
Chapter 13. Internet Services and Firewalls
This chapter gives an overview of the issues involved in using Internet services through a firewall, including the risks involved in providing services and the attacks against them, ways of evaluating implementations, and ways of analyzing services that are not detailed in this book.
The remaining chapters in Part III describe the major Internet services: how they work, what their packet filtering and proxying characteristics are, what their security implications are with respect to firewalls, and how to make them work with a firewall. The purpose of these chapters is to give you the information that will help you decide which services to offer at your site and to help you configure these services so they are as safe and as functional as possible in your firewall environment. We occasionally mention things that are not, in fact, Internet services but are related protocols, languages, or APIs that are often used in the Internet context or confused with genuine Internet services.
These chapters are intended primarily as a reference; they’re not necessarily intended to be read in depth from start to finish, though you might learn a lot of interesting stuff by skimming this whole part of the book.
At this point, we assume that you are familiar with what the various Internet services are used for, and we concentrate on explaining how to provide those services through a firewall. For introductory information about what particular services are used for, see Chapter 2.
Where we discuss the packet filtering characteristics of particular services, we use the same abstract tabular form we used to show filtering rules in Chapter 8. You’ll need to translate various abstractions like “internal”, “external”, and so on to appropriate values for your own configuration. See Chapter 8 for an explanation of how you can translate abstract rules to rules for particular products and packages, as well as more information on packet filtering in general.
Where we discuss the proxy characteristics of particular services, we rely on concepts and terminology discussed in Chapter 9.
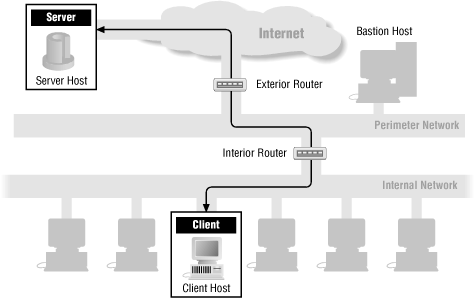
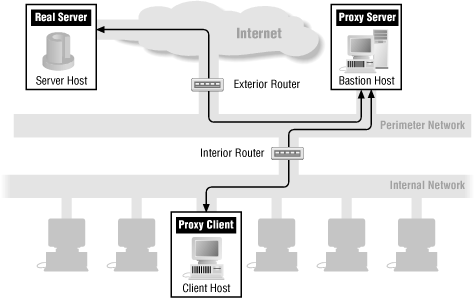
Throughout the chapters in Part III, we’ll show how each service’s packets flow through a firewall. The following figures show the basic packet flow: when a service runs directly (Figure 13.1) and when a proxy service is used (Figure 13.2). The other figures in these chapters show variations of these figures for individual services. If there are no specific figures for a particular service, you can assume that these generic figures are appropriate for that service.
Tip
We frequently characterize client port numbers as “a random port number above 1023”. Some protocols specify this as a requirement, and on others, it is merely a convention (spread to other platforms from Unix, where ports below 1024 cannot be opened by regular users). Although it is theoretically allowable for clients to use ports below 1024 on non-Unix platforms, it is extraordinarily rare: rare enough that many firewalls, including ones on major public sites that handle clients of all types, rely on this distinction and report never having rejected a connection because of it.
Attacks Against Internet Services
As we discuss Internet services and their configuration, certain concepts are going to come up repeatedly. These reflect the process of evaluating exactly what risks a given service poses. These risks can be roughly divided into two categories—first, attacks that involve making allowed connections between a client and a server, including:
Command-channel attacks
Data-driven attacks
Third-party attacks
False authentication of clients
and second, those attacks that get around the need to make connections, including:
Hijacking
Packet sniffing
Data injection and modification
Replay
Denial of service
Command-Channel Attacks
A command-channel attack is one that directly attacks a particular service’s server by sending it commands in the same way it regularly receives them (down its command channel). There are two basic types of command-channel attacks; attacks that exploit valid commands to do undesirable things, and attacks that send invalid commands and exploit server bugs in dealing with invalid input.
If it’s possible to use valid commands to do undesirable things, that is the fault of the person who decided what commands there should be. If it’s possible to use invalid commands to do undesirable things, that is the fault of the programmer(s) who implemented the protocol. These are two separate issues and need to be evaluated separately, but you are equally unsafe in either case.
The original headline-making Internet problem, the 1988 Morris worm, exploited two kinds of command-channel attacks. It attacked Sendmail by using a valid debugging command that many machines had left enabled and unsecured, and it attacked finger by giving it an overlength command, causing a buffer overflow.
Data-Driven Attacks
A data-driven attack is one that involves the data transferred by a protocol, instead of the server that implements it. Once again, there are two types of data-driven attacks; attacks that involve evil data, and attacks that compromise good data. Viruses transmitted in electronic mail messages are data-driven attacks that involve evil data. Attacks that steal credit card numbers in transit are data-driven attacks that compromise good data.
Third-Party Attacks
A third-party attack is one that doesn’t involve the service you’re intending to support at all but that uses the provisions you’ve made to support one service in order to attack a completely different one. For instance, if you allow inbound TCP connections to any port above 1024 in order to support some protocol, you are opening up a large number of opportunities for third-party attacks as people make inbound connections to completely different servers.
False Authentication of Clients
A major risk for inbound connections is false authentication: the subversion of the authentication that you require of your users, so that an attacker can successfully masquerade as one of your users. This risk is increased by some special properties of passwords.
In most cases, if you have a secret you want to pass across the network, you can encrypt the secret and pass it that way. That doesn’t help if the information doesn’t have to be understood to be used. For instance, encrypting passwords will not work because an attacker who is using packet sniffing can simply intercept and resend the encrypted password without having to decrypt it. (This is called a playback attack because the attacker records an interaction and plays it back later.) Therefore, dealing with authentication across the Internet requires something more complex than encrypting passwords. You need an authentication method where the data that passes across the network is nonreusable, so an attacker can’t capture it and play it back.
Simply protecting you against playback attacks is not sufficient, either. An attacker who can find out or guess what the password is doesn’t need to use a playback attack, and systems that prevent playbacks don’t necessarily prevent password guessing. For instance, Windows NT’s challenge/response system is reasonably secure against playback attacks, but the password actually entered by the user is the same every time, so if a user chooses to use “password”, an attacker can easily guess what the password is.
Furthermore, if an attacker can convince the user that the attacker is your server, the user will happily hand over his username and password data, which the attacker can then use immediately or at leisure. To prevent this, either the client needs to authenticate itself to the server using some piece of information that’s not passed across the connection (for instance, by encrypting the connection) or the server needs to authenticate itself to the client.
Hijacking
Hijacking attacks allow an attacker to take over an open terminal or login session from a user who has been authenticated and authorized by the system. Hijacking attacks generally take place on a remote computer, although it is sometimes possible to hijack a connection from a computer on the route between the remote computer and your local computer.
How can you protect yourself from hijacking attacks on the remote computer? The only way is to allow connections only from remote computers whose security you trust; ideally, these computers should be at least as secure as your own. You can apply this kind of restriction by using either packet filters or modified servers. Packet filters are easier to apply to a collection of systems, but modified servers on individual systems allow you more flexibility. For example, a modified FTP server might allow anonymous FTP from any host, but authenticated FTP only from specified hosts. You can’t get this kind of control from packet filtering. Under Unix, connection control at the host level is available from Wietse Venema’s TCP Wrapper or from wrappers in TIS FWTK (the netacl program); these may be easier to configure than packet filters but provide the same level of discrimination — by host only.
Hijacking by intermediate sites can be avoided using end-to-end integrity protection. If you use end-to-end integrity protection, intermediate sites will not be able to insert authentic packets into the data stream (because they don’t know the appropriate key and the packets will be rejected) and therefore won’t be able to hijack sessions traversing them. The IETF IPsec standard provides this type of protection at the IP layer under the name of “Authentication Headers”, or AH protocol (RFC 2402). Application layer hijacking protection, along with privacy protection, can be obtained by adding a security protocol to the application; the most common choices for this are Transport Layer Security (TLS) or the Secure Socket Layer (SSL), but there are also applications that use the Generic Security Services Application Programming Interface (GSSAPI). For remote access to Unix systems the use of SSH can eliminate the risk of network-based session hijacking. IPsec, TLS, SSL, and GSSAPI are discussed further in Chapter 14. ssh is discussed in Chapter 18.
Hijacking at the remote computer is quite straightforward, and the risk is great if people leave connections unattended. Hijacking from intermediate sites is a fairly technical attack and is only likely if there is some reason for people to target your site in particular. You may decide that hijacking is an acceptable risk for your own organization, particularly if you are able to minimize the number of accounts that have full access and the time they spend logged in remotely. However, you probably do not want to allow hundreds of people to log in from anywhere on the Internet. Similarly, you do not want to allow users to log in consistently from particular remote sites without taking special precautions, nor do you want users to log in to particularly secure accounts or machines from the Internet.
The risk of hijacking can be reduced by having an idle session policy with strict enforcement of timeouts. In addition, it’s useful to have auditing controls on remote access so that you have some hope of noticing if a connection is hijacked.
Packet Sniffing
Attackers may not need to hijack a connection in order to get the information you want to keep secret. By simply watching packets pass — anywhere between the remote site and your site — they can see any unencrypted information that is being transferred. Packet sniffing programs automate this watching of packets.
Sniffers may go after passwords or data. Different risks are associated with each type of attack. Protecting your passwords against sniffing is usually easy: use one of the several mechanisms described in Chapter 21, to use nonreusable passwords. With nonreusable passwords, it doesn’t matter if the password is captured by a sniffer; it’s of no use to them because it cannot be reused.
Protecting your data against sniffers is more difficult. The data needs to be encrypted before it passes across the network. There are two means you might use for this kind of encryption; encrypting files that are going to be transferred, and encrypting communications links.
Encrypting files is appropriate when you are using protocols that transfer entire files (you’re sending mail, using the Web, or explicitly transferring files), when you have a safe way to enter the information that will be used to encrypt them, and when you have a safe way to get the recipient the information needed to decrypt them. It’s particularly useful if the file is going to cross multiple communications links, and you can’t be sure that all of them will be secured, or if the file will spend time on hosts that you don’t trust. For instance, if you’re writing confidential mail on a laptop and using a public key encryption system, you can do the entire encryption on the machine you control and send on the entire encrypted file in safety, even if it will pass through multiple mail servers and unknown communications links.
Encrypting files won’t help much if you’re logging into a machine remotely. If you type in your mail on a laptop and encrypt it there, you’re relatively safe. If you remotely log into a server from your laptop and then type in the mail and encrypt it, an attacker can simply watch you type it and may well be able to pick up any secret information that’s involved in the encryption process.
In many situations, instead of encrypting the data in advance, it’s more practical to encrypt the entire conversation. Either you can encrypt at the IP level via a virtual private network solution, or you can choose an encrypted protocol (for instance, SSH for remote shell access). We discuss virtual private networks in Chapter 5, and we discuss the availability of encrypted protocols as we describe each protocol in the following chapters.
These days, eavesdropping and encryption are both widespread. You should require encryption on inbound services unless you have some way to be sure that no confidential data passes across them. You may also want to encrypt outbound connections, particularly if you have any reason to believe that the information in them is sensitive.
Data Injection and Modification
An attacker who can’t successfully take over a connection may be able to change the data inside the connection. An attacker that controls a router between a client and a server can intercept a packet and modify it, instead of just reading it. In rare cases, even an attacker that doesn’t control a router can achieve this (by sending the modified packet in such a way that it will arrive before the original packet).
Encrypting data won’t protect you from this sort of attack. An attacker will still be able to modify the encrypted data. The attacker won’t be able to predict what you’ll get when you decrypt the data, but it certainly won’t be what you expected. Encryption will keep an attacker from intentionally turning an order for 200 rubber chickens into an order for 2,000 rubber chickens, but it won’t keep the attacker from turning the order into garbage that crashes your order input system. And you can’t even be sure that the attacker won’t turn the order into something else meaningful by accident.
Fully protecting services from modification requires some form of message integrity protection, where the packet includes a checksum value that is computed from the data and can’t be recomputed by an attacker. Message integrity protection is discussed further in Appendix C.
Replay
An attacker who can’t take over a connection or change a connection may still be able to do damage simply by saving up information that has gone past and sending it again. We’ve already discussed one variation of this attack, involving passwords.
There are two kinds of replays, ones in which you have to be able to identify certain pieces of information (for instance, the password attacks), and ones where you simply resend the entire packet. Many forms of encryption will protect you from attacks where the attacker is gathering information to replay, but they won’t help you if it’s possible to just reuse a packet without knowing what’s in it.
Replaying packets doesn’t work with TCP because of the sequence numbers, but there’s no reason for it to fail with UDP-based protocols. The only protection against it is to have a protocol that will reject the replayed packet (for instance, by using timestamps or embedded sequence numbers of some sort). The protocol must also do some sort of message integrity checking to prevent an attacker from updating the intercepted packet.
Denial of Service
As we discussed in Chapter 1, a denial of service attack is one where the attacker isn’t trying to get access to information but is just trying to keep anybody else from having access. Denial of service attacks can take a variety of forms, and it is impossible to prevent all of them.
Somebody undertaking a denial of service attack is like somebody who’s determined to keep other people from accessing a particular library book. From the attackers’ point of view, it’s very desirable to have an attack that can’t be traced back and that requires a minimum of effort (in a library, they implement this sort of effect by stealing all the copies of the book; on a network, they use source address forgery to exploit bugs). These attacks, however, tend to be preventable (in a library, you put in alarm systems; in a network, you filter out forged addresses). Other attacks require more effort and caution but are almost impossible to prevent. If a group of people bent on censorship coordinate their efforts, they can simply keep all the copies of a book legitimately checked out of the library. Similarly, a distributed attack can prevent other people from getting access to a service while using only legitimate means to reach the service.
Even though denial of service attacks cannot be entirely prevented, they can be made much more difficult to implement. First, servers should not become unavailable when invalid commands are issued. Poorly implemented servers may crash or loop in response to hostile input, which greatly simplifies the attacker’s task. Second, servers should limit the resources allocated to any single entity. This includes:
The number of open connections or outstanding requests
The elapsed time a connection exists or a request is being processed
The amount of processor time spent on a connection or request
The amount of memory allocated to a connection or request
The amount of disk space allocated to a connection or request
Protecting Services
How well does a firewall protect against these different types of attacks?
- Command-channel attacks
A firewall can protect against command-channel attacks by restricting the number of machines to which attackers can open command channels and by providing a secured server on those machines. In some cases, it can also filter out clearly dangerous commands (for instance, invalid commands or commands you have decided not to allow).
- Data-driven attacks
A firewall can’t do much about data-driven attacks; the data has to be allowed through, or you won’t actually be able to do anything. In some cases, it’s possible to filter out bad data. For instance, you can run virus scanners over email and other file transfer protocols. Your best bet, however, is to educate users to the risks they run when they bring files to their machine and when they send data out, and to provide appropriate tools allowing them to protect their computers and data. These include virus checkers and encryption software.
- Third-party attacks
Third-party attacks can sometimes be prevented by the same sort of tactics used against command-channel attacks: limit the hosts that are accessible to ones where you know only the desired services are available, and/or do protocol checking to make certain that the commands you’re getting are for the service you’re trying to allow.
- False authentication of clients
A firewall cannot prevent false authentication of clients. It can, however, limit incoming connections to ones on which you enforce the use of nonreusable passwords.
- Hijacking
A firewall can rarely do anything about hijacking. Using a virtual private network with encryption will prevent it; so will protocols that use encryption with a shared secret between the client and the server, which will keep the hijacker from being able to send valid packets. Using TCP implementations that have highly unpredictable sequence numbers will decrease the possibility of hijacking TCP connections. It will not protect you from a hijacker that can see the legitimate traffic. Even somewhat unpredictable sequence numbers will help; hijacking attempts will create a burst of invalid packets that may be detectable by a firewall or an intrusion detection system. (Sequence numbers and hijacking are discussed in more detail in Chapter 4.)
- Packet sniffing
A firewall cannot do anything to prevent packet sniffing. Virtual private networks and encrypted protocols will not prevent packet sniffing, but they will make it less damaging.
- Data injection and modification
There’s very little a firewall can do about data injection or modification. A virtual private network will protect against it, as will a protocol that has message integrity checking.
- Replay
Once again, a firewall can do very little about replay attacks. In a few cases, where there is literally a replay of exactly the same packet, a stateful packet filter may be able to detect the duplication; however, in many cases, it’s perfectly reasonable for that to happen. The primary protection against replay attacks is using a protocol that’s not vulnerable to them (one that involves message integrity and includes a timestamp, for instance).
- Denial of service
Firewalls can help prevent denial of service attacks by filtering out forged or malformed requests before they reach servers. In addition, they can sometimes provide assistance by limiting the resources available to an attacker. For instance, a firewall can limit the rate with which it sends traffic to a server, or control the balance of allowed traffic so that a single source cannot monopolize services.
Evaluating the Risks of a Service
When somebody requests that you allow a service through your firewall, you will go through a process of evaluation to decide exactly what to do with the service. In the following chapters, we give you a combination of information and analysis, based on our evaluations. This section attempts to lay out the evaluation process for you, so that you can better understand the basis for our statements, and so that you can make your own evaluations of services and servers we don’t discuss.
When you evaluate services, it’s important not to make assumptions about things beyond your control. For instance, if you’re planning to run a server, you shouldn’t assume that the clients that connect to it are going to be the clients it’s designed to work with; an attacker can perfectly well write a new client that does things differently. Similarly, if you’re running a client, you shouldn’t assume that all the servers you connect to are well behaved unless you have some means of controlling them.
What Operations Does the Protocol Allow?
Different protocols are designed with different levels of security. Some of them are quite safe by design (which doesn’t mean that they’re safe once they’ve been implemented!), and some of them are unsafe as designed. While a bad implementation can make a good protocol unsafe, there’s very little that a good implementation can do for a bad protocol, so the first step in evaluating a service is evaluating the underlying protocol.
This may sound dauntingly technical, and indeed it can be. However, a perfectly useful first cut can often be done without any actual knowledge of the details of how the protocol works, just by thinking about what it’s supposed to be doing.
What is it designed to do?
No matter how little else you know about a protocol, you know what it’s supposed to be able to do, and that gives you a powerful first estimate of how risky it must be. In general, the less a protocol does, the safer it is.
For instance, suppose you are going to invent a protocol that will be used to talk to a coffee maker, so that you can put your coffee maker on the Web. You could, of course, build a web server into the coffee maker (or wait for coffee makers to come with web servers, which undoubtedly will happen soon) or use an existing protocol,[1] but as a rugged individualist you have decided to make up a completely new protocol. Should you allow this protocol through your firewall?
Well, if the protocol just allows people to ask the coffee maker how much coffee is available and how hot it is, that sounds OK. You probably don’t care who has that information. If you’re doing something very secret, maybe it’s not OK. What if the competition finds out you’re suddenly making coffee in the middle of the night? (The U.S. government discovered at one point that journalists were tracking important news stories by watching the rates at which government agencies ordered pizza deliveries late at night.)
What if the protocol lets people make coffee? Well, that depends. If there’s a single “make coffee” command, and the coffee maker will execute it only if everything’s set up to make coffee, that’s still probably OK. But what if there’s a command for boiling the water and one for letting it run through the coffee? Now your competitors can reduce your efficiency rate by ensuring your coffee is weak and undrinkable.
What if you decided that you wanted real flexibility, so you designed a protocol that gave access to each switch, sensor, and light in the machine, allowing them to be checked and set, and then you provided a program with settings for making weak coffee, normal coffee, and strong coffee? That would be a very useful protocol, providing all sorts of interesting control options, and a malicious person using it could definitely explode the coffee machine.
Suppose you’re not interested in running the coffee machine server; you just want to let people control the coffee machine from your site with the coffee machine controller. So far, there doesn’t seem to be much reason for concern (particularly if you’re far enough away to avoid injury when the coffee machine explodes). The server doesn’t send much to the client, just information about the state of the coffee machine. The client doesn’t send the server any information about itself, just instructions about the coffee machine.
You could still easily design a coffee machine client that would be risky. For instance, you could add a feature to shut down the client machine if the coffee machine was about to explode. It would make the client a dangerous thing to run without changing the protocol at all.
While you will probably never find yourself debating coffee-making protocols, this discussion covers the questions you’ll want to ask about real-life protocols; what sort of information do they give out and what can they change? The following table provides a very rough outline of things that make a protocol more or less safe.
Safer | Less Safe |
Receives data that will be displayed only to the user | Changes the state of the machine |
Exchanges predefined data in a known format | Exchanges data flexibly, with multiple types and the ability to add new types |
Gives out no information | Gives out sensitive information |
Allows the other end to execute very specific commands | Allows the other end to execute flexible commands |
Is the level of authentication and authorization it uses appropriate for doing that?
The more risky an operation is, the more control you want to have over who does it. This is actually a question of authorization (who is allowed to do something), but in order to be able to determine authorization information, you must first have good authentication. It’s no point being able to say “Cadmus may do this, but Dorian may not”, if you can’t be sure which one of them is trying to do what.
A protocol for exchanging audio files may not need any authentication (after all, we’ve already decided it’s not very dangerous), but a protocol for remotely controlling a computer definitely needs authentication. You want to know exactly who you are talking to before you decide that it’s okay for them to issue the “delete all files” command.
Authentication can be based on the host or on the user and can range considerably in strength. A protocol could give you any of the following kinds of information about clients:
No information about where a connection comes from
Unverifiable information (for instance, the client may send a username or hostname to the server expecting the server to just trust this information, as in SMTP)
A password or other authenticator that an attacker can easily get hold of (for instance, the community string in SNMP or the cleartext password used by standard Telnet)
A nonforgeable way to authenticate (for instance, an SSH negotiation)
Once the protocol provides an appropriate level of authentication, it also needs to provide appropriate controls over authorization. For instance, a protocol that allows both harmless and dangerous commands should allow you to give some users permission to do everything, and others permission to do only harmless things. A protocol that provides good authentication but no authorization control is a protocol that permits revenge but not protection (you can’t keep people from doing the wrong thing; you can only track them down once they’ve done it).
Does it have any other commands in it?
If you have a chance to actually analyze a protocol in depth, you will want to make sure that there aren’t any hidden surprises. Some protocols include little-used commands that may be more risky than the commands that are the main purpose of the protocol. One example that occurred in an early protocol document for SMTP was the TURN command. It caused the SMTP protocol to reverse the direction of flow of electronic mail; a host that had originally been sending mail could start to receive it instead. The intention was to support polling and systems that were not always connected to the network. The protocol designers didn’t take authentication into account, however; since SMTP has no authentication, SMTP senders rely on their ability to control where a connection goes to as a way to identify the recipient. With TURN, a random host could contact a server, claim to be any other machine, and then issue a TURN to receive the other machine’s mail. Thus, the relatively obscure TURN command made a major and surprising change in the security of the protocol. The TURN command is no longer specified in the SMTP protocol.
What Data Does the Protocol Transfer?
Even if the protocol is reasonably secure itself, you may be worried about the information that’s transferred. For instance, you can imagine a credit card authorization service where there was no way that a hostile client could damage or trick the server and no way that a hostile server could damage or trick the client, but where the credit card numbers were sent unencrypted. In this case, there’s nothing inherently dangerous about running the programs, but there is a significant danger to the information, and you would not want to allow people at your site to use the service.
When you evaluate a service, you want to consider what information you may be sharing with it, and whether that information will be appropriately protected. In the preceding TURN command example, you would certainly have been alert to the problem. However, there are many instances that are more subtle. For instance, suppose people want to play an online game through your firewall—no important private information could be involved there, right? Wrong. They might need to give usernames and passwords, and that information provides important clues for attackers. Most people use the same usernames and passwords over and over again.
In addition to the obvious things (data that you know are important secrets, like your credit card number, the location the plutonium is hidden in, and the secret formula for your product), you will want to be careful to watch out for protocols that transfer any of the following:
Information that identifies individual people (Social Security numbers or tax identifiers, bank account numbers, private telephone numbers, and other information that might be useful to an impersonator or hostile person)
Information about your internal network or host configuration, including software or hardware serial numbers, machine names that are not otherwise made public, and information about the particular software running on machines
Information that can be used to access systems (passwords and usernames, for instance)
How Well Is the Protocol Implemented?
Even the best protocol can be unsafe if it’s badly implemented. You may be running a protocol that doesn’t contain a “shutdown system” command but have a server that shuts down the system anyway whenever it gets an illegal command.
This is bad programming, which is appallingly common. While some subtle and hard-to-avoid attacks involve manipulating servers to do things that are not part of the protocol the servers are implementing, almost all of the attacks of this kind involve the most obvious and easy ways to avoid errors. The number of commercial programs that would receive failing grades in an introductory programming class is beyond belief.
In order to be secure, a program needs to be very careful with the data that it uses. In particular, it’s important that the program verify assumptions about data that comes from possibly hostile sources. What sources are possibly hostile depends on the environment that the program is running in. If the program is running on a secured bastion host with no hostile users, and you are willing to accept the risk that any attacker who gets access to the machine has complete control over the program, the only hostile data source you need to worry about is the network.
On the other hand, if there are possibly hostile users on the machine, or you want to maintain some degree of security if an attacker gets limited access to the machine, then all incoming data must be untrusted. This includes command-line arguments, configuration data (from configuration files or a resource manager), data that is part of the execution environment, and all data read from the network. Command-line arguments should be checked to make sure they contain only valid characters; some languages interpret special characters in filenames to mean “run the following program and give me the output instead of reading from the file”. If an option exists to use an alternate configuration file, an attacker might be able to construct an alternative that would allow him or her greater access. The execution environment might allow override variables, perhaps to control where temporary files are created; such values need to be carefully validated before using them. All of these flaws have been discovered repeatedly in real programs on all kinds of operating systems.
An example of poor argument checking, which attackers still scan for, occurred in one of the sample CGI programs that were originally distributed with the NCSA HTTP server. The program was installed by default when the software was built and was intended to be an example of CGI programming. The program used an external utility to perform some functions, and it gave the utility information that was specified by the remote user. The author of the program was even aware of problems that can occur when running external utilities using data you have received. Code had been included to check for a list of bad values. Unfortunately, the list of bad values was incomplete, and that allowed arbitrary commands to be run by the HTTP server. A better approach, based upon “That Which Is Not Expressly Permitted Is Prohibited”, would have been to check the argument for allowable characters.
The worst result of failure to check arguments is a “buffer overflow”, which is the basis for a startlingly large number of attacks. In these attacks, a program is handed more input data than its programmer expected; for instance, a program that’s expecting a four-character command is handed more than 1024 characters. This sort of attack can be used against any program that accepts user-defined input data and is easy to use against almost all network services. For instance, you can give a very long username or password to any server that authenticates users (FTP, POP, IMAP, etc.), use a very long URL to an HTTP server, or give an extremely long recipient name to an SMTP server. A well-written program will read in only as much data as it was expecting. However, a sloppily written program may be written to read in all the available input data, even though it has space for only some of it.
When this happens, the extra data will overwrite parts of memory that were supposed to contain something else. At this point, there are three possibilities. First, the memory that the extra data lands on could be memory that the program isn’t allowed to write on, in which case the program will promptly be killed off by the operating system. This is the most frequent result of this sort of error.
Second, the memory could contain data that’s going to be used somewhere else in the program. This can have all sorts of nasty effects; again, most of them result in the program’s crashing as it looks up something and gets a completely wrong answer. However, careful manipulation may get results that are useful to an attacker. For instance, suppose you have a server that lets users specify what name they’d like to use, so it can say “Hi, Fred!” It asks the user for a nickname and then writes that to a file. The user doesn’t get to specify what the name of the file is; that’s specified by a configuration file read when the server starts up. The name of the nickname file will be in a variable somewhere. If that variable is overwritten, the program will write its nicknames to the file with the new value as its name. If the program runs as a privileged user, that file could be an important part of the operating system. Very few operating systems work well if you replace critical system files with text files.
Finally, the memory that gets overwritten could be memory that’s not supposed to contain data at all, but instead contains instructions that are going to be executed. Once again, this will usually cause a crash because the result will not be a valid sequence of instructions. However, if the input data is specifically tailored for the computer architecture the program is running on, it can put in valid instructions. This attack is technically difficult, and it is usually specific to a given machine and operating system type; an attack that works on a Sun running Solaris will not work on an Intel machine running Solaris, nor will an attack that works on the same Intel machine running Windows 95. If you can’t move a binary program between two machines, they won’t both be vulnerable to exactly the same form of this attack.
Preventing a “buffer overflow” kind of attack is a matter of sensible programming, checking that input falls within expected limits. Some programming languages automatically include the basic size checks that prevent buffer overflows. Notably, C does not do this, but Java does.
Does it have any other commands in it?
Some protocol implementations include extra debugging or administrative features that are not specified in the protocol. These may be poorly implemented or less well thought out and can be more risky than those specified in the protocol. The most famous example of this was exploited by the 1988 Morris worm, which issued a special SMTP debugging command that allowed it to tell Sendmail to execute anything the intruder liked. The debugging command is not specified in the SMTP protocol.
What Else Can Come in If I Allow This Service?
Suppose somebody comes up with a perfect protocol—it protects the server from the client and vice versa, it securely encrypts data, and all the known implementations of it are bullet proof. Should you just open a hole for that protocol to any machine on your network? No, because you can’t guarantee that every internal and external host is running that protocol at that port number.
There’s no guarantee that traffic on a port is using the protocol that you’re interested in. This is particularly true for protocols that use large numbers of ports or ports above 1024 (where port numbers are not assigned to individual protocols), but it can be true for any protocol and any port number. For instance, a number of programs send protocols other than HTTP to port 80 because firewalls frequently allow all traffic to port 80.
In general, there are two ways to ensure that the packets you’re letting in belong to the protocol that you want. One is to run them through a proxy system or an intelligent packet filter that can check them; the other is to control the destination hosts they’re going to. Protocol design can have a significant effect on your ability to implement either of these solutions.
If you’re using a proxy system or an intelligent packet filter to make sure that you’re allowing in only the protocol that you want, it needs to be able to tell valid packets for that protocol from invalid ones. This won’t work if the protocol is encrypted, if it’s extremely complex, or if it’s extremely generic. If the protocol involves compression or otherwise changes the position of important data, validating it may be too slow to be practical. In these situations, you will either have to control the hosts that use the ports, or accept the risk that people will use other protocols.
Analyzing Other Protocols
In this book, we discuss a large number of protocols, but inevitably there are some that we’ve left out. We’ve left out protocols that we felt were no longer popular (like FSP, which appeared in the first edition), protocols that change often (including protocols for specific games), protocols that are rarely run through firewalls (including most routing protocols), and protocols where there are large numbers of competitors with no single clear leader (including remote access protocols for Windows machines). And those are just the protocols that we intentionally decided to leave out; there are also all the protocols that we haven’t heard about, that we forgot about, or that hadn’t been invented yet when we wrote this edition.
How do you go about analyzing protocols that we don’t discuss in this book? The first question to ask is: Do you really need to run the protocol across your firewall? Perhaps there is some other satisfactory way to provide or access the service desired using a protocol already supported by your firewall. Maybe there is some way to solve the underlying problem without providing the service across the firewall at all. It’s even possible that the protocol is so risky that there is no satisfactory justification for running it. Before you worry about how to provide a protocol, analyze the problem you’re trying to solve.
If you really need to provide a protocol across your firewall, and it’s not discussed in later chapters, how do you determine what ports it uses and so on? While it’s sometimes possible to determine this information from program, protocol, or standards documentation, the easiest way to figure it out is usually to ask somebody else, such as the members of the Firewalls mailing list[2] (see Appendix A).
If you have to determine the answer yourself, the easiest way to do it is usually empirically. Here’s what you should do:
Set up a test system that’s running as little as possible other than the application you want to test.
Next, set up another system to monitor the packets to and from the test system (using etherfind, Network Monitor, netsnoop, tcpdump, or some other package that lets you watch traffic on the local network). Note that this system must be able to see the traffic; if you are attaching systems to a switch, you will need to put the monitoring system on an administrative port, or otherwise rearrange your networking so that the traffic can be monitored.
Run the application on the test system and see what the monitoring system records.
You may need to repeat this procedure for every client implementation and every server implementation you intend to use. There are occasionally unpredictable differences between implementations (e.g., some DNS clients always use TCP, even though most DNS clients use UDP by default).
You may also find it useful to use a general-purpose client to connect to the server to see what it’s doing. Some text-based services will work perfectly well if you simply connect with a Telnet client (see Chapter 18, for more information about Telnet). Others are UDP-based or otherwise more particular, but you can usually use netcat to connect to them (see Appendix B, for information on where to find netcat). You should avoid doing this kind of testing on production machines; it’s not unusual to discover that simple typing mistakes are sufficient to cause servers to go haywire. This is something useful to know before you allow anybody to access the server from the Internet, but it’s upsetting to discover it by crashing a production system.
This sort of detective work will be simplified if you have a tool that allows you to match a port number to a process (without looking at every running process). Although netstat will tell you which ports are in use, it doesn’t always tell you the processes that are using them. A popular tool for this purpose on Windows NT is inzider . Under Unix, this is usually done with fuser, which is provided with the operating system on most systems; versions of Unix that do not have fuser will probably have an equivalent with some other name. Another useful Unix tool for examining ports and the programs that are using them is lsof. Information on finding inzider and lsof is in Appendix B.
What Makes a Good Firewalled Service?
The ideal service to run through a firewall is one that makes a single TCP connection in one direction for each session. It should make that connection from a randomly allocated port on the client to an assigned port on the server, the server port should be used only by this particular service, and the commands it sends over that connection should all be secure. The following sections look at these ideal situations and some that aren’t so ideal.
TCP Versus Other Protocols
Because TCP is a connection-oriented protocol, it’s easy to proxy; you go through the overhead of setting up the proxy only once, and then you continue to use that connection. UDP has no concept of connections; every packet is a separate transaction requiring a separate decision from the proxy server. TCP is therefore easier to proxy (although there are UDP proxies). Similarly, ICMP is difficult to proxy because each packet is a separate transaction. Once again, ICMP is harder to proxy than TCP but not impossible; some ICMP proxies do exist.
The situation is much the same for packet filters. It’s relatively easy to allow TCP through a firewall and control what direction connections are made in; you can use filtering on the ACK bit to ensure that you allow internal clients only to initiate connections, while still letting in responses. With UDP or ICMP, there’s no way to easily set things up this way. Using stateful packet filters, you can watch for packets that appear to be responses, but you can never be sure that a packet is genuinely a response to an earlier one, and you may be waiting for responses to packets that don’t require one.
One Connection per Session
It’s easy for a firewall to intercept the initial connection from a client to a server. It’s harder for it to intercept a return connection. With a proxy, either both ends of the conversation have to be aware of the existence of the proxy server, or the server needs to be able to interpret and modify the protocol to make certain the return connection is made correctly and uniquely. With plain packet filtering, the inbound connection has to be permitted all the time, which often will allow attackers access to ports used by other protocols. Stateful packet filtering, like proxying, has to be able to interpret the protocol to figure out where the return connection is going to be and open a hole for it.
For example, in normal-mode FTP the client opens a control connection to the server. When data needs to be transferred:
The client chooses a random port above 1023 and prepares it to accept a connection.
The client sends a PORT command to the server containing the IP address of the machine and the port the client is listening on.
The server then opens a new connection to that port.
In order for a proxy server to work, the proxy server must:
Intercept the PORT command the client sends to the server.
Set up a new port to listen on.
Connect back to the client on the port the client specified.
Send a replacement PORT command (using the port number on the proxy) to the FTP server.
Accept the connection from the FTP server, and transfer data back and forth between it and the client.
It’s not enough for the proxy server to simply read the PORT command on the way past because that port may already be in use. A packet filter must either allow all inbound connections to ports above 1023, or intercept the PORT command and create a temporary rule for that port. Similar problems are going to arise in any protocol requiring a return connection.
Anything more complex than an outbound connection and a return is even worse. The talk service is an example; see the discussion in Chapter 19, for an example of a service with a tangled web of connections that’s almost impossible to pass through a firewall. (It doesn’t help any that talk is partly UDP-based, but even if it were all TCP, it would still be a firewall designer’s nightmare.)
One Session per Connection
It’s almost as bad to have multiple sessions on the same connection as it is to have multiple connections for the same session. If a connection is used for only one purpose, the firewall can usually make security checks and logs at the beginning of the connection and then pay very little attention to the rest of the transaction. If a connection is used for multiple purposes, the firewall will need to continue to examine it to see if it’s still being used for something that’s acceptable.
Assigned Ports
For a firewall, the ideal thing is for each protocol to have its own port number. Obviously, this makes things easier for packet filters, which can then reliably identify the protocol by the port it’s using, but it also simplifies life for proxies. The proxy has to get the connection somehow, and that’s easier to manage if the protocol uses a fixed port number that can easily be redirected to the proxy. If the protocol uses a port number selected at configuration time, that port number will have to be configured into the proxy or packet filter as well. If the protocol uses a negotiated or dynamically assigned port, as RPC-based protocols do, the firewall has to be able to intercept and interpret the port negotiation or lookup. (See Chapter 14, for more information about RPC.)
Furthermore, for security it’s desirable for the protocol to have its very own assigned port. It’s always tempting to layer things onto an existing protocol that the firewall already permits; that way, you don’t have to worry about changing the configuration of the firewall. However, when you layer protocols that way, you change the security of the firewall, whether or not you change its configuration. There is no way to let a new protocol through without having the risks of that new protocol; hiding it in another protocol will not make it safer, just harder to inspect.
Protocol Security
Some services are technically easy to allow through a firewall but difficult to secure with a firewall. If a protocol is inherently unsafe, passing it through a firewall, even with a proxy, will not make it any safer, unless you also modify it. For example, X11 is mildly tricky to proxy, for reasons discussed at length in Chapter 18, but the real reason it’s difficult to secure through firewalls has nothing to do with technical issues (proxy X servers are not uncommon as ways to extend X capabilities). The real reason is that X provides a number of highly insecure abilities to a client, and an X proxy system for a firewall needs to provide extra security.
The two primary ways to secure inherently unsafe protocols are authentication and protocol modification. Authentication allows you to be certain that you trust the source of the communication, even if you don’t trust the protocol; this is part of the approach to X proxying taken by SSH. Protocol modification requires you to catch unsafe operations and at least offer the user the ability to prevent them. This is reasonably possible with X (and TIS FWTK provides a proxy called x-gw that does this), but it requires more application knowledge than would be necessary for a safer protocol.
If it’s difficult to distinguish between safe and unsafe operations in a protocol, or impossible to use the service at all if unsafe operations are prevented, and you cannot restrict connections to trusted sources, a firewall may not be a viable solution. In that case, there may be no good solution, and you may be reduced to using a victim host, as discussed in Chapter 10. Some people consider HTTP to be such a protocol (because it may end up transferring programs that are executed transparently by the client).
Choosing Security-Critical Programs
The world of Internet servers is evolving rapidly, and you may find that you want to use a server that has not been mentioned here in a security-critical position. How do you figure out whether or not it is secure?
My Product Is Secure Because . . .
The first step is to discount any advertising statements you may have heard about it. You may hear people claim that their server is secure because:
It contains no publicly available code, so it’s secret.
It contains publicly available code, so it’s been well reviewed.
It is built entirely from scratch, so it didn’t inherit any bugs from any other products.
It is built on an old, well-tested code base.
It doesn’t run as root (under Unix) or as Administrator or LocalSystem (under Windows NT).
It doesn’t run under Unix.
It doesn’t run on a Microsoft operating system.
There are no known attacks against it.
It uses public key cryptography (or some other secure-sounding technology).
None of these things guarantees security or reliability. Horrible security bugs have been found in programs with all these characteristics.
It contains no publicly available code, so it’s secret
People don’t need to be able to see the code to a program in order to find problems with it. In fact, most attacks are found by trying attack methods that worked on similar programs, watching what the program does, or looking for vulnerabilities in the protocol, none of which require access to the source code. It is also possible to reverse-engineer an application to find out exactly how it was written. This can take a considerable amount of time, but even if you are not willing to spend the time, it doesn’t mean that attackers feel the same way. Attackers are also unlikely to obey any software license agreements that prohibit reverse engineering.
In addition, some vendors who make this claim apply extremely narrow definitions of “publicly available code”. For instance, they may in fact use licensed code that is distributed in source format and is free for noncommercial use. Check copyright acknowledgments—a program that includes copyright acknowledgments for the University of California Board of Regents, for instance, almost certainly includes code from some version of the Berkeley Unix operating system, which is widely available. There’s nothing wrong with that, but if you want to use something based on secret source code, you deserve to get what you’re paying for.
It contains publicly available code, so it’s been well reviewed
Publicly available code could be well reviewed, but there’s no guarantee. Thousands of people can read publicly available code, but most of them don’t. In any case, reviewing code after it’s written isn’t a terribly effective way of ensuring its security; good design and testing are far more efficient.
People also point out that publicly available code gets more bug fixes and more rapid bug fixes than most privately held code; this is true, but this increased rate of change also adds new bugs.
It is built entirely from scratch, so it didn’t inherit any bugs from any other products
No code is bug free. Starting from scratch replaces the old bugs with new bugs. They might be less harmful or more harmful. They might also be identical; people tend to think along the same lines, so it’s not uncommon for different programmers to produce the same bug. (See Knight, Leveson, and St. Jean, “A Large-Scale Experiment in N-Version Programming,” Fault-Tolerant Computing Systems Conference 15, for an actual experience with common bugs.)
It is built on an old, well-tested code base
New problems show up in old code all the time. Worse yet, old problems that hadn’t been exploited yet suddenly become exploitable. Something that’s been around for a long time probably isn’t vulnerable to attacks that used to be popular, but that doesn’t predict much about its resistance to future attacks.
It doesn’t run as root/Administrator/LocalSystem
A program that doesn’t run as one of the well-known privileged accounts may be safer than one that does. At the very least, if it runs amok, it won’t have complete control of your entire computer. However, that’s a very long distance from actually being safe. For instance, no matter what user is involved, a mail delivery system has to be able to write mail into users’ mailboxes. If the mail delivery system can be subverted, it can be used to fill up disks or forge email, no matter what account it runs as. Many mail systems have more power than that.
There are two separate problems with services that are run as “unprivileged” users. The first is that the privileges needed for the service to function carry risks with them. A mail system must be able to deliver mail, and that’s inherently risky. The second is that few operating systems let you control privileges so precisely that you can give a service exactly the privileges that it needs. The ability to deliver mail often comes with the ability to write files to all sorts of other places, for instance. Many programs introduce a third problem by creating accounts to run the service and failing to turn off default privileges that are unneeded. For instance, most programs that create special accounts to run the service fail to turn off the ability for their special accounts to log in. Programs rarely need to log in, but attackers often do.
It doesn’t run under Unix, or it doesn’t run on a Microsoft operating system
People produce dozens of reasons why other operating systems are less secure than their favorite one. (Unix source code is widely available to attackers! Microsoft source code is too big! The Unix root concept is inherently insecure! Windows NT’s layered model isn’t any better!) The fact is, almost all of these arguments have a grain of truth. Both Unix and Windows NT have serious design flaws as secure operating systems; so does every other popular operating system.
Nonetheless, it’s possible to write secure software on almost any operating system, with enough effort, and it’s easy to write insecure software on any operating system. In some circumstances, one operating system may be better matched to the service you want to provide than another, but most of the time, the security of a service depends on the effort that goes into securing it, both at design and at deployment.
There are no known attacks against it
Something can have no known attacks without being at all safe. It might not have an installed base large enough to attract attackers; it might be vulnerable but usually installed in conjunction with something easier to attack; it might just not have been around long enough for anybody to get around to it; it might have known flaws that are difficult enough to exploit that nobody has yet implemented attacks for them. All of these conditions are temporary.
It uses public key cryptography (or some other secure-sounding technology)
As of this writing, public key cryptography is a popular victim for this kind of argument because most people don’t understand much about how it works, but they know it’s supposed to be exciting and secure. You therefore see firewall products that say they’re secure because they use public key cryptography, but that don’t say what specific form of public key cryptography and what they use it for. This is like toasters that claim that they make perfect toast every time because of “digital processing technology”. They can be digitally processing anything from the time delay to the temperature to the degree of color-change in the bread, and a digital timer will burn your toast just as often as an analog one.
Similarly, there’s good public key cryptography, bad public key cryptography, and irrelevant public key cryptography. Merely adding public key cryptography to some random part of a product won’t make it secure. The same is true of any other technology, no matter how exciting it is. A supplier who makes this sort of claim should be prepared to back it up by providing details of what the technology does, where it’s used, and how it matters.
Their Product Is Insecure Because . . .
You’ll also get people who claim that other people’s software is insecure (and therefore unusable or worse than their competing product) because:
It’s been mentioned in a CERT-CC advisory or on a web site listing vulnerabilities.
It’s publicly available.
It’s been successfully attacked.
It’s been mentioned in a CERT-CC advisory or on a web site listing vulnerabilities
CERT-CC issues advisories for programs that are supposed to be secure, but that have known problems for which fixes are available from the supplier. While it’s always unfortunate to have a problem show up, if there’s a CERT-CC advisory for it, at least you know that the problem was unintentional and the vendor has taken steps to fix it. A program with no CERT-CC advisories might have no problems; but it might also be completely insecure by design, be distributed by a vendor who never fixes security problems, or have problems that were never reported to CERT-CC. Since CERT-CC is relatively inactive outside of the Unix world, problems on non-Unix platforms are less likely to show up there, but they still exist.
Other lists of vulnerabilities are often a better reflection of actual risks, since they will list problems that the vendor has chosen to ignore and problems that are there by design. On the other hand, they’re still very much a popularity contest. The “exploit lists” kept by attackers, and people trying to keep up with them, focus heavily on attacks that provide the most compromises for the least effort. That means that popular programs are mentioned often, and unpopular programs don’t get much publicity, even if the popular programs are much more secure than the unpopular ones.
In addition, people who use this argument often provide big scary numbers without putting them in context; what does it mean if you say that a given web site lists 27 vulnerabilities in a program? If the web site is carefully run by a single administrator, that might be 27 separate vulnerabilities; if it’s not, it may be the same 9 vulnerabilities reported three times each. In either case, it’s not very interesting if competing programs have 270!
It’s publicly available
We’ve already argued that code doesn’t magically become secure by being made available for inspection. The other side of that argument is that it doesn’t magically become insecure, either. A well-written program doesn’t have the kind of bugs that make it vulnerable to attack just because people have read the code. (And most attackers don’t actually read code any more frequently than defenders do—in both cases, the conscientious and careful read the code, and the vast majority of people just compile it and hope.)
In general, publicly available code is modified faster than private code, which means that security problems are fixed more rapidly when they are found. This higher rate of change has downsides, which we discussed earlier, but it also means that you are less likely to be vulnerable to old bugs.
It’s been successfully attacked
Obviously, you don’t want to install software that people already know how to attack. However, what you should pay the most attention to is not attacks but the response to them. A successful attack (even a very high-profile and public successful attack) may not be important if the problem was novel and rapidly fixed. A pattern where variations on the same problem show up repeatedly or where the supplier is slow to fix problems is genuinely worrisome, but a single successful attack usually isn’t, even if it makes a national newspaper.
Real Indicators of Security
Any of the following things should increase your comfort:
Security was one of the design criteria.
The supplier appears to be aware of major types of security problems and can speak to how they have been avoided.
It is possible for you to review the code.
Somebody you know and trust actually has reviewed the code.
A process is in place to distribute notifications of security problems and updates to the server.
The server fully implements a recent (but accepted) version of the protocol.
The program uses standard error-logging mechanisms (syslog under Unix, the Event Viewer under Windows NT).
There is a secure software distribution mechanism.
Security was one of the design criteria
The first step towards making a secure program is trying to make one. It’s not something you can achieve by accident. The supplier should have convincing evidence that security was kept in mind at the design stage, and that the kind of security they had in mind is the same kind that you have in mind. It’s not enough for “security” to be a checkbox item on a list somewhere. Ask what they were trying to secure, and how this affected the final product.
For instance, a mail system may list “security” as a goal because it incorporates anti-spamming features or facilitates encryption of mail messages as they pass across the Internet. Those are both nice security goals, but they don’t address the security of the server itself if an attacker starts sending it evil commands.
The supplier can discuss how major security problems were avoided
Even if you’re trying to be secure, you can’t get there if you don’t know how. Somebody associated with your supplier and responsible for the program should be able to intelligently discuss the risks involved, and what was done about them. For instance, if the program takes user-supplied input, somebody should be able to explain to you what’s been done to avoid buffer overflow problems.
It is possible for you to review the code
Security through obscurity is often better than no security at all, but it’s not a viable long-term strategy. If there is no way for anybody to see the code, ever, even a bona-fide expert who has signed a nondisclosure agreement and is acting on behalf of a customer, you should be suspicious. It’s perfectly reasonable for people to protect their trade secrets, and it’s also reasonable for people to object to having sensitive code examined by people who aren’t able to evaluate it anyway (for instance, it’s unlikely that most people can do an adequate job of evaluating the strength of encryption algorithms). However, if you’re willing to provide somebody who’s competent to do the evaluation, and to provide strong protection for trade secrets, you should be allowed to review the code. Code that can’t stand up to this sort of evaluation will not stand the test of time, either.
You may not be able and willing to review the code under appropriate conditions. That’s usually OK, but you should at least verify that there is some procedure for code review.
Somebody you know and trust actually has reviewed the code
It doesn’t matter how many people could look at a piece of software if nobody ever does. If it’s practical to do so, it’s wise to make the investment to have somebody reasonably knowledgeable and trustworthy actually look at the code. While anybody could review open source, very few people do. It’s relatively cheap and easy, and any competent programmer can at least tell you whether it’s well-written code. Don’t assume that somebody else has done this.
There is a security notification and update procedure
All programs eventually have security problems. A well-defined process should be in place for notifying the supplier of security problems and for getting notifications and updates from them. If the supplier has been around for any significant amount of time, there should be a positive track record, showing that they react to reported problems promptly and reasonably.
The server implements a recent (but accepted) version of the protocol
You can have problems with protocols, not just with the programs that implement them. In order to have some confidence in the security of the protocol, it’s helpful to have an implementation of an accepted, standard protocol in a relatively recent version. You want an accepted and/or standard protocol so that you know that the protocol design has been reviewed; you want a relatively recent version so that you know that old problems have been fixed. You don’t want custom protocols, or experimental or novel versions of standard protocols, if you can avoid them. Protocol design is tricky, few suppliers do a competent job in-house, and almost nobody gets a protocol right on the first try.
The program uses standard error-logging mechanisms
In order to secure something, you need to manage it. Using standard logging mechanisms makes programs much easier to manage; you can simply integrate them into your existing log management and alerting tools. Nonstandard logging not only interferes with your ability to find messages, it also runs the risk of introducing new security holes (what if an attacker uses the logging to fill your disk?).
There is a secure software distribution mechanism
You should have some confidence that the version of the software you have is the correct version. In the case of software that you download across the Internet, this means that it should have a verifiable digital signature (even if it is commercial software!).
More subtly, if you’re getting a complex commercial package, you should be able to trust the distribution and release mechanism, and know that you have a complete and correct version with a retrievable version number. If your commercial vendor ships you a writable CD burned just for you and then advises you to FTP some patches, you need to know that some testing, integration, and versioning is going on. If they don’t digitally sign everything and provide signatures to compare to, they should at least be able to provide an inventory list showing all the files in the distribution with sizes, dates, and version numbers.
Controlling Unsafe Configurations
As we’ve discussed in earlier sections, your ability to trust a protocol often depends on your ability to control what it’s talking to. It’s not unusual to have a protocol that can be perfectly safe, as long as you know that it’s going to specific clients with specific configurations, or otherwise horribly unsafe. For instance, the Simple Mail Transport Protocol (SMTP) is considered acceptable at most sites, as long as it’s going to a machine with a reliable and well-configured server on it. On the other hand, it’s extremely dangerous when talking to a badly configured server.
Normally, if you want to use a protocol like this, you will use bastion hosts, and you will allow the protocol to come into your site only when it is destined for a carefully controlled and configured machine that is administered by your trusted security staff. Sometimes you may not be able to do this, however; you may find that you need to allow a large number of machines, or machines that are not directly controlled by the staff responsible for the firewall. What do you do then?
The first thing to be aware of is that you cannot protect yourself from hostile insiders in this situation. If you allow a protocol to come to machines, and the people who control those machines are actively trying to subvert your security, they will succeed in doing so. Your ability to control hostile insiders is fairly minimal in the first place, but the more protocols you allow, the more vulnerable you are.
Supposing that the people controlling the machines are not hostile but aren’t security experts either, there are measures you can take to help the situation. One option is to attempt to increase your control over the machines to the point where they can’t get things wrong; this means forcing them to run an operating system like Windows NT or Unix where you can centralize account administration and remove access to globally powerful accounts (root or Administrator). This is rarely possible, and when it is possible, it sometimes doesn’t help much. This approach will generally allow you to forcibly configure web browsers into safe configurations, for instance, but it won’t do much for web servers. Enough access to administer a web server in any useful way is enough access to make it insecure.
Another option is to attempt to increase your control over the protocol until you’re certain that it can’t be used to attack a machine even it’s misconfigured. For instance, if you can’t turn off support for scripting languages in web browsers, you can filter scripting languages out of incoming HTTP. This is at best an ongoing war—it’s usually impossible to find a safe but useful subset of the protocol, so you end up removing unsafe things as they become known. At worst, it may be impossible to do this sort of control.
If you can’t actually control either the clients or the protocol, you can at least provide peer pressure and social support to get programs safely configured. You can use local installations under Unix or profiles under Windows NT to supply defaults that you find acceptable (this will work best if you also provide localizations that are useful to the user). For instance, you can supply configuration information for web browsers that turns off scripting languages and that also correctly sets proxying information and provides bookmarks of local interest. You want to make it easier and more pleasant to do things securely than insecurely.
You can also provide a security policy that makes clear what you want people to do and why. In particular, it should explain to people why it matters to them, since few people are motivated to go to any trouble at all to achieve some abstract notion of security. (See Chapter 25, for more information on security policies.)
No matter how you end up trying to manage these configuration issues, you will want to be sure that you are monitoring for vulnerabilities. Don’t fool yourself; you will never get perfect compliance using policies and defaults. (You’ll be very lucky to get perfect compliance even when you’re using force, since it requires perfect enforcement!)