, 1988), or smoothness of the grey levels (Milanese et al., 1993). All of these methods try to measure, directly or indirectly, the density of edges, regardless of their spatial configuration.
If spatial relations of edges are to be considered, then, following early psychophysical findings (Attneave, 1954; Kaufman and Richards, 1969), interest points can be regarded also as points of high curvature of the edge map (Lamdan et al., 1988; Yeshurun and Schwartz, 1989). Similarly, one could look for edge junctions (Brunnstrome et al., 1992).
Regions of interest could also be defined by more specific features, or even by specific attributes of objects. Blobs, for example, are usually associated with objects that might attract our attention (Lindberg, 1993). Specific features are looked for in the application of fingerprints identification (Trenkle, 1994), detection of flaws in artificial objects (Magge et al., 1992), and detection of man-made objects (characterized by straight lines and corners) in general images (Lu and Aggarwal, 1993). A method to direct attention to general objects is suggested in Casasent (1993).
Other visual dimensions that could be used as the core of attentional mechanisms are depth, texture, motion and color. Vision systems are either monocular, and then regions of interest could be defined as the regions where focused objects exist, or binocular, and then the horopter and the intersection of the optical axes could be used as the relevant cues (Olson and Lockwood, 1992; Theimer et al., 1992; Coombs and Brown, 1993). Color as an attentional cue is suggested in Draper et al. (1993), and motion in Torr and Murray (1993).
Any attentional mechanism, and especially edge and feature based ones, should also consider the issue of the right scale for search. Since it is impossible to determine this scale in advance, a multi-scale representation should be preferred. This issue is discussed in Lindberg (1993), where existence of image features in multiple scales can enhance the probability of selecting a specific area for detailed analysis.
Most attentional mechanisms for computer vision applications are rather new, and thus their performance on natural images is not well studied and compared. In order to assess the performance of various attentional algorithms, one of the systems that have been recently developed (Baron et al., 1994), includes an attentional module that could be easily interchanged, thus enabling a convenient testbed for benchmarks of such algorithms under the same environmental conditions.
Recently, symmetry has been suggested as a broader concept that generalizes most of the existing context-free methods for detection of interest points. Natural and artificial objects often give rise to the human sensation of symmetry. Our sense of symmetry is so strong that most man-made objects are symmetric, and the Gestalt school considered symmetry as a fundamental principle of perception. Looking around us, we get the immediate impression that practically every interesting area consists of a qualitative and generalized form of symmetry. In computer vision research, symmetry has been suggested as one of the fundamental non-accidental properties, which should guide higher-level processes. This sensation of symmetry is more general than the strict mathematical notion. For instance, a picture of a human face is considered highly symmetric by the layman, although there is no strict reflectional symmetry between both sides of the face.
Symmetry is being widely used in computer vision (Davis, 1977; Nevatia and Binford, 1977; Blum and Nagel, 1978; Brady and Asada, 1984; Atallah, 1985; Bigun, 1988; Marola, 1989; Xia, 1989; Schwarzinger et al., 1992; Zabrodsky et al., 1992). However, it is mainly used as a means of convenient shape representation, characterization, shape simplification, or approximation of objects, which have been already segmented from the background. A schematic (and simplified) vision task consists of edge detection, followed by segmentation, followed by recognition. A symmetry transform is usually applied after the segmentation stage. The symmetry transform suggested by (Reisfeld et al., 1995) is inspired by the intuitive notion of symmetry, and assigns a symmetry magnitude and a symmetry orientation to every pixel in an image at a low-level vision stage which follows edge detection. Specifically, a symmetry map is computed, which is a new kind of an edge map, where the magnitude and orientation of an edge depends on the symmetry associated with the pixel. Based on the magnitude and orientation of the symmetry map, it is possible to compute isotropic symmetry, and radial symmetry, which emphasizes closed contours. Strong symmetry edges are natural interest points, while linked lines are symmetry axes. Since the symmetry transform can be applied immediately after the stage of edge detection, it can be used to direct higher-level processes, such as segmentation and recognition, and can serve as a guide for locating objects.
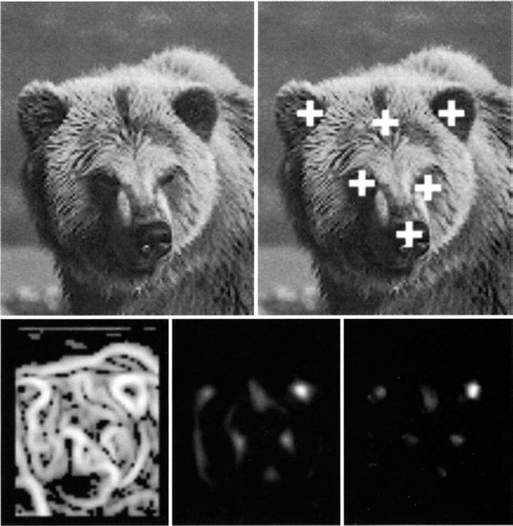
In Figure 2.1 we demonstrate the problem that might arise by using a simple edge-density-based attentional mechanism. In this image, the density of the edge map is high in too many locations, and thus it would be rather a difficult task to detect areas of interest by a simple edge map. However, if the spatial configuration of the edges is considered, as is done by using the generalized symmetry transform, more meaningful regions will be attended to. Operation of the symmetry transform on another natural image (Figure 2.3) is also demonstrated. In this case, other attentional operators might also be useful, since the targets could be detected by considering the blobs in the image. The scale issue could be demonstrated in Figure 2.2. In this image, which is obtained by zooming in on Figure 2.1, we demonstrate that the same algorithm with the same parameters could be used in different scales.

Figure 2.1 Natural image with high edge density. Top: original image and the peaks of the radial symmetry. Bottom (left to right): edge detection, isotropic symmetry and radial symmetry.

2.4 CONCLUSIONS
Machine attention should emerge from low-level mechanisms that detect visual cues at early stages, as well as from mechanisms that detect specific objects. There is however much more to attention than simple context-free mechanisms. As we have argued, attention, like almost every other visual task, is trapped in the local-global, top-down bottom-up, and context-free context-dependent vicious circle. Attention probably requires some assumptions about the environment, since it is the deviation from the expected framework and irregularities that should draw the attention of the system. This point is obviously not easily approached in computer vision, but some attempts to formalize it have been made (Zucker et al., 1975; Gong, 1992).
A possible path to follow should consist of a three-level paradigm:
• A context free direct computation of a set of simple and early mechanisms, like color, motion, edge density or the generalized symmetry.
• An analysis of the geometry of this early map, based on general, and task dependent knowledge.
• A conventional object detection and recognition performed only in locations indexed by the previous stages.
This approach is not necessarily bottom up, as it seems to be on first sight, since the specific set of context-free features used in the lower level could be selected and modified by the higher levels, once a specific task is performed.
The approach could be demonstrated, for example, in the task of detecting persons and facial features in images by using the generalized symmetry transform. First, the context-free generalized symmetry map is computed, and then one might look for a geometric pattern where the symmetry peaks are vertically arranged, below a circular symmetry peak (persons), or three symmetry peaks that form a triangle (facial features). Indexed locations could then be specifically analysed by edge based or intensity based recognition schemes.
Attention is among the most complex psychological phenomena that are being studied (Cantoni et al., 1996), and thus, it is only the first and most superficial aspects of it that are being considered in computer vision. But as we become more and more aware of the usefulness of considering biological approaches in artificial systems, the role of attention there could not be overestimated.
Aboot, A., Ahuja, N., Surface reconstruction by dynamic integration of focus, camera vergence and stereo. Proc. of the 2nd Int. Conf. on Computer Vision, 1988.
Aloimonos, J., Weiss, I., Bandyopadhyay, A. Active vision. Int. Journal of Computer Vision. 1987:334–356.
Antes, J. The time course of picture viewing. Journal of Experimental Psychology. 1974;103:62–70.
Atallah, M. On symmetry detection. IEEE Transactions on Computers. 1985;C-34:663–666.
Attneave, F. Informational aspects of visual perception. Psychological Review. 1954;61:183–193.
(8) Bajcsy, R., Active perception. Proceedings of the IEEE. 1988;76:996–1006.
Ballard, D., Animated vision. Technical Report TR 61. University of Rochester, Department of Computer Science, 1990..
Baron, T., Levine, M., Yeshurun, Y., Exploring with a foveated robot eye system. Proc. 12th IAPR Int. Conf. on Pattern Recognition. 1994:377–380.
Biancardi, A., Cantoni, V., Lombardi, L. Computer vision systems: functionality and structure integration. In: Roberto V., ed. Intelligent perceptual systems. Berlin, Germany: Springer-Verlag; 1993:70–83.
Bigun, J. Pattern recognition by detection of local symmetries. In: Gelsema E., Kanal L., eds. Pattern recognition and artificial intelligence. Amsterdam, The Netherlands: Elsevier North Holland; 1988:75–90.
Blum, H., Nagel, R. Shape description using weighted symmetric axis features. Pattern Recognition. 1978;10:167–180.
Brady, M., Asada, H. Smoothed local symmetries and their implementation. The Int. Journal of Robotics Research. 1984;3(3):36–61.
Brunnstrome, K., Lindeberg, T., Eklundh, J., Active detection and classification of junctions by foveation with a head-eye system guided by the scale-space primal sketch. Proc. of the 2nd Eur. Conf. on Computer Vision. S. Margherita, Italy, 1992:701–709.
this volume] Cantoni, V., Caputo, G., Lombardi, L., Attentional engagement in vision systems, 1996.
Casasent, D., Sequential and fused optical filters for clutter reduction and detection. Proceedings of the SPIE 1959. 1993:2–11.
Clark, J., Ferrier, N., Modal control of an attentive vision system. Proc. of the 2nd Int. Conf. on Computer Vision. 1988:514–519.
Cohen, K. The development of strategies of visual search, in eye movements. In: Fisher D., Monty R., Senders J., eds. Cognition and visual perception. Hillsdale, NJ: Erlbaum; 1981:299–314.
Coombs, D., Brown, C. Real-time binocular smooth pursuit. Int. Journal of Computer Vision. 1993;11:147–164.
Crowley, J., Towards continuously operating integrated vision systems for robotics applications. Proc. SCIA-91, 7th Scandinavian Conf. on Image Analysis. Aalborg, Denmark. 1991.
Culhane, S., Tsotsos, J., An attentional prototype for early vision. Proc. of the 2nd Eur. Conf. on Computer Vision. S. Margherita, Italy, 1992:551–560.
Davis, L. Understanding shape: I. Symmetry. IEEE Trans. on Systems, Man, and Cybernetics. 1977:204–211.
Dickmanns, E., Graefe, V. Applications of dynamic monocular machine vision. Machine Vision and Applications. 1988;1:241–261.
Draper, B.A., Buluswar, S., Hanson, A.R., Riseman, E.M., Information acquisition and fusion in the mobile perception laboratory. Proceedings of the SPIE 2059. 1993:175–187.
Gong, S., Visual behaviour: modelling ‘hidden’ purposes in motion. Proceedings of the SPIE 1766. 1992:583–593.
Haith, M., Bergman, T., Moore, M. Eye contact and face scanning in early infancy. Science. 1977;198:853–855.
Kaufman, L., Richards, W. Spontaneous fixation tendencies for visual forms. Perception and Psychophysics. 1969;5(2):85–88.
Lamdan, Y., Schwartz, J., Wolfson, H., On recognition of 3-d objects from 2-d images. Proc. of IEEE Int. Conf. on Robotics and Automation. 1988:1407–1413.
Lindberg, T. Detecting salient blob-like image structures and their scales with a scale-space primal sketch: a method for focus-of-attention. Int. Journal of Computer Vision. 1993;11:283–318.
Loftus, G., Mackworth, N. Cognitive determinants of fixation location during picture viewing. Human Perception and Performance. 1978;4:565–572.
Lu, H., Aggarwal, J. Applying perceptual organization to the detection of man-made objects in non-urban scenes. Pattern Recognition. 1993;25:835–853.
Magge, M., Seida, S., Franke, E., Identification of flaws in metallic surfaces using specular and diffuse bispectral light sources. Proceedings of the SPIE 1825. 1992:455–468.
Marola, G. On the detection of the axis of symmetry of symmetric and almost symmetric planar images. IEEE Trans. Pattern Analysis and Machine Intelligence. 1989;11(1):104–108.
Milanese, R., Pun, T., Wechsler, H. A non-linear integration process for the selection of visual information. In: Roberto V., ed. Intelligent perceptual systems. Berlin, Germany: Springer-Verlag; 1993:322–336.
Moravec, H., Towards automatic visual obstacle avoidance. Proc. of IJCAI. 1977:584–590.
Nevatia, R., Binford, T. Description and recognition of curved objects. Artificial Intelligence. 1977;8:77–98.
Olson, T.J., Lockwood, R.J., Fixation-based filtering. Proceedings of the SPIE 1825. 1992:685–695.
Peleg, S., Federbush, O., Hummel, R. Custom made pyramids. In: Uhr L., ed. Parallel computer vision. New York, NY: Academic Press; 1987:125–146.
special issue on qualitative vision Reisfeld, D., Wolfson, H., Yeshurun, Y. Context free attentional operators: the generalized symmetry transform. Int. Journal of Computer Vision. 1995;14:119–130.
Rimey, R., Brown, C., Where to look next using a Bayes net: incorporating geometric relations. Proc. of the 2nd Eur. Conf. on Computer Vision. S. Margherita, Italy, 1992:542–550.
Rojer, A., Schwartz, E., Design considerations for a space-variant visual sensor with complex logarithmic geometry. Proc. of the 10th IAPR Int. Conf. on Pattern Recognition. 1990:278–285.
Salapatek, P., Kessen, W. Prolonged investigation of a plane geometric triangle by the human newborn. Journal of Experimental Child Psychology. 1973;15:22–29.
Schwarzinger, M., Zielke, T., Noll, D., Brauckmann, M., von Seelen, W., Vision-based car following: detection, tracking, and identification. Proc. of the IEEE Intelligent Vehicles ′92 Symp., 1992:24–29.
Sorek, N., Zeevi, Y., Online visual data compression along a one-dimensional scan. Proceedings of the SPIE 1001. 1988:764–770.
Theimer, W.M., Mallot, H.A., Tolg, S., Phase method for binocular vergence control and depth reconstruction. Proceedings of the SPIE 1826. 1992:76–87.
Tistarelli, M., Sandini, G. Estimation of depth from motion using an anthropomorphic visual sensor. Image and Vision Computing. 1990;8(4):271–278.
Torr, P., Murray, D. Statistical detection of independent movement from a moving camera. Image and Vision Computing. 1993;11:180–187.
Trenkle, J.M., Region of interest detection for fingerprint classification. Proceedings of the SPIE 2103. 1994:48–59.
Vallerga, S. The phylogenetic evolution of the visual system. In: Cantoni V., ed. Human and machine vision: analogies and divergencies. New York, NY: Plenum Press; 1994:1–13.
Xia, Y. Skeletonization via the realization of the fire front’s propagation and extinction in digital binary shapes. IEEE Trans. Pattern Analysis and Machine Intelligence. 1989;11(10):1076–1089.
in press Yamamoto, H., Yeshurun, Y., Levine, M. An active foveated vision system: attentional mechanisms and scan path convergence measures. Journal of Computer Vision, Graphics and Image Processing. 1995.
Yeshurun, Y., Schwartz, E. Shape description with a space-variant sensor: algorithm for scan-path, fusion, and convergence over multiple scans. IEEE Trans. Pattern Analysis and Machine Intelligence. 1989;11(11):1217–1222.
Zabrodsky, H., Peleg, S., Avnir, D., A measure of symmetry based on shape similarity. Proc. CVPR. Urbana, Illinois. 1992.
Zimmermann, S., Kuban, D., A video pan/tilt/magnify/rotate system with no moving parts. Proc. IEEE-AIAA 11th Digital Avionics Systems. 1992:523–531.
Zucker, S., Rosenfeld, A., Davis, L., General purpose models: expectations about the unexpected. Proc. of the 4th IJCAI. 1975:716–721.
Zucker, S., Dobbins, A., Iverson, L. Two stages of curve detection suggest two styles of visual computation. Neural Computation. 1989;1:68–81.