
This chapter digs into the details of the programming mistakes that lead to exploits. If you don’t have any programming experience, you might find some of this material challenging, but most of the chapter will be accessible. The chapter does assume that you’re familiar with basic programming concepts.
This chapter is not about how to create your own exploits. There are quite enough people out there writing exploits, and there is plenty of information about how to do it. Even so, writing stable exploits that don’t blow up is difficult. Because more and more software is compiled using countermeasures such as stack tampering protection, more and more attacks that previously led to escalation of privilege are turning into denial of service attacks. This chapter helps you understand the mechanisms behind some of the exploits you might see, and helps you fix problems when you find buffer overruns on your own network.
More Info
If you are a programmer and would like more information about how to write programs that protect you from attacks, take a look at Writing Secure Code, Second Edition (Microsoft Press, 2003), by Michael Howard and David LeBlanc. For more detailed information about integer overflows and the SafeInt C++ class designed to prevent arithmetic errors, see http://msdn.microsoft.com/library/default.asp?url=/library/en-us/dncode/html/secure01142004.asp.
Some penetration testers are able to write custom exploits on demand to allow them to exploit enterprise software; however, testers who have this skill set are very rare. As with many other things, if the good guys can do it, so can the bad guys. If you find a buffer overrun in a piece of custom software running on your network, it is as potentially exploitable as a buffer overrun in more common software. See to it that these problems are fixed, and fixed correctly. If the programmer wants you to prove the buffer overrun is exploitable, ask him to prove it is not.
Tip
You usually can’t prove that something isn’t exploitable—only that you do not know how to exploit it. Just fixing the problem is almost always less work than trying to show whether the software is exploitable.
A buffer is an array of bytes in a program’s memory space. In its simplest form, it is an array of characters, and in the C and C++ programming languages (and most others that run on a PC), an ordinary character is 1 byte. You could have a buffer composed of other types—for example, a buffer that holds 32-bit integers would allow 4 bytes per element. In the C language, the first element of a buffer is element 0; in BASIC and several other languages, the first element is 1. Here’s an example:
Element | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 |
Value | H | e | l | l | o | ’ ’ | W | o | r | L | d | ’�’ |
The value held in this buffer is known as a string—an array of characters, terminated with a null character so that programs know where the end of the string is.
Buffers can be stored in two places. The most common place to store small buffers is on the stack. In a C or C++ program, these buffers would be known as local variables. Sometimes, they are known as a statically allocated buffers, though the word "static" has a special meaning, and "static" isn’t a precise definition for this type of buffer. Another place that buffers can be stored is on the heap. The heap is where memory is dynamically allocated. If an application calls malloc (which stands for memory allocate), the operating system creates the desired space—if it is available. The stack and the heap hold more information than just buffers; when an application writes more data into a buffer than will fit, the other data in the application is affected. For example, in the preceding table, if you copied "Welcome to Planet Earth" into the 11-byte buffer that holds "Hello World," you’d end up copying 12 bytes more than fit into the buffer and overwrite neighboring data.
A stack is a place that an application uses to store local data, function arguments, return addresses, and registers. The stack can be arranged in several different ways depending on how the compiler converts higher-level languages to assembly code, and even on how a compiler’s options are set. For now, let’s stick to how a simple C program works.
For historical reasons, the stack grows down; it starts at a fixed value (say, address 0x0012FF00) and then allocates local variables and pushes parameters into lower addresses. Obviously, this can lead to the problem of running out of stack space, causing the program to abort. You won’t normally run out of stack space unless the programmer has allocated a lot of data on the stack or there are a lot of function calls. One way to run out of stack space is by using recursion without limits. Recursion occurs when a function calls itself internally. A bigger problem is that if someone can overwrite a buffer, he can then overwrite important information. Let’s say I have a function named foo that that takes two parameters and then allocates a buffer on the stack. Figure 17-1 shows what the stack looks like inside the foo function.

A stack can be more complicated than the stack shown in Figure 17-1. Under some circumstances, the value in the EBP register can be stored on the stack between the buffer and the return address. How EBP is stored will turn out to be important later. If a compiler is used that supports return address checking, a value known as a canary is inserted between the local variables and the return address. If you’re looking at the stack in a debug build, things will look a little different because the compiler adds checks to try to find problems for you. Figure 17-2 shows what happens when the local buffer is overrun.

If the buffer is overwritten with user-supplied data, the attacker now controls a number of interesting parameters. Your first problem is that the attacker controls the return address, or he controls the address of the next instruction the application will try to execute once it is done with the current function. A common approach is to cause the application to jump into instructions contained in the data that you supplied.
A slightly more sophisticated attack would involve a jump into another user-supplied buffer. There is a minimum practical size for exploit code, often known as an "egg" or shell code, because the most common attack is to get the victim application to give the attacker a command shell. If an overrun occurs in a small number of bytes, it might not look practical to write an exploit, but one way around the problem is to place the shell in a larger buffer that you don’t overrun, and then trigger a jump into the larger buffer. Just because the buffer is small doesn’t mean you’re safe. Even when the local buffer is small, if the overrun is unbounded, the attacker can write the shell code nearly as far as she wants into the stack, and then jump into the overwritten area.
Your second problem is that the attacker now controls the arguments passed into the function. If the arguments are pointers, or the addresses of other parameters or buffers further up the stack, and the function writes to those addresses after the buffer is overrun, even more mischief can occur.
A variant on a stack overrun doesn’t involve overwriting the return address. Depending on compiler options and how the function looks to the compiler, a CPU register value might get placed on the stack between the buffer and the return address. Forgetting that the storage needed for a string is one more than the number of characters in the string is a fairly common programming problem. For example, "Hello World" is 11 characters long, but with the terminating null (0) character, the string needs 12 bytes-worth of storage. So now you can have a buffer that’s overwritten by exactly 1 byte.
A 1-byte overflow doesn’t seem exploitable, but it is. And the exploit seems like it would be difficult, but it is actually fairly easy. The value stored in the register gets truncated by 1 byte. For example, 0x0012ffc0 becomes 0x0012ff00. This means that when the function that called this function returns, the flow of execution will be redirected to the address in the truncated value, not where it is supposed to. There are only two prerequisites for making an off-by-one overflow exploitable: the buffer size in bytes is divisible by four; and either the buffer is large enough to allow you to control the data in which the flow execution will land or there’s another buffer that you do control at that location. You can also overwrite other registers stored on the stack and turn that into an exploit.
What this boils down to is that if you can make an application blow up by giving it "malformed" input, a clever-enough person with exploit writing experience can frequently turn it into an exploit. One way to test for this is to feed a program a long string like "AAAAAAA" (but usually much longer). If the program says that it cannot execute the instruction at 0x41414141, you have a classically exploitable stack overrun. If the programmer tries to tell you that a buffer overrun isn’t exploitable, tell her that code that blows up isn’t acceptable and to go fix the bugs.
Some programmers think that when a buffer is allocated dynamically on the heap using a function call such as malloc, overrunning the buffer won’t be exploitable. They’re wrong about this.
The buffer overrun that led to the Blaster worm was a heap overflow. If you go to any vulnerability archive such as http://www.securityfocus.com, http://cve.mitre.org, or a vendor’s security site such as http://www.microsoft.com/technet/security, and search on heap buffer overflow, you end up with a number of hits. The people who write the exploits are doing more research to figure out ways to make heap overrun exploits more reliable, and the vendors are also trying to make memory managers more resistant to heap overruns. Both sides will probably make some progress. Exactly how to exploit a heap overrun is a fairly arcane topic, and the details vary depending on the operating system and version, and also sometimes on the application. Some applications implement their own memory management. The diagram in Figure 17-3 shows how many memory managers basically work.

From an attacker’s standpoint, there are a couple of ways to take advantage of the problem. The first and most obvious issue is that data in the adjoining buffer might be important. If the information in the next buffer includes the addresses of one or more functions, overwriting the buffer might be enough to cause the program to do what the attacker wants. The second way to create an attack is to get the heap manager to move the memory around for you. The metadata contains the size of this buffer, the size of the next buffer, and flags to let the memory manager know whether the buffer is in use, and other information of interest to the memory manager. When the buffer isn’t needed any longer, the application de-allocates, or frees, the buffer. During this process, the memory manager determines where the previous and next free buffers are located and writes the addresses into what was previously the beginning of the buffer. Figure 17-4 shows a diagram of a de-allocated heap buffer.

If the attacker can overwrite the metadata for the next buffer, when the memory manager de-allocates the buffer, the memory manager can be tricked into writing 4 bytes of attacker-supplied data nearly anywhere in the application’s memory space. One of the most likely pieces of memory to attack would be a function’s return address, though there are many other portions of the application where 4 bytes could do as much damage.
A similar attack can be launched when a buffer is freed twice, and the attacker can either write directly into that buffer or the previous buffer between the first de-allocation and the second.
In programs written in C or C++, the printf family of functions is frequently used to write the output to the user. A common usage might be:
printf("Could not open file %s - error = %d
", filename, err);In this example, the printf function takes the filename passed in and inserts it in place of the %s, and replaces the %d with the error number. The results might look like Could not open file c: empfoo.ini - error = 2, which tells us that C:TempFoo.ini was not found.
A number of format specifiers are available to the printf family of functions, and one of the most interesting is the %n specifier, which writes the number of bytes that should have been written to a certain point into the address provided to the function. How does an attacker give you format specifiers? Good question: this happens when you have a lazy programmer. Take a look at two ways to do the same thing:
printf("%s
", userinput); //this is the way it should be done
printf(userinput); //this will get your program compromisedThe first example isn’t vulnerable. Here are the results from a sample application and an example of benign input:
E: emp>format_string.exe "Hello World" Hello World Hello World
Now let’s see what happens if I start passing in some more interesting strings:
E: emp>format_string.exe "%x%x%x" %x%x%x 12ffc040110f2
You have some interesting differences in the output—%x returns numbers in hexadecimal (base 16) format. You are probably wondering just where the numbers came from. The printf function doesn’t know how many parameters were passed to it, and it operates on whatever data happened to be on the stack when it was called. If the number of format specifiers match the number of arguments, everything is fine. If there were no arguments and the attacker is supplying the data, the application will tell the attacker what’s on the stack. Nearly all the format specifiers just read data, but the %n specifier allows you to write data. If I invoke my sample application with:
E: emp>format_string.exe "%x%x%n"
I get:
%x%x%n
Followed by the error message shown in Figure 17-5.
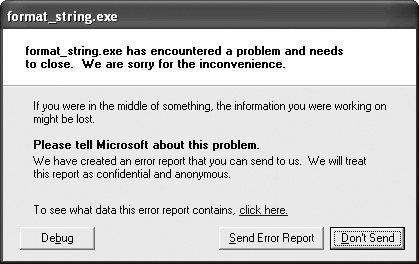
To test for format string problems, throw a few %x or %p specifiers into user input. If the specifiers are repeated back to you intact, you don’t have a problem. If you get back a bunch of numbers, you’ve found a problem.
The best countermeasure against buffer overruns is to be careful when writing a program that accepts user input, especially from the network.
More Info
One of the best books on writing robust code is Writing Solid Code: Microsoft’s Techniques for Developing Bug-Free C Programs, by Steve Maguire (Microsoft Press, 1993). Solid code typically doesn’t have the coding mistakes that lead to security problems. A second resource is Writing Secure Code, Second Edition. Writing Secure Code spends nearly 800 pages on how to write secure applications and covers secure design principles, much more information on buffer overruns than is presented here, and security testing information.
Many operating systems and compilers also offer various levels of countermeasures against buffer overruns. All these countermeasures are capable of converting some exploitable conditions into denial of service attacks. No known buffer overrun countermeasure can completely save you once you allow an attacker to write into memory he shouldn’t have. Look at it this way: ABS brakes, seatbelts, and airbags can save your life if you happen to be involved in an accident, but you don’t see anyone who has all these countermeasures in place thinking it is OK to run around having accidents. It’s good to use all the available countermeasures, but doing so doesn’t mean that you can create sloppy code and maintain security.
Another countermeasure is to write applications in managed code. Managed code makes buffer overruns extremely difficult to encounter. Though theoretically impossible, managed code can call into unmanaged code, and overruns can occur inside the unmanaged code. Remember that managed code does not prevent you from making other types of security mistakes, and you might have performance reasons to write unmanaged code.
Computers are not quite as smart about numbers as you might think. There are two types of numbers: integers and floating point numbers. Floating point numbers have a fixed number of digits allowed for accuracy, and a fixed number of digits for the exponent. Floating point numbers might be more familiar to you as scientific notation. An example of a floating point number is 1.3 × 104, which is the same as 13,000. Integers can represent only whole numbers—that is, 1, 2, or 3, but not 3.1428 (pi). The computer represents integers in binary, and the value’s range is specified by the number of bits. You can also have signed or unsigned integers. For example, an 8-bit signed integer can range from –128 through 127, and an 8-bit unsigned integer can range from 0 through 255. Let’s take a look at what happens when you add 255 + 2:
11111111 (255 in binary) 00000010 (2 in binary) -------- 100000001
As you can see, you need 9 bits to represent the result. What the computer will do with this calculation is truncate the result back down to 8 bits, so you end up with 255 + 2 = 1. Similar problems happen when you subtract, multiply, and divide integers. Division of signed numbers is interesting, because the largest negative number always has a magnitude of one larger than the largest positive number. So –(–128) can’t be represented.
More Info
There’s a lot more to the problem than this. For a recent paper explaining integer overflows in detail, see http://msdn.microsoft.com/library/default.asp?url=/library/en-us/dncode/html/secure01142004.asp.
If the code is written in C++, a SafeInt class is also presented that will mitigate the problem.
OK, so this is all very interesting, but how is it going to get you hacked? A classic example is that your application figures out how much room is needed by taking the length of the string and adding 1. Suppose a 16-bit unsigned integer is used to store the length of the string—64k ought to be enough for anybody, right? The attacker then passes you a string that is 65,535 characters long; you add one and get zero. You then proceed to ask the heap manager for zero bytes, and it cheerfully gives you back a pointer to the heap, and so you write 64k of attack-supplied data right into your buffer, writing over all sorts of things along the way.
Other examples of logic errors because of integer handling problems exist. An old problem with Network File System (NFS) involved the user ID allowing the use of 32 bits at the network level. Most systems had 16-bit user IDs. So the program tested to see whether your user ID was zero, which represented the root user. The attacker would pass in something that looked like 0xd00d0000, and the program would later just drop the upper 16 bits, leaving zero. Later checks assumed that you were root, giving the attacker full access to the resources shared by NFS.
Like buffer overflows, integer overflows should be mitigated by writing solid code in the first place. If you’re writing managed code, the checked keyword can insert integer overflow checks, and the /checked+ compiler option can cause all code outside of a checked or unchecked block to check for integer overflows. If you’re writing C++, the SafeInt class can simplify the problem quite a bit.
You can find buffer overruns by injecting overly long data into applications, especially from the network. For example, a POP3 server expects a 4-character command, followed by a space and, depending on the command, another argument. Here’s an example:
POP3 Server ready USER username +OK PASS OpenSesame +OK
If the user name and password are correct, you’re logged on. You might test the POP3 server by making the command very long, such as "USER-AAAAA[more A’s here]AAA". You could also try giving it a large number of spaces, or no spaces. Make the user name very long. You can sometimes encounter code for which an external check places limits on input larger than the limits further down in the application. You might find that when the total string length is larger than 256 characters, the server just returns—ERR, but when you feed in a user name that is 160 characters, the POP3 server aborts the connection (which means the POP3 server might be vulnerable). Try input lengths that are multiples of 2, and one more or one less than multiples of two.
You might also find buffer overruns by accident. Your scanning software might have a very long input designed to test for a particular server yet trigger an exploitable overflow in another server. I’ve seen this happen in two cases: one was with a POP3 server, and the other was with a Web interface to a network sniffer agent.
Q. | I found a buffer overrun, but the programmer doesn’t want to fix it unless I can prove it is exploitable. What do I do now? |
A. | At the very least, you’ve found a denial of service attack. Let the programmer know that unreliable code isn’t welcome and that she should fix it because it could crash. |
Q. | That didn’t work. She still won’t fix it. Now what? |
A. | Escalate the problem to her management. Another approach that can work in some environments is to have the security group ban the software from your network. This is a drastic measure, but it might be warranted. |
Q. | What else can I do? |
A. | Find a different programmer to supply your custom software. |
Q. | Is there something less drastic? |
A. | You could buy the programmer a copy of Writing Secure Code and tell her that Chapter 5 is especially interesting. |
Q. | Any other approaches? |
A. | Find her test system. Create a script that checks whether the test server is running, then crash the application. If the application automatically restarts, crash it as soon as it comes back up. Before you do something like this, let your boss know that you’re about to disrupt things and why. If you want to be really rotten about it, crash the server at random intervals one day. It probably won’t take long for that programmer to get the message. |