
Chapter 18. Security Activities Across the Technology Life Cycle
This chapter covers the following topics:
Systems Development Life Cycle: This section covers requirements, acquisition, testing and evaluation, commissioning/decommissioning, operational activities, asset disposal, and asset/object reuse.
Software Development Life Cycle: This section describes application security frameworks, software assurance, development approaches, DevOps, secure coding standards, documentation, and validation and acceptance testing.
Adapt Solutions: This section covers emerging threats, disruptive technologies, and security trends.
Asset Management (Inventory Control): Topics include asset management, inventory control, and associated concepts.
This chapter covers CAS-003 objective 5.2
When managing the security of an enterprise, security practitioners must be mindful of security across the entire technology life cycle. As the enterprise changes and new devices and technologies are introduced, maintained, and retired, security practitioners must ensure that the appropriate security controls are deployed. Providing security across the technology life cycle includes understanding both the systems development life cycle and the software development life cycle; adapting solutions to address emerging threats, disruptive technologies, and security trends; and asset management.
Systems Development Life Cycle
When an organization defines new functionality that must be provided either to its customers or internally, it must create systems to deliver that functionality. Many decisions have to be made, and a logical process should be followed in making those decisions. This process is called the systems development life cycle (SDLC). Rather than being a haphazard approach, the SDLC provides clear and logical steps to follow to ensure that the system that emerges at the end of the development process provides the intended functionality with an acceptable level of security.

The steps in the SDLC are as follows:
Step 1. Initiate
Step 2. Acquire/develop
Step 3. Implement
Step 4. Operate/maintain
Step 5. Dispose
In the initiation phase, the realization is made that a new feature or functionality is desired or required in the enterprise. This new feature might constitute an upgrade to an existing asset or the purchase or development of a new asset. In either case, the initiation phase includes making a decision about whether to purchase the product or develop it internally.
In this stage, an organization must also give thought to the security requirements of the solution. A preliminary risk assessment can detail the confidentiality integrity availability (CIA) requirement and concerns. Identifying these issues at the outset is important so that these considerations can guide the purchase or development of the solution. The earlier in the SDLC the security requirements are identified, the more likely the issues are to be successfully addressed in the final product.
In the acquisition stage of the SDLC, a series of activities provide input to facilitate making a decision about acquiring or developing the solution. The organization then makes a decision on the solution. The activities are designed to get answers to the following questions:
What functions does the system need to perform?
What potential risks to CIA are exposed by the solution?
What protection levels must be provided to satisfy legal and regulatory requirements?
What tests are required to ensure that security concerns have been mitigated?
How do various third-party solutions address these concerns?
How do the security controls required by the solution affect other parts of the company security policy?
What metrics will be used to evaluate the success of the security controls?
The answers to these questions should guide the questions during the acquisition step as well as the steps that follow this stage of the SDLC.
In the implementation stage, senior management formally approves the system before it goes live. Then the solution is introduced to the live environment, which is the operation/maintenance stage—but not until the organization has completed both certification and accreditation. Certification is the process of technically verifying the solution’s effectiveness and security. The accreditation process involves a formal authorization to introduce the solution into the production environment by management. It is during this stage that the security administrator would train all users on how to protect company information when using the new system and on how to recognize social engineering attacks.
The process doesn’t end right when the system begins operating in the environment. Doing a performance baseline is important so that continuous monitoring can take place. The baseline ensures that performance issues can be quickly determined. Any changes over time (for example, addition of new features, patches to the solution, and so on) should be closely monitored with respect to the effects on the baseline.
Instituting a formal change management process, as discussed in the “Configuration and Change Management” section, later in this chapter, ensures that all changes are both approved and documented. Because any changes can affect both security and performance, special attention should be given to monitoring the solution after any changes are made.
Finally, vulnerability assessments and penetration testing after the solution is implemented can help discover any security or performance problems that might either be introduced by a change or arise as a result of a new threat.
The disposal stage consists of removing the solution from the environment when it reaches the end of its usefulness. When this occurs, an organization must consider certain issues, including:
Does removal or replacement of the solution introduce any security holes in the network?
How can the system be terminated in an orderly fashion so as not to disrupt business continuity?
How should any residual data left on any systems be removed?
How should any physical systems that were part of the solution be disposed of safely?
Are there any legal or regulatory issues that would guide the destruction of data?
For the CASP exam, you need to understand how to cover the SDLC from end to end. For example, suppose a company wants to boost profits by implementing cost savings on non-core business activities. The IT manager seeks approval for the corporate email system to be hosted in the cloud. The compliance officer must ensure that data life cycle issues are taken into account. The data life cycle end-to-end in this situation would be data provisioning, data processing, data in transit, data at rest, and deprovisioning.
Requirements
In the acquisition stage of the SDLC, one of the activities that occurs is the definition of system requirements. The value of this process is to ensure that the system will be capable of performing all desired functions and that no resources will be wasted on additional functionality. It is also during this step that security requirements are identified, driven by the required functionality and the anticipated sensitivity of the data to be processed by the system. These requirements must be identified early and built into the system architecture.
Acquisition
In many cases, a system may be acquired rather than developed, or some part of a proposed system may need to be acquired. When this is the case, security professionals must be involved in defining the security requirements for the equipment to be acquired prior to issuing any requests for proposal (RFPs).
Test and Evaluation
In the test and evaluation phase, several types of testing should occur, including ways to identify both functional errors and security issues. The auditing method that assesses the extent of the system testing and identifies specific program logic that has not been tested is called the test data method. This method tests not only expected or valid input but also invalid and unexpected values to assess the behavior of the software in both instances. An active attempt should be made to attack the software, including attempts at buffer overflows and denial of service (DoS) attacks.
Commissioning/Decommissioning
Commissioning an asset is the process of implementing the asset in an enterprise, and decommissioning an asset is the process of retiring an asset from use in an enterprise. When an asset is placed into production, the appropriate security controls should be deployed to protect the asset. These security controls may be implemented at the asset itself or on another asset within the enterprise, such as a firewall or router. When an asset is decommissioned, it is important that the data that is stored on the asset still be protected. Sometimes an asset is decommissioned temporarily, and sometimes the decommissioning is permanent. No matter which is the case, it is important that the appropriate asset disposal and asset reuse policies be followed to ensure that the organization’s confidentiality, integrity, and availability are ensured. In most cases, you need to back up all the data on a decommissioned asset and ensure that the data is completely removed from the asset prior to disposal. These policies should be periodically reviewed and updated as needed, especially when new assets or asset types are added to the enterprise.
Let’s look at an example. Suppose an information security officer (ISO) asks a security team to randomly retrieve discarded computers from the warehouse trash bin. The security team retrieves two older computers and a broken multifunction network printer. The security team connects the hard drives from the two computers and the network printer to a computer equipped with forensic tools. They retrieve PDF files from the network printer hard drive but are unable to access the data on the two older hard drives. As a result of this finding, the warehouse management should update the hardware decommissioning procedures to remediate the security issue.
Let’s look at another example. Say that a new vendor product has been acquired to replace a legacy product. Significant time constraints exist due to the existing solution nearing end-of-life with no options for extended support. For this project, it has been emphasized that only essential activities be performed. To balance the security posture and the time constraints, you should test the new solution, migrate to the new solution, and decommission the old solution.
Operational Activities
Operational activities are activities that are carried out on a daily basis when using a device or technology. Security controls must be in place to protect all operational activities and should be tested regularly to ensure that they are still providing protection. While operational activities include day-to-day activities, they also include adding new functionality, new applications, or completely new systems to the infrastructure. Any new introduction of any type will introduce risks to the enterprise. Therefore, it is imperative that security practitioners complete a risk analysis and deploy the needed security controls to mitigate risks.
Introduction of functionality, an application, or a system can affect an organization’s security policy. For example, an organization may have a policy in place that prevents the use of any wireless technology at the enterprise level. If a new device or technology requires wireless access, the organization will need to revisit the security policy to allow wireless access. However, the organization must ensure that the appropriate security controls are implemented when wireless access is added to the enterprise. Performing a security impact analysis involves examining the impact of the new functionality, application, or system on the organization’s confidentiality, integrity, and availability. Threats, vulnerabilities, and risks are covered in greater detail in Chapter 3, “Risk Mitigation Strategies and Controls.”
Finally, as mentioned many other times throughout this book, security awareness and training are vital to ensure that day-to-day operational activities are carried out in a secure manner. Security awareness and training should be updated as new issues arise. Employees should attend this training at initial employment and at least once a year thereafter.
Monitoring
Once a system is operational, it should be monitored for both security and performance issues. Taking a performance baseline is important so that continuous monitoring can take place. The baseline ensures that performance issues can be quickly determined. Any changes over time (for example, addition of new features, patches to the solution, and so on) should be closely monitored with respect to the effects on the baseline. In many cases, significant changes may require the creation of a new baseline as the old baseline may no longer be representative of what is now the status quo.
Instituting a formal change management process ensures that all changes are both approved and documented. Because any changes can affect both security and performance, special attention should be given to monitoring the solution after any changes.
Finally, vulnerability assessments and penetration testing after the solution is implemented can help discover any security or performance problems that might either be introduced by a change or arise as a result of a new threat.
Maintenance
Maintenance involves ensuring that systems are kept up-to-date with patches, hot fixes, security updates, and service packs. Any updates should be tested in a lab environment before being introduced into production. When maintenance occurs, it is always necessary to reassess the security controls in place and to implement any new controls as risks are identified. Maintenance occurs for both hardware and software, and both of these assets are equally important in a maintenance plan. A device or an application not being used as much as others does not exempt it from getting timely updates.
Updating hardware and software can often have unanticipated consequences. A new application update may cause false positives on the enterprise firewall because the application communicates in a new manner. Simply ignoring a false positive (or disabling the alert) is not adequate. Security practitioners should research issues such as this to determine the best way to address the problem.
Another consequence could be that an update causes issues that cannot be resolved at the time of deployment. In such a case, it may be necessary to temporarily roll back the hardware or software to its previous state. However, it is important that the update not be forgotten. A plan should be implemented to ensure that the update is applied as quickly as possible. It may be necessary to allocate personnel to ensure that the issue is researched so that the update can be redeployed.
Let’s look at a maintenance example and its effects on security. Say that after a system update causes significant downtime, the chief information security officer (CISO) asks the IT manager who was responsible for the update. The IT manager responds that five different people have administrative access to the system, so it is impossible to determine the responsible party. To increase accountability in order to prevent this situation from reoccurring, the IT manager should implement an enforceable change management system and enable user-level auditing on all servers.
Any maintenance program should include documenting all maintenance activities, including the personnel who completed the maintenance, the type of maintenance that occurred, the result of the maintenance, and any issues that arose, along with the issue resolution notes. This documentation will provide guidance in the future.
Configuration and Change Management
Technology evolves, grows, and changes over time. Examples of changes that can occur include:
Operating system configuration
Software configuration
Hardware configuration
Companies and their processes also evolve and change, which is a good thing. But change should be managed in a structured way so as to maintain a common sense of purpose about the changes. By following recommended steps in a formal process, change can be prevented from becoming a problem. For guidelines to include as a part of any change control policy, see Chapter 5, “Network and Security Components, Concepts, and Architectures.”
For the CASP exam, you need to keep in mind that change management works with configuration management to ensure that changes to assets do not unintentionally diminish security. Because of this, all changes must be documented, and all network diagrams, both logical and physical, must be updated constantly and consistently to accurately reflect each asset’s configuration now and not as it was two years ago. Verifying that all change management policies are being followed should be an ongoing process.
Let’s look at an example. Suppose that a company deploys more than 15,000 client computers and 1,500 server computers. The security administrator is receiving numerous alerts from the IDS of a possible infection spreading through the network via the Windows file sharing service. The security engineer believes that the best course of action is to block the file sharing service across the organization by placing access control lists (ACLs) on the internal routers. The organization should call an emergency change management meeting to ensure that the ACLs will not impact core business functions.
In many cases, it is beneficial to form a change control board. The tasks of the change control board can include:
Ensuring that changes made are approved, tested, documented, and implemented correctly
Meeting periodically to discuss change status accounting reports
Maintaining responsibility for ensuring that changes made do not jeopardize the soundness of the verification system
Although it’s really a subset of change management, configuration management specifically focuses on bringing order out of the chaos that can occur when multiple engineers and technicians have administrative access to the computers and devices that make the network function. It follows the same basic change management process discussed in Chapter 5 but perhaps takes on even greater importance, considering the impact that conflicting changes can have (in some cases immediately) on the network.
Configuration management includes the following functions:
Report the status of change processing.
Document the functional and physical characteristics of each configuration item.
Perform information capture and version control.
Control changes to the configuration items and issue versions of configuration items from the software library.
Note
In the context of configuration management, a software library is a controlled area accessible only to approved users who are restricted to the use of an approved procedure. A configuration item (CI) is a uniquely identifiable subset of the system that represents the smallest portion to be subject to an independent configuration control procedure. When an operation is broken into individual CIs, the process is called configuration identification.
The biggest contribution of configuration management controls is ensuring that changes to the system do not unintentionally diminish security.
Asset Disposal
Asset disposal occurs when an organization has decided that an asset will no longer be used. During asset disposal, the organization must ensure that no data remains on the asset. The most reliable, secure means of removing data from magnetic storage media, such as a magnetic hard drive, is through degaussing, which involves exposing the media to a powerful alternating magnetic field. Degaussing removes any previously written data, leaving the media in a magnetically randomized (blank) state. For other disposal terms and concepts with which you should be familiar, see Chapter 8, “Software Vulnerability Security Controls.”
Functional hard drives should be overwritten three times prior to disposal or reuse, according to Department of Defense (DoD) Instruction 5220.22. Modern hard disks can defy conventional forensic recovery after a single wiping pass, based on NIST Special Publication (SP) 800-88.
Keep in mind that encrypting the data on a hard drive will make the data irretrievable without the encryption key, provided that the encryption method used has not been broken. For all media types, this is the best method for protecting data.
For example, suppose a company plans to donate 1,000 used computers to a local school. The company has a large research and development department, and some of the computers were previously used to store proprietary research data. The security administrator should be concerned about data remnants on the donated machines. If the company does not have a device sanitization section in its data handling policy, the best course of action for the security administrator to take would be to delay the donation until all storage media on the computers can be sanitized.
An organization should also ensure that an asset is disposed of in a responsible manner that complies with local, state, and federal laws and regulations.
Asset/Object Reuse
When an organization decides to reuse an asset, a thorough analysis of the asset’s original use and new use should be made and understood. If the asset will be used in a similar manner, it may only be necessary to remove or disable unneeded applications or services. However, it may be necessary to return the asset to its original factory configuration. If the asset contains a hard drive or other storage medium, the media should be thoroughly cleared of all data, especially if it contains sensitive, private, or confidential data.
Software Development Life Cycle
The software development life cycle can be seen as a subset of the systems development life cycle in that any system under development could (but does not necessarily) include the development of software to support the solution. The goal of the software development life cycle is to provide a predictable framework of procedures designed to identify all requirements with regard to functionality, cost, reliability, and delivery schedule and ensure that each is met in the final solution. This section breaks down the steps in the software development life cycle and describes how each step contributes to this ultimate goal. Keep in mind that steps in the software development life cycle can vary based on the provider, and this is but one popular example.
The following sections flesh out the software development life cycle steps in detail:
Step 1. Plan/initiate project
Step 2. Gather requirements
Step 3. Design
Step 4. Develop
Step 5. Test/validate
Step 6. Release/maintain
Step 7. Certify/accredit
Step 8. Change management and configuration management/replacement
Plan/Initiate Project
In the plan/initiate phase of the software development life cycle, the organization decides to initiate a new software development project and formally plans the project. Security professionals should be involved in this phase to determine if information involved in the project requires protection and if the application needs to be safeguarded separately from the data it processes. Security professionals need to analyze the expected results of the new application to determine if the resultant data has a higher value to the organization and, therefore, requires higher protection.
Any information that is handled by the application needs a value assigned by its owner, and any special regulatory or compliance requirements need to be documented. For example, healthcare information is regulated by several federal laws and must be protected. The classification of all input and output data of the application needs to be documented, and the appropriate application controls should be documented to ensure that the input and output data are protected.
Data transmission must also be analyzed to determine the types of networks used. All data sources must be analyzed as well. Finally, the effect of the application on organizational operations and culture needs to be analyzed.
Gather Requirements
In the gather requirements phase of the software development life cycle, both the functionality and the security requirements of the solution are identified. These requirements could be derived from a variety of sources, such as evaluating competitor products for a commercial product or surveying the needs of users for an internal solution. In some cases, these requirements could come from a direct request from a current customer.
From a security perspective, an organization must identify potential vulnerabilities and threats. When this assessment is performed, the intended purpose of the software and the expected environment must be considered. Moreover, the sensitivity of the data that will be generated or handled by the solution must be assessed. Assigning a privacy impact rating to the data to help guide measures intended to protect the data from exposure might be useful.
Design
In the design phase of the software development life cycle, an organization develops a detailed description of how the software will satisfy all functional and security goals. It involves mapping the internal behavior and operations of the software to specific requirements to identify any requirements that have not been met prior to implementation and testing.
During this process, the state of the application is determined in every phase of its activities. The state of the application refers to its functional and security posture during each operation it performs. Therefore, all possible operations must be identified to ensure that the software never enters an insecure state or acts in an unpredictable way.
Identifying the attack surface is also a part of this analysis. The attack surface describes what is available to be leveraged by an attacker. The amount of attack surface might change at various states of the application, but at no time should the attack surface provided violate the security needs identified in the gather requirements stage.
Develop
The develop phase is where the code or instructions that make the software work is written. The emphasis of this phase is strict adherence to secure coding practices. Some models that can help promote secure coding are covered later in this chapter, in the section “Application Security Frameworks.”
Many security issues with software are created through insecure coding practices, such as lack of input validation or data type checks. Security professionals must identify these issues in a code review that attempts to assume all possible attack scenarios and their impacts on the code. Not identifying these issues can lead to attacks such as buffer overflows and injection and to other error conditions.
Test/Validate
In the test/validate phase, several types of testing should occur, including identifying both functional errors and security issues. The auditing method that assesses the extent of the system testing and identifies specific program logic that has not been tested is called the test data method. This method tests not only expected or valid input but also invalid and unexpected values to assess the behavior of the software in both instances. An active attempt should be made to attack the software, including attempts at buffer overflows and denial-of-service (DoS) attacks. Some types of testing performed at this time are:
Verification testing: Determines whether the original design specifications have been met
Validation testing: Takes a higher-level view and determines whether the original purpose of the software has been achieved
Release/Maintain
The release/maintenance phase includes the implementation of the software into the live environment and the continued monitoring of its operation. At this point, as the software begins to interface with other elements of the network, finding additional functional and security problems is not unusual.
In many cases vulnerabilities are discovered in the live environments for which no current fix or patch exists. This is referred to as a zero-day vulnerability. Ideally, the supporting development staff should discover such vulnerabilities before those looking to exploit them do.
Certify/Accredit
Certification is the process of evaluating software for its security effectiveness with regard to the customer’s needs. Ratings can certainly be an input to this but are not the only consideration. Accreditation is the formal acceptance of the adequacy of a system’s overall security by management. Provisional accreditation is given for a specific amount of time and lists applications, system, or accreditation documentation required changes. Full accreditation grants accreditation without any required changes. Provisional accreditation becomes full accreditation once all the changes are completed, analyzed, and approved by the certifying body.
While certification and accreditation are related, they are not considered to be two steps in a process.
Change Management and Configuration Management/Replacement
After a solution is deployed in the live environment, additional changes will inevitably need to be made to the software due to security issues. In some cases, the software might be altered to enhance or increase its functionality. In any case, changes must be handled through a formal change and configuration management process.
The purpose of this process is to ensure that all changes to the configuration of and to the source code itself are approved by the proper personnel and are implemented in a safe and logical manner. This process should always ensure continued functionality in the live environment, and changes should be documented fully, including all changes to hardware and software.
In some cases, it may be necessary to completely replace applications or systems. While some failures may be fixed with enhancements or changes, a failure may occur that can only be solved by completely replacing the application.
Application Security Frameworks
In an attempt to bring some consistency to application security, various frameworks have been created to guide the secure development of applications. The use of these tools and frameworks can remove much of the tedium involved in secure coding. Suggestions and guidelines are covered further in this chapter.
Software Assurance
Regardless of whether software has been developed in-house or acquired commercially, security professionals must ensure that there is an acceptable assurance level that the software is not only functional but provides an acceptable level of security. There are two ways to approach this: audit the program’s actions and determine whether it performs any insecure actions or assess it through a formal process. This section covers the two formal approaches.
Auditing and Logging
An approach and a practice that should continue after software has been introduced to the environment is continual auditing of its actions and regular review of the audit data. By monitoring the audit logs, security weaknesses that might not have been apparent in the beginning or that might have gone unreported until now can be identified. In addition, any changes that are made will be recorded by the audit log and then can be checked to ensure that no security issues were introduced with the change.
Risk Analysis and Mitigation
Because risk management is an ongoing process, it must also be incorporated as part of any software development. Risk analysis determines the risks that can occur, while risk mitigation takes steps to reduce the effects of the identified risks. Security professionals should ensure that the software development risk analysis and mitigation strategy follow these guidelines:
Integrate risk analysis and mitigation in the software development life cycle.
Use qualitative, quantitative, and hybrid risk analysis approaches based on standardized risk analysis methods.
Track and manage weaknesses that are discovered throughout risk assessment, change management, and continuous monitoring.
Because software often contains vulnerabilities that are not discovered until the software is operational, security professionals should ensure that a patch management process is documented and implemented when necessary to provide risk mitigation. This includes using a change control process, testing any patches, keeping a working backup, scheduling production downtime, and establishing a back-out plan. Prior to deploying any patches, help desk personnel and key user groups should be notified. When patches are deployed, the least critical computers and devices should receive the patches first, moving up through the hierarchy until the most critical computers and devices are patched.
Once mitigations are deployed, the mitigations must be tested and verified, usually as part of quality assurance and testing. Any risk mitigation that has been completed must be verified by an independent party that is not the developer or system owner. Developers should be encouraged to use code signing to ensure code integrity, to determine who developed code, and to determine the purpose of the code. Code-signing certificates are digital certificates which ensure that code has not been changed. By signing code, organizations can determine if the code has been modified by an entity other than the signer. Code signing primarily covers running code, not stored code. While code signing verifies code integrity, it cannot guarantee freedom from security vulnerabilities or that an app will not load unsafe or unaltered code during execution.
Regression and Acceptance Testing
Any changes or additions to software must undergo regression and acceptance testing. Regression testing verifies that the software behaves the way it should. Regression testing catches bugs that may have been accidentally introduced into the new build or release candidate. Acceptance testing verifies if the software is doing what the end user expects it to do. Acceptance testing is more formal in nature and actually tests the functionality for the users based on a user story.
Security Impact of Acquired Software
Organizations often purchase commercial software or contract with other organizations to develop customized software. Security professionals should ensure that the organization understands the security impact of any acquired software.
The process of acquiring software has the following four phases:
Planning: During this phase, the organization performs a needs assessment, develops the software requirements, creates the acquisition strategy, and develops evaluation criteria and plan.
Contracting: Once planning is completed, the organization creates an RFP or other supplier solicitation forms, evaluates the supplier proposals, and negotiates the final contract with the selected seller.
Monitoring and accepting: After a contract is in place, the organization establishes the contract work schedule, implements change control procedures, and reviews and accepts the software deliverables.
Follow-on: When the software is in place, the organization must sustain the software, including managing risks and changes. At some point, it may be necessary for the organization to decommission the software.
Security professionals should be involved in the software assurance process. This process ensures that unintentional errors, malicious code, information theft, and unauthorized product changes or inserted agents are detected.
Standard Libraries
Standard libraries contain common objects and functions used by a language that developers can access and reuse without re-creating them. They can therefore reduce development time. From a security standpoint, a library used by a development team should be fully vetted to ensure that all of its contents are securely written. For example, the standard C library is filled with a handful of very dangerous functions that, if used improperly, could actually facilitate a buffer overflow attack. If you implement an application security framework when using a programming language and its library, the library can be used without fear of introducing security problems to the application. The components that should be provided by an application security library are:
Input validation
Secure logging
Encryption and decryption
Industry-Accepted Approaches
To support the goal of ensuring that software is soundly developed with regard to both functionality and security, a number of organizations have attempted to assemble software development best practices. The following sections look at some of those organizations and their most important recommendations.
WASC
The Web Application Security Consortium (WASC) is an organization that provides best practices for web-based applications, along with a variety of resources, tools, and information that organizations can use in developing web applications.
WASC continually monitors attacks and has developed a list of top attack methods in use. This list can aid in ensuring that an organization is aware of the latest attack methods and how widespread they are. It can also assist an organization in making the proper changes to its web applications to mitigate these attack types.
OWASP
The Open Web Application Security Project (OWASP) is another group that monitors attacks, specifically web attacks. OWASP maintains a list of the top 10 attacks on an ongoing basis. This group also holds regular meetings at chapters throughout the world, providing resources and tools including testing procedures, code review steps, and development guidelines.
BSI
The U.S. Department of Homeland Security (DHS) has gotten involved in promoting software security best practices. The Build Security In (BSI) initiative promotes a process-agnostic approach that makes security recommendations with regard to architectures, testing methods, code reviews, and management processes. The DHS Software Assurance program addresses ways to reduce vulnerabilities, mitigate exploitations, and improve the routine development and delivery of software solutions.
ISO/IEC 27000
The International Organization for Standardization (ISO) and the International Electrotechnical Commission (IEC) created the 27034 standard, which is part of a larger body of standards called the ISO/IEC 27000 series. These standards provide guidance to organizations in integrating security into the development and maintenance of software applications. These suggestions are relevant not only to the development of in-house applications but to the safe deployment and management of third-party solutions in the enterprise.
Web Services Security (WS-Security)
Web services typically use a protocol specification called Simple Object Access Protocol (SOAP) for exchanging structured information. SOAP employs Extensible Markup Language (XML) and is insecure by itself. Web Services Security (WS-Security, or WSS) is an extension to SOAP that is used to apply security to web services. WS-Security describes three main mechanisms:
How to sign SOAP messages to ensure integrity (and also nonrepudiation)
How to encrypt SOAP messages to ensure confidentiality
How to attach security tokens to ascertain the sender’s identity
Forbidden Coding Techniques
While covering every insecure coding technique would be impossible, there are certain approaches and techniques that should be forbidden and of which you should be aware. For example, an app should not:
Request elevated privileges unless absolutely necessary.
Relax permissions on portions of its app bundle.
Make unnecessary network connections.
Listen for connections on unnecessary network ports.
Listen for connections on public network interfaces inadvertently.
Read or write files in publicly writable folders unless directed to do so by the user.
Moreover, the following code-hardening techniques should be followed:
Add code that validates inputs to prevent integer overflows.
Replace any unsafe string function calls with calls that are buffer-size-aware to prevent buffer overflows.
Avoid passing data to interpreters whenever possible. When the use of interpreters is unavoidable, pass data to the interpreters in a safe fashion.
To prevent command injection attacks in SQL queries, use parameterized application programming interfaces (APIs) (or manually quote the strings if parameterized APIs are unavailable).
Avoid using the POSIX system function.
Set reasonable values for environment variables (PATH, USER, and so on) and do not make security decisions based on their values.
Fix bugs that cause race conditions which can lead to incorrect behavior (or worse).
NX/XN Bit Use
The two bits NX and XN are related to processors. Their respective meanings are as follows:
NX (no-execute) bit: Technology used in CPUs to segregate areas of memory for use by either storage of processor instructions (code) or storage of data.
XN (never execute) bit: Method for specifying areas of memory that cannot be used for execution.
When they are available in the architecture of the system, these bits can be used to protect sensitive information from memory attacks. By utilizing the ability of the NX bit to segregate memory into areas where storage of processor instructions (code) and storage of data are kept separate, many attacks can be prevented. Also, the ability of the XN bit to mark certain areas of memory that are off-limits to execution of code can prevent other memory attacks as well.
ASLR Use
Address space layout randomization (ASLR) is a technique that can be used to prevent memory attacks. ASLR randomly arranges the address space positions of key data areas of a process, including the base of the executable and the positions of the stack, heap, and libraries. It hinders some types of security attacks by making it more difficult for an attacker to predict target addresses.
The support for ASLR varies by operating system. The following systems offer some level of support for ASLR:
Android 7.0
DragonFly BSD
Apple iOS 4.3 and above
Microsoft Windows 7 and later
NetBSD 5.0
OpenBSD
OS X (10.5 and above)
Solaris 11.1
Code Quality
Another consideration when building security into an application is the quality of the code itself. Code quality is a term that is defined in different ways by different sources, but in general, code that has high quality has the following characteristics:
Documented: The code is self-explaining, using comments to explain its role and functions
Maintainable: The code isn’t overcomplicated, so anyone working with it need not understand the whole context of the code in order to make any changes.
Efficiency: The code doesn’t use unnecessary resources to perform a desired action.
Clarity: The code is easy to read and to understand.
Refactored: Formatting is consistent and follows the language’s coding conventions.
Well-tested: Critical bugs are identified in testing and eliminated to ensure that the software works the way it’s intended to work.
Extensible: The code will be of use for some time.
When code is of good quality, it is much less likely to be compromised and will be more likely to be resistant to attacks.
Code Analyzers
Code testing or analysis is done both by using automated tools and through manual code review. The following sections look at some forms of testing that code analysis might entail.
Fuzzer
Fuzz testing involves injecting invalid or unexpected input (sometimes called faults) into an application to test how the application reacts. It is usually done with a software tool that automates the process. Inputs can include environment variables, keyboard and mouse events, and sequences of API calls. Figure 18-1 shows the logic of the fuzzing process.
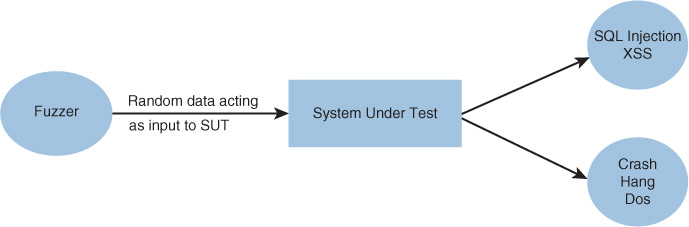
Two types of fuzzing can be used to identify susceptibility to a fault injection attack:
Mutation fuzzing: This type involves changing the existing input values (blindly).
Generation-based fuzzing: This type involves generating the inputs from scratch, based on the specification/format.
To prevent fault injection attacks:
Implement fuzz testing to help identify problems.
Adhere to safe coding and project management practices.
Deploy application-level firewalls.
Fuzzers are software tools that find and exploit weaknesses in web applications, using a process called fuzzing. They operate by injecting semi-random data into the program stack and then detecting bugs that result. They are easy to use, but one of the limitations is that they tend to find simpler bugs rather than some of the more complex ones. OWASP, an organization that focuses on improving software security, recommends several specific tools, including JBroFuzz and WSFuzzer. HTTP-based SOAP services are the main target of WSFuzzer.
A scenario in which a fuzzer would be used is during the development of a web application that will handle sensitive data. The fuzzer would help you determine whether the application is properly handling error exceptions. For example, say that you have a web application that is still undergoing testing, and you notice that when you mistype your credentials in the login screen of the application, the program crashes, and you are presented with a command prompt. If you wanted to reproduce the issue for study, you could run an online fuzzer against the login screen.
Figure 18-2 shows the output of a fuzzer called Peach. It is fuzzing the application with a mutator called StringMutator that continually alters the input. You can see in this output that some input to the tool has caused a crash. Peach has verified the fault by reproducing it. It sends more detail to a log that you can read to understand exactly what string value caused the crash.

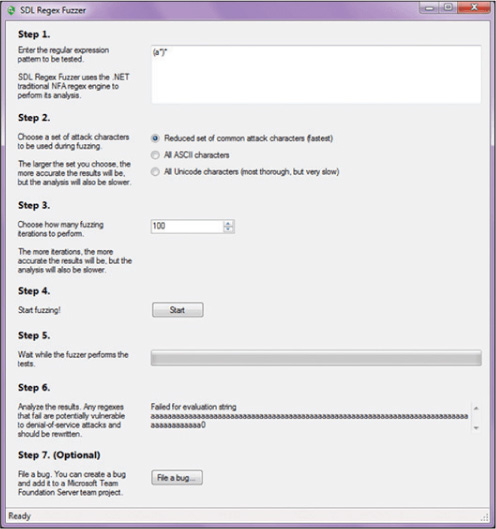
The Microsoft SDL File/Regex Fuzzer is actually composed of two tools. One is File Fuzzer, which generates random content in files, and the other is Regex Fuzzer, which tests functions that use regular expressions. These tools are no longer available, but Microsoft has a new cloud-based fuzzing service. Microsoft’s Security Risk Detection (MSRD) tool uses artificial intelligence to automate the reasoning process that security experts use to find bugs and augments this process with cloud-based scaling. Figure 18-3 shows Regex Fuzzer walking the user through the fuzzing process. As you can see in this figure, in step 1 you enter the expression pattern to be tested and then proceed through the other steps.
Static
Static testing refers to testing or examining software when it is not running. The most common type of static analysis is code review. Code review is the systematic investigation of the code for security and functional problems. It can take many forms, from simple peer review to formal code review. There are two main types of reviews:
Formal review: This is an extremely thorough, line-by-line inspection, usually performed by multiple participants using multiple phases. This is the most time-consuming type of code review but the most effective at finding defects.
Lightweight review: This type of code review is much more cursory than a formal review. It is usually done as a normal part of the development process. It can happen in several forms:
Pair programming: Two coders work side-by-side, checking one another’s work as they go.
Email: Code is emailed around to colleagues for them to review when time permits.
Over-the-shoulder: Coworkers review the code, and the author explains his or her reasoning.
Tool-assisted: Using automated testing tools is perhaps the most efficient method.
While code review is most typically performed on in-house applications, it may be warranted in other scenarios as well. For example, say that you are contracting with a third party to develop a web application to process credit cards. Considering the sensitive nature of the application, it would not be unusual for you to request your own code review to assess the security of the product.
In many cases, more than one tool should be used in testing an application. For example, an online banking application that has had its source code updated should undergo both penetration testing with accounts of varying privilege levels and a code review of the critical models to ensure that defects do not exist.
Dynamic
Dynamic testing is testing performed on software while it is running. This testing can be performed manually or by using automated testing tools. There are two general approaches to dynamic testing:
Synthetic transaction monitoring, which is a type of proactive monitoring, is often preferred for websites and applications. It provides insight into the application’s availability and performance, warning of any potential issue before users experience any degradation in application behavior. It uses external agents to run scripted transactions against an application. For example, Microsoft’s System Center Operations Manager uses synthetic transactions to monitor databases, websites, and TCP port usage.
In contrast, real user monitoring (RUM), which is a type of passive monitoring, is a monitoring method that captures and analyzes every transaction of every application or website user. Unlike synthetic monitoring, which attempts to gain performance insights by regularly testing synthetic interactions, RUM cuts through the guesswork by seeing exactly how your users are interacting with the application.
Misuse Case Testing
Misuse case testing, also referred to as negative testing, tests an application to ensure that the application can handle invalid input or unexpected behavior. This testing is completed to ensure that an application will not crash and to improve application quality by identifying its weak points. When misuse case testing is performed, organizations should expect to find issues. Misuse testing should include testing for the following conditions:
Required fields must be populated.
Fields with a defined data type can only accept data that is the required data type.
Fields with character limits only allow the configured number of characters.
Fields with a defined data range only accept data within that range.
Fields only accept valid data.
Test Coverage Analysis
Test coverage analysis uses test cases that are written against the application requirements specifications. Individuals involved in this analysis do not need to see the code to write the test cases. Once a document is written that describes all the test cases, test groups refer to a percentage of the test cases that were run, that passed, that failed, and so on. The application developer usually performs test coverage analysis as a part of unit testing. Quality assurance groups use overall test coverage analysis to indicate test metrics and coverage according to the test plan.
Test coverage analysis creates additional test cases to increase coverage. It helps developers find areas of an application not exercised by a set of test cases. It helps in determining a quantitative measure of code coverage, which indirectly measures the quality of the application or product.
One disadvantage of code coverage measurement is that it measures coverage of what the code covers but cannot test what the code does not cover or what has not been written. In addition, this analysis looks at a structure or function that is already there rather than at those that do not yet exist.
Interface Testing
Interface testing evaluates whether an application’s systems or components correctly pass data and control to one another. It verifies whether module interactions are working properly and whether errors are handled properly. Interfaces that should be tested include client interfaces, server interfaces, remote interfaces, graphical user interfaces (GUIs), APIs, external and internal interfaces, and physical interfaces.
GUI testing involves testing a product’s GUI to ensure that it meets its specifications through the use of test cases. API testing involves testing APIs directly in isolation and as part of the end-to-end transactions exercised during integration testing to determine whether the APIs return the correct responses.
Development Approaches
In the course of creating software over the past 30 years, developers have learned many things about the development process. As development projects have grown from a single developer to small teams to now large development teams working on massive projects with many modules that must securely interact, development models have been created to increase the efficiency and success of these projects. Lessons learned have been incorporated into these models and methods. The following sections discuss some of the common models, along with concepts and practices that must be understood to implement them.
The following sections discuss these software development methods:
Build and fix
Waterfall
V-shaped
Incremental
Spiral
Agile
Cleanroom
Build and Fix
While not a formal model, the build and fix approach was often used in the past and has been largely discredited; it is now used as a template for how not to manage a development project.
Simply put, build and fix involves developing software as quickly as possible and releasing it. No formal control mechanisms are used to provide feedback during the process. The product is rushed to market, and problems are fixed on an as-discovered basis with patches and service packs. Although this approach gets the product to market faster and more cheaply, in the long run, the costs involved in addressing problems and the psychological damage to the product in the marketplace outweigh any initial cost savings.
Despite the fact that this model is still in use today, most successful developers have learned to implement one of the other models discussed in this section so that the initial product, while not necessarily perfect, comes much closer to meeting all the functional and security requirements of the design. Moreover, using these models helps in identifying and eliminating as many bugs as possible without relying on the customer for quality control.
In this simplistic model of the software development process, certain unrealistic assumptions are made, including the following:
Each step can be completed and finalized without any effect from the later stages that might require rework.
Iteration (reworking and repeating) among the steps in the process, which is typically called for in other models, is not stressed in this model.
Phases are not seen as individual milestones, as they are in some other models discussed here.
Waterfall
The original Waterfall method breaks up the software development process into distinct phases. While it is a somewhat rigid approach, it sees the process as a sequential series of steps that are followed without going back to earlier steps. This approach is called incremental development. Figure 18-4 is a representation of this process.

The modified Waterfall method views each phase in the process as its own milestone in the project management process. Unlimited backward iteration (returning to earlier stages to address problems) is not allowed in this model. However, product verification and validation are performed in this model. Problems that are discovered during the project do not initiate a return to earlier stages but rather are dealt with after the project is complete.
V-Shaped
While still a somewhat rigid model, the V-shaped model differs from the Waterfall method primarily in that verification and validation are performed at each step. While this model can work when all requirements are well understood up front (which is frequently not the case) and potential scope changes are small, it does not provide for handling events concurrently as it is also a sequential process, like the Waterfall method. It does build in a higher likelihood of success because it involves performing testing at every stage. Figure 18-5 shows this process.
Prototyping
While not a formal model, prototyping involves using a sample of code to explore a specific approach to solving a problem before extensive time and cost have been invested. This allows the application development team to both identify the utility of the sample code and identify design problems with the approach. Prototyping systems can provide significant time and cost savings, as you don’t have to make the whole final product before you begin testing it.
Incremental
A refinement to the basic Waterfall model, in the Incremental model, software is developed in increments of functional capability. In this model, a working version or iteration of the solution is produced, tested, and redone until the final product is completed. It could be thought of as a series of waterfalls. After each iteration or version of the software is completed, it is tested to identify gaps in functionality and security from the original design. Then the gaps are addressed by proceeding through the same analysis, design, code, and test stages again. When the product is deemed acceptable with respect to the original design, it is released. Figure 18-6 shows this process.
Spiral
The spiral model is actually a meta-model that incorporates a number of the software development models. Like the incremental model, the spiral model is also an iterative approach, but it places more emphasis on risk analysis at each stage. Prototypes are produced at each stage, and the process can be seen as a loop that keeps circling back to take a critical look at risks that have been addressed while still allowing visibility into new risks that may have been created in the last iteration.
The spiral model assumes that knowledge gained at each iteration is incorporated into the design as it evolves. In some cases, it even involves the customer making comments and observations at each iteration as well. Figure 18-7 shows this process. The radial dimension of the diagram represents cumulative cost, and the angular dimension represents progress made in completing each cycle.
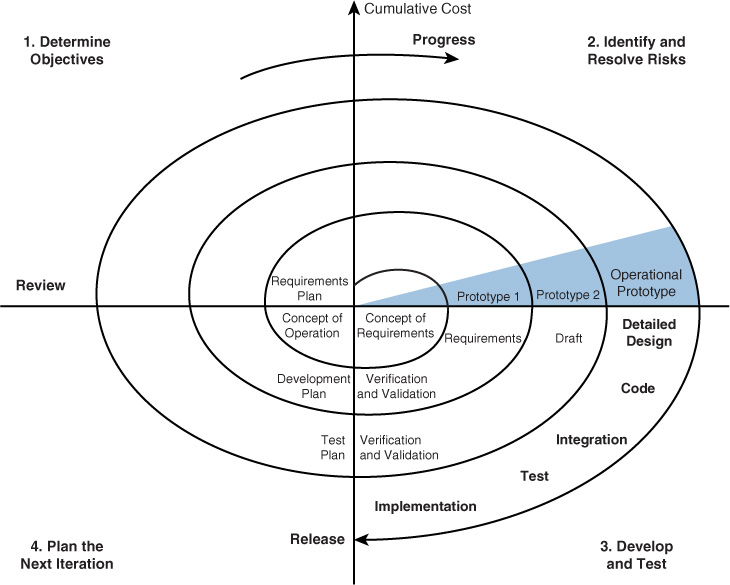
Rapid Application Development (RAD)
In the RAD model, less time is spent upfront on design, and emphasis is on rapidly producing prototypes, under the assumption that crucial knowledge can be gained only through trial and error. This model is especially helpful when requirements are not well understood at the outset and are developed as issues and challenges arise while building prototypes. Figure 18-8 compares the RAD model to traditional models in which the project is completed fully and then verified and validated.
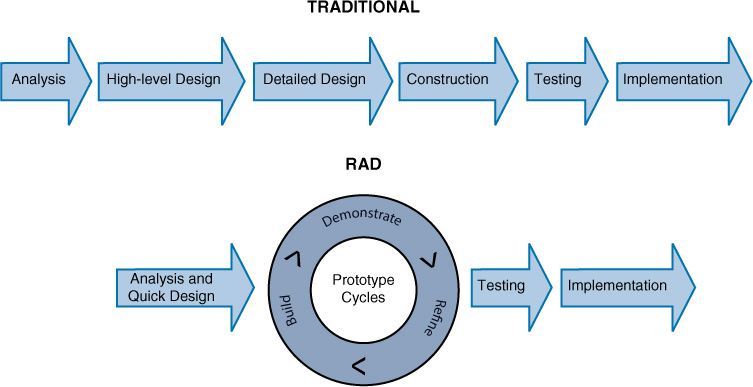
Agile
Many of the processes discussed thus far rely on rigid adherence to process-oriented models. In many cases, there is more of a focus on following procedural steps than on reacting to changes quickly and increasing efficiency. The Agile model puts more emphasis on continuous feedback and cross-functional teamwork.
Agile attempts to be nimble enough to react to situations that arise during development. Less time is spent on upfront analysis, and more emphasis is placed on learning from the process and incorporating lessons learned in real time. There is also more interaction with the customer throughout the process. Figure 18-9 compares the Waterfall model and the Agile model.
JAD
The joint analysis (or application) development (JAD) model uses a team approach. Through workshops, a team agrees on requirements and resolves differences. The theory is that by bringing all parties together at all stages, a more satisfying product will emerge at the end of the process.
Cleanroom
In contrast to the JAD model, the Cleanroom model strictly adheres to formal steps and a more structured method. It attempts to prevent errors and mistakes through extensive testing. This method works well in situations where high quality is a must, the application is mission critical, or the solution must undergo a strict certification process.
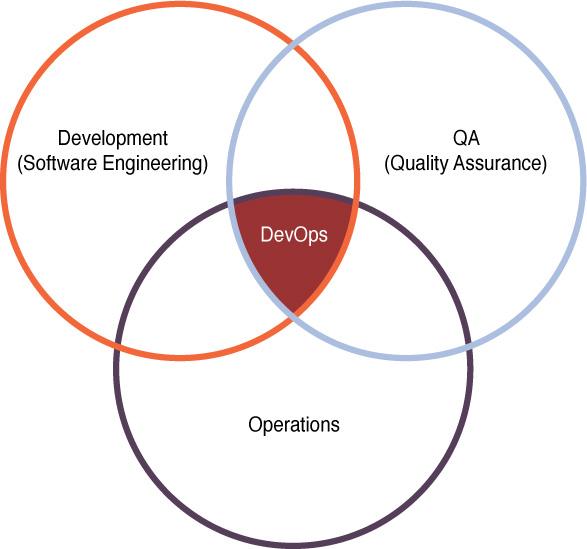
DevOps
Traditionally, three main actors in the software development process—development (Dev), quality assurance (QA), and operations (Ops)—performed their functions separately, or operated in “silos.” Work would go from Dev to QA to Ops, in a linear fashion, as shown in Figure 18-10.
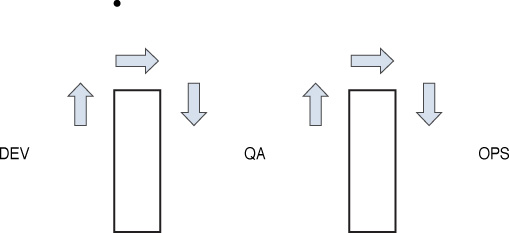
This often led to delays, finger-pointing, and multiple iterations through the linear cycle due to an overall lack of cooperation between the units.
DevOps aims at shorter development cycles, increased deployment frequency, and more dependable releases, in close alignment with business objectives. It encourages the three units to work together through all phases of the development process. Figure 18-11 shows a common symbol that represents this idea.
Security Implications of Agile, Waterfall, and Spiral Software Development Methodologies
When you implement security activities across the technology life cycle, you may need to use the Agile, Waterfall, and spiral software development methodologies. As a security practitioner, you need to understand the security implications of these methodologies.
Security Implications of Agile Software Development
Agile software development is an iterative and incremental approach. Developers work on small modules. As users’ requirements change, developers respond by addressing the changes. Changes are made as work progresses. Testing and customer feedback occur simultaneously with development. The agile method prioritizes collaboration over design.
With the Agile software development methodology, the highest priority is to satisfy the customer. Requirements for the software change often. New deliveries occur at short intervals. Developers are trusted to do their jobs. A working application is the primary measure of success.
Agile development is subject to some risks:
Security testing may be inadequate.
New requirements may not be assessed for their security impact.
Security issues may be ignored, particularly if they would cause schedule delays.
Security often falls by the wayside.
Software that functions correctly may not necessarily be secure.
To address these issues, organizations should include a security architect as part of the development team. Security awareness training should be mandatory for all team members. Security standards and best practices should be documented and followed by the entire team. Security testing tools should be used to test each development piece.
Security Implications of the Waterfall Model
The Waterfall model is a linear and sequential model. In this model, the team moves to the next phase only after the activities in the current phase are over. However, the team cannot return to the previous stage. The phases of this model are:
Requirements and analysis
Design
Coding
System integration
Testing and debugging
Delivery
Maintenance
With the Waterfall software development methodology, the development stages are not revisited, projects take longer, and testing is harder because larger pieces are released. Often risks are ignored because they can negatively impact the project. This software development method involves the following risks:
Developers cannot return to the design stage if a security issue is discovered.
Developers may end up with software that is no longer needed or that doesn’t address current security issues.
Security issues are more likely to be overlooked due to time constraints.
Security Implications of the Spiral Model
The spiral model was introduced due to the shortcomings in the Waterfall model. In the spiral model, the activities of software development are carried out like a spiral. The software development process is broken down into small projects. The phases of the spiral model are as follows:
Planning
Risk analysis
Engineering
Coding and implementation
Evaluation
With the spiral software development methodology, requirements are captured quickly and can be changed easily. But if the initial risk analysis is inadequate, the end project will have issues. Involving a risk analysis expert as part of the team can help ensure that the security is adequately assessed and designed.
Agile and spiral are usually considered better methods than the Waterfall method, especially considering how quickly the security landscape can change. However, each organization needs to decide which method best works for its particular situation.
Continuous Integration
In software engineering, continuous integration (CI) is the practice of merging all developer working copies to a shared mainline several times a day. This helps prevent one developer’s work-in-progress from breaking another developer’s copy. In its original form, CI was used in combination with automated units and was conceived of as running all unit tests in the developer’s local environment and verifying they all passed before committing them to the mainline. Later implementations introduced build servers, which automatically ran the unit tests periodically or even after every commit and reported the results to the developer.
Versioning
Versioning is an organization concept that assigns a numbering system to software versions that help indicate where the version falls in the version history. Versioning helps to ensure that developers are working with the latest versions and eventually that users are using the latest version. Several approaches can be used. Version changes might add new functionality or might correct bugs.
A sequence-based versioning numbering system uses a hierarchy to indicate major and minor revisions. An example of this type of numbering is shown in Figure 18-12. Major revision might be represented as a change from 1.1 to 1.2, while minor ones might be represented as 1.1 to 1.12.

Other systems may be based on alphanumeric codes or date of release.
Secure Coding Standards
Secure coding standards are practices that, if followed throughout the software development life cycle, help reduce the attack surface of an application. Standards are developed through a broad-based community effort for common programming languages such as C, C++, Java, and Perl. Some of this work has been spearheaded by the Computer Emergency Readiness Team (CERT). Examples of resulting publications are:
The CERT C Secure Coding Standard
The CERT C++ Secure Coding Standard
The CERT Perl Secure Coding Standard
SEI CERT C Coding Standard
SEI CERT Oracle Coding Standard for Java
Android TM Secure Coding Standard
SEI CERT Perl Coding Standard
Documentation
Proper documentation during the development process helps ensure proper functionality and adequate security. Many processes should be documented, which will generate a number of documents. The following sections look at some of these processes and the resulting documents.
Security Requirements Traceability Matrix (SRTM)
A security requirements traceability matrix (SRTM) documents the security requirements that a new asset must meet. The matrix maps the requirements to security controls and verification efforts in a grid, such as an Excel spreadsheet. Each row in the grid documents a new requirement, and the columns document the requirement identification number, description of the requirement, source of the requirement, test objective, and test verification method. It allows security practitioners and developers to ensure that all requirements are documented, met in the final design, and tested properly.
An SRTM would help to determine whether an appropriate level of assurance to the security requirements specified at project origin are carried through to implementation.
Let’s look at an example. Suppose a team of security engineers applies regulatory and corporate guidance to the design of a corporate network. The engineers generate an SRTM based on their work and a thorough analysis of the complete set of functional and performance requirements in the network specification. The purpose of an SRTM in this scenario is to allow certifiers to verify that the network meets applicable security requirements.
Requirements Definition
A requirements definition is a list of functional and security requirements that must be satisfied during a software development process. It can follow several formats. One traditional way of documenting requirements has been contract-style requirement lists, which are just what they sound like: lists of requirements. Another method is to define these requirements by use cases, with use case providing a set of scenarios that convey how the system should interact with a human user or another system to achieve a specific business goal.
System Design Document
The system design document (SDD) provides the description of the software and is usually accompanied by an architectural diagram. It contains the following information:
Data design: This type of design describes the choice of data structures and the attributes and relationships between data objects that drove the selection.
Architecture design: This type of design uses data flow diagrams and transformation mapping to describe distinct boundaries between incoming and outgoing data. It uses information flow characteristics and maps them into the program structure.
Interface design: This type of design describes all interfaces, including internal and external program interfaces, as well as the design of the human interface.
Procedural design: This type of design represents procedural detail and structured programming concepts, using graphical, tabular, and textual notations. It provides a blueprint for implementation and forms the basis for all subsequent software engineering work.
Testing Plans
A test plan is a document that describes the scope of the test (what it will test) and the specific activities that will occur during the test. There are several forms of test plans:
Master test plan: This is a single high-level test plan for a project/product that unifies all other test plans.
Testing level–specific test plan: This type of plan describes a test process at a lower level of testing, such as:
Unit test plan
Integration test plan
System test plan
Acceptance test plan
Testing type–specific test plan: This type of plan is for a specific issue, such as performance tests and security tests.
It might be beneficial to create a test template to ensure that all required operations are carried out and all relevant testing data is collected. Such a template might include the following sections (based on the IEEE template for testing documentation):
Test plan identifier: Provide a unique identifier for the document. (Adhere to the configuration management system if you have one.)
Introduction:
Provide an overview of the test plan.
Specify the goals/objectives.
Specify any constraints.
References: List the related documents, with links to them, if available, including the following:
Project plan
Configuration management plan
Test items: List the test items (software/products) and their versions.
Features to be tested:
List the features of the software/product to be tested.
Provide references to the requirements and/or design specifications of the features to be tested.
Features not to be tested:
List the features of the software/product that will not be tested.
Specify the reasons these features won’t be tested.
Approach:
Mention the overall approach to testing.
Specify the testing levels (if it’s a master test plan), the testing types, and the testing methods (manual/automated; white box/black box/gray box).
Item pass/fail criteria: Specify the criteria that will be used to determine whether each test item (software/product) has passed or failed testing.
Suspension criteria and resumption requirements:
Specify criteria to be used to suspend the testing activity.
Specify testing activities that must be redone when testing is resumed.
Test deliverables: List test deliverables and links to them, if available, including the following:
Test plan (this document itself)
Test cases
Test scripts
Defect/enhancement logs
Test reports
Test Environment:
Specify the properties of the test environment (hardware, software, network, and so on).
List any testing or related tools.
Estimate: Provide a summary of test estimates (cost or effort) and/or provide a link to the detailed estimation.
Schedule: Provide a summary of the schedule, specifying key test milestones, and/or provide a link to the detailed schedule.
Staffing and training needs:
Specify staffing needs by role and required skills.
Identify training that is necessary to provide those skills, if not already acquired.
Responsibilities: List the responsibilities of each team/role/individual.
Risks:
List the risks that have been identified.
Specify the mitigation plan and the contingency plan for each risk.
Assumptions and dependencies:
List the assumptions that have been made during the preparation of this plan.
List the dependencies.
Approvals:
Specify the names and roles of all persons who must approve the plan.
Provide space for signatures and dates (if the document is to be printed).
Validation and Acceptance Testing
Validation testing ensures that a system meets the requirements defined by the client, and acceptance testing ensures that a system will be accepted by the end users. If a system meets the client’s requirements but is not accepted by the end users, its implementation will be greatly hampered. If a system does not meet the client’s requirements, the client will probably refuse to implement the system until the requirements are met.
Validation testing should be completed before a system is formally presented to the client. Once validation testing has been completed, acceptance testing should be completed with a subset of the users.
Validation testing and acceptance testing should not just be carried out for systems. As a security practitioner, you need to make sure that validation testing and acceptance testing are carried out for any security controls that are implemented in your enterprise. If you implement a new security control that does not fully protect against a documented security issue, there could be repercussions for your organization. If you implement a security control that causes problems, delays, or any other user acceptance issues, employee morale will suffer. Finding a balance between the two is critical.
Unit Testing
Software is typically developed in pieces, or as modules of code, that are later assembled to yield the final product. Each module should be tested separately, in a procedure called unit testing. Having development staff carry out this testing is critical, but using a different group of engineers than the ones who wrote the code can ensure that an impartial process occurs. This is a good example of the concept of separation of duties.
The following should be characteristics of the unit testing:
The test data is part of the specifications.
Testing should check for out-of-range values and out-of-bounds conditions.
Correct test output results should be developed and known beforehand.
Live or actual field data is not recommended for use in the unit testing procedures.
Additional testing is recommended, including the following:
Integration testing: This type of testing assesses the way in which the modules work together and determines whether functional and security specifications have been met. The advantages to this testing include:
It provides a systematic technique for assembling system while uncovering errors.
It confirms assumptions which were made during unit testing
It can begin as soon as the relevant modules are available.
It verifies whether the software modules work in unity.
Disadvantages include:
Locating faults is difficult.
Some interface links to be tested could be missed.
It can commence only after all the modules are designed.
High-risk critical modules are not isolated and tested on priority.
User acceptance testing: This type of testing ensures that the customer (either internal or external) is satisfied with the functionality of the software. The advantages to this testing include:
The satisfaction of the client is increased.
The criteria for quality are set early.
Improved communication between team and customer.
The only disadvantage is that it adds cost to the process.
Regression testing: This type of testing takes places after changes are made to the code to ensure that the changes have reduced neither functionality nor security. Its advantages include the following:
Better integration of changes
Improved product quality
Detection of side effects
The only disadvantage is the additional cost, but it is well worth it.
Peer review: this type of testing, developers review one another’s code for security issues and code efficiency. The advantage is that it is more thorough than automated methods. The disadvantage is that it is time-consuming.
Adapt Solutions
New threats and security trends emerge every day. Organizations and the security practitioners they employ must adapt to new threats and understand new security trends to ensure that the enterprise is protected. However, the security objective of an organization rarely changes.
Address Emerging Threats
Retail organizations are increasingly under attack. One company released a public statement about hackers breaching security and stealing private customer data. Unfortunately, it seems that not every major retailer took notice when this attack occurred, as almost monthly a new victim came forth. As a result, banks and other financial institutions were forced to issue new credit/debit cards to their customers. These attacks affected the retail companies, their customers, and financial institutions. What could these companies have done differently to prevent these attacks? Perhaps more should be shared within the retail industry and between security professionals when these types of attacks occur. Occurrences like this will become the norm unless we find some solutions, and this is just one recent example of emerging threats to which organizations must adapt.
Figure 18-13 shows a popular vulnerability cycle taught in many security seminars that explains the order of vulnerability types that attackers run through over time.
Trends tend to work through this vulnerability cycle. A trending period where human interaction and social engineering are prevalent will soon be followed by a period where network attacks are prevalent. Once organizations adapt, attackers logically move to the next area in the cycle: services and servers. As time passes, organizations adapt, but so do the attackers. As a security professional, you must try to stay one step ahead of the attackers. Once you have implemented a new security control or solution, you cannot rest! You must then do your research, watch your enterprise, and discover the next threat or trend. One thing is for sure: A security practitioner with real skills and willingness to learn and adapt will always have job security!
Threat intelligence helps an organization understand new risks. Once new threats are more well understood, the organization will be better positioned to defend against them. Security professionals then will also be better prepared for those threats to which they are vulnerable.
Address Disruptive Technologies
Disruptive technologies are technologies that are so revolutionary they change the way things are done and create new ways in which people use technology. They are disruptive in the sense that they sometimes change the way an entire industry operates. For example, self-driving cars will certainly put chauffeurs out of work.
While disruptive technologies are always forward looking and revolutionary, they are not always secure. In the rush to get a disruptive technology to market, security is not always the primary focus. For this reason, many organizations allow others to ride on the “bleeding edge” of the technology.
Some of the disruptive technologies on the horizon as we approach 2020 are:
The four-year upgrade cycle will be a thing of the past. Yearly cycles for desktop updates will be the norm.
Phishing attacks will victimize 1 out every 10 users, leading security professionals to focus their efforts in the following areas going forward:
Securing the perimeter
Encrypting at rest and in transit
Bring your own device (BYOD) initiatives will drive solutions such as mobile device management (MDM).
Usability issues caused by security measures will decline.
We will see more movement to the cloud.
Artificial intelligence and machine learning will be increasingly utilized to locate new clients and customers.
5G wireless promises to be at least 40 times faster and have at least 4 times as much coverage as 4G.
Address Security Trends
Trends are, by nature, temporary—and security trends are no exception. As we look toward the 2020 decade, these are what some security visionaries see in our future:
A return to the zero-trust model: Organizations will move to a highly defensive posture in the face of ever-more-sophisticated attacks. Every privilege will be granted to a user only when absolutely required.
Deception technology will rise in the fight to secure the Internet of things (IoT): This technology floods the network and makes it mathematically impossible for cybercriminals to gain access to a legitimate set of user identities. When one of these fake credentials is compromised and used, deception technology alerts IT.
Behavioral analytics and artificial intelligence will be used in identity management: The system will learn user habits and be able to more easily identify activities that are abnormal.
Robo hunters will be used as automated threat seekers: They can learn from what they discover and then take appropriate action (for example, by isolating a bad packet or compromised device).
Blockchain will find increasing use: Blockchain allows a digital ledger of transactions to be created and shared among participants via a distributed network of computers. The blockchain ledger can detect suspicious online behavior and isolate the connection. This immutable ledger can also be presented in court and can prove that an unauthorized person extracted or copied a set of data.
Asset Management (Inventory Control)
Asset management and inventory control across the technology life cycle are critical to ensuring that assets are not stolen or lost and that data on assets is not compromised in any way. Asset management and inventory control are two related areas. Asset management involves tracking the devices that an organization owns, and inventory control involves tracking and containing inventory. All organizations should implement asset management, but not all organizations need to implement inventory control.
Device-Tracking Technologies
Device-tracking technologies allow organizations to determine the location of a device and also often allow the organization to retrieve the device. However, if the device cannot be retrieved, it may be necessary to wipe the device to ensure that the data on the device cannot be accessed by unauthorized users. As a security practitioner, you should stress to your organization the need to implement device-tracking technologies and remote wiping capabilities.
Geolocation/GPS Location
Device-tracking technologies include geolocation or Global Positioning System (GPS) location. With this technology, location and time information about an asset can be tracked, provided that the appropriate feature is enabled on the device. For most mobile devices, the geolocation or GPS location feature can be enhanced through the use of Wi-Fi networks. A security practitioner must ensure that the organization enacts mobile device security policies that include the mandatory use of GPS location features. In addition, it will be necessary to set up appropriate accounts that allow personnel to use the vendor’s online service for device location. Finally, remote locking and remote wiping features should be seriously considered, particularly if the mobile devices contain confidential or private information.
Object Tracking and Containment Technologies
Object tracking and containment technologies are primarily concerned with ensuring that inventory remains within a predefined location or area. Object tracking technologies allow organizations to determine the location of inventory. Containment technologies alert personnel within the organization if inventory has left the perimeter of the predefined location or area.
For most organizations, object tracking and containment technologies are used only for inventory assets above a certain value. For example, most retail stores implement object containment technologies for high-priced electronics devices and jewelry. However, some organizations implement these technologies for all inventory, particularly in large warehouse environments.
Technologies used in this area include geotagging/geofencing and radio frequency identification (RFID).
Geotagging/Geofencing
Geotagging involves marking a video, photo, or other digital media with a GPS location. In recent news, this feature has received bad press because attackers can use it to pinpoint personal information, such as the location of a person’s home. However, for organizations, geotagging can be used to create location-based news and media feeds. In the retail industry, it can be helpful for allowing customers to locate a store where a specific piece of merchandise is available.
Geofencing uses GPS to define geographic boundaries. A geofence is a virtual barrier, and alerts can occur when inventory enters or exits the boundary. Geofencing is used in retail management, transportation management, human resources management, law enforcement, and other areas.
RFID
RFID uses radio frequency chips and readers to manage inventory. The chips are placed on individual pieces or pallets of inventory. RFID readers are placed throughout the location to communicate with the chips. Identification and location information are collected as part of the RFID communication. Organizations can customize the information that is stored on an RFID chip to suit their needs.
Two types of RFID systems can be deployed: active reader/passive tag (ARPT) and active reader/active tag (ARAT). In an ARPT system, the active reader transmits signals and receives replies from passive tags. In an ARAT system, active tags are woken with signals from the active reader.
RFID chips can be read only if they are within a certain proximity of the RFID reader. A recent implementation of RFID chips is the Walt Disney Magic Band, which is issued to visitors at Disney resorts and theme parks. The band verifies park admission and allows visitors to reserve attraction and restaurant times and pay for purchases in the resort.
Different RFID systems are available for different wireless frequencies. If your organization decides to implement RFID, it is important that you fully research the advantages and disadvantages of different frequencies. However, that information is beyond the scope of the CASP exam.
Exam Preparation Tasks
As mentioned in the section “How to Use This Book” in the Introduction, you have a couple choices for exam preparation: the exercises here, Chapter 20, “Final Preparation,” and the practice exams in the Pearson IT Certification test engine.
Review All Key Topics
Review the most important topics in this chapter, noted with the Key Topics icon in the outer margin of the page. Table 18-1 lists these key topics and the page number on which each is found.
Table 18-1 Key Topics for Chapter 18
Key Topic Element |
Description |
Page Number |
List |
The steps in the SDLC |
665 |
List |
Functions of configuration management |
672 |
List |
Disposal terms and concepts |
673 |
List |
Software development life cycle steps |
674 |
List |
Types of testing |
676 |
List |
Software acquisition phases |
679 |
List |
NX and XN bit use |
682 |
List |
Characteristics of high-quality code |
683 |
List |
Types of fuzzing |
684 |
List |
Types of code reviews |
686 |
List |
Approaches to dynamic testing |
686 |
List |
Software development methods |
688 |
List |
Contents of a system design document |
701 |
List |
Testing plans |
702 |
List |
Unit testing procedures |
705 |
List |
Disruptive technologies |
708 |
List |
Security trends |
708 |
Define Key Terms
Define the following key terms from this chapter and check your answers in the glossary:
systems development life cycle (SDLC)
software development life cycle
application security frameworks
Web Application Security Consortium (WASC)
Open Web Application Security Project (OWASP)
Build Security In (BSI) initiative
Simple Object Access Protocol (SOAP)
Web Services Security (WS-Security, or WSS)
address space layout randomization (ASLR)
synthetic transaction monitoring
rapid application development (RAD)
joint analysis (or application) development (JAD)
security requirements traceability matrix (SRTM)
software design document (SDD)
active reader/passive tag (ARPT)
active reader/active tag (ARAT)
Review Questions
1. Which of the following is a uniquely identifiable subset of the system that represents the smallest portion to be subject to an independent configuration control procedure?
CI
AV
CU
CC
2. You have been hired as a security analyst for your company. Recently, several assets have been marked to be removed from the enterprise. You need to document the steps that should be taken in relation to security. Which of the following guidelines should be implemented?
Deploy the appropriate security controls on the asset.
Deploy the most recent updates for the asset.
Back up all the data on the asset and ensure that the data is completely removed.
Shred all the hard drives in the asset.
3. Your organization has decided to formally adopt a change management process, and you have been asked to design the process. Which of the following guidelines should be part of this new process?
Only critical changes should be fully analyzed.
After formal approval, all costs and effects of implementation should be reviewed.
Change steps should be developed only for complicated changes.
All changes should be formally requested.
4. You have been asked to join the development team at your organization to provide guidance on security controls. During the first meeting, you discover that the development team does not fully understand the SDLC. During which phase of this life cycle is the system actually deployed?
Acquire/develop
Implement
Initiate
Operate/maintain
5. A development team has recently completed the deployment of a new learning management system (LMS) that will replace the current legacy system. The team successfully deploys the new LMS, and it is fully functional. Users are satisfied with the new system. What stage of the SDLC should you implement for the old system?
Dispose
Operate/maintain
Initiate
Acquire/develop
6. You have been asked to participate in the deployment of a new firewall. The project has just started and is still in the initiation stage. Which step should be completed as part of this stage?
Develop security controls.
Assess the system security.
Ensure information preservation.
Assess the business impact of the system.
7. You are working with a project team to deploy several new firewalls. The initiation stage is complete, and now the team is engaged in the acquisition stage. Which step should the team complete as part of this stage?
Provide security categories for the new routers.
Test the routers for security resiliency.
Design the security architecture.
Update the routers with the latest updates from the vendor.
8. What documents the security requirements that a new asset must meet?
SDLC
SRTM
SSDLC
RFID
9. Which of the following is a device-tracking technology?
geolocation
geotagging
geofencing
RFID
10. Which technology uses chips and receivers to manage inventory?
geolocation
geotagging
SRTM
RFID