
CHAPTER 7
Security Operations
This domain includes questions from the following topics:
• Operations department responsibilities
• Administrative management responsibilities
• Physical security
• Secure resource provisioning
• Network and resource availability
• Preventive and detective measures
• Incident management
• Investigations
• Disaster recovery
• Liability
• Personnel safety concerns
Security operations consists of the routine tasks involved with maintaining a network and its systems after they are developed and implemented. It includes ensuring that entities have the proper access privileges, that oversight is implemented, that network and systems run correctly and securely, and that applications are running in a secure and protected manner. It is also a very important topic, because as networks and computing environments continually evolve, individuals responsible for security operations must respond accordingly.
Q QUESTIONS
1. Which of the following is not a common component of configuration management change control steps?
A. Tested and presented
B. Service level agreement approval
C. Report change to management
D. Approval of the change
2. A change management process should include a number of procedures. Which of the following incorrectly describes a characteristic or component of a change control policy?
A. Changes that are unanimously approved by the change control committee must be tested to uncover any unforeseen results.
B. Changes approved by the change control committee should be entered into a change log.
C. A schedule that outlines the projected phases of the change should be developed.
D. An individual or group should be responsible for approving proposed changes.
3. Device backup and other availability solutions are chosen to balance the value of having information available against the cost of keeping that information available. Which of the following best describes fault-tolerant technologies?
A. They are among the most expensive solutions and are usually only for the most mission-critical information.
B. They help service providers identify appropriate availability services for a specific customer.
C. They are required to maintain integrity, regardless of the other technologies in place.
D. They allow a failed component to be replaced while the system continues to run.
4. Which of the following refers to the expected amount of time it will take to get a device fixed and back into production after its failure?
A. SLA
B. MTTR
C. Hot-swap
D. MTBF
5. Which of the following correctly describes direct access and sequential access storage devices?
A. Any point on a direct access storage device may be promptly reached, whereas every point in between the current position and the desired position of a sequential access storage device must be traversed in order to reach the desired position.
B. RAIT is an example of a direct access storage device, while RAID is an example of a sequential access storage device.
C. MAID is a direct access storage device, while RAID is an example of a sequential access storage device.
D. As an example of sequential access storage, tape drives are faster than direct access storage devices.
6. Various levels of RAID dictate the type of activity that will take place within the RAID system. Which level is associated with byte-level parity?
A. RAID level 0
B. RAID level 3
C. RAID level 5
D. RAID level 10
7. RAID systems use a number of techniques to provide redundancy and performance. Which of the following activities divides and writes data over several drives?
A. Parity
B. Mirroring
C. Striping
D. Hot-swapping
8. What is the difference between hierarchical storage management and storage area network technologies?
A. HSM uses optical or tape jukeboxes, and SAN is a standard of how to develop and implement this technology.
B. HSM and SAN are one and the same. The difference is in the implementation.
C. HSM uses optical or tape jukeboxes, and SAN is a network of connected storage.
D. SAN uses optical or tape jukeboxes, and HSM is a network of connected storage systems.
9. There are often scenarios where the IT staff must react to emergencies and quickly apply fixes or change configurations. When dealing with such emergencies, which of the following is the best approach to making changes?
A. Review the changes within 48 hours of making them.
B. Review and document the emergency changes after the incident is over.
C. Activity should not take place in this manner.
D. Formally submit the change to a change control committee and follow the complete change control process.
10. Countries around the world are focusing on cyber warfare and how it can affect their utility and power grid infrastructures. Securing water, power, oil, gas, transportation, and manufacturing systems is an increasing priority for governments. These critical infrastructures are made up of different types of industrial control systems (ICS) that provide this type of functionality. Which of the following answers is not considered a common ICS?
A. Central control systems
B. Programmable logic controllers
C. Supervisory control and data acquisition
D. Distributed control systems
11. John is responsible for providing a weekly report to his manager outlining the week’s security incidents and mitigation steps. What steps should he take if a report has no information?
A. Send his manager an e-mail telling her so.
B. Deliver last week’s report and make sure it’s clearly dated.
C. Deliver a report that states “No output.”
D. Don’t do anything.
12. Brian, a security administrator, is responding to a virus infection. The antivirus application reports that a file has been infected with a dangerous virus and disinfecting it could damage the file. What course of action should Brian take?
A. Replace the file with the file saved from the day before.
B. Disinfect the file and contact the vendor.
C. Restore an uninfected version of the patched file from backup media.
D. Back up the data and disinfect the file.
13. Guidelines should be followed to allow secure remote administration. Which of the following is not one of those guidelines?
A. A small number of administrators should be allowed to carry out remote functionality.
B. Critical systems should be administered locally instead of remotely.
C. Strong authentication should be in place.
D. Telnet should be used to send commands and data.
14. In a redundant array of inexpensive disks (RAID) system, data and parity information are striped over several different disks. What is parity information?
A. Information used to create new data
B. Information used to erase data
C. Information used to rebuild data
D. Information used to build data
15. Mirroring of drives is when data is written to two drives at once for redundancy purposes. What similar type of technology is shown in the graphic that follows?
A. Direct access storage
B. Disk duplexing
C. Striping
D. Massive array of inactive disks
16. There are several different types of important architectures within backup technologies. Which architecture does the graphic that follows represent?
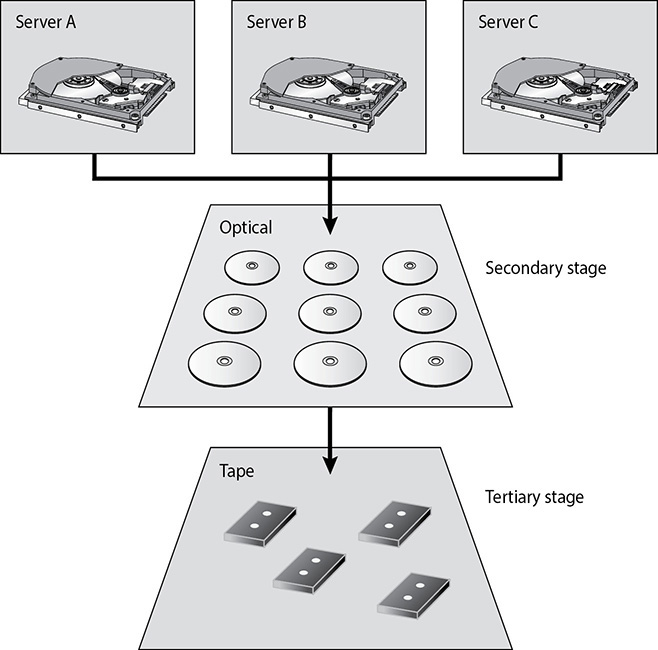
A. Clustering
B. Grid computing
C. Backup tier security
D. Hierarchical storage management
17. ___________ provides for availability and scalability. It groups physically different systems and combines them logically, which helps to provide immunity to faults and improves performance.
A. Disc duping
B. Clustering
C. RAID
D. Virtualization
18. Bob is a new security administrator at a financial institution. The organization has experienced some suspicious activity on one of the critical servers that contain customer data. When reviewing how the systems are administered, he uncovers some concerning issues pertaining to remote administration. Which of the following should not be put into place to reduce these concerns?
i. Commands and data should not be sent in cleartext.
ii. SSH should be used, not Telnet.
iii. Truly critical systems should be administered locally instead of remotely.
iv. Only a small number of administrators should be able to carry out remote functionality.
v. Strong authentication should be in place for any administration activities.
A. i, ii
B. None of them
C. ii, iv
D. All of them
19. A suspected crime has been reported within your organization. Which of the following steps should the incident response team take first?
A. Establish a procedure for responding to the incident.
B. Call in forensic experts.
C. Determine that a crime has been committed.
D. Notify senior management.
20. Which of the following is a correct statement regarding digital forensics?
A. It is the study of computer technology.
B. It is a set of hardware-specific processes that must be followed in order for evidence to be admissible in a court of law.
C. It encompasses network and code analysis, and may be referred to as electronic data discovery.
D. Digital forensic responsibilities should be assigned to a network administrator before an incident occurs.
21. Which of the following dictates that all evidence be labeled with information indicating who secured and validated it?
A. Chain of custody
B. Due care
C. Investigation
D. Motive, opportunity, and means
22. Which of the following is not true of a forensic investigation?
A. The crime scene should be modified as necessary.
B. A file copy tool may not recover all data areas of the device that are necessary for investigation.
C. Contamination of the crime scene may not negate derived evidence, but it should still be documented.
D. Only individuals with knowledge of basic crime scene analysis should have access to the crime scene.
23. Stephanie has been put in charge of developing incident response and forensics procedures her company needs to carry out if an incident occurs. She needs to ensure that their procedures map to the international principles for gathering and protecting digital evidence. She also needs to ensure that if and when internal forensics teams are deployed, they have labels, tags, evidence bags, cable ties, imaging software, and other associated tools. Which of the following best describes what Stephanie needs to build for the deployment teams?
A. Local and remote imaging system
B. Forensics field kit
C. Chain of custody procedures and tools
D. Digital evidence collection software
24. When developing a recovery and continuity program within an organization, different metrics can be used to properly measure potential damages and recovery requirements. These metrics help us quantify our risks and the benefits of controls we can put into place. Two metrics commonly used in the development of recovery programs are recovery point objective (RPO) and recovery time objective (RTO). Data restoration (RPO) requirements can be different from service restoration (RTO) requirements. Which of the following best defines these two main recovery measurements in this type of scenario?
A. RPO is the acceptable amount of data loss measured in time. RTO is the acceptable time period before a service level must be restored.
B. RTO is the earliest time period in which a data set must be restored. RPO is the acceptable amount of downtime in a given period.
C. RPO is the acceptable amount of data loss measured in time. RTO is the earliest time period in which data must be restored.
D. RPO is the acceptable amount of downtime measured. RTO is the earliest time period in which a service level must be restored.
25. An approach to alternate offsite facilities is to establish a reciprocal agreement. Which of the following describes the pros and cons of a reciprocal agreement?
A. It is fully configured and ready to operate within a few hours, but is the most expensive of the offsite choices.
B. It is an inexpensive option, but it takes the most time and effort to get up and running after a disaster.
C. It is a good alternative for companies that depend upon proprietary software, but annual testing is not usually available.
D. It is the cheapest of the offsite choices, but mixing operations could introduce many security issues.
26. The operations team is responsible for defining which data gets backed up and how often. Which type of backup process backs up files that have been modified since the last time all data was backed up?
A. Incremental process
B. Full backup
C. Partial backup
D. Differential process
27. After a disaster occurs, a damage assessment needs to take place. Which of the following steps occurs last in a damage assessment?
A. Determine the cause of the disaster.
B. Identify the resources that must be replaced immediately.
C. Declare a disaster.
D. Determine how long it will take to bring critical functions back online.
28. Of the following plans, which establishes senior management and a headquarters after a disaster?
A. Continuity of operations plan
B. Cyber-incident response plan
C. Occupant emergency plan
D. IT contingency plan
29. Gizmos and Gadgets has restored its original facility after a disaster. What should be moved in first?
A. Management
B. Most critical systems
C. Most critical functions
D. Least critical functions
30. Several teams should be involved in carrying out the business continuity plan. Which team is responsible for starting the recovery of the original site?
A. Damage assessment team
B. BCP team
C. Salvage team
D. Restoration team
31. ACME, Inc., paid a software vendor to develop specialized software, and that vendor has gone out of business. ACME, Inc., does not have access to the code and therefore cannot keep it updated. What mechanism should the company have implemented to prevent this from happening?
A. Reciprocal agreement
B. Software escrow
C. Electronic vaulting
D. Business interruption insurance
32. Which of the following incorrectly describes the concept of executive succession planning?
A. Predetermined steps protect the company if a senior executive leaves.
B. Two or more senior staff cannot be exposed to a particular risk at the same time.
C. It documents the assignment of deputy roles.
D. It covers assigning a skeleton crew to resume operations after a disaster.
33. What type of infrastructural setup is illustrated in the graphic that follows?
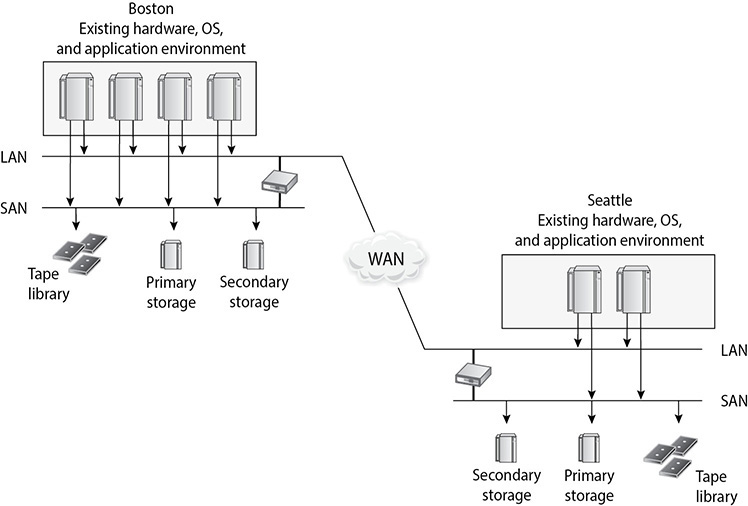
C. Hot site
B. Warm site
C. Cold site
D. Reciprocal agreement
34. There are several types of redundant technologies that can be put into place. What type of technology is shown in the graphic that follows?

A. Tape vaulting
B. Remote journaling
C. Electronic vaulting
D. Redundant site
35. Here is a graphic of a business continuity policy. Which component is missing from this graphic?
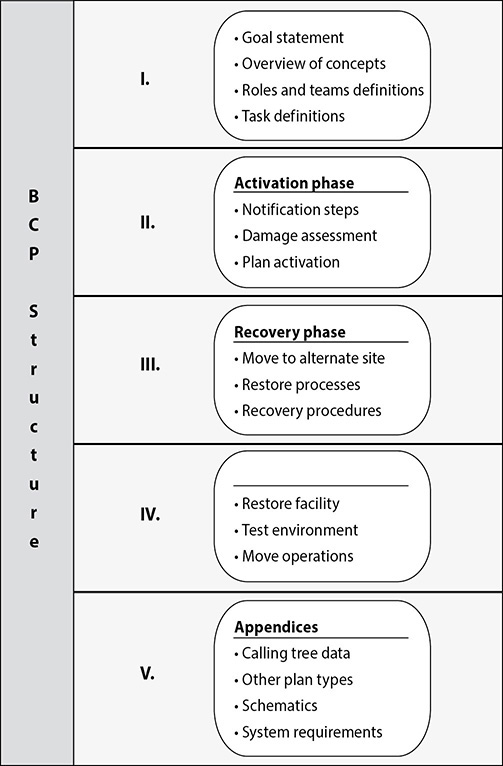
A. Damage assessment phase
B. Reconstitution phase
C. Business resumption phase
D. Continuity of operations plan
36. The recovery time objective (RTO) and maximum tolerable downtime (MTD) metrics have similar roles, but their values are very different. Which of the following best describes the difference between RTO and MTD metrics?
A. The RTO is a time period that represents the inability to recover, and the MTD represents an allowable amount of downtime.
B. The RTO is an allowable amount of downtime, and the MTD represents a time period after which severe and perhaps irreparable damage is likely.
C. The RTO is a metric used in disruptions, and the MTD is a metric used in disasters.
D. The RTO is a metric pertaining to loss of access to data, and the MTD is a metric pertaining to loss of access to hardware and processing capabilities.
37. High availability (HA) is a combination of technologies and processes that work together to ensure that specific critical functions are always up and running at the necessary level. To provide this level of high availability, a company has to have a long list of technologies and processes that provide redundancy, fault tolerance, and failover capabilities. Which of the following best describes these characteristics?
A. Redundancy is the duplication of noncritical components or functions of a system with the intention of decreasing reliability of the system. Fault tolerance is the capability of a technology to discontinue to operate as expected even if something unexpected takes place. If a technology has a failover capability, this means that if there is a failure that cannot be handled through normal means, then processing is “switched over” to a working system.
B. Redundancy is the duplication of critical components or functions of a system with the intention of increasing reliability of the system. Fault tolerance is the capability of a technology to discontinue to operate as expected even if something unexpected takes place. If a technology has a failover capability, this means that if there is a failure that cannot be handled through normal means, then processing is “switched over” to a working system.
C. Redundancy is the duplication of critical components or functions of a system with the intention of increasing reliability of the system. Fault tolerance is the capability of a technology to continue to operate as expected even if something unexpected takes place. If a technology has a failover capability, this means that if there is a failure that cannot be handled through normal means, then processing is “switched over” to a nonworking system.
D. Redundancy is the duplication of critical components or functions of a system with the intention of increasing reliability of the system. Fault tolerance is the capability of a technology to continue to operate as expected even if something unexpected takes place. If a technology has a failover capability, this means that if there is a failure that cannot be handled through normal means, then processing is “switched over” to a working system.
The following scenario applies to questions 38 and 39.
Jeff is leading the business continuity group in his company. They have completed a business impact analysis and have determined that if the company’s credit card processing functionality was unavailable for 48 hours the company would most likely experience such a large financial hit that it would have to go out of business. The team has calculated that this functionality needs to be up and running within 28 hours after experiencing a disaster for the company to stay in business. The team has also determined that the restoration steps must be able to restore data that is 60 minutes old or less.
38. In this scenario, which of the following is the work recovery time value?
A. 48 hours
B. 28 hours
C. 20 hours
D. 1 hour
39. In this scenario, what would the 60-minute time period be referred to as?
A. Recovery time period
B. Maximum tolerable downtime
C. Recovery point objective
D. Recovery point time period
40. For evidence to be legally admissible, it must be relevant, complete, sufficient, and reliably obtained. Which characteristic refers to the evidence having a reasonable and sensible relationship to the findings?
A. Complete
B. Reliable
C. Relevant
D. Sufficient
41. Alex works for a chemical distributor that assigns employees tasks that separate their duties and routinely rotates job assignments. Which of the following best describes the differences between these countermeasures?
A. They are the same thing with different titles.
B. They are administrative controls that enforce access control and protect the company’s resources.
C. Separation of duties ensures that one person cannot perform a high-risk task alone, and job rotation can uncover fraud because more than one person knows the tasks of a position.
D. Job rotation ensures that one person cannot perform a high-risk task alone, and separation of duties can uncover fraud because more than one person knows the tasks of a position.
42. Maria has been tasked with reviewing and ultimately augmenting her organization’s physical security. Of the following controls and approaches, which should be her highest priority to ensure are properly implemented?
A. Physical facility access controls, such as mechanical and device locks, on all necessary ingress points
B. Personnel access controls, such as badges, biometric systems, etc.
C. External boundary controls, including perimeter intrusion detection and assessment system (PIDAS) fencing, security guards, etc.
D. Layered facility access controls, with multiple internal and external ingress and egress controls
43. Which of the following statements is true with respect to preventing and/or detecting security disasters?
A. Information security continuous monitoring (ISCM), defined by NIST Special Publication 800-137 as maintaining an ongoing awareness of your current security posture, vulnerabilities, and threats, is the best way to facilitate sound risk management decisions.
B. Whitelisting allowed executables or, barring that, blacklisting known bad ones is the only effective means of preventing malware from compromising systems and causing a serious security breach.
C. A rigorous regime of vulnerability and patch management can effectively eliminate the risk of known malware compromising critical corporate systems.
D. By aggregating and correlating asset data and the security events concerning them, the deployment of a security information and event management (SIEM) system is the best way to ensure that attacks can be properly dealt with before they result in disaster.
44. Miranda has been directed to investigate a possible violation of her organization’s acceptable use policy (AUP) by a coworker suspected of running cryptocurrency mining software on his desktop system. Which of the following is NOT a very likely scenario that could arise during her investigation?
A. During the course of her investigation, Miranda discovered that her coworker was also downloading and storing pornographic images, many of which appeared to involve minors. What began as an administrative investigation became a criminal one.
B. Miranda was able to find evidence that appeared to corroborate the intentional use of illicit software to mine cryptocurrency using corporate resources (mainly CPU and power). As a result, Miranda’s coworker was charged with a criminal violation of the Computer Fraud and Abuse Act (CFAA).
C. As a result of Miranda’s investigation, her coworker was terminated for violating the AUP. However, he hired an attorney and sued the company for wrongful dismissal based on knowledge that other employees were also running cryptocurrency mining software but went unpunished. Her administrative case became a civil one.
D. Compelling evidence was found of a significant AUP violation, resulting in termination. However, during the subsequent wrongful dismissal suit (as described in option C), it was discovered that Miranda had not anticipated a court case, and so had not properly obtained or preserved the evidence. Consequently, the judge found summarily for the plaintiff, who got his job back along with compensatory damages.
QUICK ANSWER KEY
1. B
2. A
3. A
4. B
5. A
6. B
7. C
8. C
9. B
10. A
11. C
12. C
13. D
14. C
15. B
16. D
17. B
18. B
19. C
20. C
21. A
22. A
23. B
24. A
25. D
26. D
27. C
28. A
29. D
30. C
31. B
32. D
33. A
34. A
35. B
36. B
37. D
38. C
39. C
40. C
41. C
42. D
43. A
44. B
ANSWERS A
1. Which of the following is not a common component of configuration management change control steps?
A. Tested and presented
B. Service level agreement approval
C. Report change to management
D. Approval of the change
![]() B. A well-structured change management process should be established to aid staff members through many different types of changes to the environment. This process should be laid out in the change control policy. Although the types of changes vary, a standard list of procedures can help keep the process under control and ensure it is carried out in a predictable manner. A change control policy should include procedures for requesting a change to take place, approving the change, documentation of the change, testing and presentation, implementation, and reporting the change to management. Configuration management change control processes do not commonly have an effect on service level agreement approvals.
B. A well-structured change management process should be established to aid staff members through many different types of changes to the environment. This process should be laid out in the change control policy. Although the types of changes vary, a standard list of procedures can help keep the process under control and ensure it is carried out in a predictable manner. A change control policy should include procedures for requesting a change to take place, approving the change, documentation of the change, testing and presentation, implementation, and reporting the change to management. Configuration management change control processes do not commonly have an effect on service level agreement approvals.
![]() A is incorrect because testing and presentation should be included in a standard change control policy. All changes must be fully tested to uncover any unforeseen results. Depending on the severity of the change and the company’s organization, the change and implementation may need to be presented to a change control committee. This helps show different sides to the purpose and outcome of the change and the possible ramifications.
A is incorrect because testing and presentation should be included in a standard change control policy. All changes must be fully tested to uncover any unforeseen results. Depending on the severity of the change and the company’s organization, the change and implementation may need to be presented to a change control committee. This helps show different sides to the purpose and outcome of the change and the possible ramifications.
![]() C is incorrect because a procedure for reporting a change to management should be included in a standard change control policy. After a change is implemented, a full report summarizing the change should be submitted to management. This report can be submitted on a periodic basis to keep management up to date and ensure continual support.
C is incorrect because a procedure for reporting a change to management should be included in a standard change control policy. After a change is implemented, a full report summarizing the change should be submitted to management. This report can be submitted on a periodic basis to keep management up to date and ensure continual support.
![]() D is incorrect because a procedure for obtaining approval for the change should be included in a standard change control policy. The individual requesting the change must justify the reasons and clearly show the benefits and possible pitfalls of the change. Sometimes the requester is asked to conduct more research and provide more information before the change is approved.
D is incorrect because a procedure for obtaining approval for the change should be included in a standard change control policy. The individual requesting the change must justify the reasons and clearly show the benefits and possible pitfalls of the change. Sometimes the requester is asked to conduct more research and provide more information before the change is approved.
2. A change management process should include a number of procedures. Which of the following incorrectly describes a characteristic or component of a change control policy?
A. Changes that are unanimously approved by the change control committee must be tested to uncover any unforeseen results.
B. Changes approved by the change control committee should be entered into a change log.
C. A schedule that outlines the projected phases of the change should be developed.
D. An individual or group should be responsible for approving proposed changes.
![]() A. A well-structured change management process should be put into place to aid staff members through many different types of changes to the environment. This process should be laid out in the change control policy. Although the types of changes vary, a standard list of procedures can help keep the process under control and ensure it is carried out in a predictable manner. All changes approved by the change control committee (not just those unanimously approved) must be fully tested to uncover any unforeseen results. Depending on the severity of the change and the company’s organization, the change and implementation may need to be presented to a change control committee. This helps show different sides to the purpose and outcome of the change and the possible ramifications.
A. A well-structured change management process should be put into place to aid staff members through many different types of changes to the environment. This process should be laid out in the change control policy. Although the types of changes vary, a standard list of procedures can help keep the process under control and ensure it is carried out in a predictable manner. All changes approved by the change control committee (not just those unanimously approved) must be fully tested to uncover any unforeseen results. Depending on the severity of the change and the company’s organization, the change and implementation may need to be presented to a change control committee. This helps show different sides to the purpose and outcome of the change and the possible ramifications.
![]() B is incorrect because it is true that changes approved by the change control committee should be entered into a change log. The log should be updated as the process continues toward completion. It is important to track and document all changes that are approved and implemented.
B is incorrect because it is true that changes approved by the change control committee should be entered into a change log. The log should be updated as the process continues toward completion. It is important to track and document all changes that are approved and implemented.
![]() C is incorrect because once a change is fully tested and approved, a schedule should be developed that outlines the projected phases of the change being implemented and the necessary milestones. These steps should be fully documented, and progress should be monitored.
C is incorrect because once a change is fully tested and approved, a schedule should be developed that outlines the projected phases of the change being implemented and the necessary milestones. These steps should be fully documented, and progress should be monitored.
![]() D is incorrect because requests should be presented to an individual or group that is responsible for approving changes and overseeing the activities of changes that take place within an environment.
D is incorrect because requests should be presented to an individual or group that is responsible for approving changes and overseeing the activities of changes that take place within an environment.
3. Device backup and other availability solutions are chosen to balance the value of having information available against the cost of keeping that information available. Which of the following best describes fault-tolerant technologies?
A. They are among the most expensive solutions and are usually only for the most mission-critical information.
B. They help service providers identify appropriate availability services for a specific customer.
C. They are required to maintain integrity, regardless of the other technologies in place.
D. They allow a failed component to be replaced while the system continues to run.
![]() A. Fault-tolerant technologies keep information available not only against individual storage device faults, but even against whole system failures. Fault tolerance is among the most expensive possible solutions for availability and is commonly justified only for the most mission-critical information. All technology will eventually experience a failure of some form. A company that would suffer irreparable harm from any unplanned downtime can justify paying the high cost for fault-tolerant systems.
A. Fault-tolerant technologies keep information available not only against individual storage device faults, but even against whole system failures. Fault tolerance is among the most expensive possible solutions for availability and is commonly justified only for the most mission-critical information. All technology will eventually experience a failure of some form. A company that would suffer irreparable harm from any unplanned downtime can justify paying the high cost for fault-tolerant systems.
![]() B is incorrect because service level agreements (SLAs) help service providers, whether they are an internal IT operation or an outsourcer, decide what type of availability technology and service is appropriate. From this determination, the price of a service or the budget of the IT operation can be set. The process of developing an SLA with a business is also beneficial to the business. While some businesses have performed this type of introspection on their own, many have not, and being forced to go through the exercise as part of budgeting for their internal IT operations or external sourcing helps the business understand the real value of its information.
B is incorrect because service level agreements (SLAs) help service providers, whether they are an internal IT operation or an outsourcer, decide what type of availability technology and service is appropriate. From this determination, the price of a service or the budget of the IT operation can be set. The process of developing an SLA with a business is also beneficial to the business. While some businesses have performed this type of introspection on their own, many have not, and being forced to go through the exercise as part of budgeting for their internal IT operations or external sourcing helps the business understand the real value of its information.
![]() C is incorrect because fault-tolerant technologies do not necessarily have anything to do with data or system integrity.
C is incorrect because fault-tolerant technologies do not necessarily have anything to do with data or system integrity.
![]() D is incorrect because “hot-swappable” hardware does not require shutting down the system and may or may not be considered a fault-tolerant technology. Hot-swapping allows the administrator to replace the failed component while the system continues to run and information remains available; usually degraded performance results, but unplanned downtime is avoided.
D is incorrect because “hot-swappable” hardware does not require shutting down the system and may or may not be considered a fault-tolerant technology. Hot-swapping allows the administrator to replace the failed component while the system continues to run and information remains available; usually degraded performance results, but unplanned downtime is avoided.
4. Which of the following refers to the expected amount of time it will take to get a device fixed and back into production after its failure?
A. SLA
B. MTTR
C. Hot-swap
D. MTBF
![]() B. Mean time to repair (MTTR) is the expected amount of time it will take to get a device fixed and back into production after its failure. For a hard drive in a redundant array, the MTTR is the amount of time between the actual failure and the time when, after noticing the failure, someone has replaced the failed drive and the redundant array has completed rewriting the information on the new drive. This is likely to be measured in hours. For a nonredundant hard drive in a desktop PC, the MTTR is the amount of time between when the drive goes down and the point at which the replaced hard drive has been reloaded with the operating system, software, and any backed-up data belonging to the user. This is likely to be measured in days. For an unplanned reboot, the MTTR is the amount of time between the failure of the system and the point in time when it has rebooted its operating system, checked the state of its disks, restarted its applications, allowed its applications to check the consistency of their data, and once again begun processing transactions.
B. Mean time to repair (MTTR) is the expected amount of time it will take to get a device fixed and back into production after its failure. For a hard drive in a redundant array, the MTTR is the amount of time between the actual failure and the time when, after noticing the failure, someone has replaced the failed drive and the redundant array has completed rewriting the information on the new drive. This is likely to be measured in hours. For a nonredundant hard drive in a desktop PC, the MTTR is the amount of time between when the drive goes down and the point at which the replaced hard drive has been reloaded with the operating system, software, and any backed-up data belonging to the user. This is likely to be measured in days. For an unplanned reboot, the MTTR is the amount of time between the failure of the system and the point in time when it has rebooted its operating system, checked the state of its disks, restarted its applications, allowed its applications to check the consistency of their data, and once again begun processing transactions.
![]() A is incorrect because a service level agreement (SLA) addresses the degree of availability that will be provided to a customer, whether that customer be an internal department within the same organization or an external customer. The MTTR is the expected amount of time it will take to get a device fixed and back into production. The MTTR may pertain to fixing a component or the device or replacing the device.
A is incorrect because a service level agreement (SLA) addresses the degree of availability that will be provided to a customer, whether that customer be an internal department within the same organization or an external customer. The MTTR is the expected amount of time it will take to get a device fixed and back into production. The MTTR may pertain to fixing a component or the device or replacing the device.
![]() C is incorrect because hot-swapping refers to the replacement of a failed component while the system continues to run and information remains available. Usually degraded performance results, but unplanned downtime is avoided. Hot-swapping does not refer to the amount of time needed to get a system back up and running.
C is incorrect because hot-swapping refers to the replacement of a failed component while the system continues to run and information remains available. Usually degraded performance results, but unplanned downtime is avoided. Hot-swapping does not refer to the amount of time needed to get a system back up and running.
![]() D is incorrect because MTBF refers to mean time between failure, which is the estimated lifespan of a piece of equipment. It is calculated by the vendor of the equipment or a third party. The reason for using this value is to know approximately when a particular device will need to be replaced. It is used as a benchmark for reliability by predicting the average time that will pass in the operation of a component or a system until it needs to be replaced.
D is incorrect because MTBF refers to mean time between failure, which is the estimated lifespan of a piece of equipment. It is calculated by the vendor of the equipment or a third party. The reason for using this value is to know approximately when a particular device will need to be replaced. It is used as a benchmark for reliability by predicting the average time that will pass in the operation of a component or a system until it needs to be replaced.
5. Which of the following correctly describes direct access and sequential access storage devices?
A. Any point on a direct access storage device may be promptly reached, whereas every point in between the current position and the desired position of a sequential access storage device must be traversed in order to reach the desired position.
B. RAIT is an example of a direct access storage device, while RAID is an example of a sequential access storage device.
C. MAID is a direct access storage device, while RAID is an example of a sequential access storage device.
D. As an example of sequential access storage, tape drives are faster than direct access storage devices.
![]() A. Direct access storage device (DASD) is a general term for magnetic disk storage devices, which historically have been used in mainframe and minicomputer (mid-range computer) environments. A redundant array of independent disks (RAID) is a type of DASD. The key distinction between DASDs and sequential access storage devices (SASDs) is that any point on a DASD may be promptly reached, whereas every point in between the current position and the desired position of an SASD must be traversed in order to reach the desired position. Tape drives are SASDs. Tape storage is the lowest-cost option for very large amounts of data but is very slow compared to disk storage.
A. Direct access storage device (DASD) is a general term for magnetic disk storage devices, which historically have been used in mainframe and minicomputer (mid-range computer) environments. A redundant array of independent disks (RAID) is a type of DASD. The key distinction between DASDs and sequential access storage devices (SASDs) is that any point on a DASD may be promptly reached, whereas every point in between the current position and the desired position of an SASD must be traversed in order to reach the desired position. Tape drives are SASDs. Tape storage is the lowest-cost option for very large amounts of data but is very slow compared to disk storage.
![]() B is incorrect because RAIT stands for redundant array of independent tapes. RAIT uses tape drives, which are SASDs. In RAIT, data is striped in parallel to multiple tape drives, with or without a redundant parity drive. This provides the high capacity at low cost typical of tape storage, with higher-than-usual tape data transfer rates and optional data integrity. RAID is a type of DASD. RAID combines several physical disks and aggregates them into logical arrays. When data is saved, the information is written across all drives. A RAID appears as a single drive to applications and other devices.
B is incorrect because RAIT stands for redundant array of independent tapes. RAIT uses tape drives, which are SASDs. In RAIT, data is striped in parallel to multiple tape drives, with or without a redundant parity drive. This provides the high capacity at low cost typical of tape storage, with higher-than-usual tape data transfer rates and optional data integrity. RAID is a type of DASD. RAID combines several physical disks and aggregates them into logical arrays. When data is saved, the information is written across all drives. A RAID appears as a single drive to applications and other devices.
![]() C is incorrect because both MAID, a massive array of inactive disks, and RAID are examples of DASDs. Any point on these magnetic disk storage devices can be reached without traversing every point between the current and desired positions. This makes DASDs faster than SASDs.
C is incorrect because both MAID, a massive array of inactive disks, and RAID are examples of DASDs. Any point on these magnetic disk storage devices can be reached without traversing every point between the current and desired positions. This makes DASDs faster than SASDs.
![]() D is incorrect because SASDs are slower than DASDs. Tape drives are an example of SASD technology.
D is incorrect because SASDs are slower than DASDs. Tape drives are an example of SASD technology.
6. Various levels of RAID dictate the type of activity that will take place within the RAID system. Which level is associated with byte-level parity?
A. RAID level 0
B. RAID level 3
C. RAID level 5
D. RAID level 10
![]() B. Redundant array of inexpensive disks (RAID) provides fault tolerance for hard drives and can improve system performance. Redundancy and speed are provided by breaking up the data and writing it across several disks so that different disk heads can work simultaneously to retrieve the requested information. Recovery data is also created—this is called parity—so that if one disk fails, the parity data can be used to reconstruct the corrupted or lost information. Different activities that provide fault tolerance or performance improvements occur at different levels of a RAID system. RAID level 3 is a scheme employing byte-level striping and a dedicated parity disk. Data is striped over all but the last drive, with parity data held on only the last drive. If a drive fails, it can be reconstructed from the parity drive. The most common RAID levels used today is level 5.
B. Redundant array of inexpensive disks (RAID) provides fault tolerance for hard drives and can improve system performance. Redundancy and speed are provided by breaking up the data and writing it across several disks so that different disk heads can work simultaneously to retrieve the requested information. Recovery data is also created—this is called parity—so that if one disk fails, the parity data can be used to reconstruct the corrupted or lost information. Different activities that provide fault tolerance or performance improvements occur at different levels of a RAID system. RAID level 3 is a scheme employing byte-level striping and a dedicated parity disk. Data is striped over all but the last drive, with parity data held on only the last drive. If a drive fails, it can be reconstructed from the parity drive. The most common RAID levels used today is level 5.
![]() A is incorrect because only striping occurs at level 0. Data is striped over several drives. No redundancy or parity is involved. If one volume fails, the entire volume can be unusable. Level 0 is used for performance only.
A is incorrect because only striping occurs at level 0. Data is striped over several drives. No redundancy or parity is involved. If one volume fails, the entire volume can be unusable. Level 0 is used for performance only.
![]() C is incorrect because RAID 5 employs block-level striping and interleaving parity across all disks. Data is written in disk block units to all drives. Parity is written to all drives also, which ensures there is no single point of failure. RAID level 5 is the most commonly used mode.
C is incorrect because RAID 5 employs block-level striping and interleaving parity across all disks. Data is written in disk block units to all drives. Parity is written to all drives also, which ensures there is no single point of failure. RAID level 5 is the most commonly used mode.
![]() D is incorrect because level 10 is associated with striping and mirroring. It is a combination of levels 1 and 0. Data is simultaneously mirrored and striped across several drives and can support multiple drive failures.
D is incorrect because level 10 is associated with striping and mirroring. It is a combination of levels 1 and 0. Data is simultaneously mirrored and striped across several drives and can support multiple drive failures.
7. RAID systems use a number of techniques to provide redundancy and performance. Which of the following activities divides and writes data over several drives?
A. Parity
B. Mirroring
C. Striping
D. Hot-swapping
![]() C. Redundant array of inexpensive disks (RAID) is a technology used for redundancy and/or performance improvement. It combines several physical disks and aggregates them into logical arrays. When data is saved, the information is written across all drives. A RAID appears as a single drive to applications and other devices. When striping is used, data is written across all drives. This activity divides and writes the data over several drives. Both write and read performance are increased dramatically because more than one head is reading or writing data at the same time.
C. Redundant array of inexpensive disks (RAID) is a technology used for redundancy and/or performance improvement. It combines several physical disks and aggregates them into logical arrays. When data is saved, the information is written across all drives. A RAID appears as a single drive to applications and other devices. When striping is used, data is written across all drives. This activity divides and writes the data over several drives. Both write and read performance are increased dramatically because more than one head is reading or writing data at the same time.
![]() A is incorrect because parity is used to rebuild lost or corrupted data. Various levels of RAID dictate the type of activity that will take place within the RAID system. Some levels deal only with performance issues, while other levels deal with performance and fault tolerance. If fault tolerance is one of the services a RAID level provides, parity is involved. If a drive fails, the parity is basically instructions that tell the RAID system how to rebuild the lost data on the new hard drive. Parity is used to rebuild a new drive so that all the information is restored.
A is incorrect because parity is used to rebuild lost or corrupted data. Various levels of RAID dictate the type of activity that will take place within the RAID system. Some levels deal only with performance issues, while other levels deal with performance and fault tolerance. If fault tolerance is one of the services a RAID level provides, parity is involved. If a drive fails, the parity is basically instructions that tell the RAID system how to rebuild the lost data on the new hard drive. Parity is used to rebuild a new drive so that all the information is restored.
![]() B is incorrect because mirroring occurs when data is written to two drives at once. If one drive fails, the other drive has the exact same data available. Mirroring provides redundancy. Mirroring occurs at level 1 of RAID systems, and with striping in level 10.
B is incorrect because mirroring occurs when data is written to two drives at once. If one drive fails, the other drive has the exact same data available. Mirroring provides redundancy. Mirroring occurs at level 1 of RAID systems, and with striping in level 10.
![]() D is incorrect because hot-swappable refers to a type of disk that is in most RAID systems. RAID systems with hot-swapping disks are able to replace drives while the system is running. When a drive is swapped out, or added, the parity data is used to rebuild the data on the new disk that was just added.
D is incorrect because hot-swappable refers to a type of disk that is in most RAID systems. RAID systems with hot-swapping disks are able to replace drives while the system is running. When a drive is swapped out, or added, the parity data is used to rebuild the data on the new disk that was just added.
8. What is the difference between hierarchical storage management and storage area network technologies?
A. HSM uses optical or tape jukeboxes, and SAN is a standard of how to develop and implement this technology.
B. HSM and SAN are one and the same. The difference is in the implementation.
C. HSM uses optical or tape jukeboxes, and SAN is a network of connected storage.
D. SAN uses optical or tape jukeboxes, and HSM is a network of connected storage systems.
![]() C. Hierarchical storage management (HSM) provides continuous online backup functionality. It combines hard disk technology with the cheaper and slower optical or tape jukeboxes. The HSM system dynamically manages the storage and recovery of files, which are copied to storage media devices that vary in speed and cost. The faster media hold the data that is accessed more often, and the seldom-used files are stored on the slower devices, or near-line devices. The storage media could include optical disks, magnetic disks, and tapes. This functionality happens in the background without the knowledge of the user or any need for user intervention. A storage area network (SAN), on the other hand, consists of numerous storage devices linked together by a high-speed private network and storage-specific switches. When a user makes a request for a file, he does not need to know which server or tape drive to go to—the SAN software finds it and provides it to the user.
C. Hierarchical storage management (HSM) provides continuous online backup functionality. It combines hard disk technology with the cheaper and slower optical or tape jukeboxes. The HSM system dynamically manages the storage and recovery of files, which are copied to storage media devices that vary in speed and cost. The faster media hold the data that is accessed more often, and the seldom-used files are stored on the slower devices, or near-line devices. The storage media could include optical disks, magnetic disks, and tapes. This functionality happens in the background without the knowledge of the user or any need for user intervention. A storage area network (SAN), on the other hand, consists of numerous storage devices linked together by a high-speed private network and storage-specific switches. When a user makes a request for a file, he does not need to know which server or tape drive to go to—the SAN software finds it and provides it to the user.
![]() A is incorrect because SAN is not a standard for how to develop and implement HSM. A SAN is a network of connected storage devices. SANs provide redundancy, fault tolerance, reliability, and backups, and they allow the users and administrators to interact with the SAN as one virtual entity. Because the network that carries the data in the SAN is separate from a company’s regular data network, all of this performance, reliability, and flexibility comes without impact to the data networking capabilities of the systems on the network.
A is incorrect because SAN is not a standard for how to develop and implement HSM. A SAN is a network of connected storage devices. SANs provide redundancy, fault tolerance, reliability, and backups, and they allow the users and administrators to interact with the SAN as one virtual entity. Because the network that carries the data in the SAN is separate from a company’s regular data network, all of this performance, reliability, and flexibility comes without impact to the data networking capabilities of the systems on the network.
![]() B is incorrect because HSM and SAN are not the same. HSM uses conventional hard disk backup processes combined with optical/tape jukeboxes. A SAN uses a networked system of storage devices integrated into an established network.
B is incorrect because HSM and SAN are not the same. HSM uses conventional hard disk backup processes combined with optical/tape jukeboxes. A SAN uses a networked system of storage devices integrated into an established network.
![]() D is incorrect because the statement is backward. HSM uses optical or tape jukeboxes, and SAN is a network of connected storage systems. HSM was created to save money and time. It provides an economical and efficient way of storing data by combining higher-speed, higher-cost storage media for frequently accessed data with lower-speed, lower-cost media for infrequently accessed data. SANs, on the other hand, are for companies that have to keep track of terabytes of data and have the funds for this type of technology. They are not commonly used in large or midsized companies.
D is incorrect because the statement is backward. HSM uses optical or tape jukeboxes, and SAN is a network of connected storage systems. HSM was created to save money and time. It provides an economical and efficient way of storing data by combining higher-speed, higher-cost storage media for frequently accessed data with lower-speed, lower-cost media for infrequently accessed data. SANs, on the other hand, are for companies that have to keep track of terabytes of data and have the funds for this type of technology. They are not commonly used in large or midsized companies.
9. There are often scenarios where the IT staff must react to emergencies and quickly apply fixes or change configurations. When dealing with such emergencies, which of the following is the best approach to making changes?
A. Review the changes within 48 hours of making them.
B. Review and document the emergency changes after the incident is over.
C. Activity should not take place in this manner.
D. Formally submit the change to a change control committee and follow the complete change control process.
![]() B. After the incident or emergency is over, the staff should review the changes to ensure that they are correct and do not open security holes or affect interoperability. The changes need to be properly documented and the system owner needs to be informed of changes.
B. After the incident or emergency is over, the staff should review the changes to ensure that they are correct and do not open security holes or affect interoperability. The changes need to be properly documented and the system owner needs to be informed of changes.
![]() A is incorrect because it is not the best answer. The changes should be reviewed after the incident is over, but not necessarily within 48 hours. Many times the changes should be reviewed hours after they are implemented—not days.
A is incorrect because it is not the best answer. The changes should be reviewed after the incident is over, but not necessarily within 48 hours. Many times the changes should be reviewed hours after they are implemented—not days.
![]() C is incorrect because, while it would be nice if emergencies didn’t happen, they are unavoidable. At one point or another, for example, an IT administrator will have to roll out a patch or change configurations to protect systems against a high-profile vulnerability.
C is incorrect because, while it would be nice if emergencies didn’t happen, they are unavoidable. At one point or another, for example, an IT administrator will have to roll out a patch or change configurations to protect systems against a high-profile vulnerability.
![]() D is incorrect because if an emergency is taking place, then there is no time to go through the process of submitting a change to the change control committee and following the complete change control process. These steps usually apply to large changes that take place to a network or environment. These types of changes are typically expensive and can have lasting effects on a company.
D is incorrect because if an emergency is taking place, then there is no time to go through the process of submitting a change to the change control committee and following the complete change control process. These steps usually apply to large changes that take place to a network or environment. These types of changes are typically expensive and can have lasting effects on a company.
10. Countries around the world are focusing on cyber warfare and how it can affect their utility and power grid infrastructures. Securing water, power, oil, gas, transportation, and manufacturing systems is an increasing priority for governments. These critical infrastructures are made up of different types of industrial control systems (ICS) that provide this type of functionality. Which of the following answers is not considered a common ICS?
A. Central control systems
B. Programmable logic controllers
C. Supervisory control and data acquisition
D. Distributed control systems
![]() A. The most common types of industrial control systems (ICS) are distributed control systems (DCSs), programmable logical controllers (PLCs), and supervisory control and data acquisition (SCADA) systems. While these systems provide a type of central control functionality, this is not considered a common type of ICS because these systems are distributed in nature. DCSs are used to control product systems for industries such as water, electrical, and oil refineries. The DCS uses a centralized supervisory control loop to connect controllers that are distributed throughout a geographic location. The supervisor controllers on this centralized loop request status data from field controllers and feed this information back to a central interface for monitoring. The status data captured from sensors can be used in failover situations. The DCS can provide redundancy protection through a modular approach. This reduces the impact of a single fault, meaning that if one portion of the system went down, the whole system would not be down.
A. The most common types of industrial control systems (ICS) are distributed control systems (DCSs), programmable logical controllers (PLCs), and supervisory control and data acquisition (SCADA) systems. While these systems provide a type of central control functionality, this is not considered a common type of ICS because these systems are distributed in nature. DCSs are used to control product systems for industries such as water, electrical, and oil refineries. The DCS uses a centralized supervisory control loop to connect controllers that are distributed throughout a geographic location. The supervisor controllers on this centralized loop request status data from field controllers and feed this information back to a central interface for monitoring. The status data captured from sensors can be used in failover situations. The DCS can provide redundancy protection through a modular approach. This reduces the impact of a single fault, meaning that if one portion of the system went down, the whole system would not be down.
![]() B is incorrect because programmable logic controllers (PLCs) are common industrial control systems (ICS) and are used to connect sensors throughout the utility network and convert this sensor signal data into digital data that can be processed by monitoring and managing software. PLCs were originally created to carry out simplistic logic functions within basic hardware, but have evolved into powerful controllers used in both SCADA and DCS systems. In SCADA systems, the PLCs are most commonly used to communicate with remote field devices, and in DCS systems, they are used as local controllers in a supervisory control scheme. The PLC provides an application programming interface to allow for communication to an engineering control software application.
B is incorrect because programmable logic controllers (PLCs) are common industrial control systems (ICS) and are used to connect sensors throughout the utility network and convert this sensor signal data into digital data that can be processed by monitoring and managing software. PLCs were originally created to carry out simplistic logic functions within basic hardware, but have evolved into powerful controllers used in both SCADA and DCS systems. In SCADA systems, the PLCs are most commonly used to communicate with remote field devices, and in DCS systems, they are used as local controllers in a supervisory control scheme. The PLC provides an application programming interface to allow for communication to an engineering control software application.
![]() C is incorrect because supervisory control and data acquisition (SCADA) refers to a computerized system that is used to gather and process data and apply operational controls to the components that make up a utility-based environment. It is a common type of ICS. The SCADA control center allows for centralized monitoring and control for field sites (e.g., power grids, water systems). The field sites have remote station control devices (field devices), which provide data to the central control center. Based upon the data that is sent from the field device, an automated process or an operator can send out commands to control the remote devices to fix problems or change configurations for operational needs. This is a challenging environment to work within because the hardware and software are usually proprietary to the specific industry; are privately owned and operated; and communication can take place over telecommunication links, satellites, and microwave-based systems.
C is incorrect because supervisory control and data acquisition (SCADA) refers to a computerized system that is used to gather and process data and apply operational controls to the components that make up a utility-based environment. It is a common type of ICS. The SCADA control center allows for centralized monitoring and control for field sites (e.g., power grids, water systems). The field sites have remote station control devices (field devices), which provide data to the central control center. Based upon the data that is sent from the field device, an automated process or an operator can send out commands to control the remote devices to fix problems or change configurations for operational needs. This is a challenging environment to work within because the hardware and software are usually proprietary to the specific industry; are privately owned and operated; and communication can take place over telecommunication links, satellites, and microwave-based systems.
![]() D is incorrect because the distributed control system (DCS) is a common type of ICS. In a DCS, the control elements are not centralized. The control elements are distributed throughout the system and are managed by one or more computers. SCADA systems, DCSs, and PLCs are used in industrial sectors such as water, oil and gas, electric, transportation, etc. These systems are considered “critical infrastructure” and are highly interconnected and dependent systems. In the past, these critical infrastructure environments did not use the same type of technology and protocols as the Internet, and thus were isolated and very hard to attack. Over time, these proprietary environments have been turned into IP-based environments using networking devices and connected IP-based workstations. This shift allows for better centralized controlling and management, but opens them up to the same type of cyber attacks that the computer industry has always been vulnerable to.
D is incorrect because the distributed control system (DCS) is a common type of ICS. In a DCS, the control elements are not centralized. The control elements are distributed throughout the system and are managed by one or more computers. SCADA systems, DCSs, and PLCs are used in industrial sectors such as water, oil and gas, electric, transportation, etc. These systems are considered “critical infrastructure” and are highly interconnected and dependent systems. In the past, these critical infrastructure environments did not use the same type of technology and protocols as the Internet, and thus were isolated and very hard to attack. Over time, these proprietary environments have been turned into IP-based environments using networking devices and connected IP-based workstations. This shift allows for better centralized controlling and management, but opens them up to the same type of cyber attacks that the computer industry has always been vulnerable to.
11. John is responsible for providing a weekly report to his manager outlining the week’s security incidents and mitigation steps. What steps should he take if a report has no information?
A. Send his manager an e-mail telling her so.
B. Deliver last week’s report and make sure it’s clearly dated.
C. Deliver a report that states “No output.”
D. Don’t do anything.
![]() C. If a report has no information (nothing to report), it should state, “No output.” This ensures that the manager is aware that there is no information to report and that John isn’t just slacking in his responsibilities.
C. If a report has no information (nothing to report), it should state, “No output.” This ensures that the manager is aware that there is no information to report and that John isn’t just slacking in his responsibilities.
![]() A is incorrect because John should still deliver his manager a report. It should say, “No output.” Even though an e-mail achieves the objective of communicating that there’s nothing to report, a report should still be delivered for consistency.
A is incorrect because John should still deliver his manager a report. It should say, “No output.” Even though an e-mail achieves the objective of communicating that there’s nothing to report, a report should still be delivered for consistency.
![]() B is incorrect because delivering last week’s report does not provide documentation or communicate to John’s manager that there is nothing to report this week. He should give his manager a report that reads, “No output.”
B is incorrect because delivering last week’s report does not provide documentation or communicate to John’s manager that there is nothing to report this week. He should give his manager a report that reads, “No output.”
![]() D is incorrect because if John doesn’t do anything when there is nothing to report, his manager must track John down and ask him for the report. For all she knows, John is slacking on his job duties. By providing a report that reads, “No output,” John is communicating this information to his manager in an efficient manner that she has come to expect.
D is incorrect because if John doesn’t do anything when there is nothing to report, his manager must track John down and ask him for the report. For all she knows, John is slacking on his job duties. By providing a report that reads, “No output,” John is communicating this information to his manager in an efficient manner that she has come to expect.
12. Brian, a security administrator, is responding to a virus infection. The antivirus application reports that a file has been infected with a dangerous virus and disinfecting it could damage the file. What course of action should Brian take?
A. Replace the file with the file saved from the day before.
B. Disinfect the file and contact the vendor.
C. Restore an uninfected version of the patched file from backup media.
D. Back up the data and disinfect the file.
![]() C. The best course of action is to install an uninfected version of a patched file from backup media. Attempts to disinfect the file could corrupt it, and it is important to restore a file that is known to be “clean.”
C. The best course of action is to install an uninfected version of a patched file from backup media. Attempts to disinfect the file could corrupt it, and it is important to restore a file that is known to be “clean.”
![]() A is incorrect because the previous day’s file could also be infected. It is best to replace the file entirely with a freshly installed and patched version.
A is incorrect because the previous day’s file could also be infected. It is best to replace the file entirely with a freshly installed and patched version.
![]() B is incorrect because disinfecting the file could cause damage, as stated in the question. In addition, the vendor of the application will not necessarily be useful in this situation. It is easier to restore a clean version of the file and move on with production.
B is incorrect because disinfecting the file could cause damage, as stated in the question. In addition, the vendor of the application will not necessarily be useful in this situation. It is easier to restore a clean version of the file and move on with production.
![]() D is incorrect because backing up the file will also back up the virus, and as the question stated, disinfecting the file will cause damage and potential data loss.
D is incorrect because backing up the file will also back up the virus, and as the question stated, disinfecting the file will cause damage and potential data loss.
13. Guidelines should be followed to allow secure remote administration. Which of the following is not one of those guidelines?
A. A small number of administrators should be allowed to carry out remote functionality.
B. Critical systems should be administered locally instead of remotely.
C. Strong authentication should be in place.
D. Telnet should be used to send commands and data.
![]() D. Telnet should not be allowed for remote administration because it sends all data, including administrator credentials, in cleartext. This type of communication should go over more secure protocols, as in SSH.
D. Telnet should not be allowed for remote administration because it sends all data, including administrator credentials, in cleartext. This type of communication should go over more secure protocols, as in SSH.
![]() A is incorrect because it is true that only a small number of administrators should be able to carry out remote functionality. This helps minimize the risk posed to the network.
A is incorrect because it is true that only a small number of administrators should be able to carry out remote functionality. This helps minimize the risk posed to the network.
![]() B is incorrect because it is true that critical systems should be administered locally instead of remotely. It is safer to send administrative commands over the internal, private network than it is to do so over a public network.
B is incorrect because it is true that critical systems should be administered locally instead of remotely. It is safer to send administrative commands over the internal, private network than it is to do so over a public network.
![]() C is incorrect because it is true that strong authentication should be in place for any administration activities. Anything less than strong authentication, such as a password, would be easy for an attacker to crack and thereby gain administrative access.
C is incorrect because it is true that strong authentication should be in place for any administration activities. Anything less than strong authentication, such as a password, would be easy for an attacker to crack and thereby gain administrative access.
14. In a redundant array of inexpensive disks (RAID) system, data and parity information are striped over several different disks. What is parity information?
A. Information used to create new data
B. Information used to erase data
C. Information used to rebuild data
D. Information used to build data
![]() C. Redundant array of inexpensive disks (RAID) provides fault tolerance for hard drives and the data they hold and can improve system performance. Redundancy and speed are provided by breaking up the data and writing it across several disks so that different disk heads can work simultaneously to retrieve the requested information. Control data is also spread across each disk—this is called parity—so that if one disk fails, the other disks can work together and restore its data. If fault tolerance is one of the services a RAID level provides, parity is involved.
C. Redundant array of inexpensive disks (RAID) provides fault tolerance for hard drives and the data they hold and can improve system performance. Redundancy and speed are provided by breaking up the data and writing it across several disks so that different disk heads can work simultaneously to retrieve the requested information. Control data is also spread across each disk—this is called parity—so that if one disk fails, the other disks can work together and restore its data. If fault tolerance is one of the services a RAID level provides, parity is involved.
![]() A is incorrect because parity information is not used to create new data but is used as instructions on how to re-create data that has been lost or corrupted. If a drive fails, the parity is basically instructions that tell the RAID system how to rebuild the lost data on the new hard drive. Parity is used to rebuild a new drive so that all the information is restored.
A is incorrect because parity information is not used to create new data but is used as instructions on how to re-create data that has been lost or corrupted. If a drive fails, the parity is basically instructions that tell the RAID system how to rebuild the lost data on the new hard drive. Parity is used to rebuild a new drive so that all the information is restored.
![]() B is incorrect because parity information is not used to erase data, but is used as instructions on how to re-create data that has been lost or corrupted.
B is incorrect because parity information is not used to erase data, but is used as instructions on how to re-create data that has been lost or corrupted.
![]() D is incorrect because parity information is not used to build data, but is used as instructions on how to re-create data that has been lost or corrupted.
D is incorrect because parity information is not used to build data, but is used as instructions on how to re-create data that has been lost or corrupted.
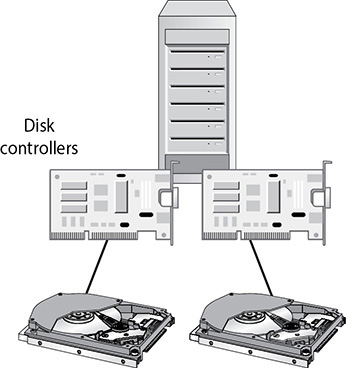
15. Mirroring of drives is when data is written to two drives at once for redundancy purposes. What similar type of technology is shown in the graphic that follows?
A. Direct access storage
B. Disk duplexing
C. Striping
D. Massive array of inactive disks
![]() B. Information that is required to always be available should be mirrored or duplexed. In both mirroring (also known as RAID 1) and duplexing, every data write operation occurs simultaneously or nearly simultaneously in more than one physical place. The distinction between mirroring and duplexing is that with mirroring the two (or more) physical places where the data is written may be attached to the same controller, leaving the storage still subject to the single point of failure of the controller itself; in duplexing, two or more controllers are used.
B. Information that is required to always be available should be mirrored or duplexed. In both mirroring (also known as RAID 1) and duplexing, every data write operation occurs simultaneously or nearly simultaneously in more than one physical place. The distinction between mirroring and duplexing is that with mirroring the two (or more) physical places where the data is written may be attached to the same controller, leaving the storage still subject to the single point of failure of the controller itself; in duplexing, two or more controllers are used.
![]() A is incorrect because direct access storage is a general term for magnetic disk storage devices, which historically have been used in mainframe and minicomputer (mid-range computer) environments. A redundant array of independent disks (RAID) is a type of direct access storage device (DASD).
A is incorrect because direct access storage is a general term for magnetic disk storage devices, which historically have been used in mainframe and minicomputer (mid-range computer) environments. A redundant array of independent disks (RAID) is a type of direct access storage device (DASD).
![]() C is incorrect because when data is written across all drives, the technique of striping is used. This activity divides and writes the data over several drives. The write performance is not affected, but the read performance is increased dramatically because more than one head is retrieving data at the same time. Parity information is used to rebuild lost or corrupted data. Striping just means data and potentially parity information is written across multiple disks.
C is incorrect because when data is written across all drives, the technique of striping is used. This activity divides and writes the data over several drives. The write performance is not affected, but the read performance is increased dramatically because more than one head is retrieving data at the same time. Parity information is used to rebuild lost or corrupted data. Striping just means data and potentially parity information is written across multiple disks.
![]() D is incorrect because in a massive array of inactive disks (MAID), rack-mounted disk arrays have all inactive disks powered down, with only the disk controller alive. When an application asks for data, the controller powers up the appropriate disk drive(s), transfers the data, and then powers the drive(s) down again. By powering down infrequently accessed drives, energy consumption is significantly reduced, and the service life of the disk drives may be increased.
D is incorrect because in a massive array of inactive disks (MAID), rack-mounted disk arrays have all inactive disks powered down, with only the disk controller alive. When an application asks for data, the controller powers up the appropriate disk drive(s), transfers the data, and then powers the drive(s) down again. By powering down infrequently accessed drives, energy consumption is significantly reduced, and the service life of the disk drives may be increased.
16. There are several different types of important architectures within backup technologies. Which architecture does the graphic that follows represent?
A. Clustering
B. Grid computing
C. Backup tier security
D. Hierarchical storage management
![]() D. Hierarchical storage management (HSM) provides continuous online backup functionality. It combines hard disk technology with the cheaper and slower optical or tape jukeboxes. The HSM system dynamically manages the storage and recovery of files, which are copied to storage media devices that vary in speed and cost. The faster media hold the data that is accessed more often, and the seldom-used files are stored on the slower devices, or near-line devices.
D. Hierarchical storage management (HSM) provides continuous online backup functionality. It combines hard disk technology with the cheaper and slower optical or tape jukeboxes. The HSM system dynamically manages the storage and recovery of files, which are copied to storage media devices that vary in speed and cost. The faster media hold the data that is accessed more often, and the seldom-used files are stored on the slower devices, or near-line devices.
![]() A is incorrect because clustering is a fault-tolerant server technology that is similar to redundant servers, except each server takes part in processing services that are requested. A server cluster is a group of servers that are viewed logically as one server to users and can be managed as a single logical system. Clustering provides for availability and scalability. It groups physically different systems and combines them logically, which provides immunity to faults and improves performance.
A is incorrect because clustering is a fault-tolerant server technology that is similar to redundant servers, except each server takes part in processing services that are requested. A server cluster is a group of servers that are viewed logically as one server to users and can be managed as a single logical system. Clustering provides for availability and scalability. It groups physically different systems and combines them logically, which provides immunity to faults and improves performance.
![]() B is incorrect because grid computing is a load-balanced parallel means of massive computation, similar to clusters, but implemented with loosely coupled systems that may join and leave the grid randomly. Most computers have extra CPU processing power that is not being used many times throughout the day. Just like the power grid provides electricity to entities on an as-needed basis, computers can volunteer to allow their extra processing power to be available to different groups for different projects. The first project to use grid computing was SETI (Search for Extraterrestrial Intelligence), where people allowed their systems to participate in scanning the universe looking for aliens who are trying to talk to us.
B is incorrect because grid computing is a load-balanced parallel means of massive computation, similar to clusters, but implemented with loosely coupled systems that may join and leave the grid randomly. Most computers have extra CPU processing power that is not being used many times throughout the day. Just like the power grid provides electricity to entities on an as-needed basis, computers can volunteer to allow their extra processing power to be available to different groups for different projects. The first project to use grid computing was SETI (Search for Extraterrestrial Intelligence), where people allowed their systems to participate in scanning the universe looking for aliens who are trying to talk to us.
![]() C is incorrect because backup tier security is not a formal technology and is a distracter answer.
C is incorrect because backup tier security is not a formal technology and is a distracter answer.
17. ___________ provides for availability and scalability. It groups physically different systems and combines them logically, which helps to provide immunity to faults and improves performance.
A. Disc duping
B. Clustering
C. RAID
D. Virtualization
![]() B. Clustering is a fault-tolerant server technology that is similar to redundant servers, except each server takes part in processing services that are requested. A server cluster is a group of servers that are viewed logically as one server to users and can be managed as a single logical system. Clustering provides for availability and scalability. It groups physically different systems and combines them logically, which helps to provide immunity to faults and improves performance. Clusters work as an intelligent unit to balance traffic, and users who access the cluster do not know they may be accessing different systems at different times. To the users, all servers within the cluster are seen as one unit.
B. Clustering is a fault-tolerant server technology that is similar to redundant servers, except each server takes part in processing services that are requested. A server cluster is a group of servers that are viewed logically as one server to users and can be managed as a single logical system. Clustering provides for availability and scalability. It groups physically different systems and combines them logically, which helps to provide immunity to faults and improves performance. Clusters work as an intelligent unit to balance traffic, and users who access the cluster do not know they may be accessing different systems at different times. To the users, all servers within the cluster are seen as one unit.
![]() A is incorrect because this is a distracter answer. There is not an official technology with this name.
A is incorrect because this is a distracter answer. There is not an official technology with this name.
![]() C is incorrect because redundant array of inexpensive disks (RAID) provides fault tolerance for hard drives and can improve system performance. Redundancy and speed are provided by breaking up the data and writing them across several disks so different disk heads can work simultaneously to retrieve the requested information. RAID does not address scalability and performance.
C is incorrect because redundant array of inexpensive disks (RAID) provides fault tolerance for hard drives and can improve system performance. Redundancy and speed are provided by breaking up the data and writing them across several disks so different disk heads can work simultaneously to retrieve the requested information. RAID does not address scalability and performance.
![]() D is incorrect because virtualization is the creation of a virtual version of something, such as a hardware platform, operating system, storage device, or network resource. Hardware virtualization or platform virtualization refers to the creation of a virtual machine that acts like a real system with an operating system. Software executed on these virtual machines is separated from the underlying hardware resources by an abstraction layer.
D is incorrect because virtualization is the creation of a virtual version of something, such as a hardware platform, operating system, storage device, or network resource. Hardware virtualization or platform virtualization refers to the creation of a virtual machine that acts like a real system with an operating system. Software executed on these virtual machines is separated from the underlying hardware resources by an abstraction layer.
18. Bob is a new security administrator at a financial institution. The organization has experienced some suspicious activity on one of the critical servers that contain customer data. When reviewing how the systems are administered, he uncovers some concerning issues pertaining to remote administration. Which of the following should not be put into place to reduce these concerns?
i. Commands and data should not be sent in cleartext.
ii. SSH should be used, not Telnet.
iii. Truly critical systems should be administered locally instead of remotely.
iv. Only a small number of administrators should be able to carry out remote functionality.
v. Strong authentication should be in place for any administration activities.
A. i, ii
B. None of them
C. ii, iv
D. All of them
![]() B. All of these countermeasures should be put into place for proper remote administration activities.
B. All of these countermeasures should be put into place for proper remote administration activities.
![]() A is incorrect because sensitive commands and data should not be sent in cleartext (that is, they should be encrypted) to critical systems. For example, SSH should be used, not Telnet. SSH is a network protocol for secure data communication. It allows for remote shell services and command execution and other secure network services between two networked systems. It was designed as a replacement for Telnet and other insecure remote shell protocols such as the Berkeley rsh and rexec protocols, which send information, notably passwords, in plaintext, rendering them susceptible to interception and disclosure.
A is incorrect because sensitive commands and data should not be sent in cleartext (that is, they should be encrypted) to critical systems. For example, SSH should be used, not Telnet. SSH is a network protocol for secure data communication. It allows for remote shell services and command execution and other secure network services between two networked systems. It was designed as a replacement for Telnet and other insecure remote shell protocols such as the Berkeley rsh and rexec protocols, which send information, notably passwords, in plaintext, rendering them susceptible to interception and disclosure.
![]() C is incorrect because sensitive commands and data should not be sent in cleartext (that is, they should be encrypted). For example, SSH should be used, not Telnet. Truly critical systems should be administered locally instead of remotely. Only a small number of administrators should be able to carry out this remote functionality.
C is incorrect because sensitive commands and data should not be sent in cleartext (that is, they should be encrypted). For example, SSH should be used, not Telnet. Truly critical systems should be administered locally instead of remotely. Only a small number of administrators should be able to carry out this remote functionality.
![]() D is incorrect because all of these countermeasures should be put into place for proper remote administration activities.
D is incorrect because all of these countermeasures should be put into place for proper remote administration activities.
19. A suspected crime has been reported within your organization. Which of the following steps should the incident response team take first?
A. Establish a procedure for responding to the incident.
B. Call in forensic experts.
C. Determine that a crime has been committed.
D. Notify senior management.
![]() C. When a suspected crime is reported, the incident response team should follow a set of predetermined steps to ensure uniformity in their approach and make sure no steps are skipped. First, the incident response team should investigate the report and determine that an actual crime has been committed. If the team determines that a crime has been carried out, senior management should be informed immediately. At this point, the company must decide if it wants to conduct its own forensic investigation or call in external experts.
C. When a suspected crime is reported, the incident response team should follow a set of predetermined steps to ensure uniformity in their approach and make sure no steps are skipped. First, the incident response team should investigate the report and determine that an actual crime has been committed. If the team determines that a crime has been carried out, senior management should be informed immediately. At this point, the company must decide if it wants to conduct its own forensic investigation or call in external experts.
![]() A is incorrect because a procedure for responding to an incident should be established before an incident takes place. Incident handling is commonly a recovery plan that responds to malicious technical threats. While the primary goal of incident handling is to contain and mitigate any damage caused by an incident and to prevent any further damage, other objectives include detecting a problem, determining its cause, resolving the problem, and documenting the entire process.
A is incorrect because a procedure for responding to an incident should be established before an incident takes place. Incident handling is commonly a recovery plan that responds to malicious technical threats. While the primary goal of incident handling is to contain and mitigate any damage caused by an incident and to prevent any further damage, other objectives include detecting a problem, determining its cause, resolving the problem, and documenting the entire process.
![]() B is incorrect because calling in a forensics team does not occur until the incident response team has investigated the report and verified that a crime has occurred. Then the company can decide if it wants to conduct its own forensic investigation or call in external experts. If experts are going to be called in, the system that was attacked should be left alone in order to try and preserve as much evidence of the attack as possible.
B is incorrect because calling in a forensics team does not occur until the incident response team has investigated the report and verified that a crime has occurred. Then the company can decide if it wants to conduct its own forensic investigation or call in external experts. If experts are going to be called in, the system that was attacked should be left alone in order to try and preserve as much evidence of the attack as possible.
![]() D is incorrect because the incident response team must first determine that a crime has indeed been carried out before it can notify senior management. There is no need to alarm senior management if the report is false.
D is incorrect because the incident response team must first determine that a crime has indeed been carried out before it can notify senior management. There is no need to alarm senior management if the report is false.
20. Which of the following is a correct statement regarding digital forensics?
A. It is the study of computer technology.
B. It is a set of hardware-specific processes that must be followed in order for evidence to be admissible in a court of law.
C. It encompasses network and code analysis, and may be referred to as electronic data discovery.
D. Digital forensic responsibilities should be assigned to a network administrator before an incident occurs.
![]() C. Forensics is a science and an art that requires specialized techniques for the recovery, authentication, and analysis of electronic data that could have been affected by a criminal act. It is the coming together of computer science, information technology, and engineering with the legal system. When discussing digital forensics with others, you might hear the terms computer forensics, network forensics, electronic data discovery, cyberforensics, and forensic computing. (ISC)2 uses digital forensics as a synonym for all of these other terms, so that’s what you will most likely see on the CISSP exam. Digital forensics encompasses all domains in which evidence is in a digital or electronic form, either in storage or on the wire.
C. Forensics is a science and an art that requires specialized techniques for the recovery, authentication, and analysis of electronic data that could have been affected by a criminal act. It is the coming together of computer science, information technology, and engineering with the legal system. When discussing digital forensics with others, you might hear the terms computer forensics, network forensics, electronic data discovery, cyberforensics, and forensic computing. (ISC)2 uses digital forensics as a synonym for all of these other terms, so that’s what you will most likely see on the CISSP exam. Digital forensics encompasses all domains in which evidence is in a digital or electronic form, either in storage or on the wire.
![]() A is incorrect because digital forensics involves more than just the study of information technology. It encompasses the study of information technology but stretches into evidence gathering/protecting and working within specific legal systems.
A is incorrect because digital forensics involves more than just the study of information technology. It encompasses the study of information technology but stretches into evidence gathering/protecting and working within specific legal systems.
![]() B is incorrect because digital forensics does not refer to hardware or software. It is a set of specific processes relating to reconstruction of computer usage, examination of residual data, authentication of data by technical analysis or explanation of technical features of data, and computer usage that must be followed in order for evidence to be admissible in a court of law.
B is incorrect because digital forensics does not refer to hardware or software. It is a set of specific processes relating to reconstruction of computer usage, examination of residual data, authentication of data by technical analysis or explanation of technical features of data, and computer usage that must be followed in order for evidence to be admissible in a court of law.
![]() D is incorrect because digital forensics should be conducted by people with the proper training and skill set, which could or could not be the network administrator. Digital evidence can be fragile and must be worked with appropriately. If someone reboots the attacked system or inspects various files, it could corrupt viable evidence, change timestamps on key files, and erase footprints the criminal may have left.
D is incorrect because digital forensics should be conducted by people with the proper training and skill set, which could or could not be the network administrator. Digital evidence can be fragile and must be worked with appropriately. If someone reboots the attacked system or inspects various files, it could corrupt viable evidence, change timestamps on key files, and erase footprints the criminal may have left.
21. Which of the following dictates that all evidence be labeled with information indicating who secured and validated it?
A. Chain of custody
B. Due care
C. Investigation
D. Motive, opportunity, and means
![]() A. A crucial piece in the digital forensics process is keeping a proper chain of custody of the evidence. Because evidence from these types of crimes can be very volatile and easily dismissed from court due to improper handling, it is important to follow very strict and organized procedures when collecting and tagging evidence in every single case. Furthermore, the chain of custody should follow evidence through its entire life cycle, beginning with identification and ending with its destruction, permanent archiving, or return to owner. When copies of data need to be made, this process must meet certain standards to ensure quality and reliability. Specialized software for this purpose can be used. The copies must be able to be independently verified and must be tamperproof. Each piece of evidence should be marked in some way with the date, time, initials of the collector, and a case number if one has been assigned. The piece of evidence should then be sealed in a container, which should be marked with the same information. The container should be sealed with evidence tape, and if possible, the writing should be on the tape so that a broken seal can be detected.
A. A crucial piece in the digital forensics process is keeping a proper chain of custody of the evidence. Because evidence from these types of crimes can be very volatile and easily dismissed from court due to improper handling, it is important to follow very strict and organized procedures when collecting and tagging evidence in every single case. Furthermore, the chain of custody should follow evidence through its entire life cycle, beginning with identification and ending with its destruction, permanent archiving, or return to owner. When copies of data need to be made, this process must meet certain standards to ensure quality and reliability. Specialized software for this purpose can be used. The copies must be able to be independently verified and must be tamperproof. Each piece of evidence should be marked in some way with the date, time, initials of the collector, and a case number if one has been assigned. The piece of evidence should then be sealed in a container, which should be marked with the same information. The container should be sealed with evidence tape, and if possible, the writing should be on the tape so that a broken seal can be detected.
![]() B is incorrect because due care means to carry out activities that a reasonable person would be expected to carry out in the same situation. In short, due care means that a company practiced common sense and prudent management and acted responsibly. If a company does not practice due care in its efforts to protect itself from computer crime, it can be found negligent and legally liable for damages. A chain of custody, on the other hand, is a history that shows how evidence was collected, analyzed, transported, and preserved in order to be presented in court. Because electronic evidence can be easily modified, a clearly defined chain of custody demonstrates that the evidence is trustworthy.
B is incorrect because due care means to carry out activities that a reasonable person would be expected to carry out in the same situation. In short, due care means that a company practiced common sense and prudent management and acted responsibly. If a company does not practice due care in its efforts to protect itself from computer crime, it can be found negligent and legally liable for damages. A chain of custody, on the other hand, is a history that shows how evidence was collected, analyzed, transported, and preserved in order to be presented in court. Because electronic evidence can be easily modified, a clearly defined chain of custody demonstrates that the evidence is trustworthy.
![]() C is incorrect because investigation involves the proper collection of relevant data during the incident response process and includes analysis, interpretation, reaction, and recovery. The goals of this stage are to reduce the impact of the incident, identify the cause of the incident, resume operations as soon as possible, and apply what was learned to prevent the incident from recurring. It is also at this stage where it is determined whether a forensic investigation will take place. The chain of custody dictates how this material should be properly collected and protected during its life cycle of being evidence.
C is incorrect because investigation involves the proper collection of relevant data during the incident response process and includes analysis, interpretation, reaction, and recovery. The goals of this stage are to reduce the impact of the incident, identify the cause of the incident, resume operations as soon as possible, and apply what was learned to prevent the incident from recurring. It is also at this stage where it is determined whether a forensic investigation will take place. The chain of custody dictates how this material should be properly collected and protected during its life cycle of being evidence.
![]() D is incorrect because motive, opportunity, and means (MOM) is a strategy used to understand why a crime was carried out and by whom. This is the same strategy used to determine the suspects in a traditional, noncomputer crime. Motive is the “who” and “why” of a crime. Understanding the motive for a crime is an important piece in figuring out who would engage in such an activity. For example, many hackers attack big-name sites because when the sites go down, it is splashed all over the news. However, once these activities are no longer so highly publicized, the individuals will eventually stop initiating these types of attacks because their motive will have been diminished. Opportunity is the “where” and “when” of a crime. Opportunities usually arise when certain vulnerabilities or weaknesses are present. If a company does not have a firewall, hackers and attackers have all types of opportunities within that network. Once a crime fighter finds out why a person would want to commit a crime (motive), she will look at what could allow the criminal to be successful (opportunity). Means pertains to the capabilities a criminal would need to be successful. Suppose a crime fighter was asked to investigate a complex embezzlement that took place within a financial institution. If the suspects were three people who knew how to use a mouse, a keyboard, and a word processing application, but only one of them was a programmer and system analyst, the crime fighter would realize that this person may have the means to commit this crime much more successfully than the other two individuals.
D is incorrect because motive, opportunity, and means (MOM) is a strategy used to understand why a crime was carried out and by whom. This is the same strategy used to determine the suspects in a traditional, noncomputer crime. Motive is the “who” and “why” of a crime. Understanding the motive for a crime is an important piece in figuring out who would engage in such an activity. For example, many hackers attack big-name sites because when the sites go down, it is splashed all over the news. However, once these activities are no longer so highly publicized, the individuals will eventually stop initiating these types of attacks because their motive will have been diminished. Opportunity is the “where” and “when” of a crime. Opportunities usually arise when certain vulnerabilities or weaknesses are present. If a company does not have a firewall, hackers and attackers have all types of opportunities within that network. Once a crime fighter finds out why a person would want to commit a crime (motive), she will look at what could allow the criminal to be successful (opportunity). Means pertains to the capabilities a criminal would need to be successful. Suppose a crime fighter was asked to investigate a complex embezzlement that took place within a financial institution. If the suspects were three people who knew how to use a mouse, a keyboard, and a word processing application, but only one of them was a programmer and system analyst, the crime fighter would realize that this person may have the means to commit this crime much more successfully than the other two individuals.
22. Which of the following is not true of a forensic investigation?
A. The crime scene should be modified as necessary.
B. A file copy tool may not recover all data areas of the device that are necessary for investigation.
C. Contamination of the crime scene may not negate derived evidence, but it should still be documented.
D. Only individuals with knowledge of basic crime scene analysis should have access to the crime scene.
![]() A. The principles of criminalistics are included in the forensic investigation process. They are identification of the crime scene, protection of the environment against contamination and loss of evidence, identification of evidence and potential sources of evidence, and collection of evidence. In regard to minimizing the degree of contamination, it is important to understand that it is impossible not to change a crime scene—be it physical or digital. The key is to minimize changes and document what you did and why, and how the crime scene was affected.
A. The principles of criminalistics are included in the forensic investigation process. They are identification of the crime scene, protection of the environment against contamination and loss of evidence, identification of evidence and potential sources of evidence, and collection of evidence. In regard to minimizing the degree of contamination, it is important to understand that it is impossible not to change a crime scene—be it physical or digital. The key is to minimize changes and document what you did and why, and how the crime scene was affected.
![]() B is incorrect because it is true that a file copy tool may not recover all data areas of the device necessary for investigation. During the examination and analysis process of a forensic investigation, it is critical that the investigator works from an image that contains all of the data from the original disk. It must be a bit-level copy, sector by sector, to capture deleted files, slack spaces, and unallocated clusters. These types of images can be created through the use of specialized tools such as FTK Imager, EnCase, or the dd Unix utility.
B is incorrect because it is true that a file copy tool may not recover all data areas of the device necessary for investigation. During the examination and analysis process of a forensic investigation, it is critical that the investigator works from an image that contains all of the data from the original disk. It must be a bit-level copy, sector by sector, to capture deleted files, slack spaces, and unallocated clusters. These types of images can be created through the use of specialized tools such as FTK Imager, EnCase, or the dd Unix utility.
![]() C is incorrect because it is true that if a crime scene becomes contaminated, that should be documented. While it may not negate the derived evidence, it will make investigating the crime and providing useful evidence for court more challenging. Whether the crime scene is physical or digital, it is important to control who comes in contact with the evidence of the crime to ensure its integrity.
C is incorrect because it is true that if a crime scene becomes contaminated, that should be documented. While it may not negate the derived evidence, it will make investigating the crime and providing useful evidence for court more challenging. Whether the crime scene is physical or digital, it is important to control who comes in contact with the evidence of the crime to ensure its integrity.
![]() D is incorrect because the statement is true. Only authorized individuals should be allowed to access the crime scene, and these individuals should have knowledge of basic crime scene analysis. Other measures to protect the crime scene include documenting who is at the crime scene and the last individuals to interact with the system. In court, the integrity of the evidence may be in question if there were too many people milling around the crime scene.
D is incorrect because the statement is true. Only authorized individuals should be allowed to access the crime scene, and these individuals should have knowledge of basic crime scene analysis. Other measures to protect the crime scene include documenting who is at the crime scene and the last individuals to interact with the system. In court, the integrity of the evidence may be in question if there were too many people milling around the crime scene.
23. Stephanie has been put in charge of developing incident response and forensics procedures her company needs to carry out if an incident occurs. She needs to ensure that their procedures map to the international principles for gathering and protecting digital evidence. She also needs to ensure that if and when internal forensics teams are deployed, they have labels, tags, evidence bags, cable ties, imaging software, and other associated tools. Which of the following best describes what Stephanie needs to build for the deployment teams?
A. Local and remote imaging system
B. Forensics field kit
C. Chain of custody procedures and tools
D. Digital evidence collection software
![]() B. When forensics teams are deployed to investigate a potential crime, they should be properly equipped with all of the tools and supplies needed. The following are some of the common items in the forensics field kits:
B. When forensics teams are deployed to investigate a potential crime, they should be properly equipped with all of the tools and supplies needed. The following are some of the common items in the forensics field kits:
• Documentation tools: tags, labels, and timelined forms
• Disassembly and removal tools: antistatic bands, pliers, tweezers, screwdrivers, wire cutters, and so on
• Package and transport supplies: antistatic bags, evidence bags and tape, cable ties, and others
![]() A is incorrect because imaging software and tools only make up some of the tools that a forensics team needs. These types of tools do not include the items identified in the question, which are labels, tags, evidence bags, cable ties, imaging software, and other associated tools. These items should be organized and be in a field kit.
A is incorrect because imaging software and tools only make up some of the tools that a forensics team needs. These types of tools do not include the items identified in the question, which are labels, tags, evidence bags, cable ties, imaging software, and other associated tools. These items should be organized and be in a field kit.
![]() C is incorrect because chain of custody procedures and tools only make up some of the components that a forensics team needs. These types of tools do not include the items identified in the question, which are labels, tags, evidence bags, cable ties, imaging software, and other associated tools. These items should be organized and be in a field kit. A chain of custody is a history that shows how evidence was collected, analyzed, transported, and preserved in order to be presented in court. Because electronic evidence can be easily modified, a clearly defined chain of custody demonstrates that the evidence is trustworthy.
C is incorrect because chain of custody procedures and tools only make up some of the components that a forensics team needs. These types of tools do not include the items identified in the question, which are labels, tags, evidence bags, cable ties, imaging software, and other associated tools. These items should be organized and be in a field kit. A chain of custody is a history that shows how evidence was collected, analyzed, transported, and preserved in order to be presented in court. Because electronic evidence can be easily modified, a clearly defined chain of custody demonstrates that the evidence is trustworthy.
![]() D is incorrect because digital evidence collection tools only make up some of the components that a forensics team needs. These types of tools do not include the items identified in the question, which are labels, tags, evidence bags, cable ties, imaging software, and other associated tools. These items should be organized and be in a field kit. There are specialized software suites that allow forensics personnel to properly collect, analyze, and manage digital evidence through its life cycle. They are important, but only one component of an overall forensics kit.
D is incorrect because digital evidence collection tools only make up some of the components that a forensics team needs. These types of tools do not include the items identified in the question, which are labels, tags, evidence bags, cable ties, imaging software, and other associated tools. These items should be organized and be in a field kit. There are specialized software suites that allow forensics personnel to properly collect, analyze, and manage digital evidence through its life cycle. They are important, but only one component of an overall forensics kit.
24. When developing a recovery and continuity program within an organization, different metrics can be used to properly measure potential damages and recovery requirements. These metrics help us quantify our risks and the benefits of controls we can put into place. Two metrics commonly used in the development of recovery programs are recovery point objective (RPO) and recovery time objective (RTO). Data restoration (RPO) requirements can be different from service restoration (RTO) requirements. Which of the following best defines these two main recovery measurements in this type of scenario?
A. RPO is the acceptable amount of data loss measured in time. RTO is the acceptable time period before a service level must be restored.
B. RTO is the earliest time period in which a data set must be restored. RPO is the acceptable amount of downtime in a given period.
C. RPO is the acceptable amount of data loss measured in time. RTO is the earliest time period in which data must be restored.
D. RPO is the acceptable amount of downtime measured. RTO is the earliest time period in which a service level must be restored.
![]() A. The recovery point objective (RPO) is the acceptable amount of data loss measured in time. This value represents the earliest point in time by which data must be recovered. The higher the value of data, the more funds or other resources that can be put into place to ensure a smaller amount of data is lost in the event of a disaster. For example, if the RPO is set to two hours, this means that the organization has to have backup and restore processes that will only allow for the loss of up to two hours of data. The restore process cannot be something as time consuming as restoring from a backup tape manually, but will need to be an automated restoration process that can restore data more quickly and allow the production environment to be up and running and carrying out business processes. The recovery time objective (RTO) is the acceptable period before a specific service level must be restored in order to avoid unacceptable consequences after a disruption or disaster. While RPO pertains to data, RTO deals with the actual processing capabilities of an environment.
A. The recovery point objective (RPO) is the acceptable amount of data loss measured in time. This value represents the earliest point in time by which data must be recovered. The higher the value of data, the more funds or other resources that can be put into place to ensure a smaller amount of data is lost in the event of a disaster. For example, if the RPO is set to two hours, this means that the organization has to have backup and restore processes that will only allow for the loss of up to two hours of data. The restore process cannot be something as time consuming as restoring from a backup tape manually, but will need to be an automated restoration process that can restore data more quickly and allow the production environment to be up and running and carrying out business processes. The recovery time objective (RTO) is the acceptable period before a specific service level must be restored in order to avoid unacceptable consequences after a disruption or disaster. While RPO pertains to data, RTO deals with the actual processing capabilities of an environment.
![]() B is incorrect because the RTO is the earliest time period in which a service level must be restored; thus, it does not explicitly deal with recovering a data set. And the RPO is the acceptable amount of data loss measured in time, not downtime in general. The definitions in this answer are backward. The RPO provides the recovery team with a requirement or goal to work toward when establishing data recovery processes. RPO values for less critical data will be higher; thus, the recovery processes can include slower and cheaper recovery solutions. If an RPO value is high, then the data is more critical in nature and the team must implement solutions that recover this type of data more quickly. RTO values also give the recovery team requirements to work with so that they know the type of recovery solutions that must be deployed. If a production environment has to be up and running within one hour after a disruption, the team must deploy redundancy into the environment so that the systems can respond quickly.
B is incorrect because the RTO is the earliest time period in which a service level must be restored; thus, it does not explicitly deal with recovering a data set. And the RPO is the acceptable amount of data loss measured in time, not downtime in general. The definitions in this answer are backward. The RPO provides the recovery team with a requirement or goal to work toward when establishing data recovery processes. RPO values for less critical data will be higher; thus, the recovery processes can include slower and cheaper recovery solutions. If an RPO value is high, then the data is more critical in nature and the team must implement solutions that recover this type of data more quickly. RTO values also give the recovery team requirements to work with so that they know the type of recovery solutions that must be deployed. If a production environment has to be up and running within one hour after a disruption, the team must deploy redundancy into the environment so that the systems can respond quickly.
![]() C is incorrect because the RTO metric pertains to how quickly services must come back online and not how quickly data must be restored. The RTO provides the recovery team with an objective, which is a goal to achieve as it pertains to getting systems and network capabilities up and running after they went down. This metric tells the team how long the organization can endure being offline and still stay in business. A small business that does not depend upon time-sensitive transactions may be able to be offline for one to two days without negatively affecting the survivability of the company. If a company like Amazon.com was offline for two days, the financial and reputation hit that it would have to endure may not put the company out of business, but this potential loss is too much to risk, thus expensive recovery solutions are necessary. If you understand how much you can potentially lose, you will make better decisions about what to put into place to make sure that any potential loss is endurable and not devastating.
C is incorrect because the RTO metric pertains to how quickly services must come back online and not how quickly data must be restored. The RTO provides the recovery team with an objective, which is a goal to achieve as it pertains to getting systems and network capabilities up and running after they went down. This metric tells the team how long the organization can endure being offline and still stay in business. A small business that does not depend upon time-sensitive transactions may be able to be offline for one to two days without negatively affecting the survivability of the company. If a company like Amazon.com was offline for two days, the financial and reputation hit that it would have to endure may not put the company out of business, but this potential loss is too much to risk, thus expensive recovery solutions are necessary. If you understand how much you can potentially lose, you will make better decisions about what to put into place to make sure that any potential loss is endurable and not devastating.
![]() D is incorrect because the RPO measurement pertains to data recovery and not service downtime. RPO is the maximum tolerable time period during which data may be unavailable, which is not the same as a measurement of how much data may be lost. For example, if a company’s main database gets corrupted and the company can absorb the impact of not having the data on this database restored for 48 hours, then the recovery team can implement tape backups that are stored and retrieved from an offsite location. The restoration timeline of this data has to take into account how long it will take for someone to go get the tape from the offsite location, bring it to the production environment, carry out the restore process, and test the newly recovered data. All of those steps have to happen successfully within the RPO window of 48 hours.
D is incorrect because the RPO measurement pertains to data recovery and not service downtime. RPO is the maximum tolerable time period during which data may be unavailable, which is not the same as a measurement of how much data may be lost. For example, if a company’s main database gets corrupted and the company can absorb the impact of not having the data on this database restored for 48 hours, then the recovery team can implement tape backups that are stored and retrieved from an offsite location. The restoration timeline of this data has to take into account how long it will take for someone to go get the tape from the offsite location, bring it to the production environment, carry out the restore process, and test the newly recovered data. All of those steps have to happen successfully within the RPO window of 48 hours.
25. An approach to alternate offsite facilities is to establish a reciprocal agreement. Which of the following describes the pros and cons of a reciprocal agreement?
A. It is fully configured and ready to operate within a few hours, but is the most expensive of the offsite choices.
B. It is an inexpensive option, but it takes the most time and effort to get up and running after a disaster.
C. It is a good alternative for companies that depend upon proprietary software, but annual testing is not usually available.
D. It is the cheapest of the offsite choices, but mixing operations could introduce many security issues.
![]() D. A reciprocal agreement, also referred to as mutual aid, means that company A agrees to allow company B to use its facilities if company B is hit by a disaster, and vice versa. This is a cheaper way to go than the other offsite choices, but it is not always the best choice. Most environments are maxed out pertaining to the use of facility space, resources, and computing capability. To allow another company to come in and work out of the same shop could prove to be detrimental to both companies. The stress of two companies working in the same environment could cause tremendous levels of tension. If it did work out, it would only provide a short-term solution. Configuration management could be a nightmare, and the mixing of operations could introduce many security issues. Reciprocal agreements have been known to work well in specific businesses, such as newspaper printing. These businesses require very specific technology and equipment that will not be available through any subscription service. For most other organizations, reciprocal agreements are generally, at best, a secondary option for disaster protection.
D. A reciprocal agreement, also referred to as mutual aid, means that company A agrees to allow company B to use its facilities if company B is hit by a disaster, and vice versa. This is a cheaper way to go than the other offsite choices, but it is not always the best choice. Most environments are maxed out pertaining to the use of facility space, resources, and computing capability. To allow another company to come in and work out of the same shop could prove to be detrimental to both companies. The stress of two companies working in the same environment could cause tremendous levels of tension. If it did work out, it would only provide a short-term solution. Configuration management could be a nightmare, and the mixing of operations could introduce many security issues. Reciprocal agreements have been known to work well in specific businesses, such as newspaper printing. These businesses require very specific technology and equipment that will not be available through any subscription service. For most other organizations, reciprocal agreements are generally, at best, a secondary option for disaster protection.
![]() A is incorrect because a hot site—not a reciprocal agreement—is fully configured and ready to operate within a few hours. A hot site is also the most expensive offsite option. The only missing resources from a hot site are usually the data, which will be retrieved from a backup site, and the people who will be processing the data. The equipment and system software must be compatible with the data being restored from the main site and must not cause any negative interoperability issues. Hot sites are a good choice for a company that needs to ensure a site will be available for it as soon as possible.
A is incorrect because a hot site—not a reciprocal agreement—is fully configured and ready to operate within a few hours. A hot site is also the most expensive offsite option. The only missing resources from a hot site are usually the data, which will be retrieved from a backup site, and the people who will be processing the data. The equipment and system software must be compatible with the data being restored from the main site and must not cause any negative interoperability issues. Hot sites are a good choice for a company that needs to ensure a site will be available for it as soon as possible.
![]() B is incorrect because it describes a cold site, an inexpensive offsite option that takes the most time and effort to actually get up and functioning right after a disaster. With cold sites the vendor supplies the basic environment, electrical wiring, air conditioning, plumbing, and flooring, but none of the equipment or additional services. It may take weeks to get the site activated and ready for work.
B is incorrect because it describes a cold site, an inexpensive offsite option that takes the most time and effort to actually get up and functioning right after a disaster. With cold sites the vendor supplies the basic environment, electrical wiring, air conditioning, plumbing, and flooring, but none of the equipment or additional services. It may take weeks to get the site activated and ready for work.
![]() C is incorrect because it describes a warm site, a good alternative for companies that depend upon proprietary software. A warm site is equipped with some equipment, but not the actual computers. It is a better choice than a reciprocal agreement or hot site for a company that depends upon proprietary and unusual hardware and software, because they will bring their own hardware and software with them to the site after a disaster hits. The disadvantage of using a warm site is that the vendors’ contracts do not usually include annual testing, which helps ensure that the company can return to an operating state within hours.
C is incorrect because it describes a warm site, a good alternative for companies that depend upon proprietary software. A warm site is equipped with some equipment, but not the actual computers. It is a better choice than a reciprocal agreement or hot site for a company that depends upon proprietary and unusual hardware and software, because they will bring their own hardware and software with them to the site after a disaster hits. The disadvantage of using a warm site is that the vendors’ contracts do not usually include annual testing, which helps ensure that the company can return to an operating state within hours.
26. The operations team is responsible for defining which data gets backed up and how often. Which type of backup process backs up files that have been modified since the last time all data was backed up?
A. Incremental process
B. Full backup
C. Partial backup
D. Differential process
![]() D. Backups can be full, differential, or incremental, and are usually used in some type of combination with each other. Most files are not altered every day, so to save time and resources, it is best to devise a backup plan that does not continually back up data that has not been modified. Backup software reviews the archive bit setting when making its determination on what gets backed up and what does not. If a file is modified or created, the file system sets the archive bit to 1, and the backup software knows to back up that file. A differential process backs up the files that have been modified since the last full backup; in other words, the last time all the data was backed up. When the data needs to be restored, the full backup is laid down first, and then the differential backup is put down on top of it.
D. Backups can be full, differential, or incremental, and are usually used in some type of combination with each other. Most files are not altered every day, so to save time and resources, it is best to devise a backup plan that does not continually back up data that has not been modified. Backup software reviews the archive bit setting when making its determination on what gets backed up and what does not. If a file is modified or created, the file system sets the archive bit to 1, and the backup software knows to back up that file. A differential process backs up the files that have been modified since the last full backup; in other words, the last time all the data was backed up. When the data needs to be restored, the full backup is laid down first, and then the differential backup is put down on top of it.
![]() A is incorrect because an incremental process backs up all the files that have changed since the last full or incremental backup. If a company experienced a disaster and it used the incremental process, it would first need to restore the full backup on its hard drives and lay down every incremental backup that was carried out before the disaster took place. So, if the full backup was done six months ago and the operations department carried out an incremental backup each month, the restoration team would restore the full backup and start with the older incremental backups and restore each one of them until they are all restored.
A is incorrect because an incremental process backs up all the files that have changed since the last full or incremental backup. If a company experienced a disaster and it used the incremental process, it would first need to restore the full backup on its hard drives and lay down every incremental backup that was carried out before the disaster took place. So, if the full backup was done six months ago and the operations department carried out an incremental backup each month, the restoration team would restore the full backup and start with the older incremental backups and restore each one of them until they are all restored.
![]() B is incorrect because with a full backup, all data is backed up and saved to some type of storage media. During a full backup, the archive bit is cleared, which means that it is set to 0. A company can choose to do full backups only, in which case the restoration process is just one step, but the backup and restore processes could take a long time.
B is incorrect because with a full backup, all data is backed up and saved to some type of storage media. During a full backup, the archive bit is cleared, which means that it is set to 0. A company can choose to do full backups only, in which case the restoration process is just one step, but the backup and restore processes could take a long time.
![]() C is incorrect because it is not the best answer to this question. While a backup can be a partial backup, it does not necessarily mean that it backs up all the files that have been modified since the last time a backup process was run.
C is incorrect because it is not the best answer to this question. While a backup can be a partial backup, it does not necessarily mean that it backs up all the files that have been modified since the last time a backup process was run.
27. After a disaster occurs, a damage assessment needs to take place. Which of the following steps occurs last in a damage assessment?
A. Determine the cause of the disaster.
B. Identify the resources that must be replaced immediately.
C. Declare a disaster.
D. Determine how long it will take to bring critical functions back online.
![]() C. The final step in a damage assessment is to declare a disaster. After information from the damage assessment is collected and assessed, it will indicate what teams need to be called to action and whether the BCP actually needs to be activated. The BCP coordinator and team must develop activation criteria before a disaster takes place. After the damage assessment, if one or more of the situations outlined in the criteria have taken place, then the team is moved into recovery mode. Different organizations have different criteria, because the business drivers and critical functions will vary from organization to organization. The criteria may consist of danger to human life, danger to state or national security, damage to facility, damage to critical systems, and estimated value of downtime that will be experienced.
C. The final step in a damage assessment is to declare a disaster. After information from the damage assessment is collected and assessed, it will indicate what teams need to be called to action and whether the BCP actually needs to be activated. The BCP coordinator and team must develop activation criteria before a disaster takes place. After the damage assessment, if one or more of the situations outlined in the criteria have taken place, then the team is moved into recovery mode. Different organizations have different criteria, because the business drivers and critical functions will vary from organization to organization. The criteria may consist of danger to human life, danger to state or national security, damage to facility, damage to critical systems, and estimated value of downtime that will be experienced.
![]() A is incorrect because determining the cause of the disaster is the first step of the damage assessment. The issue that caused the damage may still be taking place, and the team must figure out how to stop it before a full damage assessment can take place.
A is incorrect because determining the cause of the disaster is the first step of the damage assessment. The issue that caused the damage may still be taking place, and the team must figure out how to stop it before a full damage assessment can take place.
![]() B is incorrect because identifying the resources that must be replaced immediately is not the last step of a damage assessment. It does occur near the end of the assessment, however. Once the resources are identified, the team must estimate how long it will take to bring critical functions back online, and then declare a disaster, if necessary.
B is incorrect because identifying the resources that must be replaced immediately is not the last step of a damage assessment. It does occur near the end of the assessment, however. Once the resources are identified, the team must estimate how long it will take to bring critical functions back online, and then declare a disaster, if necessary.
![]() D is incorrect because determining how long it will take to bring critical functions back online is the second-to-last step in a damage assessment. If it will take longer than the previously determined maximum tolerable downtime (MTD) values to restore operations, then a disaster should be declared and the BCP should be put into action.
D is incorrect because determining how long it will take to bring critical functions back online is the second-to-last step in a damage assessment. If it will take longer than the previously determined maximum tolerable downtime (MTD) values to restore operations, then a disaster should be declared and the BCP should be put into action.
28. Of the following plans, which establishes senior management and a headquarters after a disaster?
A. Continuity of operations plan
B. Cyber-incident response plan
C. Occupant emergency plan
D. IT contingency plan
![]() A. A continuity of operations (COOP) plan establishes senior management and a headquarters after a disaster. It also outlines roles and authorities, orders of succession, and individual role tasks. Creating a COOP plan begins with assessing how the organization operates to identify mission-critical staff, materials, procedures, and equipment. If one exists, review the business process flowchart. Identify suppliers, partners, contractors, and other businesses the organization interacts with on a daily basis, and create a list of these and other businesses the organization could use in an emergency. It is important for an organization to make plans for what it will do if the building becomes inaccessible.
A. A continuity of operations (COOP) plan establishes senior management and a headquarters after a disaster. It also outlines roles and authorities, orders of succession, and individual role tasks. Creating a COOP plan begins with assessing how the organization operates to identify mission-critical staff, materials, procedures, and equipment. If one exists, review the business process flowchart. Identify suppliers, partners, contractors, and other businesses the organization interacts with on a daily basis, and create a list of these and other businesses the organization could use in an emergency. It is important for an organization to make plans for what it will do if the building becomes inaccessible.
![]() B is incorrect because a cyber-incident response plan focuses on malware, hackers, intrusions, attacks, and other security issues. It outlines procedures for incident response with the goal of limiting damage, minimizing recovery time, and reducing costs. A cyber-incident response plan should include a description of the different types of incidents, who to call when an incident occurs, and each person’s responsibilities, procedures for addressing different types of incidents, and forensic procedures. The plan should be tested, and all participants should be trained on their responsibilities.
B is incorrect because a cyber-incident response plan focuses on malware, hackers, intrusions, attacks, and other security issues. It outlines procedures for incident response with the goal of limiting damage, minimizing recovery time, and reducing costs. A cyber-incident response plan should include a description of the different types of incidents, who to call when an incident occurs, and each person’s responsibilities, procedures for addressing different types of incidents, and forensic procedures. The plan should be tested, and all participants should be trained on their responsibilities.
![]() C is incorrect because an occupant emergency plan establishes personnel safety and evacuation procedures. The goal of an occupant emergency plan is to reduce the risk to personnel and minimize the disruption to work and operations in the case of an emergency. The plan should include procedures for ensuring the safety of employees with disabilities, including their evacuation from the facility if necessary. All employees should have access to the occupant emergency response plan, and it should be practiced so that everyone knows how to execute it.
C is incorrect because an occupant emergency plan establishes personnel safety and evacuation procedures. The goal of an occupant emergency plan is to reduce the risk to personnel and minimize the disruption to work and operations in the case of an emergency. The plan should include procedures for ensuring the safety of employees with disabilities, including their evacuation from the facility if necessary. All employees should have access to the occupant emergency response plan, and it should be practiced so that everyone knows how to execute it.
![]() D is incorrect because an IT contingency plan establishes procedures for the recovery of systems, networks, and major applications after disruptions. Steps for creating IT contingency plans are addressed in the NIST 800-34 document.
D is incorrect because an IT contingency plan establishes procedures for the recovery of systems, networks, and major applications after disruptions. Steps for creating IT contingency plans are addressed in the NIST 800-34 document.
29. Gizmos and Gadgets has restored its original facility after a disaster. What should be moved in first?
A. Management
B. Most critical systems
C. Most critical functions
D. Least critical functions
![]() D. After the primary site has been repaired, the least critical components are moved in first. This ensures that the primary site is really ready to resume processing. By doing this, you can validate that environmental controls, power, and communication links are working properly. It can also avoid putting the company into another disaster. If the less critical functions survive, then the more critical components of the company can be moved over.
D. After the primary site has been repaired, the least critical components are moved in first. This ensures that the primary site is really ready to resume processing. By doing this, you can validate that environmental controls, power, and communication links are working properly. It can also avoid putting the company into another disaster. If the less critical functions survive, then the more critical components of the company can be moved over.
![]() A is incorrect because personnel should not be moved into the facility until it is determined that the environment is safe, everything is in good working order, and all necessary equipment and supplies are present. Least critical functions should be moved back first, so if there are issues in network configurations or connectivity, or important steps were not carried out, the critical operations of the company are not negatively affected.
A is incorrect because personnel should not be moved into the facility until it is determined that the environment is safe, everything is in good working order, and all necessary equipment and supplies are present. Least critical functions should be moved back first, so if there are issues in network configurations or connectivity, or important steps were not carried out, the critical operations of the company are not negatively affected.
![]() B is incorrect because the most critical systems should not be resumed in the new environment until it has been properly tested. You do not want to go through the trouble of moving the most critical systems and operations from a safe and stable site, only to return them to a main site that is untested. When you move less critical departments over first, they act as the canary. If they survive, then move on to critical systems.
B is incorrect because the most critical systems should not be resumed in the new environment until it has been properly tested. You do not want to go through the trouble of moving the most critical systems and operations from a safe and stable site, only to return them to a main site that is untested. When you move less critical departments over first, they act as the canary. If they survive, then move on to critical systems.
![]() C is incorrect because the most critical functions should not be moved over before less critical functions, which serve to test the stability and safety of the site. If the site proves to need further preparation, then no harm is done to the critical functions.
C is incorrect because the most critical functions should not be moved over before less critical functions, which serve to test the stability and safety of the site. If the site proves to need further preparation, then no harm is done to the critical functions.
30. Several teams should be involved in carrying out the business continuity plan. Which team is responsible for starting the recovery of the original site?
A. Damage assessment team
B. BCP team
C. Salvage team
D. Restoration team
![]() C. The BCP coordinator should have an understanding of the needs of the company and the types of teams that need to be developed and trained. Employees should be assigned to the specific teams based on their knowledge and skill set. Each team needs to have a designated leader, who will direct the members and their activities. These team leaders will be responsible not only for ensuring that their team’s objectives are met, but also for communicating with each other to make sure each team is working in parallel phases. The salvage team is responsible for starting the recovery of the original site. It is also responsible for backing up data from the alternate site and restoring it within the new facility, carefully terminating contingency operations, and securely transporting equipment and personnel to the new facility.
C. The BCP coordinator should have an understanding of the needs of the company and the types of teams that need to be developed and trained. Employees should be assigned to the specific teams based on their knowledge and skill set. Each team needs to have a designated leader, who will direct the members and their activities. These team leaders will be responsible not only for ensuring that their team’s objectives are met, but also for communicating with each other to make sure each team is working in parallel phases. The salvage team is responsible for starting the recovery of the original site. It is also responsible for backing up data from the alternate site and restoring it within the new facility, carefully terminating contingency operations, and securely transporting equipment and personnel to the new facility.
![]() A is incorrect because the damage assessment team is responsible for determining the scope and severity of the damage caused. Whether or not a disaster is declared and the BCP is put into action is based on this information collected and assessed by the damage assessment team.
A is incorrect because the damage assessment team is responsible for determining the scope and severity of the damage caused. Whether or not a disaster is declared and the BCP is put into action is based on this information collected and assessed by the damage assessment team.
![]() B is incorrect because the BCP team is responsible for creating and maintaining the business continuity plan. Therefore, its responsibilities also include identifying regulatory and legal requirements that must be met, identifying all possible vulnerabilities and threats, performing a business impact analysis, and developing procedures and steps in resuming business after a disaster. The BCP team is made up of representatives from a variety of business units and departments, including senior management, the security department, the communications department, and the legal department. This is not the team that starts the physical recovery of the original site.
B is incorrect because the BCP team is responsible for creating and maintaining the business continuity plan. Therefore, its responsibilities also include identifying regulatory and legal requirements that must be met, identifying all possible vulnerabilities and threats, performing a business impact analysis, and developing procedures and steps in resuming business after a disaster. The BCP team is made up of representatives from a variety of business units and departments, including senior management, the security department, the communications department, and the legal department. This is not the team that starts the physical recovery of the original site.
![]() D is incorrect because the restoration team is responsible for getting the alternate site into a working and functioning environment. Both the restoration team and the salvage team must know how to do many tasks, such as install operating systems, configure workstations and servers, string wire and cabling, set up the network and configure networking services, and install equipment and applications. Both teams must also know how to restore data from backup facilities and how to do so in a secure manner that ensures that the systems’ and data’s confidentiality, integrity, and availability are not compromised.
D is incorrect because the restoration team is responsible for getting the alternate site into a working and functioning environment. Both the restoration team and the salvage team must know how to do many tasks, such as install operating systems, configure workstations and servers, string wire and cabling, set up the network and configure networking services, and install equipment and applications. Both teams must also know how to restore data from backup facilities and how to do so in a secure manner that ensures that the systems’ and data’s confidentiality, integrity, and availability are not compromised.
31. ACME, Inc., paid a software vendor to develop specialized software, and that vendor has gone out of business. ACME, Inc., does not have access to the code and therefore cannot keep it updated. What mechanism should the company have implemented to prevent this from happening?
A. Reciprocal agreement
B. Software escrow
C. Electronic vaulting
D. Business interruption insurance
![]() B. The protection mechanism that ACME, Inc., should have implemented is called software escrow. Software escrow means that a third party holds the source code and backups of the compiled code, manuals, and other supporting materials. A contract between the software vendor, customer, and third party outlines who can do what and when with the source code. This contract usually states that the customer can have access to the source code only if and when the vendor goes out of business, is unable to carry out stated responsibilities, or is in breach of the original contract. If any of these activities takes place, then the customer is protected because it can still gain access to the source code and other materials through the third-party escrow agent.
B. The protection mechanism that ACME, Inc., should have implemented is called software escrow. Software escrow means that a third party holds the source code and backups of the compiled code, manuals, and other supporting materials. A contract between the software vendor, customer, and third party outlines who can do what and when with the source code. This contract usually states that the customer can have access to the source code only if and when the vendor goes out of business, is unable to carry out stated responsibilities, or is in breach of the original contract. If any of these activities takes place, then the customer is protected because it can still gain access to the source code and other materials through the third-party escrow agent.
![]() A is incorrect because a reciprocal agreement is an offsite facility option that involves two companies agreeing to share their facility in case a disaster renders one of the facilities unusable. Reciprocal agreements deal with disaster recovery and not software protection when dealing with the developing vendor.
A is incorrect because a reciprocal agreement is an offsite facility option that involves two companies agreeing to share their facility in case a disaster renders one of the facilities unusable. Reciprocal agreements deal with disaster recovery and not software protection when dealing with the developing vendor.
![]() C is incorrect because electronic vaulting is a type of electronic backup solution. Electronic vaulting makes copies of files as they are modified and periodically transmits them to an offsite backup site. The transmission does not happen in real time but is carried out in batches. So, a company can choose to have all files that have been changed sent to the backup facility every hour, day, week, or month. The information can be stored in an offsite facility and retrieved from that facility in a short period of time. Electronic vaulting has to do with backing up data so that it is available if there is a disruption or disaster.
C is incorrect because electronic vaulting is a type of electronic backup solution. Electronic vaulting makes copies of files as they are modified and periodically transmits them to an offsite backup site. The transmission does not happen in real time but is carried out in batches. So, a company can choose to have all files that have been changed sent to the backup facility every hour, day, week, or month. The information can be stored in an offsite facility and retrieved from that facility in a short period of time. Electronic vaulting has to do with backing up data so that it is available if there is a disruption or disaster.
![]() D is incorrect because a business interruption insurance policy covers specified expenses and lost earnings if a company is out of business for a certain length of time. This insurance is commonly purchased to protect a company in case a disaster takes place and they have to shut down their services for a specific period of time. It does not have anything to do with protection or accessibility of source code.
D is incorrect because a business interruption insurance policy covers specified expenses and lost earnings if a company is out of business for a certain length of time. This insurance is commonly purchased to protect a company in case a disaster takes place and they have to shut down their services for a specific period of time. It does not have anything to do with protection or accessibility of source code.
32. Which of the following incorrectly describes the concept of executive succession planning?
A. Predetermined steps protect the company if a senior executive leaves.
B. Two or more senior staff cannot be exposed to a particular risk at the same time.
C. It documents the assignment of deputy roles.
D. It covers assigning a skeleton crew to resume operations after a disaster.
![]() D. A skeleton crew consists of the employees who carry out the most critical functions following a disaster. They are put to work first during the recovery process. A skeleton crew is not related to the concept of executive succession planning, which addresses the steps that will be taken to fill a senior executive role should that person retire, leave the company, or die. The objective of a skeleton crew is to maintain critical operations, while the objective of executive succession planning is to protect the company by maintaining leadership roles.
D. A skeleton crew consists of the employees who carry out the most critical functions following a disaster. They are put to work first during the recovery process. A skeleton crew is not related to the concept of executive succession planning, which addresses the steps that will be taken to fill a senior executive role should that person retire, leave the company, or die. The objective of a skeleton crew is to maintain critical operations, while the objective of executive succession planning is to protect the company by maintaining leadership roles.
![]() A is incorrect because executive succession planning includes predetermined steps that protect the company if someone in a senior executive position retires, leaves the company, or is killed. The loss of a senior executive could tear a hole in the company’s fabric, creating a leadership vacuum that must be filled quickly with the right individual. The line-of-succession plan defines who would step in and assume responsibility for this role.
A is incorrect because executive succession planning includes predetermined steps that protect the company if someone in a senior executive position retires, leaves the company, or is killed. The loss of a senior executive could tear a hole in the company’s fabric, creating a leadership vacuum that must be filled quickly with the right individual. The line-of-succession plan defines who would step in and assume responsibility for this role.
![]() B is incorrect because the concept of two or more senior staff not being exposed to a particular risk at the same time is a policy that some larger organizations establish as part of their executive succession planning efforts. The idea is to protect senior personnel and the organization if a disaster were to strike. For example, an organization may decide that the CEO and president cannot travel on the same plane. If the plane went down and both individuals were killed, then the company could be in danger.
B is incorrect because the concept of two or more senior staff not being exposed to a particular risk at the same time is a policy that some larger organizations establish as part of their executive succession planning efforts. The idea is to protect senior personnel and the organization if a disaster were to strike. For example, an organization may decide that the CEO and president cannot travel on the same plane. If the plane went down and both individuals were killed, then the company could be in danger.
![]() C is incorrect because executive succession planning can include the assignment of deputy roles. An organization may have a deputy CIO, deputy CFO, and deputy CEO ready to take over the necessary tasks if the CIO, CFO, or CEO becomes unavailable. Executive succession planning is the decision to have these deputies step into the CIO, CFO, or CEO roles.
C is incorrect because executive succession planning can include the assignment of deputy roles. An organization may have a deputy CIO, deputy CFO, and deputy CEO ready to take over the necessary tasks if the CIO, CFO, or CEO becomes unavailable. Executive succession planning is the decision to have these deputies step into the CIO, CFO, or CEO roles.
33. What type of infrastructural setup is illustrated in the graphic that follows?
A. Hot site
B. Warm site
C. Cold site
D. Reciprocal agreement
![]() A. A hot site is a facility that is leased or rented and is fully configured and ready to operate within a few hours. The only missing resources from a hot site are usually the data, which will be retrieved from a backup site, and the people who will be processing the data. The equipment and system software must absolutely be compatible with the data being restored from the main site and must not cause any negative interoperability issues. A hot site is a good choice for a company that needs to ensure a site will be available for it as soon as possible.
A. A hot site is a facility that is leased or rented and is fully configured and ready to operate within a few hours. The only missing resources from a hot site are usually the data, which will be retrieved from a backup site, and the people who will be processing the data. The equipment and system software must absolutely be compatible with the data being restored from the main site and must not cause any negative interoperability issues. A hot site is a good choice for a company that needs to ensure a site will be available for it as soon as possible.
![]() B is incorrect because a warm site is a leased or rented facility that is usually partially configured with some equipment, but not the actual computers. In other words, a warm site is usually a hot site without the expensive equipment. Staging a facility with duplicate hardware and computers configured for immediate operation is extremely expensive, so a warm site provides an alternate facility with some peripheral devices. This is the most widely used model. It may be a better choice for companies that depend upon proprietary and unusual hardware and software, because they will bring their own hardware and software with them to the site after the disaster hits.
B is incorrect because a warm site is a leased or rented facility that is usually partially configured with some equipment, but not the actual computers. In other words, a warm site is usually a hot site without the expensive equipment. Staging a facility with duplicate hardware and computers configured for immediate operation is extremely expensive, so a warm site provides an alternate facility with some peripheral devices. This is the most widely used model. It may be a better choice for companies that depend upon proprietary and unusual hardware and software, because they will bring their own hardware and software with them to the site after the disaster hits.
![]() C is incorrect because a cold site is a leased or rented facility that supplies the basic environment, electrical wiring, air conditioning, plumbing, and flooring, but none of the equipment or additional services. It may take weeks to get the site activated and ready for work. The cold site could have equipment racks and dark fiber (fiber that does not have the circuit engaged) and maybe even desks, but it would require the receipt of equipment from the client, since it does not provide any. The cold site is the least expensive option but takes the most time and effort to actually get up and functioning right after a disaster.
C is incorrect because a cold site is a leased or rented facility that supplies the basic environment, electrical wiring, air conditioning, plumbing, and flooring, but none of the equipment or additional services. It may take weeks to get the site activated and ready for work. The cold site could have equipment racks and dark fiber (fiber that does not have the circuit engaged) and maybe even desks, but it would require the receipt of equipment from the client, since it does not provide any. The cold site is the least expensive option but takes the most time and effort to actually get up and functioning right after a disaster.
![]() D is incorrect because a reciprocal agreement is one in which a company promises another company it can move into its facility and share space if it experiences a disaster, and vice versa. Reciprocal agreements are very tricky to implement and are unenforceable. This is a cheaper way to go than the other offsite choices, but it is not always the best choice. Most environments are maxed out pertaining to the use of facility space, resources, and computing capability.
D is incorrect because a reciprocal agreement is one in which a company promises another company it can move into its facility and share space if it experiences a disaster, and vice versa. Reciprocal agreements are very tricky to implement and are unenforceable. This is a cheaper way to go than the other offsite choices, but it is not always the best choice. Most environments are maxed out pertaining to the use of facility space, resources, and computing capability.
34. There are several types of redundant technologies that can be put into place. What type of technology is shown in the graphic that follows?
A. Tape vaulting
B. Remote journaling
C. Electronic vaulting
D. Redundant site
![]() A. Each site should have a full set of the most current and updated information and files, and a commonly used software backup technology is referred to as tape vaulting. Many businesses back up their data to tapes that are then manually transferred to an offsite facility by a courier or an employee. With automatic tape vaulting, the data is sent over a serial line to a backup tape system at the offsite facility. The company that maintains the offsite facility maintains the systems and changes out tapes when necessary. Data can be quickly backed up and retrieved when necessary. This technology reduces the manual steps in the traditional tape backup procedures. Basic vaulting of tape data involves sending backup tapes to an offsite location, but a manual process can be error prone. Electronic tape vaulting transmits data over a network to tape devices located at an alternate data center. Electronic tape vaulting improves recovery speed and reduces errors, and backups can be run more frequently.
A. Each site should have a full set of the most current and updated information and files, and a commonly used software backup technology is referred to as tape vaulting. Many businesses back up their data to tapes that are then manually transferred to an offsite facility by a courier or an employee. With automatic tape vaulting, the data is sent over a serial line to a backup tape system at the offsite facility. The company that maintains the offsite facility maintains the systems and changes out tapes when necessary. Data can be quickly backed up and retrieved when necessary. This technology reduces the manual steps in the traditional tape backup procedures. Basic vaulting of tape data involves sending backup tapes to an offsite location, but a manual process can be error prone. Electronic tape vaulting transmits data over a network to tape devices located at an alternate data center. Electronic tape vaulting improves recovery speed and reduces errors, and backups can be run more frequently.
![]() B is incorrect because remote journaling is a technology used to transmit data to an offsite facility, but this usually only includes moving the journal or transaction logs to the offsite facility, not the actual files. This graphic specifically shows a tape controller, and remote journaling mainly takes place between databases. Remote journaling involves transmitting the journal or transaction log offsite to a backup facility. These logs contain the deltas (changes) that have taken place to the individual files. If and when data is corrupted and needs to be restored, the company can retrieve these logs, which are used to rebuild the lost data. Journaling is efficient for database recovery, where only the reapplication of a series of changes to individual records is required to resynchronize the database.
B is incorrect because remote journaling is a technology used to transmit data to an offsite facility, but this usually only includes moving the journal or transaction logs to the offsite facility, not the actual files. This graphic specifically shows a tape controller, and remote journaling mainly takes place between databases. Remote journaling involves transmitting the journal or transaction log offsite to a backup facility. These logs contain the deltas (changes) that have taken place to the individual files. If and when data is corrupted and needs to be restored, the company can retrieve these logs, which are used to rebuild the lost data. Journaling is efficient for database recovery, where only the reapplication of a series of changes to individual records is required to resynchronize the database.
![]() C is incorrect because electronic vaulting most commonly takes place between databases and makes copies of files as they are modified and periodically transmits them to an offsite backup site. The transmission does not happen in real time but is carried out in batches. So, a company can choose to have all files that have been changed sent to the backup facility every hour, day, week, or month. The information can be stored in an offsite facility and retrieved from that facility in a short period of time. This form of backup takes place in many financial institutions, so when a bank teller accepts a deposit or withdrawal, the change to the customer’s account is made locally to that branch’s database and to the remote site that maintains the backup copies of all customer records.
C is incorrect because electronic vaulting most commonly takes place between databases and makes copies of files as they are modified and periodically transmits them to an offsite backup site. The transmission does not happen in real time but is carried out in batches. So, a company can choose to have all files that have been changed sent to the backup facility every hour, day, week, or month. The information can be stored in an offsite facility and retrieved from that facility in a short period of time. This form of backup takes place in many financial institutions, so when a bank teller accepts a deposit or withdrawal, the change to the customer’s account is made locally to that branch’s database and to the remote site that maintains the backup copies of all customer records.
![]() D is incorrect because while the graphic could be illustrating that the tape controller is located at a redundant site, a redundant site is not actually a technology. Some companies choose to have redundant sites, meaning one site is equipped and configured exactly like the primary site, which serves as a redundant environment. These sites are owned by the company and are mirrors of the original production environment. This is one of the most expensive backup facility options, because a full environment must be maintained even though it usually is not used for regular production activities until after a disaster takes place that triggers the relocation of services to the redundant site.
D is incorrect because while the graphic could be illustrating that the tape controller is located at a redundant site, a redundant site is not actually a technology. Some companies choose to have redundant sites, meaning one site is equipped and configured exactly like the primary site, which serves as a redundant environment. These sites are owned by the company and are mirrors of the original production environment. This is one of the most expensive backup facility options, because a full environment must be maintained even though it usually is not used for regular production activities until after a disaster takes place that triggers the relocation of services to the redundant site.
35. Here is a graphic of a business continuity policy. Which component is missing from this graphic?

A. Damage assessment phase
B. Reconstitution phase
C. Business resumption phase
D. Continuity of operations plan
![]() B. After a disaster takes place and a company moves out of its facility, it must move back in after the facility is reconstructed. When it is time for the company to move back into its original site or a new site, the company is ready to enter into the reconstitution phase. A company is not out of an emergency state until it is back in operation at the original primary site or a new site that was constructed to replace the primary site, because the company is always vulnerable while operating in a backup facility. Many logistical issues need to be considered as to when a company must return from the alternate site to the original site. The following lists a few of these issues:
B. After a disaster takes place and a company moves out of its facility, it must move back in after the facility is reconstructed. When it is time for the company to move back into its original site or a new site, the company is ready to enter into the reconstitution phase. A company is not out of an emergency state until it is back in operation at the original primary site or a new site that was constructed to replace the primary site, because the company is always vulnerable while operating in a backup facility. Many logistical issues need to be considered as to when a company must return from the alternate site to the original site. The following lists a few of these issues:
• Ensuring the safety of employees
• Ensuring an adequate environment is provided (power, facility infrastructure, water, HVAC)
• Ensuring that the necessary equipment and supplies are present and in working order
• Ensuring proper communications and connectivity methods are working
• Properly testing the new environment
![]() A is incorrect because a role, or a team, needs to be created to carry out a damage assessment once a disaster has taken place. The assessment procedures should be properly documented and include the following steps:
A is incorrect because a role, or a team, needs to be created to carry out a damage assessment once a disaster has taken place. The assessment procedures should be properly documented and include the following steps:
• Determine the cause of the disaster.
• Determine the potential for further damage.
• Identify the affected business functions and areas.
• Identify the level of functionality for the critical resources.
• Identify the resources that must be replaced immediately.
• Estimate how long it will take to bring critical functions back online.
• If it will take longer than the previously estimated maximum tolerable downtime (MTD) values to restore operations, then a disaster should be declared and the BCP should be put into action.
After this information is collected and assessed, it will indicate which teams need to be called to action and whether the BCP actually needs to be activated. The BCP coordinator and team must develop activation criteria. After the damage assessment, if one or more of the situations outlined in the criteria have taken place, then the team is moved into recovery mode.
![]() C is incorrect because a business resumption plan focuses on how to re-create the necessary business processes that need to be reestablished instead of focusing on only IT components (i.e., it is process oriented instead of procedure oriented). This plan could be mentioned in the BCP policy, but the policy does not outline the specifics of reestablishing business processes.
C is incorrect because a business resumption plan focuses on how to re-create the necessary business processes that need to be reestablished instead of focusing on only IT components (i.e., it is process oriented instead of procedure oriented). This plan could be mentioned in the BCP policy, but the policy does not outline the specifics of reestablishing business processes.
![]() D is incorrect because a continuity of operations (COOP) plan establishes senior management and a headquarters after a disaster. It provides instructions on how to set up a command center so that all activities and communication take place centrally and in a controlled manner. This type of plan also outlines roles and authorities, orders of succession, and individual role tasks that need to be put into place after a disaster takes place. This plan could be mentioned in the BCP policy, but the policy does not outline the specifics of setting up a command center and its components.
D is incorrect because a continuity of operations (COOP) plan establishes senior management and a headquarters after a disaster. It provides instructions on how to set up a command center so that all activities and communication take place centrally and in a controlled manner. This type of plan also outlines roles and authorities, orders of succession, and individual role tasks that need to be put into place after a disaster takes place. This plan could be mentioned in the BCP policy, but the policy does not outline the specifics of setting up a command center and its components.
36. The recovery time objective (RTO) and maximum tolerable downtime (MTD) metrics have similar roles, but their values are very different. Which of the following best describes the difference between RTO and MTD metrics?
A. The RTO is a time period that represents the inability to recover, and the MTD represents an allowable amount of downtime.
B. The RTO is an allowable amount of downtime, and the MTD represents a time period after which severe and perhaps irreparable damage is likely.
C. The RTO is a metric used in disruptions, and the MTD is a metric used in disasters.
D. The RTO is a metric pertaining to loss of access to data, and the MTD is a metric pertaining to loss of access to hardware and processing capabilities.
![]() B. The RTO value is smaller than the MTD value, because the MTD value represents the time after which an inability to recover significant operations will mean severe and perhaps irreparable damage to the organization’s reputation or bottom line. The RTO assumes that there is a period of acceptable downtime. This means that a company can be out of production for a certain period of time (RTO) and still get back on its feet. But if the company cannot get production up and running within the MTD window, the company is sinking too fast to properly recover.
B. The RTO value is smaller than the MTD value, because the MTD value represents the time after which an inability to recover significant operations will mean severe and perhaps irreparable damage to the organization’s reputation or bottom line. The RTO assumes that there is a period of acceptable downtime. This means that a company can be out of production for a certain period of time (RTO) and still get back on its feet. But if the company cannot get production up and running within the MTD window, the company is sinking too fast to properly recover.
![]() A is incorrect because the MTD is a time period that represents the inability to recover, and the RTO represents an allowable amount of downtime.
A is incorrect because the MTD is a time period that represents the inability to recover, and the RTO represents an allowable amount of downtime.
![]() C is incorrect because the RTO is the earliest time period and a service level within which a business process must be restored after a disaster to avoid unacceptable consequences associated with a break in business continuity. The RTO value is smaller than the MTD value because the MTD value represents the time after which an inability to recover significant operations will mean severe and perhaps irreparable damage to the organization’s reputation or bottom line.
C is incorrect because the RTO is the earliest time period and a service level within which a business process must be restored after a disaster to avoid unacceptable consequences associated with a break in business continuity. The RTO value is smaller than the MTD value because the MTD value represents the time after which an inability to recover significant operations will mean severe and perhaps irreparable damage to the organization’s reputation or bottom line.
![]() D is incorrect because the RTO is the earliest time period and a service level within which a business process must be restored after a disaster to avoid unacceptable consequences associated with a break in business continuity. The RTO value is smaller than the MTD value because the MTD value represents the time after which an inability to recover significant operations will mean severe and perhaps irreparable damage to the organization’s reputation or bottom line. RTO is not a metric pertaining to loss of access to data, and the MTD is not a metric pertaining to loss of access to hardware and processing capabilities.
D is incorrect because the RTO is the earliest time period and a service level within which a business process must be restored after a disaster to avoid unacceptable consequences associated with a break in business continuity. The RTO value is smaller than the MTD value because the MTD value represents the time after which an inability to recover significant operations will mean severe and perhaps irreparable damage to the organization’s reputation or bottom line. RTO is not a metric pertaining to loss of access to data, and the MTD is not a metric pertaining to loss of access to hardware and processing capabilities.
37. High availability (HA) is a combination of technologies and processes that work together to ensure that specific critical functions are always up and running at the necessary level. To provide this level of high availability, a company has to have a long list of technologies and processes that provide redundancy, fault tolerance, and failover capabilities. Which of the following best describes these characteristics?
A. Redundancy is the duplication of noncritical components or functions of a system with the intention of decreasing reliability of the system. Fault tolerance is the capability of a technology to discontinue to operate as expected even if something unexpected takes place. If a technology has a failover capability, this means that if there is a failure that cannot be handled through normal means, then processing is “switched over” to a working system.
B. Redundancy is the duplication of critical components or functions of a system with the intention of increasing reliability of the system. Fault tolerance is the capability of a technology to discontinue to operate as expected even if something unexpected takes place. If a technology has a failover capability, this means that if there is a failure that cannot be handled through normal means, then processing is “switched over” to a working system.
C. Redundancy is the duplication of critical components or functions of a system with the intention of increasing reliability of the system. Fault tolerance is the capability of a technology to continue to operate as expected even if something unexpected takes place. If a technology has a failover capability, this means that if there is a failure that cannot be handled through normal means, then processing is “switched over” to a nonworking system.
D. Redundancy is the duplication of critical components or functions of a system with the intention of increasing reliability of the system. Fault tolerance is the capability of a technology to continue to operate as expected even if something unexpected takes place. If a technology has a failover capability, this means that if there is a failure that cannot be handled through normal means, then processing is “switched over” to a working system.
![]() D. High availability (HA) is a combination of technologies and processes that work together to ensure that specific critical functions are always up and running. The specific thing can be a database, a network, an application, a power supply, etc. To provide this level of high availability, the company has to have a long list of technologies and processes that provide redundancy, fault tolerance, and failover capabilities. Redundancy, fault tolerance, and failover capabilities increase the reliability of a system or network. High reliability allows for high availability.
D. High availability (HA) is a combination of technologies and processes that work together to ensure that specific critical functions are always up and running. The specific thing can be a database, a network, an application, a power supply, etc. To provide this level of high availability, the company has to have a long list of technologies and processes that provide redundancy, fault tolerance, and failover capabilities. Redundancy, fault tolerance, and failover capabilities increase the reliability of a system or network. High reliability allows for high availability.
![]() A is incorrect because redundancy within this type of technology encompasses the duplication of critical components or functions of a system with the intention of increasing reliability of the system. Redundancy is commonly built into the network at a routing protocol level. The routing protocols are configured so if one link goes down or gets congested, then traffic is routed over a different network link. Redundant hardware can also be available so if a primary device goes down the backup component can be swapped out and activated.
A is incorrect because redundancy within this type of technology encompasses the duplication of critical components or functions of a system with the intention of increasing reliability of the system. Redundancy is commonly built into the network at a routing protocol level. The routing protocols are configured so if one link goes down or gets congested, then traffic is routed over a different network link. Redundant hardware can also be available so if a primary device goes down the backup component can be swapped out and activated.
![]() B is incorrect because fault tolerance is the capability of a technology to continue to operate as expected even if something unexpected takes place (a fault). If a database experiences an unexpected glitch, it can roll back to a known-good state and continue functioning as though nothing bad happened. If a packet gets lost or corrupted during a TCP session, the TCP protocol will resend the packet so that system-to-system communication is not affected. If a disk within a RAID system gets corrupted, the system uses its parity data to rebuild the corrupted data so that operations are not affected.
B is incorrect because fault tolerance is the capability of a technology to continue to operate as expected even if something unexpected takes place (a fault). If a database experiences an unexpected glitch, it can roll back to a known-good state and continue functioning as though nothing bad happened. If a packet gets lost or corrupted during a TCP session, the TCP protocol will resend the packet so that system-to-system communication is not affected. If a disk within a RAID system gets corrupted, the system uses its parity data to rebuild the corrupted data so that operations are not affected.
![]() C is incorrect because if a technology has a failover capability, this means that if there is a failure that cannot be handled through normal means, then processing is “switched over” to a working system.
C is incorrect because if a technology has a failover capability, this means that if there is a failure that cannot be handled through normal means, then processing is “switched over” to a working system.
The following scenario applies to questions 38 and 39.
Jeff is leading the business continuity group in his company. They have completed a business impact analysis and have determined that if the company’s credit card processing functionality was unavailable for 48 hours the company would most likely experience such a large financial hit that it would have to go out of business. The team has calculated that this functionality needs to be up and running within 28 hours after experiencing a disaster for the company to stay in business. The team has also determined that the restoration steps must be able to restore data that is 60 minutes old or less.
38. In this scenario, which of the following is the work recovery time value?
A. 48 hours
B. 28 hours
C. 20 hours
D. 1 hour
![]() C. The work recovery time (WRT) is the remainder of the overall MTD value after RTO. RTO usually deals with getting the infrastructure and systems back up and running, and WRT deals with restoring data, testing processes, and then making everything “live” for production purposes.
C. The work recovery time (WRT) is the remainder of the overall MTD value after RTO. RTO usually deals with getting the infrastructure and systems back up and running, and WRT deals with restoring data, testing processes, and then making everything “live” for production purposes.
![]() A is incorrect because in this scenario 48 hours is the MTD value.
A is incorrect because in this scenario 48 hours is the MTD value.
![]() B is incorrect because in this scenario 28 hours is the RTO value.
B is incorrect because in this scenario 28 hours is the RTO value.
![]() D is incorrect because this value does not represent the WRT.
D is incorrect because this value does not represent the WRT.
39. In this scenario, what would the 60-minute time period be referred to as?
A. Recovery time period
B. Maximum tolerable downtime
C. Recovery point objective
D. Recovery point time period
![]() C. The recovery point objective (RPO) is the acceptable amount of data loss measured in time. This value represents the earliest point in time in which data must be recovered. The higher the business value of data, the more funds or other resources that can be put into place to ensure a smaller amount of data is lost in the event of a disaster.
C. The recovery point objective (RPO) is the acceptable amount of data loss measured in time. This value represents the earliest point in time in which data must be recovered. The higher the business value of data, the more funds or other resources that can be put into place to ensure a smaller amount of data is lost in the event of a disaster.
![]() A is incorrect because this is a distracter answer. Recovery time period is not an official term.
A is incorrect because this is a distracter answer. Recovery time period is not an official term.
![]() B is incorrect because the maximum tolerable downtime (MTD) value represents the time after which an inability to recover significant operations will mean severe and perhaps irreparable damage to the organization’s reputation or bottom line.
B is incorrect because the maximum tolerable downtime (MTD) value represents the time after which an inability to recover significant operations will mean severe and perhaps irreparable damage to the organization’s reputation or bottom line.
![]() D is incorrect because this is a distracter answer. Recovery point time period is not an official term.
D is incorrect because this is a distracter answer. Recovery point time period is not an official term.
40. For evidence to be legally admissible, it must be relevant, complete, sufficient, and reliably obtained. Which characteristic refers to the evidence having a reasonable and sensible relationship to the findings?
A. Complete
B. Reliable
C. Relevant
D. Sufficient
![]() C. It is important that evidence be admissible, relevant, complete, sufficient, and reliable to the case at hand. These characteristics of evidence provide a foundation for a case and help ensure that the evidence is legally permissible. For evidence to be authentic, or relevant, it must have a reasonable and sensible relationship to the findings. If a judge rules that a person’s past traffic tickets cannot be brought up in a murder trial, this means the judge has ruled that the traffic tickets are not relevant to the case at hand. Thus, the prosecuting lawyer cannot even mention them in court. In addition, authentic evidence must be original; that is, it cannot be a copy or a summary of the original.
C. It is important that evidence be admissible, relevant, complete, sufficient, and reliable to the case at hand. These characteristics of evidence provide a foundation for a case and help ensure that the evidence is legally permissible. For evidence to be authentic, or relevant, it must have a reasonable and sensible relationship to the findings. If a judge rules that a person’s past traffic tickets cannot be brought up in a murder trial, this means the judge has ruled that the traffic tickets are not relevant to the case at hand. Thus, the prosecuting lawyer cannot even mention them in court. In addition, authentic evidence must be original; that is, it cannot be a copy or a summary of the original.
![]() A is incorrect because evidence that is complete presents the whole truth. All evidence, even exculpatory evidence, must be handed over. This means that a prosecutor cannot present just part of the evidence that is favorable to his side of the case.
A is incorrect because evidence that is complete presents the whole truth. All evidence, even exculpatory evidence, must be handed over. This means that a prosecutor cannot present just part of the evidence that is favorable to his side of the case.
![]() B is incorrect because evidence that is reliable must be consistent with the facts. Evidence cannot be reliable if it is based on someone’s opinion or copies of an original document because there is too much room for error. Reliable evidence means it is factual and not circumstantial. Examples of unreliable evidence include computer-generated documentation and an investigator’s notes because they can be modified without any indication.
B is incorrect because evidence that is reliable must be consistent with the facts. Evidence cannot be reliable if it is based on someone’s opinion or copies of an original document because there is too much room for error. Reliable evidence means it is factual and not circumstantial. Examples of unreliable evidence include computer-generated documentation and an investigator’s notes because they can be modified without any indication.
![]() D is incorrect because evidence that is sufficient, or believable, is persuasive enough to convince a reasonable person of its validity. This means the evidence cannot be subject to personal interpretation. Sufficient evidence also means it cannot be easily doubted.
D is incorrect because evidence that is sufficient, or believable, is persuasive enough to convince a reasonable person of its validity. This means the evidence cannot be subject to personal interpretation. Sufficient evidence also means it cannot be easily doubted.
41. Alex works for a chemical distributor that assigns employees tasks that separate their duties and routinely rotates job assignments. Which of the following best describes the differences between these countermeasures?
A. They are the same thing with different titles.
B. They are administrative controls that enforce access control and protect the company’s resources.
C. Separation of duties ensures that one person cannot perform a high-risk task alone, and job rotation can uncover fraud because more than one person knows the tasks of a position.
D. Job rotation ensures that one person cannot perform a high-risk task alone, and separation of duties can uncover fraud because more than one person knows the tasks of a position.
![]() C. Separation of duties and job rotation are two security controls commonly used within companies to prevent and detect fraud. Separation of duties is put into place to ensure that one entity cannot carry out a task that could be damaging or risky to the company. It requires two or more people to come together to do their individual tasks to accomplish the overall task. Rotation of duties helps ensure that one person does not stay in one position for a long period of time because he may end up having too much control over a segment of the business. Such total control could result in fraud, data modification, and misuse of resources.
C. Separation of duties and job rotation are two security controls commonly used within companies to prevent and detect fraud. Separation of duties is put into place to ensure that one entity cannot carry out a task that could be damaging or risky to the company. It requires two or more people to come together to do their individual tasks to accomplish the overall task. Rotation of duties helps ensure that one person does not stay in one position for a long period of time because he may end up having too much control over a segment of the business. Such total control could result in fraud, data modification, and misuse of resources.
![]() A is incorrect because separation of duties and job rotation are two different concepts. They are, however, both put into place to reduce the possibilities of fraud, sabotage, misuse of information, theft, and other security compromises. Separation of duties makes sure that one individual cannot complete a critical task by herself. When a submarine captain needs to launch a nuclear torpedo, the launch usually requires three codes to be entered into the launching mechanism by three different senior crewmembers. This is an example of separation of duties. Job rotation ensures that no single person ends up having too much control over a segment of the business as a result of staying in one position for a long period of time.
A is incorrect because separation of duties and job rotation are two different concepts. They are, however, both put into place to reduce the possibilities of fraud, sabotage, misuse of information, theft, and other security compromises. Separation of duties makes sure that one individual cannot complete a critical task by herself. When a submarine captain needs to launch a nuclear torpedo, the launch usually requires three codes to be entered into the launching mechanism by three different senior crewmembers. This is an example of separation of duties. Job rotation ensures that no single person ends up having too much control over a segment of the business as a result of staying in one position for a long period of time.
![]() B is incorrect because answer C is a more detailed and definitive answer. Answer C describes both of these controls properly and their differences. Both of these controls are administrative in nature and are put into place to control access to company assets, but the CISSP exam requires the best answer out of four.
B is incorrect because answer C is a more detailed and definitive answer. Answer C describes both of these controls properly and their differences. Both of these controls are administrative in nature and are put into place to control access to company assets, but the CISSP exam requires the best answer out of four.
![]() D is incorrect because the description is backward. Separation of duties, not job rotation, ensures that one person cannot perform a high-risk task alone. Job rotation moves individuals in and out of a specific role to ensure that fraudulent activities are not taking place.
D is incorrect because the description is backward. Separation of duties, not job rotation, ensures that one person cannot perform a high-risk task alone. Job rotation moves individuals in and out of a specific role to ensure that fraudulent activities are not taking place.
42. Maria has been tasked with reviewing and ultimately augmenting her organization’s physical security. Of the following controls and approaches, which should be her highest priority to ensure are properly implemented?
A. Physical facility access controls, such as mechanical and device locks, on all necessary ingress points
B. Personnel access controls, such as badges, biometric systems, etc.
C. External boundary controls, including perimeter intrusion detection and assessment system (PIDAS) fencing, security guards, etc.
D. Layered facility access controls, with multiple internal and external ingress and egress controls
![]() D. Like any other defensive security discipline, physical security can be effectively implemented only via a defense-in-depth strategy, through layered defenses. It must be based on the assumption that a determined attacker will find a way to bypass any specific control, and therefore compensating controls must be deployed to enable the defender to detect and correct for any given failure to prevent a breach. The other possible answers each constitute core components of a layered facility protection regime, but cannot be relied upon individually.
D. Like any other defensive security discipline, physical security can be effectively implemented only via a defense-in-depth strategy, through layered defenses. It must be based on the assumption that a determined attacker will find a way to bypass any specific control, and therefore compensating controls must be deployed to enable the defender to detect and correct for any given failure to prevent a breach. The other possible answers each constitute core components of a layered facility protection regime, but cannot be relied upon individually.
![]() A is incorrect because regardless of the “grade” or security level provided by any given physical lock, mechanical and device locks can be bypassed by an experienced and knowledgeable adversary. Most commercial warded and tumbler locks can be defeated by amateurs and hobbyists, and even cipher locks that are not well maintained can commonly be brute forced by a savvy attacker. The bottom line is that any unattended physical lock is at best a means of delaying the access of a determined adversary.
A is incorrect because regardless of the “grade” or security level provided by any given physical lock, mechanical and device locks can be bypassed by an experienced and knowledgeable adversary. Most commercial warded and tumbler locks can be defeated by amateurs and hobbyists, and even cipher locks that are not well maintained can commonly be brute forced by a savvy attacker. The bottom line is that any unattended physical lock is at best a means of delaying the access of a determined adversary.
![]() B is incorrect because, as with physical, mechanical locks, all personnel access controls can ultimately be defeated. ID badges are trivial to forge, and “smart” badges—particularly near radio frequency varieties—can often be cloned quite readily by a trained attacker. Biometric systems can be spoofed, and so are no panacea.
B is incorrect because, as with physical, mechanical locks, all personnel access controls can ultimately be defeated. ID badges are trivial to forge, and “smart” badges—particularly near radio frequency varieties—can often be cloned quite readily by a trained attacker. Biometric systems can be spoofed, and so are no panacea.
![]() C is incorrect because, though an important first layer of defense, boundary controls must be deployed with the cognizance that we do intentionally allow individuals to enter through them. To bypass such controls, an attacker need only convince the often human-attended system that they are among the people who should be allowed in. Social engineering is the primary vector for such an attack, and is commonly no less successful in person than it is via e-mail.
C is incorrect because, though an important first layer of defense, boundary controls must be deployed with the cognizance that we do intentionally allow individuals to enter through them. To bypass such controls, an attacker need only convince the often human-attended system that they are among the people who should be allowed in. Social engineering is the primary vector for such an attack, and is commonly no less successful in person than it is via e-mail.
43. Which of the following statements is true with respect to preventing and/or detecting security disasters?
A. Information security continuous monitoring (ISCM), defined by NIST Special Publication 800-137 as maintaining an ongoing awareness of your current security posture, vulnerabilities, and threats, is the best way to facilitate sound risk management decisions.
B. Whitelisting allowed executables or, barring that, blacklisting known bad ones is the only effective means of preventing malware from compromising systems and causing a serious security breach.
C. A rigorous regime of vulnerability and patch management can effectively eliminate the risk of known malware compromising critical corporate systems.
D. By aggregating and correlating asset data and the security events concerning them, the deployment of a security information and event management (SIEM) system is the best way to ensure that attacks can be properly dealt with before they result in disaster.
![]() A. Sound risk management is impossible without a thoroughgoing and current understanding of the effectiveness of the deployed controls vis-a-vis the current threats to extant vulnerabilities in the enterprise. Information security continuous monitoring (ISCM) seeks to provide this information on a truly ongoing basis, recognizing that new vulnerabilities are not discovered, nor do new threats to them emerge, on a quarterly basis. Rather, an agile and timely approach is needed to continuously ascertain, via heavy use of metrics and automation, how prepared we actually are, and how we can continuously improve our resilience to expected adversarial tactics, techniques, and procedures (TTPs).
A. Sound risk management is impossible without a thoroughgoing and current understanding of the effectiveness of the deployed controls vis-a-vis the current threats to extant vulnerabilities in the enterprise. Information security continuous monitoring (ISCM) seeks to provide this information on a truly ongoing basis, recognizing that new vulnerabilities are not discovered, nor do new threats to them emerge, on a quarterly basis. Rather, an agile and timely approach is needed to continuously ascertain, via heavy use of metrics and automation, how prepared we actually are, and how we can continuously improve our resilience to expected adversarial tactics, techniques, and procedures (TTPs).
![]() B is incorrect because blacklisting known bad things is essentially a futile attempt to “enumerate and avoid all evil,” and although whitelisting is a vastly more effective way to avoid the execution of malware in the corporate environment, bypassing whitelisting systems is a major focus of technical advancement by modern threat actors, and techniques for doing so now constitute commodity attack strategies. Whitelisting alone simply cannot suffice without continuous monitoring for attempts to circumvent such controls.
B is incorrect because blacklisting known bad things is essentially a futile attempt to “enumerate and avoid all evil,” and although whitelisting is a vastly more effective way to avoid the execution of malware in the corporate environment, bypassing whitelisting systems is a major focus of technical advancement by modern threat actors, and techniques for doing so now constitute commodity attack strategies. Whitelisting alone simply cannot suffice without continuous monitoring for attempts to circumvent such controls.
![]() C is incorrect because even the most rigorous infrastructure for vulnerability and patch management rarely has a cycle time shorter than that of exploit development once vulnerabilities become known. Most significant breaches remain the result of the exploitation of vulnerabilities for which patches were available but simply not yet deployed. Vigorous patching is a necessary step, but no more important than proactive monitoring of, and response to, indicators of compromise and post-compromise activities.
C is incorrect because even the most rigorous infrastructure for vulnerability and patch management rarely has a cycle time shorter than that of exploit development once vulnerabilities become known. Most significant breaches remain the result of the exploitation of vulnerabilities for which patches were available but simply not yet deployed. Vigorous patching is a necessary step, but no more important than proactive monitoring of, and response to, indicators of compromise and post-compromise activities.
![]() D is incorrect because a robust SIEM deployment is a necessary but not entirely sufficient component of a defensible infrastructure. By itself, it provides no assurance that significant threat activities are properly understood and effectively responded to. Unfortunately, many organizations simply aggregate their security events with a SIEM, in order to more efficiently ignore them.
D is incorrect because a robust SIEM deployment is a necessary but not entirely sufficient component of a defensible infrastructure. By itself, it provides no assurance that significant threat activities are properly understood and effectively responded to. Unfortunately, many organizations simply aggregate their security events with a SIEM, in order to more efficiently ignore them.
44. Miranda has been directed to investigate a possible violation of her organization’s acceptable use policy (AUP) by a coworker suspected of running cryptocurrency mining software on his desktop system. Which of the following is NOT a very likely scenario that could arise during her investigation?
A. During the course of her investigation, Miranda discovered that her coworker was also downloading and storing pornographic images, many of which appeared to involve minors. What began as an administrative investigation became a criminal one.
B. Miranda was able to find evidence that appeared to corroborate the intentional use of illicit software to mine cryptocurrency using corporate resources (mainly CPU and power). As a result, Miranda’s coworker was charged with a criminal violation of the Computer Fraud and Abuse Act (CFAA).
C. As a result of Miranda’s investigation, her coworker was terminated for violating the AUP. However, he hired an attorney and sued the company for wrongful dismissal based on knowledge that other employees were also running cryptocurrency mining software but went unpunished. Her administrative case became a civil one.
D. Compelling evidence was found of a significant AUP violation, resulting in termination. However, during the subsequent wrongful dismissal suit (as described in option C), it was discovered that Miranda had not anticipated a court case, and so had not properly obtained or preserved the evidence. Consequently, the judge found summarily for the plaintiff, who got his job back along with compensatory damages.
![]() B. Though it could be argued that the employee in question had exceeded his intended, authorized access to a company computer and used it to steal corporate resources (computing and electrical power), the severity of such actions is unlikely to rise to the level of a criminal indictment under the CFAA, particularly as a single instance.
B. Though it could be argued that the employee in question had exceeded his intended, authorized access to a company computer and used it to steal corporate resources (computing and electrical power), the severity of such actions is unlikely to rise to the level of a criminal indictment under the CFAA, particularly as a single instance.
![]() A is incorrect because, unfortunately, it is a more common scenario than might easily be imagined. A thorough digital forensic examination can easily turn up evidence of criminal activities not previously detected or suspected. This is the main reason that all investigations should be conducted with the necessary professional skill and diligence to conclude them in court if such a situation arises.
A is incorrect because, unfortunately, it is a more common scenario than might easily be imagined. A thorough digital forensic examination can easily turn up evidence of criminal activities not previously detected or suspected. This is the main reason that all investigations should be conducted with the necessary professional skill and diligence to conclude them in court if such a situation arises.
![]() C is incorrect because this scenario is also quite commonplace and is another excellent example as to why all investigations and administrative proceedings should be conducted as though they may wind up in front of a judge or jury. If, through the discovery process, the plaintiff can demonstrate that others were indeed involved in the same activity, but that he alone was singled out, he is likely to prevail in court. A judge could easily find that because the AUP was not consistently enforced, no AUP exists in practicality.
C is incorrect because this scenario is also quite commonplace and is another excellent example as to why all investigations and administrative proceedings should be conducted as though they may wind up in front of a judge or jury. If, through the discovery process, the plaintiff can demonstrate that others were indeed involved in the same activity, but that he alone was singled out, he is likely to prevail in court. A judge could easily find that because the AUP was not consistently enforced, no AUP exists in practicality.
![]() D is incorrect because the scenario is at least somewhat likely. Though the bar in a civil case is merely “a preponderance of evidence,” that evidence must still be legally and reliably obtained, and its integrity properly maintained. Miranda’s evidence may not have been ruled entirely inadmissible in court, but a judge may determine that it should not be afforded sufficient weight for the defense to prevail.
D is incorrect because the scenario is at least somewhat likely. Though the bar in a civil case is merely “a preponderance of evidence,” that evidence must still be legally and reliably obtained, and its integrity properly maintained. Miranda’s evidence may not have been ruled entirely inadmissible in court, but a judge may determine that it should not be afforded sufficient weight for the defense to prevail.