
Chapter 11. Endpoint Telemetry and Analysis
This chapter covers the following topics:
• Understanding Host Telemetry
• Endpoint Security Technologies
The focus of this chapter is on understanding how analysts in a security operations center (SOC) can use endpoint telemetry for incident response and analysis. This chapter covers how to collect and analyze telemetry from Windows, Linux, and macOS systems, as well as mobile devices.
“Do I Know This Already?” Quiz
The “Do I Know This Already?” quiz allows you to assess whether you should read this entire chapter thoroughly or jump to the “Exam Preparation Tasks” section. If you are in doubt about your answers to these questions or your own assessment of your knowledge of the topics, read the entire chapter. Table 11-1 lists the major headings in this chapter and their corresponding “Do I Know This Already?” quiz questions. You can find the answers in Appendix A, “Answers to the ‘Do I Know This Already?’ Quizzes and Review Questions.”
Table 11-1 “Do I Know This Already?” Foundation Topics Section-to-Question Mapping

1. Which of the following are useful attributes you should seek to collect from endpoints? (Select all that apply.)
a. IP address of the endpoint or DNS host name
b. Application logs
c. Processes running on the machine
d. NetFlow data
2. SIEM solutions can collect logs from popular host security products, including which of the following? (Select all that apply.)
a. Antivirus or antimalware applications
b. CloudLock logs
c. NetFlow data
d. Personal (host-based) firewalls
3. Which of the following are useful reports you can collect from Cisco ISE related to endpoints? (Select all that apply.)
a. Web server log reports
b. Top Application reports
c. RADIUS Authentication reports
d. Administrator Login reports
4. Which of the following is not true about listening ports?
a. A listening port is a port held open by a running application in order to accept inbound connections.
b. Seeing traffic from a known port will always identify the associated service.
c. Listening ports use values that can range between 1 and 65,535.
d. TCP port 80 is commonly known for Internet traffic.
5. A traffic substitution and insertion attack does which of the following?
a. Substitutes the traffic with data in a different format but with the same meaning
b. Substitutes the payload with data in the same format but with a different meaning
c. Substitutes the payload with data in a different format but with the same meaning
d. Substitutes the traffic with data in the same format but with a different meaning
6. Which of the following is not a method for identifying running processes?
a. Reading network traffic from a SPAN port with the proper technology
b. Reading port security logs
c. Reading traffic inline with the proper technology
d. Using port scanner technology
7. Which of the following statements is not true about host profiling?
a. Latency is a delay in throughput detected at the gateway of the network.
b. Throughput is typically measured in bandwidth.
c. In a valley there is an unusually low amount of throughput compared to the normal baseline.
d. In a peak there is a spike in throughput compared to the normal baseline.
8. Which of the follow best describes Windows process permissions?
a. User authentication data is stored in a token that is used to describe the security context of all processes associated with the user.
b. Windows generates processes based on super user–level security permissions and limits processes based on predefined user authentication settings.
c. Windows process permissions are developed by Microsoft and enforced by the host system administrator.
d. Windows grants access to all processes unless otherwise defined by the Windows administrator.
9. Which of the following is a true statement about stacks and heaps?
a. Heaps can allocate a block of memory at any time and free it at any time.
b. Stacks can allocate a block of memory at any time and free it at any time.
c. Heaps are best when you know exactly how much memory you should use.
d. Stacks are best when you don’t know how much memory to use.
10. What is the Windows Registry?
a. A list of registered software on the Windows operating system
b. Memory allocated to running programs
c. A database used to store information necessary to configure the system for users, applications, and hardware devices
d. A list of drivers for applications running on the Windows operating system
11. Which of the following is a function of the Windows Registry?
a. To register software with the application provider
b. To load device drivers and startup programs
c. To back up application registration data
d. To log upgrade information
12. Which of the following statements is true?
a. WMI is a command standard used by most operating systems.
b. WMI cannot run on older versions of Windows such as Windows 7.
c. WMI is a defense program designed to prevent scripting languages from managing Microsoft Windows computers and services.
d. WMI allows scripting languages to locally and remotely manage Microsoft Windows computers and services.
13. What is a virtual address space in Windows?
a. The physical memory allocated for processes
b. A temporary space for processes to execute
c. The set of virtual memory addresses that reference the physical memory object a process is permitted to use
d. The virtual memory address used for storing applications
14. What is the difference between a handle and pointer?
a. A handle is an abstract reference to a value, whereas a pointer is a direct reference.
b. A pointer is an abstract reference to a value, whereas a handle is a direct reference.
c. A pointer is a reference to a handle.
d. A handle is a reference to a pointer.
15. Which of the following is true about handles?
a. When Windows moves an object such as a memory block to make room in memory and the location of the object is impacted, the handles table is updated.
b. Programmers can change a handle using Windows API.
c. Handles can grant access rights against the operating system.
d. When Windows moves an object such as a memory block to make room in memory and the location of the object is impacted, the pointer to the handle is updated.
16. Which of the following is true about Windows services?
a. Windows services function only when a user has accessed the system.
b. The Services Control Manager is the programming interface for modifying the configuration of Windows Services.
c. Microsoft Windows services run in their own user session.
d. Stopping a service requires a system reboot.
17. Which process type occurs when a parent process is terminated and the remaining child process is permitted to continue on its own?
a. Zombie process
b. Orphan process
c. Rogue process
d. Parent process
18. A zombie process occurs when which of the following happens?
a. A process holds its associated memory and resources but is released from the entry table.
b. A process continues to run on its own.
c. A process holds on to associated memory but releases resources.
d. A process releases the associated memory and resources but remains in the entry table.
19. What is the best explanation of a fork (system call) in Linux?
a. When a process is split into multiple processes
b. When a parent process creates a child process
c. When a process is restarted from the last run state
d. When a running process returns to its original value
20. Which of the following gives permissions to the group owners for read and execute; gives the file owner permission for read, write, and execute; and gives all others permissions for execute?
a. -rwx-rx-x
b. -rx-rwx-x
c. -rx-x-rwx
d. -rwx-rwx-x
21. Which is a correct explanation of daemon permissions?
a. Daemons run at root-level access.
b. Daemons run at super user–level access.
c. Daemons run as the init process.
d. Daemons run at different privileges, which are provided by their parent process.
22. Which of the following is not true about symlinks?
a. A symlink will cause a system error if the file it points to is removed.
b. Showing the contents of a symlink will display the contents of what it points to.
c. An orphan symlink occurs when the link that a symlink points to doesn’t exist.
d. A symlink is a reference to a file or directory.
23. What is a daemon?
a. A program that manages the system’s motherboard
b. A program that runs other programs
c. A computer program that runs as a background process rather than being under direct control of an interactive user
d. The only program that runs in the background of a Linux system
24. Which priority level of logging will be sent if the priority level is err?
a. err
b. err, warning, notice, info, debug, none
c. err, alert, emerg
d. err, crit, alert, emerg
25. Which of the following is an example of a facility?
a. marker
b. server
c. system
d. mail
26. What is a Trojan horse?
a. A piece of malware that downloads and installs other malicious content from the Internet to perform additional exploitation on an affected system.
b. A type of malware that executes instructions determined by the nature of the Trojan to delete files, steal data, and compromise the integrity of the underlying operating system, typically by leveraging social engineering and convincing a user to install such software.
c. A virus that replicates itself over the network infecting numerous vulnerable systems.
d. A type of malicious code that is injected into a legitimate application. An attacker can program a logic bomb to delete itself from the disk after it performs the malicious tasks on the system.
27. What is ransomware?
a. A type of malware that compromises a system and then often demands a ransom from the victim to pay the attacker in order for the malicious activity to cease, to recover encrypted files, or for the malware to be removed from the affected system
b. A set of tools used by attackers to elevate their privilege to obtain root-level access to completely take control of the affected system
c. A type of intrusion prevention system
d. A type of malware that doesn’t affect mobile devices
28. Which of the following are examples of free antivirus or antimalware software? (Select all that apply.)
a. McAfee Antivirus
b. Norton AntiVirus
c. ClamAV
d. Immunet
29. Host-based firewalls are often referred to as which of the following?
a. Next-generation firewalls
b. Personal firewalls
c. Host-based intrusion detection systems
d. Antivirus software
30. What is an example of a Cisco solution for endpoint protection?
a. Cisco ASA
b. Cisco ESA
c. Cisco AMP for Endpoints
d. Firepower Endpoint System
31. Which of the following are examples of application file and folder attributes that can help with application whitelisting? (Select all that apply.)
a. Application store
b. File path
c. Filename
d. File size
32. Which of the following are examples of sandboxing implementations? (Select all that apply.)
a. Google Chromium sandboxing
b. Java virtual machine (JVM) sandboxing
c. HTML CSS and JavaScript sandboxing
d. HTML5 “sandbox” attribute for use with iframes
Foundation Topics
Understanding Host Telemetry
Telemetry from user endpoints, mobile devices, servers, and applications is crucial when protecting, detecting, and reacting to security incidents and attacks. The following sections describe several examples of this type of telemetry and their use.
Logs from User Endpoints
Logs from user endpoints can help you not only for attribution if they are part of a malicious activity but also for victim identification. However, how do you determine where an endpoint and user are located? If you do not have sophisticated host or network management systems, it’s very difficult to track every useful attribute about user endpoints. This is why it is important what type of telemetry and metadata you collect as well as how you keep such telemetry and metadata updated and how you perform checks against it.
The following are some useful attributes you should seek to collect:
• Location based on just the IP address of the endpoint or DNS host name
• Application logs
• Processes running on the machine
You can correlate those with VPN and DHCP logs. However, these can present their own challenges because of the rapid turnover of network addresses associated with dynamic addressing protocols. For example, a user may authenticate to a VPN server, drop the connection, reauthenticate, and end up with a completely new address.
The level of logs you want to collect from each and every user endpoint depends on many environmental factors, such as storage, network bandwidth, and also the ability to analyze such logs. In many cases, more detailed logs are used in forensics investigations.
For instance, let’s say you are doing a forensics investigation on an Apple macOS device; in that case, you may need to collect hard evidence on everything that happened on that device. If you monitor endpoint machines daily, you will not be able to inspect and collect information about the device and the user in the same manner you would when doing a forensics investigation. For example, for that same Mac OS X machine, you may want to take a top-down approach while investigating files, beginning at the root directory, and then move into the User directory, which may have a majority of the forensic evidence.
Another example is dumping all the account information on the system. Mac OS X contains a SQLite database for the accounts used on the system. This includes information such as email addresses, social media usernames, and descriptions of the items.
On Windows, events are collected and stored by the Event Logging Service. This service keeps events from different sources in event logs and includes chronological information. On the other hand, the type of data that will be stored in an event log depends on system configuration and application settings. Windows event logs provide a lot of data for investigators. Some items of the event log record, such as Event ID and Event Category, help security professionals get information about a certain event. The Windows Event Logging Service can be configured to store granular information about numerous objects on the system. Almost any resource of the system can be considered an object, thus allowing security professionals to detect any requests for unauthorized access to resources.
Typically, what you do in a security operations center (SOC) is monitor logs sent by endpoint systems to a security information and event management (SIEM) system. You already learned one example of a SIEM: Splunk.
A SIM mainly provides a way to digest large amount of log data, making it easy to search through collected data. SEMs are designed to consolidate and correlate large amounts of event data so that the security analyst or network administrator can prioritize events and react appropriately. SIEM solutions can collect logs from popular host security products, including the following:
• Personal firewalls
• Intrusion detection/prevention systems
• Antivirus or antimalware
• Web security logs (from a web security appliance)
• Email security logs (from an email security appliance)
• Advanced malware protection logs
There are many other host security features, such as data-loss prevention and VPN clients. For example, the Cisco AnyConnect Secure Mobility Client includes the Network Visibility Module (NVM), which is designed to monitor application use by generating IPFIX flow information.
The AnyConnect NVM collects the endpoint telemetry information, including the following:
• The endpoint device, irrespective of its location
• The user logged in to the endpoint
• The application that generates the traffic
• The network location the traffic was generated on
• The destination (FQDN) to which this traffic was intended
The AnyConnect NVM exports the flow records to a collector (such as the Cisco Stealthwatch system). You can also configure NVM to get notified when the VPN state changes to connected and when the endpoint is in a trusted network. NVM collects and exports the following information:
• Source IP address
• Source port
• Destination IP address
• Destination port
• A universally unique identifier (UUID) that uniquely identifies the endpoint corresponding to each flow
• Operating system (OS) name
• OS version
• System manufacturer
• System type (x86 or x64)
• Process account, including the authority/username of the process associated with the flow
• Parent process associated with the flow
• The name of the process associated with the flow
• An SHA-256 hash of the process image associated with the flow
• An SHA-256 hash of the image of the parent process associated with the flow
• The DNS suffix configured on the interface associated with the flow on the endpoint
• The FQDN or host name that resolved to the destination IP on the endpoint
• The total number of incoming and outgoing bytes on that flow at Layer 4 (payload only)
Mobile devices in some cases are treated differently because of their dynamic nature and limitations such as system resources and restrictions. Many organizations use mobile device management (MDM) platforms to manage policies on mobile devices and to monitor such devices. The policies can be applied using different techniques—for example, by using a sandbox that creates an isolated environment that limits what applications can be accessed and controls how systems gain access to the environment. In other scenarios, organizations install an agent on the mobile device to control applications and to issue commands (for example, to remotely wipe sensitive data). Typically, MDM systems include the following features:
• Mandatory password protection
• Jailbreak detection
• Remote wipe
• Remote lock
• Device encryption
• Data encryption
• Geolocation
• Malware detection
• VPN configuration and management
• Wi-Fi configuration and management
The following are a few MDM vendors:
• AirWatch
• MobileIron
• Citrix
• Good Technology
MDM solutions from these vendors typically have the ability to export logs natively to Splunk or other third-party reporting tools such as Tableau, Crystal Reports, and QlikView.
You can also monitor user activity using the Cisco Identity Services Engine (ISE). The Cisco ISE reports are used with monitoring and troubleshooting features to analyze trends and to monitor user activities from a central location. Think about it: identity management systems such as the Cisco ISE keep the keys to the kingdom. It is very important to monitor not only user activity but also the activity on the Cisco ISE itself.
The following are a few examples of user and endpoint reports you can run on the Cisco ISE:
• AAA Diagnostics reports provide details of all network sessions between Cisco ISE and users. For example, you can use user authentication attempts.
• The RADIUS Authentications report enables a security analyst to obtain the history of authentication failures and successes.
• The RADIUS Errors report enables security analysts to check for RADIUS requests dropped by the system.
• The RADIUS Accounting report tells you how long users have been on the network.
• The Authentication Summary report is based on the RADIUS authentications. It tells the administrator or security analyst about the most common authentications and the reason for any authentication failures.
• The OCSP Monitoring Report allows you to get the status of the Online Certificate Status Protocol (OCSP) services and provides a summary of all the OCSP certificate validation operations performed by Cisco ISE.
• The Administrator Logins report provides an audit trail of all administrator logins. This can be used in conjunction with the Internal Administrator Summary report to verify the entitlement of administrator users.
• The Change Configuration Audit report provides details about configuration changes within a specified time period. If you need to troubleshoot a feature, this report can help you determine if a recent configuration change contributed to the problem.
• The Client Provisioning report indicates the client-provisioning agents applied to particular endpoints. You can use this report to verify the policies applied to each endpoint to verify whether the endpoints have been correctly provisioned.
• The Current Active Sessions report enables you to export a report with details about who was currently on the network within a specified time period.
• The Guest Activity report provides details about the websites that guest users are visiting. You can use this report for security-auditing purposes to demonstrate when guest users accessed the network and what they did on it.
• The Guest Accounting report is a subset of the RADIUS Accounting report. All users assigned to the Activated Guest or Guest Identity group appear in this report.
• The Endpoint Protection Service Audit report is based on RADIUS accounting. It displays historical reporting of all network sessions for each endpoint.
• The Mobile Device Management report provides details about integration between Cisco ISE and the external mobile device management (MDM) server.
• The Posture Detail Assessment report provides details about posture compliancy for a particular endpoint. If an endpoint previously had network access and then suddenly was unable to access the network, you can use this report to determine whether a posture violation occurred.
• The Profiled Endpoint Summary report provides profiling details about endpoints that are accessing the network.
Logs from Servers
![]()
Just as you do with endpoints, it is important that you analyze server logs. You can do this by analyzing simple syslog messages or more specific web or file server logs. It does not matter whether the server is a physical device or a virtual machine.
For instance, on Linux-based systems, you can review and monitor logs stored under /var/log. Example 11-1 shows a snippet of the syslog of a Linux-based system where you can see postfix database messages on a system running the GitLab code repository.
Example 11-1 Syslog on a Linux system
Sep 4 17:12:43 odin postfix/qmgr[2757]: 78B9C1120595: from=<gitlab@odin>, size=1610, nrcpt=1 (queue active) Sep 4 17:13:13 odin postfix/smtp[5812]: connect to gmail-smtp-in.l.google.com[173.194.204.27]:25: Connection timed out Sep 4 17:13:13 odin postfix/smtp[5812]: connect to gmail-smtp-in.l.google.com[2607:f8b0:400d:c07::1a]:25: Network is unreachable Sep 4 17:13:43 odin postfix/smtp[5812]: connect to alt1.gmail-smtp-in.l.google.com[64.233.190.27]:25: Connection timed out Sep 4 17:13:43 odin postfix/smtp[5812]: connect to alt1.gmail-smtp-in.l.google.com[2800:3f0:4003:c01::1a]:25: Network is unreachable Sep 4 17:13:43 odin postfix/smtp[5812]: connect to alt2.gmail-smtp-in.l.google.com[2a00:1450:400b:c02::1a]:25: Network is unreachable
You can also check the audit.log for authentication and user session information. Example 11-2 shows a snippet of the auth.log on a Linux system, where the user (omar) initially typed his password incorrectly while attempting to connect to the server (odin) via SSH.
Example 11-2 audit.log on a Linux System
Sep 4 17:21:32 odin sshd[6414]: Failed password for omar from 192.168.78.3 port 52523 ssh2 Sep 4 17:21:35 odin sshd[6422]: pam_ecryptfs: Passphrase file wrapped Sep 4 17:21:36 odin sshd[6414]: Accepted password for omar from 192.168.78.3 port 52523 ssh2 Sep 4 17:21:36 odin sshd[6414]: pam_unix(sshd:session): session opened for user omar by (uid=0) Sep 4 17:21:36 odin systemd: pam_unix(systemd-user:session): session opened for user omar by (uid=0)
Web server logs are also important and should be monitored. Of course, the amount of activity on these logs can be overwhelming—thus the need for robust SIEM and log management platforms such as Splunk, Naggios, and others. Example 11-3 shows a snippet of a web server (Apache httpd) log.
Example 11-3 Apache httpd Log on a Linux System
192.168.78.167 - - [02/Apr/2022:23:32:46 -0400] “GET / HTTP/1.1” 200 3525 “-” “Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/48.0.2564.116 Safari/537.36” 192.168.78.167 - - [02/Apr/2022:23:32:46 -0400] “GET /icons/ubuntu-logo.png HTTP/1.1” 200 3689 “http://192.168.78.8/” “Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/48.0.2564.116 Safari/537.36” 192.168.78.167 - - [02/Apr/2022:23:32:47 -0400] “GET /favicon.ico HTTP/1.1” 404 503 “http://192.168.78.8/” “Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/48.0.2564.116 Safari/537.36” 192.168.78.167 - - [03/Apr/2022:00:37:11 -0400] “GET / HTTP/1.1” 200 3525 “-” “Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/48.0.2564.116 Safari/537.36”
Host Profiling
Profiling hosts on the network is similar to profiling network behavior. This capability can be valuable in identifying vulnerable systems, internal threats, what applications are installed on hosts, and so on. We touch on how to view details directly from the host; however, the main focus is on profiling hosts as an outside entity by looking at a host’s network footprint.
Let’s start by discussing how to view data from a network host and the applications it is using.
Listening Ports
The first goal when looking at a host on a network, regardless of whether the point of a view is from a system administrator, penetration tester, or malicious attacker, is identifying which ports on the host are “listening.” A listening port is a port held open by a running application in order to accept inbound connections. From a security perspective, this may mean a vulnerable system that could be exploited. A worst-case scenario would be an unauthorized active listening port to an exploited system permitting external access to a malicious party. Because most attackers will be outside your network, unauthorized listening ports are typically evidence of an intrusion.
Let’s look at the fundamentals behind ports: Messages associated with application protocols use TCP or UDP. Both of these protocols employ port numbers to identify a specific process to which an Internet or other network message is to be forwarded when it arrives at a server. A port number is a 16-bit integer that is put in the header appended to a specific message unit. Port numbers are passed logically between the client and server transport layers and physically between the transport layer and the IP layer before they are forwarded on. This client/server model is typically seen as web client software. An example is a browser communicating with a web server listening on a port such as port 80. Port values can range between 1 and 65,535, with server applications generally assigned a valued below 1024.
The following is a list of well-known ports used by applications:
• TCP 20 and 21: File Transfer Protocol (FTP)
• TCP 22: Secure Shell (SSH)
• TCP 23: Telnet
• TCP 25: Simple Mail Transfer Protocol (SMTP)
• TCP and UDP 53: Domain Name System (DNS)
• UDP 69: Trivial File Transfer Protocol (TFTP)
• TCP 79: Finger
• TCP 80: Hypertext Transfer Protocol (HTTP)
• TCP 110: Post Office Protocol v3 (POP3)
• TCP 119: Network News Protocol (NNTP)
• UDP 161 and 162: Simple Network Management Protocol (SNMP)
• TCP 443: Secure Sockets Layer over HTTP (HTTPS)
Note
These are just industry guidelines, meaning administrators do not have to run these services over these ports. Typically, administrators will follow these guidelines; however, these services can run over other ports. The services do not have to run on the known port to service list.
There are two basic approaches for identifying listening ports on the network. The first approach is accessing a host and searching for which ports are set to a listening state. This requires a minimal level of access to the host and being authorized on the host to run commands. This could also be done with authorized applications that are capable of showing all possible applications available on the host. The most common host-based tool for checking systems for listening ports on Windows and Linux systems is the netstat command. An example of looking for listening ports using the netstat command is netstat -na, as shown in Example 11-4.
Example 11-4 Identifying Open Ports with netstat
# netstat -na Active Internet connections (servers and established) Proto Recv-Q Send-Q Local Address Foreign Address State tcp 0 0 127.0.0.53:53 0.0.0.0:* LISTEN tcp 0 0 0.0.0.0:22 0.0.0.0:* LISTEN tcp 0 912 10.1.2.3:22 192.168.88.12:38281 ESTABLISHED tcp6 0 0 :::53 :::* LISTEN tcp6 0 0 :::22 :::* LISTEN
In Example 11-4 the host is “listening” to TCP port 53 and 22 (in IPv4 and in IPv6). A Secure Shell connection from another host (192.168.88.12) is already established and shown in the output of the command.
Another host command to view similar data is the lsof -i command, as demonstrated in Example 11-5. In Example 11-5, Docker containers are also running web applications and listening on TCP ports 80 (http) and 443 (https).
Example 11-5 Identifying Open Ports with lsof
# lsof -i COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME systemd-r 647 systemd-resolve 12u IPv4 15295 0t0 UDP localhost:domain systemd-r 647 systemd-resolve 13u IPv4 15296 0t0 TCP localhost:domain (LISTEN) sshd 833 root 3u IPv4 18331 0t0 TCP *:ssh (LISTEN) sshd 833 root 4u IPv6 18345 0t0 TCP *:ssh (LISTEN) docker-pr 10470 root 4u IPv6 95596 0t0 TCP *:https (LISTEN) docker-pr 10482 root 4u IPv6 95623 0t0 TCP *:http (LISTEN)
A second and more reliable approach to determining what ports are listening from a host is to scan the host as an outside evaluator with a port scanner application. A port scanner probes a host system running TCP/IP to determine which TCP and UDP ports are open and listening. One extremely popular tool that can do this is the nmap tool, which is a port scanner that can determine whether ports are listening, plus provide many other details. The nmap command nmap-services will look for more than 2200 well-known services to fingerprint any applications running on the port.
It is important to be aware that port scanners provide a best guess, and the results should be validated. For example, a security solution could reply with the wrong information, or an administrator could spoof information such as the version number of a vulnerable server to make it appear to a port scanner that the server is patched. Newer breach detection technologies such as advanced honey pots attempt to attract attackers that have successfully breached the network by leaving vulnerable ports open on systems in the network. They then monitor those systems for any connections. The concept is that attackers will most likely scan and connect to systems that are found to be vulnerable, thus being tricked into believing the fake honey pot is really a vulnerable system.
If attackers are able to identify a server with an available port, they can attempt to connect to that service, determine what software is running on the server, and check to see if there are known vulnerabilities within the identified software that potentially could be exploited, as previously explained. This tactic can be effective when servers are identified as unadvertised because many website administrators fail to adequately protect systems that may be considered “nonproduction” systems yet are still on the network. An example would be using a port scanner to identify servers running older software, such as an older version of Apache HTTPd, NGINX, and other popular web servers and related frameworks that have known exploitable vulnerabilities. Many penetration arsenals such as Metasploit carry a library of vulnerabilities matching the results from a port scanner application. Another option for viewing “listening” ports on a host system is to use a network device such as a Cisco IOS router. A command similar to netstat on Cisco IOS devices is show control-plan host open-ports. A router’s control plane is responsible for handling traffic destined for the router itself versus the data plane being responsible for passing transient traffic.
A best practice for securing any listening and open ports is to perform periodic network assessments on any host using network resources for open ports and services that might be running and are either unintended or unnecessary. The goal is to reduce the risk of exposing vulnerable services and to identify exploited systems or malicious applications. Port scanners are common and widely available for the Windows and Linux platforms. Many of these programs are open-source projects, such as nmap, and have well-established support communities. A risk evaluation should be applied to identified listening ports because some services may be exploitable but wouldn’t matter for some situations. An example would be a server inside a closed network without external access that’s identified to have a listening port that an attacker would never be able to access.
The following list shows some of the known “bad” ports that should be secured:
• 1243/tcp: SubSeven server (default for V1.0-2.0)
• 6346/tcp: Gnutella
• 6667/tcp: Trinity intruder-to-master and master-to-daemon
• 6667/tcp: SubSeven server (default for V2.1 Icqfix and beyond)
• 12345/tcp: NetBus 1.x
• 12346/tcp: NetBus 1.x
• 16660/tcp: Stacheldraht intruder-to-master
• 18753/udp: Shaft master-to-daemon
• 20034/tcp: NetBus Pro
• 20432/tcp: Shaft intruder-to-master
• 20433/udp: Shaft daemon-to-master
• 27374/tcp: SubSeven server (default for V2.1-Defcon)
• 27444/udp: Trinoo master-to-daemon
• 27665/tcp: Trinoo intruder-to-master
• 31335/udp: Trinoo daemon-to-master
• 31337/tcp: Back Orifice
• 33270/tcp: Trinity master-to-daemon
• 33567/tcp: Backdoor rootshell via inetd (from Lion worm)
• 33568/tcp: Trojaned version of SSH (from Lion worm)
• 40421/tcp: Masters Paradise Trojan horse
• 60008/tcp: Backdoor rootshell via inetd (from Lion worm)
• 65000/tcp: Stacheldraht master-to-daemon
One final best practice we’ll cover for protecting listening and open ports is implementing security solutions such as firewalls. The purpose of a firewall is to control traffic as it enters and leaves a network based on a set of rules. Part of the responsibility is protecting listening ports from unauthorized systems—for example, preventing external attackers from having the ability to scan internal systems or connect to listening ports. Firewall technology has come a long way, providing capabilities across the entire network protocol stack and the ability to evaluate the types of communication permitted. For example, older firewalls can permit or deny web traffic via port 80 and 443, but current application layer firewalls can also permit or deny specific applications within that traffic, such as denying YouTube videos within a Facebook page, which is seen as an option in most application layer firewalls. Firewalls are just one of the many tools available to protect listening ports. Best practice is to layer security defense strategies to avoid being compromised if one method of protection is breached.
The list that follows highlights the key concepts covered in this section:
• A listening port is a port held open by a running application in order to accept inbound connections.
• Ports use values that range between 1 and 65,535.
• Netstat and nmap are popular methods for identifying listening ports.
• Netstat can be run locally on a device, whereas nmap can be used to scan a range of IP addresses for listening ports.
• A best practice for securing listening ports is to scan and evaluate any identified listening port as well as to implement layered security, such as combining a firewall with other defensive capabilities.
Logged-in Users/Service Accounts
Identifying who is logged in to a system is important for knowing how the system will be used. Administrators typically have more access to various services than other users because their job requires those privileges. Employees within Human Resources might need more access rights than other employees to validate whether an employee is violating a policy. Guest users typically require very little access rights because they are considered a security risk to most organizations. In summary, best practice for provisioning access rights is to enforce the concept of least privilege, meaning to provision the absolute least number of access rights required to perform a job.
People can be logged in to a system in two ways. The first method is to be physically at a keyboard logged in to the system. The other method is to remotely access the system using something like a Remote Desktop Connection (RDP) protocol. Sometimes the remote system is authorized and controlled, such as using a Citrix remote desktop solution to provide remote users access to the desktop, whereas other times it’s a malicious user who has planted a remote-access tool (RAT) to gain unauthorized access to the host system. Identifying post-breach situations is just one of the many reasons why monitoring remote connections should be a priority for protecting your organization from cyber breaches.
A few different approaches can be used to identify who is logged in to a system. For Windows machines, the first method involves using the Remote Desktop Services Manager suite. This approach requires the software to be installed. Once the software is running, an administrator can remotely access the host to verify who is logged in.
Another tool you can use to validate who is logged in to a Windows system is the PsLoggedOn application. For this application to work, it has to be downloaded and placed somewhere on your local computer that will be remotely checking hosts. Once it’s installed, simply open a command prompt and execute the following command:
C:PsToolspsloggedon.exe \HOST_TO_CONNECT
You can use Windows PowerShell to obtain detailed information about users logged in to the system and many other statistics that can be useful for forensics and incident response activities. Similarly to the psloggedon.exe method, you can take advantage of PowerShell modules like Get-ActiveUser available, which is documented at www.powershellgallery.com/packages/Get-ActiveUser/1.4/.
Note
The PowerShell Gallery (www.powershellgallery.com) is the central repository for PowerShell modules developed by Microsoft and the community.
For Linux machines, various commands can show who is logged in to a system, such as the w command, who command, users command, whoami command, and the last “user name” command. Example 11-6 shows the output of the w command. Two users are logged in as omar and root.
Example 11-6 Using the Linux w Command
$w 21:39:12 up 2 days, 19:18, 2 users, load average: 1.06, 0.95, 0.87 USER TTY FROM LOGIN@ IDLE JCPU PCPU WHAT root tty1 - 18:29 0.00s 0.02s 0.00s ssh 10.6.6.3 omar pts/2 10.6.6.3 21:36 0.00s 0.01s 0.00s w
Example 11-7 shows the output of the who, users, last, and lastlog Linux commands. In Example 11-7, you can see the details on the users root and omar, as well as when they logged in to the system using the last command. The lastlog command reports the most recent login of all users or of a given user. In Example 11-17, the lastlog command displays information on all users in the system.
Example 11-7 The who and users Linux Commands
$who root tty1 Jun 3 18:29 omar pts/2 Jun 3 21:36 (10.6.6.3) $users omar root $last omar pts/2 10.6.6.3 Wed Jun 3 21:36 still logged in root tty1 Wed Jun 3 18:29 still logged in wtmp begins Wed Jun 3 18:29:09 2020 $lastlog Username Port From Latest root tty1 Wed Jun 3 18:29:09 +0000 2020 daemon **Never logged in** bin **Never logged in** sys **Never logged in** sync **Never logged in** games **Never logged in** man **Never logged in** lp **Never logged in** mail **Never logged in** news **Never logged in** uucp **Never logged in** proxy **Never logged in** www-data **Never logged in** backup **Never logged in** list **Never logged in** irc **Never logged in** gnats **Never logged in** nobody **Never logged in** syslog **Never logged in** systemd-network **Never logged in** systemd-resolve **Never logged in** messagebus **Never logged in** postfix **Never logged in** _apt **Never logged in** sshd **Never logged in** uuidd **Never logged in** chelin pts/2 10.6.6.45 Tue Jun 2 11:22:41 +0000 2020 omar pts/2 10.6.6.3 Wed Jun 3 21:36:53 +0000 2020
Each option shows a slightly different set of information about who is currently logged in to a system. One command that displays the same information on a Windows system is the whoami command.
Many administrative tools can be used to remotely access hosts, so the preceding commands can be issued to validate who is logged in to the system. One such tool is a virtual network computing (VNC) server. This method requires three pieces. The first part is having a VNC server that will be used to access clients. The second part is having a VNC viewer client installed on the host to be accessed by the server. The final part is an SSH connection that is established between the server and client once things are set up successfully. SSH can also be used directly from one system to access another system using the ssh “remote_host” or ssh “remote_username@remote_host” command if SSH is set up properly. There are many other applications, both open source and commercial, that can provide remote desktop access service to host systems.
It is important to be aware that validating who is logged in to a host can help identify when a host is compromised. According to the kill chain concept, attackers that breach a network will look to establish a foothold through breaching one or more systems. Once they have access to a system, they will seek out other systems by pivoting from system to system. In many cases, attackers want to identify a system with more access rights so they can increase their privilege level, meaning gaining access to an administration account, which typically can access critical systems. Security tools that include the ability to monitor users logged in to systems can flag whether a system associated with an employee accesses a system that’s typically only accessed by administrator-level users, thus indicating a concern for an internal attack through a compromised host. The industry calls this type of security breach detection, meaning technology looking for post-compromise attacks.
The following list highlights the key concepts covered in this section:
• Employing least privilege means to provision the absolute minimum number of access rights required to perform a job.
• The two methods to log in to a host are locally and remotely.
• Common methods for remotely accessing a host are using SSH and using a remote-access server application such as VNC.
Running Processes
Now that we have covered identifying listening ports and how to check users that are logged in to a host system, the next topic to address is how to identify which processes are running on a host system. A running process is an instance of a computer program being executed. There’s lots of value in understanding what is running on hosts, such as identifying what is consuming resources, developing more granular security policies, and tuning how resources are distributed based on QoS adjustments linked to identified applications. We briefly look at identifying processes with access to the host system; however, the focus of this section is on viewing applications as a remote system on the same network.
In Windows, one simple method for viewing the running processes when you have access to the host system is to open the Task Manager by pressing Ctrl+Shift+Esc, as shown in Figure 11-1.

Figure 11-1 Windows Task Manager
A similar result can be achieved using the Windows command line by opening the command terminal with the cmd command and issuing the tasklist command, as shown in Figure 11-2.
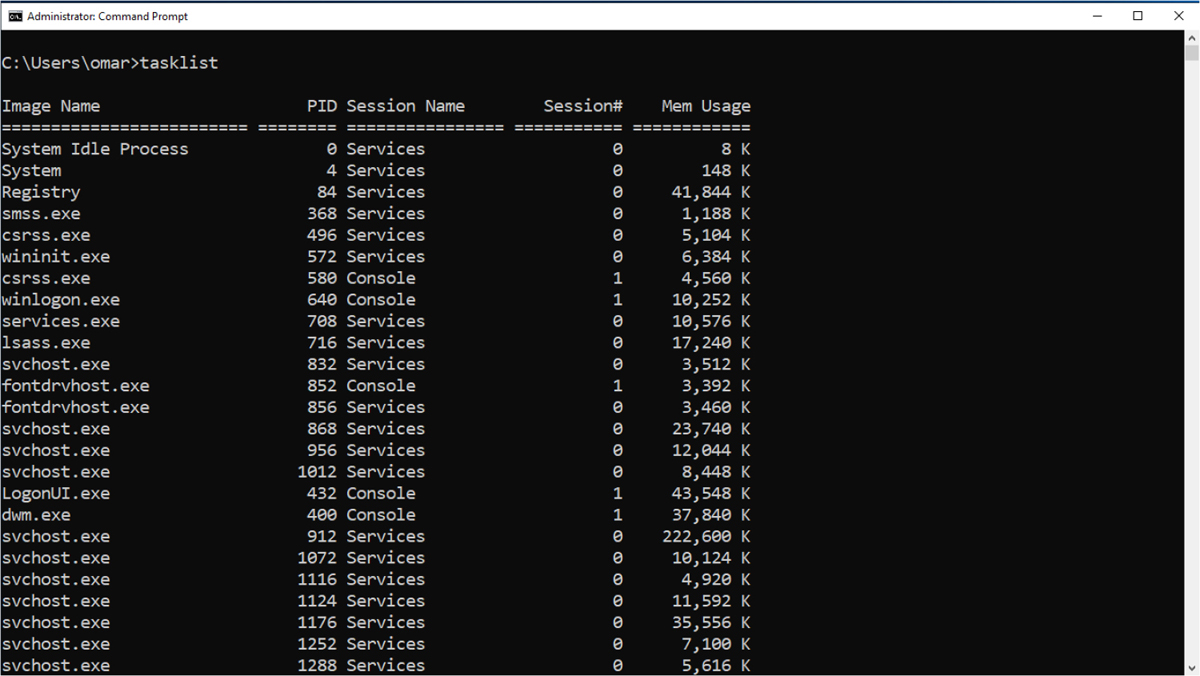
Figure 11-2 Running the tasklist Command on the Windows Command Line
For Linux systems, you can use the ps -e command to display a similar result as the Windows commands previously covered. Figure 11-3 shows executing the ps -e command to display running processes on a macOS system.

Figure 11-3 Using the ps -e Command on a macOS System
You can use the ps -u user command to see all the processes that a specific user is running. For instance, you can use the ps -u root command to see every process running as root. Similarly, you can use the ps -u omar command to see all the processes that the user omar has launched on a system.
These approaches are useful when you can log in to the host and have the privilege level to issue such commands. The focus for the CyberOps Associate exam is identifying these processes from an administrator system on the same network versus administrating the host directly. This requires evaluation of the hosts based on traffic and available ports. There are known services associated with ports, meaning that simply seeing a specific port being used indicates it has a known associated process running. For example, if port 25 shows SMTP traffic, it is expected that the host has a mail process running.
Identifying traffic from a host and the ports being used by the host can be handled using methods we previously covered, such as using a port scanner, having a detection tool inline, or reading traffic from a SPAN port.
Applications Identification
An application is software that performs a specific task. Applications can be found on desktops, laptops, mobile devices, and so on. They run inside the operating system and can be simple tasks or complicated programs. Identifying applications can be done using the methods previously covered, such as identifying which protocols are seen by a scanner, the types of clients (such as the web browser or email client), and the sources they are communicating with (such as what web applications are being used).
Note
Applications operate at the top of the OSI and TCP/IP layer models, whereas traffic is sent by the transport and lower layers, as shown in Figure 11-4.
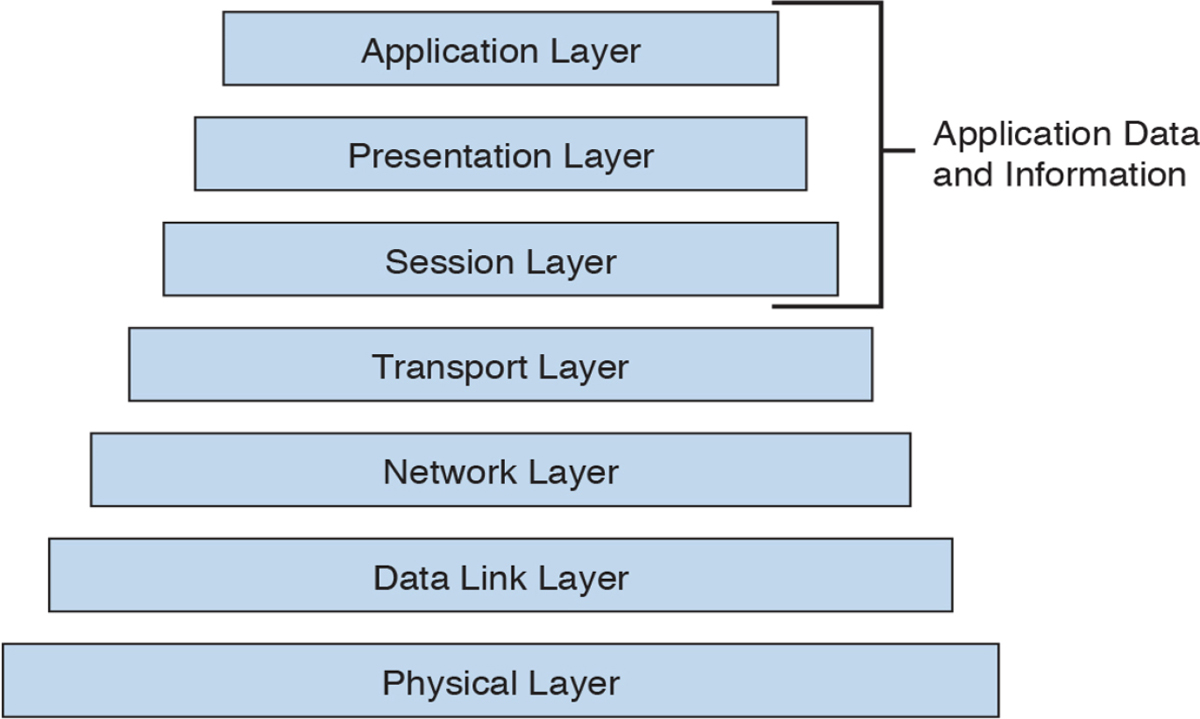
Figure 11-4 Representing the OSI and TCP/IP Layer Models
To view applications on a Windows system with access to the host, you can use the same methods we covered for viewing processes. The Task Manager is one option, as shown in Figure 11-5. In this example, notice that only applications owned or run by the user omar are displayed.
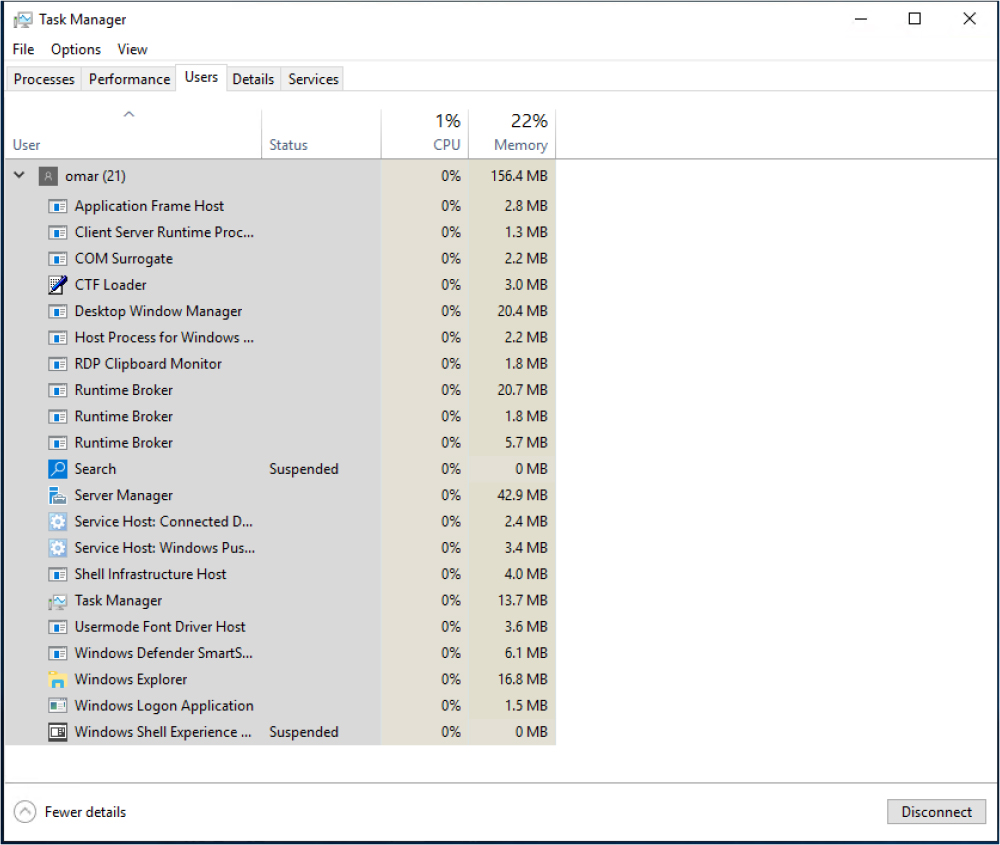
Figure 11-5 Windows Task Manager Showing Applications by User
For macOS systems, you can use the Activity Monitor tool, as shown in Figure 11-6.

Figure 11-6 macOS Activity Monitor
Once again, these options for viewing applications are great if you have access to the host as well as the proper privilege rights to run those commands or applications; however, let’s look at identifying the applications as an outsider profiling a system on the same network.
The first tool to consider is a port scanner that can also interrogate for more information than port data. Nmap version scanning can further interrogate open ports to probe for specific services. This tells nmap what is really running versus just the ports that are open. For example, running nmap -v could display lots of details, including the following information showing which port is open and the identified service:
PORT STATE SERVICE 80/tcp open http 631/tcp open ipp 3306/tcp open mysql
A classification engine available in Cisco IOS and Cisco IOS XE software that can be used to identify applications is Network-Based Application Recognition (NBAR). It works by enabling an IOS router interface to map traffic ports to protocols as well as recognize traffic that doesn’t have a standard port, such as various peer-to-peer protocols. NBAR is typically used as a means to identify traffic for QoS policies; however, you can use the show ip nbar protocol-discovery command to identify what protocols and associated applications are identified by NBAR.
Many other tools with built-in application-detection capabilities are available. Most content filters and network proxies can provide application layer details, such as Cisco’s Web Security Appliance (WSA).
Even NetFlow can have application data added when using a Cisco Stealthwatch Flow Sensor. The Flow Sensor adds detection of 900 applications while it converts raw data into NetFlow.
Application layer firewalls also provide detailed application data, such as Cisco Firepower Management Center (FMC), which is shown in Figure 11-7.

Figure 11-7 Firepower Management Center Application Statistics
You can use the Cisco Firepower Management Center (FMC) to view a table of detected applications, as shown in Figure 11-8. Then you can manipulate the event view depending on the information you are looking for as part of your incident response activities.
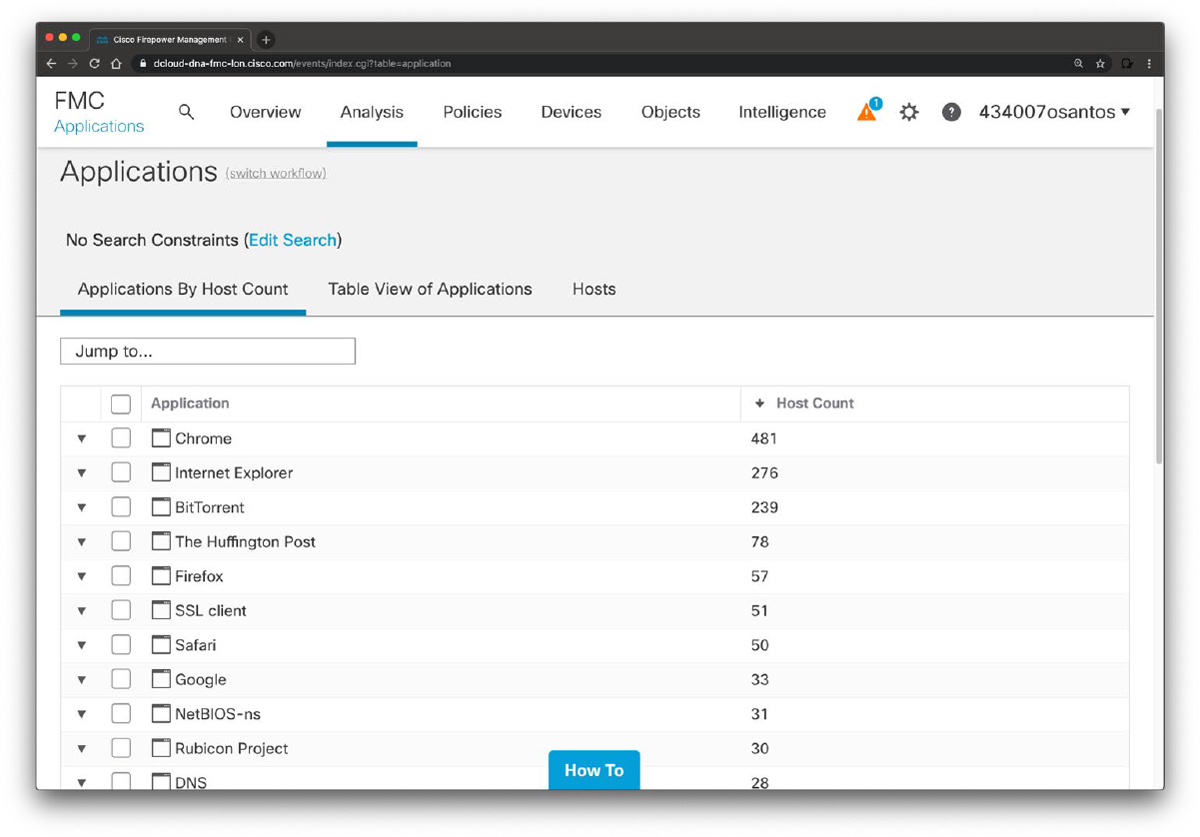
Figure 11-8 Firepower Detected Applications Table
In summary, networks tools that can detect application layer data must have access to network traffic both to and from a host, such as being inline or off a SPAN port. Examples of tools that can detect application layer data are content filters, application layer firewalls, and tools that have custom application-detection capabilities built in. Also, network scanning can be used to evaluate the ports on host and link traffic to known associated applications.
The following list highlights the key concepts covered in this section:
• An application is software that performs a specific task.
• Applications operate at the top of the OSI and TCP/IP layer models, whereas traffic is sent by the transport layer.
• NBAR in Cisco IOS devices can be used to identify applications.
• Network tools that can detect application layer data must have access to network traffic both to and from a host, such as being inline or off a SPAN port.
Now that we’ve covered profiling concepts, let’s explore how to analyze Windows endpoint logs and other artifacts.
Analyzing Windows Endpoints
In 1984 Microsoft introduced Windows as a graphical user interface (GUI) for Microsoft DOS. Over time, Windows has matured in stability and capabilities with many releases, ranging from Windows 3.0 back in 1990 to the current Windows release. More current releases of Windows have offered customized options; for example, Windows Server was designed for provisioning services to multiple hosts, and Windows Mobile was created for Windows-based phones and was not as successful as other versions of Windows.
The Windows operating system architecture is made up of many components, such as the control panel, administrative tools, and software. The control panel permits users to view and change basic system settings and controls. This includes adding hardware and removing software as well as changing user accounts and accessibility options. Administrative tools are more specific to administrating Windows. For example, System Restore is used for rolling back Windows, and Disk Defragment is used to optimize performance. Software can be various types of applications, from the simple calculator application to complex programing languages.
The CyberOps Associate exam doesn’t ask for specifics about each version of Windows; nor does it expect you to know every component within the Windows architecture. That would involve a ton of tedious detail that is out of scope for the learning objectives of the certification. The content covered here targets the core concepts you are expected to know about Windows. We start with how applications function by defining processes and threads.
Windows Processes and Threads
![]()
Let’s first run through some technical definitions of processes and threads. When you look at what an application is built from, you will find one or more processes. A process is a program that the system is running. Each process provides the required resources to execute a program. A process is made up of one or more threads, which are the basic units an operating system allocates process time to. A thread can be executed during any part of the application runtime, including being executed by another thread. Each process starts with a single thread, known as the primary thread, but can also create additional threads from any of its threads.
For example, the calculator application could run multiple processes when a user enters numbers to be computed, such as the process to compute the math as well as the process to display the answer. You can think of a thread as each number being called while the process is performing the computation that will be displayed by the calculator application. Figure 11-9 shows this relationship from a high-level view.
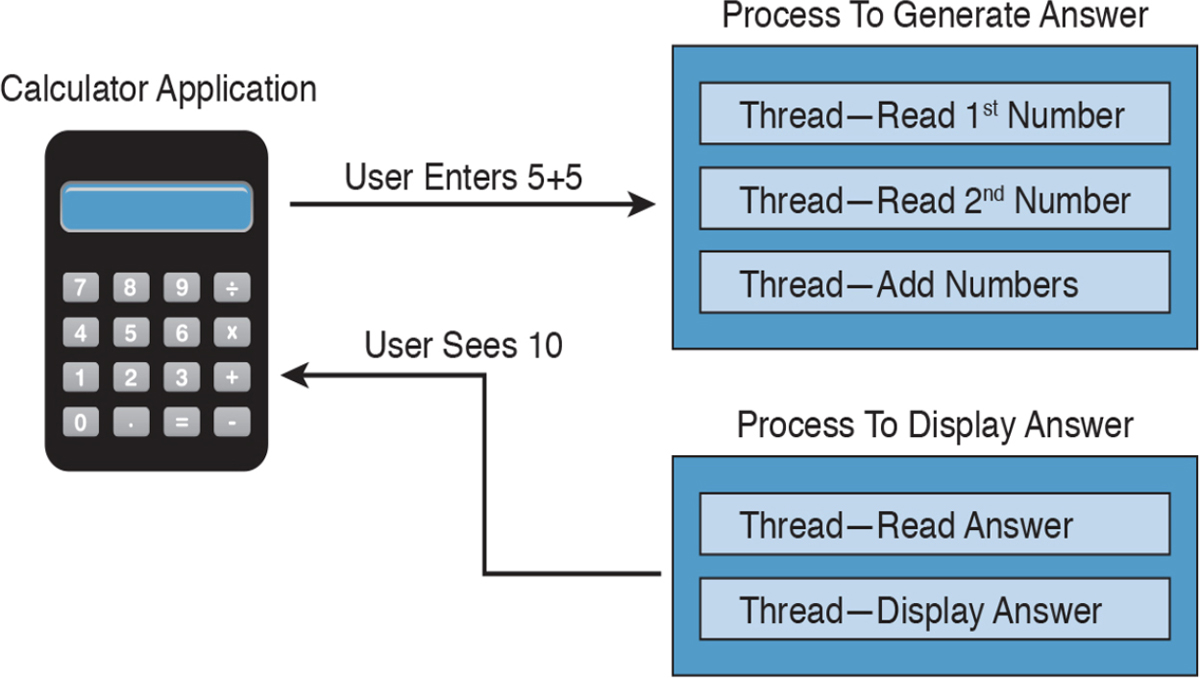
Figure 11-9 Calculator Process and Thread Example
Processes can be grouped together and managed as a unit called a job object, which can be used to control the attributes of those processes. Grouping processes together simplifies impacting those processes because any operation performed on a specific job object will impact all associated processes. A thread pool is a group of worker threads that efficiently execute asynchronous callbacks for the application. This is done to reduce the number of application threads and to manage the worker threads. A fiber is a unit of execution that is manually scheduled by an application. Threads can schedule multiple fibers; however, fibers do not outperform properly designed multithreaded applications.
Although these are the foundation concepts to be aware of, it is more important to understand how these items are generally used within Windows for security purposes. Knowing that a Windows process is a running program is important, but it’s equally as import to understand that processes must have permission to run. This keeps processes from hurting the system as well as unauthorized actions from being performed. For example, the process to delete everything on the hard drive should have some authorization settings to avoid killing the computer.
Windows permissions are based on access control to process objects tied to user rights. This means that super users such as administrators will have more rights than other user roles. Windows uses tokens to specify the current security context for a process. This can be accomplished using the CreateProcessWithTokenW function.
Authentication is typically used to provision authorization to a user role. For example, you would log in with a username and password to authenticate to an access role that has specific user rights. Windows would validate this login attempt, and if authentication is successful, you will be authorized for a specific level of access. Windows stores user authentication data in a token that describes the security context of all processes associated with the user role. This means administrator tokens would have permission to delete items of importance, whereas lower-level user tokens would provide the ability to view but not be authorized to delete.
Figure 11-10 ties this token idea to the calculator example, showing processes creating threads. The basic idea is that processes create threads, and threads validate whether they can run using an access token. In this example, the third thread is not authorized to operate for some reason, whereas the other two are permitted.

Figure 11-10 Adding Tokens to the Threads Example
It is important to understand how these components all work together when developing applications and later securing them. Threats to applications, known as vulnerabilities, could be abused to change the intended outcome of an application. This is why it is critical to include security at all stages of application development to ensure these and other application components are not abused. The next section reviews how processes and threads work within Windows memory.
The following list highlights the key process and thread concepts:
![]()
• A process is a program that the system is running and is made of one or more threads.
• A thread is a basic unit that an operating system allocates process time to.
• A job is a group of processes.
• A thread pool is a group of worker threats that efficiently execute asynchronous callbacks for the application.
• Processes must have permission to run within Windows.
• You can use a Windows token to specify the current security context for a process using the CreateProcessWithTokenW function.
• Windows stores data in a token that describes the security context of all processes associated with a particular user role.
Memory Allocation
Now that we have covered how applications function, let’s look at where they are installed and how they run. Computer memory is any physical device capable of storing information in a temporary or permanent state. Memory can be volatile or nonvolatile. Volatile memory is memory that loses its contents when the computer or hardware storage device loses power. RAM is an example of volatile memory. That’s why you never hear people say they are saving something to RAM. It’s designed for application performance.
You might be thinking that there isn’t a lot of value for the data stored in RAM; however, from a digital forensics viewpoint, the following data could be obtained by investigating RAM. (In case you’re questioning some of the items in the list, keep in mind that data that is encrypted must be unencrypted when in use, meaning its unencrypted state could be in RAM. The same goes for passwords!)
• Running processes: Who is logged in
• Passwords in cleartext: Unencrypted data
• Instant messages: Registry information
• Executed console commands: Attached devices
• Open ports: Listening applications
Nonvolatile memory (NVRAM), on the other hand, holds data with or without power. EPROM would be an example of nonvolatile memory.
Note
Memory and disk storage are two different things. Computers typically have anywhere from 1 GB to 16 GB of RAM, but they can have hundreds of terabytes of disk storage. A simple way to understand the difference is that memory is the space that applications use when they are running, whereas storage is the place where applications store data for future use.
Memory can be managed in different ways, referred to as memory allocation or memory management. In static memory allocation a program allocates memory at compile time. In dynamic memory allocation a program allocates memory at runtime. Memory can be assigned in blocks representing portions of allocated memory dedicated to a running program. A program can request a block of memory, which the memory manager will assign to the program. When the program completes whatever it’s doing, the allocated memory blocks are released and available for other uses.
Next up are stacks and heaps. A stack is memory set aside as spare space for a thread of execution. A heap is memory set aside for dynamic allocation (that is, where you put data on the fly). Unlike a stack, a heap doesn’t have an enforced pattern for the allocation and deallocation of blocks. With heaps, you can allocate a block at any time and free it at any time. Stacks are best when you know ahead of time how much memory is needed, whereas heaps are better for when you don’t know how much data you will need at runtime or if you need to allocate a lot of data. Memory allocation happens in hardware, in the operating system, and in programs and applications.
Processes function in a set of virtual memory known as virtual address space. The virtual address space for each process is private and cannot be accessed by other processes unless it is specifically shared. The virtual address does not represent the actual physical location of an object in memory; instead, it’s simply a reference point. The system maintains a page table for each process that is used to reference virtual memory to its corresponding physical address space. Figure 11-11 shows this concept using the calculator example, where the threads point to a page table that holds the location of the real memory object.
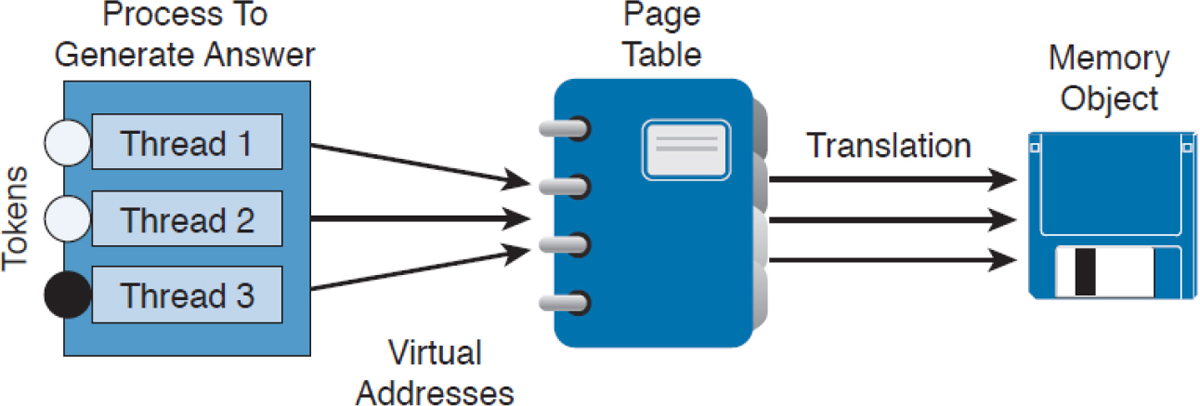
Figure 11-11 Page Table Example
The virtual address space of each process can be smaller or larger than the total physical memory available on the computer. A working set is a subset of the virtual address space of an active process. If a thread of a process attempts to use more physical memory than is currently available, the system will page some of the memory contest to disk. The total amount of virtual address space available to process on a specific system is limited by the physical memory and free space on the hard disks for the paging file.
We next touch on a few other concepts of how Windows allocates memory. The ultimate result is the same, but the approach for each is slightly different. VirtualAlloc is a specialized allocation of OS virtual memory system; it allocates straight into virtual memory by reserving memory blocks. HeapAlloc allocates any size of memory requested, meaning it allocates by default regardless of size. Malloc is another memory allocation option, but it is more programming focused and not Windows dependent. It is not important for the CyberOps Associate exam to know the details of how each memory allocation option functions. The goal is just to have a general understanding of memory allocation.
The following list highlights the key memory allocation concepts:
![]()
• Volatile memory is memory that loses its contents when the computer or hardware storage device loses power.
• Nonvolatile memory (NVRAM) holds data with or without power.
• In static memory allocation a program allocates memory at compile time.
• In dynamic memory allocation a program allocates memory at runtime.
• A heap is memory that is set aside for dynamic allocation.
• A stack is the memory that is set aside as spare space for a thread of execution.
• A virtual address space is the virtual memory that is used by processes.
• A virtual address is a reference to the physical location of an object in memory. A page table translates virtual memory into its corresponding physical addresses.
• The virtual address space of each process can be smaller or larger than the total physical memory available on the computer.
The Windows Registry
Now that we have covered what makes up an application and how it uses memory, let’s look at the Windows Registry. Essentially, anything performed in Windows refers to or is recorded into the Registry. Therefore, any actions taken by a user reference the Windows Registry. The Windows Registry is a hierarchical database for storing the information necessary to configure a system for one or more users, applications, and hardware devices.
Some functions of the Windows Registry are to load device drivers, run startup programs, set environment variables, and store user settings and operating system parameters. You can view the Windows Registry by typing the command regedit in the Run window. Figure 11-12 shows a screenshot of the Registry Editor window.
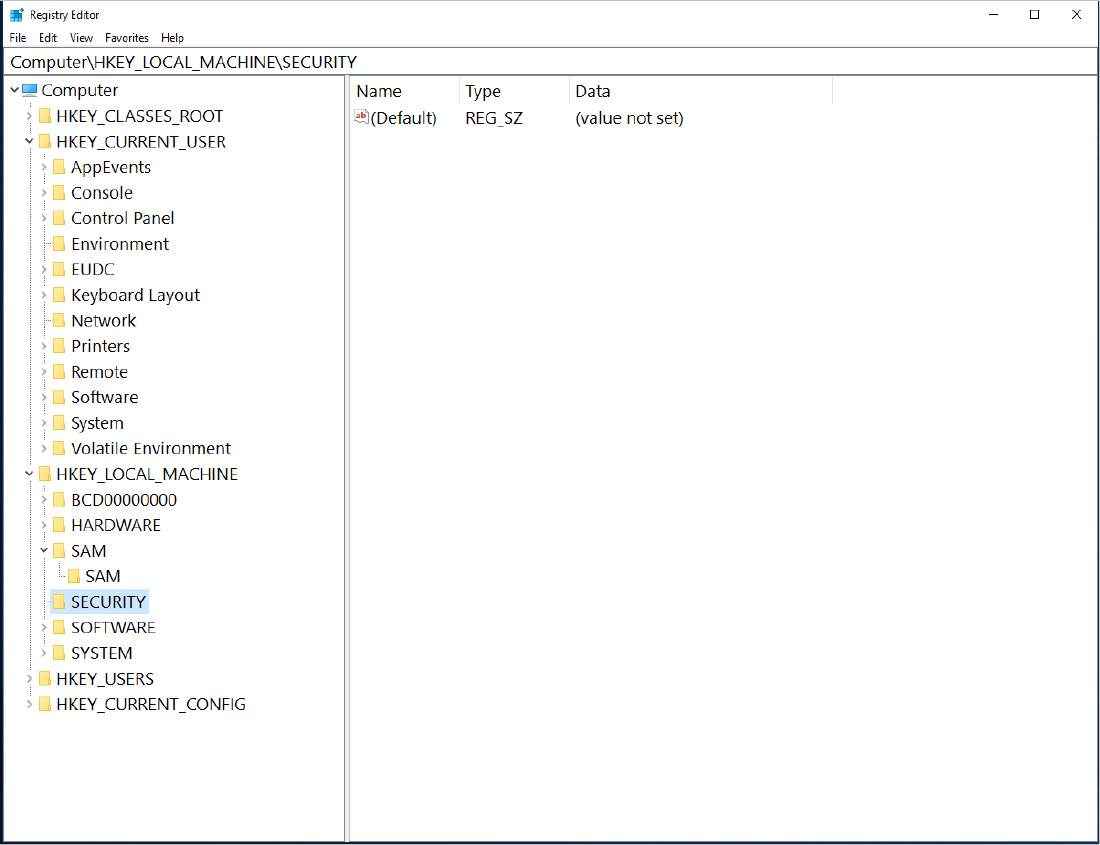
Figure 11-12 Windows Registry Editor
The Registry is like a structured file system. The five hierarchal folders on the left are called hives and begin with HKEY (meaning the handle to a key). Two of the hives are real locations: HKEY_USERS (HKU) and HKEY_LOCAL_MACHINE (HKLM). The remaining three are shortcuts to branches within the HKU and HKLM hives. Each of the five main hives is composed of keys that contain values and subkeys. Values pertain to the operation system or applications within a key. The Windows Registry is like an application containing folders. Inside an application, folders hold files. Inside the Windows Registry, the hives hold values.
The following list defines the functions of the five hives within the Windows Registry:
• HKEY_CLASSES_ROOT (HKCR): HKCR information ensures that the correct program opens when it is executed in Windows Explorer. HKCR also contains further details on drag-and-drop rules, shortcuts, and information on the user interface. The reference location is HKLMSoftwareClasses.
• HKEY_CURRENT_USER (HKCU): HKCU contains configuration information for any user who is currently logged in to the system, including user folders, screen colors, and control panel settings. The reference location for a specific user is HKEY_USERS. The reference for general use is HKU.DEFAULT.
• HKEY_CURRENT_CONFIG (HCU): HCU stores information about the system’s current configuration. The reference for HCU is HKLMConfigprofile.
• HKEY_LOCAL_MACHINE (HKLM): HKLM contains machine hardware-specific information that the operating system runs on. This includes a list of drives mounted on the system and generic configurations of installed hardware and applications. HKLM is a hive that isn’t referenced from within another hive.
• HKEY_USERS (HKU): HKU contains configuration information of all user profiles on the system. This includes application configurations and visual settings. HKU is a hive that isn’t referenced from within another hive.
Some interesting data points can be gained from analyzing the Windows Registry. All registries contain a value called LastWrite time, which is the last modification time of a file. This value can be used to identify the approximate date and time an event occurred. Autorun locations are Registry keys that launch programs or applications during the boot process. Autorun is extremely important to protect because it could be used by an attacker for executing malicious applications. The most recently used (MRU) list contains entries made due to actions performed by the user. The purpose of the MRU list is to contain items in the event the user returns to them in the future. Think of the MRU list as how a cookie is used in a web browser. The UserAssist key contains a document of what the user has accessed.
Network settings, USB devices, and mounted devices all have Registry keys that can be pulled up to identify activity within the operating system. Having a general understanding of Windows registration should be sufficient for questions found on the CyberOps Associate exam.
The following list highlights the key Windows registration concepts:
![]()
• The Windows Registry is a hierarchical database used to store information necessary to configure the system for one or more users, applications, and hardware devices.
• Some functions of the Registry are to load device drivers, run startup programs, set environment variables, and store user settings and operating system parameters.
• The five main folders in the Windows Registry are called hives. Three of these hives are reference points inside of another primary hive.
• Hives contain values pertaining to the operation system or applications within a key.
Windows Management Instrumentation
The next topic focuses on managing Windows systems and sharing data with other management systems. Windows Management Instrumentation (WMI) is a scalable system management infrastructure built around a single, consistent, standards-based, extensible, object-oriented interface. Basically, WMI is Microsoft’s approach to implementing Web-Based Enterprise Management (WBEM), which is a tool used by system management application developers for manipulating system management information. WMI uses the Common Information Model (CIM) industry standard to represent systems, applications, networks, devices, and other managed components. CIM is developed and maintained by the Distributed Management Task Force (DMTF).
It is important to remember that WMI is only for computers running Microsoft Windows. WMI comes preinstalled on all supported versions of Windows. Figure 11-13 shows a Windows computer displaying the WMI service.

Figure 11-13 Windows Computer Showing the WMI Service
The purpose of WMI is to define a set of proprietary environment-independent specifications used for management information that’s shared between management applications. WMI allows scripting languages to locally and remotely manage Microsoft Windows computers and services. The following list provides examples of what WMI can be used for:
• Providing information about the status of local or remote computer systems
• Configuring security settings
• Modifying system properties
• Changing permissions for authorized users and user groups
• Assigning and changing drive labels
• Scheduling times for processes to run
• Backing up the object repository
• Enabling or disabling error logging
Using WMI by itself doesn’t provide these capabilities or display any data. You must pull this information using scripts and other tools. WMI can be compared to the electronics data of a car, where the car dashboard is the tool used to display what the electronics are doing. Without the dashboard, the electronics are there, but you won’t be able to interact with the car or obtain any useful data. An example of WMI would be using a script to display the time zone configured on a Windows computer or issuing a command to change the time zone on one or more Windows computers.
When considering Windows security, you should note that WMI could be used to perform malicious activity. Malicious code could pull sensitive data from a system or automate malicious tasks. An example would be using WMI to escalate privileges so that malware can function at a higher privilege level if the security settings are modified. Another attack would be using WMI to obtain sensitive system information.
There haven’t been many WMI attacks seen in the wild; however, Trend Micro published a white paper on one piece of WMI malware called TROJ_WMIGHOST.A. So although such attacks are not common, they are possible. WMI requires administrative permission and rights to be installed; therefore, a best practice to protect systems against this form of exploitation is to restrict access to the WMI service.
The following list highlights the key WMI concepts:
![]()
• WMI is a scalable system management infrastructure built around a single, consistent, standards-based, extensible, object-oriented interface.
• WMI is only for Windows systems.
• WMI comes preinstalled on many Windows systems. For older Windows versions, you may need to download and install it.
• WMI data must be pulled in with scripting or tools because WMI by itself doesn’t show data.
Handles
In Microsoft Windows, a handle is an abstract reference value to a resource. Putting this another way, a handle identifies a particular resource you want to work with using the Win32 APIs. The resource is often memory, an open file, a pipe, or an object managed by another system. Handles hide the real memory address from the API user while permitting the system to reorganize physical memory in a way that’s transparent to the program.
Handles are like pointers, but not in the sense of dereferencing a handle to gain access to some data. Instead, a handle is passed to a set of functions that can perform actions on the object that the handle identifies. In comparison, a pointer contains the address of the item to which it refers, whereas a handle is an abstract of a reference and is managed externally. A handler can have its reference relocated in memory by the system without it being invalidated, which is impossible to do with a pointer because it directly points to something (see Figure 11-14).

Figure 11-14 Calculator Example Showing Handles
An important security concept is that a handle not only can identify a value but also associate access rights to that value. Consider the following example:
int fd = open(“/etc/passwd”, O_RDWR);
In this example, the program requests to read the system password file “/etc/passwd” in read/write mode (noted as 0_RDWR). This means the program asks to open this file with the specified access rights, which are read and write. If this is permitted by the operating system, it will return a handle to the user. The actual access is controlled by the operating system, and the handle can be looked at as a token of that access right provided by the operating system. Another outcome could be the operating system denying access, which means not opening the file or providing a handle. This shows why handles can be stored but never changed by the programmer; they are issued and managed by the operating system and can be changed on the fly by the operating system.
Handles generally end with .h (for example, WinDef.h) and are unsigned integers that Windows uses to internally keep track of objects in memory. When Windows moves an object, such as a memory block, to make room in memory and thus impacts the location of the object, the handles table is updated. Think of a handle as a pointer to a structure Windows doesn’t want you to directly manipulate. That is the job of the operating system.
One security concern with regard to handles is a handle leak. This occurs when a computer program requests a handle to a resource but does not free the handle when it is no longer used. The outcome of this is a resource leak, which is similar to a pointer causing a memory leak. A handle leak could happen when a programmer requests a direct value while using a count, copy, or other operation that would break when the value changes. Other times it is an error caused by poor exception handling. An example would be a programmer using a handle to reference some property and proceeding without releasing the handle. If this issue continues to occur, it could lead to a number of handles being marked as “in use” and therefore unavailable, causing performance problems or a system crash.
The following list highlights the key handle concepts:
![]()
• A handle is an abstract reference value to a resource.
• Handles hide the real memory address from the API user while permitting the system to reorganize physical memory in a way that’s transparent to the program.
• A handle not only can identify a value but also associate access rights to that value.
• A handle leak can occur if a handle is not released after being used.
Services
The next topic to tackle is Windows services, which are long-running executable applications that operate in their own Windows session. Basically, they are services that run in the background. Services can automatically kick off when a computer starts up, such as the McAfee security applications shown in Figure 11-15, and they must conform to the interface rules and protocols of the Services Control Manager.

Figure 11-15 Windows Services Control Manager
Services can also be paused and restarted. Figure 11-15 shows some services started under the Status tab. You can see whether a service will automatically start under the Startup Type tab. To view the services on a Microsoft Windows system as shown in Figure 11-15, type Services in the Run window. This brings up the Services Control Manager.
Services are ideal for running things within a user security context, starting applications that should always be run for a specific user, and for long-running functionality that doesn’t interfere with other users who are working on the same computer. An example would be monitoring whether storage is consumed past a certain threshold. The programmer could create a Windows service application that monitors storage space and set it to automatically start at bootup so it is continuously monitoring for the critical condition. If the user chooses not to monitor her system, she could open the Services Control Manager and change the startup type to Manual, meaning it must be manually turned on. Alternatively, she could just stop the service. The services inside the Services Control Manager can be started, stopped, or triggered by an event. Because services operate in their own user account, they can operate when a user is not logged in to the system, meaning that the storage space monitoring application could be set to automatically run for a specific user or for any other users, including when no user is logged in.
Windows administrators can manage services using the Services snap-in, Sc.exe, or Windows PowerShell. The Services snap-in is built into the Services Management Console and can connect to a local or remote computer on a network, thus enabling the administrator to perform some of the following actions:
• View installed services
• Start, stop, or restart services
• Change the startup type for a service
• Specify service parameters when available
• Change the startup type
• Change the user account context where the service operates
• Configure recovery actions in the event a service fails
• Inspect service dependencies for troubleshooting
• Export the list of services
Sc.exe, also known as the Service Control utility, is a command-line version of the Services snap-in. This means it can do everything the Services snap-in can do as well as install and uninstall services. Windows PowerShell can also manage Windows services using the following commands, also called cmdlets:
• Get-Service: Gets the services on a local or remote computer
• New-Service: Creates a new Windows service
• Restart-Service: Stops and then starts one or more services
• Resume-Service: Resumes one or more suspended (paused) services
• Set-Service: Starts, stops, and suspends a service, and changes its properties
• Start-Service: Starts one or more stopped services
• Stop-Service: Stops one or more running services
• Suspend-Service: Suspends (pauses) one or more running services
Other tools that can manage Windows services are Net.exe, Windows Task Manager, and MSConfig; however, their capabilities are limited compared to the other tools mentioned. For example, MSConfig can enable or disable Windows services, and Windows Task Manager can show a list of installed services as well as start or stop them.
Like other aspects of Windows, services are targeted by attackers. Microsoft has improved the security of services in later versions of the Windows operating system after finding various attack methods that compromise and completely own older versions of Windows. However, even the newer versions of Windows are not perfect, so best practice dictates securing (disabling) services such as the following unless they are needed:
• TCP 53: DNS Zone Transfer
• TCP 135: RPC Endpoint Mapper
• TCP 139: NetBIOS Session Service
• TCP 445: SMB Over TCP
• TCP 3389: Terminal Services
• UDP 137: NetBIOS Name Service
• UDP 161: Simple Network Management Protocol
• TCP/UDP 389: Lightweight Directory Access Protocol
In addition, you should enable host security solutions, such as the Windows Firewall services. Enforcing least privilege access as well as using restricted tokens and access control can reduce the damage that could occur if an attacker successfully compromises a Windows system’s services. Basically applying best practices to secure hosts and your network will also help reduce the risk of attacks against Microsoft Windows system services.
The following list highlights the key services concepts:
![]()
• Microsoft Windows services are long-running executable applications that operate in their own Windows session.
• Services Control Manager enforces the rules and protocols for Windows services.
• Services are ideal for running things within a user security context, starting applications that should always be run for a specific user, and for long-running functionality that doesn’t interfere with other users who are working on the same computer.
• Windows administrators can manage services using the Services snap-in, Sc.exe, or Windows PowerShell.
Windows Event Logs
The final topic to address in this section is Windows event logs. Logs, as a general definition, are records of events that happened in your computer. The purpose of logging in Windows is to record errors and events in a standard, centralized way. This way, you can track what happened and troubleshoot problems. The most common place for Windows logs is the Windows event log, which contains logs for the operating system and several applications, such as SQL Server and Internet Information Server (IIS). Logs are structured in a data format so they can be easily searched and analyzed. The tool commonly used to do this is the Windows Event Viewer.
The Windows event logging service records events from many sources and stores them in a single collection known as the event log. The event log typically maintains three event log types: Application, System, and Security log files. You can open the Windows Event Viewer to view these logs by simply searching for Event Viewer in the Run tab. Figure 11-16 shows an example of viewing logs in the Event Viewer in a Windows Server. The panel on the left shows the Application, System, and Security log categories, whereas the panel on the right shows the actions.

Figure 11-16 Windows Event Viewer Example
There are many panels in the Event Viewer as well as many different ways you can view the data. It is good for CyberOps analysts to have a basic understanding of what type of data can be found in a log file. In general, you will find five event types when viewing Windows event logging:
• Error: Events that represent a significant problem such as loss of data or loss of functionality.
• Warning: These events are not significant but may indicate a possible future issue.
• Information: These events represent the successful operation of an application, drive, or service.
• Success Audit: These events record audited security access attempts that were successful.
• Failure Audit: These events record audited security access attempts that failed.
Logs can eat up storage, so administrators should either set a time to have older logs deleted or export them to a storage system. Some security tools such as Security Information and Event Management (SIEM) can be used as a centralized tool for reading logs from many devices. The challenge for any system attempting to use a log is ensuring that the system is able to understand the log format.
If a system reading the file does not understand the file type or expects data in a specific format, weird results could happen, or the system might reject the file. Administrators can adjust the system receiving the logs from Windows to accept the standard event format or use a parser in Windows to modify how the data is sent.
A log parser is a versatile tool that provides universal query access to text-based data such as event logs, the Registry, the file system, XML files, CVE files, and so on. A parser works by you telling it what information you need and how you want it processed. The results of a query can be custom formatted in text-based output, or the output can be customized to a specialty target system such as SQL, SYSLOG, or a chart. Basically, a log parser gives you tons of flexibility for manipulating data. An example would be using a Windows IIS log parser to format event logs to be read by a SQL server.
It is important to protect logs because they are a critical tool for forensic investigations when an event occurs. Malicious users will likely be aware that their actions are logged by Windows and attempt to either manipulate or wipe all logs to cover their tracks. Savvy attackers will choose to modify only their impact to the log to avoid alerting administrators that an event has occurred.
The following list highlights the key Windows event log concepts:
![]()
• Logs are records of events that happen on a computer.
• The most common place for Windows logs is the Windows event log.
• Windows Event Viewer is a common tool used to view Windows event logs.
• You can generally find the Windows event logs in the C:Windowsystem3config directory.
• Event logs typically maintain three event log types: Application, System, and Security log files.
• Within the log types are generally five event types: Error, Warning, Information, Success Audit, and Failure Audit.
• A log parser is a versatile tool that provides universal query access to text-based data.
Linux and macOS Analysis
Now that we’ve covered Microsoft Windows, it’s time to move on to Linux and macOS. Learning how the Linux environment functions will not only improve your technical skills but can also help you build a strategy for securing Linux-based systems. You won’t be expected to know every detail about the Linux or macOS environments, so having an understanding of the topics covered here should be sufficient for the CyberOps Associate certification.
Processes in Linux
Previously in this chapter, you learned that on Microsoft Windows, a process is a running instance of a program. How a process works in Linux and macOS is different and is the focus of this section. The two methods for starting a process are starting it in the foreground and starting it in the background. You can see all the processes in Linux by using the ps () command in a terminal window, also known as a shell. What follows ps provides details of what type of processes should be displayed. For example, a would show all processes for all users, u would display the process’s owner, and x would show processes not attached to a terminal. Figure 11-17 shows running the ps aux command on a Linux system (Debian in this example). Notice that the aux command displays the processes, users, and owners.
Figure 11-17 Running the ps aux Command
Running a process in the foreground means you can’t do anything else in that shell while the process is running. Running the process in the background (using the ampersand &) tells Linux to allow you to do other tasks within the shell as the process is running. Here is an example of running the program named cisco as a background process:
#The program cisco will execute in the background ./cisco &
The following types of processes can run in Linux:
![]()
• Child process
• Init process
• Orphan process
• Zombie process
• Daemon process
We cover each of these processes briefly and go into a little more detail on the daemon process in a later section of this chapter because it has a few important concepts to cover for the CyberOps Associate exam. A process starts in the ready state and eventually executes when it is moved to the running state; this is known as process scheduling. Process scheduling is critical to keeping the CPU busy, delivering minimum response time for all programs, and keeping the system from crashing. This is achieved by using rules for moving processes in and out of the CPU using two different scheduling tactics. The first is nonpreemptive scheduling, which happens when executing processes give up CPU voluntarily. The other is preemptive scheduling, which occurs when the OS decides that another process has a greater importance and preempts the currently running process.
Processes can have a parent/child relationship. A child process is one created by some other process during runtime. Typically, a child process is created to execute a task within an existing process, also known as a parent process. A parent process uses a fork system call to create child processes. Usually, the shell that is created becomes the parent, and the child process executes inside of it. We examine the fork command in the next section of this chapter. All processes in Linux have a parent except for the init process, which we cover shortly. Each process is given an integer identifier, known as a process identifier or a process ID (PID). The process schedule is giving a PID value of 0 and typically termed as sched. In Figure 11-18, notice the PIDs assigned to the various processes.
The init process is the first process during the boot sequence, meaning the init process does not have a parent process. The init process is another name for the schedule process; hence, its PID value is 1. Figure 11-18 shows a diagram of the init PID creating parent processes, which in turn are creating child processes.

Figure 11-18 init PID Creating Parent Processes, Which in Turn Create Child Processes
In this diagram, a child process may receive some shared resources from its associated parent, depending on how the system is implemented. Best practice is to put restrictions in place to avoid the child process from consuming more resources than the parent process can provide, which would cause bad things to happen. The parent process can use the Wait system call, which pauses the process until the Wait returns. The parent can also issue a Run system call, thus permitting the child to continue without waiting (basically making it a background task). A process can terminate if the system sees one of the following situations:
• The system doesn’t have the resources to provide.
• The parent task doesn’t need the task completed that is assigned to the child process.
• The parent stops, meaning the associated child doesn’t have a parent process anymore. This can cause the system either to terminate the child process or to let it run as an orphan process.
• The Exit or Kill command is issued.
When the process ends, any associated system resources are freed up, and any open files are flushed and closed. If a parent is waiting for a child process to terminate, a termination status and the time of execution are returned to the parent process. The same data can be returned to the init process if the process that ended was an orphan process.
An orphan process results when a parent process is terminated and the child process is permitted to continue on its own. Orphan processes become the child process of the init process, but they are still labeled as orphan processes because their parent no longer exists. The time between when the child process ends and the status information is returned to the parent, the process continues to be recorded as an entry in the process table. During this state, the terminated process becomes a zombie process, releasing the associated memory and resources but remaining in the entry table. Usually, the parent will receive a SIGCHILD signal, letting it know the child process has terminated. The parent can then issue a Wait call that grabs the exit status of the terminated process and removes the process from the entry table. A zombie process can become a problem if the parent is killed off and not permitted to remove the zombie from the entry table. Zombie processes that linger around eventually become inherited by the init process and are terminated.
The following list highlights the key process concepts:
![]()
• The two methods for starting a process are starting it in the foreground and starting it in the background.
• The different types of processes in Linux are the child process, init process, orphan process, zombie process, and daemon process.
• All processes in Linux have a parent, except for the init process, which has a PID of 1.
• An orphan process results when a parent process is terminated and the child process is permitted to continue on its own.
• A zombie process is a process that releases its associated memory and resources but remains in the entry table.
Forks
A fork is when a parent creates a child process, or simply the act of creating a process. This means the fork command returns a process ID (PID). The parent and child processes run in separate memory spaces, and the child is a copy of the parent. The entire virtual space of the parent is replicated in the child process, including all the memory space. The child also inherits copies of the parent’s set of open file descriptors, open message queue descriptors, and open directory streams.
To verify which process is the parent and which is the child, you can issue the fork command. The result of the fork command can be one of the following.
• A negative value (±1), indicating the child process was not created, followed by the number of the last error (or errno). One of the following could be the error:
• EAGAIN: The system limited the number of threads for various reasons.
• EAGAIN Fork: The system failed to allocate the necessary kernel structures due to low memory.
• ENOMEN: The system attempted to create a child process in a PID whose init process has terminated.
• ENOSYS Fork: The process is not supported on the platform.
• ERESTARTNOINTR: The system call was interrupted by a signal and will be restarted.
• A zero, indicating a new child process was created.
• A positive value, indicating the PID of the child to its parent.
After the fork, the child and parent processes not only run the same program but also resume execution as though both had made the system call. They will then inspect the system call’s return value to determine their status and act accordingly. One thing that can impact a process’s status is what permissions it has within its space to operate. We take a deeper look at Linux permissions in the next section.
The following list highlights the key fork concepts:
![]()
• A fork is when a parent creates a child process.
• The fork command returns a PID.
• The entire virtual space of the parent is replicated in the child process, including all the memory space.
Permissions
Linux and macOS are different from other operating systems in that they are both multitasking and multiuser systems. Multitasking involves the forking concepts previously covered, and multiuser means more than one user can be operating the system at the same time. Although a laptop may have only one keyboard, that doesn’t mean others can’t connect to it over a network and open a shell to operate the computer. This functionality has always been included in the Linux operating system since the times of large mainframe computers. However, this functionality can also be a bad thing if a malicious user gets shell access to the system, even when the system owner is logged in and doing daily tasks.
This book assumes that you have familiarity with Linux and user accounts. As a refresher, in some cases users must be able to accomplish tasks that require privileges (for example, when installing a program or adding another user). This is why sudo exists.
On Linux-based systems, you can use the chmod command to set permissions values on files and directories.
To ensure the practicality of offering multiuser access, it is important to have controls put in place for each user. These controls are known as file permissions. File permissions assign access rights for the owner of the file, members of the group of related users, and everybody else. With Linux, you can set three basic permissions:
• Read (r)
• Write (w)
• Execute (x)
You can apply these permissions to any type of files or to directories.
Example 11-8 shows the permissions of a file called secret-file.txt. The user executes the ls -l command, and in the portion of the output on the left, you see -rw-rw-r--, which indicates that the current user (omar) has read and write permissions.
Example 11-8 Displaying File Permissions for a File
omar@dionysus:~$ ls -l secret-file.txt -rw-rw-r-- 1 omar omar 15 May 26 23:45 omar_file.txt
![]()
The first part of this output shows read, write, and execution rights, represented with the rwx statements. These are defined as follows:
• Read (r): Reading, opening, viewing, and copying the file are permitted.
• Write (w): Writing, changing, deleting, and saving the file are permitted.
• Execute (x): Executing and invoking the file are permitted. This includes permitting directories to have search access.
Figure 11-19 explains the Linux file permissions in detail.
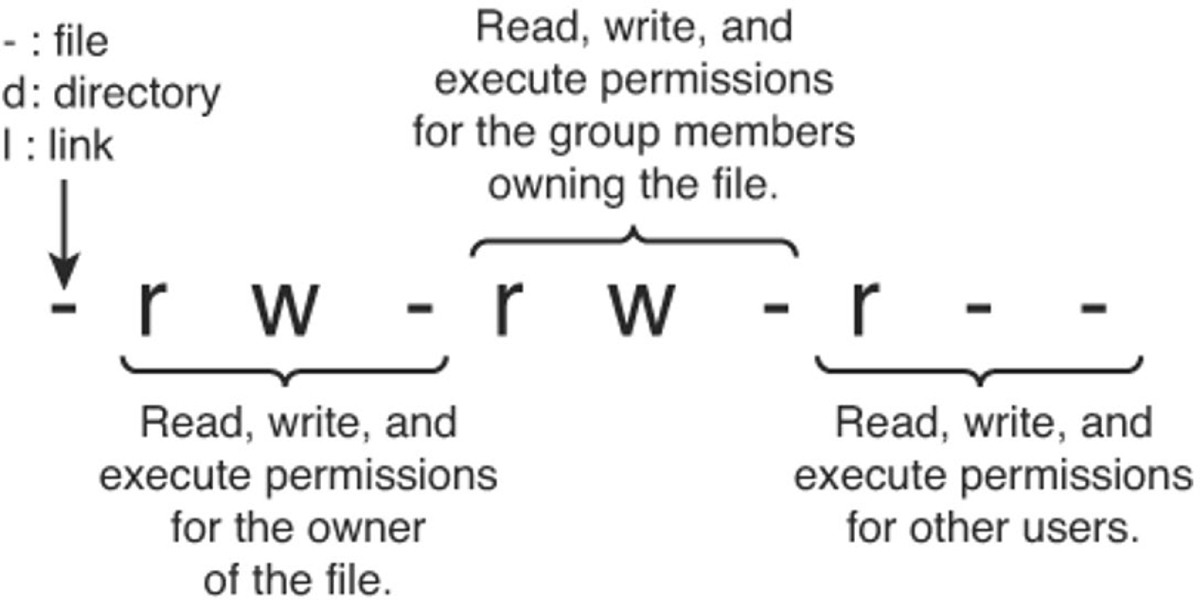
Figure 11-19 The Linux File Permissions
File permissions in Linux take a top-down approach, meaning that denying access for a directory will automatically include all subdirectories and files. For example, suppose you have the directory FILE_D with the permission drwxr-xr-x and a subdirectory SUBFILE_D with the permission drwxr-xr-x. Now suppose you want to deny read, write, and execute access for the group and everybody else without impacting the owner of FILE_D. In this case, you would use the chmod go-rwx FILE_D command, meaning -rwx removes access from FILE_D for the group and other users. This command would also impact the subdirectory SUBFILE_D, even though SUBFILE_D’s permissions are drwxr-xr-x, meaning groups and other users within SUBFILE would not have access to anything due to the parent folder FILE_D denying access, which flows down to SUBFILE.
The same concept works for whomever you assign rights to, meaning that if you give rights to the group and others in SUBFILE_D, this would not give the same rights to FILE_D. This is why sometimes an admin to a folder may give access to a file but not the folder it is contained in and then find people with access rights to the file can’t reach the file due to not being able to open the folder.
Another concept to touch on is the group, which is the set of permissions for one or more users who are grouped together. When an account is created, the user is assigned to a group. For example, you might have a group called employees for all employees and another group called administrators for network operations. Having these groups allows you to grant the same level of permissions to an entire group versus having to do so for each user. Users can be members of one or more groups. You can view which groups a user is a member of and that user’s ID by using the id command.
Example 11-9 shows how a user belonging to any group can change the permissions of the file to be read, write, executable by using the chmod 0777 command.
Example 11-9 Changing File Permissions in a Linux System
omar@dionysus:~$ chmod 0777 secret-file.txt omar@dionysus:~$ ls -l secret-file.txt -rwxrwxrwx 1 omar omar 15 May 26 23:45 secret-file.txt
As documented in the chmod man pages, the restricted deletion flag, or sticky bit, is a single bit whose interpretation depends on the file type. For directories, the sticky bit prevents unprivileged users from removing or renaming a file in the directory unless they own the file or the directory; this is called the restricted deletion flag for the directory, and it is commonly found on world-writable directories such as /tmp. For regular files on some older systems, the sticky bit saves the program’s text image on the swap device so it will load more quickly when run.
Tip
The sticky bit is obsolete with files, but it is used for directories to indicate that files can be unlinked or renamed only by their owner or the super user. Sticky bits were used with files in very old Linux machines due to memory restrictions. If the sticky bit is set on a directory, files inside the directory may be renamed or removed only by the owner of the file, the owner of the directory, or the super user (even though the modes of the directory might allow such an operation); on some systems, any user who can write to a file can also delete it. This feature was added to keep an ordinary user from deleting another’s files from the /tmp directory.
You can use the chmod command in two ways:
• Symbolic (text) method
• Numeric method
When you use the symbolic method, the structure includes who has access and the permission given. The indication of who has access to the file is as follows:
u: The user who owns the file
g: The group that the file belongs to
o: The other users (that is, everyone else)
a: All of the above (that is, use a instead of ugo)
Example 11-10 shows how to remove the execute permissions for all users by using the chmod a-x secret-file.txt command.
Example 11-10 Symbolic Method Example
omar@dionysus:~$ ls -l secret-file.txt -rwxrwxrwx 1 omar omar 15 May 26 23:45 secret-file.txt omar@dionysus:~$ chmod a-x omar_file.txt omar@dionysus:~$ ls -l omar_file.txt -rw-rw-rw- 1 omar omar 15 May 26 23:45 omar_file.txt
The chmod command enables you to use + to add permissions and ± to remove permissions. The chmod commands clears the set-group-ID (SGID or setgid) bit of a regular file if the file’s group ID does not match the user’s effective group ID or one of the user’s supplementary group IDs, unless the user has appropriate privileges. Additional restrictions may cause the set-user-ID (SUID or setuid) and set-group-ID bits of MODE or FILE to be ignored. This behavior depends on the policy and functionality of the underlying chmod system call. When in doubt, check the underlying system behavior. This is clearly explained in the man page of the chmod command (man chmod). In addition, the chmod command retains a directory’s SUID and SGID bits unless you explicitly indicate otherwise.
You can also use numbers to edit the permissions of a file or directory (for the owner, group, and others), as well as the SUID, SGID, and sticky bits. Example 11-9 shows the numeric method. The three-digit number specifies the permission, where each digit can be anything from 0 to 7. The first digit applies to permissions for the owner, the second digit applies to permissions for the group, and the third digit applies to permissions for all others.
Figure 11-20 demonstrates how the numeric method works.

Figure 11-20 Explaining the Linux File Permission Numeric Method
As shown in this figure, a binary number 1 is put under each permission granted and a 0 under each permission not granted. On the right in Figure 11-20, the binary-to-decimal conversion is done. This is why in Example 11-9, the numbers 777 make the file secret-file.txt world-writable (which means any user has read, write, and execute permissions).
Tip
A great online tool that you can use to practice setting the different parameters of Linux permissions is the Permissions Calculator, which is available at http://permissions-calculator.org (see Figure 11-21).

Figure 11-21 Permissions Calculator Online Tool
The Permissions Calculator website also provides several examples using PHP, Python, and Ruby to change file and directory permissions programmatically.
A program or a script in which the owner is root (by setting its set-user-ID [SUID] bit) will execute with super user (root) privileges. This introduces a security problem: if the system is compromised and that program is manipulated (as in the case of monolithic embedded devices), an attacker may be able to run additional executions as super user (root).
Modern Linux-based systems ignore the SUID and SGID bits on shell scripts for this reason.
An example of a SUID-based attack is the vulnerability that existed in the program /usr/lib/preserve (or /usr/lib/ex3.5preserve). This program, which is used by the vi and ex editors, automatically made a backup of the file being edited if the user was unexpectedly disconnected from the system before writing out changes to the file. The system wrote the changes to a temporary file in a special directory. The system also sent an email to the user using /bin/mail with a notification that the file had been saved. Because users could have been editing a file that was private or confidential, the directory used by the older version of the Preserve program was not accessible by most users on the system. Consequently, to let the Preserve program write into this directory and let the recovery program read from it, these programs were made SUID root.
You can find all the SUID and SGID files on your system by using the command shown in Example 11-11.
Example 11-11 Finding All the SUID and SGID Files on a System
omar@server:~$ sudo find / ( -perm -004000 -o -perm -002000 ) -type f -print [sudo] password for omar: ************ find: '/proc/3491/task/3491/fdinfo/6'/usr/sbin/postqueue /usr/sbin/postdrop /usr/lib/eject/dmcrypt-get-device /usr/lib/dbus-1.0/dbus-daemon-launch-helper /usr/lib/policykit-1/polkit-agent-helper-1 /usr/lib/x86_64-linux-gnu/utempter/utempter /usr/lib/x86_64-linux-gnu/lxc/lxc-user-nic /usr/lib/snapd/snap-confine /usr/lib/openssh/ssh-keysign /usr/bin/dotlock.mailutils /usr/bin/pkexec /usr/bin/chfn /usr/bin/screen /usr/bin/newgrp /usr/bin/crontab /usr/bin/at /usr/bin/chsh /usr/bin/ssh-agent /usr/bin/gpasswd /usr/bin/expiry /usr/bin/wall /usr/bin/sudo /usr/bin/bsd-write /usr/bin/mlocate /usr/bin/newgidmap /usr/bin/chage /usr/bin/newuidmap find: '/proc/3491/fdinfo/5': No such file or directory /sbin/mount.cifs /sbin/unix_chkpwd /sbin/pam_extrausers_chkpwd /sbin/mount.ecryptfs_private /bin/fusermount /bin/ping6 /bin/mount /bin/umount /bin/ntfs-3g /bin/su /bin/ping
In Example 11-11, the find command starts in the root directory (/) and looks for all files that match mode 002000 (SGID) or mode 004000 (SUID). The -type f option limits the search to files only.
Tip
Security Enhanced Linux (SELinux) is a collection of kernel modifications and user-space tools that are now part of several Linux distributions. It supports access control security policies, including mandatory access controls. SELinux aims to provide enforcement of security policies and simplify the amount of software required to accomplish such enforcement. Access can be constrained on variables such as which users and applications can access which resources. In addition, SELinux access controls are determined by a policy loaded on the system that cannot be changed by uneducated users or insecure applications. SELinux also allows you to configure more granular access control policies. For instance, SELinux lets you specify who can unlink, append only, or move a file instead of only being able to specify who can read, write, or execute a file. It also allows you to configure access to many other resources in addition to files. For example, it allows you to specify access to network resources and interprocess communication (IPC).
If you own a file and are a member of more than one group, you can modify the group “ownership” of that file using the chgrp command. For example, the chgrp staff file.txt command would give the group “staff” permissions to file.txt. Note that this does not impact the individual ownership of the file. Ownership can be changed only by the file owner. The chgrp command just gives group permissions to the file, as in the previous example of giving the group “staff” access. To change the owner of the file, you can use the chown command. For example, you could use chown Bob file.txt to give Bob ownership of the file.
Sometimes changing the group or owner will require super user privileges, which provide the highest access level and should be used only for specific reasons, such as performing administrative tasks. Most Linux distributions offer the su (substitute user) command, which can give super user rights for short tasks. Doing this will require you to enter the super user’s password. If successful, you will end up with a shell with super user rights. Typing exit will return you to your previous user permissions level.
Modern Linux distributions offer the sudo command, which gives super user rights on an as-needed basis. Typically, this is to execute a specific command, meaning you would type sudo whatever_command to execute the command with super user rights. The difference between su and sudo is that after entering sudo, you will be prompted for the user’s password rather than the super user’s password.
Note
Administrators should always proceed with caution when permitting super user and root-level permissions. All processes, including background daemons, should be limited to only the permissions required to successfully execute their purpose. Giving processes too much access could be a serious risk in case of a compromised process, which an attacker could use to gain full system access.
The following list highlights the key permissions concepts:
![]()
• File permissions assign access rights for the owner of the file, members of a group of related users, and everybody else.
• The chmod command modifies file permissions for a file or directory.
• Read (r) = 4, Write (w) = 2, Execute (x) = 1.
• A group is the set of permissions for one or more users grouped together.
• You can modify the group “ownership” of a file using the chgrp command.
• To change the owner of a file, you can use the chown command.
• File permissions in Linux take a top-down approach, meaning denying access for a directory will automatically include all subdirectories and files.
• Super user privileges provide the highest access level and should be used only for specific reasons, such as performing administrative tasks.
• All processes, including background daemons, should be limited to only the permissions necessary to successfully accomplish their purpose.
Symlinks
The next topic is how to link files together. A symlink (short for symbolic link and sometimes called a soft link) is any file that contains a reference to another file or directory in an absolute or relative path that affects pathname resolution. In short, a symlink contains the name for another file but doesn’t contain actual data. From a command viewpoint, a symlink looks like a standard file, but when it’s referenced, everything points to whatever the symlink is aimed at.
Let’s look at an example of creating a file. Example 11-12 shows the echo command putting the text “this is an example” into a file called file1. You can see the contents of the file by using the cat command. After file1 is created, you create a symlink by using the ln -s /tmp/file.1 /tmp/file.2 command pointing file.2 to file.1. Finally, to verify both files, you use the command ls -al /tmp/file* to show both files.
Example 11-12 Displaying File Rights for a Program
$ echo “this is an example” > /tmp/file.1 $ cat /tmp/file.1 “this is an example” $ ln -s /tmp/file.1 /tmp/file.2 $ ls -al /tmp/file* -rw-r--r-- 1 omar omar 25 Jun 4 02:21 /tmp/file.1 lrwxrwxrwx 1 omar omar 11 Jun 4 02:23 /tmp/file.2 -> /tmp/file.1
Notice in Example 11-12 how the permissions for file.2 start with the letter l, thus confirming the file is a symbolic link. The end of the statement also shows file.2 is referencing file.1 via the -> symbol between the paths. To validate this, you can issue the cat command to view the contents of file.2, which are the contents from file.1, as shown in Example 11-13.
Example 11-13 Displaying File Contents
$ cat /tmp/file.2 “this is an example”
Because a symlink is just a reference, removing the symlink file doesn’t impact the file it references. This means removing file.2 won’t have any impact on file.1. If file.1 is removed, it will cause an orphan symlink, meaning a symlink pointing to nothing because the file it references doesn’t exist anymore.
The following list highlights the key symlink concepts:
![]()
• A symlink is any file that contains a reference to another file or directory.
• A symlink is just a reference. Removing the symlink file doesn’t impact the file it references.
• An orphan symlink is a symlink pointing to nothing because the file it references doesn’t exist anymore.
• A symlink is interpreted at runtime and can exist even if what it points to does not.
Daemons
Earlier, you learned how processes can run in the foreground and background. When a process runs in the background, it is known as a daemon. Daemons are not controlled by the active user; instead, they run unobtrusively in the background, waiting to be activated by the occurrence of a specific event or condition. Linux systems usually have numerous daemons running to accommodate requests for services from other computers and responding to other programs and hardware activity. Daemons can be triggered by many things, such as a specific time, event, file being viewed, and so on. Essentially, daemons listen for specific things to trigger their response.
When initiated, a daemon, like any other process, will have an associated PID. Daemons are system processes, so their parent is usually the init process, which has a PID value of 1 (but this is not always the case). Daemon processes are created by the system using the fork command, thus forming the process hierarchy covered previously in this chapter.
The following list shows some common daemons found in UNIX. You may notice that most daemon programs end with d to indicate they are a daemon.
• xinetd: The Linux super-server daemon that manages Internet-based connectivity.
• corond: Used to run scheduled tasks
• ftdp: Used for file transfers
• lpd: Used for laser printing
• rlogind: Used for remote login
• rshd: Used for remote command execution
• telnetd: Used for telnet
Not all daemons are started automatically. Just like with other processes, daemons such as binlogd, mysqld, and apache can be set to not start unless the user or some event triggers them. This also means daemons, like any other program, can be terminated, restarted, and have their status evaluated. It is common for many daemons to be started at system boot; however, some are child processes that are launched based on a specific event. How they are started depends on the version of the system you are running.
The following list highlights the key daemon concepts:
![]()
• Daemons are programs that run in the background.
• From a permissions viewpoint, daemons are typically created by the init process.
• A daemon’s permissions level can vary depending on what is provided to it. Daemons should not always have super user–level access.
• Daemons are not controlled by the active user; instead, they run unobtrusively in the background, waiting to be activated by a specific event or condition.
• Not all daemons are started automatically.
• Children of the init process can be terminated and restarted.
Linux-Based Syslog
Linux-based systems have flexible logging capabilities, enabling the user to record just about anything. The most common form of logging is the general-purpose logging facility called syslog. Most programs send logging information to syslog. Syslog is typically a daemon found under the /var/log directory. You can see the logs by typing cd /var/log followed by ls to view all the logs. Make sure you know the location of these files.
The facility describes the application or process that submits the log message. Table 11-2 provides examples of facilities. Not all of these facilities are available in every version of Linux.
Table 11-2 Linux syslog Facilities

Not all messages are treated the same. A priority is used to indicate the level of importance of a message. Table 11-3 summarizes the priority levels.
Table 11-3 Linux Message Priorities
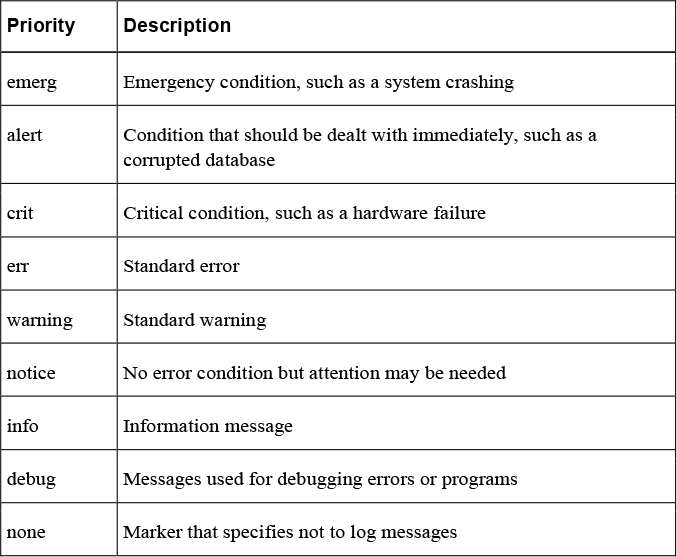
For the CyberOps Associates exam, you should know the different general log types. Transaction logs record all transactions that occur. For example, a database transaction log would log any modifications to the database. Alert logs record errors such as a startup, shutdown, space errors, and so on. Session logs track changes made on managed hosts during a web-based system manager session. Logging occurs each time an administrator uses web-based system management to make a change on a host. Threat logs trigger when an action matches one of the security profiles attached to a security rule. It is important to distinguish what type of log would go where for an event scenario. An example would be knowing that a system crash would be an alert log and that a malicious attack would be a threat log. Actions such as logging are triggered by selectors.
Selectors monitor for one or more facility and level combinations and, when triggered, perform some action. When a specific priority level is specified, the system will track everything at that level as well as anything higher. For example, if you use crit, you will see messages associated with crit, alert, and emerg. This is why enabling debug is extremely chatty because you are essentially seeing all messages.
Actions are the results from a selector triggering on a match. Actions can write to the log file, echo the message to the console or to other devices so users can read it, send a message to another syslog server, and perform other actions.
By default, several Linux distributions such as Debian and Ubuntu use rsyslog.d as the syslog demon. The configuration file for the default rsyslog.d is /etc/rsyslog.conf. Syslog-ng is an open-source implementation of the syslog protocol. If installed, it stores the configuration under /etc/syslog-ng/syslog-ng.conf and controls what syslog-ng does with the log entries it receives. This file contains one line per action; the syntax for every line is a selector field followed by an action field. The syntax used for the selector field is facility.level, which is designed to match log messages from a facility at a level value or higher. Also, you can add an optional comparison flag before the level to specify more precisely what is being logged. The syslog-ng.conf file can use multiple selector fields for the same action, separated by semicolons. The special character * sets a check to match everything. The action field points out where the logs should be sent. An example would be if something within the selector is triggered, sending a file to a remote host. Figure 11-22 shows a sample syslog-ng.conf file.

Figure 11-22 Sample syslog-ng.conf File
In this example, the first line shows that if the selector matches any message with a level of err or higher (kern.warning, auth.notice, and mail.crit), it will take the action of sending these logs to the /dev/console location. The fifth line down shows that if the selector sees all messages from mail at a level of info or above, it will take the action of having logs sent to /var/log/maillog. The syslog.conf file will vary from system to system, but this example should give you an idea of how the file is designed to work.
One common area of concern is managing logs. Many companies have log-retention requirements, such as storing logs for up to a year. Log files can grow very quickly, depending on how selectors and actions are set up, making it challenging to accommodate storage requirements as well as actually using the log information.
Logging can become extremely challenging to manage as more systems are generating logs. This is when centralized log management becomes the key to successful log management. Tons of centralized logging solutions are available, including free and open-source as well as fancier enterprise offerings.
The general concept is that the centralized log management solution must be capable of accepting logging information from the source sending the logs. Popular log management offerings can accept logs from a variety of systems; however, sometimes a system will generate logs in a unique format that requires tuning of how the message is read. Adjusting messages to an acceptable format for a centralized management system is known as “creating a custom parser.” It is recommended that you identify all systems that potentially will generate log messages and validate whether they produce logging in a universally accepted format such as syslog. Logging has been around for a while, so in most cases, any relatively current centralized logging solution should be capable of accepting most common logging formats.
The following list highlights the key Linux syslog concepts:
![]()
• The most common form of logging is the general-purpose logging facility called syslog.
• The default location of logs in Linux is the /var/log directory.
• The facility describes the application or process that submits the log message.
• A priority is used to indicate the level of importance of the message.
• Transaction logs record all transactions that occur.
• Session logs track changes made on managed hosts during a web-based system manager session.
• Alert logs record errors such as a startup, shutdown, space errors, and so on.
• Threat logs trigger when an action matches one of the security profiles attached to a security rule.
• Selectors monitor for one or more facility and level combinations and, when triggered, perform some action.
• Actions are the result of a selector triggering on a match.
• The configuration file /etc/syslog.conf controls what syslogd does with the log entries it receives.
• Newsyslog attempts to mitigate log management by periodically rotating and compressing log files.
Apache Access Logs
One important aspect of logging is monitoring the activity and performance of a server. The focus for this section is Apache logging, which is important for maintaining the health and security of such systems.
The Apache HTTP server provides a variety of different mechanisms for logging everything that happens on the server. Logging can include everything from an initial request to the final resolution of a connection, including any errors that may have happened during the process. Also, many third-party options complement the native logging capabilities; these include PHP scripts, CGI programs, and other event-sending applications.
With regard to errors, Apache will send diagnostic information and record any errors it encounters to the log file set by the ErrorLog directive. This is the first place you should go when troubleshooting any issues with starting or operating the server. You can use the command cat, grep, or any other Linux text utility for this purpose. Basically, this file can answer what went wrong and how to fix it. The file is typically error_log on Linux systems and error.log on Mac OS X.
Another important log file is the access log controlled by the CustomLog directive. Apache servers record all incoming requests and all requests to this file. Basically, this file contains information about what pages that people are viewing, the success status of a request, and how long the request took to respond.
Usually, tracking is broken down into three parts: access, agent, and referrer. Respectively, these parts track access to the website, the browser being used to access the site, and the referring URL that the site’s visitor arrives from. It is common to leverage Apache’s combined log format, which combines all three of these logs into one log file. Most third-party software prefers a single log containing this information. The combined format typically looks like this:
LogFormat “%h %l %u %t “%r” %>s %b “%{Referer}i” “%{User-Agent}i” combined
LogFormat starts the line by telling Apache that you define a log file type, which is combined. The following list explains the commands called by this file:
• %h: Command option that logs the remote host
• %l: Remote log name
• %u: Remote user
• %t: The date and time of the request
• %r: The request to the website
• %s: The status of the request
• %b: Bytes sent for the request
• %i: Items sent in the HTML header
The full list of Apache configuration codes for custom logs can be found at https://httpd.apache.org/docs/.
Like with any other Linux system, Apache logging will most likely generate a lot of data very quickly, making it necessary to have proper rotation of logs. You have many options, including auto-removing files that are too big and archiving older copies of data for reference. In a crisis situation, you may manually move the files; however, a soft restart of Apache is required before it can begin to use the new logs for new connections. An automated method would use a program such as Logrotate. Logrotate can enforce parameters that you set such as certain date, size, and so on.
The following list highlights the key Apache access log concepts:
![]()
• Apache sends diagnostic information and records any errors it encounters to the ErrorLog log.
• Apache servers record all incoming requests and all requests to the access log file.
• The combined log format lists the access, agent, and referrer fields.
NGINX Logs
NGINX is another popular open-source web server used by many organizations around the world. Similar to Apache HTTPd, NGINX stores all logs under /var/log/nginx by default. Figure 11-23 shows the location and the output of the NGNIX access logs in a Linux web server.
Figure 11-23 NGINX Access Logs
Endpoint Security Technologies
This section describes different endpoint security technologies available to protect desktops, laptops, servers, and mobile devices. It covers details about antimalware and antivirus software, as well as what are host-based firewalls and host-based intrusion prevention solutions. You also learn the concepts of application-level whitelisting and blacklisting, as well as system-based sandboxing.
Antimalware and Antivirus Software
As you probably already know, computer viruses and malware have been in existence for a long time. The level of sophistication, however, has increased over the years. Numerous antivirus and antimalware solutions on the market are designed to detect, analyze, and protect against both known and emerging endpoint threats. Before diving into these technologies, you should learn about viruses and malicious software (malware) and some of the taxonomy around the different types of malicious software.
The following are the most common types of malicious software:
![]()
• Computer virus: This malicious software infects a host file or system area to perform undesirable actions such as erasing data, stealing information, and corrupting the integrity of the system. In numerous cases, these viruses multiply again to form new generations of themselves.
• Worm: This virus replicates itself over the network, infecting numerous vulnerable systems. On most occasions, a worm will execute malicious instructions on a remote system without user interaction.
• Mailer and mass-mailer worm: This type of worm sends itself in an email message. Examples of mass-mailer worms are Loveletter.A@mm and W32/SKA.A@m (a.k.a. the Happy99 worm), which sends a copy of itself every time the user sends a new message.
• Logic bomb: This type of malicious code is injected into a legitimate application. An attacker can program a logic bomb to delete itself from the disk after it performs the malicious tasks on the system. Examples of these malicious tasks include deleting or corrupting files or databases and executing a specific instruction after certain system conditions are met.
• Trojan horse: This type of malware executes instructions determined by the nature of the Trojan to delete files, steal data, or compromise the integrity of the underlying operating system. Trojan horses typically use a form of social engineering to fool victims into installing such software on their computers or mobile devices. Trojans can also act as backdoors.
• Backdoor: This piece of malware or configuration change allows attackers to control the victim’s system remotely. For example, a backdoor can open a network port on the affected system so that the attacker can connect and control the system.
• Exploit: This malicious program is designed to “exploit,” or take advantage of, a single vulnerability or set of vulnerabilities.
• Downloader: This piece of malware downloads and installs other malicious content from the Internet to perform additional exploitation on an affected system.
• Spammer: This system or program sends unsolicited messages via email, instant messaging, newsgroups, or any other kind of computer or mobile device communication. Spammers use the type of malware for which the sole purpose is to send these unsolicited messages, with the primary goal of fooling users into clicking malicious links, replying to emails or messages with sensitive information, or performing different types of scams. The attacker’s main objective is to make money.
• Key logger: This piece of malware captures the user’s keystrokes on a compromised computer or mobile device. It collects sensitive information such as passwords, PINs, personally identifiable information (PII), credit card numbers, and more.
• Rootkit: This set of tools is used by an attacker to elevate privilege to obtain root-level access to be able to completely take control of the affected system.
• Ransomware: This type of malware compromises a system and then often demands a ransom from the victim to pay the attacker for the malicious activity to cease or for the malware to be removed from the affected system. The following are examples of ransomware:
• WannaCry
• SamSam
• Bad Rabbit
• NotPetya
There are numerous types of commercial and free antivirus software, including the following:
• Avast!
• AVG Internet Security
• F-Secure Anti-Virus
• Kaspersky Anti-Virus
• McAfee AntiVirus
• Sophos Antivirus
• Norton AntiVirus
• ClamAV
• Immunet AntiVirus
Tip
ClamAV is an open-source antivirus engine sponsored and maintained by Cisco and non-Cisco engineers. You can download ClamAV from www.clamav.net. Immunet is a free community-based antivirus software maintained by Cisco Talos. You can download Immunet from www.immunet.com.
There are numerous other antivirus software companies and products. The following link provides a comprehensive list and comparison of the different antivirus software available on the market: http://en.wikipedia.org/wiki/Comparison_of_antivirus_software.
![]()
Host-Based Firewalls and Host-Based Intrusion Prevention
Host-based firewalls are often referred to as personal firewalls. Personal firewalls and host-based intrusion prevention systems (HIPSs) are software applications that you can install on end-user machines or servers to protect them from external security threats and intrusions. The term personal firewall typically applies to basic software that can control Layer 3 and Layer 4 access to client machines. HIPS provides several features that offer more robust security than a traditional personal firewall, such as host-based intrusion prevention and protection against spyware, viruses, worms, Trojans, and other types of malware.
Today, more sophisticated software is available on the market that makes basic personal firewalls and HIPS obsolete. For example, Cisco Advanced Malware Protection (AMP) for Endpoints provides more granular visibility and controls to stop advanced threats missed by other security layers. Cisco AMP for Endpoints takes advantage of telemetry from big data, continuous analysis, and advanced analytics provided by Cisco threat intelligence to detect, analyze, and stop advanced malware across endpoints.
Cisco AMP for Endpoints provides advanced malware protection for many operating systems, including the following:
• Windows
• macOS
• Android
Attacks are getting very sophisticated, and they can evade detection of traditional systems and endpoint protection. Nowadays, attackers have the resources, knowledge, and persistence to beat point-in-time detection. Cisco AMP for Endpoints provides mitigation capabilities that go beyond point-in-time detection. It uses threat intelligence from Cisco to perform retrospective analysis and protection. Cisco AMP for Endpoints also provides device and file trajectory capabilities to allow the security administrator to analyze the full spectrum of an attack.
Cisco acquired a security company called Threat Grid that provides cloud-based and on-premises malware analysis solutions. Cisco integrated Cisco AMP and Threat Grid to provide a solution for advanced malware analysis with deep threat analytics. The Cisco AMP Threat Grid integrated solution analyzes millions of files and correlates them against hundreds of millions of malware samples. This provides a lot of visibility into attack campaigns and how malware is distributed. This solution provides security administrators with detailed reports of indicators of compromise and threat scores that help them prioritize mitigations and recovery from attacks.
In addition to host-based firewalls and HIPS, several solutions provide hardware and software encryption of endpoint data. Several solutions also provide capabilities to encrypt user data “at rest,” and others provide encryption when transferring files to the corporate network.
When people refer to email encryption, they often are referring to encrypting the actual email message so that only the intended receiver can decrypt and read the message. To effectively protect your emails, however, you should make sure of the following:
• The connection to your email provider or email server is actually encrypted.
• Your actual email messages are encrypted.
• Your stored, cached, or archived email messages are also protected.
Many commercial and free email encryption software programs are available. The following are examples of email encryption solutions:
• Pretty Good Privacy (PGP)
• GNU Privacy Guard (GnuPG)
• Secure/Multipurpose Internet Mail Extensions (S/MIME)
• Web-based encryption email services such as Sendinc and JumbleMe
S/MIME requires you to install a security certificate on your computer, and PGP requires you to generate a public and private key. Both require you to give your contacts your public key before they can send you an encrypted message. Similarly, the intended recipients of your encrypted email must install a security certificate on their workstation or mobile device and provide you with their public key before they send the encrypted email (so that you can decrypt it). Many email clients and web browser extensions for services such as Gmail provide support for S/MIME. You can obtain a certificate from a certificate authority in your organization or from a commercial service such as DigiCert or VeriSign. You can also obtain a free email certificate from an organization such as Comodo.
Many commercial and free pieces of software are available that enable you to encrypt files in an end-user workstation or mobile device. The following are a few examples of free solutions:
• GPG: This tool enables you to encrypt files and folders on a Windows, Mac, or Linux system.
• The built-in macOS Disk Utility: This tool enables you to create secure disks by encrypting files with AES 128-bit or AES 256-bit encryption.
• TrueCrypt: This encryption tool is for Windows, Mac, and Linux systems.
• AxCrypt: This is a Windows-only file encryption tool.
• BitLocker: This full disk encryption feature is included in several Windows operating systems.
• Many Linux distributions such as Ubuntu: These distributions allow you to encrypt the home directory of a user with built-in utilities.
• macOS FileVault: This program supports full disk encryption on Mac OS X systems.
The following are a few examples of commercial file encryption software:
• Symantec Endpoint Encryption
• PGP Whole Disk Encryption
• McAfee Endpoint Encryption (SafeBoot)
• Trend Micro Endpoint Encryption
![]()
Application-Level Whitelisting and Blacklisting
Three different concepts are defined in this section:
• Whitelist: A list of separate things (such as hosts, applications, email addresses, and services) that are authorized to be installed or active on a system in accordance with a predetermined baseline.
• Blacklist: A list of different entities that have been determined to be malicious.
• Graylist: A list of different objects that have not yet been established as not harmful or malicious. Once additional information is obtained, graylist items can be moved onto a whitelist or a blacklist.
Tip
The National Institute of Standards and Technology defines the concept of whitelisting and blacklisting applications in its special publication NIST.SP.800-167 available at https://nvlpubs.nist.gov/nistpubs/SpecialPublications/NIST.SP.800-167.pdf.
Application whitelisting can be used to stop threats on managed hosts where users are not able to install or run applications without authorization. For example, let’s imagine that you manage a kiosk in an airport where users are limited to running a web-based application. You may want to whitelist that application and prohibit running any additional applications in the system.
One of the most challenging parts of application whitelisting is the continuous management of what is and is not on the whitelist. It is extremely difficult to keep the list of what is and is not allowed on a system where there are hundreds of thousands of files with a legitimate need to be present and running on the system; however, several modern application whitelisting solutions are available that can help with this management nightmare. Several of these whitelisting systems are quite adept at tracking what is happening on a system when approved changes are made and managing the whitelist accordingly. These solutions do this by performing system application profiling.
Different application file and folder attributes can help with application whitelisting. The following are a few examples:
• File path: The process to permit all applications contained within a particular path or directory or folder. This attribute is very weak if used by itself because it allows any malicious files residing in such path/directory to be executed.
• Filename: This attribute is also weak if used in isolation because an attacker could simply change the name of the file to be the same as a common benign file. It is recommended to combine path and filename attributes with strict access controls or to combine a filename attribute with a digital signature attribute.
• File size: Monitoring the file size assumes that a malicious version of an application would have a different file size than the original. However, attackers can also change the size of any given file. It is better to use attributes such as digital signatures and cryptographic hashes (MD5 or SHA).
Application blacklisting works by keeping a list of applications that will be blocked on a system, preventing such applications from installing or running on that system. One of the major drawbacks of application blacklisting is that the number, diversity, and complexity of threats are constantly increasing. This is why it is very important to implement modern systems with dynamic threat intelligence feeds such as the Cisco Firepower solutions. The Cisco Firepower solutions include the Security Intelligence feature, which allows you to immediately blacklist (block) connections, applications, and files based on the latest threat intelligence provided by the Cisco Talos research team, removing the need for a more resource-intensive, in-depth analysis.
Additionally, the security intelligence feature from Cisco Firepower next-generation IPS appliances and Cisco next-generation firewalls works by blocking traffic to or from IP addresses, URLs, or domain names that have a known-bad reputation. This traffic filtering takes place before any other policy-based inspection, analysis, or traffic handling.
Some security professionals claim that, although whitelisting is a more thorough solution to the problem, it is not practical because of the overhead and resources required to create and maintain an effective whitelist.
![]()
System-Based Sandboxing
Sandboxing limits the impact of security vulnerabilities and bugs in code to only run inside the “sandbox.” The goal of sandboxing is to ensure that software bugs and exploits of vulnerabilities cannot affect the rest of the system and cannot install persistent malware in the system. In addition, sandboxing prevents exploits or malware from reading and stealing arbitrary files from the user’s machine. Figure 11-24 shows an application without being run in a sandbox. The application has complete access to user data and other system resources.

Figure 11-24 Example Without a Sandbox
Figure 11-25 shows a sandbox where the application does not have access to user data or the rest of the system resources.

Figure 11-25 Example with a Sandbox
Several system-based sandboxing implementations are available. The following are a few examples:
• Google Chromium sandboxing
• Java JVM sandboxing
• HTML5 “sandbox” attribute for use with iframes
Figure 11-26 illustrates the Google Chromium sandbox high-level architecture.

Figure 11-26 Google Chromium Sandbox High-Level Architecture
In Google Chromium’s implementation, the target process hosts all the code that runs inside the sandbox and the sandbox infrastructure client side. The broker is always the browser process, and it is a privileged controller of the activities of the sandboxed processes. The following are the responsibilities of the broker:
• Detail the policy for each target process.
• Spawn the target processes.
• Host the sandbox policy engine service.
• Host the sandbox interception manager.
• Host the sandbox interprocess communication service to the target processes. IPC is a collection of programming interfaces that allows the coordination of activities among different program processes that can run concurrently in an operating system.
• Perform the policy-allowed actions on behalf of the target process.
The broker should always outlive all the target processes that it spawned. The sandbox IPC is used to transparently forward certain API calls from the target to the broker. These calls are always evaluated against the predefined policy.
Sandboxes in the Context of Incident Response
Other types of sandboxes are used for incident response. These sandboxes (sometimes referred to as detonation boxes) are used for automating analysis of suspicious files. They makes use of custom components that monitor the behavior of the malicious processes while running in an isolated environment (typically in a virtual machine). In Chapter 9, “Introduction to Digital Forensics,” you learned that Cisco ThreatGrid provides automatic sandbox capabilities for analyzing files that may be malicious (malware). Incident responders also use other open-source solutions such as Cuckoo Sandbox (https://cuckoosandbox.org).
There are different detonation boxes or sandbox implementations for malware analysis. The following are the most popular types:
• Full system emulation: These implementations simulate the host’s physical hardware (including the processor [CPU] and memory) and operating system to allow you to obtain deep visibility into the behavior and impact of the program being analyzed.
• Emulation of operating systems: These implementations emulate the host’s operating system but not the hardware.
• Virtualized: These VM-based sandboxes contain and analyze suspicious programs.
Exam Preparation Tasks
Review All Key Topics
Review the most important topics in the chapter, noted with the Key Topic icon in the outer margin of the page. Table 11-4 lists these key topics and the page numbers on which each is found.
![]()
Table 11-4 Key Topics for Chapter 11


Define Key Terms
Define the following key terms from this chapter and check your answers in the glossary:
fiber
Windows Management Instrumentation (WMI)
viruses
worms
Review Questions
The answers to these questions appear in Appendix A, “Answers to the ‘Do I Know This Already?’ Quizzes and Review Questions.” For more practice with exam format questions, use the exam engine on the website.
1. The virtual address space is ___________ and cannot be accessed by other processes unless it is specifically shared.
2. RAM is an example of __________ memory?
3. What command is used to view the Windows Registry?
4. HKEY_CURRENT_CONFIG (HCU) is a ___________ hive?
5. What does WMI stand for?
6. What can cause a handle leak?
7. What tool can be used in Windows to format a log for a SQL server?
8. Google Chromium sandboxing and Java JVM sandboxing are examples of __________ sandboxing implementations?
9. What is a limitation of application whitelisting?
10. What is an application blacklist?