
Chapter 10
Defining Class Members
Wrox.com Code Downloads for this Chapter
You can find the wrox.com code downloads for this chapter at www.wrox.com/go/beginningvisualc#2015programming on the Download Code tab. The code is in the Chapter 10 download and individually named according to the names throughout the chapter.
This chapter continues exploring class definitions in C# by looking at how you define field, property, and method class members. You start by examining the code required for each of these types, and learn how to generate the structure of this code. You also learn how to modify members quickly by editing their properties.
After covering the basics of member definition, you'll learn some advanced techniques involving members: hiding base class members, calling overridden base class members, nested type definitions, and partial class definitions.
Finally, you put theory into practice by creating a class library that you can build on and use in later chapters.
Member Definitions
Within a class definition, you provide definitions for all members of the class, including fields, methods, and properties. All members have their own accessibility levels, defined in all cases by one of the following keywords:
publicprivateinternalprotected
The last two of these can be combined, so protected internal
Fields, methods, and properties can also be declared using the keyword static
Defining Fields
Fields are defined using standard variable declaration format (with optional initialization), along with the modifiers discussed previously:
class MyClass
{
public int MyInt;
}Fields can also use the keyword readonly, meaning the field can be assigned a value only during constructor execution or by initial assignment:
class MyClass
{
public readonly int MyInt = 17;
}As noted in the chapter introduction, fields can be declared as static using the static keyword:
class MyClass
{
public static int MyInt;
}Static fields are accessed via the class that defines them (MyClass.MyInt in the preceding example), not through object instances of that class. You can use the keyword const to create a constant value. const members are static by definition, so you don't need to use the static modifier (in fact, it is an error to do so).
Defining Methods
Methods use standard function format, along with accessibility and optional static modifiers, as shown in this example:
class MyClass
{
public string GetString() => return "Here is a string.";
}Remember that if you use the static
virtualabstractoverrideextern
Here's an example of a method override:
public class MyBaseClass
{
public virtual void DoSomething()
{
// Base implementation.
}
}
public class MyDerivedClass : MyBaseClass
{
public override void DoSomething()
{
// Derived class implementation, overrides base implementation.
}
}If overridesealed
public class MyDerivedClass : MyBaseClass
{
public override sealed void DoSomething()
{
// Derived class implementation, overrides base implementation.
}
}Using extern
Defining Properties
Properties are defined in a similar way to fields, but there's more to them. Properties, as already discussed, are more involved than fields in that they can perform additional processing before modifying state — and, indeed, might not modify state at all. They achieve this by possessing two function-like blocks: one for getting the value of the property and one for setting the value of the property.
These blocks, also known as accessors, are defined using getsetgetsetgetset
The basic structure of a property consists of the standard access modifying keyword (publicprivategetset
public int MyIntProp
{
get
{
// Property get code.
}
set
{
// Property set code.
}
}The first line of the definition is the bit that is very similar to a field definition. The difference is that there is no semicolon at the end of the line; instead, you have a code block containing nested getset
getget
// Field used by property.
private int myInt;
// Property.
public int MyIntProp
{
get { return myInt; }
set { // Property set code. }
}Code external to the class cannot access this myIntsetvalue
// Field used by property.
private int myInt;
// Property.
public int MyIntProp
{
get { return myInt; }
set { myInt = value; }
}value
This simple property does little more than shield direct access to the myIntset
set
{
if (value >= 0 && value <= 10)
myInt = value;
}Here, you modify myInt
- Do nothing (as in the preceding code).
- Assign a default value to the field.
- Continue as if nothing went wrong but log the event for future analysis.
- Throw an exception.
In general, the last two options are preferable. Deciding between them depends on how the class will be used and how much control should be assigned to the users of the class. Exception throwing gives users a fair amount of control and lets them know what is going on so that they can respond appropriately. You can use one of the standard exceptions in the System
set
{
if (value >= 0 && value <= 10)
myInt = value;
else
throw (new ArgumentOutOfRangeException("MyIntProp", value,
"MyIntProp must be assigned a value between 0 and 10."));
}This can be handled using trycatchfinally
Logging data, perhaps to a text file, can be useful, such as in production code where problems really shouldn't occur. It enables developers to check on performance and perhaps debug existing code if necessary.
Properties can use the virtualoverrideabstract
// Field used by property.
private int myInt;
// Property.
public int MyIntProp
{
get { return myInt; }
protected set { myInt = value; }
}Here, only code within the class or derived classes can use the set
The accessibilities that are permitted for accessors depend on the accessibility of the property, and it is forbidden to make an accessor more accessible than the property to which it belongs. This means that a private property cannot contain any accessibility modifiers for its accessors, whereas public properties can use all modifiers on their accessors.
C# 6 introduced a feature called expression based properties. Similar to the expression based method discussed previously in Chapter 6, this feature reduces the extent of the property to a single line of code. For example, properties that return a one-line mathematical computation on a value can use the lambda arrow followed by the equation.
// Field used by property.
private int myDoubledInt = 5;
// Property.
public int MyDoubledIntProp => (myDoubledInt * 2);The following Try It Out enables you to experiment with defining and using fields, methods, and properties.
Refactoring Members
One technique that comes in handy when adding properties is the capability to generate a property from a field. This is an example of refactoring, which simply means modifying your code using a tool, rather than by hand. This can be accomplished by right-clicking a member in a class diagram or in code view.
For example, if the MyClass
public string myString;you could right-click on the field and select Quick Actions…. That would bring up the dialog box shown in Figure 10.2.
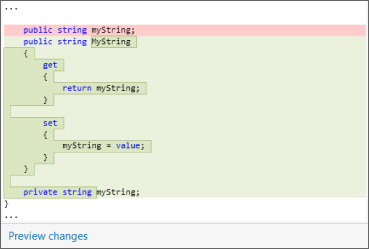
Accepting the default options modifies the code for MyClass
public string myString;
public string MyString
{
get { return myString; }
set { myString = value; }
}
private string myString;Here, the accessibility of the myStringprivateMyStringmyString
Automatic Properties
Properties are the preferred way to access the state of an object because they shield external code from the implementation of data storage within the object. They also give you greater control over how internal data is accessed, as you have seen several times in this chapter's code. However, you'll typically define properties in a very standard way — that is, you will have a private member that is accessed directly through a public property. The code for this is almost invariably similar to the code in the previous section, which was autogenerated by the Visual Studio refactoring tool.
Refactoring certainly speeds things up when it comes to typing, but C# has another trick up its sleeve: automatic properties. With an automatic property, you declare a property with a simplified syntax and the C# compiler fills in the blanks for you. Specifically, the compiler declares a private field that is used for storage, and uses that field in the getset
Use the following code structure to define an automatic property:
public int MyIntProp
{
get;
set;
}You can even define an automatic property on a single line of code to save space, without making the property much less readable:
public int MyIntProp { get; set; }You define the accessibility, type, and name of the property in the usual way, but you don't provide any implementation for the getset
When you use an automatic property, you only have access to its data through the property, not through its underlying private field. This is because you can't access the private field without knowing its name, which is defined during compilation. However, that's not really a limitation because using the property name directly is fine. The only limitation of automatic properties is that they must include both a getset
public int MyIntProp { get; private set; }Here you can access the value of MyIntProp
C# 6 introduced two new concepts pertaining to automatic properties referred to as getter-only auto-properties and initializers for auto-properties. Prior to C# 6, automatic properties required setters, which limited the utilization of immutable data types. The simple definition of an immutable data type is that it does not change state once it is created, the most famous immutable type being System.String
Concurrent programming and synchronization of threads are advanced topics and not discussed further in this book; however, it is important to know about the getter-only auto-properties. They are created by using the following syntax, notice that a setter is no longer required:
public int MyIntProp { get; }The initialization feature for auto-properties is implemented by the following which is similar to the way fields are declared:
public int MyIntProp { get; } = 9;Additional Class Member Topics
Now you're ready to look at some more advanced member topics. This section tackles the following:
- Hiding base class methods
- Calling overridden or hidden base class methods
- Using nested type definitions
Hiding Base Class Methods
When you inherit a (non-abstract) member from a base class, you also inherit an implementation. If the inherited member is virtual, then you can override this implementation with the override
You can do this simply by using code such as the following:
public class MyBaseClass
{
public void DoSomething()
{
// Base implementation.
}
}
public class MyDerivedClass : MyBaseClass
{
public void DoSomething()
{
// Derived class implementation, hides base implementation.
}
}Although this code works fine, it generates a warning that you are hiding a base class member. That warning gives you the chance to correct it if you have accidentally hidden a member that you want to use. If you really do want to hide the member, you can use the new
public class MyDerivedClass : MyBaseClass
{
new public void DoSomething()
{
// Derived class implementation, hides base implementation.
}
}This works in exactly the same way but won't show a warning. At this point, it's worthwhile to note the difference between hiding and overriding base class members. Consider the following code:
public class MyBaseClass
{
public virtual void DoSomething() => WriteLine("Base imp");
}
public class MyDerivedClass : MyBaseClass
{
public override void DoSomething() => WriteLine("Derived imp");
}Here, the overriding method replaces the implementation in the base class, such that the following code uses the new version even though it does so through the base class type (using polymorphism):
MyDerivedClass myObj = new MyDerivedClass();
MyBaseClass myBaseObj;
myBaseObj = myObj;
myBaseObj.DoSomething();This results in the following output:
Derived impAlternatively, you could hide the base class method:
public class MyBaseClass
{
public virtual void DoSomething() => WriteLine("Base imp");
}
public class MyDerivedClass : MyBaseClass
{
new public void DoSomething() => WriteLine("Derived imp");
}The base class method needn't be virtual for this to work, but the effect is exactly the same and the preceding code only requires changes to one line. The result for a virtual or nonvirtual base class method is as follows:
Base impAlthough the base implementation is hidden, you still have access to it through the base class.
Calling Overridden or Hidden Base Class Methods
Whether you override or hide a member, you still have access to the base class member from the derived class. There are many situations in which this can be useful, such as the following:
- When you want to hide an inherited public member from users of a derived class but still want access to its functionality from within the class
- When you want to add to the implementation of an inherited virtual member rather than simply replace it with a new overridden implementation
To achieve this, you use the base
public class MyBaseClass
{
public virtual void DoSomething()
{
// Base implementation.
}
}
public class MyDerivedClass : MyBaseClass
{
public override void DoSomething()
{
// Derived class implementation, extends base class implementation.
base.DoSomething();
// More derived class implementation.
}
}This code executes the version of DoSomething()MyBaseClassMyDerivedClassDoSomething()MyDerivedClassbase
The this Keyword
As well as using basethisbasethisbasethis
The most useful function of the this
public void doSomething()
{
MyTargetClass myObj = new MyTargetClass();
myObj.DoSomethingWith(this);
}Here, the MyTargetClassmyObjDoSomethingWith()System.Object
Another common use of the this
public class MyClass
{
private int someData;
public int SomeData
{
get
{
return this.someData;
}
}
}Many developers like this syntax, which can be used with any member type, as it is clear at a glance that you are referring to a member rather than a local variable.
Using Nested Type Definitions
You can define types such as classes in namespaces, and you can also define them inside other classes. Then you can use the full range of accessibility modifiers for the definition, rather than just publicinternalnewMyClassMyNestedClass
public class MyClass
{
public class MyNestedClass
{
public int NestedClassField;
}
}To instantiate MyNestedClassMyClass
MyClass.MyNestedClass myObj = new MyClass.MyNestedClass();However, you might not be able to do this, for example if the nested class is declared as private
Interface Implementation
This section takes a closer look at how you go about defining and implementing interfaces. In the last chapter, you learned that interfaces are defined in a similar way as classes, using code such as the following:
interface IMyInterface
{
// Interface members.
}Interface members are defined like class members except for a few important differences:
- No access modifiers (
publicprivateprotectedinternal - Interface members can't contain code bodies.
- Interfaces can't define field members.
- Interface members can't be defined using the keywords
staticvirtualabstractsealed - Type definition members are forbidden.
You can, however, define members using the new
interface IMyBaseInterface
{
void DoSomething();
}
interface IMyDerivedInterface : IMyBaseInterface
{
new void DoSomething();
}This works exactly the same way as hiding inherited class members.
Properties defined in interfaces define either or both of the access blocks — getset
interface IMyInterface
{
int MyInt { get; set; }
}Here the intMyIntgetset
Interfaces do not specify how the property data should be stored. Interfaces cannot specify fields, for example, that might be used to store property data. Finally, interfaces, like classes, can be defined as members of classes (but not as members of other interfaces because interfaces cannot contain type definitions).
Implementing Interfaces in Classes
A class that implements an interface must contain implementations for all members of that interface, which must match the signatures specified (including matching the specified getset
public interface IMyInterface
{
void DoSomething();
void DoSomethingElse();
}
public class MyClass : IMyInterface
{
public void DoSomething() {}
public void DoSomethingElse() {}
}It is possible to implement interface members using the keyword virtualabstractstaticconst
public interface IMyInterface
{
void DoSomething();
void DoSomethingElse();
}
public class MyBaseClass
{
public void DoSomething() {}
}
public class MyDerivedClass : MyBaseClass, IMyInterface
{
public void DoSomethingElse() {}
}Inheriting from a base class that implements a given interface means that the interface is implicitly supported by the derived class. Here's an example:
public interface IMyInterface
{
void DoSomething();
void DoSomethingElse();
}
public class MyBaseClass : IMyInterface
{
public virtual void DoSomething() {}
public virtual void DoSomethingElse() {}
}
public class MyDerivedClass : MyBaseClass
{
public override void DoSomething() {}
}Clearly, it is useful to define implementations in base classes as virtual so that derived classes can replace the implementation, rather than hide it. If you were to hide a base class member using the newIMyInterface.DoSomething()
Explicit Interface Member Implementation
Interface members can also be implemented explicitly by a class. If you do that, the member can only be accessed through the interface, not the class. Implicit members, which you used in the code in the last section, can be accessed either way.
For example, if the class MyClassDoSomething()IMyInterface
MyClass myObj = new MyClass();
myObj.DoSomething();This would also be valid:
MyClass myObj = new MyClass();
IMyInterface myInt = myObj;
myInt.DoSomething();Alternatively, if MyDerivedClassDoSomething()
public class MyClass : IMyInterface
{
void IMyInterface.DoSomething() {}
public void DoSomethingElse() {}
}Here, DoSomething()DoSomethingElse()MyClass
Additional Property Accessors
Earlier you learned that if you implement an interface with a property, you must implement matching get/setgetset
public interface IMyInterface
{
int MyIntProperty { get; }
}
public class MyBaseClass : IMyInterface
{
public int MyIntProperty { get; protected set; }
}If you define the additional accessor as public, then code with access to the class implementing the interface can access it. However, code that has access only to the interface won't be able to access it.
Partial Class Definitions
When you create classes with a lot of members of one type or another, the code can get quite confusing, and code files can get very long. One technique that can help, which you've looked at in earlier chapters, is to use code outlining. By defining regions in code, you can collapse and expand sections to make the code easier to read. For example, you might have a class defined as follows:
public class MyClass
{
#region Fields
private int myInt;
#endregion
#region Constructor
public MyClass() { myInt = 99; }
#endregion
#region Properties
public int MyInt
{
get { return myInt; }
set { myInt = value; }
}
#endregion
#region Methods
public void DoSomething()
{
// Do something..
}
#endregion
}Here, you can expand and contract fields, properties, the constructor, and methods for the class, enabling you to focus only on what you are interested in. It is even possible to nest regions this way, so some regions are visible only when the region that contains them is expanded.
An alternative to using regions is to use partial class definitions. Put simply, you use partial class definitions to split the definition of a class across multiple files. You can, for example, put the fields, properties, and constructor in one file, and the methods in another. To do that, you just use the partial
public partial class MyClass { …}If you use partial class definitions, the partial
For example, a WPF window in a class called MainWindowMainWindow.xaml.csMainWindow.g.i.csobjDebug
One final note about partial classes: Interfaces applied to one partial class part apply to the whole class, meaning that the definition,
public partial class MyClass : IMyInterface1 { … }
public partial class MyClass : IMyInterface2 { … }is equivalent to:
public class MyClass : IMyInterface1, IMyInterface2 { … }Partial class definitions can include a base class in a single partial class definition, or more than one partial class definition. If a base class is specified in more than one definition, though, it must be the same base class; recall that classes in C# can inherit only from a single base class.
Partial Method Definitions
Partial classes can also define partial methods. Partial methods are defined in one partial class definition without a method body, and implemented in another partial class definition. In both places, the partial
public partial class MyClass
{
partial void MyPartialMethod();
}
public partial class MyClass
{
partial void MyPartialMethod()
{
// Method implementation
}
}Partial methods can also be static, but they are always private and can't have a return value. Any parameters they use can't be outrefvirtualabstractoverridenewsealedextern
Given these limitations, it is not immediately obvious what purpose partial methods fulfill. In fact, they are important when it comes to code compilation, rather than usage. Consider the following code:
public partial class MyClass
{
partial void DoSomethingElse();
public void DoSomething()
{
WriteLine("DoSomething() execution started.");
DoSomethingElse();
WriteLine("DoSomething() execution finished.");
}
}
public partial class MyClass
{
partial void DoSomethingElse() =>
WriteLine("DoSomethingElse() called.");
}Here, the partial method DoSomethingElse()DoSomething()
DoSomething() execution started.
DoSomethingElse() called.
DoSomething() execution finished.If you were to remove the second partial class definition or partial method implementation entirely (or comment out the code), the output would be as follows:
DoSomething() execution started.
DoSomething() execution finished.You might assume that what is happening here is that when the call to DoSomethingElse()
As with partial classes, partial methods are useful when it comes to customizing autogenerated or designer-created code. The designer may declare partial methods that you can choose to implement or not depending on the situation. If you don't implement them, you incur no performance hit because effectively the method does not exist in the compiled code.
Consider at this point why partial methods can't have a return type. If you can answer that to your own satisfaction, you can be sure that you fully understand this topic — so that is left as an exercise for you.
Example Application
To illustrate some of the techniques you've been using so far, in this section you'll develop a class module that you can build on and make use of in subsequent chapters. The class module contains two classes:
CardDeck
You'll also develop a simple client to ensure that things are working, but you won't use the deck in a full card game application — yet.
Planning the Application
The class library for this application, Ch10CardLib, will contain your classes. Before you get down to any code, though, you should plan the required structure and functionality of your classes.
The Card Class
The Cardsuitrank
Other than that, the CardToString()SystemObjectsuitrank
The Card
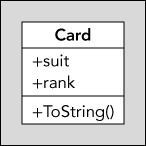
The Deck Class
The DeckCardCardGetCard()CardShuffle()Deck
![Schematic of two boxes labeled Card and Deck. Deck class displays 2 sections for -cards:Cards[] and +GetCard(),+Deck(), and +Shuffled(). The two boxes are connected by a line labeled 0...* and 1.](http://images-20200215.ebookreading.net/22/4/4/9781119096689/9781119096689__beginning-c-60__9781119096689__images__c10f005.jpg)
Writing the Class Library
For the purposes of this example, it is assumed that you are familiar enough with the IDE to bypass the standard Try It Out format, so the steps aren't listed explicitly, as they are the same steps you've used many times. The important thing here is a detailed look at the code. Nonetheless, several pointers are included to ensure that you don't run into any problems along the way.
Both your classes and your enumerations will be contained in a class library project called Ch10CardLib. This project will contain four .csCardcsCardDeckcsDeckSuitcsRankcs
You can put together a lot of this code using the Visual Studio class diagram tool.
To get started, you need to do the following:
- Create a new class library project called Ch10CardLib and save it in the directory
C:BegVCSharpChapter10 - Remove
Class1.cs - Open the class diagram for the project using the Solution Explorer window (right-click the project and then click View
 View Class Diagram). The class diagram should be blank to start with because the project contains no classes.
View Class Diagram). The class diagram should be blank to start with because the project contains no classes.
Adding the Suit and Rank Enumerations
You can add an enumeration to the class diagram by dragging an Enum from the Toolbox into the diagram, and then filling in the New Enum dialog box that appears. For example, for the Suit
Next, add the members of the enumeration using the Class Details window. Figure 10.7 shows the values that are required.
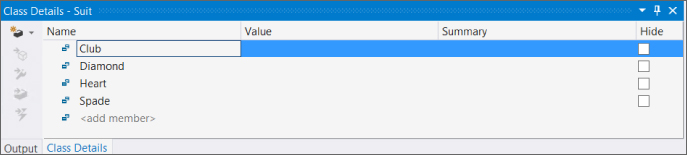
Add the Rank
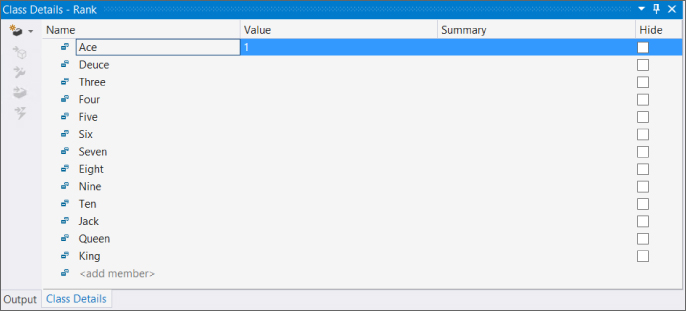
You can find the code generated for these two enumerations in the code files, Suit.csRank.csCh10CardLib folder/Suit.cs
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
namespace Ch10CardLib
{
public enum Suit
{
Club,
Diamond,
Heart,
Spade,
}
}And you can find the full code for this example in Ch10CardLib folder/Rank.cs
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
namespace Ch10CardLib
{
public enum Rank
{
Ace = 1,
Deuce,
Three,
Four,
Five,
Six,
Seven,
Eight,
Nine,
Ten,
Jack,
Queen,
King,
}
}Alternatively, you can add this code manually by adding Suit.csRank.cs
Adding the Card Class
To add the CardClassCard
Use the Class Details window to add the fields ranksuitreadonlynewSuitnewRankSuitRankToString()Inheritance Modifieroverride
Figure 10.9 shows the Class Details window and the CardCh10CardLibCard.cs
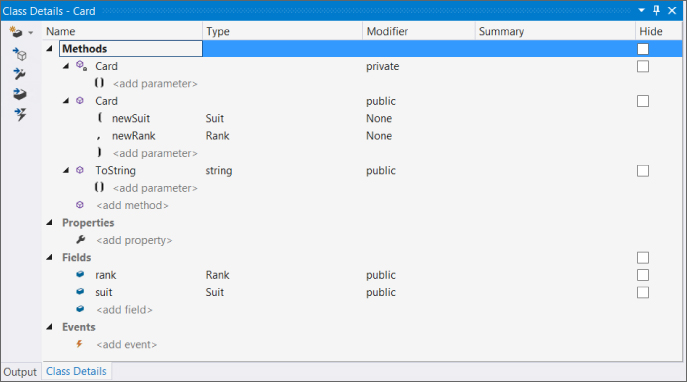
Next, modify the code for the class in Card.csCardCh10CardLib
public class Card
{
public readonly Suit suit;
public readonly Rank rank;
public Card(Suit newSuit, Rank newRank)
{
suit = newSuit;
rank = newRank;
}
private Card()
{
}
public override string ToString()
{
return "The " + rank + " of " + suit + "s";
}
}The overridden ToString()suitrank
Adding the Deck Class
The Deck
- A private field called
cardsCard[] - A public default constructor
- A public method called
GetCard()intcardNumCard - A public method called
Shuffle()void
When these are added, the Class Details window for the Deck
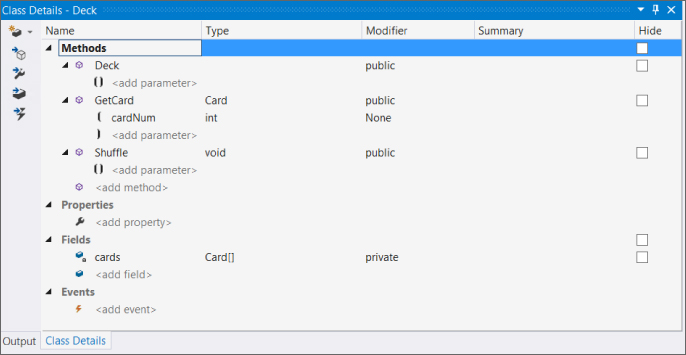
To make things clearer in the diagram, you can show the relationships among the members and types you have added. In the class diagram, right-click on each of the following in turn and select Show as Association from the menu:
cardsDecksuitCardrankCard
When you have finished, the diagram should look like Figure 10.11.
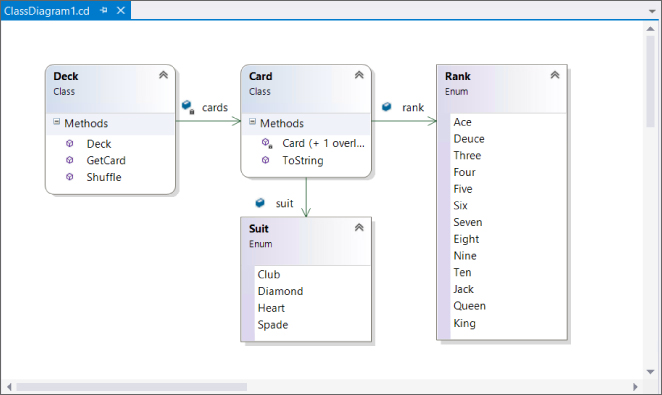
Next, modify the code in Deck.csCh10CardLibDeck.cscardscards
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.Threading.Tasks;
namespace Ch10CardLib
{
public class Deck
{
private Card[] cards;
public Deck()
{
cards = new Card[52];
for (int suitVal = 0; suitVal < 4; suitVal++)
{
for (int rankVal = 1; rankVal < 14; rankVal++)
{
cards[suitVal * 13 + rankVal -1] = new Card((Suit)suitVal,
(Rank)rankVal);
}
}
}Next, implement the GetCard()Card
public Card GetCard(int cardNum)
{
if (cardNum >= 0 && cardNum <= 51)
return cards[cardNum];
else
throw (new System.ArgumentOutOfRangeException("cardNum", cardNum,
"Value must be between 0 and 51."));
}Finally, you implement the Shuffle()cardsSystem.Random0XNext(X)Cardcards
To keep a record of assigned cards, you also have an array of booltrue
This isn't the most efficient way of doing things because many random numbers will be generated before finding a vacant slot into which a card can be copied. However, it works, it's very simple, and C# code executes so quickly you will hardly notice a delay. The code is as follows:
public void Shuffle()
{
Card[] newDeck = new Card[52];
bool[] assigned = new bool[52];
Random sourceGen = new Random();
for (int i = 0; i < 52; i++)
{
int destCard = 0;
bool foundCard = false;
while (foundCard == false)
{
destCard = sourceGen.Next(52);
if (assigned[destCard] == false)
foundCard = true;
}
assigned[destCard] = true;
newDeck[destCard] = cards[i];
}
newDeck.CopyTo(cards, 0);
}
}
}The last line of this method uses the CopyTo()System.ArraynewDeckcardsCardcardscards = newDeckcardscards
That completes the class library code.
A Client Application for the Class Library
To keep things simple, you can add a client console application to the solution containing the class library. To do so, simply right-click on the solution in Solution Explorer and select Add ![]() New Project. The new project is called Ch10CardClient.
New Project. The new project is called Ch10CardClient.
To use the class library you have created from this new console application project, add a reference to your Ch10CardLib class library project. You can do that through the Projects tab of the Reference Manager dialog box, as shown in Figure 10.12.
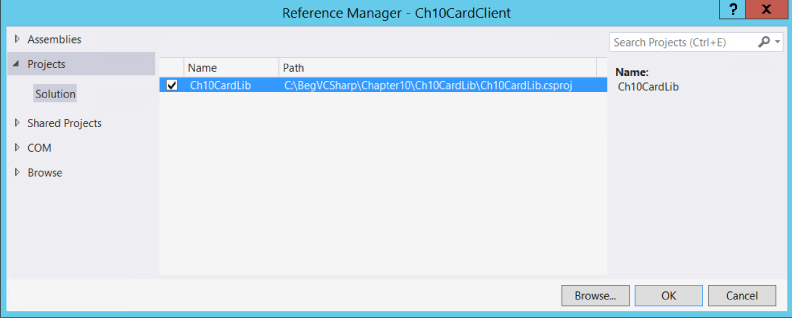
Select the project and click OK to add the reference.
Because this new project is the second one you've created, you also need to specify that it is the startup project for the solution, meaning the one that is executed when you click Run. To do so, simply right-click on the project name in the Solution Explorer window and select the Set as StartUp Project menu option.
Next, add the code that uses your new classes. That doesn't require anything particularly special, so the following code will do (you can find this code in Ch10CardClientProgram.cs
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.Threading.Tasks;
using static System.Console;
using Ch10CardLib;
namespace Ch10CardClient
{
class Program
{
static void Main(string[] args)
{
Deck myDeck = new Deck();
myDeck.Shuffle();
for (int i = 0; i < 52; i++)
{
Card tempCard = myDeck.GetCard(i);
Write(tempCard.ToString());
if (i != 51)
Write(", ");
else
WriteLine();
}
ReadKey();
}
}
}Figure 10.13 shows the result you'll get if you run this application.
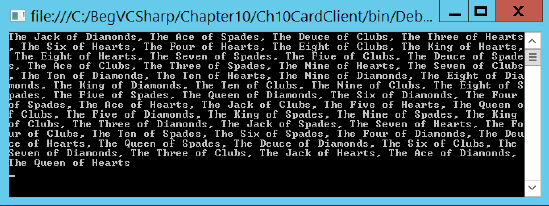
This is a random arrangement of the 52 playing cards in the deck. You'll continue to develop and use this class library in later chapters.
The Call Hierarchy Window
Now is a good time to take a quick look at another feature of Visual Studio: the Call Hierarchy window. This window enables you to interrogate code to find out where your methods are called from and how they relate to other methods. The best way to illustrate this is with an example.
Open the example application from the previous section, and open the Deck.csShuffle()
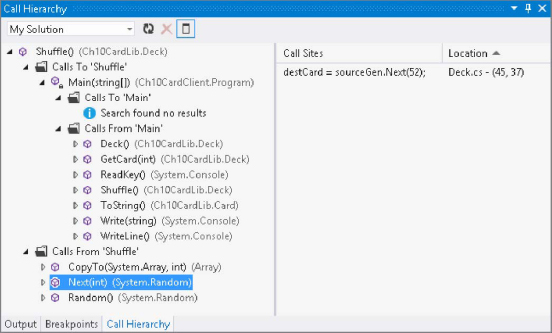
Starting from the Shuffle()Next(int)Shuffle()
You can also drill into methods further down the hierarchy — in Figure 10-19 this has been done for Main()Main()
This window is very useful when you are debugging or refactoring code, as it enables you to see at a glance how different pieces of code are related.
 What You Learned in This Chapter
What You Learned in This Chapter
| Topic | Key Concepts |
| Member definitions | You can define field, method, and property members in a class. Fields are defined with an accessibility, name, and type. Methods are defined with an accessibility, return type, name, and parameters. Properties are defined with an accessibility, name, and a |
| Member hiding and overrides | Properties and methods can be defined as |
| Interface implementation | A class that implements an interface must implement all of the members defined by that interface as public. You can implement interfaces implicitly or explicitly, where explicit implementations are only available through an interface reference. |
| Partial definitions | You can split class definitions across multiple code files with the |