
CHAPTER 5: TECHNOLOGY CONTINUITY
No one can argue the importance and significance of technology within organizations. When we say technology, we don’t only mean IT. We refer to all automation and processing functions within an organization. IT may form the biggest part of technology yet it is not the whole.
The role of technology within organizations has been continuously evolving from being a support function to the rest of the organization, to being an enabler to the business, to being a revenue-generating line of business by itself. Dependence on technology to achieve operational and strategic goals and targets in modern organizations has reached unprecedented levels and will continue to do so in the future.
As a result of this key dependence, failures in technology are critically sensitive for an organization in terms of probabilities and impacts. Dependence on technology sometimes reaches the state of total dependence. Almost all modern organizations have their most valuable assets residing on technological, or automated, platforms: data, information, and processes.
On the other hand, technology services are generally shared across an organization with common technology components serving several parties. Having such components fail would actually affect all parties utilizing them.
Technology is also, as with any product made by people, inherently susceptible to errors and bugs. Testing and quality assurance dramatically decrease such errors and bugs, but do not completely eliminate them.
Technology is also one of the main areas for outsourcing. Failures and problems at the outsourcing provider can easily propagate to the outsourcing organization. This means that the scope of the probability and impact of threats sometimes gets much larger with outsourcing.
Technology is also a specialized area where it is somehow more difficult to maintain a sufficient level of specialty and expertise all the time. The high staff turnover in technology is a key threat to consider in this sensitive area.
Because of the unique nature and role of technology within an organization, specific types of planning and management need to be provided to address and manage the specific requirements of technology within the BCM program. As we will be focusing on IT as a representative element of technology for the rest of the book, we will refer to such specific types of planning and management within IT disaster recover (ITDR) and readiness for business continuity (IRBC).
IT disaster recovery and readiness for business continuity (ITDR and IRBC)
ITDR/IRBC processes have been around for a long time, even before the formulation of BCM and other related disciplines. In fact, many of the ITDR/IRBC practices have evolved to become of those of BCM.
ITDR focuses on setting up the necessary elements: framework, processes, arrangements, and resources, to be in a state of readiness to manage, recover, and resume critical technology services in cases of disaster and disruption. As the technology role within organizations has become more and more critical, recovery and resumption of relevant services are not enough. What is now needed is continuity instead of recovery. To satisfy this requirement, IRBC has been formalized. IRBC is concerned with having the management framework and all the resources prepared and ready to ensure the continuity and availability of technology services according to BCM requirements. It aims to support and enhance the recovery levels of the organization.
While both share the same focus area, IRBC and ITDR have their differences. ITDR focuses on recovery while IRBC focuses on continuity. Because ITDR is oriented towards recovery, it mostly addresses components in isolation while IRBC looks more at end-to-end technology services. IRBC is closer to BCM as products, services, and business processes can be mapped and aligned to technology components: logical or physical. IRBC is also more capable of achieving better resilience levels against smaller outages and incidents, not only disasters and major outages.
Relationship between BCM and ITDR/IRBC
The IRBC/ITDR program is a subset of the organization-wide BCM program. IRBC/ITDR should follow BCM guidelines and should support the BCM program by meeting the continuity requirements specified in the various stages and phases of the BCM life cycle. The IRBC-focused Standard, ISO27301, proposes a life cycle for the IRBC program that is aligned to the BCM life cycle. Being aligned here indicates support, not repetition or redundancy.
It implies integration and compatibility with the BCM life cycle.
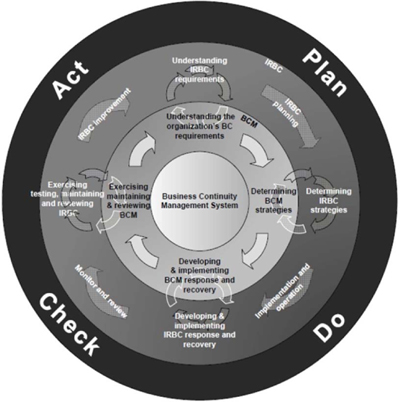
Figure 26: Integration of IRBC and BCMS
The relationship starts as early as the BCM program setup phase with the inclusion of the IRBC/ITDR program within the BCM program. It is highly risky to run two separate, disconnected programs. It will, most probably, lead to contradicting and ineffective recovery efforts as well as a waste of resources that may be under or over-allocated according to the real needs of the organization. Technology is there to help the organization achieve its goals and targets, including continuity objectives. This is valid both in normal conditions as well as in disasters.
In the BIA phase, the technology requirements are collected, reviewed, and validated along with the other information. In this regard, two main key actions are recommended:
- Include IT or technology-related departments within the BIA process as this will help in identifying the IT and technology-related departments requirements for recovering themselves as a precursor to recovering IT and technology components.
- Have specialized IT or technology staff involved in the analysis and validation process as this will help to align the products, services, and business processes with their technology resources.
In the threat and risk assessment phase, threats and risks to technology resources and components are assessed. Specifically, the assessment should cover threats and risks related to the confidentiality, integrity, availability, and currency of the technology components in accordance with the continuity specifications produced from the BIA.
Within the strategy phase, strategies set for IRBC/ITDR programs should be in line with the BCM strategy. There are no hard rules here as IRBC/ITDR strategies will cover specific areas of technology while BCM strategies cover all areas within the scope.
When it comes to planning and implementation, IRBC/ITDR plans should be consistent with the BCM plans, giving extra care to the CMP as technology incidents are among the top common causes of disasters and crises.
The technology recovery plans should support the other plans dependent on them and be in accordance with the continuity specifications and strategies set and approved by the organization.
Testing the IRBC/ITDR plans can be done separately or in conjunction with the BCPs. The main rule here is to be practical and flexible.
Training given regarding the IRBC/ITDR program is in some ways distinct from the BCM training as it includes technical information that requires specialization and expertise not necessarily available in areas outside IT and technology-related departments. Awareness, on the other hand, can be taught in similar fashion to BCM awareness as it is more beneficial to introduce common programs in an integrated manner rather than delivering separate paths of awareness for BCM and IRBC/ITDR.
Review and update processes are common to both technology and non-technology areas. In fact, technology is the area that witnesses more changes across shorter periods of time due to the fact that technology evolves at a fast pace and the services offered are getting more and more complex and advanced.
IRBC/ITDR governance model
In order to be implemented properly and in accordance with the BCM program, the IRBC/ITDR sub-program needs a clear and effective governance model. The elements of such a governance structure should be integrated with the BCM governance model:
IRBC/ITDR owner
The IRBC/ITDR sub-program needs executive support and ownership as well as accountability for its effectiveness and success. The IRBC/ITDR owner works very closely with the BCM owner, bearing in mind that the BCM owner is the ultimate owner of the BCM program and its subprograms, like the IRBC/ITDR program.
IRBC/ITDR scope
The scope of the IRBC/ITDR activities should cover the continuity specifications and requirements set out and agreed through BCM’s BIA process. If there are special requirements that were not extracted from the BIA process, the IRBC/ITDR scope may include them provided that the IRBC/ITDR owner agrees and approves such inclusion.
IRBC/ITDR policy
The IRBC/ITDR policy includes the IRBC/ITDR scope and the strategies and guidelines adopted in order to meet the specifications and requirements.
The IRBC/ITDR policy should be approved by the IRBC owner and BCM owner. It should also be documented and controlled as well as communicated to relevant stakeholders. The policy should be reviewed on a periodical
basis and as needed to make sure it is current and relevant to the status of the organization and its technology aspects.
IRBC/ITDR professionals
IRBC/ITDR professionals should be competent in both technology and other areas as they are situated on the borderline between technology and other areas. They share almost the same competencies required by the BCM team, but with more focus on the technology side.
The IRBC/ITDR life cycle
The main purpose of the IRBC/ITDR life cycle is to establish and plan for the technology aspects that support an organization’s BCM program and its implementation.
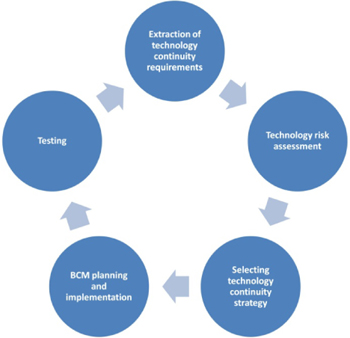
Figure 27: Technology continuity life cycle
The IRBC/ITDR life cycle, as mentioned earlier, comprises the following phases:
- extraction of technology continuity requirements;
- performance of technology risk assessment;
- selection of IRBC/ITDR strategic options;
- development and implementation of IRBC/ITDR plans;
- testing and maintenance of IRBC/ITDR sub-program;
- maintenance of IRBC/ITDR sub-program.
Extraction of technology continuity requirements
This phase starts where the BCM’s BIA process ends. The BIA results should be translated for technology services and consequently its components, as mentioned earlier, and in particular for the critical ones. If a business process or activity is approved as being critical, then the technology services supporting such a process or activity are categorized as critical. There are other points to consider here:
- Dependency: Extra care should be given to the dependencies of both business processes and activities on one hand and the dependency between technology services and components on the other hand.
- Technology-native services: Services such as the help desk, network operations, and security services will most probably be missing from the BIA results, yet they are essential to the provision of technology services. These services are automatically categorized as critical as their non-existence or non-operation would introduce high risks.
Technology services should be assigned continuity specifications. The main specifications are criticality, RTO, RPO, and dependency. Criticality, RTO, and dependency specifications play a major part in defining what technology services will be offered during disasters, where they will be offered from, and the order of their recovery and restoration. RPO is a major decision maker in the protection of data, off-site data backup, and replication.
Defining criticality, RTO, RPO, and dependency is not always an easy task, especially when technology is complex. A major factor in deciding on these specifications is the technology architecture and deployment. It is very likely that there will be cases where continuity specifications, especially RTO and RPO, cannot be satisfied due to technical constraints or the cost of implementation. In this case, a compromise needs to be reached for the derived specifications, with the endorsement of relevant stakeholders.
Once continuity specifications have been defined for technology services and their components, a gap assessment should be done of what is already in place and what is missing. Going to such an effort will help greatly in designing the IRBC/ITDR strategies and options.
The results should be reported to the IRBC/ITDR owner, the BCM manager, and the BCM owner and committee respectively for review and approval.
Performance of technology risk assessment
Once continuity specifications are defined and approved for technology components, a comprehensive risk assessment need to be done for these components. Very similar to the goal of threat and risk assessment in the BCM life cycle, the goal of this risk assessment exercise is to limit the probability and impact of risks and threats occurring and, consequently, the occurrence of disasters and crises.
The technology risk assessment needs to look at all of the technology area’s components, not just hardware, software, and network aspects. In this context, the technology risk assessment should look at the following:
- information security requirements of confidentiality, integrity, availability, and currency;
- the existence of single points of failure within technology components;
- the performance of vendors, giving special attention to technology’s outsourcing providers;
- environmental and physical preparations surrounding technology;
- knowledge concentration, retention, and management with relevance to technology;
- staff succession management within technology.
The threats should be defined in terms of probability and impact. The definition can be qualitative or quantitative. Regardless of the approach used, it should be meaningful and consistent with the approach of the BCM life cycle. Such consistency is vital in order to properly manage threats and risks across the organization in a way that gives the right weights and priorities. Using different approaches may lead to wrong prioritization of threats and risks, which leads to an ineffective reduction of the overall risk exposure of the organization. Threats and risks are then rated by multiplying probability and impact ratings.
Once threats and risks are assessed, the next step is to propose management actions for them. The management actions follow the same concepts provided within the BCM life cycle. Once management actions are defined, the risk assessment results should be reported to the IRBC/ITDR owner and BCM manager as a first step before being raised to the BCM owner and committee for review and approval.
Selection of IRBC/ITDR strategic options
This stage of the IRBC/ITDR life cycle focuses on creating strategies that satisfy the requirements of the continuity specifications as well as creating risk treatment and reduction plans.
The strategies are categorized by the components of technology.
For specific components, the strategies and RTPs will most probably share all or part of the continuity strategies and risk treatment plans that were laid out and approved through the BCM life cycle as they are going to be used across the organization, including technology.
When designing IRBC/ITDR strategy or RTPs, there are factors that play a part in deciding on the different options proposed:
- Cost-benefit analysis: The proposed strategy should satisfy the continuity specifications’ requirements within a reasonable cost.
- Available resources to use: If the resources are being provided through several allocations over several periods or timeframes, the strategy proposed should take this into consideration.
- Total cost of ongoing operation and maintenance after initial deployment: Some technology continuity strategies may require a very reasonable budget to deploy them but are relatively expensive to operate and maintain. Consider the total cost of operation and maintenance over the expected lifetime of the technology continuity strategy option.
- Applicability: The proposed strategy should be applicable and practical to implement and not some ideal design that is very difficult to implement.
- Consistency with the BCM policy and BCM continuity strategies: The proposed strategy should be consistent with the BCM policy as a higher reference for BCM across the organization and the BCM strategies that are approved to avoid contradictory actions between BCM and IRBC/ITDR.
- Consistency with other relevant technology strategies: The proposed strategy should be consistent with the relevant technology policies and frameworks in order to avoid conflict with them as well as to avoid making IRBC/ITDR a program isolated from the other technology activities.
- Technological constraints: The proposed strategy should have minimum technological constraints in order to be effective in answering the requirements of technology continuity.
Considering the factors above and the BCM continuity strategy options, the range of IRBC/ITDR strategic options to cover all of the technology components may include the following:
- People: For this technology component, the same strategies as for BCM continuity are recommended to be followed.
- Premises: For technology, it is recommended that co-location or redundant sites are available and prepared, either internally or through service providers. We will be covering this particular issue in a separate section later in this chapter. The selected site strategy should not be exclusive to hardware, software, and networks only as it should also include people placement and additional resources required as the disaster continues. There are also other options like teleworking from home or another connected area, or the use of mobile recovery facilities.
- Hardware, software, and networks: For these technology components, the answer to their continuity requirements is to have a mix of preparation and operation modes. For critical services, you may want to consider the option of clustering where a set of servers work as one, active-active setups where load balancing and load sharing are deployed, or distribute the technology services across multiple sites working actively at the same time. For less critical services, you may want to consider warm setups where equipment is located within the site but is not activated without some preparation and manual intervention. For non-critical services, cold sites and on-demand agreements with specialized vendors may be the right solutions.
- Data and information: This component should follow the selected BCM continuity strategy option to help maintain the integrity, availability, confidentiality, and currency requirements.
- Suppliers and vendors: This component is dependent on how the organization deals with technology vendors. For many organizations, technology departments are given special authorizations and empowerments to manage their relationships with relevant vendors. Others treat technology suppliers in the same way as other suppliers. It is useful, however, to make use of the BCM continuity strategy options and to have the vendors’ support and troubleshooting processes reviewed and audited in the same way as the continuity requirements of the organization.
- Processes: If possible, this component should follow the selected BCM continuity strategy option. With increasing dependency on technology, it might be difficult to create workarounds for technology-related processes.
After the options are proposed, they should be reviewed by the IRBC/ITDR owner and BCM manager before being raised to the BCM owner and committee for final review and approval.
Development and implementation of IRBC/ITDR plans
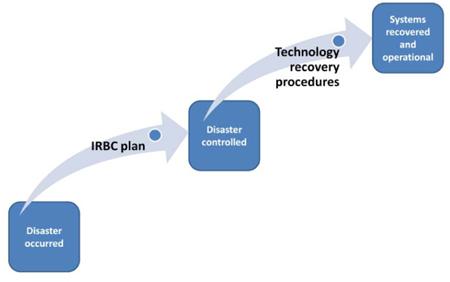
Figure 28: IRBC plan and recovery procedures
In a similar manner to the sequence of BCM life cycle, once the strategies for IRBC/ITDR components are adopted, the actual IRBC/ITDR plans need to be developed and implemented.
Within this phase, the plans developed and implemented do not concentrate exclusively on the management of and recovery from major incidents or disasters. There should also be some arrangements and planning to manage smaller incidents. The justification for this is that managing and resolving these incidents as early as possible can prevent them evolving into major incidents or disasters. Having smaller incidents management within the scope of the plans can create an integrated escalation process if smaller incidents do become major disasters.
The IRBC/ITDR plans follow a similar structure to the BCM plans. The structure of IRBC/ITDR plans is separated into two layers:
- IRBC/ITDR management plan: This plan focuses on the management of incidents and the crisis management part of technology departments or functions. These plans are not specific to individual IRBC/ITDR services but they deal with the overall technology environment as one integrated body of different components. The main purpose of these plans is to enable technology-related departments to assess incidents, control them, initiate recovery, communicate with relevant stakeholders, and get back to normal conditions.
- IRBC/ITDR recovery plans and procedures: These plans build on the IRBC/ITDR management plan and will actually start the specialized or technical recovery phases, if necessary. These plans are mapped to specific technology components or one or more technology services.
The IRBC/ITDR management plan provides the groundwork and basis for technology service recovery and continuity. The IRBC/ITDR management plan should enable the technology-related functions to:
- assess the incidents;
- contain and control the incidents, if possible;
- initiate recovery plans and procedures;
- initiate the process to go back to normal conditions;
- communicate with relevant stakeholders.
It is apparent that these objectives and purposes are very similar to the ones of the BCM’s CMP. Failure to achieve such purposes may actually undermine the readiness and recoverability state of an organization as it will be heavily dependent on technology to perform its operations, even in times of disaster.
The contents of the IRBC/ITDR management plan are also similar to the BCM CMP. A typical IRBC/ITDR management plan should contain:
- Purpose: The plan should document the purpose it serves in a clear and understandable way so that relevant stakeholders are aware of what this plan will achieve.
- Scope: The IRBC/ITDR management plan should clearly define which technology components are covered within the activities of the plan and what is not covered. In addition to specifying the components covered, continuity specifications associated with these components should also be mentioned.
- Roles and responsibilities: The plan should clearly define the various roles and responsibilities of the relevant stakeholders. In addition, there should be clear and sufficient information on the authorities (financial and non-financial) relevant to the IRBC/ITDR management plan.
- Plan ownership and maintenance: The plan should define ownership and maintenance roles and their assignments with sufficient information on the review, maintenance, and update processes.
- Contact details: The plan should contain all contact details required for the relevant stakeholders, especially staff, vendors, contractors, service providers, and important clients.
- Assessment and escalation: The plan should contain sufficient information on how to assess incidents. In this part of the plan, there may be a list of guidelines or checklists that help the decision maker assess the incident and make decisions about it. This part also includes the escalation process from one incident level to another, like the escalation from minor incident to major disaster.
- Invocation process: The plan should indicate the actions required to be performed if the plan needs to be invoked. In essence, the plan should define steps to mobilize the relevant teams, contact the stakeholders, set up the command center, and initiate the recovery process.
The other types of IRBC/ITDR plan, the IRBC/ITDR recovery plans and procedures, are more specific and focused on the goal of recovering a single group of technology services or components as required by the continuity requirements. Thus the typical contents of IRBC/ITDR recovery plans and procedures are:
- Purpose: This section specifies the goals and purposes of the plan.
- Scope: This section lists the technology services and components within the scope of the plan along with their continuity requirements.
- Technical recovery procedures: These are the actual procedures for restoration and recovery of the technology components. These procedures cover the applications, systems, activities, vendors’ actions, network, security, health and sanity checks, and other areas. The procedures should also provide details for returning to normal conditions after resolution of the incident.
- Appendices, checklists, and references: These contain other relevant information that may be useful or needed within the recovery process.
- Vendors’ and suppliers’ contact information: This contains complete contact details for the vendors and suppliers relevant to the plan.
The developed plan must be reviewed by the relevant technical managers to ensure its technical validity. After that it should be reviewed by the IRBC/ITDR owner and the BCM manager before being delivered to the BCM owner and committee for review and approval.
Testing of IRBC/ITDR plans
The developed plans need to be tested to make sure that the strategies and their implementations can satisfy the relevant requirements. In addition to this, tests and exercises build confidence in the IRBC/ITDR plans and arrangements. Testing is also a good training and awareness tool that can be used to familiarize the staff and vendors with the IRBC/ITDR plans and arrangements. Conducting tests and exercises is also an audit and regulatory requirement.
Testing and exercising IRBC/ITDR plans follow the logical path of maturity and growth. There’s almost no use in conducting full IRBC/ITDR tests that will certainly fail and prove almost nothing. It is recommended, and preferred, that the testing phase is gradual and ongoing in order to achieve the desired goals and purposes.
There are several types of IRBC/ITDR testing, from simple and easy to complex and difficult:
- Desktop test: This type of testing is similar to the BCM’s walk-through test, where the main purpose is to familiarize participants with the plans and their relevant components and to discover gaps that went unnoticed during plan development.
- Component test: In a component test, the main purpose is to make sure that the continuity and recovery arrangements made for specific components of technology actually satisfy requirements. Component testing can include the walk-through test as a preliminary stage before conducting the actual test.
- Integrated test: The scope of an integrated test includes all of the technology components related to a specific technology service. It includes several components’ tests but in an integrated and more realistic manner.
- Full IRBC/ITDR test: This kind of test is the hardest and most dangerous as well. Within this kind of test, all technology components and services are included. The full IRBC/ITDR test can be done in a pre-announced manner or could be done without warning. Lack of careful planning and execution for this test can introduce serious issues. It is therefore better to have professional help for the first few times this test is done.
The IRBC/ITDR testing process is similar to the one implemented in BCM. The test plan, dates, and scope should be reviewed by the IRBC/ITDR owner and BCM manager before being reported to the BCM owner and committee for review and approval. Test results, issues, recommendations, and modifications should be passed to the IRBC/ITDR owner and BCM manager. If required, reporting can be escalated to the BCM owner and committee for resolution.
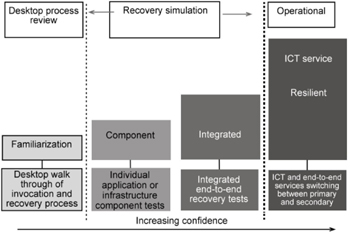
Figure 29: A progressive test and exercise program
Maintenance of IRBC/ITDR sub-program
With the continuous and ongoing changes and developments in organizations and technology, the IRBC/ITDR components need to be up to date and fit for the new developments in technology services and components. For technology in particular, the changes and updates are some of the fastest within the organization. This will actually increase the importance and burden for the IRBC/ITDR team to keep up with the changes and maintain their IRBC/ITDR sub-program.
Being part of the greater BCM program, the IRBC/ITDR sub-program should follow the guidelines for maintaining and updating its components, plans, and arrangements. As a main guideline, the IRBC program needs to be revisited and reviewed at least annually. In fast-changing organizations, the frequency can be increased to more than once a year. As for the change triggers, they may include:
- deployment of new technology services;
- deployment of new technology components in terms of hardware, software, and networking;
- changes in critical vendors in which new vendors are introduced or existing vendors change their relevant agreements;
- changes in organizational structure and in roles and responsibilities across technology-related departments;
- considerable change in staff turnover rate;
- new locations or premises for hosting technology components;
- new regulations or laws affecting technology-related services and requirements.
Regardless of the trigger, the change process needs to be controlled through a layered review and approval process. Any changes or updates need to be qualified by the IRBC/ITDR manager before being forwarded to the IRBC/ITDR owner and BCM manager for review and approval. If the change is of a critical nature, the change and update need to be forwarded to the BCM owner and committee for review and approval.
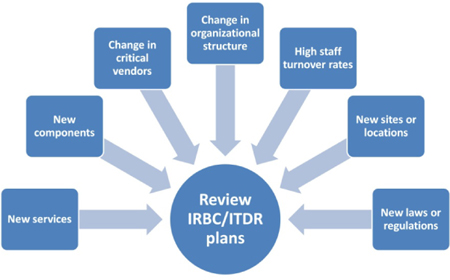
Figure 30: Triggers for review
Technology continuity sites
Technology services are delivered through an integrated set of components, as discussed earlier, which are set up, operated, and maintained within specially prepared environments. Thus, they need to be located within locations, or sites, that can control their surroundings and environments.
Owing to the unique and specific nature of sites hosting technology components, they need to be carefully planned and, if possible, distributed in a manner that provides the maximum protection and control for the hosted components. Technology hosting sites are commonly called data centers. However, this may sometimes be misleading. Among technology components, only hardware, software, and networking are hosted within data centers, while the other components are normally located outside. Technology sites include data centers and other locations that host the majority, or all, of the technology components within an organization.
Protection of technology locations
Although they host unique components, technology sites are, in the end, just locations. They are exposed to threats similar to those of other locations or buildings. Among these threats are:
- Natural hazards: These can include volcanoes, strong winds, floods, lightning, high temperatures, low temperatures, sandstorms, earthquakes, and fires.
- Man-made hazards: These can include hazardous industrial activities, proximity to sensitive locations, riots, acts of terrorism and war, acts of vandalism and sabotage, hosting activities or assets not operated or controlled by the organization, telecommunications failures, power failures, and water supply failure.
The above threats are only examples. Unfortunately, the list keeps growing. Realization of any of the threats can cause serious incidents with severe impacts affecting not only technology-related departments, but the whole organization.
The best way to protect technology sites is to avoid as many of the threats as possible. Unfortunately, this is not easily achieved. There are serious threats that are simply out of our control, especially when thinking about natural disasters.
There are, however, workarounds to such situations. These workarounds do minimize the probability and impact of many of the threats, bearing in mind that zero threats is not practically achievable. Threat minimizing looks at every threat and creates a solution for it. For natural disasters, technology sites should be located, if possible, in areas that are environmentally stable and are a sufficiently safe distance away from natural threat sources. Special site construction and treatments are needed, too. For example, the site should be resistant to earthquakes, properly insulated, have effective fire-fighting, detection, and alarm systems, and be easily evacuated to safe areas.
As for man-made threats, the site should be well away from dangerous or hazardous locations that can render the site damaged, unusable, or inaccessible. It should possess a number of different access routes and paths. It should be equipped with backup power arrangements and sufficient amounts of water to serve the site. A technology site should be protected with sufficient physical security measures and access to it should be controlled properly with a strong access control process. In addition, the site should have multiple telecommunications services and routes provided through different vendors, if possible. For further protection against disruption, the multiple telecommunications services can be routed through different media and network topologies.
Deploying multiple technology sites
The above arrangements handle only one side of the problem; the other part is the most difficult to manage. How can an organization provide the required technology services with minimal disruption, outages, or losses? What if, after taking all precautions, technology sites fail and their components fail as well? It could happen if we cannot eliminate risks and threats completely.
The logical answer is to have more than one technology site. Having this solution can satisfy a lot of technology requirements that are not necessarily exclusive to technology continuity.
The idea is to have two or more technology sites, not just one, that are operational or ready for operations. If a problem happens to one of them, the others can continue to provide the required technology services as planned.
In terms of threats, this may not reduce the probability much for a specific site but it works very effectively with reducing the impact on technology services and the organization as a whole to a minimal level that is acceptable and tolerable. This achievement represents the core concept of technology continuity sites.
The number of technology continuity sites that an organization should establish and deploy relates directly to the risk appetite of the organization, which is linked to the types and nature of the threats and risks facing the organization. Deploying more than one technology site is relatively expensive and technically challenging.
There are organizations that deploy two continuity sites. The first site contains the critical technology components that are most important and have the shortest RTO and RPO ratings. It should be possible to activate this site quickly. These sites are often called high availability (HA) sites. Usually, on these sites, technology components operate by load balancing, load sharing, or running certain critical functions away from the primary technology site. Switching between the HA and primary sites is usually easy, and in some cases is done automatically without manual intervention.
The second site contains all the critical technology components and other components chosen by the organization. This site would be activated if the primary and HA sites failed to operate. In many cases, the site is called a recovery site and is almost identical to the primary technology site.
Technology continuity sites’ deployment strategy
The main purpose of having one or more technology continuity sites is to continue offering the technology services as required by the organization. This purpose can be achieved through different strategies. The main two of these are:
- the internal deployment of technology continuity sites;
- outsourcing technology continuity sites to specialized vendors.
These two strategies are the most dominant, with the latter being adopted more nowadays. Having internal deployment of technology continuity sites gives the organization complete control over the site location, contents, capacity, use and invocation, and upgrade, if required. This does not come cheap as there is a high price tag in getting a complete technology continuity site established, ready, and maintained. It also requires the organization to have specialized and available expertise and resources to establish, deploy, and manage the sites.
Outsourcing technology sites to specialized vendors limits the organization’s control over the site in terms of capacity, contents, invocation, and even testing. Yet the remaining control level is satisfactory to many organizations. Usually the vendors own and deploy several locations: across different geographies, with different capacities, or with special arrangements. So the outsourcing organization has a wider scope of choices to select from. In difficult economic conditions, such a strategy can be very attractive to organizations of all sizes.
Some organizations follow a mixed approach where they deploy their HA sites internally and outsource their recovery sites to specialized vendors. Again, this decision is based on many factors like budgets allocated, risk appetites, threat and risk nature, and availability of specialized vendors.
Selection of technology continuity sites
After deciding the number of technology continuity sites needed and how they will deployed, the time comes for selecting the locations of these sites. The sites should adhere to the same measures mentioned above for the primary technology site, with the addition of one main feature; they should have a different exposure to threats and risks, with less impact. In other words, technology continuity sites should face different types of threat and risk and their impact, if these threats and risks materialize, should be less than for the primary technology site. How much less is unique to the site and goes back to the risk appetite of the organization.
In general, the main features of technology continuity sites are that they:
- have minimal inherent risk and threat exposure;
- avoid or minimize the threat and risk exposure of the main technology site;
- provide the capability of rapid activation and recovery;
- provide a sufficient level of protection to the technology components included within the site;
- are easy to access and use for extended periods of time;
- are expandable and modular, and can accommodate extra capacities for different technology components;
- provide a sufficient level of physical security and protection;
- have redundant telecommunications and power, water, and fuel supplies;
- are cost-effective to establish, maintain, and operate.
The above represent the main features of technology continuity sites. However, it is up to the organization to decide how far it should apply these features on their technology continuity site.
For specific site specifications, there is a common reference for the design and operation of technology sites, whether they are continuity or primary sites. The reference comes from the Uptime Institute (www.uptimeinstitute.org)8 and classifies a technology site into four main levels, or tiers, depending on their failover capability:
- Tier I – basic capacity: Site-wide shutdowns are required for maintenance or repair work. Capacity or distribution failures will impact the site.
- Tier II – redundant capacity components: Site-wide shutdowns are still required. Capacity failures may impact the site. Distribution failures will impact the site.
- Tier III – concurrently maintainable: each and every component and distribution path in a site can be removed on a planned basis for maintenance or replacement without impacting operations. The site is still exposed to an equipment failure or operator error.
- Tier IV – fault-tolerant: an individual component failure or distribution path interruption will not impact operations. A fault-tolerant site is also concurrently maintainable.
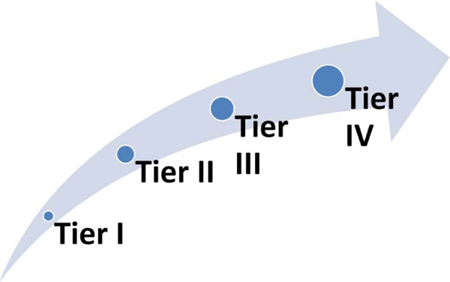
It can be seen that progressing from tier I to tier IV indicates more resilience and failover capability are invested in the technology site, with a relatively higher cost. This reference is very useful in identifying specifications and possible suitability of sites to accommodate technology components and services.
When an organization chooses to outsource it technology continuity site, or sites, externally to specialized vendors, there are some points to be considered. Usually, the vendors or providers have certain limits for the type of hardware, software, communications, invocation, testing, upgrades, and logistics related to staff, operators, contractors, and materials and supplies. It is highly recommended that you review the terms and contracts provided by the vendors covering these aspects. The vendor is not entirely dedicated to your organization as they have other clients who might use the site. If disasters affect other organizations, the site provider becomes more sensitive to having additional requirements. Thus all plans relevant to the outsourced sites should be made according to a worst-case scenario.
Other points to consider are the arrangements, tier classifications, and certifications for the sites managed and operated by the vendor. They can give you a satisfactory level of assurance that the sites will be there when you need them. It is recommended also to have analysts’ and consultants’ information, background, and history for the vendors and their effectiveness and commitment to what they offer.
In conclusion, there is, as usual, no simple answer to the question of having technology continuity sites incorporated within the IRBC/ITDR program. This area is continuously evolving in an aggressive way. There are new solutions being devised and introduced. Some of them, like Cloud Computing and advances in the convergence of mobile computing and telecommunications, can even change the way we approach the issue of technology continuity sites in a radical manner. Consider the technology outlook before choosing the strategy, location, capacity, and components related to technology continuity sites.
Technology continuity outside IT
Traditionally, across many organizations, technology was always paired with the IT department. Under this convention, technology and information technology were used interchangeably. While that might be valid in a lot of organizations, there are exceptions to this rule whereby technology does not necessarily mean common information technology. These exceptions are continuously growing in the modern economy where organizations are finding smarter uses for technology with the convergence of information technology, communications, and data and information management.
There is a specific type of organization where technology is the main service and/or product. Within these, the business/support classification of departments becomes reversed. An example of this type of organization is in the telecommunications industry where nearly all functions are there to support the telecommunication services and products offered to customers. Technology is then no longer an enabler, as without technology the organization not only fails, but loses its reason to exist.
The need for a comprehensive technology continuity program
The reason we need to discuss this issue is to make sure that continuity planning for technology in organizations is not only about IT but extends to reach all critical functions needed by an organization to fulfill its goals. While the same continuity principles apply, implementations can vary significantly due to the specific nature of the technology landscape within individual organizations. Extending the technology program to become a comprehensive one across the organization will actually cater for all of the dependencies between technology components, both inside and outside the IT department.
Comprehensive technology continuity programs can provide the organization with a platform for consolidation, saving expensive resources across multiple technology components. Through the processes of requirements gathering and building continuity strategies, professionals are more likely to highlight areas of redundancy and ineffective utilization of resources. Highlighting such findings to top management can trigger actions to increase consolidation, integration, and enhancements for technology services. These results are not only on a technical level but also on governance and people levels, among others.
Implementing comprehensive technology continuity programs
Comprehensive technology continuity programs are built on the same basis as those of technology continuity. The main idea is bring the technology owners into the governance model through the assignment of a technology continuity owner, rather than the IRBC/ITDR owner. The IRBC/ITDR continuity policy has to be upgraded to be a comprehensive technology continuity policy. Having senior technology representatives on the BCM committee is also recommended.
As a result, the technology continuity managers, who are responsible for daily activities within the technology continuity program, have to be reconsidered. There are two suggestions for handling this:
- Assign a single technology continuity manager to take care of all activities related to technology continuity.
- Assign multiple continuity managers who cover multiple specific areas of technology continuity.
Deciding on this issue depends on the unique nature of the organization. Organizations which define and enforce clear policies, roles, and responsibilities may find it attractive to have a single manager. Other organizations, which have difficulty in communicating and coordinating across departments or have an immature technology continuity program, can choose to assign specific continuity technology activities to different stakeholders with more top-management oversight and control.
The technology continuity life cycle follows the same principle as the IRBC/ITDR life cycle. The main difference is that the number of components increases and the concepts get wider to include the technology components deployed to support the technology services for the organization.
8 Uptime Institute, LLC. Data Center Infrastructure Tier Standard: Operational Sustainability. (2010)