
CHAPTER 7
Cryptography
This chapter presents the following:
• History of cryptography
• Cryptography components and their relationships
• Steganography
• Algorithm types
• Public key infrastructure (PKI)
• e-mail standards
• Quantum cryptography
• Secure protocols
• Internet security
• Attack types
Cryptography is a method of storing and transmitting data in a form that only those it is intended for can read and process. It is considered a science of protecting information by encoding it into an unreadable format. Cryptography is an effective way of protecting sensitive information as it is stored on media or transmitted through un-trusted network communication paths.
One of the goals of cryptography, and the mechanisms that make it up, is to hide information from unauthorized individuals. However, with enough time, resources, and motivation, hackers can break most algorithms and reveal the encoded information. So a more realistic goal of cryptography is to make obtaining the information too work-intensive or time-consuming to be worthwhile to the attacker.
The first encryption methods date back to 4,000 years ago and were considered more of an art form. Encryption was later adapted as a tool to use in warfare, commerce, government, and other arenas in which secrets needed to be safeguarded. With the relatively recent birth of the Internet, encryption has gained new prominence as a vital tool in everyday transactions. Throughout history, individuals and governments have worked to protect communication by encrypting it. As a result, the encryption algorithms and the devices that use them have increased in complexity, new methods and algorithms have been continually introduced, and encryption has become an integrated part of the computing world.
Cryptography has had an interesting history and has undergone many changes down through the centuries. Keeping secrets has proven very important to the workings of civilization. It gives individuals and groups the ability to hide their true intentions, gain a competitive edge, and reduce vulnerability, among other things.
The changes that cryptography has undergone closely follow advances in technology. The earliest cryptography methods involved a person carving messages into wood or stone, which was then delivered to the intended individual, who had the necessary means to decipher the messages. Cryptography has come a long way since then. Now it is inserted into streams of binary code that pass over network wires, Internet communication paths, and airwaves.
The History of Cryptography
Look, I scrambled up the message so no one can read it.
Response: Yes, but now neither can we.
Cryptography has roots that begin around 2000 B.C. in Egypt, when hieroglyphics were used to decorate tombs to tell the life story of the deceased. The intention of the practice was not so much about hiding the messages themselves; rather, the hieroglyphics were intended to make the life story seem more noble, ceremonial, and majestic.
Encryption methods evolved from being mainly for show into practical applications used to hide information from others.
A Hebrew cryptographic method required the alphabet to be flipped so each letter in the original alphabet was mapped to a different letter in the flipped, or shifted, alphabet. The encryption method was called atbash, which was used to hide the true meaning of messages. An example of an encryption key used in the atbash encryption scheme is shown here:
ABCDEFGHIJKLMNOPQRSTUVWXYZ
ZYXWVUTSRQPONMLKJIHGFEDCBA
For example, the word “security” is encrypted into “hvxfirgb.” What does “xrhhk” come out to be?
This is an example of a substitution cipher, because each character is replaced with another character. This type of substitution cipher is referred to as a monoalphabetic substitution cipher because it uses only one alphabet, whereas a polyalphabetic substitution cipher uses multiple alphabets.
 NOTE Cipher is another term for algorithm.
NOTE Cipher is another term for algorithm.
This simplistic encryption method worked for its time and for particular cultures, but eventually more complex mechanisms were required.
Around 400 B.C., the Spartans used a system of encrypting information in which they would write a message on a sheet of papyrus (a type of paper) that was wrapped around a staff (a stick or wooden rod), which was then delivered and wrapped around a different staff by the recipient. The message was only readable if it was wrapped around the correct size staff, which made the letters properly match up, as shown in Figure 7-1. This is referred to as the scytale cipher. When the papyrus was not wrapped around the staff, the writing appeared as just a bunch of random characters.
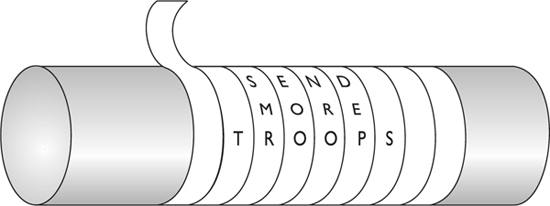
Figure 7-1 The scytale was used by the Spartans to decipher encrypted messages.
Later, in Rome, Julius Caesar (100-44 B.C.) developed a simple method of shifting letters of the alphabet, similar to the atbash scheme. He simply shifted the alphabet by three positions. The following example shows a standard alphabet and a shifted alphabet. The alphabet serves as the algorithm, and the key is the number of locations it has been shifted during the encryption and decryption process.
Standard Alphabet:
ABCDEFGHIJKLMNOPQRSTUVWXYZ
Cryptographic Alphabet:
DEFGHIJKLMNOPQRSTUVWXYZABC
As an example, suppose we need to encrypt the message “Logical Security.” We take the first letter of this message, L, and shift up three locations within the alphabet. The encrypted version of this first letter is O, so we write that down. The next letter to be encrypted is O, which matches R when we shift three spaces. We continue this process for the whole message. Once the message is encrypted, a carrier takes the encrypted version to the destination, where the process is reversed.
Plaintext:
LOGICAL SECURITY
Ciphertext:
ORJLFDO VHFXULWB
Today, this technique seems too simplistic to be effective, but in the time of Julius Caesar, not very many people could read in the first place, so it provided a high level of protection. The Caesar cipher is an example of a monoalphabetic cipher. Once more people could read and reverse-engineer this type of encryption process, the cryptographers of that day increased the complexity by creating polyalphabetic ciphers.
In the 16th century in France, Blaise de Vigenere developed a polyalphabetic substitution cipher for Henry III. This was based on the Caesar cipher, but it increased the difficulty of the encryption and decryption process.
As shown in Figure 7-2, we have a message that needs to be encrypted, which is SYSTEM SECURITY AND CONTROL. We have a key with the value of SECURITY. We also have a Vigenere table, or algorithm, which is really the Caesar cipher on steroids. Whereas the Caesar cipher used a 1 shift alphabet (letters were shifted up three places), the Vigenere cipher has 27 shift alphabets and the letters are shifted up only one place.
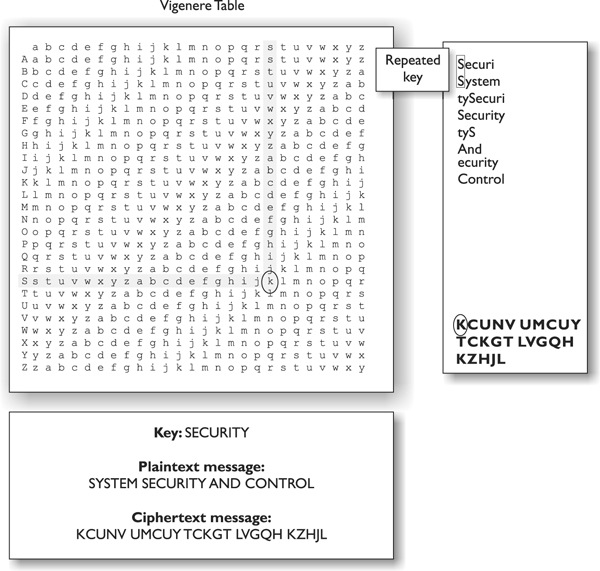
Figure 7-2 Polyalphabetic algorithms were developed to increase encryption complexity.
NOTE Plaintext is the readable version of a message. After an encryption process, the resulting text is referred to as ciphertext.
So, looking at the example in Figure 7-2, we take the first value of the key, S, and starting with the first alphabet in our algorithm, trace over to the S column. Then we look at the first value of plaintext that needs to be encrypted, which is S, and go down to the S row. We follow the column and row and see that they intersect on the value K. That is the first encrypted value of our message, so we write down K. Then we go to the next value in our key, which is E, and the next value of plaintext, which is Y. We see that the E column and the Y row intersect at the cell with the value of C. This is our second encrypted value, so we write that down. We continue this process for the whole message (notice that the key repeats itself, since the message is longer than the key). The resulting ciphertext is the encrypted form that is sent to the destination. The destination must have the same algorithm (Vigenere table) and the same key (SECURITY) to properly reverse the process to obtain a meaningful message.
The evolution of cryptography continued as countries refined it using new methods, tools, and practices throughout the Middle Ages. By the late 1800s, cryptography was commonly used in the methods of communication between military factions.
During World War II, encryption devices were used for tactical communication, which drastically improved with the mechanical and electromechanical technology that provided the world with telegraphic and radio communication. The rotor cipher machine, which is a device that substitutes letters using different rotors within the machine, was a huge breakthrough in military cryptography that provided complexity that proved difficult to break. This work gave way to the most famous cipher machine in history to date: Germany’s Enigma machine. The Enigma machine had separate rotors, a plug board, and a reflecting rotor.
The originator of the message would configure the Enigma machine to its initial settings before starting the encryption process. The operator would type in the first letter of the message, and the machine would substitute the letter with a different letter and present it to the operator. This encryption was done by moving the rotors a predefined number of times. So, if the operator typed in a T as the first character, the Enigma machine might present an M as the substitution value. The operator would write down the letter M on his sheet. The operator would then advance the rotors and enter the next letter. Each time a new letter was to be encrypted, the operator would advance the rotors to a new setting. This process was followed until the whole message was encrypted. Then the encrypted text was transmitted over the airwaves, most likely to a German U-boat. The chosen substitution for each letter was dependent upon the rotor setting, so the crucial and secret part of this process (the key) was the initial setting and how the operators advanced the rotors when encrypting and decrypting a message. The operators at each end needed to know this sequence of increments to advance each rotor in order to enable the German military units to properly communicate.
Although the mechanisms of the Enigma were complicated for the time, a team of Polish cryptographers broke its code and gave Britain insight into Germany’s attack plans and military movement. It is said that breaking this encryption mechanism shortened World War II by two years. After the war, details about the Enigma machine were published—one of the machines is exhibited at the Smithsonian Institute.
Cryptography has a deep, rich history. Mary, Queen of Scots, lost her life in the 16th century when an encrypted message she sent was intercepted. During the Revolutionary War, Benedict Arnold used a codebook cipher to exchange information on troop movement and strategic military advancements. Militaries have always played a leading role in using cryptography to encode information and to attempt to decrypt the enemy’s encrypted information. William Frederick Friedman, who published The Index of Coincidence and Its Applications in Cryptography in 1920, is called the “Father of Modern Cryptography” and broke many messages intercepted during World War II. Encryption has been used by many governments and militaries and has contributed to great victory for some because it enabled them to execute covert maneuvers in secrecy. It has also contributed to great defeat for others, when their cryptosystems were discovered and deciphered.
When computers were invented, the possibilities for encryption methods and devices expanded exponentially and cryptography efforts increased dramatically. This era brought unprecedented opportunity for cryptographic designers to develop new encryption techniques. The most well-known and successful project was Lucifer, which was developed at IBM. Lucifer introduced complex mathematical equations and functions that were later adopted and modified by the U.S. National Security Agency (NSA) to establish the U.S. Data Encryption Standard (DES) in 1976, a federal government standard. DES has been used worldwide for financial and other transactions, and was embedded into numerous commercial applications. DES has had a rich history in computer-oriented encryption and has been in use for over 25 years.
A majority of the protocols developed at the dawn of the computing age have been upgraded to include cryptography and to add necessary layers of protection. Encryption is used in hardware devices and in software to protect data, banking transactions, corporate extranet transmissions, e-mail messages, web transactions, wireless communications, the storage of confidential information, faxes, and phone calls.
The code breakers and cryptanalysis efforts and the amazing number-crunching capabilities of the microprocessors hitting the market each year have quickened the evolution of cryptography. As the bad guys get smarter and more resourceful, the good guys must increase their efforts and strategy. Cryptanalysis is the science of studying and breaking the secrecy of encryption processes, compromising authentication schemes, and reverse-engineering algorithms and keys. Cryptanalysis is an important piece of cryptography and cryptology. When carried out by the “good guys,” cryptanalysis is intended to identify flaws and weaknesses so developers can go back to the drawing board and improve the components. It is also performed by curious and motivated hackers to identify the same types of flaws, but with the goal of obtaining the encryption key for unauthorized access to confidential information.
NOTE Cryptanalysis is a very sophisticated science that encompasses a wide variety of tests and attacks. We will cover these types of attacks at the end of this chapter. Cryptology, on the other hand, is the study of cryptanalysis and cryptography.
Different types of cryptography have been used throughout civilization, but today cryptography is deeply rooted in every part of our communications and computing world. Automated information systems and cryptography play a huge role in the effectiveness of militaries, the functionality of governments, and the economics of private businesses. As our dependency upon technology increases, so does our dependency upon cryptography, because secrets will always need to be kept.
Cryptography Definitions and Concepts
Why can’t I read this?
Response: It is in ciphertext.
Encryption is a method of transforming readable data, called plaintext, into a form that appears to be random and unreadable, which is called ciphertext. Plaintext is in a form that can be understood either by a person (a document) or by a computer (executable code). Once it is transformed into ciphertext, neither human nor machine can properly process it until it is decrypted. This enables the transmission of confidential information over insecure channels without unauthorized disclosure. When data are stored on a computer, they are usually protected by logical and physical access controls. When this same sensitive information is sent over a network, it can no longer take these controls for granted, and the information is in a much more vulnerable state.
![]()
A system or product that provides encryption and decryption is referred to as a cryptosystem and can be created through hardware components or program code in an application. The cryptosystem uses an encryption algorithm (which determines how simple or complex the encryption process will be), keys, and the necessary software components and protocols. Most algorithms are complex mathematical formulas that are applied in a specific sequence to the plaintext. Most encryption methods use a secret value called a key (usually a long string of bits), which works with the algorithm to encrypt and decrypt the text.
The algorithm, the set of rules also known as the cipher, dictates how enciphering and deciphering take place. Many of the mathematical algorithms used in computer systems today are publicly known and are not the secret part of the encryption process. If the internal mechanisms of the algorithm are not a secret, then something must be. The secret piece of using a well-known encryption algorithm is the key. A common analogy used to illustrate this point is the use of locks you would purchase from your local hardware store. Let’s say 20 people bought the same brand of lock. Just because these people share the same type and brand of lock does not mean they can now unlock each other’s doors and gain access to their private possessions. Instead, each lock comes with its own key, and that one key can only open that one specific lock.
In encryption, the key (cryptovariable) is a value that comprises a large sequence of random bits. Is it just any random number of bits crammed together? Not really. An algorithm contains a keyspace, which is a range of values that can be used to construct a key. When the algorithm needs to generate a new key, it uses random values from this keyspace. The larger the keyspace, the more available values can be used to represent different keys—and the more random the keys are, the harder it is for intruders to figure them out. For example, if an algorithm allows a key length of 2 bits, the keyspace for that algorithm would be 4, which indicates the total number of different keys that would be possible. (Remember that we are working in binary and that 22 equals 4.) That would not be a very large keyspace, and certainly it would not take an attacker very long to find the correct key that was used.
A large keyspace allows for more possible keys. (Today, we are commonly using key sizes of 128, 256, 512, or even 1,024 bits and larger.) So a key size of 512 bits would provide a 2512 possible combinations (the keyspace). The encryption algorithm should use the entire keyspace and choose the values to make up the keys as randomly as possible. If a smaller keyspace were used, there would be fewer values to choose from when generating a key, as shown in Figure 7-3. This would increase an attacker’s chances of figuring out the key value and deciphering the protected information.
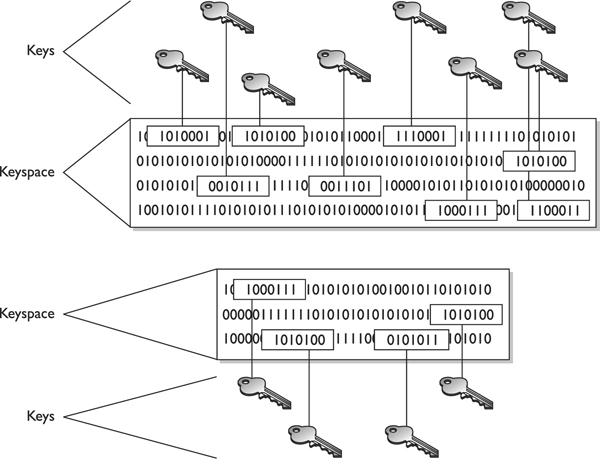
Figure 7-3 Larger keyspaces permit a greater number of possible key values.
If an eavesdropper captures a message as it passes between two people, she can view the message, but it appears in its encrypted form and is therefore unusable. Even if this attacker knows the algorithm that the two people are using to encrypt and decrypt their information, without the key, this information remains useless to the eavesdropper, as shown in Figure 7-4.
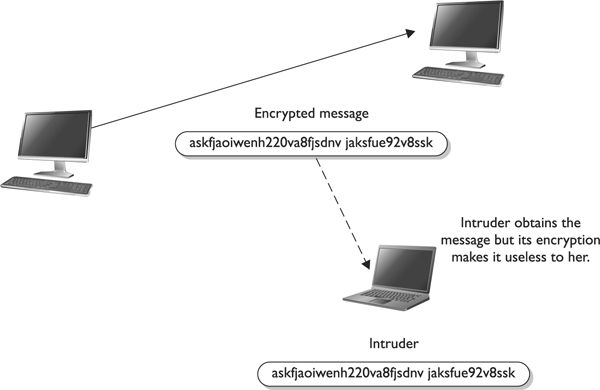
Figure 7-4 Without the right key, the captured message is useless to an attacker.
Kerckhoffs’ Principle
Auguste Kerckhoffs published a paper in 1883 stating that the only secrecy involved with a cryptography system should be the key. He claimed that the algorithm should be publicly known. He asserted that if security were based on too many secrets, there would be more vulnerabilities to possibly exploit.
So, why do we care what some guy said over 120 years ago? Because this debate is still going on. Cryptographers in certain sectors agree with Kerckhoffs’ principle, because making an algorithm publicly available means that many more people can view the source code, test it, and uncover any type of flaws or weaknesses. It is the attitude of “many heads are better than one.” Once someone uncovers some type of flaw, the developer can fix the issue and provide society with a much stronger algorithm.
But, not everyone agrees with this philosophy. Governments around the world create their own algorithms that are not released to the public. Their stance is that if a smaller number of people know how the algorithm actually works, then a smaller number of people will know how to possibly break it. Cryptographers in the private sector do not agree with this practice and do not commonly trust algorithms they cannot examine.
It is basically the same as the open-source versus compiled software debate that is in full force today.
The Strength of the Cryptosystem
You are the weakest link. Goodbye!
The strength of an encryption method comes from the algorithm, the secrecy of the key, the length of the key, the initialization vectors, and how they all work together within the cryptosystem. When strength is discussed in encryption, it refers to how hard it is to figure out the algorithm or key, whichever is not made public. Attempts to break a cryptosystem usually involve processing an amazing number of possible values in the hopes of finding the one value (key) that can be used to decrypt a specific message. The strength of an encryption method correlates to the amount of necessary processing power, resources, and time required to break the cryptosystem or to figure out the value of the key. Breaking a cryptosystem can be accomplished by a brute force attack, which means trying every possible key value until the resulting plaintext is meaningful. Depending on the algorithm and length of the key, this can be an easy task or one that is close to impossible. If a key can be broken with a Pentium Core i5 processor in three hours, the cipher is not strong at all. If the key can only be broken with the use of a thousand multiprocessing systems over 1.2 million years, then it is pretty darn strong. The introduction of dual-core processors has really increased the threat of brute force attacks.
NOTE Attacks are measured in the number of instructions a million-instruction-per-second (MIPS) system can execute within a year’s time.
The goal when designing an encryption method is to make compromising it too expensive or too time-consuming. Another name for cryptography strength is work factor, which is an estimate of the effort and resources it would take an attacker to penetrate a cryptosystem.
How strong a protection mechanism is required depends on the sensitivity of the data being protected. It is not necessary to encrypt information about a friend’s Saturday barbeque with a top-secret encryption algorithm. Conversely, it is not a good idea to send intercepted spy information using PGP. Each type of encryption mechanism has its place and purpose.
Even if the algorithm is very complex and thorough, other issues within encryption can weaken encryption methods. Because the key is usually the secret value needed to actually encrypt and decrypt messages, improper protection of the key can weaken the encryption. Even if a user employs an algorithm that has all the requirements for strong encryption, including a large keyspace and a large and random key value, if she shares her key with others, the strength of the algorithm becomes almost irrelevant.
Important elements of encryption are to use an algorithm without flaws, use a large key size, use all possible values within the keyspace, and protect the actual key. If one element is weak, it could be the link that dooms the whole process.
Services of Cryptosystems
Cryptosystems can provide the following services:
• Confidentiality Renders the information unintelligible except by authorized entities.
• Integrity Data has not been altered in an unauthorized manner since it was created, transmitted, or stored.
• Authentication Verifies the identity of the user or system that created the information.
• Authorization Upon proving identity, the individual is then provided with the key or password that will allow access to some resource.
• Nonrepudiation Ensures that the sender cannot deny sending the message.
As an example of how these services work, suppose your boss sends you a message telling you that you will be receiving a raise that doubles your salary. The message is encrypted, so you can be sure it really came from your boss (authenticity), that someone did not alter it before it arrived at your computer (integrity), that no one else was able to read it as it traveled over the network (confidentiality), and that your boss cannot deny sending it later when he comes to his senses (nonrepudiation).
Different types of messages and transactions require higher or lower degrees of one or all of the services that cryptography methods can supply. Military and intelligence agencies are very concerned about keeping information confidential, so they would choose encryption mechanisms that provide a high degree of secrecy. Financial institutions care about confidentiality, but they also care about the integrity of the data being transmitted, so the encryption mechanism they would choose may differ from the military’s encryption methods. If messages were accepted that had a misplaced decimal point or zero, the ramifications could be far reaching in the financial world. Legal agencies may care most about the authenticity of the messages they receive. If information received ever needed to be presented in a court of law, its authenticity would certainly be questioned; therefore, the encryption method used must ensure authenticity, which confirms who sent the information.
NOTE If David sends a message and then later claims he did not send it, this is an act of repudiation. When a cryptography mechanism provides nonrepudiation, the sender cannot later deny he sent the message (well, he can try to deny it, but the cryptosystem proves otherwise). It’s a way of keeping the sender honest.
The types and uses of cryptography have increased over the years. At one time, cryptography was mainly used to keep secrets secret (confidentiality), but today we use cryptography to ensure the integrity of data, to authenticate messages, to confirm that a message was received, to provide access control, and much more. Throughout this chapter, we will cover the different types of cryptography that provide these different types of functionality, along with any related security issues.
One-Time Pad
I want to use my one-time pad three times.
Response: Not a good idea.
A one-time pad is a perfect encryption scheme because it is considered unbreakable if implemented properly. It was invented by Gilbert Vernam in 1917, so sometimes it is referred to as the Vernam cipher.
This cipher does not use shift alphabets, as do the Caesar and Vigenere ciphers discussed earlier, but instead uses a pad made up of random values, as shown in Figure 7-5. Our plaintext message that needs to be encrypted has been converted into bits, and our one-time pad is made up of random bits. This encryption process uses a binary mathematic function called exclusive-OR, usually abbreviated as XOR.
XOR is an operation that is applied to two bits and is a function commonly used in binary mathematics and encryption methods. When combining the bits, if both values are the same, the result is 0 (1 XOR 1 = 0). If the bits are different from each other, the result is 1 (1 XOR 0 = 1). For example:
Message stream 1001010111
Keystream 0011101010
Ciphertext stream 1010111101
So in our example, the first bit of the message is XORed to the first bit of the onetime pad, which results in the ciphertext value 1. The second bit of the message is XORed with the second bit of the pad, which results in the value 0. This process continues until the whole message is encrypted. The result is the encrypted message that is sent to the receiver.
In Figure 7-5, we also see that the receiver must have the same one-time pad to decrypt the message by reversing the process. The receiver takes the first bit of the encrypted message and XORs it with the first bit of the pad. This results in the plaintext value. The receiver continues this process for the whole encrypted message, until the entire message is decrypted.
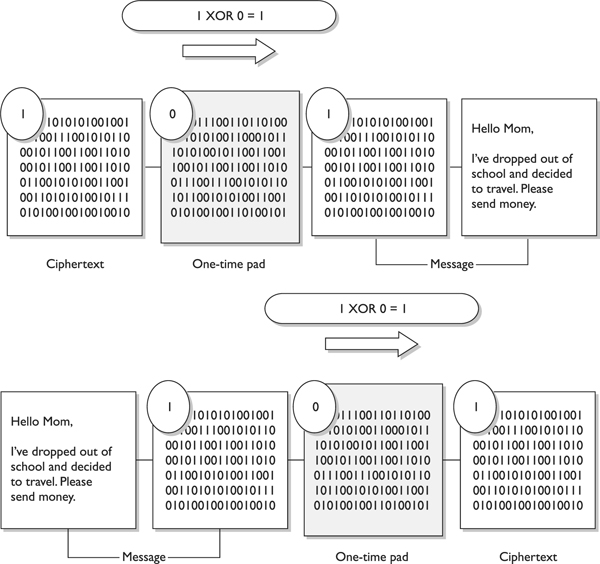
Figure 7-5 A one-time pad
The one-time pad encryption scheme is deemed unbreakable only if the following things are true about the implementation process:
• The pad must be used only one time. If the pad is used more than one time, this might introduce patterns in the encryption process that will aid the evildoer in his goal of breaking the encryption.
• The pad must be as long as the message. If it is not as long as the message, the pad will need to be reused to cover the whole message. This would be the same thing as using a pad more than one time, which could introduce patterns.
• The pad must be securely distributed and protected at its destination. This is a very cumbersome process to accomplish, because the pads are usually just individual pieces of paper that need to be delivered by a secure courier and properly guarded at each destination.
• The pad must be made up of truly random values. This may not seem like a difficult task, but even our computer systems today do not have truly random number generators; rather, they have pseudorandom number generators.
NOTE A number generator is used to create a stream of random values and must be seeded by an initial value. This piece of software obtains its seeding value from some component within the computer system (time, CPU cycles, and so on). Although a computer system is complex, it is a predictable environment, so if the seeding value is predictable in any way, the resulting values created are not truly random—but pseudorandom.
Although the one-time pad approach to encryption can provide a very high degree of security, it is impractical in most situations because of all of its different requirements. Each possible pair of entities that might want to communicate in this fashion must receive, in a secure fashion, a pad that is as long as, or longer than, the actual message. This type of key management can be overwhelming and may require more overhead than it is worth. The distribution of the pad can be challenging, and the sender and receiver must be perfectly synchronized so each is using the same pad.
One-time pads have been used throughout history to protect different types of sensitive data. Today, they are still in place for many types of militaries as a backup encryption option if current encryption processes (which require computers and a power source) are unavailable for reasons of war or attacks.
Running and Concealment Ciphers
I have my decoder ring, spyglasses, and secret handshake. Now let me figure out how I will encrypt my messages.
Two spy-novel-type ciphers are the running key cipher and the concealment cipher. The running key cipher could use a key that does not require an electronic algorithm and bit alterations, but cleverly uses components in the physical world around you. For instance, the algorithm could be a set of books agreed upon by the sender and receiver. The key in this type of cipher could be a book page, line number, and column count. If I get a message from my supersecret spy buddy and the message reads “149l6c7.299l3c7.911l5c8,” this could mean for me to look at the 1st book in our predetermined series of books, the 49th page, 6th line down the page, and the 7th column. So I write down the letter in that column, which is m. The second set of numbers starts with 2, so I go to the 2nd book, 99th page, 3rd line down, and then to the 7th column, which is p. The last letter I get from the 9th book, 11th page, 5th line, 8th column, which is t. So now I have come up with my important secret message, which is mpt. This means nothing to me, and I need to look for a new spy buddy. Running key ciphers can be used in different and more complex ways, but I think you get the point.
A concealment cipher is a message within a message. If my other supersecret spy buddy and I decide our key value is every third word, then when I get a message from him, I will pick out every third word and write it down. Suppose he sends me a message that reads, “The saying, ‘The time is right’ is not cow language, so is now a dead subject.” Because my key is every third word, I come up with “The right cow is dead.” This again means nothing to me, and I am now turning in my decoder ring.
NOTE A concealment cipher, also called a null cipher, is a type of steganography method. Steganography is described later in this chapter.
No matter which of these two types of cipher is used, the roles of the algorithm and key are the same, even if they are not mathematical equations. In the running key cipher, the algorithm may be a predefined set of books. The key indicates the book, page, line, and word within that line. In substitution ciphers, the algorithm dictates that substitution will take place using a predefined alphabet or sequence of characters, and the key indicates that each character will be replaced with another character, as in the third character that follows it in that sequence of characters. In actual mathematical structures, the algorithm is a set of mathematical functions that will be performed on the message, and the key can indicate in which order these functions take place. So even if an attacker knows the algorithm, and we have to assume he does, if he does not know the key, the message is still useless to him.
Steganography
Where’s the top-secret message?
Response: In this picture of my dogs.
Steganography is a method of hiding data in another media type so the very existence of the data is concealed. Common steps are illustrated in Figure 7-6. Only the sender and receiver are supposed to be able to see the message because it is secretly hidden in a graphic, wave file, document, or other type of media. The message is not encrypted, just hidden. Encrypted messages can draw attention because it tells the bad guy, “This is something sensitive.” A message hidden in a picture of your grandmother would not attract this type of attention, even though the same secret message can be embedded into this image. Steganography is a type of security through obscurity.
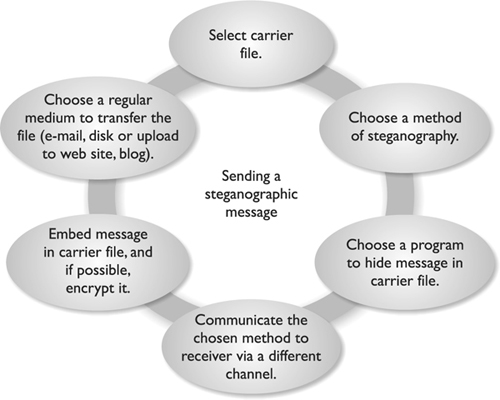
Figure 7-6 Main components of steganography
Steganography includes the concealment of information within computer files. In digital steganography, electronic communications may include steganographic coding inside of a document file, image file, program, or protocol. Media files are ideal for steganographic transmission because of their large size. As a simple example, a sender might start with an innocuous image file and adjust the color of every 100th pixel to correspond to a letter in the alphabet, a change so subtle that someone not specifically looking for it is unlikely to notice it.
Let’s look at the components that are involved with steganography, which are listed next:
• Carrier A signal, data stream, or file that has hidden information (payload) inside of it
• Stegomedium The medium in which the information is hidden
• Payload The information that is to be concealed and transmitted
So if you want to secretly send a message to me that says, “This book is so big I can kill someone with it,” and want to get it past my editor—the message would be the payload. If you send this message embedded in the picture of your grandmother, the picture would be the carrier file and the stegomedium would be a JPEG.
A method of embedding the message into some type of medium is to use the least significant bit (LSB). Many types of files have some bits that can be modified and not affect the file they are in, which is where secret data can be hidden without altering the file in a visible manner. In the LSB approach, graphics with a high resolution or an audio file that has many different types of sounds (high bit rate) are the most successful for hiding information within. There is commonly no noticeable distortion, and the file is usually not increased to a size that can be detected. A 24-bit bitmap file will have 8 bits representing each of the three color values, which are red, green, and blue. These eight bits are within each pixel. If we consider just the blue, there will be 28 different values of blue. The difference between 11111111 and 11111110 in the value for blue intensity is likely to be undetectable by the human eye. Therefore, the least significant bit can be used for something other than color information.
A digital graphic is just a file that shows different colors and intensities of light. The larger the file, the more bits that can be modified without much notice or distortion.
Several different types of tools can be used to hide messages within the carrier. Figure 7-7 illustrates one such tool that allows the user to encrypt the message along with hiding it within a file.
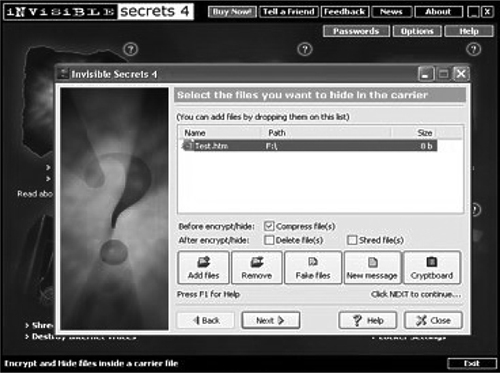
Figure 7-7 Embedding secret material
A concealment cipher (null cipher), explained earlier, is an example of a type of steganography method. The null values are not part of the secret message, but are used to hide the secret message. Let’s look at an example. If I send you the message used in the example earlier, “The saying, ‘The time is right’ is not cow language, so is now a dead subject,” you would think I was nuts. If you knew the secret message was made up of every third word, you would be able to extract the secret message from the null values. So the secret message is “The right cow is dead.” And you still think I’m nuts.
What if you wanted to get a secret message to me in a nondigital format? You would use a physical method of sending secret messages instead of our computers. You could write the message in invisible ink, and I would need to have the necessary chemical to make it readable. You could create a very small photograph of the message, called a microdot, and put it within the ink of a stamp. Another physical steganography method is to send me a very complex piece of art, which has the secret message in it that can be seen if it is held at the right angle and has a certain type of light shown on it. These are just some examples of the many ways that steganography can be carried out in the nondigital world.
Types of Ciphers
Symmetric encryption ciphers come in two basic types: substitution and transposition (permutation). The substitution cipher replaces bits, characters, or blocks of characters with different bits, characters, or blocks. The transposition cipher does not replace the original text with different text, but rather moves the original values around. It rearranges the bits, characters, or blocks of characters to hide the original meaning.
Substitution Ciphers
Give me your A and I will change it out for an M. Now, no one can read your message.
Response: That will fool them.
A substitution cipher uses a key to dictate how the substitution should be carried out. In the Caesar cipher, each letter is replaced with the letter three places beyond it in the alphabet. The algorithm is the alphabet, and the key is the instruction “shift up three.”
As a simple example, if George uses the Caesar cipher with the English alphabet to encrypt the important message “meow,” the encrypted message would be “phrz.” Substitution is used in today’s symmetric algorithms, but it is extremely complex compared to this example, which is only meant to show you the concept of how a substitution cipher works in its most simplistic form.
Transposition Ciphers
In a transposition cipher, the values are scrambled, or put into a different order. The key determines the positions the values are moved to, as illustrated in Figure 7-8.
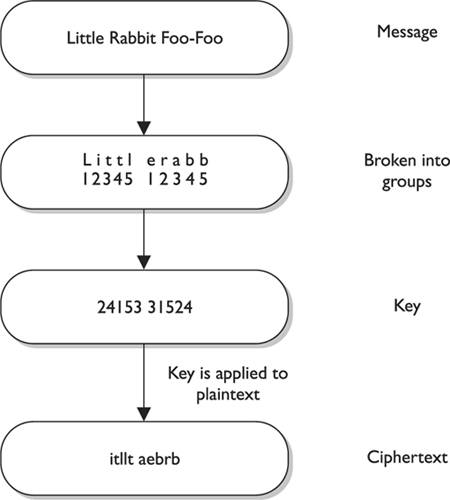
Figure 7-8 A transposition cipher
This is a simplistic example of a transposition cipher and only shows one way of performing transposition. When implemented with complex mathematical functions, transpositions can become quite sophisticated and difficult to break. Symmetric algorithms employed today use both long sequences of complicated substitutions and transpositions on messages. The algorithm contains the possible ways that substitution and transposition processes can take place (represented in mathematical formulas). The key is used as the instructions for the algorithm, dictating exactly how these processes will happen and in what order. To understand the relationship between an algorithm and a key, let’s look at Figure 7-9. Conceptually, an algorithm is made up of different boxes, each of which has a different set of mathematical formulas that dictate the substitution and transposition steps that will take place on the bits that enter the box. To encrypt our message, the bit values must go through these different boxes. If each of our messages goes through each of these different boxes in the same order with the same values, the evildoer will be able to easily reverse-engineer this process and uncover our plaintext message.
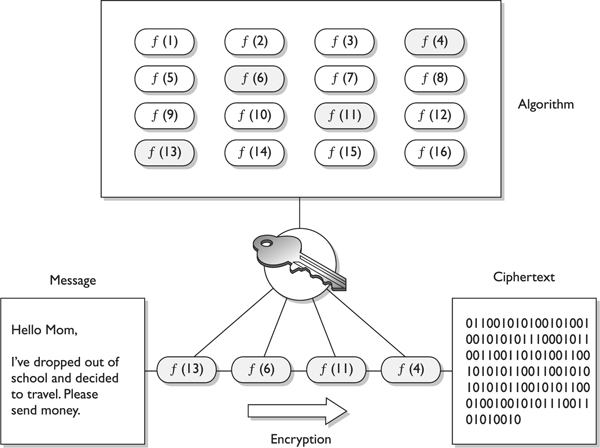
Figure 7-9 The algorithm and key relationship
To foil an evildoer, we use a key, which is a set of values that indicates which box should be used, in what order, and with what values. So if message A is encrypted with key 1, the key will make the message go through boxes 1, 6, 4, and then 5. When we need to encrypt message B, we will use key 2, which will make the message go through boxes 8, 3, 2, and then 9. It is the key that adds the randomness and the secrecy to the encryption process.
Simple substitution and transposition ciphers are vulnerable to attacks that perform frequency analysis. In every language, some words and patterns are used more often than others. For instance, in the English language, the most commonly used letter is E. If Mike is carrying out frequency analysis on a message, he will look for the most frequently repeated pattern of eight bits (which make up a character). So, if Mike sees that there are 12 patterns of eight bits and he knows that E is the most commonly used letter in the language, he will replace these bits with this vowel. This allows him to gain a foothold on the process, which will allow him to reverse-engineer the rest of the message.
Today’s symmetric algorithms use substitution and transposition methods in their encryption processes, but the mathematics used are (or should be) too complex to allow for simplistic frequency-analysis attacks to be successful.
Key Derivation Functions
For complex keys to be generated, a master key is commonly created, and then symmetric keys are generated from it. For example, if an application is responsible for creating a session key for each subject that requests one, it should not be giving out the same instance of that one key. Different subjects need to have different symmetric keys to ensure that the window for the bad guy to capture and uncover that key is smaller than if the same key were to be used over and over again. When two or more keys are created from a master key, they are called subkeys.
Key Derivation Functions (KDFs) are used to generate keys that are made up of random values. Different values can be used independently or together as random key material. The algorithm is created to use specific hash, password, and/or salt values, which will go through a certain number of rounds of mathematical functions dictated by the algorithm. The more rounds that this keying material goes through, the more assurance and security for the cryptosystem overall.
NOTE Remember that the algorithm stays static and the randomness provided by cryptography is mainly by means of the keying material.
• One-time pad Encryption method created by Gilbert Vernam that is considered impossible to crack if carried out properly
• Number generator Algorithm used to create values that are used in cryptographic functions to add randomness
• Running key cipher Substitution cipher that creates keystream values, commonly from agreed-upon text passages, to be used for encryption purposes
• Concealment cipher Encryption method that hides a secret message within an open message
• Steganography Method of hiding data in another media type with the goal of secrecy
• Digital Rights Management (DRM) Access control technologies commonly used to protect copyright material
• Transposition Encryption method that shifts (permutation) values
• Caesar cipher Simple substitution algorithm created by Julius Caesar that shifts alphabetic values three positions during its encryption and decryption processes
• Frequency analysis Cryptanalysis process used to identify weaknesses within cryptosystems by locating patterns in resulting ciphertext
• Key Derivation Functions (KDFs) Generation of secret keys (subkeys) from an initial value (master key)
Methods of Encryption
Although there can be several pieces to an encryption process, the two main pieces are the algorithms and the keys. As stated earlier, algorithms used in computer systems are complex mathematical formulas that dictate the rules of how the plaintext will be turned into ciphertext. A key is a string of random bits that will be used by the algorithm to add to the randomness of the encryption process. For two entities to be able to communicate via encryption, they must use the same algorithm and, many times, the same key. In some encryption technologies, the receiver and the sender use the same key, and in other encryption technologies, they must use different but related keys for encryption and decryption purposes. The following sections explain the differences between these two types of encryption methods.
Symmetric vs. Asymmetric Algorithms
Cryptography algorithms are either symmetric algorithms, which use symmetric keys (also called secret keys), or asymmetric algorithms, which use asymmetric keys (also called public and private keys). As if encryption were not complicated enough, the terms used to describe the key types only make it worse. Just pay close attention and you will get through this fine.
Symmetric Cryptography
In a cryptosystem that uses symmetric cryptography, the sender and receiver use two instances of the same key for encryption and decryption, as shown in Figure 7-10. So the key has dual functionality, in that it can carry out both encryption and decryption processes. Symmetric keys are also called secret keys, because this type of encryption relies on each user to keep the key a secret and properly protected. If an intruder were to get this key, they could decrypt any intercepted message encrypted with it.
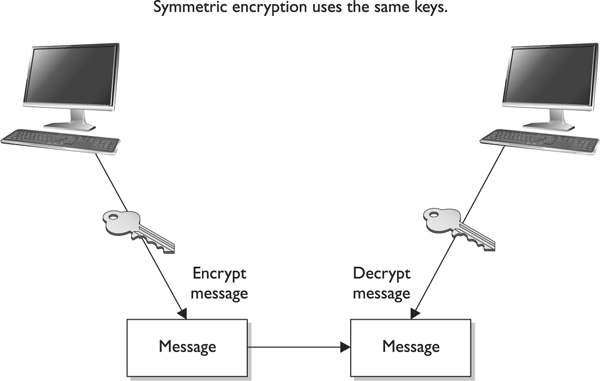
Figure 7-10 When using symmetric algorithms, the sender and receiver use the same key for encryption and decryption functions.
Each pair of users who want to exchange data using symmetric key encryption must have two instances of the same key. This means that if Dan and Iqqi want to communicate, both need to obtain a copy of the same key. If Dan also wants to communicate using symmetric encryption with Norm and Dave, he needs to have three separate keys, one for each friend. This might not sound like a big deal until Dan realizes that he may communicate with hundreds of people over a period of several months, and keeping track and using the correct key that corresponds to each specific receiver can become a daunting task. If ten people needed to communicate securely with each other using symmetric keys, then 45 keys would need to be kept track of. If 100 people were going to communicate, then 4,950 keys would be involved. The equation used to calculate the number of symmetric keys needed is
N(N – 1)/2 = number of keys
When using symmetric algorithms, the sender and receiver use the same key for encryption and decryption functions. The security of the symmetric encryption method is completely dependent on how well users protect the key. This should raise red flags for you if you have ever had to depend on a whole staff of people to keep a secret. If a key is compromised, then all messages encrypted with that key can be decrypted and read by an intruder. This is complicated further by how symmetric keys are actually shared and updated when necessary. If Dan wants to communicate with Norm for the first time, Dan has to figure out how to get the right key to Norm securely. It is not safe to just send it in an e-mail message, because the key is not protected and can be easily intercepted and used by attackers. Thus, Dan must get the key to Norm through an out-of-band method. Dan can save the key on a thumb drive and walk over to Norm’s desk, or have a secure courier deliver it to Norm. This is a huge hassle, and each method is very clumsy and insecure.
Because both users employ the same key to encrypt and decrypt messages, symmetric cryptosystems can provide confidentiality, but they cannot provide authentication or nonrepudiation. There is no way to prove through cryptography who actually sent a message if two people are using the same key.
If symmetric cryptosystems have so many problems and flaws, why use them at all? Because they are very fast and can be hard to break. Compared with asymmetric systems, symmetric algorithms scream in speed. They can encrypt and decrypt relatively quickly large amounts of data that would take an unacceptable amount of time to encrypt and decrypt with an asymmetric algorithm. It is also difficult to uncover data encrypted with a symmetric algorithm if a large key size is used. For many of our applications that require encryption, symmetric key cryptography is the only option.
The following list outlines the strengths and weakness of symmetric key systems:
Strengths
• Much faster (less computationally intensive) than asymmetric systems.
• Hard to break if using a large key size.
Weaknesses
• Requires a secure mechanism to deliver keys properly.
• Each pair of users needs a unique key, so as the number of individuals increases, so does the number of keys, possibly making key management overwhelming.
• Provides confidentiality but not authenticity or nonrepudiation.
The following are examples of symmetric algorithms, which will be explained later in the “Block and Stream Ciphers” section:
• Data Encryption Standard (DES)
• Triple-DES (3DES)
• Blowfish
• International Data Encryption Algorithm (IDEA)
• RC4, RC5, and RC6
• Advanced Encryption Standard (AES)
Asymmetric Cryptography
Some things you can tell the public, but some things you just want to keep private.
In symmetric key cryptography, a single secret key is used between entities, whereas in public key systems, each entity has different keys, or asymmetric keys. The two different asymmetric keys are mathematically related. If a message is encrypted by one key, the other key is required in order to decrypt the message.
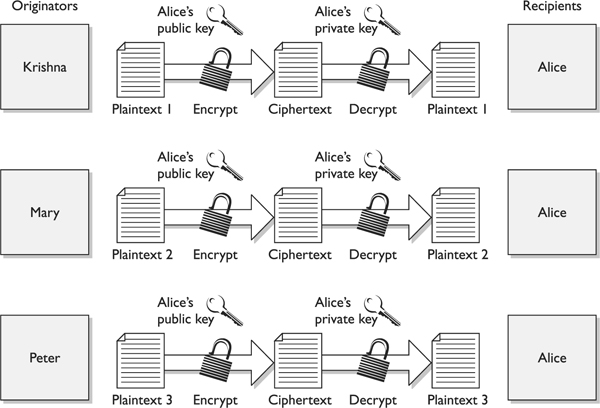
In a public key system, the pair of keys is made up of one public key and one private key. The public key can be known to everyone, and the private key must be known and used only by the owner. Many times, public keys are listed in directories and databases of e-mail addresses so they are available to anyone who wants to use these keys to encrypt or decrypt data when communicating with a particular person. Figure 7-11 illustrates the use of the different keys.
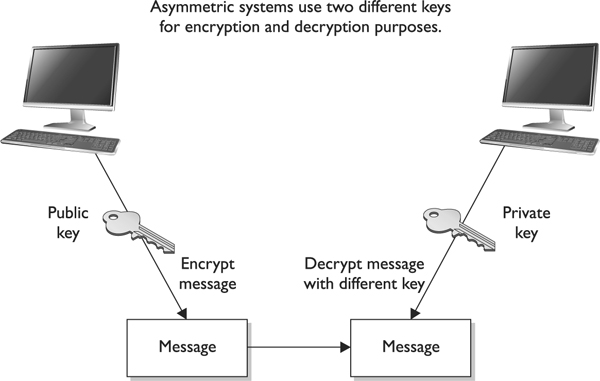
Figure 7-11 An asymmetric cryptosystem
The public and private keys of an asymmetric cryptosystem are mathematically related, but if someone gets another person’s public key, she should not be able to figure out the corresponding private key. This means that if an evildoer gets a copy of Bob’s public key, it does not mean she can employ some mathematical magic and find out Bob’s private key. But if someone got Bob’s private key, then there is big trouble—no one other than the owner should have access to a private key.
If Bob encrypts data with his private key, the receiver must have a copy of Bob’s public key to decrypt it. The receiver can decrypt Bob’s message and decide to reply to Bob in an encrypted form. All she needs to do is encrypt her reply with Bob’s public key, and then Bob can decrypt the message with his private key. It is not possible to encrypt and decrypt using the same key when using an asymmetric key encryption technology because, although mathematically related, the two keys are not the same key, as they are in symmetric cryptography. Bob can encrypt data with his private key, and the receiver can then decrypt it with Bob’s public key. By decrypting the message with Bob’s public key, the receiver can be sure the message really came from Bob. A message can be decrypted with a public key only if the message was encrypted with the corresponding private key. This provides authentication, because Bob is the only one who is supposed to have his private key. If the receiver wants to make sure Bob is the only one who can read her reply, she will encrypt the response with his public key. Only Bob will be able to decrypt the message because he is the only one who has the necessary private key.
The receiver can also choose to encrypt data with her private key instead of using Bob’s public key. Why would she do that? Authentication—she wants Bob to know that the message came from her and no one else. If she encrypted the data with Bob’s public key, it does not provide authenticity because anyone can get Bob’s public key. If she uses her private key to encrypt the data, then Bob can be sure the message came from her and no one else. Symmetric keys do not provide authenticity because the same key is used on both ends. Using one of the secret keys does not ensure the message originated from a specific individual.
If confidentiality is the most important security service to a sender, she would encrypt the file with the receiver’s public key. This is called a secure message format because it can only be decrypted by the person who has the corresponding private key.
If authentication is the most important security service to the sender, then she would encrypt the data with her private key. This provides assurance to the receiver that the only person who could have encrypted the data is the individual who has possession of that private key. If the sender encrypted the data with the receiver’s public key, authentication is not provided because this public key is available to anyone.
Encrypting data with the sender’s private key is called an open message format because anyone with a copy of the corresponding public key can decrypt the message. Confidentiality is not ensured.
Each key type can be used to encrypt and decrypt, so do not get confused and think the public key is only for encryption and the private key is only for decryption. They both have the capability to encrypt and decrypt data. However, if data are encrypted with a private key, they cannot be decrypted with a private key. If data are encrypted with a private key, they must be decrypted with the corresponding public key.
An asymmetric algorithm works much more slowly than a symmetric algorithm, because symmetric algorithms carry out relatively simplistic mathematical functions on the bits during the encryption and decryption processes. They substitute and scramble (transposition) bits, which is not overly difficult or processor-intensive. The reason it is hard to break this type of encryption is that the symmetric algorithms carry out this type of functionality over and over again. So a set of bits will go through a long series of being substituted and scrambled.
Asymmetric algorithms are slower than symmetric algorithms because they use much more complex mathematics to carry out their functions, which requires more processing time. Although they are slower, asymmetric algorithms can provide authentication and nonrepudiation, depending on the type of algorithm being used. Asymmetric systems also provide for easier and more manageable key distribution than symmetric systems and do not have the scalability issues of symmetric systems. The reason for these differences is that, with asymmetric systems, you can send out your public key to all of the people you need to communicate with, instead of keeping track of a unique key for each one of them. The “Hybrid Encryption Methods” section later in this chapter shows how these two systems can be used together to get the best of both worlds.
NOTE Public key cryptography is asymmetric cryptography. The terms can be used interchangeably.
The following list outlines the strengths and weaknesses of asymmetric key algorithms:
Strengths
• Better key distribution than symmetric systems.
• Better scalability than symmetric systems
• Can provide authentication and nonrepudiation
Weaknesses
• Works much more slowly than symmetric systems
• Mathematically intensive tasks
• The following are examples of asymmetric key algorithms:
• Rivest-Shamir-Adleman (RSA)
• Elliptic curve cryptosystem (ECC)
• Diffie-Hellman
• El Gamal
• Digital Signature Algorithm (DSA)
• Merkle-Hellman Knapsack
These algorithms will be explained further in the “Types of Asymmetric Systems” section later in the chapter.
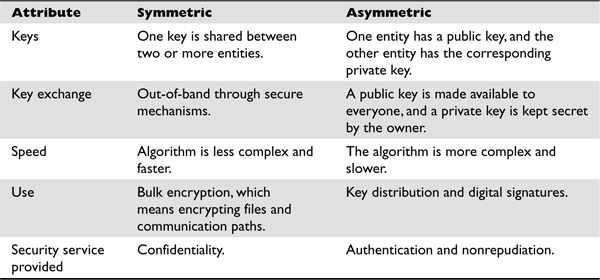
Table 7-1 summarizes the differences between symmetric and asymmetric algorithms.
Table 7-1 Differences Between Symmetric and Asymmetric Systems
NOTE Digital signatures will be discussed later in the section “Digital Signatures.”
Block and Stream Ciphers
Which should I use, the stream cipher or the block cipher?
Response: The stream cipher, because it makes you look skinnier.
The two main types of symmetric algorithms are block ciphers, which work on blocks of bits, and stream ciphers, which work on one bit at a time.
Block Ciphers
When a block cipher is used for encryption and decryption purposes, the message is divided into blocks of bits. These blocks are then put through mathematical functions, one block at a time. Suppose you need to encrypt a message you are sending to your mother and you are using a block cipher that uses 64 bits. Your message of 640 bits is chopped up into 10 individual blocks of 64 bits. Each block is put through a succession of mathematical formulas, and what you end up with is 10 blocks of encrypted text. You send this encrypted message to your mother. She has to have the same block cipher and key, and those 10 ciphertext blocks go back through the algorithm in the reverse sequence and end up in your plaintext message.
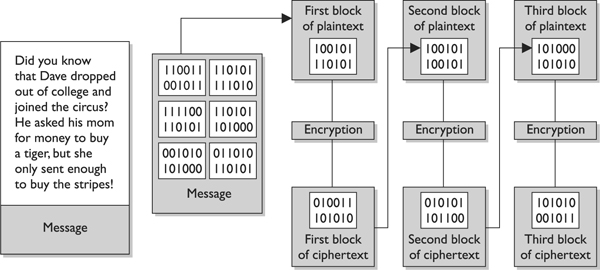
A strong cipher contains the right level of two main attributes: confusion and diffusion. Confusion is commonly carried out through substitution, while diffusion is carried out by using transposition. For a cipher to be considered strong, it must contain both of these attributes to ensure that reverse-engineering is basically impossible. The randomness of the key values and the complexity of the mathematical functions dictate the level of confusion and diffusion involved.
In algorithms, diffusion takes place as individual bits of a block are scrambled, or diffused, throughout that block. Confusion is provided by carrying out complex substitution functions so the bad guy cannot figure out how to substitute the right values and come up with the original plaintext. Suppose I have 500 wooden blocks with individual letters written on them. I line them all up to spell out a paragraph (plaintext). Then I substitute 300 of them with another set of 300 blocks (confusion through substitution). Then I scramble all of these blocks up (diffusion through transposition) and leave them in a pile. For you to figure out my original message, you would have to substitute the correct blocks and then put them back in the right order. Good luck.
Confusion pertains to making the relationship between the key and resulting ciphertext as complex as possible so the key cannot be uncovered from the ciphertext. Each ciphertext value should depend upon several parts of the key, but this mapping between the key values and the ciphertext values should seem completely random to the observer.
Diffusion, on the other hand, means that a single plaintext bit has influence over several of the ciphertext bits. Changing a plaintext value should change many ciphertext values, not just one. In fact, in a strong block cipher, if one plaintext bit is changed, it will change every ciphertext bit with the probability of 50 percent. This means that if one plaintext bit changes, then about half of the ciphertext bits will change.
A very similar concept of diffusion is the avalanche effect. If an algorithm follows a strict avalanche effect criteria, this means that if the input to an algorithm is slightly modified then the output of the algorithm is changed significantly. So a small change to the key or the plaintext should cause drastic changes to the resulting ciphertext. The ideas of diffusion and avalanche effect are basically the same—they were just derived from different people. Horst Feistel came up with the avalanche term, while Claude Shannon came up with the diffusion term. If an algorithm does not exhibit the necessary degree of the avalanche effect, then the algorithm is using poor randomization. This can make it easier for an attacker to break the algorithm.
Block ciphers use diffusion and confusion in their methods. Figure 7-12 shows a conceptual example of a simplistic block cipher. It has four block inputs, and each block is made up of four bits. The block algorithm has two layers of four-bit substitution boxes called S-boxes. Each S-box contains a lookup table used by the algorithm as instructions on how the bits should be encrypted.
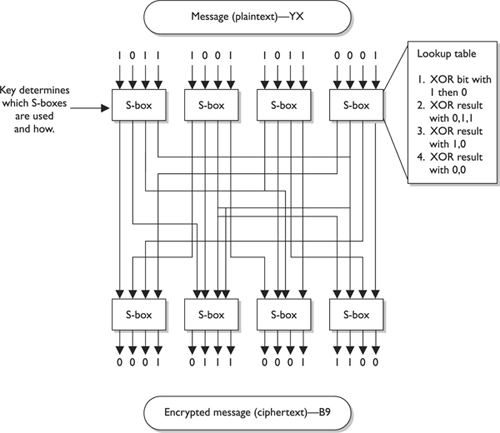
Figure 7-12 A message is divided into blocks of bits, and substitution and transposition functions are performed on those blocks.
Figure 7-12 shows that the key dictates what S-boxes are to be used when scrambling the original message from readable plaintext to encrypted nonreadable cipher text. Each S-box contains the different substitution methods that can be performed on each block. This example is simplistic—most block ciphers work with blocks of 32, 64, or 128 bits in size, and many more S-boxes are usually involved.
Stream Ciphers
As stated earlier, a block cipher performs mathematical functions on blocks of bits. A stream cipher, on the other hand, does not divide a message into blocks. Instead, a stream cipher treats the message as a stream of bits and performs mathematical functions on each bit individually.
When using a stream cipher, a plaintext bit will be transformed into a different ciphertext bit each time it is encrypted. Stream ciphers use keystream generators, which produce a stream of bits that is XORed with the plaintext bits to produce ciphertext, as shown in Figure 7-13.
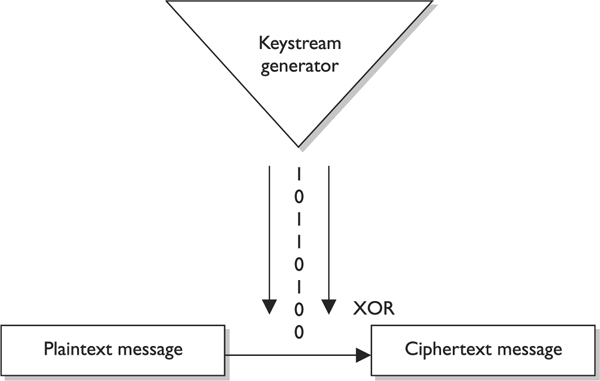
Figure 7-13 With stream ciphers, the bits generated by the keystream generator are XORed with the bits of the plaintext message.
NOTE This process is very similar to the one-time pad explained earlier. The individual bits in the one-time pad are used to encrypt the individual bits of the message through the XOR function, and in a stream algorithm the individual bits created by the keystream generator are used to encrypt the bits of the message through XOR also.
If the cryptosystem were only dependent upon the symmetric stream algorithm, an attacker could get a copy of the plaintext and the resulting ciphertext, XOR them together, and find the keystream to use in decrypting other messages. So the smart people decided to stick a key into the mix.
In block ciphers, it is the key that determines what functions are applied to the plaintext and in what order. The key provides the randomness of the encryption process. As stated earlier, most encryption algorithms are public, so people know how they work. The secret to the secret sauce is the key. In stream ciphers, the key also provides randomness, so that the stream of bits that is XORed to the plaintext is as random as possible. This concept is shown in Figure 7-14. As you can see in this graphic, both the sending and receiving ends must have the same key to generate the same keystream for proper encryption and decryption purposes.
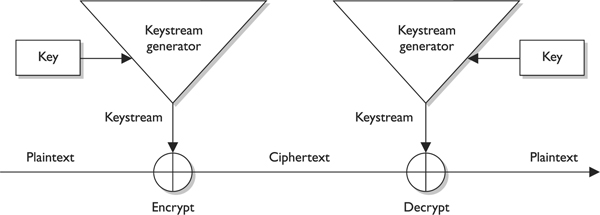
Figure 7-14 The sender and receiver must have the same key to generate the same keystream.
Initialization Vectors
Initialization vectors (IVs) are random values that are used with algorithms to ensure patterns are not created during the encryption process. They are used with keys and do not need to be encrypted when being sent to the destination. If IVs are not used, then two identical plaintext values that are encrypted with the same key will create the same ciphertext. Providing attackers with these types of patterns can make their job easier in breaking the encryption method and uncovering the key. For example, if we have the plaintext value of “See Spot run” two times within our message, we need to make sure that even though there is a pattern in the plaintext message, a pattern in the resulting ciphertext will not be created. So the IV and key are both used by the algorithm to provide more randomness to the encryption process.
A strong and effective stream cipher contains the following characteristics:
• Long periods of no repeating patterns within keystream values Bits generated by the keystream must be random.
• Statistically unpredictable keystream Bits generated from the keystream generator cannot be predicted.
• A keystream not linearly related to the key If someone figures out the keystream values, that does not mean she now knows the key value.
• Statistically unbiased keystream (as many zeroes as ones) There should be no dominance in the number of zeroes or ones in the keystream.
Stream ciphers require a lot of randomness and encrypt individual bits at a time. This requires more processing power than block ciphers require, which is why stream ciphers are better suited to be implemented at the hardware level. Because block ciphers do not require as much processing power, they can be easily implemented at the software level.
Overall, stream ciphers are considered less secure than block ciphers and are used less frequently. One difficulty in proper stream cipher implementation is generating a truly random and unbiased keystream. Many stream ciphers have been broken because it was uncovered that their keystream had redundancies. One way in which stream ciphers are advantageous compared to block ciphers is when streaming communication data needs to be encrypted. Stream ciphers can encrypt and decrypt more quickly and are able to scale better within increased bandwidth requirements. When real-time applications, as in VoIP or multimedia, have encryption requirements, it is common that stream ciphers are implemented to accomplish this task.
Cryptographic Transformation Techniques
We have covered diffusion, confusion, avalanche, IVs, and random number generation. Some other techniques used in algorithms to increase their cryptographic strength are listed here:
• Compression Reduce redundancy before plaintext is encrypted. Compression functions are run on the text before it goes into the encryption algorithm.
• Expansion Expanding the plaintext by duplicating values. Commonly used to increase the plaintext size to map to key sizes.
• Padding Adding material to plaintext data before it is encrypted.
• Key mixing Using a portion (subkey) of a key to limit the exposure of the key. Key schedules are used to generate subkeys from master keys.
Hybrid Encryption Methods
Up to this point, we have figured out that symmetric algorithms are fast but have some drawbacks (lack of scalability, difficult key management, and they provide only confidentiality). Asymmetric algorithms do not have these drawbacks but are very slow. We just can’t seem to win. So we turn to a hybrid system that uses symmetric and asymmetric encryption methods together.
Asymmetric and Symmetric Algorithms Used Together
Public key cryptography uses two keys (public and private) generated by an asymmetric algorithm for protecting encryption keys and key distribution, and a secret key is generated by a symmetric algorithm and used for bulk encryption. Then there is a hybrid use of the two different algorithms: asymmetric and symmetric. Each algorithm has its pros and cons, so using them together can be the best of both worlds.
In the hybrid approach, the two technologies are used in a complementary manner, with each performing a different function. A symmetric algorithm creates keys used for encrypting bulk data, and an asymmetric algorithm creates keys used for automated key distribution.
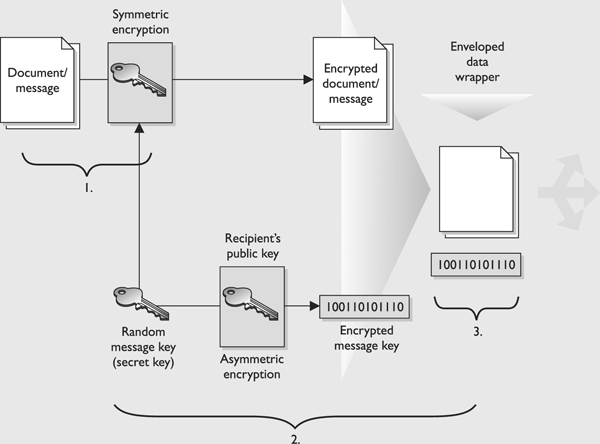
When a symmetric key is used for bulk data encryption, this key is used to encrypt the message you want to send. When your friend gets the message you encrypted, you want him to be able to decrypt it, so you need to send him the necessary symmetric key to use to decrypt the message. You do not want this key to travel unprotected, because if the message were intercepted and the key were not protected, an evildoer could intercept the message that contains the necessary key to decrypt your message and read your information. If the symmetric key needed to decrypt your message is not protected, there is no use in encrypting the message in the first place. So we use an asymmetric algorithm to encrypt the symmetric key, as depicted in Figure 7-15. Why do we use the symmetric key on the message and the asymmetric key on the symmetric key? As stated earlier, the asymmetric algorithm takes longer because the math is more complex. Because your message is most likely going to be longer than the length of the key, we use the faster algorithm (symmetric) on the message and the slower algorithm (asymmetric) on the key.
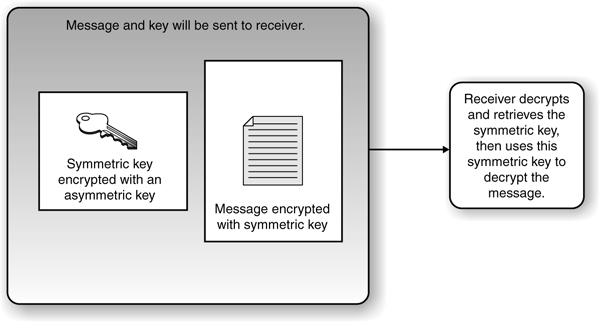
Figure 7-15 In a hybrid system, the asymmetric key is used to encrypt the symmetric key, and the symmetric key is used to encrypt the message.
How does this actually work? Let’s say Bill is sending Paul a message that Bill wants only Paul to be able to read. Bill encrypts his message with a secret key, so now Bill has ciphertext and a symmetric key. The key needs to be protected, so Bill encrypts the symmetric key with an asymmetric key. Remember that asymmetric algorithms use private and public keys, so Bill will encrypt the symmetric key with Paul’s public key. Now Bill has ciphertext from the message and ciphertext from the symmetric key. Why did Bill encrypt the symmetric key with Paul’s public key instead of his own private key? Because if Bill encrypted it with his own private key, then anyone with Bill’s public key could decrypt it and retrieve the symmetric key. However, Bill does not want anyone who has his public key to read his message to Paul. Bill only wants Paul to be able to read it. So Bill encrypts the symmetric key with Paul’s public key. If Paul has done a good job protecting his private key, he will be the only one who can read Bill’s message.
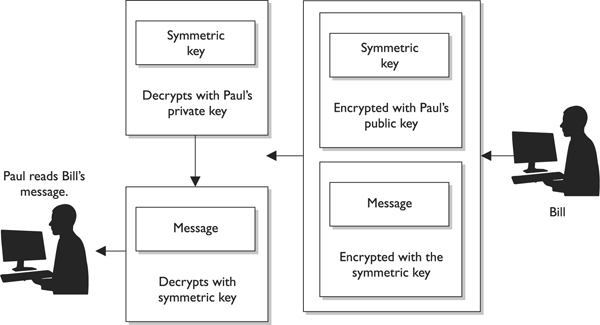
Paul receives Bill’s message and Paul uses his private key to decrypt the symmetric key. Paul then uses the symmetric key to decrypt the message. Paul then reads Bill’s very important and confidential message that asks Paul how his day is.
Now when I say that Bill is using this key to encrypt and that Paul is using that key to decrypt, those two individuals do not necessarily need to find the key on their hard drive and know how to properly apply it. We have software to do this for us—thank goodness.
If this is your first time with these issues and you are struggling, don’t worry. I remember when I first started with these concepts, and they turned my brain into a pretzel. Just remember the following points:
• An asymmetric algorithm performs encryption and decryption by using public and private keys that are related to each other mathematically.
• A symmetric algorithm performs encryption and decryption by using a shared secret key.
• A symmetric key is used to encrypt and/or decrypt the actual message.
• Public keys are used to encrypt the symmetric key for secure key exchange.
• A secret key is synonymous with a symmetric key.
• An asymmetric key refers to a public or private key.
So, that is how a hybrid system works. The symmetric algorithm creates a secret key that will be used to encrypt the bulk, or the message, and the asymmetric key encrypts the secret key for transmission.
Now to ensure that some of these concepts are driven home, ask these questions of yourself without reading the answers provided:
1. If a symmetric key is encrypted with a receiver’s public key, what security service(s) is (are) provided?
2. If data are encrypted with the sender’s private key, what security service(s) is (are) provided?
3. If the sender encrypts data with the receiver’s private key, what security services(s) is (are) provided?
4. Why do we encrypt the message with the symmetric key?
5. Why don’t we encrypt the symmetric key with another symmetric key?
6. What is the meaning of life?
Answers
1. Confidentiality, because only the receiver’s private key can be used to decrypt the symmetric key, and only the receiver should have access to this private key.
2. Authenticity of the sender and nonrepudiation. If the receiver can decrypt the encrypted data with the sender’s public key, then she knows the data was encrypted with the sender’s private key.
3. None, because no one but the owner of the private key should have access to it. Trick question.
4. Because the asymmetric key algorithm is too slow.
5. We need to get the necessary symmetric key to the destination securely, which can only be carried out through asymmetric cryptography through the use of public and private keys to provide a mechanism for secure transport of the symmetric key.
6. 42.
Session Keys
Hey, I have a disposable key!
Response: Amazing. Now go away.
A session key is a single-use symmetric key that is used to encrypt messages between two users during a communication session. A session key is no different from the symmetric key described in the previous section, but it is only good for one communication session between users.
If Tanya has a symmetric key she uses to always encrypt messages between Lance and herself, then this symmetric key would not be regenerated or changed. They would use the same key every time they communicated using encryption. However, using the same key repeatedly increases the chances of the key being captured and the secure communication being compromised. If, on the other hand, a new symmetric key were generated each time Lance and Tanya wanted to communicate, as shown in Figure 7-16, it would be used only during their one dialogue and then destroyed. If they wanted to communicate an hour later, a new session key would be created and shared.

Figure 7-16 A session key is generated so all messages can be encrypted during one particular session between users.
The use of these two technologies together can be referred to as a hybrid approach, but more commonly as a digital envelope.
A session key provides more protection than static symmetric keys because it is valid for only one session between two computers. If an attacker were able to capture the session key, she would have a very small window of time to use it to try to decrypt messages being passed back and forth.
In cryptography, almost all data encryption takes place through the use of session keys. When you write an e-mail and encrypt it before sending it over the wire, it is actually being encrypted with a session key. If you write another message to the same person one minute later, a brand-new session key is created to encrypt that new message. So if an evildoer happens to figure out one session key, that does not mean she has access to all other messages you write and send off.
When two computers want to communicate using encryption, they must first go through a handshaking process. The two computers agree on the encryption algorithms that will be used and exchange the session key that will be used for data encryption. In a sense, the two computers set up a virtual connection between each other and are said to be in session. When this session is done, each computer tears down any data structures it built to enable this communication to take place, releases the resources, and destroys the session key. These things are taken care of by operating systems and applications in the background, so a user would not necessarily need to be worried about using the wrong type of key for the wrong reason. The software will handle this, but it is important for security professionals to understand the difference between the key types and the issues that surround them.
NOTE Private and symmetric keys should not be available in cleartext. This may seem obvious to you, but there have been several implementations over time that have allowed for this type of compromise to take place.
Unfortunately, we don’t always seem to be able to call an apple an apple. In many types of technology, the exact same thing can have more than one name. This could be because the different inventors of the technology had schizophrenia, or it could mean that different terms just evolved over time that overlapped. Sadly, you could see symmetric cryptography referred to as any of the following:
• Single key cryptography
• Secret key cryptography
• Session key cryptography
• Private key cryptography
• Shared-key cryptography
We know the difference between secret keys (static) and session keys (dynamic), but what is this “single key” and “private key” mess? Well, using the term “single key” makes sense, because the sender and receiver are using one single key. I (the author) am saddened that the term “private key” can be used to describe symmetric cryptography because it only adds more confusion to the difference between symmetric cryptography (where one symmetric key is used) and asymmetric cryptography (where both a private and public key are used). But no one asked for or cares about my opinion, so we just need to remember this little quirk and still understand the difference between symmetric and asymmetric cryptography.
Types of Symmetric Systems
Several types of symmetric algorithms are used today. They have different methods of providing encryption and decryption functionality. The one thing they all have in common is that they are symmetric algorithms, meaning the sender and receiver are using two instances of the same key.
In this section, we will be walking through many of the following algorithms and their characteristics:
• Data Encryption Standard (DES)
• 3DES (Triple DES)
• Blowfish
• Twofish
• International Data Encryption Algorithm (IDEA)
• RC4, RC5, and RC6
• Advanced Encryption Standard (AES)
• Secure and Fast Encryption Routine (SAFER)
• Serpent
Data Encryption Standard
Data Encryption Standard (DES) has had a long and rich history within the computer community. The National Institute of Standards and Technology (NIST) researched the need for the protection of sensitive but unclassified data during the 1960s and initiated a cryptography program in the early 1970s. NIST invited vendors to submit data encryption algorithms to be used as a cryptographic standard. IBM had already been developing encryption algorithms to protect financial transactions. In 1974, IBM’s 128-bit algorithm, named Lucifer, was submitted and accepted. The NSA modified this algorithm to use a key size of 64 bits (with 8 bits used for parity, resulting in an effective key length of 56 bits) instead of the original 128 bits, and named it the Data Encryption Algorithm (DEA). Controversy arose about whether the NSA weakened Lucifer on purpose to enable it to decrypt messages not intended for it, but in the end the modified Lucifer became a national cryptographic standard in 1977 and an American National Standards Institute (ANSI) standard in 1978.
NOTE DEA is the algorithm that fulfills DES, which is really just a standard. So DES is the standard and DEA is the algorithm, but in the industry we usually just refer to it as DES. The CISSP exam may refer to the algorithm by either name, so remember both.
DES has been implemented in a majority of commercial products using cryptography functionality and in the applications of almost all government agencies. It was tested and approved as one of the strongest and most efficient cryptographic algorithms available. The continued overwhelming support of the algorithm is what caused the most confusion when the NSA announced in 1986 that, as of January 1988, the agency would no longer endorse DES and that DES-based products would no longer fall under compliance with Federal Standard 1027. The NSA felt that because DES had been so popular for so long, it would surely be targeted for penetration and become useless as an official standard. Many researchers disagreed, but NSA wanted to move on to a newer, more secure, and less popular algorithm as the new standard.
The NSA’s decision to drop its support for DES caused major concern and negative feedback. At that time, it was shown that DES still provided the necessary level of protection; that projections estimated a computer would require thousands of years to crack DES; that DES was already embedded in thousands of products; and that there was no equivalent substitute. NSA reconsidered its decision, and NIST ended up recertifying DES for another five years.
In 1998, the Electronic Frontier Foundation built a computer system for $250,000 that broke DES in three days by using a brute force attack against the keyspace. It contained 1,536 microprocessors running at 40 MHz, which performed 60 million test decryptions per second per chip. Although most people do not have these types of systems to conduct such attacks, as Moore’s Law holds true and microprocessors increase in processing power, this type of attack will become more feasible for the average attacker. This brought about 3DES, which provides stronger protection, as discussed later in the chapter.
DES was later replaced by the Rijndael algorithm as the Advanced Encryption Standard (AES) by NIST. This means that Rijndael is the new approved method of encrypting sensitive but unclassified information for the U.S. government; it has been accepted by, and is widely used in, the public arena today.
How Does DES Work?
How does DES work again?
Response: With voodoo magic and a dead chicken.
DES is a symmetric block encryption algorithm. When 64-bit blocks of plaintext go in, 64-bit blocks of ciphertext come out. It is also a symmetric algorithm, meaning the same key is used for encryption and decryption. It uses a 64-bit key: 56 bits make up the true key, and 8 bits are used for parity.
When the DES algorithm is applied to data, it divides the message into blocks and operates on them one at a time. The blocks are put through 16 rounds of transposition and substitution functions. The order and type of transposition and substitution functions depend on the value of the key used with the algorithm. The result is 64-bit blocks of ciphertext.
What Does It Mean When an Algorithm Is Broken?
I dropped my algorithm.
Response: Well, now it’s broken.
As described in an earlier section, DES was finally broken with a dedicated computer lovingly named the DES Cracker (also known as Deep Crack). But what does “broken” really mean?
In most instances, an algorithm is broken if someone is able to uncover a key that was used during an encryption process. So let’s say Kevin encrypted a message and sent it to Valerie. Marc captures this encrypted message and carries out a brute force attack on it, which means he tries to decrypt the message with different keys until he uncovers the right one. Once he identifies this key, the algorithm is considered broken. So does that mean the algorithm is worthless? It depends on who your enemies are.
If an algorithm is broken through a brute force attack, this just means the attacker identified the one key that was used for one instance of encryption. But in proper implementations, we should be encrypting data with session keys, which are good only for that one session. So even if the attacker uncovers one session key, it may be useless to the attacker, in which case he now has to work to identify a new session key.
If your information is of sufficient value that enemies or thieves would exert a lot of resources to break the encryption (as may be the case for financial transactions or military secrets), you would not use an algorithm that has been broken. If you are encrypting messages to your mother about a meatloaf recipe, you likely are not going to worry about whether the algorithm has been broken.
So breaking an algorithm can take place through brute force attacks or by identifying weaknesses in the algorithm itself. Brute force attacks have increased in potency because of the increased processing capacity of computers today. An algorithm that uses a 40-bit key has around 1 trillion possible key values. If a 56-bit key is used, then there are approximately 72 quadrillion different key values. This may seem like a lot, but relative to today’s computing power, these key sizes do not provide much protection at all.
On a final note, algorithms are built on the current understanding of mathematics. As the human race advances in mathematics, the level of protection that today’s algorithms provide may crumble.
DES Modes
Block ciphers have several modes of operation. Each mode specifies how a block cipher will operate. One mode may work better in one type of environment for specific functionality, whereas another mode may work better in another environment with totally different requirements. It is important that vendors who employ DES (or any block cipher) understand the different modes and which one to use for which purpose.
DES and other symmetric block ciphers have several distinct modes of operation that are used in different situations for different results. You just need to understand five of them:
• Electronic Code Book (ECB)
• Cipher Block Chaining (CBC)
• Cipher Feedback (CFB)
• Output Feedback (OFB)
• Counter Mode (CTR)
Electronic Code Book (ECB) Mode ECB mode operates like a code book. A 64-bit data block is entered into the algorithm with a key, and a block of ciphertext is produced. For a given block of plaintext and a given key, the same block of ciphertext is always produced. Not all messages end up in neat and tidy 64-bit blocks, so ECB incorporates padding to address this problem. ECB is the easiest and fastest mode to use, but as we will see, it has its dangers.
A key is basically instructions for the use of a code book that dictates how a block of text will be encrypted and decrypted. The code book provides the recipe of substitutions and permutations that will be performed on the block of plaintext. The security issue that comes up with using ECB mode is that each block will be encrypted with the exact same key, and thus the exact same code book. So, two bad things can happen here: an attacker could uncover the key and thus have the key to decrypt all the blocks of data, or an attacker could gather the ciphertext and plaintext of each block and build the code book that was used, without needing the key.
The crux of the problem is that there is not enough randomness to the process of encrypting the independent blocks, so if this mode is used to encrypt a large amount of data, it could be cracked more easily than the other modes that block ciphers can work in. So the next question to ask is, why even use this mode? This mode is the fastest and easiest, so we use it to encrypt small amounts of data, such as PINs, challenge-response values in authentication processes, and encrypting keys.
Because this mode works with blocks of data independently, data within a file does not have to be encrypted in a certain order. This is very helpful when using encryption in databases. A database has different pieces of data accessed in a random fashion. If it is encrypted in ECB mode, then any record or table can be added, encrypted, deleted, or decrypted independently of any other table or record. Other DES modes are dependent upon the text encrypted before them. This dependency makes it harder to encrypt and decrypt smaller amounts of text, because the previous encrypted text would need to be decrypted first. (Once we cover chaining in the next section, this dependency will make more sense.)
Because ECB mode does not use chaining, you should not use it to encrypt large amounts of data, because patterns would eventually show themselves.
Some important characteristics of ECB mode encryption are as follows:
• Operations can be run in parallel, which decreases processing time.
• Errors are contained. If an error takes place during the encryption process, it only affects one block of data.
• Only usable for the encryption of short messages.
• Cannot carry out preprocessing functions before receiving plaintext.
Cipher Block Chaining (CBC) Mode In ECB mode, a block of plaintext and a key will always give the same ciphertext. This means that if the word “balloon” were encrypted and the resulting ciphertext was “hwicssn,” each time it was encrypted using the same key, the same ciphertext would always be given. This can show evidence of a pattern, enabling an evildoer, with some effort, to discover the pattern and get a step closer to compromising the encryption process.
Cipher Block Chaining (CBC) does not reveal a pattern because each block of text, the key, and the value based on the previous block are processed in the algorithm and applied to the next block of text, as shown in Figure 7-17. This results in more random ciphertext. Ciphertext is extracted and used from the previous block of text. This provides dependence between the blocks, in a sense chaining them together. This is where the name Cipher Block Chaining comes from, and it is this chaining effect that hides any patterns.
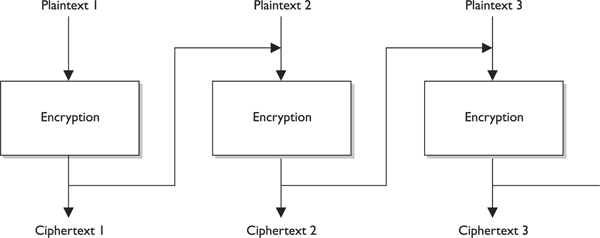
Figure 7-17 In CBC mode, the ciphertext from the previous block of data is used in encrypting the next block of data.
The results of one block are XORed with the next block before it is encrypted, meaning each block is used to modify the following block. This chaining effect means that a particular ciphertext block is dependent upon all blocks before it, not just the previous block.
As an analogy, let’s say you have five buckets of marbles. Each bucket contains a specific color of marbles: red, blue, yellow, black, and green. The first bucket of red marbles (block of bits) you shake and tumble around (encrypt) to get them all mixed up. Then you take the second bucket of marbles, which are blue, and pour in the red marbles and go through the same exercise of shaking and tumbling them. You pour this bucket of marbles into your next bucket and shake them all up. This illustrates the incorporated randomness that is added when using chaining in a block encryption process.
When we encrypt our very first block using CBC, we do not have a previous block of ciphertext to “dump in” and use to add the necessary randomness to the encryption process. If we do not add a piece of randomness when encrypting this first block, then the bad guys could identify patterns, work backward, and uncover the key. So, we use an initialization vector (IVs were introduced previously in the “Initialization Vectors” section). The 64-bit IV is XORed with the first block of plaintext, and then it goes through its encryption process. The result of that (ciphertext) is XORed with the second block of plaintext, and then the second block is encrypted. This continues for the whole message. It is the chaining that adds the necessary randomness that allows us to use CBC mode to encrypt large files. Neither the individual blocks nor the whole message will show patterns that will allow an attacker to reverse-engineer and uncover the key.
If we choose a different IV each time we encrypt a message, even if it is the same message, the ciphertext will always be unique. This means that if you send the same message out to 50 people and encrypt each one using a different IV, the ciphertext for each message will be different. Pretty nifty.
Cipher Feedback (CFB) Mode Sometimes block ciphers can emulate a stream cipher. Before we dig into how this would happen, let’s first look at why. If you are going to send an encrypted e-mail to your boss, your e-mail client will use a symmetric block cipher working in CBC mode. The e-mail client would not use ECB mode, because most messages are long enough to show patterns that can be used to reverse-engineer the process and uncover the encryption key. The CBC mode is great to use when you need to send large chunks of data at a time. But what if you are not sending large chunks of data at one time, but instead are sending a steady stream of data to a destination? If you are working on a terminal that communicates with a back-end terminal server, what is really going on is that each keystroke and mouse movement you make is sent to the back-end server in chunks of eight bits to be processed. So even though it seems as though the computer you are working on is carrying out your commands and doing the processing you are requesting, it is not—this is happening on the server. Thus, if you need to encrypt the data that go from your terminal to the terminal server, you could not use CBC mode because it only encrypts blocks of data 64 bits in size. You have blocks of eight bits you need to encrypt. So what do you know? We have just the mode for this type of situation!
Figure 7-18 illustrates how Cipher Feedback Mode (CFB) mode works, which is really a combination of a block cipher and a stream cipher. For the first block of eight bits that needs to be encrypted, we do the same thing we did in CBC mode, which is to use an IV. Recall how stream ciphers work: The key and the IV are used by the algorithm to create a keystream, which is just a random set of bits. This set of bits is XORed to the block of plaintext, which results in the same size block of ciphertext. So the first block (eight bits) is XORed to the set of bits created through the keystream generator. Two things take place with this resulting eight-bit block of ciphertext. One copy goes over the wire to the destination (in our scenario, to the terminal server), and another copy is used to encrypt the next block of eight-bit plaintext. Adding this copy of ciphertext to the encryption process of the next block adds more randomness to the encryption process.
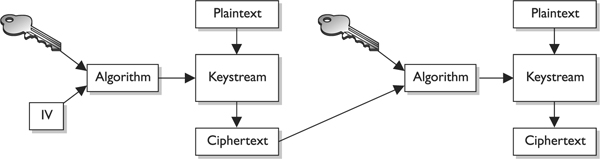
Figure 7-18 A block cipher working in CFB mode
We walked through a scenario where eight-bit blocks needed to be encrypted, but in reality, CFB mode can be used to encrypt any size blocks, even blocks of just one bit. But since most of our encoding maps eight bits to one character, using CFB to encrypt eight-bit blocks is very common.
NOTE When using CBC mode, it is a good idea to use a unique IV value per message, but this is not necessary since the message being encrypted is usually very large. When using CFB mode, we are encrypting a smaller amount of data, so it is imperative a new IV value be used to encrypt each new stream of data.
Output Feedback (OFB) Mode As you have read, you can use ECB mode for the process of encrypting small amounts of data, such as a key or PIN value. These components will be around 64 bits or more, so ECB mode works as a true block cipher. You can use CBC mode to encrypt larger amounts of data in block sizes of 64 bits. In situations where you need to encrypt a smaller amount of data, you need the cipher to work like a stream cipher and to encrypt individual bits of the blocks, as in CFB. In some cases, you still need to encrypt a small amount of data at a time (one to eight bits), but you need to ensure possible errors do not affect your encryption and decryption processes.
If you look back at Figure 7-18, you see that the ciphertext from the previous block is used to encrypt the next block of plaintext. What if a bit in the first ciphertext gets corrupted? Then we have corrupted values going into the process of encrypting the next block of plaintext, and this problem just continues because of the use of chaining in this mode. Now look at Figure 7-19. It looks terribly similar to Figure 7-18, but notice that the values used to encrypt the next block of plaintext are coming directly from the keystream, not from the resulting ciphertext. This is the difference between the two modes.
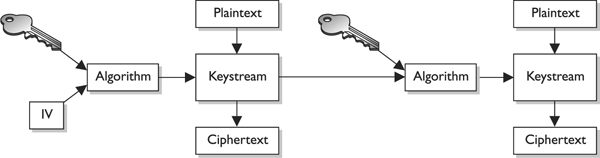
Figure 7-19 A block cipher working in OFB mode
If you need to encrypt something that would be very sensitive to these types of errors, such as digitized video or digitized voice signals, you should not use CFB mode. You should use OFB mode instead, which reduces the chance that these types of bit corruptions can take place.
So Output Feedback Mode (OFB) is a mode that a block cipher can work in when it needs to emulate a stream because it encrypts small amounts of data at a time, but it has a smaller chance of creating and extending errors throughout the full encryption process.
To ensure OFB and CFB are providing the most protection possible, the size of the ciphertext (in CFB) or keystream values (in OFB) needs to be the same size as the block of plaintext being encrypted. This means that if you are using CFB and are encrypting eight bits at a time, the ciphertext you bring forward from the previous encryption block needs to be eight bits. Otherwise, you are repeating values over and over, which introduces patterns. (This is the same reason why a one-time pad should be used only one time and should be as long as the message itself.)
Counter (CTR) Mode Counter Mode (CTR) is very similar to OFB mode, but instead of using a randomly unique IV value to generate the keystream values, this mode uses an IV counter that increments for each plaintext block that needs to be encrypted. The unique counter ensures that each block is XORed with a unique keystream value.
The other difference is that there is no chaining involved, which means no ciphertext is brought forward to encrypt the next block. Since there is no chaining, the encryption of the individual blocks can happen in parallel, which increases the performance. The main reason CTR would be used instead of the other modes is performance.
This mode has been around for quite some time and is used in encrypting ATM cells for virtual circuits, in IPSec, and is now integrated in the new wireless security standard, IEEE 802.11i. A developer would choose to use this mode in these situations because individual ATM cells or packets going through an IPSec tunnel or over radio frequencies may not arrive at the destination in order. Since chaining is not involved, the destination can decrypt and begin processing the packets without having to wait for the full message to arrive and then decrypt all the data.
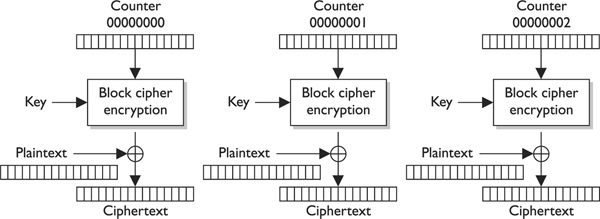
Triple-DES
We went from DES to Triple-DES (3DES), so it might seem we skipped Double-DES. We did. Double-DES has a key length of 112 bits, but there is a specific attack against Double-DES that reduces its work factor to about the same as DES. Thus, it is no more secure than DES. So let’s move on to 3DES.
Many successful attacks against DES and the realization that the useful lifetime of DES was about up brought much support for 3DES. NIST knew that a new standard had to be created, which ended up being AES, but a quick fix was needed in the meantime to provide more protection for sensitive data. The result: 3DES (also known as TDEA—Triple Data Encryption Algorithm).
3DES uses 48 rounds in its computation, which makes it highly resistant to differential cryptanalysis. However, because of the extra work 3DES performs, there is a heavy performance hit. It can take up to three times longer than DES to perform encryption and decryption.
Although NIST has selected the Rijndael algorithm to replace DES as the AES, NIST and others expect 3DES to be around and used for quite some time.
3DES can work in different modes, and the mode chosen dictates the number of keys used and what functions are carried out:
• DES-EEE3 Uses three different keys for encryption, and the data are encrypted, encrypted, encrypted.
• DES-EDE3 Uses three different keys for encryption, and the data are encrypted, decrypted, encrypted.
• DES-EEE2 The same as DES-EEE3, but uses only two keys, and the first and third encryption processes use the same key.
• DES-EDE2 The same as DES-EDE3, but uses only two keys, and the first and third encryption processes use the same key.
EDE may seem a little odd at first. How much protection could be provided by encrypting something, decrypting it, and encrypting it again? The decrypting portion here is decrypted with a different key. When data are encrypted with one symmetric key and decrypted with a different symmetric key, it is jumbled even more. So the data are not actually decrypted in the middle function, they are just run through a decryption process with a different key. Pretty tricky.
The Advanced Encryption Standard
After DES was used as an encryption standard for over 20 years and it was cracked in a relatively short time once the necessary technology was available, NIST decided a new standard, the Advanced Encryption Standard (AES), needed to be put into place. In January 1997, NIST announced its request for AES candidates and outlined the requirements in FIPS PUB 197. AES was to be a symmetric block cipher supporting key sizes of 128, 192, and 256 bits. The following five algorithms were the finalists:
• MARS Developed by the IBM team that created Lucifer
• RC6 Developed by RSA Laboratories
• Serpent Developed by Ross Anderson, Eli Biham, and Lars Knudsen
• Twofish Developed by Counterpane Systems
• Rijndael Developed by Joan Daemen and Vincent Rijmen
Out of these contestants, Rijndael was chosen. The block sizes that Rijndael supports are 128, 192, and 256 bits. The number of rounds depends upon the size of the block and the key length:
• If both the key and block size are 128 bits, there are 10 rounds.
• If both the key and block size are 192 bits, there are 12 rounds.
• If both the key and block size are 256 bits, there are 14 rounds.
Rijndael works well when implemented in software and hardware in a wide range of products and environments. It has low memory requirements and has been constructed to easily defend against timing attacks.
Rijndael was NIST’s choice to replace DES. It is now the algorithm required to protect sensitive but unclassified U.S. government information.
NOTE DEA is the algorithm used within DES, and Rijndael is the algorithm used in AES. In the industry, we refer to these as DES and AES instead of by the actual algorithms.
International Data Encryption Algorithm
International Data Encryption Algorithm (IDEA) is a block cipher and operates on 64-bit blocks of data. The 64-bit data block is divided into 16 smaller blocks, and each has eight rounds of mathematical functions performed on it. The key is 128 bits long, and IDEA is faster than DES when implemented in software.
The IDEA algorithm offers different modes similar to the modes described in the DES section, but it is considered harder to break than DES because it has a longer key size. IDEA is used in the PGP and other encryption software implementations. It was thought to replace DES, but it is patented, meaning that licensing fees would have to be paid to use it.
As of this writing, there have been no successful practical attacks against this algorithm, although there have been numerous attempts.
Blowfish
One fish, two fish, red fish, blowfish.
Response: Hmm, I thought it was blue fish.
Blowfish is a block cipher that works on 64-bit blocks of data. The key length can be anywhere from 32 bits up to 448 bits, and the data blocks go through 16 rounds of cryptographic functions. It was intended as a replacement to the aging DES. While many of the other algorithms have been proprietary and thus encumbered by patents or kept as government secrets, this wasn’t the case with Blowfish. Bruce Schneier, the creator of Blowfish, has stated, “Blowfish is unpatented, and will remain so in all countries. The algorithm is hereby placed in the public domain, and can be freely used by anyone.” Nice guy.
RC4
RC4 is one of the most commonly implemented stream ciphers. It has a variable key size, is used in the SSL protocol, and was (improperly) implemented in the 802.11 WEP protocol standard. RC4 was developed in 1987 by Ron Rivest and was considered a trade secret of RSA Data Security, Inc., until someone posted the source code on a mailing list. Since the source code was released nefariously, the stolen algorithm is sometimes implemented and referred to as ArcFour or ARC4 because the title RC4 is trade-marked.
The algorithm is very simple, fast, and efficient, which is why it became so popular. But because it has a low diffusion rate, it is subject to modification attacks. This is one reason that the new wireless security standard (IEEE 802.11i) moved from the RC4 algorithm to the AES algorithm.
RC5
RC5 is a block cipher that has a variety of parameters it can use for block size, key size, and the number of rounds used. It was created by Ron Rivest and analyzed by RSA Data Security, Inc. The block sizes used in this algorithm are 32, 64, or 128 bits, and the key size goes up to 2,048 bits. The number of rounds used for encryption and decryption is also variable. The number of rounds can go up to 255.
RC6
RC6 is a block cipher that was built upon RC5, so it has all the same attributes as RC5. The algorithm was developed mainly to be submitted as AES, but Rijndael was chosen instead. There were some modifications of the RC5 algorithm to increase the overall speed, the result of which is RC6.
Types of Asymmetric Systems
As described earlier in the chapter, using purely symmetric key cryptography has three drawbacks, which affect the following:
• Security services Purely symmetric key cryptography provides confidentiality only, not authentication or nonrepudiation.
• Scalability As the number of people who need to communicate increases, so does the number of symmetric keys required, meaning more keys must be managed.
• Secure key distribution The symmetric key must be delivered to its destination through a secure courier.
Despite these drawbacks, symmetric key cryptography was all that the computing society had available for encryption for quite some time. Symmetric and asymmetric cryptography did not arrive on the same day or even in the same decade. We dealt with the issues surrounding symmetric cryptography for quite some time, waiting for someone smarter to come along and save us from some of this grief.
The Diffie-Hellman Algorithm
The first group to address the shortfalls of symmetric key cryptography decided to attack the issue of secure distribution of the symmetric key. Whitfield Diffie and Martin Hellman worked on this problem and ended up developing the first asymmetric key agreement algorithm, called, naturally, Diffie-Hellman.
To understand how Diffie-Hellman works, consider an example. Let’s say that Tanya and Erika would like to communicate over an encrypted channel by using Diffie-Hellman. They would both generate a private and public key pair and exchange public keys. Tanya’s software would take her private key (which is just a numeric value) and Erika’s public key (another numeric value) and put them through the Diffie-Hellman algorithm. Erika’s software would take her private key and Tanya’s public key and insert them into the Diffie-Hellman algorithm on her computer. Through this process, Tanya and Erika derive the same shared value, which is used to create instances of symmetric keys.
So, Tanya and Erika exchanged information that did not need to be protected (their public keys) over an untrusted network, and in turn generated the exact same symmetric key on each system. They both can now use these symmetric keys to encrypt, transmit, and decrypt information as they communicate with each other.
NOTE The preceding example describes key agreement, which is different from key exchange, the functionality used by the other asymmetric algorithms that will be discussed in this chapter. With key exchange functionality, the sender encrypts the symmetric key with the receiver’s public key before transmission.
The Diffie-Hellman algorithm enables two systems to generate a symmetric key securely without requiring a previous relationship or prior arrangements. The algorithm allows for key distribution, but does not provide encryption or digital signature functionality. The algorithm is based on the difficulty of calculating discrete logarithms in a finite field.
The original Diffie-Hellman algorithm is vulnerable to a man-in-the-middle attack, because no authentication occurs before public keys are exchanged. In our example, when Tanya sends her public key to Erika, how does Erika really know it is Tanya’s public key? What if Lance spoofed his identity, told Erika he was Tanya, and sent over his key? Erika would accept this key, thinking it came from Tanya. Let’s walk through the steps of how this type of attack would take place, as illustrated in Figure 7-20:
1. Tanya sends her public key to Erika, but Lance grabs the key during transmission so it never makes it to Erika.
2. Lance spoofs Tanya’s identity and sends over his public key to Erika. Erika now thinks she has Tanya’s public key.
3. Erika sends her public key to Tanya, but Lance grabs the key during transmission so it never makes it to Tanya.
4. Lance spoofs Erika’s identity and sends over his public key to Tanya. Tanya now thinks she has Erika’s public key.
5. Tanya combines her private key and Lance’s public key and creates symmetric key S1.
6. Lance combines his private key and Tanya’s public key and creates symmetric key S1.
7. Erika combines her private key and Lance’s public key and creates symmetric key S2.
8. Lance combines his private key and Erika’s public key and creates symmetric key S2.
9. Now Tanya and Lance share a symmetric key (S1) and Erika and Lance share a different symmetric key (S2). Tanya and Erika think they are sharing a key between themselves and do not realize Lance is involved.
10. Tanya writes a message to Erika, uses her symmetric key (S1) to encrypt the message, and sends it.
11. Lance grabs the message and decrypts it with symmetric key S1, reads or modifies the message and re-encrypts it with symmetric key S2, and then sends it to Erika.
12. Erika takes symmetric key S2 and uses it to decrypt and read the message.
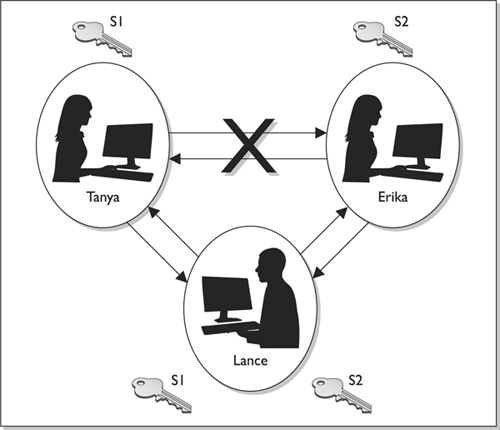
Figure 7-20 A man-in-the-middle attack
The countermeasure to this type of attack is to have authentication take place before accepting someone’s public key, which usually happens through the use of digital signatures and digital certificates.
NOTE Although the Diffie-Hellman algorithm is vulnerable to a man-in-the-middle attack, it does not mean this type of compromise can take place anywhere this algorithm is deployed. Most implementations include another piece of software or a protocol that compensates for this vulnerability. But some do not. As a security professional, you should understand these issues.
NOTE MQV (Menezes-Qu-Vanstone) is an authentication key agreement cryptography function very similar to Diffie-Hellman. The users’ public keys are exchanged to create session keys. It provides protection from an attacker figuring out the session key because she would need to have both users’ private keys.
RSA
Give me an R, give me an S, give me an… How do you spell “RSA” again?
Response: Sigh.
RSA, named after its inventors Ron Rivest, Adi Shamir, and Leonard Adleman, is a public key algorithm that is the most popular when it comes to asymmetric algorithms. RSA is a worldwide de facto standard and can be used for digital signatures, key exchange, and encryption. It was developed in 1978 at MIT and provides authentication as well as key encryption.
The security of this algorithm comes from the difficulty of factoring large numbers into their original prime numbers. The public and private keys are functions of a pair of large prime numbers, and the necessary activity required to decrypt a message from ciphertext to plaintext using a private key is comparable to factoring a product into two prime numbers.
NOTE A prime number is a positive whole number with no proper divisors, meaning the only numbers that can divide a prime number are 1 and the number itself.
What Is the Difference Between Public Key Cryptography and Public Key Infrastructure?
Public key cryptography is the use of an asymmetric algorithm. Thus, the terms asymmetric algorithm and public key cryptography are interchangeable. Examples of asymmetric algorithms are RSA, elliptic curve cryptosystem (ECC), Diffie-Hellman, El Gamal, and Knapsack. These algorithms are used to create public/private key pairs, perform key exchange or agreement, and generate and verify digital signatures.
NOTE The Diffie-Hellman algorithm can only perform key agreement and cannot generate or verify digital signatures.
Public key infrastructure (PKI) is a different animal. It is not an algorithm, a protocol, or an application—it is an infrastructure based on public key cryptography.
One advantage of using RSA is that it can be used for encryption and digital signatures. Using its one-way function, RSA provides encryption and signature verification, and the inverse direction performs decryption and signature generation.
RSA has been implemented in applications; in operating systems by Microsoft, Apple, Sun, and Novell; and at the hardware level in network interface cards, secure telephones, and smart cards. It can be used as a key exchange protocol, meaning it is used to encrypt the symmetric key to get it securely to its destination. RSA has been most commonly used with the symmetric algorithm DES, which is quickly being replaced with AES. So, when RSA is used as a key exchange protocol, a cryptosystem generates a symmetric key using either the DES or AES algorithm. Then the system encrypts the symmetric key with the receiver’s public key and sends it to the receiver. The symmetric key is protected because only the individual with the corresponding private key can decrypt and extract the symmetric key.
Diving into Numbers
Cryptography is really all about using mathematics to scramble bits into an undecipherable form and then using the same mathematics in reverse to put the bits back into a form that can be understood by computers and people. RSA’s mathematics are based on the difficulty of factoring a large integer into its two prime factors. Put on your nerdy hat with the propeller and let’s look at how this algorithm works.
The algorithm creates a public key and a private key from a function of large prime numbers. When data are encrypted with a public key, only the corresponding private key can decrypt the data. This act of decryption is basically the same as factoring the product of two prime numbers. So, let’s say I have a secret (encrypted message), and for you to be able to uncover the secret, you have to take a specific large number and factor it and come up with the two numbers I have written down on a piece of paper. This may sound simplistic, but the number you must properly factor can be 2300 in size. Not as easy as you may think.
The following sequence describes how the RSA algorithm comes up with the keys in the first place:
1. Choose two random large prime numbers, p and q.
2. Generate the product of these numbers: n = pq.
Choose a random integer to be the encryption key, e. Make sure that e and (p – 1)(q – 1) are relatively prime.
3. Compute the decryption key, d. This is ed = 1 mod (p – 1)(q – 1) or d = e–1 mod ([p – 1][q – 1]).
4. The public key = (n, e).
5. The private key = (n, d).
6. The original prime numbers p and q are discarded securely.
We now have our public and private keys, but how do they work together?
If you need to encrypt message m with your public key (e, n), the following formula is carried out:
C = me mod n
Then you need to decrypt the message with your private key (d), so the following formula is carried out:
M = cd mod n
You may be thinking, “Well, I don’t understand these formulas, but they look simple enough. Why couldn’t someone break these small formulas and uncover the encryption key?” Maybe someone will one day. As the human race advances in its understanding of mathematics and as processing power increases and cryptanalysis evolves, the RSA algorithm may be broken one day. If we were to figure out how to quickly and more easily factor large numbers into their original prime values, all of these cards would fall down, and this algorithm would no longer provide the security it does today. But we have not hit that bump in the road yet, so we are all happily using RSA in our computing activities.
One-Way Functions
A one-way function is a mathematical function that is easier to compute in one direction than in the opposite direction. An analogy of this is when you drop a glass on the floor. Although dropping a glass on the floor is easy, putting all the pieces back together again to reconstruct the original glass is next to impossible. This concept is similar to how a one-way function is used in cryptography, which is what the RSA algorithm, and all other asymmetric algorithms, are based upon.
The easy direction of computation in the one-way function that is used in the RSA algorithm is the process of multiplying two large prime numbers. Multiplying the two numbers to get the resulting product is much easier than factoring the product and recovering the two initial large prime numbers used to calculate the obtained product, which is the difficult direction. RSA is based on the difficulty of factoring large numbers that are the product of two large prime numbers. Attacks on these types of cryptosystems do not necessarily try every possible key value, but rather try to factor the large number, which will give the attacker the private key.
When a user encrypts a message with a public key, this message is encoded with a one-way function (breaking a glass). This function supplies a trapdoor (knowledge of how to put the glass back together), but the only way the trapdoor can be taken advantage of is if it is known about and the correct code is applied. The private key provides this service. The private key knows about the trapdoor, knows how to derive the original prime numbers, and has the necessary programming code to take advantage of this secret trapdoor to unlock the encoded message (reassembling the broken glass). Knowing about the trapdoor and having the correct functionality to take advantage of it are what make the private key private.
When a one-way function is carried out in the easy direction, encryption and digital signature verification functionality are available. When the one-way function is carried out in the hard direction, decryption and signature generation functionality are available. This means only the public key can carry out encryption and signature verification and only the private key can carry out decryption and signature generation.
As explained earlier in this chapter, work factor is the amount of time and resources it would take for someone to break an encryption method. In asymmetric algorithms, the work factor relates to the difference in time and effort that carrying out a one-way function in the easy direction takes compared to carrying out a one-way function in the hard direction. In most cases, the larger the key size, the longer it would take for the bad guy to carry out the one-way function in the hard direction (decrypt a message).
The crux of this section is that all asymmetric algorithms provide security by using mathematical equations that are easy to perform in one direction and next to impossible to perform in the other direction. The “hard” direction is based on a “hard” mathematical problem. RSA’s hard mathematical problem requires factoring large numbers into their original prime numbers. Diffie-Hellman and El Gamal are based on the difficulty of calculating logarithms in a finite field.
El Gamal
El Gamal is a public key algorithm that can be used for digital signatures, encryption, and key exchange. It is based not on the difficulty of factoring large numbers but on calculating discrete logarithms in a finite field. El Gamal is actually an extension of the Diffie-Hellman algorithm.
Although El Gamal provides the same type of functionality as some of the other asymmetric algorithms, its main drawback is performance. When compared to other algorithms, this algorithm is usually the slowest.
Elliptic Curve Cryptosystems
Elliptic curves. That just sounds like fun.
Elliptic curves are rich mathematical structures that have shown usefulness in many different types of applications. An elliptic curve cryptosystem (ECC) provides much of the same functionality RSA provides: digital signatures, secure key distribution, and encryption. One differing factor is ECC’s efficiency. ECC is more efficient than RSA and any other asymmetric algorithm.
Figure 7-21 is an example of an elliptic curve. In this field of mathematics, points on the curves compose a structure called a group. These points are the values used in mathematical formulas for ECC’s encryption and decryption processes. The algorithm computes discrete logarithms of elliptic curves, which is different from calculating discrete logarithms in a finite field (which is what Diffie-Hellman and El Gamal use).
Figure 7-21 Elliptic curves
Some devices have limited processing capacity, storage, power supply, and bandwidth, such as wireless devices and cellular telephones. With these types of devices, efficiency of resource use is very important. ECC provides encryption functionality, requiring a smaller percentage of the resources compared to RSA and other algorithms, so it is used in these types of devices.
In most cases, the longer the key, the more protection that is provided, but ECC can provide the same level of protection with a key size that is shorter than what RSA requires. Because longer keys require more resources to perform mathematical tasks, the smaller keys used in ECC require fewer resources of the device.
Knapsack
Over the years, different versions of knapsack algorithms have arisen. The first to be developed, Merkle-Hellman, could be used only for encryption, but it was later improved upon to provide digital signature capabilities. These types of algorithms are based on the “knapsack problem,” a mathematical dilemma that poses the following question: If you have several different items, each having its own weight, is it possible to add these items to a knapsack so the knapsack has a specific weight?
This algorithm was discovered to be insecure and is not currently used in cryptosystems.
Zero Knowledge Proof
Total knowledge zero. Yep, that’s how I feel after reading all of this cryptography stuff!
Response: Just put your head between your knees and breathe slowly.
When military representatives are briefing the news media about some big world event, they have one goal in mind: to tell the story that the public is supposed to hear and nothing more. Do not provide extra information that someone could use to infer more information than they are supposed to know. The military has this goal because it knows that not just the good guys are watching CNN. This is an example of zero knowledge proof. You tell someone just the information they need to know without “giving up the farm.”
Zero knowledge proof is used in cryptography also. If I encrypt something with my private key, you can verify my private key was used by decrypting the data with my public key. By encrypting something with my private key, I am proving to you I have my private key—but I do not give or show you my private key. I do not “give up the farm” by disclosing my private key. In a zero knowledge proof, the verifier cannot prove to another entity that this proof is real because he does not have the private key to prove it. So, only the owner of the private key can prove he has possession of the key.
Message Integrity
Parity bits and cyclic redundancy check (CRC) functions have been used in protocols to detect modifications in streams of bits as they are passed from one computer to another, but they can usually detect only unintentional modifications. Unintentional modifications can happen if a spike occurs in the power supply, if there is interference or attenuation on a wire, or if some other type of physical condition happens that causes the corruption of bits as they travel from one destination to another. Parity bits cannot identify whether a message was captured by an intruder, altered, and then sent on to the intended destination. The intruder can just recalculate a new parity value that includes his changes, and the receiver would never know the difference. For this type of protection, hash algorithms are required to successfully detect intentional and unintentional unauthorized modifications to data. We will now dive into hash algorithms and their characteristics.
The One-Way Hash
Now, how many times does the one-way hash run again?
Response: One, brainiac.
A one-way hash is a function that takes a variable-length string (a message) and produces a fixed-length value called a hash value. For example, if Kevin wants to send a message to Maureen and he wants to ensure the message does not get altered in an unauthorized fashion while it is being transmitted, he would calculate a hash value for the message and append it to the message itself. When Maureen receives the message, she performs the same hashing function Kevin used and then compares her result with the hash value sent with the message. If the two values are the same, Maureen can be sure the message was not altered during transmission. If the two values are different, Maureen knows the message was altered, either intentionally or unintentionally, and she discards the message.
The hashing algorithm is not a secret—it is publicly known. The secrecy of the oneway hashing function is its “one-wayness.” The function is run in only one direction, not the other direction. This is different from the one-way function used in public key cryptography, in which security is provided based on the fact that, without knowing a trapdoor, it is very hard to perform the one-way function backward on a message and come up with readable plaintext. However, one-way hash functions are never used in reverse; they create a hash value and call it a day. The receiver does not attempt to reverse the process at the other end, but instead runs the same hashing function one way and compares the two results.
The hashing one-way function takes place without the use of any keys. This means, for example, that if Cheryl writes a message, calculates a message digest, appends the digest to the message, and sends it on to Scott, Bruce can intercept this message, alter Cheryl’s message, recalculate another message digest, append it to the message, and send it on to Scott. When Scott receives it, he verifies the message digest, but never knows the message was actually altered by Bruce. Scott thinks the message came straight from Cheryl and it was never modified because the two message digest values are the same. If Cheryl wanted more protection than this, she would need to use message authentication code (MAC).
A MAC function is an authentication scheme derived by applying a secret key to a message in some form. This does not mean the symmetric key is used to encrypt the message, though. You should be aware of three basic types of MACs: a hash MAC (HMAC), CBC-MAC, and CMAC.
HMAC
In the previous example, if Cheryl were to use an HMAC function instead of just a plain hashing algorithm, a symmetric key would be concatenated with her message. The result of this process would be put through a hashing algorithm, and the result would be a MAC value. This MAC value is then appended to her message and sent to Scott. If Bruce were to intercept this message and modify it, he would not have the necessary symmetric key to create the MAC value that Scott will attempt to generate. Figure 7-22 walks through these steps.
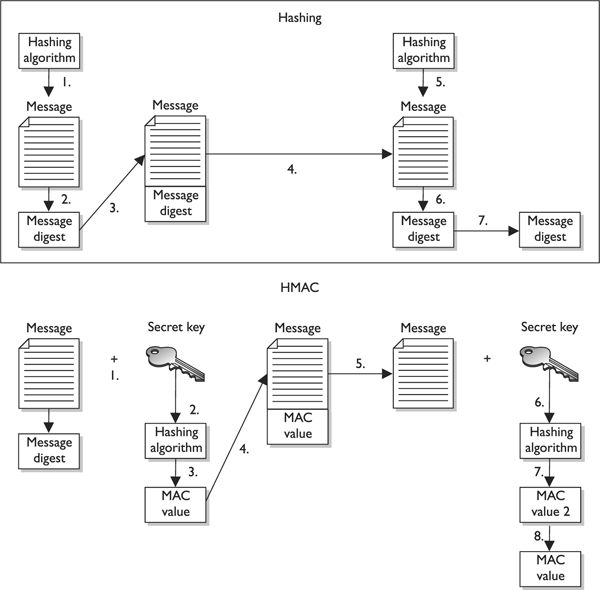
Figure 7-22 The steps involved in using a hashing algorithm and HMAC function
The top portion of Figure 7-22 shows the steps of a hashing process:
1. The sender puts the message through a hashing function.
2. A message digest value is generated.
3. The message digest is appended to the message.
4. The sender sends the message to the receiver.
5. The receiver puts the message through a hashing function.
6. The receiver generates her own message digest value.
7. The receiver compares the two message digest values. If they are the same, the message has not been altered.
The bottom half of Figure 7-22 shows the steps of an HMAC:
1. The sender concatenates a symmetric key with the message.
2. The result is put through a hashing algorithm.
4. The MAC value is appended to the message.
5. The sender sends the message to the receiver. (Just the message with the attached MAC value. The sender does not send the symmetric key with the message.)
6. The receiver concatenates a symmetric key with the message.
7. The receiver puts the results through a hashing algorithm and generates her own MAC value.
8. The receiver compares the two MAC values. If they are the same, the message has not been modified.