
Chapter 1
The Importance of Data Quality
1.0 Introduction
In this introductory chapter, we discuss the importance of data quality (DQ), understanding DQ implications, and the requirements for managing the DQ function. This chapter also sets the stage for the discussions in the other chapters of this book that focus on the building and execution of the DQ program. At the end, this chapter provides a guide to this book, with descriptions of the chapters and how they interrelate.
1.1 Understanding the Implications of Data Quality
Dr. Genichi Taguchi, who was a world-renowned quality engineering expert from Japan, emphasized and established the relationship between poor quality and overall loss. Dr. Taguchi (1987) used a quality loss function (QLF) to measure the loss associated with quality characteristics or parameters. The QLF describes the losses that a system suffers from an adjustable characteristic. According to the QLF, the loss increases as the characteristic y (such as thickness or strength) gets further from the target value (m). In other words, there is a loss associated if the quality characteristic diverges from the target. Taguchi regards this loss as a loss to society, and somebody must pay for this loss. The results of such losses include system breakdowns, company failures, company bankruptcies, and so forth. In this context, everything is considered part of society (customers, organizations, government, etc.).
Figure 1.1 shows how the loss arising from varying (on either side) from the target by Δ0 increases and is given by L(y). When y is equal to m, the loss is zero, or at the minimum. The equation for the loss function can be expressed as follows:

Figure 1.1 Quality Loss Function (QLF)
where k is a factor that is expressed in dollars, based on direct costs, indirect costs, warranty costs, reputational costs, loss due to lost customers, and costs associated with rework and rejection. There are prescribed ways to determine the value of k.
The loss function is usually not symmetrical—sometimes it is steep on one side or on both sides. Deming (1960) says that the loss function need not be exact and that it is difficult to obtain the exact function. As most cost calculations are based on estimations or predictions, an approximate function is sufficient—that is, close approximation is good enough.
The concept of the loss function aptly applies in the DQ context, especially when we are measuring data quality associated with various data elements such as customer IDs, social security numbers, and account balances. Usually, the data elements are prioritized based on certain criteria, and the quality levels for data elements are measured in terms of percentages (of accuracy, completeness, etc.). The prioritized data elements are referred to as critical data elements (CDEs).
If the quality levels associated with these CDEs are not at the desired levels, then there is a greater chance of making wrong decisions, which might have adverse impacts on organizations. The adverse impacts may be in the form of losses, as previously described. Since the data quality levels are a “higher-the-better” type of characteristic (because we want to increase the percent levels), only half of Figure 1.1 is applicable when measuring loss due to poor data quality. Figure 1.2 is a better representation of this situation, showing how the loss due to variance from the target by Δ0 increases when the quality levels are lower than m and is given by L(y). In this book, the target value is also referred to as the business specification or threshold.
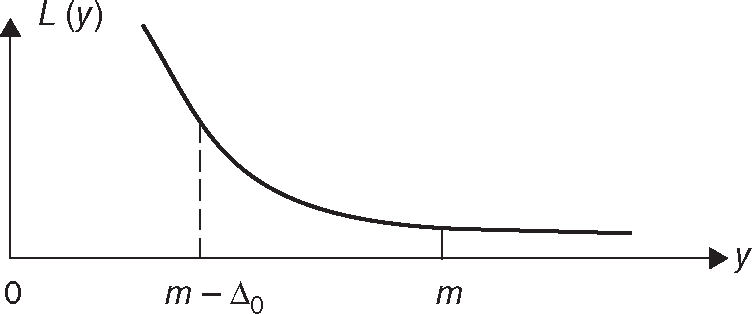
Figure 1.2 Loss Function for Data Quality Levels (Higher-the-Better Type of Characteristic)
As shown in Figure 1.2, the loss will be at minimum when y attains a level equal to m. This loss will remain at the same level even if the quality levels are greater than m. Therefore, it may be not be necessary to improve the CDE quality levels beyond m, as this improvement will not have any impact on the loss.
Losses due to poor quality can take a variety of forms (English, 2009), such as denying students entry to colleges, customer loan denial, incorrect prescription of medicines, crashing submarines, and inaccurate nutrition labeling on food products. In the financial industry context, consider a situation where a customer is denied a loan on the basis of a bad credit history because the loan application was processed using the wrong social security number. This is a good example of a data quality issue, and we can imagine how such issues can compound, resulting in huge losses to the organizations involved. The Institute of International Finance and McKinsey & Company (2011) cite one of the key factors in the global financial crisis that began in 2007 as inadequate information technology (IT) and data architecture to support the management of financial risk. This highlights the importance of data quality and leads us to conclude that the effect of poor data quality on the financial crisis cannot be ignored. During this crisis, many banks, investment companies, and insurance companies lost billions of dollars, causing some to go bankrupt. The impacts of these events were significant and included economic recession, millions of foreclosures, lost jobs, depletion of retirement funds, and loss of confidence in the industry and in the government.
All the aforementioned impacts can be classified into two categories, as described in Taguchi (1987): losses due to the functional variability of the process and losses due to harmful side effects. Figure 1.3 shows how all the costs in these categories add up.

Figure 1.3 Sources of Societal Losses
In this section, we discussed the importance of data quality and the implications of bad data. It is clear that the impact of bad data is quite significant and that it is important to manage key data resources effectively to minimize overall loss. For this reason, there is a need to establish a dedicated data management function that is responsible for ensuring high data quality levels. Section 1.2 briefly describes the establishment of such a function and its various associated roles.
1.2 The Data Management Function
In some organizations, the data management function is referred to as the chief data office (CDO), and it is responsible for the oversight of various data-related activities. One way of overseeing data-related activities is to separate them into different components such as data governance, data strategies, data standards, and data quality. The data governance component is important because it navigates subsequent data-related activities. This includes drivers such as steering committees, program management aspects, project and change management aspects, compliance with organization requirements, and similar functions. The data strategy component is useful for understanding the data and planning how to use it effectively. The data standards component is responsible for ensuring that the various parties using the data share the same understanding across the organization. This is accomplished by developing standards around various data elements and data models. The data quality component is responsible for cleaning the data and making sure that it is fit for the intended purpose, so it can be used in various decision-making activities. This group should work closely with the data strategy component.
Please note that we are presenting one of the several possible ways of overseeing the data management function, or CDO. The CDO function should work closely with various functions, business units, and technology groups across the organization to ensure that data is interpreted consistently in all functions of the organization and is fit for the intended purposes. An effective CDO function should demonstrate several key attributes, including the following:
- Clear leadership and senior management support
- Key data-driven objectives
- A visual depiction of target areas for prioritization
- A tight integration of CDO objectives with company priorities and objectives
- A clear benefit to the company upon execution
As this book focuses on data quality, various chapters provide descriptions of the approaches, frameworks, methods, concepts, tools, and techniques that can be used to satisfy the various DQ requirements, including the following:
- Developing a DQ standard operating model (DQOM) so that it can be adopted by all DQ projects
- Identifying and prioritizing critical data elements
- Establishing a DQ monitoring and controlling scheme
- Solving DQ issues and performing root-cause analyses (RCAs)
- Defining and deploying data tracing and achieving better data lineage
- Quantifying the impact of poor data quality
All of these requirements are necessary to ensure that data is fit for its purpose with a high degree of confidence.
Sections 1.3 and 1.4 explain the solution strategy for DQ problems, as well as the organization of this book, with descriptions of the chapters. The main objective of these chapters is that readers should be able to use the concepts, procedures, and tools discussed in them to meet DQ requirements and solve various DQ problems.

Figure 1.4 DQ Solution Strategy
1.3 The Solution Strategy
Given the preference for satisfying DQ-related requirements while ensuring fitness of the data with high quality levels, the top-level solution strategy focuses on building the DQ program and designing the methods for executing it. Having chosen a top-level solution strategy, the subrequirements can be defined as shown in Figure 1.4.
Much of this book is concerned with expanding the solution strategy shown in Figure 1.4 with the help of a set of equations, concepts, and methods. In addition, discussions on data analytics (including the big data context) and establishing a data quality practices center (DQPC) are also provided.
1.4 Guide to This Book
The chapters of this book are divided into two sections. Section I describes how to build a data quality program and Section II describes how to execute the data quality program.
Section I: Building a Data Quality Program. The first section includes two chapters that describe the DQ operating model and DQ methodology. Chapter 2 emphasizes the importance of the data quality program structure, objectives, and management routines, and the portfolio of projects that need to be focused on to build and institutionalize processes that drive business value. Chapter 3 provides a description of the DQ methodology with the four-phase Define, Assess, Improve, and Control (DAIC) approach. The emphasis here is on ensuring that every DQ project follows these phases to reduce costs, reduce manual processing or rework, improve reporting, or enhance the revenue opportunity.
Section II: Executing a Data Quality Program. The second section includes the remaining chapters of the book, which cover a wide range of concepts, methods, approaches, frameworks, tools, and techniques that are required for successful execution of a DQ program. Chapter 4 focuses on the quantification of the impacts of poor data quality. Chapter 5 describes statistical process control (SPC) techniques and their relevance in DQ monitoring and reporting. Chapters 6 and 7 describe the CDE identification, validation, and prioritization process, and Chapter 8 describes the importance of designing DQ scorecards and how they can be used for monitoring and reporting purposes. Chapter 9 provides an approach to resolve various issues affecting data quality. These issues can be related directly to the data or the processes providing the data.
Chapter 10 provides a methodology to identify issues or problems in source systems or operational data sources with an experimental design based approach. Chapter 11 discusses an end-to-end approach for performing data tracing so that prioritized CDEs can be traced back to the source system and proper corrective actions can be taken. Chapter 12 focuses on effective use of information to design multivariate diagnostic systems so that we can make appropriate business decisions. Chapter 13 highlights the importance of data quality to perform high-quality analytics including the big data context. This chapter also discusses the role of data innovation and its relevance in modern industry. Chapter 14, which is the concluding chapter, focuses on building a data quality practices center that has the operational capabilities to provide DQ services and satisfy all DQ requirements.
Table 1.1 shows a summary of all the chapters of this book.
Table 1.1 Guide to This Book—Descriptions of Chapters
| Section/Chapter | Description | |
| Chapter 1 | This introductory chapter discusses the importance of data quality (DQ), understanding DQ implications, and the requirements for managing the data quality function. | |
| Section I | Chapter 2 | This chapter describes the building of a comprehensive approach and methodology (referred to as the data quality operating model) that allows us to understand the current state of data quality, organize around information critical to the enterprise and the business, and implement practices and processes for data quality measurement. |
| Chapter 3 | This chapter discusses the four-phased Define, Assess, Improve, and Control approach that can be used to execute DQ projects. This comprehensive approach helps readers understand several aspects of the DQ project life cycle. | |
| Section II | Chapter 4 | This chapter focuses on the methodology that can be used to quantify the impact of poor-quality data with an illustrative example. |
| Chapter 5 | Chapter 5 describes the importance of statistical process control (SPC) along with descriptions of various control charts and the relevance of SPC in DQ monitoring and control. | |
| Chapter 6 | This chapter discusses how to identify CDEs, validate CDEs, and conduct CDE assessment with the help of data quality rules and data quality scores. | |
| Chapter 7 | This chapter discusses how to prioritize these CDEs and reduce the number of CDEs to be measured using the funnel approach. It also demonstrates the applicability of this approach using a case study. | |
| Chapter 8 | The purpose of this chapter is to describe a means to construct and implement effective DQ scorecards. Using the proposed approach, users can store, sort, and retrieve DQ defect information and perform remediation through statistical analysis. | |
| Chapter 9 | This chapter explains the linkage between data quality and process quality by providing an approach to resolve various issues affecting data quality. These issues can be related directly to the data or the processes providing the data | |
| Chapter 10 | This chapter describes a methodology that can be used to test the performance of a given system and identify failing factors that are responsible for poor information/data quality. | |
| Chapter 11 | This chapter describes the end-to-end data tracing methodology, its important aspects, and how it can be linked to data lineage to improve data quality accuracy. | |
| Chapter 12 | This chapter describes the Mahalanobis-Taguchi Strategy (MTS) and its applicability to developing a multivariate diagnostic system with a measurement scale. This type of diagnostic system is helpful in utilizing high-quality data in an effective way to come to meaningful conclusions. | |
| Chapter 13 | This chapter briefly discusses the importance of data quality to performing high-quality analytics (including the big data context) and making appropriate decisions based on the analytics. It also discusses the role of data innovation and its relevance in modern industry. | |
| Chapter 14 | This chapter focuses on building a data quality practices center (DQPC) and its fundamental building blocks. Such a center will have the operational capability to provide services, tools, governance, and outputs to deliver tangible insights and business value from the data. | |