
Chapter 9. Proxy Systems
Proxying provides Internet access to a single host, or a very small number of hosts, while appearing to provide access to all of your hosts. The hosts that have access act as proxies for the machines that don’t, doing what these machines want done.
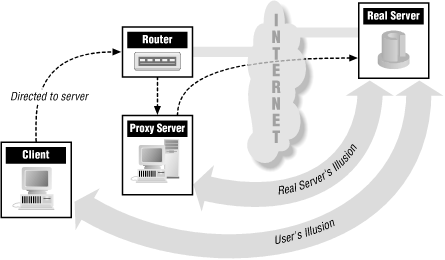
A proxy server for a particular protocol or set of protocols runs on a dual-homed host or a bastion host: some host that the user can talk to, which can, in turn, talk to the outside world. The user’s client program talks to this proxy server instead of directly to the “real” server out on the Internet. The proxy server evaluates requests from the client and decides which to pass on and which to disregard. If a request is approved, the proxy server talks to the real server on behalf of the client and proceeds to relay requests from the client to the real server, and to relay the real server’s answers back to the client.
As far as the user is concerned, talking to the proxy server is just like talking directly to the real server. As far as the real server is concerned, it’s talking to a user on the host that is running the proxy server; it doesn’t know that the user is really somewhere else.
Since the proxy server is the only machine that speaks to the outside world, it’s the only machine that needs a valid IP address. This makes proxying an easy way for sites to economize on address space. Network address translation can also be used (by itself or in conjunction with proxying) to achieve this end.
Proxying doesn’t require any special hardware, but something somewhere has to make certain that the proxy server gets the connection. This might be done on the client end by telling it to connect to the proxy server, or it might be done by intercepting the connection without the client’s knowledge and redirecting it to the proxy server.
Tip
Proxy systems are effective only when they are used in conjunction with some method of restricting IP-level traffic between the clients and the real servers, such as a screening router or a dual-homed host that doesn’t route packets. If there is IP-level connectivity between the clients and the real servers, the clients can bypass the proxy system (and presumably so can someone from the outside).
Why Proxying?
There’s no point in connecting to the Internet if your users can’t access it. On the other hand, there’s no safety in connecting to the Internet if there’s free access between it and every host at your site. Some compromise has to be applied.
The most obvious compromise is to provide a single host with Internet access for all your users. However, this isn’t a satisfactory solution because these hosts aren’t transparent to users. Users who want to access network services can’t do so directly. They have to log in to the dual-homed host, do all their work from there, and then somehow transfer the results of their work back to their own workstations. At best, this multiple-step process annoys users by forcing them to do multiple transfers and work without the customizations they’re accustomed to.
The problem is worse at sites with multiple operating systems; if your native system is a Macintosh, and the dual-homed host is a Unix system, the Unix system will probably be completely foreign to you. You’ll be limited to using whatever tools are available on the dual-homed host, and these tools may be completely unlike (and may seem inferior to) the tools you use on your own system.
Dual-homed hosts configured without proxies therefore tend to annoy their users and significantly reduce the benefit people get from the Internet connection. Worse, they usually don’t provide adequate security; it’s almost impossible to adequately secure a machine with many users, particularly when those users are explicitly trying to get to the external universe. You can’t effectively limit the available tools because your users can always transfer tools from internal machines that are the same type. For example, on a dual-homed host, you can’t guarantee that all file transfers will be logged because people can use their own file transfer agents that don’t do logging.
Proxy systems avoid user frustration and the insecurities of a dual-homed host. They deal with user frustration by automating the interaction with the dual-homed host. Instead of requiring users to deal directly with the dual-homed host, proxy systems allow all interaction to take place behind the scenes. The user has the illusion of dealing directly (or almost directly) with the server on the Internet, with a minimum of direct interaction with the dual-homed host. Figure 9.1 illustrates the difference between reality and illusion with proxy systems.

Proxy systems deal with the insecurity problems by avoiding user logins on the dual-homed host and by forcing connections through controlled software. Because the proxy software works without requiring user logins, the host it runs on is safe from the randomness of having multiple logins. It’s also impossible for anybody to install uncontrolled software to reach the Internet; the proxy acts as a control point.
How Proxying Works
The details of how proxying works differ from service to service. Some services provide proxying easily or automatically; for those services, you set up proxying by making configuration changes to normal servers. For most services, however, proxying requires appropriate proxy server software on the server side. On the client side, it needs one of the following:
- Proxy-aware application software
With this approach, the software must know how to contact the proxy server instead of the real server when a user makes a request (for example, for FTP or Telnet), and how to tell the proxy server what real server to connect to.
- Proxy-aware operating system software
With this approach, the operating system that the client is running on is modified so that IP connections are checked to see if they should be sent to the proxy server. This mechanism usually depends on dynamic runtime linking (the ability to supply libraries when a program is run). This mechanism does not always work and can fail in ways that are not obvious to users.
- Proxy-aware user procedures
With this approach, the user uses client software that doesn’t understand proxying to talk to the proxy server and tells the proxy server to connect to the real server, instead of telling the client software to talk to the real server directly.
- Proxy-aware router
With this approach, nothing on the client’s end is modified, but a router intercepts the connection and redirects it to the proxy server or proxies the request. This requires an intelligent router in addition to the proxy software (although the routing and the proxying can co-exist on the same machine).
Using Proxy-Aware Application Software for Proxying
The first approach is to use proxy-aware application software for proxying. There are a few problems associated with this approach, but it is becoming easier as time goes on.
Appropriate proxy-aware application software is often available only for certain platforms. If it’s not available for one of your platforms, your users are pretty much out of luck. For example, the Igateway package from Sun (written by Jim Thompson) is a proxy package for FTP and Telnet, but you can use it only on Sun machines because it provides only precompiled Sun binaries. If you’re going to use proxy software, you obviously need to choose software that’s available for the needed platforms.
Even if software is available for your platforms, it may not be software your users want. For example, dozens of FTP client programs are on the Macintosh. Some of them have really impressive graphical user interfaces. Others have other useful features; for example, they allow you to automate transfers. You’re out of luck if the particular client you want to use, for whatever reason, doesn’t support your particular proxy server mechanism. In some cases, you may be able to modify clients to support your proxy server, but doing so requires that you have the source code for the client, as well as the tools and the ability to recompile it. Few client programs come with support for any form of proxying.
The happy exception to this rule is web browsers like Netscape, Internet Explorer, and Lynx. Many of these programs support proxies of various sorts (typically SOCKS and HTTP proxying). Most of these programs were written after firewalls and proxy systems had become common on the Internet; recognizing the environment they would be working in, their authors chose to support proxying by design, right from the start.
Using application changes for proxying does not make proxying completely transparent to users. The application software still needs to be configured to use the appropriate proxy server, and to use it only for connections that actually need to be proxied. Most applications provide some way of assisting the user with this problem and partially automating the process, but misconfiguration of proxy software is still one of the most common user problems at sites that use proxies.
In some cases, sites will use the unchanged applications for internal connections and the proxy-aware ones only to make external connections; users need to remember to use the proxy-aware program in order to make external connections. Following procedures they’ve become accustomed to using elsewhere, or procedures that are written in books, may leave them mystified at apparently intermittent results as internal connections succeed and external ones fail. (Using the proxy-aware applications internally will work, but it can introduce unnecessary dependencies on the proxy server, which is why most sites avoid it.)
Using Proxy-Aware Operating System Software
Instead of changing the application, you can change the environment around it, so that when the application tries to make a connection, the function call is changed to automatically involve the proxy server if appropriate. This allows unmodified applications to be used in a proxied environment.
Exactly how this is implemented varies from operating system to operating system. Where dynamically linked libraries are available, you add a library; where they are not, you have to replace the network drivers, which are a more fundamental part of the operating system.
In either case, there may be problems. If applications do unexpected things, they may go around the proxying or be disrupted by it. All of the following will cause problems:
Statically linked software
Software that provides its own dynamically linked libraries for network functions
Protocols that use embedded port numbers or IP addresses
Software that attempts to do low-level manipulation of connections
Because the proxying is relatively transparent to the user, problems with it are usually going to be mysteries to the user. The user interface for configuring this sort of proxying is also usually designed for the experienced administrator, not the naive user, further confusing the situation.
Using Proxy-Aware User Procedures for Proxying
With the proxy-aware procedure approach, the proxy servers are designed to work with standard client software; however, they require the users of the software to follow custom procedures. The user tells the client to connect to the proxy server and then tells the proxy server which host to connect to. Because few protocols are designed to pass this kind of information, the user needs to remember not only what the name of the proxy server is, but also what special means are used to pass the name of the other host.
How does this work? You need to teach your users specific procedures to follow for each protocol. Let’s look at FTP. Imagine that Amalie Jones wants to retrieve a file from an anonymous FTP server (e.g., ftp.greatcircle.com). Here’s what she does:
Using any FTP client, she connects to your proxy server (which is probably running on the bastion host — the gateway to the Internet) instead of directly to the anonymous FTP server.
At the username prompt, in addition to specifying the name she wants to use, Amalie also specifies the name of the real server she wants to connect to. If she wants to access the anonymous FTP server on ftp.greatcircle.com, for example, then instead of simply typing “anonymous” at the prompt generated by the proxy server, she’ll type “[email protected]”.
Just as using proxy-aware software requires some modification of user procedures, using proxy-aware procedures places limitations on which clients you can use. Some clients automatically try to do anonymous FTP; they won’t know how to go through the proxy server. Some clients may interfere in simpler ways, for example, by providing a graphical user interface that doesn’t allow you to type a username long enough to hold the username and the hostname.
The main problem with using custom procedures, however, is that you have to teach them to your users. If you have a small user base and one that is technically adept, it may not be a problem. However, if you have 10,000 users spread across four continents, it’s going to be a problem. On the one side, you have hundreds of books, thousands of magazine articles, and tens of thousands of Usenet news postings, not to mention whatever previous training or experience the users might have had, all of which attempt to teach users the standard way to use basic Internet services like FTP. On the other side is your tiny voice, telling them how to use a procedure that is at odds with all the other information they’re getting. On top of that, your users will have to remember the name of your gateway and the details of how to use it. In any organization of a reasonable size, this approach can’t be relied upon.
Using a Proxy-Aware Router
With a proxy-aware router, clients attempt to make connections the same way they normally would, but the packets are intercepted and directed to a proxy server instead. In some cases, this is handled by having the proxy server claim to be a router. In others, a separate router looks at packets and decides whether to send them to their destination, drop them, or send them to the proxy server. This is often called hybrid proxying (because it involves working with packets like packet filtering) or transparent proxying (because it’s not visible to clients).
A proxy-aware router of some sort (like the one shown in Figure 9.2) is the solution that’s easiest for the users; they don’t have to configure anything or learn anything. All of the work is done by whatever device is intercepting the packets, and by the administrator who configures it.
On the good side, this is the most transparent of the options. In general, it’s only noticeable to the user when it doesn’t work (or when it does work, but the user is trying to do something that the proxy system does not allow). From the user’s point of view, it combines the advantages of packet filtering (you don’t have to worry about it, it’s automatic) and proxying (the proxy can do caching, for instance).
From the administrator’s point of view, it combines the disadvantages of packet filtering with those of proxying:
It’s easy for accidents or hostile actions to make connections that don’t go through the system.
You need to be able to identify the protocol based on the packets in order to do the redirection, so you can’t support protocols that don’t work with packet filtering. But you also need to be able to make the actual connection from the proxy server, so you can’t support protocols that don’t work with proxying.
All internal hosts need to be able to translate all external hostnames into addresses in order to try to connect to them.
Proxy Server Terminology
This section describes a number of specific types of proxy servers.
Application-Level Versus Circuit-Level Proxies
An application-level proxy is one that knows about the particular application it is providing proxy services for; it understands and interprets the commands in the application protocol. A circuit-level proxy is one that creates a circuit between the client and the server without interpreting the application protocol. The most extreme version of an application-level proxy is an application like Sendmail, which implements a store-and-forward protocol. The most extreme version of a circuit-level proxy is an application like plug-gw, which accepts all data that it receives and forwards it to another destination.
The advantage of a circuit-level proxy is that it provides service for a wide variety of different protocols. Most circuit-level proxy servers are also generic proxy servers; they can be adapted to serve almost any protocol. Not every protocol can easily be handled by a circuit-level proxy, however. Protocols like FTP, which communicate port data from the client to the server, require some protocol-level intervention, and thus some application-level knowledge. The disadvantage of a circuit-level proxy server is that it provides very little control over what happens through the proxy. Like a packet filter, it controls connections on the basis of their source and destination and can’t easily determine whether the commands going through it are safe or even in the expected protocol. Circuit-level proxies are easily fooled by servers set up at the port numbers assigned to other services.
In general, circuit-level proxies are functionally equivalent to packet filters. They do provide extra protection against problems with packet headers (as opposed to the data within the packets). In addition, some kinds of protections (protection against packet fragmentation problems, for instance) are automatically provided by even the most trivial circuit-level proxies but are available only from high-end packet filters.
Generic Versus Dedicated Proxies
Although “application-level” and “circuit-level” are frequently used terms in other documents, we more often distinguish between “dedicated” and “generic” proxy servers. A dedicated proxy server is one that serves a single protocol; a generic proxy server is one that serves multiple protocols. In practice, dedicated proxy servers are application-level, and generic proxy servers are circuit-level. Depending on how you argue about shades of meaning, it might be possible to produce a generic application-level proxy server (one that understands a wide range of protocols) or a dedicated circuit-level proxy server (one that provides only one service but doesn’t understand the protocol for it). Neither of these ever occur, however, so we use “dedicated” and “generic” merely because we find them somewhat more intuitive terms than “application-level” and “circuit-level”.
Intelligent Proxy Servers
A proxy server can do a great deal more than simply relay requests; one that does is an intelligent proxy server. For example, almost all HTTP proxy servers cache data, so that multiple requests for the same data don’t go out across the Internet. Proxy servers (particularly application-level servers) can provide better logging and access controls than those achieved through other methods, although few existing proxy servers take full advantage of the opportunities. As proxy servers mature, their abilities are increasing rapidly. Now that there are multiple proxy suites that provide basic functionality, they’re beginning to compete by adding features. It’s easier for a dedicated, application-level proxy server to be intelligent; a circuit-level proxy has limited abilities.
Proxying Without a Proxy Server
Some services, such as SMTP, NNTP, and NTP, naturally support proxying. These services are all designed so that transactions (email messages for SMTP, Usenet news postings for NNTP, and clock settings for NTP) move between servers, instead of going directly from a client to a final destination server. For SMTP, the messages are forwarded towards an email message’s destination. NNTP forwards messages to all neighbor servers. NTP provides time updates when they’re requested but supports a hierarchy of servers. With these schemes, each intermediate server is effectively acting as a proxy for the original sender or server.
If you examine the “Received:” headers of incoming Internet email (these headers trace a message’s path through the network from sender to recipient), you quickly discover that very few messages travel directly from the sender’s machine to the recipient’s machine. It’s far more common these days for the message to pass through at least four machines:
The sender’s machine
The outgoing mail gateway at the sender’s site (or the sender’s Internet service provider)
The incoming mail gateway at the recipient’s site
Finally, the recipient’s machine
Each of the intermediate servers (the mail gateways) is acting as a proxy server for the sender, even though the sender may not be dealing with them directly. Figure 9.3 illustrates this situation.

Using SOCKS for Proxying
The SOCKS package, originally written by David Koblas and Michelle Koblas, and subsequently maintained by Ying-Da Lee, is an example of the type of proxy system that can support both proxy-aware applications and proxy-aware clients. A reference implementation of SOCKS is freely available, and it has become the de facto standard proxying package on the Internet. It is also a proposed official Internet standard, documented in RFC 1928. Appendix B, tells you how to get the freely available version of SOCKS; multiple commercial versions are also available.
Versions of SOCKS
Two versions of the SOCKS protocol are currently in use, SOCKS4 and SOCKS5. The two protocols are not compatible, but most SOCKS5 servers will detect attempts to use SOCKS4 and handle them appropriately. The main additions in SOCKS5 are:
User authentication
UDP and ICMP
Hostname resolution at the SOCKS server
SOCKS4 does no real user authentication. It bases its decisions on whether to allow or deny connections on the same sort of information that packet filters use (source and destination ports and IP addresses). SOCKS5 provides support for several different ways of authenticating users, which gives you more precise control and logging.
SOCKS4 works only for TCP-based clients; it doesn’t work for UDP-based clients or ICMP functions like ping and traceroute. If you are using a UDP-based client, you will need to get another package. You can either use SOCKS5 or the UDP Packet Relayer. This program serves much the same function for UDP-based clients as SOCKS serves for TCP-based clients. Like SOCKS, the UDP Packet Relayer is freely available on the Internet. SOCKS5 is the only widely used freely available proxy for ICMP.
SOCKS4 requires the client to be able to map hostnames to IP addresses. With SOCKS5, the client can provide the hostname instead of the IP address, and the socks server will do the hostname resolution. This is convenient for sites that do what is called “fake root” DNS, where internal hosts use a purely internal name server that does not communicate with the Internet. (This configuration is discussed further in Chapter 20.)
SOCKS Features
In order to make it easy to support new clients, SOCKS is extremely generic. This limits the features that it can provide. SOCKS doesn’t do any protocol-specific control or logging.
SOCKS does log connection requests on the server; provide access control by user, by source host and port number, or by destination host and port number; and allow configurable responses to access denials. For example, it can be configured to notify an administrator of incoming access attempts and to let users know why their outgoing access attempts were denied.
The prime advantage of SOCKS is its popularity. Because SOCKS is widely used, server implementations and SOCKS-ified clients (i.e., versions of programs like FTP and Telnet that have already been converted to use SOCKS) are commonly available, and help is easy to find. This can be a double-edged sword; cases have been reported where intruders to firewalled sites have installed their own SOCKS-knowledgeable clients.
SOCKS Components
The SOCKS package includes the following components:
The SOCKS server. This server must run on a Unix system, although it has been ported to many different variants of Unix.
The SOCKS client library for Unix machines.
SOCKS-ified versions of several standard Unix client programs such as FTP and Telnet.
SOCKS wrappers for ping and traceroute.
The runsocks program to SOCKS-ify dynamically linked programs at runtime without recompiling.
In addition, client libraries for Macintosh and Windows systems are available as separate packages.
Figure 9.4 shows the use of SOCKS for proxying.

Converting Clients to Use SOCKS
Many Internet client programs (both commercial and freely available) already have SOCKS support built in to them as a compile-time or a runtime option.
How do you convert a client program to use SOCKS? You need to modify the program so it talks to the SOCKS server, rather than trying to talk to the real world directly. You do this by recompiling the program with the SOCKS library.
Converting a client program to use SOCKS is usually pretty easy. The SOCKS package makes certain assumptions about how client programs work, and most client programs already follow these assumptions. For a complete summary of these assumptions, see the file in the SOCKS release called What_SOCKS_expects.
To convert a client program, you must replace all calls to standard network functions with calls to the SOCKS versions of those functions. Here are the calls.
Standard Network Function | SOCKS Version |
| |
| |
| |
| |
| |
| |
You can usually do this simply by including the file
socks.h, included in the SOCKS distribution. If
not, you can use the older method of adding the following to the
CFLAGS= line of the program’s
Makefile:
-Dconnect=Rconnect
-Dgetsockname=Rgetsockname
-Dbind=Rbind
-Daccept=Raccept
-Dlisten=Rlisten
-Dselect=RselectThen, recompile and link the program with the SOCKS client library.
The client machine needs to have not only the SOCKS-modified clients, but also something to tell it what SOCKS server to contact for what services (on Unix machines, the /etc/socks.conf file). In addition, if you want to control access with Auth, the client machines must be running an Auth server (for instance, identd, which will allow the SOCKS server to identify what user is controlling the port that the connection comes from. Because there’s no way for the SOCKS server to verify that the Auth server is reliable, Auth can’t be trusted if anybody might intentionally be circumventing it; we recommend using SOCKS5 with user authentication instead. See Chapter 21, for more information about Auth.
Using the TIS Internet Firewall Toolkit for Proxying
The free firewalls toolkit (TIS FWTK), from Trusted Information Systems, includes a number of proxy servers of various types. TIS FWTK also provides a number of other tools for authentication and other purposes, which are discussed where appropriate in other chapters of this book. Appendix B, provides information on how to get TIS FWTK.
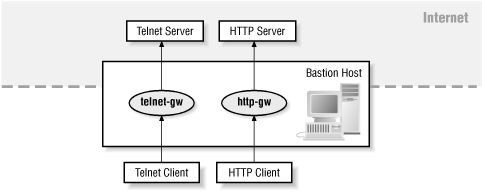
Whereas SOCKS attempts to provide a single, general proxy, TIS FWTK provides individual proxies for the most common Internet services (as shown in Figure 9.5). The idea is that by using small separate programs with a common configuration file, it can provide intelligent proxies that are provably safe, while still allowing central control. The result is an extremely flexible toolkit and a rather large configuration file.
FTP Proxying with TIS FWTK
TIS FWTK provides FTP proxying either with proxy-aware client programs or proxy-aware user procedures (ftp-gw). If you wish to use the same machine to support proxied FTP and straight FTP (for example, allowing people on the Internet to pick up files from the same machine that does outbound proxying for your users), the toolkit will support it, but you will have to use proxy-aware user procedures.
Using proxy-aware user procedures is the most common configuration for TIS FWTK. The support for proxy-aware client programs is somewhat half-hearted (for example, no proxy-aware clients or libraries are provided). Because it’s a dedicated FTP proxy, it provides logging, denial, and extra user authentication of particular FTP commands.
Telnet and rlogin Proxying with TIS FWTK
TIS FWTK Telnet (telnet-gw) and rlogin (rlogin-gw) proxies support proxy-aware user procedures only. Users connect via Telnet or rlogin to the proxy host, and instead of getting a “login” prompt for the proxy host, they are presented with a prompt from the proxy program, allowing them to specify what host to connect to (and whether to make an X connection if the x-gw software is installed, as we describe in Section 9.6.4 that follows).
Generic Proxying with TIS FWTK
TIS FWTK provides a purely generic proxy, plug-gw, which requires no modifications to clients, but supports a limited range of protocols and uses. It examines the address it received a connection from and the port the connection came in on, and it creates a connection to another host on an appropriate port. You can’t specify which host it should connect to while making that connection; it’s determined by the incoming host. This makes plug-gw inappropriate for services that are employed by users, who rarely want to connect to the same host every time. It provides logging but no other security enhancements, and therefore needs to be used with caution even in situations where it’s appropriate (e.g., for NNTP connections).
Other TIS FWTK Proxies
TIS FWTK proxies HTTP and Gopher via the http-gw program. This program supports either proxy-aware clients or proxy-aware procedures. Most HTTP clients support proxying; you just need to tell them where the proxy server is. To use http-gw with an HTTP client that’s not proxy-aware, you add http://firewall/ in front of the URL. Using it with a Gopher client that is not proxy-aware is slightly more complex, since all the host and port information has to be moved into the path specification.
x-gw is an X gateway. It provides some minimal security by requiring confirmation from the user before allowing a remote X client to connect. The X gateway is started up by connecting to the Telnet or rlogin proxy and typing “x”, which displays a control window.
Using Microsoft Proxy Server
Logically enough, Microsoft Proxy Server is Microsoft’s proxying package. It is part of Microsoft’s Back Office suite of products and is Microsoft’s recommended solution for building small firewalls on Windows NT. The Proxy Server package includes both proxying and packet filtering, in order to support a maximum number of protocols.
Proxy Server provides three types of proxying; an HTTP proxy, a SOCKS proxy, and a WinSock proxy. HTTP proxying, which will also support several other common protocols used by web browsers, including HTTPS, Gopher, and FTP, is discussed further in Chapter 15.
Proxy Server and SOCKS
Proxy Server includes a SOCKS server, which implements SOCKS Version 4.3a. Because it is a SOCKS4 server, it supports only TCP connections and only Auth authentication. On the other hand, it does provide name resolution service (which most SOCKS4 servers do not). You can use Proxy Server’s SOCKS server with any SOCKS4 client (not just Microsoft applications).
Proxy Server and WinSock
The WinSock proxy is specialized for the Microsoft environment. It uses a modified operating environment on the client to intercept Windows operating system calls that open TCP/IP sockets. It supports both TCP and UDP. Because of the architecture of the networking code, WinSock will proxy only native TCP/IP applications like Telnet and FTP; it won’t work with Microsoft native applications like file and printer sharing, which work over TCP/IP by using an intermediate protocol (NetBT, which is discussed further in Chapter 14). On the other hand, WinSock proxying will provide native TCP/IP applications with Internet access even when the machines reach the proxy by protocols other than TCP/IP. For instance, a machine that uses NetBEUI or IPX can use a WinSock proxy to FTP to TCP/IP hosts on the Internet.
Using a WinSock proxy requires installing modified WinSock libraries on all the clients that are going to use it. For this reason, it will work only with Microsoft operating systems, and it creates some administrative difficulties on them (the modified libraries must be reinstalled any time the operating system is installed, upgraded, or patched). In addition, trying to use WinSock and SOCKS at the same time on the same client machine will create confusion, as both of them attempt to proxy the same connection.
What If You Can’t Proxy?
You might find yourself unable to proxy a service for one of three reasons:
No proxy server is available.
Proxying doesn’t secure the service sufficiently.
You can’t modify the client, and the protocol doesn’t allow you to use proxy-aware procedures.
We describe each of these situations in the following sections.
No Proxy Server Is Available
If the service is proxyable, but you can’t find a proxy-aware-procedure server or proxy-aware clients for your platform, you can always do the work yourself. In many cases, you can simply use the dynamic libraries to wrap existing binaries.
If you can’t use dynamic libraries, modifying a normal TCP client program to use SOCKS is relatively trivial. As long as the SOCKS libraries are available for the platform you’re interested in, it’s usually a matter of changing a few library calls and recompiling. You do have to have the source for the client.
Writing your own proxy-aware-procedure server is considerably more difficult because it means writing the server from scratch.
Proxying Won’t Secure the Service
If you need to use a service that’s inherently insecure, proxying can’t do much for you. You’re going to need to set up a victim machine, as described in Chapter 10, and let people run the service there. This may be difficult if you’re using a dual-homed nonrouting host to make a firewall where all connections must be proxied; the victim machine is going to need to be on the Internet side of the dual-homed host.
Using an intelligent application-level server that filters out insecure commands may help but requires extreme caution in implementing the server and may make important parts of the service nonfunctional.
Can’t Modify Client or Procedures
There are some services that just don’t have room for modifying user procedures (for example ping and traceroute). Fortunately, services that don’t allow the user to pass any data to the server tend to be small, stupid, and safe. You may be able to safely provide them on a bastion host, letting users log in to a bastion host but giving them a shell that allows them to run only the unproxyable services you want to support. If you have a web server on a bastion host, a web frontend for these services may be easier and more controllable than allowing users to log in.