
Chapter 11. Scaling through messaging
This chapter covers
- A quick overview of messaging
- Using RabbitMQ with Clojure
- A framework for distributed parallel programming
Messaging has a place in system architecture for many reasons. The most obvious is to communicate between different applications or various subsystems of a single application. Using a messaging system in this manner allows for loose coupling and flexibility: message structure can be changed as needed, or messages can be transformed in the middle as required. There are many design patterns for integrating applications using messaging in this manner.
Another use of messaging is to introduce asynchronous processing into applications. Instead of handling complete requests in a synchronous manner, a message can be dropped onto a queue of some kind, which would eventually be picked up and processed later. This makes the application respond quicker to the end user, while allowing for higher request throughput.
Messaging systems can also be used as a basis for more general-purpose distributed computing. Various computing elements can communicate with each other over a messaging system in order to coordinate parts of the work they need to participate in. This can lead to elegantly scalable architecture that can grow by adding more and more machines to the grid as the load grows.
In this chapter, we’ll learn how to incorporate asynchronous processing into Clojure systems. We’ll first talk about the landscape of messaging systems in general, and then we’ll write code to work with the RabbitMQ messaging server. We’ll work our way up to writing a Clojure abstraction that will help you write parallel-processing programs. This framework will allow your Clojure systems to span not only multiple cores but multiple CPUs as well. You could then use the ideas in this chapter as the basis for a large, horizontally scalable cluster of computational elements.
11.1. Messaging systems
Messaging systems come in a variety of flavors. Ultimately, they behave as middleware systems that deliver messages from one program to another. They can usually work in several configurations ranging from point-to-point to hub and spoke and so on. They’re a great way to achieve several things at once: decoupling between components of the application, asynchronous processing, and scalability. In this section, we’ll quickly look at the landscape of available messaging systems and at a few open source ones in particular.
11.1.1. JMS, STOMP, AMQP
JMS stands for Java Messaging Service and is a typical message-oriented middleware API that was introduced as part of Java Enterprise Edition. The specification is a standard (known as JSR 914) and allows programs written using the Enterprise Edition of the JDK to communicate with each other by sending and receiving messages.
STOMP stands for Simple Text-Oriented Messaging Protocol. It’s a standard that allows clients to be written in many programming languages, and indeed, the website lists support for most popular languages in use today. STOMP prides itself on simplicity—it uses plain text, making it easy to implement new clients.
AMQP, which stands for Advanced Message Queuing Protocol, came out of a consortium of financial companies that wanted an ultra-fast messaging system that was also extensible and yet simple. Further, they wanted to be able to fully program the semantics of the server via the clients at runtime. Like the other protocols, several servers support AMQP. In this chapter, we’ll be using RabbitMQ, a super-fast, open source implementation of an AMQP messaging system. Before we get started, let’s take a quick look at some of the major players in the landscape.
11.1.2. ActiveMQ, RabbitMQ, ZeroMQ
In this section, we’ll glance at a few options for picking a middleware system. Most messaging systems do the same basic job of allowing messages to be sent and received by various producers and consumers (other programs). They might vary in the specific protocol supported for the message passing or the characteristics offered when such messages are sent (store and forward, wait for acknowledgement, and so on). Even here, most messaging servers have adapters that can be used to bridge to other protocols and may have configuration options (or external plug-ins) that allow pretty much any server to behave in almost any desired way.
Still, other characteristics differentiate the various servers available on the market today. One important characteristic is performance and reliability, with others being how actively the project is being developed and whether there’s a vibrant user community supporting it. In the following section, we’ll look quickly at ActiveMQ, RabbitMQ, and ZeroMQ, all of which are open source.
ActiveMQ
This offering is from the Apache Software Group and is considered a stable option when it comes to messaging systems. It supports OpenWire and STOMP and has clients in most languages.
Many consider ActiveMQ somewhat heavy, and the Java technology stack that it’s built upon is older than some of the other messaging systems available.
RabbitMQ
RabbitMQ is a messaging server that supports AMQP. It’s built using Erlang and Erlang/OTP, which are extremely reliable and scalable platforms that Ericson developed for its telephone switching software. It’s fast, promising latency in the single-digit milliseconds range.
RabbitMQ is a general messaging server that can be configured to behave in a variety of ways in order to implement the various patterns in the messaging world: point-to-point, publish-subscribe, store and forward, and so on. You’ll learn more about AMQP in the following section, and you’ll be using RabbitMQ later on when you build messaging support into your Clojure programs.
ZeroMQ
ZeroMQ is another open source messaging option, built to be extremely fast. It isn’t quite a messaging system as much as it is a low-level socket-oriented library that can be used to build messaging systems. It advertises latencies as low as 13 microseconds and the flexibility to implement different configurations of components: publish/subscribe, request/reply, streaming, and so on. This option is also a viable one when you’re deciding on a messaging system for your application.
11.2. Clojure and RabbitMQ
In this section, we’re going to write code to perform some basic communication tasks between Clojure processes over RabbitMQ. RabbitMQ uses AMQP, so having a basic understanding of it is useful in getting the most out of the system. Our first stop, then, will be to go over the essential elements of AMQP. We’ll then use the Java client library to send messages, following which we’ll write code to receive messages over RabbitMQ. Our last stop in this section will be to create a convenient abstraction over incoming RabbitMQ messages for our programs that need to process messages asynchronously.
The RabbitMQ project is evolving at a steady pace. The project was recently acquired by SpringSource, which is part of VMware. The version of RabbitMQ we’re going to be working with is 1.8.1, and you can download it from http://www.rabbitmq.com.
11.2.1. AMQP basics
Let’s look at a few key RabbitMQ concepts that are reflective of the AMQP underneath. Specifically, it’s important to understand the basic concepts of the message queue, the exchange, and the routing key. Once you understand these topics, it becomes quite easy to reason about message flow and how message passing should be configured in a given application. As you’ll see later on in this chapter, we’ll set up point-to-point messaging, fan-out or multicast messaging, and so on by using these concepts in various ways.
The message queue
A message queue stores messages in memory or on a disk and delivers them to various consumers (usually) in the order they come in. Message queues can be created to have a varying set of properties: private or shared, durable or not, permanent or temporary. The right combination of these properties can result in the various commonly used patterns of message queues: store and forward, temporary reply queue, and the classic publish-subscribe model. Message queues can be named, so that clients can refer to specific ones they created during the routing configuration process.
The exchange
The exchange is a sort of clearinghouse that accepts the incoming messages and then, based on certain specified criteria, routes them to specific message queues. The criteria are called bindings and are specified by the clients themselves.
AMQP defines a few exchange types, such as direct and fan-out exchanges. By naming both exchanges and queues, clients can configure them to work with each other.
The routing key
An exchange can route messages to message queues based on a variety of properties of the message. The most common way depends on a single property called the routing key. You can think of it as a virtual address that the exchange can use to route messages to consumers.
Now that you’ve seen the fundamental constructs of AMQP, you’re ready to start playing with a server that implements it. In the next section, you’ll do so using RabbitMQ.
11.2.2. Connecting to RabbitMQ
In this section, you’ll see how to connect to a RabbitMQ server. Further, you’ll abstract away the idea of a connection to the server by creating a var to hold an open connection. First, here’s the code to create a new connection:
(ns chapter14-rabbitmq
(:import (com.rabbitmq.client ConnectionFactory QueueingConsumer)))
(defn new-connection [host username password]
(.newConnection
(doto (ConnectionFactory.)
(.setVirtualHost "/")
(.setUsername username)
(.setPassword password)
(.setHost host))))
Now for the var: let’s create one called *rabbit-connection* as follows:
(def *rabbit-connection*)
You can bind this to a call to new-connection whenever you need to do something with RabbitMQ. To make this easy, create a macro to do it for you. You might call such a macro with-rabbit, and it might look like this:
(defmacro with-rabbit [[mq-host mq-username mq-password] & exprs]
`(with-open [connection# (new-connection ~mq-host
~mq-username ~mq-password)]
(binding [*rabbit-connection* connection#]
(do ~@exprs))))
Note that by using the with-open macro, the connection held in *rabbit-connection* is closed when you exit the with-rabbit form. Now, with the with-rabbit macro in hand, you’re ready to write more code to do things like sending messages to the server and receiving messages from it. The next couple of sections show how to do this.
11.2.3. Sending messages over RabbitMQ
As described in the section on AMQP, the physical manifestation of a connection to RabbitMQ is the channel. Therefore, the first thing you’ll need to do is get hold of a channel. Here’s the function that sends a message to the server, given a specific routing key:
(defn send-message [routing-key message-object]
(with-open [channel (.createChannel *rabbit-connection*)]
(.basicPublish channel "" routing-key nil
(.getBytes (str message-object)))))
In order to send a message through the RabbitMQ server, you can now call your newly defined send-message function, like so:
(with-rabbit ["localhost" "guest" "guest"]
(send-message "chapter14-test" "chapter 14 test method"))
Your next task is to receive such messages from the server. You’ll do this in the next section.
11.2.4. Receiving messages from RabbitMQ
We’re going to take a stab at writing a simple function that accepts a queue name (which in this case must match the routing key used to send messages out) and listens for messages addressed to it. Once you have this function, you’ll put the send-message function to use in testing your capability to receive messages by printing it to the console. Once you have this working, you’ll see how to write a longer-lived process that handles a stream of incoming messages.
Let’s begin with a function to fetch a message from the RabbitMQ server. Consider this implementation where next-message-from is your final, outward-facing function:

Here, you create an instance of QueueingConsumer, which is a class provided by the RabbitMQ client library. You then declare the queue name that was passed in, and then you attach the consumer to the queue name via the call to basicConsume. The delivery-from function calls the nextDelivery method on the consumer object, which is a blocking call. The execution proceeds only when the consumer receives something from RabbitMQ, and then all you do is acknowledge the message by calling basicAck and return the contents of the message as a string.
You can confirm that this works by starting up the following program as a Clojure script:
(ns chapter14-receiver (:use chapter14-rabbitmq)) (println "Waiting...") (with-rabbit ["localhost" "guest" "guest"] (println (next-message-from "chapter14-test")))
This will cause the program to block (because next-message-from blocks until a message is delivered to it from the RabbitMQ server), and in order to unblock it and see that it prints the message to the console, you have to send it a message. The following program, which can also be run as a script, does that:
(ns chapter14-sender (:use chapter14-rabbitmq)) (println "Sending...") (with-rabbit ["localhost" "guest" "guest"] (send-message "chapter14-test" "chapter 14 test method")) (println "done!")
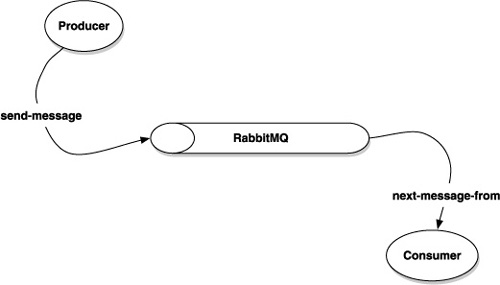
If you run these two programs in two separate shells (run the receiver first!), you’ll see your two functions, send-message and next-message-from, in action. Figure 11.1 shows the basics of this communication at a conceptual level.
Figure 11.1. After establishing a connection with RabbitMQ via a call to new-connection, a message producer can send messages with a routing key using the send-message function. Similarly, a message consumer can accept messages sent with a particular routing key via a call to next-message-from.
Now that you have basic communication going over RabbitMQ, let’s write a version of the receiver program that can handle multiple messages from the queue.
Receiving multiple messages
We wrote a program that received a single message from the RabbitMQ server, printed it, and exited. In typical projects involving messaging, a program like that might be useful for quick tests and debugging. Most production services that are meant to handle messages asynchronously, wait for such messages in a loop. These long-running processes can form the basis of a compute cluster that can offload work from services that must respond to the end user quickly. Let’s rewrite the earlier program to do its job in a loop:
(ns chapter14-receiver-multiple1
(:use chapter14-rabbitmq))
(defn print-multiple-messages []
(loop [message (next-message-from "chapter14-test")]
(println "Message: " message)
(recur (next-message-from "chapter14-test"))))
(with-rabbit ["localhost" "guest" "guest"]
(println "Waiting for messages...")
(print-multiple-messages))
You can test this program in a similar fashion to our previous example. When you run this program, it will block, waiting for the first message to be delivered to it by the server. You can use the message sender program from the previous section to send it a few messages. The output might look like this:
Waiting for messages... Message: chapter 14 test method Message: chapter 14 test method Message: chapter 14 test method
Press Ctrl-C to exit this program.
This program works but isn’t particularly reusable, because it mixes up the work of printing the incoming messages with the logic of waiting for messages in a loop. Let’s fix that problem by creating a higher-order function that will accept a function that knows how to handle a single message. Here’s the code:
(ns chapter14-receiver-multiple2
(:use chapter14-rabbitmq))
(defn handle-multiple-messages [handler]
(loop [message (next-message-from "chapter14-test")]
(handler message)
(recur (next-message-from "chapter14-test"))))
(with-rabbit ["localhost" "guest" "guest"]
(println "Waiting for messages...")
(handle-multiple-messages println))
With this higher-order function called handle-multiple-messages, you can now do whatever you please with an incoming stream of messages. Indeed, if you run several instances of this program in parallel and send messages using the same sender program, you’ll see RabbitMQ deliver messages to each in a roughly round-robin manner. As we said earlier, this can form the basis of a compute cluster of some kind.
One thing to note, is that our next-message-from function is quite inefficient. It creates a new channel each time it’s called. If you know you’re going to process multiple messages, you should improve this inadequacy. Indeed, while you’re at it, you should recognize the fact that an incoming sequence of messages can be modeled as a Clojure sequence. You’ll do this in the next section.
Message-Seq: A Sequence Abstraction for Receiving Messages
We looked briefly at lazy sequences in chapter 2. If you consider the job of next-message-from, you can think of it producing an element of a lazy sequence each time a message is delivered to it. Using that as a foundation, you can create a new abstraction to deal with messages from the RabbitMQ server. Let’s call it message-seq, and it might be implemented as follows:

Note that lazy-message-seq is a helper function that’s private to this namespace. The message-seq function is the one that you’ll use in your programs. Let’s write a version of handle-multiple-messages that does this:
(ns chapter14-receiver-multiple3
(:use chapter14-rabbitmq))
(defn handle-multiple-messages [handler]
(doseq [message (message-seq "chapter14-test")]
(handler message)))
(with-rabbit ["localhost" "guest" "guest"]
(println "Waiting for messages...")
(handle-multiple-messages println))
There are several advantages of this approach. The first is that it’s more efficient because you’re no longer creating a new channel (and consumer) for each message. Perhaps more important, because message-seq is a real Clojure sequence, you can use the full Clojure sequence library to work with it. The previous example shows the usage of doseq, but you can now map across it, filter out only those messages that you like, and so on. Here’s an example where we only print the messages in pairs:
(ns chapter14-receiver-multiple4
(:use chapter14-rabbitmq clojure.contrib.str-utils))
(defn print-two-messages [messages]
(println (str-join "::" messages)))
(with-rabbit ["localhost" "guest" "guest"]
(println "Waiting for messages...")
(let [message-pairs (partition 2 (message-seq "chapter14-test"))]
(doseq [message-pair message-pairs]
(print-two-messages message-pair))))
You can test this by sending it messages using your sender program, as usual. The output of a test run might look like the following:
Waiting for messages... chapter 14 test method::chapter 14 test method chapter 14 test method::chapter 14 test method
The fact that you can now bring the full power of the Clojure sequence library to bear on a series of messages from RabbitMQ allows you to write idiomatic Clojure programs. No function outside the scope of message-seq needs to know that the sequence is lazily being fed by a RabbitMQ server somewhere on the network.
In this section, you’ve seen how to send messages to the RabbitMQ server and also how to process messages that are delivered to your programs by a RabbitMQ server. You can use the code we wrote as a basis for real applications to handle events in an asynchronous manner. Further, you can expand your event-processing capacity by starting up more instances of your handlers. This idea forms the basis of using messaging to scale up applications. In the next section, we’ll create another abstraction on top of what we’ve done so far, in order to make it easy to write programs that make use of such architecture.
11.3. Distributed parallel programming
In the previous section, we created an abstraction called message-seq that was a series of messages from RabbitMQ represented as a Clojure sequence. Having this abstraction allows you to write handler programs easily. Further, by starting up more and more message-handler processes, you have the ability to horizontally scale up your application.
If you have such a cluster of processes waiting to process incoming messages, you could write programs that dispatch messages off to this cluster, in effect resulting in computations executing in parallel on different machines. It would be like using multiple threads to do something faster, only you’d no longer be limited to a single JVM. You could spread your processing load across a cloud of machines, one that could be scaled by adding more CPUs.
In this section, we’ll write a small, distributed computing framework, which can make it easy to write programs that use such a cloud of message-processing services.
11.3.1. Creating remote workers
In the previous section, we wrote a higher-order function called handle-multiple-messages that accepted another function that did the work of processing the message. Now, we’ll create an abstraction that makes it easy to create functions that must run on such a message-processing cluster. Next, we’ll make it easy to send off requests to such a cluster of workers.
We’re going to indulge in some wishful program design now. Imagine that you had a construct called defworker whose job it is to create a function that instead of running locally caused its computation to occur on a remote server (on one of our message-processing services). You could use it to define a worker in the following manner:
(ns chapter14-worker-example (:use chapter14-rabbitmq chapter14-worker)) (defworker long-computation-one [x y] (Thread/sleep 3000) (* x y)) (defworker long-computation-two [a b c] (Thread/sleep 2000) (+ a b c)) (defworker expensive-audit-log [z] (println "expensive audit log:" z) (Thread/sleep 4000))
These are contrived examples, but they serve to illustrate the idea of both expensive computations and the use of the imaginary defworker macro. Note also that although the chapter14-worker namespace doesn’t exist yet, we’ll build it over the next few pages.
For now, the question that presents itself is what should the defworker macro do?
Defworker: define new workers
We first need to think about realizing our imaginary defworker. Let’s start with a skeleton:
(defmacro defworker [service-name args & exprs] ;;some magic here )
Now we have something concrete to talk about. The defworker macro will need to do two things. The first is to create a function named service-name that can be used like regular functions. This function, when called, won’t perform the work embodied in exprs but will send a message to RabbitMQ requesting the associated computation to be performed on a receiver process.
The other job of defworker is to somehow store the computation embodied in exprs, which can then be run on the message-processing side when someone requests it. So, the magic from the skeleton becomes the following:
(defmacro defworker [service-name args & exprs] ;; STEP 1 – store exprs somewhere for later ;; STEP 2 – return function that when called, sends message to RabbitMQ )
Before we do anything further, we must ask ourselves a couple more questions. First, after dropping a request over RabbitMQ, is there a way to be notified when the computation completes? We can use messaging for that as well, by waiting for a reply message after dropping the request message. When the message handler picks up the request message and processes it, it will then send the result of the computation in the reply message.
The second issue to consider is the return value of the function created by defworker. Imagine that someone calls long-computation-one, which we defined earlier. What should the return value be? Clearly, the response will only be available at some point in the future, after the message that was dropped off is processed and the reply comes back. In the meantime, the callers of long-computation-one need something to hang onto. What should it be? We’ll revisit this question shortly.
In the meantime, let’s take another shot at defining defworker, based on our discussion so far. First, we’ll represent computations (as embodied by exprs) as anonymous functions and store them inside a hash map. We’ll put this map inside a ref, which we’ll declare as follows:
(def workers (ref {}))
We’ll index the map by the names of the workers being defined, so that the message-processing side can then find the appropriate function when it’s requested. Our defworker now looks like this:
(defmacro defworker [service-name args & exprs]
`(let [worker-name# (keyword '~service-name)]
(dosync
(alter workers assoc worker-name# (fn ~args (do ~@exprs)))
(def ~service-name (worker-runner worker-name# ~args))))
The first part does what we just talked about; it grabs the name of the worker being defined (as a keyword) and then stores the exprs (bound inside an anonymous function of the same signature) inside the workers map indexed by the worker name.
The last line creates a var by the value of service-name, which, when called, runs the function returned by an as-yet-undefined worker-runner. So we’ve employed imaginary design again and postponed worrying about the implementation details of worker-runner. Unfortunately, we can’t ignore it for very long, and it’s the focus of the next section.
Worker-runner: handling work requests
The job of worker-runner is to create a function that, when called, runs the worker. This involves sending a message to the waiting processes, requesting that the named worker be executed given particular arguments. It also must establish a listener for the incoming response message. Finally, it should immediately return to the caller, with some sort of an object that represents this whole asynchronous process of dispatching the request and waiting for the response.
This returned object, in a sense, is a proxy of the computation being requested and performed on a different machine. This proxy object should have the ability to be queried. It should be able to answer questions like whether the computation completed, what the return value is, whether there was an error, what the error was, and so on.
Let’s start with the first requirement, that of returning a function. Consider the following code:
(defmacro worker-runner [worker-name worker-args]
`(fn ~worker-args
(on-swarm ~worker-name ~worker-args)))
A function is returned, which when called calls another function named on-swarm, passing along the worker-name and the worker-args. The job of on-swarm, as discussed, is to send the request for the computation over RabbitMQ, establish a listener for the answer, and immediately return a proxy object that can be queried for the status of the remote computation. It’s called on-swarm because the computation runs on a remote swarm of processes. Here’s the implementation:

Here, you establish a locally created ref named worker-data that’s initialized to worker-init-value. You need to define that as follows:
(def worker-init-value :__worker_init__)
This ref will store the result of the computation once the response comes back from the swarm. The work of making the request and waiting for the response is done by dispatch-work, which we’ll examine next. Let’s look at what is returned by this function. It returns another function, which implements the same sort of command-word pattern you’ve seen before.
Here, the return value can be queried using command words like :complete?, :value, :status, and :disconnect. You’ll see examples of this in action before the end of this chapter. Our immediate attention, though, is on the dispatch-work function.
Dispatch-work: sending work requests
The job of dispatch-work is to send a message via RabbitMQ to a waiting cluster of processes, requesting a particular computation. What we have available is the name of the computation and the arguments that the computation should be run with. We’ll send all that information over as part of the request message, encoded as strings. Finally, dispatch-work also needs to set up a listener that will wait for the response. When it comes back it will set the returned value of the worker-data ref we talked about. Consider the following implementation:
(defn dispatch-work [worker-name args worker-ref]
(let [return-q-name (str (UUID/randomUUID))
request-object (request-envelope worker-name args return-q-name)
worker-transport (update-on-response worker-ref return-q-name)]
(send-message WORKER-QUEUE request-object)
worker-transport))
dispatch-work does its job by first constructing a request message that contains the name of the service being requested, the arguments it will need, and the name of the RabbitMQ queue that the response should be sent on. Then, it calls update-on-response, a function that sets up the listener that waits for the response message from the swarm. Finally, dispatch-worker sends the request to the RabbitMQ server by calling our previously defined send-message function. WORKER-QUEUE is a well-defined name, and it’s also the one your message-handling processes will be listening on. You might define it as follows:
(def WORKER-QUEUE "chapter14_workers_job_queue")
Further, you’d construct the request-object itself via a call to the request-envelope function that returns a simple Clojure map. Here’s the code:
(defn request-envelope
([worker-name args]
{:worker-name worker-name :worker-args args})
([worker-name args return-q-name]
(assoc (request-envelope worker-name args) :return-q return-q-name)))
There are two signatures, one that accepts no return-queue-name, to allow you to call workers without waiting for a response. You’ll see this in action when we add a fire-and-forget feature to our little framework. All that remains is the inner workings of update-on-response. Let’s discuss that in terms of the following implementation:
(defn update-on-response [worker-ref return-q-name]
(let [channel (.createChannel *rabbit-connection*)
consumer (consumer-for channel return-q-name)
on-response (fn [response-message]
(dosync
(ref-set worker-ref (read-string response-message))
(.queueDelete channel return-q-name)
(.close channel)))]
(future (on-response (delivery-from channel consumer)))
[channel return-q-name]))
All of this code should look familiar. A channel and consumer objects are created, which will be used for interfacing with RabbitMQ. on-response is a local function that behaves as a callback. It accepts a message and sets it as the value of the worker-ref, after which it closes the channel.
More specifically, before setting it as the value of the ref, it calls read-string on the message. Remember that the message is a string; read-string unleashes the Clojure reader on that string, resulting in the string of text being converted into a Clojure data structure. This is the job of the reader; it converts a character stream (typically source code) into Clojure data structures: lists, vectors, maps, and so on. You use the same process here as a simple form of deserialization.
Finally, on-response is called with the blocking function delivery-from. Because it’s called inside a future, it runs at a later point, on a different thread. update-on-response is free to continue execution, which it does by returning a vector containing the channel and the return queue name.
We’re finished with the complex part of our little distributed computing framework. The next piece will be to create a program that can handle the requests that you’ll send over the RabbitMQ server.
11.3.2. Servicing worker requests
In this section, we’ll write code for the other side of the picture. In the previous section, we implemented creating new workers. We wrote code that can send off requests to a waiting swarm of processes and set up a listener that waits for a response. In this section, we’ll write code to do two things: the first is to handle these requests as they come off RabbitMQ, and the second is to make life easier for the code that uses your workers. Let’s begin by implementing the request-handling part of the system.
Handling worker requests
Request handling code is a loop that waits for messages and processing them as they come in. Let’s begin by writing a function that can process a single message:
(defn handle-request-message [req-str]
(try
(let [req (read-string req-str)
worker-name (req :worker-name)
worker-args (req :worker-args)
return-q (req :return-q)
worker-handler (@workers worker-name)]
(if (not (nil? worker-handler))
(do
(println "Processing:" worker-name "with args:" worker-args)
(process-request worker-handler worker-args return-q))))
(catch Exception e)))
First, it catches all exceptions and ignores them, to ensure that an error parsing the request message doesn’t crash your entire request-processing service. In a real-world scenario, you’d probably log it or do something else useful with it.
The main thing handle-request-message does is to parse the request, find out if a worker is defined with the requested name (from the workers ref created in the previous section), and call process-request, if it exists. Our focus of inquiry must shift to process-request, which is what the next section is about.
Process-Request
If you recall, the worker handler is an anonymous function stored in the workers ref. You have the arguments needed to execute it, which handle-request-message, helpfully parsed for you. In order to get the result of the computation, you need to call the function. The return value can then be sent back to the caller using the queue name that came along with the request itself. You’ll do this on a separate thread, so that you don’t block the main one. The code for all this is quite simple:
(defn process-request [worker-handler worker-args return-q]
(future
(with-rabbit ["localhost" "guest" "guest"]
(let [response-envelope (response-for worker-handler worker-args)]
(if return-q (send-message return-q response-envelope))))))
The call to future takes care of the threading. The reason you check for return-q is that by not specifying it, you can implement the fire-and-forget feature we mentioned earlier. Lastly, in order to handle any exceptions that might be thrown while running the handler itself, you need one more level of indirection. That indirection is the function response-for, which is also the last part of this puzzle. The response-for function not only evaluates the handler with the provided worker-args but also constructs a suitable message that you can send back to the waiting caller on the other side. Here is response-for:
(defn response-for [worker-handler worker-args]
(try
(let [value (apply worker-handler worker-args)]
{:value value :status :success})
(catch Exception e
{:status :error})))
The try-catch block, as explained, ensures that you don’t crash if the handler crashes. You do create different response messages in the case of successful (and failed) handler executions.
We’re almost finished. The final thing on this end of the picture is to set up the loop.
The request-handler loop
We wrote message-seq in the previous section, which gave you the ability to apply Clojure functions to a series of RabbitMQ messages. You’re going to use that, along with handle-request-message, to implement your message-handling loop. Here it is:
(defn start-handler-process []
(doseq [request-message (message-seq WORKER-QUEUE)]
(handle-request-message request-message)))
WORKER-QUEUE is the same well-defined name with which the worker requests were being dispatched. So that’s it; you can now start message-handling processes via something similar to the following:
(with-rabbit ["localhost" "guest" "guest"] (println "Starting worker handler...") (start-handler-process))
You can add load-sharing capacity to your swarm of message-handling processes by starting more such processes, typically on more machines. This is a simple way to scale up the computation engine for a large application. Before moving on, let’s revisit the idea of the fire-and-forget feature we’ve mentioned a couple of times.
Fire and forget
Most use cases of remote computations will eventually use the return value. Sometimes, it may be useful to run a remote computation only for a side effect. An example might be the previously defined expensive-audit-log, which doesn’t return anything useful and is clearly useful only for a side effect. Here, we repeat it for your convenience:
(defworker expensive-audit-log [z] (println "expensive audit log:" z) (Thread/sleep 4000))
What we’d like is a way to call this, without having to wait for a response. The way we implemented our request-handling loop gives you a natural way to add this feature. Consider the following function:
(defn run-worker-without-return [worker-name-keyword args]
(let [request-object (request-envelope worker-name-keyword args)]
(send-message WORKER-QUEUE request-object)))
This sends a message to your waiting cluster of worker process handlers that contains only the worker name being requested and the arguments. Your handler loop won’t return anything unless a return queue name is also provided, so you’re finished. Calling it might look like this:
(run-worker-without-return :expensive-audit-log 100)
This works, but it’s a somewhat awkward way of calling a worker. Caller convenience is another perfect excuse for a macro, so that calls might look like this instead:
(fire-and-forget expensive-audit-log 100)
The implementation of this macro, as you can imagine, is trivial:
(defmacro fire-and-forget [worker-symbol & args] `(run-worker-without-return (keyword '~worker-symbol) '~args))
So, we’re now at a point where we can put together all the code we wrote so far. You’ll do that in the following section, and you’ll also run a few tests to see if everything works as expected.
11.3.3. Putting it all together
Listing 11.1 shows all the code we’ve written so far, in one place. It also includes some you haven’t seen yet, but we’ll discuss that portion when you test our little remote worker framework. This listing contains all the code related to defining and using workers. We’ll put the code that handles worker requests in another listing.
Listing 11.1. A simple messaging-based distributed-computing framework for Clojure


There are a few things in listing 11.1 that you’ve not seen yet. Specifically, the from-swarm macro and related functions such as wait-until-completion are new and we’ll discuss these shortly. Meanwhile, consider the following listing, which should be familiar, because we discussed all of it in the previous section.
Listing 11.2. Distributed worker processes to handle worker requests

Figure 11.2 shows the various pieces of our remote worker framework.
Figure 11.2. Message flow between a client and a bank of remote worker processes. A client makes a request by calling a worker function, which sends a message over RabbitMQ via a global, well-known work queue. One of several workers picks it up and services the request. When finished, it sends the response back via a temporary routing key that was specified by the calling client.

Now that we’ve put all our code together, let’s test our little framework.
Testing the framework
In order to test our little parallel, distributed-computing framework, you first have to run the code shown in listing 11.2 as a process. It will leave the program waiting in a loop for incoming RabbitMQ messages, each representing a request for a particular worker. The code might look like this:
(ns chapter14-worker-example (:use chapter14-worker-example)) (with-rabbit ["localhost" "guest" "guest"] (println "Starting worker handler...") (start-handler-process))
Remember that you saw the chapter14-worker-example namespace before, when we defined the long-computation-one and long-computation-two functions. Now that you have that going, you can write a little program that exercises the workers, like the one shown here:
(ns chapter14-worker-usage
(:use chapter14-rabbitmq chapter14-worker chapter14-worker-example))
(println "Dispatching...")
(with-rabbit ["localhost" "guest" "guest"]
(let [one (long-computation-one 10 20)
two (long-computation-two 3 5 7)]
(fire-and-forget expensive-audit-log 100)
(from-swarm [one two]
(println "one:" (one :value))
(println "two:" (two :value)))))
(println "done!")
When this program runs, you’ll see output such as the following:
Dispatching... one: 200 two: 15 done!
And as this example runs, your worker service will show output something like the following:
Starting worker handler... Serving up 3 workers.
Processing: :long-computation-one with args: [10 20] Processing: :long-computation-two with args: [3 5 7] Processing: :expensive-audit-log with args: 100
If you were to start multiple worker services, the requests would be distributed across them in a roughly round-robin manner. This way, you could add capacity as the load increases.
This example used something we haven’t discussed before: the call to from-swarm. Let’s talk about that now.
From-swarm
This framework is asynchronous in nature. When a worker is called, a request is fired off over RabbitMQ to a waiting bank of processes. The worker call itself is nonblocking. The object returned by the call to the worker is a proxy to the computation that happens on the cluster of processes, and the return value of the computation eventually gets set inside it.
This allows the main program to make calls to as many workers as it needs, without blocking. At some point, the program will need the return values in order to proceed, and this is where from-swarm comes in. It introduces the idea of a sync point, where execution will block until the responses for the specified worker (proxy) objects come in from the remote swarm. The implementation is shown in listing 11.1, but the macro itself is reproduced here for convenience:
(defmacro from-swarm [swarm-requests & expr]
`(do
(wait-until-completion ~swarm-requests 5000)
~@expr))
This way, you can wait for any number of worker proxies. The macro calls a helper function wait-until-completion, which loops with a short sleep until either all the results return from the swarm or the timer expires. The timeout is hard-coded to five seconds, but that can easily be parameterized. This is a simple spin-lock, and while this works for the most part, there are better ways to implement this sync point. This is left as an exercise to the reader.
Note that in order for the worker service to handle requests for a particular worker, it needs to know about it. This is done in our example by including it in the namespace via the :use option. For instance, our earlier example had the following namespace declaration:
(ns chapter14-worker-process (:use chapter14-rabbitmq chapter14-worker))
The reason it needs to include the chapter14-worker namespace is so that the definitions for the workers (long-computation-one and long-computation-two) get loaded up. Then, when the message-processing loop starts, it has the workers’ computations available in the workers ref.
This covers the essential parts of our little framework. You can now easily define new functions that will run on remote machines by calling defworker (instead of defn). Calling these functions is no different than calling regular functions, and the only difference in semantics is in using the return values. Because the object returned by a worker function is a proxy to the computation being performed on a remote machine, it needs to be handled slightly differently than if the computation was performed locally. The from-swarm construct provides a convenient sync point for this purpose.
Our last extension to this framework will be to add a feature to broadcast a call to all worker processes. This multicast can be used for a variety of purposes, such as a health-check service where return values imply that the server is up and running, or as a way to live update code on all workers (something we’ll do in chapter 15), and so on.
11.3.4. Multicasting messages to multiple receivers
In order to implement this feature, we’re going to take advantage of RabbitMQ’s exchange types. The fan-out exchange delivers messages to all message queues that have set up bindings for the exchange. We’ll begin by extending our send-message function to handle exchange types. This will allow you to use a fan-out exchange to deliver a message to all subscribers. We’ll later build on this function to create a mechanism to call a worker on all worker services. Next, we’ll extend next-message-from to handle listening to such broadcasts. Finally, we’ll modify message-seq to enable it to subscribe to a sequence of broadcast messages.
For clarity, we’ll create a new version of the chapter14-rabbitmq namespace that we saw in the previous section. We’ll call it chapter14-rabbitmq-multicast, and the complete implementation is shown later on in listing 11.3. The next few sections explain individual functions of interest that build up the code.
Send-message
Our first order of business will be to modify send-message in order to handle sending messages to a specific named exchange. This will allow you to later set up listeners on the same named exchange but bound using a fan-out exchange type. Let’s first define a couple of useful vars to represent the default exchange and the (default) direct exchange type.
(def DEFAULT-EXCHANGE-NAME "default-ex") (def DEFAULT-EXCHANGE-TYPE "direct") (def FANOUT-EXCHANGE-TYPE "fanout")
Here’s the new definition:
(defn send-message
([routing-key message-object]
(send-message DEFAULT-EXCHANGE-NAME routing-key message-object))
([exchange-name routing-key message-object]
(with-open [channel (.createChannel *rabbit-connection*)]
(.exchangeDeclare channel exchange-name "fanout")
(.queueDeclare channel routing-key)
(.basicPublish channel exchange-name routing-key nil
(.getBytes (str message-object))))))
After this change, our old code from the previous section should continue to work, because it uses the first variant of send-message that accepts the two parameters routing-key and message-object. The second version accepts an extra parameter, exchange-name, which allows you to now use send-message to target messages at a specific exchange. We’ve now changed what we needed to on the send side of the equation. Our next stop will be to make a few modifications to the other side of the picture, beginning with next-message-from and moving on to message-seq.
Next-message-from
Our modifications to the next-message-from function will reflect the same notion we introduced in send-message, that of addressing a specific exchange in a specific manner. First, let’s create a helper function called random-queue-name that will help you create listeners for specific routing keys, where the name of the queue itself isn’t important. Here’s the function:
(defn random-queue-name [] (str (java.util.UUID/randomUUID)))
Our original next-message-from function accepted only a queue name, and it internally depended on the fact that RabbitMQ defaults to using the default (direct exchange) and a routing key that’s the same as the queue name. In this new implementation, we’ll allow all the parameters to be specified. Here’s the code:

There are three signatures of the next-message-from function. Notice that the first signature allows all existing code to continue to function as before. It does this by explicitly passing the default exchange name and exchange type, as well as the value of the queue name for the routing key. This satisfies the defaults as discussed previously.
The third signature of the function accepts all the important parameters: exchange-name, exchange-type, queue-name, and routing-key ![]() . The second signature is a helper version; it passes along a random queue name when we’re only interested in the routing
key.
. The second signature is a helper version; it passes along a random queue name when we’re only interested in the routing
key.
This change requires us to also change the definition of consumer-for to handle these new parameters. Here’s the updated implementation:
(defn consumer-for [channel exchange-name exchange-type
queue-name routing-key]
(let [consumer (QueueingConsumer. channel)]
(.exchangeDeclare channel exchange-name exchange-type)
(.queueDeclare channel queue-name)
(.queueBind channel queue-name exchange-name routing-key)
(.basicConsume channel queue-name consumer)
consumer))
And with that, you’re all set to try out our new multicast version of senders and receivers. Here’s a program that uses the new send-message to multicast message to all interested listeners:
(ns chapter14-sender-multicast
(:use chapter14-rabbitmq-multicast))
(println "Multicasting...")
(with-rabbit ["localhost" "guest" "guest"]
(send-message "fanex" FANOUT-EXCHANGE-TYPE
"chapter-14-ghz" "Broadcast! Chapter 14 multicast!"))
(println "done!")
We’re sending a message to a fan-out exchange named "fanex", with a routing key of "chapter-14-ghz". Now we need corresponding receivers on the other side, which listen to incoming messages using our new next-message-from. The following will do quite well:
(ns chapter14-receiver-multicast
(:use chapter14-rabbitmq-multicast))
(println "Waiting for broadcast...")
(with-rabbit ["localhost" "guest" "guest"]
(println (next-message-from "fanex"
FANOUT-EXCHANGE-TYPE "chapter-14-ghz")))
This creates a process that will wait until a message is delivered on an exchange named "fanex", set up as a fan-out. The routing key used is also "chapter-14-ghz", so it matches the previous sender. If you now start up several instances of this receiver and use our sender program to drop messages, you’ll see the following output on all the receiver processes:
Waiting for broadcast... Broadcast! Chapter 14 multicast!
Now that you know how to wait for individual broadcast messages, let’s modify message-seq to complete the picture we built in the previous section.
Broadcasts and message-seq
The final piece of the puzzle is the ability of a process to handle a stream of broadcast messages. By modifying message-seq, we can continue to write code the way we did in the last section. All of Clojure’s sequence libraries can be used to handle broadcast messages as well. Here’s the modified version:
(defn message-seq
([queue-name]
(message-seq DEFAULT-EXCHANGE-NAME DEFAULT-EXCHANGE-TYPE
queue-name queue-name))
([exchange-name exchange-type routing-key]
(message-seq exchange-name exchange-type
(random-queue-name) routing-key))
([exchange-name exchange-type queue-name routing-key]
(let [channel (.createChannel *rabbit-connection*)
consumer (consumer-for channel exchange-name exchange-type
queue-name routing-key)]
(lazy-message-seq channel consumer))))
As usual, the first signature is to support our older code that doesn’t care about any of this multicast stuff. It passes along the default exchange name and type, as well as the same value of the queue name as the routing key.
The third signature handles all the important parameters, as we did with next-message-from function. Finally, the second signature is for caller convenience for the case where we only care about the routing key, as you’ll see shortly. We’ve now completed the required changes to support multicasting. The following listing shows the new version of the chapter-14-rabbitmq namespace (renamed to chapter14-rabbitmq-multicast).
Listing 11.3. The new multicast-capable messaging code
(ns chapter14-rabbitmq-multicast
(:import (com.rabbitmq.client ConnectionFactory QueueingConsumer)))
(def *rabbit-connection*)
(def DEFAULT-EXCHANGE-NAME "default-ex")
(def DEFAULT-EXCHANGE-TYPE "direct")
(def FANOUT-EXCHANGE-TYPE "fanout")
(defn new-connection [host username password]
(.newConnection
(doto (ConnectionFactory.)
(.setVirtualHost "/")
(.setUsername username)
(.setPassword password)
(.setHost host))))
(defmacro with-rabbit [[mq-host mq-username mq-password] & exprs]
`(with-open [connection# (new-connection ~mq-host
~mq-username ~mq-password)]
(binding [*rabbit-connection* connection#]
(do ~@exprs))))
(defn send-message
([routing-key message-object]
(send-message DEFAULT-EXCHANGE-NAME routing-key message-object))
([exchange-name exchange-type routing-key message-object]
(with-open [channel (.createChannel *rabbit-connection*)]
(.exchangeDeclare channel exchange-name exchange-type)
(.queueDeclare channel routing-key)
(.basicPublish channel exchange-name routing-key nil
(.getBytes (str message-object))))))
(defn delivery-from [channel consumer]
(let [delivery (.nextDelivery consumer)]
(.basicAck channel (.. delivery getEnvelope getDeliveryTag) false)
(String. (.getBody delivery))))
(defn consumer-for [channel exchange-name exchange-type
queue-name routing-key]
(let [consumer (QueueingConsumer. channel)]
(.exchangeDeclare channel exchange-name exchange-type)
(.queueDeclare channel queue-name)
(.queueBind channel queue-name exchange-name routing-key)
(.basicConsume channel queue-name consumer)
consumer))
(defn random-queue-name []
(str (java.util.UUID/randomUUID)))
(defn next-message-from
([queue-name]
(next-message-from DEFAULT-EXCHANGE-NAME DEFAULT-EXCHANGE-TYPE
queue-name queue-name))
([exchange-name exchange-type routing-key]
(next-message-from exchange-name exchange-type
(random-queue-name) routing-key))
([exchange-name exchange-type queue-name routing-key]
(with-open [channel (.createChannel *rabbit-connection*)]
(let [consumer (consumer-for channel exchange-name exchange-type
queue-name routing-key)]
(delivery-from channel consumer)))))
(defn- lazy-message-seq [channel consumer]
(lazy-seq
(let [message (delivery-from channel consumer)]
(cons message (lazy-message-seq channel consumer)))))
(defn message-seq
([queue-name]
(message-seq DEFAULT-EXCHANGE-NAME DEFAULT-EXCHANGE-TYPE
queue-name queue-name))
([exchange-name exchange-type routing-key]
(message-seq exchange-name exchange-type
(random-queue-name) routing-key))
([exchange-name exchange-type queue-name routing-key]
(let [channel (.createChannel *rabbit-connection*)
consumer (consumer-for channel exchange-name
exchange-type queue-name routing-key)]
(lazy-message-seq channel consumer))))
You’re now ready to see this in action.
Putting it together
In order to test our new message-seq, you can use the same multicast sender program we created earlier. You only need to write a new listener that will process the message sequence. Here’s a simple program that does that:
(ns chapter14-receiver-multicast-multiple
(:use chapter14-rabbitmq-multicast))
(println "Waiting for broadcast...")
(with-rabbit ["localhost" "guest" "guest"]
(doseq [message (message-seq "fanex"
FANOUT-EXCHANGE-TYPE "chapter-14-ghz")]
(println message)))
If you run a few instance of this program and use the multicast sender from before, you’ll see the following output on all the listeners:
Waiting for broadcast... Broadcast! Chapter 14 multicast! Broadcast! Chapter 14 multicast! Broadcast! Chapter 14 multicast!
Now that you have all the plumbing in place, you’re ready to implement the final feature for this mini distributed computing framework: a way to request a computation on all workers at once. As alluded to earlier, this is useful for a number of things, such as making it easy to run diagnostics/health checks on all worker processes or possibly updating code on all remote machines.
11.3.5. Calling all workers
The way we implemented making a call to a remote worker is via sending a message over RabbitMQ. The caller then (behind the scenes) creates a proxy object that holds a listener for the response that the remote worker will eventually send. We then implemented a way to call workers via fire-and-forget semantics. We did this by sending a request message over RabbitMQ and not setting up any proxy to wait for the response. We’ll use this latter approach, combined with the multicast feature we wrote in the last section, to implement this new feature.
Run-worker-everywhere
We’ll make some modifications to our worker code. For starters, let’s add code to create the communication channel for broadcasting. We’ll do this in a way that’s similar to what you saw in the previous section. Here are some useful vars:
(def BROADCAST-QUEUE "chapter14_workers_broadcast_queue") (def BROADCAST-EXCHANGE "chapter14_workers_fanex")
Our new construct will use this queue and exchange to send the request over. The following function will suffice:
(defn run-worker-on-all-servers [worker-name-keyword args]
(let [request-object (request-envelope worker-name-keyword args)]
(send-message BROADCAST-EXCHANGE FANOUT-EXCHANGE-TYPE
BROADCAST-QUEUE request-object)))
This will let you run a particular worker on all worker-servicing processes, by making a call such as the following:
(run-worker-on-all-servers :expensive-audit-log 777)
Similarly to the earlier case where we implemented the fire and forget feature, this is a rather awkward way of making this call. The following macro makes it easier:
(defmacro run-worker-everywhere [worker-symbol & args] `(run-worker-on-all-servers (keyword '~worker-symbol) '~args))
With this in place, you can now call workers on all remote servers using code such as this:
(run-worker-everywhere expensive-audit-log 777)
Now that you know what the calling side looks like, let’s shift our attention to the receiving end. In this next section, we’ll write code to handle such worker-request broadcasts.
Handling worker-request broadcasts
There are two parts to the worker-handling loop. The first is a function that will process a message-seq of broadcast requests. The other is a way to ensure that the worker-handling process continues to listen to the regular work queue. Let’s do the first:
(defn start-broadcast-listener []
(println "Listening to broadcasts.")
(doseq [request-message (message-seq BROADCAST-EXCHANGE
FANOUT-EXCHANGE-TYPE BROADCAST-QUEUE)]
(handle-request-message request-message)))
Nothing new here—you’ve seen similar code before. For the second requirement, we’ll have to write the program that starts the worker-handling loop in a slightly different way:
(ns chapter14-worker-process-multicast-example
(:use chapter14-worker-process-multicast
chapter14-worker-multicast-example
chapter14-rabbitmq-multicast))
(future
(with-rabbit ["localhost" "guest" "guest"]
(start-broadcast-listener)))
(future
(with-rabbit ["localhost" "guest" "guest"]
(start-handler-process)))
By starting each message-handling loop inside a future, you can ensure that both the loops run concurrently. The following listing shows the updated code to support this program and all the features we’ve added so far.
Listing 11.4. A new implementation of the framework for fire and forget and multicasting
(ns chapter14-worker-multicast
(:use chapter14-rabbitmq-multicast)
(:import (java.util UUID)))
(def workers (ref {}))
(def worker-init-value :__worker_init__)
(def WORKER-QUEUE "chapter14_workers_job_queue")
(def BROADCAST-QUEUE "chapter14_workers_broadcast_queue")
(def BROADCAST-EXCHANGE "chapter14_workers_fanex")
(defn all-complete? [swarm-requests]
(every? #(% :complete?) swarm-requests))
(defn disconnect-worker [[channel q-name]]
(.queueDelete channel q-name))
(defn disconnect-all [swarm-requests]
(doseq [req swarm-requests]
(req :disconnect)))
(defn wait-until-completion [swarm-requests allowed-time]
(loop [all-complete (all-complete? swarm-requests)
elapsed-time 0]
(if (> elapsed-time allowed-time)
(do
(disconnect-all swarm-requests)
(throw (RuntimeException. (str "Remote worker timeout exceeded "
allowed-time " milliseconds!"))))
(if (not all-complete)
(do
(Thread/sleep 100)
(recur (all-complete? swarm-requests) (+ elapsed-time 100)))))))
(defmacro from-swarm [swarm-requests & expr]
`(do
(wait-until-completion ~swarm-requests 5000)
~@expr))
(defn update-on-response [worker-ref return-q-name]
(let [channel (.createChannel *rabbit-connection*)
consumer (consumer-for channel DEFAULT-EXCHANGE-NAME
DEFAULT-EXCHANGE-TYPE return-q-name return-q-name)
on-response (fn [response-message]
(dosync
(ref-set worker-ref (read-string response-message))
(.queueDelete channel return-q-name)
(.close channel)))]
(future (on-response (delivery-from channel consumer)))
[channel return-q-name]))
(defn request-envelope
([worker-name args]
{:worker-name worker-name :worker-args args})
([worker-name args return-q-name]
(assoc (request-envelope worker-name args) :return-q return-q-name)))
(defn dispatch-work [worker-name args worker-ref]
(let [return-q-name (str (UUID/randomUUID))
request-object (request-envelope worker-name args return-q-name)
worker-transport (update-on-response worker-ref return-q-name)]
(send-message WORKER-QUEUE request-object)
worker-transport))
(defn attribute-from-response [worker-internal-data attrib-name]
(if (= worker-init-value worker-internal-data)
(throw (RuntimeException. "Worker not complete!")))
(if (not (= :success (keyword (worker-internal-data :status))))
(throw (RuntimeException. "Worker has errors!")))
(worker-internal-data attrib-name))
(defn on-swarm [worker-name args]
(let [worker-data (ref worker-init-value)
worker-transport (dispatch-work worker-name args worker-data)]
(fn [accessor]
(condp = accessor
:complete? (not (= worker-init-value @worker-data))
:value (attribute-from-response @worker-data :value)
:status (@worker-data :status)
:disconnect (disconnect-worker worker-transport)))))
(defmacro worker-runner [worker-name should-return worker-args]
`(fn ~worker-args
(if ~should-return
(on-swarm ~worker-name ~worker-args))))
(defmacro defworker [service-name args & exprs]
`(let [worker-name# (keyword '~service-name)]
(dosync
(alter workers assoc worker-name# (fn ~args (do ~@exprs))))
(def ~service-name (worker-runner worker-name# true ~args))))
(defn run-worker-without-return [worker-name-keyword args]
(let [request-object (request-envelope worker-name-keyword args)]
(send-message WORKER-QUEUE request-object)))
(defmacro fire-and-forget [worker-symbol & args]
`(run-worker-without-return (keyword '~worker-symbol) '~args))
(defn run-worker-on-all-servers [worker-name-keyword args]
(let [request-object (request-envelope worker-name-keyword args)]
(send-message BROADCAST-EXCHANGE FANOUT-EXCHANGE-TYPE BROADCAST-QUEUE
request-object)))
(defmacro run-worker-everywhere [worker-symbol & args]
`(run-worker-on-all-servers (keyword '~worker-symbol) '~args))
(ns chapter14-worker-process-multicast
(:use chapter14-rabbitmq-multicast chapter14-worker-multicast))
(defn response-for [worker-handler worker-args]
(try
(let [value (apply worker-handler worker-args)]
{:value value :status :success})
(catch Exception e
{:status :error})))
(defn process-request [worker-handler worker-args return-q]
(future
(with-rabbit ["localhost" "guest" "guest"]
(let [response-envelope (response-for worker-handler worker-args)]
(if return-q (send-message return-q response-envelope))))))
(defn handle-request-message [req-str]
(try
(let [req (read-string req-str)
worker-name (req :worker-name) worker-args
(req :worker-args) return-q (req :return-q)
worker-handler (@workers worker-name)]
(if (not (nil? worker-handler))
(do
(println "Processing:" worker-name "with args:" worker-args)
(process-request worker-handler worker-args return-q))))
(catch Exception e)))
(defn start-handler-process []
(println "Serving up" (count @workers) "workers.")
(doseq [request-message (message-seq WORKER-QUEUE)]
(handle-request-message request-message)))
(defn start-broadcast-listener []
(println "Listening to broadcasts.")
(doseq [request-message (message-seq BROADCAST-EXCHANGE
FANOUT-EXCHANGE-TYPE BROADCAST-QUEUE)]
(handle-request-message request-message)))
That covers everything you’ve seen so far. You can run several instances of the worker-handling processes. By changing the localhost setting for RabbitMQ to something more specific, you can run multiple such processes on any number of computers. Our last order of business will be to test it, and for this, we’ll write a tiny program to exercise the latest code.
Testing run-worker-everywhere
The following program is a short test of the new features. It looks similar to the example you saw with the fire-and forget-section, but it serves our purpose nicely. Here it is:
(ns chapter14-worker-multicast-usage
(:use chapter14-worker-multicast chapter14-rabbitmq-multicast chapter14-
worker-multicast-example))
(println "Dispatching...")
(with-rabbit ["localhost" "guest" "guest"]
(let [one (long-computation-one 10 20)
two (long-computation-two 3 5 7)]
(run-worker-everywhere expensive-audit-log 777)
(from-swarm [one two]
(println "one:" (one :value))
(println "two:" (two :value)))))
(println "done!")
Running this on the console looks no different from the previous case:
Dispatching... one: 200 two: 15 done!
Our worker processes (if there are two running) might look something like this:
Console output for the first worker process:
Listening to broadcasts. Serving up 3 workers. Processing: :long-computation-one with args: [10 20] Processing: :expensive-audit-log with args: (777) expensive audit log: 777
And here’s the output for the second one:
Listening to broadcasts. Serving up 3 workers. Processing: :long-computation-two with args: [3 5 7] Processing: :expensive-audit-log with args: (777) expensive audit log: 777
The specific output may look slightly different on your computer. The key is that work is being distributed across multiple processes and that the call made via run-worker-everywhere does run on both.
We’re finished for now! You’ve seen a lot of things so far. We first looked at basic communication using RabbitMQ, and then we built on that to write a simple distributed computing framework. Obviously, weighing in at around a couple of hundred lines of Clojure, it doesn’t support all the functionality you’d expect from a production version. This could form a nice base for such a system. In the next section, we’ll discuss a few additional things you might add to such a framework.
11.3.6. Additional features
We’ve managed to build a fairly reasonable distributed computing framework over the last few sections. In a production environment, though, you might want it to sport a few more features. Examples might be better information when exceptions happen, logging, making it more unit-testing friendly, and so on. We’ll discuss a few of these now.
Distributed mode
Writing unit tests for code that calls a remote worker is a little difficult. This is because the tests end up requiring that the worker-handling processes (at least one) be running. That in turn means that RabbitMQ needs to be running. All of these external dependencies make unit testing hard and tedious. If unit tests are difficult to run, they will be run less often, and that’s a bad situation to be in. Adding a configuration parameter that can make all code written using this framework run in a nondistributed mode would be a useful thing.
Exception info
When an exception occurs inside a worker running on a remote machine, our framework sends back an error status. It would be easy to send information about the exception along with the return message. Examples of such data would be the name of the exception class and even the stack trace itself. This information would make it easier for the callers to debug things when they go wrong.
Request priorities
Our framework treats all request messages with the same level of importance. In the real world, you might have several levels of priority. It would be useful for the framework to expand in order to offer multiple levels of importance; it would be great if the caller could specify a level when the call is being made. Perhaps the default would be “medium,” but the caller could specify “low” or “high” when making the call.
Parameterize wait time
In our from-swarm macro, we wait for 10 seconds to see if the requests we made return their responses. In many production use cases, this would be too long. And indeed, in some it would be too short. It would be a good idea to parameterize this wait duration and to provide a nonintrusive macro, which could make it easy to provide and use.
Bindings and rebindings
This little framework uses futures to run each request on a different thread. It allows the main program to continue listening for incoming requests and also to handle more requests concurrently (especially if the nature of the work being done mostly isn’t CPU bound). Unfortunately, because Clojure bindings are thread local, the code that runs inside a future can’t see any specially set-up bindings. A useful feature to add to this distributed-computing framework would be a way to easily rebind specific dynamic vars inside the future where the request is being processed.
With these features added, and more that might be useful to specific domains, this framework could find use in a real-world application. Because RabbitMQ itself is horizontally scalable, this framework could be useful in writing applications that can also scale by adding machines.
11.4. Summary
This was another fairly long chapter! We started off using RabbitMQ to send and receive messages between Clojure applications. We then wrote a convenient abstraction (message-seq) to deal with the fact that most receiving programs process incoming messages in a loop. This made it ideal to treat the stream of messages being delivered by RabbitMQ as a sequence, thereby allowing programs to unleash the full power of the Clojure sequence library on such a message stream.
After we got the basics out of the way, we implemented a little framework to write distributed Clojure applications in an easy and intuitive manner. This framework made it simple to write applications that made use of multiple JVM processes running across machines. Over the course of the chapter, we added features to this framework, and we brought it to a point where it could form the basis of something useable in the real world. And the whole thing clocked in at fewer than 200 lines of code.
Adding a distributed computing story to Clojure opens up a whole new world of possibilities. It adds a dimension of scalability that allows truly web-scale applications to be written in the language. This is definitely useful in the large, whereas all of Clojure’s other features—macros, functional programming, lazy sequences, and so on—can be brought to bear in the small. This is a great combination.