
9. Inside Ethereum
By Tim McCallum
In the previous chapters, you learned how to interact with the Ethereum blockchain from the outside as a client. The chapters covered topics such as executing transactions, developing and deploying smart contracts, and developing dapps using tools like the web3 library. However, to truly understand how Ethereum works and perhaps modify its behavior for your own purposes, we will need to look deeper beneath the external interface of the blockchain platform.
In this chapter, I deconstruct Ethereum to provide you with an understanding of its data storage layer, and I introduce the concept of blockchain state. Also, I cover the theory behind the Patricia trie data structure and demonstrate Ethereum’s concrete implementation of tries using Google’s LevelDB database. From this point, you will be able to execute transactions and explore how Ethereum’s state responds to activities such as transactions.
What Is Blockchain State?
Bitcoin’s state is represented by its global collection of unspent transaction outputs (UTXOs). The transfer of value in Bitcoin is actioned through transactions. More specifically, a Bitcoin user can spend one or more UTXOs by creating a transaction and adding one or more UTXOs as the transaction’s input.
A full explanation of UTXOs is beyond the scope of this chapter. However, I mention UTXOs in the following paragraphs to point out a fundamental difference between Bitcoin and Ethereum. Specifically, the following two Bitcoin examples will provide contrast between Bitcoin’s UTXO model and Ethereum’s world state.
First, Bitcoin UTXOs cannot be partially spent. If a Bitcoin user spends 0.5 Bitcoin (using her only UTXO, which is worth 1 Bitcoin), the user has to deliberately self-address (send herself ) 0.5 Bitcoins (BTC) in return change (Figure 9.1). If the user doesn’t send change, she will lose the 0.5 Bitcoin change to the Bitcoin miner who mines her transaction.

Figure 9.1 Sending a partial Bitcoin
Second, at the most fundamental level, Bitcoin does not maintain user account balances. With Bitcoin, a user simply holds the private keys to one or more UTXOs at any given point in time (Figure 9.2). Digital wallets make it seem like the Bitcoin blockchain automatically stores and organizes user account balances and so forth. This is not the case.

Figure 9.2 Computing account balance for Bitcoin
A user account balance in Bitcoin is an abstract notion. Realistically, a user’s account balance is the sum total of each individual UTXO (for which that user holds the corresponding private key), as shown in Figure 9.3. The key that a user holds can be used to individually sign/spend each of the UTXOs.
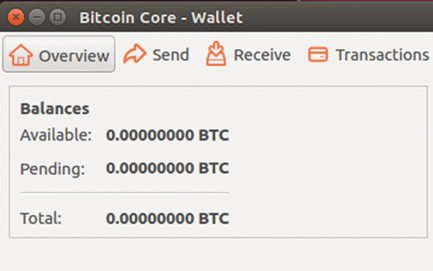
Figure 9.3 A Bitcoin wallet aggregates UTXOs to show account balances.
The UTXO system in Bitcoin works well, in part, because digital wallets are able to facilitate most of the tasks associated with transactions. This includes but is not limited to the following:
Handling UTXOs
Storing keys
Setting transaction fees
Providing return change addresses
Aggregating UTXOs (to show available, pending, and total balances)
Interestingly, a backup of a nondeterministic wallet (like the Bitcoin core wallet pictured in Figure 9.3) provides only a snapshot of the UTXOs (at that point in time). If a user performs any transactions (sending or receiving), the original backup that the user made will be out-of-date.
To summarize, you now know the following:
The Bitcoin blockchain does not hold account balances.
Bitcoin wallets hold keys to UTXOs.
If included in a transaction, an entire UTXO is spent (in some cases partially received as change in the form of a new UTXO).
Next, let’s look into the Ethereum blockchain.
Ethereum State
In contrast to the previous information, the Ethereum world state is able to manage account balances and more. The state of Ethereum is not an abstract concept. It is part of Ethereum’s base protocol layer. Ethereum is a transaction-based state machine; in other words, it’s a technology on which all transaction-based state machine concepts can be built.
Storing state data on each Ethereum node allows for light clients that do not necessarily need to download the entire blockchain to function. Light clients just need access to the state database on a node to get the current state of the entire system and send in transactions to alter the state. That enables a whole range of applications to be developed on the Ethereum blockchain efficiently. Without stored data on nodes and light clients, most smart contracts or dapp use cases would be impossible.
For example, an interesting idea mentioned in the Ethereum white paper is the notion of a savings account. In this scenario, two users (perhaps a husband and wife, or business partners) can each withdraw 1 percent of the account’s total balance per day. This idea is mentioned in the “Further Applications” section of the white paper, but it’s interesting because it, in theory, could be implemented as part of Ethereum’s base protocol layer (as opposed to having to be written as part of a second-layer solution or third-party wallet). You may recall the discussion about Bitcoin UTXOs earlier in this chapter. UTXOs are blind to blockchain data, and as discussed, the Bitcoin blockchain does not actually store a user’s account balance. For this reason, the base protocol layer of Bitcoin is far less likely (or perhaps unable) to implement any sort of daily spend limits.
Next, let’s look into the actual structure of the Ethereum state data store.
Data Structure
Let’s start at the beginning. As with all other blockchains, the Ethereum blockchain begins life at its own genesis block. From this point (genesis state at block 0) onward, activities such as transactions, contracts, and mining will continually change the state of the Ethereum blockchain. In Ethereum, an example of this is an account balance (stored in the state trie, as shown in Figure 9.4), which changes every time a transaction, in relation to that account, takes place.
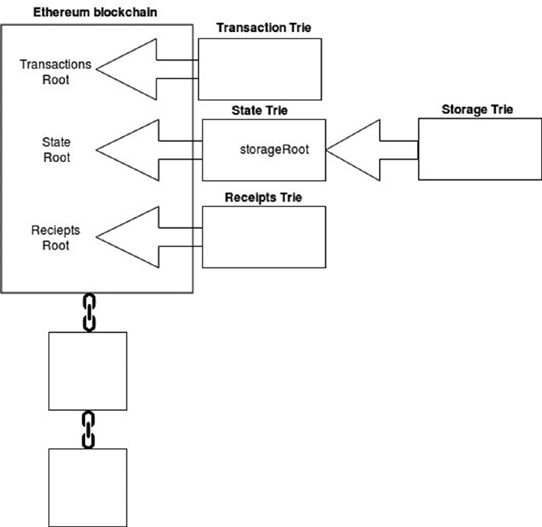
Figure 9.4 The internal structure of data storage in an Ethereum node
Importantly, data such as account balances is not stored directly in the blocks of the Ethereum blockchain. Only the root node hashes of the transaction trie, state trie, and receipts trie are stored directly in the blockchain.
You will also notice, from Figure 9.4, that the root node hash of the storage trie (where all of the smart contract data is kept) actually points to the state trie, which in turn points to the blockchain. I will zoom in and cover all of this in more detail soon.
There are two vastly different types of data in Ethereum: permanent data and ephemeral data. An example of permanent data is a transaction. Once a transaction has been fully confirmed, it is recorded in the transaction trie and never altered. An example of ephemeral data is the balance of a particular Ethereum account address. The balance of an account address is stored in the state trie and is altered whenever transactions against that particular account occur. It makes sense that permanent data, such as mined transactions, and ephemeral data, such as account balances, should be stored separately. Ethereum uses trie data structures (as broadly outlined earlier) to manage data. The next section will take a detour and provide a quick overview on tries.
Trie (or Tree)
A trie (or tree) is a well-known data structure that is used for storing sequences of characters. Ethereum exclusively uses what is known as the “practical algorithm to retrieve information coded in alphanumeric” (Patricia) trie. The main advantage of the Patricia trie is its compact storage. We will now analyze the inner workings of the standard (more traditional) trie versus the Patricia trie.
Standard Trie
Figure 9.5 shows the structure of a standard trie that stores words. Each character in the word is a node in the tree, and each word is terminated by a special null pointer.

Figure 9.5 A standard trie storing two words. The special character � represents the null pointer.
Rules for Adding a Word to the Trie
We follow the search path for the word we are adding. If we encounter a null pointer, we create a new node. When we have finished adding our word, we create a null pointer (terminator). When adding a (shorter) word that is contained in another (longer) word, we just exhaust all of the characters and then add a null pointer (terminator).
Rules for Deleting a Word from the Trie
We search for a leaf (the end of a branch) on the trie that represents the string (which we want to delete). We then start deleting all nodes from the leaf back to the root of the trie—unless we hit a node with more than one child; in this case, we stop.
Rules for Searching for a Word in the Trie
We examine each of the characters in the string for which we are searching and follow the trie for as long as it provides our path (in the right sequence). If we encounter a null pointer before exhausting all the characters in the string (which we are searching for), then we can conclude that the string is not stored in the trie. On the contrary, if we reach a leaf (the end of a branch) and that path (from the leaf back to the root of the trie) represents our string, we conclude that the string is stored in the trie.
Patricia Trie
Figure 9.6 shows the structure of a Patricia trie that stores words. The storage is more compact than the standard trie. Each word is terminated by a special null pointer.
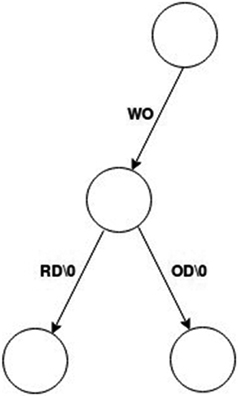
Figure 9.6 A Patricia trie storing two words
Rules for Adding a Word to the Patricia Trie
Patricia tries group all common characters into a single branch. Any unusual characters will constitute a new branch in the path. When adding a word to a Patricia trie, we exhaust all the characters and then add the null pointer (terminator), as shown in Figure 9.7.
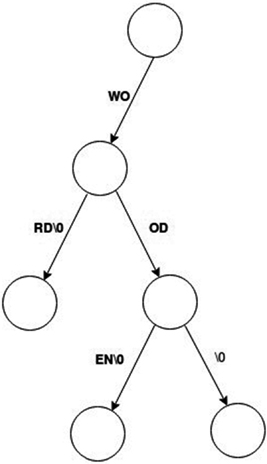
Figure 9.7 Adding a word (wooden) to the Patricia trie
Rules for Deleting a Word from the Patricia Trie
This is the same as with a traditional trie, except for when deleting nodes (from the leaf back to the root), we must ensure that all parent nodes must be in possession of at least two child nodes. It is okay for a single child node to just have characters and a null pointer (this occurs in Figure 9.7, at the end of every word). It is also okay for a single node to just have a null pointer (this occurs if a shorter word is contained in a longer word). See Figure 9.7, which illustrates how wood and wooden coexist in the same trie.
Importantly, when deleting from a trie, a path cannot be left with a parent node that connects to just a single child node. If this occurs (when deleting, we need to concatenate the appropriate characters to resolve this). This is illustrated in Figure 9.8 (where we delete the word from the trie).

Figure 9.8 Deleting a word (word) from the Patricia trie and reorganizing it
Rules for Searching for a Word in the Patricia Trie
The rules for searching the Patricia trie are the same as for searching the standard trie.
Similarities between the Trie and Patricia Trie
The runtime “O” for adding is O(mN), where “m” is the length of the string we are adding and “N” is the size of the available alphabet.
The runtime for deleting is O(mN), where “m” is the length of the string we want to delete and “N” is again the size of the available alphabet.
The runtime for searching is O(m), where “m” is the length of the string we are searching for.
Main Difference between the Trie and Patricia Trie
The main advantage of using the Patricia trie is in relation to storage.
The storage requirement “O” for the standard trie is O(MN), where “M” is the total length of all strings in the trie and “N” is the size of the available alphabet.
The storage requirement “O” for the Patricia trie is O(nN+M), where “n” is the number of strings stored in the Patricia trie, “N” is the size of the available alphabet, and “M” is the total length of all strings in the trie.
In short, you will have noticed a marked difference in the depth of the tries. The Patricia trie is less deep (shallower). This is because of the Patricia trie’s ability to group common characters (and concatenate null pointers to leaves).
Modified Merkle Patricia Trie
In the Ethereum state database, the data is stored in a modified Merkle Patricia trie, which means the root node of the trie is a hash of the data in its leaves. This design makes the state database on each node resistant to tampering, just like the blockchain itself.
Every function (put, update, and delete) performed on a trie in Ethereum utilizes a deterministic cryptographic hash. Further, the unique cryptographic hash of a trie’s root node can be used as evidence that the trie has not been tampered with.
For example, any changes to a trie’s data, at any level (such as increasing an account’s balance), will completely change the root hash. This cryptographic feature provides an opportunity for light clients (devices that do not store the entire blockchain) to quickly and reliably query the blockchain; in other words, does account 0x…4857 have enough funds to complete this purchase at block height 5044866?
Trie Structure in Ethereum
Let’s look at the state, storage, and transaction tries in a bit more depth.
State Trie : The One and Only
There is one, and one only, global state trie in Ethereum. This global state trie is constantly updated. The state trie contains a key-value pair for every account that exists on the Ethereum network.
The key is a single 160-bit identifier (the address of an Ethereum account).
The value in the global state trie is created by encoding the following account details of an Ethereum account (using the recursive-length prefix [RLP] encoding method): nonce, balance, storageRoot, codeHash.
The state trie’s root node (a hash of the entire state trie at a given point in time) is used as a secure and unique identifier for the state trie; the state trie’s root node is cryptographically dependent on all internal state trie data. The state trie’s root node is stored in the Ethereum block header corresponding to the time when the state trie was updated (see Figure 9.9) and can be queried from the block (Figure 9.10).

Figure 9.9 Relationship between the state trie (LevelDB implementation of a Merkle Patricia trie) and an Ethereum block

Figure 9.10 Showing the trie roots
Storage Trie : Where the Contract Data Lives
A storage trie is where all the contract data lives. Each Ethereum account has its own storage trie. A Keccak 256-bit hash of the storage trie’s root node is stored as the storageRoot value in the global state trie (Figure 9.11).
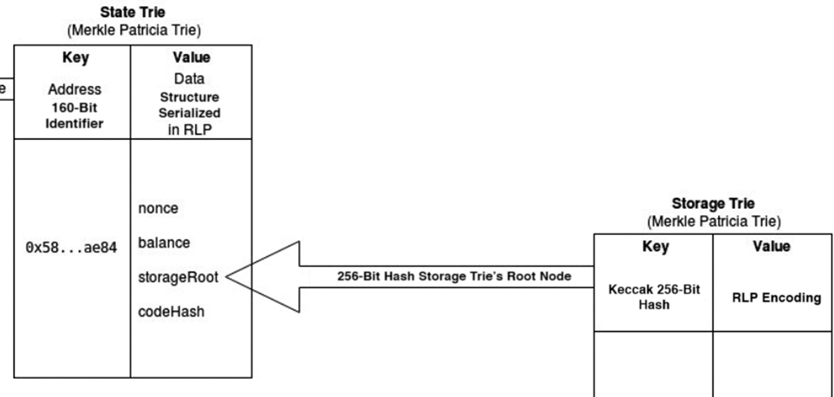
Figure 9.11 State trie — Keccak 256-bit hash of the state trie’s root node stored as the stateRoot value in a given block
Transaction Trie : One per Block
Each Ethereum block has its own separate transaction trie. A block contains many transactions. The order of the transactions in a block is of course decided by the miner who assembles the block. The path to a specific transaction in the transaction trie is via the RLP encoding of the index of where the transaction sits in the block. Mined blocks are never updated; the position of the transaction in a block never changes. This means that once you locate a transaction in a block’s transaction trie, you can return to the same path over and over to retrieve the same result. Figure 9.12 shows how the transaction trie’s root hash is stored in an Ethereum block header.

Figure 9.12 The transaction trie stores data about each transaction in a block.
Concrete Examples of Tries in Ethereum
The main Ethereum clients use two different database software solutions to store their tries. Ethereum’s Rust client, Parity, uses RocksDB. Ethereum’s Go, C++, and Python clients all use LevelDB.
RocksDB is out of scope for this book. Let’s explore how three out of the four major Ethereum clients utilize LevelDB.
LevelDB is an open source Google key-value storage library that provides, among other things, forward and backward iterations over data, ordered mapping from string keys to string values, custom comparison functions, and automatic compression. The data is automatically compressed using Snappy, an open source Google compression/decompression library. While Snappy does not aim for maximum compression, it aims for very high speeds. LevelDB is an important storage and retrieval mechanism that manages the state of the Ethereum network. As such, LevelDB is a dependency for the most popular Ethereum clients (nodes) such as go-ethereum, cpp-ethereum, and pyethereum.
To learn more, we have to access the data in LevelDB using the appropriate Patricia trie libraries. To do this, we will need an Ethereum installation (see Chapter 5). Once you have set up your Ethereum private network, you will be able to execute transactions and explore how Ethereum’s state responds to network activities such as transactions, contracts, and mining. In the next section, I will provide code examples and screen captures from an Ethereum private network.
Analyzing the Ethereum Database
As mentioned previously, there are many Merkle Patricia tries (referenced in each block) within the Ethereum blockchain: state trie, storage trie, transaction trie, and receipts trie.
To reference a particular Merkle Patricia trie in a particular block, we need to obtain its root hash as a reference. The following commands allow us to obtain the root hashes of the state, transaction, and receipt tries in the genesis block:
web3.eth.getBlock(0).stateRoot web3.eth.getBlock(0).transactionsRoot web3.eth.getBlock(0).receiptsRoot
If you want the root hashes of the latest block (instead of the genesis block), please use the following command:
web3.eth.getBlock(web3.eth.blockNumber).stateRoot
We will be using a combination of the nodejs, level, and ethereumjs commands (which implements Ethereum’s VM in JavaScript) to inspect the LevelDB database. The following commands will further prepare our environment (in Ubuntu Linux):
cd ~ sudo apt-get update sudo apt-get upgrade curl -sL https://deb.nodesource.com/setup_9.x | sudo -E bash - sudo apt-get install -y nodejs sudo apt-get install nodejs npm -v nodejs -v npm install levelup leveldown rlp merkle-patricia-tree --save git clone https://github.com/ethereumjs/ethereumjs-vm.git cd ethereumjs-vm npm install ethereumjs-account ethereumjs-util --save
Get the Data
From this point, running the following code will print a list of the Ethereum account keys (which are stored in the state root of your Ethereum private network). The code connects to Ethereum’s LevelDB database, enters Ethereum’s world state (using a stateRoot value from a block in the blockchain), and then accesses the keys to all accounts on the Ethereum private network (Figure 9.13).

Figure 9.13 Raw data read from the trie in LevelDB
//Just importing the requirements
var Trie = require('merkle-patricia-tree/secure');
var levelup = require('levelup');
var leveldown = require('leveldown');
var RLP = require('rlp');
var assert = require('assert');
//Connecting to the leveldb database
var db = levelup(leveldown(
'/home/user/geth/chaindata'));
//Adding the "stateRoot" value from the block so that
//we can inspect the state root at that block height.
var root = '0x8c777…2976';
//Creating a trie object of the merkle-patricia-tree library
var trie = new Trie(db, root);
//Creating a nodejs stream object so that we can access the data
var stream = trie.createReadStream()
//Turning on the stream
stream.on('data', function (data){
//printing out the keys of the "state trie"
console.log(data.key);
});
Decoding the Data
You will have noticed that querying LevelDB returns encoded results. This is because Ethereum uses its own specially modified Merkle Patricia trie implementation when interacting with LevelDB. The Ethereum wiki provides information about the design and implementation of both Ethereum’s modified Merkle Patricia trie and RLP encoding. In short, Ethereum has extended the trie data structures described earlier. For example, the modified Merkle Patricia trie contains a method that can shortcut the descent (down the trie) through the use of an extension node.
In Ethereum, a single modified Merkle Patricia trie node is one of the following:
An empty string (referred to as NULL)
An array that contains 17 items (referred to as a branch)
An array that contains two items (referred to as a leaf )
An array that contains two items (referred to as an extension)
As Ethereum’s tries are designed and constructed with rigid rules, the best way to inspect them is through the use of computer code. The following example uses ethereum.js. The following code (when provided with a particular block’s stateRoot as well as an Ethereum account address) will return that account’s correct balance in a human-readable form (Figure 9.14):

Figure 9.14 The decoded results
//Mozilla Public License 2.0
//Getting the requirements
var Trie = require('merkle-patricia-tree/secure');
var levelup = require('levelup');
var leveldown = require('leveldown');
var utils = require('ethereumjs-util');
var BN = utils.BN;
var Account = require('ethereumjs-account');
//Connecting to the leveldb database
var db = levelup(leveldown('/home/user/geth/chaindata'));
//Adding the "stateRoot" value from the block
//so that we can inspect the state root at that block height.
var root = '0x9369577...73028';
//Creating a trie object of the merkle-patricia-tree library
var trie = new Trie(db, root);
var address = '0xccc6b46fa5606826ce8c18fece6f519064e6130b';
trie.get(address, function (err, raw) {
if (err) return cb(err)
//Create an instance of an account
var account = new Account(raw)
console.log('Account Address: ' + address);
//Decode and present the account balance
console.log('Balance: ' + (new BN(account.balance)).toString());
})
Read and Write the State LevelDB
So far, I have shown how to access the Ethereum state’s LevelDB database using JavaScript on a local node. If you are familiar with GO and can work with Ethereum source code, there is an easier way. You could just import the go-ethereum source code in GO and call its functions to read and even modify the LevelDB database. The write function will not only change the values in the nodes but also update the root hash to reflect the changes. Specifically, the functions are in the following source code file:
https://github.com/ethereum/go-ethereum/blob/master/core/state/statedb.go
It contains methods such as GetBalance, AddBalance, SubBalance, and SetBalance to operate on the account balances. However, changing the state LevelDB in this way will change the data on only one node and will likely cause this node to go out of sync with the rest of the nodes on the network. The right way to change the state is to follow how go-ethereum processes a transaction and records it on the blockchain. That is out of scope for this book.
Conclusion
In this chapter, I demonstrated that Ethereum has the ability to manage its state. This clever up-front design has many advantages, allowing for light clients and many different kinds of dapps that do not need to run the entire blockchain. It is important to understand the inner workings of Ethereum to write great smart contracts and applications on the Ethereum platform.