
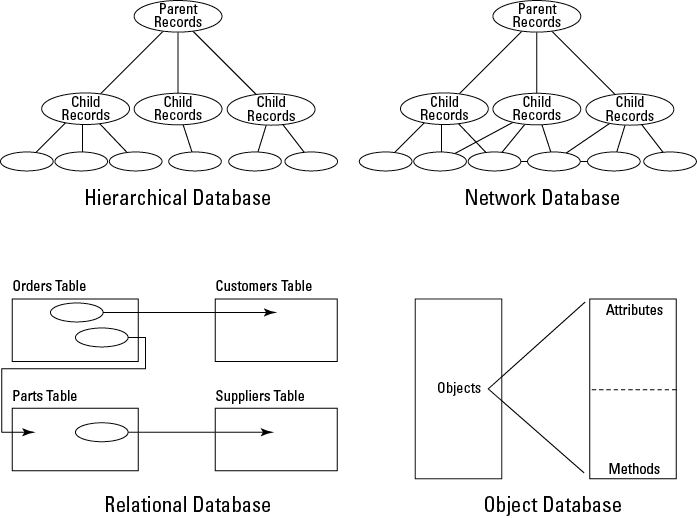
Figure 7-2: Database models.
Databases
A database is a mechanism used to define, store, and manipulate data. It contains data used by one or more applications, as well as a programming and command interface used to create, manage, and administer data. In many modern software applications, database management systems exist on a server that is logically or physically separate from the server containing the application programs.
 DBMSs (database management systems) generally contain an access-control mechanism used to protect data and permit only certain users, or classes of users, to view or modify data residing in certain portions of the database. We describe access control mechanisms in databases more fully in Chapter 4.
DBMSs (database management systems) generally contain an access-control mechanism used to protect data and permit only certain users, or classes of users, to view or modify data residing in certain portions of the database. We describe access control mechanisms in databases more fully in Chapter 4.
The three most common types of databases in use today are relational databases, hierarchical databases, and object-oriented databases.
Database security
The granularity of access control means how finely you can control who can see and manipulate data in which databases, tables, rows, and fields. An example of low granularity is Read or Read/Write access to all rows and fields in a table. High granularity restricts access to certain fields and even certain rows. High granularity means that either the database administrator (good if this isn’t you) or the security administrator (bad if this is you) has to work a lot of extra hours managing all those permissions.
You can employ views to simplify security issues. A view is a virtual table that consists of the rows and fields from one or more tables in the database. Then, you give users access to these views, rather than to the actual tables. You can manage this setup really easily, meaning that the database administrator or security administrator can manage security with somewhat higher granularity and still have a life.
Aggregation is a matter of serious concern from a security and privacy perspective. Aggregation refers to the process of combining low-sensitivity data items together, resulting in high-sensitivity data. Consider this example: If you get Conan O’Brien’s home address from one database, his Social Security Number from another, his driver’s license number from another, and his date of birth from yet another, then you have some potentially damaging — or valuable — information. Add a diabolical, hungry mind, some motivation, and soon you’re buying Brooks Brothers suits and driving shiny red Italian sports cars, all “courtesy of” Conan O’Brien. If you still don’t get it, we’re talking about identity theft here. By themselves, dates of birth or a home address don’t mean a lot, but put them together, you’ve got something. That’s the power — and risk — of aggregation.
 The term aggregation refers to the process of combining separate low-sensitivity data items to produce a high-sensitivity data item.
The term aggregation refers to the process of combining separate low-sensitivity data items to produce a high-sensitivity data item.
We’d be remiss if we didn’t mention inference. This concept refers to the ability of someone to deduce or infer something about sensitive information that’s beyond normal reach because of its sensitivity level. For example, an application that cites the existence of highly sensitive information will make users (and potential intruders) think that there is a treasure trove of data waiting to be stolen.
Data dictionaries
A data dictionary is a database of databases. In a large application that has many tables (some applications have hundreds of tables), a data dictionary exists as a database that contains all the information about all the tables and fields in a given application. The DBMS, the application, and security tools (such as access control) use a data dictionary. You can use a data dictionary to create or re-create tables, to manage security access, and as a control point for managing the schema of the application’s database.
Data warehouses
A data warehouse is a special-purpose database that’s used for business research, decision support, and planning; comparatively, typical databases support daily business operations.
Why have a data warehouse? Ultimately it’s for performance reasons. Every large company has a department full of people who play what-if games with the corporate data — and they get paid for it! For instance, a bank executive may want a list of customers who have more than $35,000 in their checking accounts who haven’t made any deposits in the past month and live in the 98039 Zip code. (You know, the Redmond billionaires.) The people in Operations may get a little upset if the VP ties up computer resources combing through the database all day long doing queries on nonindexed fields. The tellers who have to wait 45 seconds for deposits to clear because of all this extra processing might get a little miffed, too.
The point is that the company’s main production database isn’t the place for the what-iffers to go play (okay, work). You can tune the database for inserts and updates (activities typical in regular production databases) or large queries (activities typical of data warehouses), but not both. These two activities require opposite tuning settings in the database. They don’t get along. Here’s an analogy: If you want to drive fast, pick the sports car; if you want to haul stuff, choose the pickup truck. Use the right tool for the right job. The same goes for business data processing versus research and forecasting.
The old-school term for the game that what-iffers play with scenarios is decision support. These folks try to figure out trends about their customers, their business activities, or what-have-you, in order to support strategic decisions. The new fancy-pants terms for decision support are data mining and business intelligence. Data mining should conjure up a vivid word-picture of a strip mine where frantic diggers comb through tons of ore for grams of gold, uranium, and kryptonite. Data mining is like that: Executives and business planners do comb through gigabytes of historical data in order to find hard-to-spot and potentially valuable trends that could help them to unlock future value.
Another common application of data mining is fraud detection. Banks and credit card companies sift through mountains of transactions looking for spending trends in individual accounts to sniff out whether someone may have stolen a credit card number from a poorly protected e-commerce company’s data warehouse. (Talk about a cruel irony.)
Someone who needed to sell more databases came up with the idea that building a separate database optimized for humongous queries to sustain decision support would, in the end, be better than trying to accommodate production operations and decision support on the same system. History bears this out; data warehouses work pretty well when they’re well designed and well managed.
The type of database used for decision support is called a data warehouse.
Types of databases
Because designers first developed them over 40 years ago, several types of databases have enjoyed commercial use. These different types of databases refer to various data architectures, or methods for organizing data. We describe the more common types in the following sections. Figure 7-2 depicts the types of databases discussed.
Hierarchical database
Data in a hierarchical database is arranged in a tree structure, with parent records at the top of the database, and a hierarchy of child records in successive layers.
One of the most well-known hierarchical databases is IBM’s IMS (Information Management System) product, which was first used in the 1960s. IBM mainframes still use IMS widely today.
Network database
Network databases represent an improvement in the design of hierarchical databases. In the hierarchical model, relationships between records are defined by the database’s tree structure. In a network database, records can be networked to other records through paths that are different from the hierarchy itself.
Relational database
The designers of hierarchical and network databases were on to something good. Relational databases are the culmination of database design. A relational database has relationships between data sets with the freedom of a network database, but without the constraints of a hierarchical database. Instead, application developers or database administrators customize the relationships between data sets to meet the exact needs of the business.
The structure of a relational database is defined by its schema. Records are often called rows, and rows are stored in tables. A table can have a primary key, which is one of the fields in the table that contains a unique value. A primary key permits rapid table lookups (queries to find specific records) through binary searches and other data lookup algorithms. An index can also be built for any of the other fields in a table, to facilitate more rapid lookups.
One of the most powerful features of a relational database is the use of a foreign key, which is a field in a table that points to a primary key in a different table.
Stored procedures are subroutines that can be accessed by software applications. As their name suggests, stored procedures are actually stored in the relational database.
Prepared statements (sometimes called parameterized statements) are basically canned statements that can be called by the application.
 Both stored procedures and prepared statements can help an application be more resistant to SQL Injection attacks.
Both stored procedures and prepared statements can help an application be more resistant to SQL Injection attacks.
Distributed database
A distributed database is a database whose components exist in multiple physical locations. A distributed database is so named because of its location, not because of its design. A distributed database can be hierarchical, network, relational, object, or any other design.
Object database
An object database model is a part of the overall object-oriented application design — the objects in an object database include data records, as well as their methods (application code). Like OO application programming languages, object databases can have classes (data types), instantiations (individual data records), inheritance, and encapsulation.
Object databases are a niche player in the market for database management systems, where relational databases dominate.
Database transactions
A transaction is an action that is performed on a database that results in the addition, alteration, or removal of data. An application program performs transactions through function calls, using the database management system’s API. One of the advantages of using a database management system is that the software developer can leave the details of data management to the relational database and concentrate on the application’s main functions.
The dominant computer language used to manipulate data in a database is Structured Query Language (SQL). Developed in the 1970s, SQL (pronounced SEE-kwul) is used to query a database, update data, define the structure of the database, and perform access management. An application program can dynamically construct SQL statements and pass them to the database management system in order to perform queries or update data.
The principal SQL commands are SELECT (which queries a database by requesting that it return specific records), UPDATE (which changes one or more fields or rows in a table), and INSERT (which adds new rows to a table).
SQL statements can also be grouped together in a transaction, to ensure that all of the statements are executed together, thus guaranteeing the integrity of the database. For example, a business transaction might consist of updates to several tables at the same time, and all the updates must occur — or none of them do — in an all-or-nothing arrangement.
Databases employ a mechanism known as locking in order to avoid collisions in which two or more programs may be trying to update the same table or row at the same time. A lock can be placed on a field, an entire row, or an entire table. The database management system manages these locks, and it follows certain rules if parts of a database are locked for a long time.
..................Content has been hidden....................
You can't read the all page of ebook, please click here login for view all page.