
If your computer could only ever process data stored within the main memory of the machine, the scope and variety of applications you could deal with would be severely limited. Virtually all serious business applications require more data than would fit into main memory and depend on the ability to process data that’s persistent and stored on an external device such as a disk drive. In this chapter, you’ll explore how you can process data stored in files.
C provides a range of functions in the header file stdio.h for writing to and reading from external devices. The external device you would use for storing and retrieving data is typically a disk drive, but not exclusively. Because, consistent with the philosophy of C, the library facilities you’ll use for working with files are device independent, they apply to virtually any external storage device. However, I’ll assume in the examples in this chapter that we are dealing with disk files.
What a file is
How files are processed
How to write and read formatted files
How to write and read binary files
How to access data in a file randomly
How to create and use temporary work files
How to update binary files
How to write a file viewer program
The Concept of a File
With all the examples up to now, any data that the user enters are lost once the program ends. If the user wants to run the program with the same data, he or she must enter it again each time. There are a lot of occasions when this not only is inconvenient but also makes the programming task impossible.
If you want to maintain a directory of names, addresses, and telephone numbers, for instance, a program in which you have to enter all the names, addresses, and telephone numbers each time you run it is worse than useless! The answer is to store data on permanent storage that continues to be maintained after your computer is switched off. As I’m sure you know, this storage is called a file, and a file is usually stored on a disk.
You’re probably familiar with the basic mechanics of how a disk works. If so, this can help you recognize when a particular approach to file usage is efficient and when it isn’t. On the other hand, if you know nothing about disk file mechanics, don’t worry at this point. There’s nothing in the concept of file processing in C that depends on any knowledge of physical storage devices.

Structure of a file
Positions in a File
A file has a beginning and an end, and it has a current position, typically defined as so many bytes from the beginning, as Figure 12-1 illustrates. The current position is where any file action (a read from the file or a write to the file) will take place. You can move the current position to any point in the file. A new current position can be specified as an offset from the beginning of the file or, in some circumstances, as a positive or negative offset from the previous current position. You can also move the position to the end of the file in some situations.
File Streams
The C library provides functions for reading and writing to or from data streams. As you know from Chapter 10, a stream is an abstract representation of any external source or destination for data, so the keyboard, the command line on your display, and files on a disk are all examples of things you can work with as streams. You use the same input/output functions for reading and writing any external device that is mapped to a stream.
There are two ways of writing data to a stream that represents a file. First, you can write a file as a text file, in which case data are written as a sequence of characters organized as lines, where each line is terminated by a newline character. Obviously, binary data such as values of type int or type double have to be converted to characters to allow them to be written to a text file, and you have already seen how this formatting is done with the printf() and printf_s() functions. Second, you can write a file as a binary file . Data written to a binary file are written as a series of bytes exactly as they appear in memory, so a value of type double, for example, would be written as the 8 bytes that appear in memory.
Of course, you can write any data you like to a file, but once a file has been written, it just consists of a series of bytes. Regardless of whether you write a file as a binary file or as a text file, it ultimately ends up as just a series of bytes. This means that the program must know what sort of data the file represents to read it correctly. You’ve seen many times now that exactly what a series of bytes represents is dependent upon how you interpret it. A sequence of 12 bytes in a binary file could be 12 characters, 12 8-bit signed integers, 12 8-bit unsigned integers, 6 16-bit signed integers, a 32-bit integer followed by an 8-byte floating-point value, and so on. All of these will be more or less valid interpretations of the data, so it’s important that a program that is reading a file has the correct assumptions about what was written.
Accessing Files
The files that are resident on your disk drive each have a name, and the rules for naming files are determined by your operating system. In the examples in this chapter, I’ll use Microsoft Windows file names. If you’re using a different operating system environment, you’ll need to adjust the names of the files appropriately. It would not be particularly convenient if a program that processes a file would only work with a specific file with a particular name. If it did, you would need to produce a different program for each file you might want to process. For this reason, your program references a file through a file pointer or more accurately a stream pointer. You associate a stream pointer with a particular file programmatically when the program is run. A program can associate a given stream pointer with different files on different occasions, so the same program can work with a different file each time it executes. A file pointer points to a struct of type FILE that represents a stream.
The FILE structure to which a file pointer points contains information about the file. This will be such things as whether you want to read or write or update the file, the address of the buffer in memory to be used for data, and a pointer to the current position in the file for the next operation. You don’t need to worry about the contents of this structure in practice. It’s all taken care of by the input/output functions. However, if you really want to know all the gory details of the FILE structure , you will find them in the code for the stdio.h library header file.
I’ll be referring to a stream pointer that references a file as a file pointer in this chapter, but keep in mind that all the operations I describe in the context of file pointers apply to any data source or destination that can be treated as a stream. If you want to use several files simultaneously in a program, you need a separate file pointer for each file, although as soon as you’ve finished using one file, you can associate the file pointer you were using with another file. So if you need to process several files, but you’ll be working with them one at a time, you can do it with one file pointer.
Opening a File
The first argument to the function is a pointer to a string that is the name of the external file you want to process. You can specify the name explicitly as an argument, or you can use an array or a variable of type pointer to char that contains the address of the character string that defines the file name. You would typically obtain the file name through some external means, such as from the command line when the program is started, or you could arrange to read it in from the keyboard. Of course, you can also define a file name as a constant at the beginning of a program when the program always works with the same file.
File Modes
Mode | Description |
|---|---|
"w" | Open a text file for write operations. If the file exists, its current contents are discarded |
"a" | Open a text file for append operations. All writes are to the end of the file |
"r" | Open a text file for read operations |
Notice that a file mode specification is a character string between double quotes, not a single character between single quotes.
These three modes only apply to text files, which are files that are written as characters. We will discuss later on "More Open Modes for Text Files" about optional parameters that make life easier. You can also work with binary files that are written as a sequence of bytes, and I’ll discuss that in the section “Binary File Input and Output” later in this chapter. Assuming the call to fopen() is successful, the function returns a pointer of type FILE* that you can use to reference the file in further input/output operations using other functions in the library. If the file cannot be opened for some reason, fopen() returns NULL.
The pointer returned by fopen() is referred to as either a file pointer or a stream pointer.
A call to fopen() does two things: it creates a file pointer—an address—that identifies the specific file on a disk from the name argument you supply, and it determines what you can do with that file. As I mentioned earlier, when you want to have several files open at once, they must each have their own file pointer variable, and you open each of them with a separate call to fopen(). There’s a limit to the number of files you can have open at one time, which will be determined by the value of the symbol FOPEN_MAX that’s defined in stdio.h. The C standard requires that the value of FOPEN_MAX be at least eight, including stdin, stdout, and stderr, so as a minimum you will be able to be working with up to five files simultaneously, but typically it’s many more, often 256, for example.
You need to define the symbol __STDC_WANT_LIB_EXT1__ as 1 to use this function. The function fopen_s() is a little different from fopen(). The first parameter is a pointer to a pointer to a FILE structure, so you pass the address of your FILE* variable that is to store the file pointer as the first argument. The function will verify that the last two arguments you pass are not NULL, and it will fail if either is. It returns a value of type errno_t , which indicates how the operation went. Type errno_t is an integer type that is defined by a typedef in stdio.h, often as equivalent to type int. The function returns 0 if everything went well and a nonzero integer if it was unable to open the file for some reason. In the latter case, the file pointer will be set to NULL.
You can use the same mode strings with this function as with fopen(), but you can optionally begin the mode strings with u, so they can be "uw" when you want to write a file or "ua" when you want to append to a file. Whether or not concurrent access to a file is permitted is controlled by your operating system, and you can influence this where your operating system allows it. With the set of modes without the u, you open a file with exclusive access; in other words, you are the only one who can access the file while it is open. Adding the u to the file mode string causes a new file to have system default file permissions when it is closed. I’ll be using fopen_s() in the examples from here on. The security issues with using fopen() are not huge, but undoubtedly it is better to use the safer version.
Write Mode
This opens the file and associates the file with the name myfile.txt with your file pointer pfile. Because you’ve specified the mode as "w", you can only write to the file; you can’t read it. The string you supply as the first argument is limited to a maximum of FILENAME_MAX characters, where FILENAME_MAX is defined in the stdio.h. This value is usually large enough that it isn’t a real restriction.
If a file with the name myfile.txt does not exist, the call to fopen_s() in the previous statement will create a new file with this name. Because you have just provided the file name without any path specification as the second argument to the function, the file is assumed to be in the current directory; if the file is not found there, that’s where it will be created. You can also specify a string that is the full path and name for the file, in which case the file will be assumed to be at that location and a new file will be created there if necessary. Note that if the directory that’s supposed to contain the file doesn’t exist when you specify the file path, neither the directory nor the file will be created, and the fopen_s() call will fail. If the call to fopen_s() does fail for any reason, a nonzero integer will be returned, and pfile will be set to NULL. If you then attempt further operations with a NULL file pointer, it will cause your program to terminate.
You now know how to create a new text file. Simply call fopen_s() with mode "w" and the second argument specifying the name you want to assign to the new file.
On opening a file for writing, the file length is truncated to zero, and the position will be at the beginning of any existing data for the first operation. This means that any data that were previously written to the file will be lost and overwritten by any write operations.
Append Mode
I won’t test the return value each time in code fragments, but don’t forget that you should. When you open a file in append mode, all write operations will be at the end of the data in the file on each write operation. In other words, all write operations append data to the file, and you cannot update the existing contents in this mode.
Read Mode
You have specified the mode argument as "r", indicating that you want to read the file, so you can’t write to this file. The file position will be set to the beginning of the data in the file. Clearly, if you’re going to read the file, it must already exist. If you inadvertently try to open a file for reading that doesn’t exist, fopen_s() will set the file pointer to NULL and return a nonzero value. You should always check the value returned from fopen_s() to make sure you really are accessing the file you want.
Buffering File Operations
The first parameter is the file pointer to an open file. You can only call setvbuf() to determine the buffering before you have performed any other operation with the file pointed to by the first argument. The second parameter specifies an array that is to be used for buffering, and the fourth parameter is the size of the array. If you specify NULL as the second argument, setvbuf() will allocate a buffer for you with the size you specify as the fourth argument. Unless you have a good reason not to, I recommend always specifying the second argument as NULL because then you don’t have to worry about creating the buffer or its lifetime.
_IOFBF causes the file to be fully buffered. When input and output is fully buffered, data are written or read in blocks of arbitrary size.
_IOLBF causes operations to be line buffered. When input and output is line buffered, data are written or read in blocks terminated by a newline.
_IONBF causes input and output to be unbuffered. With unbuffered input and output, data are transferred character by character. This is extremely inefficient, so you would only use this mode when it was essential.
Note that you must ensure that your buffer continues to exist as long as the file is open. This implies that you must take great care when you use an automatic array that will expire at the end of the block in which you create it. If the second argument to setbuf() is NULL, the file operations will not be buffered.
Renaming a File
The integer that’s returned will be 0 if the name change was successful and nonzero otherwise. The file must not be open when you call rename(); otherwise, the operation will fail.
This will change the name of myfile.txt in the temp directory on drive C to myfile_copy.txt. A message will be produced that indicates whether the name change succeeded. Obviously, if the file path is incorrect or the file doesn’t exist, the renaming operation will fail.
Note the double backslash in the file path string. If you forget to use the escape sequence for a backslash when specifying a Microsoft Windows file path, you won’t get the file name you want.
Closing a File
The result of calling fclose() is that the connection between the pointer, pfile, and the physical file is broken, so pfile can no longer be used to access the file it represented. If the file was being written, the current contents of the output buffer are written to the file to ensure that data are not lost. It’s good practice to always set the file pointer to NULL when you have closed a file.
EOF is a special character called the end-of-file character. In fact, the symbol EOF is defined in stdio.h as a negative integer that is usually equivalent to the value –1. However, it isn’t necessarily always this value, so you should use EOF rather than an explicit value. EOF indicates that no more data are available from a stream.
It’s good programming practice to close a file as soon as you’ve finished with it. This protects against output data loss, which could occur if an error in another part of your program caused the execution to be stopped in an abnormal fashion. This could result in the contents of the output buffer being lost, as the file wouldn’t be closed properly. You must also close a file before attempting to rename it or remove it.
Another reason for closing files as soon as you’ve finished with them is that the operating system will usually limit the number of files you may have open at one time. Closing files as soon as you’ve finished with them minimizes the chances of you falling foul of the operating system in this respect.
The fflush() function returns a value of type int, which is normally 0 but will be EOF if an error occurs.
Deleting a File
This will delete the file that has the name myfile.txt from the current directory. Note that the file cannot be open when you try to delete it. If the file is open, the effect of calling remove() is implementation defined, so consult your library documentation. You always need to double-check any operations on files, but you need to take particular care with operations that delete files. You could wreck your system if you don’t.
Writing a Text File
Once you’ve opened a file for writing, you can write to it anytime from anywhere in your program, provided you have access to the file pointer that has been set by fopen_s(). So if you want to be able to access a file from anywhere in a program that contains multiple functions, either you need to ensure the file pointer has global scope or you must arrange for it to be passed as an argument to any function that accesses the file.
As you’ll recall, to ensure that the file pointer has global scope, you place its declaration outside all of the functions, usually at the beginning of the source file.
The function writes the character specified by the first argument to the file identified by the second argument, which is a file pointer. If the write is successful, it returns the character that was written; otherwise, it returns EOF.
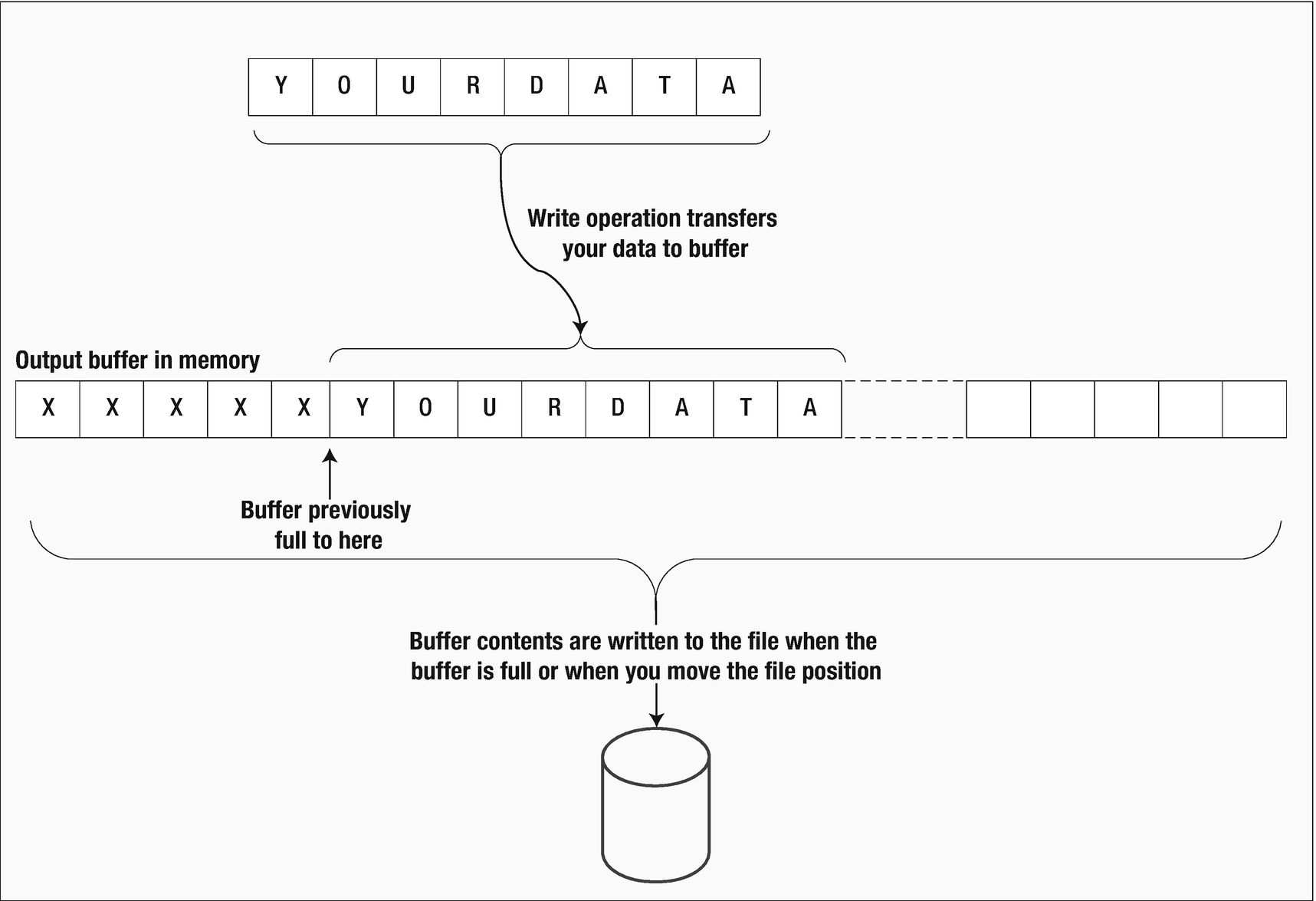
Writing a file
Note that the putc() function is equivalent to fputc() . It requires the same arguments, and the return type is the same. The difference between them is that putc() may be implemented in the standard library as a macro, whereas fputc() is definitely a function.
Reading a Text File
The mchar is type int because EOF will be returned if the end of the file has been reached. EOF is a negative integer that cannot be returned or stored as type char when char is an unsigned type. Behind the scenes, the actual mechanism for reading a file is the inverse of writing to a file. A whole block of characters is read into a buffer in one go. The characters are then handed over to your program one at a time as you request them, until the buffer is empty, whereupon another block is read. This makes the process very fast, because most fgetc() operations won’t involve reading the file but simply moving a character from the buffer in main memory to the place where you want to store it.
Note that the function getc(), which is equivalent to fgetc(), is also available. It requires an argument of type FILE* and returns the character read as type int, so it’s virtually identical to fgetc(). The only difference between them is that getc() may be implemented as a macro, whereas fgetc() is a function. This is a deja vu of Chapter 10, where we declared getc, getchar, and ungetc(); the last one put a character back to the stream, and this time the stream is a file that must be provided as an argument. Then the following call will retrieve that char.
Of course, pfile must correspond to a file that is open.
How It Works
This statement defines the file with the name myfile.txt in the current directory. If you want to locate it somewhere else, add the file path. As I noted earlier, you must use the escape sequence '' to get a backslash character. If you forget to do this and just use a single backslash, the compiler will think that you’re writing an escape sequence, which it won’t recognize as valid.
Before running this program—or indeed any of the examples working with files—make sure you don’t have an existing file with the same name and path. If you have a file with the same name as that used in the example, you should change the initial value for filename in the example; otherwise, your existing file will be overwritten.
The condition in this if statement calls fopen_s() to create the new file myfile.txt in the current directory, opens it for writing, and stores the file pointer in pfile. The third argument determines the mode as writing the file. The block of statements will be executed if fopen_s() returns a nonzero integer, so in this case you display a message and call the exit() function that is declared in stdlib.h for an abnormal end to the program.
We have limited keyboard input to a total of LENGTH characters, so BUFSIZ for the size of the output buffer will be more than enough.
The loop index is varied from a value corresponding to the last character in the string back to 0. Therefore, the fputc() function call within the loop writes to the new file character by character, in reverse order. The particular file you’re writing is specified by pfile as the second argument to fputc(). This is a situation where you don’t want to use a control variable of type size_t, although you do use it to index an array. Ending the loop depends on the control variable being less than 0, and this is not possible with size_t because it’s an unsigned type.
The mode specification "r" indicates that you intend to read the file, so the file position will be set to the beginning of the file. You have the same check for a nonzero return value as when you wrote the file.
The file is read character by character. The read operation takes place within the loop continuation condition. As each character is read, it’s displayed on the screen using the function putchar() within the loop. The process stops when EOF is returned by fgetc() at the end of the file.
These provide the necessary final tidying up, now that you’ve finished with the file. After closing the file and resetting the file pointer to NULL, the program calls the remove() function , which will delete the file identified by the argument. This avoids cluttering up the disk with stray files. If you want to check the contents of the file that was written using a text editor, you can remove or comment out the call to remove().
Reading and Writing Strings to a Text File
The function reads a string into the memory area pointed to by str, from the file specified by pfile. Characters are read until either an ' ' is read or nchars-1 characters have been read from the stream, whichever occurs first. If a newline character is read, it’s retained in the string. A '�' character will be appended to the end of the string in any event. If there is no error, fgets() returns the pointer, str; otherwise, NULL is returned. Reading EOF causes NULL to be returned.
The first argument is a pointer to the character string that’s to be written to the file, and the second argument is the file pointer. The operation of the function is slightly odd in that it continues to write characters from a string until it reaches a '�' character, which it doesn’t write to the file. This can complicate reading back variable-length strings from a file that have been written by fputs(). It works this way because it’s a character-write operation, not a binary-write operation, so it’s expecting to write a line of text that has a newline character at the end. A newline character isn’t required by the operation of the function, but it’s very helpful when you want to read the file back using fgets(), as you’ll see.
This will output the string appearing as the first argument to the file pointed to by pfile.
How It Works
You specify the three sayings as initial values for the array elements, and this causes the compiler to allocate the space necessary to store each string. Each string is terminated with a newline character.
The contents of each of the memory areas pointed to by elements of the proverbs[] array are written to the file in the for loop using fputs(). This function is extremely easy to use; it just requires a pointer to the string as the first argument and a pointer to the file as the second. You test the return value for EOF because that indicates something went wrong.
You call setvbuf() to buffer output operations with an internal buffer. Because you have the open mode specified as "a", the file is opened in append mode. The current position for the file is automatically set to the end of the file in this mode, so subsequent write operations will be appended to the end of the file.
Each additional proverb that’s stored in the more array is written to the file using fputs(). You always expect trouble with file operations, so you check for EOF being returned. Because you’re in append mode, each new proverb will be added at the end of the existing data in the file. The loop terminates when an empty line is entered. An empty line will result in a string containing just ' ' followed by the string terminator.
Here, more is used as the format string. This will work most of the time, but it is not a good idea. If the user includes a % in a proverb that is stored in more, things will go wrong.
The reading of each proverb by fgets() is terminated by detecting the ' ' character at the end of each string. The loop terminates when the function fgets() returns NULL, which will be when EOF is reached. Finally, the file is closed and then deleted using remove() in the same fashion as the previous example.
Formatted File Input and Output
Writing characters and strings to a text file is all very well as far as it goes, but you normally have many other types of data in your programs. To write numerical data to a text file, you need something more than you’ve seen so far, and where the contents of a file are to be human readable, you need a character representation of the numerical data. The mechanism for doing just this is provided by the functions for formatted file input and output.
Formatted Output to a File
The difference between this and the prototype for printf_s() is the first parameter that identifies the output stream. You specify the format string according to the same rules as for printf_s(), including the conversion specifiers. The function returns the number of characters written to the stream when everything works as it should or a negative integer when it doesn’t.
This example writes the values of the three variables num1, num2, and pi to the file specified by the file pointer pfile, under control of the format string specified as the second argument. The first two variables are of type int and are written with a field width of 12, and the third variable is of type float and is written with a field width of 14. Thus, this will write 38 characters to myfile.txt, overwriting any existing data that are in the file.
Formatted Input from a File
This function works in exactly the same way scanf_s() does with stdin, except here you’re obtaining input from a stream specified by the first argument. The same rules govern the specification of the format string and the operation of the function as apply to scanf_s(). The function returns EOF when things go wrong or the end of file is reached or the number of input items assigned values when the operation is successful.
The fscanf_s() function would return 3 when this works, as it should because three values are stored.
How It Works
This example writes the values of num1, num2, and num3 to the file myfile.txt in the current directory. You reference the file through the pointer pfile . The file is closed and reopened with mode "r" for reading, and the values are read from the file in the same format as they are written but stored in num4, num5, and num6. It’s a relief that these values are identical to num1, num2, and num3.
This statement moves the current file position back to the beginning of the file so you can read it again. You could have achieved the same thing by closing the file and then reopening it again, but with rewind() you do it with one function call, and the operation will be a lot faster.
This reads the same data from the file into elements of the ival array and the floating-point variable fnum, but with different formats from those used for writing the file. You can see from the output that the file contents are just a string of characters once it has been written, exactly the same as the output to the screen would be from printf_s().
Note You can lose information when you write a text file if you choose a format specifier that outputs fewer digits’ precision than the stored value holds.
The values you get back from a text file when you read it will depend on both the format string you use and the variable list you specify in the fscanf_s() function.
None of the intrinsic source information that existed when you wrote the file is necessarily maintained. Once the data are in the file, it’s just a sequence of bytes in which the meaning is determined by how you interpret them. This is demonstrated quite clearly by this example, in which you’ve converted the original three values into seven new values. To make sense of the data in a file, you must know how they were written.
Lastly, you leave everything neat and tidy in this program by closing the file and using the function remove() to delete it.
Dealing with Errors
The examples in this book have included minimal error checking and reporting because the code for comprehensive error checking and reporting tends to take up a lot of space and makes programs look rather more complicated than they really are. In real-world programs, however, it’s essential that you do as much error checking and reporting as you can.
The merit of writing to stderr is that the output will always be directed to the command line and it will always be written immediately to the display device. This means you will always see the output directed to stderr, as long as you have not reassigned stderr to another destination. The stdin stream is buffered, so there is the risk that data could be left in the buffer and never displayed if your program crashes. Terminating a program by calling exit() ensures that output stream buffers will be flushed so output will be written to the ultimate destination.
As seen in Chapter 9, a good practice is to use the macros provided by stdlib.h because various operating systems may expect different return values (most are 1 or 0 based on UNIX design). Since ANSI C, macros EXIT_FAILURE and EXIT_SUCCESS were included to use with exit().
The error-specific message string will be appended to the string you supply as the argument and separated from it by a colon. If you just want the error message, you pass NULL to the function.
I didn’t write the message to stderr here because reaching the end of the file isn’t necessarily an error.
The errno.h header file defines a value of type int with the name errno that may indicate what kind of file error has occurred. You need to read the documentation for your C implementation to find out the specifics of what the error codes are. The value of errno may be set for errors other than just file operations.
You should always include some basic error checking and reporting code in all of your programs. Once you’ve written a few programs, you’ll find that including some standard bits of code for each type of operation warranting error checks is no hardship. With a standard approach, you can copy most of what you need from one program to another.
More Open Modes for Text Files
Text mode is the default mode of operation with the open modes you have seen up to now, but in earlier versions of C, you could specify explicitly that a file is to be opened in text mode. You could do this by adding t to the end of the existing specifiers. This gives you the mode specifiers "wt", "rt", and "at" in addition to the original three. I am only mentioning this because you may come across it in other C programs. Although some compilers support this, it’s not specifically part of the current C standard, so it is best not to use this option in your code.
Open Modes for Use with fopen_s()
Mode | Description |
|---|---|
"r" | Open a text file to read it |
"r+" | Open a text file to read and write it |
"w" | Open or create a text file to write it. If the file exists, its length is truncated to zero so the contents will be overwritten |
"wx" | Create and open a text file to write it with nonshared access |
"w+" | Truncate an existing text file to zero length and open it for update. If the file does not exist, create it and open it for updating |
"w+x" | Create a text file for updating with nonshared access |
"a" | Open or create a text file to append to it. All writes will be to the end of the file |
"a+" | Open or create a text file for update, with all writes adding data at the end of the file |
Note that nonshared access can only be specified when you create a new file. Opening an existing file with a mode string that includes "x" will fail. When you open a file to append to it (a mode string containing "a"), all write operations will be to the end of the file, regardless of the current file position.
When you open a file to update it (a mode string containing "+"), you can read and write to the file. However, an input operation that immediately follows an output operation must be preceded by a call to fflush() or to a function that changes the file position. This ensures that the output buffer is flushed before the read operation. When you want to write to a file immediately following a read operation, there must be a call to a file positioning function preceding the write unless the file position is at the end of the file. The functions that change the file position are rewind(), which you know about, and fseek() and fsetpos(), which you’ll learn about later in this chapter.
The freopen_s( ) Function
When filename is NULL, the function will attempt to change the mode for the stream specified by the fourth argument, stream, to mode. Which mode changes are possible depends on your C implementation.
When filename is not NULL, the function first tries to close the file pointed to by stream. It then opens the file and associates the existing stream passed as the fourth argument, stream, with the file. The stream pointer is stored in pNew when the operation is successful. When it fails, pNew will be set to NULL. As with fopen_s(), the return value is 0 when everything goes according to plan and a nonzero integer when an error occurs.
After executing this fragment, pOut contains the stream pointer stdout, and this is now associated with myfile.txt, so all subsequent output to stdout will be written to myfile.txt. When you want to use a program that normally reads from stdin to accept input from a file, you can use freopen_s() to reassign stdin to the file in a similar way. Clearly the file must already exist and contain suitable input data when you do this.
Binary File Input and Output
The alternative to text mode operations on a file is binary mode . In this mode, no transformation of the data takes place, and there’s no need for a format string to control input or output, so it’s much simpler than text mode. The binary data as they appear in memory are transferred directly to the file. Characters such as ' ' and '�' that have specific significance in text mode are of no consequence in binary mode.
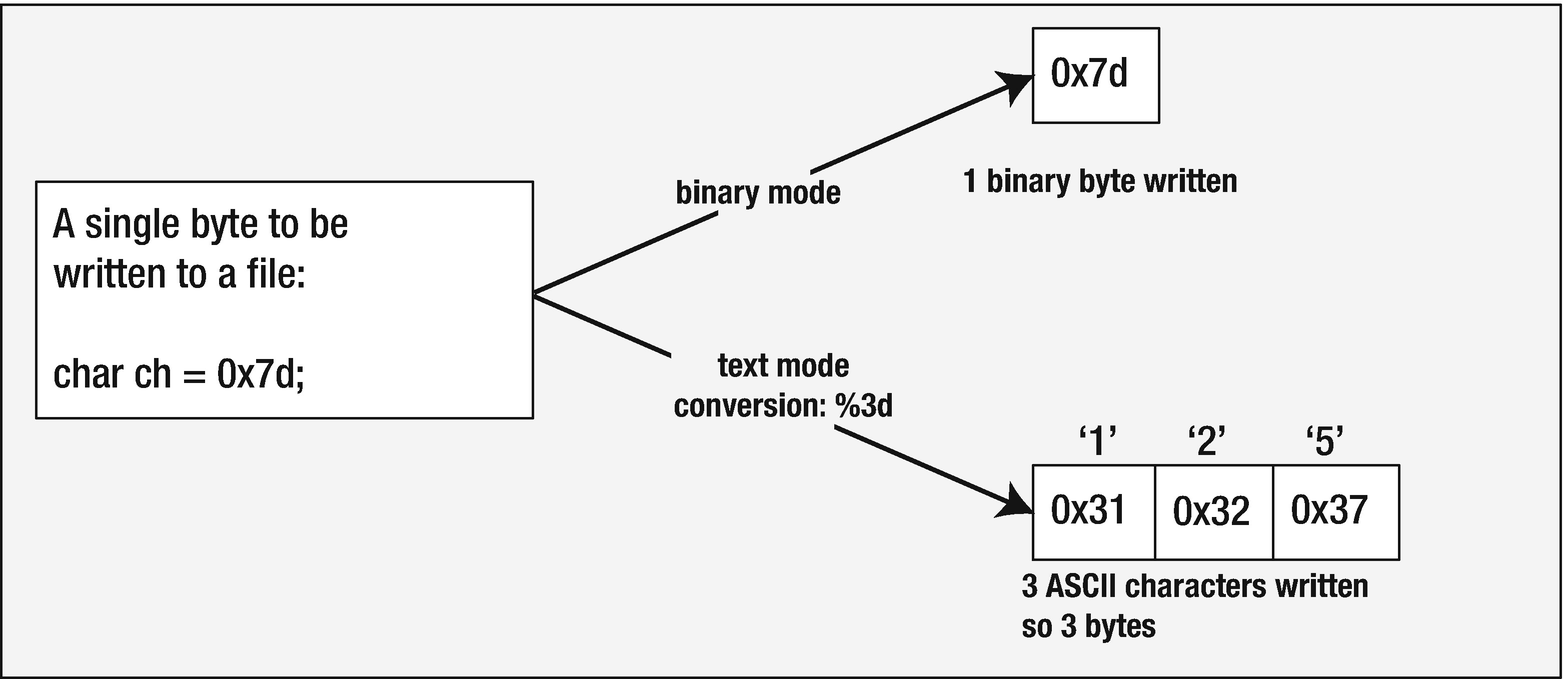
Contrasting binary mode and text mode
Opening a File in Binary Mode
Mode Strings for Binary Operations
"rb" | Open a binary file to read it |
"rb+" or "r+b" | Open a binary file to read and write it |
"wb" | Open or create a binary file to write it. If the file exists, its length is truncated to zero so the contents will be overwritten |
"wbx" | Create and open a binary file to write it with nonshared access |
"wb+" or "w+b" | Truncate an existing binary file to zero length and open it for update. If the file does not exist, create it and open it for updating |
"wb+x" or "w+bx" | Create a binary file for updating with nonshared access |
"ab" | Open or create a binary file to append to it. All writes will be to the end of the file |
"ab+" or "a+b" | Open or create a binary file for update, with all writes adding data at the end of the file |
Because binary mode involves handling the data to be transferred to and from the file in a different way from text mode, you have a new set of functions to perform input and output.
Writing a Binary File
The first parameter is the address of an array of data items to be written. With a parameter type void*, any type of array can be passed as the argument to the function. The second parameter is the size of an array element, and the third parameter is the number of array elements. The last parameter is the pointer to the file stream. The integer returned is the number of items written. This will be less than nitems if a write error occurs that prevents all of the data from being written. If size or nitems is 0, nothing is written to the file.
The fwrite() function operates on the principle of writing a specified number of binary data items to a file, where each item is a given number of bytes. This writes all of the data array to the file. Note that there is no check that you opened the file in binary mode when you call fwrite(). The write operation will write binary data to a file you open in text mode. Equally, there is nothing to prevent you from writing text data to a binary file. Of course if you do this, a considerable amount of confusion is likely to result.
Because fwrite() is geared toward writing a number of binary objects of a given length to a file, you can write in units of your own structures as easily as you can write values of type int or double or sequences of individual bytes. This doesn’t mean that the data items you write in any given output operation all have to be of the same type. You might allocate some memory using malloc(), for instance, into which you assemble a sequence of data items of different types and lengths. You could then write the whole block of memory to a file in one go as a sequence of bytes. Of course, when you come to read them back, you need to know the precise sequence and types for the values in the file if you are to make sense of them.
Reading a Binary File
The parameters are the same as for fwrite(): pdata is the address of an array into which the data items are to be read, size is the number of bytes per item, nitems is the number of items to be read, and pfile is the file pointer.
This operates exactly inverse of the write operation. Starting at the address specified by data, the function reads num_items objects, each occupying the number of bytes specified by the second argument. The function returns the count of the number of items that were read. If the read isn’t completely successful, the count will be less than the number of objects requested.
You can apply binary file operations in a version of Program 7.11 that calculates primes. This time, you’ll use a file as a buffer to allow a much larger number of primes to be produced. You can make the program automatically spill primes into a disk file if the array assigned to store the primes is insufficient for the number of primes requested. In this version of the program to find primes, you’ll improve the checking process a little.
In addition to the main() function, which will contain the prime finding loop, you’ll write a function to test whether a value is prime called is_prime() , a helper function that will check a given value against a block of primes called check(), a function called list_primes() that will retrieve the primes from the file and display them, and another helper function that lists primes in the array in memory.
After the symbol definition to make optional functions accessible and the usual #include directives, you define symbols for the number of primes to be output per line and the number of primes to be stored in memory. By making the latter a multiple of the number per line, you make it easier to manage outputting the primes stored in a file.
Next, you have the prototypes for the functions used in the program. Function prototypes can be written with or without parameter names, but the parameter types must be specified. Generally, it’s better to include names, because they give a clue to the purpose of the parameters. The names in the prototype can be different from the names used in the definition of the function, but you should only do this if it helps to make the code more readable. To allow the maximum range of possible prime values, you store them as values of type unsigned long long.
The prototypes are followed by the definition of an anonymous struct that contains global variables as members. The instance of the structure must be defined in the same statement as the struct type definition because this is an anonymous struct. By defining global variables as members of the global structure object, you minimize the risk of conflicts with local variable names because the global variables must be qualified with the name of the structure object to which they belong. You initialize the members of global using the notation that identifies the member names. They are in order of their appearance in the structure type definition, but they don’t have to be.
The members of the struct are filename, which points to the name of the file that will store primes; the file stream pointer, pfile; the primes array, which will hold up to MEM_PRIMES values in memory; and count, which records the current number of elements in the primes array that have values.
How It Works
The first statement stores the prime you’ve found in the global.primes array. You keep track of how many primes you have so far with the variable num_primes, and this value controls the outer while loop. The struct member variable global.count records how many you have in memory at any given time so you can tell when the array is full.
If you’ve filled the global.primes array, the if condition will be true, and you’ll call write_file(), which you’ll implement to write the contents of the global.primes array to the file. The function can use global.count to determine how many elements must be written out.
When the while loop ends because the required number of primes have been found, there may be primes stored in the global.primes array. A file will only have been written if more primes were required than the capacity of the global.primes array. If this were the case and a file exists and there are primes left in the array, you call write_file() to write them to the file. You’ll implement the list_primes() function to output the primes so that it will either read the primes from the file if it exists using global.primes as a buffer or just list the primes in the global.primes array.
If it is necessary to write a file, global.pfile will be non-NULL, so you can use this to determine when there is a file to delete before the program ends.
The if statement determines whether there is a file containing primes by checking global.pfile. When this is not NULL, the file is opened, and primes are read from the file into the local array, buffer, in the while loop. The while loop condition is the negation of the value returned by feof(). The feof() returns true when the end of file has been read, so this indicates the entire file has been read and the loop will end. The check() function that is called in the loop tests n against the primes in buffer.
The last step after the loop ends is to check division by any primes that are in memory, again using check(). These are checked last because these are the latest and largest primes discovered.
The function returns 1 if n is prime, 0 if it is not prime, and -1 if further checks may be necessary. The function determines whether n is prime by dividing n by each of the primes in the array that are less than the square root of n. You don’t need to try values greater than this because if a value greater than the square root divides into n, the result will be a factor that is less than the square root, which you will already have tried. If any existing prime divides exactly, the process ends by returning 0 because n is clearly not prime. If none of the existing primes up to the square root of n divide into n exactly, n must be prime, so 1 is returned. If all the primes in the array have been checked, the result is not determined because there may be more divisors that need to be tried, so -1 is returned.
You open the file in binary mode to append data. The first time this occurs, a new file will be created. On subsequent calls of fopen_s(), the existing file will be opened with the current position set at the end of the data in the file, ready for the next block to be written. After writing a block, the file is closed, because you’ll want to open it in read mode in the is_prime() function that checks prime candidates. When the contents of the array have been safely stowed in the file, the count of the number of primes in memory is reset to 0.
It first checks whether there is a file. If global.pfile is NULL, then there is no file, and all the primes are in the global.primes array, so you just call list_array() to list them and you are done. When there is a file, you open it in read mode. You then read primes from the file into global.primes in the while loop and call list_array() to list the contents. The fread() function returns the number of primes read, so global.count will always reflect the number of primes in the global.primes array. The loop continues until the end-of-file indicator is set, which will result in feof() returning true.
This requires little explanation. The for loop lists however many primes there are in the global.primes array with PER_LINE primes on each output line.
Moving Around in a File
For many applications, you need to be able to access data in a file other than in the sequential order you’ve used up to now. You can always find some information that’s stored in the middle of a file by reading from the beginning and continuing in sequence until you get to what you want. But if you’ve written a few million items to the file, this may take some time.
Of course, to access data in random sequence requires that you have some means of knowing where the data that you would like to retrieve are stored in the file. Arranging for this is a complicated topic in general. There are many different ways to construct pointers or indexes to make direct access to the data in a file faster and easier. The basic idea is similar to that of an index in a book. You have a table of keys that identify the contents of each record in the file you might want, and each key has an associated position in the file defined that records where the data are stored. Let’s look at the basic tools in the library that you need to enable you to deal with this kind of file input and output.
You cannot update a file in append mode. Regardless of any operations you may invoke to move the file position, all writes will be to the end of the existing data.
File Positioning Operations
There are two aspects to file positioning : finding out where you are in a file and moving to a given point in a file. The former is basic to the latter: if you never know where you are, you can never decide how to get to where you want to go; this doesn’t just apply to files!
You can access a file at a random position regardless of whether you opened the file concerned in binary mode or in text mode. However, accessing text mode files randomly can get rather complicated in some environments, particularly Microsoft Windows. This is because the number of characters recorded in the file can be greater than the number of characters you actually write to the file. This is because a newline (' ' character) in memory, which is a single byte, can translate into two characters when written to a file in text mode (a carriage return character, CR, followed by a linefeed character, LF). Of course, your C library function for reading the information sorts everything out when you read the data back. A problem only arises when you think that a point in the file is 100 bytes from the beginning. When you write 100 characters to a file in text mode under Microsoft Windows, the number of bytes actually appearing in the file depends on how many newline characters it includes; it will only be 100 bytes if there are no newline characters. If you subsequently want to overwrite the data with different data that are the same length in memory as the original, it will only be the same length as the existing data in the file if it contains the same number of ' ' characters. Thus, writing to text files randomly is best avoided. For this reason, I’ll sidestep the complications of moving about in text files and concentrate the examples on the much more useful—and easier—context of randomly accessing the data in binary files.
Finding Out Where You Are
The fpos variable now holds the current position in the file; and, as you’ll see, you can use this to return to this position at any subsequent time. The value is the offset in bytes from the beginning of the file.
The first parameter is your old friend, the file pointer. The second parameter is a pointer to a type that’s defined in stdio.h, fpos_t, which will be a type that is able to record every position within a file. On my system it is a structure. If you’re curious about what type fpos_t is on your system, then have a look at it in stdio.h.
This records the current file position in the variable here that you have defined. You’ll be able to use this to return to this position later.
Note that you must declare a variable of type fpos_t. It’s no good just declaring a pointer of type fpos_t* because there won’t be any memory allocated to store the position data.
Setting a Position in a File
The first parameter is a pointer to the file you’re repositioning. The second and third parameters define where you want to go in the file. The second parameter is an offset from a reference point specified by the third parameter. The reference point can be one of three values that are specified by the predefined names SEEK_SET, which defines the beginning of the file; SEEK_CUR, which defines the current position in the file; and SEEK_END, which, as you might guess, defines the end of the file. SEEK_END may not be supported for binary files. Of course, all three values are defined in stdio.h.
For a text mode file, the second argument must be a value returned by ftell() if you’re to avoid getting lost. The third argument for text mode files must be SEEK_SET. So for text mode files, all operations with fseek() are performed with reference to the beginning of the file.
For binary files, the offset argument is simply a relative byte count. You can therefore supply positive or negative values for the offset when the reference point is specified as SEEK_CUR.
The first parameter is a pointer to the open file, and the second is a pointer of the type you can see, where the position that is stored at the address was obtained by calling fgetpos().
The variable here was previously set by a call to fgetpos(). The fsetpos() returns a nonzero value on error or 0 when it succeeds. Because this function is designed to work with a value that is returned by fgetpos(), you can only use it to get to a place in a file that you’ve been before, whereas fseek() allows you to go to any position just by specifying the appropriate offset.
Note that the verb seek is used to refer to operations of moving the read and write heads of a disk drive directly to a specific position in the file. This is why the function fseek() is so named.
With a file that you’ve opened for update by specifying the mode as "rb+" or "wb+", for example, either a read or a write may be safely carried out on the file after executing either of the file positioning functions, fsetpos() or fseek(). This is regardless of what the previous operation on the file was.
To exercise your newfound skills with files, you can create a program to keep a dossier on family members. You’ll create a file containing data on all family members, and then you’ll process the file to output data on each member and that member’s parents. The structures used in the example only extend to a minimum range of data on family members. You can, of course, embellish these to hold any kind of scuttlebutt you like on your relatives.
The first structure has no type name, so it’s an anonymous structure. This contains members that store the file name that will store family data and the file pointer for use with file operations.
The second structure represents a date as a day, month, and year. The statement combines the definition of the type, struct Date, and the definition of the type name Date as equivalent to struct Date.
The third structure definition statement also incorporates the typedef. It defines struct Family with the four members you see and Family as the equivalent type name. You are able to specify dob as type Date because of the preceding typedef.
How It Works
There are six functions in addition to main() . The getname() function will read a name from stdin and store it in the name array that is passed as the first argument. The get_person() function will read data on a family member from stdin and store it in a Family object that is accessed through the pointer argument. The show_person_data() function will output information about all the family members in the file. The get_parent_dob() function will search the file for the dates of birth of the parents. The open_file() function packages up the code to open a file in any mode. The close_file() function just closes the file and sets the file pointer to NULL. This is a very short function, so it is inline.
The basic idea of the program is that it will read data on as many family members as you like. For each it will record a name, a date of birth, and the names of both parents. When input is complete, it will list each of the family members in the file. For each family member, it will attempt to discover the date of birth for both parents. This provides an opportunity for searching the file and leaving its position in an arbitrary state and then seeking to recover the position. Obviously, unless the family history is very strange, the data are bound to be incomplete. Thus, some members will have parents who are not in the file, and therefore their dates of birth will not be known.
You use fgets() to read a name because this allows spaces to be included in the input. The first parameter is a pointer to the char array where the name is to be stored, and the second is the size of the array. If the input exceeds size characters, including the terminating null, the name will be truncated. You don’t need the newline that fgets() stores, so you overwrite it with a null terminator.
The parameter is the address of a Family object for which parents’ birth dates are to be found. To find the parents for a family member, the function must read records from the file starting at the beginning. Before rewinding the file, you store the current file position in current by calling fgetpos(). This will allow the file position to be restored by calling fsetpos() before returning to the calling function, so the calling function will never know that the file position has been moved.
The file is read from the beginning in the while loop. You check each record to see if it corresponds with a parent of the Family object pointed to by pmember. If it does, you output the data. As soon as both parents have been found, you exit the loop. The printf_s() call following the loop writes a newline if at least one parent was found or a message if no parents were found. The fsetpos() call restores the file to the way it was at the start. Of course, the function could be written equally well using ftell() and fseek() as positioning functions.
The function first checks for global.pfile being non-NULL, in which case close_file() is called to close the file and reset global.pfile to NULL. This ensures we won’t have a file handle leak if we were to call open_file() more than once in the program.
As in the previous examples in this chapter, the program uses a specific file name, and the file is deleted at the end of the program execution.
There’s a way to create temporary files that saves you the trouble of deleting files when you only need them during program execution, so let’s look into that next.
Using Temporary Work Files
Very often you need a work file just for the duration of a program. You use it only to store intermediate results, and you can throw it away when the program is finished. The program that calculates primes in this chapter is a good example; you really only need the file during the calculation. You have a choice of two standard functions to help with temporary file usage, plus optional improved versions. Each has advantages and disadvantages.
Creating a Temporary Work File
The function takes no arguments and returns a pointer to the temporary file. If the file can’t be created for any reason—for example, if the disk is full—the function returns NULL. The binary file is created and opened for update, so it can be written and read, but obviously it needs to be in that order because you can only ever get out what you have put in. The file is automatically deleted on exit from your program, so there’s no need to worry about any mess left behind. You’ll never know what the file is called, and because it doesn’t last, this doesn’t matter.
The function will store the stream pointer for the temporary file in pfile or NULL if the file could not be created. Obviously, the address you pass as the argument must not be NULL. The function returns 0 if the file was created and a nonzero integer if it was not. You can create multiple temporary binary files. The maximum number is TMP_MAX for the standard function or TMP_MAX_S for the optional version. Both are defined in stdio.h.
Creating a Unique File Name
If the argument is NULL , the file name is generated in an internal static object, and a pointer to that object is returned. If you want the name stored in a char array that you create, it must be at least L_tmpnam characters long, where L_tmpnam is an integer constant that is defined in stdio.h. In this case, the file name is stored in the array that you specify as the argument, and a pointer to your array is also returned. If the function is unable to create a unique name, it will return NULL.
Because the argument to tmpnam() is NULL, the file name will be generated as an internal static object whose address will be returned and stored in filename. As long as filename is not NULL, you call fopen_s() to create the file with the mode "wb+". Of course, you can also create temporary text files.
Apart from the fact there is a possibility that tmpnam() may return NULL, you also no longer have access to the file name, so you can’t use remove() to delete the file.
The first argument is the address of the char array in which the name is to be stored, and this cannot be NULL. The second argument is the size of the filename array, which cannot be greater than RSIZE_MAX. The function creates a different name each time it is called. If the name could not be created for any reason, the function returns a nonzero integer; otherwise, it returns 0.
I chose the maximum file name length I am prepared to work with as 20. This could prevent tmpnam_s() from creating the name. If I want to be sure the array size will not be a constraint, I must define it with L_tmpnam_s elements. This time I created the file as a text file for update.
It is much better to use tmpfile_s() to create a temporary file, rather than tmpnam() or tmpnam_s(), and to create the file yourself. One reason is that it is possible that a file could be created by another program that is executing concurrently after you obtain a unique file name using tmpnam_s() but before you have created a file using the name. You also have to take care of removing the file at the end of the program when you create it. Of course, if you need a temporary text file, you have to create and manage it yourself. Remember, the assistance you’ve obtained from the standard library is just to provide a unique name. It’s your responsibility to delete any files created.
Updating Binary Files
The mode "r+b" or "rb+" opens an existing binary file for both reading and writing. With this open mode, you can read or write anywhere in the file.
The mode "w+b" or "wb+" truncates the length of an existing binary file to zero so the contents will be lost; you can then carry out both read and write operations but, obviously, because the file length is zero, you must write something before you can read the file. If the file does not exist, a new file will be created when you call fopen_s() with mode "wb+" or "w+b".
The mode "a+b" or "ab+" opens an existing file for update. This mode only allows write operations at the end of the file.
Although you can write each of the open modes for updating binary files in two ways, I prefer to always put the + at the end because for me it is more obvious that the + is significant and means update. We can first put together an example that uses mode "wb+" to create a new file, which we can then update using the other modes.
How It Works
Names and ages are read from the keyboard in a do-while loop . The loop ends when n or N is entered in response the prompt. The in the format string to scanf_s() causes whitespace to be skipped, so it ensures that a whitespace character is not read into answer.
This is necessary because the read operation for a single character that appears in the loop condition will leave a newline character in stdin on all loop iterations after the first. If you don’t get rid of this character, the read operation for the name will not work correctly because the newline will be read as an empty name string. As mentioned before, certain compilers may behave differently, and a while(((c = getchar()) != ' ') && c != EOF); should be used instead.
The names will vary in length, and you have basically two ways to deal with this. You can write the entire name array to the file each time and not worry about the length of a name string. This is simpler to code but means that there would be a lot of spurious data in the file. The alternative is to adopt the approach used in the example. The length of each name string is written preceding the name, so to read the file, you will first read the length and then read that number of characters from the file as the name. Note that the '�' string terminator is not written to the file, so you must add this at the end of each name string when you read the file back.
The loop allows as many records as you want to be added to the file because it continues as long as you enter 'y' or 'Y' when prompted. When the loop ends, you close the file and call the listfile() function, which lists the contents of the file on stdout. The listfile() function opens the file for binary read operations with the mode "rb". In this mode, the file pointer will be positioned at the beginning of the file, and you can only read it.
The call to fread() reads one item of sizeof(length) bytes into the location specified by &length. When the operation is successful, the fread() function returns the number of items read, but when the end of file is reached, the function will return less than the number requested because there are no more data to be read. Thus, when we reach the end of file, the loop will end.
The feof() function tests the end-of-file indicator for the stream specified by the argument and returns true if the indicator is set. Thus, when the end of file is reached, the break statement will be executed, and the loop will end.
Remember that the name in the file does not have a terminating '�' character, so you have to allow for that in the name array. Hence, you compare length + 1 with MAXLEN.
Changing the Contents of a File
This defines the struct and Record as a type name for struct Record. A Record object packages the name and age for a person. If we wrote Record objects to the file, the entire name array would be written, including unused elements, so a lot of space would be wasted in the file. We also would not encounter the problem of dealing with file records that vary in length, which is one of the things this example is about.
Make sure the directory exists before you run the example; otherwise, it will fail.
main(): Controls overall operation of the program and allows the user to select from a range of operations on the file.
list_file(): Outputs the contents of the file to stdout.
update_file(): Updates an existing record in the file.
write_file(): Operates in two modes: either writes a new file with records read from stdin or appends a record to the existing file.
get_person(): Reads data on a person from stdin and stores it in a Record object.
get_name(): Reads a name from stdin.
write_record(): Writes a record to the file at the current file position.
read_record(): Reads a record from the file at the current file position.
find_record(): Finds the record in the file with a name that matches input.
duplicate_file(): Reproduces the file replacing a single updated record. This function is used to update a record when the new record will be a different length from the record being replaced.

The hierarchy of function calls in Program 12.7
Creating a Record from Keyboard Input
The only slight complication is the need to deal with the ' ' that is stored by the fgets() function. If the input exceeds size characters, then the ' ' will still be in the input buffer and not stored in the array pointed to by pname, so you must check that it’s there. You’ll need to read a name at more than one location in the program, so packaging the operation in the get_name() function is convenient. Specifying the size of the pname array by the second parameter makes the get_name() function more general.
Writing a Record to a File
The first parameter is a pointer to a Record structure that has the name and age that are to be written to the file as members. The second argument is the file pointer.
It is the responsibility of the calling function to ensure that the file has been opened in the correct mode and the file position has been set appropriately. The function writes the length of the string to the file, followed by the string itself, excluding the terminating '�'. This is to enable the code that will read the file to determine first how many characters are in the name string. Finally, the age value is written to the file.
Reading a Record from a File
The file to be read is identified by the second parameter, a file pointer. Purely as a convenience, the return value is the address that is passed as the first argument.
Like the write_record() function, read_record() assumes the file has been opened with the correct mode specified and attempts to read a record from the current position. Each record starts with a length value that is read first. Of course the file position could be at the end of the file, so you check for EOF by calling feof() with the file pointer as the argument after the read operation. If it is the end of file, the feof() function returns a nonzero integer value, so in this case you return NULL to signal the calling function that EOF has been reached.
If all is well, the name and age are read from the file and stored in the members of the record object. A '�' is appended to the name string to avoid disastrous consequences when working with the string subsequently.
Writing a File
The parameter is the file open mode to be used. With "wb+" as the mode, the function will write to a file discarding any existing contents or create a new file if it does not already exist. If the mode is "ab+", records will be appended to an existing file, or a new file will be created if there isn’t one already.
After opening the file with the mode passed as the argument, the function writes the file in the do-while loop. Reading from stdin and writing to the file are done in the single statement that calls write_record() with a call to get_person() as the first argument. The get_person() returns the address that is passed to it, and this is passed directly as the first argument to the write_record() function. The operation ends when the user enters anything other than 'y' or 'Y' to indicate that no more data are to be entered. The file is closed before returning from the function.
Listing the File Contents
The function will take care of opening the file initially and then closing it when the operation is complete. The file name is accessible at global scope, so no parameters are needed.
The function generates a format string that will adjust the field width for the output specifier for the name string to be MAXLEN characters, where MAXLEN is a symbol that we’ll define. The sprintf_s() function writes the format string to the format array.
The file is opened in binary read mode, so the initial position will be at the beginning of the file. If the file is opened successfully, records are read from the file in the while loop by calling the read_record() function , which was defined earlier. The read_record() is called in the loop condition, so when NULL is returned, signaling the end of file has been detected, the loop ends. Within the loop you write the members of the Record object that was initialized by read_record() to stdout using the string in the format array that was created initially. When all the records have been read, the file is closed by calling fclose() with the file pointer as the argument.
Updating the Existing File Contents
- 1.
Open the file for update.
- 2.
Find the index (first record is at index 0) for the record to be updated.
- 3.
Get the data for the record to replace the old record.
- 4.
Check if the record can be updated in place. This is possible when the lengths of the names are the same. If so, move the current position back by the length of the old record and write the new record to the old file.
- 5.
If the names are different lengths, duplicate the file with the new record replacing the old in the duplicate file.
After opening the file for update, the function calls the find_record() function , which I’ll get to in a moment. The find_record() will read the name for the record to be updated from the keyboard and then return the index value for that record if it exists. It will return –1 if the record is not found.
If the old and new names are the same length, you move the file position back by the length of the old record by calling fseek(). You then write the new record to the file and flush the output buffer. Calling fflush() for the file forces the new record to be transferred to the file.
- 1.
Create a new file with a unique name.
- 2.
Copy all records preceding the record to be changed from the old file to the new file.
- 3.
Write the new record to the new file and skip over the record to be updated in the old file.
- 4.
Write all the remaining records from the old file to the new file.
- 5.
Close both files.
- 6.
Delete the old file and rename the new file with the name of the old file.
Once the new file is created using the name generated by tmpnam_s(), records are copied from the original file to the new file, with the exception that the record to be updated is replaced with the new record in the new file. The copying of the first index records is done in the for loop where the pointer that is returned by read_record() reading the old file is passed as the argument to write_record() for the new file. The copying of the records that follow the updated record is done in the while loop. Here you have to continue copying records until the end of the file is reached in the old file. Finally, after closing both files, delete the old file to free up its name and then rename the new file to the old. If you want to do this more safely, you can rename the old file in some way rather than deleting it, perhaps by appending "_old" to the existing file name or generating another temporary name. You can then rename the new file as you do here. This would leave a backup file in the directory that would be useful if the update goes awry.
This function reads a name for the record that is to be changed and then reads successive records from the file starting at the beginning, looking for a name that matches the name that was entered. If read_record() returns NULL, –1 is returned by find_record() to signal to the calling function that the record is not in the file. If a name match is found, the function returns the index value of the matching record.
You can now assemble the complete working example.
How It Works
The code in main() is very simple. The indefinite while loop offers a series of choices of action, and the choice entered is determined in the switch statement. Depending on the character entered, one of the functions you developed for the program is called. Execution continues until the option 'Q' or 'q' is entered to end the program.
File Open Modes Summary
File Modes for fopen_s()
Mode | Description |
|---|---|
"w" | Open a text file and truncate to zero length or create a text file for write operations. "uw" is the same but with default permissions |
"wx" | Create a text file for write operations. "uwx" is the same but with default permissions |
"a" | Open a text file for append operations, adding to the end of the file. "ua" is the same but with default permissions |
"r" | Open a text file for read operations |
"wb" | Open a binary file and truncate to zero length or create a binary file for write operations. "uwb" is the same but with default permissions |
"wbx" | Create a binary file for write operations. "uwbx" is the same but with default permissions |
"ab" | Open a binary file for append operations. "uab" is the same but with default permissions |
"rb" | Open a binary file for read operations |
"w+" | Open or create a text file for update operations. An existing file will be truncated to zero length. "uw+" is the same but with default permissions |
"a+" | Open or create a text file for update operations, adding to the end of the file |
"r+" | Open a text file for update operations (read and write anywhere) |
"w+x" | Create a text file for updating. "uw+x" is the same but with default permissions |
"w+b" or "wb+" | Open or create a binary file for update operations. An existing file will be truncated to zero length. "uw+b" or "uwb+" is the same but with default permissions |
"w+bx" or "wb+x" | Create a binary file for update operations. "uw+bx" or "uwb+x" is the same but with default permissions |
"a+b" or "ab+" | Open a binary file for update operations, adding to the end of the file. "ua+b" or "uab+" is the same but with default permissions |
"r+b" or "rb+" | Open a binary file for update operations (read and write anywhere) |
Note that opening a file with 'r' as the first character in the mode fails if the file does not exist, and opening a file with 'x' as the last character in the mode fails if the file already exists.
Designing a Program
Now that you’ve come to the end of this chapter, you can put what you’ve learned into practice with a final program. This program will be shorter than the previous example, but nonetheless it’s an interesting program you may find useful.
The Problem
The problem you’re going to solve is to write a file viewer program. This will display any file in hexadecimal representation and as characters.
The Analysis
The program will open the file as binary read-only and then display the information in two columns, the first being the hexadecimal representation of the bytes in the file and the second being the bytes represented as characters. The file name will be supplied as a command-line argument, or if there’s no command-line argument for the file name, the program will ask for it.
- 1.
If the file name isn’t supplied, get it from the user.
- 2.
Open the file.
- 3.
Read and display the contents of the file.
The Solution
This section outlines the steps you’ll take to solve the problem.
Step 1
You need to specify parameters for the function main() to retrieve command-line arguments. You’ll recall from Chapter 9 that when main() is called, two arguments may be passed to it. The first argument is an integer indicating the number of parameters in the command line, and the second is an array of pointers to strings. The first string in the array will be the name you use to start the program at the command line, and the remaining strings will be the command-line arguments that follow at the .exe file name. This mechanism allows an arbitrary number of values to be entered at the command line and passed to main().
FILENAME_MAX is a macro defined in stdio.h that expands to an integer specifying the maximum number of characters in a file name string that is guaranteed to be opened within the current implementation, so we use this to specify the size of the filename array. If argv is 1, you prompt for entry of the file name. If the first argument to main() isn’t 1, then you have at least one more argument, which you assume is the file name. You therefore copy the string pointed to by argv[1] to the filename array.
Step 2
You have no idea what is in the file and whether or not it is a text file, but by opening it in binary mode, you can read anything—it’s all just bytes. You create an internal buffer for input operations on the file by passing NULL as the second argument to setvbuf().
Step 3
You can now output the file contents. You’ll do this by reading the file 1 byte at a time and saving these data in a char array. Of course, you won’t be accessing the file 1 byte at a time because it is buffered. The host environment will read a buffer full of data at a time, and your read operations will extract from the file buffer. Once the buffer is full or the end of file has been reached, you’ll output the buffer in the format you want.
You’ll output the hexadecimal values for a sequence of bytes from the file on a line with a field width of two and a following space. You’ll output the sequence of character equivalents to the hexadecimal on the same line occupying one character each. Thus, each character read from the file occupies four characters on a line. If the output line length is DISPLAY, the size of buffer needs to be DISPLAY/4 – 1. You subtract 1 to allow four characters for a separator string between the hexadecimal output and the corresponding characters.
The loop condition tests for the EOF indicator for the file being set by calling feof(). When it is, the end of file has been reached, so the loop ends. The read operation tries to read a buffer full of data at a time, which corresponds to one line of output. This will be the case for every line except the last, when less than a buffer full of data may be available from the file. The fread() function returns the number of characters read, and you store this in count.
After a block has been read, the contents of the buffer array are first written to the current line as hexadecimal values in the first for loop. When the last block of data is read from the file, it is likely that the buffer array will not be full, and in this case you’ll write three spaces for each of the buffer elements that were not filled by the read operation. This ensures that on the last line of output, the text to the right of the line remains aligned. You then write a vertical bar as a separator and write the contents of buffer as characters to the line in the second for loop.
When you output the data as characters, you must first check that the character is printable; otherwise, strange things may start happening on the screen. You use the isprint() function that is declared in ctype.h for this. If the character isn’t printable, you output a period instead. After buffer has been written out, you write a newline to move to the next line. The if statement at the end of the loop tests for 'e' or 'E' being entered after each PAGE_LENGTH lines of output. If you just press Enter after a page of output, the output for the next page will be displayed. If you enter 'e' or 'E', this terminates the output and the program. This is desirable because you could conceivably be listing a very large file, and you don’t necessarily want to see the entire 10 million lines. The EOF indicator will be set when the last block of data is read, and the while loop and the program will end.
I didn’t show the entire file. I just entered 'e' after the first two blocks.
Summary
Within this chapter, I’ve covered all of the basic tools necessary to enable you to program the complete spectrum of file operations in C. The degree to which these have been demonstrated in examples has been, of necessity, relatively limited. There are many ways of applying these tools to provide more sophisticated ways of managing and retrieving information in a file. For example, it’s possible to write index information into the file, either as a specific index at a known place in the file, often the beginning, or as position pointers within the blocks of data, rather like the pointers in a linked list. You should experiment with file operations until you feel confident that you understand the mechanisms involved.
Although the functions I discussed in this chapter cover most of the abilities you’re likely to need in C programming, you’ll find that the input and output library provided with your compiler offers quite a few additional functions that give you even more options for handling your file operations. For example, the C library does not provide any way to create or delete folders or directories, but it is more than likely that the library that comes with your compiler will provide functions for such operations.
The following exercises enable you to try out what you’ve learned in this chapter. If you get stuck, look back over the chapter for help. If you’re still stuck, you can download the solutions from the Source Code/Download area of the Apress website (www.apress.com), but that really should be a last resort.
Exercise 12-1. Write a program that will write an arbitrary number of strings to a file. The strings should be entered from the keyboard, and the program shouldn’t delete the file, as it will be used in the next exercise.
Exercise 12-2. Write a program that will read the file that was created by the previous exercise, and retrieve the strings one at a time in reverse sequence and then write them to a new file in the sequence in which they were retrieved. For example, the program will retrieve the last string and write that to the new file, then retrieve the second to last and write that to the file, and so on, for each string in the original file.
Exercise 12-3. Write a program that will read names consisting of a first name and a second name and associated telephone numbers from the keyboard and write them to a new file if a file doesn’t already exist and add them if the file does exist. The program should optionally list all the entries.
Exercise 12-4. Extend the program from the previous exercise to implement retrieval of all the numbers corresponding to a given second name. The program should allow further inquiries, adding new name/number entries and deleting existing entries.