
In the last chapter, we created our first implementations of a recommender system. That sets the stage for further improvements. We only provided recommendations that were global in nature. Now we will focus on recommendations that are tuned for the current user. We will discuss the following topics in this chapter:
- Content-based recommendation
- Collaborative filtering based recommendation
- Comparison of the two approaches
The main idea in the content-based recommendation system is to recommend items to a customer X similar to previous items rated highly by the same customer X. Notice in this definition that we find "similar" items, which means we need to have a measure of similarity between items. To measure similarity of two items we decode item features and then apply a similarity function.
What is a similarity function? A similarity function takes two items (or their feature representations) and returns a value that indicates degree of similarity of two items. Now there are many different kinds of similarity functions because there are different ways we can represent an item.
We can represent an item as a set of features. For example, an item has the color red, is square shaped, and is made in India. Another item could be colored red, square shaped, and made in Italy. So we can represent these items as two sets:
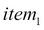
= {color red, square-shaped, made in India}
= {color red, square-shaped, made in Italy}
So how similar are these two items? We will see that later in this chapter.
We need to have a common representation that is well understood by a similarity function. Also, there can be thousands or millions of features that we can extract for an item. For this, we can use a vector-based representation for an item. Notice that this is different from a set-based representation. So for ![]() and
and ![]() , with vector representation how do we now calculate the similarity?
, with vector representation how do we now calculate the similarity?
To answer these questions, we have different similarity (or dissimilarity/distance) metrics. Some of these we have already discussed earlier, but let's visit them again here. We will discuss the following similarity metrics:
- Pearson correlation
- Euclidean distance
- Cosine measure
- Spearman correlation
- Tanimoto coefficient
- Log likelihood test
The Pearson correlation value is in the range -1.0 to 1.0, where 1.0 indicates a very high correlation or high similarity and -1.0 indicates the opposite or high dissimilarity. As we had seen in an earlier chapter, the Pearson correlation of two series is the ratio of their covariance to the product of their variances. For a detailed review of Pearson correlation, read this Wikipedia article (https://en.wikipedia.org/wiki/Pearson_product-moment_correlation_coefficient).
Pearson correlation expects the series to have the same length, and it doesn't take into account the number of features in which two series preferences overlap. Pearson correlation is also undefined if either of the series of feature values are identical because that makes the variance zero. Therefore, the result is undefined.
Euclidean distance is the geometric distance between two n-dimensional points. So given two series of feature values, we can consider both as vectors and calculate the geometric distance. Note that this is a distance metric but we want a similarity measure. So to convert it into a similarity metric, we can use the following formulas:
Where ![]() is Euclidean similarity and
is Euclidean similarity and ![]() = Euclidean distance.
= Euclidean distance.
Cosine measure or cosine similarity is the cosine of angle between two vectors (or points with respect to origin). The value of cosine ranges from -1.0 to 1.0.
Also note that the meaning of the cosine measure value is exactly similar to Pearson correlation. So we can also use Pearson correlation to the same effect. Therefore the same challenges apply to cosine measure too.
Spearman correlation, also called Spearman rank correlation, has already been covered in an earlier chapter. Essentially, Spearman correlation is applicable when we have features in a vector that can be ranked somehow (for example, time and rating both have an implicit ordering). Well, this measure works only if there is an implicit ordering of features. This free video gives a very simple and concise description of calculating Spearman correlation.
Tanimoto coefficient, also known as Jaccard coefficient, is the measure of overlap between two sets.
TC = intersection of preferences/union of preferences

Where ![]() is number of feature overlap and
is number of feature overlap and ![]() is the joint number of features. The value of this measure is always from 0 to 1. So it is easy to convert into a distance measure using the following formula:
is the joint number of features. The value of this measure is always from 0 to 1. So it is easy to convert into a distance measure using the following formula:
Note that this measure is defined for sets, so we need to make an appropriate representation for our item features to make it work. For example, we can have an item vector with 1s wherever a feature is present. So for ![]() and
and ![]() examples, which we saw earlier, we can have the following representation:
examples, which we saw earlier, we can have the following representation:
= [1,1,1,0]= [1,1,0,1]
Where the universal set would be [1,1,1,1] representing [color red, square-shaped, made in India, made in Italy]. So for ![]() and
and ![]() the similarity measure is:
the similarity measure is: ![]() .
.
This is quite similar to the Tanimoto coefficient, which measures an overlap. However, the log likelihood test is an expression of how unlikely users will have so much overlap, given the total number of items and the number of items each user has a preference for.
Two similar users are likely to rate a movie common to them. However, two dissimilar users are unlikely to rate a common movie. Therefore, the more unlikely the two users would rate the same movie, and still rate the same movie, the more similar two users should be. The resulting value can be interpreted as a probability that an overlap isn't just due to chance. You may also want to refer to this video for a nice explanation.