
Chapter 3 introduced the foundational elements in the Spark SQL module, including the core abstraction, structured operations for manipulating structured data, and various supported data sources to read data from and write data to. Building on top of that foundation, this chapter covers some of the advanced capabilities in the Spark SQL module and peeks behind the curtain to understand the optimization and execution efficiency that the Catalyst optimizer and Tungsten engine provide. To help you with performing complex analytics, Spark SQL provides a set of powerful and flexible aggregation capabilities, the ability to join with multiple datasets, a large set of built-in and high-performant functions, an easy way to write your own custom function, and a set of advanced analytic functions. This chapter covers each of these topics in detail.
Aggregations
Treat a DataFrame as one group.
Divide a DataFrame into multiple groups using one or more columns and perform one or more aggregations on each group.
Divide a DataFrame into multiple windows and perform moving average, cumulative sum, or ranking. If a window is based on time, the aggregations can be done per tumbling or sliding windows.
Aggregation Functions
In Spark, all aggregations are done via functions. The aggregation functions are designed to perform aggregation on a set of rows, whether rows consist of all the rows or a subgroup of rows in a DataFrame. The documentation of the complete list of aggregation functions for the Scala language is available at http://spark.apache.org/docs/latest/api/scala/index.html#org.apache.spark.sql.functions$. For the Spark Python APIs, sometimes there are some gaps in the availability of some functions.
Common Aggregation Functions
Commonly Used Aggregation Functions
Operation | Description |
|---|---|
count(col) | Return the number of items per group. |
countDistinct(col) | Return the unique number of items per group. |
approx_count_distinct(col) | Return the approximate number of unique items per group. |
min(col) | Return the minimum value of the given column per group. |
max(col) | Return the maximum value of the given column per group. |
sum(col) | Return the sum of the values in the given column per group. |
sumDistinct(col) | Return the sum of the distinct values of the given column per group. |
avg(col) | Return the average of the values of the given column per group. |
skewness(col) | Return the skewness of the distribution of the values of the given column per group. |
kurtosis(col) | Return the kurtosis of the distribution of the values of the given column per group. |
variance(col) | Return the unbiased variance of the values of the given column per group. |
stddev(col) | Return the standard deviation of the values of the given column per group. |
collect_list(col) | Return a collection of values of the given column. The returned collection may contain duplicate values. |
collect_set(col) | Return a collection of unique values of the given column. |
Create a DataFrame from Reading Flight Summary Dataset
Each row represents the flights from the origin_airport to dest_airport. The count column has the number of flights.
All the aggregation examples below are performing aggregation at the entire DataFrame level. Examples of performing aggregations at the subgroups level are given later in the chapter.
count(col)
Computing the Count for Two Columns in the flight_summary DataFrame
Counting Items with Null Value
The output table confirms that the count(col) function doesn’t include null the in the final count.
countDistinct(col)
This function does what it sounds like. It only counts the unique items per group. Listing 4-4 shows the differences in the count result between the countDistinct function and the count function . As it turns out, there are 322 unique airports in the flight_summary dataset.
Counting Unique Items in a Group
Counting the exact number of unique items in each group in a very large dataset is an expensive and time-consuming. In some use cases, it is sufficient to have an approximate unique count. One of those use cases is in the online advertising business, where there are hundreds of millions of ad impressions per hour. There is a need to generate a report on the number of unique visitors per certain type of member segment. Approximating a count of distinct items is a well-known problem in computer science. It is also known as the cardinality estimation problem .
Counting Unique Items in a Group
min(col), max(col)
Get the Minimum and Maximum Values of the Count Column
sum(col)
Using sum Function to Sum up the Count Values
sumDistinct(col)
Using sumDistinct Function to Sum up the Distinct Count Values
avg(col)
Computing the Average Value of the Count Column Using Two Different Ways
skewness(col), kurtosis(col)

Negative and positive skew examples from https://en.wikipedia.org/wiki/Skewness
Compute the Skewness and Kurtosis of Column Count
The result suggests the distribution of the counts is not symmetric, and the right tail is longer or fatter than the left tail. The kurtosis value suggests that the distribution curve is pointy.
variance(col), stddev(col)

Example of samples from two population from https://en.wikipedia.org/wiki/Variance
Compute the Variance and Standard Deviation Using variance and sttdev Functions
It looks like the count values are pretty spread out in flight_summary DataFrame.
Aggregation with Grouping
This section covers aggregation with the grouping of one or more columns. The aggregations are usually performed on datasets that contain one or more categorical columns, which have low cardinality. Examples of categorical values are gender, age, city name, or country name. The aggregation is done through functions similar to the ones mentioned earlier. However, instead of performing aggregation on the global group in the DataFrame, they perform the aggregation on each subgroup.
Grouping by origin_airport and Perform Count Aggregation
Listing 4-12 shows the flights out of Melbourne International Airport (Florida) go to only one other airport. However, the flights out of the Kahului Airport land at one of 18 other airports.
Grouping by origin_state and origin_city and Perform Count Aggregation
In addition to grouping by two columns, the statement filters the rows to only the ones with a “CA” state. The orderBy transformation makes it easy to identify which city has the greatest number of destination airports. It makes sense that both San Francisco and Los Angeles in California have the largest number of destination airports that one can fly to.
The RelationalGroupedDataset class provides a standard set of aggregation functions that you can use to apply to each subgroup. They are avg(cols), count(), mean(cols), min(cols), max(cols), sum(cols). Except for the count() function, all the remaining ones operate on numeric columns.
Multiple Aggregations per Group
Multiple Aggregations After a Group by of origin_airport
By default, the aggregation column name is the aggregation expression, making the column name a bit long and difficult to refer to. Therefore, a common pattern is to use the Column.as function to rename the column to something more suitable.
Specifying Multiple Aggregations Using a Key-Value Map
The result is the same as the one from Listing 4-14. Notice there isn’t an easy to rename the aggregation result column name. One advantage this approach has over the first one is the map can programmatically be generated. When writing production ETL jobs or performing exploratory analysis, the first approach is used more often than the second one.
Collection Group Values
Using collection_list to Collect High Traffic Destination Cities Per Origin State
Aggregation with Pivoting
Pivoting is a way to summarize the data by specifying one of the categorical columns and then performing aggregations on other columns so that the categorical values are transposed from rows into individual columns. Another way of thinking about pivoting is that it is a way to translate rows into columns while applying one or more aggregations. This technique is commonly used in data analysis or reporting. The pivoting process starts with grouping one or more columns, pivots on a column, and finally ends with applying one or more aggregations on one or more columns.
Pivoting on a Small Dataset
Multiple Aggregations After Pivoting
The number of columns added after the group columns in the result table is the product of the number of unique values of the pivot column and the number of aggregations.
Selecting Values of Pivoting Column to Generate the Aggregations For
Specifying a list of distinct values for the pivot column speeds up the pivoting process. Otherwise, Spark spends some effort in figuring out a list of distinct values on its own.
Joins
To perform any kind of complex and interesting data analysis or manipulations, you often need to bring together the data from multiple datasets through the process of joining. This is a well-known technique in SQL parlance. Performing a join combines the columns of two datasets (could be different or same), and the combined dataset contains columns from both sides. This enables you to further analyze the combined dataset so that it is not possible with each set. Let’s take an example of the two datasets from an online e-commerce company. One represents the transactional data that contains information about which customers purchased what products (a.k.a. fact table). The other one represents the information on each customer (a.k.a. dimension table). By joining these two datasets, you can extract insights about which products are more popular with certain segments of customers in terms of age or location.
This section covers how to perform joining in Spark SQL using the join transformation and the various types of join it supports. The last portion of this section describes how Spark SQL internally performs the joining.
In the world of performing data analysis using SQL, a join is a technique used quite often. If you are new to SQL, it is highly recommended that you learn the fundamental concepts and the different kinds of join at https://en.wikipedia.org/wiki/Join_(SQL). A few tutorials about joins are provided at www.w3schools.com/sql/sql_join.asp.
Join Expression and Join Types
Join Types
Type | Description |
|---|---|
Inner join (a.k.a. equi-join) | Return rows from both datasets when the join expression evaluates to true. |
Left outer join | Return rows from the left dataset even when the join expression evaluates as false. |
Right outer join | Return rows from the right dataset even when the join expression evaluates as false. |
Outer join | Return rows from both datasets even when the join expression evaluates as false. |
Left anti-join | Return rows only from the left dataset when the join expression evaluates as false. |
Left semi-join | Return rows only from the left dataset when the join expression evaluates to true. |
Cross (a.k.a. Cartesian) | Return rows by combining each row from the left dataset with each row in the right dataset. The number of rows is a product of the size of each dataset. |
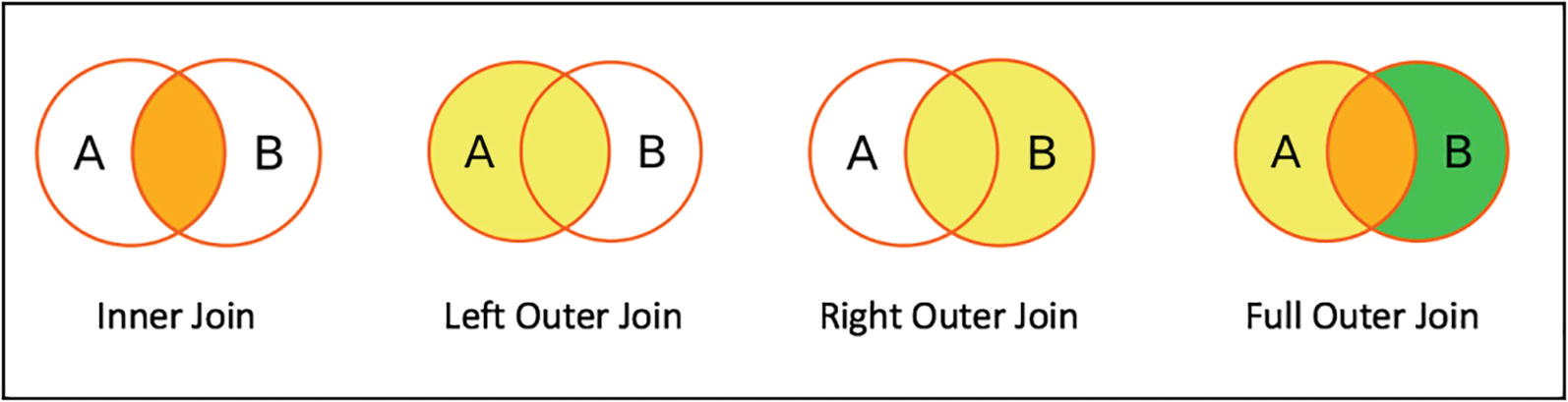
Venn diagrams for common join types
Working with Joins
Creating Two Small DataFrames to Use in the Following Join Type Examples
Inner Joins
Performing Inner Join by the Department ID
As expected, the joined dataset contains only the rows with matching department IDs from both employee and department datasets and the columns from both datasets. The output tells you exactly which department each employee belongs to.
Different Ways of Expressing a Join Expression
Join expression is simply a Boolean predicate, and therefore it can be as simple as comparing two columns or as complex as chaining multiple logical comparisons of pairs of columns .
Left Outer Joins
Performing a Left Outer Join
As expected, the marketing department doesn’t have any matching rows from the employee dataset. The joined dataset tells you the department that an employee is assigned to and which departments have no employees .
Right Outer Joins
Performing a Right Outer Join
As expected, the marketing department doesn’t have any match rows from the employee dataset. The joined dataset tells you the department that an employee is assigned to and which departments have no employees.
Outer Joins (a.k.a. Full Outer Joins)
Performing an Outer Join
The result from the outer join allows you to see which department an employee is assigned to and which departments have employees and which employees are not assigned to a department and which departments don’t have any employees.
Left Anti-Joins
Performing a Left Anti-Join
The result from the left anti-join can easily tell you which employees are not assigned to a department. Notice the right anti-join type doesn’t exist; however, you can easily switch the datasets around to achieve the same goal .
Left Semi-Joins
Performing a Left Semi-Join
Cross (a.k.a. Cartesian)
Performing a Cross Join
Dealing with Duplicate Column Names
Simulate a Joined DataFrame with Multiple Names That Are the Same
Projecting Column dept_no in the dupNameDF DataFrame
As it turns out, there are several ways to deal with this issue.
Use Original DataFrame
Using the Original DataFrame deptDF2 to Refer to dept_no Column in the Joined DataFrame
Renaming Column Before Joining
Another approach to avoid a column name ambiguity issue is to rename a column in one of the DataFrames using the withColumnRenamed transformation . Since this is simple, I leave it as an exercise for you.
Using Joined Column Name
Performing a Join Using Joined Column Name
Notice there is only one dept_no column in the noDupNameDF DataFrame.
Overview of Join Implementation
Joining is one of the most complex and expensive operations in Spark. At a high level, there are a few strategies Spark uses to perform the joining of two datasets. They are shuffle hash join and broadcast join. The main criteria for selecting a particular strategy are based on the size of the two datasets. When the size of both datasets is large, then the shuffle hash join strategy is used. When the size of one of the datasets is small enough to fit into the memory of the executor, then the broadcast join strategy is used. The following sections go into detail on how each joining strategy works.
Shuffle Hash Join
Conceptually, joining is about combining the rows of two datasets that meet the condition in the join expression. To do that, rows with the same column values need to be transferred across the network, co-located on the same partition.
The shuffle hash join implementation consists of two steps. The first step computes the hash value of the column(s) in the join expression of each row in each dataset and then shuffles those rows with the same hash value to the same partition. To determine which partition a particular row is moved to, Spark performs a simple arithmetic operation, which computes the modulo of the hash value by the number of partitions. The second step combines the columns of those rows that have the same column hash value. At the high level, these two steps are like the steps in the MapReduce programming model.
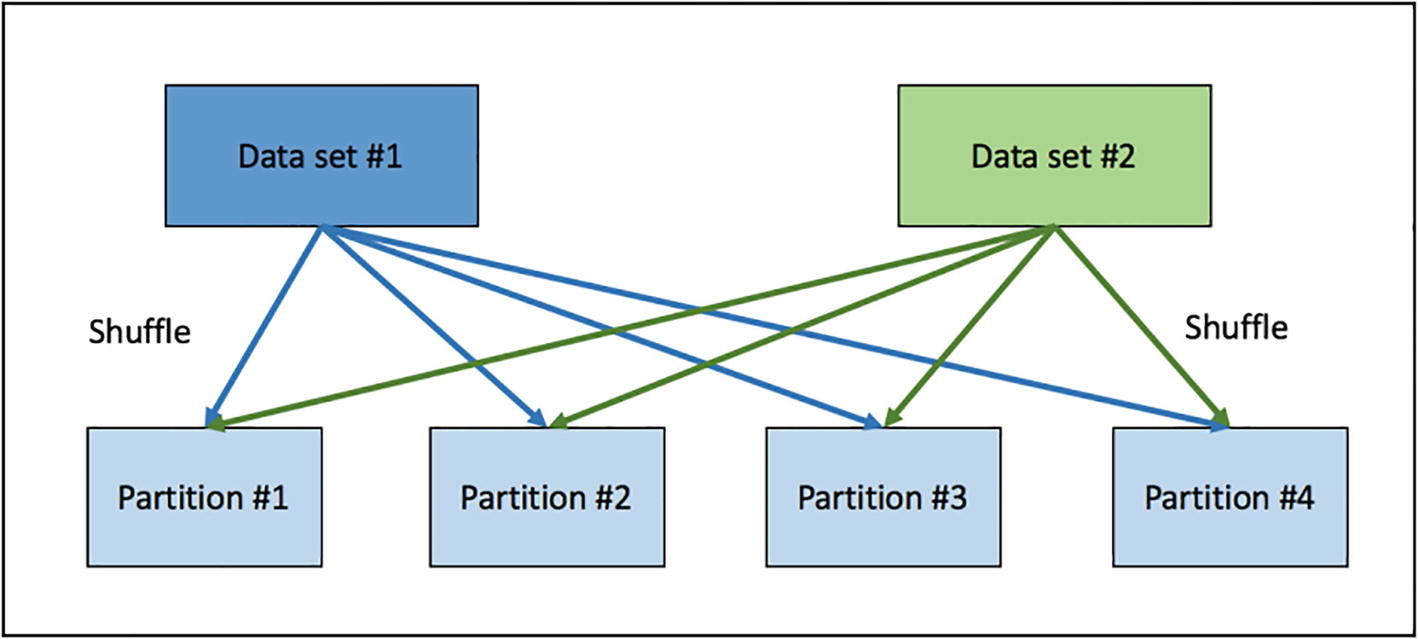
Shuffle hash join
Broadcast Hash Join

Broadcast hash join
Provide a Hint to Use Broadcast Hash Join
Functions
The DataFrame APIs are designed to operate or transform individual rows in a dataset, such as filtering and grouping. If you want to transform the column value of each row, such as converting a string from uppercase to camel case, you use a function. Functions are methods that are applied to columns. Spark SQL provides a large set of commonly needed functions and an easy way to create new ones. Approximately 30 new built-in functions were added in Spark 3.0 version.
Working with Built-in Functions
To be effective and productive at using Spark SQL to perform distributed data manipulations, you must be proficient at working with Spark SQL built-in functions . These built-in functions are designed to generate optimized code for execution at runtime, so it is best to take advantage of them before coming up with your own functions. One commonality among these functions is they are designed to take one or more columns of the same row as the input, and they return only a single column as the output. Spark SQL provides more than 200 built-in functions, and they are grouped into different categories. These functions can be used in DataFrame operations, such as select, filter, and groupBy.
A Subset of Built-in Functions for Each Category
Category | Description |
|---|---|
Date time | unix_timestamp, from_unixtime, to_date, current_date, current_timesatmp, date_add, date_sub, add_months, datediff, months_between, dayofmonth, dayofyear, weekofyear, second, minute, hour, month, make_date, make_timestamp, make_interval |
String | concat, length, levenshtein, locate, lower, upper, ltrim, rtrim, trim, lpad, rpad, repeat, reverse, split, substring, base64 |
Math | cos, acos, sin, asin, tan, atan, ceil, floor, exp, factorial, log, pow, radian, degree, sqrt, hex, unhex |
Cryptography | cr32, hash, md5, sha1, sha2 |
Aggregation | approx._count_distinct, countDistinct, sumDistinct, avg, corr, count, first, last, max, min, skewness, sum, |
Collection | array_contain, explode, from_json, size, sort_array, to_json, size |
Window | dense_rank, lag, lead, ntile, rank, row_number |
Misc. | coalesce, isNan, isnull, isNotNull, monotonically_increasing_id, lit, when |
Most of these functions are easy to understand and straightforward to use. The following sections provide working examples of some of the interesting ones.
Working with Date Time Functions
The more you use Spark to perform data analysis, the more chance you encounter datasets that have one more date or time-related columns. The Spark built-in data time functions broadly fall into the following three categories: converting the date or timestamp from one format to another, performing a data-time calculation, and extracting specific values from a date or timestamp, such as year, month, day of the week, and so on.
Converting date and timestamp String to Spark Date and Timestamp Type
Converting Date, Timestamp, and Unix Timestamp to Time String
Date Time Calculation Examples
Extract Specific Fields from a Date Value
Working with String Functions
Undoubtedly most columns in the majority of datasets are of string type. The Spark SQL built-in string functions provide versatile and powerful ways of manipulating this type of column. These functions fall into two broad buckets. The first one is about transforming a string, and the second one is about applying regular expressions either to replace some part of a string or to extract certain parts of a string based on a pattern.
Different Ways of Transforming a String With Built-in String Functions
Regular expressions are a powerful and flexible way to replace some portion of a string or extract substrings out of a string. The regexp_extract and regexp_replace functions are designed specifically for those purposes. Spark leverages the Java regular expressions library for the underlying implementation of these two string functions.
Using regexp_extract string Function to Extract “fox” Out Using a Pattern
Using regexp_replace String Function to Replace “fox” and “crow” with “animal”
Working with Math Functions
Demonstrates the Behavior of round with Various Scales
Working with Collection Functions
The collection functions are designed to work with complex data types such as arrays, maps, or structs. This section covers the two specific types of collection functions. The first one is about working with an array data type. The second one is about working with the JSON data format.
Using Array Collection Functions to Manipulate a List of Tasks
Examples of Using from_json and to_json Functions
Working with Miscellaneous Functions
A few of the functions in the miscellaneous category are interesting and can be useful in certain situations. This section covers the following functions: monotonically_increasing_id, when, coalesce, and lit.
monotonically_increasing_id in Action
Use the when Function to Convert a Numeric Value to a String
Using coalesce to Handle null Value in a Column
Working with User-Defined Functions (UDFs)
Even though Spark SQL provides a large set of built-in functions for most common use cases, there are always cases where none of those functions can provide the functionality your use cases need. However, don’t despair. Spark SQL provides a simple facility to write user-defined functions (UDFs) and uses them in your Spark data processing logic or applications similarly to using built-in functions. UDFs are effectively one of the ways you can extend Spark’s functionality to meet your specific needs.
Another thing that I like about Spark because UDFs can be written in either Python, Java, or Scala, and they can leverage and integrate with any necessary libraries. Since you can use a programming language that you are most comfortable with to write UDFs, it is extremely easy and fast to develop and test UDFs.
Conceptually, UDFs are just regular functions that take some inputs and provide an output. Although UDFs can be written in either Scala, Java, or Python, you must be aware of the performance differences when UDFs are written in Python. UDFs must be registered with Spark before they are used, so Spark knows to ship them to executors to be used and executed. Given that executors are JVM processes written in Scala, they can execute Scala or Java UDFs natively in the same process. If a UDF is written in Python, then an executor can’t execute it natively, and therefore it must spawn a separate Python process to execute the Python UDF. In addition to the cost of spawning a Python process, there is a high cost in terms of serializing data back and forth for each row in the dataset.
A Simple UDF in Scala to Convert Numeric Grades to Letter Grades
Advanced Analytics Functions
The previous sections covered the built-in functions Spark SQL provides for basic analytic needs such as aggregation, joining, pivoting, and grouping. All those functions take one or more values from a single row and produce an output value, or they take a group of rows and return an output.
This section covers the advanced analytics capabilities Spark SQL offers. The first one is about multidimensional aggregations, which is useful for use cases involving hierarchical data analysis. Calculating subtotals and totals across a set of grouping columns is commonly needed. The second capability is about performing aggregations based on time windows, which is useful when working with time-series data such as transactions or sensor values from IoT devices. The third one is the ability to perform aggregations within a logical grouping of rows, referred to as a window. This capability enables you to easily perform calculations such as a moving average, a cumulative sum, or the rank of each row.
Aggregation with Rollups and Cubes
Rollups and cube are more advanced versions of grouping on multiple columns, and they generate subtotals and grand totals across the combinations and permutations of those columns. The order of the provided set of columns is treated as a hierarchy for grouping.
Rollups
Performing Rollups with Flight Summary Data
This output shows the subtotals per state on the third and seventh lines. The last line shows the total with a null value in both the original_state and origin_city columns. The trick is to sort with the asc_nulls_last option, so Spark SQL order null values last.
Cubes
A cube is a more advanced version of a rollup. It performs the aggregations across all the combinations of the grouping columns. Therefore, the result includes what a rollup provides, as well as other combinations. In the cubing by origin_state and origin_city example, the result includes the aggregation for each of the original cities. The way to use the cube function is similar to how you use the rollup function.
Performing a Cube Across the origin_state and origin_city Columns
In the table, the lines with a null value in the origin_state column represent an aggregation of all the cities in a state. Therefore, the result of a cube always has more rows than the result of a rollup.
Aggregation with Time Windows
Aggregation with time windows was introduced in Spark 2.0 to make it easy to work with time-series data, consisting of a series of data points in time order. This kind of dataset is common in industries such as finance or telecommunications. For example, the stock market transaction dataset has the transaction date, opening price, close price, volume, and other pieces of information for each stock symbol. Time window aggregations can help answer questions such as the weekly average closing price of Apple stock or the monthly moving average closing price of Apple stock across each week.
Window functions come in a few versions, but they all require a timestamp type column and a window length, specified in seconds, minutes, hours, days, or weeks. The window length represents a time window with a start time and end time, and it determines which bucket a particular piece of time-series data should belong to. Another version takes additional input for the sliding window size, which tells how much a time window should slide when calculating the next bucket. These versions of the window function are the implementations of the tumbling window and sliding window concepts in world event processing, and they are described in more detail in Chapter 6.
Using the Time Window Function to Calculate the Average Closing Price of Apple Stock
Listing 4-50 uses a one-week tumbling window, where there is no overlap.
Use the Time Window Function to Calculate the Monthly Average Closing Price of Apple Stock
Since the sliding window interval is one week, the previous result table shows that the start time difference between two consecutive rows is one week apart. Between two consecutive rows, there are about three weeks of overlapping transactions, which means a transaction is used more than once to calculate the moving average .
Window Functions
You know how to use functions such as concat or round to compute an output from one or more column values of a single row and leverage aggregation functions such as max or sum to compute an output for each group of rows. Sometimes there is a need to operate on a group of rows and return a value for every input row. Window functions provide this unique capability to make it easy to perform calculations such as a moving average, a cumulative sum, or the rank of each row.
There are two main steps for working with window functions. The first one is to define a window specification that defines a logical grouping of rows called a frame, which is the context in which each row is evaluated. The second step is to apply a window function appropriate for the problem you are trying to solve. You learn more about the available window functions in the following sections.
The window specification defines three important components the window functions use. The first component is called partition by, and this is where you specify one or more columns to group the rows by. The second component is called order by, and it defines how the rows should be ordered based on one or more columns and whether the ordering should be in ascending or descending order. Out of the three components, the last one is more complicated and requires a detailed explanation. The last component is called a frame, and it defines the boundary of the window in the current row. In other words, the “frame” restricts which rows to be included when calculating a value for the current row. A range of rows to include in a window frame can be specified using the row index or the actual value of the order by expression. The last component is applicable for some of the window functions, and therefore it may not be necessary for some scenarios. A window specification is built using the functions defined in the org.apache.spark.sql.expressions.Window class. The rowsBetween and rangeBetweeen functions define the range by row index and actual value, respectively.
Ranking Functions
Name | Description |
|---|---|
rank | Returns the rank or order of rows within a frame based on some sorting order. |
dense_rank | Similar to rank, but leaves no gaps in the ranks when there are ties. |
percen_rank | Returns the relative rank of rows within a frame. |
ntile(n) | Returns the ntile group ID in an ordered window partition. For example, if n is 4, the first quarter of the rows get a value of 1, the second quarter of rows get a value of 2, and so on. |
row_number | Returns a sequential number starting with 1 with a frame. |
Analytic Functions
Name | Description |
|---|---|
cume_dist | Returns the cumulative distribution of values with a frame. In other words, the fraction of rows that are below the current row. |
lag(col, offset) | Returns the value of the column that is offset rows before the current row. |
lead(col, offset) | Returns the value of the column that is offset rows after the current row. |
User Shopping Transactions
Name | Date | Amount |
|---|---|---|
John | 2017-07-02 | 13.35 |
John | 2016-07-06 | 27.33 |
John | 2016-07-04 | 21.72 |
Mary | 2017-07-07 | 69.74 |
Mary | 2017-07-01 | 59.44 |
Mary | 2017-07-05 | 80.14 |
With this shopping transaction data, let’s try using window functions to answer the
For each user, what are the two highest transaction amounts?
What is the difference between the transaction amount of each user and their highest transaction amount?
What is the moving average transaction amount of each user?
What is the cumulative sum of the transaction amount of each user?
Apply the Rank Window Function to Find out the Top Two Transactions per User
Applying the max Window Function to Find the Difference of Each Row and the Highest Amount
Applying the Average Window Function to Compute the Moving Average Transaction Amount
Applying the sum Window Function to Compute the Cumulative Sum of Transaction Amount
The default frame of a window specification includes all the preceding rows and up to the current row. In Listing 4-55, it is unnecessary to specify the frame, so you should get the same result. The window function examples were written using the DataFrame APIs. You can achieve the same goals using SQL with the PARTITION BY, ORDER BY, ROWS BETWEEN, and RANGE BETWEEN keywords.
Example of a Window Function in SQL
When using the window functions in SQL, the partition by, order by, and frame
window must be specified in a single statement .
Exploring Catalyst Optimizer
The easiest way to write efficient data processing applications is to not worry about it and automatically optimize your data processing applications. That is the promise of the Spark Catalyst, which is a query optimizer and is the second major component in the Spark SQL module. It plays a major role in ensuring the data processing logic written in either DataFrame APIs or SQL runs efficiently and quickly. It was designed to minimize end-to-end query response times and be extensible such that Spark users can inject user code into the optimizer to perform custom optimization.

Catalyst optimizer
Logical Plan
The first step in the Catalyst optimization process is to create a logical plan from either a DataFrame object or the abstract syntax tree of the parsed SQL query. The logical plan is an internal representation of the user data processing logic in a tree of operators and expressions. Next, the Catalyst analyzes the logical plan to resolve references to ensure they are valid. Then it applies a set of rule-based and cost-based optimizations to the logical plan. Both types of optimizations follow the principle of pruning unnecessary data as early as possible and minimizing per-operator cost.
The rule-based optimizations include constant folding, project pruning, predicate pushdown, and others. For example, during this optimization phase, the Catalyst may decide to move the filter condition before performing a join. For curious minds, the list of rule-based optimizations is defined in the org.apache.spark.sql.catalyst.optimizer.Optimizer class.
The cost-based optimizations were introduced in Spark 2.2 to enable Catalyst to be more intelligent in selecting the right kind of join based on the statistics of the data being processed. The cost-based optimization relies on the detailed statistics of the columns participating in the filter or join conditions, and that’s why the statistics collection framework was introduced. Examples of the statistics include cardinality, the number of distinct values, max/min, and average/max length.
Physical Plan
Once the logical plan is optimized, the Catalyst generates physical plans using the physical operators that match the Spark execution engine. In addition to the optimizations performed in the logical plan phase, the physical plan phase performs its own ruled-based optimizations, including combining projections and filtering into a single operation and pushing the projections or filtering predicates down to the data sources that support this feature, i.e., Parquet. Again, these optimizations follow the data pruning principle. The final step the Catalyst performs is to generate the Java bytecode of the cheapest physical plan.
Catalyst in Action
This section shows how to use the explain function of the DataFrame class to display the logical and physical plans.
You can call the explain function with the extended argument as a boolean true value to see both the logical and physical plan. Otherwise, this function displays only the physical plan.
Using the explain Function to Generate the Logical and Physical Plans
If you carefully analyze the optimized logical plan, you see that it combines both filtering conditions into a single filter. The physical plan shows that Catalyst both pushes down the filtering of produced_year and performs the projection pruning in the FileScan step to optimally read in only the needed data.
The Various Modes of the Output Format
Mode | Description |
|---|---|
simple | Print only a physical plan. |
extended | Print both logical and physical plans. |
codegen | Print a physical plan and the generated codes (if they are available). |
cost | Print a logical plan and statistics if they are available. |
formatted | Split the explain output into two sections; a physical plan outline and details. |
Using the explain Function with formatted Mode
The output clearly shows Spark’s four steps to compute the latestMoviesDF: scan or read the input parquet file, convert the data in columnar format into rows, filter them based on the two specified conditions, and finally project the title and produced decade columns.
Project Tungsten
Manage memory explicitly by using off-heap management techniques to eliminate the overhead of the JVM object model and minimize garbage collection.
Use intelligent cache-aware algorithms and data structures to exploit memory hierarchy.
Use whole-stage code generation to minimize virtual function calls by combining multiple operators into a single function.
Demonstrating the Whole-Stage Code Generation by Looking at the Physical Plan
The whole-stage code generation combines the logic of filtering and summing integers into a single function.
Summary
Aggregation is one of the most commonly used features in the world of big data analytics. Spark SQL provides many of the commonly needed aggregation functions such as sum, count, and avg. Aggregation with pivoting provides a nice way of summarizing the data as well as transposing columns into rows.
Performing any complex and meaningful data analytics or processing often requires joining two or more datasets. Spark SQL supports many of the standard join types that exist in the SQL world.
Spark SQL comes with a rich set of built-in functions, which should cover most of the common needs for working with strings, math, date and time, and so on. If none meets a particular need of a use case, then it is easy to write a user-defined function that can be used with the DataFrame APIs and SQL queries.
Window functions are powerful and advanced analytics functions because they can compute a value for each row in the input group. They are particularly useful for computing moving averages, a cumulative sum, or the rank of each row.
The Catalyst optimizer enables you to write efficient data processing applications. The cost-based optimizer was introduced in Spark 2.2 to enable Catalyst to be more intelligent about selecting the right kind of join implementation based on the collected statistics of the processed data.
Project Tungsten is the workhorse behind the scenes that speeds up the execution of data process applications by employing a few advanced techniques to improve the efficiency of using memory and CPU.