
CHAPTER 5
Investigating and Remediating Cyber Breaches
Investigating a cyber breach can be a complex and often long process. The level of sophistication of the attacker, dwell time on the compromised network, and how far the attacker progressed through the cyberattack lifecycle directly contribute to the complexity of the investigation.
Incident responders follow a lifecycle-based process to investigate cyber breaches. The process typically includes multiple iterations of data collection and analysis in order to identify evidence of attacker activity. In some cases, the evidence is indisputable. In other cases, analysts must correlate and corroborate data from multiple sources to draw conclusions about attacker activity.
An investigation consists of many components that must work in tandem in order to determine the scope and extent of a breach. Investigating a large-scale breach requires a team of professionals with complementary skill sets, such as digital forensics, malware analysis, and cyber threat intelligence (CTI). Moreover, the order in which analysts discover evidence of attacker activity may not correspond to the order of the attack progression. For this reason, it is helpful to map digital evidence to a cyberattack framework in order to identify additional sources of potential evidence and reconstruct the “full picture” of an attack.
The evidence that analysts identify is crucial for containment and eradication. A remediation team uses information relating to the attacker operation to secure crucial assets and eradicate the attacker from the compromised environment.
This chapter draws on the information discussed thus far in this book, and it provides an in-depth discussion about investigating and remediating cyber breaches. The primary focus of this chapter is on large-scale network compromises. However, the reader can easily use the information presented to investigate smaller incidents as well.
Investigating Incidents
Historically, enterprises leveraged traditional computer forensics to determine attacker activity on a compromised system. However, scalability was a significant challenge associated with this approach. Furthermore, the methodologies that underpinned traditional computer forensics focused on investigating computer crimes and were not flexible enough to support large-scale investigations in enterprise environments.
With the evolution of live response tools, enterprise incident response emerged. This approach combines digital forensics, live response technology, and CTI to allow organizations to respond to large-scale incidents efficiently. To facilitate enterprise incident response, victim organizations deploy incident response technology into their environments in order to collect and analyze forensic data at scale. Traditional computer forensic techniques still play a vital role in this process. However, incident responders acquire forensic images of specific systems of interest for more targeted analysis driven by investigative objectives.
With the introduction of endpoint detection and response (EDR) tools into the security market, organizations now have the ability to collect system events and other system metadata in the course of system operations to detect and investigate threats.
Regardless of the approach, effective incident response investigations follow a well-established process to gain a full understanding of an incident and remediate it successfully, as depicted in Figure 5.1.

Figure 5.1: Incident investigation process
Determine Objectives
The first step in the incident investigation process is to gather initial information about a reported incident and establish objectives for the investigation. Not all incidents require the same level of response. Furthermore, depending on the nature and scope of an incident, an organization may have different priorities and objectives for the investigation. For example, if analysts identify evidence of data theft, the discovery may lead to legal exposure if the data is subjected to regulatory compliance. Consequently, the objectives of the investigation may be different from those of a ransomware attack.
Incident responders must establish objectives for an investigation and use the information to drive investigative activities. Incident response is about managing residual risk, and the response effort must be proportional to the level of risk and impact associated with an incident. The following list briefly discusses typical activities in this step.
- Review initial incident data. The first step in the investigation process is to review incident information. Depending on the nature of the incident, this data may include readily available indicators of compromise (IOC), observables, alerts generated by security tools, and evidence of connectivity to an IP address with a poor reputation, among others. This information is necessary to establish the investigative leads discussed later in this section.
- Interview personnel. Interviewing personnel is another critical step necessary to gather contextual information about an incident. The interview process should include technical personnel who detected and reported the incident, as well as business stakeholders who set priorities for the investigation, such as a business unit leader or legal counsel. Interviewing personnel who may have business context and who understand the architecture and configuration of the impacted technology is also essential.
- Establish objectives. Based on the information gathered during the previous two steps, establish objectives for the investigation. Objectives serve as a reference point and allow stakeholders to determine whether an investigation progresses in the right direction. Ensure that crucial stakeholders are in agreement about the objectives and priorities. A good practice is to document the objectives and get written approval from the key stakeholders. Establishing objectives for an investigation is also a crucial step in planning.
- Establish a hypothesis. This is a critical, and often missed, step in incident investigations. It is rare that a malware alert or evidence of command and control (C2) communication is an isolated event. In many cases, attackers progress through earlier phases of the cyberattack lifecycle, such as privilege escalation or lateral movement, before their activity tirggers an alert. For this reason, establishing a hypothesis and investigative leads is critical to ensuring that an investigation does not miss critical findings. Mapping evidence of attacker activity to a cyberattack framework throughout an investigation can help establish and refine a hypothesis. For example, if analysts discover evidence of data staging in a compromised environment, then it is likely that evidence of lateral movement exists too.
- Create a plan. Based on the information established during the previous steps, create an investigation plan. A short plan listing crucial activities, their respective owners, and target dates is sufficient to start an investigation on the right foot. A plan may contain activities, such as technology deployment for live response, data collection through traditional forensics, cadence of communication with key stakeholders, roles and responsibilities, and data preservation. The plan must be aligned with the objectives and agreed on with key stakeholders. Some of the stakeholders may be vendors or even regulators, which adds another layer of complexity to planning and execution.
Acquire and Preserve Data
Chapter 3 discussed data acquisition methods in detail. Furthermore, Chapter 6 discusses this topic from a legal perspective with a particular emphasis on data preservation. The following list focuses on general data acquisition and preservation considerations and best practices for small- and large-scale incidents.
- Identify data of interest. The first step in the acquisition process is to decide what data to acquire. This step is necessary to answer crucial questions about the incident and to accomplish the objectives of the investigation. In some cases, an analyst may want to examine data from multiple systems to determine the root cause of an incident. For example, if a system triggered a malware alert, the analyst may also want to acquire firewall or Internet proxy logs to establish evidence of communication to an attacker C2 infrastructure.
- Decide on an acquisition method. Depending on the nature of the incident, affected systems, and their locations, as well as business priorities, analysts may leverage various acquisition methods, such as forensic imaging, live response, memory acquisition, and log acquisition from enterprise services, or a combination thereof. Incident responders need to choose a method that captures the data necessary to answer crucial investigative questions. The temporal aspect of data is a vital consideration during data acquisition. Volatile data, such as network connections, typically has a short lifespan. Other types of data, such as artifacts in Windows registry files, persist on disk even if a system is powered down. Furthermore, the attacker dwell time may also drive decisions during this step.
- Create a plan to preserve data. At first, data preservation seems to be a straightforward task. However, in practice, data preservation can quickly become complex to manage as the scope of an investigation grows and analysts acquire data from multiple sources. This consideration is particularly applicable in cases where an incident response investigation might result in a legal proceeding, such as civil litigation. In some cases, an organization may even hire an external firm to preserve forensic data. An essential aspect of data preservation is ensuring data integrity, chain of custody, and a data retention policy. Chapter 6 discusses this topic in detail.
- Acquire data. A vital consideration in data acquisition, especially in the case of live response and memory acquisition, is to limit changes to the state of the acquired system. Small changes are inevitable, since most acquisition methods must interact with the system to collect forensic data. For this reason, analysts must produce detailed documentation of the acquisition process. Another consideration is to use sound, industry-accepted data acquisition protocols. The premise behind a sound and defensible technical protocol is that another analyst can repeat the protocol and arrive at the same results.
- Document actions and decisions. I cannot stress enough the importance of this step. Analysts must document the decisions that they make and the actions that they take in order to ensure that the acquisition and preservation protocol is defensible and accounts for deviations from standard practices. This step is of vital importance in cases that may result in a legal proceeding or are subject to scrutiny from regulators and auditors. Furthermore, adequate and complete documentation survives employee turnover, and it can provide information about an investigation years after its completion.
It is important to emphasize that the data that analysts require to answer crucial investigative questions may not exist. This scenario frequently happens during investigations of cyber breaches. For example, it is not uncommon for IT personnel to destroy forensic data by reimaging or rebuilding systems to contain an incident. In other cases, systems may not comply with security configuration baselines or retain log data as per the data retention policy. The result is that often vital forensic data is missing. Incident responders must document any missing data and communicate it with crucial stakeholders. Missing data is another reason why adequate and complete documentation is vital to the acquisition and preservation process.
The final point is that organizations must establish data acquisition and retention protocols as part of their incident response plan. Attempting to determine a protocol during an incident typically leads to confusion, conflicts of priorities, and inappropriate handling of digital evidence.
Perform Analysis
Arguably, analysis is the crux of incident response. The purpose of this step is to analyze available artifacts and other data to determine the root cause and full extent of an incident.
It is vital to emphasize that analysis is an iterative process. Analysts iterate through the lifecycle until they reach diminishing returns relating to new findings, such as discovering additional compromised systems or identifying additional attacker tools, tactics, and procedures (TTP) relevant to the investigated case. In simple terms, if consecutive iterations of the lifecycle no longer produce relevant findings, that is when the process typically terminates.
Analysis is a complex discipline, and it requires skills in multiple incident response domains, such as digital forensics, CTI, or malware reverse-engineering. During large-scale investigations, organizations typically assemble a team of analysts with complementary skills to progress analysis.
During enterprise incident response, organizations typically employ a lifecycle approach, as depicted in Figure 5.2, to analyze incidents.
- Analyze data. Analyzing data entails examining the data acquired during the acquisition and preservation step to answer crucial investigative questions. This step is typically the more labor-intensive process that involves digital forensics, malware analysis, and CTI. During significant incidents, enterprises often choose to hire an external firm with specialized skills and capabilities in this area.

Figure 5.2: Analysis lifecycle
- Perform intelligence enrichment. CTI augments the analysis step by providing contextual information to help drive further investigative activities. Malware analysis and contextual CTI research are vital parts of this process. CTI analysts often leverage incident information that forensic analysts determine based on the analysis of compromised systems. Malware analysis is another rich source of information for CTI analysts. For example, a CTI analyst may use the data initially gathered to make a preliminary attribution assessment of the responsible threat actor. With this knowledge, the analyst can provide relevant IOCs and observables to incident responders to identify other compromised systems and rapidly scope the incident. IOCs are forensic artifacts indicative of attacker activity.
- Generate IOCs. Based on the outcome of the analysis and CTI augmentation, the next step is to generate IOCs to continue scoping the compromise. IOCs can take many forms, including IP addresses, hashes of malicious files, signatures of exploits, or compromised accounts, among others. As analysts continue to investigate and scope the incident, the list of indicators typically grows.
- Scan for IOCs. During enterprisewide intrusions, attackers typically compromise multiple systems and establish persistence in the compromised environment. To scope the compromise effectively, analysts should import previously identified IOCs into security tools that can alert on attacker activity and identify additional compromised systems. During enterprise incident response, analysts typically import IOCs into an incident response technology, such as EDR, and scan the environment for the presence of those IOCs.
- Acquire additional data. Based on the findings that arise from monitoring and scanning for IOCs, analysts may identify new systems of interest that they need to examine. Consequently, analysts may choose to acquire the data of interest through traditional forensic imaging or collect specific data types through live response. Furthermore, based on the findings during the previous step, analysts often acquire additional contextual data, such as firewall or web proxy logs. This step, in turn, feeds into the analysis phase, and the lifecycle continues until analysts have a reasonable degree of confidence that they identified all compromised systems and have a good grasp of the full scope and extent of the incident.
Analysis is an iterative process. As analysts investigate an incident, they may decide to acquire and analyze additional data in order to understand the attacker's operations. This approach is particularly applicable to large-scale investigations. For example, during a forensic examination of a compromised system, an analyst may recover new IOCs. A logical step is to scan the environment for the indicators to determine if there were previously unknown compromised systems. If there are matches, the analyst may acquire data from the new systems for further analysis.
Contain and Eradicate
Once incident responders have a reasonable degree of confidence that they have understood the scope of an incident and have answers to the investigative questions, it is time to contain the incident and eradicate the threat actor from the compromised environment. Chapter 4 briefly discusses remediation as part of the incident response lifecycle. This topic is so important to cyber breach response that I dedicate an entire section to incident containment and eradication later in this chapter.
Conducting Analysis
As previously mentioned, incident analysis is a complex process that requires skills in domains, such as digital forensics, CTI, and malware analysis. Each of these domains in turn is a complex discipline and requires specialized skills. During large-scale incidents, victim organizations typically convene a team with complementary skills across these domains. The personnel work together to answer crucial investigative questions and understand the scope of the incident. This section discusses each of the domains mentioned earlier and how they contribute to the overall investigative process.
Digital Forensics
Digital forensics is a specialized discipline that focuses on the analysis and recovery of digital data from compromised systems. Forensic analysts use specialized tools and techniques to reconstruct events on an examined system to determine how an attacker interacted with the system and to develop IOCs. Digital forensics can also help organizations recover deleted data to prove or refute a hypothesis. For example, in some cases, analysts may recover files deleted by an attacker that provide evidence of data staging.
Digital forensics is a broad discipline that requires skills and experience across various technologies. Three primary areas of digital forensics are computer, network, and mobile forensics. However, with cloud computing and other trends in technology, traditional forensics skills by themselves are no longer enough. Incident responders must be well versed in numerous technologies and be able to adapt to investigate incidents effectively. Arguably, specific knowledge and skills in traditional computer forensics are no longer enough in today's evolving digital work. Incident response professionals must understand the underlying methodologies that underpin the digital forensics and incident response (DFIR) domain to respond to different types of incidents and effectively work with business and technology stakeholders.
Digital Forensics Disciplines
The following list discusses various aspects of digital forensics that organizations need to consider when building incident response capabilities.
- Computer Forensics Historically, traditional computer forensics has been associated with law enforcement and electronic discovery cases. Computer forensics focuses on analyzing persistent and volatile system artifacts in order to answer investigative questions. For example, a forensic analyst may review program execution artifacts to determine when an attacker has installed malware on the examined system. Analysts may leverage traditional disk forensics, also referred to as “dead box” forensics, live response, memory forensics, or a combination thereof. Chapter 3 discusses this topic in detail from a technology perspective.
It is important to emphasize that during large-scale investigations, analysts typically leverage a combination of the methods mentioned earlier. One frequent use case is to leverage live response techniques for rapid triage and acquire disk and physical memory images for an in-depth analysis. This approach makes the incident response process scalable.
- Network Forensics Network forensics is a branch of digital forensics that focuses on analyzing network data for intrusion detection. Gathering network telemetry has two primary uses: reconstructing network events associated with past attacker activity and monitoring for additional activities to scope an incident. Some network data is volatile and dynamic, whereas other data is persistent. For example, data that flows through the network is volatile and requires in-transit capture. Firewall traffic logs, on the other hand, are more persistent.
Network forensics can be a stand-alone discipline and is sometimes the only source of evidence of attacker activity. However, in the majority of enterprise incident response cases, network forensics complements traditional host forensics and live response, and it provides corroborating evidence of attacker activity.
There are many challenges associated with network forensics. Organizations often encrypt communications, and decrypting the data can be a challenge, as well as violate regulatory requirements in some cases. Furthermore, network address translation (NAT) and the dynamic nature of IP address assignment on client systems, most of which use Dynamic Host Configuration Protocol (DHCP) to obtain ephemeral IP addresses, makes it challenging to track the sources of network connections. Finally, due to a significant amount of telemetry, network data is often stored for a short period of time unless specifically retained in a long-term storage solution.
- Mobile Device Forensics Historically, mobile forensics has played an important role in law enforcement cases and electronic discovery. However, attackers have been increasingly targeting mobile enterprise users by exploiting vulnerabilities in apps, installing malware on mobile devices, and using other techniques to harvest sensitive data, such as credentials.
Although mobile device forensics is not a mainstream discipline in enterprise incident response, it plays an increasingly important role in internal investigations, such as employee-related cases or electronic discovery for civil litigation. Analysts may recover and analyze a variety of artifacts from mobile devices, such as historical geolocation data, Internet browsing history, call history, documents, and data from installed apps, and they may even recover deleted data, among other artifacts. As of this writing, I have not come across cases where a threat actor used a compromised mobile device to pivot to an enterprise network.
- Cloud Computing Forensics Cloud computing forensics is a relatively new addition to the digital forensics field. Cloud computing forensics combines traditional forensic techniques with cloud-native tools. The steps that incident responders take to investigate breaches of cloud systems depend on the level of access to those systems. With the infrastructure as a service (IaaS) model, incident responders may acquire virtual machines, cloud service logs, and other data. However, with platform as a service (PaaS) and software as a service (SaaS), incident responders may be limited to log analysis, such as event logs associated with programmatic access to cloud service resources. Chapter 3 discusses data acquisition from cloud platforms in detail.
As a field, digital forensics continually evolves, and there is ongoing research into various technologies to uncover system artifacts that may be of value to forensic analysts. Another important consideration is that forensic artifacts and techniques may vary from system to system. For these reasons, incident responders must continually strive to acquire new skills and stay abreast of new developments in this field.
Timeline Analysis
Operating systems create many artifacts that have temporal characteristics, including filesystem, event logs, application logs, network connection logs, and registry entries, among others. Timeline analysis is a forensic technique that allows analysts to reconstruct events on the examined systems by arranging relevant events in a timeline. Timeline analysis is a powerful technique that allows analysts to answer questions relating to which events occurred before and after a given event, such as malware infection, and to gain valuable insights into attacker activity.
Timeline analysis is a particularly powerful tool during large-scale investigations. To arrive at a timeline of attacker activity during an incident, incident responders typically create timelines for individual compromised systems and combine them into a single master timeline consisting of significant events. This information is invaluable for reporting and reconstruing the picture of an attack. In my personal experience, a timeline with a narrative in business security language is particularly useful for reporting and communicating investigative findings to senior-level management.
One crucial consideration in building a timeline is to ensure that all timestamps are expressed in Coordinated Universal Time (UTC). UTC is the de facto standard for timestamping event logs. However, some organizations choose to use a time that is local to their geographic region instead. As a result, analysts must translate non-UTC time to UTC time before timelining events.
Other Considerations in Digital Forensics
Digital forensics often relies on artifacts produced in the course of system operation, such as program execution artifacts, to answer vital investigative questions. In some cases, the data necessary to answer those questions may not be available. For example, a system has overwritten specific artifacts in the course of its operations or the necessary logging policies were not configured to capture the data of interest.
Even if specific artifacts are available, analysts may have to correlate and corroborate them with other sources of data, such as network telemetry to determine attacker activity. For example, during data theft cases, analysts typically correlate system artifacts with data relating to network connections in order to prove or refute a data theft hypothesis.
It is essential to keep in mind that digital forensics may not always provide all the answers to questions that business stakeholders ask. Another crucial consideration is that sophisticated threat actors often leverage anti-forensic techniques to make the discovery and investigation of their attacks challenging. For example, an attacker may manipulate the timestamps of a malware binary file to minimize the possibility of detection. Incident response professionals refer to this technique as timestomping.
To maximize the chances of answering vital investigative questions, enterprises need to configure logging and log retention policies to support incident response investigations. The enforcement of those policies across the enterprise is vital.
Cyber Threat Intelligence
Chapter 1 briefly described CTI as a driver for cyber breach response. This section discusses intelligence-driven incident response, with a particular focus on tactical intelligence to support investigations.
Intelligence-driven response is an approach to incident response that leverages intelligence processes and concepts as an integral part of the overall investigation process.1 CTI augments digital forensic processes by researching and applying contextual threat information in order to identify attacker activity and scope an incident effectively. Not only is CTI necessary to understand the root cause and scope of a compromise, but it is also essential in containing an incident and eradicating the threat actor from the compromised environment.
CTI analysts leverage various techniques to gather information necessary to support incident investigations, such as attacker-centric and asset-centric approaches.2 This book discusses the attacker-centric approach only. Analysts also rely on structured analytical techniques, such as analysis of competing hypotheses (ACH),3 in order to reduce or eliminate analytical bias in the process. All too often, even the most veteran analysts have at some point made an attribution assessment based on past experiences instead of applying the appropriate rigor to their assessment.
CTI research typically starts with known information about an incident. For example, an organization has detected malware, a network connection to a known C2 domain, or evidence of a suspicious tool, such as credential harvesting software. The initial information acts as a starting point for the research. Analysts start with the initial indicators and perform research that may provide an insight into the TTP that an attacker leverages, uncover additional IOC, or even attribute the attack. CTI professionals often refer to this approach as intelligence enrichment. CTI research is like unraveling a thread. For example, I worked on cases where CTI enrichment of a single IOC opened up an entire investigation and allowed the analysts to uncover additional evidence of attacker activity in the compromised environment.
Attributing a cyberattack to a specific threat actor is often a part of the CTI process. Chapter 6 discusses attribution in depth. For the purposes of this chapter, it is worth noting that cyber attribution is becoming increasingly difficult as threat actors move away from using custom malware and leverage tools that they find in compromised environments to progress through the cyberattack lifecycle.
Cyber Threat Intelligence Lifecycle
CTI analysts gather threat information and analyze the information to answer specific questions relating to an investigation. This section discusses the CTI lifecycle, with a particular emphasis on tactical intelligence to support incident response investigations.
CTI enrichment is an iterative process consisting of five phases. The last phase provides a feedback loop to the first phase to continue the process until the analysts have enough information to achieve the investigation's objectives or they reach diminishing returns relating to new findings This process is tightly coupled with forensic analysis and monitoring for attacker activity, as depicted in Figure 5.3.

Figure 5.3: The CTI lifecycle
- Direction Initial findings and leads that incident responders establish early on during an investigation provide a preliminary direction for CTI gathering. These leads can come from security monitoring, network traffic analysis, malware analysis, forensic findings, or third-party notifications, such as law enforcement. Analysts must establish objectives for the CTI research. The overall investigation objectives typically drive this activity.
- Collection In this step, analysts typically pivot on the initial findings and investigative leads and collect information about past potentially related incidents and reports from researchers, vendors, and law enforcement agencies in order to perform an attacker-centric research and gather contextual information about the incident. As part of this step, analysts also verify if the collected information is relevant to the investigated case.
- Processing After collecting data, analysts must process the data into an appropriate format for the target audience, such as a listing of IP addresses and domain names for importing into security tools or a dossier on a particular, identified group for consumption by the incident response team.
- Dissemination As the next step, analysts disseminate the produced intelligence to the appropriate stakeholders, such as incident responders for scoping or managers to make decisions about investigative priorities. For example, management may be interested in attacker goals, whereas a forensic analyst typically is more interested in stand-alone IOCs, such as malware hashes or C2 domains.
- Feedback Feedback occurs at the incident management and technical levels. From a technical perspective, forensic analysts can notify CTI analysts if they identify any systems with the indicators discovered through CTI enrichment. In contrast, from an incident management perspective, an incident manager or a senior stakeholder may leverage CTI findings to drive investigative priorities. For example, if CTI analysts determine that the goal of the threat actor behind an attack is to steal intellectual property, the enterprise may choose to focus on securing the environments that host that type of data while the investigation continues to minimize the possibility of data theft.
It is crucial to emphasize that the intelligence-driven approach involves all the components mentioned here to support an investigation.
Identifying Attacker Activity with Cyber Threat Intelligence
The following list briefly describes common components of the attacker-centric approach that analysts often leverage in investigations.
- Attack Vector An attack vector is a means by which an attacker gains unauthorized access to a system or network. There are numerous attack vectors that attackers can leverage to gain initial access to a system or computer network before progressing through the remaining phases of the cyberattack lifecycle. For example, phishing is a popular attack vector that attackers use to entice their victims to open an attachment or click on a link that takes the victim to a rogue website. This technique allows attackers to deliver a malicious payload that executes on the victim's system and leads to unauthorized access. In the case of phishing, a malicious attachment contains embedded code that constitutes the payload.
- Indicators of Compromise In simple terms, an IOC is a forensic artifact indicative of attacker activity. Analysts often derive IOCs through forensic analysis of compromised systems and CTI enrichment. Examples of IOCs are hash values, IP addresses, domain names, filesystem and program execution artifacts, or signatures of attack patterns, among others. I discuss IOC categorization later in this chapter.
It is important not to confuse IOCs with indicators of attack (IOA). The latter represents the actions that an attacker takes before compromising a system or network, such as reconnaissance.
- Behavioral Characteristics Behavioral characteristics refer to the TTPs that represent the way that an attacker operates to progress through the cyberattack lifecycle. Behavioral characteristics are useful in developing contextual information associated with specific threat groups. For example, a specific threat group may exploit vulnerable web servers and place a web shell on those web servers for remote access. A web shell is a script that allows an attacker to use a web server as an entry point into a system or network.
- Goals Goals require specific effort and represent the desired outcome that an attacker tries to achieve. Threat actors compromise systems and networks to achieve specific goals, such as financial data theft, theft of intellectual property, encryption of systems and data for ransom, or espionage. Attacker goals are arguably the most abstract type of information that CTI analysts can gather. Also, some attackers may adjust the way that they operate in response to detection, but goals typically do not change.
Not all CTI is equal. Attackers may easily change some indicators, whereas others are more difficult to change without significantly adjusting the way that a particular attacker operates. To demonstrate this concept, David Bianco created the Pyramid of Pain,4 as represented in Figure 5.4. The pyramid orders IOCs in an increasing level of difficulty for attackers to change. At the bottom, the pyramid lists more volatile indicators that are trivial to change, such as hashes and IP addresses. Toward the top, the pyramid lists indicators that are harder for attackers to change and that have more extended longevity.
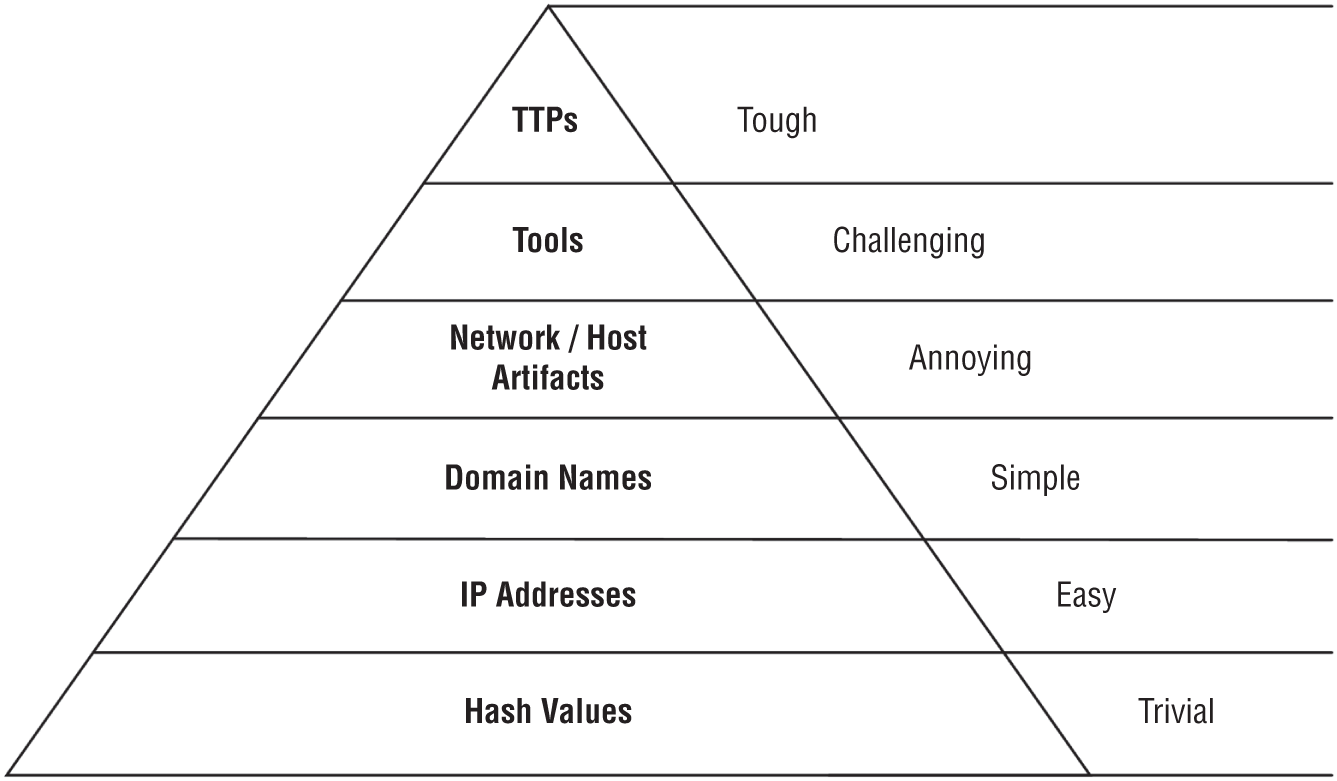
Figure 5.4: The Pyramid of Pain
According to David Bianco, the entire point of indicators is to use them in response and remediation. For this reason, incident responders need to keep in mind that some indicators are temporal. In contrast, other indicators, such as a particular way of executing an attack, are more reliable in the long term. For example, during client incident investigations, I have observed that indicators, such as C2 IP addresses or malware hash values, change. However, I have not come across a case where an attacker would suddenly change their behavioral characteristics in response to an investigation.
The CTI community uses the same acronym “TTP” to refer to two different but related terms that describe how threat actors operate: 1) tactics, techniques, and procedures and 2) tools, tactics, and procedures. In this book, I use the latter term to call out attacker tools explicitly. However, both terms are correct, and the community uses them interchangeably.
According to the Pyramid of Pain, TTPs are associated with behavioral characteristics and are the hardest to change. Tools are software applications, such as malware, utilities, and other software that a specific threat actor uses as part of their attack operations. Tactics describe how a threat actor operates at various phases of the cyberattack lifecycle and how the activities relate to one another. An example of a tactic used to escalate privileges on a compromised system is when a threat actor can use credential dumping software to harvest credentials from volatile memory and uses those credentials for lateral movement. Procedures describe a sequence of actions a threat actor executes during each phase of the cyberattack lifecycle. For example, during the lateral movement phase, an adversary may leverage harvested administrative credentials to access remote systems via services that accept remote connections, such as Secure Shell (SSH) on Unix-like systems.
Categorizing Indicators
Not all IOCs are equal. Analysts may have different levels of confidence in the information that they gather as part of the CTI lifecycle. One way to categorize the information is in terms of fidelity.
- High-Fidelity Indicators High-fidelity indicators, also known as hard indicators, are artifacts and other information that has concrete links to the investigated case and that provide additional contextual information about the potential threat. The use of a known C2 domain registered with an email address attributable to a specific threat actor is an example of a high-fidelity indicator. Incident responders typically ingest high-fidelity indicators into security tools for monitoring and investigative purposes. Incident responders also use this information to scan the compromised network to identify additional, unknown compromised systems and to identify attacker activity in the compromised environment.
- Low-Fidelity Indicators Low-fidelity indicators and behaviors, also known as soft indicators, are information that may be indicative of attacker activity but that is not strong enough on its own. The IP address of a virtual private network (VPN) exit node that a threat actor used to access a compromised service is an example of a low-fidelity indicator. In some cases, low-fidelity indicators may result in a high rate of false-positive events. Incident responders need to correlate and corroborate low-fidelity indicators with other incident information before drawing specific conclusions, such as the compromise of a system.
Another critical consideration is to classify IOCs into specific categories, such as network, host, or behavioral indicators. Grouping indicators and assigning them a fidelity level allows responders to search and filter for data of interest easily, as well as to identify specific information for further investigative steps and CTI enrichment.
It is also worth mentioning that the SANS Institute and many practitioners classify IOCs as follows:5
- Atomic Discrete data points that may indicate adversary activity on their own. According to the SANS Institute, those indicators may not always exclusively represent an activity associated with a threat actor. For example, if a threat actor compromises a legitimate website and uses it to launch their attack, an outbound network connection to that website is not necessarily indicative of a compromise by itself.
- Computed Computed indicators are calculated based on data obtained through forensic analysis. For example, an analyst may compute a hash value associated with a malware binary or create a signature to detect a network-based exploit.
- Behavioral Behavioral indicators closely resemble TTPs described in the previous section. They are composed of specific behaviors and characteristics attributed to a specific threat actor. For example, a threat actor may use a specific tactic to maintain persistence in the compromised environment, such as installing malware as a Windows service or placing a web shell script on a publicly accessible web server and using it as an entry point into the compromised network.
Finally, it is of crucial importance to document the indicators alongside their source and link them to the investigation. As investigations grow and include multiple, simultaneous workstreams, accurate and comprehensive documentation is what allows stakeholders to remain informed about how the threat actor operates in the compromised environment.
It is also worth noting that enterprises can choose to participate in intelligence sharing communities to gain access to CTI that otherwise might not be available to them. This information can be of vital importance during incident investigations. By participating in intelligence sharing programs, enterprises can draw on the collective knowledge and capabilities of their members. Examples of entities that create intelligence sharing programs include government agencies, cybersecurity vendors, and industry-specific CTI centers. These entities usually make CTI available for consumption in the following formats:
- IOCs
- TTPs
- Advisories
- CTI reports
Some platforms and websites make specific CTI available to the cybersecurity community at no cost, such as IBM X-Force Exchange or VirusTotal. These services also offer premium access to organizations that require access to advanced features.
Another option is to partner with a specific CTI vendor that can assist with strategic, operational, and tactical intelligence packages. In my personal experience, partnering with CTI vendors during incident investigations has been invaluable in understanding and scoping enterprisewide intrusions.
Malware Analysis
Malware analysis is an integral part of incident response investigations and requires breadths and depths of understanding of various technical disciplines. Attackers leverage malware and other software tools to gain unauthorized access to a computer network, move laterally, steal data, or encrypt data for ransom, among other things.
Malware has significantly evolved over the years from primitive, self-contained binaries to highly modular malware that often implements obfuscation techniques, such as encryption or polymorphism, to make it difficult to detect and analyze it. Sophisticated malware often relies on a complex infection chain that includes downloaders and droppers, payloads, and a C2 infrastructure. Furthermore, some malware types leverage legitimate applications as part of the infection chain. For example, many malware infections start with the execution of macros embedded in Microsoft Excel files.
With the evolution of the threat landscape, sophisticated attackers often rely on malware providers who offer malware-as-a-service on the dark web. Historically, it was common to attribute attacks based on the malware alone. With the malware-as-a-service model, attribution based purely on malware is rare.
This section discusses common malware types and malware analysis techniques that analysts leverage as part of the incident response lifecycle.
Classifying Malware
Several ways to classify malware exist, such as behavior or infection vector. Malware taxonomy is a process of classifying malware based on specific characteristics and attributes. The following list briefly discusses common malware types that threat actors leverage during enterprise intrusions.
- Viruses A virus is a malicious piece of code that attaches itself to a legitimate program or a file in order to spread from computer to computer and execute its logic. Another name for a virus is a file infector.
- Network Worms A network worm is a stand-alone malware that uses a programmatic approach to spread from computer to computer using mechanisms such as file sharing protocols and peer-to-peer networks.
- Backdoors Backdoor malware allows an attacker to bypass access control mechanisms and gain unauthorized access to a computer system. An example of backdoor malware is a web shell that an attacker places on a compromised web server. A term closely associated with backdoor malware is Remote-Access Trojan (RAT). A RAT is a remote administrative tool that has backdoor capabilities and typically allows an attacker to gain, often root-level, access to a system and remotely control the system.
- Information Stealer An information stealer is a class of malware that steals information by using techniques such as using keylogging, using desktop recording, enumerating local systems and remote data stores for specific types of data, and scraping memory for unencrypted sensitive information.
- Ransomware Ransomware is a type of malware that holds data or access to a computer system hostage until the victim pays a ransom. Three primary techniques exist to achieve this goal: data encryption, data distraction, and user lockout. Data destruction refers to inevitably threatening to destroy the data if the victim does not pay, typically to create a sense of urgency.
- Destructive Malware Malware authors develop destructive malware to render infected systems inoperable and make recovery challenging. Stuxnet6 is a primary example of destructive malware.
Another way of looking at malware is in terms of how attackers use it and its purpose. Commodity malware is a category of malware that is widely available for purchase or free download and does not require any customization. Threat actors typically leverage commodity malware in opportunistic attacks by employing a “spray and pray” strategy. Dridex7 is an example of commodity malware.
In contrast, targeted malware, also referred to as bespoke malware, is very precise malware that threat actors leverage while targeting specific users or a specific entity. Malware authors often write targeted malware for very specific purposes after performing an extensive reconnaissance to maximize the chances of achieving their objectives. Targeted malware is often associated with advanced persistent threat (APT) groups, such as nation-state threat actors. Stuxnet is a primary example of targeted, destructive malware.
An important point to cover before discussing specific malware analysis techniques is fileless malware and “living off the land” techniques. Traditional malware requires attackers to place a binary file on disk, which leaves forensic artifacts behind. Fileless malware, on the other hand, lives entirely in computer memory and does not leave evidence on a disk volume. This technique makes it much harder to detect with traditional tools, such as antivirus, and requires memory forensics to uncover evidence of its execution.
Living off the land is a technique that attackers often use alongside fileless malware. Attackers increasingly rely on legitimate administrative tools that they find in the compromised environment to progress through the cyberattack lifecycle. This technique is appealing because system administrators often whitelist tools that they require for day-to-day tasks. Furthermore, the use of legitimate tools as part of an attack makes it challenging for incident responders to identify malicious activity.
Static Analysis
Depending on the objectives of an investigation, analysts can perform basic or advanced static malware analysis or a combination of thereof.
Basic static analysis is the process of examining an executable file to determine whether the file is malicious and to provide fundamental information about it. During basic static analysis, analysts do not examine the actual code instructions. Instead, they gather and examine the file metadata, including hash, file type, and size. Analysts also search for strings that may provide information about the file's functionality, such as hard-coded IP addresses and URLs.
Static analysis may also check for obfuscation. Malware authors use this technique to obscure meaningful information to make it harder to analyze their malware. In some cases, basic static analysis may yield enough information to generate a signature.
To understand a malware sample fully, analysts may resort to advanced static analysis, which focuses on disassembling malware at the code level and examining the actual instructions. Analysts typically use tools, such as a disassembler, to break down a compiled malware binary file into machine-code instructions. By performing advanced static analysis, analysts can understand the full capabilities of the malware.
Depending on the size and complexity of the malware, reverse-engineering a malware sample can take days or even weeks. For this reason, analysts resort to advanced analysis when dealing with unknown malware, or they need to understand the malware capabilities fully to drive containment and eradication.
Dynamic Analysis
Dynamic analysis is the process of running a malware sample in a controlled environment in order to determine its behavior. One of the most common techniques that analysts leverage for dynamic analysis is a sandbox. A sandbox is a dedicated, isolated system with installed dynamic analysis software that collects telemetry when the malware executes.
Dynamic analysis typically focuses on the changes that malware makes to the system, such as creating new processes, making changes to the registry, network connections, or creating persistence mechanisms. The goal of dynamic analysis is to gather information necessary to identify the examined malware in the compromised environment.
Malware Analysis and Cyber Threat Intelligence
During incident response investigations, malware analysis and CTI go hand in hand. CTI often provides focus and direction for malware analysis. For example, if prior analysis yielded evidence of data theft, a reverse engineer may focus on looking for code instructions that may enumerate various repositories for data of interest.
At the same time, malware analysis can provide rich information on how a particular threat actor operates, including IOCs or tactics. This information, in turn, feeds into the CTI lifecycle. This process is iterative. The information that analysts glean from malware analysis initiates a full CTI enrichment process and servers as pivot points. The outcome of the enrichment process, in turn, allows analysts to identify additional malware that a threat actor may have used as part of their operations in the compromised environment.
Threat Hunting
Threat hunting is an approach to threat detection that combines a methodology, technology, skills, and CTI to detect attacker activity proactively that programmatic approaches, such as traditional antivirus software, may miss.8
Although threat hunting is primarily a proactive approach, incident responders also leverage threat hunting in situations where an organization discovers a suspicious activity but there are no specific IOCs to inform the investigation.
I led investigations where clients reported a suspicious behavior on their network or received a third-party notification about a potential compromise but did not identify specific IOCs. Without a “smoking gun,” our team had to resort to threat hunting techniques to identify IOCs and scope the intrusions.
The premise behind threat hunting is that programmatic approaches to threat detection, such as traditional antivirus, network traffic inspection, or even statistical analysis methods, may not uncover all attacker activity. This approach is particularly applicable to attacks where threat actors employ stealthy techniques or evasion methods, or heavily rely on “living off the land” methods.
Prerequisites to Threat Hunting
Developing threat hunting capabilities requires commitment from senior management, dedicated resources, and an investment into appropriate technologies. The following list describes vital components that organizations must consider in order to enable threat hunting.
- Framework Organizations must develop a systematic analysis-driven approach to hunt for cyber threats effectively. Developing a process based on an established framework with dedicated resources is vital. Appropriate technology, skills, and CTI are crucial components of a sound methodology.
- Technology To hunt for evidence of compromise, analysts must collect the necessary network and endpoint data. Appropriate data must be available, accurate, complete, reliable, and relevant. There is no silver bullet technology to accomplish this task. Threat hunters typically leverage a combination of tools, such as EDR, Security Information and Event Management (SIEM), network-based detection systems, and others.
- Skills To become effective threat hunters, analysts must possess a wealth of skills across various technical disciplines. During threat hunting, analysts look for outliers in data sets and must be able to distinguish between normal versus abnormal activities on a computer network. Threat hunting also requires soft skills, such as critical thinking, analysis, or curiosity.
- Cyber Threat Intelligence CTI provides information about TTPs, and it is a vital component in threat hunting. High-quality CTI augments analysis in two ways: it helps identify low-hanging fruit through a programmatic approach, and it provides contextual information during manual analysis. In some cases, CTI delivers specific information that analysts may hunt for in their environments, such as information on how a specific threat actor operates.
Threat Hunting Lifecycle
Threat hunting is an iterative process with clearly defined phases. Moreover, organizations have two options at their disposal to perform threat hunting: data-driven and target-driven threat hunting.9
The data-driven approach involves collecting a specific data set and analyzing it for evidence of suspicious activity. For example, an analyst may choose to collect program execution artifacts from specific environments and look for evidence of malware and other suspicious tools.
In contrast, a target-driven approach allows organizations to determine whether a particular threat is present in their environments. For example, an analyst may compile a list of IOCs associated with a specific threat actor and leverage tools, such as EDR, to query endpoints for those indicators. Organizations with a mature threat hunting capability typically combine both approaches.
Figure 5.5 depicts a typical lifecycle approach that organizations can leverage to hunt for threats in their environment.10
- Determine Purpose Determine why a specific threat activity must occur, including any assumptions and limitations. Additionally, determine a specific outcome stemming from the activity. A clearly defined purpose provides general guidance and direction for hunting. For example, an organization may choose to perform threat hunting following a corporate merger and acquisition to gain assurance before connecting corporate networks.
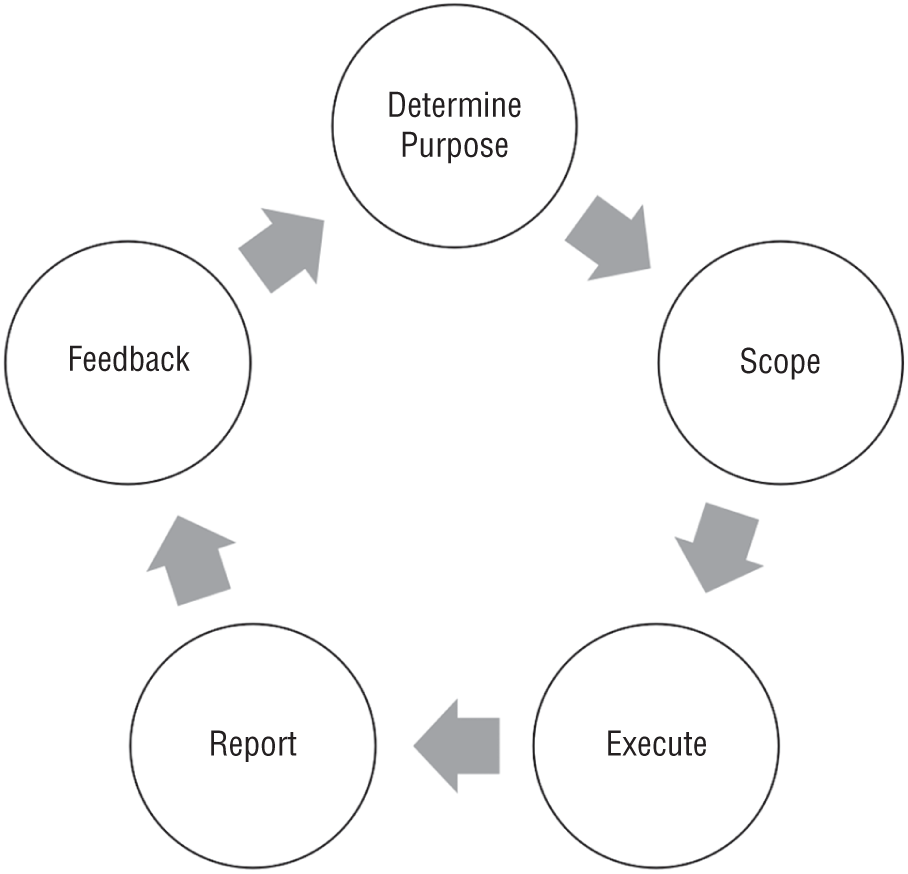
Figure 5.5: Threat hunting lifecycle
- Scope Scoping includes two activities: defining a specific environment or network segment for hunting and generating a hypothesis. The former identifies the technology in scope. The latter allows analysts to generate analytical questions to drive the hunting activity. CTI, situational awareness, and domain knowledge typically help analysts formulate a hypothesis.
- Execute The execution stage includes multiple iterations of data acquisition and analysis. The techniques that analysts employ depend on whether their hunting is data- or target-driven. The purpose of this phase is to collect data from systems in scope and use analysis techniques to prove or disprove the hypothesis developed during the scoping phase.
- Report Preparing a threat hunting report concludes the execution phase. Analysts should produce a formal report for large-scale threat hunting exercises, especially if senior leadership requested the activity based on risk concerns. Ongoing threat hunting activity does not typically require a formal, extensive report.
A formal report should clearly state the purpose and scope of a threat hunting activity before discussing the outcome and findings. A sound report also briefly articulates the analysis techniques that analysts employed and any limitations and obstacles.
- Feedback Feedback is a process that analysts employ to evaluate the previous stages of the lifecycle and to take corrective actions to improve the overall threat hunting methodology and framework. For example, analysts may evaluate the scoping phase to determine whether the scope was too narrow, just right, or too big. This evaluation can help ensure scoping future hunting activities more precisely. Consequently, feedback allows organizations to improve and optimize their threat hunting capability continuously.
Some threat hunting activities may lead analysts to discover evidence of a historical or ongoing network intrusion. In such cases, organizations must consider transitioning the hunting activity into an incident investigation. By declaring an incident, organizations can ensure that they dedicate the necessary resources to appropriately respond to the incident.
Reporting
Reporting is a critical but often forgotten part of the analysis phase. An adequate report summarizes an incident in a succinct yet complete manner, and it helps key stakeholders understand significant incident events. There are three types of reports that incident responders typically produce during enterprise incident response.
- Technical Reports Technical reports capture low-level technical information relating to a specific aspect of an investigation or analysis. An example of a technical report is a malware reverse-engineering report that captures the technical details and capabilities of a malware sample. The primary audience for technical reports is technical personnel who set the technical direction for an investigation and incident response analysts.
- Periodic Management Reports During large-scale, prolonged investigations, management may require periodic reports to understand the overall progress and findings during the investigation in order to make informed decisions about priorities. Periodic management reports should summarize investigative activities and vital findings in an easy-to-understand business security language and clearly articulate the next steps with defined timelines.
- Investigation Report An investigation report is a comprehensive report that focuses on an incident as a whole and helps key stakeholders understand significant incident events. Incident responders should produce a final investigation report after concluding an investigation. An investigation report typically consists of two major sections: an executive summary and a detailed incident discussion section.
The following paragraphs provide general recommendations that can help incident responders produce high-quality reports that communicate their findings to key stakeholders effectively.
- Create a report template. Create a template for reporting. Templates make the reporting style consistent and they save time. Also, reporting using a consistent style and a clear structure can help communicate findings in the long term, especially for internal reporting.
- Focus on facts. A well-written report provides an objective and impartial statement of the analysis effort and its findings. For this reason, report authors must focus on facts and avoid speculation or assumptions. Where speculation is unavoidable, the authors should clearly state that they speculate about specific events. Furthermore, authors must provide evidence, such as tables describing artifacts, to support their statements.
- Know your audience. A report for executive personnel has a very different focus compared to a report for technical audiences. Report authors must tailor the content and the presentation style for the intended audience to communicate their message effectively.
- Write in formal language and active voice. Formal language and active voice are the de facto styles for technical writing. Active voice adds impact to writing. Passive voice often leads to wordy and vague sentences and ambiguity. Active voice, on the other hand, makes writing more concise, actionable, and engaging. Active voice also helps move the narrative, improve flow, and generally improve readability.
To write in the formal style, report authors must use objective, impersonal, and precise language and avoid slang and informal expressions. Also, ensuring correct grammar, clear transitions, and logical flow between different sections of a report is vital.
I cannot emphasize enough the importance of reporting. Organizations may require investigation reports for a variety of purposes, including compliance, cyber insurance, or for anticipated litigation. Furthermore, reports are more reliable than human memory and outlive investigations. After several months or even a few years, a report may constitute the only reliable information available about a past incident.
Evidence Types
Systems and software applications often generate significant volumes of artifacts that incident responders may leverage during their investigations to determine attacker activity in a compromised environment.
Some of the artifacts are byproducts of normal system operations that happen to have forensic value. For example, the Windows operating system implements performance and software compatibility mechanisms that generate artifacts relating to program execution. These artifacts are an invaluable source of information on malware and other tools that a threat actor executed on a compromised system.
Furthermore, system administrators configure security policies that cause systems and applications to generate artifacts in response to specific events. For example, authentication logs provide information, such as user accounts that successfully and unsuccessfully attempted to log in to a computer system.
Before diving into a detailed conversation about digital evidence, it is crucial to understand the difference between artifacts and evidence. An artifact is a piece of data that a system or software application produces in the course of its operations. For example, an event log showing a successful authentication attempt is an artifact. In contrast, an artifact that is relevant to an investigated case because it either supports or refutes a hypothesis becomes evidence. For example, if an analyst identifies a program execution artifact associated with attacker malware, that artifact becomes digital evidence.
System Artifacts
Operating systems generate several types of artifacts that allow analysts to establish attacker activity on a compromised system. Chapter 3 discussed data acquisition in detail. Depending on the acquisition method, incident responders can collect persistent and volatile artifacts from systems of interest.
Persistent Artifacts
Persistent artifacts constitute data that resides in persistent storage, such as a hard drive, and outlives the process that created the data. For example, systems generate and write event logs to a persistent storage volume. If an administrator reboots the system that generated the event logs, the data is still available on the storage volume. The following list discusses typical persistent artifacts that systems generate in the course of their operations.
- Filesystem Artifacts A filesystem provides analysts with a catalog of all the files that exist on a disk volume. In some cases, a filesystem also contains residual metadata associated with recently deleted files. Analysts use filesystem artifacts to establish evidence of attacker-created files, such as malware, or evidence of data staging during data theft cases. In some cases, analysts can also recover deleted data if the system did not overwrite it with other data.
- Program Execution Threat actors often run malware, utilities, and other software on compromised systems as part of their operations. Operating systems may record artifacts related to their execution that enable analysts to establish what malware and software application a threat actor ran and, in some cases, recover their corresponding binary files for detailed analysis.
- Account Usage Account usage artifacts provide analysts with information about successful and unsuccessful login attempts and other security-related events that systems and applications generate in response to a security policy. Analysts leverage this information to establish evidence of activities, such as unauthorized access to systems, lateral movement, or privilege escalation.
- External Devices Whenever a user connects an external device to a system, the system may generate persistent configuration data for the device. This information is invaluable for investigating cases, such as data theft by an insider threat or malware infections through external storage media.
- Browsing History Forensic artifacts associated with browsing history allow analysts to determine what websites users accessed, evidence of social engineering attacks, or what files users downloaded, including malware. The artifacts vary from browser to browser.
- File and Folder Opening Systems generate file and folder opening artifacts for various reasons, such as recording the size of Explorer windows in the case of Microsoft Windows. File and folder opening artifacts provide an insight into the files and folders with which a threat actor interacted, browsing history, access to files on a remote media, or execution of software through the graphical user interface (GUI). In some cases, this artifact category can also help determine evidence of files that no longer exist in the filesystem.
- Network Activity Persistent network activity artifacts allow analysts to establish what networks an examined system connected to and, in some cases, even establish the physical location of those networks.
This list is by no means exhaustive. It is important to emphasize that artifacts may vary from system to system. For example, production Linux systems that support core applications typically do not have a GUI subsystem installed. For that reason, the systems do not generate browsing history artifacts.
Volatile Artifacts
In contrast to persistent artifacts, volatile artifacts constitute data that resides in system memory and is typically short-lived. The data ceases to exist when a user or administrator powers down the system or the process that created the data terminates. Analysts typically acquire volatile data through live response or by acquiring a forensic image of the system memory. The following list discusses typical volatile artifacts that systems generate in the course of their operations.
- Process Data In simple terms, a process is a program that is loaded into memory and currently executing on a computer system. A listing of running processes can help identify evidence of malware and other utilities that a threat actor may leverage as part of their operations. As part of collecting process information, analysts may be interested in attributes such as the full path of a binary file, the command line used to launch the process, loaded modules, security context, or how long the process has been running.
- Network Connections By listing and enumerating currently open connections, analysts may discover evidence of lateral movement or malware beaconing out to an attacker C2 infrastructure. In some cases, analysts may also identify suspicious programs that typically do not communicate over a network.
- Mapped Drives and Shares Information about mapped drives and shares can help analysts establish evidence of suspicious activities, such as lateral movement or data staging. This information is particularly useful for administrative shares that threat actors may use for lateral movement and deploying malware.
- Logged-on Users During an investigation, analysts may want to collect information about the currently logged-on user. Users can log into a system locally or remotely. In both cases, the information may provide context to other artifacts, such as running processes or access to specific files.
- Clipboard Contents Each time a user copies data from one application to another application, the operating system copies that data into the clipboard. In some cases, analysts may recover data that a threat actor copied, such as harvested credentials or files of interest.
- Open Files Enumerating open files allows analysts to identify files that remotely logged-on users accessed. This information is especially useful in cases when a threat actor uses harvested administrative credentials to access remote systems and enumerate them for valuable information.
- Service Information Services are background running processes. Service applications are often started at system boot, but administrators can also start them manually. Information about services is key to investigations because malware often runs as a service to maintain persistence and survive system reboots.
As in the case of persistent artifacts, this list is by no means comprehensive. The purpose of this section is to demonstrate the type of evidence that analysts may uncover during forensic examination of compromised systems. It is also worth mentioning that certain artifacts reside in memory first before the operating system writes them to persistent storage.
Network Artifacts
Network data is an invaluable source of evidence during incident investigations. It often augments host forensics and helps prove or refute a hypothesis surrounding an investigated incident. In some situations, network data is the only source of evidence that analysts have available.
Several use cases exist for acquiring and analyzing network telemetry as part of an incident investigation. The following list presents some common use cases:
- Scoping By importing IOCs associated with attacker activity into network monitoring tools, incident responders can identify additional compromised systems that they did not discover through endpoint analysis.
- Identifying Evidence of Lateral Movement Network telemetry helps establish evidence of lateral movement by correlating and tracking network connections associated with compromised systems, including the timing and duration of those connections.
- Determining Data Theft When correlated with evidence of data staging, network telemetry can provide corroborating evidence of data theft, such as network connections to an attacker-controlled infrastructure or evidence of data transfers. Data staging refers to the staging of data in a centralized location before transporting it out of the compromised environment.
- Gaining Additional Visibility into Attacker Activity By monitoring network connections and correlating network telemetry with endpoint-based artifacts, incident responders can better understand how the attacker operates in a compromised environment. This may include identifying additional C2 infrastructure associated with deployed malware, identifying the timing when the attacker is typically active on the network, or determining how the attacker performs reconnaissance within the compromised environment. Furthermore, event-based detection tools allow responders to determine whether the attacker uses network-based exploits or abuses network protocols as part of their operations.
- Identifying Web-Based Indicators Collecting data from tools such as proxy servers and web gateways allows incident responders to establish evidence of access to malicious domains or determine whether a user downloaded a malicious document from a rogue website.
Security Alerts
Alerts triggered by host and network security tools are often the first indication of a cybersecurity incident. Although alerts by themselves may not be enough to determine attacker activity in a compromised environment, they often help analysts to establish a hypothesis and create initial leads to drive further investigation. There are typically two types of security tools that enterprises deploy: host and network. The following list discusses typical information that analysts can glean from security alerts.
- Evidence of Malware Antivirus software and EDR alerts are often the first symptoms of an active threat in the enterprise environment. Endpoint detection tools are so ubiquitous in the enterprise that most organizations have some capability to detect a threat on their network.
- C2 Communication Most modern malware these days leverages a C2 infrastructure to receive instructions, download additional malware, or even exfiltrate data. Host- and network-based security tools can often alert on this activity, especially if they have CTI feeds integrated from a reputable source.
- Vulnerability Exploitation Many security tools use signatures of well-known attacks and heuristic capabilities to detect attempts to exploit vulnerabilities. These alerts can help analysts establish early evidence of attacker activity and lateral movement.
- Data Theft Solutions such as data loss prevention (DLP) can alert analysts on attempts to steal data from a compromised environment. Insider threat activities often trigger DLP alerts. In the case of an external attacker, DLP alerts typically trigger when the attacker progressed through the cyberattack lifecycle and attempts to extract data from compromised systems.
- Unauthorized Access to Resources Some access control and management tools monitor access to resources, such as database tables, and may alert on unauthorized access attempts to those resources.
Remediating Incidents
Remediation is the final step of the incident response lifecycle. Remediation encompasses the containment, eradication, and recovery phases. Each of these phases is necessary to protect crucial assets while an investigation is under way, eradicate the threat actor from the compromised environment, and recover technology into a fully operational state, respectively. Remediation is a complex process that typically starts at the onset of an investigation. It requires establishing a dedicated team and precise planning to be successful.
This section discusses vital considerations that victim organizations need to take into account when remediating large-scale breaches, including establishing a remediation team, planning, and execution. It is worth noting that in many enterprises, recovery is a function of information technology. For this reason, this section primarily addresses the containment and eradication phases of remediation.
Remediation Process
Chapter 2 briefly discussed the incident response lifecycle in detail. In this chapter, I focus on the overall process to remediate cyber breaches, as depicted in Figure 5.6.

Figure 5.6: A remediation process workflow
- Establish a remediation team. Remediation requires skills and expertise in various technical and nontechnical domains. At the onset of an investigation, the victim organization must establish a remediation team and start planning containment and eradication of the attacker from the compromised environment.
- Develop a remediation plan. Remediation of large-scale incidents requires a coordinated and orchestrated effort to succeed. As part of establishing a remediation team, the victim organization must assign a remediation lead and a remediation owner, who are responsible for the planning and execution of containment and eradication activities.
- Contain the incident. Depending on incident type, scope, and its severity, an enterprise may choose to execute short-term containment actions first to prevent the incident from exacerbating and causing further severe damage. This step is specifically applicable to destructive attacks. The victim organization must also develop and execute a long-term containment plan to deny the attacker access to vital assets while the investigation is under way.
- Eradicate the attacker. Eradication removes the attacker from the compromised environment and ensures that the attacker cannot come back to the network. Eradication actions may vary depending on the technologies deployed in the enterprise, the security posture of the network, or the TTPs that the attacker leveraged as part of their operations.
- Recover technology. Cyberattacks often negatively impact business operations. After containing an incident and eradicating the threat actor from the compromised environment, the victim organization must recover the affected technologies to ensure that the business returns to a fully operational state.
Establishing a Remediation Team
Remediation requires cross-functional effort that often involves skills and expertise in multiple domains across various business, technology, and security disciplines. Chapter 2 discussed a cybersecurity incident response team (CSIRT) coordination model in detail, including roles and responsibilities of stakeholders who participate in incident response.
A CSIRT fulfills two primary functions: incident investigations and incident remediation. Although these two domains are related to each other, they often require different skills and experience. The former focuses primarily on analysis and answering vital investigative questions, whereas the latter focuses on specific actions necessary to contain the investigated incident and eradicate the threat actor from the compromised environment.
This section briefly discusses two roles that are critical and distinct to remediation: remediation lead and remediation owner. Chapter 2 discusses other business, technology, and third-party roles that may participate in remediation as part of a CSIRT.
Remediation Lead
During smaller incidents, a single individual can assume the roles of an incident manager and a remediation lead. However, during large-scale and complex incidents, organizations need to designate a dedicated individual to lead the remediation effort. In such cases, an incident manager focuses on the overall investigation, whereas a remediation lead is responsible for planning and executing containment and eradication. The following list briefly describes the skills that an effective remediation lead must possess.
- Technology Skills and Experience A remediation lead is a senior technical person with breadth and depth of skills and experience across various technical disciplines. The person does not have to be an expert in every technology. However, a remediation lead must have a sufficient understanding of the technologies in scope to work effectively with technical subject-matter experts. For example, a remediation lead with a system administration background also needs to understand disciplines, such as networking, applications, and cloud computing, to plan and lead the remediation effort effectively.
- Soft Skills In addition to technical expertise, a remediation lead must possess soft skills, such as planning, attention to detail, and ability to communicate with technical and nontechnical audiences, including senior management. Execution focus and authority are also vital skills. Planning remediation is often a complex undertaking, and the remediation lead must have the necessary authority and project management skills to lead technical teams and execute remediation while managing business expectations.
Remediation Owner
A remediation owner is a senior business stakeholder who closely works with the remediation lead and holds the overall responsibility for the remediation. In many cases, a remediation owner is synonymous with the role of an incident officer, described in Chapter 2.
The remediation of large-scale incidents often results in interruption to business operations and causes anxiety and stress for senior leaders. A remediation owner provides strategic oversight of remediation and works closely with other senior leaders in order to ensure that remediation planning includes business priorities. For example, an organization might choose to switch to an alternate site or system to support core business functions during a disruptive remediation. The remediation owner must work closely with the remediation lead to ensure that technical priorities align with business priorities.
A crucial responsibility of a remediation owner is to assign authority to the remediation lead and communicate the authority downstream to ensure that technical teams prioritize remediation over day-to-day responsibilities. If there is a conflict of priorities, then the remediation owner must resolve it.
Sometimes remediations run into unexpected complications. For example, a victim organization may need additional budget to hire consultants, conflicting priorities, exceeded timelines, and others. The remediation lead typically works with the remediation owner to resolve any complications. Figure 5.7 depicts how information flows between vital stakeholders responsible for incident response, including remediation.

Figure 5.7: Coordination between crucial roles
Remediation Planning
The remediation of a large-scale breach is a complex undertaking and requires cross-business collaboration and coordination. For this reason, planning and project management are vital components of remediation. In some cases, an organization may choose to assign a dedicated project manager to remediation to allow the remediation lead to focus on the overall planning and preparation for execution.
Business Considerations
As part of containment and eradication planning, the remediation lead must identify and consider business needs and priorities and ensure that technical staff have the necessary resources available. The following list briefly describes business considerations that organizations need to take into account before planning and executing containment and eradication.
- Executive Buy-In The first step in planning containment and eradication is executive buy-in. The remediation of large-scale incidents often interrupts business operations and requires additional resources, such as funding to hire external consultants or procure technology. A remediation owner must work with other senior leaders to obtain their buy-in, and secure the necessary resources required to remediate an incident.
- Communications Remediation typically leads to inquiries from employees and external entities regarding interruptions to business operations and other activities. For this reason, the remediation lead and owner need to work closely with corporate communications and corporate legal counsel to ensure appropriate messaging. In some cases, an organization may choose to release a statement proactively.
- Execution Timing Business priorities often conflict with eradication and containment. For example, an organization may have planned a major product or service launch, or payroll runs during specific days. The remediation lead and the remediation owner must work with crucial business stakeholders and consider business priorities before deciding on the execution timing.
- Business Partners Most medium- to large-sized enterprises leverage a complex ecosystem of business partners to operate their business. In some cases, containment and eradication may impact vital business partners and the service level agreements (SLAs) that the organization has in place with them. Consequently, the organization must include and work with business partners during remediation to minimize the potential impact to their business.
- Budget Remediation often requires additional budget to procure technology, hire external consultants, and compensate employees for additional labor. For this reason, the remediation lead and the remediation owner must work with finance to ensure that the necessary resources are available.
Technology Considerations
Containment and eradication often require changes to the technologies that support business functions. The following list briefly describes technology considerations when planning containment and eradication.
- Procuring and Deploying Additional Technology In many cases, an organization may need to procure and deploy new technologies as part of the containment and eradication effort. For example, to prevent the execution of attacker malware or exploits, the organization may need to deploy an EDR tool to its environments. Technology deployment requires planning and testing to prevent a potential negative business impact.
- Enhancing Monitoring Capabilities As part of incident response, organizations often need to enhance their monitoring capabilities to ensure that incident responders can gain additional visibility into attacker activity. The enhancements are also necessary to monitor for any evidence of the attacker after executing eradication. Examples of monitoring enhancement include increasing logging verbosity on specific technologies, shipping event logs to a log management server for long-term storage and correlation, developing attack signatures, or building SIEM correlation rules.
- Upgrading Legacy Technology Threat actors often exploit vulnerabilities in insecure, legacy technologies that vendors no longer support. Often, the only feasible option to prevent further exploits and damage is to decommission or upgrade legacy technologies to more up-to-date and secure solutions. If this is not feasible in the short term, then an organization needs to deploy compensating controls to reduce this risk. In either case, the remediation lead must closely work with technology stakeholders and ensure that the organization takes this requirement seriously.
Logistics
Including logistics as part of remediation planning helps to ensure that the necessary resources, support, and services are available to the remediation personnel. The following list briefly discusses logistical matters that organizations need to consider when executing containment and eradication.
- Facilities The remediation team needs to set up a command center or war room to provide a centralized location for coordinating containment and eradication activities, as well as to make rooms available for technical and management personnel. Another consideration is accommodation. Executing a remediation plan may take several hours and, in some cases, even days. Making accommodation available for remediation personnel is necessary to ensure that they can rest and refresh.
- Communications The remediation team must have available the necessary communications equipment and other tools available to communicate effectively during the execution phase. Setting up separate conference bridges for personnel working remotely or instant messaging channels is crucial. Also, the remediation lead must plan and set cadence for technical and management updates during the execution.
- Food Food is often a forgotten but essential consideration for remediation that may take an extended time. The remediation lead needs to ensure that food, drinks, and other refreshments are available to the remediation team, especially for personnel who cannot leave their tasks or assignment.
Assessing Readiness
I cannot emphasize enough how vital it is to conduct a comprehensive investigation and determine the full scope and extent of a breach before executing the containment and eradication phases of the incident response lifecycle. As part of their operations, threat actors may plant backdoors on numerous systems to maintain persistence in the compromised environment. If eradication does not cover the full scope of a breach, it is just a matter of time before the threat actor comes back and continues the attack.
Moreover, the remediation team must understand and take into account attacker TTPs and the associated IOCs to ensure that containment and eradication are comprehensive and effective. Forensic and CTI analysts derive this information during their investigation and refer to it as actionable intelligence. In practical terms, this information is necessary to inform containment and eradication. Gathering actionable intelligence is another reason why a comprehensive investigation is vital before eradicating a threat actor from the compromised environment.
The remediation of large-scale incidents is a complex task, and the planning typically starts in the early phases of the investigation. However, an organization must first understand the full scope of the incident before deciding on execution timing. The only exception to this rule is when an attacker becomes destructive, and the organization must immediately prevent any further damage.
Consequences of Alerting the Attacker
Incident responders and the remediation team should make every possible effort to prevent the attacker from becoming aware of the investigation. Depending on the attacker and their level of confidence, they may react in different ways. Their response may also be detrimental to the investigation. In some cases, where the attacker compromised systems that support communications tools, such as email or instant messaging, the incident response team must consider moving incident communications to an out-of-band communication channel. The following list briefly describes some frequent implications of alerting an attacker.
- Becoming Dormant An attacker may become dormant and remain hidden in the environment for a period of time, only to become active again after remediation. A victim organization may reimage end-user workstations and rebuild servers as part of remediation. However, after becoming active again, the attacker may plant additional backdoor malware and compromise additional user accounts to reinforce their presence in the environment. Incident responders often use the term “rinse and repeat” to describe this scenario.
- Change in Operations According to the Pyramid of Pain described earlier in this chapter, attackers can change how they operate. This point is particularly applicable in cases where an attacker becomes aware of an active investigation. For example, an attacker may recompile malware to change the corresponding hash value of the malware binary. An attacker may also employ defense evasion or antiforensic techniques, such as clearing log files or obfuscation. These actions can cause a loss of visibility into attacker activity and extra work for the incident response team.
- Becoming Destructive In some rare cases, attackers may engage in destructive activities upon discovering an active investigation. Examples of destructive activities include encrypting data for a ransom, deleting files, deploying destructive malware, or defacing web pages.
Developing an Execution Plan
An execution plan contains a detailed definition of the activities that a remediation team must execute as part of the remediation effort, including a listing of resources and a schedule. An effective plan typically focuses on containment and eradication activities. Recovery can take days, weeks, or even months in the most severe cases, and it often requires separate planning. The disaster recovery (DR) function typically handles this task. The following list discusses other considerations and highlights the main components of a containment and eradication plan.
- Execution Scheduling The remediation lead must develop a detailed execution schedule of containment and eradication tasks. The schedule should consist of high-level task categories accompanied by low-level activities with clearly assigned owners and validation criteria as required. In some cases, it is useful to organize those tasks into separate workstreams.
A vital part of the plan is an execution sequence of the activities mentioned earlier with clearly defined start and end times. Furthermore, it is a good practice to create milestones to demonstrate progress, as well as to include technical and management updates in the execution sequence.
- Procedures Some containment and eradication activities can be quite complex by themselves and may require a tested and documented procedure to ensure that the remediation personnel execute all of the necessary steps. For example, installing a security tool on a system may require specific configurations that the remediation team must test and document before remediation. Subject-matter experts are typically responsible for creating low-level procedures for activities in their respective domains.
- Inventory The execution plan must contain an inventory of all assets that are in scope of the remediation, compromised accounts, malware hashes, malicious domains, attacker IP addresses, and other information that is necessary to execute the remediation. An inventory is another reason why scoping an incident is crucial before executing eradication.
- Resource Allocation A sound plan must assign and schedule personnel to work on specific tasks. Building a roster with resource allocation to every task within each work stream is crucial. Also, each work stream must have assigned a lead with the appropriate skills and level of authority. A resource allocation plan is especially vital when a containment and eradication may require shift work.
Containment and Eradication
Containment focuses on protecting critical assets, whereas eradication allows the victim organization to remove the attacker from the compromised environment. The following sections examine these two phases.
Containment
The remediation team determines and executes containment actions to deny the attacker access to vital assets in order to minimize impact and prevent further damage. Containment does not remove the attacker's access to the compromised environment. Instead, it limits the attacker's ability to achieve their objective. For example, if an attacker gains access to a system that handles highly sensitive data, the remediation team may put measures in place to prevent further access and data theft. The measures may include multifactor authentication (MFA), access control lists (ACLs), and other access control mechanisms that limit access to the system or network segment.
The remediation lead must plan containment measures with key technology stakeholders and consult with management about the plan before execution. It is important to emphasize that the involvement of third-party organizations, such as external vendors and technology outsourcing partners, often adds a layer of complexity to this process that the remediation lead must take into account.
Containment often requires changes to how users and administrators access certain technologies. The remediation lead must identify and prioritize, with the help of management and business stakeholders, mission-critical assets that the victim organization must protect. Furthermore, the remediation lead also must work with technical groups to understand technical constraints and the potential impact of implementing containment measures such as MFA.
Some containment actions are short-term and designed to prevent immediate damage. For example, during a ransomware outbreak, the victim organization may take immediate actions, such as isolating network segments from the rest of the network to limit the spread of the malware. The premise behind short-term containment is to “stop the bleeding.”
In contrast, the remediation team executes long-term containment actions as temporary fixes. The term “long-term” may be misleading in this context. What it really means is that the organization makes temporary changes after “stopping the bleeding” before planning long-term, strategic controls to secure the environment. For example, the victim organization may implement a temporary jump server and lock down access to an environment that hosts highly sensitive data. This measure may prevent the attacker from accessing the environment while allowing the organization to investigate the incident and create an eradication plan. The following list includes examples of typical containment actions:
- Deploying a jump server to limit access to specific environments
- Implementing MFA to prevent access to environments with compromised credentials
- Network segmentation to limit lateral movement
- Micro-segmentation to protect specific systems or applications from unauthorized access
- Restricting access to the Internet from internal networks
- Restricting access to environments or applications to specific users
Eradication
The purpose of eradication is to remove the attacker from the compromised environment. The remediation team executes eradication during an agreed-on window, which typically lasts several hours.
One crucial consideration in remediating large-scale breaches is network isolation. In severe cases where an attacker gained a significant footprint in the enterprise environment, the victim organization may need to disconnect their internal networks from the Internet entirely. This approach is necessary to ensure that the attacker cannot react in response to eradication, and the organization can execute the plan and verify all steps before reconnecting the internal network back to the Internet. This approach is the most effective, but it also has a significant impact on business operations. For this reason, this approach is used relatively infrequently.
An alternative approach is to isolate the network segments in scope for the remediation. However, the victim organization must have confidence that the attacker did not compromise systems in any other environment. As with the previous approach, the remediation team must execute eradication activities before reconnecting the network segments to the Internet and other internal networks.
No network isolation typically works for small incidents that have no significant impact on business operations. Even in such cases, it is a good practice to isolate or disconnect the affected systems from the network. However, remediating large-scale incidents without network isolation is often a counterproductive effort that puts eradication at risk.
One vital consideration in eradication is execution timing. The incident response team must fully understand the scope and extent of the breach before executing eradication. The remediation team relies on the actionable intelligence that incident responders deliver to plan eradication. Another consideration is timing. If possible, the remediation team should plan the eradication window outside the attacker's standard operating hours to minimize the possibility of the attacker attempting to interrupt the eradication.
The following list provides examples of typical eradication activities that the remediation team may execute:
- Removing or disabling compromised user, service, and administrative accounts
- Resetting account credentials
- Removing backdoors and cleaning up other malware
- Patching vulnerabilities exploited by the attacker
- Blocking C2 IP addresses and domains
- Hardening systems and installing security tools
- Hardening and securing authentication and access control mechanisms and services, such as Microsoft Active Directory
Monitoring for Attacker Activity
Once the victim organization executed the eradication plan, there is one more thing to do: monitor for attacker activity. In some cases, even a thorough investigation may not uncover all attacker backdoors and entry points into the network, or every possible IOC associated with the attacker. More advanced attackers plan for being discovered and take the necessary measures to maintain persistence in the compromised environment. In other cases, an attacker may re-compromise the network to continue their attack. Attackers often invest significant resources into their operations and may not give up that easily, even after successful eradication.
For the reasons mentioned here, organizations must import the IOCs discovered during the analysis phase into their security tools and monitor for attacker activity for several weeks before closing the investigation. Even after the formal incident closure, the victim organization should still monitor for any indicators as part of day-to-day operations.
Summary
Incident responders leverage a lifecycle-based approach to investigate incidents. The first step is to generate an incident hypothesis and establish objectives to ensure that business priorities drive the investigation. The next step is to acquire and preserve the necessary data to support the investigation. Incident responders typically acquire data from host and network systems, event logs from enterprise services, and data generated by security tools.
Data analysis is a complex, iterative process that includes domains, such as digital forensics, malware analysis, and CTI. Digital forensics focuses on the analysis and recovery of digital data to answer investigative questions. CTI augments forensic analysis by providing contextual threat information necessary to scope and remediate an incident. As part of an investigation, incident responders may also analyze malware to understand the threat. Analysts leverage static and dynamic analysis techniques to achieve this objective. The final step in the analysis process is to produce an analysis report tailored to the target audience.
Enterprises can employ threat hunting techniques to identify evidence of a historical or ongoing compromise. This approach is necessary when an organization detects a suspicious activity or receives a third-party incident notification but has no specific incident information available, such as IOCs, to establish leads and generate a hypothesis. Organizations can leverage a threat-centric and data-centric approach to threat hunting.
The final phase of an incident investigation is remediation. Victim organizations must start planning containment and eradication activities as soon as an investigation commences. Containment allows organizations to deny the attacker access to crucial assets. In contrast, eradication removes the attacker from the compromised environment. After containing and eradicating the attacker, the final step is to restore technology to a fully operational state.
Notes
- 1. Scott J. Roberts, and Rebekah Brow, Intelligence-Driven Incident Response, O'Reilly Media, Inc, 2017.
- 2. Roberts and Brow, Intelligence-Driven Incident Response.
- 3. Central Intelligence Agency (CIA), “Psychology of Intelligence Analysis, Analysis of Competing Hypotheses,” 2008,
www.cia.gov/library/center-for-the-study-of-intelligence/csi-publications/books-and-monographs/psychology-of-intelligence-analysis/index.html. - 4. Enterprise Detection and Response, “The Pyramid of Pain,” January 17, 2014,
detect-respond.blogspot.com/2013/03/the-pyramid-of-pain.html. - 5. SANS Digital Forensics and Incident Response Blog, “Security Intelligence: Attacking the Cyber Kill Chain,” 2019,
www.sans.org/blog/security-intelligence-attacking-the-cyber-kill-chain. - 6. European Union Agency for Cybersecurity (ENISA), Stuxnet Analysis,
www.enisa.europa.eu/news/enisa-news/stuxnet-analysis. - 7. Cybersecurity and Infrastructure Security Agency (CISA), “Alert (AA19-339A): Dridex Malware,” 2020,
www.us-cert.gov/ncas/alerts/aa19-339a. - 8. VMWare Carbon Black, “What Is Cyber Threat Hunting?,”
www.carbonblack.com/resources/definitions/what-is-cyber-threat-hunting. - 9. InfoSec Institute, “Threat-Hunting Techniques: Conducting the Hunt,”
resources.infosecinstitute.com/category/enterprise/threat-hunting/threat-hunting-process/threat-hunting-techniques/conducting-the-hunt/#gref. - 10. SANS Institute, “A Practical Model for Conducting Cyber Threat Hunting, 2018,”
www.sans.org/reading-room/whitepapers/threathunting/paper/38710.