
CHAPTER 4
Crafting an Incident Response Plan
Having an incident response plan is a critical step in cyber breach response. The worst time for an organization to realize that they are not prepared for an incident is when a cyber breach occurs.
An effective incident response plan encompasses an incident management process, roles and responsibilities, communication flows, escalations, and postmortem activities, among other components. Each of those components is vital to respond effectively to various types of incidents and help organizations operate during significant cyberattacks.
This chapter discusses the incident response lifecycle, how to build an effective incident response plan, and how to improve incident response capabilities continuously.
Incident Response Lifecycle
An incident response lifecycle is a conceptual model that represents the different phases during the lifespan of a cybersecurity incident. To respond to incidents effectively, incident responders need to follow a structured and organized approach with clearly defined roles and responsibilities.
Various industry standards present slightly different lifecycle approaches. However, they draw on similar concepts, and there is usually a significant amount of overlap between them.
Figure 4.1 displays a lifecycle that the National Institute of Standards and Technology (NIST) in the United States included in its Computer Security Incident Handling Guide.1
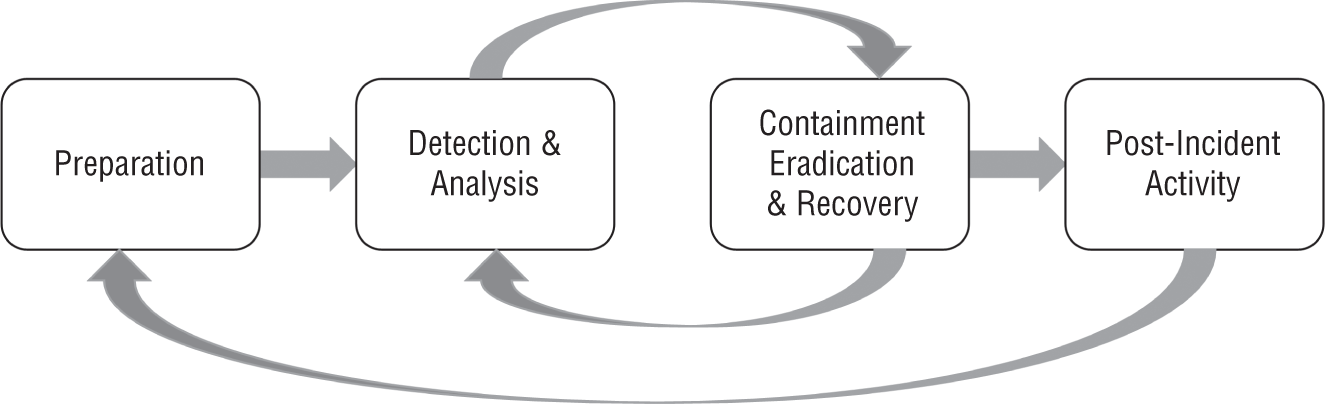
Figure 4.1: NIST Incident Response Lifecycle
In my personal experience, this lifecycle closely reflects the typical sequence of stages and functional activities during the incident response process and is a good model for organizations of all sizes to follow.
Preparing for an Incident
Preparation is a fundamental component of the incident response lifecycle that directly impacts the remaining stages. Without appropriate and continuous preparation, incident response teams cannot effectively execute activities in the remaining stages.
Preparation encompasses a wide range of activities that require an integrated and cross-functional effort, funding, and other resources, as well as executive-level support. Arguably, this book is all about preparation and ensuring that enterprises can develop capabilities to enable them to respond to and handle cybersecurity incidents effectively.
It is crucial to emphasize that preparation is not a one-off activity. Instead, it is a continuous and incremental effort that tightly integrates with a continual improvement process that I discuss later in this chapter.
The following list describes common activities that enterprises may undertake as part of the preparation phase. This list is by no means comprehensive. Strategic planning typically drives these activities.
- Planning Planning includes all the activities that enterprises must adopt before operationalizing incident response capabilities. Depending on the current state and maturity of a cyber breach response program, enterprises may enact policies, create new or extend the existing capabilities, and dedicate additional funding and other resources to cyber breach response.
- Hiring and Training Incident Response Personnel As organizations respond to external and internal factors that drive the requirement for cyber breach response, enterprises may need to hire additional personnel or train existing employees to ensure that their skills are up to date.
- Documenting Processes and Procedures As enterprises evolve and cyber risk changes, incident response teams need to update existing documentation continuously and create new procedures to stay abreast of cyber threats and continually improve their capabilities.
- Acquiring and Sourcing Technology Innovation drives changes in the technologies that enterprises deploy to support their business operations. Incident responders need to evaluate and adjust their tools and other investigative technologies periodically to ensure that they can respond to incidents that involve a wide range of technologies deployed within the enterprise.
- Building Relationships with Key Stakeholders As discussed in Chapter 2, a Cybersecurity Incident Response Team (CSIRT) is a cross-functional team. Incident responders need to maintain and build new relationships with technology and business stakeholders to support incident investigations. This step may also include building relationships with vendors and entering into a retainer agreement with a digital forensics and incident response (DFIR) firm.
- Continual Improvement Continual improvement refers to the ongoing effort to identify underperforming areas of incident response and to implement specific improvements to address those areas.
Detecting and Analyzing Incidents
Incident symptoms can manifest themselves in numerous ways. Analysts must pay close attention to potential adverse events to determine whether those events are indicative of an incident, or even a breach. Incident detection and analysis is the process of identifying suspicious events and assessing their details to determine an appropriate response procedure.
Detection and Triage
Systems and software applications may generate a significant volume of events each day. Analysts often rely on correlation tools and alerting mechanisms to detect those events that may be indicative of potentially malicious activity.
After detecting a suspicious event, analysts must triage it to determine whether the event warrants an incident declaration. As part of the triage phase, analysts need to apply business and technology context to determine the nature of the event. For example, an analyst might review a configuration baseline of a specific application to determine whether an investigated event could have been generated in the course of normal system operations and that it represents an expected system behavior. The outcome of the detection and triage phases is a decision whether or not to proceed with incident declaration.
During the detection and triage phases, analysts typically document known event information; collect contextual data, such as asset configuration and system and network architecture; correlate the incident information with previous similar incidents; and review cyber threat intelligence (CTI) associated with the events of interest.
If an event warrants incident declaration, analysts typically determine the scope and impact, assign classification and prioritization to the incident, and log an incident ticket in a case management platform. Analysts may also escalate the incident if it reaches a specific severity threshold. It is crucial to note that as the investigation progresses and analysts establish new evidence, the scope, impact, and severity of the incident may change.
The detection and triage phases can be performed as one task or two separate activities. The latter approach is typical of organizations that have a mature incident response capability or have outsourced security monitoring to a managed security service provider (MSSP).
Analyzing Incidents
In some situations, it is clear that an event is indicative of an incident. For example, an internal server attempts to open a network connection to an infrastructure associated with a threat actor. In other cases, an analyst might escalate an event to incident response personnel to perform a more in-depth analysis to establish whether the event is indicative of a cyber incident.
Incident analysis refers to a structured process designed to examine security data and evaluate the cause of an incident. As part of the analysis phase, incident responders create indicators of compromise (IOC) that the enterprise can use to drive containment and eradication activities. To perform a sound and thorough analysis, incident responders must possess advanced skills and experience in the area of digital forensics. Chapter 2 discusses skills in detail. Depending on the nature of an incident, typical analysis activities may include the following:
- Acquiring and preserving forensic data
- Developing investigative leads
- Analyzing host and network data
- Malware analysis
- CTI enrichment
- Scoping the incident
- Creating a timeline of attacker activity
- Reporting
Containment, Eradication, and Recovery
Containment, eradication, and recovery are the final phases of the incident response lifecycle. Organizations often refer to these activities as remediation.
Containing a Breach
Containment encompasses specific actions that enterprises take to prevent a threat from spreading, thereby limiting the damage that a cyberattack has on their business. Depending on the nature of a cyberattack, incident responders may execute containment activities in a single step or take a two-phased approach: short-term containment and long-term containment.
- Short-Term Containment Short-term containment constitutes an immediate action that an enterprise may take to prevent the exacerbation or propagation of a threat. Examples include isolating systems infected with malware from the network or implementing access control mechanisms to prevent malware from connecting to an attacker's command and control (C2) infrastructure.
- Long-Term Containment Long-term containment refers to implementing temporary security measures to secure access to and prevent a threat actor from accessing crucial assets while the investigation process and remediation planning are underway. For example, as part of long-term containment, an enterprise may implement a jump host to control access to an environment that stores or processes highly confidential data. If deemed appropriate during postincident activities, these measures may become more permanent adjustments to strengthen the organization's defenses further.
Eradicating a Threat Actor
After successfully containing an incident, the next step is to take short-term and medium-term steps to eradicate the threat actor from the compromised environment. As in the case of containment, eradication strategies vary from incident to incident. For this reason, incident response teams should document containment and eradication procedures for common incident types that occur in their environments. Examples of eradication actions include the following:
- Upgrading legacy and unsupported technologies to more secure technologies
- Resetting credentials for compromised users
- Patching vulnerabilities that an attacker exploited to advance their attack strategy
- Implementing strict access control mechanisms to allow only authorized users and applications access to specific resources
- Removing malware and persistence mechanisms
Incident responders need to understand the full scope of a compromise and the associated IOCs before executing containment and eradication activities. As part of the attack strategy, attackers typically establish several footholds in the compromised environment. An insufficiently remediated environment may still allow the attacker access to the network. If there is a means for the attacker to come back to the compromised network, they will likely do so.
Containment and eradication may sometimes be at odds with forensic data acquisition. In some cases, ad hoc containment or eradication can destroy forensic evidence. For example, it is not uncommon for information technology support personnel to re-image malware-infected end-user workstations without considering the need to acquire and preserve digital evidence. Consequently, creating and documenting containment strategies for specific incident types is vital to ensure a balance between effective containment and preserving forensic evidence, especially if the evidence may be required for legal purposes.
Recovering Business Operations
The objective of the recovery phase is to restore the affected systems and software applications fully into an operational state. Also, as part of recovery, enterprises need to ensure that the restored systems and applications have appropriate controls in place to prevent similar incidents from reoccurring. For example, if a threat actor compromised domain administrative credentials, an enterprise may need to consider controls such as multifactor authentication (MFA) to prevent a similar compromise in the future. MFA is an authentication scheme that requires at least two independent pieces of information from separate categories of credentials, such as a password and a random number generated by an authentication token, to authenticate into a system.
During incidents and breaches that have a severe impact on business operations, enterprises may need to activate a disaster recovery (DR) plan and switch operations to alternate systems that are in a known good state during recovery. Enterprises can leverage standards, such as ISO 22301:2019, to prepare for, respond to, and recover from disruptive events.2
Enterprises typically recover systems and software applications in a phased approach. Depending on the nature and scope of an incident, it may take days or even weeks to recover fully. For this reason, project management and close collaboration between technology and business stakeholders, as well as vendors, is vital.
Post-Incident Activities
Post-incident activities include steps that enable organizations to capture opportunities for improvement and implement specific measures to enhance their cyber breach response program. Post-incident activities are typically part of continual improvement that enterprises implement to govern a cyber breach response program. Organizations can implement two types of measures as part of continual improvement: tactical and strategic.
Tactical measures encompass relatively simple program enhancements that do not require substantial funding or dedicated projects. Enterprises typically identify tactical measures through a lessons-learned meeting and a root cause analysis. To identify tactical improvement measures, organizations need to hold a lessons-learned meeting after each major incident, as well as regular meetings to review responses to minor incidents. The outcome of a lessons-learned meeting is a set of tactical measures that enterprises can implement within a relatively short time.
If an enterprise identifies major gaps and issues that cannot be resolved as part of day-to-day operations, the incident response manager must escalate those issues to senior management for risk evaluation. Based on the outcome of the risk evaluation process, an enterprise may decide to implement strategic measures that typically require funding and dedicated projects. In other words, strategic measures are long-term enhancements that require dedicated resources. For example, an organization may choose to implement an endpoint detection and response (EDR) tool as a strategic measure to reduce the risk associated with threats that evade traditional antimalware software. Another way of thinking about tactical vs. strategic measures is in terms of short-term and long-term enhancements.
Process-mature organizations typically implement strategic measures as part of a continuous improvement process. Enterprises implement this process as part of governance to evaluate the performance of a cyber breach response program continually against its objectives. A steering committee is typically a body that is responsible for implementing and enforcing governance.
Understanding Incident Management
The purpose of a cybersecurity incident management process is to minimize the operational and informational impact of a cybersecurity incident, as well as to ensure that the enterprise can continue business operations while under a cyberattack.3 Consequently, the objectives of the incident management process include the following:
- Use standardized procedures and incident models to manage incidents and cyber breaches consistently.
- Ensure that all stakeholders who participate in the incident management process have clearly assigned roles and responsibilities.
- Increase the visibility and reinforce the need for cyber breach response among business and technology stakeholders.
- Align the response to cyberattacks with risk appetite and business priorities.
- Facilitate effective communication among tactical teams and management.
An effective incident management process helps enterprises manage residual risk and ensure that business, cybersecurity, and technology stakeholders work together toward the same goals.
The scope of an incident management process encompasses all cybersecurity incidents that negatively impact an enterprise, not only cyber breaches. If not addressed promptly, even minor incidents can progress into enterprise breaches that may negatively impact revenue, brand reputation, and business operations and lead to legal exposure. For this reason, enterprises need to create a cross-functional cybersecurity incident management process to address the aftermath of a cyberattack before real damage occurs.
An effective incident management process delivers several benefits to organizations:
- Minimizes the impact of cyberattacks on business operations
- Addresses incidents and system breaches before substantial damage occurs
- Identifies defensive weaknesses and gaps through lessons learned and continual improvement
- Reduces legal exposure resulting from cyber breaches
- Prioritizes response activities based on business priorities
- Helps to identify risks that can lead to exposure
Identifying Process Components
An incident management process is a structured and coordinated set of activities designed to address the aftermath of a cyberattack. A high-quality process contains several components that work in tandem to produce a desired and repeatable outcome.
Defining a Process
Enterprises should define specific events that trigger an incident management process. When an event triggers an incident management process, the process takes an input, executes a set of activities, and produces an outcome. For example, a security alert may trigger an incident management process. Incident responders take all known information about the incident and proceed through a series of activities to understand its nature and prevent its spread within the enterprise. The outcome of the process may be incident resolution and control recommendations designed to prevent similar incidents from reoccurring.
Figure 4.2 captures an incident management process as a set of components organized into three categories: controls, enablers, and the process itself. I derived this model from the Information Technology Infrastructure Library (ITIL).4

Figure 4.2: Process model
- Activities Process activities are a core component of an incident management process. Process activities constitute the actions that stakeholders participating in the process must execute to achieve a specific outcome, such as incident detection and classification.
- Procedures An incident management process typically has defined procedures for each activity executed as part of its workflow. An incident management procedure outlines how to carry out the activity.
- Work Instructions Work instructions provide a detailed description of how to perform a specific task referenced in a procedure; for example, a step-by-step instruction on how to acquire event logs from a specific technology.
- Roles A role is an entity that participates in an incident management process and is responsible for executing specific activities. A single role may be responsible for one or more activities within the incident management process.
- Metrics Metrics refers to standard measures that an enterprise may choose to collect and evaluate to assess how the process performs against its objectives.
- Improvements Process improvements are activities that an enterprise implements to address underperforming areas or proactively optimize the process and enhance its quality.
It is worth mentioning that not all organizations choose to implement metrics and process improvements. Chapter 1 discussed the Capability Maturity Model Integration (CMMI) model that defines process maturity levels.5 Striving to quantitatively manage and optimize an incident management process may not be the end goal for all organizations. In fact, for smaller organizations that still do not grasp cybersecurity, this approach may lead to inefficient use of organizational resources.
Furthermore, the ISO 9001:2015 standard6 established a hierarchical relationship between process, procedure, and work instruction, and helped to clarify crucial terms that apply to incident management. Figure 4.3 depicts the relationship between these concepts.
Process Controls
Controls are process components that are necessary to ensure that the process produces outcomes in accordance with the established objectives. Process controls are also vital to continual improvement. Enterprises need to establish the following controls to ensure that their incident management process is up to managing the response to cyberattacks effectively.
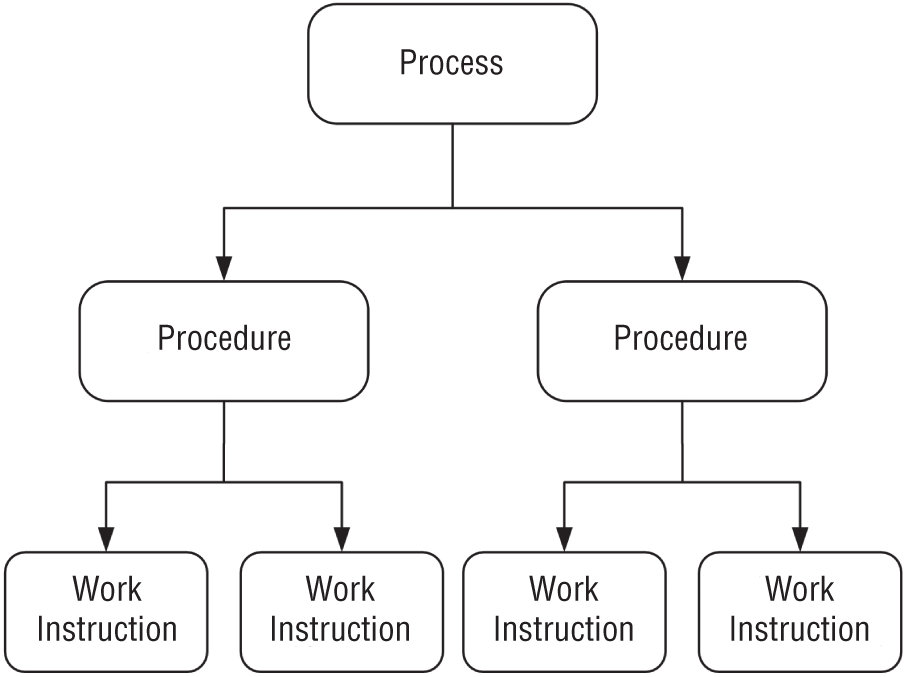
Figure 4.3: Relationship between process, procedure, and work instruction
- Process Policy A process policy is a set of rules and statements intended to govern the decisions and actions within an incident management process. A process policy may be composed of issue-specific policies, such as escalation policy, forensic data retention policy, or handling of incidents relating to unauthorized disclosure of protected data.
- Process Objectives A process objective defines the results and outcomes that the process should deliver, such as using standardized response procedures to respond to similar incidents consistently or to ensure that stakeholders are aware of their roles and responsibilities pertaining to the process.
- Process Owner A process owner ensures that the process is fit for its intended purpose and has the authority to make changes to the process. An owner also needs to make sure that the process integrates with other organizational processes and takes into account response aspects, such as legal and regulatory requirements. In larger enterprises, a process owner is typically a senior manager.
- Process Custodian A process owner may delegate the responsibility of managing some aspects of the process to a custodian. A process custodian is a stakeholder who is responsible for the implementation and day-to-day execution of the process. In smaller organizations, the roles of a process owner and a process custodian might be combined into one.
- Process Documentation Process documentation outlines the necessary steps and provides supporting information required to execute the process in a consistent and repeatable manner. The primary users of the documentation are stakeholders with assigned process roles who leverage the documentation to fulfill their responsibilities pertaining to the process.
- Process Feedback Process feedback is information that enterprises collect and analyze to determine if the process performs well against its objectives. Enterprises can use this information to identify underperforming areas and implement specific improvement initiatives.
Process Enablers
Process enablers make up the resources and capabilities required to support an incident management process and achieve specific outcomes.
- Resources Resources encompass all the assets that are necessary to support and execute an incident management process. Assets may include financial capital, infrastructure, applications, information, and people.
- Capabilities Capabilities represent the ability to achieve a specific outcome by leveraging assets. Capabilities may include management, organization, processes, and people. People can be both resources and capabilities. For example, an enterprise may hire forensic analysts and procure the necessary technology to establish a digital forensics capability.
Process Interfaces
Chapter 2 discussed a CSIRT as a cross-functional team consisting of cybersecurity, technology, and business stakeholders, as well as third parties that convene to respond to cybersecurity incidents. As part of defining an incident management process, enterprises need to establish interfaces to other organizational functions and integrate with their processes to ensure effective response.
A process interface determines the inputs that an incident management process receives from other processes, as well as the outputs that it produces that may trigger other, subsequent processes. In practical terms, the inputs and outputs are pieces of information that various organizational functions receive or pass into the incident management process so that it can achieve its objectives.
For example, a technology support group may investigate an operational incident, diagnose a cyberattack as its root cause, and trigger the cybersecurity incident management. The outcome from the operational investigation feeds as an input into the cybersecurity incident management process. In contrast, if the cybersecurity incident management process produces evidence of unauthorized access to data that is subjected to legal and regulatory requirements, the findings would trigger and feed into a data privacy process.
To make the transitions between various organizational processes smooth, enterprises need to create communication templates to ensure that the information they pass from one process to another is fit for its intended purpose. For example, the information should contain the necessary details, yet be succinct, written for the target audience, and actionable to facilitate decision making.
The following list briefly describes the typical processes that integrate with a cybersecurity incident management process.
- IT Incident Management In some situations, operational incidents are the first symptoms of a cyberattack. In other cases, incident responders may need to trigger the IT incident management process to receive support from technical groups. For these reasons, enterprises need to integrate those two processes. For example, a denial-of-service attack typically leads to a system or application availability issue first before it is escalated to an incident response team.
- Asset and Configuration Management Asset management is a process that allows enterprises to keep track of the IT assets that they deploy to support business operations. Configuration management, on the other hand, enables enterprises to track the configurations of those assets, as well as the relationships between their components. Incident responders require access to this information to analyze and scope incidents effectively. For example, an analyst may consult a configuration management database to determine whether an investigated event represents normal system behavior or is indicative of an attacker activity.
- Event Management Event management is a process that allows enterprises to monitor operational and security events in their environments. As part of an incident investigation, incident responders may need to implement additional monitoring to provide alerting of attacker activity and scope incidents effectively. For example, analysts may ingest IOCs, such as IP addresses, into network monitoring tools to detect malware-infected systems that connect to an attacker C2 infrastructure.
- Change Management The purpose of the change management process is to minimize the risk of interruptions resulting from changes in technologies that support business operations. As part of investigations, incident responders may need to make changes to systems and applications. To minimize the risk associated with those changes, inform other impacted parties, document the change details, and create a backout plan, enterprises may invoke the change management process. For example, installing a network tap in a data center requires a temporary network outage that organizations must manage through their change management process.
- Vulnerability Management Vulnerability management is the process of identifying, evaluating, reporting, and remediating security vulnerabilities. The output of a cybersecurity incident management process may feed into the vulnerability management process to prevent similar incidents and system breaches from reoccurring in the future. For example, if an incident response team determines that an attacker compromised administrative credentials because of deficiencies in access control policies, the information should feed into the vulnerability management process for evaluation.
- Vendor Management The purpose of the vendor management process is to ensure that suppliers deliver on their contractual commitments. Cybersecurity incidents involving third parties have become commonplace, and enterprises may need to engage third parties as part of the incident management process. In such cases, incident responders typically engage the vendor management function to facilitate initial communication. For example, if an attacker compromises an application component that an external vendor manages, then vendor management may initiate communication between the two parties.
- Business Continuity and Disaster Recovery Business continuity and disaster recovery (BCDR) is a set of processes and practices that help organizations recover from a disaster and resume business operations. With destructive cyberattacks and remediations that interrupt business activity, BCDR is an integral part of cyber resilience, and organizations need to integrate it with a cybersecurity incident management process. For example, during destructive attacks, the incident response team works closely with DR to restore impacted data from backups.
- Financial Management In some cases, responding to a cybersecurity incident may require additional funding and resources. It is the finance department that typically approves of and makes additional funding available to hire external consultants or purchase additional technology. For example, during a significant incident, an enterprise may need to obtain additional funding to hire an external DFIR firm to assist with the investigation.
- Compliance and Data Privacy Management An intrusion may lead to unauthorized access or disclosure of information that is subject to legal and regulatory requirements. Compliance and data privacy professionals need to interpret investigative findings to ensure adherence to data breach notification requirements in various jurisdictions. For this reason, incident management should integrate with compliance, data privacy, and other necessary legal processes. For example, an incident response team closely works with the compliance and data privacy functions when an organization receives a common point of purchase (CPP) notification by a payment brand.
Roles and Responsibilities
A cybersecurity incident management process typically includes several roles that are responsible for fulfilling various activities within the process. Chapter 2 identified typical business, technology, and third-party functions that an incident response team may call upon to assist in their respective domains. Enterprises must identify, assign, and document roles and responsibilities to those functions to ensure that they carry out and fulfill their activities within the incident management process.
An outline of roles and responsibilities should be succinct, yet contain the necessary details relating to the process. Typically, a brief description of the role and a bulleted list of responsibilities works well.
Another, often complementary, method to documenting roles and responsibilities is to create a responsibility assignment chart. A RACI chart allows organizations to map out roles and responsibilities to activities. The acronym is derived from four responsibilities that organizations typically designate:
- Responsible Responsible refers to the role that carries out a specific process activity.
- Accountable Accountable refers to the role that has the overall responsibility for fulfilling a specific activity but may not carry out the actual work.
- Consulted Consulted refers to the role that provides information or acts in an advisory capacity to the role that carries out an activity.
- Informed Informed refers to the role that does not actively participate in the process but is informed about its progress. Senior management is a primary example of a role that an incident manager informs about the status of an investigation.
Service Levels
Enterprises can leverage service level agreements (SLAs) and operational level agreements (OLAs) to ensure that entities that participate in the incident management process complete their tasks within the expected time frame and to the agreed-on quality. An SLA is a formal agreement between an organization and a service provider. In contrast, an OLA represents a formal commitment between internal entities.7 For example, an enterprise may establish a response SLA with an incident response firm as part of a retainer agreement. An example of an OLA is an agreement between an incident response team and a technical group within the same organization to establish commitments, such as response time to support an investigation.
Enterprises need to establish SLAs and OLAs that are measurable to determine whether the entities that participate in the incident management process meet their targets. Chapter 1 discussed the SMART framework. Enterprises can also leverage this framework to create unambiguous targets as part of defining OLAs and SLAs.
SLAs and OLAs are excellent tools to set and measure process targets. However, a poor choice of SLAs and OLAs may lead to an incorrect perception of a cyber breach response program. For example, in the world of IT operations, incidents typically have obvious symptoms, such as the low performance of an application component. In such cases, response and resolution targets make perfect sense. In contrast, the symptoms of a cybersecurity incident may not be so obvious. In some cases, a threat actor may dwell on a compromised network for weeks or even months before detection. It may also take a complex investigation that consumes a considerable amount of time before the enterprise determines the full scope and impact of the compromise. For this reason, targets that make perfect sense in IT operations may not always be appropriate for a cyber breach response program. Organizations must very carefully define SLAs and OLEs to ensure that they convey accurate information and are useful in making decisions. For example, defining a metric focused on the time it takes to close an incident typically results in incident response teams focusing on resolving incidents to meet metric requirements at the expense of a thorough investigation. In contrast, agreeing to a support response time SLA with an incident response partner is more beneficial and sets clear expectations for how soon the partner must start providing support.
Incident Management Workflow
A workflow is a sequence of activities executed in a chronological order to manage the lifecycle of an incident. A typical workflow includes decision points that determine the direction of activity flow based on conditions and rules. A workflow may also contain interfaces to other processes and subprocesses. This section presents a conceptual workflow that captures the main steps in an incident management process. In practice, workflows may be more complex with many decision points. Furthermore, incident response teams often iterate over some of the steps as they scope intrusions and learn about how a threat actor operates in a compromised environment as depicted in Figure 4.4.
Sources of Incident Notifications
Enterprises can detect and identify incidents and cyber breaches through numerous sources. For this reason, it is critical that business and technology stakeholders know how to report suspicious events and incidents to the incident response team. The following list briefly discusses the typical avenues that lead to the detection or identification of an incident.
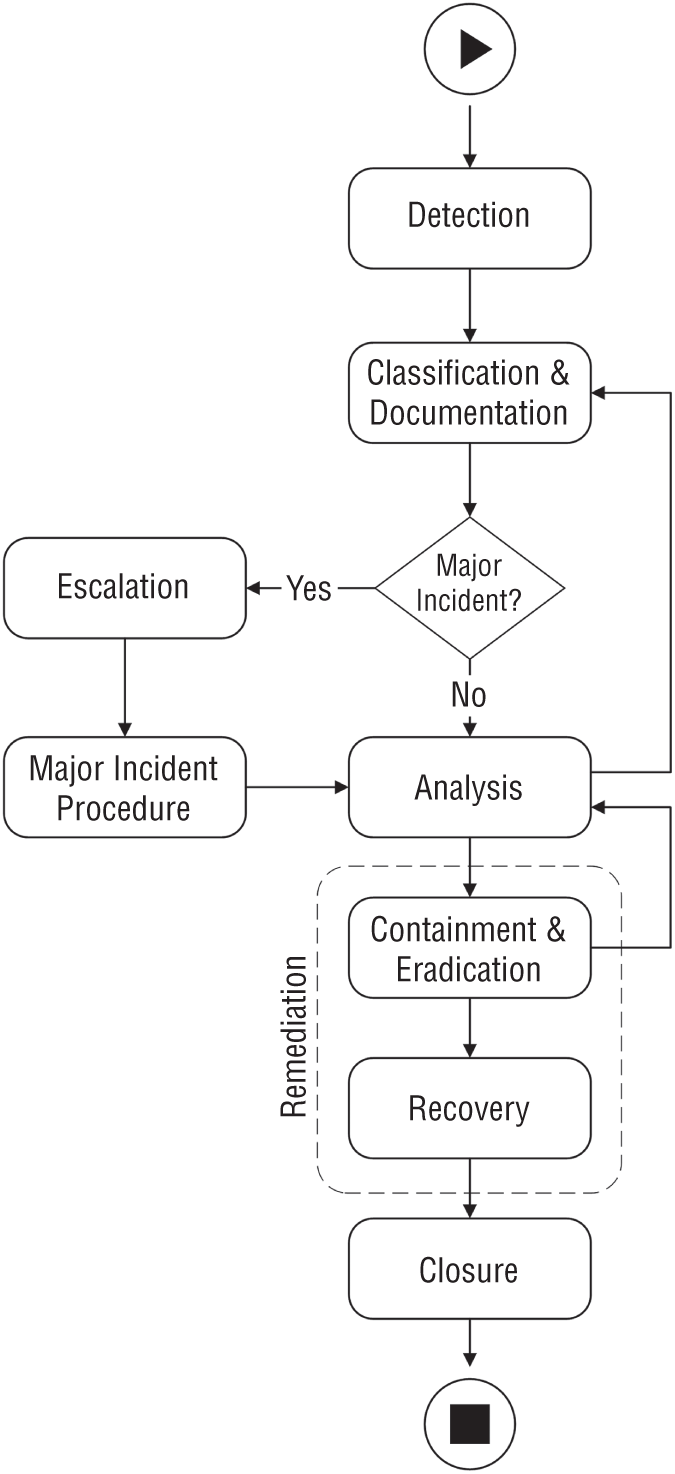
Figure 4.4: Incident management workflow
- Service Desk The majority of medium- and large-sized organizations implement a service desk function that acts as a single point-of-contact for employees for technology-related inquiries. Employees can report to the service desk any suspicious events and incidents. The service desk may perform a basic triage and escalate the notifications to the incident response function.
- Event Management Event management is a generic term that refers to the automated monitoring of events across the network to detect and report events that are outside the established baseline. Security tools, such as Security Information and Event Management (SIEM), can collect data from disparate sources and correlate that data to alert on suspicious activities.
- IT Incident Management Process In some cases, the symptoms of a cyberattack manifest as operational issues, such as degraded system performance. After the initial diagnosis, a technical group may escalate to the incident response function if they believe that a cyberattack may have caused the issue.
- Policy Violations In certain cases, employees may observe and report activities relating to unauthorized access to resources or other suspicious behavior that may be indicative of an insider threat. Security monitoring personnel may also discover evidence of policy violations through monitoring and log review.
- External Notifications It is not uncommon for organizations to learn about a potential cybersecurity incident through a third-party notification. For example, a CPP notification is a notification that card payment brands issue to organizations that likely experienced a breach of card payment data.8 Law enforcement is another common source of a breach notification.
Organizations need to identify and triage events and incidents that stakeholders report through these sources to establish whether those notifications warrant incident declaration. The next step is to classify and document the incidents before commencing an in-depth analysis.
Incident Classification and Documentation
A vital element of incident management is incident classification and documentation. Organizations need to record and maintain a full historical record of incidents for several reasons, including the following:
- Regulatory compliance
- Providing groups participating in the incident management process with contextual information and the necessary details to fulfill their responsibilities
- Tracking the progress of incidents throughout their lifecycle
- Trend analysis and continual improvement
- Collecting incident data required for the vulnerability management process
- Tracking historical incident information for governance purposes
As part of incident documentation, analysts need to classify incidents by assigning an appropriate category and severity level to them. Incident classification helps communicate the nature and impact of an incident to business and technology stakeholders. It is also vital to establishing metrics and measuring a cyber breach response program.
Incident Categorization
Incident categorization involves assigning a category to an incident that reflects the nature of the incident and the resources required to address it. Organizations should establish a categorization scheme that is most appropriate for their maturity and metric requirements.
A single-tier scheme typically works for enterprises that are in the early phases of setting up a cyber breach response program. As the program matures and the management identifies the need to track metrics at a granular level to make precise operational adjustments, an organization may choose to implement a two-tier scheme.
A single-tier scheme typically encompasses several high-level categories, such as malware or denial of service. A two-tier scheme, on the other hand, defines high-level incident categories at the top tier and incident types or subcategories at the lower tier. For example, an incident of type “malware” may be further categorized as virus, ransomware, bot, or worm.
To communicate cybersecurity incidents clearly throughout the organization, enterprises must create an incident taxonomy or adopt a taxonomy established by an industry framework. For example, NIST SP 800-61 Revision 2 proposes the following taxonomy:9
- External/Removable Media
- Attrition
- Web
- Impersonation
- Improper Usage
- Loss of Theft of Equipment
- Other
Severity Assignment
Severity identifies the importance of an incident to the enterprise, and it is the primary driver for response actions that an organization takes to resolve it. Two primary criteria exist to determine a severity level of a cybersecurity incident: impact and urgency.
Impact is a measure of the potential damage that an incident causes before it is contained. An incident can cause an operational or informational impact.10
- Operational Impact Operational impact occurs when a cyberattack impairs an enterprise's ability to conduct business operations, such as ransomware encrypting systems that support core business functions. Enterprises can determine operational impact based on the scope of an incident or the number of business functions that the incident impacts.
- Informational Impact Informational impact occurs when a cyberattack negatively impacts the confidentiality, integrity, and availability of information assets. For example, if a cyberattack leads to a data privacy breach or theft of intellectual property, enterprises need to include this factor in severity calculation.
Enterprises should establish both operational and informational criteria to identify the severity of an incident accurately. Enterprises historically used impact on business operations as a criterion to calculate the severity of an IT incident. However, cybersecurity incidents may severely impact organizations while not having an operational impact. For example, unauthorized access or theft of protected data may lead to legal exposure, brand reputation damage, or a loss of competitive advantage in the marketplace in case of intellectual property theft. For this reason, cybersecurity incidents require informational impact evaluation, too. In cases when a cyberattack causes both operational and informational impact, organizations should use the higher impact score in the severity calculation.
Operational and informational impact criteria may vary among organizations, depending on factors such as risk appetite and the nature of the business. Table 4.1 and Table 4.2 provide examples of typical impact criteria that enterprises may establish.
Urgency is the time that must elapse before an incident has a significant business impact. The shorter the time, the higher the urgency. For example, a ransomware outbreak on the corporate network may need immediate action to prevent a severe business impact. Evidence of a threat actor performing reconnaissance of an Internet-exposed web application may not necessitate the same level of response.
Table 4.1: An example of operational impact criteria
| IMPACT | DESCRIPTION |
| Extensive | An incident severely impacts multiple core business functions and significantly impairs business operations. An extensive impact may also warrant a crisis declaration. |
| Significant | An incident severely impacts one or two core business functions. |
| Moderate | An incident has little impact on business operations. |
| Minor | An incident has no impact on business operations and is handled as part of day-to-day operations. |
Table 4.2: An example of informational impact criteria
| IMPACT | DESCRIPTION |
| Extensive | An attacker exfiltrates trade secrets, intellectual property, or a significant amount of data that is subjected to legal and regulatory requirements. |
| Significant | An attacker gains unauthorized access to protected data and exfiltrates a small subset of that data. There is also a possibility that the attacker can exfiltrate additional data. |
| Moderate | An attacker has gained a foothold in an environment and actively enumerates systems and applications for the data of interest. However, there is no evidence of unauthorized access to or exfiltration of protected data. |
| Minor | An attacker has compromised a non-business-critical system or application that does not store or process protected data. Also, there is no evidence of lateral movement within the environment. |
As with impact, enterprises need to establish clear urgency criteria to use in severity calculation. Table 4.3 provides an example of typical urgency criteria based on how far an attacker progressed through the cyberattack lifecycle.
By correlating impact and urgency, organizations can derive the severity level for an incident. The higher the severity, the more damage an incident may cause. The severity level drives the resources that an enterprise dedicates to resolve it.
Table 4.3: An example of urgency criteria
| IMPACT | DESCRIPTION |
| Critical | An attacker accesses highly confidential data or actively deploys destructive malware. |
| High | An attacker establishes C2 communication and has moved laterally within the compromised network. |
| Medium | An attacker exploits a vulnerability and gains unauthorized access to a system or a software application. The attacker may also establish a foothold to maintain access to the network. |
| Low | An attacker performs an active attack on the organization. However, there is no evidence that the attack succeeded. |
One way to establish the severity of an incident is to create a matrix of impact and urgency. Enterprises can also leverage the matrix to create a heat map by shading matrices with colors. Table 4.4 provides a matrix example based on the impact and urgency criteria discussed earlier in this section.
Table 4.4: An example of a severity matrix
| URGENCY | EXTENSIVE | IMPACT SIGNIFICANT |
MODERATE | MINOR |
| Critical | 1 | 1 | 2 | 2 |
| High | 1 | 2 | 2 | 3 |
| Medium | 2 | 2 | 3 | 3 |
| Low | 3 | 3 | 4 | 4 |
Enterprises can use a numerical or descriptive scheme to designate severity levels. Regardless of the choice of a scheme, organizations need to determine what level of response warrants each severity level. The following list contains examples of severity definitions based on the impact and urgency criteria examples discussed earlier in this section.
- Severity 1 An incident has a significant impact on business operations or protected data, and the enterprise must take immediate action to minimize damage caused by the cyberattack. Senior management actively participates in the decision-making process.
- Severity 2 An incident severely impacts one or two business functions or a subset of protected data, and the enterprise must respond as soon as possible to prevent further damage. Senior management provides guidance and strategic direction but does not actively participate in the incident management process.
- Severity 3 An incident has a limited impact on business operations, or an attacker has compromised a non-business-critical system but has not moved laterally in the environment. The enterprise needs to respond as soon as possible to minimize the possibility of any damage. Senior management may be informed but does not actively participate in the incident management process.
- Severity 4 An incident does not have any operational or informational impact. However, the enterprise needs to respond to the incident within a few days to prevent the attacker from progressing to the next stage of the attack.
Incident classification is a dynamic process, and enterprises may need to adjust the category and severity assignment throughout its lifecycle to reflect its impact and scope accurately.
Capturing Incident Information
Nowadays, most enterprises use a ticketing tool or a dedicated incident response platform to track incidents. Analysts leverage those tools to create records that contain a set of data relating to incidents. Some platforms also allow their users to associate incident records with other items, such as a known vulnerability, among other features.
Enterprises need to consider incident record requirements carefully. Specific information, such as a case number or an incident type, applies to all records. Other information may be incident-specific or not available at the time when an analyst creates an incident record, such as the incident scope. I have come across organizations that enforce strict documentation requirements in their case management systems by configuring mandatory fields. However, this approach can hinder the analyst's ability to create a ticket at the early stages of an event, especially in cases where the available information is limited or unknown. A more sensible approach is to enact a policy that requires an incident response team to document information throughout an investigation and update electronic incident records appropriately. Furthermore, management can review incident documentation regularly and implement specific controls when the documentation is lacking in detail or quality.
The following list contains typical incident attributes that enterprises may choose to track in an incident record:
- Unique incident reference number; most tools autogenerate this value
- Incident category
- Incident severity
- Date open
- Status
- Affected configuration items, service, location, or business unit
- Ownership
- Short description of the incident
- Subtasks
- Worklog
- Next expected activity
A cybersecurity incident typically progresses through several stages from the initial detection to its closure. The following list briefly explains each of those states.
- Open An analyst has raised an incident, but no one has been assigned to work on it. This situation typically happens when a service desk or a stakeholder who is external to the incident response team raises a cybersecurity incident. The incident response team receives the incident notification and then assigns an analyst to the case.
- In Progress An incident response analyst is assigned to an incident and actively investigates it. Some tools combine the Open and In Progress states into a single state.
- Cancelled An analyst may cancel an incident if a false positive event triggered it or if there is already an existing incident record for the report case.
- Resolved An analyst may place an incident into a Resolved state after containing the threat and remediating the affected assets.
- Closed Once an incident has been resolved and its symptoms do not reoccur within a specific time frame, an analyst may permanently close the incident. Some tools combine the Resolved and Closed states into a single state.
Incident Escalations
As part of their cybersecurity incident management process, enterprises need to establish escalation procedures. Incidents that typically require escalation may become major incidents, and organizations need to ensure appropriate response before they cause a significant operational or informational impact. Two types of escalations can occur: hierarchical and functional.
Hierarchical Escalations
A hierarchical escalation raises an incident to higher management levels. Incident response personnel may engage senior management during major incidents to set priorities and provide a strategic direction to the incident response team. For example, when containment requires the organization to isolate a system that supports a core business function from the network, senior management needs to decide whether system availability or containment takes precedence.
A hierarchical escalation may also be necessary if the incident response team requires additional resources or a higher level of support from a group that participates in the process.
Functional Escalation
Functional escalation raises an incident to a higher level of skill or expertise. Some investigations may require advanced DFIR expertise. In such cases, an analyst may escalate an incident to senior personnel to support or take over the investigation. Another example of functional escalation is hiring external consultants to assist with a specific aspect of the investigation, such as malware reverse-engineering.
Functional and hierarchical escalations are not mutually exclusive, and in some cases, they complement each other. In the previous example, an incident response team needs to escalate an incident to senior management that typically has the required level of authority to engage external consultants.
Creating and Managing Tasks
Investigating complex incidents and breaches typically requires the contribution of multiple cybersecurity, business, and technical stakeholders. To make this effort manageable, enterprises can break down a case into tasks and assign those tasks to specific roles.
A task is a unit of work that a specific role must complete to advance an investigation. For example, an incident manager may assign the task of acquiring forensic images of compromised hosts to one analyst, whereas another analyst may perform log analysis. An incident manager must associate all tasks with the investigated case and track their progress. Furthermore, a single role may be responsible for one or more tasks.
Some incident response platforms allow enterprises to create templates for specific incident types. As part of a template, analysts can create predefined tasks that an incident manager can assign during an investigation. This approach saves time and helps ensure a consistent response to similar incidents. The next section discusses how organizations can leverage this approach to build playbooks for specific incident types.
Major Incidents
Major incidents are incidents that cause a significant operational or informational impact and require prompt response. Severity 1 and Severity 2 incidents, as defined in a previous section, would qualify as major incidents.
Major incidents require vertical escalation to senior management and often a dedicated management workstream in addition to the technical workstream. For this reason, enterprises need to develop a major incident response process. The process should include the necessary provisions for both tactical and management workstreams that may include the following:
- Setting up a war room to convene key stakeholders to respond to the incident. A war room is also known as a command center or a situation room.
- Splitting the response effort into technical and management workstreams and establishing communication between those workstreams.
- Assigning an incident manager and an incident officer to lead those workstreams, respectively.
- Establishing a communication channel for each workstream.
- Establishing alternate communications protocols. This measure may be required if an attacker compromised internal communications systems, or an incident has an informational impact and may lead to legal exposure.
Communication and collaboration are vital to managing major incidents. Both business and technical stakeholders need to be informed about the progress of the incident investigation. For this reason, enterprises need to develop a comprehensive communications plan. Chapter 2 established a CSIRT coordination model with two key roles: incident manager and incident officer. As part of the process, enterprises have to assign a dedicated incident manager to lead the tactical workstream and directly work with the incident officer to ensure that business priorities drive the investigation. These two stakeholders are crucial to managing communication at the tactical and management levels, respectively.
Furthermore, enterprises need to conduct a post-incident review after each major incident to evaluate the response and identify opportunities for improvement. The section “Continual Improvement” discusses this topic in depth.
Incident Closure
Incident closure is the final activity in the process. It follows recovery and typically includes the following steps:
- Verifying that the incident record information is complete and accurate
- Ensuring that all activities within the processes have been completed
- Verifying that the incident indicators have not reoccurred
Crafting an Incident Response Playbook
An incident response playbook is a predefined series of steps that an incident response team takes when responding to a particular incident type. This approach allows organizations to streamline their processes and handle similar or routine incidents efficiently and consistently. Playbooks are also known as standard operating procedures (SOPs), runbooks, or incident models.
Playbook Overview
A playbook is an extension of an incident management process, and all of the steps that it contains must conform to the process. An incident management process focuses on an overarching approach to handle the lifecycle of all cybersecurity incidents. In contrast, a playbook focuses on a step-by-step procedure to respond to a specific incident type. Another way of thinking about playbooks is in terms of incident-specific response procedures. For example, a malware outbreak playbook contains concrete steps describing how to handle a malware outbreak at each phase of the incident response lifecycle.
As illustrated in Figure 4.3, organizations can also create work instructions describing how to perform specific steps within a playbook. Specific work instructions may apply across multiple playbooks and are typically valuable to new hires or junior personnel. For example, if a playbook contains a step to acquire a forensic image of a compromised system, an analyst can reference a documented work instruction on how to perform this task for a specific platform, such as Windows or Linux.
A typical playbook contains the following components:
- A workflow consisting of a series of steps arranged in sequential order, including dependencies
- Roles and responsibilities associated with each step
- Timescales for completing the steps
- Predefined severity level based on urgency and impact
- Predefined values for specific attributes, such as severity level based on impact and urgency
- Escalation procedure
A playbook may also contain interfaces to invoke other playbooks or processes. For example, an Unauthorized Data Access playbook could contain a step to trigger a data privacy incident process.
For playbooks to be effective, they must address specific incident types and focus on steps that are specific to those types only. For example, developing separate playbooks for ransomware and backdoor malware is more effective than creating a generic malware playbook. Also, playbooks should be concise, practical, and in the majority of cases, limited to no more than 25 steps. If a playbook requires more than 25 steps and a complex workflow with several decision points, it is likely too generic and should be broken down into more specific playbooks.
In my consulting engagements, I regularly come across organizations with a “playbook mentality,” who believe that scripting response procedures is a silver bullet to incident response. This cannot be further from the truth. Enterprises should create playbooks to guide their incident response teams and provide a repeatable procedure with documented preapproved decisions. However, it is vital to understand that even incidents of the same type vary in complexity, scope, and the tools, tactics, and procedures (TTP) that an adversary employs to progress through the cyberattack lifecycle. For this reason, even the most sophisticated playbook cannot replace critical thinking and the experience of a seasoned incident response professional.
For that reason, during client engagements I emphasize to senior management that playbooks should guide rather constrain incident responders. Furthermore, depending on a specific case, analysts may need to deviate from a standard procedure based on a sound and logical judgment of a specific situation. Enterprises must be cognizant of the fact that playbooks do not replace critical thinking. Security analysts and other stakeholders that participate in the incident response process still need to apply critical thinking and demonstrate the necessary skills and experience in their respective domains.
Identifying Workflow Components
This section discusses generic content and recommendations that enterprises may choose to include in their incident response playbooks. The content is organized by the stages of the incident response lifecycle.
Detection
Arguably, an incident response team invokes a playbook after incident detection. For this reason, specific technical means of identifying incidents are typically out of scope. However, a playbook should still include specific triage steps. Triage allows incident responders to determine whether the reported event is a cybersecurity incident and collect contextual information before diving into detailed analysis. Typical steps in this phase include the following:
- Triage During the triage step, analysts must take steps to review the reported event data, establish whether the event constitutes a cybersecurity incident, and collect contextual data. This data may include technical information about the affected systems and their business context. Furthermore, analysts may want to collect additional data through live response and assess that data before declaring an incident.
- Incident Classification and Documentation As described earlier, analysts must establish impact and urgency factors to determine the severity level of an incident. In some cases, it is a good practice to establish impact and urgency factors as part of the playbook definition, especially if the playbook is for a particular scenario.
- Documentation After triaging and classifying an incident, analysts must document all the required information in an incident record. If an organization leverages an incident response platform for automation, analysts can preconfigure some attributes as part of the incident template or model, such as owner, automatic notifications of specific stakeholders, or triggering of other processes. Some platforms can also automatically calculate incident severity based on the urgency and impact factors that analysts enter or preconfigure as part of the template.
- Escalation Some incidents may be relatively straightforward to resolve and do not require advanced expertise and skills. Other incidents may require a specialized skill set or management attention. As part of a playbook definition, enterprises may choose to define the required functional and hierarchical escalations and assign specific roles as owners to the incident.
Analysis
Depending on the nature of an incident and its scope, analysts may acquire and examine different types of data. The purpose of the analysis phase is to determine attacker activity in the compromised environment and understand the full scope of the incident.
The analysis steps must focus on the objectives of the analysis and the type of incident that a playbook addresses. At the same time, the steps must be generic enough not to constrain the analyst. For example, when investigating a backdoor malware on a server system, an analyst may choose to focus on program execution artifacts rather than reviewing every possible forensic artifact that the system may have produced. However, including separate steps to review each program execution artifact would be excessive and impractical. Typical steps in this phase include the following:
- Data Acquisition and Preservation This step should contain information about the types of data that incident responders must acquire and preserve and the acquisition techniques. Depending on the incident type, analysts may need to collect network data, forensic images, or logs from enterprise services.
- Technical Analysis The technical analysis steps relate to the analysis objectives and methods that analysts need to leverage to achieve those objectives. The objectives and techniques that analysts employ may differ depending on an incident type. For example, to determine evidence of malware execution on a system, analysts typically examine program execution artifacts.
- Scoping The steps refer to enumerating other systems on the network for IOCs determined during the previous step. Analysts may leverage various scoping techniques and execute different scoping steps depending on the incident type and available tools. For example, analysts can leverage an EDR tool to enumerate systems on a corporate network for evidence of specific malware execution artifacts.
- Creating a Timeline For some incidents, analysts may need to conduct a timeline analysis based on the findings during previous steps. The purpose of the analysis is to reconstruct attacker activity in the compromised environment and understand the full scope of the compromise. Analysts reconstruct a timeline of attacker activity by organizing relevant time-stamped data into a timeline.
- Creating Actionable Cyber Threat Intelligence For some incidents, analysts need to create actionable CTI to inform containment and eradication activities. For example, analysts may compile a list of C2 IP addresses recovered through malware analysis and discovered through CTI enrichment. Victim organizations can then block network connections to those IP addresses to deny an attacker access to the compromised environment.
- Adjust Incident Severity Based on the findings during the previous steps, enterprises may need to adjust the urgency and impact factors to change the severity of the incident. This activity is particularly applicable in cases where incident responders discover new, significant information relating to the investigated incident.
It is crucial to emphasize that analysis is an iterative, and often incremental, process. For this reason, analysts iterate through the lifecycle until they reach diminishing returns relating to new findings, such as discovering additional compromised systems. It is essential to communicate this concept to vital stakeholders and set expectations accordingly, particularly during high-pressure incidents.
Containment and Eradication
The information that analysts compile during the analysis steps drives containment and eradication activities. These activities are specific to a threat type, and their execution heavily depends on the architecture of the compromised environment, available tools, policies, and other controls. Another crucial factor that impacts containment and eradication is business priorities. For example, isolating a critical server from a network may be a sensible containment strategy from a technical perspective, but not feasible from a business point of view.
The first activity in defining containment and eradication steps as part of a playbook definition is to create a strategy and then select tools and technology to implement that strategy. A strategy to contain an incident and eradicate a threat actor may include the following:
- Enforcing access control mechanisms
- System hardening
- Patching vulnerabilities
- Resetting credentials
- Implementing security tools
- Blocking direct attack vectors
- Adjusting system policies and locking down permissions
Furthermore, enterprises can enhance security monitoring to detect additional attacker activities or attempts to come back to the compromised network after remediation.
Recovery
Recovery is typically outside the scope of an incident response playbook. However, in some cases, organizations may want to include in an incident response playbook steps relating to invoking functions that typically participate in the recovery process, such as the DR function or technical groups. For example, an enterprise may choose to include a step in the recovery phase to re-image malware-infected workstations and assign the ownership of that step to a workplace services group.
Other Workflow Components
In addition to the steps necessary to investigate and remediate an incident, organizations need to consider these other components relating to the overall incident management process:
- Communications Different types of stakeholders may need to be informed about the progress of an investigation of specific incident types. An effective playbook should include steps to facilitate communications with key stakeholders.
- Process Integration Enterprises also must ensure to include steps that invoke other necessary organizational processes during the response to a specific threat type. For example, an analyst may need to invoke the configuration management process to determine crucial information about an investigated system or an HR process for insider threat cases.
Post-Incident Evaluation
The post-incident phase, also referred to as postmortem, includes activities that follow the recovery phase. Vulnerability management and lessons learned are two vital processes that can help organizations determine the root cause of an incident and the necessary improvements to prevent or reduce the impact of similar incidents in the future. The outcome of these processes typically feeds into the continual improvement process discussed in the next section.
Vulnerability Management
This section briefly discusses vulnerability management as it pertains to cyber breach response. The purpose of an incident management process is to address the aftermath of a cyberattack and minimize the damage it causes to the enterprise. However, if the enterprise does not address the underlying security weaknesses that allow attackers to compromise systems in the first place, similar incident types are likely to recur. This reactive approach often leads to inefficient use of resources and reduced security posture. Vulnerability management is a process that allows enterprises to address the issue.11
Purpose and Objectives
As stated previously, vulnerability management is the process of identifying, evaluating, reporting, and remediating security vulnerabilities. A vulnerability is a weakness in a computer system, software application, design, implementation, or control that a threat actor can exploit to gain unauthorized access to a computer network and progress through the cyberattack lifecycle. The purpose of vulnerability management is to identify and mitigate vulnerabilities and minimize the attack surface of computer systems and software applications.
Vulnerability management is often an independent function within the overall cybersecurity program. Investigative findings and security posture weaknesses discovered during incident response must feed into the vulnerability management process to prevent similar incident types from reoccurring. In simple terms, incident management is a reactive process, whereas vulnerability management attempts to address issues proactively.
Vulnerability Management Lifecycle
The vulnerability management lifecycle, as it pertains to incident response, consists of five steps necessary to identify and address vulnerabilities that lead to cybersecurity incidents. The lifecycle approach applies to vulnerabilities that incident responders identify during incident investigations. A comprehensive vulnerability management program contains additional stages, such as asset discovery and prioritization, that the approach does not include. Figure 4.5 depicts the lifecycle.
- Identify The first step in the process is to identify and recognize that there is a security weakness that gives rise to cybersecurity incidents. An organization may identify a vulnerability by performing an incident root cause analysis. Furthermore, in organizations with mature governance practices, the leadership may identify a pattern of reoccurring incidents and request a root cause analysis to identify the underlying weakness.
- Evaluate Most enterprises do not have unlimited resources and must address more severe vulnerabilities first. For this reason, organizations need to assess and prioritize the identified vulnerabilities that can lead to the most significant impact on their business first. Addressing vulnerabilities in system design and implementation often requires dedicated projects and funding.
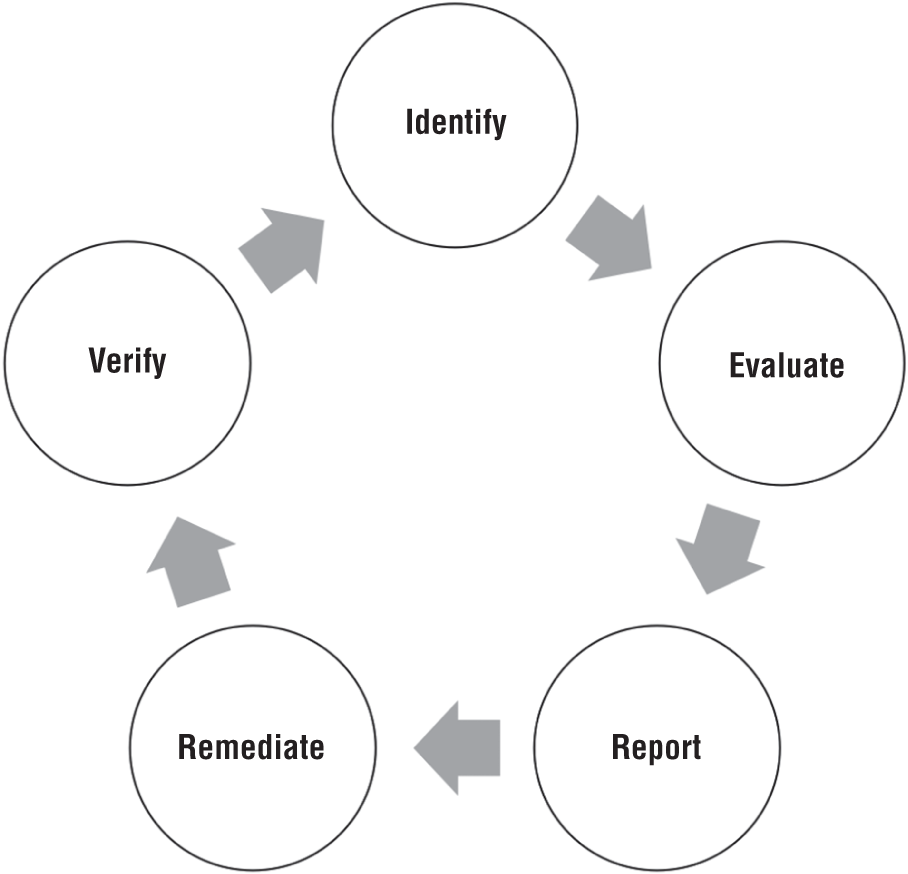
Figure 4.5: Vulnerability management lifecycle
- Report Incident responders must document and report to management any identified weaknesses during an investigation. Reporting less severe weaknesses, such as missing patches for noncritical vulnerabilities, to mid-level management is typically sufficient. However, high-severity weaknesses, such as poor network segmentation, typically require the attention of senior management.
- Remediate Some security weaknesses may be relatively easy to address, whereas others may require cross-functional coordination and management support. In some cases, organizations may also be able to implement a compensating control if addressing a security weakness may require significant effort and resources. Enterprises must evaluate each vulnerability from a risk perspective and apply cost-effective risk mitigation measures.
- Verify After remediating a vulnerability, enterprises must verify that the vulnerability no longer exists in the environment. This approach may include verifying installed patches and configuration settings, performing vulnerability scanning, or attempting to exploit the vulnerability.
Integrating Vulnerability Management and Risk Management
Chapter 1 discussed risk management as a driver for cyber breach response. In the cybersecurity domain, vulnerability management has a strong relationship with risk management.
Incident response teams should submit underlying security weaknesses that they identify as part of a root cause analysis to the risk management function for evaluation. For this reason, enterprises must integrate their vulnerability management process with risk management to determine cost-effective measures to address those weaknesses. The risk response process includes the following options:
- Avoid If an enterprise deems a risk to be too high, it may decide to eliminate it altogether by terminating the activity that leads to the risk. For example, an enterprise may choose to decommission a legacy service that is not critical to the business if the underlying technology has significant vulnerabilities that the organization cannot address in a cost-effective manner.
- Transfer An enterprise may choose to transfer a risk to a third party. Outsourcing a certain business function or process is one option. Another popular option is to purchase a cyber insurance policy.
- Reduce To reduce a risk, enterprises implement specific administrative, physical, or logical controls that make it more challenging for a threat actor to compromise a system. For example, an enterprise may choose to upgrade unsupported platforms or migrate a service to newer technology.
- Accept Organizations may choose to accept a risk if the cost of the consequences is lower than mitigating the risk.
Lessons Learned
Lessons learned is the learning that enterprises gain from responding to cybersecurity incidents. The purpose of lessons learned is to identify and document information about positive aspects of incident response, as well as to identify any roadblocks and issues. The outcome of a lessons-learned session is a set of specific action items designed to improve future response.
Action items may fall within one of the following categories: operational, tactical, or strategic. Organizations can implement operational items as part of day-to-day operations. However, tactical and strategic action items typically require funding and other resources. For this reason, they must feed into the continual improvement process. I discuss this topic in more detail in the “Continual Improvement” section.
Organizations should conduct a lessons-learned meeting after every major incident. It is also a good practice to hold regular lessons-learned meetings to evaluate the response to less severe incidents to identify actionable improvements.
Lessons-Learned Process Components
Lessons learned is an iterative process consisting of several steps necessary to evaluate and improve response to cyberattacks continuously, as depicted in Figure 4.6.
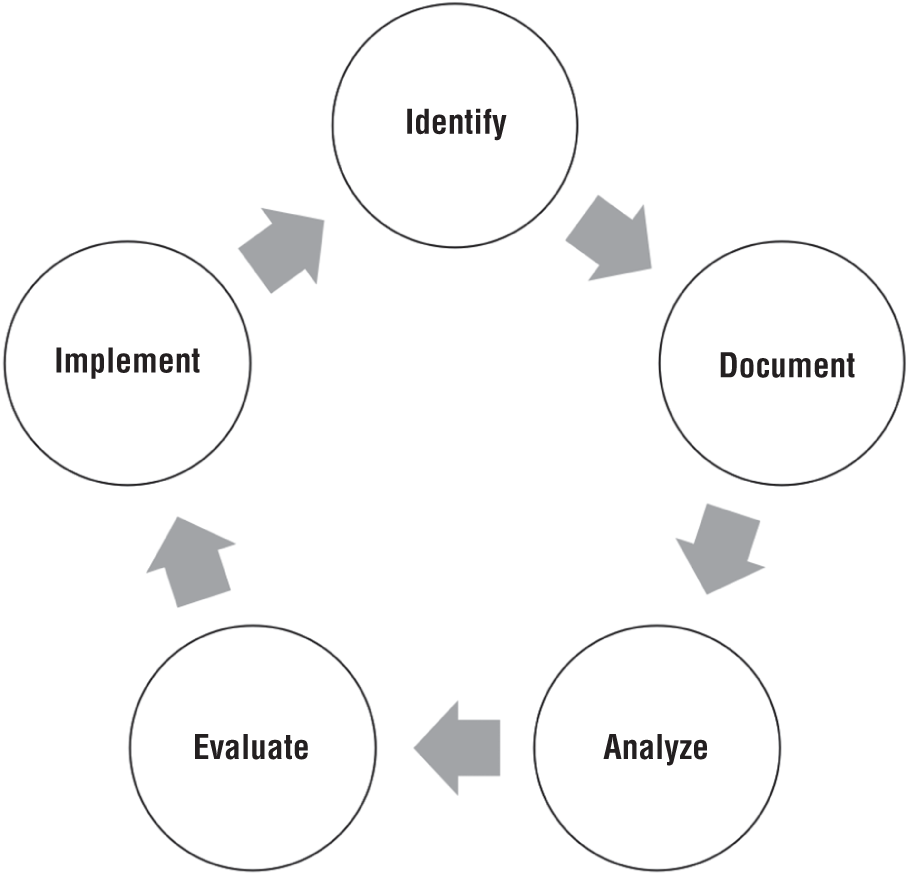
Figure 4.6: Lessons-learned process
- Identify Identify what worked well and any gaps or problematic areas that the enterprise should address to improve response to future incidents.
- Document Document and share the findings identified during the previous step with key stakeholders. One way to organize the findings is to assign each finding to one of the following categories: people, process, or technology.
- Analyze Analyze each gap and problematic area identified in the first step and determine possible solutions. Enterprises need to raise issues with senior management that may lead to significant risk.
- Evaluate Evaluate the feasibility of each solution determined during the previous step and obtain approval from key stakeholders to implement feasible solutions.
- Implement Implement solutions to address gaps and problematic areas identified in the first step. Tactical and strategic solution proposals must feed into the continual improvement process as an input and may require a business case to secure funding and other necessary resources for implementation.
People, process, and technology are critical components of effective incident response. To identify lessons learned, enterprises need to evaluate the performance of each of those components.
The people component encompasses all the stakeholders who participate in the incident response process. The following list provides examples of discussion topics that may help identify lessons learned relating to this component:
- Availability of skills and experience in specific domains
- Understanding of roles and responsibilities
- Communication
- Authority to make decisions
- Resource redundancy
The process component is necessary to execute the incident management process in a structured and coordinated manner. The following list provides examples of discussion topics that may help identify lessons learned relating to this component:
- Coordination of activities between roles participating in the incident management process
- Availability of specific incident response playbooks
- Vertical and horizontal escalations
- Specific process elements, with emphasis on gaps and problematic areas
- Fulfillment of each activity within the process
- Availability of information necessary to execute the process
- Information tracking
- Interfacing with other processes and organizational functions
The technology component refers to the tools and technologies necessary to respond to incidents effectively, as well as other technology considerations during incident investigations. The following list provides examples of discussion topics that may help identify lessons learned for this component:
- Availability of tools and other technologies necessary to support investigations
- Availability of forensic data
- Any challenges with acquiring forensic data
- Ability to detect attacker activity on the compromised network
Conducting a Lessons-Learned Meeting
This section contains general recommendations for conducting fruitful lessons-learned sessions.
- General Rules Plan a meeting structure, send out the agenda in advance, and encourage all participants to document their observations before the meeting. Also, develop a standard template for documenting lessons learned and other observations.
- During the Meeting Stick to the meeting structure and agenda, and keep the discussion focused. Ensure that there is one person who leads the discussion and another person responsible for taking notes. It is easy for a discussion to sidetrack, and having a clear plan helps keep the meeting focused. An excellent way to start a meeting is to discuss what went well first.
- After the Meeting Document, analyze, and evaluate action items identified during the meeting and disseminate this information to the participants. Be sure to assign an owner to each action. Also, make sure to follow up on the action items to ensure that stakeholders advance them.
It is critical that the person who leads the discussion makes the attendees comfortable and facilitates the discussion in a nonconfrontational way. During review meetings, stakeholders tend bring up negative experiences, so keeping the discussion balanced is vital to ensuring that stakeholders identify lessons learned as opposed to assigning blame.
Some participants may be introverted or lack the confidence to speak. Encourage them to participate. In my personal experience, some of the most valuable contributions come from those who quietly evaluate their observations before bringing them up in front of others.
Lastly, an excellent technique to facilitate a meeting is to ask open-ended questions and then follow up with specific targeted questions to extrapolate further details. Starting with open-ended questions allows the facilitator to collect general feedback before drilling into specific areas of interest.
Continual Improvement
Chapter 1 briefly discussed the need for continual improvement as a vehicle to evaluate and improve a cyber breach response program continuously. The chapter also discussed the drivers for continual improvement, as well as the organizational levels at which it can take place. This section discusses this topic in depth and provides a methodology that can help organizations successfully implement a continual improvement process.
Continual Improvement Principles
This section presents two conceptual models that form the foundation of continual improvement: the Deming cycle and the Data, Information, Knowledge, Wisdom (DIKW) hierarchy. The former model describes quality management principles, whereas the latter model explains the principles of knowledge management.
The Deming Cycle
The Deming cycle is a continuous quality improvement model that consists of a sequence of four steps: Plan, Do, Check, and Act (PDCA), as depicted in Figure 4.7. The PDCA cycle is a fundamental tenet of many quality management standards, such as ISO/IEC 27001.12
- Plan Review and evaluate a cyber breach response program regularly. The purpose of the review is to identify any underperforming areas, as well as to determine any required changes to the program in response to increased cyber risk, legal and regulatory requirements, or changing business objectives. As part of this step, organizations also need to establish the current state and a future desired state, as well as the metrics necessary to measure progress against improvement objectives.
- Do Conduct a trial of specific improvement initiatives through a small pilot project. As part of the trial, collect the quantitative data necessary to establish whether the initiatives achieve the desired outcome.
- Check After conducting a trial, process, organize, and analyze the collected data. The purpose of this phase is to produce and analyze metrics to determine whether the initiatives achieved the desired outcome. If the initiatives failed to produce the desired results, go back to planning.
- Act If the piloted improvement initiatives produced the desired outcome, make them permanent and update processes and the necessary documentation. The improved state becomes the baseline for the next iteration of the PDCA cycle.

Figure 4.7: Deming cycle
DIKW Hierarchy
The DIKW hierarchy is a knowledge management model that describes how data evolves into information, knowledge, and wisdom, respectively, as represented in Figure 4.8.13

Figure 4.8: DIKW hierarchy
- Data The evolution starts with generating data. Data is a set of discrete elements that do not provide any meaning by themselves. Security event logs that systems and applications generate are an example of data.
- Information When an enterprise processes, organizes, and structures data in a way that makes it meaningful, the data becomes information. For example, when a security analyst processes and organizes the event logs mentioned earlier, they might discover that 100 authentication attempts occurred on a specific system during the previous days with three user accounts. Eighty percent of those authentication attempts failed and were associated with a single user account. Enterprises can derive information from data by asking the who, what, when, and where questions.
- Knowledge Organizations form knowledge by applying context and experience to information, as well as by connecting it with other pieces of information. Following the previous example, the analyst might determine that the authentication failures occurred as a result of a password brute-force attack. To derive knowledge from information, organizations need to answer the how question.
- Wisdom Wisdom is the last step in the hierarchy, and it represents knowledge applied in action. Considering the previous example, the analyst may determine that a threat actor gained access to the network and performed a password brute-force attack in an attempt to elevate their privileges.
The Seven-Step Improvement Process
The ITIL seven-step improvement process builds on the improvement principles discussed in the previous section. It presents a sequence of actionable steps that can help organizations implement a continual improvement process as part of their governance.14
- Step 1: Define a vision for improvement including goals and objectives.
- Step 2: Define metrics.
- Step 3: Collect the data necessary to produce the metrics.
- Step 4: Process and organize the data to derive information.
- Step 5: Analyze the information, identify trends, and determine whether the improvement initiatives produce the desired outcome. In this step, information becomes knowledge.
- Step 6: Assess the findings and create an appropriate improvement plan.
- Step 7: Implement the plan.
Figure 4.9 provides a visual representation of this process. The next section provides practical guidance on how to implement each step.

Figure 4.9: The seven-step improvement process
Step 1: Define a Vision for Improvement
Chapter 1 discussed how to create a vision as part of the overall cyber breach response program. The same strategies apply to defining a vision for improvement.
As part of this step, enterprises need to make sure that their strategy is realistic and aligned to their risk appetite. Answering the following questions is a good start for developing a continual improvement strategy:
- Is there any new business development under way that may require changes to the cyber breach response program?
- Are there any new developments in the threat landscape that lead to increased cyber risk?
- Are there any legislative changes that may impact how the organization currently responds to incidents?
- Does the organization contain most incidents before they cause a negative impact?
After identifying specific improvement initiatives, organizations must document them in a continual improvement register, assign an owner to each initiative, and review them regularly.
Step 2: Define Metrics
Metrics and key performance indicators (KPI) are vital components for measuring the performance of a program. They must be quantifiable and allow visualization of trends over time.15
- Metrics Metrics allow organizations to measure a specific activity or aspect of their program. For example, an enterprise may choose to measure the number of critical-, high-, and medium-severity incidents weekly.
- Key Performance Indicators KPIs, on the other hand, enable organizations to determine how well their program performs against the objectives. Considering the previous example, an organization may leverage the metrics it collects to create a trend chart to determine if the incidents at each category decrease, increase, or remain at the same level over a period of six months.
Ideally, organizations need to establish metrics and KPIs for each objective established during the first step. As with the previous step, enterprises must document the metrics and KPIs that they decide to measure. The following list contains practical tips for getting started with metrics and KPIs:
- Keep it simple and focus on fewer but vital metrics that can facilitate decision making. Creating a complex metric system often leads to confusion and unnecessary overhead.
- Ensure that the metrics are quantifiable and that the organization can collect the necessary data to support those metrics.
- Leverage automation tools that allow you to preconfigure metrics, visualize trends, and provide point-in-time information.
A common mistake is to create a metric system that is not suitable for the target audience. For example, presenting data relating to SQL injection attacks against a web application to a board of directors is not the most effective way to communicate risk. Instead, focus on metrics that can support KPIs and communicate the intended message. For example, measuring the occurrence of specific incident types and presenting trends over a period of time helps senior management communicate risk more effectively and secure the necessary resources to keep that risk at an acceptable level.
Enterprises may also choose to create a metric database or some other index to provide metadata on metrics. The metadata can include the following elements for each metric:
- A unique identifier
- What question the metric answers
- Target audience
- Update frequency
- Sources of data
- An example for presentation purposes
This approach can help organizations understand their metric system and keep it organized.
Step 3: Collect Data
The quality of metrics that an enterprise produces heavily depends on the data that the organization uses to produce those metrics. The characteristics that define data quality include the following:
- Availability Ensure that all data needed to support the necessary metrics is available. In some cases, organizations may need to audit and adjust their logging baselines to ensure that systems and applications generate the necessary log data to support metrics.
- Accuracy The collected data must be accurate. For example, including false-positive events in metrics that demonstrate adverse activities against the corporate network can lead to poor decisions and inefficient use of organizational resources.
- Completeness Make sure that the collected data is comprehensive. When certain types of data cannot be collected from certain segments, this must be clearly communicated to management when presenting metrics.
- Reliability Reliability means that data from one source does not contradict data from another source. If various pieces of data contradict each other, the enterprise cannot rely on the data to produce accurate metrics.
- Relevance Ensure that the collected data is relevant for the metrics that the organization produces.
- Timeliness Timeliness means that the required data to produce metrics must be up to date and available when needed.
The following list contains practical tips for ensuring data quality in support of metrics:
- Define data collection requirements for metrics.
- Establish whether the necessary data is available in the enterprise.
- Determine the means to collect the data.
- Determine collection frequency based on reporting requirements.
- Assign an owner and a custodian to the data collection task to ensure accountability and fulfillment, respectively.
Step 4: Process Data
After the collection phase, organizations must convert raw data into information. Data processing usually consists of the following steps:
- Validation Ensure that the data is correct and relevant. Checking a sample of values after each collection for anomalies, such as empty or missing data fields, is a good start.
- Determine Formatting Establish a presentation format that is appropriate for the target audience. Senior leadership may be interested in high-level trends, whereas mid-level management typically needs more detailed information to make decisions.
- Choose Tools Determine and choose the tools suited to transform the data into the required format. In simple cases, an Excel worksheet might be sufficient. Large and complex data typically require specialized tools.
- Convert Data Convert data into the required format. This may require techniques such as sorting, aggregations, frequency analysis, or other statistical methods to convert the raw data into information.
Step 5: Analyze Information
In this step, organizations extract actionable intelligence by applying business context to the information and metrics established during the previous step. Stakeholders typically review the presented information for trends and patterns to guide decision making. They may also ask specific questions relating to the program, such as these:
- Does the analysis show any undesired trends?
- Is there an identifiable cause for a trend?
- Is there a specific cause for anomalies?
- Do we have the necessary capabilities to keep risk at an acceptable level?
- Is our program performing as per the established objectives?
Step 6: Assess Findings and Create Plan
In this step, management assesses the analysis results and makes decisions regarding specific improvement plans. The presentation style and level of detail must be appropriate for management to enable them to make decisions. The following list contains practical tips for ensuring effective presentation:
- Know your target audience and tailor the presentation to their requirements. For example, executive personnel are typically interested in understanding the bigger picture rather than low-level details.
- Choose the correct format for the audience, such as a slide deck or a report.
- Be clear and concise, and remain focused. Present only the relevant information.
- Present information impartially and remain objective.
- Use visual formats where appropriate, such as trend charts.
- Attempt to garner the audience's interest by giving examples, telling a story, or personalizing the presented information.
Step 7: Implement the plan
In this step, an enterprise implements the improvement plans agreed to during the previous step. This step may include the following:
- Evaluating a proposed plan to determine whether it is cost-effective
- Building and submitting a business case
- Securing funding and other resources
- Planning and executing projects
Summary
An incident response plan contains several components that must work in tandem to allow organizations to respond to cybersecurity incidents effectively.
Most incidents have a predictable lifecycle. An effective incident management process helps organizations manage incident response activities in a structured and coordinated manner and ensure that they can continue business operations during cyberattacks. It consists of several components and activities that integrate the people, process, and technology dimensions.
For specific incident types, organizations may choose to create playbooks. Playbooks allow organizations to create repeatable procedures and accelerate response activities. However, organizations need to remember that even a state-of-the-art playbook cannot replace skills, experience, and critical thinking.
Finally, to improve their cyber breach response capabilities continually, enterprises need to conduct lessons learned, identify vulnerabilities, and implement measures to prevent reoccurring incidents or reduce their impact on their business. Continual improvement is vital to successful governance, and it helps organizations mature and improve their programs incrementally.
Notes
- 1. NIST SP 800-61, “Computer Security Incident Handling Guide Revision 2,” August 2012,
nvlpubs.nist.gov/nistpubs/SpecialPublications/NIST.SP.800-61r2.pdf. - 2. ISO 22301:2019, “Security and resilience—Business continuity management systems — Requirements,”
www.iso.org/standard/75106.html. - 3. Carnegie Mellon University, “CRR Supplemental Resource Guide: Volume 5, Incident Management,” Version 1.1,
www.us-cert.gov/sites/default/files/c3vp/crr_resources_guides/CRR_Resource:Guide-IM.pdf. - 4. “ITIL Maturity Model and Self-assessment Service: User Guide,” October 2013,
www.tsoshop.co.uk/gempdf/ITIL_Maturity_Model_SA_User_Guide_v1_2W.pdf. - 5. CMMI Institute,
cmmiinstitute.com. - 6. ISO 9001:2015, “Quality management systems — Requirements,”
www.iso.org/standard/62085.html. - 7. Helen Morris and Liz Gallacher, ITIL Intermediate Certification Companion Study Guide, Sybex, September 2017.
- 8. VISA, “What to Do If Compromised: Visa Supplemental Requirements, Version 6,”
usa.visa.com/dam/VCOM/download/merchants/cisp-what-to-do-if-compromised.pdf. - 9. NIST SP 800-61, “Computer Security Incident Handling Guide Revision 2,” August 2012,
nvlpubs.nist.gov/nistpubs/SpecialPublications/NIST.SP.800-61r2.pdf. - 10. “CISA Cyber Incident Scoring System,”
www.us-cert.gov/CISA-Cyber-Incident-Scoring-System. - 11. Morey J. Haber and Brad Hibbert, Asset Attack Vectors: Building Effective Vulnerability Management Strategies to Protect Organizations, Apress, June 2018.
- 12. ISO/IEC 27001:2013, “Information technology — Security techniques — Information security management systems — Requirements,”
www.iso.org/standard/54534.html. - 13. Waseem Afzal, Management of Information Organizations, Chandos Publishing, June 2012.
- 14. Helen Morris and Liz Gallacher, ITIL Intermediate Certification Companion Study Guide, Sybex, September 2017.
- 15. Douglas W. Hubbard, Richard Seiersen, Daniel E. Geer Jr., and Stuart McClure, How to Measure Anything in Cybersecurity Risk, Wiley, July 2016.