
Chapter 9. Business Continuity and Disaster Recovery
This chapter helps you prepare for the Certified Information Systems Auditor (CISA) exam by covering the following ISACA objectives, which include understanding the role and importance of business continuity and disaster recovery. This includes items such as the following:
Tasks
Evaluate the adequacy of backup and restoration provisions to ensure the availability of information required to resume processing.
Evaluate the organization’s disaster recovery plan to ensure that it enables the recovery of IT processing capabilities in the event of a disaster.
Evaluate the organization’s business continuity plan to ensure its ability to continue essential business operations during the period of an IT disruption.
Knowledge Statements
Knowledge of data backup, storage, maintenance, retention and restoration processes, and practices
Knowledge of regulatory, legal, contractual, and insurance concerns related to business continuity and disaster recovery
Knowledge of business impact analysis (BIA)
Knowledge of the development and maintenance of the business continuity and disaster recovery plans
Knowledge of business continuity and disaster recovery testing approaches and methods
Knowledge of human resources management practices as related to business continuity and disaster recovery (e.g., evacuation planning, response teams)
Knowledge of processes used to invoke the business continuity and disaster recovery plans
Knowledge of types of alternate processing sites and methods used to monitor the contractual agreements (e.g., hot sites, warm sites, cold sites)
Disasters and Disruptive Events
Verification of Disaster Recovery and Business Continuity Process
This chapter addresses information you need to know about business continuity and disaster recovery. An organization can have controls in place to manage risk and ensure that business processes are properly controlled, yet not be prepared for disasters. It is not a matter of whether a disaster will occur, but when. The objective of this chapter is to ensure that, as a CISA, you understand and can provide assurance that an organization’s policies sufficiently guard against disruptions. The CISA is tasked with verifying that the business continuity and disaster recovery process will ensure timely resumption of IT services while minimizing the impact to the business. The following are the primary topics a CISA candidate should review for the exam:
![]() Understand the threats that natural and man-made disasters represent
Understand the threats that natural and man-made disasters represent
![]() Know the BCP process in terms of how ISACA interprets it
Know the BCP process in terms of how ISACA interprets it
![]() Restate the importance of business continuity and disaster recovery, and the role an IT auditor plays in reducing this threat
Restate the importance of business continuity and disaster recovery, and the role an IT auditor plays in reducing this threat
![]() Understand the most common methods for testing disaster recovery plans
Understand the most common methods for testing disaster recovery plans
![]() Describe hardware and software alternatives for business continuity
Describe hardware and software alternatives for business continuity
Introduction
This chapter focuses on an organization’s ability to recover from natural or man-made disasters and return to normal operations. Unfortunately, this is often an overlooked area of an IT audit. The need to develop plans to deal with such disasters is critical, as is the need to test such plans to make sure they are viable. Notable recent events such as 9/11 and Hurricane Katrina have highlighted the need to be adequately prepared. After both of these events, individuals reported that companies seriously underestimated how long it would take to restore operations. It has also been noted that many companies had not updated their plans as the company grew, changed, or modified existing processes. Some companies suffered significant vital record problems because of flaws in their backup and offsite storage programs, while others had no workstation recovery plans for end users. Even after such calamitous events, most U.S. companies still spend an average of only 3.7% of the IT budget on disaster recovery planning, while best practice calls for 6%. These low expenditures can have many reasons such as the fact that only a small percentage of businesses are required by regulation to have a disaster recovery plan. Another is that disaster recovery must compete for limited funds. Companies might be lulled into thinking that these funds might be best spent for more immediate needs. Some businesses might simply underestimate the risk and hope that adverse events don’t happen to them. Disaster recovery planning requires a shift of thinking from reactive to proactive.
Disaster Recovery
Knowledge Statement
![]() Knowledge of regulatory, legal, contractual, and insurance concerns related to business continuity and disaster recovery
Knowledge of regulatory, legal, contractual, and insurance concerns related to business continuity and disaster recovery
A disaster is any sudden, unplanned, calamitous event that brings about great damage or loss. Businesses face special challenges because they have a responsibility to shareholders and employees to protect life and guard company assets. In the realm of business, a disaster can be seen as any event that creates an inability to support critical business functions for an undetermined period of time.
Disasters and Disruptive Events
Many of us would prefer not to plan for disasters. Many might see it as an unpleasant exercise or something that we would prefer to ignore. Sadly, we all must deal with disasters and incidents. They are dynamic by nature. For example, mainframes face a different set of threats than distributed systems, just as computers connected to modems (or wired network connections) face a different set of threats than wireless networked computers. This means that management must be dynamic and be able to change with time. Threats can be man-made, technical, or natural; however, regardless of the source, they have the potential to cause an incident. Incidents might or might not cause disruptions to normal operations. What is needed is a way to measure these incidents and quantify their damage. Table 9.1 lists the incident classification per ISACA.
Table 9.1 Incident Classification

Note
Disruptive incidents such as a crisis or major or minor events should be tracked and analyzed so that corrective actions can be taken to prevent these events from occurring in the future.
Good incident response and a method to measure the disruption to the organization enable the company to reduce the potential impact of these situations. This gives organizations a structured method for developing procedures that provide management with sufficient information to develop an appropriate course of action. With these procedures in place, the organization can maintain or restore business continuity, defend against future attacks, and even prosecute violators when possible.
Reputation and Its Value
What comes to mind when you hear the word reputation? I always think of this quote by Benjamin Franklin: “It takes many good deeds to build a good reputation, and only one bad one to lose it.” If you are wondering what this has to do with disaster recovery, consider the following brand names:
![]() Enron—A symbol of corporate fraud and corruption
Enron—A symbol of corporate fraud and corruption
![]() Apple—An industry leader of innovative products such as the iPod and iPhone
Apple—An industry leader of innovative products such as the iPod and iPhone
![]() Arthur Andersen—A firm that voluntarily surrendered its licenses in 2002 over its handling of the auditing of Enron
Arthur Andersen—A firm that voluntarily surrendered its licenses in 2002 over its handling of the auditing of Enron
![]() Dom Perignon—A famous, high-quality, and expensive champagne
Dom Perignon—A famous, high-quality, and expensive champagne
![]() ValuJet—A once-fast-growing airline until a deadly crash in the Florida Everglades in 1996
ValuJet—A once-fast-growing airline until a deadly crash in the Florida Everglades in 1996
![]() Rolls Royce—Known for high-quality hand-made automobiles
Rolls Royce—Known for high-quality hand-made automobiles
![]() Yugo—A cheaply made car that was released in the United States in the mid-1980s
Yugo—A cheaply made car that was released in the United States in the mid-1980s
![]() Ruth’s Chris Steak House—An upscale eatery known for serving high-quality steaks that are seared at 1800°
Ruth’s Chris Steak House—An upscale eatery known for serving high-quality steaks that are seared at 1800°
![]() Food Lion—Received a large amount of bad press in the 1990s over alleged unsanitary food practices.
Food Lion—Received a large amount of bad press in the 1990s over alleged unsanitary food practices.
As you read through these names, you probably had different thoughts as you looked at each name on the list. Some of these companies have worked for years to gain a level of respect and positive reputation. Catastrophes don’t just happen. Most occur because of human error or as the result of a series of overlooked mistakes. Will a mistake be fatal to your organization? Reputations can be easily damaged. That is why disaster recovery is so important: The very future of the organization might rest on it. Damaging rumors can easily start, and it is important to have protocols in place for dealing with these incidents, accidents, and catastrophes. Negative public opinion can be costly. It is important to have a properly trained spokesperson to speak and represent the organization. Meeting with the media during a crisis is not an easy task or something that should be done without preparation. The appointed spokesperson should interface with senior management and legal counsel before making any public statement.
Preparing for these events should include creating communiqués that address each possible incident in a generic fashion. This gives the responsible parties a framework to work with in case a real disaster occurs. Liability should not be assumed; the spokesperson should simply state that an investigation has begun.
Note
A good example of a public relations fiasco is Coca-Cola’s handling of its “New Coke” product. The company spent millions on blind taste tests, yet no one asked consumers, “Would you buy this product?” Sony is another company that suffered damage to its brand name when it denied the existence of its XCP rootkit. In that incident, the media giant inadvertently violated users’ desktop security in an ill-conceived effort to enforce CD music antipiracy controls.
BCP in the Real World
The business continuity plan (BCP) is developed to prevent interruptions to normal business. If these events cannot be prevented, the goals of the plan are to minimize the outage and reduce the potential damage that such disruptions might cost the organization. Therefore, the BCP should also be designed to help minimize the cost associated with the disruptive events and mitigate the risks associated with these disruptive events. Disasters can be natural events; storms, floods, and so on; man-made events; computer viruses, malicious code, and so on; technical events; equipment failure, programming errors, and so on. Figure 9.1 diagrams the hierarchy of these threats.
Figure 9.1 Security threats and their sources.

ISACA and the BCP Process
One of the best sources of information about the BCP process is the Disaster Recovery Institute International (DRII), which you can find online at http://www.drii.org. The process that DRII defines for BCP is much broader in scope than what ISACA defines. DRII breaks down the disaster recovery process into ten domains:
![]() Project Initiation and Management
Project Initiation and Management
![]() Risk Evaluation and Control
Risk Evaluation and Control
![]() Business Impact Analysis
Business Impact Analysis
![]() Developing Business Continuity Management Strategies
Developing Business Continuity Management Strategies
![]() Emergency Response and Operations
Emergency Response and Operations
![]() Developing and Implementing Business Continuity Plans
Developing and Implementing Business Continuity Plans
![]() Awareness and Training Programs
Awareness and Training Programs
![]() Exercising and Maintaining Business Continuity Plans
Exercising and Maintaining Business Continuity Plans
![]() Crisis Communications
Crisis Communications
![]() Coordination with External Agencies
Coordination with External Agencies
The BCP process as defined by ISACA has a much narrower scope and focuses on the following seven steps, each of which is discussed in greater detail in the following sections:
1. Project management and initiation
2. Business impact analysis
3. Recovery strategy
4. Plan design and development
5. Training and awareness
6. Implementation and testing
7. Monitoring and maintenance
Step 1: Project Management and Initiation
Before the BCP process can begin, management must be on board. Management is ultimately responsible and must be actively involved in the process. Management sets the budget, determines the team leader, and gets the process started. The BCP team leader determines who will be on the BCP team. The team’s responsibilities include the following:
![]() Identifying regulatory and legal requirements
Identifying regulatory and legal requirements
![]() Identifying all possible threats and risks
Identifying all possible threats and risks
![]() Estimating the possibilities of these threats and their loss potential and ranking them determined by the likelihood of the event occuring
Estimating the possibilities of these threats and their loss potential and ranking them determined by the likelihood of the event occuring
![]() Performing a business impact analysis (BIA)
Performing a business impact analysis (BIA)
![]() Outlining which departments, systems, and processes must be up and running before any others
Outlining which departments, systems, and processes must be up and running before any others
![]() Developing procedures and steps in resuming business after a disaster
Developing procedures and steps in resuming business after a disaster
![]() Assigning tasks to individuals that they would perform during a crisis situation
Assigning tasks to individuals that they would perform during a crisis situation
![]() Documenting, communicating to employees, and performing training and drills
Documenting, communicating to employees, and performing training and drills
One of the first steps the team is tasked with is meeting with senior management. The purpose is to define goals and objectives, discuss a project schedule, and discuss the overall goals of the BCP process. This should give everyone present some idea of the scope of the final BCP policy.
It’s important for everyone involved to understand that the BCP is the most important corrective control the organization will have an opportunity to shape. Although the BCP is primarily corrective, it also has the following elements:
![]() Preventive—Controls to identify critical assets and develop ways to prevent outages
Preventive—Controls to identify critical assets and develop ways to prevent outages
![]() Detective—Controls to alert the organization quickly in case of outages or problems
Detective—Controls to alert the organization quickly in case of outages or problems
![]() Corrective—Controls to return to normal operations as quickly as possible
Corrective—Controls to return to normal operations as quickly as possible
Step 2: Business Impact Analysis
Knowledge Statement
![]() Knowledge of business impact analysis (BIA)
Knowledge of business impact analysis (BIA)
Chance and uncertainty are part of the world we live in. We cannot predict what tomorrow will bring or whether a disaster will occur—but this doesn’t mean that we cannot plan for it. As an example, the city of Tampa, Florida, is in an area prone to hurricanes. Just because the possibility of a hurricane in winter in Tampa is extremely low doesn’t mean that planning can’t take place to reduce the potential negative impact. This is what the BIA is about. Its purpose is to think through all possible disasters that could take place, assess the risk, quantify the impact, determine the loss, and develop a plan to deal with the incidents that seem most likely to occur.
As a result, the BIA should present a clear picture of what is needed to continue operations if a disaster occurs. The individuals responsible for the BIA must look at the organization from many different angles and use information from a variety of inputs. For the BIA to be successful, the BIA team must know what key business processes are. Questions the team must ask when determining critical processes might include the following:
![]() Does the process support health and safety?—Items such as the loss of an air traffic control system at a major airport or the loss of power in a hospital operating room could be devastating to those involved and result in the loss of life.
Does the process support health and safety?—Items such as the loss of an air traffic control system at a major airport or the loss of power in a hospital operating room could be devastating to those involved and result in the loss of life.
![]() Does the loss of the process have a negative impact on income?—As an example, a company such as eBay would find the loss of Internet connectivity devastating, whereas a small nonprofit organization might be able to live without connectivity for days.
Does the loss of the process have a negative impact on income?—As an example, a company such as eBay would find the loss of Internet connectivity devastating, whereas a small nonprofit organization might be able to live without connectivity for days.
![]() Does the loss of the process violate legal or statutory requirements?—As an example, a coal-powered electrical power plant might be using scrubbers to clean the air before emissions are released. Loss of these scrubbers might violate federal law and result in huge regulatory fines.
Does the loss of the process violate legal or statutory requirements?—As an example, a coal-powered electrical power plant might be using scrubbers to clean the air before emissions are released. Loss of these scrubbers might violate federal law and result in huge regulatory fines.
![]() How does the loss of the process affect users?—Returning to the example electrical power plant, it is easy to see how problems with the steam-generation process would shut down power generation and leave many residential and business customers without power. This loss of power in the Alaskan winter or in the Houston summer would have a large impact.
How does the loss of the process affect users?—Returning to the example electrical power plant, it is easy to see how problems with the steam-generation process would shut down power generation and leave many residential and business customers without power. This loss of power in the Alaskan winter or in the Houston summer would have a large impact.
As you might be starting to realize, performing the BIA is no easy task. It requires not only the knowledge of business processes, but also a thorough understanding of the organization itself. This includes IT resources, individual business units, and the interrelationship of each of these pieces. This task requires the support of senior management and the cooperation of IT personnel, business unit managers, and end users. The general steps of the BIA are as follows:
1. Determine data-gathering techniques.
2. Gather business impact analysis data.
3. Identify critical business functions and resources.
4. Verify completeness of data.
5. Establish recovery time for operations.
6. Define recovery alternatives and costs.
Note
Many BIA programs look no further than the traditional network. They focus on mainframe systems and LAN-based distributed systems. It is important that the BIA also look at systems and information that might normally be overlooked, such as information stored on end-user systems that are not backed up and laptops used by the sales force or management.
The BIA typically includes both quantitative and qualitative components:
![]() Quantitative analysis deals with numbers and dollar amounts. It attempts to assign a monetary value to the elements of risk assessment and to place dollar amounts on the potential impact, including both loss of income and expenses. Quantitative impacts can include all associated costs, including these:
Quantitative analysis deals with numbers and dollar amounts. It attempts to assign a monetary value to the elements of risk assessment and to place dollar amounts on the potential impact, including both loss of income and expenses. Quantitative impacts can include all associated costs, including these:
![]() Lost productivity
Lost productivity
![]() Delayed or canceled orders
Delayed or canceled orders
![]() Value of the damaged equipment or lost data
Value of the damaged equipment or lost data
![]() Cost of rental equipment
Cost of rental equipment
![]() Cost of emergency services
Cost of emergency services
![]() Cost to replace the equipment or reload data
Cost to replace the equipment or reload data
![]() Qualitative assessment is scenario driven and does not attempt to assign dollar values to components of the risk analysis. A qualitative assessment ranks the seriousness of the impact into grades or classes, such as low, medium, and high. These are usually associated with items to which no dollar amount can be easily assigned:
Qualitative assessment is scenario driven and does not attempt to assign dollar values to components of the risk analysis. A qualitative assessment ranks the seriousness of the impact into grades or classes, such as low, medium, and high. These are usually associated with items to which no dollar amount can be easily assigned:
![]() Low—Minor inconvenience. Customers might not notice.
Low—Minor inconvenience. Customers might not notice.
![]() Medium—Some loss of service. Might result in negative press or cause customers to lose some confidence in the organization.
Medium—Some loss of service. Might result in negative press or cause customers to lose some confidence in the organization.
![]() High—Will result in loss of goodwill between the company and a client or employee. Negative press also reduces the outlook for future products and services.
High—Will result in loss of goodwill between the company and a client or employee. Negative press also reduces the outlook for future products and services.
Although different approaches for calculating loss exist, one of the most popular methods of acquiring data is the questionnaire. The team develops a questionnaire for senior management and end users, and might hand it out or use it during an interview process. Figure 9.2 provides an example of a typical BIA questionnaire.
The questionnaire can even be used in a round-table setting. This method of performing information gathering requires the BIA team to bring the required key individuals into a meeting and discuss as a group what impact specific types of disruptions would have on the organization. Auditors play a key role because they might be asked to contribute information such as past transaction volumes or the impact to the business if specific systems were unavailable.
Reviewing the results of this information is the next step of the BIA process. During this step, the BIA team should ask questions such as these:
![]() Are the systems identified critical?—All departments like to think of themselves as critical, but that is usually not the case. Some departments can be offline longer than others.
Are the systems identified critical?—All departments like to think of themselves as critical, but that is usually not the case. Some departments can be offline longer than others.
![]() What is the required recovery time for critical resources?—If the resource is critical, costs will mount the longer the resource is offline. Depending on the service and the time of interruption, these times will vary.
What is the required recovery time for critical resources?—If the resource is critical, costs will mount the longer the resource is offline. Depending on the service and the time of interruption, these times will vary.

All this information might seem a little overwhelming; however, it is needed because at the core of the BIA are two critical items:
![]() Recovery point objective (RPO)—The RPO defines how current the data must be or how much data an organization can afford to lose. The greater the RPO, the more tolerant the process is to interruption.
Recovery point objective (RPO)—The RPO defines how current the data must be or how much data an organization can afford to lose. The greater the RPO, the more tolerant the process is to interruption.
![]() Recovery time objective (RTO)—The RTO specifies the maximum elapsed time to recover an application at an alternate site. The greater the RTO, the longer the process can take to be restored.
Recovery time objective (RTO)—The RTO specifies the maximum elapsed time to recover an application at an alternate site. The greater the RTO, the longer the process can take to be restored.
The lower the time requirements are, the higher the cost will be to reduce loss or restore the system as quickly as possible. For example, most banks have a very low RPO because they cannot afford to lose any processed information. Figure 9.3 presents an overview of how RPO and RTO are related.
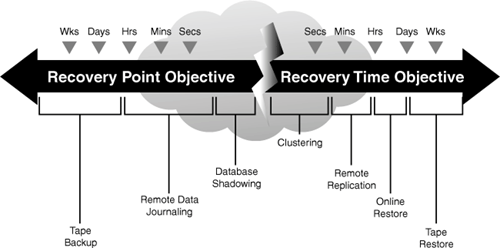
Tip
The RTO specifies the maximum elapsed time to recover an application at an alternate site. The greater the RTO, the longer the process can take to be restored.
These items must be considered in addition to RTO and RPO:
![]() Maximum acceptable outage—This value is the time that systems can be offline before causing damage. This value is required in creating RTOs and is also known as maximum tolerable downtime (MTD).
Maximum acceptable outage—This value is the time that systems can be offline before causing damage. This value is required in creating RTOs and is also known as maximum tolerable downtime (MTD).
![]() Service delivery objective (SDO)—This defines the level of service provided by alternate processes while primary processing is offline. This value should be determined by examining the minimum business need.
Service delivery objective (SDO)—This defines the level of service provided by alternate processes while primary processing is offline. This value should be determined by examining the minimum business need.
![]() Maximum tolerable outages—This defines the maximum amount of time the organization can provide services at the alternate site. This value can be determined by items such as contractual values.
Maximum tolerable outages—This defines the maximum amount of time the organization can provide services at the alternate site. This value can be determined by items such as contractual values.
![]() Core processing—These activities are specifically required for critical process and produce revenue.
Core processing—These activities are specifically required for critical process and produce revenue.
![]() Supporting processes—These activities are required to support the minimum services needed to generate revenue.
Supporting processes—These activities are required to support the minimum services needed to generate revenue.
![]() Discretionary processes—These include all other processes that are not part of the core or supporting processes, and that are not required for any critical processes or functions.
Discretionary processes—These include all other processes that are not part of the core or supporting processes, and that are not required for any critical processes or functions.
Criticality Analysis
How do you classify systems and resources according to their value or order of importance? You determine the estimated loss if a disruption occurred and calculate the likelihood that the disruption will occur. The quantitative method for this process involves the following three steps:
1. Estimate potential losses (SLE)—This step involves determining the single loss expectancy (SLE). SLE is calculated as follows:
Single Loss Expectancy = Asset Value × Exposure Factor
Items to consider when calculating the SLE include the physical destruction of man-made events, the loss of data, and threats that might cause a delay or disruption in processing. The exposure factor is the measure or percent of damage that a realized threat would have on a specific asset.
2. Conduct a threat analysis (ARO)—The purpose of a threat analysis is to determine the likelihood that an unwanted event will happen. The goal is to estimate the annual rate of occurrence (ARO). Simply stated, how many times is this expected to happen in one year?
3. Determine annual loss expectancy (ALE)—This third and final step of the quantitative assessment seeks to combine the potential loss and rate/year to determine the magnitude of the risk. This is expressed as annual loss expectancy (ALE). ALE is calculated as follows:
Annualized Loss Expectancy (ALE) =
Single Loss Expectancy (SLE) × Annualized Rate of Occurrence (ARO)
As an example, suppose that the potential loss due to a hurricane on a business based in Tampa, Florida, is $1 million. By examining previous weather patterns and observing historical trends, there has been an average of one hurricane of serious magnitude to hit the city every 10 years, which translates to 1/10, or 0.1% per year. This means the assessed risk that the organization will face a serious disruption is ($1 million × 0.1= $100,000.00) per year. That value is the annualized loss expectancy and, on average, is the amount per year that the disruption will cost the organization. Placing dollar amounts on such risks can aid senior management in determining what processes are most important and should be brought online first. Qualitatively, these items might be categorized not by dollar amount, but by a risk-ranking scale. Per ISACA, the scale shown in Table 9.2 is used to classify systems according to their importance to the organization.
Table 9.2 System Classification

After addressing all these questions, the BCP team can start to develop recommendations and look at some potential recovery strategies. The BCP team should report these findings to senior management as a prioritized list of key business resources and the order in which restoration should be processed. The report should also offer potential recovery scenarios.
Before presenting the report to senior management, however, the team should distribute it to the various department heads. These individuals were interviewed, and the plan affects them and their departments; therefore, they should be given the opportunity to review it and note any discrepancies. The information in the BIA must be correct and accurate because all future decisions will be based upon its findings. Now let’s move to the next step, recovery strategies.
Note
Interdependencies can make criticality analysis very complex. For example, you might have two assets that on their own are noncritical, but in certain contexts or situations they become critical!
Step 3: Recovery Strategy
At this point, the team has completed both the project initiation and the BIA. Now it must determine the most cost-effective recovery mechanisms to be implemented based on the critical processes and threats determined during the BIA. An effective recovery strategy should apply preventive, detective, and corrective controls to meet the following objectives:
![]() Remove identified threats
Remove identified threats
![]() Reduce the likelihood of identified risks
Reduce the likelihood of identified risks
![]() Reduce the impact of identified risks
Reduce the impact of identified risks
The recovery strategies should specify the best way to recover systems and processes in case of interruption. Operations can be interrupted in several different ways:
![]() Data interruptions—Caused by the loss of data. Solutions to data interruptions include backup, offsite storage, and remote journaling.
Data interruptions—Caused by the loss of data. Solutions to data interruptions include backup, offsite storage, and remote journaling.
![]() Operational interruptions—Caused by the loss of equipment. Solutions to this type of interruption include hot sites, redundant equipment, RAID, and BPS.
Operational interruptions—Caused by the loss of equipment. Solutions to this type of interruption include hot sites, redundant equipment, RAID, and BPS.
![]() Facility and supply interruptions—Caused by interruptions due to fire, loss of inventory, transportation problems, HVAC problems, and telecommunications. Solutions to this type of interruption include redundant communication and transporting systems.
Facility and supply interruptions—Caused by interruptions due to fire, loss of inventory, transportation problems, HVAC problems, and telecommunications. Solutions to this type of interruption include redundant communication and transporting systems.
![]() Business interruptions—Caused by interruptions due to loss of personnel, strikes, critical equipment, supplies, and office space. Solutions to this type of interruption include redundant sites, alternate locations, and temporary staff.
Business interruptions—Caused by interruptions due to loss of personnel, strikes, critical equipment, supplies, and office space. Solutions to this type of interruption include redundant sites, alternate locations, and temporary staff.
The selection of a recovery strategy is based on several factors, including cost, criticality of the systems or process, and the time required to recover. To determine the best recovery strategy, follow these steps:
1. Document all costs for each possible alternative.
2. Obtain cost estimates for any outside services that might be needed.
3. Develop written agreements with the chosen vendor for such services.
4. Evaluate what resumption strategies are possible if there is a complete loss of the facility.
5. Document your findings and report your chosen recovery strategies to management for feedback and approval.
Normally, any IT system that runs a mission-critical application needs a recovery strategy. There are many to choose from; the right choice is based on the impact to the organization of the loss of the system or process. Recovery strategies include the following:
![]() Continuous processing
Continuous processing
![]() Standby processing
Standby processing
![]() Standby database shadowing
Standby database shadowing
![]() Remote data journaling
Remote data journaling
![]() Electronic vaulting
Electronic vaulting
![]() Mobile site
Mobile site
![]() Warm site
Warm site
![]() Cold site
Cold site
![]() Reciprocal agreements
Reciprocal agreements
Each of these options are discussed later in the chapter, when recovery alternatives are reviewed. To get a better idea of how each of these options compares to the cost of implementation, take a moment to review Figure 9.4. At this point, it is important to realize that there must be a balance between the level of service needed and the recovery method.
Figure 9.4 Recovery options and cost.

Note
Recovery strategies should be based on the disruptive cost versus the recovery costs. Finding a balance between the two offers recovery at the minimized cost.
Step 4: Plan Design and Development
Knowledge Statement
![]() Knowledge of the development and maintenance of the business continuity and disaster recovery plans
Knowledge of the development and maintenance of the business continuity and disaster recovery plans
In the plan design and development phase, the team prepares and documents a detailed plan for recovering critical business systems. This plan should be based on information gathered during the project initiation, the BIA, and the recovery strategies phase. The plan should be a guide for implementation. The plan should address factors and variables such as these:
![]() Selecting critical functions and priorities for restoration
Selecting critical functions and priorities for restoration
![]() Determining support systems critical functions need
Determining support systems critical functions need
![]() Estimating potential disasters and calculating the minimum resources needed to recover from the catastrophe
Estimating potential disasters and calculating the minimum resources needed to recover from the catastrophe
![]() Determining the procedures for declaring a disaster and under what circumstances this will occur
Determining the procedures for declaring a disaster and under what circumstances this will occur
![]() Identifying individuals responsible for each function in the plan
Identifying individuals responsible for each function in the plan
![]() Choosing recovery strategies and determining what systems and equipment will be needed to accomplish the recovery
Choosing recovery strategies and determining what systems and equipment will be needed to accomplish the recovery
![]() Determining who will manage the restoration and testing process
Determining who will manage the restoration and testing process
![]() Calculating what type of funding and fiscal management is needed to accomplish these goals
Calculating what type of funding and fiscal management is needed to accomplish these goals
The plan should be written in easy-to-understand language that uses common terminology that everyone will understand. The plan should detail how the organization will interface with external groups such as customers, shareholders, the media, and community, region, and state emergency services groups during a disaster. Important teams should be formed so that training can be performed. The final step of the phase is to combine all this information into the BCP plan and then interface it with the organization’s other emergency plans.
Exam Alert
Copies of the BCP plan should be kept both on-site and off-site.
Step 5: Training and Awareness
The goal of training and awareness is to make sure all employees know what to do in case of an emergency. Studies have shown that training improves response time and helps employees be better prepared. Employees need to know where to call or how to maintain contact with the organization if a disaster occurs. Therefore, the organization should design and develop training programs to make sure each employee knows what to do and how to do it. Training can include a range of specific programs, such as CPR, fire drills, crisis management, emergency procedures, and so on. Employees assigned to specific tasks should be trained to carry out needed procedures. Cross-training of team members should occur, if possible, so that team members are familiar with a variety of recovery roles and responsibilities. Some people might not be able to lead under the pressure of crisis command; others might not be able to report to work. Table 9.3 describes some of the key groups involved in the BCP process and their responsibilities.
Table 9.3 BCP Process Responsibilities

Exam Alert
The number one priority of any BCP or DRP is to protect the safety of employees.
Step 6: Implementation and Testing
Knowledge Statements
![]() Knowledge of business continuity and disaster recovery testing approaches and methods
Knowledge of business continuity and disaster recovery testing approaches and methods
![]() Knowledge of human resources management practices as related to business continuity and disaster recovery (e.g., evacuation planning, response teams)
Knowledge of human resources management practices as related to business continuity and disaster recovery (e.g., evacuation planning, response teams)
![]() Knowledge of processes used to invoke the business continuity and disaster recovery plans
Knowledge of processes used to invoke the business continuity and disaster recovery plans
The BCP team has now reached the implementation and testing phase. This is where the previously agreed-upon steps are implemented. No demonstrated recovery exists until the plan has been tested. Before examining the ways in which the testing can occur, look at some of the teams that are involved in the process:
![]() Incident response team—Team developed as a central clearinghouse for all incidents.
Incident response team—Team developed as a central clearinghouse for all incidents.
![]() Emergency response team—The first responders for the organization. They are tasked with evacuating personnel and saving lives.
Emergency response team—The first responders for the organization. They are tasked with evacuating personnel and saving lives.
![]() Emergency management team—Executives and line managers that are financially and legally responsible. They must also handle the media and public relations.
Emergency management team—Executives and line managers that are financially and legally responsible. They must also handle the media and public relations.
![]() Damage assessment team—The estimators. They must determine the damage and estimate the recovery time.
Damage assessment team—The estimators. They must determine the damage and estimate the recovery time.
![]() Salvage team—Those responsible for reconstructing damaged facilities. This includes cleaning up, recovering assets, creating documentation for insurance filings or legal actions, and restoring paper documents and electronic media.
Salvage team—Those responsible for reconstructing damaged facilities. This includes cleaning up, recovering assets, creating documentation for insurance filings or legal actions, and restoring paper documents and electronic media.
![]() Communications team—Those responsible for installing communications (data, voice, phone, fax, radio) at the recovery site.
Communications team—Those responsible for installing communications (data, voice, phone, fax, radio) at the recovery site.
![]() Security team—Those who manage the security of the organization during the time of crisis. They must maintain order after a disaster.
Security team—Those who manage the security of the organization during the time of crisis. They must maintain order after a disaster.
![]() Emergency operations team—Individuals who reside at the alternative site and manage systems operations. They are primarily operators and supervisors who are familiar with system operations.
Emergency operations team—Individuals who reside at the alternative site and manage systems operations. They are primarily operators and supervisors who are familiar with system operations.
![]() Transportation team—Team responsible for notifying employees that a disaster has occurred. They are also in charge of providing transportation, scheduling, and lodging for those who will be needed at the alternative site.
Transportation team—Team responsible for notifying employees that a disaster has occurred. They are also in charge of providing transportation, scheduling, and lodging for those who will be needed at the alternative site.
![]() Coordination team—Team tasked with managing operations at different remote sites and coordinating the recovery efforts.
Coordination team—Team tasked with managing operations at different remote sites and coordinating the recovery efforts.
![]() Finance team—Team that provides budgetary control for recovery and accurate accounting of costs.
Finance team—Team that provides budgetary control for recovery and accurate accounting of costs.
![]() Administrative support team—Team that provides administrative support and also handles payroll functions and accounting.
Administrative support team—Team that provides administrative support and also handles payroll functions and accounting.
![]() Supplies team—Team that coordinates with key vendors to maintain needed supplies.
Supplies team—Team that coordinates with key vendors to maintain needed supplies.
![]() Relocation team—Team in charge of managing the process of moving from the alternative site to the restored original location.
Relocation team—Team in charge of managing the process of moving from the alternative site to the restored original location.
![]() Recovery test team—Individuals deployed to test the BCP/DRP plans and determine their effectiveness.
Recovery test team—Individuals deployed to test the BCP/DRP plans and determine their effectiveness.
Did you notice that the last team listed is the recovery test team? These are the individuals who test the BCP plan; this should be done at least once a year. Without testing the plan, there is no guarantee that it will work. Testing helps bring more theoretical plans into reality. To build confidence, the BCP team should start with easier parts of the plan and build to more complex items. The initial tests should focus on items that support core processing and should be scheduled during a time that causes minimal disruption to normal business operations. Tests should be observed by an auditor who can witness the process and record accurate test times. Having an auditor is not the only requirement: Key individuals who would be responsible in a real disaster must play a role in the testing process. The actual testing methods vary among organizations and range from simple to complex. Regardless of the method or types of testing performed, the idea is to learn from the practice and improve the process each time a problem is discovered. As a CISA candidate, you should be aware of the three different types of BCP testing as defined by the ISACA:
![]() Paper tests
Paper tests
![]() Preparedness tests
Preparedness tests
![]() Full operation tests
Full operation tests
The following sections describe these basic testing methods in more detail.
Exam Alert
ISACA defines three types of BCP tests: paper tests, preparedness tests, and full operation tests.
Paper Tests
The most basic method of BCP testing is the paper test. Although it is not considered a replacement for a real test, this is a good start. A paper test is an exercise that can be performed by sending copies of the plan to different department managers and business unit managers for review. Each person the plan is sent to can review it to make sure nothing has been overlooked, and that everything that is being asked of them is possible.
A paper test can also be performed by having the members of the team come together and discuss the BCP plan. This is sometimes known as walk-through testing. The plans are laid out across the table so that attendees have a chance to see how an actual emergency would be handled. By reviewing the plan in this way, some errors or problems should become apparent. Under either method, sending the plan around or meeting to review the plan, the next step is usually a preparedness test.
Preparedness Tests
A preparedness test is a simulation in which team members go through an exercise that reenacts an actual outage or disaster. This type of test is typically used to test a portion of the plan. The preparedness test consumes time and money because it is an actual test that measures the team’s response to situations that might someday occur. This type of testing provides a means of incrementally improving the plan.
Tip
During preparedness tests, team leaders might want to adopt the phrase exercise because the term test denotes passing or failing. Adding this type of additional pressure on team members can be detrimental to the goals of continual improvement. As an example, during one disaster recovery test I was involved in, the backup media was to be returned from the offsite location to the primary site. When the truck arrived with the media, it was discovered that the tapes had not been properly secured. The tapes were scattered around the bed of the truck. Even though the test could not continue, it was not a failure as it uncovered a weakness in the existing procedure.
Full Operation Tests
The full operation test is as close to the actual service disruption as you can get. The team should have performed paper tests and preparedness tests before attempting this level of interruption. This test is the most detailed, time consuming, and thorough of all discussed. A full interruption test mimics a real disaster, and all steps are performed to start up backup operations. This involves all the individuals who would be involved in a real emergency, including internal and external organizations. Goals of the full operation test include the following:
![]() Verifying the business continuity plan
Verifying the business continuity plan
![]() Evaluating the level of preparedness of the personnel involved
Evaluating the level of preparedness of the personnel involved
![]() Measuring the capability of the backup site to operate as planned
Measuring the capability of the backup site to operate as planned
![]() Assessing the ability to retrieve vital records and information
Assessing the ability to retrieve vital records and information
![]() Evaluating the functionality of equipment
Evaluating the functionality of equipment
![]() Measuring overall preparedness for an actual disaster
Measuring overall preparedness for an actual disaster
Exam Alert
The disaster recovery and continuity plan should be tested at least once yearly. Environments change; each time the plan is tested, more improvements might be uncovered.
Step 7: Monitoring and Maintenance
When the testing process is complete, individuals tend to feel their job is done. If someone is not made responsible for this process, the best plans in the world can start to become outdated in six months or less. Don’t be surprised to find out that no one really wants to take on the task of documenting procedures and processes. The responsibility of performing periodic tests and maintaining the plan should be assigned to a specific person. The plan’s maintenance can be streamlined by incorporating change-management procedures to address issues that might affect the BCP plan.
A few additional items must be done to finish the BCP plan. The primary remaining item is to put controls in place to maintain the current level of business continuity and disaster recovery. This is best accomplished by implementing change-management procedures. If changes are required to the approved plans, you will then have a documented structured way to accomplish this. A centralized command and control structure will ease this burden. Life is not static; neither should be the organization’s BCP plans
Recovery Alternatives
Knowledge Statement
![]() Knowledge of types of alternate processing sites and methods used to monitor the contractual agreements (e.g., hot sites, warm sites, cold sites)
Knowledge of types of alternate processing sites and methods used to monitor the contractual agreements (e.g., hot sites, warm sites, cold sites)
Recovery alternatives are the choices the organization has to restore critical systems and the data in those systems. Recovery alternatives can include the following:
![]() Alternate processing sites
Alternate processing sites
![]() Hardware recovery
Hardware recovery
![]() Software recovery
Software recovery
![]() Telecommunications recovery
Telecommunications recovery
![]() Backup and restoration
Backup and restoration
The goal is to find the recovery alternative that balances the cost of downtime, the criticality of the system, and the likelihood of occurrence. As an example, if you have an RTO of less than 12 hours and the resource you are trying to recover is a mainframe computer, a cold-site facility would never work. Why? Because you can’t buy a mainframe, install it, and get the cold site up and running in less than 12 hours. Therefore, although cost is important, so are criticality and the time to recover. The total outage time that the organization can endure is referred to as maximum tolerable downtime (MTD). Table 9.4 shows some MTDs used by many organizations.
Table 9.4 Required Recovery Times

Alternate Processing Sites
For disasters that have the potential to affect the primary facility, plans must be made for a backup process or an alternate site. Some organizations might opt for a redundant processing site. Redundant sites are equipped and configured just like the primary site. They are owned by the organization, and their cost is high. After all, the company has spent a large amount of funds to build and equip a complete, duplicate site. Although the cost might seem high, it must be noted that organizations that choose this option have done so because they have a very short (if any) RPO. A loss of services for even a very short period of time would cost the organization millions. The organization also might be subjected to regulations that require it to maintain redundant processing. Before choosing a location for a redundant site, it must be verified that the site is not subject to the same types of disasters as the primary site. Regular testing is also important to verify that the redundant site still meets the organization’s needs and that it can handle the workload to meet minimum processing requirements.
Mobile sites are another alternate processing alternative. Mobile sites are usually tractor-trailer rigs that have been converted into data-processing centers. They contain all the necessary equipment and can be transported to a business location quickly. These can be chained together to provide space for data processing and can provide communication capabilities. Used by the military and large insurance agencies, they are a good choice in areas where no recovery facilities exist. Other types of recovery alternatives include subscription services such as hot sites, warm sites, and cold sites.
The hot site facility is ready to go. It is fully configured and is equipped with the same system as the production network. It can be made operational within just a few hours. A hot site merely needs staff, data files, and procedural documentation. Hot sites are a high-cost recovery option, but they can be justified when a short recovery time is required. Because a hot site is typically a subscription-based service, a range of fees are associated with it, including a monthly cost, subscription fees, testing costs, and usage or activation fees. Contracts for hot sites need to be closely examined; some might charge extremely high activation fees to prevent users from utilizing the facility for anything less than a true disaster.
Regardless of what fees are involved, the hot site needs to be periodically tested. These tests should evaluate processing abilities as well as security. The physical security of the hot site should be at the same level or greater than the primary site. Finally, it is important to remember that the hot site is intended for short-term usage only. As a subscriber service, other companies might be competing for the same resource. The organization should have a plan to recover primary services quickly or move to a secondary location.
Exam Alert
Hot sites should not be externally identifiable because this increases the risk of sabotage and other potential disruptions.
For a slightly less expensive alternative, an organization can choose a warm site. A warm site has data equipment and cables, and is partially configured. It could be made operational in anywhere from a few hours to a few days. The assumption with a warm site is that computer equipment and software can be procured in case of a disaster. Although the warm site might have some computer equipment installed, it is typically of lower processing power than at the primary site. The costs associated with a warm site are similar to those of a hot site but are slightly lower. The warm site is the most popular subscription alternative.
For organizations that are looking for a cheaper alternative and that have determined that they can tolerate a longer outage, a cold site might be the right choice. A cold site is basically an empty room with only rudimentary electrical, power, and computing capability. It might have a raised floor and some racks, but it is nowhere near ready for use. It might take several weeks to a month to get the site operational. A common misconception with cold sites is that the organization will be able to get the required equipment after a disaster. This might not be true. For a large disaster, such as what was experienced with Katrina, there could be a run on equipment so that vendors simply cannot meet demand. Backorders could push out the operation dates of the cold site to much longer than planned. Cold sites offer the least of the three subscription services discussed. Table 9.5 shows some example functions and their recovery times.
Exam Alert
Cold sites are a good choice for the recovery of noncritical services.
Table 9.5 Example Functions and Recovery Times

Reciprocal agreements are less frequently used. In this method, two organizations pledge assistance to one another in the event of a disaster. These agreements are carried out by sharing space, computer facilities, and technology resources. On paper, this appears to be a cost-effective solution because the primary advantage is its low cost. However, reciprocal agreements have drawbacks. The parties to this agreement are trusting that the other organization will aid in the event of a disaster. However, the nonvictim might be hesitant to follow through if such a disaster occurs based on concerns such as the realization that the damaged party might want to remain on location for a long period of time or that their presence will degrade their own network services. Even concerns about the loss of competive advantage can drive this hesitation. The issue of confidentiality also arises: The damaged organization is placed in a vulnerable position and must rely on the other party with confidential information. Finally, if the parties to the agreement are near each other, there is always the danger that disaster could strike both parties and thereby render the agreement useless. The legal departments of both firms will need to look closely at such an agreement. ISACA recommends that organizations considering reciprocal agreements address the following issues before entering into such an agreement:
![]() What amount of time will be available at the host computer site?
What amount of time will be available at the host computer site?
![]() Will the host site’s employees be available for help?
Will the host site’s employees be available for help?
![]() What specific facilities and equipment will be available?
What specific facilities and equipment will be available?
![]() How long can emergency operations continue at the host site?
How long can emergency operations continue at the host site?
![]() How frequently can tests be scheduled at the host site?
How frequently can tests be scheduled at the host site?
![]() What type of physical security is at the host site?
What type of physical security is at the host site?
![]() What type of logical security is available at the host site?
What type of logical security is available at the host site?
![]() Is advance notice required for using the site? If so, how much?
Is advance notice required for using the site? If so, how much?
![]() Are there any blocks of time or dates when the facility is not available?
Are there any blocks of time or dates when the facility is not available?
Exam Alert
Although reciprocal agreements are not usually appropriate for organizations with large databases, some organizations, such as small banks, have been known to sign reciprocal agreements for the use of a shared hot site.
When reviewing alternative processing options, subscribers should look closely at any agreements and at the actual facility to make sure it meets the need of the organization. One common problem is oversubscription. If situations such as Hurricane Katrina occur, there could be more organizations demanding the subscription service than the vendor can supply. The subscription agreement might also dictate when the organization may inhabit the facility. Thus, even though an organization might be in the path of a deadly storm, it might not be able to move into the facility yet because the area has not been declared a disaster area. Procedures and documentation should also be kept at the off-site location, and even backup must be available. It’s important to note that backup media should be kept in an area that is not subject to the same type of natural disaster. As an example, if the primary site is in the hurricane zone, the backup needs to be somewhere less prone to those conditions. If backup media is at another location, agreements should be in place to ensure that the media is moved to the alternate site so it is available for the recovery process. A final item is that organizations must also have prior financial arrangements to procure needed equipment, software, and supplies during a disaster. This might include emergency credit lines, credit cards, or agreements with hardware and software vendors.
Hardware Recovery
Recovery alternatives are just one of the items that must be considered to cope with a disaster. Hardware recovery is another. Remember that an effective recovery strategy involves more than just corrective measures; it is also about prevention. Hardware failures are one of the most common disruptions that can occur. This means that it is important to examine ways to minimize the likelihood of occurrence and to reduce the effect if it does occur. This process can be enhanced by making well-informed decisions when buying equipment. At purchase time, you should know two important numbers:
![]() The mean time between failure (MTBF)—The MTBF calculates the expected lifetime of a device. A higher MTBF means the equipment should last longer.
The mean time between failure (MTBF)—The MTBF calculates the expected lifetime of a device. A higher MTBF means the equipment should last longer.
![]() The mean time to repair (MTTR)—The MTTR estimates how long it would take to repair the equipment and get it back into use. For MTTR, lower numbers mean the equipment takes less time to repair and can be returned to service sooner.
The mean time to repair (MTTR)—The MTTR estimates how long it would take to repair the equipment and get it back into use. For MTTR, lower numbers mean the equipment takes less time to repair and can be returned to service sooner.
For critical equipment, the organization might consider a service level agreement (SLA), a contract with the hardware vendor that provides a certain level of protection. For a fee, the vendor agrees to repair or replace the equipment within the contracted time.
Fault tolerance can be used at the server or the drive level. At the server level is clustering, which is technology that groups several servers together yet allows them to be viewed logically as a single server. Users see the cluster as one unit, although it is actually many. The advantage is that if one server in the cluster fails, the remaining active servers will pick up the load and continue operation. Fault tolerance on the drive level is achieved primarily with Redundant Array of Inexpensive Disks (RAID), which is used for hardware fault tolerance and/or performance improvements. This is achieved by breaking up the data and writing it to multiple disks. To applications and other devices, RAID appears as a single drive. Most RAID systems have hot-swappable disks, which means that the drives can be removed or added while the computer systems are running. If the RAID system uses parity and is fault tolerant, the parity date is used to rebuild the newly replaced drive. Another RAID technique is striping, which simply means that the data is divided and written over several drives. Although write performance remains almost constant, read performance drastically increases. RAID has humble beginnings that date back to the 1980s at the University of California. According to ISACA, the most common levels of RAID used today include these:
![]() RAID 0
RAID 0
![]() RAID 3
RAID 3
![]() RAID 5
RAID 5
RAID level descriptions are as follows:
![]() Level 0—Striped Disk Array without Fault Tolerance: Provides data striping and improves performance, but provides no redundancy.
Level 0—Striped Disk Array without Fault Tolerance: Provides data striping and improves performance, but provides no redundancy.
![]() Level 1—Mirroring and Duplexing: Disk mirroring duplicates the information on one disk to another. It provides twice the read transaction rate of single disks and the same write transaction rate as single disks, yet effectively cuts disk space in half.
Level 1—Mirroring and Duplexing: Disk mirroring duplicates the information on one disk to another. It provides twice the read transaction rate of single disks and the same write transaction rate as single disks, yet effectively cuts disk space in half.
![]() Level 2—Error-Correcting Coding: ECC is rarely used because of the extensive computing resources needed. It stripes data at the bit level instead of the block level.
Level 2—Error-Correcting Coding: ECC is rarely used because of the extensive computing resources needed. It stripes data at the bit level instead of the block level.
![]() Level 3—Parallel Transfer with Parity: Uses byte-level striping with a dedicated disk. Although it provides fault tolerance, it is rarely used.
Level 3—Parallel Transfer with Parity: Uses byte-level striping with a dedicated disk. Although it provides fault tolerance, it is rarely used.
![]() Level 4—Shared Parity Drive: Similar to RAID 3, but provides block-level striping with a parity disk. If a data disk fails, the parity data is used to create a replacement disk. Its primary disadvantage is that the parity disk can create write bottlenecks.
Level 4—Shared Parity Drive: Similar to RAID 3, but provides block-level striping with a parity disk. If a data disk fails, the parity data is used to create a replacement disk. Its primary disadvantage is that the parity disk can create write bottlenecks.
![]() Level 5—Block Interleaved Distributed Parity: Provides data striping of both data and parity. Level 5 has good performance and fault tolerance. It is a popular implementation of RAID.
Level 5—Block Interleaved Distributed Parity: Provides data striping of both data and parity. Level 5 has good performance and fault tolerance. It is a popular implementation of RAID.
![]() Level 6—Independent Data Disks with Double Parity: Level 6 provides high fault tolerance with block-level striping and parity data distributed across all disks.
Level 6—Independent Data Disks with Double Parity: Level 6 provides high fault tolerance with block-level striping and parity data distributed across all disks.
![]() Level 10—A Stripe of Mirrors: This level of RAID is known to have very high reliability. IT requires a minimum of four drives.
Level 10—A Stripe of Mirrors: This level of RAID is known to have very high reliability. IT requires a minimum of four drives.
![]() Level 0+1—A Mirror of Stripes: This mode of RAID is not one of the original RAID levels. RAID 0+1 uses RAID 0 to stripe data and creates a RAID 1 mirror. It provides high data rates.
Level 0+1—A Mirror of Stripes: This mode of RAID is not one of the original RAID levels. RAID 0+1 uses RAID 0 to stripe data and creates a RAID 1 mirror. It provides high data rates.
One final drive-level solution worth mentioning is Just a Bunch of Disks (JBOD). It is similar to RAID 0 but offers few of the advantages. What it does offer is the capability to combine two or more disks of various sizes into one large partition. It also has an advantage over RAID 0: In case of drive failure, only the data on the affected drive is lost; the data on surviving drives remains readable. This means that JBOD has disaster recovery advantages. JBOD does not carry the performance benefits associated with RAID 0. With our discussion of hardware recovery complete, let’s move on to discuss software-recovery options.
Software and Data Recovery
Knowledge Statement
![]() Knowledge of data backup, storage, maintenance, retention and restoration processes, and practices
Knowledge of data backup, storage, maintenance, retention and restoration processes, and practices
Because data processing is essential to most organizations, having the software and data needed to continue this operation is critical to the recovery process. The objectives are to back up critical software and data, and be able to restore these quickly. Policy should dictate when backups are performed, when the media is stored, who has access to the media, and what its reuse or rotation policy is. Backup media can include tape reels, tape cartridges, removable hard drives, disks, and cassettes. The organization must determine how often backups should be performed and what type of backup should be performed. These operations will vary depending on the cost of the media, the speed of the restoration needed, and the time allocated for backups. Typically, the following four backup methods are used:
![]() Full backup—All data is backed up. No data files are skipped or bypassed. All items are copied to one tape, set of tapes, or backup medium. If restoration is needed, only one tape or set of tapes is needed. A full backup requires the most time and space on the storage medium but takes the least time to restore.
Full backup—All data is backed up. No data files are skipped or bypassed. All items are copied to one tape, set of tapes, or backup medium. If restoration is needed, only one tape or set of tapes is needed. A full backup requires the most time and space on the storage medium but takes the least time to restore.
![]() Differential backup—A full backup is done typically once a week, and a daily differential backup is done only to those files that have changed since the last full backup. If you need to restore, you need the last full backup and the most recent differential backup. This method takes less time per backup but longer to restore because both the full and differential backups are needed.
Differential backup—A full backup is done typically once a week, and a daily differential backup is done only to those files that have changed since the last full backup. If you need to restore, you need the last full backup and the most recent differential backup. This method takes less time per backup but longer to restore because both the full and differential backups are needed.
![]() Incremental backup—This method backs up only those files that have been modified since the previous incremental backup. An incremental backup requires additional backup media because the last full backup, the last incremental backup, and any additional incremental backups are required to restore the media.
Incremental backup—This method backs up only those files that have been modified since the previous incremental backup. An incremental backup requires additional backup media because the last full backup, the last incremental backup, and any additional incremental backups are required to restore the media.
![]() Continuous backup—Some backup applications perform a continuous backup that keeps a database of backup information. These systems are useful because if a restoration is needed, the application can provide a full restore, a point-in-time restore, or a restore based on a selected list of files.
Continuous backup—Some backup applications perform a continuous backup that keeps a database of backup information. These systems are useful because if a restoration is needed, the application can provide a full restore, a point-in-time restore, or a restore based on a selected list of files.
Although tape and optical systems still have the majority of market share for backup systems, hardware alternatives are making inroads. One of these technologies is Massive Array of Inactive Disks (MAID). MAID offers a hardware storage option for the storage of data and applications, and was designed to reduce the operational costs and improve long-term reliability of disk-based archives and backups. MAID is similar to RAID, except that it provides power management and advanced disk monitoring. The MAID system powers down inactive drives, reduces heat output, reduces electrical consumption, and increases the drive’s life expectancy. This represents real progress to concerns of using hard disks to back up data. Storage Area Networks (SANs) are another alternative. SANs are designed as a subnetwork of high-speed, shared storage devices. When software- and data-recovery methods have been determined, the next item is to look at backup and data-restoration provisions.
Backup and Restoration
Task
![]() Evaluate the adequacy of backup and restoration provisions to ensure the availability of information required to resume processing.
Evaluate the adequacy of backup and restoration provisions to ensure the availability of information required to resume processing.
Knowledge Statement
![]() Knowledge of data backup, storage, maintenance, retention and restoration processes, and practices
Knowledge of data backup, storage, maintenance, retention and restoration processes, and practices
Where the backup media is stored can have a real impact on how quickly data can be restored and brought back online. The media should be stored in more than one physical location, to reduce the possibility of loss. A tape librarian should manage these remote sites by maintaining the site, controlling access, rotating media, and protecting this valuable asset. Unauthorized access to the media is a huge risk because it could impact the organization’s ability to provide uninterrupted service. Encryption can help mitigate this risk. Transportation to and from the remote site is also an important concern. Items of importance include these:
![]() Secure transportation to and from the site must be maintained.
Secure transportation to and from the site must be maintained.
![]() Delivery vehicles must be bonded.
Delivery vehicles must be bonded.
![]() Backup media must be handled, loaded, and unloaded in an appropriate way.
Backup media must be handled, loaded, and unloaded in an appropriate way.
![]() Drivers must be trained on the proper procedures to pick up, handle, and deliver backup media.
Drivers must be trained on the proper procedures to pick up, handle, and deliver backup media.
![]() Access to the backup facility should be 24×7 in case of emergency.
Access to the backup facility should be 24×7 in case of emergency.
Off-site storage should be contracted with a known firm that has control of the facility and is responsible for its maintenance. Physical and environmental controls should be equal or better than those of the organization’s facility. A letter of agreement should specify who has access to the media and who is authorized to drop off or pick up media. There should also be an agreement on response time that is to be met in times of disaster. On-site storage should be maintained to ensure the capability to recover critical files quickly. Backup media should be secured and kept in an environmentally controlled facility that has physical control sufficient to protect such a critical asset. This area should be fireproof, with controlled access so that anyone depositing or removing media is logged. Although most backup media is rather robust, it will not last forever and will fail over time. This means that tape rotation is another important part of backup and restoration. Backup media must be periodically tested. Backups will be of little use if you find during a disaster that they have malfunctioned and no longer work. Common media-rotation strategies include the following:
![]() Simple—A simple backup-rotation scheme is to use one tape for every day of the week and then repeat the next week. One tape can be for Mondays, one for Tuesdays, and so on. You would add a set of new tapes each month and then archive the monthly sets. After a predetermined number of months, you would put the oldest tapes back into use.
Simple—A simple backup-rotation scheme is to use one tape for every day of the week and then repeat the next week. One tape can be for Mondays, one for Tuesdays, and so on. You would add a set of new tapes each month and then archive the monthly sets. After a predetermined number of months, you would put the oldest tapes back into use.
![]() Grandfather-father-son—This rotation method includes four tapes for weekly backups, one tape for monthly backups, and four tapes for daily backups. It is called grandfather-father-son because the scheme establishes a kind of hierarchy. Grandfathers are the one monthly backup, fathers are the four weekly backups, and sons are the four daily backups.
Grandfather-father-son—This rotation method includes four tapes for weekly backups, one tape for monthly backups, and four tapes for daily backups. It is called grandfather-father-son because the scheme establishes a kind of hierarchy. Grandfathers are the one monthly backup, fathers are the four weekly backups, and sons are the four daily backups.
![]() Tower of Hanoi—This tape-rotation scheme is named after a mathematical puzzle. It involves using five sets of tapes, each set labeled A through E. Set A is used every other day; set B is used on the first non-A backup day and is used every fourth day; set C is used on the first non-A or non-B backup day and is used every eighth day; set D is used on the first non-A, non-B, or non-C day and is used every 16th day; and set E alternates with set D.
Tower of Hanoi—This tape-rotation scheme is named after a mathematical puzzle. It involves using five sets of tapes, each set labeled A through E. Set A is used every other day; set B is used on the first non-A backup day and is used every fourth day; set C is used on the first non-A or non-B backup day and is used every eighth day; set D is used on the first non-A, non-B, or non-C day and is used every 16th day; and set E alternates with set D.
Note
Encryption and Backups—An organization’s backups are a complete mirror of the organization’s data. Although most backups are password-protected, this really offers only limited protection. If attackers have possession of the backup media, they are not under any time constraints. This gives them ample time to crack passwords and access the data. Encryption can offer an additional layer of protection and help protect the confidentiality of the data.
SANs are an alternative to tape backup. SANs support disk mirroring, backup and restore, archival and retrieval of archived data, and data migration from one storage device to another. SANs can be implemented locally or can use storage at a redundant facility. If this is beyond the organization’s budget, it can opt for electronic vaulting, the transfer of data by electronic means to a backup site, as opposed to the physical shipment. With electronic vaulting, organizations contract with a vaulting provider. The organization typically loads a software agent onto systems to be backed up, and the vaulting service accesses these systems to copy the selected files. If large amounts of data are to be moved, this can slow WAN service. Another backup alternative is standby database shadowing. A standby database is an exact duplicate of a database maintained on a remote server. In case of disaster, it is ready to go. Changes are applied from the primary database to the standby database to keep records synchronized.
What about situations when backup is not the problem? What if the software developer goes bankrupt or is no longer in business? How is the organization supposed to maintain or update the needed code? These concerns can be addressed by a software escrow agreement. Software escrow allows the organization to maintain access to the source code of an application if the vendor goes bankrupt. Although the organization can modify the software for continued use, it can’t steal the design or sell the code on the open market. This is simply one way of protecting you in case things go wrong and the vendor is no longer in business.
Telecommunications Recovery
Telecommunications recovery should play a key role in recovery. After all, the telecommunication network is a critical asset and should be given a high priority for recovery. Although these communications networks can be susceptible to the same threats as data centers, they also face some unique threats. Protection methods include redundant WAN links, bandwidth on demand, and dial backup. Whatever the choice, the organization should verify capacity requirements and acceptable outage times. The primary methods for network protection include the following:
![]() Redundancy—This involves exceeding what is required or needed. Redundancy can be added by providing extra capacity, providing multiple routes, using dynamic routing protocols, and using failover devices to allow for continued operations.
Redundancy—This involves exceeding what is required or needed. Redundancy can be added by providing extra capacity, providing multiple routes, using dynamic routing protocols, and using failover devices to allow for continued operations.
![]() Diverse routing—This is the practice of routing traffic through different cable facilities. Organizations can obtain both diverse routing and alternate routing, yet the cost is not cheap. Most of these systems use facilities that are buried. These systems usually emerge through the basement and can sometimes share space with other mechanical equipment. This adds risk. Many cities have aging infrastructures, which is another probable point of failure.
Diverse routing—This is the practice of routing traffic through different cable facilities. Organizations can obtain both diverse routing and alternate routing, yet the cost is not cheap. Most of these systems use facilities that are buried. These systems usually emerge through the basement and can sometimes share space with other mechanical equipment. This adds risk. Many cities have aging infrastructures, which is another probable point of failure.
![]() Alternate routing—This is the ability to use another transmission line if the regular line is busy or unavailable. This can include using a dial-up connection in place of a dedicated connection, a cell phone instead of a land line, or microwave communication in place of a fiber connection.
Alternate routing—This is the ability to use another transmission line if the regular line is busy or unavailable. This can include using a dial-up connection in place of a dedicated connection, a cell phone instead of a land line, or microwave communication in place of a fiber connection.
![]() Long-haul diversity—This is the practice of having different long-distance communication carriers. This recovery facility option helps ensure that service is maintained; auditors should verify that it is present.
Long-haul diversity—This is the practice of having different long-distance communication carriers. This recovery facility option helps ensure that service is maintained; auditors should verify that it is present.
![]() Last-mile protection—This is a good choice for recovery facilities, in that it provides a second local loop connection and can add to security even more if an alternate carrier is used.
Last-mile protection—This is a good choice for recovery facilities, in that it provides a second local loop connection and can add to security even more if an alternate carrier is used.
![]() Voice communication recovery—Many organizations are highly dependent on voice communications. Some of these organizations have started making the switch to VoIP because of the cost savings. Some land lines should be maintained to provide recovery capability.
Voice communication recovery—Many organizations are highly dependent on voice communications. Some of these organizations have started making the switch to VoIP because of the cost savings. Some land lines should be maintained to provide recovery capability.
Note
Recovery strategies have historically focused on computing resources and data. Networks are susceptible to many of the same problems, yet many times they are not properly backed up. This can be a real problem because there is a heavy reliance on networks to deliver data when needed.
Verification of Disaster Recovery and Business Continuity Process
Tasks
![]() Evaluate the organization’s disaster recovery plan to ensure that it enables the recovery of IT processing in the event of a disaster.
Evaluate the organization’s disaster recovery plan to ensure that it enables the recovery of IT processing in the event of a disaster.
![]() Evaluate the organization’s business continuity plan to ensure its ability to continue essential business operations during the period of an IT disruption.
Evaluate the organization’s business continuity plan to ensure its ability to continue essential business operations during the period of an IT disruption.
As an IT auditor, you will be tasked with understanding and evaluating DR/BCP strategy. The auditor should review the plan and make sure that it is current and up-to-date. The auditor also will want to examine last year’s test to verify the results and look for any problem areas. The business continuity coordinator is responsible for maintaining previous tests. Upon examination, the auditor should confirm that the test met targeted goals or minimum standards. The auditor will also want to inspect the off-site storage facility and review its security, policies, and configuration. This should include a detailed inventory that checks data files, applications, system software, system documentation, operational documents, consumables, supplies, and a copy of the BCP plan.
Contracts and alternative processing agreements should also be reviewed. Any off-site processing facilities should be audited, and the owners should have a reference check. All agreements should be made in writing. The off-site facility should meet the same security standards as the primary facility and should have environmental controls such as raised floors, HVAC controls, fire prevention and detection, filtered power, and uninterruptible power supplies. If the location is a shared site, the rules that determine who has access and when they have access should be examined. Another area of concern is the BCP plan itself. The auditor must make sure the plan is written in easy-to-understand language and that users have been trained. This can be confirmed by interviewing employees.
Finally, insurance should be reviewed. The auditor will want to examine the level and types of insurance the organization has purchased. Insurance can be obtained for each of the following items:
![]() IS equipment
IS equipment
![]() Data centers
Data centers
![]() Software recovery
Software recovery
![]() Business interruption
Business interruption
![]() Documents, records, and important papers
Documents, records, and important papers
![]() Errors and omissions
Errors and omissions
![]() Media transportation
Media transportation
Insurance is not without its drawbacks, which include high premiums, delayed claim payout, denied claims, and problems proving financial loss. Finally, most policies pay for only a percentage of actual loss and do not pay for lost income, increased operating expenses, or consequential loss.
Review Break
The business continuity process follows a structured path that includes the following steps:
1. Project management and initiation—Management identifies a need for the BCP and appoints a team leader.
2. Business impact analysis—The team determines various risks and determines a threat level based on qualitative or quantitative assessment.
3. Recovery strategy—Based on identified threats, the team determines what is needed to recover from identified disasters.
4. Plan design and development—The team designs a plan and develops a procedure to recover from disasters determined in the BIA.
5. Training and awareness—The team trains employees and makes sure all employees are aware of BCP policies and procedures.
6. Implementation and testing—No recovery is guaranteed until the plan has been tested. Tests can be paper-based tests or complete real interruption tests.
7. Monitoring and maintenance—Changes to the network and systems require plans to be periodically updated.
Chapter Summary
This chapter discussed the process of business continuity planning. This process is the act of preparing for the worst possible events that could happen to the organization. Not uncommonly, many organizations give it low priority for a host of reasons, including cost, people’s inability to quantify some potential threats, and the belief that they can somehow escape these events.
Initiation is the first step. This requires that senior management establish business continuity as a priority. Developing and carrying out a successful business continuity plan takes much work and effort, and should be done in a modular format. The business impact analysis is the next step. Although auditors are unlikely to be directly involved in this process, they can be of help here in providing data on the impact to the business if specific systems are unavailable. The goal of the business impact analysis is to determine which processes need to come on first, second, third, and so on. Each step of the business continuity process builds on the last; this requires the BCP team members to know the business and have worked with other departments and management to determine critical processes.
Recovery strategies must also be determined. As an example, in case of loss of power, will a generator be used, or might the process continue at another location that has power? With these decisions made, a written plan must be developed that locks into policy whatever choices have been decided upon.When the plan is implemented, the process is still not complete because the team must test the plan. During the test, an IS auditor should be present to observe the results. No demonstrated recovery exists until the plan has been tested. Common test methods include paper tests, preparedness tests, and full operation tests. To make sure these plans and procedures do not grow old or become obsolete, disaster recovery should become part of the decision-making process so that when changes are made, issues that may affect the policies can be updated. Business continuity and disaster recovery plans can also be added to job responsibilities and to yearly performance reviews.
Key Terms
![]() Data communications
Data communications
![]() Local area network (LAN)
Local area network (LAN)
![]() Open Shortest Path First
Open Shortest Path First
![]() Redundant Array of Inexpensive Disks
Redundant Array of Inexpensive Disks
![]() Resilience
Resilience
Apply Your Knowledge
This chapter documented the importance of business continuity and disaster recovery. This “Apply Your Knowledge” section has you review some of the items an IS auditor would need to review.
The exercise has you examine a hypothetical organization and list possible audit items.
Exercises
9.1 Business Impact and Risk
Estimated Time: 10 Minutes
Review the following profile and then answer the following questions.
Kerney, Cleveland, and Glass Law Firm
Driving Concern
This high-flying law firm located in the Washington, D.C., area has serviced a who’s who of individuals inside and outside the beltway. The firm recently suffered a major network outage after a key server failed and it was determined that the backup media was corrupt. Management has existing BCP plans but could not contact the person in charge of backups during this late-night problem. They are now worried that the plans are not adequate.
Overview
The firm has two offices: one in the D.C. area and the other on the West Coast. The firm handles many confidential documents, often of high monetary value. The firm is always looking for ways to free up the partners from administrative tasks so that they can have more billable hours. Partners access their data from wireless LANs and remotely through a corporate VPN.
1. The two offices are connected by a T1 leased line. Only the D.C. office has a connection to the Internet. The West Coast office connects to the Internet through the D.C. office. The wireless network supports Windows servers in the D.C. office. Partners also carry notebook computers that contain many confidential documents needed at client sites. No encryption is used, and there is no insurance to protect against downtime or disruptions.
Which of the following items should you perform if you were asked to audit the law firm’s BCP plans?
Verify that the business continuity plan provides for the recovery of all systems? Yes/No
Require that you or another auditor is present during a test of the BCP plan? Yes/No
Verify that the notification directory is being maintained and is current? Yes/No
Verify that the IS department is responsible for declaring a disaster if such a situation repeated itself? Yes/No
Suggest that the law firm increase its recovery time objective? Yes/No
Determine the most critical finding? Lack of insurance/Loss of data
2. Examine the list from item 1 and compare your answers with the following:
Verify that the business continuity plan provides for the recovery of all systems? Yes/No (Typically, only 50% of information is critical.)
Require that you or another auditor is present during a test of the BCP plan? Yes/No (The auditor should be present to make sure the test meets required targets.)
Verify that the notification directory is being maintained and is current? Yes/No (Without a notification system, there is no easy way to contact employees or for them to check in case of disaster.)
Verify that the IS department is responsible for declaring a disaster if such a situation repeated itself? Yes/No (Senior management should designate someone for that task.)
Suggest that the law firm increase its recovery time objective? Yes/No (This would increase recovery time, not decrease it.)
Determine the most critical finding? Lack of insurance/Loss of data (The most vital asset for an organization is its data.)
Exam Questions
1. Tape backup should be used as a recovery strategy when:
![]() A. The RPO is high.
A. The RPO is high.
![]() B. The RPO is low.
B. The RPO is low.
![]() C. The RTO is low.
C. The RTO is low.
![]() D. Fault tolerance is low.
D. Fault tolerance is low.
2. Which of the following is the best reason to use a hot site?
![]() A. It can be used for long-term processing.
A. It can be used for long-term processing.
![]() B. It is not a subscription service.
B. It is not a subscription service.
![]() C. There is no additional cost for usage or periodic testing.
C. There is no additional cost for usage or periodic testing.
![]() D. It is ready for service.
D. It is ready for service.
3. Which of the following describes the greatest advantage of JBOD?
![]() A. In case of drive failure, only the data on the affected drive is lost.
A. In case of drive failure, only the data on the affected drive is lost.
![]() B. It is superior to disk mirroring.
B. It is superior to disk mirroring.
![]() C. It offers greater performance gains than RAID.
C. It offers greater performance gains than RAID.
![]() D. Compared to RAID, it offers greater fault tolerance.
D. Compared to RAID, it offers greater fault tolerance.
4. Which of the following processes is most critical in terms of revenue generation?
![]() A. Discretionary
A. Discretionary
![]() B. Supporting
B. Supporting
![]() C. Core
C. Core
![]() D. Critical
D. Critical
5. How often should BCP plans be updated?
![]() A. Every 5 years
A. Every 5 years
![]() B. Every year or as required
B. Every year or as required
![]() C. Every 6 months
C. Every 6 months
![]() D. Upon any change or modification
D. Upon any change or modification
6. When maintaining data backups at off-site locations, which of the following is the most important control concern?
![]() A. That the storage site is as secure as the primary site
A. That the storage site is as secure as the primary site
![]() B. That a suitable tape-rotation plan is in use
B. That a suitable tape-rotation plan is in use
![]() C. That backup media is tested regularly
C. That backup media is tested regularly
![]() D. That copies of current critical information are kept off-site
D. That copies of current critical information are kept off-site
7. The most important purpose of the BIA is which of the following?
![]() A. Identify countermeasures
A. Identify countermeasures
![]() B. Prioritize critical systems
B. Prioritize critical systems
![]() C. Develop recovery strategies
C. Develop recovery strategies
![]() D. Determine potential test strategies
D. Determine potential test strategies
8. Which of the following is not a valid BCP test type?
![]() A. Paper test
A. Paper test
![]() B. Structured walk-through
B. Structured walk-through
![]() C. Full operation
C. Full operation
![]() D. Preparedness test
D. Preparedness test
9. Which of the following is the practice of routing traffic through different cable facilities?
![]() A. Alternate routing
A. Alternate routing
![]() B. Long-haul diversity
B. Long-haul diversity
![]() C. Diverse routing
C. Diverse routing
![]() D. Last-mile protection
D. Last-mile protection
10. When classifying critical systems, which category describes the following description: “These functions are important and can be performed by a backup manual process, but not for a long period of time.”
![]() A. Vital
A. Vital
![]() B. Sensitive
B. Sensitive
![]() C. Critical
C. Critical
![]() D. Demand driven
D. Demand driven
Answers to Exam Questions
1. B. The recovery point objective is the earliest point in time at which recovery can occur. If RPO is low, tape backup or another solution is acceptable. Answer A is incorrect because a high RPO would require mirroring or other type of timely recovery method. Answer C is incorrect because a low RTO would mean that little time is available for recovery. Answer D is incorrect because a low fault tolerance indicates that little time is available for unavailable services.
2. D. Although hot sites are an expensive alternative, they are ready for service. Answer A is incorrect because they cannot be used for long-term processing. Answer B is incorrect because a hot site is a subscription service. Answer C is incorrect because there are additional fees; the organization must pay a variety of fees for usage, testing, and access.
3. A. JBOD allows users to combine multiple drives into one large drive. JBOD’s only advantage is that, in case of drive failure, only the data on the affected drive is lost. Answers B, C, and D are incorrect because JBOD is not superior to disk mirroring, is not faster than RAID, and offers no fault tolerance.
4. C. Critical processes that produce revenue are considered a core activity. Answer A is incorrect because discretionary process are considered nonessential. Answer B is incorrect because supporting processes require only minimum BCP services. Answer D does not specify a process; critical is a term used to describe how important the service or process is.
5. D. BCP planning is an ongoing process that should be revisited each time there is a change to the environment. Therefore, answers A, B, and C are incorrect.
6. D. The most critical concern is keeping the copies of critical information current at an off-site location. Answers A, B, and C are important but are not the most important.
7. B. The BIA is an important part of the BCP process. The purpose of the BIA is to document the impact of outages, identify critical systems, prioritize critical systems, analyze outage impact, and determine recovery times needed to keep critical systems running. Answers A, C, and D are incorrect because they do not specify steps performed during the BIA.
8. B. There is no BCP test known as a structured walk-through. Valid types are listed in answers A, C, and D: paper tests, full operation test, and preparedness test.
9. C. Diverse routing is the practice of routing traffic through different cable facilities. Answer A is incorrect because alternate routing is the ability to use another transmission line if the regular line is busy or unavailable. Answer B is incorrect because long-haul diversity is the practice of having different long-distance communication carriers. Answer D is incorrect because last-mile protection provides a second local loop connection.
10. A.Vital meets the description of functions that are important and can be performed by a backup manual process, but not for a long period of time. Answer B is incorrect because it describes tasks that are important but can be performed manually at a reasonable cost. Answer C is incorrect because critical refers to extremely important functions. Answer D is incorrect because demand driven does not describe a valid functional label.
Need to Know More?
![]() Five Steps to Risk Assessment: http://tinyurl.com/2tn5tx
Five Steps to Risk Assessment: http://tinyurl.com/2tn5tx
![]() Business Continuity Planning Model: http://www.drj.com/new2dr/model/bcmodel.htm
Business Continuity Planning Model: http://www.drj.com/new2dr/model/bcmodel.htm
![]() BCP Good Practice Guidelines: http://www.thebci.org/gpg.htm
BCP Good Practice Guidelines: http://www.thebci.org/gpg.htm
![]() Contingency Planning: http://tinyurl.com/2n2b99
Contingency Planning: http://tinyurl.com/2n2b99
![]() SLAs: http://www.disasterrecoveryworld.com/sla.htm
SLAs: http://www.disasterrecoveryworld.com/sla.htm
![]() Business Impact Analysis: http://tinyurl.com/2ornyb
Business Impact Analysis: http://tinyurl.com/2ornyb
![]() Exploring Backup Alternatives: http://www.ameinfo.com/39672.html
Exploring Backup Alternatives: http://www.ameinfo.com/39672.html
![]() Auditing BCP Plans: http://tinyurl.com/2l2mqf
Auditing BCP Plans: http://tinyurl.com/2l2mqf