
Chapter 12. Data processing with Clojure
- The map/reduce pattern of data processing
- Analyzing log files using map/reduce
- Distributing the data processing
- Master/slave parallelization
A computer program accepts data that is given, manipulates it in some way, and provides some output. The growing volume of data collected every minute of every day is evidence that data processing is alive in most software today. This chapter is about writing such programs. Naturally, you’ll want to do this in as functional and as Clojure-esque a way as possible.
We’re going to examine two approaches to processing large volumes of data. The first is the approach known as map/reduce. We’ll show what it is, use it to parse log data, and discuss a few open source projects that provide distributed versions of map/reduce.
Next, we’ll look at a different approach, one that uses a master to dispatch works to multiple workers. Master/slave parallelization schemes inspire this traditional approach. We’ll use our lessons from the chapter on messaging in order to implement a simple master/slave data processing framework.
12.1. The map/reduce paradigm
Google popularized the map/reduce approach to distributed computing where large volumes of data can be processed using a large number of computers. The data processing problem is broken into pieces, and each piece runs on an individual machine. The software then combines the output from each computer to produce a final answer. The breaking up of the problem into smaller problems and assigning them to computers happens in the map stage, whereas the output from individual computers is taken and combined into a single entity in the reduce stage.
Google’s map/reduce is based on the functional concepts of map and reduce, functions that you’ve seen repeatedly in this book so far. In this section, we’ll explore this combination of map and reduce to see how it can be useful in processing data. We’ll use the basic ideas of mapping and reducing, and over the course of this section we’ll process data that we read from files. We’ll build abstractions on top of simple file input so that we eventually end up processing Ruby on Rails server log files.
12.1.1. Getting started with map/reduce—counting words
We’re going to use a traditional example in order to understand the idea of map/ reduce. The problem is to count the number of times each word appears in a corpus of text. The total volume of text is usually large, but we’ll use a small amount in order to illustrate the idea. The following is the first stanza of a poem by Lewis Carroll, called “The Jabberwocky”:
Twas brillig and the slithy toves
Did gyre and gimble in the wabe
All mimsy were the borogoves
And the mome raths outgrabe
It’s easy to find this poem on the internet, because it’s from the famous book Through the Looking Glass. Note that for convenience, we’ve removed all punctuation from the text. We put the text in a file called jabberwocky.txt in a convenient folder. Let’s write some code to count the number of times each word appears in the poem.
Consider the following function that operates on only a single line of the poem:
(defn parse-line [line]
(let [tokens (.split (.toLowerCase line) " ")]
(map #(vector % 1) tokens)))
This will convert a given line of text into a sequence of vectors, where each entry contains a single word and the number 1 (which can be thought of as a tally mark that the word appeared once), for instance:
user> (parse-line "Twas brillig and the slithy toves") (["twas" 1] ["brillig" 1] ["and" 1] ["the" 1] ["slithy" 1] ["toves" 1])
Next, we’ll combine the tally marks, so to speak, to get an idea of how many times each word appears. Consider this:
(defn combine [mapped]
(->> (apply concat mapped)
(group-by first)
(map (fn [[k v]]
{k (map second v)}))
(apply merge-with conj)))
This works by creating a map, where the keys are the words found by parse-line, and the values are the sequences of tally marks. The only thing of curiosity here should be the group-by function. As you can see, it takes two arguments: a function and a sequence. The return value is a map where the keys are the results of applying the function on each element of the sequence, and the values are a vector of corresponding elements. The elements in each vector are also, conveniently, in the same order in which they appear in the original sequence.
Here’s the combine operation in action:
user> (use 'clojure.contrib.io)
nil
user> (combine (map parse-line
(read-lines "/Users/amit/tmp/jabberwocky.txt")))
{"were" (1), "all" (1), "in" (1), "gyre" (1), "toves" (1), "outgrabe" (1),
"wabe" (1), "gimble" (1), "raths" (1), "the" (1 1 1 1), "borogoves" (1),
"slithy" (1), "twas" (1), "brillig" (1), "mimsy" (1), "and" (1 1 1),
"mome" (1), "did" (1)}
The read-lines function reads in the content of a file into a sequence of lines. Consider the output. For example, notice the word the. It appears multiple times, and the associated value is a list of 1s, each representing a single occurrence.
The final step is to sum the tally marks. This is the reduce step, and it’s quite straightforward. Consider the following code:
(defn sum [[k v]]
{k (apply + v)})
(defn reduce-parsed-lines [collected-values]
(apply merge (map sum collected-values)))
And that’s all there is to it. Let’s create a nice wrapper function that you can call with a filename:
(defn word-frequency [filename]
(->> (read-lines filename)
(map parse-line)
(combine)
(reduce-parsed-lines)))
Let’s try it at the REPL:
user> (word-frequency "/Users/amit/tmp/jabberwocky.txt")
{"were" 1, "all" 1, "in" 1, "gyre" 1, "toves" 1, "outgrabe" 1, "wabe" 1,
"gimble" 1, "raths" 1, "the" 4, "borogoves" 1, "slithy" 1, "twas" 1,
"brillig" 1, "mimsy" 1, "and" 3, "mome" 1, "did" 1}
So there you have it. It might seem a somewhat convoluted way to count the number of times words appear in text, but you’ll see why this is a good approach for generalized computations of this sort.
12.1.2. Generalizing the map/reduce
In the previous section, we wrote a fair bit of code to compute the frequency of words in a given piece of text. The following listing shows the complete code.
Listing 12.1. Computing the frequency of words in given text
(ns chapter-data.word-count-1
(:use clojure.contrib.io
clojure.contrib.seq-utils))
(defn parse-line [line]
(let [tokens (.split (.toLowerCase line) " ")]
(map #(vector % 1) tokens)))
(defn combine [mapped]
(->> (apply concat mapped)
(group-by first)
(map (fn [[k v]]
{k (map second v)}))
(apply merge-with conj)))
(defn sum [[k v]]
{k (apply + v)})
(defn reduce-parsed-lines [collected-values]
(apply merge (map sum collected-values)))
(defn word-frequency [filename]
(->> (read-lines filename)
(map parse-line)
(combine)
(reduce-parsed-lines)))
As pointed out earlier, there are probably more direct ways to do the job. We said that we did this so we could generalize the code to compute other kinds of things. We’ll do that in this section.
Consider the word-frequency function in listing 12.1. Clearly, the first thing to pull out is how the input lines of text are provided. By decoupling the rest of the code from the call to read-lines, you can pass in any other lines of text you might have to process. So your new top-level function will accept the input as a parameter.
Next, you’ll decouple the code from the parse-line function. That way, the user of your map/reduce code can decide how to map each piece of input into the intermediate form. Your new top-level function will accept the mapper function. Figure 12.1 shows the conceptual phase of the mapping part of the map/reduce approach.
Figure 12.1. The mapping phase of the map/reduce approach applies a function to each input value, producing a list of key/value pairs for each input. All these lists (each containing several key/value pairs) are gathered into another list to constitute the final output of the mapping phase.
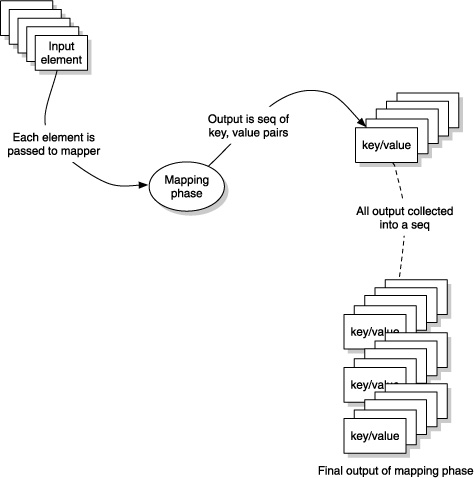
Finally, you’ll also decouple the map/reduce code from the way in which the reduce happens, so that the user of your code can decide how to do this part of the computation. You’ll also accept the reducer function as a parameter.
Given these considerations, your top-level map-reduce function may look like this:
(defn map-reduce [mapper reducer args-seq]
(->> (map mapper args-seq)
(combine)
(reducer)))
The first line of this function is simple, and the combine function from our previous word count example is sufficient. Finally, reducer will accept the combined set of processed input to produce the result.
So with this map-reduce function and the combine function from the previous example, you have enough to try the word count example again. Recall that the idea of the combine phase is to group together common keys in order to prepare for the final reduce phase. Figure 12.2 shows the conceptual view, and listing 12.2 shows the extracted bits, followed by the word count example.
Figure 12.2. The combine phase takes the output of the mapping phase and collects each key and associated values from the collection of lists of key/value pairs. The combined output is then a map with unique keys created during the mapping process, with each associated value being a list of values from the mapping phase.
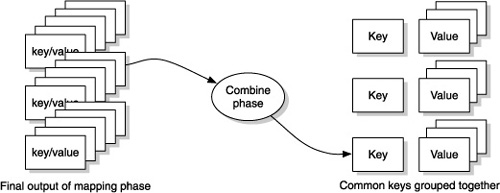
Listing 12.2. General map/reduce extracted out of the word-count example
(ns chapter-data.map-reduce
(:use clojure.contrib.seq-utils))
(defn combine [mapped]
(->> (apply concat mapped)
(group-by first)
(map (fn [[k v]]
{k (map second v)}))
(apply merge-with conj)))
(defn map-reduce [mapper reducer args-seq]
(->> (map mapper args-seq)
(combine)
(reducer)))
It’s time to see it in action. Consider the rewritten word-frequency function:
(defn word-frequency [filename] (map-reduce parse-line reduce-parsed-lines (read-lines filename)))
And here it is on the REPL:
user> (word-frequency "/Users/amit/tmp/jabberwocky.txt")
{"were" 1, "all" 1, "in" 1, "gyre" 1, "toves" 1, "outgrabe" 1, "wabe" 1,
"gimble" 1, "raths" 1, "the" 4, "borogoves" 1, "slithy" 1, "twas" 1,
"brillig" 1, "mimsy" 1, "and" 3, "mome" 1, "did" 1}
Note that in this case, the final output is a map of words to total counts. The map/ reduce algorithm is general in the sense that the reduce phase can result in any arbitrary value. For instance, it can be a constant, or a list, or a map, as in the previous example, or any other value. The generic process is conceptualized in figure 12.3.
Figure 12.3. The input to the reduce phase is the output of the combiner, which is a map, with keys being all the unique keys found in the mapping operation and the values being the collected values for each key from the mapping process. The output of the reduce phase can be any arbitrary value.
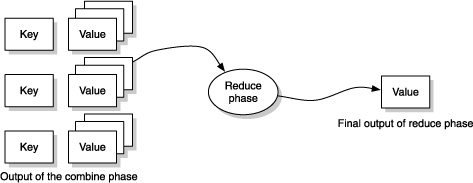
The obvious question is, how general is this map/reduce code? Let’s find the average number of words per line in the text. The code to do that’s shown in the following listing.
Listing 12.3. Using map/reduce to calculate average number of words in each line
(ns chapter-data.average-line-length
(:use chapter-data.map-reduce
clojure.contrib.io))
(def IGNORE "_")
(defn parse-line [line]
(let [tokens (.split (.toLowerCase line) " ")]
[[IGNORE (count tokens)]]))
(defn average [numbers]
(/ (apply + numbers)
(count numbers)))
(defn reducer [combined]
(average (val (first combined))))
(defn average-line-length [filename]
(map-reduce parse-line reducer (read-lines filename)))
user> (average-line-length "/Users/amit/tmp/jabberwocky.txt") 23/4 user> (float (average-line-length "/Users/amit/tmp/jabberwocky.txt")) 5.75
In this version of parse-line, you don’t care about what line has what length, and you use a placeholder string "_" (named IGNORE because you don’t use it later). Now, in the next section, you’ll use our map/reduce code to parse some log files.
12.1.3. Parsing logs
Most nontrivial applications generate log data. Often, the logs contain information that’s particularly useful in debugging or in learning how certain aspects of the application are used. In this section, you’ll parse some Ruby on Rails log files to demonstrate the map/reduce approach a bit more.
The log-file format
Let’s start by looking at what we’re dealing with. Here are a few lines from a typical Rails log file:
# Logfile created on Wed Apr 28 05:49:46 +0000 2010
Processing LoginController#show (for 10.245.114.15 at 2010-04-28 05:50:31)
[GET]
Session ID: f1a7b029e4f8845d67cca2157785d646
Parameters: {"action"=>"show", "controller"=>"login"}
Cookie set: cinch=cd36cdb5c80313c5b0114facd82b24db666c62ec79d7916f; path=/;
expires=Thu, 28 Apr 2011 05:50:34 GMT
Rendering login/login
Completed in 2237ms (View: 1, DB: 567) | 200 OK
[http://10.195.218.143/login]
Processing LoginController#show (for 10.245.114.15 at 2010-04-28 05:50:35)
[GET]
Session ID: 9c985b243b385a86255487d11f693af4
Parameters: {"action"=>"show", "controller"=>"login"}
Cookie set: cinch=97601bd094e608e1079c4c178e37bfb51f0c021c790c346c; path=/;
expires=Thu, 28 Apr 2011 05:50:35 GMT
Rendering login/login
Completed in 654ms (View: 1, DB: 567) | 200 OK
[http://10.195.218.143/login]
Processing LoginController#show (for 10.245.114.15 at 2010-04-28 05:50:51)
[GET]
Session ID: 5d1bab09ffeadb336ea0a5387be8eaf3
Parameters: {"action"=>"show", "controller"=>"login"}
Cookie set: cinch=e1dc75b5747750e952b75f9d5ab264a13aaa135fd10f3240; path=/;
expires=Thu, 28 Apr 2011 05:50:54 GMT
Rendering login/login
Completed in 1771ms (View: 1, DB: 685) | 200 OK
[http://10.195.218.143/login]
Notice that the first line is a header line noting when the logging started. A blank line follows this header. Further, a few lines of text represent each web request, and each such set is separated by two blank lines. You’ll start by creating a way to operate at the level of individual web requests, as opposed to at individual lines of text. We’ll call this abstraction request-seq.
A sequence of requests
In order to create request-seq, you’ll need to first read the log file. The read-lines function from clojure.contrib.io is perfect for this job. Consider the following top-level function:
(defn request-seq [filename]
(->> (read-lines filename)
(drop 2)
(lazy-request-seq)))
It reads the text from the specified file and then drops the first two lines (consisting of the header and the following blank line). The resulting lines are passed to the lazy-request-seq, which parses and builds the sequence of web requests. Here’s an implementation:
(defn lazy-request-seq [log-lines]
(lazy-seq
(let [record (next-log-record log-lines)]
(if (empty? record)
nil
(cons (remove empty? record)
(lazy-request-seq (drop (count record) log-lines)))))))
As you can see, the lazy-request-seq uses lazy-seq to create a lazy sequence of requests. Each request is represented by a sequence of lines from the log file, pertaining to the request. The bulk of the work, then, is in next-log-record, which is shown here:
(defn next-log-record [log-lines]
(let [head (first log-lines)
body (take-while (complement record-start?) (rest log-lines))]
(remove nil? (conj body head))))
The only function remaining is the support function record-start?, which is defined here:
(defn record-start? [log-line] (.startsWith log-line "Processing"))
The basic approach is that you look for lines that begin with "Processing", in order to identify requests. The rest is cleaning up the blank lines, terminating when the text lines run out. You can now create a request-seq by using the top-level function:
user> (def rl (request-seq "/Users/amit/tmp/logs/rails.log")) #'user/rl
You can begin your exploration of this abstraction with a simple call to count:
user> (count rl) 145
Clearly, this is a small log file. To compare, you can check how many raw lines are in the underlying log file:
user> (count (read-lines "/Users/amit/tmp/logs/rails.log")) 1004
Yes, it’s a small file containing 1004 lines that represent a total of 145 requests. Let’s also see what a request record looks like:
user> (first rl)
("Processing LoginController#show (for 10.245.114.15 at 2010-04-28
05:50:31) [GET]" " Session ID: f1a7b029e4f8845d67cca2157785d646" "
Parameters: {"action"=>"show", "controller"=>"login"}" "Cookie set:
cinch=cd36cdb5c80313c5b0114facd82b24db666c62ec79d7916f; path=/;
expires=Thu, 28 Apr 2011 05:50:34 GMT" "Rendering login/login" "Completed
in 2237ms (View: 1, DB: 567) | 200 OK [http://10.195.218.143/login]")
As we described earlier, each request record is a list of the individual lines from the log file. Now that you have request-seq, you can build a few useful functions that operate at the level of an individual request record (which, as a reminder, is a sequence of individual lines), for instance:
(defn controller-name [log-record] (second (.split (first log-record) " ")))
Let’s see it working:
user> (controller-name (first rl)) "LoginController#show"
This (in Rails terminology) is saying that a request was made to a controller named LoginController and to an action named show. Here’s another useful function:
(defn execution-time [log-record]
(let [numbers (re-seq #"d+" (last log-record))]
(if (empty? numbers)
0
(read-string (first numbers)))))
It parses out the total execution time of each request, also handling the case where the time isn’t present because of some error. Here it is on the REPL:
user> (execution-time (first rl)) 2237
Notice that this is in milliseconds and that you used read-string to convert it into a number. Finally, here’s a function that tells you the date the request was made:
(defn day-of-request-str [log-record]
(->> (first log-record)
(re-seq #"d+-d+-d+")
(first)))
And here it is on the REPL:
user> (day-of-request-str (first rl)) "2010-04-28"
These few functions are sufficient for our purposes here, but you can certainly imagine expanding this set to include other useful tasks. For instance, you might define a function to tell when a request was made:
(defn time-of-request [log-record]
(->> (first log-record)
(re-seq #"d+-d+-d+ d+:d+:d+")
(first)
(.parseDateTime GMT-FORMAT)))
Note that we’re using the Joda time library to handle dates and times. You’ll need to download it and ensure that the JAR file is on your classpath. GMT-FORMAT may be defined as the following:
(def DT-FORMAT (DateTimeFormat/forPattern "yyyy-MM-dd HH:mm:ss")) (def GMT-FORMAT (.withZone DT-FORMAT (DateTimeZone/forID "GMT")))
You might also define a function to get the session-id of a request:
(defn session-id [log-record] (second (.split (second log-record) ": ")))
The complete code for our request-seq abstraction is shown in the following listing.
Listing 12.4. The request-seq abstraction for Ruby on Rails log files
(ns chapter-data.rails-log
(:use clojure.contrib.io)
(:import (org.joda.time DateTimeZone)
(org.joda.time.format DateTimeFormat)))
(def DT-FORMAT (DateTimeFormat/forPattern "yyyy-MM-dd HH:mm:ss"))
(def GMT-FORMAT (.withZone DT-FORMAT (DateTimeZone/forID "GMT")))
(defn record-start? [log-line]
(.startsWith log-line "Processing"))
(defn next-log-record [log-lines]
(let [head (first log-lines)
body (take-while (complement record-start?) (rest log-lines))]
(remove nil? (conj body head))))
(defn lazy-request-seq [log-lines]
(lazy-seq
(let [record (next-log-record log-lines)]
(if (empty? record)
nil
(cons (remove empty? record)
(lazy-request-seq (drop (count record) log-lines)))))))
(defn request-seq [filename]
(->> (read-lines filename)
(drop 2)
(lazy-request-seq)))
(defn controller-name [log-record]
(second (.split (first log-record) " ")))
(defn execution-time [log-record]
(let [numbers (re-seq #"d+" (last log-record))]
(if (empty? numbers)
0
(read-string (first numbers)))))
(defn day-of-request-str [log-record]
(->> (first log-record)
(re-seq #"d+-d+-d+")
(first)))
(defn time-of-request [log-record]
(->> (first log-record)
(re-seq #"d+-d+-d+ d+:d+:d+")
(first)
(.parseDateTime GMT-FORMAT)))
(defn session-id [log-record]
(second (.split (second log-record) ": ")))
Now you’re ready to try some map/reduce on this request-seq. The next section does that.
Rails requests and map/reduce
You’ll now write some code to count the number of times each controller was called. This will look similar to the earlier word count example. Consider the mapper function shown here:
(defn parse-record [log-record]
(let [data {:total 1}
data (assoc data (controller-name log-record) 1)]
[[(day-of-request-str log-record) data]]))
You’re going to count the total number of requests (denoted by the :total key in our datum) and also the number of times an individual controller was called (denoted by the presence of the controller name as a key, along with a 1 as a tally mark). Next up is the reducer code:
(defn reduce-days [[date date-vals]]
{date (apply merge-with + date-vals)})
(defn rails-reducer [collected-values]
(apply merge (map reduce-days collected-values)))
This should remind you of the word-count example. All that remains now is the top-level function:
(defn investigate-log [log-file] (map-reduce parse-record rails-reducer (request-seq log-file)))
Let’s see it in action!
user> (investigate-log "/Users/amit/tmp/logs/rails.log")
{"2010-04-28"
{"JsonfetchController#campaign_message_templates_json" 17,
"JsClientFileNamesController#index" 23,
"InsertsController#index" 35,
"PageLogsController#create" 8,
:total 145,
"ConsumersController#update_merchant_session" 25,
"CartsController#create" 1,
"CartsController#show" 16,
"LoginController#show" 4,
"LoginController#consumer_status" 16}}
We said earlier that it’s similar to the word-count example but not quite the same. The difference here is that you’re grouping the results by day. You didn’t have this extra level of grouping when you were counting words. As you can see from the following listing, which contains the complete code for this Rails log analysis, you can do this rather easily.
Listing 12.5. Analyzing Rails log to compute frequencies of controller calls
ns chapter-data.rails-analyzer
(:use chapter-data.rails-log
chapter-data.map-reduce))
(defn parse-record [log-record]
(let [data {:total 1}
data (assoc data (controller-name log-record) 1)]
[[(day-of-request-str log-record) data]]))
(defn reduce-days [[date date-vals]]
{date (apply merge-with + date-vals)})
(defn rails-reducer [collected-values]
(apply merge (map reduce-days collected-values)))
(defn investigate-log [log-file]
(map-reduce parse-record rails-reducer (request-seq log-file)))
It’s easy to gather other kinds of metrics from the Rails log files. All you have to do is add the appropriate code to the mapper function (in this case, parse-record) and make the respective change (if any) to the reducer code.
Notice how you started out reading the log file with read-lines. This returns a sequence of each line of text in the file. Then you built up the request-seq abstraction on top of it, which allows you to operate at the level of requests. In the next section, we’ll show how to build one more abstraction on top this, so you can deal with data at the level of sessions.
12.1.4. Analyzing Rails sessions
In the last section, you analyzed web requests from a Rails log file. You determined how many times each controller was called on a daily basis. In this section, you’ll calculate how long a web session is (in terms of the number of requests) and how long it lasts (in terms of time). In order to do this, we’d like to raise our level of abstraction beyond request-seq, so you can avoid dealing with requests directly.
Our new abstraction will be session-seq, which is a grouping of requests by their session-id. Luckily we already wrote a function to determine the session id of a request (we called it session-id and it’s in the chapter-data.rails-log namespace, shown in listing 12.4). You can use it to do your grouping.
Session-seq
Let’s get started on our new abstraction. Consider the following function:
(defn session-seq [requests] (group-by session-id requests))
The familiar group-by function makes this trivial to do. Next, you’ll write some code to support the analysis of your sessions. The first thing we said we wanted was the length in terms of the number of requests. You can use count to do that. The other thing we wanted was a way to determine how long a session lasted in, say, milliseconds. Here’s a function that does it:
(defn duration [requests]
(let [begin (time-of-request (first requests))
end (time-of-request (last requests))]
(- (.getMillis end) (.getMillis begin))))
Here’s an example:
user> (def rl (request-seq "/Users/amit/tmp/logs/rails.log")) #'user/rl user> (def ss (session-seq rl)) #'user/ss user> (duration (val (first ss))) 18000
So that works, and it seems that the first session lasted 18 seconds even. The complete code for our session-seq namespace is shown in the following listing.
Listing 12.6. session-seq built on top of request-seq
(ns chapter-data.session-seq
(:use chapter-data.rails-log
clojure.contrib.seq-utils))
(defn session-seq [requests]
(group-by session-id requests))
(defn duration [requests]
(let [begin (time-of-request (first requests))
end (time-of-request (last requests))]
(- (.getMillis end) (.getMillis begin))))
Now that you have the basics down, you need to decide how you’re going to implement the functions needed to do the analysis. That’s the focus of the next section.
Sessions analysis
We wanted to determine what the average length of a session is, both in terms of the number of requests in each session and in how long a session lasts in milliseconds. Because we’re using our map/reduce approach, the first thing you’ll need is the mapper function. Consider the following:
(defn parse-session [[session-id requests]]
(let [metrics {:length (count requests)
:duration (duration requests)}]
[[session-id metrics]]))
This gathers the metrics you want for a single session. You can test it at the REPL, like so:
user=> (parse-session (first ss))
[["03c008692b0a79cd99aa011c32305885" {:length 4, :duration 18000}]]
So all you need now is a way to reduce a collection of such data. Consider this:
(defn averages [collected-values]
(let [num-sessions (count collected-values)
all-metrics (apply concat (vals collected-values))
total-length (apply + (map :length all-metrics))
total-duration (apply + (map :duration all-metrics))]
{:average-length (/ total-length num-sessions)
:average-duration (/ total-duration num-sessions)}))
The final step is to pass these mapper and reducer functions to our map-reduce function. Here’s a function called investigate-sessions that does this and also prints the results in a nice, readable format:
(defn investigate-sessions [filename]
(let [results (map-reduce parse-session averages
(session-seq (request-seq filename)))]
(println "Avg length:" (* 1.0 (:average-length results)))
(println "Avg duration:" (* 1.0 (:average-duration results)))))
Now you’re ready to try this at the REPL:
user=> (investigate-sessions "/Users/amit/tmp/logs/rails.log") Avg length: 1.746987951807229 Avg duration: 3024.096385542169 nil
Done; that gives you the required averages. The complete code for the analysis work is provided in the following listing.
Listing 12.7. Computing the average length of sessions from a Rails log file
(ns chapter-data.session-analyzer
(:use chapter-data.map-reduce
chapter-data.rails-log
chapter-data.session-seq))
(defn parse-session [[session-id requests]]
(let [metrics {:length (count requests)
:duration (duration requests)}]
[[session-id metrics]]))
(defn averages [collected-values]
(let [num-sessions (count collected-values)
all-metrics (apply concat (vals collected-values))
total-length (apply + (map :length all-metrics))
total-duration (apply + (map :duration all-metrics))]
{:average-length (/ total-length num-sessions)
:average-duration (/ total-duration num-sessions)}))
(defn investigate-sessions [filename]
(let [results (map-reduce parse-session averages
(session-seq (request-seq filename)))]
(println "Avg length:" (* 1.0 (:average-length results)))
(println "Avg duration:" (* 1.0 (:average-duration results)))))
What you’ve accomplished here is the ability to take a Rails log file and in a few lines of code run computations at the level of web sessions. You did this by building layers of abstractions, both on the data side and also on the map/reduce side. You can easily compute more metrics about sessions by adding to our mapper and reducer code.
In the next section, we’ll go over a few examples of how this pattern of data processing is used for large-scale computations.
12.1.5. Large-scale data processing
The last section looked at using Clojure’s map and reduce functions to operate on sequences of data in order to produce a desired output. The same basic principles have also been applied to large-scale computing. As you can imagine, as the volume of data that needs to be processed grows, more computers need to participate in the processing. Although distributed computing and multiprocessor parallelism aren’t new concepts by any means, Google has popularized the distributed map/reduce approach in the industry. In 2006, they released a white paper that described their approach to large-scale data processing (http://labs.google.com/papers/mapreduce.html), and there have been several open source projects that implemented their ideas since then.
One of the more popular ones is a project called Hadoop, which is part of the Apache family of projects. Because it’s written in Java, you can imagine using it from Clojure. In this section, we’ll discuss a few related open source projects in this area. Note that detailed discussions and examples of using these from Clojure are beyond the scope of this book. The concepts from the previous sections should serve to get you started, and the documentation for most of these tools is quite good.
Hadoop map/reduce, clojure-hadoop
Hadoop’s map/reduce framework is built on the Google map/reduce white paper. It’s a framework for writing data processing applications that can handle terabytes of input, on clusters consisting of thousands of machines. Jobs consist of map tasks and reduce tasks, and these roughly correspond to the concepts from the previous section. These tasks run in parallel on the cluster, and the framework takes care of scheduling them, monitoring them, and rescheduling them in the case of failures.
The Hadoop map/reduce framework and associated HDFS (which stands for Hadoop Distributed File System, similar in nature to the Google File System) serve as the basis for several other projects. For instance, we looked at HBase in the chapter on data storage. Although it’s true that Clojure’s Java Interop facilities make it easy to use Java libraries, using Hadoop map/reduce from Clojure can be less than straightforward. There are several open source projects that make this easier; in particular, clojure-hadoop (written by Stuart Sierra) is a usable wrapper.
Although simple wrappers are sufficient in many situations, some folks like to build higher abstractions on top of existing ones. We’ll discuss a couple of them in the next section.
Cascading, cascading-clojure
Cascading is a Java library that sits on top of Hadoop map/reduce. It offers up a way to avoid thinking in map/reduce terms; instead it provides an alternative way to construct distributed data processing workflows. The way to write applications using Cascading is to think about data processing as “pipe assemblies” where data flows through processor stages (or pipes) from a “source” to a “sink.” An assembly can have multiple stages that can transform data in ways that advance the computation.
Again, because it’s a Java library, it’s easy to use Cascading from within your Clojure programs. There are wrappers for Cascading that make programming with it closer to the Clojure style. One such library is cascading-clojure, written by Bradford Cross.
Whether you decide to directly use Cascading or use it via a wrapper, it may make sense to consider raw Hadoop map/reduce as low-level constructs that your application should stay above. Our last visit will be to a new but quite interesting project that sits even higher than Cascading.
Cascalog
Cascalog is a Clojure-based query language for Hadoop. It’s inspired by Datalog and shares some similarities with it, not the least is the syntax used to name variables in queries. Like Datalog, it’s a declarative language, letting users type out their queries almost from a SQL-like frame of mind. Under the covers, it figures out what data needs to be looked up, how it must be joined, and what map/reduce jobs are required.
It’s a relatively new project, but it’s worth considering for projects that require this sort of declarative (or interactive) querying of large data sets.
This part of the chapter was about map/reduce. We first looked at what it was, from a functional language point of view, and wrote simple code to understand it. We then wrote some log-parsing code on top of it in order to understand some simple use cases. We then touched on a few industry-grade distributed map/reduce projects out there that you can incorporate into your Clojure applications. In the next chapter, we’ll look at a different approach to processing data.
12.2. Master/slave parallelization
In this section, we’ll create our own little framework to handle batch-processing requirements. We’ll leverage our work from previous chapters in order to build it; specifically, we’ll use our remote workers from chapter 11. Our tool will allow us to specify the individual computation as a function and then to apply the function to a sequence of parameters. Because each worker is a remote server, we’ll then be able to start multiple instances (on multiple machines) in order to process large batches of input.
By itself, this isn’t too complicated, because we’ve already written all the code for it. We’ll add check pointing into the mix, so that if our program crashes, we’ll be able to recover. We’ll use Redis to store the status of the various jobs, and you already know how to talk to Redis. We’ll first create a construct that will describe the job and then some code to manage its status. We’ll then look at executing a job. Finally, we’ll look at handling errors and recovering from them.
Let’s get started writing this framework. The first thing you’ll need to do is to specify the parameters of the batch-processing run.
12.2.1. Defining the job
We’ll call a complete batch-processing run a job. A job may consist of multiple tasks, and the purpose of this little tool is to run large jobs. The benefit of using such a framework is that you can run large jobs on a cluster of machines where each machine could run one or more worker servers. As we mentioned earlier, we’ll be using Redis to store the status of a job run. We’ll want to give each job an identifier so you can distinguish between multiple running jobs. We’ll also want to identify each child task that will run as part of the job. We could use a random, unique identifier for this, but we’ll let the choice of such an id be influenced by the user of our framework.
Here’s a function that will serve to define a new job:
(defn new-job [job-id worker batch-size batch-wait-time id-generator]
{:tasks-atom (atom {})
:job-id job-id
:worker worker
:batch-size batch-size
:batch-wait-time batch-wait-time
:id-gen id-generator})
It creates a map containing a few self-explanatory keys. The value of :tasks-atom is an atom containing an empty map. We’ll use it to store tasks as they’re run. The value of :id-gen is the function used to create the identifier of each task. You’ll see all of these in action shortly.
12.2.2. Maintaining status
Now that we can create the representation of new tasks, we can think about running them. We know that in order to run, we’ll need a list of the arguments that need to be processed. Eventually, we’ll dispatch each argument (which could in turn be another list), and it will be processed by one of our remote workers. As part of the dispatch (and also execution on the worker side), we’ll also track the status of each task. We’ll create a key in Redis for each dispatched task, and we’ll make it a compound key containing both the job id and the task id. Here’s some code to create the key:
(def KEY-SEPARATOR "___") (defn managed-key [job-id task-id] (str job-id KEY-SEPARATOR task-id))
Now that you have a key for each task being dispatched, you can write a function to mark the status of a task. We’ll use the latest version of Redis (which at the time of this writing is 2.0.0 Release Candidate 2). This version of Redis supports the hash data type (similar to the lists and sets you saw in the chapter on data storage). Here’s how you can mark the status of a task:
(def STATUS-FIELD "status") (defn update-status-as [job-id task-id status] (redis/hset (managed-key job-id task-id) STATUS-FIELD status))
Note that we’re using the same redis-clojure library you used earlier. Because it’s advisable to group related code into a separate namespace, you could put all the status-related code into a new namespace. Further, instead of having to pass a value for status each time you call update-status-as, you can build a function on top of it that will more clearly express what you intend to do, for instance:
(def DISPATCHED "dispatched") (defn mark-dispatched [job-id task-id] (update-status-as job-id task-id DISPATCHED))
Now you have enough to get started with dispatching a job and a few functions for maintaining status of various tasks. Before writing them, let’s think through the transitions of statuses as tasks are dispatched and run. Clearly, you’ll start by dispatching a task; mark-dispatched can handle that situation. What happens next?
Let’s imagine that the worker will first mark the status as “initial processing started” or something like that. When it completes the processing, it will mark the task as “complete.” You also need to handle the situation where an error occurs, so you could have the worker mark the task as “being in an error state.” Finally, you’ll want to retry tasks that haven’t completed, so you might have a status called “recovery being attempted” and another called “second attempt in progress.” You’ll also create an “unknown” status in case something unexpected happens and you want to mark it explicitly (useful for debugging). So let’s first define the various statuses:
(def INITIAL "initial") (def COMPLETE "complete") (def ERROR "error") (def RECOVERY "recovery") (def SECONDARY "secondary") (def UNKNOWN "unknown")
These are in addition to the DISPATCHED status you already defined earlier. The next step is to write a few convenience functions to mark tasks appropriately:
(defn mark-error [job-id task-id] (update-status-as job-id task-id ERROR)) (defn mark-recovery [job-id task-id] (update-status-as job-id task-id RECOVERY))
Further, instead of defining functions to mark each status, you can define a sort of progression of status, as a sort of a status transition chain. Consider this:
(def next-status {
DISPATCHED INITIAL
INITIAL COMPLETE
RECOVERY SECONDARY
SECONDARY COMPLETE
"" UNKNOWN
nil UNKNOWN
UNKNOWN UNKNOWN
})
With this map, given the current status of a task, you can easily look up what the next status ought to be. You’ll use this to change statuses of the tasks as they run. The first thing you’ll need to do is to find the current status of a particular task. Here’s that function:
(defn status-of [job-id task-id] (redis/hget (managed-key job-id task-id) STATUS-FIELD))
With this function in hand, you can write a function to increment the status of a task based on our next-status map. Here it is:
(defn increment-status [job-id task-id]
(->> (status-of job-id task-id)
(next-status)
(update-status-as job-id task-id)))
Most of the status management functions are in place. Our next stop will be to write the code that will dispatch a job.
12.2.3. Dispatching a job
As we discussed, the first step of dispatching a task is to mark its status as dispatched. We wrote the code for that in the preceding section, so you’re now ready to jump right into making the call to your remote worker. You’ll break up your job run into batches of tasks, so you can avoid dispatching all the tasks immediately and flooding our workers with requests. Start with your top-level function to kick off the job:
(defn start-job [{:keys [batch-size] :as job} args-seq]
(let [args-batches (partition-all batch-size args-seq)]
(doseq [args-batch args-batches]
(run-batch job args-batch))))
It accepts a job map as constructed by our new-job function from earlier in the chapter. The only thing of interest at this level is batch-size, so you destructure that out of the job map while also retaining the complete map as job. You also accept an argsseq parameter that’s a sequence of sequences, each inner sequence being a set of arguments to the worker.
You break the args-seq into batches by calling partition-all, a function from clojure.contrib.seq-utils. partition-all that behaves in a manner similar to partition, but it gathers remaining elements of the sequence being partitioned into a final sequence. You then call run-batch over each partitioned batch of arguments. Here’s the definition of run-batch:
(defn run-batch [{:keys [id-gen tasks-atom batch-wait-time] :as job}
args-batch]
(doseq [args args-batch]
(run-task job (apply id-gen args) args mark-dispatched))
(wait-until-completion (map :proxy (vals @tasks-atom)) batch-wait-time))
This time you destructure id-generator and tasks-atom (along with batch-wait-time) out of the job map. You then iterate over args-batch (containing one batch-size worth of the args-seq) and fire off calls to run-task, one per set of arguments. Note also that you pass to run-task the function mark-dispatched that we wrote a while back. This marks the status of a task as having been dispatched. Before proceeding, you wait for the batch to complete for the duration as specified by batch-wait-time. The final piece, then, is run-task:
(defn run-task [{:keys [job-id worker tasks-atom]}
task-id args mark-status]
(mark-status job-id task-id)
(let [task-info {:args args
:proxy (apply worker [job-id task-id args])}]
(swap! tasks-atom assoc task-id task-info)))
run-task does the work of making the call to the worker. Note that the arguments passed to the worker aren’t args but a vector containing the job-id, the task-id, and the args. You do this so the worker also knows what task is being run. It will use this information to update the status of the task, and you’ll soon write a convenient macro that will help you write task-aware worker functions.
Note that you’re keeping track of the dispatched worker proxies inside our tasks-atom. Specifically, you don’t maintain only the tasks but also the arguments used to call the worker. You do this so you can retry the worker in case it doesn’t succeed. You’ll see this in action very shortly.
Now that you have the basics of dispatching jobs, let’s look at the worker side of the picture.
12.2.4. Defining the slave
So far, you’ve written code to track the status of tasks and to dispatch jobs. Our goal in this section is to create workers that can process tasks. Because we’re using the remote worker framework we created in the previous chapter, you can build on that. We’ll use a simple example to illustrate the point; keep in mind that worker functions are usually computationally intensive. Consider the following code:
(defn fact [n acc]
(if (= n 0)
acc
(recur (dec n) (* n acc))))
It’s a trivial way to compute the factorial of a given number, for instance:
user> (fact 5 1) 120 user> (fact 6 1) 720
Consider the situation where you have to calculate the factorial of each number in a large list of numbers. Using our framework, you can write a worker function similar to fact shown here and then use that to do the work in a distributed fashion. A task-processing function, as you saw, needs to be able to keep track of the status of the task executing in it. To facilitate this, this function needs to accept parameters for the jobid and the task-id.
This calls for a wrapper function, one that accepts a job-id, a task-id, and the parameters that will be used to delegate to the underlying function beneath. Here’s an implementation:
(defn slave-wrapper [worker-function]
(fn [job-id task-id worker-args]
(redis/with-server (redis-config)
(increment-status job-id task-id)
(try
(let [return (apply worker-function worker-args)]
(increment-status job-id task-id)
return)
(catch Exception e
(mark-error job-id task-id))))))
slave-wrapper accepts a regular function and returns a new function with the interface you need. Specifically, the new function accepts the job-id, task-id, and the original worker’s arguments (denoted here by worker-args). Remember that you were dispatching calls to the remote workers using this set of arguments in our run-task function earlier. The first thing this new wrapped function does is increment the status of the task it’s about to run. Then, it attempts to carry out the computation by calling the underlying function and passing it the worker-args. If that succeeds, it will increment the status of the task again and return the computed value. If the computation fails, it will mark the status of the task as “having encountered an error.”
The only other thing of interest here is the call to redis/with-server and the function redis-config. You saw this being used in the chapter on data storage, so this should be familiar to you. As you can imagine, redis-config returns a map containing the connection parameters for the redis server. For now, you can have it return the simple map as follows:
(defn redis-config []
{:host "localhost"})
In the real world, redis-config might return something read from a configuration file or something similar.
So you’re nearly there as far as defining your remote slaves is concerned. You have a function that can be used to create a task status–aware version of a regular function. You need to now convert functions created by slave-wrapper into a remote worker. Here’s a macro that makes it convenient:
(defmacro slave-worker [name args & body]
`(let [simple-function# (fn ~args (do ~@body))
slave-function# (slave-wrapper simple-function#)]
(defworker ~name [~'job-id ~'task-id ~'worker-args]
(slave-function# ~'job-id ~'task-id ~'worker-args))))
You’ve already seen defworker in the chapter on using messaging to scale out our Clojure programs. The slave-worker macro is a simple way to write our task status–aware remote workers. Here’s our factorial function from before:
(slave-worker factorial [n]
(let [f (fact n 1)]
(println "Calculated factorial of" n "value:" f)
f))
We’ve added some extra logging here so that you can see this in action on the console. All it does is call our fact function with the parameter n and the initial value of the accumulator set to 1. When called, it will calculate the factorial and then print the value to the standard and then return the computed result. We’re now ready to give it a shot.
12.2.5. Using the master-slave framework
We’ve written most of the happy path code. Let’s test it all out, so that you can be sure that things work so far. First, we’ll put together the worker side of things. Here’s the code:
(ns chapter-data.dist-fact
(:use chapter-data.master-core))
(defn fact [n acc]
(if (= n 0)
acc
(recur (dec n) (* n acc))))
(slave-worker factorial [n]
(let [f (fact n 1)]
(println "Calculated factorial of" n "value:" f)
f))
You’ve seen these two functions before; we’ve now put them in a single namespace called chapter-data.dist-fact, inside a file called dist_fact.clj. You’ll now load this in a sort of boot file, which you’ll use to kick-start your remote worker process. Here it is:
(ns chapter-data.boot-task-processor
(:use chapter14-rabbitmq-multicast
chapter14-worker-process-multicast
chapter-data.dist-fact))
(with-rabbit ["localhost" "guest" "guest"]
(start-handler-process))
This is straightforward and should be familiar from the previous chapter on messaging. When you run this script via the usual Clojure incantation, you get the following output:
Serving up 1 workers.
Remember that when your worker process starts up, it informs the user about the number of workers that it has available. At that point, it’s ready to begin accepting requests for remote worker computations.
Now, let’s try to run the factorial program. Consider the following code:
(ns chapter-data.dist-fact-client
(:use chapter-data.dist-fact
chapter-data.status
chapter14-worker-multicast
chapter14-rabbitmq-multicast))
(defn dispatch-factorial [job-id task-id n]
(redis/with-server (redis-config)
(mark-dispatched job-id task-id)
(factorial job-id task-id [n])))
(with-rabbit ["localhost" "guest" "guest"]
(let [f (dispatch-factorial "test-job" "test-task" 5)]
(from-swarm [f]
(println "Got the answer:" (f :value)))))
When you run this program, you get a simple confirmation that things have worked:
Got the answer: 120
Similarly, the remote worker server has some relevant output:
Processing: :factorial with args: [test-job test-task [5]] Calculated factorial of 5 value: 120
Finally, let’s see if the status of the task is as you expect it to be:
user=> (redis/with-server (redis-config)
(status-of "test-job" "test-task"))
"complete"
So far, so good. You’re now ready to test if a larger sequence of such calls can be made, say to calculate the factorials of a series of numbers. It’s exactly the reason we wrote this little framework, so let’s get to it!
12.2.6. Running a job
You’re ready to run our factorial function against a larger sequence of arguments. Remember that the sequence of arguments should be a nested one, because a function may take multiple arguments. In keeping with this, you’ll generate your arguments thusly:
user=> (map list (take 10 (iterate inc 1))) ((1) (2) (3) (4) (5) (6) (7) (8) (9) (10))
You’ll also add another functionality to the status namespace, which will let you check on the results of the job run. The following code does that:
(defn from-proxies [job proxy-command]
(->> @(:tasks-atom job)
(vals)
(map :proxy)
(map #(% proxy-command))))
(defn values-from [job]
(from-proxies job :value))
You’re now ready to define the job you want to execute. We’ve already written a function to do this, so you can use it:
(def fact-job (new-job "fact-job" factorial 5 10000 identity))
We’ve also written a function start-job to execute your jobs. The following program exercises it with our factorial function:
(ns chapter-data.dist-fact-client
(:use chapter-data.dist-fact
chapter-data.master-core
chapter-data.status
chapter14-worker-multicast
chapter14-rabbitmq-multicast))
(defn dispatch-factorial [job-id task-id n]
(redis/with-server (redis-config)
(mark-dispatched job-id task-id)
(factorial job-id task-id [n])))
(def fact-job (new-job "fact-job" factorial 5 10000 identity))
(with-rabbit ["localhost" "guest" "guest"]
(start-job fact-job (map list (take 10 (iterate inc 1))))
(println "Values:" (values-from fact-job)))
Let’s also start up two (or more!) worker processes, so that you can see the work distributed across more than one worker server. The output of this program is, again, easy to follow:
Values: (1 2 6 24 120 720 5040 40320 362880 3628800)
The output of our worker servers is as follows. First, the one:
Serving up 1 workers. Processing: :factorial with args: [fact-job 1 (1)] Processing: :factorial with args: [fact-job 3 (3)] Processing: :factorial with args: [fact-job 5 (5)] Calculated factorial of 5 value: 120 Calculated factorial of 1 value: 1 Calculated factorial of 3 value: 6 Processing: :factorial with args: [fact-job 7 (7)] Calculated factorial of 7 value: 5040 Processing: :factorial with args: [fact-job 9 (9)] Calculated factorial of 9 value: 362880
And now, the second:
Serving up 1 workers. Processing: :factorial with args: [fact-job 2 (2)] Processing: :factorial with args: [fact-job 4 (4)] Calculated factorial of 4 value: 24 Calculated factorial of 2 value: 2 Processing: :factorial with args: [fact-job 6 (6)] Calculated factorial of 6 value: 720 Processing: :factorial with args: [fact-job 8 (8)] Calculated factorial of 8 value: 40320 Processing: :factorial with args: [fact-job 10 (10)] Calculated factorial of 10 value: 3628800
Your output may vary depending on how many worker processes you have and on the speed of your computer. Try it with a larger sequence of arguments and more worker servers. Figure 12.4 shows the high-level conceptual view of this master/slave worker framework.
Figure 12.4. The master/slave work framework builds on the remote worker code written in the chapter on scaling out Clojure programs with RabbitMQ. A master accepts a sequence of input elements and farms out the processing of each to a bank of remote worker processes. Each task sent off this way is tracked in the Redis key/value store, and this status is updated by the master as well as by the workers.
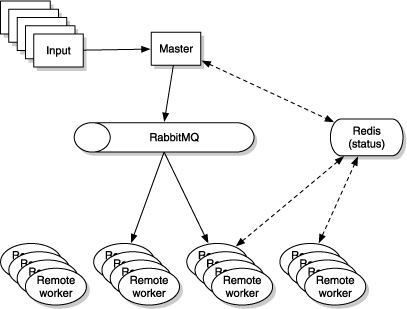
Now that the basics all work, we’re going to see about handling errors during job runs.
12.2.7. Seeing task errors
You’re now able to define and run jobs as shown in the previous section. So far, you haven’t taken any advantage of the status of the tasks that are created as the job runs. You’ll now see what happens when there’s an error, and then you’ll write some code to recover.
Before you get to that, let’s add to our status namespace by creating a couple of functions to check on our jobs. The first will be a function to let us check if all tasks belonging to a job are complete. You can build on top of the from-proxies function we wrote earlier to support values-from. Consider the following definition of job-complete?:
(defn job-complete? [job] (every? true? (from-proxies job :complete?)))
This function merely tells you if a task has completed running; you’ll also need a function to see if the tasks all completed successfully. Here’s the code:
(defn task-successful? [job-id task-id]
(= COMPLETE (status-of job-id task-id)))
(defn job-successful? [job]
(->> @(:tasks-atom job)
(keys)
(map (partial task-successful? (:job-id job)))
(every? true?)))
Remember that task-successful? (as with all other Redis-backed functions) needs to run inside Redis connection bindings. Next, in order to see how errors may manifest themselves in your job runs, let’s add some random errors to our factorial function. Here’s one way to do it:
(defn throw-exception-randomly []
(if (> 3 (rand-int 10))
(throw (RuntimeException. "Some error occured in fibonacci!"))))
(slave-worker factorial [n]
(throw-exception-randomly)
(let [f (fact n 1)]
(println "Calculated factorial of" n "value:" f)
f))
What we’ve done is made our factorial function throw an exception at random. The idea is that if you run it enough times, it will eventually succeed. You can use this to test your error-management code. Ensure that this code is in the dist-fact namespace as before.
Let’s add a convenience macro to our master-core namespace that will help you run your jobs:
(defmacro with-rabbit-redis [& body]
`(with-rabbit ["localhost" "guest" "guest"]
(redis/with-server (redis-config)
~@(do body))))
Let’s start by seeing how all this behaves. You’ll modify our chapter-data.dist-fact-client namespace to use our new code:
(ns chapter-data.dist-fact-client
(:use chapter-data.dist-fact
chapter-data.master-core
chapter-data.status
chapter14-worker-multicast
chapter14-rabbitmq-multicast))
(defn dispatch-factorial [job-id task-id n]
(redis/with-server (redis-config)
(mark-dispatched job-id task-id)
(factorial job-id task-id [n])))
(def fact-job (new-job "fact-job" factorial 5 10000 identity))
(with-rabbit-redis
(start-job fact-job (map list (take 10 (iterate inc 1))))
(println "Status:" (job-successful? fact-job))
(println "Values:" (values-from fact-job)))
Running this results in the following output:
Status: false Values: (false 2 6 24 120 720 5040 40320 362880 false)
This indicates that the success of the job was false, and that of the expected return values, the first and the last happened to throw the random exception. Let’s explore this some more, and to do that, you’ll run a job from the REPL. Consider this code:
user=> (with-rabbit-redis
(start-job fact-job (map list (take 10 (iterate inc 1))))
(println "Job success:" (job-successful? fact-job))
(println "Values:" (values-from fact-job))
(println "Tasks:" (task-statuses fact-job)))
The output, of which we’re particularly interested in the statuses of all our tasks, looks like this:
Job success: false
Values: (false 2 false false 120 720 5040 40320 362880 3628800)
Tasks: (error complete error error complete complete complete complete
complete complete)
As you can see, there are three tasks that have errors (you will probably see different results, thanks to the fact that our factorial function throws an exception at random). Your next job is to try to rerun those tasks that have errors. That’s the focus of the next section.
12.2.8. Rerunning the job
So we ran our job, and a few tasks failed. We simulated this with our random exception throwing factorial function. In the real world, for heavy tasks, this might signify things like a broken connection, an unavailable service, or something else. Either way, it may make sense to retry the failed tasks at least once.
In order to do this, you need to be able to rerun the job. There’s one more situation where you may want to do this, and that’s if for some reason your job run itself crashes, the program crashes while it’s dispatching tasks. It should be smart enough to not run tasks that have already been run before.
So let’s begin by writing a should-run? function whose job it is to figure out whether it should dispatch a task to your remote servers. You can put this in your chapter-data.status namespace:
(defn should-run? [job-id task-id]
(let [status (status-of job-id task-id)]
(or (nil? status)
(some #{status} [DISPATCHED RECOVERY INITIAL SECONDARY ERROR]))))
Now, in order to change the way tasks are dispatched, you only have to change the run-task function so that it uses our new should-run? function. Consider the changed version:
(defn run-task [{:keys [job-id worker tasks-atom]}
task-id args mark-status]
(println "Running task [" job-id task-id "]")
(when (should-run? job-id task-id)
(mark-status job-id task-id)
(let [task-info {:args args
:proxy (apply worker [job-id task-id args])}]
(swap! tasks-atom assoc task-id task-info))))
We’ve also added a println so that you can see the progress at the console. We’ll clear Redis and start a new job run:
user=> (with-rabbit-redis (redis/flushall)) "OK"
Let’s now create a new job that you’ll use to test job recovery:
user=> (def fact-job (new-job "fact-job" factorial 5 3000 identity)) #'user/fact-job
Let’s run it with a sample set of 10 arguments, as we’ve done so far:
user=> (with-rabbit-redis
(start-job fact-job (map list (take 10 (iterate inc 1)))))
Running task [ fact-job 1 ]
Running task [ fact-job 2 ]
Running task [ fact-job 3 ]
Running task [ fact-job 4 ]
Running task [ fact-job 5 ]
Running task [ fact-job 6 ]
Running task [ fact-job 7 ]
Running task [ fact-job 8 ]
Running task [ fact-job 9 ]
Running task [ fact-job 10 ]
nil
Now let’s check on the statuses of the tasks:
user=> (with-rabbit-redis
(doall (task-statuses fact-job)))
("error" "complete" "complete" "complete" "complete" "complete" "complete"
"error" "error" "complete")
It appears that three tasks have failed. By the way, if you got a “Not connected to Redis” error, you must remember to wrap your call to task-statuses in a doall, or else the lazy sequence of statuses will be realized outside the Redis connection binding.
Let’s now try this same job again, in order to see if the failed tasks complete this time:
user=> (with-rabbit-redis
(start-job fact-job (map list (take 10 (iterate inc 1)))))
Running task [ fact-job 1 ]
Running task [ fact-job 8 ]
Running task [ fact-job 9 ]
nil
Notice how it ran only the tasks that hadn’t been run before? Let’s see if they succeeded:
user=> (with-rabbit-redis (doall (task-statuses fact-job)))
("error" "complete" "complete" "complete" "complete" "complete" "complete"
"error" "complete" "complete")
One more task completed successfully, but there are still a couple in an error state. You can try this repeatedly until they all succeed:
user=> (with-rabbit-redis
(start-job fact-job (map list (take 10 (iterate inc 1)))))
Running task [ fact-job 1 ]
Running task [ fact-job 8 ]
nil
user=> (with-rabbit-redis (job-successful? fact-job))
true
This time, both tasks completed successfully, resulting in job-successful? returning true.
Notice that in order to rerun the job, you passed it the same sequence of arguments each time. You don’t have to do this; you could have found out what arguments needed to be rerun and passed only a sequence of those. Rerunning the entire job this way is useful when the program crashes and you want to start over. You could write another function that looks inside tasks-atom to see what to rerun. Here it is, suitable for the chapter-data.status namespace:
(defn incomplete-task-ids [{:keys [job-id tasks-atom]}]
(remove (partial task-successful? job-id) (keys @tasks-atom)))
This function, given a job that has been run already, will tell you what tasks need to be run again in order for the job to complete. You can use this in a function that will attempt this recovery:
(defn recover-job [{:keys [tasks-atom] :as job}]
(doseq [incomplete-id (incomplete-task-ids job)]
(let [args (get-in @tasks-atom [incomplete-id :args])]
(run-task job incomplete-id args mark-recovery))))
All this function does is iterate over each incomplete task id, get the arguments used from the previously attempted dispatch, and redispatch it. Note that this time, you pass the run-task function a different status-marker function, mark-recovery. Let’s look at it in action:
First, you define a new job:
user=> (def fact-job (new-job "fact-job" factorial 5 3000 identity)) #'user/fact-job
Here’s our first attempt:
user=> (with-rabbit-redis (start-job fact-job (map list (take 10 (iterate inc
1)))))
Running task [ fact-job 1 ]
Running task [ fact-job 2 ]
Running task [ fact-job 3 ]
Running task [ fact-job 4 ]
Running task [ fact-job 5 ]
Running task [ fact-job 6 ]
Running task [ fact-job 7 ]
Running task [ fact-job 8 ]
Running task [ fact-job 9 ]
Running task [ fact-job 10 ]
nil
You’ve seen this before; here’s the current set of statuses:
user=> (with-rabbit-redis (doall (task-statuses fact-job)))
("complete" "complete" "complete" "complete" "error" "complete" "complete"
"error" "complete" "error")
Here are the tasks that are still incomplete:
user=> (with-rabbit-redis (doall (incomplete-task-ids fact-job))) (5 8 10)
Attempting to recover:
user=> (with-rabbit-redis (recover-job fact-job)) Running task [ fact-job 5 ] Running task [ fact-job 8 ] Running task [ fact-job 10 ] nil
As you can see, only incomplete tasks were fired off. If you check the statuses of the tasks now, you can hope to see some progress:
user=> (with-rabbit-redis (doall (task-statuses fact-job)))
("complete" "complete" "complete" "complete" "error" "complete" "complete"
"complete" "complete" "complete")
Only one task remains incomplete. You can try it again:
user=> (with-rabbit-redis (recover-job fact-job)) Running task [ fact-job 5 ]
And finally:
user=> (with-rabbit-redis (doall (task-statuses fact-job)))
("complete" "complete" "complete" "complete" "complete" "complete"
"complete" "complete" "complete" "complete")
You ran recover-job multiple times because you could be certain our factorial function would eventually succeed. This may not be the case in a real-world application, so you’d need to make a decision on how many retries are worth doing and what to do after the final failure.
Note also that the main advantage of using recover-job is that it doesn’t need to be supplied the arguments sequence again, because it already has the arguments for each task. This may be useful if it’s expensive to obtain the arguments. It may also be a memory problem if the arguments sequence is extremely large, so it may make sense to have such argument caching as an optional operation.
Listing 12.8 shows the complete code that handles the definition and dispatch of batch jobs. It’s followed by listing 12.9, which shows the complete code that handles the status of a job.
Listing 12.8. The core namespace for our master/slave batch-processing framework
ns chapter-data.master-core
(:use chapter14-rabbitmq-multicast
chapter14-worker-multicast
chapter-data.status
clojure.contrib.seq-utils)
(:require redis))
(defn new-job [job-id worker batch-size batch-wait-time id-generator]
{:tasks-atom (atom {})
:job-id job-id
:worker worker
:batch-size batch-size
:batch-wait-time batch-wait-time
:id-gen id-generator})
(defn run-task [{:keys [job-id worker tasks-atom]}
task-id args mark-status]
(when (should-run? job-id task-id)
(println "Running task [" job-id task-id "]")
(mark-status job-id task-id)
(let [task-info {:args args
:proxy (apply worker [job-id task-id args])}]
(swap! tasks-atom assoc task-id task-info))))
(defn run-batch [{:keys [id-gen tasks-atom batch-wait-time] :as job}
args-batch]
(doseq [args args-batch]
(run-task job (apply id-gen args) args mark-dispatched))
(wait-until-completion (map :proxy (vals @tasks-atom)) batch-wait-time))
(defn start-job [{:keys [batch-size] :as job} args-seq]
(redis/with-server (redis-config)
(let [args-batches (partition-all batch-size args-seq)]
(doseq [args-batch args-batches]
(run-batch job args-batch)))))
(defn recover-job [{:keys [tasks-atom] :as job}]
(doseq [incomplete-id (incomplete-task-ids job)]
(let [args (get-in @tasks-atom [incomplete-id :args])]
(run-task job incomplete-id args mark-recovery))))
(defn slave-wrapper [worker-function]
(fn [job-id task-id worker-args]
(redis/with-server (redis-config)
(increment-status job-id task-id)
(try
(let [return (apply worker-function worker-args)]
(increment-status job-id task-id)
return)
(catch Exception e
(mark-error job-id task-id))))))
(defmacro slave-worker [name args & body]
`(let [simple-function# (fn ~args (do ~@body))
slave-function# (slave-wrapper simple-function#)]
(defworker ~name [~'job-id ~'task-id ~'worker-args]
(slave-function# ~'job-id ~'task-id ~'worker-args))))
(defmacro with-rabbit-redis [& body]
`(with-rabbit ["localhost" "guest" "guest"]
(redis/with-server (redis-config)
~@(do body))))
Listing 12.9. The status namespace for our master/slave batch-processing framework
(ns chapter-data.status
(:require redis))
(def KEY-SEPARATOR "___")
(def STATUS-FIELD "status")
(def DISPATCHED "dispatched")
(def INITIAL "initial")
(def COMPLETE "complete")
(def ERROR "error")
(def RECOVERY "recovery")
(def SECONDARY "secondary")
(def UNKNOWN "unknown")
(def next-status {
DISPATCHED INITIAL
INITIAL COMPLETE
RECOVERY SECONDARY
SECONDARY COMPLETE
"" UNKNOWN
nil UNKNOWN
UNKNOWN UNKNOWN
})
(defn redis-config []
{:host "localhost"})
(defn managed-key [job-id task-id]
(str job-id KEY-SEPARATOR task-id))
(defn status-of [job-id task-id]
(redis/hget (managed-key job-id task-id) STATUS-FIELD))
(defn update-status-as [job-id task-id status]
(redis/hset (managed-key job-id task-id) STATUS-FIELD status))
(defn mark-dispatched [job-id task-id]
(update-status-as job-id task-id DISPATCHED))
(defn mark-error [job-id task-id]
(update-status-as job-id task-id ERROR))
(defn mark-recovery [job-id task-id]
(update-status-as job-id task-id RECOVERY))
(defn increment-status [job-id task-id]
(->> (status-of job-id task-id)
(next-status)
(update-status-as job-id task-id)))
(defn task-successful? [job-id task-id]
(= COMPLETE (status-of job-id task-id)))
(defn job-successful? [job]
(->> @(:tasks-atom job)
(keys)
(map (partial task-successful? (:job-id job)))
(every? true?)))
(defn from-proxies [job proxy-command]
(->> @(:tasks-atom job)
(vals)
(map :proxy)
(map #(% proxy-command))))
(defn values-from [job]
(from-proxies job :value))
(defn job-complete? [job]
(every? true? (from-proxies job :complete?)))
(defn task-statuses [{:keys [job-id tasks-atom]}]
(->> @tasks-atom
(keys)
(map #(status-of job-id %))))
(defn should-run? [job-id task-id]
(let [status (status-of job-id task-id)]
(or (nil? status)
(some #{status} [DISPATCHED RECOVERY INITIAL SECONDARY ERROR]))))
(defn incomplete-task-ids [{:keys [job-id tasks-atom]}]
(remove (partial task-successful? job-id) (keys @tasks-atom)))
You’ve implemented a fair bit of functionality for our little master/slave worker framework. The complete code is shown in listings 12.1 and 12.2, which shows the code for the core and status namespaces respectively. The code doesn’t do everything that a robust, production-ready framework might do, but it shows a possible approach.
12.3. Summary
In this chapter, we’ve looked at a few different ways to process data. Each application that you’ll end up writing will need a different model based on the specifics of the domain. Clojure is flexible enough to solve the most demanding problems, and the functional style helps by reducing the amount of code needed while also increasing the readability of the code. And in the case where rolling your own data-processing framework isn’t the best course, there are plenty of Java solutions that can be wrapped with a thin layer of Clojure.