
7
Risk Management, Controls, and Policies
One of the most important things to sort out, aside from preparing all the documentation needed and confirming support from management, is to have a list of all the entity’s assets. In this chapter, we will be covering risk management, data classification, and the controls defined within ISO 27001.
An asset is a resource having economic worth that a person, business, or nation owns or manages with the idea that it will produce future benefits. The balance sheet of a firm lists its assets. They are acquired or established to raise the value of a company or to boost its operations. In our context, an asset is defined as any goods or services, tangible or intangible, that are considered part of an entity.
So a firewall, for instance, is an asset; a pen is an asset; but also the documents on the local or online repository of the company are considered to be an asset, as well as that server that they were supposed to dismiss five years ago, but for some reasons as unknown as the Bermuda triangle, is still there.
Why in the world is a document (MS Word, Excel, PowerPoint, you name it) considered an asset? Well, of course it’s not due to the document(s) themselves, but because of what those documents are worth: let’s suppose that you are the King of Reign1 and your plans for invading Reign2 and therefore becoming Emperor of the Galaxy are in your safe waiting to be used – how much are they worth? Or let’s suppose that you’ve got 50 kilos of bearer shares? What is their value? Or all the notebooks that you used while at primary school, how much are they worth, according to your parents?
You got the point: if the shape of water depends on the container that encloses it, the value of a document does not depend on the physical document but on the information it contains.
In this chapter, we will cover the following topics:
- Elements of project risk management
- Data classification
- ISO 27001 controls
Elements of project risk management
Project risk management is an essential project management strategy that aims to minimize the number of surprises that occur during a project’s execution. Despite the fact that it is impossible to forecast the future with absolute certainty, a straightforward and simplified risk management method may be used to anticipate uncertainties and reduce their occurrence or effect. This raises the probability that the project will be completed successfully and decreases the implications of these risks.
The basic processes for project risk management are therefore the following:
- Risk identification, or the identification of risks or their sources.
- Risk evaluation, or the evaluation of risks in terms of probability and impact to establish an order of priority among the identified risks.
- Risk handling, which is the process that identifies, evaluates, selects, and implements various remediations in order to obtain an acceptable risk threshold in compliance with the constraints and objectives of the project. In particular, it includes what must be done, when, who is responsible for it, and the related cost and schedule.
- Risk controlling, meaning the continuous reporting and monitoring of both risks and their management mechanisms.
Risk reporting in particular has a dual purpose: in the immediate term, it enhances communication within the project, and in the long term, it generates historical precedents that may be utilized to produce more accurate risk forecasts in future projects.
The risk management plan
During my career, also as a risk manager, I learned some fundamentals of risk management:
Risk management is uninteresting to 99 percent of the population of the globe. They see no value in it.
I developed a risk register strategy that was as straightforward as I deemed it needed to be in order to assist conversations and decision-making. It worked well, and after a few years as a general risk manager, I transitioned into the information security field, carrying the strategy with me to the current day.
Fundamental notions
A few broad views on risk management
Risk management is a management method that helps your organization accomplish its goals by concentrating on helping you understand some of the undesirable events that might prevent you from reaching your goals. It then assists you in deciding what you might do to handle these negative events, and perhaps prevent them from occurring. It is a managerial approach designed to aid in decision-making; if it is not aiding in decision-making, then it is a waste of time. Risk management is a subpar method for managing hazards, but it is the best method available, and like other management method, it sometimes works and sometimes does not. Again, like any management strategy, it requires some talent to be effective, and the more you practice, the better you get at it. Like the finest management strategies, it is fundamentally straightforward.
Risk evaluation
To select the most effective risk reduction approach, it is necessary to analyze risks. There are three stages involved:
- Identification: Identifying and defining the kinds of risks your firm confronts is the first step. Both internal and external threats exist. Consider also whether the risks are avoidable, such as operational risks, or not, such as natural calamities, when recognizing them.
- Impact assessment: Once a risk has been identified, its effect may be assessed. This entails defining the likelihood of a risk’s occurrence and its corresponding effect or outcome.
- Develop strategies: Finally, you may establish the required approach for risks with a medium or high likelihood of occurring. Despite the fact that you may still choose to monitor minor risks, they are less important when it comes to taking the next step and developing a strategy.
Risk characteristics
These are the 10 characteristics that each risk should be ascribed:
- Risk ID of some form, e.g., R0417. This can be anything that allows you to individually distinguish each risk.
- Risk description: What is the undesirable event that might lead to the loss of confidentiality, availability, or integrity of information under your scope? You should strive for clarity on the business repercussions of this negative event and its source or causes.
- Risk owner: There must be a designated risk owner. This individual must be able to make risk-related choices and is often a senior member of staff. Who will have to deal with the consequences if this unfortunate event occurs? What is sometimes advantageous is having a delegated risk manager who reports to the risk owner but can handle the risk on a continuing basis. Nonetheless, it is essential that the risk owner possess some degree of comprehension of and responsibility for the risk. It is uncommon for certification auditors, in my experience, to speak with risk owners to inquire about their awareness of the risks and the decisions they have made. But they must!
- Existing essential controls: What do you currently have in place that aids your risk management? You don’t need to mention every control already in place to manage the risk, since the standard just asks you to describe the essential measures. Try to keep the number of items on this list modest. If there are controls that you believe should be in place but are not, you should explain them in your risk improvement actions.
- Current likelihood: How probable is it that something will occur during the next 12 months? People use many scales, but I propose a range from 1 (low) to 5 (high). I propose basing this probability assessment on your current awareness of how effectively the controls are working to manage the risk today – i.e., how effective they are today in light of any presently known deficiencies in the controls.
- Current effects: What is the single-number business effect of the loss of confidentiality, availability, and integrity of the impacted information? Typically, this is a single number from 1 (low) to 5 (high). Some individuals like to use three different numbers/evaluations – one for each of confidentiality, availability, and integrity – but to keep things simple, I suggest using a single value. The criterion does not require three separate evaluations. As with the probability, this should account for any information on the present efficacy and known current flaws of the controls managing the risk.
- Current risk rating: There are more intricate approaches but multiplying the numbers for probability and effect will suffice. This is also referred to as the level of risk, i.e., a value from 1 to 25.
- Current risk assessment: This indicates whether or not this risk is within your risk appetite, however that is defined. Typically, this is determined by the risk score. For example, All hazards with a score over 12 exceed the risk appetite. People often have two breaking points: one for risks that are far outside their risk appetite (e.g., with a score above 20) and one for risks that are above the risk appetite but not quite as far – e.g., between 12 and 21. This is represented by the colors red, amber, and green.
(Optional) Should you be pleased with this result? Yes, if the current risk score is within the risk tolerance. Otherwise, the answer is no. This characteristic is optional, however it may facilitate thought.
- Risk treatment determination: If the risk is acceptable, Accept should be selected. This means we are satisfied with this risk and no more action is required. Depending on your risk assessment methodology and risk acceptance criteria, Accept might be selected if the risk exceeds your risk tolerance. Nonetheless, if it exceeds risk tolerance, the most probable response is Treat, i.e., take action. You might alternatively select Avoid or Transfer as the risk treatment choice, but these options are unlikely to be utilized much, if ever.
- Risk improvement activities: If you have selected the Treat option, you will add one or more new controls or enhance existing controls in the majority of situations. The expectation is that, after these steps have been implemented, they will have some influence on the probability or impact, which will ideally be sufficient to bring the risk below the established risk tolerance. Each activity should have a designated owner and a deadline for completion.
Hopefully, this was clear enough to let you understand the list of characteristics that a risk should have. Next stop, heatmaps.
Risk heatmaps
Risk heatmaps are often used in operational risk management and are especially beneficial for visually representing a company’s risks and emphasizing those that need closer supervision. Typically, while analyzing operational risk, the risk manager will utilize a spreadsheet to record the company’s important hazards and estimate their effect and likelihood (or probability).
Some entities still use spreadsheets to manage broader risks and display heatmaps, which are typically included in management information reports for senior management and other senior executives. Despite the fact that many companies have risk management systems that provide this functionality, some companies still rely on spreadsheets to manage broader risks and display heatmaps.
The total risk score is the product of the likelihood (or probability) and effect ratings. The formula for calculating the risk score is as follows:
Risk Score = Likelihood Score x Impact Score
When the list of risks is broad, often spanning many departments or business sectors, it is a significant difficulty for the risk manager to plot these risks on a heatmap, ensuring that all relevant hazards are shown appropriately. The hazards will be shown on a heatmap based on their respective scores. According to their individual scores, the hazards on the heatmap will be colored red, amber, or green (RAG).
The first example demonstrates how a comprehensive variety of hazards may be displayed using Excel in an understandable manner (the data sheet feeding into this chart has more than 100 risks).
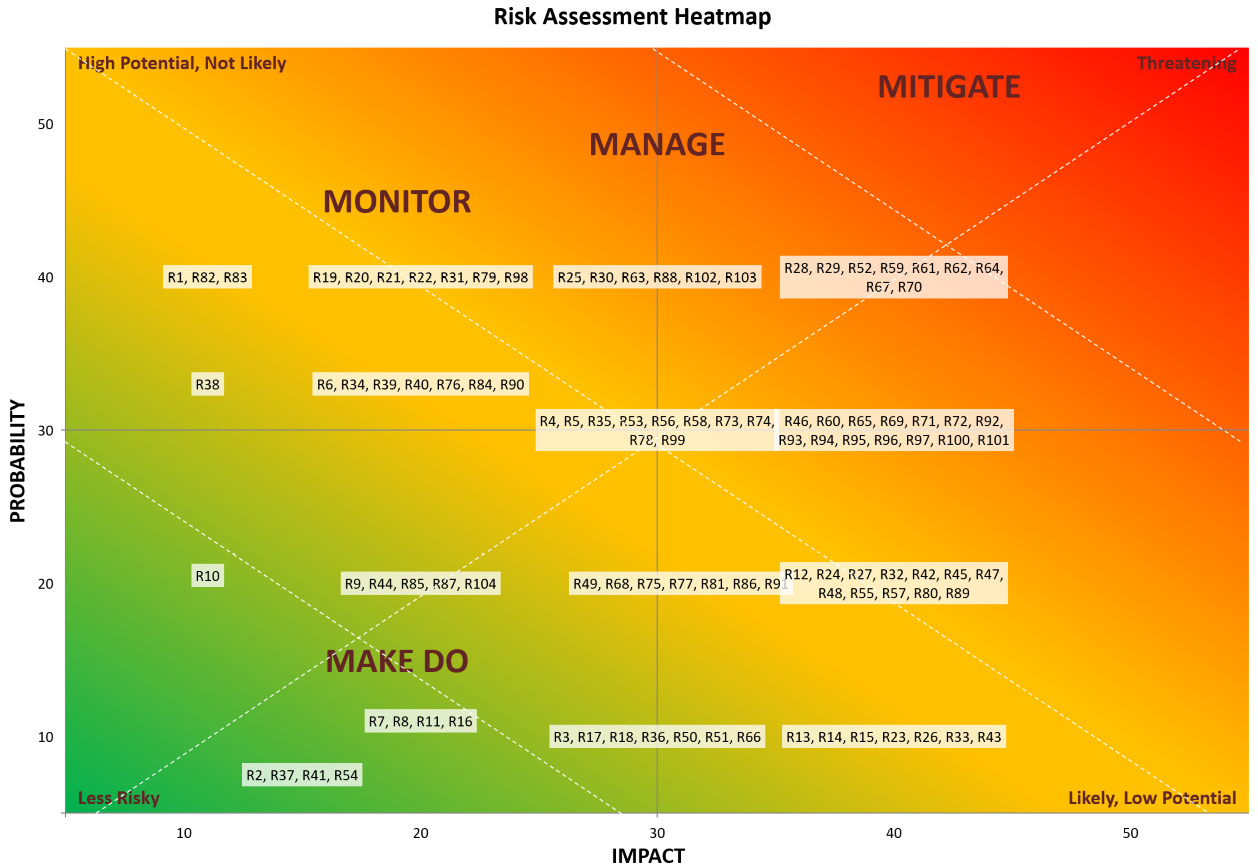
Figure 7.1 – Risk assessment heatmap
The second example illustrates a summarized heatmap in tabular format.
|
LIKELIHOOD | ||||||
|
10 Low |
20 Medium |
30 High |
40 Very High | |||
|
IMPACT |
10 |
Low |
4 |
1 |
1 |
3 |
|
20 |
Medium |
4 |
5 |
7 |
7 | |
|
30 |
High |
7 |
7 |
10 |
6 | |
|
40 |
Very High |
7 |
12 |
14 |
9 | |
NOTE
The figure shows the total number of identified risks per probability and impact score (e.g., P=10 and I=10, P=10 and I=20, and so on)
Figure 7.2 – Heatmap in tabular format
Well, now that we have defined how much a risk is hot, we need to find a way to take care of these risks, or, using the proper jargon, to mitigate them.
Risk mitigation
Risk mitigation refers to the methods to decrease risk and lessen the chance of an event happening. Risk mitigation is ensuring that your organization is completely safeguarded, which necessitates a continual focus on your main risks and concerns. The processes that govern and direct an organization are sometimes referred to as controls or mitigation activities.
To further comprehend this, let’s examine it in connection to the overall Enterprise Risk Management (ERM) process. The objective of your controls is to avoid certain hazards from materializing. This results in the development of policies and procedures designed to reduce the probability of risks materializing, remove the possibility that they will materialize, or raise the likelihood that your processes will protect you should the risk materialize.
Best risk mitigation strategies
At any one given time, every firm confronts a plethora of hazards. They incur more risks when doing anything new (such as a project or initiative) or experiencing any form of organizational change. These inherent hazards are often related to the procedures involved in achieving the final objective. However, there are ways to reduce the likelihood (possibility) of occurrences that may be used to identify and guide better risk mitigation plans.
Consequently, the four most prevalent strategies are as follows:
- Risk acceptance, an idea that can be reduced to taking the chance. This means accepting that the danger exists and that there is nothing you can do to lessen or alter it. Instead, it involves comprehension of the likelihood of its occurrence and acceptance of the potential repercussions. This is the optimal method when the danger is low or the risk is unlikely to occur. When the cost of minimizing or avoiding risk is greater than the cost of accepting and leaving it to chance, it makes sense to accept the risk.
- Risk avoidance: If the risk associated with initiating a project, introducing a product, relocating your firm, and so on is too great to take, it may be preferable to forgo it. In this instance, risk avoidance involves avoiding engaging in the risk-causing behavior. Managing risk in this manner most closely resembles how individuals manage personal hazards. Despite the fact that some individuals are risk-seekers and others are risk-averse, everyone has a tipping point at which things become too hazardous to undertake.
- Risk mitigation: When evaluating risks, it is preferable not to avoid or accept certain hazards. In this case, risk minimization is investigated. Risk mitigation refers to the activities and techniques used to manage and mitigate risk. When risk and its likelihood are identified, management resources can be allocated appropriately.
- Risk reduction: Businesses may choose an acceptable degree of risk, known as the residual risk level. Risk minimization is the most prevalent method since there is often a means to minimize risk. It entails taking actions to mitigate the effects of outcomes. An example of risk reduction is risk transfer, such as purchasing insurance.
- Risk transfer: As previously stated, risk transfer includes transferring the risk to a third person or institution. As is the case of leasing property, risk transfers might be outsourced, transferred to an insurance company, or provided to a new organization. Not often do risk transfers result in decreased costs. A risk transfer is preferable when it can be utilized to mitigate future harm. Therefore, insurance may be costly, but it may be more cost-effective than experiencing the risk and being fully liable for repairs.
Tip – What is the most effective risk management strategy?
Obviously, the optimal technique depends on the risk you want to avoid. A solid rule of thumb for deciding which strategy to pursue is to undertake a risk assessment first. This will allow you to detect policy and activity gaps. Based on this input, you may effectively rank your efforts.
Just remember: there is no one size fits all formula here. 99.9% of the entities I have consulted for use the preceding strategies in conjunction with each other, according to their business needs.
How to establish risk mitigation strategies
All risks and benefits are evaluated differently based on your company’s particular objectives. To effectively create risk reduction measures, you must engage in the following:
- Understand the user’s requirements: Understand your clients’ wants. Consider their needs while evaluating risks, since they are the foundation of your organization.
- Seek out and use experts: Risk need not be addressed in isolation. There are both software systems and subject matter experts available as resources.
- Recognize risk that arises: The worst thing you can do as a company leader is to ignore the existence of risk, since this is neither practical nor useful. When you are able to identify, define, and handle risk, you may better train your team and management to cope with its many varieties.
- Encourage risk-taking: Sometimes, taking risks is the best course of action. If your firm is capable of handling risk, promote risk-taking. Have backup plans and explain them so that everyone is on the same page to make this less intimidating.
- Recognize possibilities: Taking a risk may lead to the discovery of new opportunities. If you frame the discourse around risk in this manner, you may foster a problem-solving mindset that is adept at managing risk.
- Promote consideration of mitigating strategies: Consider comments from your team and include everyone. Everyone may have a unique risk mitigation strategy or approach. You can utilize data and analytics to evaluate alternatives and choose the optimal course of action.
Not every risk requires a mitigating strategy: as stated previously, it is occasionally preferable to take risk. Recognize that this is an option, and that some risks need no strategic response at all.
I tried my best here to give you all the basic (and non-basic) notions, but if you want to continue exploring the interesting world of risk management, you will find a plethora of books in your favorite bookstore that can help you to dig into the matter. For us, it’s time to move on to data classification.
Data classification
We started this chapter talking about assets, and data classification is the process of organizing data assets, so it’s worth a mention here.
Data classification involves building a classification scheme and defining one or more taxonomies for the whole organization. A categorization system facilitates the efficient determination of data action priorities and intensities. Data classification depends on characteristics such as criticality, security, access and usage, privacy, ethics, data quality, and storage needs.
Why is the classification of data important?
Classification of data offers businesses with an interface for implementing rules and processes across data types, structures, and storage systems. Classified data enables an organization to create and apply a single handling policy for sensitive data across numerous systems and data items. Defining many rules for each sort of data item is impractical in contexts with plentiful data today.
The categorization of data provides a corporate context to applications and processes. On the basis of data categorization, for instance, an organization might identify apps that handle sensitive data and specify stronger security criteria for such applications:
- Compliance: Data categorization makes it simpler to comply with regulatory frameworks such as GDPR, CCPA, HIPAA, and PCI, and also demonstrates compliance
- Security: Data categorization makes the organization aware of the data’s sensitivity, both as a whole and each time new data is presented, and enables the organization to apply the appropriate degree of security control based on this context
- Governance: Data categorization facilitates the mapping, monitoring, and management of data
What are the four levels of data classification?
In information security, there are commonly four categorization levels for data:
- Public: Data that may exist in the public domain and can be freely shared with anybody outside the organization, a flyer outlining the company’s goods and services, for example
- Internal: Company-wide data that is retained inside the organization and should not be shared outside, while not being sensitive, for instance, instructions on how to contact the company’s IT support
- Confidential: This is information is domain-specific data, may be shared with particular individuals or teams, and includes sensitive corporate information; a pricing list for one of the company’s goods, for instance
- Restricted: Highly sensitive information that should only be accessible on a need-to-know basis is restricted, for example, employment agreements
What are the various types of data classification?
While data is categorized depending on the requirements of each organization, there are a few typical methods of data classification:
- Data-based: A classification that explains the characteristics of the data. A credit card number or an email address are examples.
- Context-based: Classification that describes the business context of the data, for instance, sensitive information or earnings data.
- Source-based: Categorization that identifies the data source, for instance, consumer information gathered through a webinar registration form.
Difficulties with data classification
While data categorization is necessary for performing a variety of operations, information security focuses primarily on sensitive data. In the majority of businesses, sensitive data is categorized into various sensitivity levels and then mapped to distinct sensitive data categories (e.g., personal information).
Typically, companies confront the following obstacles when categorizing data:
- False positives: The same data may appear in several forms and circumstances. False classifications are more likely to be produced by classification algorithms that disregard the format and context of the input. As classification efforts often entail enormous volumes of data, even very low false positive rates might prohibit an organization from classifying properly.
- False negatives: According to different regulatory requirements, data may be deemed sensitive in one circumstance but not another. For instance, a name may be deemed non-sensitive by itself, but sensitive when paired with a medical record. Oftentimes, inaccurate categorization results from classifying data outside of its use context.
- Big data: Data lakes and data warehouses represent ever-expanding dynamic data stores, posing a formidable challenge for categorization methods that are not continuous.
- Cost: For the majority of classification tools, the cost of adopting and maintaining a data categorization strategy is contingent upon the quantity of data and the number of rules imposed. This procedure limits a company’s ability to categorize massive datasets with rigorous access rules.
Effects of compliance standards on data classification
Many legislation and compliance requirements mandate that enterprises classify their data. Depending on the kind of data used, processed, collected, sent, and stored by an organization, each compliance standard may have varying requirements.
Here are several common compliance standards and their data classification requirements:
- GDPR: Under GDPR, organizations that handle the personal data of European data subjects must categorize all the kinds of data gathered. As mentioned in the previous chapters, GDPR classifies as special data pertaining to race, political beliefs, healthcare, ethnic origin, and biometrics. This information needs greater security.
- PCI-DSS: Entities are required by PCI DSS Requirement 9.6.1 to classify data such that the sensitivity of the data may be assessed.
- SOC2: Trust Services (SOC2) Entities are required by SOC2 criteria to show that they routinely identify and manage sensitive information in accordance with their specific confidentiality goals.
- HIPAA: Protectedthanks health information (PHI) is a high-risk asset under HIPAA. The HIPAA Security Rule mandates that businesses and related business associates (BA) to whom the law is applicable identify PHI and adopt protections to assure its availability, confidentiality, and integrity. The HIPAA Privacy Rule restricts the uses and disclosures of protected health information (PHI) and requires those applicable businesses and business partners to implement data categorization methods.
Preciousness of data is heavily dependent of the value we attribute to it.
Let’s use an example to better understand this concept: let’s suppose there is a country named XYZ and their king wants to conquer the adjacent country of ZYX. He calls all his counselors, ministries and advisers and prepares a war plan and puts it in the safe. This plan, as you may imagine, has enormous value. But, for some reason, the king never decides to use this plan and, instead, he agrees a long-lasting peace agreement with the other country. When his successor (or an opponent, or a revolution, you name it) ascends to the throne and finds the attack plan, what will the plan's value be then?
The answer is I don’t know, and you probably don’t know either. But for sure its value will be different than in the past because of the successful peace agreement, because the old king is dead, and many other different reasons. Data classification is the technique of ascribing value to some information.
Data classification levels
Data sensitivity levels assist in establishing how to handle each form of classified data. For instance, the Center for Internet Security (CIS) proposes three information classes:
- Public
- Business Confidential
- Sensitive
With seven categories of data sensitivity, the US Government has a more comprehensive categorization system:
- Controlled Unclassified Information (CUI)
- Public Trust
- Confidential
- Secret
- Top Secret
- Code Word Classification
- Restricted Data/Formerly Restricted Data
Using more than three layers might complicate data categorization and make it difficult to monitor and maintain. Using less than three tiers is deemed too basic and may result in inadequate protection and privacy. As recommended by the CIS, the majority of enterprises employ three categorization levels.
Here is a simplified version of the CIS classification definitions that you can use in your efforts to classify data:
- Low-sensitivity data: This consists of publicly available data that does not require access restrictions, such as web pages, blog posts, and job postings.
- Medium-sensitivity data: This is intended exclusively for internal use, and a breach might have a significant effect on the business, for instance, company strategies, client lists, and anonymous personal data.
- High-sensitivity data: This consists of information that is protected by rules or compliance requirements, necessitating tight access restrictions and security measures. The data, if compromised, might cause serious damage to people or the company, as well as incur compliance penalties or fines.
Developing a policy for data classification
A data categorization policy outlines the manner in which your business manages its information life cycle. The objective is to guarantee that sensitive data is handled according to the amount of risk it presents. A data categorization policy should handle access and authorization, taking the data structure and its typical business applications into consideration.
Here are numerous important aspects that your policy should address:
- Objectives: The rationale for applying data categorization and the desired outcomes, together with quantifiable key performance indicators (KPIs).
- Workflows: Clarify how the whole categorization process should be structured and coordinated. Explain how this procedure will affect all workers and how they should handle various degrees of sensitive information.
- Location: Identify where the data is kept, such as on site, in the cloud, on backup systems, in databases, files, and so on.
- Schema: Determine and describe the data classification categories.
- Data owners: Clarify the roles and responsibilities of all stakeholders participating in the categorization management process. Describe how each position should organize and allow access to data.
- Compliance: Clearly identify what information is governed by compliance standards and what steps are necessary to achieve compliance.
Data classification procedures
Here are a few recommended practices that may help you enhance your organization’s data categorization:
- Conduct a data risk assessment: A full awareness of all data needs, including those connected to corporate rules and compliance standards, may be attained via a data risk assessment. You should also identify the contractual obligations for privacy and confidentiality. Define goals for data categorization in collaboration with all stakeholders, including IT, security, and legal teams.
- Create a data inventory: Before you can categorize data, you must identify it using methods and tools for data discovery. Once all sensitive data has been found, it must be identified and classified to ensure that each category of data is adequately secured. To make the procedure faster and more precise, you may mark any item containing sensitive data. This may considerably enhance the enforcement of your data categorization rules. You may manually or automatically label data.
This procedure may be automated via the use of intelligent categorization systems. Using specified criteria, for instance, a data classification system may automatically recognize and categorize data, and then tag it with the relevant categorization label. Throughout the entire data lifespan, these systems may continually monitor data to ensure that it is always appropriately categorized.
- Establish data security measures: Each level of data categorization needs a unique degree of protection. To guarantee that each level is adequately secured, standardize your security methods. Define the policy-based controls for each label categorization.
- Maintenance and supervision: Data is dynamic and must be continuously monitored and maintained. It may be copied, generated, edited, removed, and transferred regularly. Due to the fact that data undergoes several transformations during its existence, classifying it may be a time-consuming endeavor. Identifying which data actually needs to be safeguarded and focusing classification efforts there is a crucial step in reducing classification time. Automated categorization systems are an additional method for reducing workloads and expediting the identification and processing of newly produced sensitive data. Lastly, verify that your data categorization standards are adaptable enough to accommodate changes in data structure, the introduction of new data kinds, and an increase in data volume.
Now that we have exhaustively dealt with data and its classification, it’s time to move to ISO 27001 controls and why they are so important.
ISO 27001 controls
The ISO 27001 standard is comprised of the standard itself, plus a second part, called Annex A, where all the controls (114 divided into 14 categories) exist:
- Information Security Policies
- Organization of Information Security
- Human Resources Security
- Asset Management
- Access Control
- Cryptography
- Physical and Environmental Security
- Operational Security
- Communications Security
- System Acquisition, Development, and Maintenance
- Supplier Relationships
- Information Security Incident Management
- Information Security Aspects of Business Continuity Management
- Compliance
Each of the 14 categories provide you with a clear explanation of the primary objective(s) of that category.
Control Category A.5 – Information Security Policies (1 objective and 2 controls)
This category’s aim is to give management guidance and assistance on information security in accordance with the organization’s needs and applicable laws and regulations. This is accomplished by the documentation of a set of information security rules that must be authorized, publicized, disseminated, and reviewed at certain intervals.
Control Category A.6 – Organization of Information Security (2 objectives and 7 controls)
The first purpose is to develop a management structure that starts and regulates the implementation and operation of information security. This involves ensuring the following:
- Information security roles and responsibilities are explained and understood
- Segregation of duties is recognized and maintained
- Appropriate contact information is created and maintained with authorities, including the ICO, and special interest organizations, such as ISACA
No matter the kind of project, information security is developed and handled in project management. The second purpose is to protect the security of mobile devices and remote work.
This is accomplished by developing and executing a policy and supplementary security measures to control the risks associated with the usage of mobile devices and to safeguard information remotely accessed, processed, or stored.
Control Category A.7 – Human Resource Security (3 objectives and 6 controls)
The primary purpose is to ensure that employees understand their obligations and are qualified for the positions for which they are being evaluated. This is accomplished by completing adequate background checks on all applicants and including information security duties in employment contracts.
The second purpose is to ensure that employees are aware of and comply with their information security duties. To do this, they must implement information security in accordance with organizational rules and procedures. The organization is responsible for ensuring that personnel get proper training and frequent updates.
A structured and disclosed disciplinary procedure must also be developed so that any person who violates information security may be punished. The end purpose of this category is to safeguard an organization’s interests when employees change jobs or leave the organization by defining, communicating, and enforcing restrictive covenants.
Control Category A.8 – Asset Management (3 objectives and 10 controls)
The first aim requires the identification of information assets and the assignment of suitable protection tasks. This is accomplished by developing an asset inventory that identifies asset owners. Document and execute rules on the permissible use of these assets. When recovered, assets must also be secured and maintained. The subsequent purpose is to guarantee that data is adequately safeguarded.
To do this, it is necessary to develop a categorization system and classify the assets properly. Therefore, all electronic and physical assets must be labeled in line with the categorization system, and procedures for managing assets must also be designed and executed. The final purpose is to prevent unauthorized disclosure, alteration, deletion, or destruction of information stored on media. This can be accomplished by employing removable-media management methods. These processes must address the safe disposal and transit of storage media holding sensitive information.
Control Category A.9 – Access Control (4 objectives and 14 controls)
The primary goal is to restrict access to information and data processing resources: this is accomplished in part by developing and enforcing an access control policy and limiting user access to just the systems and network regions they require to execute their jobs.
The second goal is to guarantee authorized user access and prevent unauthorized access.
The following controls are used for this purpose:
- A structured procedure for user registration and de-registration
- A structured procedure for user access provisioning
- Restriction and management of the assignment and use of privileged access rights
- A structured method for managing the distribution of passwords, PINs, and so on
- The examination of access rights
- Users’ access privileges are revoked when they leave an organization or switch positions
The third purpose is to hold users responsible for protecting their passwords, PINs, tokens, and so on. As a result, it is necessary to adhere to prescribed procedures for the usage of secret authentication information. This category’s end purpose is to prevent unauthorized access to systems and applications. To fulfill this purpose, controls must limit access to information and systems and, where applicable, implement secure login processes. In addition to restricting utility applications that may circumvent system and application constraints, access to program source code must also be controlled. For this purpose, password management solutions are often used.
Control Category A.10 – Cryptography (1 objective and 2 controls)
This category’s purpose is to guarantee that cryptography is utilized properly to safeguard the confidentiality, integrity, and validity of information.
This is accomplished by creating and implementing a cryptographic policy that includes information on the usage, protection, and lifespan of cryptographic keys.
Control Category A.11 – Physical and Environmental Security (2 objectives and 15 controls)
The primary purpose of this category is to prevent unauthorized physical access to, damage of, and interference with data- and information-processing infrastructure.
Controls used to achieve these aims include the following:
- Defining and utilizing physical boundary security
- Ensuring that physical access controls are installed and used
- Protecting offices, rooms, and infrastructure
- Safeguarding against external and environmental dangers
- Developing and enforcing protocols for working in secure environments
- Securing delivery and loading locations regardless of location
The second purpose is to avoid the loss, theft, compromise, or destruction of assets and the disruption of activities.
Controls to achieve this purpose include the following:
- Equipment placement and protection, to prevent information from being neglected or equipment from being harmed by the environment
- The administration and safeguarding of supporting utilities, including uninterruptible power supply (UPS), electricity, gas, and water
- Guarding against inadvertent or deliberate damage to power and communication connections
- Regularly maintaining and servicing equipment, including heating, ventilation, and air conditioning (HVAC) as applicable
- Managing the removal of assets from the organization’s premises in an efficient manner
- Protecting valuables that are removed from the property
- Reusing and discarding equipment in a safe way
- Ensuring users adequately safeguard unattended equipment
- Implementing a policy for a clean desk and screen
Control Category A.12 – Operations Security (7 objectives and 14 controls)
The first objective is to guarantee that information processing facilities are properly and securely managed.
To do this, operational procedures must be recorded and made accessible.
Change management is included in these procedures to govern modifications to business processes, information processing facilities, and systems.
Capacity management must also be used to monitor and forecast capacity requirements.
Additionally, it should be highlighted that the development, testing, and operational environments must be segregated in order to decrease the danger of unauthorized access or modifications to operational environments.
The following purpose is to safeguard information and information-processing facilities against malware. This is done by implementing anti-malware software to identify, prevent, and recover from attacks.
Users must be aware of the organization’s anti-malware software and its guidelines on permissible and undesirable use.
The third objective is to defend against data loss by ensuring that frequent backups of information, software, and systems are performed and tested in accordance with an established backup strategy.
The subsequent aim involves documenting occurrences and producing proof. This is achieved by generating, storing, evaluating, and preserving user activity logs, including those of administrators and ordinary users, exception reports, and information security event logs.
All pertinent information-processing system clocks must be synchronized to a single reference time source, such as the network time protocol (NTP).
The fifth objective is to ensure the integrity of operating systems.
Implementing and using control processes to oversee the installation of software on operating systems accomplishes this objective.
The following purpose is to avoid the exploitation of technological flaws and may be achieved by collecting data about technological vulnerabilities, assessing the dangers they may cause, and implementing corrective measures.
Additionally, regulations controlling software installation must be defined and enforced. This category’s end purpose is to minimize the effect of audit operations on operating systems.
In order to minimize interruptions, strategies must be agreed upon regarding audit requirements and actions requiring verification of operating systems.
Control Category A.13 – Communications Security (2 objectives and 7 controls)
The second purpose is to preserve the security of both internal and external information transfers, and this may be accomplished by creating formal transfer rules, processes, and controls to secure information being transmitted across all kinds of communication facilities, including electronic messaging via email, communications platforms, and social media.
Therefore, information transfer agreements must include provisions for the safe sharing of business information.
Control Category A.14 – System Acquisition, Development, and Maintenance (3 objectives and 13 controls)
The primary purpose is to guarantee that information security is an intrinsic component of information systems throughout their entire lifespan, including the requirements for information systems that provide services via public networks. This implies that information security needs must be included into the specifications for any new or upgraded information systems.
Protecting data involved in application services that traverse public networks is a further control that may assist in achieving this purpose. Information involved in application service transactions must also be safeguarded to avoid incomplete transmission, misrouting, unauthorized message modification, unauthorized message disclosure, unauthorized message duplication, and unauthorized message replay.
The subsequent purpose is to guarantee that information security is established and executed within the development life cycle, which is closely related to design and development activities.
The following controls may assist in achieving this goal:
- Rules for software and system development must be developed and implemented
- Changes made to systems throughout the development life cycle must be governed by established change control processes
- When operating systems are modified, mission-critical applications must be examined and verified for negative effects on operations and security
- Software package modifications must be discouraged
- If modifications are needed, they must be confined to those that are essential and rigorously governed
- Any information system implementation activities must define, record, and use secure system engineering principles
- Establishing and adequately protecting secure development environments
- Any outsourced development operations must be managed and monitored
- During development, security functionality must be evaluated
- Programs and criteria for system acceptability testing must be created for new information systems, upgrades, and new versions
The final objective is to ensure the security of data used for testing by carefully choosing data, encrypting or otherwise safeguarding it, and restricting access to only authorized employees.
It is necessary to create and apply guidelines for software and system development. Changes made to systems during the lifespan of development must be managed by defined change control methods.
When operating systems are updated, mission-critical applications must be analyzed for adverse implications on operations and security. It is necessary to discourage software package change. If alterations are necessary, they must be limited to the bare minimum and strictly regulated. Any operations involving the development of an information system must define, document, and execute secure system engineering principles.
Creating and appropriately safeguarding secure development environments
Any outsourced development activities need management and oversight. Security functionality must be examined throughout the development process. For new information systems, updates, and new versions, programs and criteria for system acceptability testing must be devised.
The ultimate goal is to secure the data used for testing by selecting data with care, encrypting or otherwise protecting it, and limiting access to only authorized personnel.
Control Category A.15 – Supplier relationships (2 objectives and 5 controls)
The primary purpose of this category is to safeguard supplier-accessible assets. To achieve this, information security standards to limit risks associated with suppliers having access to assets must be exhaustively specified in a policy for supplier management.
As a result, written agreements must be negotiated and executed with each supplier, including all pertinent criteria outlined in the supplier management policy. Information security risks linked with information and communications technology services and the supply chain must be addressed in these formal agreements.
The second goal is to maintain an established degree of information security and service delivery in accordance with supplier contracts. To do this, suppliers must be watched, examined, and in certain instances audited on a regular basis. Changes to supplier services must also be handled, along with the maintenance and improvement of current information security policies, procedures, and controls; taking into account the importance of corporate information, systems, processes, and reassessment of risks.
Control Category A.16 – Information security incident management (1 objective and 7 controls)
This category has a single aim, which is to establish a uniform and effective approach to the management of information security incidents, including communications on security events and vulnerabilities.
The following controls may assist in achieving this objective:
- For a prompt, effective, and systematic reaction to information security events, management responsibilities and processes must be developed and executed
- Information security incidents must be promptly reported via the proper management channels
- Employees and contractors are required to disclose any identified or suspected information security vulnerabilities
- Information security incidents must be evaluated carefully to determine their classification as occurrences
- Deficiencies or occurrences, i.e., missing occurrences
- Information security issues must be addressed in accordance with established processes
- Utilize the knowledge acquired from analyzing and resolving information security events to lessen the possibility or effect of future occurrences
- Documented processes must outline the identification, gathering, acquisition, and preservation of information that may be used as evidence
Control Category A.17 – Information security aspects of business continuity management (2 objectives and 4 controls)
The initial purpose of this category is to prevent violations of legal, legislative, regulatory, or contractual information security duties and security requirements.
To achieve this purpose, it is necessary to identify the needs for information security and the continuity of information security management under bad scenarios. Processes, procedures, and controls must then be created, documented, implemented, and maintained. Once in place, these arrangements must be frequently evaluated and validated to guarantee their efficacy.
The second purpose is to guarantee that information processing facilities are available. This is performed by establishing redundant information-processing facilities to satisfy availability needs.
Control Category A.18 – Compliance (2 objectives and 8 controls)
The primary purpose of this category is to prevent violations of legal, legislative, regulatory, or contractual information security duties and security standards. Identifying and recording pertinent legal, statutory, regulatory, and contractual requirements, as well as the strategy for satisfying them, are examples of controls that might assist in achieving this purpose:
- Implementing processes to assure compliance with legal, statutory, regulatory, and contractual obligations for intellectual property rights and the usage of proprietary software products
- Protecting records against loss, tampering, falsification, unauthorized access, and unauthorized disclosure, in accordance with legal, statutory, regulatory, contractual, and corporate requirements
- As required by applicable laws and regulations, ensuring the privacy and security of personally identifiable information
- Utilizing cryptographic controls in accordance with all applicable international and national agreements, laws, and regulations
The second purpose is to guarantee that information security is established and managed in compliance with the rules and procedures of the organization. This is accomplished by conducting independent evaluations of the strategy for managing information security and its execution at predetermined intervals or in response to substantial changes.
The compliance of information processing and processes within their areas of responsibility of given managers must also be routinely reviewed by them; finally, information systems must undergo frequent compliance reviews, which may be accomplished via penetration testing.
Who is charged for implementing Annex A controls?
There are two essential considerations for addressing this question.
Less than forty percent of ISO 27001 Annex A controls are technology-based. Information security vulnerabilities are often caused by human behavior. Therefore, contrary to popular belief, IT cannot and should not be the only answer.
Information security is, in reality, about constructing a system of mature, resilient rules. The present Annex A framework applies the following percentages to control locations inside an organization:
- 37% – Technology
- 36% – Organizational/documentation
- 13% – Physical security
- 5% – Supplier and buyers
- 5% – Human resource management
- 4% – Legal protection
Consequently, applying the controls stated in Annex A is and must always be the responsibility of a number of persons and departments within an organization, the number of which is dependent on the size and complexity of the organization.
Using the ISO 27001 controls
The controls outlined in Annex A of ISO 27001 are a vital component of risk treatment and must be chosen based on a comprehensive analysis of an organization’s information security threats.
Typically, chosen controls must be justified by one of the following:
- Risk assessment
- Business need or best method
- Legal or contractual requirement
Once controls have been identified, organizations must submit a Statement of Applicability (SoA) that must contain, at a minimum, all 114 controls listed in Annex A of ISO 27001, along with reasons for inclusions and, preferably, concise descriptions of how they have been implemented. The SoA acts as a tool for providing senior management with accurate information on the degree of risk to which their organizations are exposed and the status of risk treatment efforts.
Identification of ISO 27001 controls to implement
Only after a thorough evaluation of an organization’s inherent information security threats can it be determined which measures should be adopted. Once the risks are known, the appropriate countermeasures may be determined. Possibly, the greater the number of controls adopted, the greater the likelihood that the organization can minimize or at least mitigate exposure to recognized risks.
Nonetheless, Annex A controls may be omitted if deemed irrelevant. An example of this would be a company that does not produce software.
Obviously, there would be no need for a strategy of secure growth. If a control is to be omitted, a complete rationale must be included in the SoA.
Summary
This chapter was very discursive, but we talked about risk management, data classification (still, as part of risk management) and all the controls within Annex A of ISO 27001.
In the next chapter, we will discuss preparing foolproof policies and procedures to avoid internal risks. We will examine security systems and devices, cybersecurity vulnerabilities, social engineering, common pain points, and critical success factors.